
Тег rel=»canonical» — инструкция по применению.

Когда вы создаете сайт, или работаете над ним, то вы можете столкнутся с различными, непонятными терминами. Один из таких терминов – canonical. Давайте разберемся, что он означает и для чего он нужен.

Тег canonical
Канонический тег (он же «rel canonical») — это способ сообщить поисковым системам, что конкретный URL-адрес представляет собой главную копию страницы.
Это связано с тем, что с одной стороны, поисковики очень не любят дубли страниц, за что можно попасть под фильтр. А с другой стороны, любой сайт неизбежно будет иметь, так сказать, «технические» дубли.
Фактически, с помощью тега canonical, вы сообщаете, какая страница должна быть в поиске и при этом, не учитывать остальные дубли этой страницы.
Пример технических дублей.
Хотя на первый взгляд, любая страница сайта является уникальной, но по факту, практически любая страница будет иметь различные URL адреса:
https://life-webmaster.ru
http://life-webmaster.ru
https://www.life-webmaster.ru
http://www.life-webmaster.ru
https://life-webmaster.ru/index.html
http://life-webmaster.ru/index.html
https://www.life-webmaster.ru/index.html
http://www.life-webmaster.ru/index.html
Для человека это все одно и тоже. Каждый из этих адресов открывает одну и туже страницу. Однако, для поисковиков это совершенно разные адреса. И если не проставить тег canonical, то все эти страницы, поисковики будут считать считать дублями.
Кроме адресов главной страницы, ваша CMS может создать и другие технические дубли.
Как проставить тег canonical
Тег canonical относится к языку разметки HTML и ставится в заголовке страницы сайта. То есть, между тегами «head и «/head». Далее нам нужно выбрать, какая страница будет главной. Возьмем к примеру этот сайт и URL — https://life-webmaster.ru. Тогда вот как будет выглядеть наш тег.


Отличие тега canonical от 301 редиректа.
Есть определенное сходство между этими двумя решениями. Оба они указывают главную страницу. Однако, не стоит их путать, поскольку фактически, это два совершенно разных решения.
301 редирект, перенаправляет посетителя на определенную страницу. Тем самым, исходную страницу он вообще никогда не увидит. Тогда как тег canonical указывает поисковикам, какую страницу считать главной, и в тоже же время, физически он пользователя никуда не перенаправляет. На какую страницу пользователь изначально зашел, на той странице он и останется.
Некоторые аспекты по использованию
Обязательно указывайте канонические страницы.
Любая страница вашего сайта, по определению будет иметь дубли. В первую очередь это связано с использованием WWW и безопасным протоколом. То есть, каждая страница сайта будет иметь версию с WWW и без. С безопасным протоколом https и обычным протоколом http.
В некоторых случаях еще может и ваша CMS тоже создать дубли страниц. Поэтому, обязательно указывайте, какую страницу поисковики должны считать главной.
Тег может указывать на свою страницу
Тег canonical может указывать на страницу, на которой он расположен. Это нормально. То есть, если на странице https://life-webmaster.ru мы проставим
то это будет правильным решением.
Не смешивайте страницы.
Не нужно указывать страницы по кругу. То есть, если на странице https://life-webmaster.ru/statya1, указали главной страницу https://life-webmaster.ru/statya2, а на этой странице указали главной https://life-webmaster.ru/statya1, то это будет ошибкой.
Тег canonical может проставляться на разных доменах.
Если у вас несколько сайтов, и вы публикуете сообщение, статью или новость сразу на двух и больше разных доменах, то вы тоже должны указать главный домен, который и будет ранжироваться в поиске.
При этом надо учитывать, что остальные домены не будут ранжироваться в поиске и на тех страницах не будет поискового трафика. Но зато и не будет проблем для всех сайтов, из-за дубликатов.
Как проверить тег canonical на странице.
Тег canonical имеет огромное значение для продвижения сайта в поисковиках. Его отсутствие или неправильное использование является одной из грубейших ошибок в SEO, в результате чего, добиться высоких позиций в поиске будет намного сложнее.
Поэтому вы должны определить, используется ли canonical на вашем сайте. Это можно сделать двумя путями:
Просмотрев код страницы.
Откройте нужную страницу в поиске и откройте ее код HTML (это можно сделать, нажав ctrl+u) и посмотрите, есть ли этот тег на странице.

Используя MozBar
Другой путь, это использовать MozBar. Это бесплатное расширение для браузера, которое позволит вам быстро найти тег canonical на странице (и многое другое). Скачать его можно отсюда.

Таким образом, вы теперь знаете, что такое тег canonical и как его использовать. Ну а если у вас остались вопросы, то задавайте их в комментариях.
 Загрузка…
Загрузка…Подпишитесь на обновления блога Life-Webmaster.ru и получайте в числе первых новые статьи про создание блога, раскрутку и заработок на нем!
Атрибут rel=»canonical» — полное руководство использования канонической ссылки в SEO
26 Апреля 2019При работе сайта часто возникает проблема дублирования контента. Если рассматривать на примере интернет-магазина, частым случаем является создания одинаковых товаров в разных категориях. Эти товары доступны по разным URL-адресам и, как уже понятно, содержат идентичный контент. Решение было представлено в феврале 2009 года. Ведущие компании в интернет сфере (google, bing, Yahoo) представили тег link с атрибутом rel=“canonical”. Данный элемент предназначен для обозначения канонической ссылки, которая указывает роботу на приоритетную страницу для индексирования, что позволяет избежать появления дублированного контента в индексе поисковой системы.

Что такое rel=canonical
Тег link с атрибутом rel=“canonical” является элементом html-кода. Его часто называют канонической ссылкой. Как и говорилось ранее, данный тег позволяет быстро и просто разрешить проблему дублирования контента. Суть такова, что имея два и более URL-адреса по которым доступен один и тот же контент с помощью каноникла мы указываем “главную” (каноническую) страницу. Это позволяет ПС “не обращать” внимания на множество дублей, а индексировать только один указанный документ. Грамотное использование данного атрибута положительно сказывается на SEO сайта.
Использование canonical
Для начала разберемся, как и где его нужно прописать, чтоб данный тег учитывался поисковым роботом, а потом рассмотрим в каких случаях его можно, и даже нужно, применять для извлечения максимальной выгоды в представлении сайта в ПС.
Размещение rel=canonical в исходном коде

Данный атрибут прописывается в исходном коде, внутри контейнера <head>, пример представлен выше. Тег <link> устанавливает связь со сторонним документом, будь то файл или страница. Для указания канонического урла нужно разместить внутри тега атрибуты “rel” и “href” со значениями “canonical” и URL-адресом канонической страницы соответственно.
<link rel=“canonical” href=“http://example.ru/category/item/”>
Атрибут rel — показывает отношения текущего документа к файлу на который делается ссылка, в нашем случае выражает зависимость текущей страницы перед ссылаемой, href — указывает путь к файлу.
Из написанного ранее можно догадаться: чтоб в индексе была всего одна страница, нужно чтоб на всех документах с дублирующимся контентом был расположен canonical со ссылкой, на выбранную вами, каноническую страницу.
Применение canonical на практике
Страницы пагинаций


Почти на каждом сайте имеется раздел со страницами пагинаций, будь то каталог с большим количеством товаров, новостная или статейная лента. Как вы понимаете, контент таких страниц почти идентичен, а ЧПУ отличаются. Есть мнение, что пагинацию на сайте стоит закрывать от индексации, разумеется кроме первой страницы. Данную точку зрения легко опровергнуть простыми логическими выкладками. На второй странице, третий и далее, размещен различный контент. Если их закрыть, то не имея сложной схемы перелинковки на сайте, робот просто не сможет пройти по ссылкам, расположенным не на первой странице пагинаций. Соответственно, существует риск выпадения страниц из поиска, а также, общее снижение лояльности ПС к сайту, в силу того что на сайте имеются материалы на которые пользователь не сможет попасть путешествую по сайту. Более того, возможен случай добавления большого количество контента разом, такое что некоторые материалы окажутся на второй странице, тогда робот и вовсе может не узнать о данном материале и никогда не проиндексирует его.
Товары в интернет-магазине
С развитием интернета появилось много online площадок по продаже различного товара. При проработке структуры каталога получается так, что товар может быть закреплен в разных категориях, в таком случае он будет иметь разный url, например:
- example.ru/odezda/shapka/
- example.ru/brand/shapka/
Видим, что один и тот же материал имеет разный ЧПУ. С точки зрения рядового посетителя это будет одна и та же страница, но для робота поисковой машины это не так. Canonical приходит к нам на помощь. Он позволяет указать роботу, что контент одинаков и нет смысла держать обе страницы в индексе. Завершающим шагом остается правильно выбрать каноническую страницу, об этом поговорим позже.
Canonical для статейных сайтов и блогов
При ведении блога или статейного сайта часто получается, что одна статья закреплена за разными рубриками. При этом, если на вашем сайте настроен вывод рубрики в ЧПУ, то возникает уже известная нам проблема, которая решается с помощью canonical:
- articles.com/seo-optimization/canonical/
- articles.com/html-tegy/canonical/
Страницы с GET-параметром

Часто на интернет ресурсах используется get-параметр для разных нужд. Этот параметр изменяет URL, фактически не изменяя контента. Настройка canonical для таких страниц не всегда обязательна, порой, проще закрыть от индексации. Однако, существуют исключения. Рассмотрим на примере версии для печати. Обычно, данная версия отдается в адресной строке браузера путем приписывания к URL параметра ?print=Y или другие его вариации. Получаются следующие страницы:
- http://site.ru/product/
- http://site.ru/product/?print=Y
Нет смысла держать в поиске данную версию. В таком случае следует настроить каноникал со ссылкой на страницу http://site.ru/product/, являющейся оригинальным документом.
Переезд сайта с http на https и другие зеркала сайта
Canonical можно настраивать и при смене протокола безопасности. При этом на каждой страницы с http протоколом нужно разместить каноникал со ссылкой на ту же страницу, но с протоколом https. Рел каноникал можно использовать и при обозначении главного зеркала сайта. Но о целесообразности подхода представленного в этом пункте будем рассуждать ниже.
Как выбрать канонический урл
Вернемся к теме выбора канонической страницы, это является немаловажным фактором в настройки canonical является. Правильное определение документа куда будут ссылаться наши дубли очень важно. Рассмотрим основные пункты на которые стоит выделить особое внимание при выборе канонического URL:
- если страницы создавались в разные временные промежутки, то правильным решением будет выбор самой старой страницы, так как она уже в поиске и обладает ссылочной массой;
- если файлы создавались в одно время, то лучше выбрать страницу, которая будет продвигаться;
- при прочих равных, за каноническую страницу, среди дублирующихся, будет лучше взять URL с наименьшей вложенностью и наиболее подходящей под общую структуру сайта.
Правила и некоторые особенности настройки canonical
- Тег rel=“canonical” не является строгим правилом для роботов поисковых систем, а только лишь советует страницу в качестве каноничной.
- Для настройки атрибута не обязательно стопроцентное совпадение контента. Подтверждения тому страницы пагинаций. Однако, не стоит злоупотреблять. Если ПС уличит вас в использовании canonical для материалов с совершенно разным контентом, то впредь на данный атрибут внимания обращать не будут.
- При написании canonical допускается использование как относительных, так и абсолютных ссылок. Но нужно быть аккуратным, могут возникнуть проблемы связанные с зеркалами сайтов. Пример написания в исходном коде таких ссылок выглядит следующим образом:
- <link rel=“canonical” href=“http://site.com/page”>
- <link rel=“canonical” href=“/page”>

301 редирект или rel=“canonical”
Если возникают сомнения между использованием 301 редиректа и настройки canonical, что тогда? Если 301 редирект не будет нарушать логику образования ЧПУ, а также структуру сайта, то стоит отдавать предпочтение нужно редиректу. К этому же и относится переезд сайта с http на https, о чем мы говорили ранее.
Настройка canonical в разных CMS
Во многих cms предусмотрены штатные решения для настройки каноникла, которые позволяют быстро и просто достичь желаемого результата.
WordPress

В Вордпресс представлено большое количество дополнительных плагинов для SEO оптимизации и не только, позволяющие настроить canonical без каких-либо проблем. Приведем самые популярные и удобные из них:
- All in SEO Pack;
- Yoast SEO;
- Canonical SEO Content Syndication WordPress Plugin;
После установки данных плагинов настройка canonical становится приятным занятием. Можно и использовать любой другой плагин, обладающим данным функционалом. Однако, стоит уделять большое внимание проверке исходного кода страницы на предмет корректного размещения канонической ссылки, так как не все разработчики плагинов являются добросовестными.
Joomla и Opencart
В данных движках сайта имеются проблемы с настройками rel=“canonical”, которые тянутся еще со старых версиях. Проблема выражается в записи некорректного URL адреса и криво настроенной адресации в CMS. Существует множество вариантов решения данной проблемы. Для обозревания каждого, можно написать не одну статью, но все они уже предложены умельцами на различных форумах и справочных ресурсах. На каком варианте остановиться выбирать только вам, каждый из них имеет плюсы и минусы.
Bitrix
Битрикс одна из самых гибких и передовых cms. Ее функционал поражает воображение, а в умелых руках сайт на bitrix становится произведением искусства. Для настройки canonical потребуется небольшие знания php и понимания работы самой CMS. А количество вариантов размещения ограничивается только вашим воображением. Каждый случай уникальный, зависит от настроенной адресацией на сайте. Приведем несколько незамысловатых примеров. Самый простой способ написания канонической ссылки самой на себя это в теге <head> написать следующую строчку:
<link rel=»canonical» href=»http://<?= $_SERVER[‘HTTP_HOST’] . $APPLICATION->GetCurPage() ?>» />
Наверное, один из самых “деревянных” и топорных методов. Для страниц пагинаций нужно применять более изящные и сложные конструкции. Пусть на вашем сайте задана адресация для страниц пагинаций следующим образом: http://site.ru/catalog/?PAGEN_1=2.
Тогда для настройки rel=“canonical” нужно воспользоваться знанием регулярных языков и также, как в примере выше, прописать функциональную часть кода:

Битрикс при генерировании страницы подставит данную строчку в тело тега head.
Заключение: rel=canonical мощный инструмент для представления сайта в поиске
Атрибут canonical является незаменимым и мощным инструментом в распоряжении SEO специалиста и вебмастера для поддержания корректного представления сайта в выдаче поисковых систем. Правильное использование канонических ссылок убережет ваш сайт от появления дублей в поиске, тем самым повысится авторитет вашего сайта для ПС и шансы оказаться на заветной первой строчки выдачи заметно повышаются.
что это, где его применяют, как прописать
В далеком 2009 году компания Google представила миру атрибут canonical, который был призван помочь SEO-шникам в борьбе с дублями на сайтах. В 2011 году и «Яндекс» тоже начал поддерживать этот тег.
Для чего же необходим тег rel canonical, в каких ситуациях его стоит проставлять и как это правильно сделать? Вопросов много, но на каждый из них я дам ответ в статье.
Что такое rel canonical и каноническая страница?
Дубли – настоящий страшный сон СЕО-специалиста! Так называют страницы, которые при разных url содержат идентичный контент. Каждая из них продвигается по чуть-чуть, но ни одна в итоге – полноценно. Если в индексе уйма дублей, рассчитывать на хорошие позиции сайта совершенно бессмысленно.

Есть несколько способов борьбы с дублями. Страницы-«близнецы», например, можно закрыть от индексации в файле robots.txt. Но тогда не удастся использовать впрок их ссылочный вес. Альтернатива – применение rel=”canonical”.
Используя канонические ссылки, можно сохранить и передать не только ссылочный вес, но и иные характеристики (вроде RageRank).
Применение Каноникала даёт синергический эффект. Вес всех дублей суммируется и присваивается одной – той, которую признали «адресатом» при проставлении тега. Эта страница называется канонической. Именно она будет индексироваться поисковой системой. Дубли останутся «за бортом» и не станут мешать продвижению.
В каких случаях применяют Рел Каноникал?
О теге должен знать всякий владелец интернет-магазина с обширным каталогом. «Yandex» советует настраивать Рел Каноникал на всех страницах пагинации – начиная со второй (www.site.com/catalog/page/2; www.site.com/catalog/page/3 и так далее). Первую при этом следует назначить канонической.

Применять Canonical приходится и в других случаях – например, чтобы исключить из индекса страницу для печати.
Где и как прописать?
Тег размещается внутри контейнера HEAD на дублированной странице. В html-коде это выглядит следующим образом:
<html>
<head>
<link rel=”canonical” href=”основная”>
</head>
<body>
…
Обратите внимание, что тег в коде может встречаться только однажды. Тег нельзя помещать ни в <footer>, ни в <body>.
Основные ошибки применения
Начинающие SEO-специалисты чаще всего допускают такие ошибки:
- Не проверяют доступность канонической страницы. А ведь она должна быть в порядке. Ответ сервера 200 – не иначе!
- Не заглядывают в robots.txt. А вдруг дубли уже закрыты через Роботс? Тогда проводить манипуляции с Canonical бессмысленно.
- Создают цепочки ссылок. Страница пагинации №4 ссылается на №3, та, в свою очередь, на №2. И только вторая связана с основной. Такая конструкция окажется проигнорирована роботом.
- Канонически ссылаются на другой домен. Rel Canonical можно настроить только внутри одного домена или поддомена.
На заметку особо изобретательным и любопытным: rel canonical можно сделать сам на себя. Это не принесёт никакой пользы, но и вреда не будет.
Настройка в WordPress
Проставить Рел Каноникал на Вордпресс-сайте можно, не залезая своими руками в код – если воспользоваться специальными плагинами.
Yoast SEO
При размещении статьи найдите блок Yoast SEO, проследуйте в режим «Настройки» (иконка с изображением шестерёнки) и в поле «Канонический URL-адрес» пропишите адрес страницы, которая выбрана главной.

All in SEO Pack
Плагин All in SEO тоже даёт возможность настраивать canonical.

Поставьте галочку в поле напротив пункта «Включить пользовательские канонические URL». Это позволит настраивать ссылки для отдельных постов. Обратите внимание, что выше есть пункт «Запретить пагинацию для канонических URL». Если вы установите галочку напротив него, то по поводу пагинации вам переживать не придётся – вторая и последующие страницы автоматически будут ссылаться на первую (главную).
Заключение
Использование тега я считаю более эффективным способом борьбы с дублями, чем закрытие дублей через Роботс. Однако нужно подходить к процедуре предельно внимательно. Если ошибётесь и назначите не ту каноническую страницу, какую хотели, сайт наверняка потеряет часть трафика.
А как ты борешься с дублями на сайте? Используешь ли канонический тег? Рассказывай в комментариях!
Полезен ли был этот пост?
Кликни на звездочку, чтобы оценить его!
Submit RatingСредний рейтинг 5 / 5. Итог: 1
Статьи по теме
rel=«canonical»: использование, особенности, проверка | RuKala
Содержание статьи
Одна из самых актуальных проблем в процессе SEO-оптимизации – устранение страниц-дублей. Чаще всего для разрешения ситуации используют 301-редирект. Но применять его не всегда возможно, либо же бывают случаи, когда страницы нужны для просмотра посетителями. Тогда целесообразно применять атрибут rel=«canonical». Он позволяет оперативно справляться с проблемами дублирования.

Главный способ – на странице ресурса. Чтобы оставить для страницы ее канонический урл, нужно в пределах <head></head> прописать:
link rel=»canonical» href=»http://site.com/canonical-link.html»
Второй способ – использование xml-карты сайта. При этом канонический урл нужно прописать для каждой страницы карты. Однако нет гарантий, что поисковики будут учитывать эту информацию.
Если речь идет не о html, а о других документах, можно указывать канонический урл в http заголовке. Нужно, чтобы на запрос дублирующего файла сервер отдавал такую информацию:
Link: <http://site.com/main-file.pdf>; rel=»canonical»
Но если говорить о поисковой системе Гугл, она поддерживает подобный элемент заголовка только для веб-поиска.
- Если есть точное понимание, когда появятся дубли на сайте. Если владелец сайта точно понимает причину, по которой возникают схожие либо аналогичные страницы, но при этом все эти страницы должны быть доступными на сайте, то следует определить главную из них и поставить на нее канонические ссылки.
- Если нереально или сложно сделать 301-редирект. Использование редиректа – рекомендуемая мера, но если нет возможности, rel=«canonical» станет альтернативой. Как уверяют представители Гугл, вес, который передается по каноническим урлам, соответствует весу от 301 редиректа.
- Если для серии товаров нужно несколько страниц. Часто случается, что в ассортименте магазина встречаются одинаковые товары, отличающиеся цветом или другой незначительной характеристикой. Соответственно, один из товаров нужно сделать типичным (главным) и поставить на него rel=»canonical» с других товаров.
- Если применимы различные способы сортировки. С любых сортировочных комбинаций нужно оставить канонические урлы на каталог с сортировкой, демонстрируемой по умолчанию.
- Если создается страница каталога. Гугл рекомендует проставлять канонический урл со всех страниц каталога на общую страницу с товарами либо статьями сайта. Для реализации этого способа нужно создать раздел «Показать все» и проставить на него канонические урлы со всех страниц пагинации. Способ отличается высокой сложностью.
- Если предоставляется просмотр страниц в версии для печати. Тогда нужно проставлять канонический урл на основную версию.
- Если сайт подключен к партнерке. Использование партнерки либо иной реферальной системы требует прописывания rel=«canonical» для всех страниц, на которые ссылаются партнерские программы. Если это не сделать, поиск заполнят дубли этих страниц. Для Гугл можно указать все неактуальные при индексации параметры: в частности, partner.
- Если одинаковый контент применяют на разных доменных именах либо языковых версиях. В таких ситуациях нужно использовать rel=«canonical» на главную версию страниц с контентом.

Одна из распространенных ошибок – применение на всех страницах пагинации канонического урла, ведущего на первую страницу. Такой подход закрывает от индексации всю серию. Бывает, что каноническая ссылка не относится к разряду индексируемых. Чтобы проверить ее, следует убедиться, что она отдает код 200 сервера, а страницы не защищены от индексации.
Еще одна ошибка – несколько rel=«canonical», ведущих с одной страницы. Главное правило: 1 страница – 1 канонический урл. Также важно следить за тем, чтобы указывать одинаковые канонические страницы, реализуя это комплексно: например, через rel=«canonical» или карту сайта.
Так же нет смысла в применении rel=«canonical» для картинок. Поисковые системы не поддерживают и не распознают этот тег по отношению к изображениям.
После настройки на сайте канонических урлов не помешает проверить весь ресурс на то, как поняли указания роботы поисковых систем. Это можно сделать, к примеру, с помощью программы Screaming Frog SEO Spider. Проведя индексацию, она предоставит данные о страницах, на которых установлен rel=«canonical» и куда он направляет, а также о страницах, где нет rel=«canonical».
Применение атрибута rel=«canonical» позволит разработчику сайта оптимизировать затраты времени. Но если использовать атрибут для готового проекта, следует либо учитывать все тончайшие нюансы применения, либо готовиться к возникновению проблем. Поэтому, получив готовый сайт, важно проверить, насколько грамотно использованы канонические ссылки и обеспечен ли доступ к индексации ключевых страниц. Провести такой анализ сможет профессиональный специалист.
Первое — помните о базовых моментах
- не дублируйте текст описания с первой страницы на страницах пагинации;
- делайте уникальными тайтлы страниц пагинации, при этом мета-теги с описаниями и ключевыми словами можно не использовать;
- ссылка на первую страницу пагинации не должна дублировать первую страницу категории.
Второе – закрывая страницы пагинации от индексирования, вы можете ухудшить процесс индексации товарных карточек. Так что столь радикальные действия не нужны.
Третье – перед любыми операциями со страницами пагинации удостоверьтесь, не являются ли они источниками поискового трафика. Делать из страниц пагинации посадочные умышленно не стоит: для этого можно воспользоваться подкатегориями или тегами. Но если трафик уже идет, не стоит от него отказываться.
Четвертое – будьте более осторожным с рекомендацией по поводу того, что не нужно индексировать текст для страницы пагинации, а только переходить по ссылкам.
Атрибут link rel=»canonical» как еще один эффективный способ борьбы с дублями и не только

Привет, друзья. Пора бы мне уже довести до логического завершения тему про управление индексацией сайта. Я вам напомню, какие методы управления индексацией вообще существуют: файл robots.txt, мета-тег robots, заголовок X-Robots-Tag, ну и 301-редирект здесь можно упомянуть, как метод борьбы с дублями, что так же является неотъемлемой частью качественной индексации. И обо всем этом я вам уже рассказывал, но есть еще один очень важный и интересный способ борьбы с дублями, в чем-то альтернатива редиректу, это атрибут rel=»canonical», который присваивается тегу link и располагается в части любой html-страницы.Выглядит это как-то так: <link rel="canonical" href="https://alaev.info/blog" />
Что немаловажно – данный тег поддерживается всеми поисковыми системами, в том числе нашими любимыми Яндекс и Google.
Итак, сегодня я вам расскажу, как и для чего нужно использовать тег rel canonical, в каких ситуациях он действительно эффективен, а заодно убедимся в этой самой эффективности на реальном эксперименте. Приготовьтесь 🙂
Для начала напомню вам о тех постах, что я затронул в начале:
X-Robots-Tag HTTP header как способ управления индексацией содержимого сайта
Особенности индексации сайтов при использовании robots.txt и мета-тега robots
Теория, практика и правила использования редиректов
Сперва стоит пройтись по теории, чтобы понять для чего данный атрибут вообще был создан, какие цели преследовались и узнать, что же рекомендуют поисковики.
Теория и справка от поисковых систем
Привожу ссылки на официальную позицию поисковых систем: Google об атрибуте rel=»canonical» и Яндекс про атрибут rel=»canonical» тега <link>. Разумеется, и mail.ru тут как тут – про значение canonical в теге — не могли же они отстать от Яндекса, но это и хорошо, все под копирку, нам же проще.
Я знаю, что вы лентяи и читать справку не будете, хотя я настоятельно рекомендую это сделать, а потом приведу ниже все самые основные выдержки из справки:
Что такое каноническая страница? Это рекомендуемый экземпляр из набора страниц с очень похожим содержанием.
Зачем нужно указывать каноническую страницу? Если поисковая система видит, что страницы очень похожи или одинаковы, то согласно алгоритмам в результатах поиска появится только одна предпочтительная страница, которая, по мнению поисковой системы, лучше всего отвечает на запрос пользователя.
А как мы знаем, поисковик не всегда угадывает наши желания, потому лучше перестраховаться и указать нужную страницу самостоятельно. Сделать это можно добавив ссылку rel=»canonical» в раздел <head> неканонических версий всех страниц HTML.
Еще оказывается, можно указывать каноническую ссылку для не HTML содержимого, а, например, для pdf, doc или других файлов при помощи заголовков. Типа как X-Robots-Tag HTTP header, только тут будет Link HTTP header. Но это уже совсем для гик-маньяков, так что рассказывать об этом не буду.
Должна ли эта ссылка быть абсолютной или относительной? Можно указывать и так и так, но чтобы избежать ошибок и последующих недоразумений, стоит использовать абсолютные ссылки.
Что будет, если атрибут rel=»canonical» указывает на несуществующую страницу? А если каноническими назначено несколько страниц набора? В этом случае поисковая система просто проигнорирует данные правила и будет поступать, как и раньше — вычислять подходящий экземпляр из набора страниц согласно алгоритмам.
Можно ли использовать атрибут rel=»canonical» для указания канонического URL на другом домене? Можно, но не нужно. Важно понимать, что атрибут canonical это всего лишь подсказка или рекомендация, а не строгое правило в отличие от редиректа, который и стоит использовать в данном случае.
На основании всего вышенаписанного, а так же по информации из других официальных источников (блоги поисковых систем и блоги их сотрудников) можно сделать выводы о том, что тег link rel=»canonical»:
- Это рекомендация, а не правило, а потому может быть проигнорирован в следующих случаях:
- Документ по каноническому адресу не существует, отдает ответ 404;
- Каноническая страница закрыта от индексации в robots.txt или мета-тегом;
- В html-коде страницы указано сразу несколько атрибутов rel canonical;
- Адрес канонического документа указывает на другой домен или поддомен;
- Присутствует цепочка назначений rel=»canonical», т.е. для документа А каноническим указан документ Б, а в это время для документа Б указан каноническим документ В;
- Необходимо указывать только для дублирующих или очень схожих страниц, а не для склейки двух разных страниц или передачи веса;
- Адрес канонической страницы может указывать сам на себя;
- Поддерживается всеми поисковыми системами: в Яндексе с 23 мая 2011 года, в Google с 12 февраля 2009.
Практическое применение и эксперимент
Все, с теорией покончено, теперь я вам расскажу, зачем и для чего я использую тег rel=»canonical» на своих сайтах. Главное и основное – это борьба и предупреждение появления дублей. В основном это дубли, связанные с параметрами или метками в url. Не всегда уместно бороться с этими проблемами при помощи 301-редиректов. Метки иногда очень важны, например, когда ведется кампания в контексте и в метках передаются важные статистические сведения, да и много еще чего можно отслеживать метками. Закрывать такие адреса в robots.txt мне не по душе, использовать мета роботс не получится, а редирект уничтожит все данные.
Классический пример использования канонических адресов это интернет магазины с кучей сортировок по еще большей куче различных параметров товаров – мне кажется, ради этого и придумали данный атрибут.
Это все понятно. Но вот только о самом главном для нас seo’шников нигде не сказано – а как дела обстоят с передачей ссылочного веса? Что если на неканонический адрес стоят ссылки, что же будет с канонической страницей, получит ли она от этого бонусы? А если сперва появилась ссылка, а rel=»canonical» был указан позже? А что будет, если все наоборот?
Вопросов много, а официальных комментариев нет. На вопросы кто виноват и что делать, ответ один – надо ставить эксперимент! Хотел я такой эксперимент поставить, но оказалось, что его уже не так давно провел Игорь, автор блога bakalov.info, за что ему огромное спасибо.
Вот цитата с его блога о том, какова цель, какие варианты развития событий и ожидаемый результат:
Цель эксперимента: выяснить, будет ли передан «вес ссылки» со страницу А на страницу С, в том случае, если страница А ссылается на страницу Б, а на странице Б стоит rel=»canonical», который указывает, что канонической страницей является страница С.
Если со страницы А на страницу С «вес ссылки» передается, то необходимо выяснить имеет ли значение «первоочередность».
Вариант №1. Страница А ссылается на страницу Б и эта ссылка проиндексирована поисковыми системами. Через некоторое время на странице Б устанавливается rel=»canonical», который указывает, что канонической является страница С, что в итоге приводит к исключению страницы Б из индекса.
Вариант №2. На странице Б устанавливается rel=»canonical», который указывает, что канонической является страница С, что приводит к исключению страницы Б из индекса. Через некоторое время после этого со страницы А на страницу Б устанавливается ссылка.
Необходимо выяснить в каком из двух вариантов будет передан «вес ссылки» со страницы А на страницу С. Под «весом ссылки» я понимаю так называемый «анкорный вес», т.е. если страница акцептор ищется по тексту стоящей на нее ссылки, то считаем, что «вес ссылки» передается, если не ищется, то не передается.
Полное описание и ход эксперимента смотрите по ссылке.
Я же сообщу результаты эксперимента и выводы:
Для Яндекса не имеет значения, что появилось раньше – rel=»canonical», или внешняя ссылка – в любом случае «вес ссылки» будет передан с неканонического URL на канонический.
Для Google на самом деле все аналогично, хотя в посте Игоря говорится иначе: если канонический адрес был указан и страницы уже склеились, а потом появилась внешняя ссылка, то вес передается, а если внешняя ссылка появилась раньше, чем каноникал, то вес не перетекает.
Просто «перетекание» веса во втором случае заняло несколько больше времени, ведь согласно комментарию на блоге сказано, что каноническая страница все же ищется по анкорному тексту.
Короче, все работает!
В очередной раз обобщая всю информацию изложенную в посте, хочу сказать, что использовать тег link rel=»canonical» нужно. В первую очередь это отличный способ предотвратить дублирование контента (особенно это касается ошибок и недоработок большинства CMS) и наложение санкций за это со стороны поисковых систем.
Удачи вам, друзья! Оставляйте комментарии и задавайте вопросы.
Мета-теги canonical: проверка
Опубликовано: 02.04.2018. Обновлено: 19.08.2019 226 0
При помощи тега мета-тега canonical можно указывать главную из ряда похожих страниц поисковыми системам, чтобы только одна, основная страница, участвовала в поиске.
Подробнее: https://yandex.ru/support/webmaster/controlling-robot/html.html#canonical
Довольно часто теги каноникал подключаются сразу для всего сайта автоматически, поэтому неверное подключение может приводить к серьёзным проблемам.
Проверка тегов canonical на всём сайте
Чтобы проверить правильность размещения тега, сканируем сайт Компарсером с обычными настройками:

Затем в статистике просматриваем все случаи, где адрес, указанный в мета-теге каноникал, и адрес страницы не совпадает:

Если таких случаев вообще нет, или адреса не совпадают по каким-то объективным причинам (исключение из поиска похожих страниц), то менять ничего не нужно.
Не совпадающие по объективным причинам адреса — делаются намеренно. Как правило, таких страниц немного на сайте (относительно общего количества страниц).
Если есть проблемы в мета-тегах каноникал
Если проблемы наблюдаются на всём сайте, проверяемый ресурс небольшой, имеет простую структуру, и причин для использования тегов каноникал нет, то самое простое решение, вообще их удалить.
Если всё-таки теги нужно оставить, то первым делом следует идентифицировать способ, каким они были установлены на сайт:
- внутренними настройками системы управления;
- установленным плагином/дополнением;
- добавлением кода программистом.
Затем внести правки самостоятельно, либо составить тз программисту.
Что нужно учитывать при установке тегов canonical
Если на сайте присутствуют материалы, которые по каким-то причинам размещены в двух и более разделах и удалять дублирующий материал нежелательно (например, один товар по характеристикам должен находится в двух разных категориях) или невозможно, необходимо устанавливать теги каноникал.
При указании канонического адреса нужно учитывать распределение ссылочных весов на сайте таким образом, чтобы нанести минимальный ущерб. Например, материал главной страницы сайта дублируется где-то во внутреннем разделе. Главная страница акцептирует и является донором ссылочного веса многих внутренних страниц, часто релевантна высокочастотному запросу, поэтому во всех случаях её нужно делать канонической, то есть, оставлять в индексе поисковых систем.
Тег rel=»canonical» не склеивает страницы
Влад Наумов
Head of SEO
Тег rel=»canonical», согласно справке поисковой системы Google, предназначен для указания канонической версии страницы в случаях если одна страница доступна по нескольким url-адресам либо же есть несколько страниц с очень похожим контентом.
Каноническая страница будет намного чаще сканироваться поисковой системой чем неканонические страницы. Т.е. страницы «дубликаты» тоже будут сканироваться.
Google рекомендует указывать какой url-адрес является каноническим, а если этого не сделать то поисковая система выберет его на основании своего алгоритма, либо же будет воспринимать несколько url-адресов равнозначными.
Проблема в данном случае заключается в том что далеко не всегда поисковая система склеивает страницы при помощи rel=»canonical».
Поисковая система Google не склеивает страницы, если они, по мнению алгоритма, разные.
Т.е. если прописать rel=»canonical» со страницы https://inweb.ua/seo на страницу https://inweb.ua/ppc то поисковая система просто проигнорирует данный тег и обе страницы будут продолжать также ранжироваться, как и раньше.
Если посмотреть на розетку или другие крупные сайты, то у них такая же проблема. Страницы пагинации либо фильтров, с которых прописан canonical, находятся в индексе Google.
Пример страниц пагинации в индексе у rozetka.com.ua:
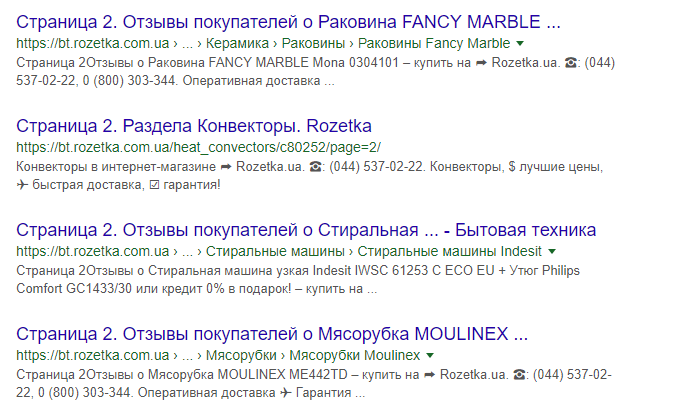
Страницы есть в индексе поисковой системы, хотя там прописан rel=»canonical».
Как исправить проблему?
Не стоит мусорные страницы сайта пытаться склеить при помощи rel=»canonical», если они значительно отличаются от канонической страницы. Такие страницы лучше закрывать в файле Robots.txt либо при помощи мета тега robots.
А то что страницы пагинации находятся в индексе, то это не проблема. Главное оптимизировать данные страницы при помощи rel=»next» и rel=»prev».
Дата сообщения: 15.11.2018, 19:30