
Excel-кластеризатор ключевых слов по весу — IT-Agency
Excel-кластеризатор ключевых слов по весу — IT-Agency
Рассказывает
Роман Игошин,
управляющий партнёр
Эта статья о том, как распределить по группам 20–30 тысяч ключевых слов. Поможет сэкономить время маркетологам, которые регулярно создают рекламные кампании.
Вручную группировать запросы не всегда эффективно: перебрать 200–300 запросов можно за час, на 20–30 тысяч уйдет неделя. Автоматическим сервисам группировку я не доверю, так как она определяет структуру и управляемость кампании.
Поэтому придумал свой метод, который ускоряет кластеризацию и даёт осознанный результат. Облегчает жизнь при работе с СЯ от 2–3 тысяч ключевых слов. Пробовал работать с 45 000 — Excel начинал умирать. Список из 200–300 запросов быстрее перебрать руками.
Далее расскажу про свой метод кластеризации в теории, а затем — как реализую
его в Excel. Дам ссылку на готовый Excel-кластеризатор.
Метод
Кластеризация — распределение запросов по кластерам. Кластер — это группа запросов, схожих по смыслу и набору слов. Чтобы выделить такие запросы и объединить их в кластер, нужен признак.
Используем для этого нормализованную форму запроса — уберём окончания и выстроим слова в порядке важности:
Пример готовых кластеров
Удаление окончаний позволит охватить все возможные словоформы для конкретного слова, а сортировка «по важности» — игнорировать порядок слов.
Слово без окончания — это признак, который объединяет разные словоформы:
Объединение словоформ
Чтобы убирать окончания я использую mystem. Это лемматизатор от Яндекса. Он обрабатывает список слов и возвращает нормализованные значения — леммы.
Если система не уверена, какая лемма правильная, то покажет 2–3 варианта.
Например,
для слова «банку» mystem вернёт две леммы: «банк» и «банка».
Сортировка «по важности» позволит игнорировать порядок слов. При сортировке нормализованных значений фраз по алфавиту мы получим готовые кластеры — группы запросов, схожих по смыслу и набору слов.
Важность слова — вычисляемый параметр для конкретного списка ключевых слов. Он не определяет важность слова в общей картине мира.
Важность слова рассчитывается из частотности и количества упоминаний слов в списке. Рассмотрим на примере.
Берём список запросов с частотностью
- Купить бумеранг — 1000
- Бумеранги цена — 700
- Бумеранги в москве — 750
- Купить классический бумеранг — 450
- Цены на бумеранги в москве — 350
- Купить классический бумеранг в москве — 100
В списке запросов встречаются слова: купить, бумеранг, классический, москва, цена, в, на. Вес слова равен сумме долей частотностей помноженных на количество упоминаний слова.
Считаем доли частотностей
- Купить бумеранг — 1000 = 1000/2 = 500
- Бумеранги цена — 700 = 700/2 = 350
- Бумеранги в москве — 750 = 750/3 = 250
- Купить классический бумеранг — 450 = 450/3 = 150
- Цены на бумеранги в москве — 350 = 350/5 = 70
- Купить классический бумеранг в москве — 100 = 100/5 = 20
Считаем вес слов
- Купить — (500+150+20)*3 = 2010
- Бумеранг — (500+350+250+150+70+20)*6 = 8040
- Классический — (150+20)*2 = 340
- Москва — (250+70)*2 = 640
- Цена — (350+70)*2 = 840
- В — 20
- На — 70
Сортируем по важности
- 8040 — бумеранг
- 2010 — купить
- 840 — цена
- 640 — москва
- 340 — классический
- 70 — на
- 20 — в
Располагаем запросы по важности
- Купить бумеранг — бумеранг | купить
- Бумеранги цена — бумеранг | цена
- Бумеранги в москве — бумеранг | москва
- Купить классический бумеранг — бумеранг | купить | классический
- Цены на бумеранги в москве — бумеранг | цена | москва | на | в
- Купить классический бумеранг в москве — бумеранг | купить | москва | классический | в
Упорядочиваем и чистим
- Бумеранг | купить: купить бумеранг — 1000
- Бумеранг | купить | классический: купить классический бумеранг — 450
- Бумеранг | купить | москва | классический: купить классический бумеранг в москве — 100
- Бумеранг | москва: бумеранги в москве — 750
- Бумеранг | цена: бумеранги цена — 700
- Бумеранг | цена | москва: цены на бумеранги в москве — 350
В итоге получили первые группы объявлений, с которыми можно работать дальше: укрупнять,
объединять, кросс-минусовать.
Реализация в Excel
Выполняем последовательность действий в таблице (XLS, 537 КБ) с формулами. Кластеризация 1000 запросов займет 30 минут.
Собираем СЯ → собираем частотность → разбиваем запросы по словам и вычисляем доли весов → формируем таблицу-справочник с весами слов → выделяем леммы для слов → вычисляем «вес» леммы → формируем таблицу-справочник с леммами → делаем первичную кластеризацию → укрупняем полученные группы.
Лист «Кластеризация», таблица «Main»
Чтобы избежать правки формул называйте все листы и таблицы аналогично таблице-примеру
- Вычисляем доли весов:
- Доли весов = Частотность / Кол-во слов.
- Кол-во слов =LEN ([@Ключ])-LEN (SUBSTITUTE ([@Ключ],» «,»»))+1.
Расчёт кол-ва слов и доли веса слова
- Разбиваем слова по фразам функцией «Text to columns»:
Результаты работы функции «Text to columns»
Лист «Слова — Леммы», таблица «Word»
- Копируем столбцы W1—W7 на новый лист.

- Преобразуем таблицу из формата
[W1] [W2] [W3] [W4] [W5] [W6] [W7] [Доли весов] в формат:
[W1] → [Доли весов]
[W2] → [Доли весов]
[W3] → [Доли весов]
[W4] → [Доли весов]
[W5] → [Доли весов]
[W6] → [Доли весов]
[W7] → [Доли весов]:Формирование справочника со словами
- Удаляем пустые ячейки и считаем кол-во упоминаний каждого слова.

Лист «Слова — Леммы», таблица «Word»
- Копируем полученный на прошлом шаге список слов «как есть».
- Обрабатываем через mystem → получаем леммы для каждого слова.
- Считаем кол-во упоминаний каждой леммы.
Справочник слов
Лист «Леммы», таблица «Lemmas»
- Копируем полученный список лемм на новый лист и удаляем дубли.
- Из справочника со словами подтягиваем VLOOKUP-ом кол-во упоминаний каждой леммы.
- Считаем кол-во символов в лемме.
- Вычисляем «вес» леммы:
Вес Леммы= [Сумма долей весов слов, входящих в Лемму] * [Кол-во упоминаний Леммы].
Формула:
=(SUMIF (Words[Lemma],[@Лемма], Words[Доли весов]))*[@[Кол-во упоминаний]]. - Сортируем леммы по столбцу «вес» — от большего к меньшему.
- Проставляем «Статус» для лемм — минимальный для старшей леммы (лучше начать с 1 000),
дальше +1 к следующему статусу:
Справочник лемм

Лист «Кластеризация», таблица «Main»
Для каждого слова в столбцах W1—W7 подтягиваем VLOOKP-ом значения «Статус» → записываем их столбцы L1 – L7 :
«Статусы» слов
Итак, что мы сделали. Разбили запросы по словам. Для каждого слова выделили лемму — можем объединить запросы по общим словам. Для каждой леммы посчитали вес. Остаётся выстроить слова в запросе в порядке важности. Тогда при сортировке по алфавиту запросы сами объединятся в группы объявлений.
Выстраиваем слова в порядке важности функцией SMALL. В диапазоне статусов L1 – L7 ищем
самый маленький статус — это самое важное слово во фразе. Затем, ищем второй
самый маленький
статус — это второе по важности слово во фразе. И так еще пять раз — проверяем
оставшиеся столбцы L3 – L7.
И так еще пять раз — проверяем
оставшиеся столбцы L3 – L7.
Получаем последовательность статусов. Например, 37 → 100 → 200 → 700. Для каждого статуса подтягиваем VLOOKP-ом соответствующую Лемму из справочника Лемм. Соединяем Леммы CONCATENATE-ом и получаем нормализованное значение фразы. Я использую его как название группы объявлений.
Сортируем по алфавиту:
Результаты работы Кластеризатора
Полная рабочая формула в файле-примере.
Игнорируя окончания и порядок слов, мы объединили запросы с одинаковым набором слов. Количество групп стремится к количеству слов — это 100 % точность инструмента. Можно использовать, если вы предпочитаете работать с запросами в точном соответствии.
Чтобы укрупнить группы, нужно уменьшить точность — снизить количество лемм, которые составляют «нормализованную форму».
Что можно удалить:
- одинокие буквы, цифры, предлоги, доменные зоны. Леммы длиной 1–3 символа;
- редкие леммы — кол-во упоминаний меньше среднего по списку;
- леммы с малым весом — недостаточно «важные»;
- в редких случаях — топонимы.

Важно: лемму не удаляем, только её «Статус» — этого достаточно, чтобы лемма не попала в «нормализованную форму»:
Процесс укрупнения групп объявлений
В основной таблице ничего править не надо — результат обновится самостоятельно.
До какой степени укрупнять: я стремлюсь к среднему показателю 2–3 запроса в одной группе объявлений и слежу за максимальным количеством фраз (помним про ограничения систем контекстной рекламы).
Дашборд для укрупнения в справочнике Лемм
Резюме
Полученный список групп удобно кросс-минусовать и двигать между кампаниями. Название группы поможет писать объявления — вы сами определяете важные слова в названии группы.
Ещё раз алгоритм: собираем СЯ → собираем частотность → разбиваем запросы по словам
и вычисляем доли весов → формируем таблицу-справочник с весами слов → выделяем
леммы
для слов → вычисляем «вес» леммы → формируем таблицу-справочник с леммами → делаем
первичную кластеризацию → укрупняем полученные группы.
Отзывы джедаев о кластеризаторе
Илья Ерошкин, старший джедай:
«Я помогал Роме с созданием инструмента на ранних этапах. Всем рекомендую попробовать кластеризатор для ядра от 2000 ключевых слов → сэкономит время.
Инструмент можно улучшить и превратить в автоматический сервис. Также можно дорабатывать формулы определения веса лемм. Но и в текущем виде он поможет специалистам по контексту, которые работают с большой семантикой.»
Егор Холов, старший джедай:
«С помощью кластеризатора сильно удобнее и быстрее сгруппировать фразы и потом писать объявления для них. Из недостатков — первый раз кажется, что это сложновато. Но когда попробуешь, то всё довольно понятно. Но эту штуку лучше автоматизировать.»
Михаил Стерликов, старший джедай:
«Методику пробовал, но не использую в работе, потому что нечасто собираю контекст в больших объемах.
Хорошо подойдет для работы с большой семантикой, особенно в свете последних нововведений яндекса по низкочастотным запросам. Группировки помогут сэкономить много времени при подготовке ключевых фраз.
Группировки помогут сэкономить много времени при подготовке ключевых фраз.
Методика на первый взгляд кажется сложной и громоздкой, но если разобраться, то процесс становится понятным и удобным.»
Александра Мурашко, джедай:
«Кластеризация от Ромы просто находка! Методом пользуюсь каждый раз когда работаю с семантикой — собираю или корректирую кампании.
Больше всего мне нравятся три вещи:
- я регулирую какие фразы попадут в группу. Если вес фразы небольшой, то объединяю с похожими. Не придерживаюсь принципа «один ключ — одна группа», иначе управлять кампанией сложно;
- понимаю механику и вижу какие фразы должны быть в заголовке. Конечно, важно делать полное вхождение ключевого слова. Часто оно не вмещается полностью и я строю заголовок из фраз с бо́льшим весом;
- это Excel, который всем знаком. Не нужно устанавливать дополнительные программы и платить за сервис. Если разобраться в формулах, то уже немного прокачаешься.

Из минусов: все формулы я копирую из готового шаблона и переключаться между окнами одной программы неудобно. Я бы хотела иметь формулы под рукой, а может сделать в будущем какой-нибудь шаблон, чтобы сократить количество копирований. Ещё хотелось бы сократить время группировки, но пока не нашла способ.
В целом, способ мне нравится тем, что механика простая и понятная, её легко внедрить и потом управлять кампаниями.»
Что дальше
Если у вас СЯ от 2–3 тысяч ключевых слов, используйте этот алгоритм. Прогоните алгоритм 2–3 раза, чтобы «впитать».
Таблица-пример537 КБ
Если у вас список из 200–300 запросов, переберите
руками — так быстрее.
Если хотите готовое решение — попросите программистов написать скрипт.
Я постоянно дорабатываю кластеризатор. В следующих итерациях хочу проработать
кросс-минусовку
групп, добавить справочники минус-слов и максимально автоматизировать кластеризатор на Power
Query. Следите за обновлениями!
Следите за обновлениями!
Будут вопросы — пишите: [email protected] или Facebook.
14 февраля 2017
Рассказал Роман Игошин
Записал и отредактировал Виталий Семыкин
Подпишитесь, чтобы не пропустить свежие статьи
Новые статьи из Академии и открытые вакансии каждые две недели:
| Согласен с условиями передачи данных |
Ещё по теме
Роман Игошин «Кластеризатор ключевых слов на Power Query»
Эльдар Забитов «Коннектор для выгрузки статистики из AmoCRM в Excel и Power BI»
Эльдар Забитов «Коннектор для выгрузки статистики из AmoCRM в Excel и Power BI»
Продолжая пользоваться сайтом, вы принимаете соглашение о передаче данных.
Как распределить ключевые фразы и запросы по посадочным страницам
24942
| How-to | – Читать 12 минут |
Прочитать позже
ЧЕК-ЛИСТ: СЕМАНТИКА
Инструкцию одобрил
Основатель Wixfy
Дмитрий Угниченко
Работа с семантическим ядром входит в список основных задач SEO-продвижения сайта. От эффективности сбора ключевых фраз и их корректного распределения по страницам проекта зависит видимость сайта в поисковых системах и его посещаемость.
От эффективности сбора ключевых фраз и их корректного распределения по страницам проекта зависит видимость сайта в поисковых системах и его посещаемость.
Содержание
- Что такое семантическое ядро сайта
- Использование Планировщика ключевых слов Google Adwords для сбора семантического ядра
- Подбор ключевых фраз в Яндекс.Wordstat
- Расширение семантического ядра с помощью модуля «Похожие фразы» Serpstat
- Распределение ключевых фраз по сайту
— Кластеризация фраз с помощью Serpstat
Заключение
Что такое семантическое ядро сайта
Семантическое ядро — список всех ключевых фраз, которые используются для продвижения сайта.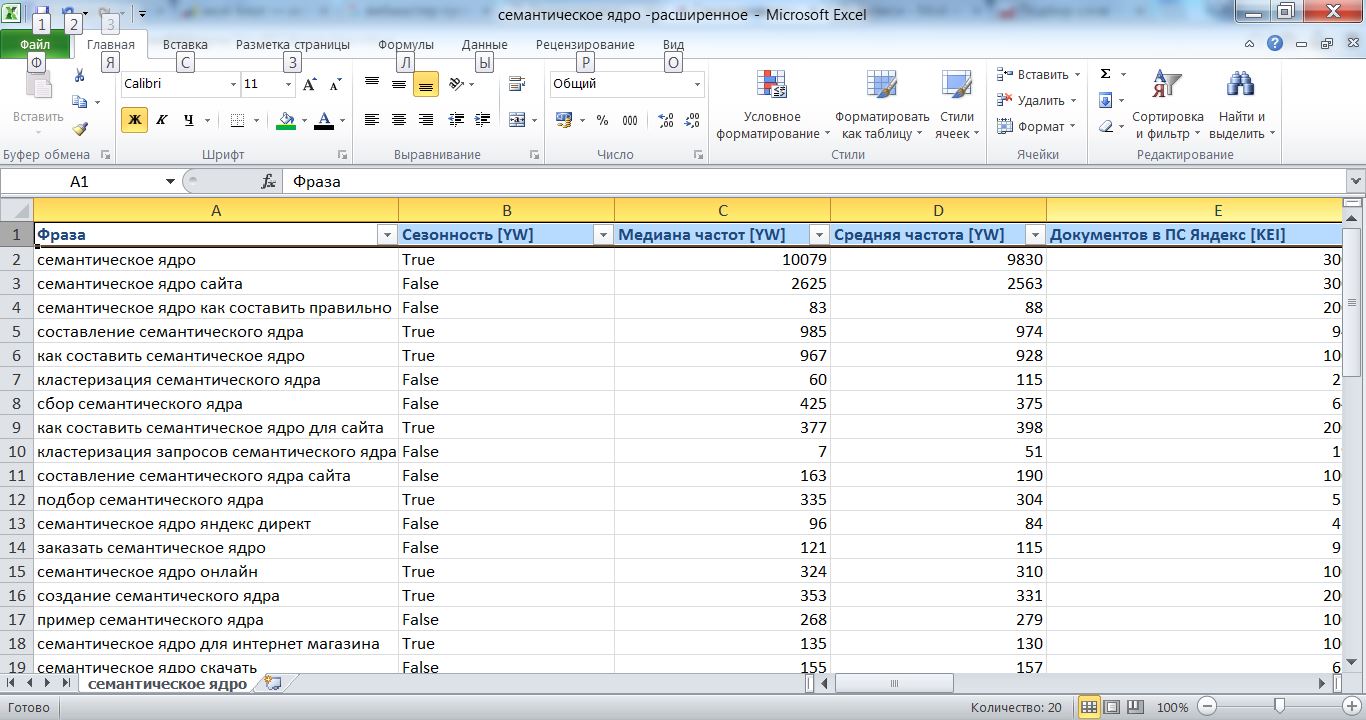 Количество таких фраз зависит от тематики проекта и на больших порталах может исчисляться в миллионах. Основная цель сбора семантического ядра — охват спроса и разработка стратегии по продвижению сайта для повышения видимости в поисковых системах.
Количество таких фраз зависит от тематики проекта и на больших порталах может исчисляться в миллионах. Основная цель сбора семантического ядра — охват спроса и разработка стратегии по продвижению сайта для повышения видимости в поисковых системах.Составление семантического ядра происходит при помощи различных инструментов, наиболее популярные — Яндекс.Wordstat, Планировщик ключевых слов Google AdWords, Похожие фразы Serpstat, Key Collector и другие.
Семантическое ядро сайта состоит из низко-, средне- и высокочастотных запросов. Частотность определяется средним количеством ежемесячных показов в поисковых системах. Для разных тематик числовые показатели, характеризующие частотность, будут отличаться.
Для популярных тематик, например, одежда или игрушки, высокочастотные запросы достигают десятков тысяч показов ежемесячно. В некоторых случаях сверхпопулярные ключевые слова могут запрашиваться миллионы раз в месяц. Например, запрос «Фильмы» в точном вхождении показывается в Яндексе более трех миллионов раз ежемесячно:
Если тематика сайта не популярная, узкая и специфичная, с небольшой целевой аудиторией, то высокочастотными запросами будут считаться ключевые фразы, которые поисковая система показывает 300-500 раз в месяц:
В среднем, классификация для достаточно популярных тематик такова:- низкочастотные запросы — меньше тысячи ежемесячно;
- среднечастотные — от тысячи до трех тысяч в месяц;
- высокочастотные — более трех тысяч ежемесячно.

Использование Планировщика ключевых слов Google Adwords для сбора семантического ядра
Планировщик ключевых слов позволяет подбирать запросы исходя из заданной тематики и указанных словосочетаний. Для работы с Планировщиком нажмем «Начать»:
После этого выберем в меню «Инструменты» — «Планировщик ключевых слов»:
Дальше выберем вариант «Найти новые ключевые слова»:
Предположим, что нам нужно собрать семантическое ядро для онлайн-магазина, в котором есть три категории товаров — мотоциклы, мопеды и спортивные велосипеды.Введем перечисленные ключевые слова и нажмем «Начать» для создания семантического ядра:
Планировщик предложил более трех тысяч запросов по нужной тематике:
Полученную информацию можно использовать как для создания семантического ядра сайта, так и для запуска рекламной кампании. В отчете отображаются ключевые слова, диапазоны показов запросов в месяц, степень конкурентности и стоимость клика по объявлениям при использовании словосочетаний в рекламной кампании.
В данном отчете можно применять фильтры, например, по уровню конкуренции или ставке. Также можно просмотреть группы ключевых слов, объединенные общим смыслом:
Группировка позволит распределить большое семантическое ядро
по разделам и страницам сайта:
Для дальнейшей работы скачаем полученные варианты в .csv формате:
Подбор ключевых фраз в Яндекс.Wordstat
Яндекс.Wordstat позволяет посмотреть статистику по выбранному запросу и узнать все сходные словосочетания. Введем ключевое слово «Мотоцикл», чтобы собрать семантическое ядро данной тематики:
Отобразится общее число всех запросов, в которых использовалось данное слово в любой форме. Возможно, часть запросов не будут релевантна содержимому сайта. Например, для интернет-магазина новых мотоциклов неактуальны запросы «Игры мотоциклы» и «Мотоциклы б/у».Чтобы посмотреть, сколько было запросов с точным соответствием, нужно заключить слово в кавычки и поставить перед ним восклицательный знак:
Онлайн-сервис также позволяет просматривать количество запросов в определенном регионе. Для просмотра такой статистики нужно выбрать вкладку «По регионам»:
Для просмотра такой статистики нужно выбрать вкладку «По регионам»:
Можно переключиться на режим карты, где регионы выделяются разным цветом в зависимости от популярности запроса. В данном примере минимальная популярность соответствует желтому цвету, а максимальная — красному:
Чтобы упростить сбор семантического ядра, можно воспользоваться расширением Yandex Wordstat Helper для Google Chrome. Данное расширение позволяет добавлять нужные словосочетания, нажимая «+», а затем копировать полученный список в буфер обмена для экспорта в файл:
Таким методом в Яндекс. Wordstat можно подобрать все подходящие ключевые слова и добавить их в Excel-файл, созданный ранее посредством «Планировщика ключевых слов». Затем можно найти еще варианты ключевых слов, используя инструмент «Похожие фразы» Serpstat.
Wordstat можно подобрать все подходящие ключевые слова и добавить их в Excel-файл, созданный ранее посредством «Планировщика ключевых слов». Затем можно найти еще варианты ключевых слов, используя инструмент «Похожие фразы» Serpstat.
Расширение семантического ядра с помощью модуля «Похожие фразы» Serpstat
Модуль Serpstat находится в разделе «Анализ ключевых фраз» — «SEO-анализ» — «Похожие фразы». Введем нужное ключевое слово, нажмем «Найти» и получим статистику по всем похожим фразам из ТОП-20:
После получения новых ключевых фраз с помощью модуля стоит добавить их в общий файл, отсортировать по алфавиту и удалить дублирующиеся варианты. Затем нужно перейти к группировке запросов.Для начала работы с модулем просто введите ключевую фразу в форму ниже:
Если вам необходимо быстро проанализировать большое количество фраз, можно сэкономить время и воспользоваться специальной Google Таблицей, разработанной командой Serpstat. Этот документ позволит быстро выгружать информацию из API Serpstat в удобном формате. Подробная инструкция по его использованию доступна в блоге.
Подробная инструкция по его использованию доступна в блоге.
Распределение ключевых фраз по сайту
Группировка ключевых фраз семантического ядра
Для успешного продвижения все полученные ранее фразы необходимо правильно сгруппировать. Анализ ключевых слов помогает правильно определить структуру сайта — высокочастотные и среднечастотные запросы должны соответствовать названиям категорий и подкатегорий, низкочастотные — продвигаться на отдельных страницах.Правильное составление семантического ядра и распределение фраз требует соблюдения следующих правил:
Одна ключевая фраза не должна продвигаться на нескольких страницах одновременно. В противном случае возникает эффект каннибализации запросов.В этой ситуации поисковые роботы либо показывают в выдаче только одну релевантную запросу страницу сайта, либо вообще понизят позиции ресурса, показывая на высоких позициях проекты с более четкой оптимизацией.
Фразы добавляют в текст продвигаемой страницы в различных формах вхождения, помимо этого их используют в мета-тегах и заголовках.
Например, на странице, оптимизированной под запрос «Мотоциклы купить», могут быть такие фразы: «Мотоциклы купить в нашем магазине выгоднее, чем в остальных», «Мотоциклы, купить которые мечтает каждый фанат Харлей-Дэвидсон», «Байки приобрести теперь гораздо проще» и т.д.
Нужно разделить запросы на две группы:- информационные — представляют познавательную ценность, помогают увеличить трафик сайта. Эти запросы привлекают пользователей, заинтересованных тематикой проекта, но не ориентированных в данный момент нa совершение покупки на сайте. Такие запросы могут содержать слова «Как», «Где», «Почему», «Инструкция» и т.д.
Например, в тематике мотоциклов информационными запросами будут: «Езда на мотоцикле», «Тюнинг мотоциклов» и т.д. Для подобных запросов на коммерческом сайте должен быть создан отдельный контентный раздел — блог, новости либо статьи. Нельзя, чтобы такие запросы продвигались на страницах товаров или категорий;
- коммерческие запросы, ориентированные на целевую аудиторию, готовую совершить покупку. Продвижение таких ключевых фраз обеспечивает наиболее высокую конверсию, так как приводит на сайт покупателей, а не просто интересующихся тематикой проекта пользователей.
Основные слова, которые используются в транзакционных запросах — «Купить», «Заказать», «Цена». Например, «Купить мотоцикл Днепр», «Мотоцикл Урал цена» и прочие варианты. Эти запросы размещаются в зависимости от частотности в категориях сайта и карточках товаров.
 Продвижение таких ключевых фраз обеспечивает наиболее высокую конверсию, так как приводит на сайт покупателей, а не просто интересующихся тематикой проекта пользователей.
Продвижение таких ключевых фраз обеспечивает наиболее высокую конверсию, так как приводит на сайт покупателей, а не просто интересующихся тематикой проекта пользователей.В полученных группах ищутся сходные по смыслу словосочетания для распределения по страницам. Например, на одной странице могут продвигаться такие запросы: «Приобрести мотоцикл Ямаха», «Мотоцикл Ямаха цена», «Купить мотоцикл Yamaha».
Помимо текста в карточках товаров, категориях и статьях, ключевые фразы используются для внутренней перелинковки и тегирования. Среднечастотные и низкочастотные запросы, которые не использовались в названиях категорий, можно применять в качестве тегов, чтобы объединять сходные группы товаров или статей.Аналогичной цели служат фильтры, с помощью которых можно создавать посадочные страницы под запросы «красные мотоциклы», «мотоциклы по цене до 1000 долларов», а также сортировать транспортные средства по категориям и прочим параметрам:
Кластеризация фраз с помощью Serpstat
Группировка семантического ядра, содержащего тысячи запросов, может быть трудоемкой и занимать много времени. Предельно упростить и автоматизировать данный процесс можно с помощью модуля «Кластеризация» Serpstat, который доступен в «Инструментах»:
Предельно упростить и автоматизировать данный процесс можно с помощью модуля «Кластеризация» Serpstat, который доступен в «Инструментах»:
Выберем «Создать проект». Введем название, экспортируем ключевые фразы из файла с семантическим ядром, затем выберем регион и поисковую систему:
Затем нужно установить силу связи и тип кластеризации.Сила связи Strong требует большего количества общих URL в топ-30 результатов поисковой выдачи по фразе, Weak — меньшего.
При выборе параметра Soft фразы объединяются в кластер, если хотя бы у одной пары из кластеризуемых фраз есть одинаковые URL в выдаче. При Hard-кластеризации у всех фраз в одном кластере должны присутствовать общие URL в результатах.
Для каждого полученного кластера отображается показатель «Однородность» — степень смысловой связанности ключевых слов между собой. Также в отчете можно просмотреть сайты, занимающие лидирующие позиции по запросам кластера (вкладка «Метатоп»):
Полученные кластеры можно экспортировать в удобном формате:
Хотите узнать, как с помощью Serpstat собрать и кластеризовать ключевые фразы?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
Заключение
- Полное и правильно сгруппированное семантическое ядро — основа внутренней оптимизации и фундамент для продвижения проекта. В SEO семантическое ядро сайта помогает сделать ресурс отвечающим на запросы целевой аудитории на разных этапах воронки продаж и в полной мере предоставлять ей всю необходимую информацию;
- разработка семантического ядра начинается со сбора всех подходящих ключевых фраз, которые будут в дальнейшем использоваться для продвижения;
- собранные фразы необходимо сгруппировать для дальнейшего распределения по страницам сайта;
- ключевые фразы из семантического ядра используются в различных формах в названиях категорий, текстах сайта, мета-тегах страниц, фильтрах категорий, при внутренней перелинковке и создании посадочных страниц.
 В SEO семантическое ядро сайта помогает сделать ресурс отвечающим на запросы целевой аудитории на разных этапах воронки продаж и в полной мере предоставлять ей всю необходимую информацию;
В SEO семантическое ядро сайта помогает сделать ресурс отвечающим на запросы целевой аудитории на разных этапах воронки продаж и в полной мере предоставлять ей всю необходимую информацию;«Список задач» — готовый to-do лист, который поможет вести учет
о выполнении работ по конкретному проекту. Инструмент содержит готовые шаблоны с обширным списком параметров по развитию проекта, к которым также можно добавлять собственные пункты.
| Начать работу со «Списком задач» |
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
7 дней бесплатноОцените статью по 5-бальной шкале
4.53 из 5 на основе 30 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Используйте лучшие SEO инструменты
Подбор ключевых слов
Поиск ключевых слов – раскройте неиспользованный потенциал вашего сайта
Возможности Serpstat
Возможности Serpstat – комплексное решение для эффективного продвижения вебсайтов
Кластеризация ключевых слов
Кластеризация ключевых слов автоматически обработает до 50 000 запросов в несколько кликов
SEO аудит страницы
Проанализируйте уровень оптимизации документа используя SЕО аудит страницы
Рекомендуемые статьи
How-toАнастасия СотулаКак настроить подписку на обновления сайта
How-toDenys KondakКак проверить отображение сайта во всех браузерах
How-toАнастасия СотулаПокупка трафика: как купить трафик на сайт и где это сделать
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Группировка ключевых слов на основе слов в Excel
Отличное исследование ключевых слов является одной из основных основ вашей стратегии SEO.
Некоторые считают это одной из наиболее «базовых» задач SEO, которую часто делегируют младшему члену команды.
Однако существует огромная разница между базовым исследованием ключевых слов и подробным, эффективно сгруппированным исследованием, подготовленным для определения приоритетов и использования для других задач SEO.
Существует множество блестящих материалов о процессе исследования ключевых слов, так что я не буду вдаваться в подробности.
Я добавляю в беседу способ группировки и пометки ключевых слов на основе содержащихся в них слов, все делается в Excel.
Метод, который я собираюсь использовать, отлично работает, потому что:
- Он быстрый
- Вам не нужно знать, как кодировать
- Масштабируемость — с помощью этого я классифицировал наборы ключевых слов в 10 000 единиц.
Тем не менее, у него есть свои подводные камни. Основная из них заключается в том, что теги ключевых слов на основе слов не могут точно определить намерение. Если вы ищете решение для этого, у Кевина Индига есть блестящий процесс.
Электронная таблица
Как я уже сказал, я построил это с помощью Excel, чтобы сделать его максимально доступным. Это не мой «полный» лист исследования ключевых слов, а только часть, которую я использую для категоризации. Вот ссылка для скачивания:
Скачать
Таблица состоит из двух частей: фактического списка ключевых слов (на вкладке «Исследование ключевых слов») и вкладки «Конфигурация — Категоризация».
На этой вкладке вы найдете различные длинные таблицы с заголовками вверху, которые соответствуют заголовку, указанному на вкладке «Исследование ключевых слов». По умолчанию установлены значения «Категория», «Подкатегория», «Пользовательский 1» и «Пользовательский 2».
По умолчанию установлены значения «Категория», «Подкатегория», «Пользовательский 1» и «Пользовательский 2».
Обычно я редактирую их, чтобы они соответствовали требованиям клиента, в зависимости от того, как я хочу их классифицировать. Редактирование заголовков на листе «Исследование ключевых слов» автоматически отразится на листе классификации.
Например, я недавно пометил ключевые слова на основе следующего для клиента, который создает контент для казино/бинго.
В каждой таблице есть столбцы «Искать» и «Возврат». Левый столбец — это то, что вы проверяете (используя логику «содержит»), а затем правый столбец будет возвращен на листе «Исследование ключевых слов».
Вы, наверное, уже поняли суть.
После того, как вы провели исследование, скопируйте и вставьте список ключевых слов в первый столбец листа «Исследование ключевых слов».
Затем перейдите на вкладку категоризации и начните использовать каждую таблицу для категоризации ключевых слов по своему усмотрению.
Это так просто.
Некоторые ключевые моменты, на которые следует обратить внимание:
- Таблицы имеют приоритет снизу вверх. Если ваше ключевое слово соответствует нескольким запросам, самое низкое значение в таблице определяет, как оно будет классифицировано.
- Использование может использовать подстановочные знаки! Если вы посмотрите пример снимка экрана, которым я поделился выше, вы увидите, что у меня есть одна категория, которая ищет «бинго * слот». Когда оба термина отображаются в указанном порядке в ключевом слове, оно будет отнесено к категории «Бинго и игровые автоматы», независимо от того, какие слова находятся между ними.
Еще одна вещь, которую вы заметите, как только вы начнете, это быстро, и формула проста .
Почти два года назад я написал в Твиттере об аналогичной методологии с использованием функций SERP, которую я планирую развивать и выпускать в будущем.
Мне было интересно, поэтому я решил написать твит, пример быстрой группировки ключевых слов с использованием функций SERP для определения намерений пользователя и слов в ключевом слове для категоризации 🏃♂️💨
Более 4000 ключевых слов, и это занимает меньше секунды 🤓 #seo #SEOChat #KeywordResearch pic.
— Сэм Андервуд 🇬🇧 (@SamUnderwoodUK) 23 апреля 2019 г.
 twitter.com/haHSYdT2FH
twitter.com/haHSYdT2FHКак это работает
Я видел еще один способ категоризации на основе слов — использование ПОИСКФункция 0072. Формула выглядит следующим образом, когда вы хотите проверить несколько слов:
=ЕСЛИ(ИЛИ(НЕ(ЕОШИБКА(ПОИСК("есть",A3))), НЕ(ЕОШИБКА(ПОИСК("статья", A3))),НЕ(ISERR(ПОИСК("лучше",A3))),НЕ(ISERR(ПОИСК("увеличение",A3))),НЕ(ISERR(ПОИСК("can",A3)))= ИСТИНА,"Осведомленность",ЕСЛИ(ИЛИ(НЕ(ISERR(ПОИСК("альтернатива",A3))),НЕ(ISERR(ПОИСК("приложение",A3))),НЕ(ISERR(ПОИСК("сравнение", A3))),НЕ(ISERR(ПОИСК("выгода",A3))),НЕ(ISERR(ПОИСК("лучшее",A3))),НЕ(ISERR(ПОИСК("компании",A3))), НЕ(ЯОШИБКА(ПОИСК("направления",A3))),НЕ(ЯОШИБКА(ПОИСК("оценка",A3))), НЕ(ЯОШИБКА(ПОИСК("признак",A3))),НЕ(ЯОШИБКА( ПОИСК("оборудование",A3))),НЕ(ISERR(ПОИСК("установка",A3))),НЕ(ISERR(ПОИСК("как",A3))),НЕ(ISERR(ПОИСК("ведущий" ,A3))),НЕ(ISERR(ПОИСК("рядом со мной",A3))),НЕ(ISERR(ПОИСК("или",A3))),НЕ(ISERR(ПОИСК("программа",A3)) ),НЕ(ISERR(ПОИСК("обзор",A3))),НЕ(ISERR(ПОИСК("услуга",A3)))=ИСТИНА,"Рассмотрение",ЕСЛИ(ИЛИ(НЕ(ISERR(ПОИСК("получить ",A3))),НЕ(ISERR(ПОИСК("агентство",A3))),НЕ(ISERR(ПОИСК("агент",A3))),НЕ(ISERR(ПОИСК("анализ",A3)) ),НЕ(ISERR(ПОИСК("применить",A3)))=ИСТИНА,"Решение","Намерение не найдено"))))))
Кодовый язык: Excel (excel) Этот метод замедлит вашу машину до полной остановки при работе с большими наборами данных. И это также отнимает много времени и трудно управлять. Вам придется многократно копировать и вставлять формулу каждый раз, когда вы ищете другое слово.
И это также отнимает много времени и трудно управлять. Вам придется многократно копировать и вставлять формулу каждый раз, когда вы ищете другое слово.
У меня проще. Это выглядит так:
=ЕСЛИОШИБКА(ПРОСМОТР(2,1/СЧЕТСЛИ([@Keyword],"*"&категория[Искать]&"*"),категория[Возврат]),"")
Язык кода: PHP (php) Да, верно, это просто две функции, используемые вместе, ПРОСМОТР и СЧЁТЕСЛИ .
ПРОСМОТР предназначен для возврата правильного результата из вашей таблицы. COUNTIF возвращает «1», если запрос в столбце ключевых слов найден в столбце «Искать» таблицы.
Вывод намерения
Наряду с группировкой похожих ключевых слов в логические категории на основе схожести вам также может потребоваться группировка на основе намерения ключевого слова.
На вкладке категоризации вы увидите, что я создал для этого таблицу.
Разделяет ключевые слова на:
- Навигация: Пользователи, желающие перейти на определенный сайт
- Информационное: Пользователи ищут информацию
Информационные термины классифицируются на основе стандартных терминов, которые люди используют при поиске информации, например. что, где, как, лучший, советы и т. д.
Навигационные термины классифицируются на основе общих шаблонов URL или из списка названий брендов, которые вы можете ввести (перезаписывая «Бренд 1» и т. д. в столбце «Поиск»).
Вы заметите, что коммерческие термины не классифицируются по категориям. Это потому, что без анализа SERP или более интеллектуального алгоритма категоризации мы не можем быть уверены, что ключевое слово является коммерческим.
Мы могли бы сказать, что если ключевое слово не включает ни одно из упомянутых нами, пометить его как коммерческое. Однако возьмем термин «Эйфелева башня».
Это информационный термин, но вы не можете сделать вывод, просто взглянув на эти два слова, не понимая сути (Google делает это благодаря своей сети знаний).
Если вы хотите пометить «Коммерческие» или добавить дополнительные информационные категории, вручную добавьте в эту таблицу дополнительные фразы.
Или комбинируйте эту методологию с отображением намерений на основе функций SERP.
Что дальше?
После того, как вы классифицировали свои ключевые слова, вы можете перейти к:
- Оценка возможностей — Измерение потенциального роста в различных рыночных нишах
- Анализ рынка — Анализ положения конкурентов в различных рыночных нишах
- Структура сайта — Организация сайта на основе различных способов поиска
Все три из вышеперечисленных требуют отдельного поста о том, как их делать (у меня уже есть один для структуры сайта).
Сейчас я объясню, какую пользу им приносит описанный выше процесс пометки.
Анализ рынка
Одна из замечательных особенностей точной пометки ключевых слов заключается в том, что вы можете точно определить, работают ли конкретные стратегии конкурентов.
Вот пример.
После пометки ключевых слов мы начинаем анализ конкурентов и замечаем, что один из конкурентов включает слово «лучший» в теги h2 и title, а наш сайт — нет.
Мы пометили наши ключевые слова и создали группу для всех терминов, содержащих слово «лучший». Итак, подытожив объем поиска, мы знаем, что существует разумное количество запросов «лучший [название продукта]».
Хорошо ли работает этот конкурент в этих поисковых запросах?
Вы можете выяснить это вручную (о чем я напишу в будущем), но если вы используете трекер рангов, поддерживающий как тегирование, так и импорт через CSV, вы можете отфильтровать «лучший» тег и посмотреть, видимость выше, чем у конкурентов для этого термина.
Это может дать вам полезную информацию для предложений, которые вы сделаете в рамках своей стратегии SEO.
Структура сайта
Эффективная маркировка также упрощает формирование тематических кластеров и эффективных таксономий для структуры сайта.
Это достигается за счет эффективного использования столбцов категорий и подкатегорий. Было бы лучше, если бы вы классифицировали так, чтобы столбец «Категория» мог быть страницами столба.
Подкатегории должны быть страницами контента, исходящими из основной страницы.
Например, у нас может быть категория «Нью-Йорк», но затем подкатегории для:
- Население
- Чем заняться
- Окрестности
- Время
- Мэр
- Минимальная заработная плата
- Университеты
Анализ и исследование SERP необходимы, чтобы понять, нужны ли отдельные страницы для каждого из вышеперечисленных.
Однако только из этих двух примеров видно, что выполнение работы на этом этапе делает будущие SEO-задачи более эффективными.
Другие методы группировки ключевых слов
Помимо группировки по словам, есть еще один отличный способ категоризировать ключевые слова — посмотреть, насколько похожи результаты поиска для разных ключевых слов.
Если результаты поиска похожи или URL ранжируется по нескольким ключевым словам, мы можем предположить, что ключевые слова в наборе данных должны быть связаны.
Это эффективный способ группировки ключевых слов, поскольку вы изучаете понимание Google назначения различных ключевых слов.
Звучит здорово, но каковы недостатки?
- Скрапинг Google может быть дорогостоящим
- После этого вы, вероятно, захотите внести некоторые ручные корректировки
- Группировка не является иерархической, т.е. без категорий и подкатегорий
Смешанный подход между этим методом и категоризацией на основе слов противодействует некоторым недостаткам, и это, как правило, то, что я делаю.
Вот несколько инструментов, которые помогут вам начать работу, если вы заинтересованы:
- SE Ranking Keyword Grouper — этот инструмент делает именно то, что я объяснил ранее, и позволяет вам ввести свой собственный набор данных для группировки. 0016
- Кластеризация ключевых слов Serpstat — то же, что и выше
- Родительское ключевое слово Ahrefs — в инструменте обозревателя ключевых слов Ahrefs есть столбец для родительского ключевого слова; это использует поисковую выдачу и объемы поиска, чтобы определить, как ключевые слова должны быть сгруппированы.
 0016
0016Заключительные слова
Надеюсь, вы найдете это полезным. Один из лучших способов улучшить вашу SEO-игру — это улучшить процесс, когда дело доходит до исследований и расстановки приоритетов, поэтому я надеюсь найти время, чтобы больше рассказать об этой теме в будущем.
Исследование и анализ ключевых слов в Excel - Группировка ключевых слов
ИССЛЕДОВАНИЕ И АНАЛИЗ КЛЮЧЕВЫХ СЛОВ В EXCEL: ГРУППИРОВКА КЛЮЧЕВЫХ СЛОВ (+ БЕСПЛАТНЫЙ ШАБЛОН)
Четверг, 19 января 2023 г. Делия Модест
9000 2 Если вы проводите исследование ключевых слов для SEO или анализа текста для других целей, Excel может быть очень удобен, если вы реализуете некоторые приемы, которыми я собираюсь поделиться с вами в серии постов под названием «Исследование ключевых слов в Excel».
В этом посте мы рассмотрим одну из основных концепций исследования ключевых слов — группировку ключевых слов.
Почему важна группировка ключевых слов?
Когда вы проводите исследование ключевых слов для SEO, результатом этого исследования будет карта ключевых слов, которая по существу представляет собой список ключевых слов и их объемов поиска, сгруппированных по определенным интересующим темам. Конечно, всегда есть несколько предопределенных тем, но наиболее важные темы обычно обнаруживаются в ходе самого исследования. И именно поэтому нам нужна группировка — чтобы определить темы с лучшими комбинациями ключевых слов и их соответствующими объемами поиска.
Придумайте следующие примеры группировки: брендированные ключевые слова, населенный пункт (город, регион), год, транзакционные, информационные.
Подготовка и очистка данных.
Обо всем по порядку. В любых задачах, связанных с большими объемами данных, самое главное — правильно подготовленные и чистые данные. У нас уже есть несколько таблиц с различными ключевыми словами. После того, как мы объединим их в один список со столбцами «Ключевое слово», «Объем поиска» и «Конкуренция», вот что мы собираемся сделать:
У нас уже есть несколько таблиц с различными ключевыми словами. После того, как мы объединим их в один список со столбцами «Ключевое слово», «Объем поиска» и «Конкуренция», вот что мы собираемся сделать:
1. Сделайте из этого списка «умную таблицу», щелкнув любую ячейку в вашем списке и нажав CTRL+T на клавиатуре (или перейдите в верхнее меню «Вставка» → «Таблица»).
Вы увидите, что Excel автоматически обнаружил весь список и выбрал все необходимые ячейки. Если этого не произошло, то выделите вручную весь диапазон и затем повторите создание таблицы.
2. Удалите повторяющиеся ключевые слова из таблицы. Нажмите на любую ячейку в вашей таблице и перейдите в верхнее меню Данные → Удалить дубликаты.
В новом всплывающем окне снимите выделение со всех столбцов, нажав кнопку «Снять выделение со всех», затем выберите только столбец «Ключевое слово» и нажмите «ОК».
Базовая группировка: количество слов и объем поиска.
Теперь вы готовы начать группировать ключевые слова. Проведем базовую группировку: по количеству слов во фразе и по объему поиска.
Проведем базовую группировку: по количеству слов во фразе и по объему поиска.
Поскольку не существует формулы по умолчанию для подсчета слов в одной ячейке, сейчас мы собираемся вычислить количество пробелов между словами (если они есть).
Вот формула для этого:
=ДЛСТР([@Ключевое слово])-ДЛСТР(ПОДСТАВИТЬ([@Ключевое слово], “,”))+1
Группировка по объему поиска возможна с числом вложенные операторы ЕСЛИ. Нам просто нужно определить размер ведра. Давайте воспользуемся следующими сегментами/группами:
- Ниже 100
- 100-499
- 500-999
- 1000+
Вот формула для такого группирования:
=ЕСЛИ([@[Объем поиска] ]<100,0-100″,IF([@[Объем поиска]]<500,100-499″,IF([@[Search Volume]]<1000,500-999″,1000+”)))
Обратите внимание, что в случае вложенных операторов IF важен порядок вложенных формул: Excel вычисляет такие формулы слева направо, то есть сначала будет проверяться самое первое условие, если условие не выполняется, то будет проверяться второе условие, затем третье и так далее. В нашем случае, если поставить условие «<1000» на первое место, то первых двух групп мы не увидим.
В нашем случае, если поставить условие «<1000» на первое место, то первых двух групп мы не увидим.
Расширенная группировка: использование дополнительных таблиц для автоматизации формул.
Пример с вложенными операторами IF — это тот, который мы сейчас собираемся улучшить, чтобы выполнить расширенную группировку. Мы также собираемся использовать функции Total Row наших «умных таблиц».
Давайте кратко рассмотрим, что такое Total Row «умного стола».
Total Row , если он включен, предлагает ряд вычислений, которые он может выполнять для каждого столбца: подсчитывать строки, суммировать числа, показывать минимальное или максимальное значение и т. д. Также можно использовать другие встроенные функции Excel. Лучшее в Total Row заключается в том, что он работает независимо от размера «умной таблицы», то есть независимо от того, есть ли строки 5 или 5000, он будет выполнять один и тот же расчет. Итак, зная все, что мы собираемся использовать Total Row , чтобы быстро создать несколько условий IF для нашей расширенной группировки с помощью функции REPT (повтор).
Взгляните на пример ниже.
Здесь вы видите таблицу с двумя столбцами: Lookup и Formula . Первый столбец предназначен только для ручного ввода. Формула автоматически создает условие ЕСЛИ, которое мы собираемся использовать в дальнейшем. Он просто берет значение столбца Lookup и объединяет его с другими текстовыми элементами, чтобы сделать из него строку формулы. Другими словами, результаты формул в этом столбце — это другие формулы (пока воспринимаемые Excel как текстовые строки).
Вот формула, которая принимает значения и объединяет их:
="ЕСЛИ(ЧИСЛО(ПОИСК("""&ПОДСТАВИТЬ([@Lookup]", ",*")&""""&",[@Keyword ]"&"))",""&[@Lookup]&"""",
А вот результат этой формулы:
IF(ISNUMBER(SEARCH("seo",[@Keyword]))",seo",
Теперь вы можете увидеть несколько условий IF в этом столбце для каждой строки . И да, ошибки нет — закрывающие скобки были специально опущены. Но как мы можем объединить все это в одну формулу? Магия происходит в Total Row , где мы используем следующую формулу для объединения всех Условия ЕСЛИ в одной длинной строке:
=CONCAT("=",[Формула],FALSE,REPT(")",COUNTA([Формула])))
Эта формула берет все значения из столбца Формула и объединяет их в одну строку. Он также добавляет символ «=» и добавляет закрывающие круглые скобки, чтобы результирующая строка выглядела точно так, как должна выглядеть формула Excel.
Он также добавляет символ «=» и добавляет закрывающие круглые скобки, чтобы результирующая строка выглядела точно так, как должна выглядеть формула Excel.
Однако в Excel есть два ограничения, о которых вы должны знать.
Первый заключается в том, что максимальное количество вложенных операторов ЕСЛИ в формуле равно 64, что означает, что для одного столбца с группами ключевых слов мы можем использовать не более 64 различных ключевых слов. Вот почему, например, в анализе ключевых слов с географической группировкой по городам потребуется две такие колонки для городов Германии с населением более 100 000 человек.
Второе ограничение — длина формулы Excel. Он не может превышать 8,192 символа. Это ограничение никогда не затрагивало мои самые сложные формулы, но все же оно существует.
Реализация правил группировки.
Итак, что нам теперь делать со всеми этими столбцами, строками и формулами?
- Скопируйте полученную ячейку столбца Formula в нашу Total Row .
