
Поиск Яндекса с инженерной точки зрения. Лекция в Яндексе / Яндекс corporate blog / Habr
Сегодня мы публикуем ещё один из докладов, прозвучавших на летней встрече об устройстве поиска Яндекса. Выступление руководителя отдела ранжирования Петра Попова получилось в тот день самым доступным для широкой аудитории: минимум формул, максимум общих понятий о поиске. Но интересно было всем, потому что Пётр несколько раз переходил к деталям и в итоге рассказал много такого, о чём Яндекс никогда раньше публично не заявлял.Кстати, одновременно с публикацией этой расшифровки начинается вторая встреча из серии, посвящённой технологиям Яндекса. Сегодняшнее мероприятие — уже не про поиск, а про инфраструктуру. Вот ссылка на трансляцию.
Ну а под катом — лекция Петра Попова и часть слайдов.
Меня зовут Пётр Попов, я работаю в Яндексе. Здесь я уже примерно семь лет. До этого программировал компьютерные игры, занимался 3D-графикой, знал про видеокарточки, писал на SSE-ассемблере, в общем, такими вещами занимался.
Сейчас я расскажу достаточно полно, но не очень глубоко о том, как выглядит наш поиск. Что такое Яндекс? Это поисковик. Мы должны получить запрос пользователя и сформировать десятку результатов. Почему именно десятку? Пользователи чрезвычайно редко переходят на более далёкие страницы. Можно считать, что десять документов — это всё, что мы показываем.
Не знаю, есть ли в зале люди, которые занимаются рекламой Яндекса, потому что они считают, что основной продукт Яндекса — это совсем другое. Как обычно, здесь две точки зрения и обе правильные.
Мы считаем, что основное — это счастье пользователя. И, как ни удивительно, от состава десятки и того, как десятка отранжирована, это счастье зависит. Если мы ухудшаем выдачу, пользователи пользуются Яндексом меньше, уходят в другие поисковики, плохо себя чувствуют.
Какую конструкцию мы соорудили ради решения этой простой задачи — показать десять документов? Конструкция достаточно мощная, снизу, видимо, разработчики на неё взирают.
Наша модель работы. Нам нужно сделать всего несколько вещей. Нам нужно обойти интернет, проиндексировать получившиеся документы. Документом мы называем скачанную веб-страницу. Проиндексировать, сложить в поисковый индекс, запустить над этим индексом поисковую программу, ну и ответить пользователю. В общем-то, всё, профит.
Пройдемся по шагам этого конвейера. Что такое интернет и какого он объема? Интернет, считай, бесконечный. Возьмем любой сайт, который продает что-нибудь, какой-нибудь интернет-магазин, сменим там параметры сортировки — появится другая страничка. То есть можно задавать СGI-параметры страницы, и содержание будет совсем другое.
Сколько мы знаем принципиально значащих страниц с точностью до отбрасывания незначащих CGI-параметров? Сейчас — порядка нескольких триллионов. Скачиваем мы странички со скоростью порядка нескольких миллиардов страничек в день. И казалось бы, что нашу работу мы могли бы выполнить за конечное время, там, за два года.
Как мы вообще находим новые странички в интернете? Мы обошли какую-то страничку, вытянули оттуда ссылки. Они — наши потенциальные жертвы для скачивания. Возможно, за два года мы обойдем эти триллионы URL, но появятся новые, и в процессе парсинга документов появятся ссылки на новые странички. Уже тут видно, что наша основная задача — бороться с бесконечностью интернета, имея на руках конечные инженерные ресурсы в виде дата-центров.
Мы скачали все безумные триллионы документов, проиндексировали. Дальше нужно положить их в поисковый индекс. В индекс мы кладем не всё, а только лучшее из того, что скачали.
Есть товарищ Ашманов, широко известный в узких кругах специалист по поисковым системам в интернете. Он строит разные графики качества поисковых систем. Это график полноты поисковой базы. Как он строится? Задается запрос из редкого слова, смотрится, какие документы есть во всех поисковиках, это 100%. Каждый поисковик знает про какую-то долю. Сверху красным цветом мы, снизу черным цветом — наш основной конкурент.
Тут можно задаться вопросом: как мы такого достигли? Возможны несколько вариантов ответа. Вариант первый: мы пропарсили страничку с этими тестами, выдрали оттуда все URL, все запросы, которые задает товарищ Ашманов и проиндексировали странички. Нет, мы так не делали. Второй вариант: для нас Россия является основным рынком, а для конкурентов она — что-то маргинальное, где-то на периферии зрения. Этот ответ имеет право на жизнь, но он мне тоже не нравится.
Ответ, который мне нравится, заключается в том, что мы проделали большую инженерную работу, сделали проект, который называется «большая база», под это закупили много железа и сейчас наблюдаем этот результат. Конкурента тоже можно бить, он не железный.
Документы мы скачали. Как мы строим поисковую базу? Вот схема нашей контент-системы. Есть интернет, облачко документов. Есть машины, которые его обходят — спайдеры, пауки. Документ мы скачали. Для начала — положили его в сохраненную копию. Это, фактически, отдельная междатацентровая хеш-таблица, куда можно читать и писать на случай, если мы потом захотим этот документ проиндексировать или показать пользователю как сохраненную копию на выдаче.
Дальше мы документ проиндексировали, определили язык и вытащили оттуда слова, приведенные согласно морфологии языка к основным формам. Ещё мы вытащили оттуда ссылки, ведущие на другие страницы.
Есть еще один источник данных, который мы широко используем при построении индекса и вообще в ранжировании — логи Яндекса. Задал пользователь запрос, получил десятку результатов и как-то там себя ведёт. Ему показались документы, он кликает или не кликает.
Разумно предположить, что если документ показался в выдаче, или, тем более, если пользователь по нему кликнул, провел какое-то взаимодействие, то такой документ нужно оставить в поисковой базе. Кроме того, логично предположить, что ссылки с такого хорошего документа ведут на документы, которые тоже хороши и которые неплохо бы приоритетно скачать. Здесь изображено планирование обхода. Стрелочка от планирования обхода должна вести в обход.
Дальше есть стадия построения поискового индекса. Эти округлые прямоугольнички лежат в MapReduce, нашей собственной реализации MapReduce, которая называется YT, Yandex Table. Тут я немножко лакирую — на самом деле построение базы и шардирование оперируют с индексами как с файлами. Мы это немножко зафиксим. Эти округлые прямоугольнички будут лежать в MapReduce. Суммарный объем данных здесь — порядка 50 ПБ. Тут они превращаются в поисковые индексы, в файлики.
В этой схеме есть проблемы. Основная связана с тем, что MapReduce — сугубо батчевая операция. Чтобы определить приоритетные документы для обхода, например, мы берем весь линковый граф, мёржим его со всем пользовательским поведением и формируем очередь для скачки. Это процесс достаточно латентный, занимающий какое-то время. Ровно так же с построением индекса. Там есть стадии обработки — они батчевые для всей базы. И выкладка так же устроена, мы или дельту выкладываем, или всё.
Важная задача при этих объемах — ускорить процедуру доставки индекса. Надо сказать, что эта задача для нас сложная. Речь идёт о борьбе с батчевым характером построения базы. У нас есть специальный быстрый контур, который качает всякие новости в real time, доносит до пользователя. Это наше направление работы, то, чем мы занимаемся.
А вот вторая сторона медали. Первая — контент-система, вторая — поиск. Можно понять, почему я рисовал пирамидку — потому что поиск Яндекса действительно похож на пирамиду, такую иерархическую структуру. Сверху стоят балансеры, фронты, которые генерируют выдачу. Чуть пониже — агрегирующие метапоиски, которые агрегируют выдачу с разных вертикалей. Надо сказать, что на выдаче вы наверняка видели веб-документы, видео и картинки. У нас три разных индекса, они опрашиваются независимо.
Каждый ваш поисковый запрос уходит по этой иерархии вниз и спускается до каждого кусочка поисковой базы. Мы весь индекс, который построили, разбили на тысячи кусков. Условно, — на две-три-пять тысяч. Над каждым куском подняли поиск, и этот запрос всюду спустился.
Тут же видно, что поиск Яндекса — большая штука. Почему она большая? Потому что мы в своей памяти храним, как вы видели на предыдущих слайдах, достаточно репрезентативный и мощный кусок интернета. Храним не один раз: в каждом дата-центре от двух до четырёх копий индекса. Запрос наш спускается до каждого поиска, фактически проходится по каждому индексу. Сейчас используемые структуры данных — такие, что мы вынуждены всё это хранить напрямую в оперативке.
Что нужно делать? Вместо дорогой оперативки использовать дешевый SSD, ускорить поиск, допустим, в два раза, и получить профит — десятки или сотни миллионов долларов капитальных расходов. Но тут не нужно говорить: кризис, Яндекс экономит и всё такое. На самом деле всё, что мы сэкономим, мы пустим в полезное дело. Мы увеличим индекс в два раза. Мы будем по нему качественнее искать. И это то, ради чего осуществляется такого рода сложная инженерка. Это реальный проект, правда, достаточно тяжелый и вялотекущий, но мы действительно так делаем, хотим поиск наш улучшить.
Поисковый кластер не только достаточно большой — он ещё и очень сложный. Там реально крутятся миллионы инстансов разных программ. Я вначале написал — сотни тысяч, но товарищи из эксплуатации меня поправили — таки миллионы. На каждой машинке в очень многих экземплярах 10-20 штук точно крутится.
У нас тысячи разных типов сервисов размазаны по кластеру. Надо пояснить: кластер — это такие машинки, хосты, на них запущены программы, все они общаются по TCP/IP. Программы имеют разное потребление CPU, памяти, жесткого диска, сети — короче, всех этих ресурсов. Программы живут на хостах в общежитии. Точнее, если будем сажать одну программу на хост, то утилизация кластера будет никакой. Поэтому мы вынуждены селить программы друг с другом.
Дальше слайд про то, что с этим делать. А здесь — небольшое замечание, что все данные программы, все релизы мы катаем с помощью торрентов, и число раздач на нашем торрент-трекере превышает оное число на Pirate Bay. Мы реально большие.
Что нужно делать со всей этой кластерной конструкцией? Нужно улучшать механизмы виртуализации. Мы реально вкладываемся в разработку ядра Linux, у нас есть собственная система управления контейнерами а-ля Docker, про неё Олег подробнее расскажет.
Нам нужно заранее планировать, на каких хостах какие программы друг с другом селить, это тоже сложная задача. У нас постоянно что-то на кластер едет. Сейчас там наверняка десять релизов катятся.
Нам нужно грамотно селить программы друг с другом, нужно улучшать виртуализацию, нужно-таки объединить два больших кластера — роботный и поисковый. Мы как-то независимо заказывали железо и считали, что есть отдельно машинки с огромным числом дисков и отдельно — тонкие блейды для поиска. Сейчас мы поняли, что лучше заказывать унифицированное железо и запускать MapReduce и поисковые программы в изоляции: одно жрет в основном диски и сеть, второе в основном CPU, но по CPU у них баланс, нужно туда-сюда крутить. Это большие инженерные проекты, которые мы тоже ведем.
Что мы с этого получаем? Пользу в десятки миллионов долларов экономии капитальных расходов. Вы уже знаете, как мы эти деньги потратим — мы потратим их на улучшение нашего поиска.
Здесь я рассказал о конструкции в целом. Какие-то отдельные строительные блоки. Эти блоки люди долбили стамеской, и у них что-то получилось.
Ранжирующая функция Матрикснет. Достаточно простая функция. Можете почитать — там лежат в векторе бинарные признаки документа, а в этом цикле происходит вычисление релевантности. Я уверен, что среди вас есть специалисты, которые умеют на SSE программировать, и они бы живо это ускорили в десять раз. Так оно в какой-то момент и случилось. Тысяча строчек кода нам спасли 10-15% общего потребления CPU на нашем кластере, что опять же составляет десятки миллионов долларов капитальных расходов, которые мы знаем, как потратить. Это тысяча строчек кода, которая стоят очень дорого.
Мы более-менее вычистили из репозитория, соптимизировали, но там ещё есть что поделать.
Имеется у нас платформа для машинного обучения. Индексы с предыдущего слайда нужно подбирать жадным образом, перебирая все возможности. На CPU это делать долго. На GPU — быстро, зато пулы для обучения не лезут в память. Что нужно делать? Или покупать кастомные решения, куда этих железок много-много втыкается, или связывать машинки быстрым, использовать интерконнект какой-то, infiniband, учиться с этим жить. Оно типично глючит, не работает. Это очень забавный инженерный вызов, с которым мы тоже встречаемся. Он, казалось бы, совсем не связа с нашей основной деятельностью, но тем не менее.
Во что мы ещё инвестируем, так это в алгоритмы сжатия данных. Основная задача сжатия выглядит примерно следующим образом: есть последовательность целых чисел, нужно её как-то компрессировать, но не просто компрессировать — нужно ещё иметь случайный доступ к i-тому элементу. Типичный алгоритм — маленькими блоками сжать это, иметь разметку для общего потока данных. Такая задача — совсем другая, нежели контекстное сжатие типа zip или LZ-family. Там совсем другие алгоритмы. Можно сжать Хаффманом, Varlnt, блоками типа PFORX. У нас есть собственный патентованный алгоритм, мы его улучшаем, и это опять же 10-15% экономии оперативной памяти на простенький алгоритм.
У нас есть всякие забавные мелочи, например доработки в CPU, планировщики Linux. Там какая проблема с гипертредными камнями от Intel? То, что на физическом ядре есть два потока. Когда там два треда занимают два потока, то они работают медленно, латенция увеличивается. Нужно правильно раскидывать задачки по физическим процессорам.
Если раскидывать правильно, а не так, как делает стоковый планировщик, можно получить 10-15% латентности нашего запроса, условно. Это то, что видят пользователи. Сэкономленные миллисекунды умножайте на число поисков — вот и сэкономленное время для пользователей.
У нас есть какие-то совсем странные вещи типа собственной реализации malloc, который на самом деле не работает. Он работает в аренах, и каждая локация просто сдвигает указатель внутри этой арены. Ну и ref counter арены поднимает на единичку. Арена жива, пока жива последняя локация. Для всякой смешанной нагрузки, когда у нас есть короткоживущая и долгоживущая локация, это не работает, это выглядит как утечка памяти. Но наши серверные программы устроены не так. Приходит запрос, мы там аллоцируем внутренние структуры, как-то работаем, потом отдаем ответ пользователю, всё сносится. Этот аллокатор идеально работает для наших серверных программ, которые без состояния. За счет того, что все локации локальны, последовательны в арене, оно работает очень быстро. Там нет никаких page fault, cache miss и т. п. Очень быстро — это от 5% до 25% скорости работы наших типичных серверных программ.
Это инженерка, что ещё можно делать? Можно заниматься машинным обучением. Про это вам с любовью расскажет Саша Сафронов.
А сейчас вопросы и ответы.
Я возьму очень понравившийся мне вопрос, который пришел на рассылку и который следовало бы включить в мою презентацию. Товарищ Анатолий Драпков спрашивает: есть знаменитый слайд про то, как быстро росла формула до внедрения Матрикснета. На самом деле и до, и после. Есть ли сейчас проблемы роста?
Проблемы роста у нас стоят в полный рост. Очередной порядок увеличения числа итераций в формуле ранжирования. Сейчас мы там порядка 200 тысяч итераций делаем в функции Матрикснет, чтобы ответить пользователю. Был получен следующим инженерным шагом. Раньше мы ранжировали на базовых. Это значит, что каждый базовый запускает у себя Матрикснет и выдает сто результатов. Мы сказали: давайте мы лучшие сто результатов объединим на среднем и отранжируем ещё раз совсем тяжелой формулой. Да, мы это сделали, на среднем можно вычислять в нескольких потоках функцию Матрикснет, потому что ресурсов нужно в тысячу раз меньше. Это проект, который нам позволил достичь очередного порядка увеличения объемов ранжирующей функции. Что будет ещё — не знаю.
Андрей Стыскин, руководитель управления поисковых продуктов Яндекса:
— Сколько занимала байт первая формула ранжирования Яндекса?
Пётр:
— Десяток, наверное.
Андрей:
— Ну, да, наверное, где-то символов сто. А сколько сейчас занимает формула ранжирования Яндекса?
Пётр:
— Где-то 100 МБ.
Андрей:
— Формула релевантности. Это для наших смотрителей с трансляций, специалистов по SEO. Попробуйте зареверсинженирить наши 100 МБ ранжирования.
Алеся Болгова, Intel:
— По последнему слайду про malloc не могли бы пояснить, как вы выделяете память? Очень интересно.
Пётр:
— Берется обычная страничка, 4 КБ, в начале у нее rev counter, и дальше мы каждую аллокацию… если маленькие аллокации меньше страницы, мы просто двигаемся в этой страничке. В каждом треде, естественно, эта страничка своя. Когда страничку закрыли — всё, про неё забыли. Единственное, у неё rev counter в начале.
Алеся:
— То есть вы страницу выделяете?
Пётр:
— Внутри страницы аллокациями вот так растем. Единственное, страничка живет, пока в ней последняя аллокация живет. Для обычного workload это выглядит как утечка, для нашего — как нормальная работа.
— Как вы определяете качество страницы, стоит её класть в индекс или нет? Тоже машинное обучение?
Пётр:
— Да, конечно. У странички есть множество факторов, от её размера до показов на поиске, до…
Андрей:
— До robot rank. Она находится на каком-то хосте, в какой-то поддиректории хоста, на неё сколько-то входящих ссылок. Те, кто на неё ссылаются, обладают каким-то качеством. Все это берем и пытаемся предсказать, с какой вероятностью, если данную страничку скачать, на ней будет информация, которая попадет по какому-то запросу в выдачу. Это предсказывается, отбирается топ с учетом размера документов — потому что в зависимости от размера документа вероятность, что она хоть по какому-то запросу попадет, повышается. Задача об оптимальном наполнении рюкзака. Отбирается с учетом размера документа и кладется топовая в индекс.
— …
Андрей:
— Давай мы тебя представим сначала.
— Может, не стоит?
Андрей:
— Владимир Гулин, начальник ранжирования поисковика Mail.Ru.
Владимир:
— Первый мой вопрос — про количество поисков вообще. Вы говорили, что вы там драматически увеличили размер базы. Хочется вообще понимать, с какого объема вы стартовали, каков был объем русского индекса, иностранного индекса, сколько документов приходилось на каждый шард, ну и после увеличения…
Пётр:
— Это такие цифры, слишком технические. Может, в кулуарах я бы сказал. Я могу сказать, во сколько раз мы примерно увеличились — на полтора порядка где-то. В 30 раз, условно. За последние три года.
Владимир:
— Я тогда абсолютные цифры в кулуарах уточню.
Пётр:
— Да, за отдельную плату, что называется.
Владимир:
— Ладно. Что касается свежести — какой приблизительно сейчас в Яндексе объем быстрого индекса? И вообще с какой скоростью вы это всё обновляете, смешиваете?
Пётр:
— Индекс реально реалтаймовый, там порядка двух минут латенции на то, чтобы добавить документ в индекс. От момента, как мы его проиндексировали, и дискавери тоже — скачка быстрая.
Владимир:
— Но именно найти документ. Сначала надо узнать, что документ существует.
Пётр:
— Я понимаю, что вопрос такой — непонятно, когда в интернете появилась первая ссылка на данный документ. Когда мы узнали первую ссылку, то дальше это вопрос минут в быстром слое.
Андрей:
— Речь идет о миллионах документов, которые ежедневно находятся в этом быстром индексе. Про них обычно очень много внешней информации: упоминание в Твиттере, сайтмэпы, упоминание новости на сайте Lenta.ru. И так как мы перекачиваем чуть ли не каждую секунду морду Lenta.ru, мы очень быстро обнаруживаем эти документы и в течение единиц минут в худшем случае доставляем их до поиска. Они могут искаться. По сравнению с большим индексом речь идет про драматически маленькое число документов, это миллионы.
Пётр:
— Да, на 3-4 порядка меньше.
Андрей:
— Да, это миллионы документов, которые умеют обновляться real time.
Владимир:
— Миллионы документов в сутки?
Пётр:
— Побольше чуть-чуть, но примерно так, да.
Владимир:
— Теперь вопрос про смешивание свежих результатов и результатов основного поиска.
Пётр:
— У нас два способа смешивания. Один — документ той же формулой ранжируется, что и батчевый обычный документ. А второй — специальное новостное подмешивание, когда мы определяем интент запроса, понимаем, что он реально свежий и что нужно что-то такое показать. Два способа.
Владимир:
— Как вы боретесь с ситуацией, когда у вас по популярным запросам, где дофига кликов, появляются свежие результаты? Как вы определяете, что свежий результат надо показывать выше того результата, который уже накликан? Спросили у вас: «Google». Вы вроде знаете, какие результаты по такому запросу хорошие. Но тем не менее, в новостях ещё что-то, какие-то статьи…
Пётр:
— Это всякие запросные факторы, всякие тренды и всё такое.
Андрей:
— Для всех поясню, в чем сложность задачи и в чем вопрос. Про документ, который долго существует в интернете, мы много чего знаем. Мы много знаем входящих на него ссылок, знаем, сколько на нем люди проводили времени, а про свежие документы этого всего не знаем. Поэтому сложность задачи ранжирования свежих документов и новостей — угадывать, будут ли люди это читать, уметь предсказывать количество ссылок, которые он наберет за какое-то время, чтобы его показывать нормально. И для подмешивания документов по запросу «Google», когда Google что-то хорошее сделал, там существует некая оптимизационная метрика, которая у нас называется профицит. Мы её умеем оптимизировать.
Пётр:
— Мы знаем поток запросов, содержание свежескачанных страниц. Эти две вещи мы можем анализировать и понимать, что реально свежий запрос требует подмешивания.
Андрей:
— А потом, на основе ручной оценки и пользовательского поведения именно в эту секунду в этот день, мы понимаем, что именно сегодня эта новость по запросу важна и у неё есть такие факторы: документ только появился, на него столько-то ретвитов. И поэтому следующую новость, которая будет с таким же распределением признаков, тоже нужно показывать, когда она наберет соответствующие значения.
Пётр:
—А факторы там могут быть такими: число найденного в обычном слое против числа найденного по этому запросу в свежем. Такие, самые наивные, хотя мы его выпиливаем тщательно.
Андрей:
— Для тех, кого пугает слово «факторы», специально будет третий доклад, где мы расскажем базовые принципы — как вообще устроено машинное обучение, ранжирование, что такое факторы, как с помощью этого сделать поисковик, который выдает нормальные хорошие результаты.
Владимир:
— Спасибо, остальное спрошу потом.
Никита Пустовойтов:
— Получается, у вас существует большое количество урлов, про которые вы в принципе знаете, а качать вы можете на несколько порядков меньше. Поскольку за время скачивания будут появляться новые, больше вы никогда не посетите. Для выбора применяется машинное обучение, какие-то эвристики?
Пётр:
—Только машинное обучение. Идея там простая: мы имеем сигнал на какой-то документ, любой, число показов, и его распространяем по ссылочному графу. Всё это агрегируем на странице «цель ссылки», дальше машинным обучением так же обучаем шанс показаться, исходя из этих данных.
Никита:
— Второй вопрос — инженерный. Вы говорили, что у вас много CPU-затратных задач. Рассматривали ли вы вариант использования процессора Xeon Phi от Intel? Он вроде гораздо быстрее работает с оперативной памятью, чем GPU.
Пётр:
— Мы его рассматривали для задач обучения именно нашего Матрикснета, нашей формулы, и там он феерично плохо себя показал. А так вообще у нас профиль очень плоский, у нас топовая функция где-то 1,5%. Мы всё, что можно, руками соптимизировали, а так у нас портянки С++-кода, который туда не ложится.
— Насколько я знаю, Яндекс был первым поисковиком, который начал работать с русской морфологией. Скажите, на данный момент это всё ещё является каким-либо преимуществом или все поисковики одинаково хорошо работают с русской морфологией?
Пётр:
— Сейчас в области морфологии наука не стоит на месте. Саша Сафронов расскажет о том, чего мы сейчас достигаем, там реально есть новые подходы и новые способы решения проблем. Например, определение запросов, похожих на этот, по пользовательскому поведению. Не расширение отдельных слов, а расширение запросов запросами.
Андрей:
— То есть это не совсем морфология. Морфологию действительно, наверное, все поисковики более-менее освоили, но это базовая вещь. А вот лингвистика, нахождение, чем и какие слова запроса можно расширить, какие ещё вещи стоит поискать в документе, чтобы найти кандидатов, которые будут более релевантные — про это будет третий доклад. Там наше ноу-хау, мы расскажем.
Пётр:
— По крайней мере, намекнем.
Андрей (зритель):
— Спасибо за краткий экскурс в столь сложную технологию, как поиск Яндекса. Использует ли Яндекс deep learning и алгоритмы обучения с подкреплением в построении быстрого индекса или кеша? Вообще если используете где-то, то как?
Пётр:
— Deep learning используем для того, чтобы факторы ранжирования обучать. Безотносительно к быстрому или медленному индексу. Он используется для картинок, веба и всего такого.
Андрей Стыскин:
— Летом запустили версию ранжирования, которая дала 0,5% прироста качества, где мы правильно сварили deep learning на словах. Приезжали наши бывшие коллеги из-за границы и рассказывали, что там такое не работает, а мы научились.
Пётр:
— А может, это потому, что мы для топ-100 документов это делаем. Речь идёт об очень затратной задаче. Наш способ построения пайплайна поиска позволяет для сотни документов это делать.
Андрей Стыскин:
— Невозможно посчитать deep learning для всех кандидатов, которых сотни миллионов на запросы, но для топа документов можно провернуть, и у нас эта схема поиска ровно так работает — позволяет такие очень сложные наукоемкие алгоритмы внедрять.
Игорь:
— Про будущее поисковика в целом. Интернет сейчас растет очень быстро, объем, наверное, растет экспоненциально. Уверены ли вы, что через 10 лет вы будете успевать за ростом интернета, и уверены ли, что будете охватывать его в таком же объеме? Повторите ещё раз, в каком объеме сейчас интернет охвачен по вашей оценке, и что будет через 10 лет?
Пётр:
— К сожалению, можно только процентно по отношению с кем-то степень охвата определять. Потому что он реально бесконечный.
Андрей:
— Это красивый философский вопрос. Пока мы в нашем коллективе за законом Мура успеваем, каждый год кратно увеличиваем наш размер базы. Но это правда сложно, правда интересно, и, конечно же, нам даже не хватает рук, чтобы это делать, но мы хотим и знаем, как это увеличивать в ближайшие несколько лет некоторыми сериями улучшений.
Пётр:
— 10 лет — слишком далеко, но ближайшие годы да, осилим.
Андрей (зритель):
— Сколько весит реплика интернета, как она разносится между ДЦ, и как осуществляется синхронизация реплик?
Пётр:
— Полный объем роботных данных — порядка 50 ПБ, реплика меньше, индекс меньше. Можете умножить на коэффициент, который вам кажется разумным. Вы же инженер, прикиньте.
Андрей:
— А как разносится?
Пётр:
— Разносится банально — через torrent, torrent share. Потом качаем этот файлик.
Андрей:
— То есть в какой-то момент времени они не консистентны?
Пётр:
— Нет, там потом консистентные переключения. Бывает, что переключаем по ДЦ, когда ночью оно вдруг не консистентно.
Андрей:
— То есть можно через F5 — если нажимаем, один документ имеем…
Пётр:
— Мы боремся с этой проблемой, знаем о ней, ее решение стоит в наших планах.
Иван:
— Как вы боретесь с различными бот-системами и за что можно отправиться в бан?
Пётр:
— У нас есть специальные люди, которые знают ответ на этот вопрос, но они не скажут.
Андрей Стыскин:
— На сегодняшнем мероприятии мы хотели поговорить про технические детали.
Пётр:
— Про роботоловилку мы можем ответить. Нас действительно регулярно ддосят, поэтому у нас прямо на балансере, на первом слое, когда запрос попадает, есть детекция, что запрос из какой-то сети пришел негодной. Это быстро обновляется, мы быстро реджектим, оно не валит наш кластер.
Андрей:
— И это тоже устроено методом машинного обучения. Показывается капча, и в зависимости от того, как ты её разгадываешь, мы получаем положительные и отрицательные примеры. На каких-то факторах — типа айпишника подсетки, какого-то поведения, времени между действиями — обучаем и баним или не баним такие запросы. DDoS не пройдет.
Андрей Аксёнов, Sphinx Search:
— У меня технические вопросы. Проходной вопрос — почему память? Неужели даже децл подисковать на SSD не получается, чтобы индекс чуть-чуть не влезал, изредка упирался в SSD?
Пётр
— Там получается так, что футпринт одного запроса порядка 50-100 МБ, он прямо жесткий. С такой скоростью ты не сможешь сервить тысячу запросов в секунду, как мы хотим. Мы работаем над тем, чтобы этот футпринт уменьшить. Проблема, что данные про документ рассыпаны по всему диску. Мы хотим их собрать в одно место, и тогда наша общая мечта осуществится.
Андрей Аксёнов:
— Упирается в bandwidth или latency?
Пётр:
— В оба. Мы и последовательно пейджфолдимся, и объемы большие.
Андрей Аксёнов:
— То есть невероятно, но факт: даже если чуть-чуть…
Пётр:
— Да, даже если чуть-чуть отожрешь — всё.
Андрей Аксёнов:
— Экспоненциальное падение во много раз?
Пётр:
— Да-да.
Андрей Аксёнов:
— Теперь важнейший вопрос для промышленного хозяйства: сколько классов строка и классов векторов в базе?
Пётр:
— А вот всё меньше и меньше.
Андрей Аксёнов:
— Ну конкретнее.
Пётр:
— У нас пришли правильные люди, они насаждают правильные порядки. Сейчас это число уменьшается.
Андрей Аксёнов:
— Векторов-то сколько и строк?
Пётр:
— Сейчас векторов, наверное, даже один-два максимум.
Андрей Аксёнов:
— Один не бывает, два хоть…
Пётр:
— Ну вот видишь.
Андрей Аксёнов:
— А строк?
Пётр:
— Ну должен же быть корпоративный какой-то дух Яндекса.
Андрей Аксёнов:
— Скажи, не томи, ну.
Пётр:
— Строк две минимум. Ну три, может.
Андрей Аксёнов:
— Не пять?
Пётр:
— Не пять.
Андрей Аксёнов:
— Налицо прогресс, спасибо.
Фёдор:
— Про вашу схему с метапоисками. У вас очень высокий каскад. Какие тайминги на каждом уровне, можете озвучить?
Пётр Попов:
— Прямо сейчас вставляем ещё один слой, не хватает. Времена ответов… Средний метапоиск делает три раунда хождений туда-сюда, у него порядка 250 мс, 95-я квантиль. Дальше построение выдачи не очень быстрое, но вся конструкция где-то за 700 мс отрабатывает.
Андрей Стыскин:
— Да, там выше JavaScript, так что это 250 мс, а там 700.
Пётр:
— То, что снизу, оно делает кучу раундов. У нас тоже специалисты заняты прямо сейчас решением этой проблемы.
Фёдор:
— У вас нарисовано три группы вертикалей. Но у вас есть ещё Афиша, Новости и так далее. Где вы их замешиваете в итоге?
Пётр:
— В построении выдачи у нас есть такой блендер, который объединяет все эти вертикали, по пользовательскому поведению решает, кого показать. Это как раз построение выдачи.
Андрей:
— Вертикалей порядка сотни, это слой, который называется верхним метапоиском. В нём сливаются результаты средних метапоисков из вертикали веба, Картинок, Видео и ряда других, а также из маленьких базовых источников типа Афиши, Расписаний, ТВ и Электричек.
Пётр:
— Это к вопросу о том, почему у нас тысячи разных типов программ. Там очень много всяких источников, оно набегает.
Фёдор:
— Раз у вас так много вертикалей, есть ли среди них сторонние, которые не вы считаете?
Пётр:
— Особо нет. Реклама наша тоже вертикальная, отдельно от поиска, но стороннего особо нет.
Артём:
— У вашего основного конкурента выдача всегда была real time, он дельта-индексами докидывал. А у Яндекс был up выдачи. Складывалось впечатление, что темной ночью раз в семь дней человек нажимает рычаг и раскатывает индексы.
Пётр:
— К сожалению, так и происходит.
Артём:
— Правильно понимаю, что быстрый индекс был сделан для того, чтобы актуализировать выдачу real time?
Пётр:
— Да, но решение общее. Многие так реально делают, в том числе и наш основной конкурент.
Артём:
— Стремитесь ли вы к тому, чтобы тоже дельта-индексами подкидывать, просто отказаться от быстрого индекса?
Пётр:
— Естественно, стремимся. Ещё бы знать, как.
Артём:
— Когда это можно ожидать?
Пётр:
— Хороший вопрос. На тех же графиках Ашманова видно, как мы обновляем индекс. Сейчас это видно меньше, и мы делаем так, чтобы это проходило совсем быстро и незаметно. Такова одна из наших задач.
Артём:
— Вы каждый раз обрабатываете запрос пользователя? Приходит запрос, вы отсылаете его на бэкенд, рассчитывается формула и результат?
Пётр:
— Есть кеши, но они работают в 50% случаев. 40-50% запросов пользователей — уникальные и никогда больше не будут заданы. Очень много по-настоящему уникальных запросов пользователей вообще за всю жизнь Яндекса. Кешируем 50-60%. Для кеширования тоже своя система.
«Поисковые системы» — Яндекс.Знатоки
Отметим, что чаще всего никакой необходимости «добавлять сайт в поисковую систему» нет. Ведь поисковые машины очень быстро сами обнаружат ваш сайт и начнут его индексировать.
Тем более, если ваш сайт существует хотя бы полгода, можете быть уверены, что вас заметили и вы уже находитесь в выдаче. А уж место, которое ваш сайт занимает в выдаче, зависит только от качества вашего сайта.
Конечно, бывает полезно добавить сайт в «вебмастер» «Яндекса». Там можно управлять сайтом. «Вебмастер» укажет на ошибки, которые есть на сайте, сформирует отчет по внешним и внутренним битым ссылкам. В этом же сервисе можно настроить регион показа вашего сайта, проверить файл robots.txt и сделать многое другое.
Разумеется, можно специально указывать сайту на новые страницы, ставя их в очередь на индексирование.
Аналогичные инструменты существует у Google.
Вообще, если вы хотите узнать все о своем сайте, рекомендую вам сервисы для анализа сайтов https://otzyvmarketing.ru/best/servisy-dlya-analiza-sajtov/. По ссылке вы найдете не только описания сервисов, но и отзывы специалистов-вебмастеров, которые уже успели поработать с сервисами и узнали их сильные и слабые стороны. Так вы сможете выбрать площадки с наиболее подходящим вам функционалом.
Давайте теперь поговорим о том, как «добавить» сайт в поисковую систему. Чтобы поисковая машина узнала о существовании вашего сайта как можно быстрее после его появления, нужно добавиться в «вебмастер» «Яндекса» и аналитику Google. Сделать это можно в обоих поисковиках. Просто введите соответствующие запросы.
После этого вам придется завести две почты в Google и «Яндекс». Тогда вы получите доступ в эти системы. Там вам нужно будет зарегистрировать свой сайт и подтвердить на него права.
Лично я подтверждаю права с помощью добавления строки html. В любом случае, вы должны иметь доступ к файла сайта, чтобы подтвердить на него права. В этом основной смысл этой процедуры. Сама по себе она достаточно простая, так что вы во всем разберетесь. После подтверждения прав вы получите доступ к аналитике Google и «вебмастеру».
Надеюсь, мой ответ смог вам помочь. Я постаралась изложить в ответе суть. Конечно, я могла забыть какие-то важные вещи, но формат не позволяет мне ответить досконально. Желаю вам удачи и всего хорошего! Если вы хотите у меня что-то спросить или, наоборот, высказать свою точку зрения, оставляйте свои комментарии под моим ответом!
Как работает поисковая система? — Блог веб-программиста
- Подробности
- июня 21, 2014
- Просмотров: 6898
Что такое поисковые системы? Как работают поисковые системы? Ответы на эти вопросы вы найдете здесь.
Что такое поисковик?
По определению, интернет-поисковик это система поиска информации, которая помогает нам найти информацию во всемирной паутине. Это облегчает глобальный обмен информацией. Но интернет является неструктурированной базой данных. Он растет в геометрической прогрессии, и стал огромным хранилищем информации. Поиск информации в интернете, является трудной задачей. Существует необходимость иметь инструмент для управления, фильтра и извлечения этой океанической информации. Поисковая система служит для этой цели.
Как работает поисковая система?
Поисковые системы интернета являются двигателями, поиска и извлечения информации в интернете. Большинство из них используют гусеничную архитектуру индексатора. Они зависят от их гусеничных модулей. Сканеры также называют пауками это небольшие программы, которые просматривают веб-страницы.
Сканеры посещают первоначальный набор URL-адресов. Они добывают URL-адреса, которые появляются на просканированных страницах и отправляют эту информацию в модуль гусеничный управления. Гусеничный модуль решает, какие страницы посетить в следующий раз и дает эти URL-адреса сканерам.
Темы, охватываемые различными поисковыми системами, варьируются в зависимости от алгоритмов, которые они используют. Некоторые поисковые системы запрограммированы на поисковые сайты по конкретной теме, в то время как сканеры других могут посещать столько мест, сколько возможно.
Модуль управления может использовать ссылки предыдущего сканирования или шаблоны, чтобы помочь в стратегии сканирования.
Модуль индексации извлекает информацию из каждой страницы, которую он посещает и вносит URL в базу. Это приводит к образованию огромной таблицы поиска, из списка URL-адресов указывающих на страницы с информацией. В таблице приведены те страницы, которые были покрыты в процессе обхода.
Модуль анализа является еще одной важной частью архитектуры поисковой системы. Он создает индекс полезности. Индекс утилита может предоставить доступ к страницам заданной длины или страниц, содержащих определенное количество картинок на них.
В процессе сканирования и индексирования, поисковик сохраняет страницы, которые он извлекает. Они временно хранятся в хранилище страницы. Поисковые системы поддерживают кэш страниц которые они посещают, чтобы ускорить извлечение уже посещенных страниц.
Модуль запроса поисковой системы получает поисковый запросов от пользователей в виде ключевых слов. Модуль ранжирования сортирует результаты.
Архитектура гусеничного индексатора имеет много вариантов. Они изменяются в распределенной архитектуре поисковой системы. Эти архитектуры состоят из собирателей и брокеров. Собиратели собирают информацию индексации с веб-серверов в то время как брокеры дают механизм индексирования и интерфейс запросов. Брокеры индексируют обновление на основе информации, полученной от собирателей и других брокеров. Они могут фильтровать информацию. Многие поисковые системы сегодня используют этот тип архитектуры.
Поисковые системы и ранжирования страниц
Когда мы создаем запрос в поисковой системе, результаты отображаются в определенном порядке. Большинство из нас, как правило, посещают страницы верхнего порядка и игнорируют последние. Это потому, что мы считаем, что верхние несколько страниц несут большую актуальность для нашего запроса. Так что все заинтересованы в рейтинге своих страниц в первых десяти результатов в поисковой системе.
Слова, указанные в интерфейсе запроса поисковой системы являются ключевыми словами, которые запрашивались в поисковых системах. Они представляют собой список страниц, имеющих отношение к запрашиваемым ключевым словам. Во время этого процесса, поисковые системы извлекают те страницы, которые имеют частые вхождений этих ключевых слов. Они ищут взаимосвязи между ключевыми словами. Расположение ключевых слов также считается, как и рейтинг страницы, содержащие их. Ключевые слова, которые встречаются в заголовках страниц или в URL, приведены в больший вес. Страницы, имеющие ссылки, указывающие на них, делают их еще более популярными. Если многие другие сайты, ссылаются на какую либо страницу, она рассматривается как ценная и более актуальная.
Существует алгоритм ранжирования, который использует каждая поисковая система. Алгоритм представляет собой компьютеризированную формулу разработанную, чтобы предоставлять соответствующие страницы по запросу пользователя. Каждая поисковая система может иметь различный алгоритм ранжирования, который анализирует страницы в базе данных двигателя, чтобы определить соответствующие ответы на поисковые запросы. Различные сведения поисковые системы индексируют по-разному. Это приводит к тому, что конкретный запрос, поставленный двум различным поисковым машинам, может принести страницы в различных порядках или извлечь разные страницы. Популярность веб-сайта являются факторами, определяющими актуальность. Клик-через популярность сайта является еще одним фактором, определяющим его ранг. Это мера того, насколько часто посещают сайт.
Веб-мастера пытаются обмануть алгоритмы поисковой системы, чтобы поднять позиции своего сайта в поисковой выдаче. Заполняют страницы сайта ключевыми словами или используют мета теги, чтобы обмануть стратегии рейтинга поисковой системы. Но поисковые системы достаточно умны! Они совершенствуют свои алгоритмы так, чтобы махинации веб-мастеров не влияли на поисковую выдачу.
Нужно понимать, что даже страницы после первых нескольких в списке могут содержать именно ту информацию, которую вы искали. Но будьте уверены, что хорошие поисковые системы всегда принесут вам высоко релевантные страницы в верхнем порядке!
Читайте также
Как работают поисковики Интернет: общие принципы работы
Вступление
Основная задача оптимизации сайта это повышение позиций сайта в поисковой выдаче поисковых систем. Позиции сайта в выдаче определяются согласно алгоритмам поисковых систем. По алгоритмам, поисковики собирают нужные страницы сайтов, обрабатывают их и заносят в базу поисковой выдаче, ранжируя по соответствию поисковым запросам.
SEO оптимизация сайта
Цель SEO оптимизации сайта, повышение позиций страниц сайта в поисковой выдаче поисковых систем. Всем знакомы названия популярных поисковых систем мира: Google, Yahoo, MSN и Рунета: Яндекс, Рамблер, Апорт. Именно, поисковые системы, осуществляют поиск в сети по запросу пользователя, выявляя по своим алгоритмам, наиболее подходящие страницы сайтов.
Работа поисковых систем основана на взаимосвязанной работе нескольких специальных программ. Перечислим основные компоненты поисковых систем и их принципы работы.
Каждая поисковая система имеет свой алгоритм поиска запрашиваемой пользователем информации. Алгоритмы эти сложные и чаще держатся в секрете. Однако общий принцип работы поисковых систем можно считать одинаковым. Любой поисковик:
- Сначала собирает информацию, черпая её со страниц сайтов и вводя её в свою базы данных;
- Индексирует сайты и их страницы, и переводит их из базы данных в базу поисковой выдачи;
- Выдает результаты по поисковому запросу, беря их из базы проиндексированных страниц;
- Ранжирует результаты (выстраивает результаты по значимости).
Как работают поисковики
Всю работу поисковых систем выполняют специальные программы и комбинации этих программ. Перечислим основные составляющие алгоритмов поисковых систем:
- Spider (паук) – это браузероподобная программа, скачивающая веб-страницы. Заполняет базу данных поисковика.
- Crawler (краулер, «путешествующий» паук) – это программа, проходящая автоматически по всем ссылкам, которые найдены на странице.
- Indexer (индексатор) – это программа, анализирующая веб-страницы, скачанные пауками. Анализ страниц сайта для их индексации.
- Database (база данных) – это хранилище страниц. Одна база данных это все страницы загруженные роботом. Вторая база данных это проиндексированные страницы.
- Search engine results engine (система выдачи результатов) – это программа, которая занимается извлечением из базы данных проиндексированных страниц, согласно поисковому запросу.
- Web server (веб-сервер) – веб-сервер, осуществляющий взаимодействие пользователя со всеми остальными компонентами системы поиска.
Реализация механизмов поиска у поисковиков может быть самая различная. Например, комбинация программ Spider+ Crawler+ Indexer может быть создана, как единая программа, скачивающая и анализирующая веб-страницы и находящая новые ресурсы по найденным ссылкам. Тем не менее, нижеупомянутые общие черты программ присущи всем поисковым системам.
Программы поисковых систем
Spider
«Паук» скачивает веб-страницы так же как пользовательский браузер. Отличие в том, что браузер отображает содержащуюся на странице текстовую, графическую или иную информацию, а паук работает с html-текстом страницы напрямую, у него нет визуальных компонент. Именно, поэтому нужно обращать внимание на ошибки в html кодах страниц сайта.
Crawler
Программа Crawler, выделяет все находящиеся на странице ссылки. Задача программы вычислить, куда должен дальше направиться паук, исходя из заданного заранее, адресного списка или идти по ссылках на странице. Краулер «видит» и следует по всем ссылкам, найденным на странице и ищет новые документы, которые поисковая система, пока еще не знает. Именно, поэтому, нужно удалять или исправлять битые ссылки на страниц сайта и следить за качеством ссылок сайта.
Indexer
Программа Indexer (индексатор) делит страницу на составные части, далее анализирует каждую часть в отдельности. Выделению и анализу подвергаются заголовки, абзацы, текст, специальные служебные html-теги, стилевые и структурные особенности текстов, и другие элементы страницы. Именно, поэтому, нужно выделять заголовки страниц и разделов мета тегами (h2-h5,h5,h6), а абзацы заключать в теги <p>.
Database
База данных поисковых систем хранит все скачанные и анализируемые поисковой системой данные. В базе данных поисковиков хранятся все скачанные страницы и страницы, перенесенные в поисковой индекс. В любом инструменте веб мастеров каждого поисковика, вы можете видеть и найденные страницы и страницы в поиске.
Search Engine Results Engine
Search Engine Results Engine это инструмент (программа) выстраивающая страницы соответствующие поисковому запросу по их значимости (ранжирование страниц). Именно эта программа выбирает страницы, удовлетворяющие запросу пользователя, и определяет порядок их сортировки. Инструментом выстраивания страниц называется алгоритм ранжирования системы поиска.
Важно! Оптимизатор сайта, желая улучшить позиции ресурса в выдаче, взаимодействует как раз с этим компонентом поисковой системы. В дальнейшем все факторы, которые влияют на ранжирование результатов, мы обязательно рассмотрим подробно.
Web server
Web server поисковика это html страница с формой поиска и визуальной выдачей результатов поиска.
Повторимся. Работа поисковых систем основана на работе специальных программ. Программы могут объединяться, компоноваться, но общий принцип работы всех поисковых систем остается одинаковым: сбор страниц сайтов, их индексирование, выдача страниц по результатам запроса и ранжирование выданных страниц по их значимости. Алгоритм значимости у каждого поисковика свой.
©wordpress-abc.ru
Еще статьи
- Внутренние факторы ранжирования, как основная задача веб-мастеров
- Правильный SEO контент сайта, основа поискового продвижения
- Три последних поисковых алгоритма Яндекс: история алгоритмов
- Первичная индексация сайта в поисковых системах
- Обмен ссылками, схемы обмена ссылками, санкции за неправильный обмен
- Поисковые системы Интернет: Яндекс, Google, Mail, Bing, Рамблер
- Что такое каталог Яндекс, адрес каталога, как попасть в каталог Яндекс
Похожие посты:
Принципы работы поисковых систем — блог Indigo
Karina | 09.09.2014
Две основные функции поисковых систем в Интернете – сканирование сайтов и создание индекса, а также предоставление ответов на поставленные вопросы посредством поиска и структурирования по релевантности имеющихся в индексе страниц данной тематики. Алгоритм, по которому работают поисковики, является тайной, которую пытаются разгадать оптимизаторы и владельцы сайтов.
Сканирование и индексация сайта поисковыми машинами
Как понять, что собой представляет Всемирная паутина? Проще всего вспомнить схему метро со множеством станций, где вместо остановок будут уникальные станицы или файлы. Поисковые системы вынуждены путешествовать по этой сети ежесекундно, используя для перемещения ссылки.
Например, представьте, что ваша страница – это станция метро и, чтобы поисковик до нее добрался, ему понадобится преодолеть значительное количество других станций, т. е. страниц.
 Схема метро как пример структуры Всемирной паутины
Схема метро как пример структуры Всемирной паутиныНаличие ссылок связывает страницы между собой, как перегоны в метро связывают станции, и именно по ним двигаются от материала к материалу поисковые роботы, сканируя бесконечное количество веб-страниц. Найденные страницы расшифровываются (поисковик видит всё как код, а не как страницу с дизайном) и сохраняются на жёстких дисках. Наиболее популярные поисковые системы, например Google, уже имеют распространённую сеть дата-центров по всему миру, где хранится весь объём данных. Огромные здания содержат наиболее современную технику, которая обрабатывает и передаёт информацию с колоссальной скоростью, потому как даже задержка в 1-2 секунды может вызвать недовольство у пользователя и переключить его интерес на другую систему поиска.
Формирование выдачи
Вводя интересующую информацию в поисковик, пользователь хочет получить ответ, который полностью удовлетворит его интерес. Машинный поиск рассматривает множество страниц, чтобы составить список релевантных и актуальных результатов. Современные поисковые системы по одному и тому же запросу включают в выдачу страницы разнообразной тематики, которые могут соответствовать данному ключевому слову. К примеру, если в Google мы вводим запрос «Нептун», поисковая система предложит множество вариантов: информацию о планете, мифологию, компании, рестораны и т. д. с идентичным названием.
То есть, без ввода уточняющего запроса поисковая система предложит пользователю все возможные варианты ответов, которые он предположительно мог искать по данному слову.
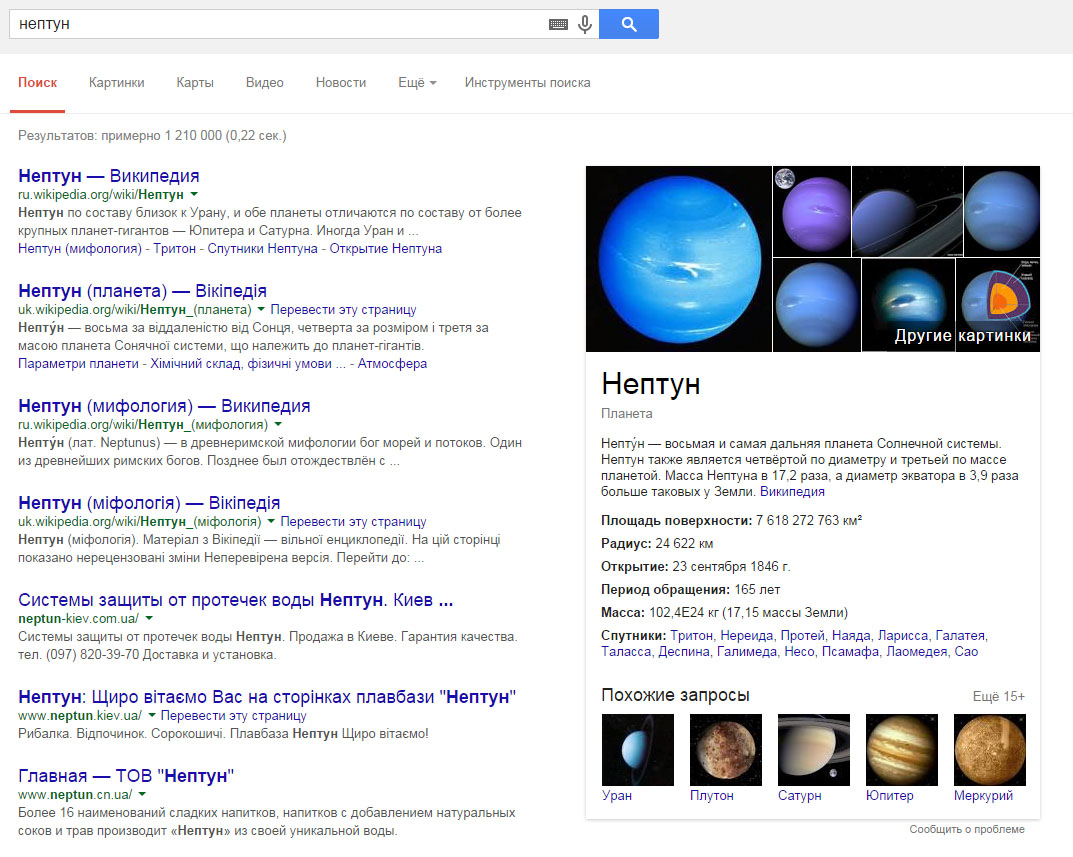
Нептун может быть богом, планетой, плавбазой или системой защиты от потопа
Инженерами было разработано множество факторов, которые дополнительно влияют на ранжирование. По информации Google, на данный момент в их результатах используются сотни таких факторов. Некоторые из них мы подробно рассматриваем в нашем блоге.
Как поисковики находят необходимый контент
В настоящее время всё ещё актуально мнение, что чем популярнее страница, тем более релевантный контент на ней размещен. Этот фактор не определяется вручную – существуют определённые алгоритмы, которые и помогают выяснить, какие ресурсы интересны пользователям.
Принцип отбора постоянно меняется и, судя по результатам в выдаче одного и того же сайта, может значительно отличаться в разных поисковиках. Зачастую в отборе популярных веб-страниц участвуют социальные факторы, наличие тематических ссылок, посещаемость страниц ресурса.
Как видят сайт поисковые системы
У каждого поисковика в Интернете свои, достаточно сложные алгоритмы поиска, информацией о которых они делятся неохотно. Но понять их основные принципы можно, проанализировав рекомендации для веб-мастеров, которые размещены на официальных сайтах систем. В русскоязычном сегменте наиболее популярными являются поисковые системы Google и Яндекс, и вот что они рекомендуют.
Рекомендации для веб-мастеров (Google)
Для увеличения ранжирования в этой поисковой системе желательно:
- создавать страницы для людей, не делать искусственную оптимизацию под поисковые системы, не создавать скрытый контент для поисковых роботов;
- разрабатывать сайт с чёткой иерархией, органичными текстовыми ссылками, к каждой странице делать хоть одну статичную текстовую ссылку;
- создавать интересный информационный ресурс, который будет наполнен актуальными и уникальными материалами с сопутствующими тегами, полностью соответствующими содержанию;
- использовать ключевые слова для создания понятных людям адресов URL;
- не допускать появления дублей страниц, использовать 301-й редирект или
rel="canonical", в зависимости от необходимости.

Советы веб-мастеру (Яндекс)
Чтобы в этой поисковой системе находилось всё, что вы разместили для пользователей в Интернете, будет полезно делать следующее:
- писать оригинальный контент или предоставлять уникальные услуги, которые заинтересуют посетителей;
- думать о пользователях, а не о поисковиках, продумывать мелочи, чтобы людям было удобно на сайте;
- делать полезные и органичные ссылки на сторонние ресурсы;
- разрабатывать хороший и понятный дизайн с акцентом на основную информацию;
- оптимизировать страницы в соответствии с их содержанием.
Универсальные рекомендации по оптимизации
Несмотря на наличие множества рекомендаций для веб-мастеров, прямой информации о том, как осуществляется поиск и почему именно так, в открытом доступе нет. Чтобы успешно развивать веб-ресурсы, маркетологи и SEO-специалисты постоянно проводят различные эксперименты, которые дают приблизительную информацию о том, что именно может влиять на хорошие позиции в выдаче и подводят к пониманию того, как работают поисковые системы.

Вот некоторые рекомендации:
- Зарегистрируйте домен, включающий название бренда, тип товара или услуг, которые на нём предлагаются.
- Создавайте страницы, в адресах которых будет ключевая информация о размещённом материале, товаре.
- Форматируйте текст одинаково, равномерно используйте ключевые слова, органично вписывайте ссылки. Делайте текст приятным для чтения.
- Размещайте актуальный контент, который может заинтересовать другие сайты со схожей тематикой и побудить их написать о вас и сделать на вас ссылку. Не усердствуйте с покупкой множества ссылок, делайте их интересными для пользователей – это поможет увеличить количество и качество посещений.
- Отслеживайте индексацию и ранжирование страниц (результаты в выдаче) для интересующих регионов.
- Делайте различные изменения на схожих страницах для выявления более действенных методов.
- Отмечайте действия, давшие результат, проверяйте их на других доменах, и в случае успеха радуйтесь тому, что нашли один из принципов ранжирования этой поисковой системы.
- Постоянно обновляйте контент на сайте тематическими статьями и новостями.
Таким образом, становится понятным, что SEO – это не набор законов и правил, выполнение которых повлечёт стабильный результат. Раскрутка в поисковых системах – это эксперименты, риски и опыт, который приобретается с каждым новым достижением. Самостоятельная оптимизация – достаточно сложный путь, который потребует больших затрат времени и сил.
Как работают поисковые системы Яндекс и Google / webentrance.ru
 В этой публикации разберемся, как работают поисковые системы. При вводе запроса в поисковую строку, например, Яндекса, не нужно думать, что бедная поисковая система будет искать по всему интернету, чтобы найти для вас нужную информацию.
В этой публикации разберемся, как работают поисковые системы. При вводе запроса в поисковую строку, например, Яндекса, не нужно думать, что бедная поисковая система будет искать по всему интернету, чтобы найти для вас нужную информацию.
Совсем нет, Яндекс действует исключительно в границах собственной поисковой базы данных.
К основным компонентам поисковых систем, как известно, относятся:
Spider (паук) – браузероподобная программа, занимающаяся скачиванием веб-страниц;
Crawler (краулер, «странствующий» паук) – программа, проходящая по всем ссылкам, которые она находит на странице;
Indexer (индексатор) – программа, занимающаяся анализом веб-страниц, скаченных Spider;
Database (база данных) – в которой хранятся скаченные и обработанные документы;
Search engine results engine (система выдачи результатов) – занимается извлечением результатов поиска из своей базы данных.
Как работают поисковые системы
Все перечисленные компоненты поисковых систем предназначаются для того, чтобы найти нужную информацию, например, ваш сайт в интернете, разделить его на отдельные параметры, сохранить информацию у себя в базе данных и затем выдать информацию при запросе пользователя.
При обращении поисковой системы к вашему сайту с помощью программы Spider, она не видит его в графическом исполнении, а видит код, то есть html-разметку и текст. Именно в таком виде программа скачивает страницы.
Программа Crawler по найденным пауком ссылкам в документе находит маршрут, по которому в дальнейшем и направляет паука Spider.
Вся эта информация попадает на обработку программе Indexer, которая разбивает информацию на составные части. Она в частности не воспринимает разметку, а берет текст, видит теги форматирования и т. д.
Обработанная в необходимом программе формате информация помещается в базу данных. И вот эту сохраненную информацию система выдачи результатов показывает в результатах поиска при извлечении ее из базы данных.
После ознакомления с принципами работы, остается сделать вывод, что поисковые системы ищут лишь по собственной базе данных, а не по всемирной сети.
Значит материал, который хранится на вашем ресурсе, может регулярно обновляться, но поисковые системы какое-то время могут не посещать ваш сайт и не видеть обновленную информацию.
Еще надо отметить, что коль скоро существует индексатор, разбивающий страницу на составные детали, то можно подумать, что некоторые из них более важные, а другие не очень. Поэтому при оптимизации сайта необходимо учитывать это обстоятельство.
Система выдачи результатов выстраивает в выдаче список документов по релевантности, по отношению к запросу, то есть, насколько документ соответствует введенному запросу.
Более релевантные документы, конечно, будут стоять первыми в выдаче, а менее релевантные займут, соответственно, нижние позиции. Процедура выстраивания документов по релевантности запроса называется ранжирование.
Надо понимать, что сайты в выдаче ранжируются в зависимости от действующего алгоритма той или иной поисковой системы. Обновление базы данных поисковых систем происходит периодически и это называется updates.
Итак, как работают поисковые системы. У Яндекса updates базы данных идут в пределах от двух до семи дней, а у Google периодичности, как таковой, нет, он находится в постоянном апдейте.
Google по сравнению с Яндексом имеет много преимуществ и самое основное, это быстрая индексация.
Периодичность апдейтов Яндекса есть возможность увидеть на сайте tools.promosite.ru, где приводятся последние обновления базы данных Яндекса.

Видим, например, что последний updates был 10 сентября, предыдущий – 8 сентября и т. д.
Алгоритмы поисковых систем
Google, в отличие от Яндекса, у которого все доступно и понятно, старается не анонсировать свои алгоритмы, то есть играет в молчанку.
По заявлению своих сотрудников, Google добавляет в год до 500 самых разных факторов ранжирования, есть у него в частности привязка к регионам, но по большей части эти факторы неизвестны.
Яндекс в свою очередь играет в города. Сначала был алгоритм Находка, в котором была полная вседозволенность. Сайты при этом можно было продвинуть довольно быстро, достаточно было добавить ключевые слова в текст и проставить ссылки. Не обязательно было заботиться о качестве текста и т. д.
Первые серьезные изменения в выдачах Яндекса произошли при внедрении алгоритма Арзамас, при котором внедрили региональную выдачу, то есть для разных регионов Яндекс показывает разную выдачу.
Регион определяется на основе IP-адреса, который присваивается непосредственно нашим сайтам. При внедрении алгоритма многие сайты повыпадали из поисковой выдачи, но на самом деле введение региональной выдачи дало очень хорошие возможности в плане продвижения сайтов в регионах.
Следующим глобальным изменением стал алгоритм Снежинск. Это эпоха машинного обучения. Ранжированием стала заниматься машина и при этом число учтенных факторов, влияющих на продвижение сайта, значительно выросло. Были введены различные фильтры, затеялась основательная борьба с нехорошими сайтами.
Последний алгоритм – Краснодар, при котором была введена технология «Спектр». Эта технология в первую очередь разбавляет выдачу по общим запросам, когда неизвестно точно по запросу, что имел в виду пользователь.
Это отразилось на оптимизации таким образом, что мест по высокочастотным запросам стало меньше и стало сложнее работать оптимизаторам. Но в целом все происходит адекватно, поэтому не следует пугаться таких слов, как машинное обучение или региональная выдача.
Вот примерно разобрались, как работают поисковые системы Яндекс и Google, по каким принципам и алгоритмам, но надо иметь ввиду, что новые алгоритмы у поисковиков появляются постоянно и надо быть всегда готовым к этим изменениям.
Другие записи по теме:
Несколько слов о том, как работают роботы поисковых машин
Эта статья вовсе не является попыткой объяснить, как работают поисковые машины вообще (это know-how их производителей). Однако, по моему мнению, она поможет понять как можно управлять поведением поисковых роботов (wanderers, spiders, robots — программы, с помощью которых та или иная поисковая система обшаривает сеть и индексирует встречающиеся документы) и как правильно построить структуру сервера и содержащихся на нем документов, чтобы Ваш сервер легко и хорошо индексировался.
Первой причиной того, что я решился написать эту статью, явился случай, когда я исследовал файл логов доступа к моему серверу и обнаружил там следующие две строки:
lycosidae.lycos.com - - [01/Mar/1997:21:27:32 -0500] "GET /robots.txt HTTP/1.0" 404 - lycosidae.lycos.com - - [01/Mar/1997:21:27:39 -0500] "GET / HTTP/1.0" 200 3270
то есть Lycos обратился к моему серверу, на первый запрос получил, что файла /robots.txt нет, обнюхал первую страницу, и отвалил. Естественно, мне это не понравилось, и я начал выяснять что к чему.
Оказывается, все «умные» поисковые машины сначала обращаются к этому файлу, который должен присутствовать на каждом сервере. Этот файл описывает права доступа для поисковых роботов, причем существует возможность указать для различных роботов разные права. Для него существует стандарт под названием Standart for Robot Exclusion.
По мнению Луиса Монье (Louis Monier, Altavista), только 5% всех сайтов в настоящее время имеет не пустые файлы /robots.txt если вообще они (эти файлы) там существуют. Это подтверждается информацией, собранной при недавнем исследовании логов работы робота Lycos. Шарль Коллар (Charles P.Kollar, Lycos) пишет, что только 6% от всех запросов на предмет /robots.txt имеют код результата 200. Вот несколько причин, по которым это происходит:
- люди, которые устанавливают Веб-сервера, просто не знают ни об этом стандарте, ни о необходимости существования файла /robots.txt
- не обязательно человек, инсталлировавший Веб-сервер, занимается его наполнением, а тот, кто является вебмастером, не имеет должного контакта с администратором самой «железяки»
- это число отражает число сайтов, которые действительно нуждаются в исключении лишних запросов роботов, поскольку не на всех серверах имеется такой существенный трафик, при котором посещение сервера поисковым роботом, становится заметным для простых пользователей
Файл /robots.txt предназначен для указания всем поисковым роботам (spiders) индексировать информационные сервера так, как определено в этом файле, т.е. только те директории и файлы сервера, которые НЕ описаны в /robots.txt. Это файл должен содержать 0 или более записей, которые связаны с тем или иным роботом (что определяется значением поля agent_id), и указывают для каждого робота или для всех сразу что именно им НЕ НАДО индексировать. Тот, кто пишет файл /robots.txt, должен указать подстроку Product Token поля User-Agent, которую каждый робот выдает на HTTP-запрос индексируемого сервера. Например, нынешний робот Lycos на такой запрос выдает в качестве поля User-Agent: Lycos_Spider_(Rex)/1.0 libwww/3.1.
Если робот Lycos не нашел своего описания в /robots.txt — он поступает так, как считает нужным. Как только робот Lycos «увидел» в файле /robots.txt описание для себя — он поступает так, как ему предписано.
При создании файла /robots.txt следует учитывать еще один фактор — размер файла. Поскольку описывается каждый файл, который не следует индексировать, да еще для многих типов роботов отдельно, при большом количестве не подлежащих индексированию файлов размер /robots.txt становится слишком большим. В этом случае следует применять один или несколько следующих способов сокращения размера /robots.txt:
- указывать директорию, которую не следует индексировать, и, соответственно, не подлежащие индексированию файлы располагать именно в ней
- создавать структуру сервера с учетом упрощения описания исключений в /robots.txt
- указывать один способ индексирования для всех agent_id
- указывать маски для директорий и файлов
Общее описание формата записи.
[ # comment string NL ]* User-Agent: [ [ WS ]+ agent_id ]+ [ [ WS ]* # comment string ]? NL [ # comment string NL ]* Disallow: [ [ WS ]+ path_root ]* [ [ WS ]* # comment string ]? NL [ # comment string NL | Disallow: [ [ WS ]+ path_root ]* [ [ WS ]* # comment string ]? NL ]* [ NL ]+
Описание параметров, применяемых в записях /robots.txt
[…]+ Квадратные скобки со следующим за ними знаком + означают, что в качестве параметров должны быть указаны один или несколько терминов.
Например, после «User-Agent:» через пробел могут быть указаны один или несколько agent_id.
[…]* Квадратные скобки со следующим за ними знаком * означают, что в качестве параметров могут быть указаны ноль или несколько терминов.
Например, Вы можете писать или не писать комментарии.
[…]? Квадратные скобки со следующим за ними знаком ? означают, что в качестве параметров могут быть указаны ноль или один термин.
Например, после «User-Agent: agent_id» может быть написан комментарий.
..|.. означает или то, что до черты, или то, что после.
WS один из символов — пробел (011) или табуляция (040)
NL один из символов — конец строки (015) , возврат каретки (012) или оба этих символа (Enter)
User-Agent: ключевое слово (заглавные и прописные буквы роли не играют).
Параметрами являются agent_id поисковых роботов.
Disallow: ключевое слово (заглавные и прописные буквы роли не играют).
Параметрами являются полные пути к неиндексируемым файлам или директориям
# начало строки комментариев, comment string — собственно тело комментария.
agent_id любое количество символов, не включающих WS и NL, которые определяют agent_id различных поисковых роботов. Знак * определяет всех роботов сразу.
path_root любое количество символов, не включающих WS и NL, которые определяют файлы и директории, не подлежащие индексированию.
Каждая запись начинается со строки User-Agent, в которой описывается каким или какому поисковому роботу эта запись предназначается. Следующая строка: Disallow. Здесь описываются не подлежащие индексации пути и файлы. КАЖДАЯ запись ДОЛЖНА иметь как минимум эти две строки (lines). Все остальные строки являются опциями. Запись может содержать любое количество строк комментариев. Каждая строка комментария должна начинаться с символа # . Строки комментариев могут быть помещены в конец строк User-Agent и Disallow. Символ # в конце этих строк иногда добавляется для того, чтобы указать поисковому роботу, что длинная строка agent_id или path_root закончена. Если в строке User-Agent указано несколько agent_id, то условие path_root в строке Disallow будет выполнено для всех одинаково. Ограничений на длину строк User-Agent и Disallow нет. Если поисковый робот не обнаружил в файле /robots.txt своего agent_id, то он игнорирует /robots.txt.
Если не учитывать специфику работы каждого поискового робота, можно указать исключения для всех роботов сразу. Это достигается заданием строки User-Agent: *
Если поисковый робот обнаружит в файле /robots.txt несколько записей с удовлетворяющим его значением agent_id, то робот волен выбирать любую из них.
Каждый поисковый робот будет определять абсолютный URL для чтения с сервера с использованием записей /robots.txt. Заглавные и строчные символы в path_root ИМЕЮТ значение.
Пример 1:
User-Agent: * Disallow: / User-Agent: Lycos Disallow: /cgi-bin/ /tmp/
В примере 1 файл /robots.txt содержит две записи. Первая относится ко всем поисковым роботам и запрещает индексировать все файлы. Вторая относится к поисковому роботу Lycos и при индексировании им сервера запрещает директории /cgi-bin/ и /tmp/, а остальные — разрешает. Таким образом сервер будет проиндексирован только системой Lycos.
Пример 2
User-Agent: Copernicus Fred Disallow: User-Agent: * Rex Disallow: /t
В примере 2 файл /robots.txt содержит две записи. Первая разрешает поисковым роботам Copernicus и Fred индексировать весь сервер. Вторая — запрещает всем и осебенно роботу Rex индексировать такие директории и файлы, как /tmp/, /tea-time/, /top-cat.txt, /traverse.this и т.д. Это как раз случай задания маски для директорий и файлов.
Пример 3:
# This is for every spider! User-Agent: * # stay away from this Disallow: /spiders/not/here/ #and everything in it Disallow: # a little nothing Disallow: #This could be habit forming! # Don't comments make code much more readable!!!
В примере 3 — одна запись. Здесь всем роботам запрещается индексировать директорию /spiders/not/here/, включая такие пути и файлы как /spiders/not/here/really/, /spiders/not/here/yes/even/me.html. Однако сюда не входят /spiders/not/ или /spiders/not/her (в директории ‘/spiders/not/’).
Незаконченность стандарта (Standart for Robot Exclusion)
К сожалению, поскольку поисковые системы появились не так давно, стандарт для роботов находится в стадии разработки, доработки, ну и т.д. Это означает, что в будущем совсем необязательно поисковые машины будут им руководствоваться.
Увеличение трафика
Эта проблема не слишком актуальна для российского сектора Internet, поскольку не так уж много в России серверов с таким серьезным трафиком, что посещение их поисковым роботом будет мешать обычным пользователям. Собственно, файл /robots.txt для того и предназначен, чтобы ограничивать действия роботов.
Не все поисковые роботы используют /robots.txt
На сегодняшний день этот файл обязательно запрашивается поисковыми роботами только таких систем как Altavista, Excite, Infoseek, Lycos, OpenText и WebCrawler.
Начальный проект, который был создан в результате соглашений между программистами некоторого числа коммерческих индексирующих организаций (Excite, Infoseek, Lycos, Opentext и WebCrawler) на недавнем собрании Distributing Indexing Workshop (W3C) , ниже.
На этом собрании обсуждалось использование мета-тагов HTML для управления поведением поисковых роботов, но окончательного соглашения достигнуто не было. Были определены следующие проблемы для обсуждения в будущем:
- Неопределенности в спецификации файла /robots.txt
- Точное определение использования мета-тагов HTML, или дополнительные поля в файле /robots.txt
- Информация «Please visit»
- Текущий контроль информации: интервал или максимум открытых соединений с сервером, при которых можно начинать индексировать сервер
Этот таг предназначен для пользователей, которые не могут контролировать файл /robots.txt на своих веб-сайтах. Таг позволяет задать поведение поискового робота для каждой HTML-страницы, однако при этом нельзя совсем избежать обращения робота к ней (как возможно указать в файле /robots.txt).
<META NAME="ROBOTS" CONTENT="robot_terms">
robot_terms — это разделенный запятыми список следующих ключевых слов (заглавные или строчные символы роли не играют): ALL, NONE, INDEX, NOINDEX, FOLLOW, NOFOLLOW.
NONE — говорит всем роботам игнорировать эту страницу при индексации (эквивалентно одновременному использованию ключевых слов NOINDEX, NOFOLLOW).
ALL — разрешает индексировать эту страницу и все ссылки из нее (эквивалентно одновременному использованию ключевых слов INDEX, FOLLOW).
INDEX — разрешает индексировать эту страницу
NOINDEX — неразрешает индексировать эту страницу
FOLLOW — разрешает индексировать все ссылки из этой страницы
NOFOLLOW — неразрешает индексировать ссылки из этой страницы
Если этот мета-таг пропущен или не указаны robot_terms, то по умолчанию поисковый робот поступает как если бы были указаны robot_terms= INDEX, FOLLOW (т.е. ALL). Если в CONTENT обнаружено ключевое слово ALL, то робот поступает соответственно, игнорируя возможно указанные другие ключевые слова.. Если в CONTENT имеются противоположные по смыслу ключевые слова, например, FOLLOW, NOFOLLOW, то робот поступает по своему усмотрению (в этом случае FOLLOW).
Если robot_terms содержит только NOINDEX, то ссылки с этой страницы не индексируются. Если robot_terms содержит только NOFOLLOW, то страница индексируется, а ссылки, соответственно, игнорируются.
<META NAME="KEYWORDS" CONTENT="phrases">
phrases — разделенный запятыми список слов или словосочетаний (заглавные и строчные символы роли не играют), которые помогают индексировать страницу (т.е. отражают содержание страницы). Грубо говоря, это те слова, в ответ на которые поисковая система выдаст этот документ.
<META NAME="DESCRIPTION" CONTENT="text">
text — тот текст, который будет выводиться в суммарном ответе на запрос пользователя к поисковой системе. Сей текст не должен содержать тагов разметки и логичнее всего вписать в него смысл данного документа на пару-тройку строк.
Некоторые коммерческие поисковые роботы уже используют мета-таги, позволяющие осуществлять «связь» между роботом и вебмастером. Altavista использует KEYWORDS мета-таг, а Infoseek использует KEYWORDS и DESCRIPTION мета-таги.
Вебмастер может «сказать» поисковому роботу или файлу bookmark пользователя, что содержимое того или иного файла будет изменяться. В этом случае робот не будет сохранять URL, а броузер пользователя внесет или не внесет это файл в bookmark. Пока эта информация описывается только в файле /robots.txt, пользователь не будет знать о том, что эта страница будет изменяться.
Мета-таг DOCUMENT-STATE может быть полезен для этого. По умолчанию, этот мета-таг принимается с CONTENT=STATIC.
<META NAME="DOCUMENT-STATE" CONTENT="STATIC"> <META NAME="DOCUMENT-STATE" CONTENT="DYNAMIC">
Генерируемые страницы — страницы, порождаемые действием CGI-скриптов. Их наверняка не следует индексировать, поскольку если попробовать провалиться в них из поисковой системы, будет выдана ошибка. Что касается зеркал, то негоже, когда выдаются две разные ссылки на разные сервера, но с одним и тем же содержимым. Чтобы этого избежать, следует использовать мета-таг URL с указанием абсолютного URL этого документа (в случае зеркал — на соответствующую страницу главного сервера).
<META NAME="URL" CONTENT="absolute_url">
- Charles P.Kollar, John R.R. Leavitt, Michael Mauldin, Robot Exclusion Standard Revisited, www.kollar.com/robots.html
- Martijn Koster, Standard for robot exclusion, info.webcrawler.com/mak/projects/robots/robots.html