
Как работать с Key Collector и Key Assort?
Автор статьи
Андрей Буйлов
Подробнее об авторе
Сегодня будет проведен обзор совместной работы лучшей программы для сбора семантики Key Collector и лучшей программы для кластеризации запросов Key Assort.
Key Collector
Заходим в программу.
1. Здесь уже собрались какие-то запросы и у нас получилось 383 фразы. Уже есть определенные данные.
Например, мы работаем с поисковой выдачей, с частотами и т.д, и нам нужно здесь распределить эти фразы по страницам. И алгоритм, который встроен в Key Collector, нас по какой-то причине не устраивает.
Мы можем уже здесь собрать данные – они нужны будут нам в Key Collector (доля главных страниц, количество вхождений в заголовки). Эти данные нужно будет еще раз собирать и в KeyAssort.
Эти данные нужно будет еще раз собирать и в KeyAssort.
И вот чтобы не делать это дважды, мы соберем эти данные только в Key Collector. Открываем вкладку «Парсинг/Собрать данные из ПС Yandex»
Идет парсинг
Далее видим, что собрались данные по поисковой выдаче.
Что делаем дальше?
Переходим во вкладку «Файл/Экспорт/Поисковая выдача».
Выбираем Яндекс. Сниппеты не загружаем. Выбираем Экспортировать.
Выпадает вкладка, в которой нужно ввести имя файла – назовем «экспорт» (он в Excel).
Key Assort
Далее идем в KeyAssort.
-
Создаем проект (у нас он уже создан).
-
Выбираем следующее: «Файл/Импорт/С данными о поисковой выдаче».
-
В выпавшем меню о запросе безвозвратно удалить все данные нажимаем «да».

-
В появившемся окне выбираем «Выдача».
-
Появилась вкладка «Параметры импорта». Проверяем: столбец «А» — это запрос; столбец «N» — конкретные сайты.
-
Теперь выбираем в настройках тип кластеризации: «Сервис/Настройки программы/Кластеризация».

Запросы добавились. Собирать данные не нужно, они есть (в нижней строке экрана написано «Собрано данных 384 из 384»)
Здесь делаем все настройки, которые нам нужны, индивидуально.
В данном случае выбираем Силу – 4; вид кластеризации – Hard, сохраняем.
Далее в верхней панели жмем вкладку «Кластеризовать». Получаем результат.
Здесь дополнительно ничего парсить не нужно. Напомним, что эту кластеризацию нужно проверять, т. е. нужно просмотреть выборочно или все группы, корректно ли он сгруппировал.
е. нужно просмотреть выборочно или все группы, корректно ли он сгруппировал.
Часто бывает так, что наша стандартная кластеризация – и тип, и сила – могут для конкретных проектов показать себя не очень хорошо. И тогда мы будем играться с силой: уменьшать, увеличивать. Допустим, получились слишком маленькие группы и слишком много несгруппированных запросов, тогда можно силу уменьшить.
Итак, все сгруппировано.
Дальше нам нужно перетащить все проекты направо. Для этого переходим в правую часть экрана, там во вкладке «Группа/Форма» вводим название – не важно, как это называется, назовем, к примеру, «категория».
Клавишей «Shift» выделяем все файлы левой части экрана и тащим направо.
Если мы не хотим никак дополнительно называть эти группы ключей, тогда назовем их как один из запросов этой группы. Если хотим, чтобы группы более осмысленно уже на этом этапе назывались, тогда здесь их просто переименовываем.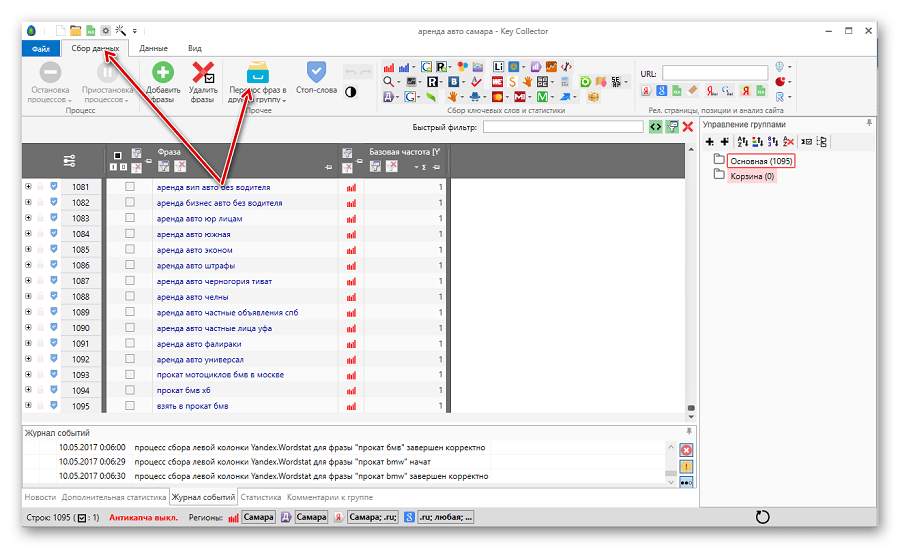
Все.
Что делаем дальше?
Экспорт. И здесь нужно экспортировать не как обычно в Excel, а экспортировать в Key Collector. Для этого в правой части экрана в верхней вкладке выбираем «Экспорт/Key Collector». Жмем, делаем файл – даем ему название в выпавшем меню.
Все, экспортировали.
Возвращаемся в Key Collector и выбираем «Файл/Импорт/Проект KeyAssort». В выпавшем меню выбираем наш файл.
В предлагаемом меню выбираем «не проверять дубли фраз» и «проверять статистику». Жмем импортировать. И он сейчас эти фразы сразу распределит по вкладкам, так же, как у нас это было в Key Assort.
Получаем категории и фразы, уже распределенные по категориям.
И дальше можно с ними работать, собирать по ним дальше данные и можно также переименовывать здесь эти группы, назвать их как-то по другому.
И если у нас получилась слишком большая группа, можно еще раз выгрузить это в Key Assort, там сгруппировать и утащить это обратно, если это вдруг для каких-то целей понадобится.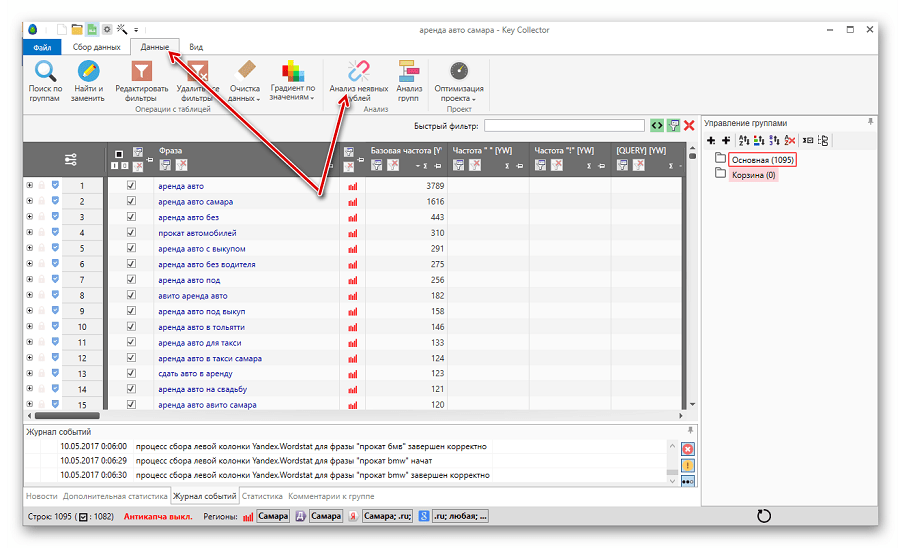
Вот такая связка. Сейчас последняя версия Key Assort и последняя версия Key Collector очень удобны для этого. И рекомендуется для этого их и использовать.
Как группировать СЯ в Key Collector для Директа
Главная » Контекстная реклама » Как группировать семантическое ядро в Кей Коллектор
Продолжаем обучаться работе с Key Collector. Из всей массы функций это программы мы разбираем только те, которые нам нужны для работы с контекстной рекламой. Конечно, SEO-специалистам это тоже пригодится, но упор в моих материалах на директологов.
Напомню, что в прошлых статьях мы уже разобрали где скачать и как настроить Кей Коллектор, а так же как собрать минус-слова для нашей РК через эту программу. Так же я писал о том, как получить бесплатно Кей Коллектор и какие у него аналоги.
Как кластеризировать семантику через Key Collector
Кластеризация или другими словами группировка — это процесс объединения фраз в группы по определенным параметрам.
Для SEO-специалистов всегда объединяются запросу по интенту, то есть по намерениям пользователя, а для директологов бывают и другие типы кластеризации.
На мой взгляд, наиболее правильно объединять именно по интенту.
Например, запросы вида «купить еду в макдаке» и «заказать еду в макдональдс» будут разные, но ищут по ним одну и ту же информацию и намерение пользователей не отличается.
Можно еще группировать по ключевым словам, которые указаны в запросе. Таким образом директологи пытаются добиться максимально релевантных заголовков, чтобы как можно больше слов подсвечивалось в вашем объявлении и был выше CTR.
Дело в том, что часто именно во втором варианте допускаются ошибки и CTR ниже, потому что мы не всегда можем понять у всех ли запросов одинаковый интент, если запросы похожи, но часто даже похожие запросы имеют совершенно разный интент.
Итак. Для начала создаем проект
Заказать настройку рекламы
Напоминаю, что лучше в названии указывать на каком этапе ваше СЯ, дата создания и для какого проекта. Таким образом вы не запутаетесь в файлах со временем.
Таким образом вы не запутаетесь в файлах со временем.
Затем добавляем фразы в программу.
Фразы можно взять из Вордстата, специальных сервисов по сбору СЯ, собрать напрямую в Кей Коллекторе через стартовые фразы или любым другим способом.
Если у вас очень маленькая семантика (до 100 запросов), то можно собрать и в Вордстате, а если больше, то надо сначала собрать базисы (стартовые запросы) в Вордстате, затем спарсить СЯ по этим запросам через КейКоллектор.
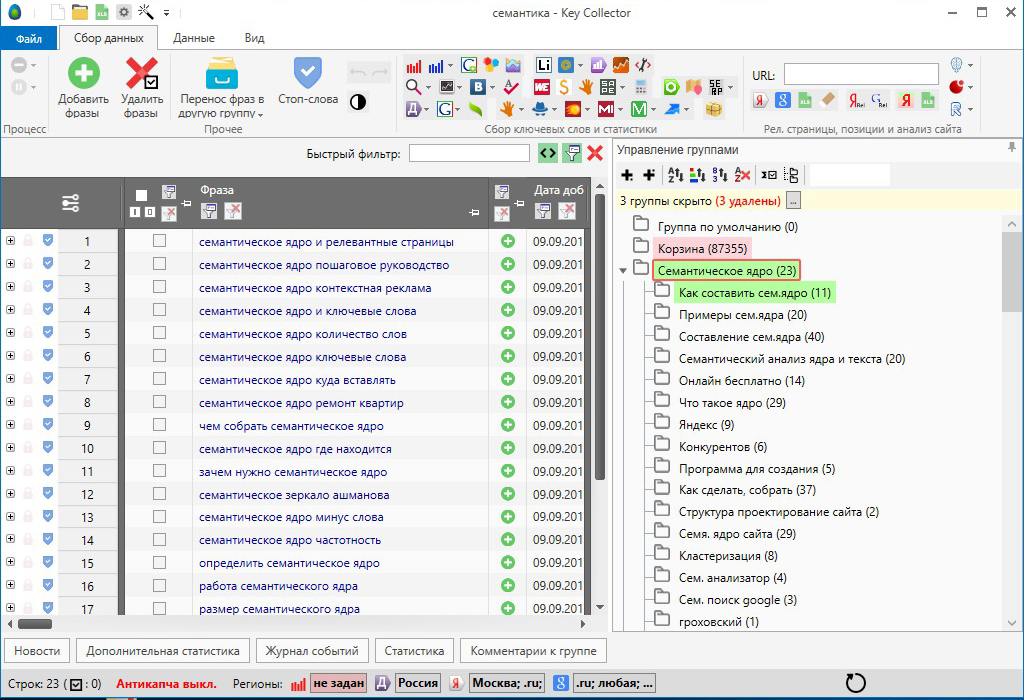
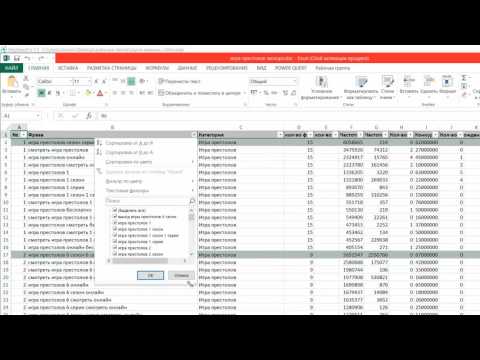
Далее переходим на вкладку «данные», выбираем «анализ групп» и настраиваем группировку по вашим параметрам. Если по интенту, то выбираете пункт «по поисковой выдаче», а если по отдельным словам или по составу фраз, то тоже выбираете соответствующий пункт. Затем эту таблицу можно выгрузить в Эксель.
Выглядят группированные запросы следующим образом:
Это группировка по составу фраз. То есть фразы объединяются по нескольким наиболее часто встречающимся словам.
Если группируете по поисковой выдаче, то есть по интенту, то выбираете поискову систему и силу SERP. Сила SERP — это то, как часто запросы пересекаются в выдаче между собой. А поисковую систему выбирайте ту, по которой настраиваете рекламу. Разница между интентами запросов у Гугла и Яндекса редко, но бывает.
Сила SERP — это то, как часто запросы пересекаются в выдаче между собой. А поисковую систему выбирайте ту, по которой настраиваете рекламу. Разница между интентами запросов у Гугла и Яндекса редко, но бывает.
Для кластеризации по интенту лучше всего использовать сервис Кулакова или Арсенкина, а для большой семантики программу KeyAssort. Перед началом работы рекомендую сначала настроить Кей Коллектор.
Заказать настройку рекламы
Управление кластерами и коллекторами
Подробные шаги по добавлению новых серверов-коллекторов в моноблочную систему и новых серверов-коллекторов в существующую систему Opsview Monitor с несколькими серверами и существующими коллекторами.
- Хост развертывания под управлением поддерживаемой операционной системы версии Opsview
- Корневой доступ к хосту развертывания
- SSH-доступ с хоста развертывания ко всем хостам Opsview (включая новые серверы, добавляемые в качестве хостов-сборщиков)
- Аутентификация должна использовать открытые ключи SSH
- Удаленный пользователь должен быть «root» или иметь доступ «sudo» без пароля и без TTY
Чтобы добавить новые серверы-сборщики в существующую систему Opsview Monitor с одним сервером, откройте файл /opt/opsview/deploy/etc/opsview_deploy. и добавьте следующие строки. 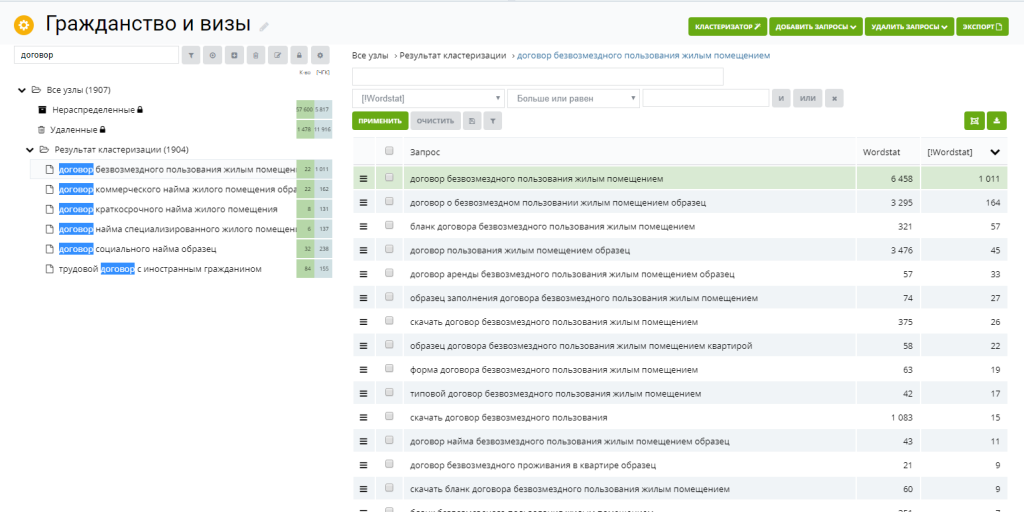 yml
yml
Примечание: Не изменять существующие строки в opsview_deploy.yml:
collect_clusters:
коллекционеры-де:
коллектор_хост:
opsview-de-1: {ip: 10.12.0.9}
Замените «opsview-de-1» и «10.12.0.9» на имя хоста и IP-адрес вашего нового коллектора и дайте имя кластеру коллекторов, изменив «collectors-de».
Вы можете добавить несколько кластеров коллекторов и несколько коллекторов в каждый кластер, например:
кластеры_коллекторов:
коллекционеры-де:
коллектор_хост:
opsview-de-1: {ip: 10.12.0.9}
opsview-de-2: {ip: 10.12.0.19}
opsview-de-3: {ip: 10.12.0.29}
коллекторы-fr:
коллектор_хост:
opsview-fr-1: {ip: 10.7.0.9}
opsview-fr-2: {ip: 10.7.0.19}
opsview-fr-3: {ip: 10.7.0.10}
opsview-fr-4: {ip: 10.7.0.20}
opsview-fr-5: {ip: 10.7.0.30}
🚧
Размер кластера
В кластере сборщиков всегда должно быть нечетное количество узлов: 1, 3, 5 и т.
д. Это необходимо для повышения отказоустойчивости и предотвращения проблем с разделением мозгов.
В кластере с четным числом, если половина узлов выйдет из строя, другая половина перестанет функционировать, поскольку кластер внутри opsview-datastore и opsview-messagequeue не будет иметь кворума и не будет принимать обновления, пока не будут восстановлены другие элементы кластера.
Мы не поддерживаем кластеры только с двумя коллекторами по вышеуказанной причине.

В приведенном выше примере конфигурации создаются два новых кластера коллекторов с именами «collectors-de» и «collectors-fr».
«collectors-de» требует минимум 3 узла-сборщика, а «collectors-fr» имеет 5 узлов-сборщиков с указанными именами хостов и IP-адресами.
После изменения opsview_deploy.yml запустите opsview deploy следующим образом:
cd /opt/opsview/deploy ./bin/opsview-deploy lib/playbooks/check-deploy.yml ./bin/opsview-deploy lib/playbooks/setup-hosts.yml ./bin/opsview-deploy lib/playbooks/setup-infrastructure.yml ./bin/opsview-deploy lib/playbooks/collector-install.yml

После запуска opsview-deploy проверьте раздел «Регистрация новых серверов Collector в Opsview Web».
Если вы хотите зарегистрировать свой сборщик автоматически и добавить предложенные шаблоны хостов и связанные с ними переменные, необходимые для этих шаблонов, запустите setup-monitoring.yml для вашего нового сборщика(ов)/collector_cluster (используя -l (для Лима), как указано далее в этом руководстве).
корень:~# cd /opt/opsview/deploy корень:/opt/opsview/deploy# ./bin/opsview-deploy lib/playbooks/setup-monitoring.yml
Пожалуйста, примените изменения в пользовательском интерфейсе после успешного завершения, чтобы этот шаг вступил в силу.
КРИТИЧЕСКИЙ: Не удалось подключиться к локальному хосту Код ответа: 401 Неавторизованный
Если у вас уже есть несколько сборщиков и вы хотите добавить новые сборщики, откройте /opt/opsview/deploy/etc/opsview_deploy. на сервере развертывания (обычно это хост opsview с оркестратором и opsview-web) и добавьте новые кластеры коллекторов или хосты коллекторов после существующих, например: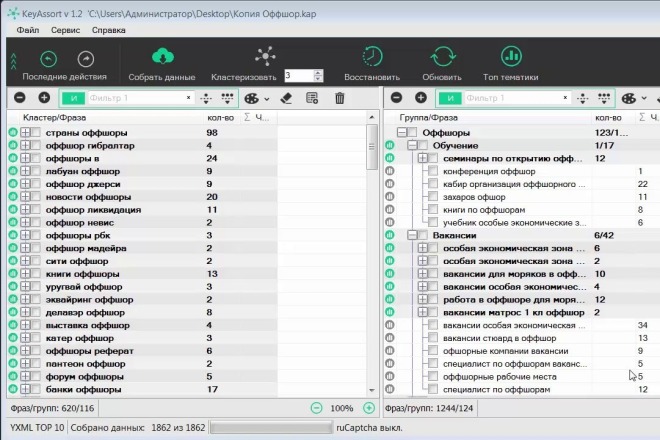 yml
yml
коллектор_кластеров:
существующий-коллектор1:
коллектор_хост:
существующий хост1: {ip: 10.12.0.9}
новый хост1: {ip: 10.12.0.19}
новый хост2: {ip: 10.12.0.29}
новый коллектор-кластер1:
коллектор_хост:
новый хост3: {ip: 10.7.0.9}
новый хост4: {ip: 10.7.0.19}
новый хост5: {ip: 10.7.0.29}
В приведенном выше примере существует 5 новых хостов-сборщиков (новый-хост1, новый-хост2, новый-хост3, новый-хост4 и новый-хост5) и добавлен 1 новый кластер сборщиков (новый-сборщик-кластер1).
- new-host1 и 2 добавляются в существующий кластер сборщиков (existing-collector1)
- new-host3, 4 и 5 добавляются в новый кластер сборщиков (new-collector-cluster1).
После изменения opsview_deploy.yml запустите opsview deploy следующим образом:
cd /opt/opsview/deploy .
 /bin/opsview-deploy lib/playbooks/check-deploy.yml
./bin/opsview-deploy lib/playbooks/setup-hosts.yml
./bin/opsview-deploy lib/playbooks/setup-infrastructure.yml
./bin/opsview-deploy lib/playbooks/datastore-reshard-data.yml
./bin/opsview-deploy lib/playbooks/collector-install.yml
/bin/opsview-deploy lib/playbooks/check-deploy.yml
./bin/opsview-deploy lib/playbooks/setup-hosts.yml
./bin/opsview-deploy lib/playbooks/setup-infrastructure.yml
./bin/opsview-deploy lib/playbooks/datastore-reshard-data.yml
./bin/opsview-deploy lib/playbooks/collector-install.yml
Если вы хотите ускорить этот процесс, вы можете указать кластер сборщиков, который вы обновляете или создаете.
Наилучший способ сделать это — указать кластер сборщиков, используя минус строчную букву «-l» (l для Lima). правильно
компакт-диск /opt/opsview/развернуть ./bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/check-deploy.yml ./bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/setup-hosts.yml ./bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/setup-infrastructure.yml .
 /bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/datastore-reshard-data.yml
./bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/collector-install.yml
/bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/datastore-reshard-data.yml
./bin/opsview-deploy -l opsview_cluster_existing_collector1 lib/playbooks/collector-install.yml
Вы также можете использовать имена сборщиков в двойных кавычках, если это новые кластеры сборщиков
Для одного нового кластера сборщиков (кластера или одного) вы можете использовать имя или имена сборщиков
для удаления коллектора из кластера.
Вы можете установить конкретную конфигурацию компонента для любого коллектора. Настройки могут быть развернуты для отдельных или для всех коллекторов с помощью /opt/opsview/deploy/etc/user_vars.yml 9.0020 и /opt/opsview/deploy/etc/opsview_deploy.yml . В этом примере мы рассмотрим настройку конкретных примеров для конфигурации opsview-executor для всех сборщиков, а затем для сервера exists-collector1 .
Чтобы передать конфигурацию всем сборщикам при развертывании, вам потребуется указать раздел «ov_component_overrides» и соответствующий раздел компонента, например «opsview_executor_config» — это устанавливается в пределах /opt/opsview/deploy/etc/user_vars.yml . Эти изменения применяются к компонентам конфигурационный файл, поэтому для исполнителя это /opt/opsview/executor/etc/executor.yaml . Приведенное ниже изменит системные значения по умолчанию для initial_worker_count на 4 (системное значение по умолчанию 2) и max_concurrent_processes на 10 (системное значение по умолчанию 25).
ov_component_overrides:
opsview_executor_config:
Initial_worker_count: 4
max_concurrent_processes: 10
Затем запустите развертывание с помощью playbook setup_everything. yaml, чтобы распространить эту конфигурацию на все коллекторы.
yaml, чтобы распространить эту конфигурацию на все коллекторы.
Если конфигурация требуется только для одного сборщика, измените файл /opt/opsview/deploy/etc/opsview_deploy.yml , чтобы добавить переопределения в раздел vars: для конкретного сборщика следующим образом:
collect_clusters:
кластер коллекторов:
коллектор_хост:
существующий-коллектор1:
IP-адрес: 10.12.0.9
вары:
ov_component_overrides:
opsview_executor_config:
Initial_worker_count: 4
max_concurrent_processes: 10
Вместо того, чтобы запускать весь процесс развертывания, используйте плейбук collect-install.yml для конкретного сборщика (как подробно описано в разделе выше). Если несколько сборщиков в одном и том же кластере изменены, убедитесь, что вы запускаете playbook для всех из них одновременно, используя параметр -l collection1,collector2,collector3 .
Войдите в пользовательский интерфейс Opsview Monitor и перейдите на страницу Configuration > Monitoring Collectors .
Вы должны увидеть желтое сообщение «Ожидание регистрации» справа, как показано ниже:
Щелкните значок меню справа от имени хоста вашего коллектора и нажмите «Зарегистрировать», как показано ниже:
появится другое окно для регистрации коллектора. :
Нажмите «Отправить изменения и далее». Появится новое окно для создания «Нового кластера мониторинга»:
Дайте новому кластеру мониторинга то же имя, которое вы добавили в opsview_deploy.yml, например «collectors-de». Выберите сборщики, которые должны быть в этом кластере мониторинга, из списка сборщиков, затем щелкните Отправить изменения.
После добавления первого кластера мониторинга вы можете зарегистрировать коллектор в существующем кластере мониторинга, выбрав «Существующий кластер» и выбрав кластер мониторинга из раскрывающегося списка:
После регистрации новых коллекторов вы должны увидеть свои кластеры и количество коллекторов в каждом кластере на вкладке «Кластеры»:
Вы даже можете щелкнуть числа в столбце «СБОРНИКИ», чтобы увидеть имена хостов коллекторов:
После регистрации новых коллекторов перейдите в «Конфигурация» > «Применить изменения», чтобы запустить коллекторы в производство.
Убедитесь, что коллекторы работают правильно, проверив вкладку «Обзор системы» в разделе «Конфигурация» > «Моя система»:
На странице «Конфигурация» > «Мониторинг коллекторов» отображаются сведения о работоспособности как отдельных узлов коллекторов, так и каждого кластера.
- Статус ONLINE/OFFLINE напрямую связан с обработкой очереди состояния кластера, показанной во время вывода команды
/opt/opsview/messagequeue/sbin/rabbitmqctl list_queues. Если вы видите здесь накопление, то последние статусы не будут отображаться, и эту очередь нужно будет очистить, прежде чем они будут. - Это можно сделать с помощью команды rabbitmqctl
purge_queue cluster-health-queue; обычно необходимо запускать только на сервере оркестратора. - Если очередь не очищается, остановите и запустите компоненты
opsview-schedulerиopsview-orchestrator
В столбце Состояние показано текущее состояние кластера.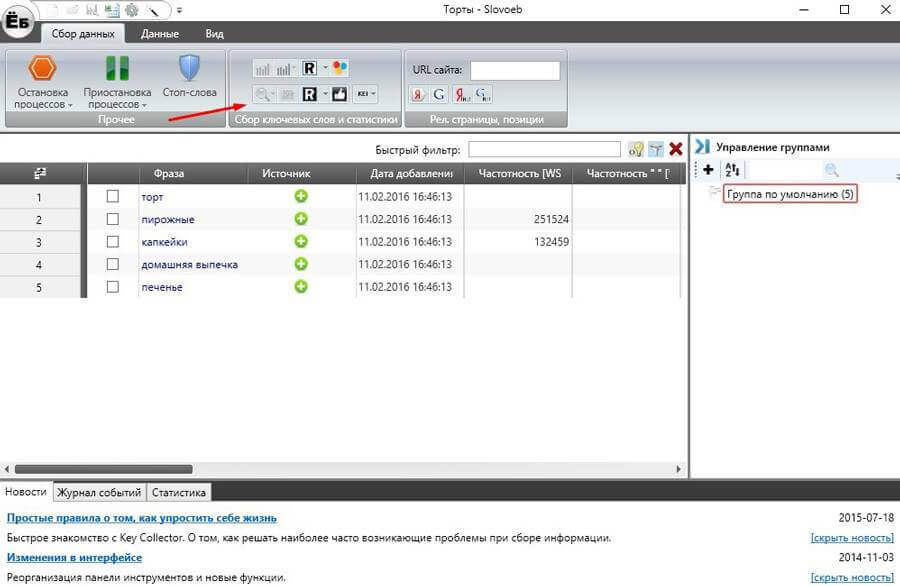 Возможные значения:
Возможные значения:
- ОНЛАЙН — Кластер работает нормально
- DEGRADED — Проблемы с кластером. Наведите курсор на статус, чтобы получить список будильников
- OFFLINE — Кластер не ответил в течение заданного периода времени, поэтому предполагается, что он находится в автономном режиме
В таблице ниже описаны возможные сигналы тревоги, которые будут отображаться, когда пользователи наводят указатель мыши на состояние кластера DEGRADED. Эти аварийные сигналы относятся к состояниям следующих компонентов Opsview:
- opsview-schedulers
- opsview-исполнители
- отправитель результатов opsview
| Аварийные сигналы | Описание | Предложения/действия |
|---|---|---|
| Все компоненты [Имя компонента] недоступны например. Все компоненты opsview-executor недоступны. | Главный сервер/сервер Orchestrator не может обмениваться данными с какими-либо компонентами [Имя компонента] в кластере сборщика. Это может быть из-за проблемы с сетью/связью или из-за того, что в кластере не запущены компоненты [Имя компонента]. Это может быть из-за проблемы с сетью/связью или из-за того, что в кластере не запущены компоненты [Имя компонента].Примечание. Этот аварийный сигнал срабатывает только тогда, когда все компоненты [Имя компонента] в кластере коллекторов недоступны, поскольку кластер может быть сконфигурирован так, чтобы эти компоненты работали только на подмножестве коллекторов. Кроме того, кластер может продолжать мониторинг с остановкой некоторых (хотя и не всех) компонентов [Имя компонента]. | Чтобы решить эту проблему, убедитесь, что главный сервер/оркестратор может обмениваться данными с кластером коллекторов (т. е. разрешать любые сетевые проблемы) и что по крайней мере один планировщик работает. т. е. SSH для сбора и запуска /opt/opsview/watchdog/bin/opsview-monit start [Имя компонента] |
Получено недостаточно сообщений ([Имя компонента 1] → [Имя компонента 2]): [Период времени ] [Процент полученных сообщений]%. напр. Получено недостаточно сообщений (opsview-scheduler → opsview-executor): [15m] 0%. | Менее 70% сообщений, отправленных [Имя компонента 1], были получены [Имя компонента 2] в течение периода времени. Это может указывать на проблемы со связью между компонентами в кластере сборщиков или на то, что [Имя компонента 2] перегружен и не может своевременно обрабатывать получаемые сообщения. напр. 0% сообщений, отправленных планировщиком, были получены исполнителем в течение 15-минутного периода. | Если 0% отправленных сообщений было получено [Имя компонента 2] и нет других аварийных сигналов, это может означать сбой связи в кластере. Чтобы решить эту проблему, убедитесь, что все сборщики в кластере могут взаимодействовать через все порты (см. https://knowledge.opsview.com/docs/ports#collector-clusters) и что opsview-messagequeue выполняется на всех сборщиках без ошибок. В качестве альтернативы это может указывать на то, что не все необходимые компоненты работают на сборщиках в кластере. Если > 0 % отправленных сообщений были получены [Имя компонента 2], это, вероятно, указывает на проблему с производительностью в кластере. Чтобы решить эту проблему, вы можете: Уменьшить нагрузку на кластер, т.е. |
 Запустите /opt/opsview/watchdog/bin/opsview-monit summary на каждом сборщике, чтобы убедиться, что все компоненты находятся в рабочем состоянии. Если какие-либо из них остановлены, запустите /opt/opsview/watchdog/bin/opsview-monit start [имя компонента], чтобы запустить их.
Запустите /opt/opsview/watchdog/bin/opsview-monit summary на каждом сборщике, чтобы убедиться, что все компоненты находятся в рабочем состоянии. Если какие-либо из них остановлены, запустите /opt/opsview/watchdog/bin/opsview-monit start [имя компонента], чтобы запустить их.
Примечание. Для нового коллектора/кластера, который только что был настроен или активность которого минимальна, предупреждение «Недостаточно сообщений получено» будет подавлено, чтобы избежать ненужного беспокойства администратора/пользователя. Это не влияет на аварийный сигнал «Все компоненты [Имя компонента] недоступны», который по-прежнему будет выдаваться для автономного коллектора.
Если ваша подписка включает функцию топологии сети, на странице Конфигурация > Мониторинг коллекторов можно включить или отключить регулярное определение топологии сети для каждого кластера.
В столбце «Топология сети» показано, включено ли обычное определение топологии сети для каждого кластера. Чтобы включить, щелкните значок меню и «Включенные функции»:
Затем щелкните переключатель «Топология сети»:
. щелкнув значок меню для этого кластера, а затем «Просмотреть топологию»:
Для получения дополнительной информации о содержимом карты топологии сети см. Просмотр карт топологии сети
Просмотр карт топологии сети
В столбце Состояние отображается текущее состояние коллектора. Возможные значения:
- ОНЛАЙН — Сборщик работает нормально, судя по статусу opsview-scheduler .
- OFFLINE — Collector не ответил в течение заданного периода времени, поэтому предполагается, что он находится в автономном режиме
Чтобы удалить коллектор из кластера, нажмите «КОНФИГУРАЦИЯ > МОНИТОРИНГ КОЛЛЕКТОРОВ» в верхнем меню, а затем перейдите на вкладку «Кластеры». Затем щелкните значок меню и «Изменить»:
Затем отмените выбор коллектора, который вы хотите удалить, и нажмите кнопку «Отправить изменения». Теперь вы можете перейти в «Конфигурация» > «Применить изменения», чтобы подтвердить изменение и завершить работу коллектора.
Чтобы добавить коллектор в кластер, отредактируйте кластер, а затем выберите коллектор (используйте Cntrl в Windows или Cmd в Mac OS, чтобы выбрать в дополнение к существующим выборам). Перейдите в «Конфигурация» > «Применить изменения», чтобы подтвердить изменение.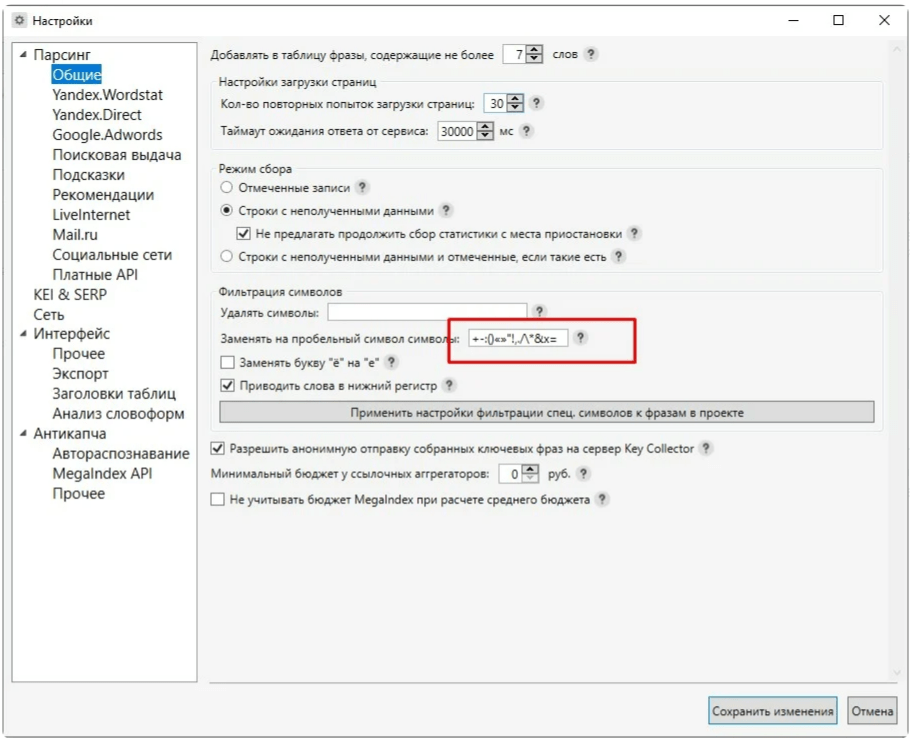
Шаги немного отличаются в зависимости от размера кластера.
Примечание: Если вы удалили коллектор, но затем хотите зарегистрировать его снова, вы не увидите, что он станет доступным в сетке незарегистрированных коллекторов, пока вы не остановите планировщик на этом коллекторе хотя бы на целую минуту, а затем перезапустите это.
1. Отключите кластер (Конфигурация > Мониторинг коллекторов > Кластеры).
Отредактируйте кластер, затем снимите флажок «Активировано» и нажмите Отправить изменения . Затем вам нужно будет Применить изменения .
2. Удалить кластер (Конфигурация > Мониторинг коллекторов > Кластеры).
3. Удалить коллектор (Конфигурация > Мониторинг коллекторов > Коллекторы).
4. Удалить коллектор как отслеживаемый хост (Конфигурация > Хосты).
5. Выполнить Применить изменения .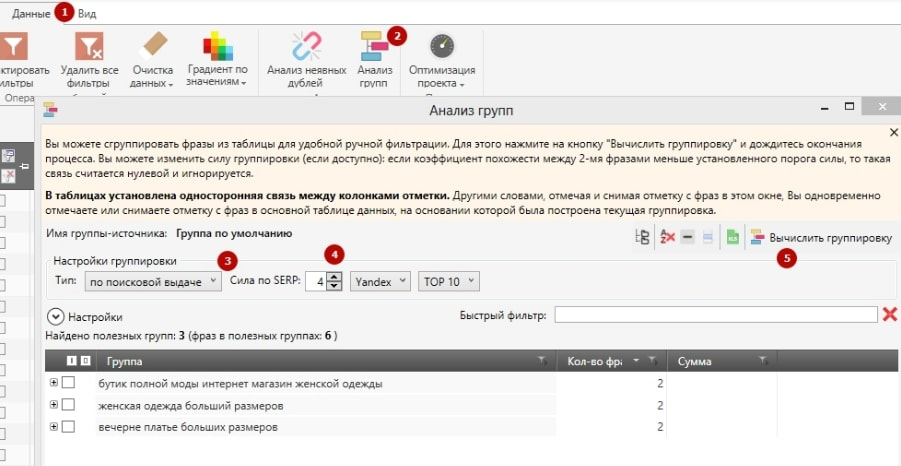
6. Отредактируйте файлы развертывания (opsview_deploy.yml, user_vars.yml и другие в зависимости от ситуации), закомментировав или удалив строки для удаленного Collector.
1. Удалить коллектор из его кластера (Конфигурация > Мониторинг коллекторов > Кластеры).
Отредактируйте кластер и отмените выбор коллектора, который вы хотите удалить, чтобы были выделены только те коллекторы, которые вы хотите оставить в кластере, затем нажмите Отправить изменения .
2. Удалить коллектор (Конфигурация > Мониторинг коллекторов > Коллекторы).
3. Удалить Collector как отслеживаемый хост (Конфигурация > Хосты).
4. Выполнить Применить изменения .
5. Отредактируйте файлы развертывания (opsview_deploy.yml, user_vars.yml и другие в зависимости от ситуации), закомментировав или удалив строки для удаленного Collector.
6. Запустите полное развертывание в кластере, например.
Запустите полное развертывание в кластере, например. /opt/opsview/deploy/bin/opsview-deploy -l collection1,collector2,collector3 /opt/opsview/deploy/lib/playbooks/setup-everything.yml .
Обновить Collector так же просто, как обновить все пакеты Opsview на сервере Collector. Чтобы избежать простоев, отключите соединение от Collector к главному серверу MessageQueue, обновите все пакеты и перезагрузите систему. Как только соединение будет восстановлено, коллектор автоматически присоединится к кластеру, и теперь вы сможете выполнить обновление других коллекторов.
В распределенной системе Opsview Monitor сценарии мониторинга в Collectors могут не синхронизироваться со сценариями в Orchestrator, если:
- новые пакеты Opspack, сценарии мониторинга или подключаемые модули были импортированы в Orchestrator.
- сценариев мониторинга были обновлены непосредственно в Orchestrator.
В таких случаях папку сценариев мониторинга ( /opt/opsview/monitoringscripts ) в Оркестраторе необходимо синхронизировать со всеми коллекторами с помощью доступного плейбука под названием 9. 0019 sync_monitoringscripts.yml .
0019 sync_monitoringscripts.yml .
Playbook sync_monitoringscripts.yml использует rsync для отправки соответствующих обновлений каждому сборщику (при необходимости он будет установлен автоматически), исключая определенные наборы файлов.
Следующие каталоги и файлы (относительно /opt/opsview/monitoringscripts ) не синхронизируются:
.../lib/* .../tmp/* .../делиться/* .../перл/* .../плагины/utils.pm .../вар/* .../opspacks/* .../etc/notificationmethodvariables.cfg .../etc/plugins/check_snmp_interfaces_cascade
Например, при использовании приведенного выше списка исключений файлы в каталоге /opt/opsview/monitoringscripts/lib/ и определенные файлы, такие как /opt/opsview/monitoringscripts/etc/notificationmethodvariables.cfg , не будут синхронизированы.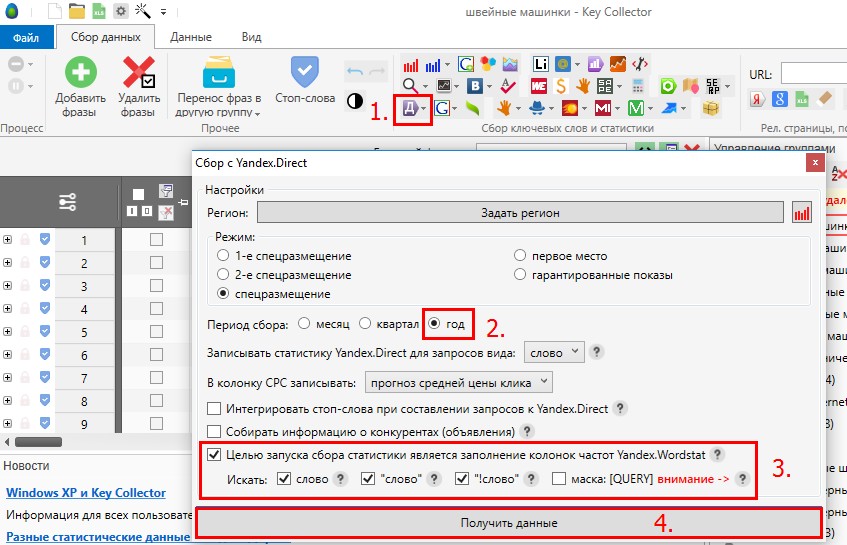 .
.
Кроме того, если у Collector не та же версия ОС, что и у Orchestrator, будут синхронизированы только статически связанные исполняемые файлы и текстовые файлы. Это делается для того, чтобы двоичные файлы, используемые в Orchestrator, не синхронизировались с несовместимым Collector. Например, двоичный файл AMD64 не будет отправлен в коллектор на базе ARM32.
- Интерпретируемые файлы сценариев, такие как сценарии Python, Perl и Bash и файлы конфигурации, являются текстовыми файлами, и будут синхронизированы.
- Динамически связанные исполняемые файлы не будут синхронизированы, поскольку они могут работать неправильно из-за зависимостей во время выполнения. Такие динамически связанные исполняемые файлы необходимо устанавливать на сборщики вручную, если у сборщиков другая версия ОС, чем у Orchestrator.
Ключи SSH настроены между Orchestrator и коллекторами (это уже должно быть на месте, если Opsview Deploy ранее использовался для установки или обновления системы).
Выполните следующие команды от имени пользователя root в Orchestrator:
cd /opt/opsview/deploy/ bin/opsview-deploy lib/playbooks/sync_monitoringscripts.yml
Если ваш сервер развертывания не является Orchestrator, вы можете выполнять те же команды на своем сервере развертывания, но ключи SSH должны быть настроены между Orchestrator и сборщиками для пользователей SSH, определенных для ваших сборщиков в вашем файле opsview_deploy.yml.
Обновлено 5 месяцев назад
Кластеры AWS CloudHSM — AWS CloudHSM
AWS CloudHSM предоставляет аппаратные модули безопасности (HSM) в кластере . Кластер представляет собой набор отдельных модулей HSM, которые AWS CloudHSM синхронизирует. Вы можете думать о кластере как об одном логический ХСМ. Когда вы выполняете задачу или операцию на одном HSM в кластере, другие HSM в этот кластер автоматически обновляется.
Вы можете создать кластер, содержащий от 1 до 28 модулей HSM (по умолчанию
ограничение составляет 6 модулей HSM на аккаунт AWS в каждом регионе AWS).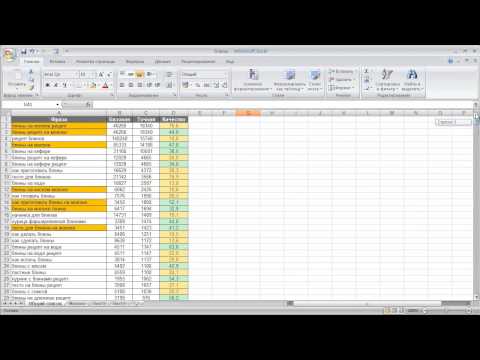 Вы можете разместить HSM в разных
Зоны доступности в регионе AWS. Добавление большего количества модулей HSM в кластер обеспечивает более высокую производительность.
производительность. Распределение кластеров по зонам доступности обеспечивает избыточность и высокую производительность.
доступность.
Вы можете разместить HSM в разных
Зоны доступности в регионе AWS. Добавление большего количества модулей HSM в кластер обеспечивает более высокую производительность.
производительность. Распределение кластеров по зонам доступности обеспечивает избыточность и высокую производительность.
доступность.
Совместная работа отдельных модулей HSM в синхронизированном резервном высокодоступном кластере может быть сложной задачей, но AWS CloudHSM сделает за вас часть недифференцированной тяжелой работы. Можете добавить удалите модули HSM в кластере и позвольте AWS CloudHSM поддерживать подключение и синхронизацию модулей HSM для вас.
Чтобы создать кластер, см. раздел Начало работы.
Дополнительные сведения о кластерах см. в следующих разделах.
Темы
- Кластерная архитектура
- Синхронизация кластера
- Высокая доступность и нагрузка кластера балансировка
Архитектура кластера
При создании кластера вы указываете Amazon Virtual Private Cloud (VPC) в своей учетной записи AWS и один или
больше подсетей в этом VPC. Мы рекомендуем вам создать одну подсеть в каждой зоне доступности.
(AZ) в выбранном вами регионе AWS. Вы можете создавать частные подсети при создании VPC. Чтобы узнать больше, см.
Создайте виртуальное частное облако (VPC).
Мы рекомендуем вам создать одну подсеть в каждой зоне доступности.
(AZ) в выбранном вами регионе AWS. Вы можете создавать частные подсети при создании VPC. Чтобы узнать больше, см.
Создайте виртуальное частное облако (VPC).
Каждый раз при создании HSM вы указываете кластер и зону доступности для HSM. К размещая HSM в разных зонах доступности, вы получаете избыточность и высокую доступность в случае недоступности одной из зон доступности.
При создании HSM AWS CloudHSM помещает эластичный сетевой интерфейс (ENI) в указанный подсети в вашей учетной записи AWS. Эластичный сетевой интерфейс — это интерфейс для взаимодействия с ХСМ. HSM находится в отдельном VPC в учетной записи AWS, принадлежащей AWS CloudHSM. Модуль HSM и соответствующий ему сетевой интерфейс находятся в одной зоне доступности.
Для взаимодействия с модулями HSM в кластере требуется клиентское программное обеспечение AWS CloudHSM. Обычно вы
установите клиент на экземпляры Amazon EC2, известные как экземпляра клиента , которые
находятся в том же VPC, что и HSM ENI, как показано на следующем рисунке. Это не
хотя технически требуется; вы можете установить клиент на любой совместимый компьютер, если
он может подключаться к HSM ENI. Клиент взаимодействует с отдельными модулями HSM в вашем
кластер через свои ENI.
Это не
хотя технически требуется; вы можете установить клиент на любой совместимый компьютер, если
он может подключаться к HSM ENI. Клиент взаимодействует с отдельными модулями HSM в вашем
кластер через свои ENI.
На следующем рисунке представлен кластер AWS CloudHSM с тремя модулями HSM, каждый из которых Зона доступности в VPC.
Синхронизация кластера
В кластере AWS CloudHSM AWS CloudHSM поддерживает синхронизацию ключей на отдельных модулях HSM. Вам не нужно делать что-либо для синхронизации ключей на ваших модулях HSM. Чтобы сохранить пользователей и политики на каждом HSM синхронизирован, обновите файл конфигурации клиента AWS CloudHSM, прежде чем управлять пользователями HSM. Дополнительные сведения см. в разделе Хранение пользователей HSM в синхронизировать
При добавлении нового HSM в кластер AWS CloudHSM создает резервную копию всех ключей, пользователей и политик.
на существующем HSM. Затем он восстанавливает эту резервную копию на новый HSM. Это удерживает два модуля HSM в
синхронизировать
Это удерживает два модуля HSM в
синхронизировать
Если HSM в кластере не синхронизированы, AWS CloudHSM автоматически выполняет повторную синхронизацию их. Для этого AWS CloudHSM использует учетные данные устройства. пользователь. Этот пользователь существует на всех HSM, предоставляемых AWS CloudHSM, и имеет ограниченные права. Это может получить хэш объектов в HSM и может извлекать и вставлять замаскированные (зашифрованные) объекты. AWS не может просматривать или изменять ваших пользователей или ключи и не может выполнять какие-либо криптографические операции. используя эти ключи.
Высокая доступность и нагрузка кластера балансировка
При создании кластера AWS CloudHSM с более чем одним HSM вы автоматически получаете нагрузку
балансировка. Балансировка нагрузки означает, что AWS CloudHSM
клиент распределяет криптографические операции по всем HSM в кластере на основе
емкость каждого модуля HSM для дополнительной обработки.
Когда вы создаете HSM в разных зонах доступности AWS, вы автоматически получаете доступность. Высокая доступность означает, что вы получаете более высокую надежность, поскольку ни один HSM — это единая точка отказа. Мы рекомендуем иметь как минимум два модуля HSM в каждом кластер, где каждый HSM находится в разных зонах доступности в регионе AWS.
Например, на следующем рисунке показано приложение базы данных Oracle, которое распространяется в две разные зоны доступности. Экземпляры базы данных хранят свои главные ключи в кластер, включающий модуль HSM в каждой зоне доступности. AWS CloudHSM автоматически синхронизирует ключи к обоим модулям HSM, чтобы они были немедленно доступны и дублированы.
Javascript отключен или недоступен в вашем браузере.
Чтобы использовать документацию Amazon Web Services, должен быть включен Javascript. Инструкции см. на страницах справки вашего браузера.