
Robots.txt — как настроить и загрузить на сайт
Михаил Шумовский
07 октября, 2022
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т.
 д.
д.
 д.
д.Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
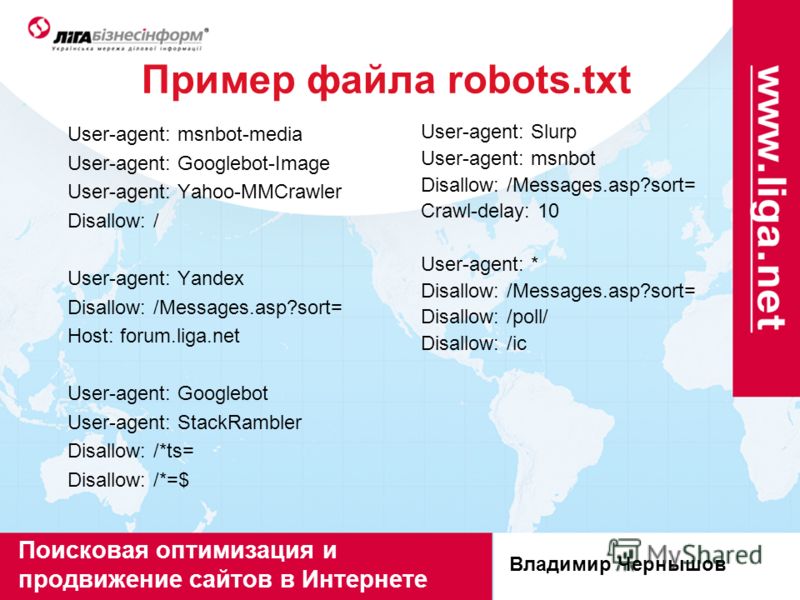
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot-Image. Индексирует изображения.
 Индексирует изображения.
Индексирует изображения.Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.

Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt
.Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *. js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой. Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
Автогенерация robots.
 txt и sitemap.xml
txt и sitemap.xmlФайлы robots.txt и sitemap.xml – это самые важные для SEO-продвижения файлы сайта. В них содержатся команды для поисковых роботов. Благодаря им они понимают, какие страницы индексировать, а какие нет.
Функционал доступен только при использовании региональности на поддоменах.
При создании интернет-магазина эти файлы создаются администратором сайта. Подробности читайте в документации 1С-Битрикс:
Генератор robots.txt
Генерация файла карты сайта
Далее вам нужно сгенерировать эти же файлы для каждого региона. Обычно файлы robots.txt и sitemap.xml для различных регионов создаются, настраиваются и редактируются вручную. В Аспро: Максимум реализована возможность автоматической генерации файлов. Это принципиально новое решение задачи, которое позволит вам сэкономить время SEO-специалиста и сократить количество ошибок, которые возможны при ручном создании robots.txt и sitemap.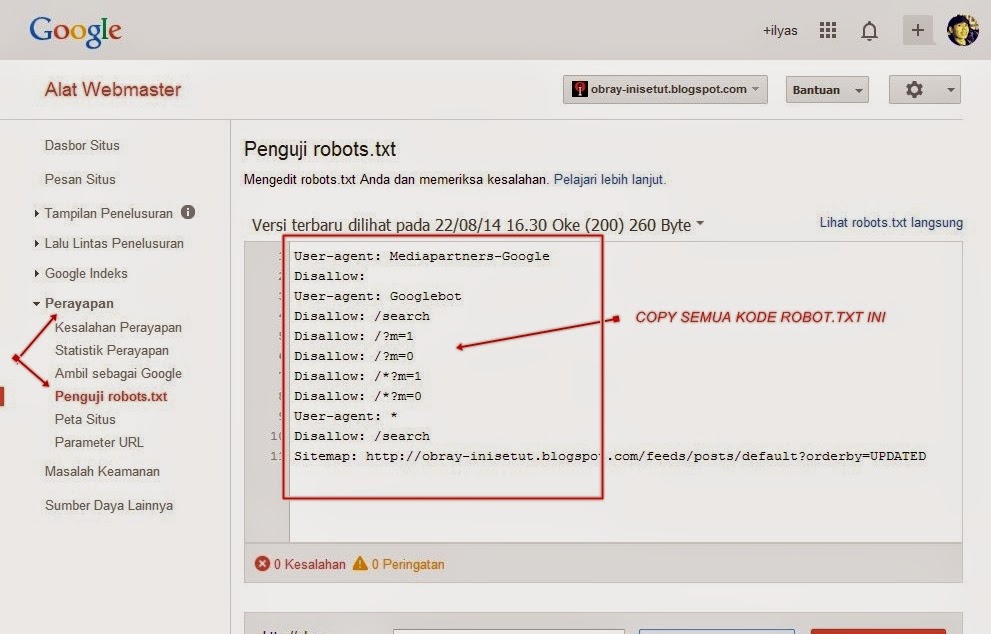 xml под каждый регион. Рассмотрим, как работает этот функционал и как с его помощью научиться автоматически генерировать нужные файлы.
xml под каждый регион. Рассмотрим, как работает этот функционал и как с его помощью научиться автоматически генерировать нужные файлы.
После того, как вы создали файлы robots.txt и sitemap.xml для основного домена, инструкции из них можно продублировать в файлы, настраивающие доступ поисковых роботов к поддоменам. И здесь вам понадобится функция генерации файлов.
Чтобы воспользоваться автоматической генерацией robots.txt, перейдите в административной части сайта в Аспро → Аспро: Max → Генерация файлов → robots.txt. Используйте кнопку «Пересоздать robots.txt» для копирования основного файла robots.txt в директорию /aspro_regions/robots/ для каждого поддомена. Копии основного файла для поддоменов именуются по шаблону «robots_DOMAIN. txt». В каждой из них запись директивы Host будет изменена.
txt». В каждой из них запись директивы Host будет изменена.
Также предусмотрена возможность пересоздания файла robots.txt только для конкретного поддомена. Для редактирования файлов используйте одноименные кнопки.
Затем перейдите в административной части сайта в Аспро → Аспро: Max → Генерация файлов → sitemap.xml. Кнопка «Пересоздать sitemap.xml» копирует все файлы в корне сайта с маской, указанной здесь же в поле «Адрес карты сайта», в директорию /aspro_regions/sitemap/ для каждого поддомена. Копии файлов для поддоменов имеют вид «файлы_по_маске_DOMAIN.xml». В этих копиях адрес сайта заменяется на значение, указанное в поле «Адрес сайта в карте сайта».
Если региональные поддомены не подставляются, необходимо проверить настройки по статье из базы знаний.
Внимание! Если вы настраивали региональность, а затем ее отключили в настройках и не планируете дальнейшее использование, то в директории /aspro_regions/robots/ рекомендуется удалить все созданные файлы robots. txt для поддоменов. Это нужно для корректной индексации поисковыми системами.
txt для поддоменов. Это нужно для корректной индексации поисковыми системами.
Как создать файл robots.txt
В ЭТОЙ СТАТЬЕ:
Объяснение SEO людям может быть трудным, потому что есть много маленьких шагов, которые могут показаться не очень важными на первый взгляд, но они в сумме приносят большие выгоды в поисковые рейтинги, когда все сделано правильно.
Один из важных шагов, который легко упустить из виду, — дать роботам поисковых систем знать, какие страницы индексировать, а какие нет. Это можно сделать с помощью файла robots.txt.
В сегодняшней статье я собираюсь объяснить, как именно создать файл robots.txt, чтобы вы могли привести в порядок эту фундаментальную часть своего сайта и убедиться, что поисковые роботы взаимодействуют с вашим сайтом так, как вы хотите.
Что такое файл robots.txt?
Файл robots.txt представляет собой простую директиву, сообщающую поисковым роботам, какие страницы вашего сайта следует сканировать и индексировать.
Это часть протокола исключения роботов (REP), семейства стандартных процедур, которые определяют, как роботы поисковых систем сканируют Интернет, оценивают и индексируют контент сайта, а затем предоставляют этот контент пользователям. В этом файле указывается, где сканерам разрешено сканировать, а где нет. Он также может содержать информацию, которая может помочь поисковым роботам более эффективно сканировать веб-сайт.
REP также включает «мета-теги роботов», которые представляют собой директивы, включенные в HTML-код страницы и содержащие конкретные инструкции о том, как поисковые роботы должны сканировать и индексировать определенные веб-страницы, а также изображения или файлы, которые они содержат.
В чем разница между Robots.txt и тегом Meta Robots?
Как я уже упоминал, протокол исключения роботов также включает «мета-теги роботов», которые представляют собой фрагменты кода, включенные в HTML-код страницы. Они отличаются от файлов robots. txt тем, что указывают направление поисковым роботам на определенные веб-страницы , запрещающие доступ либо ко всей странице, либо к определенным файлам, содержащимся на странице, таким как фотографии и видео.
txt тем, что указывают направление поисковым роботам на определенные веб-страницы , запрещающие доступ либо ко всей странице, либо к определенным файлам, содержащимся на странице, таким как фотографии и видео.
Файлы robots.txt, напротив, предназначены для предотвращения индексации целых сегментов веб-сайта, например подкаталогов, предназначенных только для внутреннего использования. Файл robots.txt находится в корневом домене вашего сайта, а не на конкретной странице, а директивы структурированы таким образом, что они влияют на все страницы, содержащиеся в каталогах или подкаталогах, на которые они ссылаются.
Зачем мне нужен файл robots.txt?
Файл robots.txt — обманчиво простой текстовый файл, имеющий большое значение. Без него поисковые роботы будут просто индексировать каждую найденную страницу.
Почему это важно?
Во-первых, сканирование всего сайта требует времени и ресурсов. Все это стоит денег, поэтому Google ограничивает объем сканирования сайта, особенно если этот сайт очень большой. Это известно как «краулинговый бюджет». Бюджет сканирования ограничен несколькими техническими факторами, включая время отклика, малоценные URL-адреса и количество обнаруженных ошибок.
Это известно как «краулинговый бюджет». Бюджет сканирования ограничен несколькими техническими факторами, включая время отклика, малоценные URL-адреса и количество обнаруженных ошибок.
Кроме того, если вы разрешите поисковым системам беспрепятственный доступ ко всем вашим страницам и позволите их поисковым роботам индексировать их, вы можете столкнуться с раздуванием индекса. Это означает, что Google может ранжировать неважные страницы, которые вы не хотите показывать в результатах поиска. Эти результаты могут вызвать у посетителей плохой опыт, и они могут даже конкурировать со страницами, для которых вы хотите ранжироваться.
Когда вы добавляете файл robots.txt на свой сайт или обновляете существующий файл, вы можете сократить краулинговый бюджет и ограничить раздувание индекса.
Где найти файл robots.txt?
Есть простой способ узнать, есть ли на вашем сайте файл robots.txt: найдите его в Интернете.
Просто введите URL-адрес любого сайта и добавьте в конец «/robots. txt». Например: victoriousseo.com/robots.txt показывает вам нашу.
txt». Например: victoriousseo.com/robots.txt показывает вам нашу.
Попробуйте сами, введя URL своего сайта и добавив в конце «/robots.txt». Вы должны увидеть одну из трех вещей:
- Несколько строк текста, указывающих на действительный файл robots.txt
- Совершенно пустая страница, указывающая на отсутствие фактического файла robots.txt
- Ошибка 404
Если вы проверяете свой сайт и получаете один из двух вторых результатов, вам нужно создать файл robots.txt чтобы помочь поисковым системам лучше понять, на чем они должны сосредоточить свои усилия.
Как создать файл robots.txt
Файл robots.txt содержит определенные команды, которые роботы поисковых систем могут читать и выполнять. Вот некоторые из терминов, которые вы будете использовать при создании файла robots.txt.
Общие термины Robots.txt, которые следует знать
User-Agent : User-agent — это любая часть программного обеспечения, задача которой заключается в извлечении и представлении веб-контента конечным пользователям. В то время как веб-браузеры, медиаплееры и подключаемые модули могут считаться примерами пользовательских агентов, в контексте файлов robot.txt пользовательский агент — это поисковый робот или паук (например, Googlebot), который сканирует и индексирует Ваш сайт.
В то время как веб-браузеры, медиаплееры и подключаемые модули могут считаться примерами пользовательских агентов, в контексте файлов robot.txt пользовательский агент — это поисковый робот или паук (например, Googlebot), который сканирует и индексирует Ваш сайт.
Разрешить: Если эта команда содержится в файле robots.txt, она позволяет агентам пользователя сканировать любые страницы, следующие за ней. Например, если команда гласит «Разрешить: /», это означает, что любой поисковый робот может получить доступ к любой странице, которая следует за косой чертой в «https://www.example.com/». Вам не нужно добавлять это для всего, что вы хотите сканировать, поскольку все, что не запрещено в robots.txt, неявно разрешено. Вместо этого используйте его, чтобы разрешить доступ к подкаталогу, находящемуся на запрещенном пути. Например, на сайтах WordPress часто есть директива disallow для папки /wp-admin/, что, в свою очередь, требует от них добавления директивы allow, позволяющей поисковым роботам получать доступ к /wp-admin/admin-ajax. php, не обращаясь ни к чему другому в папке. основная папка.
php, не обращаясь ни к чему другому в папке. основная папка.
Disallow: Эта команда запрещает определенным пользовательским агентам просматривать страницы, следующие за указанной папкой. Например, если команда гласит «Запретить: /blog/», это означает, что пользовательский агент не может сканировать любые URL-адреса, содержащие подкаталог /blog/, что исключит весь блог из поиска. Вы, вероятно, никогда не хотели бы этого делать, но вы могли бы. Вот почему очень важно учитывать последствия использования директивы disallow каждый раз, когда вы думаете о внесении изменений в файл robots.txt.
Crawl-delay: Хотя эта команда считается неофициальной, она предназначена для защиты серверов от потенциально перегруженных запросов поисковых роботов. Обычно это реализуется на веб-сайтах, где слишком много запросов могут вызвать проблемы с сервером. Некоторые поисковые системы поддерживают его, но Google — нет. Вы можете настроить скорость сканирования для Google, открыв Google Search Console, перейдя на страницу настроек скорости сканирования вашего ресурса и отрегулировав там ползунок.![]() Это работает только в том случае, если Google считает, что это не оптимально. Если вы считаете, что это неоптимально, и Google с этим не согласен, вам может потребоваться отправить специальный запрос на его корректировку. Это потому, что Google предпочитает, чтобы вы позволяли им оптимизировать скорость сканирования вашего сайта.
Это работает только в том случае, если Google считает, что это не оптимально. Если вы считаете, что это неоптимально, и Google с этим не согласен, вам может потребоваться отправить специальный запрос на его корректировку. Это потому, что Google предпочитает, чтобы вы позволяли им оптимизировать скорость сканирования вашего сайта.
Карта сайта XML: Эта директива делает именно то, что вы и предполагали: сообщает поисковым роботам, где находится ваша карта сайта в формате XML. Он должен выглядеть примерно так: «Карта сайта: https://www.example.com/sitemap.xml». Вы можете узнать больше о лучших методах работы с картами сайта здесь.
Пошаговые инструкции по созданию файла robots.txt
Чтобы создать собственный файл robots.txt, вам потребуется доступ к простому текстовому редактору, например Блокноту или TextEdit. Важно не использовать текстовый процессор, так как он обычно сохраняет файлы в проприетарных формах и может добавлять в файл специальные символы.
Для простоты мы будем использовать «www.example.com».
Начнем с настройки параметров пользовательского агента. В первой строке введите:
User-agent: *
Звездочка означает, что всем поисковым роботам разрешено посещать ваш сайт.
Некоторые веб-сайты используют разрешающую директиву, указывающую, что ботам разрешено сканирование, но в этом нет необходимости. Любые части сайта, которые вы не запретили, неявно разрешены.
Далее мы введем параметр запрета, если это необходимо. Дважды нажмите «возврат», чтобы вставить разрыв после строки пользовательского агента, затем введите параметр disallow, за которым следует каталог, который вы не хотите сканировать. Вот как выглядит наш:
Запретить: /wp/wp-admin/
Запретить: /*?*
Первая команда гарантирует, что наши страницы администратора WordPress (где мы редактируем такие вещи, как эта статья) не сканируются. Это страницы, которые мы не хотим ранжировать в поиске, и было бы пустой тратой времени Google сканировать их, потому что они защищены паролем. Вторая команда запрещает поисковым роботам сканировать URL-адреса, содержащие вопросительный знак, например внутренние страницы результатов поиска по блогам.
Это страницы, которые мы не хотим ранжировать в поиске, и было бы пустой тратой времени Google сканировать их, потому что они защищены паролем. Вторая команда запрещает поисковым роботам сканировать URL-адреса, содержащие вопросительный знак, например внутренние страницы результатов поиска по блогам.
После того, как вы выполнили свои команды, создайте ссылку на карту сайта. Хотя этот шаг не является обязательным с технической точки зрения, это рекомендуемая передовая практика, поскольку она указывает веб-паукам на наиболее важные страницы вашего сайта и делает архитектуру вашего сайта понятной. После вставки другого разрыва строки введите:
Карта сайта: https://www.example.com/sitemap.xml
Теперь ваш веб-разработчик может загрузить ваш файл на ваш сайт.
Создание файла Robots.txt в WordPress
Если у вас есть доступ администратора к вашему WordPress, вы можете изменить файл robots.txt с помощью плагина Yoast SEO или AIOSEO.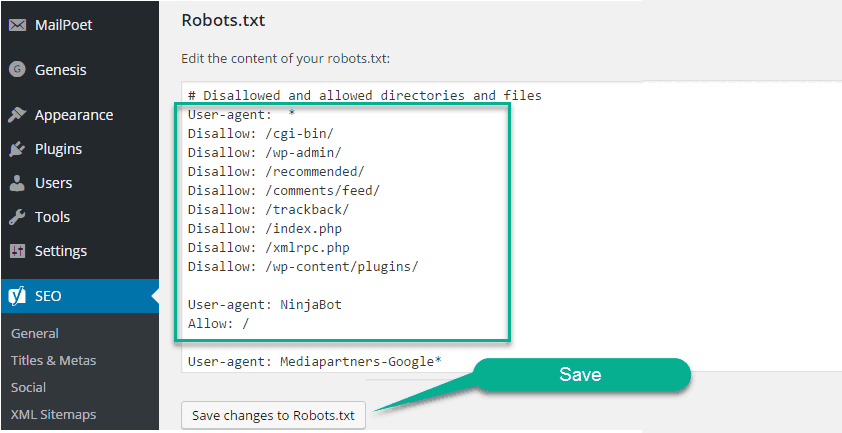 Кроме того, ваш веб-разработчик может использовать клиент FTP или SFTP для подключения к вашему сайту WordPress и доступа к корневому каталогу.
Кроме того, ваш веб-разработчик может использовать клиент FTP или SFTP для подключения к вашему сайту WordPress и доступа к корневому каталогу.
Не перемещайте файл robots.txt куда-либо, кроме корневого каталога. Хотя некоторые источники предлагают разместить его в подкаталоге или поддомене, в идеале он должен находиться в вашем корневом домене: www.example.com/robots.txt.
Как протестировать файл robots.txt
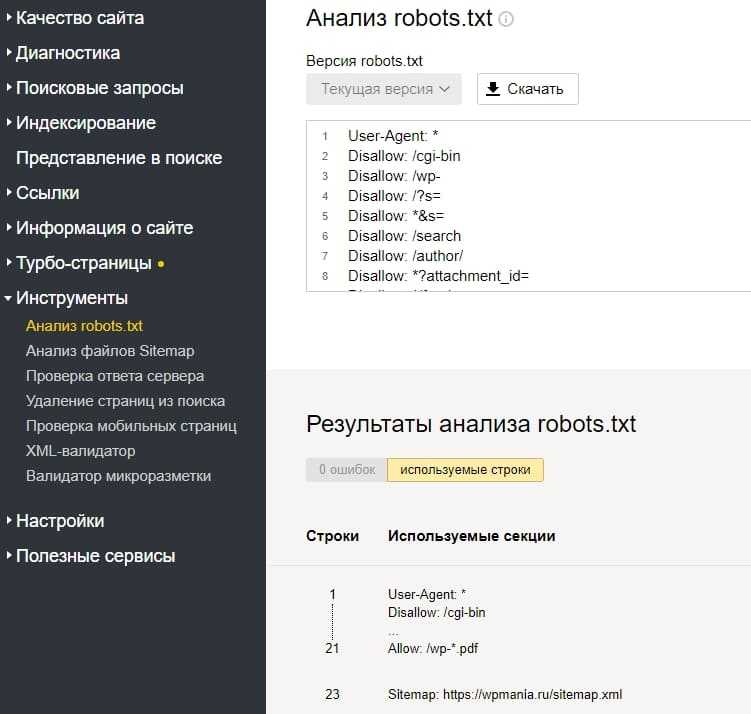
Теперь, когда вы создали файл robots.txt, пришло время протестировать его. К счастью, Google упрощает это, предоставляя тестер robots.txt как часть Google Search Console.
После того, как вы откроете тестер для своего сайта, вы увидите все синтаксические предупреждения и выделенные логические ошибки.
Чтобы проверить, как определенный робот Googlebot «видит» вашу страницу, введите URL-адрес вашего сайта в текстовое поле внизу страницы, а затем выберите один из различных роботов Googlebot в раскрывающемся списке справа. Нажатие «TEST» смоделирует поведение выбранного вами бота и покажет, не запрещают ли роботу Googlebot доступ к странице какие-либо директивы.
Недостатки Robots.txt
Файлы robots.txt очень полезны, но у них есть свои ограничения.
Файлы robots.txt не должны использоваться для защиты или сокрытия частей вашего веб-сайта (это может привести к нарушению Закона о защите данных). Помните, я предлагал вам найти собственный файл robots.txt? Это означает, что любой может получить к нему доступ, а не только вы. Если есть информация, которую необходимо защитить, лучше всего защитить паролем определенные страницы или документы.
Кроме того, директивы вашего файла robots.txt являются просто запросами. Вы можете ожидать, что Googlebot и другие законные поисковые роботы будут подчиняться вашим указаниям, но другие боты могут просто их игнорировать.
Наконец, даже если вы попросите сканеры не индексировать определенные URL-адреса, они не будут невидимыми. Другие веб-сайты могут ссылаться на них. Если вы не хотите, чтобы определенная информация на вашем веб-сайте была доступна для всеобщего обозрения, вам следует защитить ее паролем. Если вы хотите убедиться, что он не будет проиндексирован, рассмотрите возможность добавления на страницу тега noindex.
Если вы хотите убедиться, что он не будет проиндексирован, рассмотрите возможность добавления на страницу тега noindex.
Узнайте больше о техническом SEO: загрузите наш контрольный список
Хотите узнать больше о SEO, включая пошаговые инструкции о том, как взять SEO вашего сайта в свои руки? Загрузите наш Контрольный список SEO на 2023 год, чтобы получить исчерпывающий список дел, включая ценные ресурсы, которые помогут вам повысить рейтинг в поисковых системах и привлечь больше органического трафика на ваш сайт.
Контрольный список SEO & Инструменты планирования
Готовы ли вы изменить направление SEO? Получите интерактивный контрольный список и инструменты планирования и приступайте к работе!
НАЧНИТЕ РЕЙТИНГ СЕГОДНЯ
Получите бесплатную консультацию по SEO
Заполните форму для бесплатного анализа сайта.
Имя *
Фамилия *
Электронная почта компании *
Сколько вы хотите инвестировать в SEO? *
— Пожалуйста, выберите — я еще не уверен / мне нужна помощь с этим $2,999 – 5 000 в месяц 5 000–10 000 долларов в месяц 10 000 – 20 000 долларов в месяц 20 000 долларов США в месяц
Как создать файл robots.
 txt в cPanel Искать
txt в cPanel ИскатьСодержание
Если вы когда-либо создавали свой веб-сайт, возможно, вы слышали о файле robotx.txt и задавались вопросом, для чего этот файл? Ну, вы в правильном месте! Ниже мы рассмотрим этот файл и его важность.Что такое файл robots.txt?
Во-первых, robots.txt — это не что иное, как простой текстовый файл (ASCII или UTF-8), расположенный в вашем домене корневой каталог , который блокирует (или разрешает) поисковым системам доступ к определенным областям вашего сайта. robots.txt содержит простой набор команд (или директив) и обычно применяется для ограничения трафика поисковых роботов на ваш сервер, что предотвращает нежелательное использование ресурсов.
Поисковые системы используют так называемые сканеры (или боты) для индексации частей веб-сайта и возврата их в качестве результатов поиска. Возможно, вы захотите, чтобы определенные конфиденциальные данные, хранящиеся на вашем сервере, были недоступны для веб-поиска. Файл robots.txt поможет вам сделать это.
Файл robots.txt поможет вам сделать это.
Примечание: Файлы или страницы на вашем веб-сайте не удаляются полностью из поисковых роботов, если эти файлы проиндексированы или на них есть ссылки с других веб-сайтов. Чтобы ваш URL не отображался в поисковых системах Google, вы можете защитить файлы паролем прямо с вашего сервера.
Как создать файл robots.txt
Чтобы создать файл robots.txt (если он еще не существует), выполните следующие действия:
1. Войдите в свою учетную запись cPanel
2. Перейдите в раздел ФАЙЛЫ и нажмите Диспетчер файлов
cPanel > Файлы > Диспетчер файлов Файл ” >> Введите «robots.txt» >> Нажмите « Создать новый файл ».4. Теперь вы можете редактировать содержимое этого файла, дважды щелкнув по нему.
Примечание: можно создать только один файл r obots. txt для каждого домена. Дубликаты не допускаются на одном и том же корневом пути. Каждый домен или поддомен должен содержать собственный файл robots.txt .
txt для каждого домена. Дубликаты не допускаются на одном и том же корневом пути. Каждый домен или поддомен должен содержать собственный файл robots.txt .
Примеры правил использования и синтаксиса
Обычно файл robots.txt содержит одно или несколько правил, каждое из которых находится в отдельной строке. Каждое правило блокирует или разрешает доступ данному сканеру к указанному пути к файлу или ко всему веб-сайту.
- Запретить всем сканерам (пользовательским агентам) доступ к каталогам журналов и ssl .
Агент пользователя:* Запретить: /журналы/ Запретить: /ssl/
- Заблокировать все поисковые роботы для индексации всего сайта.
Агент пользователя: * Disallow: /
- Разрешить всем пользовательским агентам доступ ко всему сайту.
Агент пользователя: * Разрешить: /
- Блокировать индексацию всего сайта от определенного поискового робота.

Агент пользователя: Bot1 Disallow: /
- Разрешить индексирование для определенного поискового робота и предотвратить индексирование другими.
Агент пользователя: Googlebot Запретить: Пользовательский агент: * Disallow: /
- Под User-agent : вы можете ввести имя конкретного поискового робота. Вы также можете включить все поисковые роботы, просто введя символ звездочки (*). С помощью этой команды вы можете отфильтровать все поисковые роботы, кроме сканеров AdBot, которые необходимо перечислить явно. Вы можете найти список всех сканеров в Интернете.
- Кроме того, чтобы команды Разрешить и Запретить работали только для определенного файла или папки, вы всегда должны включать их имена между « / ».
- Обратите внимание, что обе команды чувствительны к регистру? Особенно важно знать, что по умолчанию агенты сканера имеют доступ к любой странице или каталогу, если они не заблокированы правилом Disallow : .
