
что такое канонические ссылки и как их настраивать
Что такое canonical URL
Тег canonical URL был создан для решения проблемы дублирования страниц. В большинстве случаев для решения этой задачи лучше всего использовать редирект. Но, когда мы не можем использовать 301 редиректы, либо нам нужны страницы, которые будут просматриваться пользователями, тогда нам поможет атрибут rel=”canonical”.
Каноническим называется URL страницы, которую роботы Google считают главной среди нескольких ее вариантов на вашем сайте. Например, если одна и та же страница размещена по нескольким URL, таким как example.com?dress=1234 и example.com/dresses/1234, одна из версий будет выбрана в качестве канонической. Обратите внимание, что страницы могут быть не полностью идентичными. Они могут различаться, например, настройками фильтров или сортировки (сортировка по цене или фильтрация товаров по цвету не делают страницу уникальной). Домен канонической страницы может отличаться от домена дубликата.Справка Google Search Console
Как настроить rel=”canonical”
1. На странице сайта (основной способ)
<link rel="canonical" href="http://site.com/canonical-link.html"/>
2. Через xml-карту сайта
Для каждой страницы в xml-карте сайта вы можете проставить свою каноническую ссылку. Но иногда поисковые системы могут игнорировать эти рекомендации.
3. Через ответ сервера
Если вам нужно указать канонические ссылки для документов другого типа (не-html), например, для pdf-файлов, вы можете поставить каноническую ссылку в http-заголовке. В таком случае при запросе дублирующего файла сервер должен выдать следующее:
Link: <http://site.com/main-file.pdf>; rel="canonical".
Но следует иметь ввиду, что сейчас Google поддерживает этот элемент заголовка только для веб-поиска.
Когда использовать канонические ссылки
1. Если вы точно знаете, что на вашем сайте есть дубликаты
Если вы четко понимаете причину появления похожих страниц на собственном сайте, и в то же время каждая такая страница должна присутствовать на сайте, нужно определить, какая из набора этих страниц является главной. Тогда изо всех остальных страниц следует проставить канонические ссылки на эту приоритетную страницу.2. Когда трудно или невозможно выполнить 301-редирект
Обычно для решения проблемы с дублями, лучше всего использовать 301-редирект. Но если процесс переадресации реализовать сложно или долго, то вы можете использовать атрибут rel=”canonical”. Согласно Google, через канонические ссылки вес передается точно так же, как при использовании переадресации с помощью 301-редиректа.
3. Несколько страниц для одного типа продуктов
Если у вас есть серия продуктов в интернет-магазине, которые отличаются, например, только по цвету, то лучше выбрать один продукт как основной (типичный) и проставить на него канонические ссылки из страниц других продуктов.
4. Для разных видов товаров в каталоге
Если на вашем сайте предусмотрены разные способы сортировки товаров, а параметр сортировки указан в URL-адресе.
http://site.com/dresses.html?sort=price
Тогда важно из всего разнообразия сортировок поставить канонические ссылки на каталог с сортировкой по умолчанию. Обычно это категория URL без параметров, которые отвечают за сортировку товаров.
<link rel="canonical" href="http://site.com/dresses.html" />
5. При создании страницы каталога со всеми продуктами
Согласно рекомендациям Google, способ, с помощью которого вы проставляете каноническую ссылку со всех страниц каталога на страницу со всеми продуктами/статьями, оптимальный как для индексации страниц каталога, так и для всех продуктов/статей на сайте. С помощью этого метода для каждого раздела сайта вам необходимо создать страницу «Просмотреть все», и с каждой страницы пагинации поставить на нее каноническую ссылку.
6. Страница печати
Если печать страниц на сайте осуществляется с помощью дополнительного параметра, например,
http://site.com/news-1.html?print=yes
тогда необходимо поставить каноническую ссылку на основную версию страницы.
<link rel="canonical" href="http://site.com/news-1.html" />
7. При использовании партнерской программы на сайте
Если на вашем сайте есть партнерская программа или любая другая реферальная система, то очень важно прописать канонические ссылки для всех страниц, которые могут содержать аффилированные ссылки. Если вы забудете сделать это, то в индексе очень быстро могут появиться десятки или даже сотни дубликатов страниц сайта, поскольку по внешним ссылкам поисковые роботы быстро индексируют необходимые страницы.
Поэтому для всех страниц с партнерскими ссылками
http://site.com/dresses.html?partner=dkfEi3dj1
нужно прописывать следующую инструкцию:
<link rel="canonical" href="http://site.com/dresses.html" />
Также вы можете сообщить Google о всех параметрах, которые не стоит индексировать с помощью специального инструмента. В этом случае вы должны отметить партнерский параметр, чтобы он не менял содержимое страницы.
Старая версия Google Search Console > Сканирование > Параметры URL
8. Для склейки файла индекса каталога
Важно проверить, чтобы файлы в каталоге типа index.html не дублировались: подобное происходит, когда два таких адреса доступны для индексирования: http://site.com/dresses/ и http://site.com/dresses/index.html. В подобных ситуациях для решения проблемы проще внести такую каноническую ссылку в файл http://site.com/dresses/index.html
<link rel="canonical" href="http://site.com/dresses/" />
9. При использовании одинакового контента на разных доменах или различных языковых версиях
Когда вы создаете аналогичные сайты, либо различные языковые версии своего контента, и при этом используете одинаковый контент на разных сайтах/языковых версиях, тогда вам нужно использовать rel=”canonical” в главной версии контента.
Главные ошибки при использовании rel=”canonical”
1. Использование на странице пагинации
Очень часто при пагинации или с некоторыми сериями страниц на сайте, для всех страниц этой серии предписывается первая каноническая страница. Это неправильно, потому что подобное препятствует индексированию всех страниц серии.
2. Каноническая ссылка не индексируется
Если мы проставляем каноническую ссылку на другую страницу, следует убедиться, что эта страница индексируется:
- страница отдает 200 код ответа сервера.
- на странице не запрещена индексация (через мета-тег robots и noindex).
Найдите неиндексируемые страницы
Запустите аудит и узнайте какие из канонических ссылок запрещены к сканированию поисковыми ботами
3. Несколько ссылок rel=”canonical” со страницы
Для одной страницы должна быть одна каноническая ссылка. Если указано несколько страниц, будет приниматься во внимание только первая инструкция.
4. Разные канонические URL-адреса
Всегда указывайте одни и те же канонические страницы для разных вариантов реализаций (например, через xml-карту сайта или через rel=”canonical” на самой странице).
5. Неправильное использование относительных ссылок
При указании канонических ссылок лучше всегда предписывать абсолютные ссылки
поскольку, когда вы указываете относительные ссылки, существует очень высокая вероятность ошибки:
<link rel="canonical" href="site.com/dresses.html" />
Тогда поисковые системы просто проигнорируют эти инструкции.
sitechecker.pro
Простое руководство по тегу Canonical
Тематический трафик – альтернативный подход в продвижении бизнеса

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Теги Canonical существуют с 2009 года. То есть, почти десять лет. Цель, для которой их создали — помочь вебмастерам решить проблему дублирующегося контента.
Что такое тег canonical
Это фрагмент HTML-кода, который определяет основную версию для нескольких страниц с похожим или полностью дублирующимся контентом. Другими словами, если по разным адресам есть одинаковый контент, вы можете использовать этот тег, чтобы указать, какая страница является основной, и следовательно, которую нужно проиндексировать.
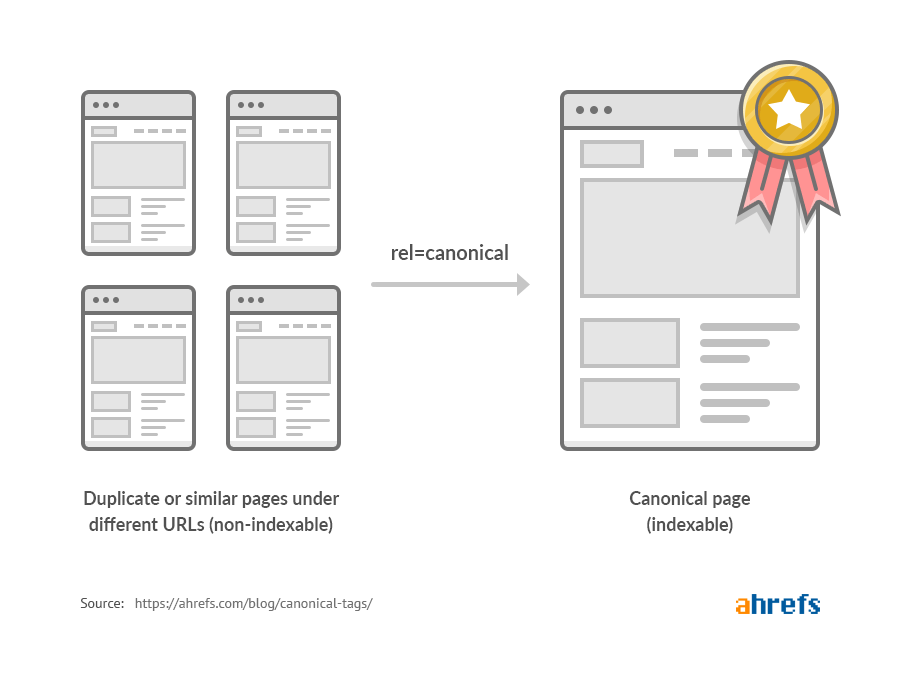
Как выглядит тег canonical
Теги используют простой и согласованный синтаксис, размещаются в разделе веб-страницы:
<link rel=»canonical» href=»https://example.com/sample-page/» />
Что значит каждая часть:
- link rel=”canonical”: ссылка является основной (канонической) версией этой страницы;
- href=»https://example.com/sample-page/»: каноническую версию можно найти по этому URL.
Важность канонических тегов для SEO
Google не любит дублирующийся контент, потому что сложно выбирать оригинал:
- Какую версию страницы надо проиндексировать?
- Какая версия страницы подходит для ранжирования по релевантным запросам?
- Нужно ли объединять ссылочный профиль на одной странице или разбивать его на несколько версий?
Слишком большое количество дублирующегося контента также может повлиять на бюджет сканирования. Это значит, что Google будет тратить время на сканирование нескольких версий одной и той же страницы вместо поиска другого важного материала на вашем сайте.
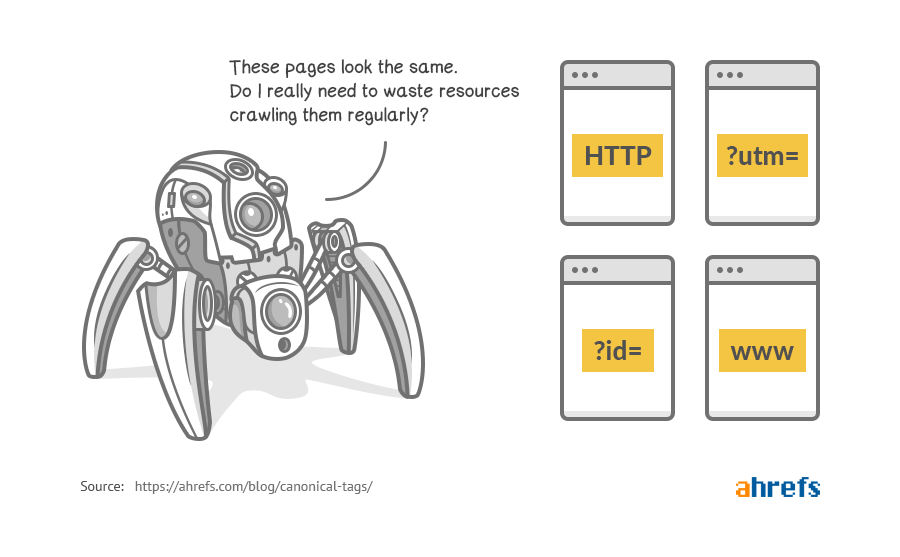
Канонические теги решают все эти проблемы. Они позволяют вам сообщить, какую версию страницы следует сканировать и ранжировать, где консолидировать любые ссылки.
Если вы не укажите канонический адрес, Google все решит за вас. Самостоятельно.
А полагаться на его грамотный выбор — опрометчиво. Система может выбрать в качестве основной страницы ту, которая в действительности таковой не является.
…но у меня же нет дублирующегося контента!
Да, наверняка вы не стали публиковать одну и ту же статью несколько раз. Но поисковые системы обходят URL, а не страницы.
Это значит, что они воспринимают адреса example.com/product и example.com/product?color=red как уникальные, даже если на них содержится, по факту, один и тот же контент.
Это — параметрические адреса. Они — частая причина возникновения дублирующегося контента. Особенно, если у вас интернет-магазин с фасетной или фильтрованной навигацией.
Например, Brown Bag Clothing продает рубашки. Вот адрес для основной категории товаров:
https://www.bbclothing.co.uk/en-gb/clothing/shirts.html
Если в фильтре выбрать показы только рубашки размером XL, в адрес добавится параметр:
https://www.bbclothing.co.uk/en-gb/clothing/shirts.html?Size=XL
А если нам нужны вдобавок только рубашки голубого цвета, увидим еще один параметр:
https://www.bbclothing.co.uk/en-gb/clothing/shirts.html?Size=XL&color=Blue
Это все отдельные страницы для Гугла, а содержание практически одно и то же.
Однако, такая проблема встречается не только для сайтов электронной коммерции. Вот еще несколько случаев:
- Параметры поисковых запросов в URL (example.com?q=search-term)
- Параметры сессии (https://example.com?sessionid=3)
- Наличие раздельных версий страницы для просмотра и для печати ( example.com/page и example.com/print/page)
- Уникальный url для постов в разных категориях (example.com/services/SEO/ и example.com/specials/SEO/)
- Отдельные адреса для версий страниц для разных девайсов.
- Наличие версий страницы с AMP и без нее.
- Наличие одинакового контента по адресу с www и без него.
В этих случаях использование канонических тегов имеет решающее значение. Кроме того, важны проблемы дублирования контента на разных доменах. Например, при синдикации контента: газета хочет процитировать ваш текст. В таком случае вам надо попросить разместить на вас каноническую ссылку.
Во-первых, вы будете получать реферальный трафик. Во-вторых, обезопасите уникальность вашего контента.
Основы применения тега canonical
Применять легко. Мы рассмотрим четыре способа это сделать далее. Пока — пять основным правил, которые нужно знать и соблюдать.
Правило 1. Использовать абсолютные URL
Джон Мюллер из Google утверждает, что не рекомендуется использовать относительные ссылки вместе с тегом canonical. Чтобы они точно корректно обработались, используйте абсолютные URL.
То есть, вот так:
<link rel=“canonical” href=“https://example.com/sample-page/” />
Вместо:
<link rel=“canonical” href=”/sample-page/” />
Правило 2: Соблюдать нижний регистр
Google может обработать и нижний, и верхний регистры как два разных адреса. Поэтому вначале установите принудиттельно строчные адреса на своем сервере, а затем используйте нижний регистр для написания адресов в ссылках с каноническим тегом.
Правило 3: Правильно использовать версию домена
Если переходите на SSL-сертификат, проверьте, что используете верный протокол передачи данных в адресе, то есть, HTTPS. Теоритически, это тоже может привести к путанице и неожиданным результатам.
Вот так правильно:
<link rel=“canonical” href=“https://example.com/sample-page/” />
А вот так — нет:
<link rel=“canonical” href=“http://example.com/sample-page/” />
Правило 4: Использовать самоссылочные канонические теги
Джон Мюллер говорит, что это — рекомендация, а не обязательство.
Это — каноническая ссылка сама на себя. Например, если URL — https://example.com/sample-page, то каноническая “самоссылка” будет такой:
<link rel=“canonical” href=“https://example.com/sample-page” />
Располагаться она будет на этой же странице.
Большинство популярных CMS делают это автоматически. Но на всякий случай проверьте.
Правило 5: Использовать один канонический тег на странице
В противном случае Googlebot проигнорирует вообще все канонические теги на странице.
Как применять канонические адреса
Всего есть 4 способа:
- HTML-тег;
- HTTP header;
- Карта сайта;
- 301 редирект.
Для подробностей можно посмотреть официальную справку.
1. Установка в HTML-тегах
Самый простой способ — указать тег rel-canonical в адресе. Добавьте нижеследующий код в раздел header:
<link rel=“canonical” href=“https://example.com/canonical-page/” />
Пример
Предположим, у вас есть интернет-магазин футболок. Вы хотите установить адрес https://yourstore.com/tshirts/black-tshirts/ каноническим. Учтем, что по разным адресам доступен одинаковый контент.
Можно просто на все дублирующиеся страницы добавить такую строку кода:
<link rel=“canonical” href=“https://yourstore.com/tshirts/black-tshirts/” />
Обратите внимание, что если вы используете CMS, возиться с кодом не нужно. Есть более простой способ.
Настройка канонических тегов в WordPress
Установите плагин Yoast SEO. Сможете автоматически добавлять канонические адреса. Используйте вкладку “Дополнительно”.

Установка канонических тегов в Shopify
Shopify добавляет по умолчанию канонические адреса для продуктов и блогов. Чтобы установить пользовательские каноничные URL, отредактируйте файлы шаблона напрямую.
Установка канонических тегов в Squarespace
Squarespace добавляет рекурсивные URL-адреса также по умолчанию. Как и в случае со Shopify, придется редактировать код напрямую, если нужно добавить пользовательский канонический тег.
2. Установка канонических тегов в HTTP header
Для документов — например, PDF — нет возможности разместить канонические теги в заголовке страницы, потому что нет раздела. В таких случаях нужно использовать заголовки HTTP.
Пример
Например, представим, что создаем PDF-версию поста в блоге Ahrefs.
HTTP/1.1 200 OK
Content-Type: application/pdf
Link: <http://ahrefs.com/blog/canonical-tags/>; rel=»canonical»
3. Установка канонических адресов через карту сайта
Google заявляет, что неканонические страницы не нужно включать в карту сайта. Т. е. все страницы из карты сайта Google считает каноническими.
Но тем не менее, система не всегда воспринимает все адреса из sitemap должным образом: “Мы не гарантируем, что размещение адреса в sitemap — подтверждение его каноничности. Карта сайта — способ сказать Google, какие страницы сайта владелец считает наиболее важными”.
4. Настройка канонических тегов при помощи 301 редиректа
Используйте 301 редирект в случае, если вам надо перенаправить трафик с дубликата URL-адреса на каноническую версию.
Пример
Ваша страница доступна по адресам:
- example.com
- example.com/index.php
- example.com/home/
Выбираем страницу, которая будет основной. На остальных размещаем редирект на нее.
Обратите внимание: обязательно должно быть соответствие протоколов передачи данных (HTTPS/HTTP и наличие/отсутствие www).
Распространенные ошибки и их профилактика
Есть много недоразумений и неправильных представлений о том, как правильно устанавливать каноничные адреса. Вот некоторые распространенные ошибки.
Ошибка 1: Блокирование канонического адреса через robots.txt
Блокировка URL-адреса в файле robots.txt не позволит Google его просканировать. А значит, он не увидит канонический тег на этой странице. В свою очередь, он не сможет определить отношение между страницами с одинаковым или схожим контентом.
Ошибка 2: Канонический URL и тег noindex
Никогда не смешивайте теги noindex и rel=canonical. Они противоречат друг другу.
Google обычно отдает приоритет каноничности, а не noindex, по словам Джона Мюллера. Но это все равно плохая практика. Если вам нужно запретить индексировать канонический URL, воспользуйтесь 301 редиректом.
Ошибка 3: Установка 4XX статуса HTTP для канонического URL
Установка состояния 4XX для канонизированного URL имеет те же последствия, что и использование тега noindex. Google не сможет увидеть канонический адрес и передать вес ссылок нужной версии страницы.
Ошибка 4: Канонизация всех страниц навигации на корневую директорию
Страницы навигации не нужно канонизировать относительно первой странице в цепочке. Вместо этого нужно использовать канонические ссылки на саму страницу.
Джон Мюллер заявил, что иной способ канонизации нецелесообразен.
Ошибка 5: Не использование hreflang при канонизации
Hreflang используют, когда нужно указать языковую версию страницы.
Google утверждает, что при использовании hreflang вам также нужно указывать каноническую страницу на том же языке.
Как найти и решить проблемы с каноническими адресами на сайте
1. Проблемы с 4XX
Возникает, когда вебмастер на страницах указывает канонический URL с кодом ответа вида 4ХХ.
Поисковые системы не индексируют страницы 4ХХ, потому что они — не рабочие. В результате поисковик игнорирует любые канонические теги, которые указывают на такие страницы. В итоге в индекс попадает неверная версия страницы.
Поэтому проверьте канонические ссылки, и если в них указан адрес с подобным кодом ответа — исправьте.
2. Проблемы с 5ХХ
Аналогично предыдущему пункту.
Коды ответа такого вида сигнализируют о проблемах на сервере. В результате каноническая страница все равно оказывается недоступна (как и в предыдущем случае).
Нужно, опять-таки, заменить все канонизированные урлы с кодом ответа 5ХХ на доступные. Однако отметим, что код ответа 5ХХ может быть временной проблемой на сервере — например, когда сервер перегружен. В таком случае ничего делать не нужно.
3. Проблемы с редиректами
Предупреждение срабатывает, когда на канонизированном адресе стоит перенаправление на другой URL.
Канонические урлы всегда должны указывать на самую авторитетную версию страницы. Сами понимаете, если на этой “авторитетной” странице стоит редирект, ее надежность под сомнением.
Замените канонические ссылки прямыми линками на наиболее авторитетную версию страницы, которая возвращает код 200.
4. Дублирующие страницы без канонизации
Возникает, когда существует одна или несколько дублирующихся страниц, для которых не указана каноническая версия.
Google будет пытаться самостоятельно определить наиболее подходящую страницу для показа в результатах поиска. В итоге он может выбрать не ту версию, которую хотите увидеть в выдаче вы.
Посмотрите группы дублирующихся страниц. Выберите одну каноническую версию, на остальных укажите ее в качестве основной версии. А на канонической странице установите рекуррентную каноническую ссылку.
5. Hreflang и non-canonical
Срабатывает, когда одна или несколько страниц содержат неканонический URL в аннотациях hreflang.
Ссылки в теге hreflang всегда должны указывать на канонические страницы. Ссылки на неканоническую версию могут ввести в заблуждение поисковую систему.
Поэтому проверьте и замените.
6. Канонический URL не имеет входящих ссылок
Проблема возникает, когда один или несколько указанных канонических адресов не имеет внутренних входящих ссылок.
Канонические адреса без внутренних ссылок недоступны для пользователей сайта. Вместо этого человек попадает на неканоническую версию страницы.
Поэтому проверьте на сайте внутренние ссылки на канонические адреса.
7. Неканонические страницы в sitemap
Возникает, когда в карте сайта указаны неканонические страницы.
Google утверждает, что указывать в картах сайта неканонические страницы не следует. Поэтому он предполагает, что все страницы в файле — те, которые вы хотите проиндексировать.
Не канонические страницы из карты сайта уберите.
8. Неканоническая страница определена как каноническая
Проблема возникает, когда на одной или нескольких страницах указывается канонический URL, который одновременно является каноническим для другой страницы.

Такие цепочки могут ввести в заблуждение поисковик.
Замените неканонические ссылки в канонических тегах затронутых страниц прямыми ссылками на канонические версии. Например, если для страницы А канонической страницей указана В, а для В — страница С, замените каноническую страницу для А с В на С.
9. Open Graph URL не соответствует каноническому
Возникает при несоответствии между указанным каноническим и URL-адресом Open Graph на одной или нескольких страницах.
Если URL-адрес Open Graph не совпадает с каноническим, то неканоническая версия страницы будет опубликована в социальных сетях.
Замените в OpenGraph адрес на канонический, чтобы в соцсети попадала правильная версия страницы.
Заключение
Canonical — это не сложно, если как следует разобраться в логике их работы.
Просто помните, что канонические теги — это не директива, а сигнал для поисковых систем. Другими словами, они могут выбрать каноническую страницу отличную от той, которую укажете вы.
Можно использовать URL Inspection Tool в GSC, чтобы понимать всю картину.

Источник.
semantica.in
Каноническая ссылка rel=canonical: полное руководство
256
Каноническая ссылка позволяет сообщить поисковым системам о том, что определенные схожие URL-адреса на самом деле являются одинаковыми. Случается, так что ваши продукты или контент встречаются на нескольких URL-адресах (или даже веб-сайтах), но благодаря использованию канонических ссылок (HTML-тегов ссылок с атрибутом rel=canonical), можно оставить все как есть, не нанеся при этом ущерба ранжированию своего сайта.
Что такое каноническая ссылка?

История атрибута rel=canonical
В феврале 2009 года Google, Bing и Yahoo! презентовали тег link с атрибутом rel=canonical – если интересна эта история, статья Мэтта Каттса отлично просветит вас. Хотя сама по себе идея проста, нюансы использования часто трудны для понимания.
Атрибут rel=canonical, часто называемый «канонической ссылкой», является элементом HTML и помогает веб-мастерам предотвратить проблемы, связанные с дублированным контентом. Он выполняет свои функции, определяя «канонический URL» («предпочтительную» версию веб-страницы) или даже оригинальный ресурс. Использование этого атрибута значительно улучшает оптимизацию сайта SEO.
Ироническое замечание
Термин «Канонический» пришел из римско-католической традиции, согласно которой был создан список священных книг, принятый в качестве подлинного и названный каноническим Евангелием Нового Завета. По иронии судьбы, чтобы прийти к этому, Римско-католическая церковь потратила около 300 лет и приняла участие во множестве боев. В конечном счете было выбрано четыре версии одной и той же истории…
Идея проста: если у вас есть несколько похожих вариаций одного и того же контента, нужно выбрать одну «каноническую» и сообщить об этом поисковым системам. Это решает проблему с дублированным контентом, когда поисковые системы не знают какой вариант содержимого отображать в результатах поиска. В этой статье вы узнаете, как и когда пользоваться каноническими ссылками, а также как избежать распространенных ошибок.
Польза атрибута rel=canonical для SEO
Выбор правильного канонического URL для каждой группы схожих адресов, улучшает SEO оптимизацию вашего сайта. Все потому, что поисковая система знает какая из вариаций каноническая и, следовательно, может рассматривать ссылки на все многообразие версий, как ссылки на конкретную каноническую. Назначение страницы канонической, сродни 301 редиректу, только без фактической переадресации.
Процесс «канонизации»
Когда у вас на выбор несколько URL-адресов для одного и того же продукта, канонизацией называют выбор одного из этих адресов. Во многих случаях совершенно очевидно, что одни URL-адреса будут более подходящим выбором, чем другие. Порой это не так очевидно, но все также легко – просто выберите один из них! Отказ от канонизации своего URL-адреса является не самой лучшей практикой.
Назначение URL- адреса каноническим
Правильный пример использования атрибута rel=canonical
Предположим, что вы располагаете двумя версиям одной и той же страницы, содержимое которых совпадает на 100%. Отличаются они лишь расположением в отдельных частях сайта, вследствие чего цвет фона и активные пункты меню отличны — вот и всё. На обе версии ссылаются с других сайтов, так что важность самого контента очевидна. Какую же версию поисковым системам отображать в результатах поиска?
К примеру, они имеют следующие URL-адреса:
http://example.com/wordpress/seo-plugin/
http://example.com/wordpress/plugins/seo/
Для подобных ситуаций и был изобретен атрибут rel=canonical и, к сожалению, они не редкость, в особенности для многочисленных систем электронной коммерции. У продукта может быть несколько разных URL-адресов, зависящих от того по какой ссылке вы перешли на требуемую страницу. В этом случае атрибут rel=canonical применяется следующим образом:
- Выберите одну из принадлежащих вам двух страниц в качестве канонической. Лучше, чтобы это была версия, которую вы считаете самой важной. Если вам все равно, выберите ту у которой большее число ссылок или посетителей, при прочих равных просто бросьте монету. Все что нужно сделать – это выбрать.
- Добавьте ссылку rel=canonical с неканонической страницы на каноническую. Таким образом, если в качестве нашего канонического URL-адреса мы выбрали самый короткий, оставшийся URL-адрес будет ссылаться на него в заголовочной части <head> своей страницы, как приведено ниже:
<link rel=»canonical» href=»http://example.com/wordpress/seo-plugin/» />
Вот и все. Ни больше ни меньше.
С точки зрения поисковой системы это приводит к «объединению» двух страниц воедино. Это «мягкая переадресация» без перенаправления пользователя. Ссылки на оба URL-адреса теперь расцениваются, как ссылки на одну каноническую версию URL.
В каких случаях следует пользоваться каноническими ссылками?
301 редирект или каноническая ссылка?
Если вы не можете выбрать между 301 редиректом и созданием канонической ссылки, что тогда? Ответ прост: если нет каких-либо технических причин поступить иначе, всегда следует отдавать предпочтение редиректу. Если вы не можете воспользоваться редиректом из-за потенциального вреда опыту пользователя или же проблем другого характера, в таком случае воспользуйтесь используйте канонический URL.
Нужна ли странице каноническая ссылка на себя?
В приведенном выше примере мы ссылаемся с неканонической страницы на ее каноническую версию. Но нужно ли устанавливать атрибут rel=canonical для неё самой? Этот вопрос активно обсуждается среди тех, кто занимается SEO оптимизацией. Мы настоятельно рекомендуем размещать каноническую ссылку на всех страницах и Google подтвердил, что так будет действительно лучше. Это связано с тем, что большинство CMS позволяют применять параметры URL не меняя содержимое. Таким образом каждый из этих адресов будет отображать один и тот же контент:
http://example.com/wordpress/seo-plugin/
http://example.com/wordpress/seo-plugin/?isnt=it-awesome
http://example.com/wordpress/seo-plugin/?cmpgn=twitter
http://example.com/wordpress/seo-plugin/?cmpgn=facebook
Дело в том, что отсутствие на странице канонического URL-адреса, ведущего на свою собственную страницу (самую чистую версию из числа подобных), может нести определенные последствия. Если не вы, то кто-то другой может выполнить данное условие и тем самым привести к проблемам, связанным с дублированным контентом. Исходя из этого добавление канонической странице, ведущей на нее ссылки, является хорошей защитой с точки зрения SEO оптимизации.
Кросс-доменные канонические ссылки
Возможно, контент аналогичный вашему, находится на нескольких доменах. Есть сайты или блоги, самостоятельно публикующие статьи с других веб-сайтов, поскольку считают их содержимое важным для своих пользователей. В HTML коде этих статьей можно найти ссылку с атрибутом rel=canonical, ведущую обратно к оригинальному ресурсу. Это означает, что все ссылки, указывающие на собственную версию статьи, сказываются на ранжировании данной канонической версии. Они пользуются нашим контентом, чтобы порадовать свою аудиторию, но и наше преимущество от этого очевидно. Все в выигрыше.
Неправильные канонические ссылки: часто задаваемые вопросы
Существует много примеров того, как неправильная реализация атрибута rel=canonical может привести к огромным проблемам. Я наталкивался на несколько сайтов, с домашних страниц которых атрибут rel=canonical указывал на какую-либо статью, просто для того, чтобы увидеть, как домашняя страница исчезает с результатов поиска. Есть и другие вещи, которые ни в коем случае не стоит делать с указанным атрибутом. Вот самые важные из них:
- Не канонизируйте архив с пагинацией на первую страницу. Атрибут rel=canonical на странице 2 должен указывать на страницу 2. Если вы сошлетесь с неё на страницу 1, поисковые системы не будут индексировать ссылки более глубоких страниц архива…
- Делайте ссылки совершенно точными. По разным причинам, многие сайты используют ориентированные на протокол ссылки, чтобы убрать часть ссылки указывающую наименование протокола (http/https). Так делать не стоит. Поскольку у вас есть предпочтительный вариант, укажите его.
- Размещайте каноническую ссылку на запрашиваемый URL-адрес. Если вы используете переменные вроде URL домена либо URL запрашиваемой страницы для того чтобы попасть на текущую страницу, генерируя при этом атрибут rel=canonical, вы движетесь в неправильном направлении. У вашего контента должны быть собственные URL-адреса. В противном случае, ваш контент все еще может размещаться по разным адресам (к примеру, на example.com и www.example.com), причем каждый из этих адресов будет восприниматься другим, как канонизированный.
- Несколько канонических ссылок на одной странице приводят к хаосу. Порой разработчики плагинов или расширений считают себя Божьим даром для человечества и уверены в том, что знают, как распределять канонические ссылки по страницам наилучшим образом. Порой они оказываются правы, но поскольку они не мы, ошибки иногда случаются. Когда видим, что подобное происходит в плагинах WordPress, мы пытаемся связаться с соответствующими разработчиками и научить их уму разуму, что правда не меняет ситуацию коренным образом. И когда к нам не прислушиваются, результат совершенно непредсказуем.
Атрибут rel=canonical и социальные сети
Facebook и Twitter тоже учитывают атрибут rel=canonical, что может повлечь за собой странные ситуации. Если вы размещаете на Facebook ссылку на каноническую страницу, размещенную за пределами ресурса, Facebook поделится данными канонической ссылки. Иначе говоря, если добавить кнопку «like» на страницу, каноническая ссылка которой указывает на другой ресурс, счетчик «лайков» будет относится к тому каноническому ресурсу, а не к текущему. В Twitter дела обстоят также.
Использование атрибута rel=canonical. Продвинутый уровень.
Канонические ссылки в заголовках HTTP
В поисковой системе Google также предусмотрена поддержка канонических ссылок в заголовках HTTP. Такой заголовок выглядит следующим образом:
Link: <http://www.example.com/white-paper.pdf>;
rel=»canonical»
Заголовки HTTP с каноническими ссылками могут быть весьма полезны для канонизации таких файлов, как PDF, поэтому имеет смысл знать о их существовании.
Атрибут rel=canonical для не очень похожих страниц
Хотя подобное не рекомендую, знайте, что вам подвластно пользоваться атрибутом rel=canonical в очень агрессивной манере. Google чтит канонизацию почти до безумия, так что можете связывать через атрибут rel=canonical страницы с совершенно разным контентом. Однако, если поисковик Google вас застукает, он перестанет доверять каноническим ссылкам вашего сайта и тем самым вы нанесете себе больше вреда…
Сочетание атрибутов rel=canonical и hreflang
Также мы упоминаем о канонических ссылках в нашей статье «Атрибут hreflang и как его использовать». Все потому, что при использовании этого атрибута очень важно, чтобы все канонические ссылки страниц, написанных на других языках, вели на свою оригинальную страницу. Перед тем, как внедрять в жизнь атрибут hreflang, убедитесь в том, что хорошо понимаете, как пользоваться каноническими ссылками. В противном случае ваш опыт в этом может оказаться провальным.
Заключение: атрибут rel=canonical является мощным инструментом
Атрибут Rel=canonical является мощным инструментом в арсенале SEO специалиста, но, как вы понимаете, чтобы не сделать хуже, подобными инструментами нужно пользоваться с умом. Для больших сайтов процесс канонизации может оказаться невероятно важным и привести к значительным улучшениям в плане SEO оптимизации.
Полезный контент: «Хорошее SEO продвижение сайта wordpress за 8 шагов»
starting-constructor.ru
Что такое каноническая ссылка rel=»canonical»?
Что такое каноническая ссылка c атрибутом rel=»canonical»? Как проверить корректность разметки канонических ссылок и главную страницу среди дублей? О примерах канонических страниц, а также способах их проверки читайте в данной статье!
Содержание статьи
Атрибут rel со значением canonical элемента link обозначает канонические страницы на сайте. Каноническая страница для поисковых систем является предпочитаемой страницей среди дублей, либо страниц со схожим контентом, например, для отдельных страниц мобильной и десктопной версии сайта. Именно канонические страницы сайта среди прочих участвуют в поисковой выдаче и переобходятся роботами Яндекс и Google гораздо чаще остальных.
Канонические ссылки rel=»canonical» — что это?
Канонические ссылки — это ссылки, которые содержит атрибут rel со значением canonical. Например, для данной статьи канонической ссылкой является:
<link rel="canonical" href="https://naked-seo.ru/blog/chto-takoe-kanonicheskaya-ssyilka-rel-canonical">
Данная ссылка не является строгой директивой, а лишь указывается поисковым системам предпочтительную для индексирования страницу среди прочих дублей. Дублирующийся контент замедляет индексирование вашего сайта, а также заставляет поисковых роботов тратить свои мощности на переобход страниц с высокой степенью схожести.
Как правило, большое количество дублирующихся страниц генерируется неоптимизированными CMS. Если данные страницы
- не имеют общих параметров в url-адресе и их нельзя объединить директивой Disallow в robots.txt;
- используются для внутренней работы, которая не позволяет настроить 301 редирект.
Для них необходимо указать каноническую ссылку на ту страницу, которая является оригинальной и предназначений для ранжирования в поиске. Использование канонических ссылок является важным элементом seo-оптимизации, и позволяет улучшить взаимодействие вашего сайта с поисковыми роботами. Так, страницы с атрибутом rel=»canonical» будут переобходиться поисковыми роботами гораздо чаще и, с высокой долей вероятности, будут участвовать в поисковый выдаче.
Однако существуют исключения, при которых роботы могут не учитывать и не ранжировать канонические ссылки:
- Недоступность. Каноническая ссылка должна отдавать код ответа 200. Недоступность канонической ссылки (404 код ответа) или 301 редирект могут заставить поисковые системы проигнорировать данный атрибут.
- Каноническая ссылка ведет на другой ресурс. Помните, что для поисковых роботов сайт с www и без www, а также сайты с разными протоколами http и https являются разными ресурсами. При этом при переезде сайта и склейке зеркал в канонической ссылке нужно указывать главное зеркало сайта, даже если вы сохраняете доступными обе версии сайта (напр. с http и с https)
- В коде несколько канонических ссылок. Тег link с атрибутом rel=»canonical» должен быть единственным на странице.
- Цепочка канонических ссылок может игнорироваться, если вы, например, указали для страницы site.ru/1 каноническую ссылку site.ru/2, а на странице site.ru/2 каноническую ссылку site.ru/3.
- Google может проигнорировать каноническую ссылку, если ее условный дубликат обладает более высокими поведенческими факторами и более богатой историей взаимодействия с пользователями.
Канонические ссылки также выполняют важную функцию консолидации внешних ссылок на сайт. Так если пользователи попадают на одинаковые страницы https://site.ru/1 и https://site.ru/2 вашего сайта с разными url-адресами, и впоследствие делятся ссылками на ваш ресурс в сети, каноническая ссылка поможет объединить внешние ссылки на https://site.ru/1 и https://site.ru/2 для суммирования веса и их влияния как фактора ранжирования.
Примеры использования канонических ссылок rel=»canonical»
Рассмотрим несколько примеров дублирующихся страниц и соответствующие канонические ссылки для них. К примеру, ваша CMS может генерировать подобные дубликаты одной страницы:
https://site.ru/cat?id=7 https://m.site.ru/cat?id=7 https://site.ru/category/phones http://site.ru/phones
Если среди представленных url страницей, которая должна участвовать выдаче является — https://site.ru/category/phones. Значит в коде страниц:
https://site.ru/cat?id=7 https://m.site.ru/cat?id=7 http://site.ru/phones
нужно указать каноническую ссылку на основную страницу:
<link rel="canonical" href="https://site.ru/category/phones">
Содержимое атрибута href указывает на основную ссылку всех дубликатов.
Нужны ли канонические ссылки для страниц пагинации?
У многих вебмастеров возникает закономерный вопрос: «как правильно оптимизировать страницы пагинации?», ведь данные страницы содержат, как правило, один и тот же текстовый контент. Нужно ли закрывать данные страницы директивой Disallow в robots.txt, либо необходимо указать канонический адрес ссылки? Для ответа на данный вопрос давайте обратимся к поддержке Яндекс:

Для страниц пагинации необходимо использовать каноническую ссылку. Таким образом, дублирующиеся страницы не попадут в выдачу поисковых систем, однако, их внутренний статический вес будет передаваться основной странице. При этом поведенческие факторы поисковики смогут учитывать со страниц пагинации даже если они будут закрыты от индексации в robots.txt:

Важные детали
Также стоит обратить внимание, на некоторые важные детали использования канонических станиц:
- Для основной страницы указание атрибута rel с содержимым canonical необязательно.
- Если у основной страницы есть мобильная версия с отдельным url-адресом, добавьте на канонический вариант link с атрибутом rel=»alternate», указывающий на эту версию: <link rel=»alternate» media=»only screen and (max-width: 640px)» href=»http://m.site.ru/phones»>.
- В теге link с атрибутом rel=»canonical» используйте абсолютные, а не относительные пути. Например, https://site.ru/phones, а не //site.ru/phones и /phones.
- Добавьте в ваш Sitemap.xml именно канонические страницы. Таким образом вы повысите вероятность, что поисковые системы будут использовать для индексации именно их.
Как проверить каноническую ссылку?
Тег link с атрибутом rel=»canonical» находится внутри тега <head>. Дл проверки канонической ссылки на вашем сайте, откройте панель разработчика браузера, в поиске по коду наберите «canonical». Тег link с данным атрибутом должен быть единственным на страницы, поэтому его поиск не должен вызвать у вас сложностей.

Подписывайтесь на блог, делитесь статьей в социальных сетях, задавайте свои вопросы в комментариях и делитесь своим мнение по поводу роли канонических ссылок в SEO-оптимизации ресурсов.
Поделитесь статьей в социальных сетях:naked-seo.ru
Что такое canonical, как и зачем его настраивать
Зачем нужны canonical-адреса
Канонический URL (canonical) позволяет указать поисковой системе, какая ссылка является предпочтительной для индексации. Настройкой canonical необходимо заниматься, если у вас на сайте имеются страницы с одинаковым содержанием. Ввиду особенностей CMS сайта могут автоматически создаваться страницы с одним и тем же контентом по разным адресам URL (более подробно читайте ниже). Появление подобных страниц возможно вследствие таких причин:
- Если вы написали одно и то же сообщение в разных темах блога, то есть вероятность автоматического создания еще одной страницы сайта.
- Например, у вас есть несколько доменов: http://article.example.com и http://blogs.example.com. И вы планируете размещать информацию сразу на обоих ресурсах. В таком случае размещаемый контент будет дублированным.
- Если была обновлена структура вашего сайта, после чего URL страниц сайта могли быть изменены.
Чтобы не допустить дублирования страниц сайта в поисковой выдаче, необходимо настроить канонические URL, после чего поисковик сможет определить, какую страницу нужно индексировать. Рассмотрим причины, из-за которых важно заниматься настройкой canonical:
- Если на разных страницах вашего сайта публикуется частично или полностью идентичная информация, то следует указать, какую страницу следует считать основной.
- Одна и та же информация, размещенная на разных страницах, затрудняет получение статистики о данных страницах.
Как настроить канонические адреса
Рассмотрим способы настройки «канонических» URL:
- Следует указать, какой URL считается основным. Сделать это можно при помощи атрибута rel=»canonical» тега link. Например, на сайте присутствует несколько страниц с идентичным содержимым. Для того чтобы задать URL https://example.com/buyingcar в качестве основного, указываем на страницах с дублируемым контентом в блоке head кода страницы тег вида <link rel=»canonical» href=»https://example.com/buyingcar» />. В данной ситуации вы задаете главный URL, который в дальнейшем будет использован для просмотра сообщения о покупке автомобилей. Также эта страница будет показываться в результатах поисковой выдачи. Предпочтительнее задавать адрес сайта в абсолютном виде (https://example.com/buyingcar), избегайте относительных путей (/buyingcar).
- В карту сайта добавляем только канонические URL, в таком случае вы сможете сообщить поисковому роботу, какие страницы сайта вы считаете основными. При индексировании сайта поисковой робот не будет заходить на неканонические страницы, тем самым быстрее индексируя сайт.
- Для различных CMS существуют различные плагины, которые позволяют настроить канонические URL, например, для WordPress можно воспользоваться Yoast SEO.

Для OpenCart настройка атрибута canonical производится средствами CMS. Необходимо зайти в настройки товара и задать параметр SEO URL.

Для настройки canonical в Joomla нужно включить в настройках CMS функцию SEF. После включения для технических страниц вида /index.php?option будет добавлен атрибут rel=»canonical» (с указанием URL на страницу с настроенным ЧПУ).

Как проверить дублированный контент
Проверить, настроен canonical для страниц вашего сайта или нет, можно с помощью следующих инструментов:
1. Для проверки настройки canonical, открываем html-код страницы и проверяем наличие атрибута canonical у тега link (в блоке <head> кода страницы).

Плагин для браузеров RDS Bar позволит просмотреть эту информацию без совершения лишних действий. Включаем данную опцию в настройках плагина (Параметры – SEO – теги – Canonical), после чего при переходе на страницы, где canonical настроен, будет отображаться следующая информация:

2. Проверить наличие дублируемого контента можно с помощью Расширенного поиска Яндекса. Для этого указываем адрес сайта и часть текста со страницы, контент которой будем проверять на дублирование. В результатах поиска будет указано, нашлись точные совпадения или нет. Если дублирование отсутствует, то будут предложены варианты по запросу.

Также проверить контент на наличие дублей можно с помощью операторов поиска, рассмотрим на примере Google. Для этого нужно ввести в поисковую строку site:имя_домена «запрос», в итоге аналогично поиску от Яндекса по результатам поисковой выдачи делаем вывод о наличии дублированного контента.

3. Еще один способ найти дублируемый контент – уникальность. В этом нам помогут специальные программы и сервисы, мы рассмотрим на примере сервиса text.ru. Для анализа необходимо добавить информацию со страницы вашего сайта в сервис и запустить проверку. В результате вы увидите, на каких сайтах в Интернете есть такой же текст, и на сколько процентов ваш текст совпадает с текстами других сайтов.

Итог
Грамотно настроенный canonical повышает эффективность работы и ускоряет индексирование сайта. Если у вас не получится самостоятельно это сделать, то вы можете обратиться к нашим специалистам, и мы сделаем настройку rel=»canonical» для вашего сайта.
1ps.ru
Rel=canonical: как можно и как нельзя канонизировать URL
 Контент-стратег краулера JetOctopus Представьте ситуацию: поисковой бот приходит к вам на сайт, сканирует контент и находит несколько одинаковых страниц. Как боту выбрать лучший вариант для ранжирования?
Контент-стратег краулера JetOctopus Представьте ситуацию: поисковой бот приходит к вам на сайт, сканирует контент и находит несколько одинаковых страниц. Как боту выбрать лучший вариант для ранжирования?Бот доверится подсказкам, которые вы ему предоставите (если только вы не будете манипулировать алгоритмами поисковика). Если же вы не укажете, какой URL является каноническим (оригинальным / более важным для вас), бот сделает выбор за вас. А еще бот может расценить дублирующие страницы как одинаково важные. Тогда поисковик потратит краулинговый бюджет на повторяющийся контент, а прибыльные страницы могу в индекс так и не попасть.
Как избежать такого расклада? Ответ может показаться сложным, но в этой статье я объясню все просто. Итак, чтобы бот забрал в индекс выгодные страницы, их нужно канонизировать.
Читайте ниже, что это значит, как это нужно и не нужно делать.
Вы уверены, что у вас на сайте нет дубликатов?
Канонический URL – это страница, которую Google воспринимает как наиболее важную из нескольких дублирующихся URL-ов на сайте. Возможно вы думаете: «Я не копирую URL-ы у себя на сайте, поэтому мне не о чем беспокоиться». На самом деле дубликаты могут быть созданы автоматически. Например, поисковые роботы могут зайти на вашу страницу разными способами:
- Через протоколы HTTP и HTTPS:
http://www.yourwebsite.com
https://www.yourwebsite.com
- Через WWW и не WWW:
http://example.com
http://www.example.com/
Как лучше попасть к вам на сайт? Выберите лучший способ и не забудьте рассказать поисковым системам о своем выборе.
Рассмотрим еще один пример, когда множество дубликатов создается на коммерческом сайте автоматически. Сортировка товаров с помощью URL параметров по размеру, цвету, бренду и т. д. генерирует тысячи дубликатов. Например:
- yourwebsite.com/products/girls?category=dresses&color=white
yourwebsite.com/products/girls?category=dresses&color=black
- yourwebsite.com/dress?style=casual,long-sleeve
yourwebsite.com/dress?style=casual&style=long-sleeve)
Когда бот находит на сайте практически идентичный контент на разных URL-ах, авторитет сайта/позиция в органическом поиске снижается. Ведь поисковики ценят уникальный контент и ранжируют его выше, а дубликаты только тратят их ресурсы. Поэтому важно оптимальным способом разметить, какой контент на вашем сайте оригинальный, а какой нет. В статье я расскажу о четырех способах канонизации страниц. Мы поговорим о плюсах, минусах и особенностях использования каждого из них.
1. Тег Rel=canonical
Предположим, вы хотите сделать страницу https://yourwesite.com/page.php/ канонической. Для этого добавьте элемент link с атрибутом rel=»canonical» и ссылку на каноническую страницу в заголовок head всех дубликатов:

Если у канонической страницы есть вариант для мобильных устройств, добавьте элемент link с атрибутом rel=»alternate» и ссылкой на мобильную версию, например:
link rel=»alternate» media=»only screen and (max-width: 660px)» href=»https://m.yourwesite.com/page.php/»
Элемент link с атрибутом rel=»canonical» должны содержать абсолютный URL (полный), а не относительный (сокращенный) адрес.
2. Rel=canonical HTTP header
Тег Rel=canonical канонизирует HTML-страницы. Для других же форматов, как, например, PDF, Google рекомендует прописывать атрибут rel=canonical в HTTP-заголовке. PDF на сайте необходимо канонизировать потому, что боты просматривают и индексируют такие файлы так же, как и HTML страницы.
Этим способом можно воспользоваться только если у вас есть доступ к настройкам сервера. Не буду детально описывать процесс создания rel=canonical HTTP, так как необходимо углубиться в технические детали, и статья растянется страниц на 10. Оставляю ссылку на хорошую статью от MOZ со всеми нюансами внедрения rel=»canonical» HTTP Headers. Так же, как и в rel=canonical link, URL-ы в HTTP-заголовке должны быть абсолютными.
3. 301 редирект
301 статус код – это перенаправление пользователей и ботов на другой URL.
Когда лучше применить 301 статус код:
- смена домена сайта;
- для ошибки 404 и контента, утратившего актуальность, но имеющего релевантные ссылки и большой трафик;
- для контента, который переехал на другой URL навсегда.
4. Sitemap/Карта сайта
Sitemap, или по-русски карта сайта — это XML-файл с информацией о местонахождении URL-ов, дате их последнего обновления, частоте обновления и др. Вебмастер Google Джон Мюллер подтвердил, что страницы в картах сайта бот воспринимает как приоритетные для индексации и ранжирования.
«…мы используем URL-ы в sitemap как способ понять, какой URL следует считать каноническим для определенного контента».
Все страницы в этом файле бот считает каноническими.
Не добавляйте в Sitemap неканонические страницы.
Как делать НЕ нужно
1. НЕ канонизируйте несколько дубликатов разными способами. Предположим, у вас есть страницы А и В с одинаковым контентом. В body страницы А вы добавляете тег rel=canonical, а страницу В указываете в sitemap (напоминаю, что все страницы в sitemap бот считает каноническими). Теперь бот запутался и потратил время и ресурсы, пытаясь понять, какой же контент считать оригинальным. Не надо так.
2. НЕ используйте rel=canonical link tag/ HTTP header на страницах категорий товаров и фильтров. На коммерческих сайтах товары можно отсортировать по цвету, размеру, бренду и т.д. Если на каждой странице поставить тег canonical, то бот будет ходить по каждому параметру URL-а и тратить краулинговый бюджет там. Страницы сортировки лучше закрыть в robots.txt или в meta “noindex”, в зависимости от размера сайта и его специфики.
3. Не используйте robots.txt для канонизации. Директивы в robots.txt показывают, какие страницы/папки нужно краулить боту, а какие нет. Однако вебмастер Google не рекомендует таким образом канонизировать страницы, ведь бот не может даже зайти на страницу и понять, что это дубликат/оригинал.

Источник: Twitter
Джон Мюллер:
Блокировка через robots.txt работает так, что мы даже не можем сказать, что это дубликаты. Лучше дать поисковой системе понять, что дубликаты есть, но ранжировать нужно страницу с rel=canonical элементом…
4. НЕ линкуйте дубликаты URL-ов внутри вашего сайта. Если вы канонизируете страницу, вы считаете ее более важной. Согласитесь, это странно, если вы ссылаетесь на неканонические/менее важные версии страниц.
5. НЕ вписывайте дубликаты в URL removal tool в Google Search Console. Этот метод временно блокирует доступ ботов не только к дублям, но и к оригинальным версиям.

6. НЕ канонизируйте HTTP, если на сайте есть версия страницы с HTTPS-протоколом. Наличие SSL-сертификата (который поддерживает HTTP) является одним из факторов ранжирования Google, поэтому переход на протокол HTTPS повышает позиции страницы в поиске.
Коротко о главном
Итак, канонизация – это способ показать Google, какие страницы предпочтительно показывать в поисковой выдаче.
Используйте эти четыре рекомендованных Google способа канонизации:
- Rel=canonical link tag – когда нужно канонизировать HTML страницы;
- Rel=canonical HTTP header – когда нужно канонизировать не HTML-файлы;
- 301 redirect – когда контент навсегда переезжает на другую страницу;
- XML Sitemap — чтобы перечислить все канонические страницы на сайте и облегчить боту сканирование (теги canonical также необходимо проставить).
Чтобы оптимизировать краулинговый бюджет и отправить прибыльные страницы в индекс, следуйте этим советам:
- Не канонизируйте несколько URL-ов с одинаковым контентом разными способами;
- Нe используйте rel=canonical tag на страницах фильтров;
- Не используйте robots.txt для канонизации;
- Не линкуйте дубликаты внутри вашего сайта;
- Не отправляйте дубликаты страниц в removal tool от GSC;
- Не канонизируйте HTTP-страницы.
www.seonews.ru
Канонические URL адреса страниц или link rel=»canonical»
Что такое канонические URL адреса?
В широком смысле слова, канонический означает «принятый за образец», «твердо установленный». То есть, канонический URL это, грубо говоря, основной адрес страницы.
Обычно, один материал имеет один URL адрес, к примеру www.example.ru/1.html. Но иногда одна и так же страница может быть доступна по нескольким адресам. К примеру: www.example.ru/1.html и www.example.ru/1/1.html. В таком случае, необходимо определить, какой из 2-х адресов является основным или каноническим.
Предположим, что www.example.ru/1.html был выбран в качестве основного URL. Тогда на странице с данным адресом (а так же, других страницах с копией контента) необходимо разместить следующий элемент:
<link rel="canonical" href="www.example.ru/1.html" />Размещается он в шапке сайта, между тегов <head></head>.
Внимание! Что бы снизить вероятность ошибки, внутри элемента link rel=»canonical» необходимо использовать абсолютные, а не относительные адреса. То есть, добавлять к ссылке домен.
Убедитесь, что в технической карте сайта sitemap.xml размещены именно канонические ссылки. Иначе это может привести к ошибкам индексирования.
Примеры канонических адресов
Предположим, что мы создали статью о продвижении Интернет-магазина одежды, для которой сделали красивый, понятный для человека URL.

Но статья осталась доступна по техническому адресу, который мы больше видеть не хотим.

В этом случае, на странице со статьей, нам необходимо прописать элемент <link rel=»canonical» href=»https://dh-agency.ru/prodvijenie-magazina-odejdy/» />, в котором указан основной, канонический адрес.
Вот таким образом:

Теперь адрес https://dh-agency.ru/prodvijenie-magazina-odejdy/ будет считаться основным.
Роль канонических адресов страниц в SEO
С точки зрения поисковой оптимизации, наличие одного основного URL адреса страницы просто необходимо. Во-первых, это позволяет сэкономить время, так как роботу не приходится загружать копии контента. Во-вторых, не остается никаких сомнений, какой адрес должен участвовать в поисковой выдаче. В-третьих, снижается нагрузка на сайт, что так-же важно для посещаемого ресурса.
Нужно понимать, что краулер отводит ограниченное количество времени на индексацию сайта, поэтому многочисленные дубли страниц могут сильно ударить по эффективности его работы.
Правильно устанавливаем канонические URL адреса
Правильно установленный канонический адрес отвечает следующим требованиям:
Каноническая страница, указанная в элементе link rel=»canonical», обязательно должна существовать и быть доступна для пользователей;
Канонический адрес должен быть указан только для одного домена и поддомена. Грубо говоря, не должно быть ссылок на другие ресурсы;
Для страницы может быть указан один единственный канонический адрес;
Убедитесь, что на сайте отсутствуют рекурсии или «цепочки» канонических адресов. То есть, одна страница не должна ссылаться на другую, которая, в свою очередь, ссылается на третью или первую;
Элемент link rel=»canonical» должен находится между тегами <head></head>.
Уверены, что Ваши канонические адреса соответствуют всем вышеуказанным требованиям? Тогда можете считать их просто превосходными!
Понятие «каноническая ссылка»
Те, кто только начал окунаться в основы поисковой оптимизации, иногда разделяют понятия «канонический адрес» и «каноническая ссылка». На самом деле, речь идет об одном и том же — о главном URL адресе страницы.
Нет никаких канонических <a href=»»> </a> и «главных ссылок ссылок для перелинковки».
301 редирект — замена rel=»canonical»?
Когда речь заходит о выборе между 301 редиректом и элементом link rel=»canonical», мы обычно советуем использовать именно переадресацию. Все дело в том, что тег link rel=»canonical» не является обязательным, то есть, может быть проигнорирован поисковой системой.
Использование link rel=»canonical» актуально только тогда, когда сделать 301 редирект невозможно или проблематично.
Есть и еще один плюс link rel=»canonical» перед 301 редиректом — его простановку возможно сделать автоматической при создании страницы. К примеру, в WordPress эта функция уже реализована. То есть, заранее указав канонический адрес, Вы можете избавить себя от будущих проблем с индексацией.
Яндекс Вебмастер — статус «неканоническая»
В Яндекс Вебмастере есть раздел «Исключенные страницы«, добраться туда можно из меню «Индексирование» -> «Страницы в поиске» -> «Исключенные страницы«.
Перейдя в этот раздел, Вы увидите все материалы, которые были по какой либо причине загружены в базу, но исключены из поиска.

Среди прочих причин исключения Вы можете увидеть статус «Неканоническая». Нажав на троеточие, отроется сообщение следующего вида:
«Страница проиндексирована по каноническому адресу https://dh-agency.ru/category/vnutrennyaya-optimizaciya/design/, который был указан в атрибуте rel=»canonical» в исходном коде. Исправьте или удалите атрибут canonical, если он указан некорректно. Робот отследит изменения автоматически.»
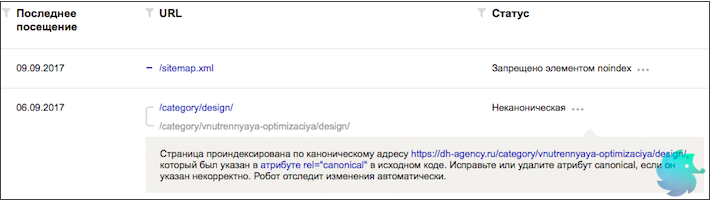
Что это значит?
Ничего страшного не произошло. Робот Яндекса проиндексировал страницу по первому (написанному синем шрифтом) URL, при этом на самой странице стоял элемент link rel=»canonical», в котором, в качестве канонического, был указан другой адрес (написанный серым шрифтом).

Пользуясь данной инструкцией, робот исключил неканонический URL.
Переживать, что материал был полностью исключен из поиска не стоит, он находится в выдаче, но по другому URL адресу.
Что с этим делать?
Если Вас не устраивает URL, который был выбран в качестве основного, необходимо поменять адрес в элементе link rel=»canonical» на предпочтительный. После изменения, страницу желательно отправить на переобход индексирующему роботу.
(«Индексирование» -> «Переобход страниц«)

Так изменения будут загружены в базу в самое ближайшее время.
Только не забудьте изменить адрес в файле sitemap.xml.
dh-agency.ru