
Поиск в тексте документа
Простой визуальный просмотр текста документа, а также переход по пунктам оглавления, не всегда позволяют быстро найти в документе интересующую информацию. В связи с этим в программе «ГРАНД-СтройИнфо» предусмотрена специальная функция для быстрого поиска в тексте документа отдельных ключевых слов или более сложных словосочетаний.
Для перехода к поиску необходимо нажать функциональную клавишу F3, комбинацию клавиш Ctrl+F, либо совершить одиночный щелчок левой кнопки мыши по специальной строке поиска, которая постоянно находится на экране, и расположена непосредственно под панелью инструментов. До этого момента строка поиска была в неактивном состоянии, зато после выполнения указанного действия в строке поиска появляется мигающий курсор, что означает возможность ввода текста.
Приступая к поиску, следует открыть на панели инструментов вкладку Главная, на которой расположены все необходимые команды и настройки (опции) для поиска.
Рис. 27. Поиск в тексте документа.
Многие необходимые рекомендации по поводу поиска информации в электронной библиотеке «ГРАНД-СтройИнфо» уже были даны в пункте, посвящённом поиску документов в базе. Поэтому здесь остаётся только напомнить основные положения и ещё кое-что добавить в дополнение к ранее написанному.
В качестве поискового запроса можно ввести одно или несколько слов, разделённых пробелами. При вводе очередного слова автоматически открывается выпадающий список, где предлагаются целые слова, которые начинаются с введённого фрагмента и присутствуют в тексте текущего открытого документа. Если в тексте документа не оказалось ни одного подходящего слова, то введённый фрагмент подчёркивается красным.
Как обычно, следует иметь в виду, что используя в поисковом запросе вместо целого слова только корневую часть без окончания, можно получить более полный результат поиска с учётом всех возможных форм данного слова. При этом опция Точное совпадение слов в группе Поиск на вкладке Главная обязательно должна быть отключена.
В дополнение к ранее написанному рассмотрим теперь особый случай, когда поиск в тексте документа выполняется по нескольким словам. Например, если при работе с МДС 81-35.2004 необходимо найти в данном документе информацию об особенностях определения сметной стоимости работ, выполняемых при ремонте и реконструкции зданий и сооружений. Приняв решение, что указанную тему определяют два ключевых слова – ремонт и реконструкция – мы вводим в строке поиска поисковый запрос ремонт реконст.
Ясно, что в соответствии с логикой наших действий все заданные слова из поискового запроса должны располагаться в тексте документа рядом друг с другом, в пределах относительно небольшого текстового фрагмента. Поэтому при поиске по нескольким словам необходимо выбрать какое-либо ограничение при помощи опций в группе Расположение слов на панели инструментов на вкладке Главная.
В рассматриваемом примере выбираем ограничение по дистанции (отмечаем флажком опцию Диапазон слов) и указываем количество слов в диапазоне, равное 5. В качестве альтернативного варианта здесь предлагается ограничение по параграфам – то есть, вместо опции Диапазон слов можно было бы отметить флажком опцию Количество параграфов и указать, что все заданные ключевые слова должны входить в один параграф (либо два последовательных параграфа, три последовательных параграфа и т. д.).
В качестве альтернативного варианта здесь предлагается ограничение по параграфам – то есть, вместо опции Диапазон слов можно было бы отметить флажком опцию Количество параграфов и указать, что все заданные ключевые слова должны входить в один параграф (либо два последовательных параграфа, три последовательных параграфа и т. д.).
Для того чтобы запустить поиск в тексте документа с заданными настройками поиска, требуется нажать кнопку Поиск на панели инструментов, либо просто подтвердить введённый поисковый запрос нажатием клавиши Enter. После завершения поиска выполняется переход на найденный текст, при этом в документе выделяются слова, использованные в поисковом запросе.
Рис. 28. Результат выполненного поиска отображается в тексте документа.
В ситуации, когда в документе несколько раз встречается текст, удовлетворяющий заданному поисковому запросу, можно автоматически переходить на следующее либо предыдущее найденное совпадение. Для этого предназначены кнопки Поиск и Поиск назад, расположенные на панели инструментов на вкладке Главная.
Для этого предназначены кнопки Поиск и Поиск назад, расположенные на панели инструментов на вкладке Главная.
Алгоритмы для выделения ключевых слов: Rake, YAKE!, TextRank
Время прочтения: 7 мин.
Задача
В условиях значительного потока информации, в том числе и текстовой, появляется необходимость фильтровать ее автоматически, с помощью алгоритмов. Одним из возможных подходов к выделению смысла текста и оценке его релевантности является задача извлечения ключевых слов. Идея заключается в том, чтобы выделить слова или фразы, которые являются наиболее важными для всего текста и передают его основную тематику.
Алгоритмы без учителя обладают преимуществом в условиях большого объема данных – нет необходимости в разметке данных, которая для данной задачи является достаточно трудоемкой. Дополнительной характеристикой методов, о которых пойдет речь, является отсутствие моделей. Все 3 метода основаны на эвристиках, которые заданы заранее, а не обучаются. Это позволяет обрабатывать каждый текст отдельно и не требует большой выборки текстов.
Это позволяет обрабатывать каждый текст отдельно и не требует большой выборки текстов.
Rake
Основной идеей алгоритма является то, что ключевые слова зачастую находятся в окружении стоп-слов и пунктуации.
| Стоп-словами называют слова, которые сами по себе не несут высокой смысловой нагрузки и используются совместно с другими словами |
Обычно в множество стоп-слов входят предлоги, союзы и другие функциональные части речи. В большинстве приложений интеллектуального текстового анализа стоп-слова считаются незначимыми и убираются на этапе предобработки, однако в данном методе играют важную роль.
Стоп-слова и пунктуация расценивается как разделители фраз – текст разбивается по этим элементам на фразы кандидаты. Далее фразы-кандидаты ранжируются по метрике deg(w)/freq(w) и выбираются k кандидатов с наибольшим значением метрики.
Метрика основана на следующей логике:
- freq(w) – Частота слова в тексте, поощряет часто встречающиеся слова
- deg(w) — Определяется как сумма совместных появлений других слов с этим словом.
 Совместным появлением считается появление в одной фразе. Данная метрика поощряет слова, которые часто встречаются в длинных кандидатах
Совместным появлением считается появление в одной фразе. Данная метрика поощряет слова, которые часто встречаются в длинных кандидатах - freq(w)/deg(w) – Поощряет слова, которые появляются в основном в длинных кандидатах
 Совместным появлением считается появление в одной фразе. Данная метрика поощряет слова, которые часто встречаются в длинных кандидатах
Совместным появлением считается появление в одной фразе. Данная метрика поощряет слова, которые часто встречаются в длинных кандидатахYAKE!
Этот метод похож по смыслу на Rake, однако была убрана идея о выделении фраз на основе стоп-слов. В данном методе используется стандартная для текстового анализа методика выделения слов и фраз с помощью токенизации. Фактически такая методика позволяет проверить все сочетания слов на их важность, а не только разделенные стоп-словами. YAKE! использует более сложную метрику, чем Rake – она собирается из 5 отдельных метрик.
Casing
Метрика Casing основана на идее о том, что ключевые слова зачастую могут быть названиями или аббревиатурами. Она измеряет количество раз, когда слово в тексте встречается с большой буквы или является аббревиатурой (написано полностью большими буквами).
Где:
- TF(U(w)) – Количество раз, когда слово начинается с большой буквы
- TF(A(w)) – Количество раз, когда слово отмечается алгоритмом, как аббревиатура (Состоит из больших букв)
- TF(w) – Общая частота слова
Word Position
Авторы утверждают, что ключевые слова чаще стоят в начале текста. Из-за этого вводится метрика Word Position, которая учитывает положение слова относительно других.
Из-за этого вводится метрика Word Position, которая учитывает положение слова относительно других.
Где:
- Senw — множество позиций слова в документе
Word Frequency
Как и в Rake учитывается частота слова. В данном случае частота слова нормируется с учетом среднего и стандартного отклонения частоты:
Где:
- TF(w) – Частота слова в тексте
Word Relatedness to Context
Авторы утверждают, что данная метрика способна оценивать, насколько слово похоже на стоп-слово – насколько оно важно для контекста. Метрика использует количество слов, появляющихся слева и справа от слова-кандидата
Где:
- WL – отношение количества слов слева от кандидата к количеству всех слов, которые появляются вместе с ним
- WR – отношение количества слов справа от кандидата к количеству всех слов, которые появляются вместе с ним
- PL – Отношение количества разных слов, которые появляются слева от кандидата к MaxTF
- PR — Отношение количества разных слов, которые появляются справа от кандидата к MaxTF
Утверждается, что стоп-слова имеют высокое значение метрики Wrel
DifSentence
Эта метрика учитывает количество предложений, в которых используется слово-кандидат.
Где:
- SF(w) – Частота появления слова в предложениях
- # Sentences – Количество предложений в тексте
Итоговая метрика
Итоговая метрика составляется из описанных выше метрик.
Далее происходит сортировка ключевых слов по этой метрике и выбирается k наиболее значимых.
TextRank
Метод TextRank наиболее сильно отличается от двух предыдущих. Он использует идею, что любой текст можно представить в виде графа, где слова являются вершинами, а связи между ними – ребрами графа. После переведения текста в графовое представление используется классическая метрика важности вершин графа PageRank.
Построение графа
Для построения графа вокруг каждого слова берется контекст – берутся все слова, которые находятся на расстоянии n-слов от главного. Например, для контекста размера 2 берутся два слова слева и два слова справа от текущего. Все слова в контексте текущего связываются с ним ребрами графа.
PageRank
Рассмотрим метрику, которая используется для выделения важных вершин на графе.
Где:
Важность инициализируется случайными числами и потом итеративно сходится к правильным значениям. Таким образом, важность слова определяется связью с другими важными словами.
Python-реализация алгоритмов
Для демонстрации работы алгоритмов используем текст про алгоритм Евклида из Википедии.
Rake
!pip install nlp-rake
!pip install nltk
from nlp_rake import Rake
import nltk
from nltk.corpus import stopwords
nltk.download ("stopwords")
stops = list(set(stopwords.words("russian")))
rake = Rake (stopwords = stops, max_words = 3)
rake.apply(text) [:10]
[('который впервые описал', 9.0),
('старейших численных алгоритмов', 9.0),
('формирует новую пару', 9.0),
('другие математические структуры', 9.0),
('открытым ключом rsa', 9.0),
('построение непрерывных дробей', 9.0),
('сумме четырех квадратов', 9.0),
('евклид предложил алгоритм', 8.75),
('позже алгоритм евклида', 8.75),
('также алгоритм используется', 8. 75)] 75)]
75)]YAKE!
!pip install yake
import yake
extractor = yake.KeywordExtractor (
lan = "ru", # язык
n = 3, # максимальное количество слов в фразе
dedupLim = 0.3, # порог похожести слов
top = 10 # количество ключевых слов
)
extractor.extract_keywords(text)
[('нахождения наибольшего общего', 0.007730938617944613),
('алгоритм евклида', 0.02890147800046243),
('меры двух отрезков', 0.03272710509306345),
('общего делителя', 0.037949396773603226),
('эффективный алгоритм', 0.08642709208765043),
('целых чисел', 0.09043705959596256),
('III век', 0.09429235043018239),
('евклида применяется', 0.14724083794565102),
('делителя двух целых', 0.15952161600757106),
('честь греческого математика', 0.1598415740734964)]TextRank
!pip install summa
from summa import keywords
text_clean = ""
# уберем стоп-слова
for i in text.split():
if i not in stops:
text_clean += i + " "
keywords.keywords (text_clean, language = "russian"). split("\n")
['алгоритм'
'алгоритмов',
'алгоритма',
'числом',
'евклида',
'евклид',
'такого',
'такие',
'меньшего числа',
'паре',
'пары',
'общей',
'таких теорема',
'число наибольший общий делитель',
'пару которая',
'целые',
'это',
'в',
'наибольшего общего делителя двух целых чисел',
'полиномы',
'основным',
'основная',
'который',
'век',
'математических',
'математические',
'является',
'веке обобщен другие',
'меньшим',
'теорем',
'теории',
'современной',]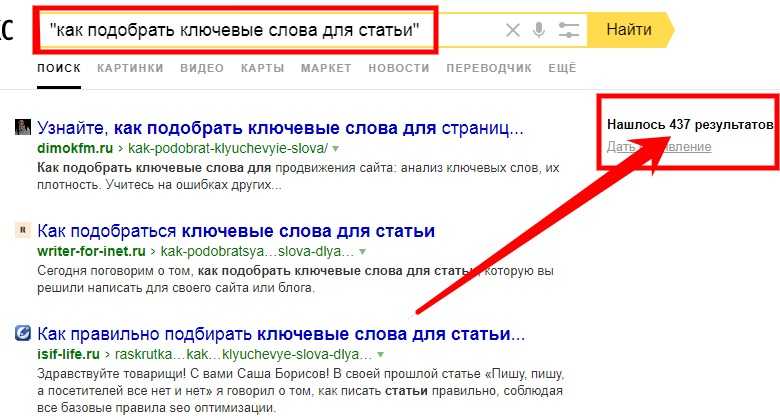
Вывод
Все три алгоритма решают одну и ту же задачу с разных сторон и с использованием разной логики. Результаты работы алгоритмов из-за этого отличаются. Нельзя однозначно сказать, какой из них лучше решает конкретную задачу. На отдельной задаче имеет смысл тестировать качество каждого из алгоритмов и делать выбор исходя из этого.
Что такое ключевое слово? | База знаний SimpleTexting
Прочитайте эту статью, чтобы узнать о ключевых словах, которые облегчают людям участие в ваших SMS-кампаниях.
Ключевое слово — это слово, фраза или другая комбинация цифр и букв, которая позволяет людям получать маркетинговые и коммуникационные SMS-сообщения.
Ключевые слова позволяют людям легко подписаться и получать сообщения, отправленные отдельным лицом, волонтерской организацией, церковью или синагогой, бизнесом, некоммерческой организацией, школой или государственным учреждением.
Ключевые слова можно рекламировать и/или продвигать где угодно и когда угодно!
Они могут размещаться на видном месте на веб-сайтах и страницах в социальных сетях, упоминаться в радио- и/или телевизионной рекламе, печататься в нижней части квитанций, указываться в меню ресторанов, добавляться в рекламные щиты/наружную рекламу, размещаться в информационных бюллетенях по электронной почте, включаться в визитные карточки, представленные в церковных программах или новых студенческих ориентационных пакетах, и многое другое.
Советы для профессионалов:
Ключевые слова НЕ чувствительны к регистру
Ключевые слова могут состоять из 3-20 букв и цифр, но не ВСЕХ цифр. в быстро меняющейся среде (например, при движении мимо рекламного щита на большой скорости)
Однако более длинные ключевые слова так же эффективны в ситуациях, когда у потенциальных подписчиков есть несколько секунд, чтобы сразу же зарегистрироваться
Ключевые слова уникальны для каждой учетной записи SimpleTexting.
Ключевое слово — это уникальный «адрес» вашей SMS-маркетинговой и коммуникационной кампании для отправки и получения сообщений по вашему номеру телефона
 Ключевое слово — это уникальный «адрес» вашей SMS-маркетинговой и коммуникационной кампании для отправки и получения сообщений по вашему номеру телефона
Ключевое слово — это уникальный «адрес» вашей SMS-маркетинговой и коммуникационной кампании для отправки и получения сообщений по вашему номеру телефонаКлючевые слова в действии:
Барбара К. владеет фургончиком с едой в Мемфисе, и она специализируется — как вы уже догадались! — курица барбекю и ребрышки.
Дела идут хорошо, но могло быть и лучше. Поскольку грузовик Барбары каждый день меняет свое местоположение, ей было трудно создать постоянную клиентскую базу. Чтобы решить эту проблему, Барбара обращается к SimpleTexting.
Барбара хочет использовать ключевое слово БАРБЕКЮ, чтобы ее клиенты могли подписаться на получение текстовых купонов, еженедельных специальных предложений и ежедневных обновлений местоположения.
Барбара создает учетную запись здесь, в SimpleTexting, затем пытается зарезервировать ключевое слово первого выбора: БАРБЕКЮ.
К сожалению, она получает сообщение об ошибке, указывающее, что ключевое слово BARBECUE уже используется другим клиентом SimpleTexting.
Потратив несколько минут на мозговой штурм, Барбара предлагает следующие варианты:
BBQ
BARBQ
MEMPHISBBQ
BBQTRUCK
BBQMEMPHIS
и (потому что у нее необычное чувство юмора) BARBIEQ.
Ей повезло! Оказывается, все ее варианты доступны.
Она выбирает барбекю в качестве ключевого слова и настраивает его всего за несколько минут.
Сразу же Барбара начинает продвигать свое ключевое слово в социальных сетях и на своем веб-сайте.
Она даже добавляет строчку в конце своих квитанций: «Отправьте сообщение о барбекю на номер 541-761-19.23, чтобы получать купоны, еженедельные специальные предложения и обновления местоположения».
В течение трех недель у нее более 100 подписчиков… а также несколько новых подписчиков каждый день.
Каждое утро она отправляет своим подписчикам короткое сообщение, в котором указывается дневное меню и местоположение… а также ссылка на адрес на Google Maps.
В течение шести недель Барбара уже добилась очевидной отдачи от своих инвестиций: независимо от того, где находится ее фургон с едой в определенный день, люди знают, как ее найти.
И… они появляются. Регулярно.
В течение трех месяцев бизнес Барбары по доставке продуктов питания стал настолько загружен (и настолько популярен), что она наняла сотрудника на неполный рабочий день.
Бизнес никогда не был лучше, поэтому Барбара обновила свой тарифный план SimpleTexting, включив в него больше сообщений.
Она также записалась на повторный сеанс SimpleTexting 101 и научилась опрашивать своих клиентов, прежде чем добавлять новые блюда в свое меню.
И, чтобы ее бизнес продолжался (и рос) в более медленные зимние месяцы, Барбара устраивает конкурс Text-2-Win.
Она создает и настраивает еще два ключевых слова — BBQHOLIDAYS и BBQPARTY — чтобы распространить информацию о том, что ее фургон с едой может принимать заказы на праздничное питание и частные вечеринки.
Что еще могут сделать для вас ключевые слова? Ознакомьтесь с нашим полным руководством по SMS-маркетингу, чтобы узнать больше.
Извлечение ключевых слов из текста на основе квантовой механики
Priceonomics
Допустим, вы хотите извлечь ключевые слова из большого фрагмента текста: как бы вы это сделали? Мы решили создать приложение, которое будет делать именно это, и включить его в Priceonomics Analysis Engine, наш инструмент для сканирования и анализа веб-данных.
Вы можете начать с поиска слов, которые чаще всего встречаются в тексте. Это дало бы вам довольно плохие результаты, так как наиболее распространенные слова обычно включают такие вещи, как «а», «тот», «есть» и т. д.
Или вы можете найти слова, которые встречаются в тексте гораздо чаще, пересмотреть, чем они делают в более общий корпус текстов. Если в этом сообщении блога неоднократно упоминается слово « корпус » , и это слово очень редко используется в нашем блоге, это хороший признак того, что это важное ключевое слово. Проблема с этим подходом заключается в том, что вам нужен огромный и релевантный корпус текста, чтобы сравнить ваши тексты, а это дорого, если вы не крупная компания с очень специфическими активами.
Amazon, например, использует все текста, который она оцифровала — для своего «Ищи внутри!» фича — в качестве корпуса сравнения для выявления наиболее «статистически невероятных фраз» ключевых слов в книгах. Их алгоритм может перечислить наименее вероятные фразы практически для любой книги, потому что он имеет доступ к широкому корпусу фраз во многих различных областях:
Их алгоритм может перечислить наименее вероятные фразы практически для любой книги, потому что он имеет доступ к широкому корпусу фраз во многих различных областях:
Например, большинство SIP для книги по налогам связаны с налогами. Но поскольку мы отображаем SIP в порядке их оценки невероятности, первые SIP будут посвящены налоговым темам, которые в этой книге упоминаются чаще, чем в других книгах по налогам. Для художественных произведений SIP, как правило, представляют собой характерные сочетания слов, которые часто намекают на важные элементы сюжета.
Amazon может сделать это только потому, что его база данных настолько обширна и разнообразна. Эта база данных также является частной. То есть это правильный инструмент для них, и, вероятно, не для Priceonomics Analysis Engine. Даже если бы мы приобрели достаточно хороший корпус, нам все равно нужно было бы поддерживать его и расширять в соответствии с нашими потребностями. Некоторые из них, возможно, должны быть помечены людьми, чтобы они были полезны для алгоритма, и если мы когда-нибудь захотим проанализировать текст на другом языке, нам понадобится совершенно новый корпус.
***
Когда мы разрабатывали инструмент для извлечения ключевых слов, мы искали быстрый и легкий алгоритм, который мог бы анализировать текст априори — он не требовал обучения и не требовал никакой информации о текст, который он анализировал (например, на английском или испанском). Наиболее распространенные методы не соответствовали этим критериям, но мы нашли один, который соответствовал в «Уровневой статистике слов: поиск ключевых слов в литературных текстах и символических последовательностях» Карпены
Суть подхода такова: в заданном массиве текста неважные слова распределяются случайным образом, а очень важные слова имеют тенденцию появляться группами и неслучайными узорами. Чтобы измерить эту кластеризацию, алгоритм заимствует из квантовой механики, поэтому анализ основан на аналогии с энергетическими спектрами. Мы преобразуем текст в массив слов, а затем строим «спектр» для каждого слова, показывающий целочисленную позицию каждого вхождения слова в массиве.
Мы преобразуем текст в массив слов, а затем строим «спектр» для каждого слова, показывающий целочисленную позицию каждого вхождения слова в массиве.
Источник: Carpena et al.
Приведенные выше спектры берут первые 50 000 слов Don Quixote в качестве исходного текста. Хотя слова Quixote (более релевантные) и , но (менее релевантные) встречаются примерно с одинаковой частотой, они имеют очень разные модели распространения.
Анализируя расстояние между этими спектрами, мы можем получить метрику кластеризации. Эта метрика кластеризации объединяется с необработанной частотой слова, чтобы найти окончательную метрику релевантности. Затем мы можем ранжировать слова по релевантности: верхние слова в этом рейтинге, вероятно, будут лучшими ключевыми словами.
Этот алгоритм имеет некоторые недостатки. Он не так хорошо работает с очень короткими текстами, как с более длинными: если ваш исходный текст состоит всего из пары сотен слов, даже важное слово может появиться только два или три раза, что делает его довольно разреженным и не очень удобным.