
какие данные нужно скрывать и как проверить работу запрета. — Топвизор
Содержание
В статье о том, зачем и как закрыть сайт от индексации в robots.txt, что можно скрыть и как проверить, что вы всё сделали правильно.
Эта статья — часть нашего бесплатного курса по SEO для начинающих, с ней помогал главный эксперт курса Александр Сопоев. Если хотите разобраться, как продвигать сайты в ТОП поисковых систем, заходите на курс. В конце — сертификат от Топвизора!
Зачем закрывать сайт от индексации
Когда поисковые роботы просканировали и проиндексировали страницы сайта, они начинают показываться в поисковых системах.
При этом сайт может состоять из множества разных страниц, и некоторые из них пользователям и поисковым системам видеть не нужно. Например, служебные страницы, дубли страниц и другой малополезный контент. Страницы с таким контентом поисковые системы могут и сами «выбрасывать» из индекса или понижать их позиции, но тогда это может отразиться на ранжировании всего сайта.
Кроме того, стоит учитывать и краулинговый бюджет сайта — лимит на количество страниц сайта, которые поисковые роботы смогут обойти за сутки. И этот лимит может тратиться на неважные страницы сайта, в то время как важные целевые страницы могут долго быть непроиндексированными. Подробнее об этом мы писали в статье «Как оптимизировать краулинговый бюджет».
Что можно закрыть от индексации
Дубль
Это страницы сайта, которые отличаются URL‑адресом, но содержат одинаковый или практически одинаковый контент.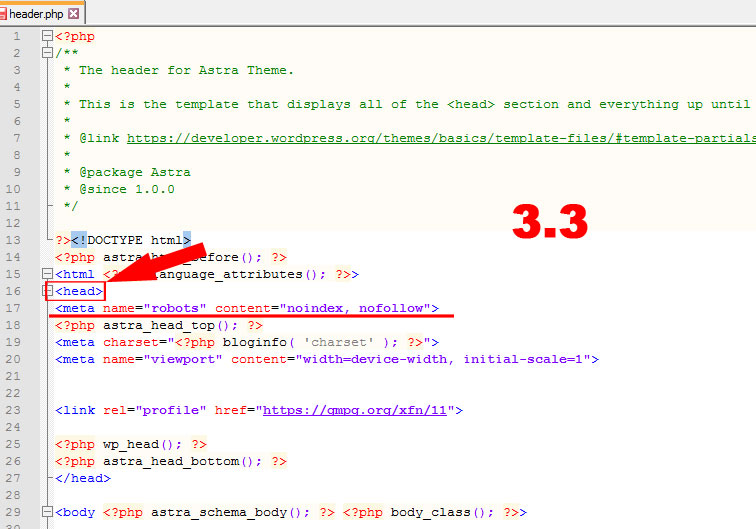
снижение скорости индексирования новых страниц. Индексирующий робот может медленнее доходить до новых страниц, из‑за того что будет обходить дубли;
поисковая система «склеит» дубли и сама выберет среди них основную страницу. При этом есть риск, что эта выбранная страница не будет вашей целевой;
в индексе останутся все дубли. Тогда все они могут конкурировать между собой, «моргать» в выдаче и т. д. Это может влиять на положение сайта в поиске.
Подробнее про дубли в Яндекс.Справке
Документ для скачивания
В некоторых случаях может быть нужно закрыть от индексации документы, например в формате pdf, docx и т. п. С помощью robots.txt это можно сделать.
С одной стороны, когда документы можно скачать из выдачи, не переходя на сайт, это может приводить к потере трафика, с другой стороны, может, наоборот, положительно повлиять на посещаемость сайта.
Страницы, которые находятся в разработке
Если на странице нет контента или есть, но он дублирует другую страницу, если на странице идёт редизайн или доработка и мы пока не хотим её выкатывать и в других подобных случаях можно запретить её индексацию.
Если оставить такие страницы доступными для индексации, то ПС может сама понизить или исключить их из индекса, что может сказаться на оценке сайта в целом.
Техническая страница
Все служебные, технические страницы не содержат полезного контента для пользователей или вовсе могут быть пустыми. Поэтому их стоит закрыть от индексации.
Такими страницами, в зависимости от конкретного сайта и особенностей проекта, могут быть: страницы регистрации, авторизации, результаты поиска по страницам сайта, Личный кабинет, Корзина, Избранное и т. д.
Папка
Файлы сайта обычно распределяются по папкам, например по категориям, каталогам, разделам, подразделам и т. д. Если какой‑то раздел на сайте устарел целиком, то можно скрыть от индексации всю папку, а не только отдельные страницы.
д. Если какой‑то раздел на сайте устарел целиком, то можно скрыть от индексации всю папку, а не только отдельные страницы.
Картинка
Помимо закрытия страниц сайта, можно также закрыть от индексации отдельный тип контента, например все картинки определённого формата или фотографии.
Если вы размещаете информативные и полезные изображения, закрывать их от индексации нежелательно.
Ссылка
С помощью robots.txt мы не можем запретить индексацию одной ссылки. Чтобы робот не переходил по ссылкам на странице, мы можем закрыть от индексации страницу, на которой размещена ссылка, или страницу, на которую она ведёт.
Чтобы скрыть от индексирования конкретную ссылку, Яндекс рекомендует использовать атрибут rel.
Блок на сайте
Мы не можем закрывать в robots.txt отдельные блоки на странице.
Запретить индексирование части текста в Яндексе можно с помощью тега noindex, но Google данный тег не поддерживает.
Как запретить индексацию в robots.
 txt
txtФайл robots.txt — это текстовый документ формата .txt, в котором прописаны специальные правила (директивы) для поисковых роботов. Они помогают управлять индексацией сайта.
С помощью этих правил можно указать поисковым роботам, какие страницы и файлы сайта не должны присутствовать в поисковой выдаче, а какие, наоборот, должны.
В файле robots.txt можно:
разрешить или запретить индексацию страниц или разделов сайта;
указать ссылку на карту сайта Sitemap.xml;
заблокировать показ изображений, видеороликов и аудиофайлов в результатах поиска.
В robots.txt мы обычно закрываем страницы массово: весь каталог, конкретные типы страниц, страницы или файлы с определёнными характеристиками.
Если у сайта есть robots.txt, то обычно он хранится он в корневой папке сайта — там, куда загружаются каталоги и другие файлы.
Кроме того, на некоторых сайтах robots. txt можно найти по ссылке site.ru/robots.txt, где site.ru — это ваш сайт. Например, https://topvisor.com/robots.txt.
txt можно найти по ссылке site.ru/robots.txt, где site.ru — это ваш сайт. Например, https://topvisor.com/robots.txt.
Если файла нет, значит, скорее всего, сейчас для индексации доступны все страницы сайта и у поисковых роботов нет специальных указаний.
Поэтому файл нужно создать самостоятельно. Сделать это можно в Блокноте или другом текстовом редакторе. В файле нужно прописать специальные директивы, о которых расскажем ниже.
После этого сохраняем документ в формате .txt с названием robots и загружаем в корневую папку сайта.
Основные директивы robots.txt
User‑Agent — обязательная директива, которая говорит, какому именно поисковому роботу адресуются указанные ниже правила. В документе эта директива может повторяться несколько раз — с неё начинается каждая новая группа правил для конкретного бота.
В файле эта строка будет выглядеть так:
User‑agent:
После двоеточия мы прописываем название бота, к которому будут обращены последующие правила.
Чаще всего используем такие:
- * — когда обращаемся ко всем поисковым роботам;
- Googlebot — когда обращаемся к роботам Google;
- Yandex — когда обращаемся к роботам Яндекса.
Записи в файле будут выглядеть так:
User‑agent: * или: User‑agent: Yandex или: User‑agent: Googlebot
Список User‑agent поисковых роботов Google
Список User‑agent поисковых роботов Яндекса
Перед каждой новой директивой User‑agent, которую вы прописываете в документе, необходимо ставить дополнительный пропуск строки.
Например, если бы нам нужно было закрыть весь сайт от индексации для Яндекса и Google, мы бы написали так:
User‑agent: Googlebot Disallow: / User‑agent: Yandex Disallow: /
Disallow — этой директивой мы можем запретить роботу индексировать определённые разделы сайта, страницы или файлы. Здесь могут закрываться от индексации, например:
технические страницы: страницы регистрации, авторизации и др.
 , у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;
, у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;страницы сортировок, которые изменяют вид отображения информации;
страницы внутреннего поиска и т. д.
 , у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;
, у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;Правила указания директивы такие:
Сначала указываем саму директиву и двоеточие. Например: Disallow:
После этого указываем раздел или страницу в корневой папке текущего сайта без указания самого домена. Например: /ru/marketing/.
Например, чтобы запретить роботам Яндекса индексацию всего раздела «Маркетинг» в Топвизор‑Журнале, мы бы написали в robots.txt так:
User‑agent: Yandex Disallow: /ru/marketing/
Allow — директива указывает поисковому роботу, какие разделы сайта можно индексировать. Обычно используется для указания подправила директивы Disallow, например, когда мы хотим разрешить сканирование какой‑то страницы или каталога внутри закрытого директивой Disallow раздела.

User‑agent: Yandex Disallow: /catalog/ Allow: /catalog/auto/ # запрещает скачивать страницы, начинающиеся с '/catalog/', # но разрешает скачивать страницы, начинающиеся с '/catalog/auto/'
Если в документе одновременно указаны директивы Allow и Disallow для одного и того же элемента, то предпочтение отдаётся директиве Allow — элемент будет проиндексирован.
О директиве Disallow и Allow у Яндекса
О директиве Disallow и Allow у Google
Дополнительно
При указании пути к разделу, странице или файлам может использоваться спецсимвол «*».
Он означает любую (в том числе пустую) последовательность символов. Может ставиться как префикс в начале адреса или как суффикс в конце.
Например:
Disallow: /catalog/*/shopinfo — запрещает индексацию любых страниц в разделе catalog, в URL которых есть shopinfo.
Disallow: *shopinfo — запрещает индексацию всех страниц, содержащих в URL “shopinfo”, например: /ru/marketing/shopinfo.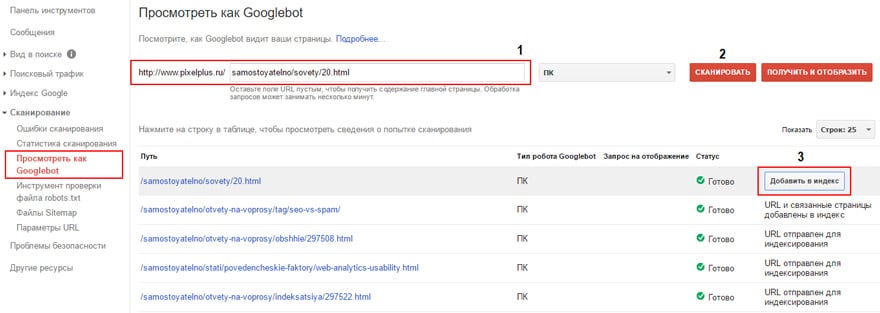
Подробнее о спецсимволах и правилах их использования в Яндексе
Спецсимволы работают в том числе и с директивой Allow.
Путь указывается через директиву Sitemap, а сам путь должен быть полным, с указанием домена, как в браузере:
Sitemap: https://site.com/sitemaps1.xml
Если карт сайта несколько, директиву можно повторять несколько раз с новой строки.
Директива считается межсекционной: поисковые роботы увидят путь к карте сайта вне зависимости от места в файле robots.txt, где он указан.
О директиве Sitemap в Яндекс.Справке
О директиве Sitemap в Google Справке
Яндекс предупреждает, что если не закрыть страницы с параметрами через Clean‑param, то в поиске могут появиться многочисленные дубли страниц, что может негативно отразиться на ранжировании.
Синтаксис и правила оформления:
файл должен называться robots.txt;
размер файла не больше 500 КБ;
на сайте должен быть только один такой файл;
файл размещён в корневом каталоге сайта, но не в подкаталоге.
Нужно вот так: https://www.example.com/robots.txt, а так нельзя: https://example.com/pages/robots.txt;файл отдаёт ответ сервера 200 OK.
 Нужно вот так: https://www.example.com/robots.txt, а так нельзя: https://example.com/pages/robots.txt;
Нужно вот так: https://www.example.com/robots.txt, а так нельзя: https://example.com/pages/robots.txt;Подробные правила оформления robots.txt у Яндекса.
Подробные правила оформления robots.txt у Google.
Дополнительно про файл robots.txt:
есть директивы, которые одни ПС воспринимают, а другие нет. Например, Clean‑param для Яндекса;
те страницы, которые вы запретили в файле, всё равно могут быть проиндексированы. Например, Google говорит, что страницы могут попасть в индекс, если поисковый робот нашёл их по ссылке с других сайтов или страниц. Чтобы полностью скрыть информацию от краулеров, стоит использовать другие способы, например метатег robots и HTTP‑заголовок X‑Robots‑Tag и др.
Как проверить запрет
После создания из загрузки файла на сайт убедитесь, что он существует, размещён в корневом каталоге сайта и без проблем открывается. Для проверки введите в строку браузера адрес сайта с указанием файла в формате https://site.ru/robots.txt.
Для проверки введите в строку браузера адрес сайта с указанием файла в формате https://site.ru/robots.txt.
После этого можно проверить файл в панелях веб‑мастеров Яндекс.Вебмастер и Google Search Console.
Яндекс.Вебмастер
В Вебмастере открываем «Инструменты» → «Анализ robots.txt». Обычно содержимое файла сразу будет отображаться в строке. Если нет, копируем из браузера и вставляем сюда. Затем нажимаем кнопку «Проверить»:
Проверка файла в ВебмастереЕсли в файле будут ошибки, Вебмастер подскажет, как их исправить.
Google Search Console
Для того чтобы проверить файл robots.txt с помощью валидатора Google, необходимо:
1. Зайти в аккаунт Google Search Console.
2. Перейти в инструмент проверки robots.txt.
3. В открывшемся окне вы увидите уже подгруженную информацию из файла. Если нет, вставьте её из браузера.
GSC покажет, есть ли в файле ошибки и как их исправить.
Проверка файла в GSCКраткий конспект
На сайте может быть необходимо скрыть некоторые страницы, например:
Закрывать от индексации можно как сайт полностью, так и отдельные страницы, файлы, изображения.
В robots.txt с помощью специальных директив мы обычно закрываем страницы массово: весь каталог, конкретные типы страниц, страницы или файлы с определёнными характеристиками.
После создания правил для индексирования сайта в robots.txt важно его проверить. Сделать это можно бесплатно в панелях веб‑мастеров Яндекс.Вебмастер и Google Search Console.
Как запретить индексацию сайта или отдельных страниц, разделов или изображений
В процессе индексации поисковые роботы Google и Яндекс сохраняют в свои базы содержимое сайта: картинки, видео, текст, код.
Правильно когда в индекс поисковых систем попадают только полезные и нужные пользователям материалы. Часто повторяющаяся ошибка среди веб-мастеров — не исключать из индекса страницы, которые не следует показывать в результатах поиска.
Почему нельзя индексировать весь сайт
- Пользователям, которые ищут в сети полезную информацию, ни к чему видеть «лишний» для них контент. Он мешает поиску нужной информации. Поисковые системы это заметят и также не оставят без внимания.
- Поисковые роботы любят, чтобы контент на страницах был уникальным. Поэтому без запрета индексации не обойтись если сайт тестируют на другом домене (поисковые системы также могут принять это за копирование).
- Поисковые системы отводят определенное время (мощности своего поискового бота) на индексирование каждого сайта. Если это время будет уходить на ненужную и не полезную информацию (на редиректы, спам и т.д.) это может замедлить индексацию важных страниц.
- При смене дизайна сайта или его структуры, когда он находится в разработке.
 Поисковые системы это заметят и также не оставят без внимания.
Поисковые системы это заметят и также не оставят без внимания.Что нужно закрывать от индексации
- Страницы сайта в разработке. Если сайт находится в разработке, лучшим решением будет закрыть его от индекса на время. Ограничить доступ к сайту или его страницам нужно через файл robots.txt.
- Копии сайта. Чтобы верно указать копию сайта, необходимо корректное зеркало (с помощью 301 редиректа или атрибута rel=»canonical»), чтобы рейтинг главного ресурса не падал. К тому же, поисковые системы так будут лучше понимать — где главный сайт, а где его копия. Рабочий ресурс не должен быть скрыт от индексации! Так можно потерять репутация ресурса, наработанную годами.
- Печатные страницы. Печатные страницы могут быть полезны посетителю. Необходимая информация может быть распечатана в адаптированном текстовом формате: статья, информация о продукте, схема расположения компании. По сути, печатная страница является копией своей основной версии. Если эта страница открыта для индексации, поисковый робот может выбрать ее в качестве приоритетной и посчитать более релевантной.
- Ненужные документы. Кроме страниц, полезных для пользователей, на сайте могут также присутствовать документы для скачивания (PDF, DOC, XLS). И когда пользователь ищет информацию, он может видеть в выдаче не только нужные страницы, но и заголовки pdf-файлов. Эти файлы не несут практической ценности для пользователей. Либо документы появляются в результатах поиска над html страницами сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от индекса в файле robots.txt.
- Пользовательские формы и элементы. Эти элементы могут быть полезны для пользователей сайта, но при этом не нести никакой информационной пользы в поисковой выдаче. Соответственно, оттуда их нужно убирать. Такие элементы, как форма регистрации и заявки, корзина, личный кабинет и прочее.
- Технические данные сайта. Только владелец ресурса должен иметь доступ к техническим страницам (это может быть форма входа в панель управления). В поисковой выдаче эти страницы — ни к чему.
- Личная информация о клиенте. Это информация должна быть конфиденциальной и, ни в коем случае, не индексироваться. Это могут быть данные пользователя, его банковская информация и так далее.
 К тому же, поисковые системы так будут лучше понимать — где главный сайт, а где его копия. Рабочий ресурс не должен быть скрыт от индексации! Так можно потерять репутация ресурса, наработанную годами.
К тому же, поисковые системы так будут лучше понимать — где главный сайт, а где его копия. Рабочий ресурс не должен быть скрыт от индексации! Так можно потерять репутация ресурса, наработанную годами. В этом случае индексация документов нежелательна, и их лучше закрыть от индекса в файле robots.txt.
В этом случае индексация документов нежелательна, и их лучше закрыть от индекса в файле robots.txt.Запретить индексирование сайта, раздела или страницы
Как запретить индексирование в robots txt всего сайта
Иногда необходимо запретить весь сайт к индексу роботами Яндекса и Google. Так, для Яндекса стоит ввести следующий текст в robots.txt:
Так, для Яндекса стоит ввести следующий текст в robots.txt:
User-agent: Yandex
Disallow: /
Чтобы закрыть сайт от всех поисковых систем, стоит прописать:
User-agent: *
Disallow: /
Как закрыть папку от индексации
Иногда требуется закрыть определенную папку (например, служебную). Для этого нужно:
- Открыть файл robots.txt.
- Указать на каких поисковых роботов будет распространятся запрет: на все (User-agent: *) или только на Яндекс (User-agent: Yandex).
- Создать правило Disallow с названием папки/раздела, который хотите запретить: Disallow: /catalog/ (вместо «catalog» — название папки, которую необходимо запретить к индексу).
Как закрыть поддомен
Иногда появляется необходимость закрыть поддомены от индекса (например, при мультирегиональных или мультиязычных сайтах поддомены не всегда должны попадать в выдачу).
Для этого необходимо добавить инструкцию
User-agent: *
Disallow: /
На каждом поддомене, который требуется закрыть.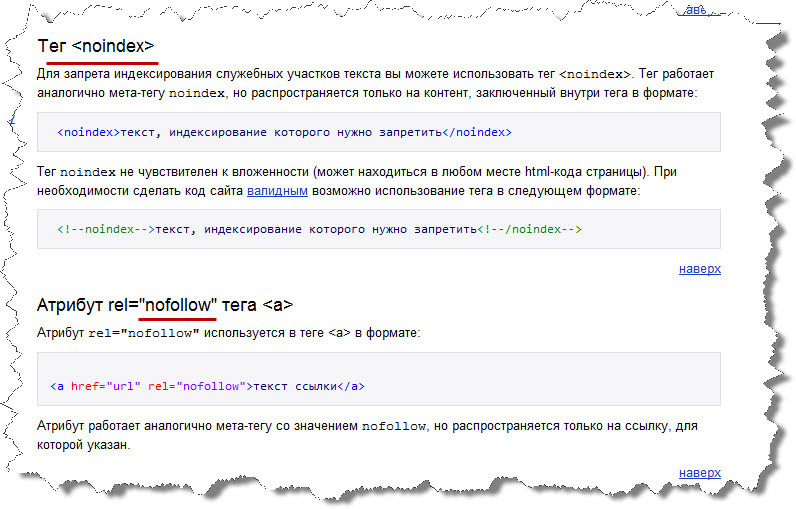
Как запретить индексацию страницы в robots txt и метатегах
Отдельную страницу можно закрыть при помощи следующих способов:
- Использования метатега «noindex». Добавление метатега «noindex» — метод управления индексацией отдельно взятой страницы. Необходимо вставить следующий тег в раздел <head> HTML-разметки страницы: <meta name=»robots» content=»noindex»>. Это необходимо сделать для каждой страницы, которую вы не хотите индексировать.
- Использования HTTP-заголовка X-ROBOTS-TAG. Тег X-Robots-Tag нужно добавлять в заголовок ответа HTTP для данного URL-адреса. Он имеет тот же эффект, что и тег «noindex», но с дополнительными параметрами для указания условий для разных поисковых систем. Чтобы деиндексировать страницу, нужно добавить тег «X-Robots-Tag: noindex».
- В robots.txt в Disallow: прописать полный адрес страницы.
Как запретить индексацию контента
Можно также скрыть от индекса поисковыми системами отдельные виды контента: картинки, часть текса и ссылки.
Как закрыть все картинки от индексации
Чтобы скрыть все картинки на сайте от индекса в Яндекс, нужно в файл robots.txt добавить следующее:
User-Agent: Yandex
Disallow: *.jpg
Disallow: *.gif
Disallow: *.png
Для Google стоит прописать:
User-Agent: Googlebot
Disallow: *.jpg
Disallow: *.gif
Disallow: *.png
Для скрытия конкретной картинки:
User-Agent: *
Disallow: /img/pixelplus.gif
Дополнительно можно закрывать от индексации папку, где эти картинки расположены.
Как скрыть от индексации часть текста
Часть текста стоит закрывать от индекса в том случае, если он не должен попадать в выдачу, но все же несет информационную ценность для посетителей. Для Яндекса стоит использовать тег <noindex>. Он показывает поисковой системе, что часть текста, находящуюся между тегами <noindex></noindex> индексировать не нужно.
Для Google есть возможность закодировать нужную часть текста с помощью асинхронного JavaScript.
Как скрыть от индекса ссылки на странице
В HTML-коде страницы необходимо указать метатег «robots» с директивой nofollow. В таком случае поисковые роботы не станут переходить по ссылкам на данной странице. Или же использовать в атрибутах ссылки <noindex><a href=»http://адрес_сайта/» rel=»nofollow»>Текст ссылки</a></noindex>.
Как закрыть от индексации страницы пагинации
Добавить на страницы пагинации теги:
<meta name=»robots» content=»noindex» />
Закрыть их в robots.txt или внедрить rel = «canonical». Это лучший вариант.
Как проверить, корректно ли работает запрет индексации
Есть несколько способов чтобы узнать, корректно ли работает ваш запрет на индексацию сайта или отдельной страницы:
- Яндекс.Вебмастер. Кликнуть на кнопку «Инструменты» и далее «Проверка ответа сервера». Вставить адрес нужной вам страницы. Если она запрещена к индексу, то вы увидите соответствующее сообщение.
- Google Search Console. Нажать на «Проверка URL» и вписать адрес нужной вам страницы.
- Ввести в строку поиска (в Google или Яндекс) site:https:// + URL интересующего сайта/страницы. Так вы увидите выдает ли поисковик вашу страницу.
 Нажать на «Проверка URL» и вписать адрес нужной вам страницы.
Нажать на «Проверка URL» и вписать адрес нужной вам страницы.Как удалить страницу из индекса Google: удаление некачественных страниц
Добро пожаловать в наш следующий выпуск серии статей и видео от Inseev! Сегодня мы сосредоточимся на теме, которая многих оптимизаторов смущает и не до конца понимает.
Удаление страниц из индекса Google
Существует несколько способов удалить страницу из индекса Google. От инструментов, предлагаемых Google, до команд робота — мы рассмотрим все способы вывода страниц из индекса. Проверьте их ниже!
Что такое тонкий контент?
Во-первых, важно определить низкокачественный контент. Проще говоря, тонкий контент — это страница на вашем сайте, которая практически не приносит пользы пользователю. Это может быть пустая страница или страница с неработающим текстом или множеством ошибок. Дублированный контент также является типом тонкого контента, поскольку дублированная страница не добавляет никакой дополнительной ценности пользователю.
Тонкий контент очень важен для алгоритма Google Panda. Panda теперь является частью основного алгоритма, и это не очень сложное обновление. Плохие или некачественные страницы вредны для вашего сайта. Период.
Период.
Как найти страницы низкого качества
Поиск страниц низкого качества можно найти с помощью специальных инструментов. Этот пост не посвящен идентификации этих страниц, и у нас есть отдельный пост об аудите контента для SEO здесь.
Однако для начала неплохо использовать операторов расширенного поиска Google или инструменты сканирования, такие как Deep Crawl или Screaming Frog.
Проверить, проиндексированы ли вложенные папки, несложно. Вы можете просто ввести «сайт: domain.com inurl: подпапка ». Обязательно используйте строчные буквы. Вот пример:
Итак, у вас много тонких страниц? Что мы можем сделать? Что нам не следует делать? Давайте начнем с неправильного пути.
Неправильный способ удаления страниц из индекса Google: блокировка страниц в файле Robot.txt
Одна из основных вещей, которую мы видим, когда говорим разработчику, Привет. Мы нашли эти страницы — они входят в файл robots. txt (на который я дам ссылку здесь), и они просто помещают директиву блокировки на страницы или каталог, если есть шаблон каталога, который они хотят заблокировать. Это самое худшее, что вы могли сделать.
txt (на который я дам ссылку здесь), и они просто помещают директиву блокировки на страницы или каталог, если есть шаблон каталога, который они хотят заблокировать. Это самое худшее, что вы могли сделать.
Если у вас есть 2900 страниц, на которых нет контента, и это очень, очень тонкие страницы, что снижает общий показатель качества Google с точки зрения сайта, и вы открываете файл robots.txt и блокируете все эти страницы от сканирования, они будут следовать внутренним ссылкам, которые они изначально нашли на сайте, чтобы найти эти страницы. Затем они просто ударят по файлу robots.txt. Это первое, на что натыкается бот, когда начинает сканировать сайт, и он собирается развернуться. На самом деле он никогда не перейдет на страницу и не удалит ее из индекса. Он просто поймет, что не может его просканировать, и будет постепенно удалять его из индекса через год или два.
Пока вы помещаете их в robots.txt, все, что вы делаете, это увековечивает проблему, а не устраняет ее. Правильно? Это неправильно, и именно этого вам следует избегать
Правильный способ удаления страниц из индекса
В конечном счете, вы хотите попытаться заставить Google зарегистрировать, что вы каким-то образом удаляете страницы.
301 страницу на другой URL-адрес и заставить Google просканировать ее.
Допустим, я всего 301 их всех на одной странице. Теперь, если Google захочет просканировать этот 301, он будет медленно говорить: 9.0033 Хорошо. Это новая страница. Они не хотят этого. Они больше не хотят, чтобы эта страница была в моем индексе. Я собираюсь выбросить это . Это первое решение. Опять же, это не всегда верное решение.
Посмотрите 301-ю страницу Moz здесь.Я не буду вдаваться в подробности того, почему это может быть или не быть решением, но попытка понять, какое решение вам нужно, также очень важно.
Иногда на веб-сайте могут быть страницы, которые не сканировались в течение трех лет, но они все еще есть в индексе Google. Мы знаем, что это старые страницы, потому что знаем, сколько на них результатов. Компания больше не обслуживает эти страницы, даже не объединяет их. Если мы поместим 301 на место, они могут ссылаться на эту страницу из очень, очень старого поста в блоге. Google сканирует этот пост в блоге раз в шесть месяцев. Они просматривают его, а затем им требуется шесть месяцев, чтобы просканировать его снова. Когда они, наконец, проползают его, они видят 301.
Google сканирует этот пост в блоге раз в шесть месяцев. Они просматривают его, а затем им требуется шесть месяцев, чтобы просканировать его снова. Когда они, наконец, проползают его, они видят 301.
Допустим, мы действительно хотим быстро вывести страницы из индекса — тогда нам нужно заставить Google просканировать 301.
Как вы можете это сделать, вы можете, очевидно, создать фальшивую HTML-карту сайта и просто поместить в нее все свои ссылки, и заставить Google сканировать это. Это один из способов. Другой способ — создать статическую HTML-страницу со всеми ссылками на них, а затем отправить ее через консоль поиска.
Это быстрый способ заставить Google просканировать все 301, которые вам нужны для мгновенной обработки. Надеюсь, вы сможете получить некоторые из них в течение следующей недели или двух недель. Если вы продолжите это делать и заставите Google сканировать один и тот же файл каждый день, они будут удалять их через неделю или две.
Добавьте тег noindex в метатег страницы и принудительно просканируйте страницу
Другая вещь, которую вы можете сделать, это, очевидно, добавить noindex в метатег URL. Если бы у меня было 2900 страниц, от которых я хотел избавиться, но я не хотел их 301 — это маркетинговые страницы или что-то в этом роде, и я не мог их 301 — тогда я мог бы добавить к ним тег noindex. Это то, что я на самом деле предлагаю в сценарии в видео.
Если бы у меня было 2900 страниц, от которых я хотел избавиться, но я не хотел их 301 — это маркетинговые страницы или что-то в этом роде, и я не мог их 301 — тогда я мог бы добавить к ним тег noindex. Это то, что я на самом деле предлагаю в сценарии в видео.
Если вы действительно хотите получить их быстрее, добавив их в карту сайта HTML, в карту сайта XML, просто на пустую страницу — все, что вам нужно сделать — тогда удалите их из индекса и удалить эту страницу. Удалите ссылки из карты сайта туда, куда вы их добавили, и все будет хорошо.
Канонизация URL-адреса на другой базовый URL-адрес
Канонизация — это когда вы хотите сообщить Google, что существует альтернативная версия страницы или основная версия страницы, которую они должны индексировать. Затем они должны объединить все одиночные файлы в этот единый URL-адрес из всех объединенных URL-адресов, а не просто удалить его из индекса. Это достигается. Он избавляется от URL-адресов с очень и очень похожими параметрами. В общем, вы хотите использовать канонические символы, когда имеете дело с такими вещами, как параметры URL.
В общем, вы хотите использовать канонические символы, когда имеете дело с такими вещами, как параметры URL.
Не используйте канонический тег для удаления информации из индекса, если в этом нет крайней необходимости. Мы использовали канонические теги, когда к нам приходила компания и говорила что-то вроде: У нас нет решения noindex. Мы не можем сделать это на нашем сайте . Если вы не можете сделать это на своем веб-сайте, мы должны что-то придумать. Если вы можете использовать канонические символы, может быть, мы можем хотя бы попытаться заставить это. Google в этом хорош. Каноническая директива не так сильна. Google иногда игнорирует канонические имена. Они никогда не будут игнорировать наш robots.txt и никогда не будут игнорировать noindex. Это куда более сильные директивы. Это те, которые мы хотим использовать.
Вот пример правильной канонической маркировки. Вот как они должны работать, когда вы используете параметр для настройки контента конкретно на странице. Это создаст новый URL-адрес, который мы не хотим индексировать. Если нет канонического тега, Google будет индексировать как отдельный URL-адрес, дублирующую страницу, поэтому мы просто хотим канонизировать ее до базовой версии, как вы видите выше.
Это создаст новый URL-адрес, который мы не хотим индексировать. Если нет канонического тега, Google будет индексировать как отдельный URL-адрес, дублирующую страницу, поэтому мы просто хотим канонизировать ее до базовой версии, как вы видите выше.
Опять же, канонический не всегда является решением. Это правильно, когда у вас есть параметры. В общем, если вы пытаетесь быстро удалить страницы из индекса, это, вероятно, не потому, что у вас есть параметры. Вероятно, это потому, что вы сделали что-то глупое, например, оставили индекс субдомена, который был промежуточным субдоменом, или вы нашли массу пустых страниц.
Если у вас есть 2900 страниц, я даже не думаю, что вы могли бы сделать это больше, когда вы удаляете их вручную. В Google старый интерфейс консоли поиска Google здесь — который может быть не закрыт, если вы смотрите это видео — он все еще работает по состоянию на февраль 2019 года. Если вы нажмете и действительно захотите удалить что-то из индекса, вы можете сделать что. Говорит, что это временно. Если они повторно просканируют его, они могут переиндексировать его, но я могу просто попросить его удалить — что в данной ситуации я должен сделать, потому что на этой странице нет контента. Опять же, это чистая страница.
Говорит, что это временно. Если они повторно просканируют его, они могут переиндексировать его, но я могу просто попросить его удалить — что в данной ситуации я должен сделать, потому что на этой странице нет контента. Опять же, это чистая страница.
Для 2900 URL это не сработает. Я почти уверен, что после того, как вам исполнится 50, время истекло, и вы не сможете удалить больше. Это намного лучше решения для пары URL-адресов. Мне нравится делать одно из этих решений. Мне нравится брать ту страницу, на которой я размещаю все URL-адреса, и удалять их вручную. Мне нужно убедиться, что я избавился от своей страницы, а это просто набор ссылок — это просто пустая страница для Google — и принудительно просканировать.
Позвольте страницам 404
Последнее, что вы можете сделать, это разрешить всем этим страницам 404, и Google удалит их естественным образом, но опять же, это не правильное решение, если вы пытаетесь заставить Google их удалить. быстро.\
Если вы думаете, что это проблема с производительностью — например, 75% вашего сайта пусто, и теперь его просматривает Google.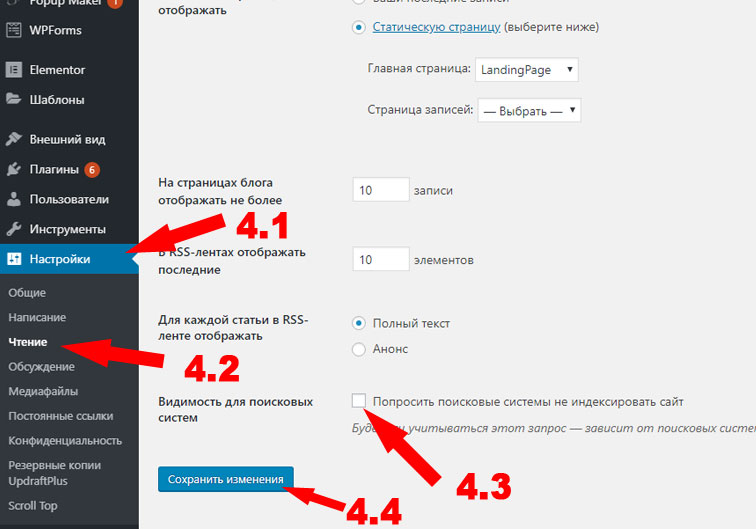 Ваш клиент только что был раздавлен обновлением алгоритма или испытывает много проблем с производительностью — и вы считаете, что это связано с тем, что Google думает, что сайт очень похож на пустой веб-сайт — не делайте этого.
Ваш клиент только что был раздавлен обновлением алгоритма или испытывает много проблем с производительностью — и вы считаете, что это связано с тем, что Google думает, что сайт очень похож на пустой веб-сайт — не делайте этого.
Не позволяйте страницам 404 выпадать естественным образом. Это может занять от 6 до 12 месяцев, прежде чем вы заметите какое-либо улучшение.
Я бы посоветовал сначала попытаться запретить индексирование этих страниц, получить как можно больше с помощью принудительного сканирования, а затем оставить их все 404, и со временем вы сможете начать улучшать качество остальных страниц.
Это можно сделать разными способами. Все сводится к техническим рекомендациям и ситуации, в которой вы находитесь. В будущем будет больше видео о канонизации и о том, как это работает. Вы также можете провести дополнительные исследования, если вам это нужно самостоятельно. В общем, это базовый фреймворк для удаления страниц из индекса.
Нужна дополнительная поддержка SEO? Наша команда проделывает фантастическую работу по выявлению некачественного контента в рамках нашей услуги SEO-аудита.
Как удалить веб-страницу из индекса Google?
Одним из основных факторов, влияющих на успех SEO, является эффективное использование концепции «краулингового бюджета» на нашем веб-сайте. Поэтому все методы, упомянутые в этой статье, преследуют две общие цели;
- Тем, кто хочет удалить определенную страницу из Google
- Тем, кто считает эффективность SEO и хочет эффективно использовать краулинговый бюджет, гарантируя, что недостойные/ненужные страницы не будут найдены в индексе.
Как удалить веб-страницу из индекса?
Первое, что нужно сделать, это определить, какую страницу или группы страниц следует удалить из индекса Google. Идентификация — это первый шаг, и он действительно очень важен. Потому что, если мы применим разработки, упомянутые ниже, к ценной для SEO странице или группе страниц, мы можем столкнуться с нежелательной потерей трафика.
Инструмент Google Analytics будет важным справочным материалом и руководством для нас на этом этапе. Когда мы переходим к данным о трафике нашего веб-сайта за последний год, если есть какие-либо группы страниц, не вызывающие никакого трафика, не будет проблемой удалить эти страницы из индекса и заблокировать сканирование.
Когда мы переходим к данным о трафике нашего веб-сайта за последний год, если есть какие-либо группы страниц, не вызывающие никакого трафика, не будет проблемой удалить эти страницы из индекса и заблокировать сканирование.
Как правило, эти ненужные страницы являются страницами «тегов» и «авторов» для блогов. Пользовательские страницы, такие как «корзина», «регистрация», «вход» и «фильтр» для сайтов электронной коммерции.
Как мы упоминали в видео, первое, что нам нужно сделать, это найти общий шаблон для этих страниц. Шаблон может быть общим параметром в URL-адресе или общей вложенной папке. Например;
https://www.example.com/en/men-shorts?filter=66
https://www.example.com/en/women-shorts?filter=blue
Общим шаблоном для приведенного выше URL является параметр «?filter=».
https://www.example.com/blog/tag/italian-foods
https://www.example.com/blog/tag/italian-nights
Общий шаблон для приведенного выше URL является подпапкой «/tag/».
Следующим шагом для удаления страниц из индекса является проверка их наличия в индексе. Чтобы проверить, есть ли в индексе конкретная страница или группа страниц, в которой мы обнаружили закономерность, нам нужно выполнить поисковые запросы в Google:
сайт: https://www.example.com/blog/tag/italian-foods
или
сайт: https://www.example.com/blog inurl /tag/
Другой пример:
сайт: https://www.example.com/en/women-shorts?filter=blue
или
9003 сайт3 https3:9003 //www.example.com/en
inurl:?filter=Как вы можете видеть на живом примере выше, страниц фильтра почти 9k проиндексировано в Google. Кроме того, почти нет трафика, вызванного этими страницами фильтров.
Теперь, когда мы закончили с этапом идентификации, мы можем перейти к тому, как удалить группу страниц или отдельную страницу из Google.
Как заблокировать страницу для индексации?
Во-первых, нам нужно проверить, открыт ли шаблон связанной группы страниц для сканирования из файла Robots.txt. В файле Robots.txt не должно быть строки «Disallow: …», относящейся к элементу файла.
Чтобы полностью удалить нашу страницу из индекса Google, боты должны иметь возможность видеть наш запрос на удаление и легко сканировать страницу.
Затем нам нужно добавить приведенную ниже строку тега к исходному коду каждой страницы, которую мы хотим заблокировать для индексации.
Таким образом роботы поисковых систем будут знать, что страница не будет проиндексирована и будет удалена из index, если он уже проиндексирован.
После добавления соответствующего тега в исходный код вы можете применить шаги, упомянутые в видео, чтобы боты быстрее заходили на страницу и видели тег.
Мы войдем в учетную запись Google Search Console нашего веб-сайта. Затем;
Затем;
1) Выберите «Получить как Google» в левом меню:
2) Введите оставшуюся часть URL-адреса, по которому мы хотим, чтобы боты заходили на нашу страницу. Например, если адрес страницы «https://www.example.com/en/women-shorts?filter=blue», мы пишем «ru/women-shorts?filter=blue».
3) Нажмите «FETCH AND RENDER» и немного подождите.
Выполняя эти шаги, мы вручную вызываем бота на нашу страницу и делаем так, чтобы они быстрее видели тег « noindex », который мы добавили в исходный код.
Продолжительность процесса удаления из индекса может варьироваться в зависимости от размера веб-сайта и интенсивности группы страниц, которую мы хотим удалить. Невозможно указать конкретное время, но через некоторое время мы увидим, что все страницы с тегом «noindex» полностью удалены из индекса Google.
Что делать, чтобы предотвратить переиндексацию после удаления моей страницы?
Чтобы эффективно использовать краулинговый бюджет, о котором мы упоминали ранее, нам нужно убедиться, что боты не будут сканировать страницы, которые мы удалили из индекса.
Заблокировав страницы, которые больше не входят в индекс для сканирования, можно предотвратить потенциальное повторное индексирование, и боты будут больше фокусироваться на важных страницах, а не на этих страницах.
Для этого нам нужно заблокировать шаблон групп страниц, которые мы удалили из индекса, одной строкой из файла Robots.txt. Например, если мы не хотим, чтобы страницы фильтров снова сканировались, как в https://www.example.com/en/women-shorts?filter=blue, мы можем добавить строку ниже в Robots.txt. файл:
Disallow: *filter=*
Метки (*) — это регулярные выражения, которые включают все части до и после параметра «filter=».
К сожалению, для некоторых инфраструктур электронной коммерции может быть невозможно добавить тег «noindex» в исходный код. В этом случае, хотя и не безошибочно, есть способ удалить страницы из индекса через файл Robots.txt.
Лично я провел тесты по этому вопросу успешно и вы можете использовать этот метод как последний вариант.