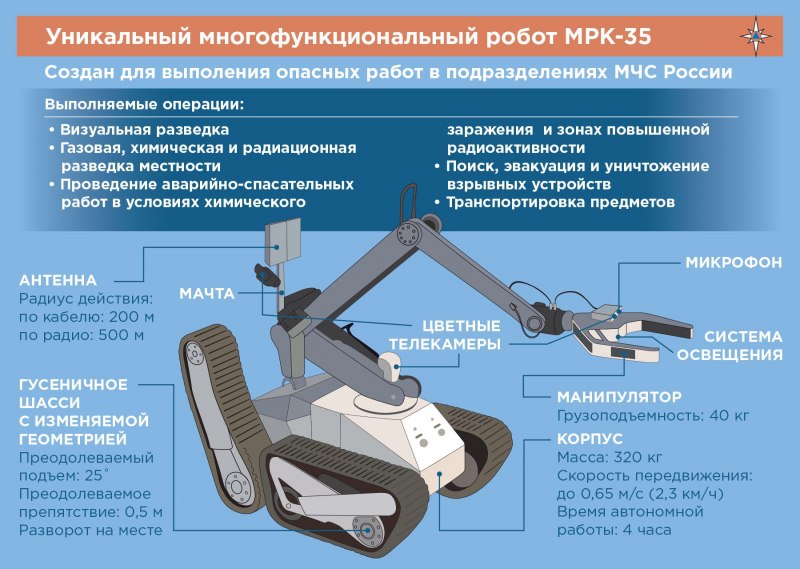
Что такое поисковые роботы? — Оптимизатор
Главной составной частью поисковой системы является поисковый робот. При использовании интернета каждый пользователь ежедневно сталкивается с ним, сам того не подозревая. Поисковый робот сайтов – именно тот элемент, без которого Google, Яндекс и другие системы не могут полноценно работать. Предлагаем ознакомиться с назначением и функциями этих алгоритмов.
Робот поисковой системы: что это такое
Сам по себе, робот поисковой системы – это специализированная программа, отвечающая за индексацию сайтов. В каждой поисковой системе присутствует собственный набор ботов, способных выполнять одну большую работу, множество маленьких функций, либо все вместе.
Разбирая, какую работу выполняют роботы поисковых машин, многие думают, что робот занимается анализом найденного контента. Это не так. Задача алгоритма заключается в передаче найденного контента на один из серверов поисковых систем. Уже там происходит финальная обработка и формирование результатов.
Основные функции
Робот поисковой системы работает по-разному, в зависимости от типа ПС.
Функции, перечисленные ниже, ложатся на один алгоритм, либо на несколько одновременно:
- Сканирование базового контента. В этом и заключается основная функция – найти новые страницы и считать контент, имеющиеся на них.
- Сканирование фотоматериалов. Как Гугл, так и Яндекс может искать изображения, а также отличать их от миллионов других. Для выполнения этой задачи используется отдельный робот.
- Сканирование зеркал. Для этих целей есть отдельный паук в поисковой системе Яндекс. С помощью набора специальных ботов обходятся сайты, чей контент совпадает, но адреса меняются.
Принцип работы
Как видит поисковый робот? После прихода на сайт ему необходимо максимально быстро обработать все содержимое. Поэтому действия, запрограммированные здесь, являются стандартизированными и всегда одинаковыми.
Сайт глазами поискового робота – это, прежде всего, информация из специально предназначенного файла, который хранится на хостинге под именем robots. txt. С его помощью предотвращаются потери ресурсов на индексацию контента, находящегося в закрытом доступе. Далее, если бот первый раз заходит на сайт, он попадает на его главную страницу, а потом – на все внутренние ссылки.
txt. С его помощью предотвращаются потери ресурсов на индексацию контента, находящегося в закрытом доступе. Далее, если бот первый раз заходит на сайт, он попадает на его главную страницу, а потом – на все внутренние ссылки.
На следующем этапе происходят переходы по ссылкам, ведущим с внутренних страниц. За один заход поисковые роботы очень редко обходят весь сайт сразу, добравшись до страниц, расположенных глубоко. Соответственно, чем меньшее количество переходов между искомой и главной страницей, тем быстрее произойдет индексация.
Робот не способен анализировать найденный контент. Его задача заключается исключительно в переходе на сервера ПС. Как упоминалось ранее, уже там ведется обработка. Кто корректирует поведение поисковых роботов? Программисты поисковой системы, а также веб-мастеры, меняющие структуру сайта таким образом, чтобы обработка велась быстрее.
Для заказа поисковой оптимизации и ускоренной индексации в ПС рекомендуем обратиться к специалистам портала optimizator. com.ru. Мы гарантируем высокую оперативность обработки и доступные цены.
com.ru. Мы гарантируем высокую оперативность обработки и доступные цены.
Download Best WordPress Themes Free Download
Download Nulled WordPress Themes
Download WordPress Themes Free
Download WordPress Themes Free
online free course
Роботы массовой информации / Хабр
В начале 2006 года медиамагнат Руперт Мердок предупредил, что издания, которые к 2010 году не будут иметь в штате роботов-редакторов, обречены на провал. Однако уже сегодня есть СМИ, которые не только имеют роботов-редакторов, но и не имеют редакторов-людей. Речь идет о специальных компьютерных программах-роботах, которые ищут информацию, структурируют ее и публикуют.Нажми и скопируй
В середине 90-х в Нью-Йорке прошел любопытный судебный процесс. Американский издатель Олег Погребной наладил неплохой бизнес — выпускал для русских эмигрантов газету «Курьер», которая целиком состояла из перепечатанных материалов российских СМИ. Разумеется, за перепечатку он ничего не платил, рассчитывая на то, что пострадавшие издания («Московский комсомолец», «АиФ», КП, «Московские новости», «Мегаполис-Экспресс» и др. ) не станут искать правды за океаном. Те, однако, в конце концов подали соответствующий иск в суд города Нью-Йорка. Суд присудил им компенсацию в размере $500 тыс.
) не станут искать правды за океаном. Те, однако, в конце концов подали соответствующий иск в суд города Нью-Йорка. Суд присудил им компенсацию в размере $500 тыс.
Олег Погребной запустил свое предприятие в неудачное время. Десятилетием раньше ему ничего бы не грозило. Десятилетием позже — тоже, но при условии, что он перенес бы свой бизнес в интернет.
Интернет породил не только СМИ новой формации, но и масштабное явление под названием «копипастинг». Процесс кражи информации из газеты или журнала свелся к двум простым и, главное, бесплатным операциям. Сначала нажать на клавиатуре компьютера клавиши Ctrl-C и скопировать информацию (по-английски — Copy), затем нажать Ctrl-V и вставить информацию (по-английски — Paste) в другое место. Copy и Paste — это и есть копипастинг.
Именно распространение копипастинга привело к возникновению роботизированных СМИ. Когда перекрестное воровство информации приобретает массовый характер, о каких-либо эффективных юридических мерах по его пресечению речь, видимо, идти не может. Технические меры также не эффективны. Ведь противная сторона может дать технический ответ, и тогда затраты на такую борьбу превысят возможную выгоду от устранения копипастинга.
Технические меры также не эффективны. Ведь противная сторона может дать технический ответ, и тогда затраты на такую борьбу превысят возможную выгоду от устранения копипастинга.
Как следствие, родился механизм автоматической трансляции материалов СМИ на другие сайты, так называемый RSS (Really Simple Syndication — «простое получение информации»). RSS максимально удешевил процесс копипастинга, исключив какой-либо ручной труд: достаточно было произвести однократную настройку, и материалы с чужого сайта автоматически оказывались на вашем.
Появились «агрегаторы новостей» — сетевые СМИ, на которые автоматически стягивались материалы, позаимствованные у разных источников. По мнению Николая Мациевского, руководителя отдела онлайн-маркетинга компании Parallels, на данный момент оптимальным механизмом для отслеживания информационного потока в рунете — определенных тем или ключевых слов в новостях — является сервис «Яндекс.Новости».
Однако появление RSS имело и негативные последствия, сыграв на руку манимейкерам,— так называют огромную и пока еще мало изученную группу мелких сетевых предпринимателей, которые хватаются за любое дело, которое может принести хоть какой-то доход. В основном это молодежь — студенты и даже старшеклассники, желающие подработать в интернете и проявляющие на этой ниве чудеса изобретательности.
Манимейкеры почти мгновенно сообразили, что RSS дает хорошую возможность заработка без особых усилий, и в интернете начали тысячами плодиться новостные сайты, которые на самом деле служили лишь местом для размещения рекламы и платных ссылок.
Творческий фактор
По мнению некоторых экспертов, говорить о каких-то заметных подвижках в области RSS-СМИ нет смысла, процессы идут уже много лет. «Мне кажется,— отмечает руководитель компании „Ашманов и Партнеры“ Игорь Ашманов,— никакой революции в этой области в настоящее время не происходит. Все технологии уже созданы несколько лет назад. Пресс-клиппинг с помощью автоматического поиска и фильтрации новостей применяется несколько лет. „Яндекс.
Так или иначе, RSS-агрегаторы можно считать первым поколением робоСМИ. Они выполняли сугубо техническую работу: брали материал из одного указанного им места и перекладывали в другое. Информацию, скажем, из блогосферы так не соберешь.
Издательские роботы второго поколения пришли не из издательской отрасли, как можно было ожидать, а из смежного бизнеса, который, в зависимости от конъюнктуры, иногда называют «аналитикой», а иногда — «промышленной разведкой». Одна из задач, которые всегда выполняли фирмы этого профиля,— мониторинг СМИ по определенным критериям. Интернет, во-первых, дал возможность автоматизировать этот процесс, а во-вторых, позволил включить в мониторинг блоги и форумы, на которых имеется ценная информация, зачастую отсутствующая в традиционных СМИ.
Одна из задач, которые всегда выполняли фирмы этого профиля,— мониторинг СМИ по определенным критериям. Интернет, во-первых, дал возможность автоматизировать этот процесс, а во-вторых, позволил включить в мониторинг блоги и форумы, на которых имеется ценная информация, зачастую отсутствующая в традиционных СМИ.
«Наша фирма довольно долго занималась автоматизированным анализом традиционных, бумажных СМИ,—вспоминает гендиректор компании PresScan Николай Докучаев.— И мы изначально добивались, чтобы его делали не аналитики из плоти и крови, а роботы, программы. Заинтригованные словами Мердока о возможном провале изданий, которые к 2010 году не будут иметь в штате роботов-редакторов, мы стали экспериментировать с подбором данных и очень быстро поняли, что это весьма перспективное направление. В конце концов мы создали сайт 1001tema.ru, куда транслируются тематические новостные потоки, собранные роботами самостоятельно. В открытом доступе лишь небольшая часть материала, но подписчики имеют доступ к очень богатой информационной базе».
Типичная задача, решаемая в рамках промышленной разведки,— мониторинг блогов и форумов. Так можно, например, выявить на начальной стадии подготовки недружественные по отношению к фирме акции или в кратчайшие сроки получить представление о реакции потребителя на новый продукт. Разумеется, робот, выполняющий подобные задачи, должен быть достаточно разумным, чтобы, как минимум, самостоятельно определить тематику и новизну сообщения или отследить динамику развития новой темы.
По мнению Ильи Соловьева, исполнительного директора агентства «Презент», ключевым преимуществом робоСМИ является способность быстро предоставить точную выборку тематических информации. В том числе, за счет изучения блогосферы, форумов, ресурсов Web 2.0 — выдать объективную картину общественного мнения по тому или иному вопросу.
Постепенно аналитические фирмы (из российских фирм, владеющих технологиями анализа и структуризации информационных потоков, помимо PresScan, можно упомянуть Flexum.ru, Avicom. ru, Quintura.com; из зарубежных систем наибольшую известность получила Ontos.com) поняли, что создаваемые ими информационные структуры — это практически готовый продукт, годящийся на роль СМИ, и стали предлагать его рынку. Продукт сразу полюбили интернет-магазины, турагентства — все те, кому было желательно по тем или иным соображениям иметь на своем сайте новостную ленту или тематическую подборку статей, но в чьи планы не входило заводить с этой целью собственную редакцию. Примеры сайтов с роботизированными новостными лентами — exotik.ru, digital-expert.ru.
ru, Quintura.com; из зарубежных систем наибольшую известность получила Ontos.com) поняли, что создаваемые ими информационные структуры — это практически готовый продукт, годящийся на роль СМИ, и стали предлагать его рынку. Продукт сразу полюбили интернет-магазины, турагентства — все те, кому было желательно по тем или иным соображениям иметь на своем сайте новостную ленту или тематическую подборку статей, но в чьи планы не входило заводить с этой целью собственную редакцию. Примеры сайтов с роботизированными новостными лентами — exotik.ru, digital-expert.ru.
Традиционные интернет-СМИ также используют роботизированные ленты новостей, но не только не афишируют этого, но и тщательно скрывают. По утверждениям поставщиков роботизированной информации, интернет-СМИ предпочитают покупать информацию не в чистом виде, а в виде своего рода полуфабриката для дальнейшей обработки редакторами.
По мнению Николая Докучаева, робот может определить тематику информации, выудить из потока все новое, но вряд ли в состоянии оценить качество материала и понять, насколько он интересен читателю. Робот может выполнить 90-95% всей предварительной работы по наполнению интернет-газеты актуальным содержанием. Но сделать последний штрих — решить, пустить ли материал в работу, и на какую страницу его поместить — на первую или поглубже, может только человек.
Робот может выполнить 90-95% всей предварительной работы по наполнению интернет-газеты актуальным содержанием. Но сделать последний штрих — решить, пустить ли материал в работу, и на какую страницу его поместить — на первую или поглубже, может только человек.
Однако не за горами широкое распространение полностью роботизированных СМИ, работающих вовсе без участия человека. Пока такие сайты нацелены на очень узкие ниши, решают узкоспециализированные информационные задачи. Например, в связи с событиями в Южной Осетии открылся сайт-робот Цхинвал.SU, который отслеживал появление в Live Journal сообщений на тему конфликта и тут же оперативно транслировал их на центральную ленту. А поскольку в Live Journal писали по горячим следам многие очевидцы и участники событий, то новую информацию Цхинвал.SU давал порой на несколько часов раньше, чем новостные агентства. Кроме того, так достигалась некоторая объективность картины, поскольку она освещалась с точки зрения всех сторон конфликта.
Тем не менее, по мнению Кирилла Вишнепольского, главного редактора журнала «Русский Newsweek», роботизация затронет в основном новостные СМИ: «На данный момент мы имеем три почти не пересекающихся рынка: информационную журналистику (это прежде всего информагентства), поставляющую на рынок свежайшие новости; журналистику мнений и оценок — это ежедневная и еженедельная общественно-политическая пресса, а также развлекательные СМИ — это телевидение (ну и глянцевая пресса, если ее вообще можно классифицировать как СМИ). Последним двум рынкам роботы не угрожают никак — эти СМИ продают зрителю своих звезд, аналитиков, комментаторов, их роботами не заменишь. Я хочу слышать оценки грузинского кризиса от конкретных Максима Соколова или Михаила Фишмана, а не „белый шум“, собранный роботами по блогам».
Последним двум рынкам роботы не угрожают никак — эти СМИ продают зрителю своих звезд, аналитиков, комментаторов, их роботами не заменишь. Я хочу слышать оценки грузинского кризиса от конкретных Максима Соколова или Михаила Фишмана, а не „белый шум“, собранный роботами по блогам».
Камо грядеши
Сейчас РобоСМИ уже утвердились в сфере поставки информации, но если говорить о рынке традиционных СМИ, то роботы только начали на него выходить, и даже не все еще осознали, что происходит. Роботы уже практически отняли хлеб у журналистов в смежных областях. Если раньше владельцы порталов и интернет-магазинов нанимали журналистов (хотя бы в качестве фрилансеров) для подготовки тематических информационных лент для сайтов, то теперь практически все такие ленты делаются автоматически — либо посредством механизма RSS, либо с помощью роботов следующего поколения. Даже если подписка на такую новостную ленту обходится в несколько сотен у. е. в месяц, это дешевле, чем содержать журналистов и редакторов. При сопоставимом конечном результате.
При сопоставимом конечном результате.
Начинаются тяжелые времена и у сотрудников традиционных инернет-СМИ, занятых подборкой и сортировкой информации для лент новостей. Для них роботы не помощники, а конкуренты — выполняют эту работу не хуже или ненамного хуже человека, но обходятся существенно дешевле, не болеют и не требуют соцпакета.
Похоже, что в скором времени все виды бизнеса, так или иначе связанные с подбором и поставкой информации, станут уделом роботов. Так, по словам Кирилла Вишнепольского, роботы могут подмять под себя рынок PR-консультирования. Многие PR-агентства зарабатывают тем, что готовят для клиентов пресс-клиппинги — подборки публикаций на заданную тему или по конкретному объекту. Этот кусок хлеба роботы в состоянии отобрать у пиарщиков запросто.
Есть уже довольно много технически подкованных журналистов, которые хоть и пишут статьи самостоятельно, но всю черновую работу — сбор исходных данных, поиск экспертов, подборку статистической информации — поручают роботам. Пример робота, который предназначен для обслуживания этой журналистской прослойки,— сервис flexum.ru.
Пример робота, который предназначен для обслуживания этой журналистской прослойки,— сервис flexum.ru.
Сергей Леонов, заместитель главного редактора журнала «Компьютерра», полагает, что журналистику, как и многие другие виды человеческой деятельности, следует рассматривать и как творчество, и как ремесло. Четкой грани между этими категориями нет, но в случае с робоСМИ она все же видна хорошо. Если попытки внедрения в творческий процесс автоматизации любого рода воспринимаются в штыки, то журналистика как ремесло, где главное — объективность и оперативность, отодвигает личностные оценки на второй план, и потому относится к роботизированному сбору и анализу данных более лояльно.
Еще один сектор рынка, который фактически был создан роботами, можно условно назвать «информагенство блогосферы». В блогах есть много интересной информации, но она теряется в огромном количестве мелких информационных потоков. Конечно, рано или поздно большинство интересных тем из блогосферы всплывает на поверхность, и соответствующие факты становятся широко известными. Но СМИ в этом случае оказывается в хвосте: писать о том, что все и так знают,— занятие неблагодарное.
Но СМИ в этом случае оказывается в хвосте: писать о том, что все и так знают,— занятие неблагодарное.
Андрей Калинин, руководитель проекта Flexum.ru компании «Поисковые технологии», видит в роботах инструмент, позволяющий решить эту проблему. Если профессиональный журналист мучительно ищет путь к своему читателю, замечает он, то блогер пишет часто ради собственного удовольствия, не наращивая специальными средствами аудиторию. Между тем информационная ценность заметок в блогах может быть ничуть не меньше, чем у новостей информагентств. Таким образом, возникает необходимость в новом звене между производителями информации и ее потребителями. Средства по автоматическому сбору новостей, их классификации и фильтрации, как раз и являются таким звеном.
Тем не менее Борис Соркин, управляющий директор информационного агентства «Регнум», считает, что роботы не смогут отбить хлеб у традиционных информагентств: «Роботизация традиционных СМИ, возможно, и изменит сильно рынок, но я не думаю, чтобы это всерьез повлияло на работу информагентств. Ведь информация, с которой работает робот, не появляется в интернете сама собой. Ее источником являются именно информагентства с их корреспондентскими сетями. Традиционный репортерский труд никуда не денется, его роль может только вырасти. Ведь сам факт поступления информации от информагентства подразумевает, что в ее основе лежит квалифицированный труд профессиональных журналистов, и это отличает ее от той же блогосферы. Дело кончится тем, что у информагентств просто появится еще один тип потребителей информации — роботы. Скорее всего, вырастет наш авторитет как источника информации».
Ведь информация, с которой работает робот, не появляется в интернете сама собой. Ее источником являются именно информагентства с их корреспондентскими сетями. Традиционный репортерский труд никуда не денется, его роль может только вырасти. Ведь сам факт поступления информации от информагентства подразумевает, что в ее основе лежит квалифицированный труд профессиональных журналистов, и это отличает ее от той же блогосферы. Дело кончится тем, что у информагентств просто появится еще один тип потребителей информации — роботы. Скорее всего, вырастет наш авторитет как источника информации».
Единственное, что сейчас сдерживает массированное наступление роботов на рынок СМИ,— то, что еще не конца сформировались механизмы извлечения дохода из робоСМИ, или как сейчас модно говорить, их «монетизации». Основным источником дохода поставщиков роботизированного контента на сегодня является платная подписка на информацию, при этом стоимость подписки устанавливается так, чтобы потребителю «нанимать» робота было выгоднее, чем человека: она редко когда превышает пять-шесть сотен у. е. в месяц. При этом покупатели новостных лент могут заработать, размещая на них контекстную рекламу, больше, чем потратят на подписку. Впрочем, массовое распространение роботов может изменить и наверняка изменит такой расклад.
е. в месяц. При этом покупатели новостных лент могут заработать, размещая на них контекстную рекламу, больше, чем потратят на подписку. Впрочем, массовое распространение роботов может изменить и наверняка изменит такой расклад.
Сергей Леонов считает, что, как и в любой другой сфере, роботизация производства имеет следствием снижение цены продукции. А значит, может упасть и стоимость рекламы, за счет которой в основном и существуют онлайновые СМИ. Если это произойдет, то следует, видимо, ожидать, взрывного роста количества малобюджетных информационных сайтов. И далеко не всегда это будут сайты надлежащего качества. Манимейкеры, как водится, используют подвернувшуюся возможность легкого заработка. По разным экспертным оценкам, сейчас в рунете доля «мусорных» информационных сайтов, не имеющих никакой информационной ценности и служащих лишь для размещения рекламных ссылок,— 20-30%. Как только публикация информации при помощи роботов станет доступна по цене, таких сайтов будет больше половины. В этом случае сам термин «сетевое новостное СМИ», возможно, приобретет совсем другой смысл, нежели имеет сейчас. Или вообще утратит его.
В этом случае сам термин «сетевое новостное СМИ», возможно, приобретет совсем другой смысл, нежели имеет сейчас. Или вообще утратит его.
По мнению Николая Докучаева, на смену эпохе СМИ идет эпоха СИИ — средств индивидуальной информации. Она, понятно, формируется роботами, которые обучены собирать только то, что интересно конкретному человеку в данный момент. «Персонально для себя я настроил несколько направлений — как по работе, так и для души, где все мне интересное находят наши роботы. То есть у меня есть личное робоСМИ»,— говорит Николай Докучаев.
АНДРЕЙ ШИПИЛОВ
Журнал «Коммерсант — Деньги» № 34(689) от 01.09.2008
Ссылка на оригинальный материал
Как работают сканеры поисковых систем?
Сэм Марсден
SEO и контент-менеджер
Давайте делиться
| 4 минуты чтения
Теперь, когда вы получили общее представление о том, как работают поисковые системы, давайте углубимся в процессы, которые поисковые системы и поисковые роботы используют для понимания сети. Начнем с процесс сканирования .
Что такое сканирование поисковыми системами?
Сканирование — это процесс, используемый сканерами поисковых систем (ботами или пауками) для посещения и загрузки страницы и извлечения ее ссылок для обнаружения дополнительных страниц.
Страницы, известные поисковой системе, периодически сканируются, чтобы определить, были ли внесены какие-либо изменения в содержание страницы с момента последнего сканирования. Если поисковая система обнаружит изменения на странице после сканирования страницы, она обновит свой индекс в ответ на эти обнаруженные изменения.
См. дополнительные ресурсы по сканированию поисковых систем в Академии веб-аналитики LumarКак работает веб-сканирование?
Поисковые системы используют свои собственные поисковые роботы для обнаружения и доступа к веб-страницам.
Все коммерческие сканеры поисковых систем начинают сканирование веб-сайта с загрузки его файла robots.txt, который содержит правила о том, какие страницы поисковые системы должны или не должны сканировать на веб-сайте. Файл robots.txt также может содержать информацию о картах сайта; он содержит списки URL-адресов, которые сайт хочет сканировать поисковым роботом.
Поисковые роботы используют ряд алгоритмов и правил, чтобы определить, как часто страница должна повторно сканироваться и сколько страниц на сайте должно быть проиндексировано. Например, страница, которая регулярно изменяется, может сканироваться чаще, чем страница, которая изменяется редко.
Как можно идентифицировать сканеры поисковых систем?
Боты поисковых систем, сканирующие веб-сайт, можно определить по строке пользовательского агента, которую они передают веб-серверу при запросе веб-страниц.
Вот несколько примеров строк пользовательского агента, используемых поисковыми системами:
- Пользовательский агент Googlebot
Mozilla/5. 0 (совместимый; Googlebot/2.1; +https://www.google.com/bot.html)
0 (совместимый; Googlebot/2.1; +https://www.google.com/bot.html) - Агент пользователя Bingbot
Mozilla/5.0 (совместимый; bingbot/2.0; +https://www.bing.com/bingbot.htm) - Агент пользователя Baidu
Mozilla/5.0 (совместимый; Baiduspider/2 .0 ; +https://www.baidu.com/search/spider.html) - Яндекс User Agent
Mozilla/5.0 (совместимый; YandexBot/3.0; +https://yandex.com/bots)
 0 (совместимый; Googlebot/2.1; +https://www.google.com/bot.html)
0 (совместимый; Googlebot/2.1; +https://www.google.com/bot.html)Любой может использовать тот же пользовательский агент, что и поисковые системы. Однако IP-адрес, с которого был сделан запрос, также может использоваться для подтверждения того, что он поступил от поисковой системы — процесс, называемый обратным поиском DNS.
Сканирование изображений и других нетекстовых файлов
Обычно поисковые системы пытаются сканировать и индексировать каждый встречающийся URL-адрес.
Однако, если URL-адрес представляет собой файл нетекстового типа, такой как изображение, видео- или аудиофайл, поисковые системы, как правило, не смогут прочитать содержимое файла, кроме связанного имени файла и метаданных.
Хотя поисковая система может извлекать только ограниченный объем информации о нетекстовых типах файлов, они все равно могут индексироваться, ранжироваться в результатах поиска и получать трафик.
Полный список типов файлов, которые Google может индексировать, доступен здесь.
Сканирование и извлечение ссылок со страниц
Сканеры обнаруживают новые страницы, повторно сканируя уже известные им страницы, а затем извлекая ссылки на другие страницы для поиска новых URL-адресов. Эти новые URL добавлены в очередь сканирования , чтобы их можно было загрузить позже.
Благодаря этому процессу перехода по ссылкам поисковые системы могут обнаружить каждую общедоступную веб-страницу в Интернете, на которую есть ссылка хотя бы с одной другой страницы.
Файлы Sitemap
Другой способ обнаружения новых страниц поисковыми системами — сканирование файлов Sitemap.
Файлы Sitemap содержат наборы URL-адресов и могут создаваться веб-сайтом для предоставления поисковым системам списка страниц для сканирования. Это может помочь поисковым системам найти контент, спрятанный глубоко внутри веб-сайта, и может предоставить веб-мастерам возможность лучше контролировать и понимать области индексации и частоты сайта.
Это может помочь поисковым системам найти контент, спрятанный глубоко внутри веб-сайта, и может предоставить веб-мастерам возможность лучше контролировать и понимать области индексации и частоты сайта.
Отправка страниц
Кроме того, отправка отдельных страниц часто может осуществляться непосредственно в поисковые системы через соответствующие интерфейсы. Этот ручной метод обнаружения страниц можно использовать, когда на сайте публикуется новый контент или если произошли изменения, и вы хотите свести к минимуму время, необходимое поисковым системам для просмотра измененного контента.
Google утверждает, что для больших объемов URL-адресов следует использовать XML-карты сайта, но иногда метод отправки вручную удобен при отправке нескольких страниц. Также важно отметить, что Google ограничивает веб-мастеров до 10 отправок URL-адресов в день.
Кроме того, Google сообщает, что время отклика для индексации для карт сайта такое же, как и для отдельных представлений.
Следующая глава: индексирование в поисковых системах
Полное руководство по работе поисковых систем:
Как работают поисковые системы?
Как поисковые системы сканируют веб-сайты
Как работает индексирование в поисковых системах?
Каковы различия между поисковыми системами?
Что такое краулинговый бюджет?
Что такое Robots.txt? Как robots.txt используется поисковыми системами?
Руководство по директивам Robots.txt
Дополнительные учебные ресурсы
Полное руководство по здоровью веб-сайтов
Вот как добиться успеха в поиске в будущем, включив здоровье веб-сайтов и SEO в свои более широкие маркетинговые стратегии.
Как сделать свой сайт мультипликатором производительности для формирования спроса
Узнайте, как использовать состояние веб-сайта и поисковую оптимизацию в качестве мультипликаторов эффективности для усилий маркетинговых групп по формированию спроса.
Начните улучшать онлайн-опыт уже сегодняLumar — это интеллектуальная и автоматизирующая платформа для прибыльных веб-сайтов
Начните с Lumar
Сэм Марсден
SEO и контент-менеджер
Сэм Марсден — бывший менеджер Lumar по поисковой оптимизации и контенту, а в настоящее время — руководитель отдела SEO в Busuu. Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых изданий, таких как Search Engine Journal и State of Digital.
Поисковые сканеры и сканирование
Что такое поисковый робот?
Сканеры поисковых систем, также называемые пауками, роботами или просто ботами, представляют собой программы или скрипты, которые систематически и автоматически просматривают страницы в Интернете. Цель этого автоматического просмотра обычно состоит в том, чтобы прочитать страницы, которые посещает сканер, чтобы добавить их в индекс поисковой системы.
Цель этого автоматического просмотра обычно состоит в том, чтобы прочитать страницы, которые посещает сканер, чтобы добавить их в индекс поисковой системы.
Поисковые системы, такие как Google, используют поисковые роботы для чтения веб-страниц и сохранения списка слов, найденных на странице, и того, где эти слова расположены. Они также собирают данные об удобстве использования, такие как скорость и статусы ошибок HTTP.
Эти данные хранятся в «индексе» поисковых систем по существу огромных баз данных веб-страниц.
Когда вы выполняете поиск в Google, вы на самом деле ищете в индексе Google, а не в реальной сети. Затем Google отображает проиндексированные страницы, соответствующие запросу, и предоставляет ссылки на фактические страницы.
Поскольку современная сеть содержит несколько различных типов контента, а поисковые системы имеют способы поиска именно этого типа контента, самые крупные поисковые системы имеют сканеры, предназначенные для сканирования определенных типов страниц или файлов. Эти поля включают в себя:
Эти поля включают в себя:
- Общий веб-контент
- Изображения
- Видео
- Новости
- Объявления
- Мобильные устройства
Каждый тип сканера имеет свой пользовательский агент. Посмотрите, что сканирует каждый пользовательский агент, в нашем руководстве robots.txt.
Как работают сканеры поисковых систем?
На практике «сканирование» происходит, когда сканер получает URL-адрес для проверки, извлекает страницу и затем сохраняет ее на локальном компьютере. Вы можете сделать это самостоятельно, перейдя на страницу, щелкнув правой кнопкой мыши и выбрав «Сохранить ка껦»
Поисковые роботы получают свои URL-адреса, проверяя карту сайта домена или переходя по ссылкам, которые они находят на другой странице.
Файлы Sitemap играют важную роль на этом этапе, поскольку они предоставляют поисковым роботам удобный, упорядоченный список URL-адресов для доступа. Они также предоставляют сведения, влияющие на то, как Google решает сканировать каждую страницу.
Что такое краулинговый бюджет?
Конечно, даже Google имеет ограниченные ресурсы (независимо от того, насколько высок этот предел). Поэтому Googlebot работает с так называемым «краулинговым бюджетом». Бюджет сканирования — это просто количество URL-адресов на веб-сайте, которые Google хочет и может сканировать.
Есть 2 компонента, которые входят в краулинговый бюджет Google для веб-сайта:
- Ограничение скорости сканирования: Google не хочет влиять на взаимодействие с пользователем веб-сайта при его сканировании, поэтому он ограничивает количество страниц, которые его поисковый робот может получить сразу.
- Запрос на сканирование: Проще говоря, это желание Google просканировать ваш сайт. Google не заинтересован в сканировании URL-адресов, которые не выглядят так, как будто они приносят пользу пользователям (параметры URL-адресов, фасетная навигация, идентификаторы сеансов и т. д.). Таким образом, даже если робот Googlebot не достигнет предела скорости сканирования, он не будет тратить собственные ресурсы на сканирование этих страниц.
Хорошей новостью является то, что ограничение скорости сканирования и потребность в сканировании могут меняться в зависимости от того, что Google находит на вашем веб-сайте. На краулинговый бюджет вашего сайта влияют следующие факторы:
- Скорость сайта: Google не любит ждать, поэтому быстрые страницы побуждают его сканировать больше страниц. Кроме того, скорость является признаком работоспособности веб-сайта, поэтому Google сможет выделить больше ресурсов для сканирования.
- Страницы с ошибками: Если сервер отвечает на множество запросов от Google с кодами ошибок, Google не будет пытаться сканировать страницы, потому что это будет выглядеть как веб-сайт с множеством проблем.
- Популярность: Чем более популярной Google считает вашу страницу, тем чаще он будет ее сканировать, чтобы поддерживать актуальность в своем индексе.
- Свежесть: Не секрет, что Google любит свежий (новый, актуальный) контент. Публикация нового контента сообщит Google, что на вашем веб-сайте регулярно появляются новые страницы для сканирования. Более свежий контент означает больше обходов.
 Публикация нового контента сообщит Google, что на вашем веб-сайте регулярно появляются новые страницы для сканирования. Более свежий контент означает больше обходов.
Публикация нового контента сообщит Google, что на вашем веб-сайте регулярно появляются новые страницы для сканирования. Более свежий контент означает больше обходов.Альтернативные URL-адреса, такие как AMP или hreflang, могут сканироваться Google одинаково для JavaScript и CSS.
Что такое поисковое индексирование?
После сканирования страницы Google необходимо извлечь информацию о странице для сохранения в индексе. Поисковые системы используют различные алгоритмы и эвристики, чтобы определить, какие слова в содержании страницы являются важными и релевантными. Добавление семантической разметки, такой как Schema.org, поможет поисковым системам лучше понять вашу страницу.
После того, как страница выбрана, сохранена и проанализирована, извлеченная из нее информация сохраняется в индексе поисковой системы. Когда кто-то использует запрос в поиске, информация в индексе используется для определения страниц, релевантных этому запросу.
Как оптимизировать сканирование Google
Чтобы занять место в результатах поиска, страница должна быть сначала проиндексирована. Для того, чтобы быть проиндексированной, страницу нужно сначала просканировать. Таким образом, сканируемость (или ее отсутствие) оказывает огромное влияние на SEO.
Для того, чтобы быть проиндексированной, страницу нужно сначала просканировать. Таким образом, сканируемость (или ее отсутствие) оказывает огромное влияние на SEO.
Вы не можете напрямую контролировать, какие страницы поисковые роботы Google решают сканировать, но вы можете дать им подсказки о том, какие страницы им лучше сканировать, а какие следует игнорировать.
Существует три основных способа контролировать, когда, где и как Google сканирует ваши страницы. Они не являются абсолютными (у Google есть собственное мнение), но они помогут обеспечить поиск наиболее важных страниц поисковыми роботами.
Роль файла Robots.txt
Первое, что делает сканер, попадая на страницу, — открывает файл robots.txt сайта. Это делает файл robots.txt первой возможностью указать сканерам в сторону от URL-адресов с низким значением.
Вы можете использовать директиву disallow в файле robots.txt, чтобы удерживать сканеры от страниц, которые вам не нужны в результатах поиска:
- Спасибо или страница подтверждения заказа
- Дублированный контент
- Страницы результатов поиска по сайту
- Нет в наличии или другие страницы ошибок
Не используйте файл robots. txt для запрета встроенных URL-адресов, таких как JavaScript или CSS. Поисковые роботы должны использовать краулинговый бюджет для этих URL-адресов, но Google требуется , чтобы иметь возможность полностью отображать страницу, чтобы правильно ее понять.
txt для запрета встроенных URL-адресов, таких как JavaScript или CSS. Поисковые роботы должны использовать краулинговый бюджет для этих URL-адресов, но Google требуется , чтобы иметь возможность полностью отображать страницу, чтобы правильно ее понять.
Блокировка файлов CSS и JS приведет к неточному или неполному сканированию и индексированию, из-за чего Google будет видеть страницу не так, как люди, что может даже привести к снижению рейтинга.
Роль карт сайта XML
Прочтите руководство по картам сайта XML, чтобы узнать больше о том, как они влияют на сканирование.
Карты сайта в формате XML аналогичны файлу robots.txt. Они сообщают поисковым системам, какие страницы им следует сканировать. И хотя Google не обязан сканировать все URL-адреса в карте сайта (в отличие от robots.txt, который является обязательным), вы можете использовать информацию о страницах, чтобы помочь Google сканировать страницы более разумно.
Ваша карта сайта также очень важна для обеспечения того, чтобы Google мог найти страницы на вашем сайте, жизненно важный инструмент, если ваша внутренняя структура ссылок не очень надежна.
Использование тегов nofollow
Помните, что поисковые роботы перемещаются со страницы на страницу, переходя по ссылкам. Однако вы можете добавить атрибут rel=»nofollow», чтобы роботы , а не , переходили по ссылкам. Когда поисковая система встречает ссылку nofollow, она ее игнорирует.
Вы можете использовать nofollow по ссылке двумя способами:
- Метатег: если вы не хотите, чтобы поисковые системы сканировали любую ссылку на странице, добавьте атрибут content=»nofollow» в метатег robots. Тег выглядит так:
- Теги привязки: если вам нужен детальный подход к ссылкам nofollow, добавьте атрибут rel=»nofollow» к фактическому тегу ссылки, например:
- < a href="www.example.com" rel=" nofollow>анкорный текст
Таким образом, поисковые роботы не будут переходить по этой ссылке, но смогут переходить по другим ссылкам на странице.
Использование rel= «nofollow» в тегах ссылок не будет передавать ссылочный вес на целевую страницу, но эта ссылка все равно будет учитываться в количестве ссылочного веса, доступного для передачи по каждой ссылке. 0003
0003
В обоих случаях (метатег или тег привязки) целевой URL-адрес все еще может быть просканирован и проиндексирован, если на эту страницу указывает другая ссылка. Так что запретите эту страницу через robots.txt, не полагайтесь на nofollow для внутренних ссылок.
Вам может быть интересно, как использование атрибута «noindex» в метатеге robots влияет на сканирование. Короче говоря, это не так. Google по-прежнему будет сканировать страницу с атрибутом noindex и переходить по всем ссылкам dofollow на странице. Он просто не будет хранить страницу и ее данные в индексе.
Поиск ошибок сканирования
Ошибки сканирования возникают, когда Google пытается получить страницу, но по какой-либо причине не может получить доступ к URL-адресу. Ошибки сканирования могут возникать на уровне всего сайта (DNS, простои сервера или проблемы robots.txt) или на уровне страницы (время ожидания, программная ошибка 404, не найдено и т. д.).
Сканирование сайта WooRank проверяет ваш веб-сайт на наличие проблем, которые могут мешать вашему сайту работать хорошо в поисковых системах.