
что это, виды и типы поисковых запросов
5686
| How-to | – Читать 12 минут |
Прочитать позже
Анастасия Сотула
Редактор блога Serpstat
Среднестатистический пользователь ПК каждый день генерирует множество видов запросов — от «количества звезд на небе» и «ближайшей станции техобслуживания» до «кредитов онлайн», «как влюбить в себя парня» или «чем кормить котенка 2 месяца».
С одной стороны, классификация поисковых запросов нужна сеошникам и контентщикам, чтобы повышать показатели эффективности (KPI) своей работы. С другой – использование основных типов поисковых запросов по назначению позволит пользователю находить в сети действительно релевантную информацию.
Содержание
Что такое поисковые запросы?
Основные типы запросов в поисковых системах
Виды поисковых запросов
Как определить частотность ключевых слов
Другие виды запросов
— Типы поисковых запросов по степени конкурентности
— Типизация ценности поисковых запросов
— Какие еще бывают поисковые запросы?
FAQ
Выводы
Что такое поисковые запросы?
Поисковые запросы — слова, которые пользователь ввел в строку поисковика. Самый популярный поисковик Google, за ним идут Bing, Baidu, Yahoo, в рунете Яндекс и Рамблер, в Китае — Soso. При помощи введения поискового запроса в соответствующую строку пользователь запрашивает у глобальной сети нужную ему информацию.
Самый популярный поисковик Google, за ним идут Bing, Baidu, Yahoo, в рунете Яндекс и Рамблер, в Китае — Soso. При помощи введения поискового запроса в соответствующую строку пользователь запрашивает у глобальной сети нужную ему информацию.
Виды запросов зависят от информации, которая нужна пользователю, от типа поисковой системы, от устройства (десктоп, планшет, смартфон). Самый распространенный способ введения поискового запроса в Гугл — слово или группа слов. Но, взять информацию у поисковой системы можно с помощью картинки, фотографии, аудио-послания. А вот и пример любопытной инверсии в мире запросов: задаем запрос словом, а результат получаем в виде изображения.
Еще одна особенность поисковых запросов — они не регулируются правилами синтаксиса. Пользователь может пропустить предлоги, не обязан использовать знаки препинания. Например, фраза «количество звезд на небе» в поисковой строке может выглядеть, как «звезды небо количество», а результаты выдачи будут идентичными.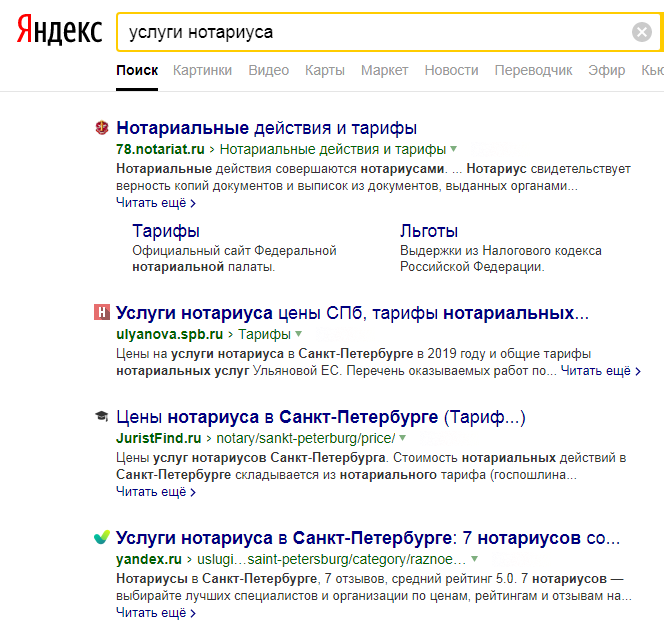
Типы поисковых запросов, а также их частотность, находится в сфере интересов, а также ответственности специалистов по SEO и контекстной рекламе.
Основные типы запросов в поисковых системах
Эксперты (SEO-специалисты) разделяют поисковые запросы на три основные группы: информационные, навигационные, транзакционные. И, хотя эта систематика нигде не поддерживается теоретически, эмпирически ее подтверждают фактические запросы в поисковых системах.
- Информационные запросы — словесные задачи для поисковой системы самой широкой тематики. Пользователю нужна информация. Ему все равно, на каком сайте она опубликована. Ему всего лишь нужен ответ на вопрос — чем кормить ежика, что сказал Воланд Маргарите перед балом, писать «присоедЕниться или присоединиться», пингвин живет в Арктике или в Антарктике? Именно информационные запросы составляют основную массу вопросов пользователя к глобальной сети.

- Навигационные запросы — задача для поисковой системы найти конкретный сайт или отдельную страницу веб-ресурса. Самый простой пример — пользователь пишет имя/фамилию коллеги и дописывает слово «инстаграм». Или пишет «обручальное кольцо» в сочетании с брендом — известным производителем ювелирных украшений, или слово «красное» с немецкой, японской или американской маркой автомобиля.
- Транзакционные запросы демонстрируют намерение пользователя выполнить конкретное действие: купить, продать, смотреть, скачать, открыть, закрыть, взять, арендовать, утилизировать, читать. Типичные «волшебные» транзакционные слова — «дом купить», «мелодраму смотреть», «мусор утилизировать», «лыжи продать».
Виды поисковых запросов
Еще одна классификация видов поисковых запросов ранжирует пользовательский интерес относительно частоты употребления ключевых слов:
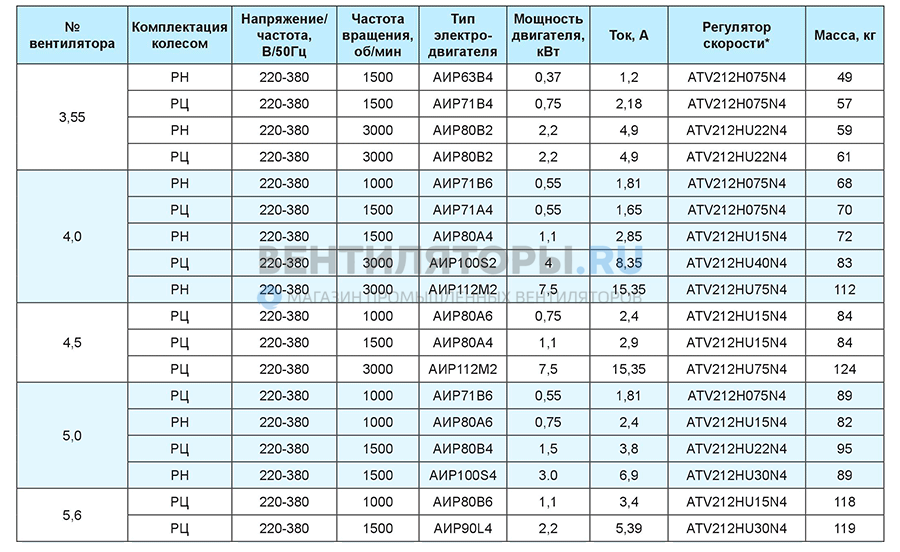
- Высокочастотные запросы (ВЧ). Ключевые слова, которые состоят из 1-3 слов. Имеют общую смысловую нагрузку — квартира купить, Египет путевка, ремонт под ключ, свадебное платье. Именно их задают люди, когда хотят только изучить вопрос — посмотреть, что вообще может предложить им Гугл. Высокочастотные — самые высококонкурентные запросы. Вывести свой сайт в ТОП-10 по запросу ВЧ — сложно, престижно, выгодно. Использование высокочастотных слов в текстах позволяет органически увеличить охват аудитории.
- Среднечастотные запросы (СЧ). Ключевые слова состоят из 3-5 слов. Они четко позволяют определить намерение пользователя — «квартира купить дешево в Москве», «Египет путевка отель 4 звезды», «ремонт под ключ в Минске», «свадебное платье русалка на прокат». Использование среднечастотных запросов позволяет повысить коэффициент конверсии трафика — количество посетителей сайта, которые совершили заказанное целевое действие (открыли, скачали, купили).
- Низкочастотные запросы (НЧ). Ключевые слова с максимальной конкретизацией. Например, «двухкомнатная квартира купить дешево в Москве, во Внуково», «Египет путевка отель Альбатрос 4 звезды апрель», «свадебное платье русалка зеленого цвета на прокат в Кемерово». Настолько конкретные запросы набирают считанные единицы пользователей ПК. Зато, люди, которые забивают в поисковую строку такой запрос, ищут конкретный предмет/услугу, и если их запрос удовлетворен, то они готовы купить. Соответственно, продвижение по НЧ дает максимально высокий коэффициент конверсии трафика. А сайт по низкочастотным запросам вывести в ТОП-10 намного легче, чем по ВЧ и СЧ.
 Имеют общую смысловую нагрузку — квартира купить, Египет путевка, ремонт под ключ, свадебное платье. Именно их задают люди, когда хотят только изучить вопрос — посмотреть, что вообще может предложить им Гугл. Высокочастотные — самые высококонкурентные запросы. Вывести свой сайт в ТОП-10 по запросу ВЧ — сложно, престижно, выгодно. Использование высокочастотных слов в текстах позволяет органически увеличить охват аудитории.
Имеют общую смысловую нагрузку — квартира купить, Египет путевка, ремонт под ключ, свадебное платье. Именно их задают люди, когда хотят только изучить вопрос — посмотреть, что вообще может предложить им Гугл. Высокочастотные — самые высококонкурентные запросы. Вывести свой сайт в ТОП-10 по запросу ВЧ — сложно, престижно, выгодно. Использование высокочастотных слов в текстах позволяет органически увеличить охват аудитории. Настолько конкретные запросы набирают считанные единицы пользователей ПК. Зато, люди, которые забивают в поисковую строку такой запрос, ищут конкретный предмет/услугу, и если их запрос удовлетворен, то они готовы купить. Соответственно, продвижение по НЧ дает максимально высокий коэффициент конверсии трафика. А сайт по низкочастотным запросам вывести в ТОП-10 намного легче, чем по ВЧ и СЧ.
Настолько конкретные запросы набирают считанные единицы пользователей ПК. Зато, люди, которые забивают в поисковую строку такой запрос, ищут конкретный предмет/услугу, и если их запрос удовлетворен, то они готовы купить. Соответственно, продвижение по НЧ дает максимально высокий коэффициент конверсии трафика. А сайт по низкочастотным запросам вывести в ТОП-10 намного легче, чем по ВЧ и СЧ.Нюанс! В контекстной рекламе высокочастотные фразы лучше не использовать. Они не дают четкого представления о товаре или услуге. Поэтому большинство людей, которые перейдут по такой рекламе на сайт продавца, будут разочарованы. Они быстро покинут сайт, чем дадут системе ложный сигнал, что сайт — не очень хороший, не соответствует запросам пользователя, что может опустить веб-ресурс в поисковой выдаче.
Как определить частотность ключевых слов
Частотность основных типов поисковых запросов определяется по тому, сколько раз конкретная фраза (кредит онлайн, пиццу заказать быстро, серьги с сапфиром каталог смотреть) была введена разными людьми в строку поисковика за определенный промежуток времени — в течение месяца, за декаду, за неделю, за один день.
Где берем цифры и проверяем частоту запросов?
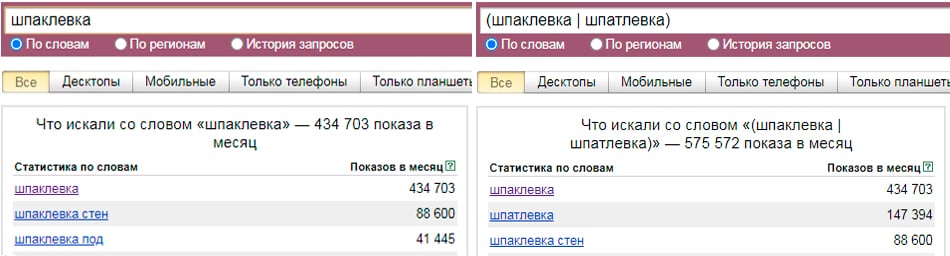
Узнать частотность по любой поисковой системе и региональной базе данных можно с помощью Serpstat. Достаточно ввести ключевую фразу в поисковую строку, выбрать нужную поисковую базу и нажать «Поиск».
Проверка частотности ключевых слов в Serpstat
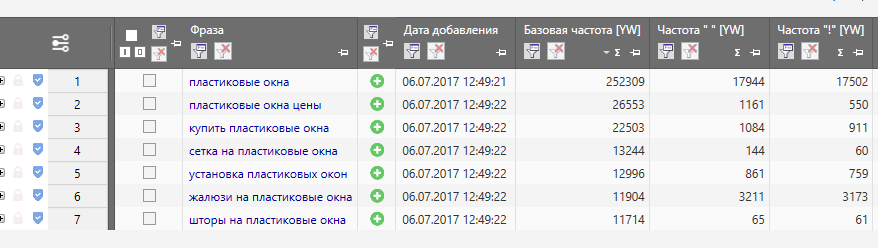
Если нас интересует поисковая система Яндекс, то используем сервис Вордстат. Он бесплатный. Забиваем в окошечко сервиса Yandex WordStat одно или несколько слов по интересующей нас тематике. Кроме того, выставляем период, например, месяц. Пара секунд — и Яндекс выбрасывает нам результат. Вверху таблицы будут размещены высокочастотные запросы, потом среднечастотные и низкочастотные, которые позволят оценить пользовательский интерес к вашей тематике.
Если нас интересует поисковая система Гугл, то используем сервис Google Ads (AdWords). Для этого нужно зайти в свой аккаунт Google Рекламы. Выбрать строку «Все кампании», а в ней — «Поисковые запросы» и запросить «Отчет». В него попадут наборы слов, которые вводили в поисковую строку пользователи за последние 30 дней. Или запросы, на которые припал максимальный объем поиска. В результате вы получите столбец «Ключевое слово» с цифрами и столбец «тип соответствия». Это позволит подобрать слова, близкие к вашему списку ключевых фраз, чтобы создать новые или выбрать самые удачные комбинации ключевых слов для органического продвижения.
Выбрать строку «Все кампании», а в ней — «Поисковые запросы» и запросить «Отчет». В него попадут наборы слов, которые вводили в поисковую строку пользователи за последние 30 дней. Или запросы, на которые припал максимальный объем поиска. В результате вы получите столбец «Ключевое слово» с цифрами и столбец «тип соответствия». Это позволит подобрать слова, близкие к вашему списку ключевых фраз, чтобы создать новые или выбрать самые удачные комбинации ключевых слов для органического продвижения.
Важно! Частота запросов Гугл оценивается лишь с учетом ниши бизнеса. Потому что количество людей, которые хотят купить «сосну Веймута саженцы» и «путевку в Турцию» отличается на несколько порядков. Для «сосны Веймута саженцы» — 80 запросов в месяц будут высокочастотными, а вот для «путевка в Турцию» может понадобиться не меньше, чем 80 000 человек.
Другие виды запросов
Еще одна классификация поисковых запросов показывает те, которые забрасывают в одну из систем поисковиков пользователи, относительно локации объекта поиска. Геозависимые вопросы — «парикмахерская улица Персиковая Киев», «СТО Виноградарь». А геонезависимые лишены этой привязки к улице, микрорайону, району, населенному пункту.
Геозависимые вопросы — «парикмахерская улица Персиковая Киев», «СТО Виноградарь». А геонезависимые лишены этой привязки к улице, микрорайону, району, населенному пункту.
Отдельное беспокойство господам-сеошникам доставляют безликие, обрубленные поисковые запросы. Например, человек пишет Гуглу — «автомобиль». Что он хочет — купить, продать, арендовать, посмотреть каталог или отремонтировать, непонятно.
А вот и другие виды поисковых запросов — по степени конкурентности и своей коммерческой ценности.
Типы поисковых запросов по степени конкурентности
Эта систематика подобна высокочастотным, среднечастотным, низкочастотным запросам, но используется в основном теми, кто занимается настройкой и ведением контекстной рекламы — это их классификация и их хлеб.
- Высококонкурентные запросы. Если вписать в объявление такие ключевые слова, то они дадут максимальное количество переходов на сайт. Соответственно, объявления с ними имеют высокую стоимость. Поэтому их не получается использовать тем, у кого бюджеты ограничены.
- Среднеконкурентные запросы. Эти ключевые слова активно используются в объявлениях контекстной рекламы и для органического продвижения сайтов.
- Низкоконкурентные запросы. Объявления с ними стоят дешево, но чтобы получить ожидаемый эффект, их нужно внедрять в текст целыми пачками.
 Поэтому их не получается использовать тем, у кого бюджеты ограничены.
Поэтому их не получается использовать тем, у кого бюджеты ограничены.Узнать конкурентность запроса как для органики, так и для платной выдачи также можно в отчете по ключевым фразам Serpstat.
- Это уровень конкуренции (сложности) для продвижения по ключевой фразе в органике.
- Это конкуренция по запросу в платной выдаче.
Конкурентность запросов в Serpstat
Типизация ценности поисковых запросов
А вот и самые интересные виды запросов в поисковых системах — коммерческие и некоммерческие.
Коммерческие запросы. В них есть действие (купить, продать, заказать) или упомянуты волшебные слова «цена», «стоимость». Именно их использование в контекстной рекламе регулярно приводит на сайт заказчика целевой трафик.
В них есть действие (купить, продать, заказать) или упомянуты волшебные слова «цена», «стоимость». Именно их использование в контекстной рекламе регулярно приводит на сайт заказчика целевой трафик.
Некоммерческие запросы. Содержат фразы, которые помогают пользователю найти инструкцию, рецепт, создать обзор, изготовить игрушку своими руками. Такой тип контента является полезным для пользователя и, соответственно, для сайта, но в контекстной рекламе его не используют.
Критерий коммерческой ценности активно используется в классификации видов запросов в поисковых системах, потому что с его помощью оценивают экономический выхлоп и финансовые перспективы.
Какие еще бывают поисковые запросы?
Сезонные запросы появляются в привязке ко времени года, к конкретному празднику. Их популярность растет в сезон или увеличивается к определенной дате, а потом резко падает. Например, «смартфон черная пятница», «сноуборд дешево», «костюм снежинки на прокат». Если заранее учесть сезонные запросы в стратегии продвижения сайта и рекламных объявлений, то можно отщипнуть для себя (заказчика) жирный кусок целевого трафика.
Хотите узнать, как с помощью Serpstat оптимизировать сайт?
Нажимайте на космонавта и заказывайте бесплатную персональную демонстрацию сервиса! Наши специалисты вам все расскажут! 😉
Как проверить частоту запросов?
Частота запросов проверяется с помощью специальных сервисов – Google Ads, Вордстат Яндекса.
Что такое транзакционные запросы?
Транзакционные запросы открывают намерение пользователя поисковой системой – купить, продать, скачать, арендовать. Например, «квартиру купить» или «машину продать».
По каким запросам лучше продвигаться в поиске?
Для продвижения сайта в поиске разумно использовать комбинацию из высокочастотных (увеличивает охват), среднечастотных (дает трафик) и низкочастотных запросов (улучшает показатели конверсии и повышает ценность сайта в конкретной поисковой системе).
Выводы
Существует несколько классификаций поисковых запросов: основная и другие. Их объединяют в группы по смыслу, частоте, конкурентности, коммерческой ценности и сезонности. Понимание типизации ключевых слов позволяет узким специалистам в интернет-маркетинге разработать эффективные стратегии продвижения сайта и создания контекстной рекламы.
Их объединяют в группы по смыслу, частоте, конкурентности, коммерческой ценности и сезонности. Понимание типизации ключевых слов позволяет узким специалистам в интернет-маркетинге разработать эффективные стратегии продвижения сайта и создания контекстной рекламы.
Чтобы быть в курсе всех новостей блога Serpstat, подписывайтесь рассылку. А также вступайте в чат любителей Серпстатить и подписывайтесь на наш канал в Telegram.
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Получить бесплатный доступ на 7 дней
Оцените статью по 5-бальной шкале
4.86 из 5 на основе 7 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
How-to
Анастасия Сотула
Что такое LTV клиента, как считается показатель и почему он важен
How-to
Анастасия Сотула
Этапы создания интернет-магазина
How-to
Анастасия Сотула
Что такое фишинговая ссылка и как проверить ее наличие
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Классификация запросов по частотности. Видимость сайта
Что такое облачное SEO? » Блог
Поговорим о классификации. Существуют разные способы классификации запросов.
Первый способ классификации запросов – по частотности. Они делятся на три группы: высокочастотные, среднечастотные и низкочастотные. В зависимости от тематики, высокочастотными запросами называют запросы, которые используются частотностью, равной более 1000 раз в месяц. Среднечастотные запросы – это те, которые используются больше 100, но меньше 1000 раз. А низкочастотные — это запросы, частотность которых составляет меньше 100 раз. Сейчас принято включать в классификацию еще одну группу, которая называется длинный хвост и означает длинный запрос. Семантическое ядро на 95% должно состоять из длинных хвостов. Это те запросы, частотность которых равняется не более 10 раз в месяц. В семантическое ядро обычно включают все запросы, входящие в классификацию.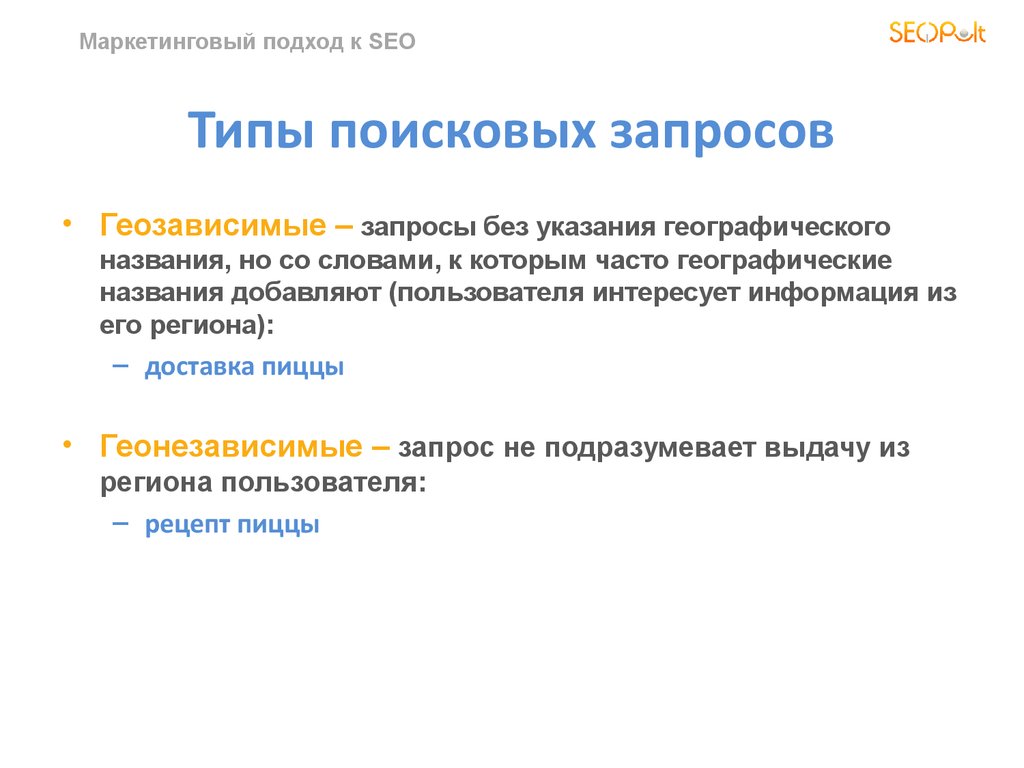
Все больше и больше людей при поиске более точно формулирует запрос, который больше никогда не повторяется в истории поисковой системы. Google провел исследование, показывающее, что количество людей, которые используют не длинный хвост, а уникальный запрос, достигло больше 50%. Поэтому возникает вопрос: «Нужно ли включать в ядро запросы с такой частотностью?» Если хотя бы 1 раз каждый месяц используются запрос, то включать в ядро нужно, если даже такой частоты нет, то это бессмысленно. Поэтому нужно понимать, что даже если мы правильно проработаем сайт и по данному ядру добьемся хорошей позиции, вследствие чего получим какой-то каркас посетителей, то все равно мы будем получать, кроме потенциального трафика, еще и другой трафик.
Мы можем видеть трафик по каждому запросу и оценивать потенциальный трафик. Например, мы спланировали семантическое ядро из 1000 запросов и по каждому оказались в топ-3. Тогда по каждому запросу у нас будет планируемое количество просмотров в месяц, потому что обычно люди заходят на первые 3 страницы, а дальше не все заходят, в итоге процент вхождения уменьшается.
Вначале нужно продвигаться по тем запросам, у которых низкая частотность, потому что это легче, проще и дешевле. Когда сайт по всем низкочастотным уже хорошо видим, то можно переходить к среднечастотным и высокочастотным.
Обычно для раскрученного сайта еще определяют такой параметр, как видимость. Например, если все запросы попали в топ-10, то видимость будет 100%. А если только половина запросов вошла в топ-10, тогда видимость будет равна 50%. Потому что другая половина не вошла и для них видимость равна 0%.
Потому что другая половина не вошла и для них видимость равна 0%.
Имея данные по частотности, мы уже можем давать какие-то прогнозы, делать какие-либо анализы, выводы и можем что-то планировать. Это достаточно эффективная характеристика, поэтому в классификации она всегда участвует.
- 1000 грн
в месяц
- 50
ключевых фраз - Мягкое продвижение сайта
Облачное SEO
Оплатить
2000 грн
в месяц
- 100
ключевых фраз - Комфортное продвижение сайта
Облачное SEO
Оплатить
4000 грн
в месяц
- 200
ключевых фраз - Активное продвижение сайта
Облачное SEO
Оплатить
8000 грн
в месяц
- 400
ключевых фраз - Только для больших сайтов,
имеющих несколько тысяч страниц Облачное SEO
Оплатить
Посмотреть все отзывы на Фрилансе
Отзывы на Веблансер Дмитрий А. ..
..
Посмотреть все отзывы на kwork
Отзывы на Веблансер Игорь К.
Что пишут об Облачном SEO?
Как ругают Облачное SEO?
Облачное SEO
- О нас
- Цены
- Контакты
Расширенное представление с контрастными потерями для классификации запросов с длинным хвостом в электронной коммерции
Lvxing Zhu, Хао Чен, Чао Вэй, Weiru Zhang
Abstract
Классификация запросов является фундаментальной задачей в поисковой системе электронной коммерции, которая присваивает одну или несколько предопределенных категорий продуктов в ответ на каждый поисковый запрос. Использование журналов кликов в качестве обучающих данных в методах глубокого обучения является распространенным и эффективным подходом к классификации запросов. Однако частотное распределение запросов обычно имеет свойство длинного хвоста, что означает, что для большинства запросов существует мало журналов.
- Anthology ID:
- 2022.ecnlp-1.17
- Volume:
- Proceedings of the Fifth Workshop on e-Commerce and NLP (ECNLP 5)
- Month:
- May
- Year:
- 2022
- Адрес:
- Дублин, Ирландия
- Места:
- ECNLP
- SIG:
- Издатель:
- Ассоциация для вычислительной лингвистики
- Примечание:
- Page: 13 140010.
- URL:
- https://aclanthology.org/2022.ecnlp-1.17
- doi:
- 10.18653/v1/2022.ecnlp-1.17
- Bibkey: 1111.19.19.17
- : 911111111.
- Люсин Чжу, Хао Чен, Чао Вэй и Вейру Чжан. 2022. Улучшенное представление с контрастными потерями для классификации запросов с длинным хвостом в электронной коммерции. In
- Процитируйте (неофициально):
- Расширенное представление с контрастными потерями для классификации запросов с длинным хвостом в электронной коммерции (Zhu et al., ECNLP 2022)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2022.ecnlp-1.17.pdf
- Видео:
- https://aclanthology.org/2022.ecnlp-1.17.mp4 90825 PDF Процитировать Поиск Видео
- BibTeX
- МОДЫ XML
- Конечная сноска
- Предварительно отформатированный
- Расширенное представление с контрастными потерями для классификации запросов с длинным хвостом в электронной коммерции (Zhu et al., ECNLP 2022)
- Lvxing Zhu, Hao Chen, Chao Wei и Weiru Zhang. 2022. Улучшенное представление с контрастными потерями для классификации запросов с длинным хвостом в электронной коммерции. В Материалы пятого семинара по электронной коммерции и НЛП (ECNLP 5) , стр. 141–150, Дублин, Ирландия. Ассоциация компьютерной лингвистики.
- Список журналов
- AMIA Annu Symp Proc
- v. 2003; 2003 г.
- PMC1480194
 0010 Язык:
0010 Язык: @inproceedings{zhu-etal-2022-Enhanced,
title = "Расширенное представление с контрастными потерями для классификации запросов с длинным хвостом в электронной коммерции",
автор = "Чжу, Лвсин и
Чен, Хао и
Вэй, Чао и
Чжан, Вейру»,
booktitle = "Материалы пятого семинара по электронной коммерции и НЛП (ECNLP 5)",
месяц = май,
год = "2022",
address = "Дублин, Ирландия",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology. org/2022.ecnlp-1.17",
doi = "10.18653/v1/2022.ecnlp-1.17",
страницы = "141--150",
abstract = "Классификация запросов — фундаментальная задача в поисковой системе электронной коммерции, которая присваивает одну или несколько предопределенных категорий продуктов в ответ на каждый поисковый запрос. Использование журналов кликов в качестве обучающих данных в методах глубокого обучения является распространенным и эффективным подходом. для классификации запросов. Однако частотное распределение запросов обычно имеет свойство длинного хвоста, что означает, что для большинства запросов существует мало журналов. Отсутствие надежной информации обратной связи с пользователями приводит к худшей производительности запросов с длинным хвостом по сравнению с частыми запросы. Чтобы решить вышеуказанную проблему, мы предлагаем новый метод, который использует вспомогательный модуль для улучшения представления запросов с длинным хвостом за счет использования надежной контролируемой информации о различных частых запросах. Запросы с длинным хвостом управляются контрастной потерей для получения выровненных по категориям представлений во вспомогательном модуле, где вариантные частые запросы служат якорями в представлении пространство. Мы обучаем нашу модель с помощью реальных данных о кликах с AliExpress и проводим оценку как по размеченным данным в автономном режиме, так и по онлайн-тесту AB. Результаты и дальнейший анализ демонстрируют эффективность предложенного нами метода.»,
}
 org/2022.ecnlp-1.17",
doi = "10.18653/v1/2022.ecnlp-1.17",
страницы = "141--150",
abstract = "Классификация запросов — фундаментальная задача в поисковой системе электронной коммерции, которая присваивает одну или несколько предопределенных категорий продуктов в ответ на каждый поисковый запрос. Использование журналов кликов в качестве обучающих данных в методах глубокого обучения является распространенным и эффективным подходом. для классификации запросов. Однако частотное распределение запросов обычно имеет свойство длинного хвоста, что означает, что для большинства запросов существует мало журналов. Отсутствие надежной информации обратной связи с пользователями приводит к худшей производительности запросов с длинным хвостом по сравнению с частыми запросы. Чтобы решить вышеуказанную проблему, мы предлагаем новый метод, который использует вспомогательный модуль для улучшения представления запросов с длинным хвостом за счет использования надежной контролируемой информации о различных частых запросах.
org/2022.ecnlp-1.17",
doi = "10.18653/v1/2022.ecnlp-1.17",
страницы = "141--150",
abstract = "Классификация запросов — фундаментальная задача в поисковой системе электронной коммерции, которая присваивает одну или несколько предопределенных категорий продуктов в ответ на каждый поисковый запрос. Использование журналов кликов в качестве обучающих данных в методах глубокого обучения является распространенным и эффективным подходом. для классификации запросов. Однако частотное распределение запросов обычно имеет свойство длинного хвоста, что означает, что для большинства запросов существует мало журналов. Отсутствие надежной информации обратной связи с пользователями приводит к худшей производительности запросов с длинным хвостом по сравнению с частыми запросы. Чтобы решить вышеуказанную проблему, мы предлагаем новый метод, который использует вспомогательный модуль для улучшения представления запросов с длинным хвостом за счет использования надежной контролируемой информации о различных частых запросах.
<моды> <информация о заголовке> Улучшенное представление с контрастными потерями для классификации запросов с длинным хвостом в электронной коммерции <название типа="личное">Lvxing Чжу <роль>автор <название типа="личное">Хао Чен <роль>автор <название типа="личное">Чао Вэй <роль>автор <название типа="личное">Вейру Чжан <роль>автор <информация о происхождении>2022-05 текст <информация о заголовке> Материалы пятого семинара по электронной коммерции и НЛП (ECNLP 5) <информация о происхождении>Ассоциация компьютерной лингвистики <место>Дублин, Ирландия публикация конференции Классификация запросов — это фундаментальная задача в поисковой системе электронной коммерции, которая присваивает одну или несколько предопределенных категорий продуктов в ответ на каждый поисковый запрос. zhu-etal-2022-Enhanced 10.18653/v1/2022.ecnlp-1.17 <местоположение> https://aclanthology.org/2022.ecnlp-1.17 <часть> <дата>2022-05 <единица экстента="страница">141 150
 Использование журналов кликов в качестве обучающих данных в методах глубокого обучения является распространенным и эффективным подходом к классификации запросов. Однако частотное распределение запросов обычно имеет свойство длинного хвоста, что означает, что для большинства запросов существует мало журналов. Отсутствие надежной информации об отзывах пользователей приводит к снижению производительности длинных запросов по сравнению с частыми запросами. Чтобы решить указанную выше проблему, мы предлагаем новый метод, использующий вспомогательный модуль для улучшения представления запросов с длинным хвостом за счет использования надежной контролируемой информации о различных частых запросах. Запросы с длинным хвостом руководствуются контрастной потерей для получения представлений, выровненных по категориям, во вспомогательном модуле, где частые варианты запросов служат якорями в пространстве представления. Мы обучаем нашу модель с помощью реальных данных о кликах с AliExpress и проводим оценку как по размеченным данным в автономном режиме, так и по онлайн-тесту AB.
Использование журналов кликов в качестве обучающих данных в методах глубокого обучения является распространенным и эффективным подходом к классификации запросов. Однако частотное распределение запросов обычно имеет свойство длинного хвоста, что означает, что для большинства запросов существует мало журналов. Отсутствие надежной информации об отзывах пользователей приводит к снижению производительности длинных запросов по сравнению с частыми запросами. Чтобы решить указанную выше проблему, мы предлагаем новый метод, использующий вспомогательный модуль для улучшения представления запросов с длинным хвостом за счет использования надежной контролируемой информации о различных частых запросах. Запросы с длинным хвостом руководствуются контрастной потерей для получения представлений, выровненных по категориям, во вспомогательном модуле, где частые варианты запросов служат якорями в пространстве представления. Мы обучаем нашу модель с помощью реальных данных о кликах с AliExpress и проводим оценку как по размеченным данным в автономном режиме, так и по онлайн-тесту AB.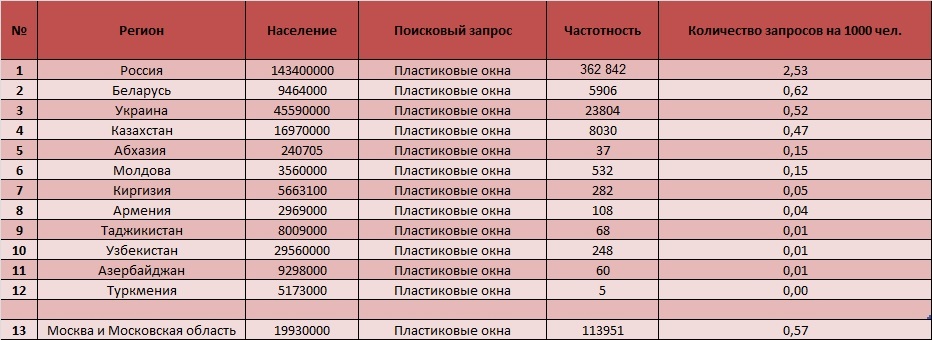 Результаты и дальнейший анализ демонстрируют эффективность предложенного нами метода.
Результаты и дальнейший анализ демонстрируют эффективность предложенного нами метода.%0 Материалы конференции %T Расширенное представление с контрастными потерями для классификации запросов с длинным хвостом в электронной коммерции %A Zhu, Lvxing %А Чен, Хао %А Вэй, Чао %А Чжан, Вейру %S Материалы пятого семинара по электронной коммерции и НЛП (ECNLP 5) %D 2022 %8 мая %I Ассоциация компьютерной лингвистики %C Дублин, Ирландия %F zhu-etal-2022-расширенный Классификация %X Query — это фундаментальная задача в поисковой системе электронной коммерции, которая присваивает одну или несколько предопределенных категорий продуктов в ответ на каждый поисковый запрос.
 Использование журналов кликов в качестве обучающих данных в методах глубокого обучения является распространенным и эффективным подходом к классификации запросов. Однако частотное распределение запросов обычно имеет свойство длинного хвоста, что означает, что для большинства запросов существует мало журналов. Отсутствие надежной информации об отзывах пользователей приводит к снижению производительности длинных запросов по сравнению с частыми запросами. Чтобы решить указанную выше проблему, мы предлагаем новый метод, использующий вспомогательный модуль для улучшения представления запросов с длинным хвостом за счет использования надежной контролируемой информации о различных частых запросах. Запросы с длинным хвостом руководствуются контрастной потерей для получения представлений, выровненных по категориям, во вспомогательном модуле, где частые варианты запросов служат якорями в пространстве представления. Мы обучаем нашу модель с помощью реальных данных о кликах с AliExpress и проводим оценку как по размеченным данным в автономном режиме, так и по онлайн-тесту AB.
Использование журналов кликов в качестве обучающих данных в методах глубокого обучения является распространенным и эффективным подходом к классификации запросов. Однако частотное распределение запросов обычно имеет свойство длинного хвоста, что означает, что для большинства запросов существует мало журналов. Отсутствие надежной информации об отзывах пользователей приводит к снижению производительности длинных запросов по сравнению с частыми запросами. Чтобы решить указанную выше проблему, мы предлагаем новый метод, использующий вспомогательный модуль для улучшения представления запросов с длинным хвостом за счет использования надежной контролируемой информации о различных частых запросах. Запросы с длинным хвостом руководствуются контрастной потерей для получения представлений, выровненных по категориям, во вспомогательном модуле, где частые варианты запросов служат якорями в пространстве представления. Мы обучаем нашу модель с помощью реальных данных о кликах с AliExpress и проводим оценку как по размеченным данным в автономном режиме, так и по онлайн-тесту AB. Результаты и дальнейший анализ демонстрируют эффективность предложенного нами метода.
%R 10.18653/v1/2022.ecnlp-1.17
%U https://aclanthology.org/2022.ecnlp-1.17
%U https://doi.org/10.18653/v1/2022.ecnlp-1.17
%Р 141-150
Результаты и дальнейший анализ демонстрируют эффективность предложенного нами метода.
%R 10.18653/v1/2022.ecnlp-1.17
%U https://aclanthology.org/2022.ecnlp-1.17
%U https://doi.org/10.18653/v1/2022.ecnlp-1.17
%Р 141-150
Уценка (неформальная)
[Расширенное представление с контрастными потерями для классификации запросов с длинным хвостом в электронной коммерции] (https://aclanthology.org/2022.ecnlp-1.17) (Zhu et al., ECNLP 2022)
ACL
Какова распространенность запросов о здоровье во Всемирной паутине? Качественный и количественный анализ поисковых запросов в Интернете
 2003; 2003 г.
2003; 2003 г.AMIA Annu Symp Proc. 2003 г.; 2003: 225–229.
1), 2) и 2)
Информация об авторе Информация об авторских правах и лицензиях Отказ от ответственности связанных со здоровьем поисковых запросов в Интернете отсутствуют. В настоящем исследовании мы стремились определить распространенность поисковых запросов, связанных со здоровьем, в Интернете, анализируя поисковые запросы, вводимые людьми в популярные поисковые системы. Мы также предприняли некоторые предварительные попытки качественно описать и классифицировать эти поиски. Периодические трудности с определением того, что представляет собой поиск «связанный со здоровьем», заставили нас предложить и проверить простой метод автоматической классификации строки поиска как «связанной со здоровьем». Этот метод основан на определении доли страниц в Интернете, содержащих строку поиска и слово «здоровье», как доли от общего количества страниц, содержащих только строку поиска. Используя человеческие коды в качестве золотого стандарта, мы построили кривую ROC и эмпирически определили, что если эта «коэффициент встречаемости» превышает 35%, можно сказать, что строка поиска связана со здоровьем (чувствительность: 85,2%, специфичность 80,4%). . Результаты нашего «человеческого» кодирования поисковых запросов определили, что около 4,5% всех поисков «связаны со здоровьем». По нашим оценкам, во всем мире каждый день в Интернете выполняется не менее 6,75 миллионов поисковых запросов, связанных со здоровьем, что примерно равно количеству поисковых запросов, которые выполнялись в системе NLM Medlars за 19 годов.96 за полный год.
Этот метод основан на определении доли страниц в Интернете, содержащих строку поиска и слово «здоровье», как доли от общего количества страниц, содержащих только строку поиска. Используя человеческие коды в качестве золотого стандарта, мы построили кривую ROC и эмпирически определили, что если эта «коэффициент встречаемости» превышает 35%, можно сказать, что строка поиска связана со здоровьем (чувствительность: 85,2%, специфичность 80,4%). . Результаты нашего «человеческого» кодирования поисковых запросов определили, что около 4,5% всех поисков «связаны со здоровьем». По нашим оценкам, во всем мире каждый день в Интернете выполняется не менее 6,75 миллионов поисковых запросов, связанных со здоровьем, что примерно равно количеству поисковых запросов, которые выполнялись в системе NLM Medlars за 19 годов.96 за полный год.
Часто говорят, что наиболее распространенной причиной, по которой люди выходят в интернет, является поиск медицинской информации. Это утверждение, по-видимому, основано в первую очередь на результатах опросов, таких как Pew Internet Survey, в котором утверждается, что 55% тех, у кого есть доступ в Интернет, использовали Интернет для получения информации о здоровье или медицинской информации 1 .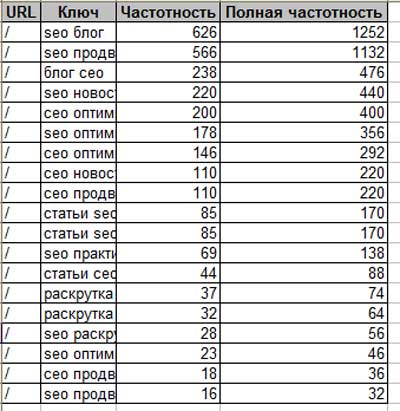 Однако неясно, каковы фактический объем и распространенность поисковых запросов, связанных со здоровьем, в Интернете по отношению к общему количеству поисковых запросов, проводимых ежедневно в Интернете. Учитывая богатый источник данных, который представляет собой Интернет для изучения поведения, связанного с поиском личной информации о здоровье, наблюдается удивительная нехватка данных о том, что потребители ищут в Интернете и как потребители это делают 9.0140 2 . Подобно тому, как Дайана Форсайт когда-то утверждала, что «разработка и внедрение соответствующих автоматизированных решений предполагает знание информационных потребностей врачей» 3 , и впервые применила метод этнографических методов для облегчения непосредственного наблюдения за общением об информационных потребностях врачей, мы считаем, что понимание здоровья потребителей информационные потребности являются необходимым условием для создания решений в области информатики для здоровья потребителей 4 ; 5 и, в свою очередь, требует прямого наблюдения за информационным поведением потребителей.
Однако неясно, каковы фактический объем и распространенность поисковых запросов, связанных со здоровьем, в Интернете по отношению к общему количеству поисковых запросов, проводимых ежедневно в Интернете. Учитывая богатый источник данных, который представляет собой Интернет для изучения поведения, связанного с поиском личной информации о здоровье, наблюдается удивительная нехватка данных о том, что потребители ищут в Интернете и как потребители это делают 9.0140 2 . Подобно тому, как Дайана Форсайт когда-то утверждала, что «разработка и внедрение соответствующих автоматизированных решений предполагает знание информационных потребностей врачей» 3 , и впервые применила метод этнографических методов для облегчения непосредственного наблюдения за общением об информационных потребностях врачей, мы считаем, что понимание здоровья потребителей информационные потребности являются необходимым условием для создания решений в области информатики для здоровья потребителей 4 ; 5 и, в свою очередь, требует прямого наблюдения за информационным поведением потребителей. Наша собственная предыдущая работа в этой области включает полуколичественный контент-анализ электронных писем пациентов, обращающихся к врачам 9.0140 6 , качественное исследование с фокус-группами и прямое наблюдение лаборатории юзабилити о том, как потребители ищут в Интернете 7 . В настоящем исследовании мы стремились определить фактическую распространенность запросов, связанных со здоровьем, в Интернете путем анализа поисковых запросов, введенных людьми в популярные поисковые системы, и сделать некоторые предварительные попытки качественно описать и классифицировать эти запросы.
Наша собственная предыдущая работа в этой области включает полуколичественный контент-анализ электронных писем пациентов, обращающихся к врачам 9.0140 6 , качественное исследование с фокус-группами и прямое наблюдение лаборатории юзабилити о том, как потребители ищут в Интернете 7 . В настоящем исследовании мы стремились определить фактическую распространенность запросов, связанных со здоровьем, в Интернете путем анализа поисковых запросов, введенных людьми в популярные поисковые системы, и сделать некоторые предварительные попытки качественно описать и классифицировать эти запросы.
Исследования, изучающие распространенность запросов, связанных со здоровьем (или связанные исследования, пытающиеся определить, например, количество веб-сайтов, связанных со здоровьем), осложняются трудностью определения того, что означает «связанный со здоровьем». Определение ВОЗ здоровья как «состояния полного физического, психического и социального благополучия, а не просто отсутствия болезней или физических дефектов» (Преамбула к Уставу Всемирной организации здравоохранения) настолько широко, что даже финансовая информация может быть оспорена. быть «связанным со здоровьем».
быть «связанным со здоровьем».
Трудности определения того, что является «связанным со здоровьем» (и трудоемкий процесс ручного кодирования), побудили нас разработать и проверить простой алгоритм для автоматического определения запросов, связанных со здоровьем. Этот метод также предлагает рабочее определение того, что представляет собой «связанная со здоровьем» информация или поисковое выражение.
Сбор поисковых запросов
Поисковые термины были собраны из двух поисковых систем, которые позволяют «заглянуть» в поиск, т. е. пользователи могут видеть, какие запросы в настоящее время вводят другие пользователи. Двумя используемыми поисковыми системами были Metaspy (http://www.metaspy.com/), в которой перечислены поисковые запросы из Metacrawler и AskJeeves (http://www.ask.com/docs/peek/). В то время как Metaspay перечисляет традиционные условия поиска, запросы Askjeeves имеют форму вопросов, например «Где я могу найти информацию о морских растениях и водорослях?». Был разработан временной скрипт, который периодически посещал и «счищал» эту информацию, т. е. HTML анализировался, из него извлекалась соответствующая информация (поисковый запрос) и записывалась в базу данных. 29В период с февраля 2001 г. по апрель 2002 г. в MetaSpy было получено 85 поисковых запросов, а в период с февраля 2001 г. по апрель 2001 г. — 475 поисковых запросов. Это должна быть случайная выборка поисковых запросов, введенных пользователями.
Был разработан временной скрипт, который периодически посещал и «счищал» эту информацию, т. е. HTML анализировался, из него извлекалась соответствующая информация (поисковый запрос) и записывалась в базу данных. 29В период с февраля 2001 г. по апрель 2002 г. в MetaSpy было получено 85 поисковых запросов, а в период с февраля 2001 г. по апрель 2001 г. — 475 поисковых запросов. Это должна быть случайная выборка поисковых запросов, введенных пользователями.
Кодирование поисковых запросов человеком
Был разработан веб-интерфейс, позволяющий кодировщикам классифицировать запросы. Меташпионские поиски были классифицированы как «не связанные со здоровьем», «отчасти связанные со здоровьем» и «явно связанные со здоровьем». Последние две категории позже были объединены для анализа в одну категорию запросов, связанных со здоровьем. Вопросы AskJeeves также были классифицированы как «не связанные со здоровьем» или «связанные со здоровьем», а запросы из последней категории также были закодированы с помощью таксономии Ely, которая была разработана для классификации информационных потребностей врачей и предлагает в общей сложности 66 различных кодов. 8 . Одним из аспектов этого исследования было изучение того, в какой степени эта таксономия будет полезна и применима к вопросам кодирования потребителей. Все запросы были закодированы двумя кодерами независимо друг от друга, и был рассчитан межнаблюдательный коэффициент надежности.
8 . Одним из аспектов этого исследования было изучение того, в какой степени эта таксономия будет полезна и применима к вопросам кодирования потребителей. Все запросы были закодированы двумя кодерами независимо друг от друга, и был рассчитан межнаблюдательный коэффициент надежности.
Автоматизированный метод классификации запросов, связанных со здоровьем
Высокая изменчивость разных наблюдателей в определении того, что связано со здоровьем, и трудоемкое ручное кодирование послужили мотивом для разработки и проверки автоматического метода классификации поисковых терминов и запросов как «связанных со здоровьем». .
В нашем методе автоматической классификации предлагается использовать допущение о том, что поисковые термины, связанные со здоровьем, должны встречаться на результирующих веб-страницах вместе со словом «здоровье» чаще, чем поисковые термины, не связанные со здоровьем. Мы используем поисковую систему (google) для определения количества страниц, найденных с поисковым запросом И словом «здоровье», по отношению к количеству страниц, найденных только с поисковым запросом. Эта пропорция, которую в дальнейшем мы называем «коэффициентом совпадения» (c), показывает, насколько часто поисковые термины встречаются на одной странице со словом «здоровье», и может рассматриваться как метрика того, как здоровье связано с поиском. запрос:
Эта пропорция, которую в дальнейшем мы называем «коэффициентом совпадения» (c), показывает, насколько часто поисковые термины встречаются на одной странице со словом «здоровье», и может рассматриваться как метрика того, как здоровье связано с поиском. запрос:
Если страницы (запрос)=0, то c:= 0.
Если c>=? тогда говорят, что запрос связан со здоровьем, иначе не связан со здоровьем.
Где
c := частота совпадений
Запрос := поисковый запрос
Pages() := количество совпадений (страниц), полученных Google
?:= порог [0,1 ]
Для поисковых запросов или терминов, не связанных со здоровьем (например, «Лондон»), с должно быть маленьким, что означает, что очень небольшая часть страниц, содержащих поисковые термины, также содержит слово «здоровье». Напротив, для запросов, связанных со здоровьем, этот показатель должен быть ближе к 1, что указывает на высокую степень совпадения со словом «здоровье». Если c больше или равно порогу? тогда поисковый запрос можно считать связанным со здоровьем. Оптимальный порог? который делит поисковые термины, связанные со здоровьем, от поисковых терминов, не связанных со здоровьем, был эмпирически определен как 0,35 (см. ниже), т. е. если более 35% страниц с поисковыми терминами также содержат слово «здоровье», то можно сказать, что поисковый запрос является связанные со здоровьем.
Оптимальный порог? который делит поисковые термины, связанные со здоровьем, от поисковых терминов, не связанных со здоровьем, был эмпирически определен как 0,35 (см. ниже), т. е. если более 35% страниц с поисковыми терминами также содержат слово «здоровье», то можно сказать, что поисковый запрос является связанные со здоровьем.
Например, если мы хотим узнать, связан ли поисковый запрос «кисты яичников» со здоровьем, мы вводим этот поисковый запрос в Google и записываем количество найденных страниц (59100 просмотров), затем вводим поисковый запрос «кисты яичников». здоровье» (обратите внимание, что Google использует неявный оператор И), который вызвал 49 800 обращений, в результате чего частота совпадений составила 49 800/59 100 = 84,2%. Напротив, такой поисковый запрос, как «Regents Park London», дает коэффициент совпадения только 59 600/10 800 = 18,1% и, следовательно, может быть исключен как «не связанный со здоровьем».
Для автоматического определения c для каждого из 2985 поисковых запросов из Metaspy мы разработали компьютерный сценарий, использующий Google API (http://www. google.com/apis/) для автоматического запроса к базе данных Google страниц, содержащих поисковые запросы. запрос – сначала вводится сам по себе, а затем в сочетании со словом здоровье. Скрипт считывал количество обращений (страниц), найденных по этим двум запросам, результаты записывались в базу данных, а коэффициент совпадения для каждого запроса рассчитывался путем деления цифр по приведенной выше формуле. Если исходный поисковый запрос имеет 0 совпадений (что произошло 113 раз), коэффициент совпадения (COR) устанавливается равным нулю.
google.com/apis/) для автоматического запроса к базе данных Google страниц, содержащих поисковые запросы. запрос – сначала вводится сам по себе, а затем в сочетании со словом здоровье. Скрипт считывал количество обращений (страниц), найденных по этим двум запросам, результаты записывались в базу данных, а коэффициент совпадения для каждого запроса рассчитывался путем деления цифр по приведенной выше формуле. Если исходный поисковый запрос имеет 0 совпадений (что произошло 113 раз), коэффициент совпадения (COR) устанавливается равным нулю.
Проверка метода автоматической классификации
Мы проверили описанный выше автоматический метод на соответствие кодированию поисковых запросов человеком, сведя в таблицу коэффициенты совпадений в сравнении с консенсусной классификацией человека для каждого поискового запроса. Мы нарисовали кривую рабочих характеристик приемника (ROC) и кривую точности-отзыва, чтобы определить чувствительность (=отзыв), специфичность и точность (=положительное прогностическое значение) этого метода для различных точек отсечки?.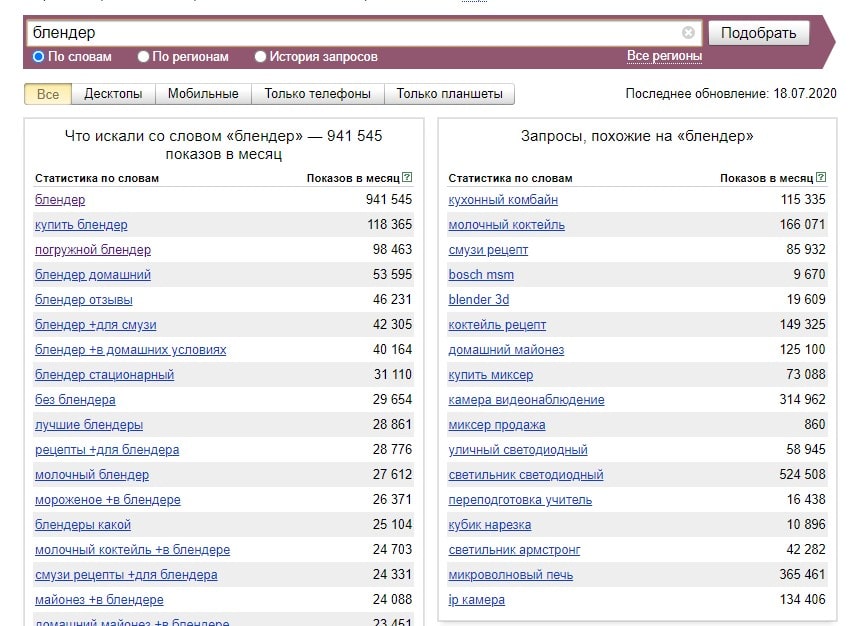
Ручное кодирование условий поиска метакраулера
2985 поисковых выражений, собранных из Metacrawler, были закодированы двумя авторами (GE, CK) независимо друг от друга как «связанные со здоровьем» (включая «отчасти связанные со здоровьем») или «не связанные со здоровьем». 108 (3,6%) запросов были закодированы обоими кодировщиками как «связанные со здоровьем», 2827 (94,7%) запросов были согласованно классифицированы как не связанные со здоровьем, а 50 (1,7%) получили несогласную классификацию. Поисковые выражения, которые были закодированы несогласованно, включали, например, «лечение зависимости от порнографии», «транссексуалы», «прекратите сосать палец», «статистика подростковых самоубийств», «кристаллы кальция» и т. д. Эти запросы иллюстрируют иногда трудности с определением того, что « связанные со здоровьем». Мы еще раз прошлись по всем несогласованным поисковым выражениям, чтобы определить консенсусное кодирование. Большинство поисковых запросов, закодированных одним из кодировщиков как связанные со здоровьем, в конечном итоге получили консенсусное кодирование как «связанное со здоровьем».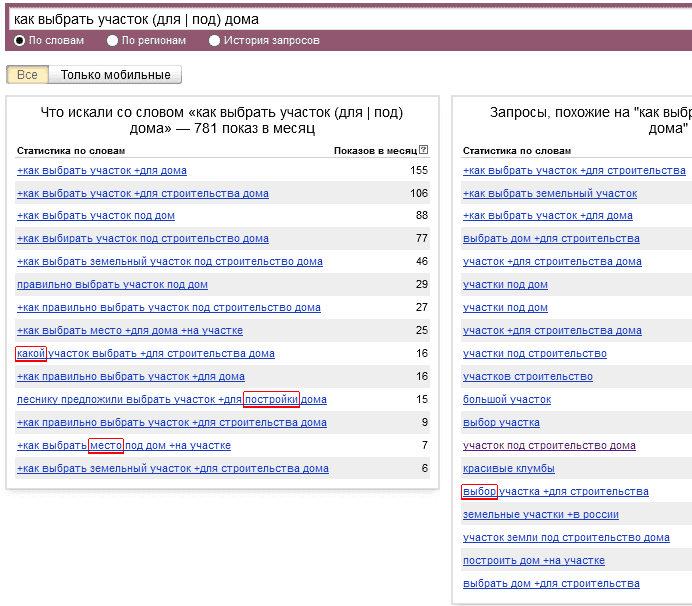 Согласно итоговому консенсус-рейтингу, 135 (4,5%) всех поисковых запросов можно считать «связанными со здоровьем». Хотя формально они не были закодированы, большинство оставшихся поисковых запросов оказались связанными с порнографическими материалами.
Согласно итоговому консенсус-рейтингу, 135 (4,5%) всех поисковых запросов можно считать «связанными со здоровьем». Хотя формально они не были закодированы, большинство оставшихся поисковых запросов оказались связанными с порнографическими материалами.
Ручное кодирование вопросов AskJeeves
475 вопросов AskJeeves были закодированы двумя кодировщиками независимо друг от друга (). Два кодировщика определили 48 и 45 (10,1% и 9,5%) вопросов, связанных со здоровьем, соответственно. 44 вопроса (9,3%) были последовательно закодированы как «связанные со здоровьем» (дискордантно закодированные вопросы включают, например, «Что нужно каждому ребенку для полноценного развития?», «Как долго я буду жить?», «Где я могу увидеть изображения ДНК ?» и «Где я могу найти ресурсы от Britannica.com по апатии?»). 36 из них были закодированы с использованием согласующихся кодов Эли, а 8 вопросов были закодированы несогласованно. Подавляющее большинство вопросов (22) были закодированы как «немедицинские – образование – пациент». Таксономия Эли, первоначально разработанная для классификации информационных потребностей врачей, оказалась не очень полезной для кодирования вопросов потребителей. Поэтому в настоящее время мы разрабатываем новую систему кодирования вопросов о здоровье потребителей.
Таксономия Эли, первоначально разработанная для классификации информационных потребностей врачей, оказалась не очень полезной для кодирования вопросов потребителей. Поэтому в настоящее время мы разрабатываем новую систему кодирования вопросов о здоровье потребителей.
Table 1
Codings of the AskJeeves questions with the Ely classification 8
| Coder 1 | Coder 2 | n |
|---|---|---|
| Not health related | Не связанный со здоровьем | 426 |
| Не связанный со здоровьем | Эпидемиология — не классифицированная в других рубриках | 1 |
| Диагноз — причина/интерпретация клинического симптома | 4 | |
| Diagnosis — orientation – condition | 1 | |
| Treatment — drug prescribing — adverse effects — findings caused by drug/adverse effects of drug | 1 | |
| Treatment — drug prescribing- orientation/ состав | 1 | |
| Лечение – назначение лекарств – механизм действия | Лечение – назначение лекарств/состав | 1 |
| Лечение — не ограничивается, но может включать назначение лекарств — как это делать | Не связанно со здоровьем | 1 |
| Лечение — не ограничивается, но может включать назначение лекарств — как это делать | 2 | 0 Лечение – не классифицированное в других рубриках | 1 |
| Ведение (без уточнения диагностики или терапии) – не классифицировано в других рубриках | 1 | |
| Ведение (без уточнения диагностики или терапии) – не классифицировано в других рубриках | Эпидемиология — ни в чем ничем не классифицировано | 1 |
| Неклинический — Образование — Пациент | Не связанный со здоровьем | 3 |
| 3 | ||
. Неналовый. Неналовый. | ||
| неклинические — обучение — пациент | лечение — не классифицированное в других рубриках | 1 |
| неклиническое — обучение — пациент | 22 | |
| nonclinical — education- patient | nonclinical — not elsewhere classified | 1 |
| nonclinical — education- patient | nonclinical — legal | 1 |
| 475 | ||
Open в отдельном окне
Во время кодирования также стало ясно, что вопросы, предоставленные AskJeeves как «то, что люди спрашивают прямо сейчас», вряд ли были реальными вопросами, заданными людьми. Скорее, большинство вопросов, казалось, были «предварительно подготовленными» вопросами, предоставленными AskJeeves, которые были сопоставлены с запросами, введенными пользователями. Кроме того, вопросы, похоже, были отфильтрованы, так как не отображались вопросы сексуальной направленности (которые в меташпионском анализе составляли большинство поисковых запросов). Таким образом, отображаемые вопросы AskJeeves, вероятно, дают предвзятое и нерепрезентативное представление об информационных потребностях людей. Это объясняет более высокую распространенность запросов, связанных со здоровьем, по сравнению с поисками Metaspy.
Скорее, большинство вопросов, казалось, были «предварительно подготовленными» вопросами, предоставленными AskJeeves, которые были сопоставлены с запросами, введенными пользователями. Кроме того, вопросы, похоже, были отфильтрованы, так как не отображались вопросы сексуальной направленности (которые в меташпионском анализе составляли большинство поисковых запросов). Таким образом, отображаемые вопросы AskJeeves, вероятно, дают предвзятое и нерепрезентативное представление об информационных потребностях людей. Это объясняет более высокую распространенность запросов, связанных со здоровьем, по сравнению с поисками Metaspy.
Валидация метода автоматической классификации
«Коэффициенты совпадения» для каждого поискового запроса поисковых запросов метакраулера как метрики их связи со здоровьем были рассчитаны, как описано выше (как соотношение между страницами с поисковым запросом и здоровье на страницы только с поисковым запросом). показывает распределение частоты совпадений во всем наборе данных Metacrawler.
Открыть в отдельном окне
Распределение «коэффициентов совпадения» поисковых запросов от метакраулера. Чем выше показатель, тем выше доля страниц, на которых поисковый запрос и слово «здоровье» встречаются вместе, и, предположительно, тем больше поисковый запрос связан со здоровьем. Коэффициент сочетанности можно рассматривать как «индекс связанности со здоровьем».
Чтобы найти оптимальный порог? (точка отсечки для частоты совпадения), которая позволяет оптимально различать связанные со здоровьем и не связанные со здоровьем поисковые термины, мы нарисовали кривую рабочих характеристик приемника (ROC) с различными пороговыми параметрами? (), показывая характеристики теста как компромисс между специфичностью и чувствительностью, с человеческим кодированием в качестве золотого стандарта и автоматической классификацией с порогом? как тест на то, насколько поиск связан со здоровьем. Другой способ оценить метод — посмотреть на кривую точность-отзыв ().
Открыть в отдельном окне
Кривая ROC (рабочие характеристики приемника)
Кривая ROC показывает, что точка отсечки? =35% имеет оптимальный компромисс между чувствительностью 85,2% (115/135, т. е. доля терминов, связанных со здоровьем, правильно подобранных этим методом) и специфичностью 80,4% (2292/2850 поисковых терминов, не связанных со здоровьем). были отфильтрованы) (см. ).
е. доля терминов, связанных со здоровьем, правильно подобранных этим методом) и специфичностью 80,4% (2292/2850 поисковых терминов, не связанных со здоровьем). были отфильтрованы) (см. ).
Таблица 2
Таблица непредвиденных обстоятельств с истинно положительными (TP), ложноположительными (FP), ложноотрицательными (FN) и истинно отрицательными (TN) для метода автоматической классификации с порогом? = 0,35 для частоты встречаемости
| Manual coding | |||
|---|---|---|---|
| Auto-coding | Health-related | Non-health | |
| c >= .35 | 115 (TP) | 558 (FP ) | 673 |
c < . 35 35 | 20 (FN) | 2292 (TN) | 2312 |
| 135 | 2850 | 2985 | |
Открыть в отдельном окне
Автоматический метод можно сделать более чувствительным (в ущерб специфичности) если порог ниже? выбран. Например, если качественный исследователь хочет сделать предварительный выбор всех возможных поисковых запросов, связанных со здоровьем, не рискуя отфильтровать слишком много истинных терминов, связанных со здоровьем, он / она выберет более низкий порог. Например, с? из 20% метод по-прежнему выявляет 123/135 запросов, связанных со здоровьем (чувствительность 91,1%), со специфичностью 58,7% (отфильтровано 1673/2850 терминов, не связанных со здоровьем). Чтобы не пропустить много терминов, связанных со здоровьем, исследователю достаточно просмотреть менее половины (45,6%) первоначальных поисковых запросов.
Чтобы не пропустить много терминов, связанных со здоровьем, исследователю достаточно просмотреть менее половины (45,6%) первоначальных поисковых запросов.
Для других приложений может быть уместна очень конкретная классификация. Например, если порог установлен на 80 %, всего остается только 56 поисковых запросов, и метод является максимально точным с точностью (= положительное прогностическое значение) 66 % (это означает, что 66 % из 56 поисковых терминов на самом деле связаны со здоровьем). Специфика 99,3%, но чувствительность (отзыв) составляет 27,4% (это означает, что в окончательный набор входят только 37/135 терминов, связанных со здоровьем).
На основе нашего анализа мы подсчитали, что примерно 4,5% всех поисковых запросов в Интернете могут быть связаны со здоровьем. Хотя запросы, связанные со здоровьем, составляют относительно небольшую часть поисковых запросов в Интернете, абсолютные цифры по-прежнему впечатляют: Google сообщает о 150 миллионах поисковых запросов в день на всех региональных партнерских сайтах вместе взятых, что означает, что около 6,75 миллионов поисковых запросов, связанных со здоровьем в день только в Google ведется. Для сравнения, в 1996 году NLM сообщила о 7 миллионах поисковых запросов в системе MEDLARS (Medline) в год .
Для сравнения, в 1996 году NLM сообщила о 7 миллионах поисковых запросов в системе MEDLARS (Medline) в год .
Хотя наша оценка распространенности в 4,5% основана на данных одной поисковой системы (MetaCrawler), мало оснований полагать, что более широко используемая поисковая система, такая как Google, имеет другую распространенность запросов, связанных со здоровьем. Более высокая распространенность запросов, связанных со здоровьем, на AskJeeves, вероятно, является результатом предвзятого (отфильтрованного) отображения запросов на этом сайте.
Мы считаем, что прямой анализ поисковых запросов дает гораздо более точную картину того, что люди делают и что ищут в Интернете, чем, например, данные опросов, таких как Pew Internet Survey, которые в настоящее время доминируют в литературе. Мало того, что людям трудно вспомнить в ходе опроса, какую информацию они чаще всего находят в Интернете, точность данных опроса также страдает от предвзятости социальной желательности — например, редко люди признаются, что ищут порнографические материалы, хотя такие поиски, по-видимому, являются наиболее распространенными.
Для облегчения дальнейших исследований и классификации поисковых запросов мы также разработали и утвердили автоматический метод определения запросов, связанных со здоровьем. Этот метод, который рассматривает совпадения терминов со словом «здоровье», может быть расширен, чтобы классифицировать любые короткие фразы или тексты как связанные со здоровьем. Потенциальные приложения включают автоматический анализ электронных писем и классификацию на связанные со здоровьем и не связанные со здоровьем, чтобы автоматически направлять входящие электронные письма техническому или медицинскому персоналу. Каждое предложение электронной почты может быть подвергнуто анализу совпадений, и может быть рассчитана средняя частота совпадений. В настоящее время проводится валидация этого метода.
Джим Лай запрограммировал сценарии, Дэвид Мейсон обеспечил техническую поддержку.
1. Проект Pew Internet and American Life. Революция в области онлайн-здравоохранения: как Интернет помогает американцам лучше заботиться о себе.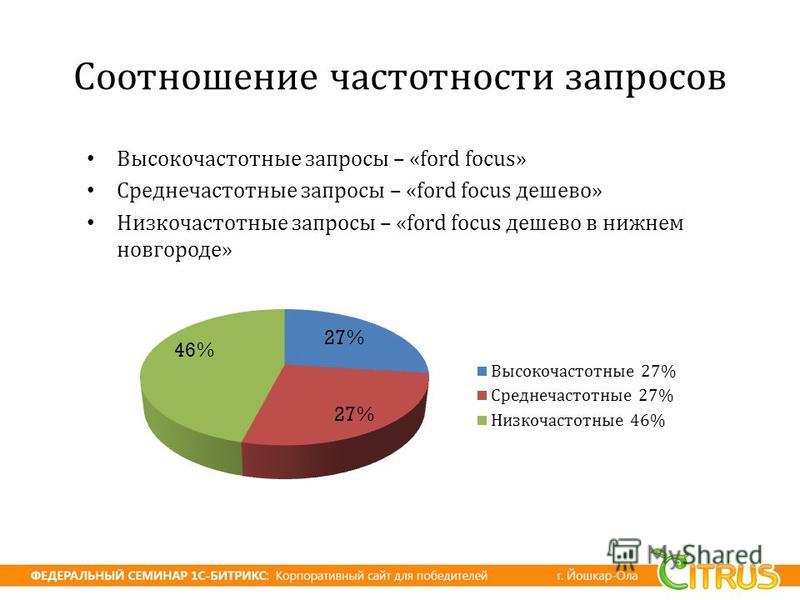 26.11.2000.
26.11.2000.
2. Ставри ПЗ. Поиск информации о личном здоровье: качественный обзор литературы. Мединфо. 2001; 10:1484–8. [PubMed] [Google Scholar]
3. Forsythe DE, Buchanan BG, Osheroff JA, Miller RA. Расширение концепции медицинской информации: наблюдательное исследование информационных потребностей врачей. Компьютер Биомед Рез. 1992;25:181–200. [PubMed] [Google Scholar]
4. Эйзенбах Г. Информатика здоровья потребителей. БМЖ. 2000;320:1713–6. [Бесплатная статья PMC] [PubMed] [Google Scholar]
5. Хьюстон Т.К., Чанг Б.Л., Браун С., Кукафка Р. Информатика здоровья потребителей: согласованное описание и комментарии членов Американской ассоциации медицинской информатики. Proc AMIA Symp. 2001: 269–73. [Бесплатная статья PMC] [PubMed] [Google Scholar]
6. Eysenbach G, Diepgen TL. Пациенты ищут информацию в Интернете и обращаются за телеконсультацией: мотивация, ожидания и неправильные представления, выраженные в электронных письмах, отправленных врачам.