
Посмотреть сайт глазами поискового робота
В некоторых случаях бывает интересно посмотреть HTML код понравившейся станицы. Например узнать какой .js библиотекой достигнут тот или иной функционал, а может заинтересовали CSS стили оформления и.т.д. Но откравая страницу правой кнопкой мыши мы можем иногда наблюдать сжатый код написанный в одну строчку, ну и разумеется без подсветки кода. Что согласитесь затрудняет поиск заинтересовавшего куска кода. Наш онлайн сервис поможет открыть HTML в удобочитаемом виде с подсветкой и форматированием кода.
Глаз робота отличается от пользователя.
Это связано с тем, что некоторые сайты могут отдавать различный контент в зависимости от пользователя или робота.
Например интернет магазин для пользователя может отдаваться различый контент в зависимости от региона проживания.
Метод черной поисковой оптимизации — называется «клоакинг» Термин произошел от английского слова to cloak – маскировать, прятать, скрывать — Сайты, отдающие разный контент пользователям и роботам поисковых систем.
Такие сайты Яндекс и Google относят к некачественным сайтам и объявили за клоакинг жесткие штрафные санкции, от пессимизации до бана.
Ярким примером клоакинга могут служить каталоги ссылок скрывающие прямые ссылки от роботов , но показывающие их простому пользователю, который никак не может понять почему же его сылка не видна в поисковых системах.
Обратите внимание, что к клоакингу не относится показ различного содержание веб-ресурса если пользователь просматривает его как авторизованный (через логин и пароль). Также не имеет отношение к клоакингу просмотр динамических страниц с разными URL переменными например URL = user и URL = bot.

Наш онлайн инструмент для веб-мастера позволяет просмотреть код HTML глазами поискового робота Googlebot и робота Яндекса.
Список HTTP USER AGENT:
Пользователь — Я Mozilla/5.0 (X11; Linux x86_64; rv:33.0) Gecko/20100101 Firefox/33.0
Основной робот Яндекса — Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)
Зеркальщик — робот Яндекса — Mozilla/5.0 (compatible; YandexBot/3.0; MirrorDetector; +http://yandex.com/bots)
Картинки — робот Яндекса — Mozilla/5.0 (compatible; YandexImages/3.0; +http://yandex.com/bots)
Видео — робот Яндекса Mozilla/5.0 (compatible; YandexVideo/3.0; +http://yandex.com/bots)
Вебмастер — робот Яндекса Mozilla/5.0 (compatible; YandexWebmaster/2.0; +http://yandex.com/bots)
Индексатор мультимедийных данных — робот Яндекса Mozilla/5.0 (compatible; YandexMedia/3.0; +http://yandex.com/bots)
Поиск по блогам — робот Яндекса Mozilla/5.0 (compatible; YandexBlogs/0.99; robot; +http://yandex.com/bots)
APIs-Google — робот Google PIs-Google (+https://developers.google.com/webmasters/APIs-Google.html)
AdSense — робот Google Mediapartners-Google
AdsBot Mobile Web Android — робот Google Mozilla/5.0 (Linux; Android 5.0; SM-G920A) AppleWebKit (KHTML, like Gecko) Chrome Mobile Safari (compatible; AdsBot-Google-Mobile; +http://www.google.com/mobile/adsbot.html)
AdsBot Mobile Web — робот Google Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13B143 Safari/601.1 (compatible; AdsBot-Google-Mobile; +http://www.google.com/mobile/adsbot.html)
AdsBot-Google (+http://www.google.com/adsbot.html) AdsBot — робот Google)
Googlebot Images — робот Google Googlebot-Image/1.0
Googlebot News — робот Google Googlebot-News
Googlebot Video — робот Google Googlebot-Video/1.0
Googlebot — робот Google Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Mobile AdSense — робот Google (compatible; Mediapartners-Google/2.1; +http://www.google.com/bot.html)
Mobile Apps Android — робот Google AdsBot-Google-Mobile-Apps
Взгляните на свою страницу глазами робота Googlebot / Google corporate blog / Habr
Уровень подготовки веб-мастера: любой
Функция «Просмотреть как Googlebot» в Инструментах для веб-мастеров позволяет понять, как ваша страница выглядит для роботов Googlebot. Заголовки серверов и код HTML помогают выявить ошибки и последствия взлома, но иногда разобраться в них бывает затруднительно. Веб-мастера обычно хватаются за голову, когда им приходится заниматься решением таких проблем. Чтобы помочь вам в подобных ситуациях, мы усовершенствовали эту функцию, и теперь она может показывать страницу с помощью того же алгоритма, который использует робот Googlebot.
Как отображается просканированная страница
При обработке страницы робот Googlebot ищет и импортирует из внешних источников все связанные с ней файлы. Обычно это изображения, таблицы стилей, элементы JavaScript и другие файлы, встраиваемые с помощью CSS или JavaScript. Система использует их для отображения страницы так, как ее видит робот Googlebot.
Функция Просмотреть как Googlebot доступна в разделе «Сканирование» вашего аккаунта Инструментов для веб-мастеров. Обратите внимание, что обработка страницы с ее последующим показом может занять достаточно продолжительное время. После ее завершения наведите указатель мыши на строку, в которой указан нужный URL, чтобы просмотреть результат.
для обычного робота Googlebot
для робота Googlebot для смартфонов
Обработка ресурсов, заблокированных в файле robots.txt
При обработке кода робот Googlebot учитывает инструкции, указанные в файле robots.txt. Если они запрещают доступ к тем или иным элементам, система не будет использовать такие материалы для предварительного просмотра. Это произойдет и в том случае, если сервер не отвечает или возвращает ошибку. Соответствующие данные можно найти в разделе Ошибки сканирования вашего аккаунта Инструментов для веб-мастеров. Кроме того, полный перечень таких сбоев отобразится после того, как будет создано изображение страницы для предварительного просмотра.
Мы рекомендуем обеспечить Googlebot доступ ко всем встроенным ресурсам, которые есть на сайте или в макете. Это упростит работу с функцией «Просмотреть как Googlebot», позволит роботу обнаружить и правильно проиндексировать контент вашего сайта, а также поможет вам понять, как выполняется сканирование ваших страниц. Некоторые фрагменты кода, такие как кнопки социальных сетей, скрипты инструментов аналитики и шрифты, обычно не определяют оформление страницы, а значит их сканирование не обязательно. Подробнее о том, как Google анализирует веб-контент, читайте в предыдущей статье.
Паучье зрение или как поисковый робот видит страницу сайта?
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Роботы-краулеры — это своего рода автономные программы-браузеры. Они заходят на сайт, сканируют содержимое страниц, делают текстовую копию и отправляют в поисковую базу. От того что увидят краулеры на вашем сайте зависит его индексация в поисковике. Есть также более узкопрофильные программы-пауки.
- «Зеркальщики» — распознают повторяющиеся ресурсы.
- «Дятлы» — определяют доступность сайта.
- «Быстроботы» — роботы для считывания часто обновляемых ресурсов. А также программы для сканирования картинок, иконок, определения частоты визитов и других характеристик.
Что робот видит на сайте
- Текст ресурса.
- Внутренние и внешние ссылки.
- HTML-код страницы.
- Ответ сервера.
- Файл robots. txt — это основной документ для работы с пауком. В нем вы можете задать одни параметры для привлечения внимания робота, а другие наоборот закрыть от просмотра. Также при повторном заходе на сайт, краулер пользуется именно эти файлом.
В какой форме робот видит страницу сайта?
Есть несколько способов посмотреть на ресурс глазами программы. Если вы являетесь владельцем сайта, то для вас Google придумал Search Console.
- Добавляем ресурс на сервис. Как это можно сделать читайте здесь.
- После этого выбираем инструмент «Просмотреть как Googlebot».
- Нажимаем «Получить и отобразить».После выполнения сканирования будет вот такой результат.

Этот способ отображает самую полную и верную картину того, как робот видит сайт. Если же вы не являетесь владельцем ресурса то, для вас есть другие варианты.
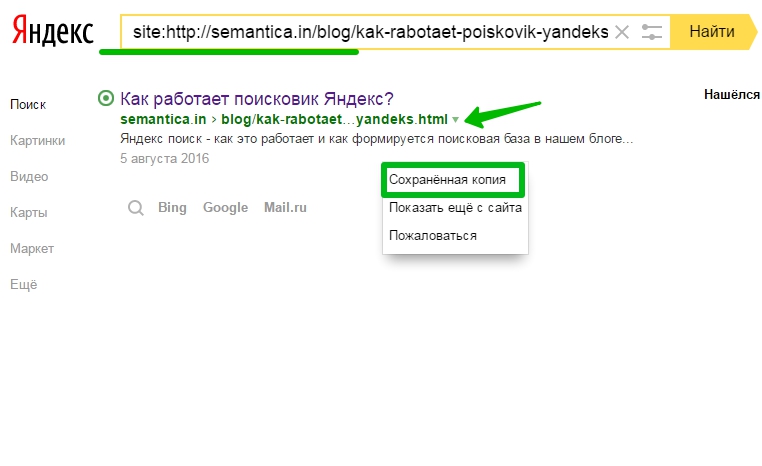
Самый простой — через сохраненную копию в поисковой системе.
- Вбиваете в поле поисковика «site:интересующий вас URL».
- Кликаете на зеленый треугольничек рядом ссылкой и открываете «Сохраненную копию».

3. В ней выбираете текстовый режим и получаете вот такую картину.
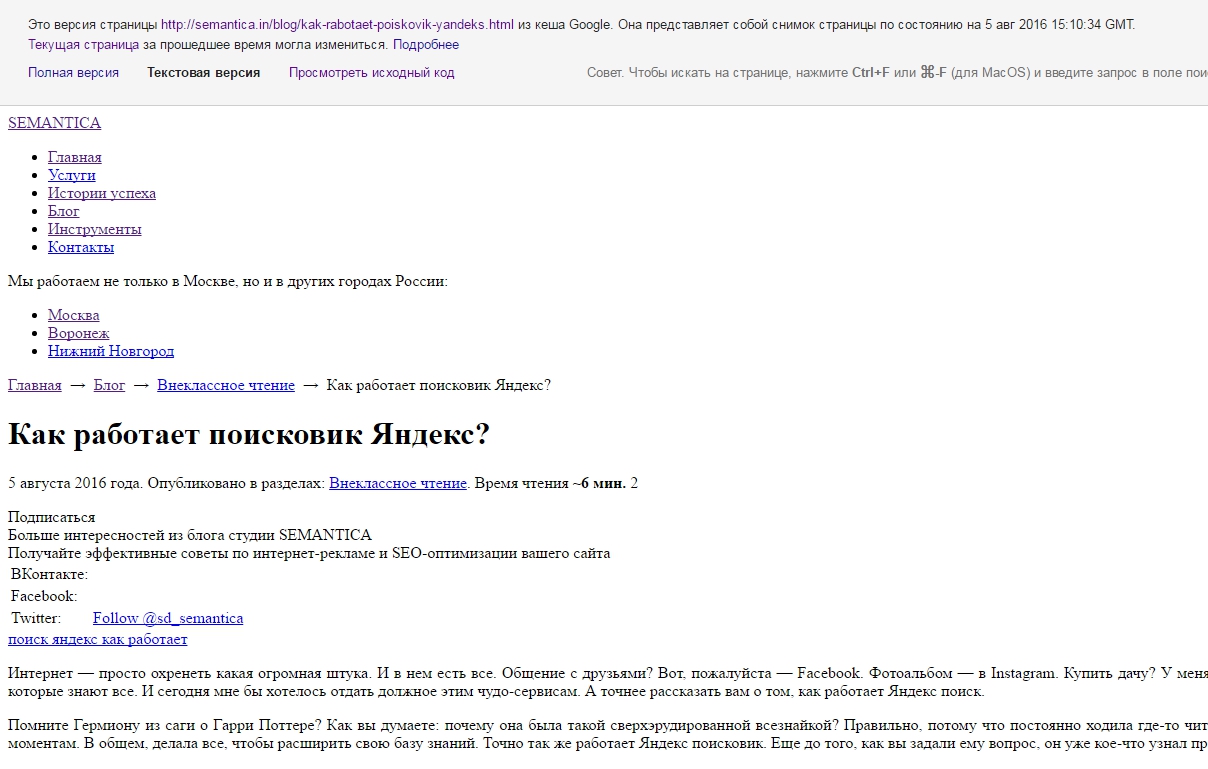
Предположим, что ресурс ещё не проиндексирован, и вы не можете найти его в поисковике. В таком случае, чтобы узнать, как робот видит сайт, нужно выполнить следующий алгоритм.
- Устанавливаем Mozila Firefox.
- Добавляем в этот браузер плагин.
- Под полем URL появится бар, в котором мы:
в «Cookies» выбираем «Disable Cookies»;
в «Disable» кликаем на «Disable JavaScript» и «Disable ALL JavaScript». - Обязательно перезагружаем страницу.
- Все в том же инструменте:
в «CSS» жмем на «Disable styles» и «Disable all styles»;
и в «Images» ставим галочку на «Display ALT attributes» и «Disable ALL images». Готово!
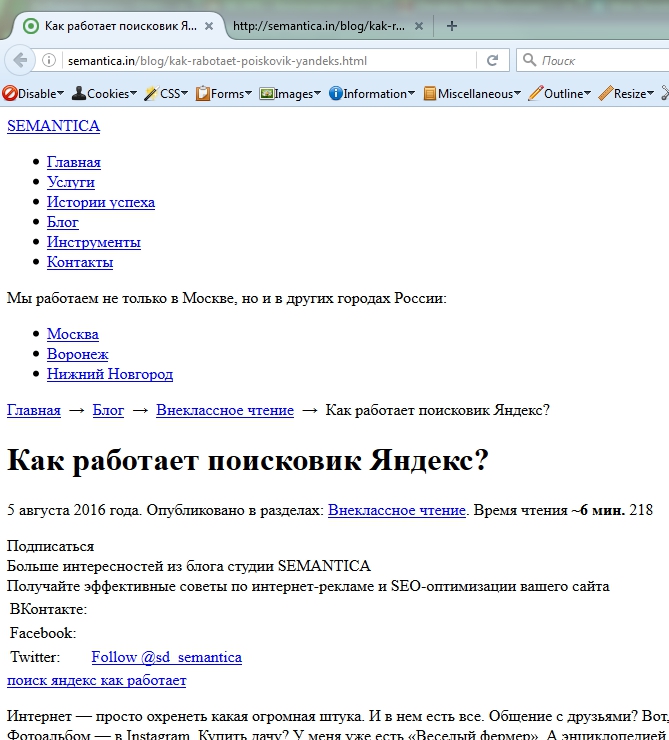
Зачем нужно проверять то, как робот видит сайт?
Когда поисковик видит на вашем сайте одну информацию, а пользователь другую — значит, ресурс появляется не в той выдаче. Соответственно, пользователь спешно покинет его, не найдя интересующей его информации. Если так будет делать большое количество посетителей, то ваш сайт опустится на самое дно выдачи.
Проверять нужно минимум 15−20 страниц сайта и стараться охватывать все типы страниц.
Бывает, что некоторые хитрецы специально проворачивают такие аферы. Ну, например, вместо сайта о мягких игрушках пиарят какое-нибудь казино «Кукан». Поисковик со временем это (в любом случае) обнаружит и отправит такой ресурс под фильтры.
Что такое Googlebot и как он может помочь вам в SEO?
В словаре SEO-специалистов часто можно услышать о таком понятии, как “дружественность сайта к поисковым системам”. Что это значит? Процесс сканирования и индексирования сайта это достаточно затратный процесс для всех поисковых систем, особенно с таким ростом количества сайтов и страниц, как происходит сейчас. Чем дороже процесс по ресурсам, тем больше лимитов и жестких правил устанавливают поисковики. Понимание того, по каким правилам работают поисковые роботы (в частности, Googlebot) поможет постепенно сделать свой сайт “дружественным” для поисковиков. А это помогает быстрее индексировать новые и обновленные страницы, быстрее находить ошибки и т.д.
Что такое Googlebot?
Поисковые роботы (например, Googlebot) – это роботы, которые сканируют веб-страницы и добавляют их индекс. Если код на странице дает боту команду на индексирование, тогда он добавляет эту страницу в индекс, и только тогда она становится доступной пользователям. Очень хорошо этот процесс описан в этом руководстве Google. Ключевыми правилами сканирования, являются четыре следующие шага:
Если страница высоко ранжируется, поисковый робот Google будет тратить больше времени на её сканирование.
Здесь мы можем поговорить о «краулинговом бюджете», представляющем собой точное количество времени, затрачиваемого веб-роботами на сканирование определенного сайта: чем более авторитетна веб-страница, тем больший бюджет она получит.
Google бот постоянно сканирует сайт
Вот что об этом говорит Google: «Поисковый робот Google не имеет доступа к сайту чаще, чем один раз в секунду». Это означает, что сайт находится под постоянным контролем веб-пауков, если у них есть доступ к нему. Сегодня многие SEO специалисты спорят о так званой «скорости обхода» и пытаются найти оптимальный способ обхода сайта роботом, чтобы получить высокий уровень ранжирования. Тем не менее, «скорость обхода» – это всего лишь скорость запросов поискового робота Google, а не повторение сканирования. Вы даже можете изменить этот показатель самостоятельно с помощью Webmasters Tools. Огромное количество внешних ссылок, наличие ссылок с 404 ошибкой, уникальность и упоминания в соцсетях влияют на вашу позицию в результатах поиска. Также важно уточнить, что веб-пауки не сканируют каждую страницу непрерывно, поэтому намного выгоднее сразу создавать полезный и уникальный контент.
Файл Robots.txt – это первое, что сканируют роботы Google
Если страница отмечена в файле robots.txt как запрещенная для сканирования, роботы не будут её сканировать и соответственно в индекс она не попадет.
Файл Sitemap.xml – это руководство для ботов Google
Файл Sitemap.xml помогает ботам понять, какие части сайта нужно просканировать и проиндексировать. Так как сайты в основном различаются по своей структуре, гуглбот не может краулить все страницы на сайте автоматически. Качественный файл Sitemap может помочь страницам с низким рейтингом, небольшим количеством обратных внутренних ссылок и бесполезным контентом попасть в индекс на равне с более авторитетными страницами.
Как оптимизировать сайт для лучшего сканирования поисковым роботом Googlebot?
Не недооценивайте файл robots.txt
Файл robots.txt является вместилищем команд для поисковых роботов. И так как ваш “краулинговый бюджет” ограничен, уделите время и постарайтесь закрыть от сканирования все необходимые страницы. Так, ваши самые ценные страницы будет индексироваться быстрее и чаще.
Полезный и уникальный контент действительно имеет значение
Основной тезис такой – контент, который сканируется чаще, ранжируется выше и соответственно приносит больше трафика. Особенно это становится важно сейчас. Google все больше ориентируется на новизну, актуальность страниц. Обновляйте контент на ваших топовых страницах, добавляйте их в индекс вручную и постепенно гуглбот будет сам уделять им больше внимания. Если у сайта слишком большое количество открытых страниц пагинации, то есть вероятность, что нужные вебмастеру страницы могут быть не проиндексированы. Это связано с тем, что поисковых бот израсходует краулинговый бюджет на продублированные страницы.
Пора начать использовать внутренние ссылки
Внутренние ссылки не только упрощают использование сайта для пользователя, но и делают проще процесс сканирования для поисковых ботов. Если ранее вы не уделяли внимания каждой ссылке на странице, воспользуйтесь Google Search Console, чтобы отследить активные ссылки. Для еще более глубокого исследования, добавьте ваш сайт в наш краулер и оцените всю структуру внутренних ссылок, анкор лист, распределение весов. Также вы можете попробовать запустить аудит сайта, чтобы найти ошибки и проанализировать внутреннюю структуру сайта, включаяя ссылки.
Sitemap.xml жизненно важен
Еще раз, почему этот файл так важен? Sitemap – это карта местности для бота. Без неё он блуждает по сайту только на основе внутренних ссылок, и страницы которые слабо перелинкованы получают мало внимания, или вообще могут быть не замечены. Это один из важных факторов, которые поисковая система гугл использует при сканировании сайтов.
Как анализировать работу Googlebot?
Для анализа работы гуглбота, просто регулярно проверяйте раздел «Сканирование» в Webmaster Tools.
Популярные ошибки при сканировании
Страница “Ошибки сканирования” помогает быстро найти как критические ошибки, так и неопасные уведомления. К этому блоку чаще всего стоит обращаться, когда вы заметили какие то резкие изменения в индексации, снижение количества трафика.
Файлы Sitemap
Используйте эту функцию, если хотите поработать с картой сайта: изучить, добавить или выяснить, какой контент индексируется.
Посмотреть как Googlebot
Функция «Посмотреть как Googlebot» один из самых быстрых способов добавить страницу в индекс гугла.
Статистика сканирования
Эта вкладка помогает оценить динамику сканирования сайта в разрезе 90 дней.
Параметры URL
Google не рекомендует использовать эту функцию без необходимости. По задумке, объяснение значений отдельных частей URL-адреса помогает гуглу лучше понимать как сканировать каждый тип страниц.
Посмотрите на сайт глазами поисковой машины
Продвижение вашего сайта должно включать оптимизацию страниц, чтобы привлечь внимание поисковых пауков. До того, как вы начнете создавать веб сайт дружественный поисковым машинам, вы должны знать, как боты видят ваш сайт.
Поисковые машины на самом деле не пауки, а небольшие программы, которые посылаются для анализа вашего сайта после того, как они узнают урл вашей страницы. Поисковики, так же могут добраться до вашего сайта через ссылки на ваш вебсайт, оставленные на других интернет ресурсах.
Как только робот доберется до вашего веб сайта, то сразу же начнет индексировать страницы, читая содержимое тега BODY. Он так же полностью читает все HTML теги и ссылки на другие сайты.
Затем, поисковые машины копируют содержимое сайта в главную базу данных для последующего индексирования. Этот процесс в целом может занять до трех месяцев.
Поисковая оптимизация не такое уж легкое дело. Вы должны создать сайт дружественный поисковым паукам. Боты не обращают внимание на флеш вебдизайн, они только хотят получить информацию. Если на вебсайт посмотреть глазами поискового робота, он бы имел довольно глупый вид.
Еще интересней посмотреть глазами паука на сайты конкурентов. Конкурентов не только в вашей области, но просто популярные ресурсы, которым возможно не нужна ни какая поисковая оптимизация. Вообще, очень интересно посмотреть, как выглядят разные сайты глазами роботов.
Только текст
Поисковые роботы видят ваш сайт в большей степени, как это делают текстовые браузеры. Они любят текст и игнорируют информацию, содержащуюся в картинках. Пауки могут прочитать о картинке, если вы не забудете добавить тег ALT с описанием. Вызывают глубокое разочарование веб дизайнеры, создающие сложные сайты с красивыми картинками и с очень малым содержанием текста.
На самом деле, поисковики просто обожают любой текст. Они могут читать только HTML код. Если у вас на странице много форм или яваскрипта или чего-нибудь еще, что может блокировать поисковую машину для чтения HTML кода, паук просто будет игнорировать ее.
Что поисковые роботы хотят видеть
Когда поисковая машина сканирует вашу страницу, она ищет ряд важных вещей. Заархивировав ваш сайт, поисковый робот начнет ранжировать его в соответствии со своим алгоритмом.
Поисковые пауки охраняют и часто изменяют свои алгоритмы, что бы спамеры не могли приспособиться под них. Очень тяжело спроектировать сайт, который займет высокие позиции во всех поисковых машинах, но вы можете получить некоторое преимущество, включив следующие элементы во все ваши веб страницы:
- Ключевые слова
- META теги
- Заглавия
- Ссылки
- Выделенный текст
Читайте как поисковая машина
После того как вы разработали сайт, вам остается его развивать и продвигать в поисковых машинах. Но смотреть на сайт только в браузер не является лучшей и успешной техникой. Не очень-то легко оценить свой труд непредвзято.
Гораздо лучше взглянуть на ваше творение глазами поискового симулятора. В этом случае вы получите гораздо больше информации о страницах и о том, как их видит паук.
Мы создали не плохой, по нашему скромному мнению, имитатор поисковых машин. Вы сможете увидеть веб страницу, как ее видит поисковый паук. Также будет показано количество введенных вами ключевых слов, локальные и исходящие ссылки и так далее.
Новый агент пользователя Googlebot для смартфонов / Google corporate blog / Habr
Уровень подготовки веб-мастера: высокий
Google индексирует контент, оптимизированный для обычных мобильных телефонов и смартфонов с широким набором функций и возможностей, с помощью разных поисковых роботов. Но мы заметили, что, так как они оба называются
Googlebot-Mobile, это нередко вызывает путаницу. Например, веб-мастера, намереваясь запретить сканирование и индексацию сайта для простых мобильных телефонов с ограниченными техническими возможностями, по ошибке запрещают сканирование сайта для всех устройств. Конечно, все это отрицательно сказывается на посещаемости веб-сайта.Новый Googlebot для смартфонов
Чтобы веб-мастерам было проще разобраться в настройках, через 3–4 недели мы переименуем агент пользователя в нашем поисковом роботе для смартфонов. Название
Googlebot-Mobile будет заменено на Googlebot с добавлением слова mobile в строку агента пользователя. Вы можете сравнить отличия ниже.Googlebot – новый агент пользователя для смартфонов:
Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible;<b>Googlebot</b>/2.1; +http://www.google.com/bot.html)
Googlebot-Mobile – старый агент пользователя для смартфонов, который вскоре будет заменен:
Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)
Эти изменения касаются только
Googlebot-Mobile для смартфонов. У обычного робота Googlebot останется тот же агент пользователя, а у двух оставшихся поисковых роботов Googlebot-Mobile в строке агента пользователя по-прежнему будут указаны телефоны среднего класса. Как это выглядит, смотрите ниже.Агент пользователя у обычного поискового робота Googlebot:
Mozilla/5.0 (compatible; Googlebot/2.1;
+http://www.google.com/bot.html)
Агенты пользователя у двух поисковых роботов Googlebot-Mobile для телефонов среднего класса:
SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)DoCoMo/2.0 N905i(c100;TB;W24h26) (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html)
Проверить, смогут ли эти поисковые роботы проиндексировать ваш сайт, можно с помощью функции «Просмотреть как Googlebot» в Инструментах для веб-мастеров. Полный список наших поисковых роботов опубликован в Справочном центре.
Сканирование и индексирование
Обратите внимание, что после смены поискового агента новый
Googlebot для смартфонов будет руководствоваться правилами в robots.txt, метатеге robots и HTTP-заголовках, которые касаются Googlebot, а не Googlebot-Mobile. Вот, например, правило в robots.txt, запрещающее сканировать сайт как обычному роботу Googlebot, так и новому роботу Googlebot для смартфонов:User-agent: Googlebot
Disallow: /
А такое правило в
robots.txt запретит сканирование поисковым роботам Google для простых мобильных телефонов:User-agent: Googlebot-Mobile
Disallow: /
По нашим подсчетам, это обновление затронет менее 0,001% веб-страниц, но при этом позволит веб-мастерам точнее управлять сканированием и индексацией их контента. Если у вас возникнут вопросы, вы можете:
Что не видит поисковый робот
 В статье Как работают поисковые машины интернета рассказано, что поисковый робот («паук») двигается по интернету только по гиперссылкам, и соответственно, рассмотрим случаи, когда они скрыты и него.
В статье Как работают поисковые машины интернета рассказано, что поисковый робот («паук») двигается по интернету только по гиперссылкам, и соответственно, рассмотрим случаи, когда они скрыты и него.
Он смотрит на сайты совершенно не так, как живые люди. Есть специальные сервисы, на которых можно посмотреть его глазами. например, сервис pr-cy.ru

Вбиваем проверяемеый сайт и жмем кнопку «Проверить» и внизу всё видно.
Еще пример. Окрыли сайт и видим кусок страницы, на которой имеется картинка
А вот этот же кусок, но глазами поисковика:
» title=»Туристическая поисковая система» src=»http://delajblog.ru/wp-content/uploads/2015/08/sletat.jpg» alt=»туристическая поисковая система» width=»151» height=»66» /></a>Принципиально новая система sletat ru, которая поможет туристам искать более выгодные туры по интересующей их стране. Сервис дарит своим пользователям интересную возможность – вы можете сравнить несколько предложений в плане цены от разных туристических компаний с схожими условиями.</p>
Чувствуете разницу?
Итак, что какие ссылки робот не видит.
Находятся в формах подписки
Довольно часто на сайтах имеются различные подписные формы, т.е. посетителю предлагается некая форма, в которую он вносит необходимую информацию (например, Имя. Фамилию и т.д.), затем нажимает на кнопку подписки (отправки введенных данных). В любом случае, любая информация введенная в формы – невидима для поисковых роботов. «Паук» не может «заползти» внутрь формы.
Вот форма подписки.

Для того, чтобы подписаться нужно ввести сой email и нажать кнопку -это делать робот не умеет и соответственно ссылки он здесь не видит.
Находятся в Javascript
При её нахождении в Javascript, поисковый робот вообще не видит, либо «залазит» по ссылке очень редко. Т.о. при использовании Javascript все используемые ссылки должны сопровождаться HTML кодом.
Примечание: ходят упорные слухи, что некоторые поисковики уже видят, что внутри яваскрипта.
Заблокированы мета тегами или файлом robots.txt
Файл robots.txt позволяет владельцу ресурса ограничить поисковому роботу допуск к веб-странице. Прописывая определенные мета теги в этом файле можно управлять действиями робота (запрещать к индексации веб- страницу, разделы и т.п).
Примечание: блокировка в robots.txt, конечно вещь хорошая, но 100% гарантии не дает фактически это только рекомендации поисковику, а будет или нет он их выполнять неизвестно.
Находятся во фреймах
Технически ссылки находящееся во фреймах (кадрах) видимы для «пауков», однако по мнению многих практиков, нужно избегать использования фреймов.
Ссылки в flash, java
Ссылки встроенные в коды flash, java и т.п. технологий не видимы для поисковых роботов.
Ссылки на веб-страницах имеющих сотни ссылок
Поисковые роботы, как правило, «ползают» только по 100 страницам и не более. Т.к. предполагается, что страница имеющая огромное количество ссылок предназначена исключительно для спама.
Ссылки расположены в графике
Любые ссылки или любой текст, написанный на изображениях не видим для поисковых роботов.