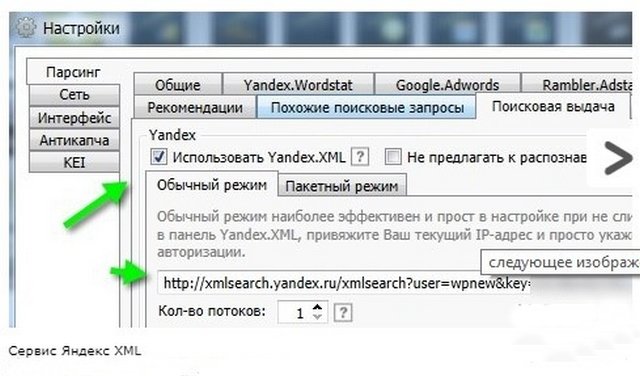
Яндекс XML лимиты — за что дают?
Как Яндекс XML начисляет баллы для возможности пользования своим API? Какие факторы на это влияют?
Считается, что баллы Яндекс XML начисляются по количеству страниц в индексе поисковой системы. Чем больше страниц проиндексировал поисковый робот, тем больше баллов появится у администратора сайта (передаст он их кому-нибудь или оставит себе — это уже другой вопрос).
А может быть что-то ещё добавляет баллы? — подумали мы и проверили, как на «XML баллы» влияют:
- количество проиндексированных страниц (чтобы лишний раз убедиться, что это так),
- возраста домена,
- индекс цитирования (тИЦ),
- присутствие в Яндекс.Каталоге.
Мы проводили исследование на 103 сайтах. Для начала давайте поглядим, что же из себя представляет выборка, которую мы подготовили. Получились такие графики:
Что мы видим:
- Подтверждается зависимость количества баллов Яндекс.
 XML от количества страниц в индексе.
XML от количества страниц в индексе. - Возраст сайта не на количество баллов Яндекс.XML (на количество страниц — тоже).
- С тИЦ и Яндекс.Каталогом — как-то не очень понятно
 XML от количества страниц в индексе.
XML от количества страниц в индексе.Обратите внимание, мы здесь использовали логарифмическую шкалу (10-100-1000, а не 10-20-30).
Содержание поста
- 1 Регрессионная модель
- 1.1 Какие переменные значимы?
- 2 Итог (Что делать?)
Регрессионная модель
Мы с 10-й попытки смогли найти нужные символы, чтобы составить эту красивую модель:
\[\hat{Score} = \hat{\beta_0} + \hat{\beta_1}Age + \hat{\beta_2}YandexCatalog + \hat{\beta_3}YandexIndex + \hat{\beta_5}YandexCitation\]
А ещё Евгений Летов долго требовал поиграть в ней шрифтами.
Какие переменные значимы?
На 5% уровне значимы:
- Количество страниц в индексе. Каждая проиндексированная страничка дает примерно 0,3 XML-балла.
- тИЦ. Каждый дополнительный балл тИЦ добавляет 0,6 XML-балла.

Возраст сайта и присутствие в Яндекс.Каталоге роли не сыграли.
«Ха! Всё равно вы что-нибудь да пропустили!»
Да, мы могли что-то пропустить. Поэтому провели RESET-тест Рамсея, который создан как раз для таких случаев.
На нашей выборке p-value составил 0.95 — поэтому на данной выборке нет оснований полагать, что мы действительно что-то упустили.
Итог (Что делать?)
Приоритетные направления деятельности любителей Яндекс.XML:
- Увеличивать тИЦ ваших ресурсов.
- Загонять индекс побольше страниц.
P.S. 103 сайта — это довольно маленькая выборка. Кто его знает, может быть всё совсем не так — ведь мы «игрались» только с опекаемыми нами сайтами, в которых реальное количество страниц примерно соответствует количеству проиндексированных.
Если вы хотите помочь нашему исследованию стать точнее, можете отправлять списки вида «сайт» — «количество баллов» на почту [email protected].
P. P.S. При подготовке материала ни один SEO’шник не пострадал (разве что от скуки).
P.S. При подготовке материала ни один SEO’шник не пострадал (разве что от скуки).
Соавтор статьи
Решить задачу на Python (парсинг XML) — Заказы — Хабр Фриланс
Common Requirements
- Code must correspond to pep8 (use pycodestyle utility for self-check).
- You can set line lengths up to 120 symbols.
Task Description For this task, you can join with an RSS reader using Python 3.10.
For the testing, you are going to isolate the parts you will work on. Namely, you are going to work only on the RSS (XML) scrapping part. Your task is to parse the RSS document and provide two formatted outputs: JSON and the standard output.
You are going to:
- Command line parsing.
- Receive the XML document from the web.
Because you can create your own style of formatting, it will be difficult to test you. So, we will provide you with the exact style for the format to ease the testing part.
So, we will provide you with the exact style for the format to ease the testing part.
The format of the RSS feed that you are going to parse is RSS 2.0. You can follow the link to get a full understanding of the specification. But in this task, we are asking for the following requirements:
<channel>…</channel> <!— Required tags are <title>, <link>, <description> but we are asking you to be able to parse <title>, <link>, <description>, <category>, <language>, <lastBuildDate>, <managingEditor>, <pubDate>, <item> —>
<item>…</item> <!— All of the fields here are optional, but each item should have at least <title> or <description>, but for the purposes of the test we are asking to be able to parse <title>, <author>, <pubDate>, <link>, <category>, <description> —>
The order of the RSS items in all the output types should be the following:
- For <channel> element:
- <title>
- <link>
- <lastBuildDate>
- <pubDate>
- <language>
- <category> for category in categories
- <managinEditor>
- <description>
- <item> for item in items
- For <item> element:
- <title>
- <author>
- <pubDate>
- <link>
- <category>
- <description>
The CLI is going to have the following interface. You can use it for testing purposes when you develop XML document parsing.
You can use it for testing purposes when you develop XML document parsing.
usage: rss_reader.py [-h] [—json] [—limit LIMIT]
source
Pure Python command-line RSS reader.
positional arguments:
source RSS URL
optional arguments:
-h, —help show this help message and exit
—limit LIMIT Limit news topics if this parameter is provided
Command Line Arguments
- If the limit is not specified, then the user should get all available feeds.
- If the limit is larger than the feed size, then the user should get all available news.
- The limit argument should also affect JSON generation
- In the case of using the —json argument, your utility should convert the news into the JSON format.
Console Output:
- For <channel> element:
- <title> is equal to Feed
- <link> is equal to Link
- <lastBuildDate> is equal to Last Build Date
- <pubDate> is equal to Date
- <language> is equal to Language
- <category> for category in categories is equal to Categories: category1, category2
- <managinEditor> is equal to Editor
- <description> is equal to Description
- <item> for item in items each item is separated by a custom separator, and all items within except for the description are stuck together.
- For <item> element:
- <title> is equal to Title
- <author> is equal to Author
- <pubDate> is equal to Date
- <link> is equal to Link
- <category> is equal to Categories: category1, category2
- <description> is on a separate line without any name.
For the console output you are looking for the order of things – channel items go first and then the other items. You should also have a space between the channel elements and items. Also, the description within the item should be on the new line, separated by space. For example:
Feed: Yahoo News — Latest News & Headlines
Link: https://news.yahoo.com/rss
Description: Yahoo news description
Title: Nestor heads into Georgia after tornados damage Florida
Date: Sun, 20 Oct 2019 04:21:44 +0300
Link: https://news.yahoo.com/wet-weekend-tropical-storm-warnings-131131925. html
html
Nestor raced across Georgia as a post-tropical cyclone late Saturday, hours after the former tropical storm spawned a tornado that damaged homes and a school in central Florida while sparing areas of the Florida Panhandle devastated one year earlier by Hurricane Michael. The storm made landfall Saturday on St. Vincent Island, a nature preserve off Florida’s northern Gulf Coast in a lightly populated area of the state, the National Hurricane Center said. Nestor was expected to bring 1 to 3 inches of rain to drought-stricken inland areas on its march across a swath of the U.S. Southeast… <— !!! THIS IS DESCRIPTION !!!
Title: Some Other Title
Date: Sun, 20 Oct 2019 04:21:44 +0300
Link: https://some.other.link/some-other-news
Some other new cool information. <— !!! THIS IS DESCRIPTION
JSON Output: For the JSON output, you are looking for the exact names of the tags. Ask for the pretty output:
{
«title»: «Yahoo News — Latest News & Headlines»,
«link»: «https://news. yahoo.com/rss»,
yahoo.com/rss»,
«description»: «Yahoo news description»,
«items»: [
{
«title»: «Nestor heads into Georgia after tornados damage Florida»,
«pubDate»: «Sun, 20 Oct 2019 04:21:44 +0300»,
«link»: «https://some.other.link/some-other-news»,
«description»: «Nestor raced across Georgia as a post-tropical cyclone late Saturday, hours after the former tropical storm spawned a tornado that damaged homes and a school in central Florida while sparing areas of the Florida Panhandle devastated one year earlier by Hurricane Michael. The storm made landfall Saturday on St. Vincent Island, a nature preserve off Florida’s northern Gulf Coast in a lightly populated area of the state, the National Hurricane Center said. Nestor was expected to bring 1 to 3 inches of rain to drought-stricken inland areas on its march across a swath of the U.S. Southeast…»
{
«title»: «Some other title»,
«pubDate»: «Sun, 20 Oct 2019 04:21:44 +0300»,
«link»: «https://some.
 other.link/some-other-news»,
other.link/some-other-news», «description»: «Some other new cool information.»
}
]
}
максимальный размер для XML-файлов
спросил
Изменено 5 лет, 5 месяцев назад
Просмотрено 40 тысяч раз
Каково ваше эмпирическое правило для максимального размера файлов xml.
Что делать, если я задаю максимальное количество записей, а одна запись имеет, например, 10 значений? Еще одно условие — мы загружаем его из Интернета.
1
Мое правило таково: если он слишком медленный, чтобы делать то, что я хочу, то он слишком большой , и ваши данные, вероятно, нужно переместить в какой-то другой формат… базу данных или что-то в этом роде.
Обход узлов XML или использование XPath может быть проблемой.
Возможно, это не то, что вы хотели бы услышать, но… Если вы думаете о размере ваших XML-файлов, скорее всего, вам следует использовать базу данных вместо файлов (даже если это не плоские файлы, а структурированные). как XML). Базы данных оптимизированы для эффективного хранения огромных массивов данных. Лучшие алгоритмы для извлечения данных находятся в кодовой базе баз данных.
Их нет. Однако существуют максимальные размеры файлов, которые зависят от используемой файловой системы.
2
Существует нет ограничений на размер XML-файла , но требуется памяти (ОЗУ) как размер файла XML-файла , поэтому длинный XML-файл размер синтаксического анализа составляет удар по производительности .
Рекомендуется использовать длинный XML размером , используя SAX для . NET для анализа длинных XML-документов.
NET для анализа длинных XML-документов.
Я думаю, это зависит от контекста, откуда берется/создается файл, что вы собираетесь с ним делать, пропускной способности любого соединения, через которое он должен проходить, размера системной оперативной памяти и т. д.?
какой у вас контекст?
Несмотря на то, что не все синтаксические анализаторы считывают весь файл в память, если вам действительно нужно эмпирическое правило, я бы сказал, что не больше половины доступной оперативной памяти. Все, что больше, вероятно, будет слишком медленным 🙂
Я не думаю, что у вас должно быть эмпирическое правило для максимального размера данных, будь то XML или что-то еще. Если вам нужно хранить несколько гигабайт данных, вы сохраняете эти данные. Разница в том, какой API вы используете для обработки этих данных. Однако XML может быть не лучшим выбором, если ваш набор данных очень велик. В этих случаях реляционная или XML-база данных, вероятно, будет работать лучше, чем один XML-файл.
2
В 2010 году я работал над проектом, где мне нужно было перенести веб-сайт газеты с Typo 3 на Drupal 7, и самым быстрым способом в то время было экспортировать весь контент в виде xml, а затем проанализировать его в drupal (Xpath). Мы пытались сделать это за один раз, но у нас были проблемы с 4Gigs. Таким образом, мы разделили xmls на год, и у каждого файла было меньше времени для анализа и размер файла в МБ, и все прошло нормально. Другие чтения предполагают, что максимальный файл может зависеть от вашего барана.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
xmlhttprequest — Максимальный размер для передачи данных в XML?
спросил
Изменено 11 лет, 11 месяцев назад
Просмотрено 5к раз
Кто-нибудь когда-нибудь пробовал передать 5 ГБ данных в xml. Используют ли веб-службы, которым требуется передать большой объем данных, XML через http для передачи данных.
Используют ли веб-службы, которым требуется передать большой объем данных, XML через http для передачи данных.
Я с нетерпением жду внесения изменений в систему для передачи данных. Я запутался, должен ли я передавать данные в формате XML для 5 ГБ данных, поскольку моя основная память составляет всего 2 ГБ.
Сломается ли приложение?
Спасибо
- xml
- xmlhttprequest
- передача данных
2
XML — это просто язык разметки/формат данных, не имеющий ограничений по размеру. При желании вы можете создать XML-файл размером 1000 ГБ.
Вещи, которые манипулируют файлом XML размером 5 ГБ (или любым другим типом файла размером 5 ГБ), могут сломаться, если они не предназначены для работы с файлами больших размеров. В общем, если вы просто загружаете свой большой файл в веб-службу, все должно быть в порядке, потому что почти любой современный модуль загрузки файлов будет поддерживать кэширование загрузки на диск по мере его получения, так что весь файл не требуется.
быть в памяти. Однако у вас могут возникнуть проблемы с анализом документа после его размещения на сервере, в зависимости от того, какую библиотеку вы используете для анализа. Возможно, вы захотите изучить, какие потоковые XML-парсеры доступны для вашей веб-службы/платформы (или даже написать свой собственный парсер, специально предназначенный для вашего формата XML-документа, поскольку тогда вы можете сделать упрощающие предположения, которые позволят вам ограничить объем памяти требуется в любой момент времени).Я полагаю, что большинство веб-сервисов, передающих большие объемы данных, а не будут использовать XML в качестве формата передачи данных. Пропускная способность стоит дорого, а высокая задержка или длительное время загрузки могут ухудшить работу пользователя. Поэтому я ожидаю, что такие сервисы чаще будут использовать оптимизированный двоичный формат. Разумное приближение к этому можно получить, просто применив сжатие gzip к XML-документу перед его отправкой.
 быть в памяти. Однако у вас могут возникнуть проблемы с анализом документа после его размещения на сервере, в зависимости от того, какую библиотеку вы используете для анализа. Возможно, вы захотите изучить, какие потоковые XML-парсеры доступны для вашей веб-службы/платформы (или даже написать свой собственный парсер, специально предназначенный для вашего формата XML-документа, поскольку тогда вы можете сделать упрощающие предположения, которые позволят вам ограничить объем памяти требуется в любой момент времени).
быть в памяти. Однако у вас могут возникнуть проблемы с анализом документа после его размещения на сервере, в зависимости от того, какую библиотеку вы используете для анализа. Возможно, вы захотите изучить, какие потоковые XML-парсеры доступны для вашей веб-службы/платформы (или даже написать свой собственный парсер, специально предназначенный для вашего формата XML-документа, поскольку тогда вы можете сделать упрощающие предположения, которые позволят вам ограничить объем памяти требуется в любой момент времени).
У меня был некоторый опыт работы с большими файлами XML, но, возможно, не 5 ГБ.
Если это существующая система, использующая XML, хорошо подумайте, прежде чем переходить с XML на какой-либо другой формат, потому что само изменение может принести больше проблем, чем пользы. Сжатие файла значительно упростит передачу по сети. XML-файл, сжатый с помощью gzip, может быть столь же эффективным, как и собственный двоичный формат.
Скорее всего, узким местом будет синтаксический анализ и обработка файла. Если «записи» XML независимы друг от друга (например, если это длинный список типов xml), вы должны иметь возможность использовать потоковый синтаксический анализатор XML, чтобы избежать загрузки всего в память. Также рассмотрите возможность использования синтаксического анализатора без проверки (или отключения проверки) для повышения производительности.
Если вы можете выполнять какую-либо обработку файлов в XSLT, то вы можете обнаружить, что это работает лучше, чем разбор всего файла в программе для обработки.