
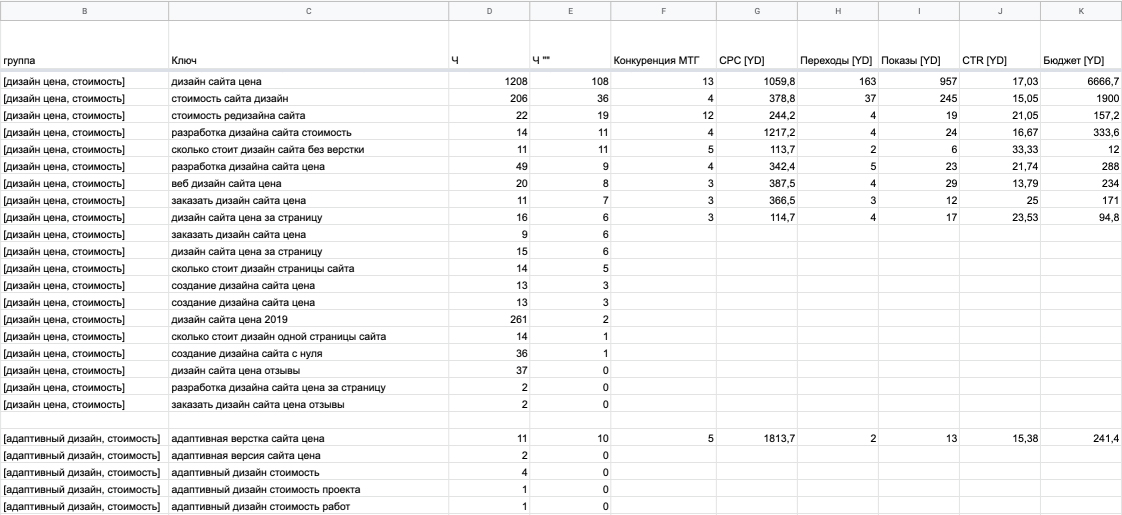
Как работать с Key Collector и Key Assort?
Автор статьи
Андрей Буйлов
Подробнее об авторе
Сегодня будет проведен обзор совместной работы лучшей программы для сбора семантики Key Collector и лучшей программы для кластеризации запросов Key Assort.
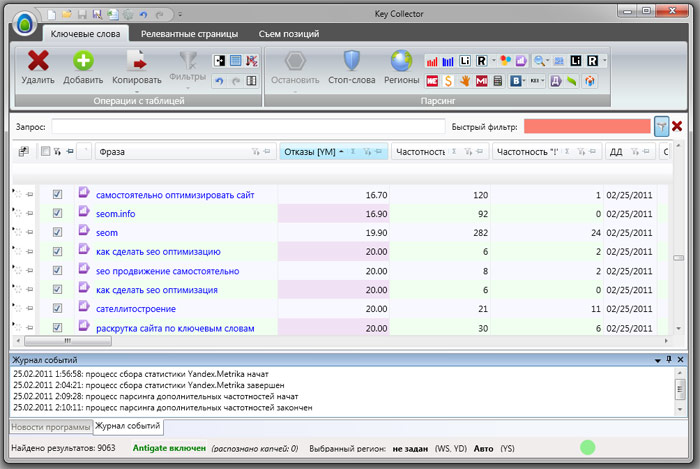
Key Collector
Заходим в программу.
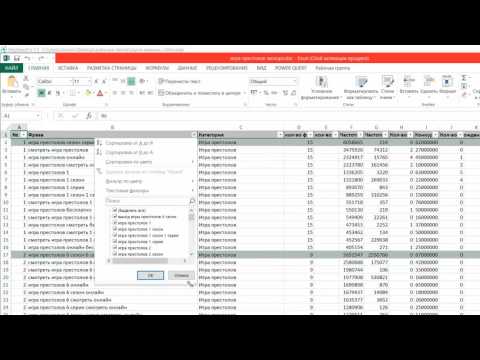
1. Здесь уже собрались какие-то запросы и у нас получилось 383 фразы. Уже есть определенные данные.
Например, мы работаем с поисковой выдачей, с частотами и т.д, и нам нужно здесь распределить эти фразы по страницам. И алгоритм, который встроен в Key Collector, нас по какой-то причине не устраивает.
Мы можем уже здесь собрать данные – они нужны будут нам в Key Collector (доля главных страниц, количество вхождений в заголовки). Эти данные нужно будет еще раз собирать и в KeyAssort.
Эти данные нужно будет еще раз собирать и в KeyAssort.
И вот чтобы не делать это дважды, мы соберем эти данные только в Key Collector. Открываем вкладку «Парсинг/Собрать данные из ПС Yandex»
Идет парсинг
Далее видим, что собрались данные по поисковой выдаче.
Что делаем дальше?
Переходим во вкладку «Файл/Экспорт/Поисковая выдача».
Выбираем Яндекс. Сниппеты не загружаем. Выбираем Экспортировать.
Выпадает вкладка, в которой нужно ввести имя файла – назовем «экспорт» (он в Excel).
Key Assort
Далее идем в KeyAssort.
-
Создаем проект (у нас он уже создан).
-
Выбираем следующее: «Файл/Импорт/С данными о поисковой выдаче».
-
В выпавшем меню о запросе безвозвратно удалить все данные нажимаем «да».

-
В появившемся окне выбираем «Выдача».
-
Появилась вкладка «Параметры импорта». Проверяем: столбец «А» — это запрос; столбец «N» — конкретные сайты.
-
Теперь выбираем в настройках тип кластеризации: «Сервис/Настройки программы/Кластеризация».

Запросы добавились. Собирать данные не нужно, они есть (в нижней строке экрана написано «Собрано данных 384 из 384»)
Здесь делаем все настройки, которые нам нужны, индивидуально.
В данном случае выбираем Силу – 4; вид кластеризации – Hard, сохраняем.
Далее в верхней панели жмем вкладку «Кластеризовать». Получаем результат.
Здесь дополнительно ничего парсить не нужно. Напомним, что эту кластеризацию нужно проверять, т. е. нужно просмотреть выборочно или все группы, корректно ли он сгруппировал.
е. нужно просмотреть выборочно или все группы, корректно ли он сгруппировал.
Часто бывает так, что наша стандартная кластеризация – и тип, и сила – могут для конкретных проектов показать себя не очень хорошо. И тогда мы будем играться с силой: уменьшать, увеличивать. Допустим, получились слишком маленькие группы и слишком много несгруппированных запросов, тогда можно силу уменьшить.
Итак, все сгруппировано.
Дальше нам нужно перетащить все проекты направо. Для этого переходим в правую часть экрана, там во вкладке «Группа/Форма» вводим название – не важно, как это называется, назовем, к примеру, «категория».
Клавишей «Shift» выделяем все файлы левой части экрана и тащим направо.
Если мы не хотим никак дополнительно называть эти группы ключей, тогда назовем их как один из запросов этой группы. Если хотим, чтобы группы более осмысленно уже на этом этапе назывались, тогда здесь их просто переименовываем.
Все.
Что делаем дальше?
Экспорт. И здесь нужно экспортировать не как обычно в Excel, а экспортировать в Key Collector. Для этого в правой части экрана в верхней вкладке выбираем «Экспорт/Key Collector». Жмем, делаем файл – даем ему название в выпавшем меню.
Все, экспортировали.
Возвращаемся в Key Collector и выбираем «Файл/Импорт/Проект KeyAssort». В выпавшем меню выбираем наш файл.
В предлагаемом меню выбираем «не проверять дубли фраз» и «проверять статистику». Жмем импортировать. И он сейчас эти фразы сразу распределит по вкладкам, так же, как у нас это было в Key Assort.
Получаем категории и фразы, уже распределенные по категориям.
И дальше можно с ними работать, собирать по ним дальше данные и можно также переименовывать здесь эти группы, назвать их как-то по другому.
И если у нас получилась слишком большая группа, можно еще раз выгрузить это в Key Assort, там сгруппировать и утащить это обратно, если это вдруг для каких-то целей понадобится.
Вот такая связка. Сейчас последняя версия Key Assort и последняя версия Key Collector очень удобны для этого. И рекомендуется для этого их и использовать.
Альтернатива Key Collector — сравнение Key Collector и Serpstat
Serpstat – это отличная альтернатива Key Collector для маркетологов и больших SEO-команд, которая, кроме сбора семантического ядра, позволяет найти и исправить технические ошибки, провести анализ конкурентов, мониторинг позиций, проверку обратных ссылок и многое другое. Serpstat
можно использовать бесплатно для небольших проектов.Начать использовать бесплатно
Более 30 инструментов в одной платформе в помощь SEO-специалистам и большим digital-агентствам для полного анализа и продвижения сайта.
Запросить демо
Запросить демо
Запросить демо
Serpstat vs Key Collector: Сравнение возможностей
Инструменты исследования ключевых слов
Интеграция Google Analytics
Отслеживание ключевых слов
Пакетный анализ ключевых слов
Кластеризация ключевых слов
Техподдержка пользователей
Бесплатное использование
Анализ доменов и URL
Аудит сайта и одной страницы
Собственный индекс обратных ссылок
Текстовая аналитика
Мультиюзерность
Готовые списки задач для работы команды
White label и брендированные отчеты
Доступ к API во всех тарифах
Запросить демо
Запросить демо
Запросить демо
Заказать демо
Запросить демо
Запросить демо
Запросить демо
Ключевые преимущества Serpstat
В Serpstat самые большие региональные базы ключевых фраз и подсказок для поисковых систем Google и Яндекс.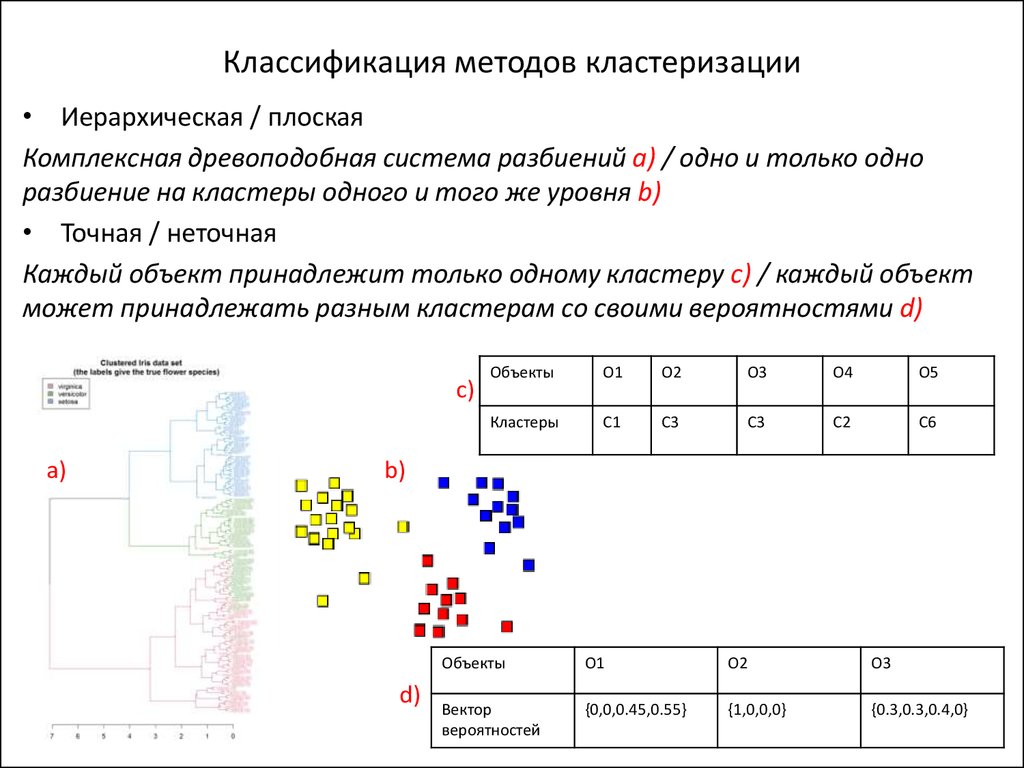 Это 6+ млрд. ключевых слов, которые ищет в поисковиках ваша аудитория.
Это 6+ млрд. ключевых слов, которые ищет в поисковиках ваша аудитория.
для анализа доменов и ключевых фраз Serpstat предоставляет 230 региональных баз Google и 9 баз Яндекса, которые содержат 6,7 млрд. ключевых фраз;
превосходящая конкурента база ключевых фраз Google США — 3,6 млрд. ключей;
самая большая на рынке база данных Google Украина, в которой собрано 307,5 млн. ключевых фраз;
максимально чистая и полная база ключевых фраз Google Россия (141,4 млн.) и различных регионов Яндекса.
6,7 млрд
Ключевых фраз
баз Google
баз Яндекса
Самые большие базы данных Google и Яндекс для анализа ключевых слов и конкурентов
В отличие от Key Collector Serpstat дает возможность полностью проанализировать ваш ссылочный профиль. Serpstat индексирует ссылки самостоятельно, ссылочный индекс содержит 1,7 трлн. ссылок по 168 млн. доменов и увеличивается каждый день на 2 млрд. ссылок.
Собственный ссылочный индекс
Serpstat дает возможность работать с API без ограничения по тарифным планам. Key Collector предоставляет возможность работать с API только через интегрированные сервисы.
Key Collector предоставляет возможность работать с API только через интегрированные сервисы.
минимальный тариф Serpstat Lite за $69 включает API-лимиты для анализа сайта, ключевых слов и ссылок, технического аудита сайта;
в тарифе Standard и выше методы API доступны также для проверки позиций. Это позволяет автоматизировать получение информации в любых проектах вне зависимости от их размеров;
Serpstat дает возможность докупить дополнительные лимиты и настраивать подписку под потребности проекта;
API для автоматизации задач
Мультиюзерность — это возможность управлять командой от 3 до 7 пользователей в рамках одного аккаунта и отслеживать эффективность работы сотрудников. Сервис-конкурент позволяет работать только с одного ПК.
Мультиюзерность для командной работы с проектами
В отличие от Key Collector Serpstat дает возможность ежедневно отслеживать локальные и глобальные позиции своего сайта в десктопе и мобайл, чтобы увеличить видимость и трафик на целевые страницы. В любом тарифном плане Serpstat доступны:
В любом тарифном плане Serpstat доступны:
отслеживание платной, органической, мобильной и десктопной выдачи;
автоматическая отправка отчетов white label о позициях сотрудникам компании и клиентам по заданному расписанию.
Отслеживание позиций сайта
анализ динамики позиций собственного сайта и сайта конкурентов для определения наилучшей стратегии;
ежедневные изменения позиций ключевых слов мобильной и десктопной выдачи для всех указанных сайтов и сравнение их с конкурентами;
Для эффективной работы с инструментами Serpstat предоставляет множество вариантов обучения и консультаций по использованию сервиса.
бесплатная консультация для всех пользователей в онлайн-чате на сайте;
для платных пользователей предоставляется персональный Customer Success менеджера для пользователей с подпиской;
в отличие от Key Kollector Serpstat предоставляет множество видеоматериалов, примеры и мини-кейсы для самостоятельного ознакомления;
Техническая поддержка и обучение
бесплатная консультация по любому проекту и функционалу Serpstat.
Запросить демо
Запросить демо
Запросить демо
Serpstat vs Key Collector: Сравнение тарифов
Сэкономить 5 000$ в год и получить многофункциональную платформу возможно только с Serpstat.
Годовая подписка на тариф Serpstat Lite стоит 660$, при этом вы получаете многофункциональную платформу для полного анализа сайта, сбора семантики, анализа ссылок, аудита, кластеризации и ежедневного мониторинга позиций. Первая, базовая лицензия в Key Collector стоит 30$, но вы получаете только инструменты для сбора семантики.
В бизнес-тарифах Serpstat вы экономите до 5 200$ в год.
Enterprise тариф позволяет получать доступ к проектам семи сотрудникам и максимальные лимиты по всем модулям, при этом, в год вы экономите 1 200$, когда Key Collector повышает цену для юридических лиц из-за необходимости оформления документов.
Самая доступная альтернатива для Рунета
Персональная демонстрация
Оставьте заявку и мы проведем для вас персональную демонстрацию сервиса, предоставим пробный период и предложим комфортные условия для старта использования инструмента.
Запросить демо
Инструмент, который стал нашим помощником в трафиковом отделе, позволяет значительно сократить временные затраты на анализ сайтов конкурентов и получить на основе этого анализа готовую семантику для собственных проектов.
Serpstat — находка для SEO-шника =) Пользуюсь сервисом уже давно, всем доволен, очень удобно. С нетерпением жду новых крутых фишек!)
Отличный сервис анализа и аудита конкурентов. Другие альтернативы стоят дороже, и не всегда есть тот функционал который нужен нам. Очень часто чекаем конкурентов на трафикообразующие страницы, в общем есть все что нужно для взрывного маркетинга и трафика.
Инструмент удобен как для частных SEO-оптимизаторов (при небольших бюджетах), так и для крупных SEO-компаний. После работы с сервисом остаются приятные впечатления. В тоже время большинство предложенных функций упрощают жизнь оптимизатора, к тому же огромным плюсом является структурированная подача информации.
Илья Василенко
Александр Шпион
ART LEMON
Дмитрий Ваврик
OdesSeo
Александр Sli
My-Master
Алексей Бузин
SEO-IMPULSE
С Serpstat работаем с тех времен когда он еще назывался Prodvigator. Must Have инструмент для SEO-специалистов на каждый день 😉
Must Have инструмент для SEO-специалистов на каждый день 😉
Запросить демо
Запросить демо
Запросить демо
Как перейти с Key Collector на Serpstat
Оставьте заявку на бесплатную демонстрацию возможностей Serpstat и проконсультируйтесь, как перейти с альтернативного сервиса. Сохраните данные по проекту и продолжайте работу над продвижением в Serpstat.
Запросить демо
Фильтрация крупного семантического ядра в Key Collector
Начал писать эту статью довольно давно, но перед самой публикацией оказалось, что меня опередили соратники по профессии и выложили практически идентичный материал.
Поначалу я решил, что публиковать свою статью не буду, так как тему и без того прекрасно осветили более опытные коллеги. Михаил Шакин рассказал о 9-ти способах чистки запросов в KC, а Игорь Бакалов отснял видео об анализе неявных дублей. Однако, спустя какое-то время, взвесив все за и против, пришел к выводу, что возможно моя статья имеет право на жизнь и кому-то может пригодиться – не судите строго.
Если вам необходимо отфильтровать большую базу ключевых слов, состоящую из 200к или 2 миллионов запросов, то эта статья может вам помочь. Если же вы работаете с малыми семантическими ядрами, то скорее всего, статья не будет для вас особо полезной.
Рассматривать фильтрацию большого семантического ядра будем на примере выборки, состоящей из 1 миллиона запросов по юридической теме.
Что нам понадобится?
- Key Collector (Далее KC)
- Минимум 8гб оперативной памяти (иначе нас ждут адские тормоза, испорченное настроение, ненависть, злоба и реки крови в глазных капиллярах)
- Общие Стоп-слова
- Базовое знание языка регулярных выражений
Если вы совсем новичок в этом деле и с KC не в лучших друзьях, то настоятельно рекомендую ознакомиться с внутренним функционалом, описанным на официальных страницах сайта. Многие вопросы отпадут сами собой, также вы немножечко разберетесь в регулярках.
Итак, у нас есть большая база ключей, которые необходимо отфильтровать. Получить базу можно посредством самостоятельного парсинга, а также из различных источников, но сегодня не об этом.
Получить базу можно посредством самостоятельного парсинга, а также из различных источников, но сегодня не об этом.
Всё, что будет описано далее актуально на примере одной конкретной ниши и не является аксиомой! В других нишах часть действий и этапов могут существенно отличаться! Я не претендую на звание Гуру семантика, а лишь делюсь своими мыслями, наработками и соображениями на данный счет.
Оглавление
- Шаг 1. Удаляем латинские символы
- Шаг 2. Удаляем спец. Символы
- Шаг 3. Удаляем повторы слов
- Шаг 4. Удаляем фразы, состоящие из 1 и 7+ слов
- Шаг 5. Очистка неявных дублей
- Шаг 6. Фильтруем по стоп-словам
- Шаг 7. Удаляем 1 и 2 символьные «слова»
- Шаг 8. Удаляем фразы с числами
- Группировка/кластеризация фраз (опционально)
Шаг 1. Удаляем латинские символы
Удаляем все фразы, в которых встречаются латинские символы. Как правило, у таких фраз ничтожная частотка (если она вообще есть) и они либо ошибочны, либо не относятся к делу.
Все манипуляции с выборками по фразам проделываются через вот эту заветную кнопку
Далее выставляем настройки, указанные на скриншоте, и жахаем «применить».
Если вы взяли миллионное ядро и дошли до этого шага – то здесь глазные капилляры могут начать лопаться, т.к. на слабых компьютерах/ноутбуках любые манипуляции с крупным СЯ могут, должны и будут безбожно тормозить.
Выделяем/отмечаем все фразы и удаляем.
Вернуться к оглавлению
Шаг 2. Удаляем спец. Символы
Операция аналогична удалению латинских символов (можно проводить обе за раз), однако я рекомендую делать все поэтапно и просматривать результаты глазами, а не «рубить с плеча», т.к. порой даже в нише, о которой вы знаете, казалось бы, все, встречаются вкусные запросы, которые могут попасть под фильтр и о которых вы могли попросту не знать.
Небольшой совет, если у вас в выборке встречается множество хороших фраз, но с запятой или другим символом, просто добавьте данный символ в исключения и всё.
Еще один вариант (самурайский путь)
- Выгрузите все нужные фразы со спецсимволами
- Удалите их в KC
- В любом текстовом редакторе замените данный символ на пробел
- Загрузите обратно.
Теперь фразоньки чисты, репутация их отбелена и выборка по спец. символам их не затронет.
Вернуться к оглавлению
Шаг 3. Удаляем повторы слов
И снова воспользуемся встроенным в KC функционалом, применив правило
Тут и дополнить нечем – все просто. Убиваем мусор без доли сомнения.
Если перед вами стоит задача произвести жесткую фильтрацию и удалить максимум мусора, при этом пожертвовав какой-то долей хороших запросов, то можете все 3 первых шага объединить в один.
Выглядеть это будет так:
ВАЖНО: Не забудьте переключить «И» на «ИЛИ»!
Вернуться к оглавлению
Шаг 4. Удаляем фразы, состоящие из 1 и 7+ слов
Кто-то может возразить и рассказать о крутости однословников, не вопрос – оставляйте, но в большинстве случаев ручная фильтрация однословников занимает очень много времени, как правило соотношение хороший/плохой однословник – 1/20, не в нашу пользу. Да и вбить их в ТОП посредством тех методов, для которых я собираю такие ядра из разряда фантастики. Поэтому, поскрипывая сердечком отправляем словечки к праотцам.
Да и вбить их в ТОП посредством тех методов, для которых я собираю такие ядра из разряда фантастики. Поэтому, поскрипывая сердечком отправляем словечки к праотцам.
Предугадываю вопрос многих, «зачем длинные фразы удалять»? Отвечаю, фразы, состоящие из 7 и более слов по большей части, имеют спамную конструкцию, не имеют частотку и в общей массе образуют очень много дублей, дублей именно тематических. Приведу пример, чтоб было понятней.
К тому же частотка у подобных вопросов настолько мала, что зачастую место на сервере обходится дороже, чем выхлоп от таких запросов. К тому же, если вы просмотрите ТОП-ы по длинным фразам, то прямых вхождений ни в тексте ни в тегах не найдете, так что использование таких длинных фраз в нашем СЯ – не имеет смысла.
Вернуться к оглавлению
Шаг 5. Очистка неявных дублей
Предварительно настраиваем очистку, дополняя своими фразами, указываю ссылку на свой список, если есть, чем дополнить – пишите, будем стремиться к совершенству вместе.
Если этого не сделать, и использовать список, любезно предоставленный и вбитый в программу создателями KC по умолчанию, то вот такие результаты у нас останутся в списке, а это, по сути, очень даже дубли.
Можем выполнить умную группировку, но для того, чтобы она отработала корректно – необходимо снять частотку. А это, в нашем случае не вариант. Т.к. Снимать частотку с 1млн. кеев, да пусть хоть со 100к – понадобится пачка приватных проксей, антикапча и очень много времени. Т.к. даже 20 проксей не хватит – уже через час начнет вылезать капча, как не крути. И займет это дело очень много времени, кстати, бюджет антикапчи тоже пожрет изрядно. Да и зачем вообще снимать частотку с мусорных фраз, которые можно отфильтровать без особых усилий?
Если же вы все-таки хотите отфильтровать фразы с умной группировкой, снимая частотности и поэтапно удаляя мусор, то расписывать процесс подробно не буду – смотрите видео, на которое я сослался в самом начале статьи.
Вот мои настройки по очистке и последовательность шагов
Вернуться к оглавлению
Шаг 6.
 Фильтруем по стоп-словам
Фильтруем по стоп-словамНа мой взгляд – это самый муторный пункт, выпейте чая, покурите сигаретку (это не призыв, лучше бросить курить и сожрать печеньку) и со свежими силами сядьте за фильтрацию семантического ядра по стоп-словам.
Не стоит изобретать велосипед и с нуля начинать составлять списки стоп-слов. Есть готовые решения. В частности, вот вам священный Грааль, в качестве основы более, чем пойдет.
Советую скопировать табличку в закорма собственного ПК, а то вдруг братья Шестаковы решат оставить «вашу прелесть» себе и доступ к файлику прикроют? Как говорится «Если у вас паранойя, это еще не значит, что за вами не следят…»
Лично я разгрупировал стоп-слова по отдельным файлам для тех или иных задач, пример на скриншоте.
Файл «Общий список» содержит все стоп-слова сразу. В Кей Коллекторе открываем интерфейс стоп-слов и подгружаем список из файла.
Я ставлю именно частичное вхождение и галочку в пункте «Искать совпадения только в начале слов». Данные настройки особенно актуальны при огромном объеме стоп-слов по той причине, что множество слов состоят из 3-4 символов. И если поставите другие настройки, то вполне можете отфильтровать массу полезных и нужных слов.
Данные настройки особенно актуальны при огромном объеме стоп-слов по той причине, что множество слов состоят из 3-4 символов. И если поставите другие настройки, то вполне можете отфильтровать массу полезных и нужных слов.
Если мы не поставим вышеуказанную галочку, то пошлое стоп-слово «трах» найдется в таких фразах как «консультация государственного страхования» , «как застраховать вклады» и т.д. и т.п. Вот ещё пример, по стоп слову «рб» (республика Беларусь) будет отмечено огромное кол-во фраз, по типу «возмещение ущерба консультация», «предъявление иска в арбитражном процессе» и т.д. и т.п.
Иными словами — нам нужно, чтобы программа выделяла только фразы, где стоп-слова встречаются в начале слов. Формулировка ухо режет, но из песни слов не выкинешь.
Отдельно замечу, что данная настройка приводит к существенному увеличению времени проверки стоп слов. При большом списке процесс может занять и 10 и 40 минут, а все из-за этой галочки, которая увеличивает время поиска стос-слов во фразах в десять, а то и более раз. Однако это наиболее адекватный вариант фильтрации при работе с большим семантическим ядром.
Однако это наиболее адекватный вариант фильтрации при работе с большим семантическим ядром.
После того как мы прошлись по базовым списком рекомендую глазами просмотреть не попали ли под раздачу какие-то нужные фразы, а я уверен, так оно и будет, т.к. общие списки базовых стоп-слов, не универсальны и под каждую нишу приходится прорабатывать отдельно. Вот тут и начинаются «танцы с бубном.
Оставляем в рабочем окне только выделенные стоп слов, делается это вот так.
Затем нажимаем на «анализ групп», выбираем режим «по отдельным словам» и смотрим, что лишнего попало в наш список из-за неподходящих стоп-слов.
Удаляем неподходящие стоп-слова и повторяем цикл. Таким образом через некоторое время мы «заточим» универсальный общедоступный список под наши нужды. Но это еще не все.
Теперь нам нужно подобрать стоп-слова, которые встречаются конкретно в нашей базе. Когда речь идет об огромных базах ключевиков, там всегда есть какой-то «фирменный мусор», как я его называю. Причем это может быть совершенно неожиданный набор бреда и от него приходится избавляться в индивидуальном порядке.
Причем это может быть совершенно неожиданный набор бреда и от него приходится избавляться в индивидуальном порядке.
Для того, чтобы решить эту задачку мы снова прибегнем к функционалу Анализа групп, но на этот раз пройдемся по всем фразам, оставшимся в базе, после предыдущих манипуляций. Отсортируем по количеству фраз и глазами, да-да-да, именно ручками и глазами, просмотрим все фразы, до 30-50 в группе. Я имею в виду вторую колонку «кол-во фраз в группе».
Слабонервных поспешу предупредить, на первый взгляд бесконечный ползунок прокрутки», не заставит вас потратить неделю на фильтрацию, прокрутите его на 10% и вы уже дойдете до групп, в которых содержится не более 30 запросов, а такие фильтровать стоит только тем, кто знает толк в извращениях.
Прямо из этого же окна мы можем добавлять весь мусор в стоп слова (значок щита слева от селектбокса).
Дополнительный совет: Рекомендую просматривать глазами словоформы. И вместо того, чтобы добавлять все, добавлять лишь корень, приведу пример:
Вместо того, чтобы добавлять все эти стоп слова (а их гораздо больше, просто я не хотел добавлять длиннющий по вертикали скриншот), мы изящно добавляем корень «фильтрац» и сразу отсекаем все вариации. В результате наши списки стоп-слов не будут разрастаться до огромных размеров и что самое главное, мы не будем тратить лишнее время на их поиск. А на больших объемах — это очень важно.
В результате наши списки стоп-слов не будут разрастаться до огромных размеров и что самое главное, мы не будем тратить лишнее время на их поиск. А на больших объемах — это очень важно.
Вернуться к оглавлению
Шаг 7. Удаляем 1 и 2 символьные «слова»
Не могу подобрать точное определение к данному типу сочетания символов, поэтому обозвал «словами». Возможно, кто-то из прочитавших статью подскажет, какой термин подойдет лучше, и я заменю. Вот такой вот я косноязычный.
Многие спросят, «зачем вообще это делать»? Ответ прост, очень часто в таких массивах ключевых слов встречается мусор по типу:
Общий признак у таких фраз — 1 или 2 символа, не имеющие никакого смысла (на скриншоте пример с 1 символм). Вот это мы и будем фильтровать. Здесь есть свои подводные камни, но обо всем по порядку.
Как убрать все слова, состоящие из 2-х символов?
Для этого используем регулярку
Дополнительный совет: Всегда сохраняйте шаблоны регулярок! Они сохраняются не в рамках проекта, а в рамках KC в целом.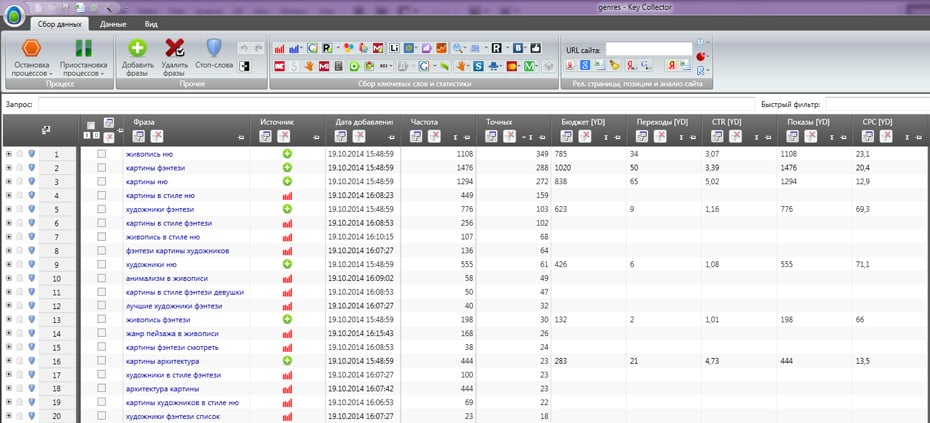 у)
у)
Традиционно – первая строка сама регулярка, вторая – исключения, третья – исключает те фразы, в которых перечисленные символы встречаются в начале фразы. Ну, оно то и логично, ведь перед ними не стоит пробела, следовательно, вторая строка не исключит их присутствие в выборке.
А вот второй вариант при помощи которого я и удаляю все фразы с односимвольным мусором, простой и беспощадной, который в моем случае помог избавиться от очень большого объема левых фраз.
( й | ц | е | н | г | ш | щ | з | х | ъ | ф | ы | а | п | р | л | д | ж | э | ч | м | т | ь | б | ю )
Москв
Я исключил из выборки все фразы, где встречается «Москв», потому что было очень много фраз по типу:
а мне оно нужно сами догадываетесь для чего.
Вернуться к оглавлению
Шаг 8. Удаляем фразы с числами
На мой взгляд этот шаг наиболее индивидуальный и творческий, в различных нишах настройки отличаются кардинально.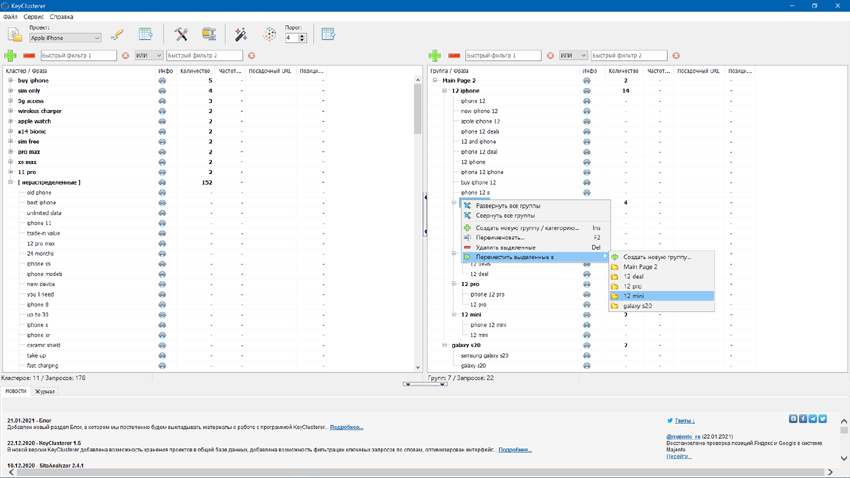 В частности в e-commerce подобная чистка удалит все фразы с числами, например, «Товар какой-то по цене такой-то» — порой это кластер довольно жирных фраз с низкой конкуренцией, по которым можно и нужно делать посадочные. Чтоб не быть голословным, вот пример:
В частности в e-commerce подобная чистка удалит все фразы с числами, например, «Товар какой-то по цене такой-то» — порой это кластер довольно жирных фраз с низкой конкуренцией, по которым можно и нужно делать посадочные. Чтоб не быть голословным, вот пример:
Поэтому сначала подумайте как применить фильтрацию фраз с числами в случае с вашей темой и базой запросов, а потом приступайте.
Вот как я удалил все ненужное в нашем случае
Расписывать не буду – тут и так все очевидно. Единственное, на чем заострю внимание — «\d+» это регулярное выражение, при помощи которого мы выделяем все фразы, содержащие числовые значения. Также можно использовать «[0-9]+» как вашей душе угодно.
Расскажу, как под ту или иную нишу подобрать свой вариант.
- Выделяем все фразы, содержащие числовые значения через вышеуказанные регулярки.
- Глазами просматриваем результат и выделяем интенты нужных фраз – то есть, какие-то общие признаки. После этого добавляем их в исключения (смотрите мой скриншот выше) и так несколько раз, пока в выдаче не останется один мусор.
- Какая-то часть белых и пушистых фраз может и останется – но я придерживаюсь правила: лучше удалить 1 хорошую фразу, чем оставить 10 плохих.

ГОТОВО! В результате из базы ключевых слов в 1 миллион у меня получилось ядро на 230к. Конечно, если просмотреть глазами, там можно найти нелепые и мусорные фразы, но не имеющие общих признаков, а в ручную фильтровать такие массивы — это какой-то Сешоный АдЪ.
Для тех, кто все-таки решил кластеризовать/сгрупировать фразы и не хочет пользоваться платными сервисами, опишу свой вариант.
Вернуться к оглавлению
Группировка/кластеризация фраз (опционально)
Это самая ресурсоемкая процедура и если ваш дорг…. ой, то есть движок не поддерживают работу с подобной структурой, то забудьте, забейте и радуйтесь – первые 8 шагов уже отфильтровали львиную долю мусора.
Далее мы будем обрабатывать полученный результат, а не продолжать очистку.
Способ 1
Существуют тривиальные способы фильтрации, позволяющие на автомате сгруппировать фразы по отдельным словам (упоминал в шаге 6), а также по составу фраз. В большинстве случаев для кластеризации запросов нам вполне подойдет режим «по составу фраз».
В большинстве случаев для кластеризации запросов нам вполне подойдет режим «по составу фраз».
Обычно я выставляю следующие настройки.
Процедура анализа может занять очень много времени, так что рекомендую сразу же определиться с силой по составу фраз. Что для этого надо?
- Рассортируйте фразы по алфавиту (просто нажмите на столбик фраза)
- Создайте пустую группу
- Выделите 10-30к запросов
- Скопируйте их в созданную группу
- Попробуйте разные варианты силы по составу фраз на данном объеме.
Когда найдете оптимальный показатель приступайте к группировке всего ядра.
Еще несколько слов о «силе по составу». Для тех, кто не совсем понимает, что это такое и как быть. Данная цифра отвечает за количество слов, которые должны пересекаться во фразах для того, чтобы те были объединены в группы. Иными словами чем выше показатель — тем меньше будет групп. Вряд ли вы найдете множество фраз в которых повторяет 7 и более слов — это скорее дубли, а не какие-то группы.
В принципе — оптимально ставить 3-4 (четверку ставьте для особо чистых и жирных ядер).
После того, как программа закончит обрабатывать данные делаем выгрузку в Excel. Готово!
Отдельно хочу заметить — что это и близко не тоже самое, что кластеризация запросов в платных сервисах и для особо белых проектов подобная группировка будет слишком топорной и вряд ли окажется полезной. Здесь все-же работа с объемом ставится превыше качества. Чтобы сгруппировать такое ядро в любом из доступных сервисов придется поставить зубы на полку и перейти на «Доширак», а то и вовсе на «Мивину».
Способ 2
В некоторых случаях нам нужно выделить группы из ядра не по составу фраз, а по каким-то собственным, нетривиальным задачам.
Представим, что нам нужно получить все фразы для раздела сайта вопрос-ответ по теме «аренда земли». Иными словами все вопросительные фразы. Здесь нам придется включить голову и вернуться к функционалу регулярок, но уже в другом ключе, особые знания регулярных выражений не понадобятся.
Собираем все части речи, присущие нашему кластеру запросов, кстати, вот мой список из конкретного примера, может кому-то пригодится. И выставляем вот такие настройки.
В результате получаем нужные нам фразы, которые мы можем перенести в отдельную группу или просто экспортировать.
Рекомендую вот такие шаблоны регулярок всегда сохранять отдельно и в результате для любого проекта у вас будет ряд универсальных решений, позволяющих делать быстрые выборки фраз.
Надеюсь данный материал окажется для кого-нибудь полезным. Если у вас есть вопросы или дополнения — пишите в комментариях.
P.S. Хотел написать, «подписывайтесь на наш сайт», но мы до сих пор не прикрутили RSS и рассылку, так-что добавляйте бложек в закладки и ставьте лайки на Facebook 🙂
Управление кластерами и коллекторами
В этом разделе описаны действия по добавлению новых серверов-коллекторов в существующую систему Opsview Monitor. Сначала объясняется, как добавить новые серверы-сборщики в единую систему Opsview Monitor, а затем как добавить новые серверы-сборщики в существующую систему Opsview Monitor с несколькими серверами и некоторыми существующими сборщиками.
Перед добавлением сборщиков необходимо следующее:
- Хост развертывания под управлением ОС, поддерживаемой желаемой версией Opsview 9.0008
- Корневой доступ к хосту развертывания
- SSH-доступ с хоста развертывания ко всем хостам Opsview (включая новые серверы, которые будут добавлены в качестве хостов-сборщиков)
- Аутентификация должна использовать открытые ключи SSH
- Удаленный пользователь должен быть «root» или иметь доступ «sudo» без пароля и без TTY
🚧
В кластере коллекторов всегда должно быть нечетное количество узлов; 1, 3, 5 и т. д. Это поможет повысить отказоустойчивость и избежать проблем с разделением ресурсов, когда что-то случится с узлом в кластере.
Чтобы добавить новые серверы-сборщики в существующую систему Opsview Monitor с одним сервером, откройте файл /opt/opsview/deploy/etc/opsview_deploy.yml и добавьте следующие строки.
Примечание: Не изменять существующие строки в opsview_deploy.yml:
collect_clusters:
коллекционеры-де:
коллектор_хост:
opsview-de-1: {ip: 10.12.0.9}
Вам необходимо заменить «opsview-de-1» и «10.12.0.9» на имя хоста и IP-адрес вашего нового коллектора. Кроме того, вы можете дать имя своему кластеру коллекторов, заменив «collectors-de» на желаемое имя кластера.
Точно так же вы можете добавить несколько кластеров-коллекторов и несколько кластеров-коллекторов в каждый кластер, например:
collection_clusters:
коллекционеры-де:
коллектор_хост:
opsview-de-1: {ip: 10.12.0.9}
opsview-de-2: {ip: 10.12.0.19}
opsview-de-3: {ip: 10.12.0.29}
коллекторы-fr:
коллектор_хост:
opsview-fr-1: {ip: 10.7.0.9}
opsview-fr-2: {ip: 10.7.0.19}
opsview-fr-3: {ip: 10.7.0.29}
opsview-fr-4: {ip: 10.7.0.39}
opsview-fr-5: {ip: 10.7.0.49}
Приведенная выше конфигурация, например, добавит 2 новых кластера коллекторов с именами «collectors-de» и «collectors-fr», где «collectors-de» имеет 3 коллектора, а «collectors-fr» имеет 5 коллекторов с именами хостов и IP-адресами. указаны адреса.
указаны адреса.
После изменения opsview_deploy.yml запустите opsview deploy следующим образом:
cd /opt/opsview/deploy ./bin/opsview-deploy lib/playbooks/check-deploy.yml ./bin/opsview-deploy lib/playbooks/setup-hosts.yml ./bin/opsview-deploy lib/playbooks/setup-infrastructure.yml ./bin/opsview-deploy lib/playbooks/collector-install.yml
После запуска opsview-deploy проверьте раздел «Регистрация новых серверов Collector в Opsview Web».
Если у вас уже есть несколько сборщиков и вы хотите добавить новые сборщики, откройте /opt/opsview/deploy/etc/opsview_deploy.yml на сервере развертывания (обычно это хост opsview с оркестратором и opsview-web) и добавьте новые кластеры коллекторов или хосты коллекторов после существующих, например:
collect_clusters:
существующий-коллектор1:
коллектор_хост:
существующий-хост1: {ip: 10.12.0.9}
новый хост1: {ip: 10. 12.0.19}
новый хост2: {ip: 10.12.0.29}
новый коллектор-кластер1:
коллектор_хост:
новый хост3: {ip: 10.7.0.9}
новый хост4: {ip: 10.7.0.19}
новый хост5: {ip: 10.7.0.42}
 12.0.19}
новый хост2: {ip: 10.12.0.29}
новый коллектор-кластер1:
коллектор_хост:
новый хост3: {ip: 10.7.0.9}
новый хост4: {ip: 10.7.0.19}
новый хост5: {ip: 10.7.0.42}
12.0.19}
новый хост2: {ip: 10.12.0.29}
новый коллектор-кластер1:
коллектор_хост:
новый хост3: {ip: 10.7.0.9}
новый хост4: {ip: 10.7.0.19}
новый хост5: {ip: 10.7.0.42}
В приведенном выше примере было добавлено 5 новых хостов-сборщиков (новый-хост1, новый-хост2, новый-хост3, новый-хост4 и новый-хост5) и 1 новый кластер сборщиков (новый-сборщик-кластер1). new-host1 и new-host2 были добавлены в существующий кластер сборщиков (existing-collector1), а new-host3, new-host4 и new-host5 были добавлены в новый кластер сборщиков (new-collector-cluster1).
После изменения opsview_deploy.yml запустите opsview deploy следующим образом:
cd /opt/opsview/deploy ./bin/opsview-deploy lib/playbooks/check-deploy.yml ./bin/opsview-deploy lib/playbooks/setup-hosts.yml ./bin/opsview-deploy lib/playbooks/setup-infrastructure.yml ./bin/opsview-deploy lib/playbooks/collector-install.yml
Если вы добавляете новые коллекторы и у вас уже определено их количество, вы можете ускорить процесс, указав имена новых коллекторов для работы с
компакт-диск /opt/opsview/развернуть .
 /bin/opsview-deploy lib/playbooks/check-deploy.yml
./bin/opsview-deploy -l "новый-хост1 новый-хост2" lib/playbooks/setup-hosts.yml
./bin/opsview-deploy -l "новый-хост1 новый-хост2" lib/playbooks/setup-infrastructure.yml
./bin/opsview-deploy -l "новый-хост1 новый-хост2" lib/playbooks/collector-install.yml
/bin/opsview-deploy lib/playbooks/check-deploy.yml
./bin/opsview-deploy -l "новый-хост1 новый-хост2" lib/playbooks/setup-hosts.yml
./bin/opsview-deploy -l "новый-хост1 новый-хост2" lib/playbooks/setup-infrastructure.yml
./bin/opsview-deploy -l "новый-хост1 новый-хост2" lib/playbooks/collector-install.yml
Войдите в пользовательский интерфейс Opsview Monitor и перейдите на страницу Конфигурация > Мониторинг коллекторов.
Вы должны увидеть желтое сообщение «Ожидание регистрации» справа, как показано ниже:
Щелкните значок меню справа от имени хоста вашего коллектора и нажмите Зарегистрировать, как показано ниже:
Появится другое окно для регистрации коллектора:
Нажмите «Отправить изменения и далее». Появится новое окно для создания «Нового кластера мониторинга»:
Дайте новому кластеру мониторинга то же имя, которое вы указали в opsview_deploy.yml, например «collectors-de», и выберите коллекторы, которые должны быть в этом кластере мониторинга, из список или коллекторы. Затем нажмите «Отправить изменения».
Затем нажмите «Отправить изменения».
После добавления первого кластера мониторинга вы также можете зарегистрировать коллектор в существующем кластере мониторинга, выбрав «Существующий кластер». увидеть свои кластеры и количество коллекторов в каждом кластере на вкладке «Кластеры»:
Вы даже можете щелкнуть числа в столбце «СБОРНИКИ», чтобы увидеть имена хостов коллекторов:
После регистрации новых коллекторов перейдите в раздел «Конфигурация» > Примените изменения, чтобы запустить их в производство.
Убедитесь, что коллекторы работают правильно, проверив вкладку «Обзор системы» в разделе «Конфигурация» > «Моя система»:
Чтобы удалить коллектор из кластера, нажмите «КОНФИГУРАЦИЯ > МОНИТОРИНГ КОЛЛЕКТОРОВ» в верхнем меню, а затем щелкните вкладку «Кластеры». Затем щелкните значок меню и «Изменить»:
Затем отмените выбор коллектора, который вы хотите удалить, и нажмите кнопку «Отправить изменения». Теперь вы можете перейти в «Конфигурация» > «Применить изменения», чтобы подтвердить изменение и завершить работу коллектора.
Чтобы добавить коллектор в кластер, отредактируйте кластер, а затем выберите коллектор (используйте Cntrl в Windows или Cmd в Mac OS, чтобы выбрать в дополнение к существующим выборам). Перейдите в «Конфигурация» > «Применить изменения», чтобы подтвердить изменение.
Кластер можно удалить в любое время. Все коллекторы, связанные с кластером, останутся зарегистрированными, но не будут связаны ни с одним кластером.
Узлы, отслеживаемые удаленным кластером, будут изменены для наблюдения за главным кластером (обычно на основном сервере). Вам нужно будет перейти в «Конфигурация»> «Применить изменения», чтобы это вступило в силу.
Если вам нужно вывести Коллектор из эксплуатации, вы должны сделать следующее:
- Удалите Коллектор из всех Кластеров, прежде чем пытаться его удалить. Вы можете удалить Коллекторы из Кластеров на вкладке Кластеры.
- Удалить запись коллектора. Удаление коллектора удалит его из списка известных коллекторов. Вы можете удалить коллекторы на вкладке Коллекторы на странице Конфигурация > Мониторинг коллекторов.
- Удалите связанную запись хоста в настройках хоста, чтобы полностью удалить ее из Opsview.
Примечание: Если вы удалили коллектор, но затем хотите зарегистрировать его снова, вы не увидите, что он станет доступным в сетке незарегистрированных коллекторов, пока вы не остановите планировщик на этом коллекторе хотя бы на целую минуту, а затем перезапустите Это.
Обновить Collector так же просто, как обновить все пакеты Opsview на сервере Collector. Чтобы избежать простоев, отключите соединение от Collector к главному серверу MessageQueue, обновите все пакеты и перезагрузите систему. Как только соединение будет восстановлено, коллектор автоматически присоединится к кластеру, и теперь вы сможете выполнить обновление других коллекторов.
В распределенной системе Opsview Monitor сценарии мониторинга в Collectors могут не синхронизироваться со сценариями в Orchestrator, если:
- новые пакеты Opspack, сценарии мониторинга или подключаемые модули были импортированы в Orchestrator. Сценарии мониторинга
- были обновлены непосредственно в Orchestrator.

В таких случаях папку сценариев мониторинга ( /opt/opsview/monitoringscripts ) в Оркестраторе необходимо синхронизировать со всеми коллекторами с помощью доступного плейбука под названием 9.0027 sync_monitoringscripts.yml .
Playbook sync_monitoringscripts.yml использует rsync для отправки соответствующих обновлений каждому сборщику (при необходимости он будет установлен автоматически), исключая определенные наборы файлов.
Следующие каталоги и файлы (относительно /opt/opsview/monitoringscripts ) не синхронизируются:
.../lib/* .../tmp/* .../Поделиться/* .../перл/* .../плагины/utils.pm .../вар/* .../opspacks/* .../etc/notificationmethodvariables.cfg .../etc/plugins/check_snmp_interfaces_cascade
Например, при использовании приведенного выше списка исключений файлы в каталоге /opt/opsview/monitoringscripts/lib/ и определенные файлы, такие как /opt/opsview/monitoringscripts/etc/notificationmethodvariables., не будут синхронизированы. . cfg
cfg
Кроме того, если у Collector не та же версия ОС, что и у Orchestrator, будут синхронизированы только статически связанные исполняемые файлы и текстовые файлы. Это делается для того, чтобы двоичные файлы, используемые в Orchestrator, не синхронизировались с несовместимым Collector. Например, двоичный файл AMD64 не будет отправлен в коллектор на базе ARM32.
- Интерпретируемые файлы сценариев, такие как сценарии Python, Perl и Bash и файлы конфигурации, являются текстовыми файлами, и будут синхронизированы.
- Динамически связанные исполняемые файлы не будут синхронизированы, поскольку они могут работать неправильно из-за зависимостей во время выполнения. Такие динамически связанные исполняемые файлы необходимо устанавливать на сборщики вручную, если у сборщиков другая версия ОС, чем у Orchestrator.
Ключи SSH настроены между Orchestrator и коллекторами (это уже должно быть на месте, если Opsview Deploy ранее использовался для установки или обновления системы).
Выполните следующие команды от имени пользователя root в Orchestrator:
cd /opt/opsview/deploy/ bin/opsview-deploy lib/playbooks/sync_monitoringscripts.yml
Если ваш сервер развертывания не является Orchestrator, вы можете выполнять те же команды на своем сервере развертывания, но ключи SSH должны быть настроены между Orchestrator и сборщиками для пользователей SSH, определенных для ваших сборщиков в вашем файле opsview_deploy.yml.
Обновлено около 3 лет назад
Использование допусков для управления размещением модуля ведения журнала кластера — Настройка развертывания ведения журнала кластера | Ведение журнала
- Использование допусков для управления размещением модуля хранилища журналов
- Использование допусков для управления размещением модуля визуализатора журнала
- Использование допусков для управления размещением модуля сбора журналов
- Дополнительные ресурсы
Вы можете использовать пометки и допуски, чтобы убедиться, что модули ведения журнала кластера работают
на определенных узлах и что никакая другая рабочая нагрузка не может выполняться на этих узлах.
Пороки и допуски просты пара ключ:значение . Загрязнение на узле
указывает узлу отклонять все модули, которые не терпят заражения.
Ключ — это любая строка длиной до 253 символов, а значение — любая строка длиной до 63 символов.
Строка должна начинаться с буквы или цифры и может содержать буквы, цифры, дефисы, точки и символы подчеркивания.
Пример регистрации кластера CR с допусками
apiVersion: "logging.openshift.io/v1"
вид: "ClusterLogging"
метаданные:
имя: "экземпляр"
пространство имен: openshift-логирование
спецификация:
managementState: "Управляемый"
логсторе:
тип: "эластичный поиск"
эластичный поиск:
количество узлов: 1
допуски: (1)
- ключ: "регистрация"
оператор: "Существует"
эффект: "Не выполнять"
допустимые секунды: 6000
Ресурсы:
пределы:
память: 8Gi
Запросы:
процессор: 100 м
память: 1Gi
хранилище: {}
redundancyPolicy: «Нулевая избыточность»
визуализация:
тип: "кибана"
кибана:
допуски: (2)
- ключ: "регистрация"
оператор: "Существует"
эффект: "Не выполнять"
допустимые секунды: 6000
Ресурсы:
пределы:
память: 2Gi
Запросы:
процессор: 100 м
память: 1Gi
реплики: 1
коллекция:
журналы:
тип: "свободный"
свободно говорил:
допуски: (3)
- ключ: "регистрация"
оператор: "Существует"
эффект: "Не выполнять"
допустимые секунды: 6000
Ресурсы:
пределы:
память: 2Gi
Запросы:
процессор: 100 м
память: 1Gi | 1 | Этот допуск добавлен в модули Elasticsearch. |
| 2 | Этот допуск добавлен в модуль Kibana. |
| 3 | Этот допуск добавлен к модулям сбора журналов. |
Вы можете контролировать, на каких узлах работают модули хранилища журналов, и предотвращать другие рабочие нагрузки от использования этих узлов с помощью допусков на модулях.
Вы применяете допуски к модулям хранилища журналов через ClusterLogging пользовательский ресурс (CR)
и применить пометки к узлу через спецификацию узла. Заражение на узле — это пара ключ:значение 9.0028 что
указывает узлу отклонять все модули, которые не терпят заражения. Использование определенной пары ключ: значение которого нет на других модулях, гарантирует, что на этом узле могут работать только модули хранилища журналов.
По умолчанию модули хранилища журналов имеют следующие допуски:
допуски:
- эффект: "Не выполнять"
ключ: «node. kubernetes.io/диск-давление»
оператор: "Существует"  kubernetes.io/диск-давление»
оператор: "Существует"
kubernetes.io/диск-давление»
оператор: "Существует" Предпосылки
Процедура
Используйте следующую команду, чтобы добавить taint к узлу, на котором вы хотите запланировать модули ведения журнала кластера:$ oc adm taint nodes <имя-узла> <ключ>=<значение>:<эффект>Например:$ oc adm taint nodes node1 elasticsearch=node:NoExecuteВ этом примере заражение размещается наnode1с ключомelasticsearch, значениемnodeи эффектом зараженияNoExecute. Узлы с эффектомNoExecuteпланируют только те модули, которые соответствуют заражению, и удаляют существующие модули. что не совпадают.Отредактируйте разделlogstoreвClusterLoggingCR, чтобы настроить допуск для модулей Elasticsearch:logStore: тип: "эластичный поиск" эластичный поиск: количество узлов: 1 допуски: - ключ: "elasticsearch" (1) оператор: "Есть" (2) эффект: "NoExecute" (3) допустимые секунды: 6000 (4)1 Укажите ключ, который вы добавили к узлу. 2 Укажите оператор Exists, чтобы требовать присутствия на узле taint с ключомelasticsearch.3 Укажите эффект NoExecute.4 При необходимости укажите tolerationSeconds, чтобы указать, как долго модуль может оставаться привязанным к узлу, прежде чем будет вытеснен.

Этот допуск соответствует taint, созданному командой oc adm taint . Модуль с таким допуском может быть запланирован на node1 .
Вы можете управлять узлом, на котором работает модуль визуализатора журнала, и предотвращать
другие рабочие нагрузки от использования этих узлов с помощью допусков на модулях.
Вы применяете допуски к блоку визуализатора журнала через ClusterLogging пользовательский ресурс (CR)
и применить пометки к узлу через спецификацию узла. Заражение на узле — это пара
Заражение на узле — это пара ключ:значение , которая
указывает узлу отклонять все модули, которые не терпят заражения. Использование определенной пары ключ: значение которого нет на других модулях, гарантирует, что только модуль Kibana может работать на этом узле.
Предпосылки
Процедура
Используйте следующую команду, чтобы добавить taint к узлу, где вы хотите запланировать модуль визуализатора журнала:$ oc adm taint nodes <имя-узла> <ключ>=<значение>:<эффект>Например:$ oc административные узлы node1 kibana=node:NoExecuteВ этом примере заражение помещается наnode1с ключомkibana, значениемnodeи эффектом зараженияNoExecute. Вы должны использовать эффект зараженияNoExecute.NoExecuteпланирует только те модули, которые соответствуют заражению, и удаляет существующие модули. что не совпадают.Отредактируйте раздел визуализацииClusterLoggingCR, чтобы настроить допуск для модуля Kibana:визуализация: тип: "кибана" кибана: допуски: - ключ: "кибана" (1) оператор: "Есть" (2) эффект: "NoExecute" (3) допустимые секунды: 6000 (4)1 Укажите ключ, который вы добавили к узлу. 2 Укажите оператор Exists, чтобыключ/значение/эффектпараметры совпадали.3 Укажите эффект NoExecute.4 При необходимости укажите параметр tolerationSeconds, чтобы указать, как долго модуль может оставаться привязанным к узлу, прежде чем будет вытеснен.
 что не совпадают.
что не совпадают.
Этот допуск соответствует taint, созданному командой oc adm taint . Pod с таким допуском сможет запланировать node1 .
Вы можете определить, на каких узлах работают модули сбора журналов, и предотвратить
другие рабочие нагрузки от использования этих узлов с помощью допусков на модулях.
Вы применяете допуски к модулям сборщика журналов через ClusterLogging пользовательский ресурс (CR)
и применить пометки к узлу через спецификацию узла. Вы можете использовать taints и tolerations
чтобы гарантировать, что модуль не будет выселен из-за таких вещей, как проблемы с памятью и процессором.
По умолчанию модули сборщика журналов имеют следующие допуски:
допуски:
- ключ: "node-role.kubernetes.io/master"
оператор: "Существует"
эффект: "NoExecute" Предпосылки
Процедура
Используйте следующую команду, чтобы добавить taint на узел, где вы хотите, чтобы модули сборщика журналов планировали модули сборщика журналов:$ oc adm taint nodes <имя-узла> <ключ>=<значение>:<эффект>Например:$ oc административные узлы node1 collection=node:NoExecuteВ этом примере заражение помещается наnode1с ключомколлектор, значениемnodeи эффектом зараженияNoExecute. Вы должны использовать эффект заражения NoExecute.NoExecuteпланирует только те модули, которые соответствуют заражению, и удаляет существующие модули. что не совпадают.Редактирование коллекцииClusterLoggingпользовательский ресурс (CR) для настройки допуска для модулей сборщика журналов:Коллекция: журналы: тип: "свободный" свободно говорил: допуски: - ключ: "коллектор" (1) оператор: "Есть" (2) эффект: "NoExecute" (3) допустимые секунды: 6000 (4)1 Укажите ключ, который вы добавили к узлу. 2 Укажите оператор Exists, чтобыключ/значение/эффектпараметры совпадали.3 Укажите эффект NoExecute.4 При необходимости укажите параметр tolerationSeconds, чтобы указать, как долго модуль может оставаться привязанным к узлу, прежде чем будет вытеснен.
 Вы должны использовать эффект заражения
Вы должны использовать эффект заражения 
Этот допуск соответствует taint, созданному командой oc adm taint . Pod с таким допуском сможет запланировать node1 .
Sharding-Руководство MongoDB
на этой странице
Sharded ClusterШард КлавишиКускиБалансировщик и равномерное распределение Chunk.0008Подключение к разделенному кластеруСтратегия разделенияЗоны в разделенных кластерахСопоставления в разделенииПотоки изменениймашины. MongoDB использует сегментирование для поддержки развертываний с очень большими данными. наборы и высокопроизводительные операции.Системы баз данных с большими наборами данных или приложениями с высокой пропускной способностью могут бросить вызов мощности одного сервера. Например, высокая частота запросов может исчерпать ресурсы процессора сервера. Размеры рабочего набора больше, чем системная оперативная память нагружает емкость ввода-вывода дисковых накопителей.
Существует два метода решения проблемы роста системы: вертикальный и горизонтальный. масштабирование.
Вертикальное масштабирование предполагает увеличение емкости одного сервера, например как использование более мощного процессора, добавление большего объема оперативной памяти или увеличение объема пространство для хранения. Ограничения в доступных технологиях могут машина от быть достаточно мощной для данной рабочей нагрузки. Кроме того, Облачные провайдеры имеют жесткие ограничения в зависимости от доступного оборудования. конфигурации. В результате получается практический максимум для вертикального масштабирования.
Горизонтальное масштабирование включает в себя разделение набора системных данных и загрузку несколько серверов, добавляя дополнительные серверы для увеличения емкости по мере необходимости. Хотя общая скорость или мощность отдельной машины могут быть невысокими, каждая машина обрабатывает часть общей рабочей нагрузки, потенциально обеспечивая лучшее эффективность по сравнению с одним высокоскоростным сервером большой емкости. Расширение мощность развертывания требует только добавления дополнительных серверов по мере необходимости, что может быть более низкой общей стоимостью, чем высокопроизводительное оборудование для одной машины. Компромисс заключается в увеличении сложности инфраструктуры и обслуживания для развертывание.
MongoDB поддерживает горизонтальное масштабирование посредством сегментирования.
Sharded Cluster
Sharded кластер MongoDB состоит из следующих компонентов:
сегмент: Каждый сегмент содержит подмножество сегментированных данных.
Каждый сегмент можно развернуть как набор реплик.монго:
монгодействует как Маршрутизатор запросов, обеспечивающий интерфейс между клиентскими приложениями и сегментированный кластер. Начиная с MongoDB 4.4,монгосможет поддерживать хеджированные чтения для минимизации задержек.серверы конфигурации: Конфигурация серверы хранят метаданные и параметры конфигурации для кластера.
На следующем рисунке показано взаимодействие компонентов внутри сегментированный кластер:
MongoDB осколки данных на уровне коллекции, распределяя сбор данных по осколкам в кластере.
Осколочные ключи
MongoDB использует осколочный ключ для распределять документы коллекции по осколкам. Осколочный ключ состоит из поля или нескольких полей в документах.
Начиная с версии 4.4 документы в сегментированных коллекциях можно отсутствуют поля ключа сегмента. Отсутствующие поля ключа сегмента рассматриваются как имеющие нулевые значения при распределении документов по осколкам, но не при маршрутизации запросов.
Для получения дополнительной информации см.
Отсутствуют поля ключа сегмента.В версии 4.2 и более ранних поля ключа сегмента должны существовать в каждом документ для сегментированной коллекции.
Вы выбираете ключ сегмента при сегментировании коллекции.
Начиная с MongoDB 5.0, вы можете повторно разделить коллекцию, изменив ключ сегмента коллекции.
Начиная с MongoDB 4.4, вы можете уточнить ключ сегмента, добавив поле или поля суффикса к существующему осколочный ключ.
В MongoDB 4.2 и более ранних версиях выбор ключа сегмента невозможен. быть изменены после шардинга.
Значение ключа сегмента документа определяет его распределение по осколки.
Начиная с MongoDB 4.2, вы можете обновить значение ключа сегмента документа если ваше поле ключа осколка не является неизменным
_idполе. Видеть Измените значение ключа сегмента документа для получения дополнительной информации.В MongoDB 4.0 и более ранних версиях значение поля ключа сегмента документа равно неизменный.
Индекс ключа сегмента
Чтобы сегментировать заполненную коллекцию, она должна иметь индекс, который начинается с ключа сегмента. При разбивании пустого коллекция, MongoDB создает вспомогательный индекс, если коллекция еще не имеют соответствующего индекса для указанного ключа сегмента. Видеть Индексы Shard Key.
Стратегия ключа сегмента
Выбор ключа сегмента влияет на производительность, эффективность и масштабируемость сегментированного кластера. Кластер с наилучшим аппаратным обеспечением и узким местом в инфраструктуре может быть выбор ключа сегмента. Выбор ключ сегмента и его резервный индекс также могут повлиять на стратегию сегментирования, которую может использовать ваш кластер.
См. также:
Выберите ключ сегмента
Фрагменты
MongoDB разделяет сегментированные данные на фрагменты.
Каждый
чанк имеет инклюзивный нижний и исключительный верхний диапазон на основе
осколочный ключ.Балансировщик и равномерное распределение чанков
В попытке добиться равномерного распределения чанков по всем шардов в кластере, балансировщик работает в фоновом режиме, чтобы переносить куски по осколкам.
См. также:
Разделение данных на фрагменты
Преимущества сегментирования
Чтение/запись
MongoDB распределяет рабочую нагрузку чтения и записи по осколки в сегментированном кластере, что позволяет каждому осколку обрабатывать подмножество кластерных операций. Рабочие нагрузки чтения и записи могут быть масштабируется горизонтально по всему кластеру путем добавления большего количества осколков.
Для запросов, включающих ключ сегмента или префикс составного ключа сегмента,
mongosможет нацелить запрос на конкретный шард или набор шардов. Эти целевые операции, как правило, более эффективны, чем широковещательная рассылка на каждый шард в кластере.Начиная с MongoDB 4.4,
mongosмогут поддерживать хеджирование читает, чтобы минимизировать задержки.Емкость хранилища
Разделение распределяет данные по сегментам в кластер, что позволяет каждому сегменту содержать подмножество общих данных кластера. В качестве набор данных растет, дополнительные шарды увеличивают емкость хранилища кластер.
Высокая доступность
Развертывание серверов конфигурации и сегментов, предоставляемых наборами реплик повышенная доступность.
Даже если один или несколько наборов реплик осколков станут полностью недоступными, сегментированный кластер может продолжать выполнять частичное чтение и запись. То есть, пока данные о недоступных осколках недоступны, чтение или запись, направленные на доступные осколки, все еще могут быть успешными.
Соображения перед шардингом
Требования к инфраструктуре шардированного кластера и сложность требуют тщательное планирование, выполнение и обслуживание.
После разделения коллекции MongoDB не предоставляет методов для разблокировать раздробленную коллекцию.
Пока вы можете перешардить свою коллекцию позже важно тщательно обдумать выбор ключа осколка, чтобы избежать проблем с масштабируемостью и производительностью.
См. также:
Выберите ключ сегмента
Чтобы понять эксплуатационные требования и ограничения для сегментирования вашей коллекции, см. Операционные ограничения в сегментированных кластерах.
Если запросы делают , а не включают ключ сегмента или префикс составной осколочный ключ,
mongosвыполняет широковещательная операция, запрос все сегментов в сегментированном кластере. Эти запросы на разброс/сбор могут быть длительными операциями.Запуск в MongoDB 5.1, при запуске, перезапуске или добавлении шард-сервер с
sh.addShard()Проблема записи в масштабе кластера (CWWC) должен быть установлен.Если
CWWCне установлен и шард настроен так что проблема записи по умолчанию{ w : 1 }сервер сегмента не запустится или не будет добавлен и возвращает ошибку.См. расчеты записи по умолчанию для подробности о том, как рассчитывается проблема записи по умолчанию.
Если у вас есть действующий контракт на поддержку с MongoDB, рассмотрите возможность обращения вашему представителю по работе с клиентами для помощи с шардированным кластером планирование и развертывание.
Разделенные и неразделенные коллекции
База данных может содержать как разделенные, так и неразделенные коллекции. Разделенный коллекции разделены и распределены по осколки в кластере. Нераспределенные коллекции хранятся на первичный осколок. Каждая база данных имеет свой основной шард.
Подключение к разделенному кластеру
Вы должны подключиться к маршрутизатору mongos для взаимодействия с любой коллекцией в сегментированный кластер. Сюда входят сегментированные и несегментированные коллекции. Клиенты никогда не должны подключаться к одному сегменту, чтобы выполнять операции чтения или записи.
Вы можете подключиться к
mongosтак же, как вы подключаетесь кmongodс использованиемmongoshили Драйвер MongoDB.Стратегия разделения
MongoDB поддерживает две стратегии сегментирования для распространения данных через сегментированные кластеры.
Разделение по хэшу
Разделение по хэшу включает вычисление хэша поля ключа сегмента ценность. Затем каждому фрагменту назначается диапазон на основе хешированные значения ключей осколков.
MongoDB автоматически вычисляет хэши при разрешении запросов с использованием хешированные индексы. Приложения , а не должны вычислять хэши.
Хотя диапазон ключей осколков может быть «близким», их хешированные значения маловероятны. быть на одном куске. Распределение данных на основе хешированных значений способствует более равномерному распределению данных, особенно в наборах данных, где ключ шарда изменяется монотонно.
Однако хешированное распределение означает, что запросы на основе диапазона по ключу сегмента с меньшей вероятностью нацелены на один сегмент, что приводит к более широкому кластеру широковещательные операции
Дополнительную информацию см. в разделе Разделение хеширования.
Разделение по диапазонам
Разделение по диапазонам включает разделение данных на диапазоны на основе значения ключа шарда. Затем каждому фрагменту назначается диапазон на основе значения ключа шарда.
Диапазон ключей осколков со значениями «близко» с большей вероятностью будет находиться на тот самый кусок. Это позволяет целенаправленно операции как
mongosможет маршрутизировать операции только с теми осколками, которые содержат необходимые данные.Эффективность дальнего сегментирования зависит от выбранного ключа сегмента. Плохо рассматриваемые осколочные ключи могут привести к неравномерному распределению данных, что может сводят на нет некоторые преимущества сегментирования или могут привести к снижению производительности.
Видеть
выбор ключа сегмента для сегментирования на основе диапазона.Дополнительные сведения см. в разделе Разделение на расстоянии.
Зоны в сегментированных кластерах
Зоны могут помочь улучшить локальность данных для сегментированных кластеров, которые охватывать несколько центров обработки данных.
В сегментированных кластерах можно создавать зоны сегментированных данных на основе на осколочном ключе. Вы можете связать каждую зону с одним или несколькими осколками в кластере. Осколок может быть связан с любым количеством зон. В сбалансированном кластере, MongoDB переносит фрагменты, охватываемые зоной, только в те осколки, связанные с зоной.
Каждая зона охватывает один или несколько диапазонов значений ключа сегмента. Каждый диапазон Покрытия зоны всегда включают ее нижнюю границу и исключают ее верхняя граница.
Вы должны использовать поля, содержащиеся в ключе сегмента, при определении нового диапазон охвата зоны.
При использовании составного осколка
key, диапазон должен включать префикс ключа сегмента. См. ключи осколков
в зонах для получения дополнительной информации.Следует принять во внимание возможное использование зон в будущем внимание при выборе шардового ключа.
Начиная с MongoDB 4.0.3, настройка зон и диапазонов зон до вы разбиваете пустую или несуществующую коллекцию, что позволяет быстрее настройка зонального шардинга.
Дополнительную информацию см. в зонах.
Сопоставления в сегментировании
Используйте команду
shardCollectionс сопоставлением: { locale : "simple" }параметр для разделения коллекции, которая имеет сопоставление по умолчанию. Успешный шардинг требует, чтобы:При создании новых коллекций с сопоставлением обеспечить эти условия выполняются до сегментирования коллекции.
Запросы к сегментированной коллекции продолжают использовать значение по умолчанию параметры сортировки, настроенные для коллекции.
Чтобы использовать осколочный ключ
индекс простая сортировка, укажите{локаль: "простая"}в документе сопоставления запроса.См.
shardCollectionдля получения дополнительной информации о сегментировании и сопоставление.Потоки изменений
Начиная с MongoDB 3.6, потоки изменений доступно для наборов реплик и сегментированных кластеров. Потоки изменений позволяют приложения для доступа к изменениям данных в реальном времени без сложности и риск слежки за оплогом. Приложения могут использовать потоки изменений для подписаться на все изменения данных в коллекции или коллекциях.
Транзакции
Начиная с MongoDB 4.2, с введением распределенной операции, многодокументные операции доступны в сегментированных кластерах.
Пока транзакция не будет зафиксирована, изменения данных, сделанные в транзакции не видны вне транзакции.
Однако, когда транзакция записывает в несколько сегментов, не все внешние операции чтения должны дождаться результата зафиксированного транзакция должна быть видна через осколки.
 наборы и высокопроизводительные операции.
наборы и высокопроизводительные операции.
 Каждый сегмент можно развернуть как набор реплик.
Каждый сегмент можно развернуть как набор реплик. Для получения дополнительной информации см.
Отсутствуют поля ключа сегмента.
Для получения дополнительной информации см.
Отсутствуют поля ключа сегмента.
 Каждый
чанк имеет инклюзивный нижний и исключительный верхний диапазон на основе
осколочный ключ.
Каждый
чанк имеет инклюзивный нижний и исключительный верхний диапазон на основе
осколочный ключ.



 Видеть
выбор ключа сегмента для сегментирования на основе диапазона.
Видеть
выбор ключа сегмента для сегментирования на основе диапазона. При использовании составного осколка
key, диапазон должен включать префикс ключа сегмента. См. ключи осколков
в зонах для получения дополнительной информации.
При использовании составного осколка
key, диапазон должен включать префикс ключа сегмента. См. ключи осколков
в зонах для получения дополнительной информации. Чтобы использовать осколочный ключ
индекс
Чтобы использовать осколочный ключ
индекс 