Ве́б-обозрева́тель, или бра́узер (от англ. Web browser, бро́узер — неправильно[1][2]) — программное обеспечение для поиска, просмотра веб-сайтов, то есть для запроса веб-страниц (преимущественно из Сети), для их обработки, вывода и перехода от одной страницы к другой.
Большинство браузеров также наделены способностями к просмотру оглавления персонального компьютера. Ныне браузер — комплексное приложение для обработки и вывода разных составляющих веб-страницы и для предоставления интерфейса между веб-сайтом и его посетителем. Практически все популярные браузеры распространяются бесплатно или «в комплекте» с другим приложением: Internet Explorer (неотъемлемая часть Microsoft Windows), Mozilla Firefox (бесплатно, свободное ПО), Safari (совместно с Mac OS или бесплатно для Windows).
По данным компании Net Applications, за май 2009 года рыночная доля Internet Explorer составляла 65,50 %, Firefox — 22,51 %, Google Chrome — 1,80 %, Netscape — 0,74 %, Opera Mini — 0,08 %, Pocket Internet Explorer — 0,01 %, прочие — около 0 %.
[3]
Популярные
Internet Explorer, Mozilla Firefox, [5], Flock[6], Google Chrome
Менее распространённые
Avant Browser, Netscape Navigator, [7], Epiphany, Charon, Dillo, [8]
↑ Browser Market Share, May 2009. Net Applications. Проверено 1 июня 2009.
↑ The Multi-Principal OS Construction of the Gazelle Web Browser. Microsoft Research (19 февраля 2009). Проверено 5 апреля 2009.
↑ Основан на коде Konqueror.
↑ Основан на коде Mozilla Firefox.
↑ Оболочка для Internet Explorer.
↑Текстовый браузер — веб-браузер, отображающий веб-страницы исключительно в виде текста. Большинство текстовых браузеров предназначены для использования в консоли или эмуляторе терминала, то есть не нуждаются в графическом интерфейсе.
↑ Активная версия Links.
↑ Нет активности.
↑ Существует дополнение для вывода изображений.
См. также
Сравнение веб-браузеров
Список браузеров
Временная шкала браузеров
User Agent
Оффлайн-браузеры
Ссылки
Статистика использования браузеров в Рунете и Интернете
Блог о веб-браузерах и интернет-технологиях
Тестирование браузеров на низкоскоростном соединении
Wikimedia Foundation.
2010.
Игры ⚽Нужно решить контрольную?
Синонимы:
программа
Брохман Сигне Мария
Брох Г.
Полезное
Браузер Yandex — Блог Яндекса
Блог Яндекса
1 октября 2012, 11:05
Сегодня мы выпускаем первую версию своего нового браузера. Он получил то же имя, что наша компания — Yandex. Это простой и быстрый браузер с лаконичным интерфейсом, встроенным поиском и защитой от вирусов.
До недавнего времени браузеры состояли из двух основных частей: «движка», который отображает страницы, и пользовательского интерфейса. Но в последнее время всё более важной становится третья часть: облачная. При отображении страниц, при вводе поисковых запросов, при проверке орфографии и переводе, определении местоположения и проверке на вирусы могут и должны использоваться многочисленные знания, которые есть только у некоторых мировых компаний. Не все производители браузеров имеют свои облачные технологии, поэтому им приходится сотрудничать с теми, у кого они есть. К счастью, Яндекс как раз обладает полным спектром облачных сервисов. Именно в этом направлении будут сосредоточены многие наши усилия.
Умная строка объединяет в себе адресную и поисковую. Она выполнена в форме поисковой стрелки Яндекса, показывая пользователю, что можно вводить и адреса сайтов, и запросы. Строка снабжена подсказками с мгновенными ответами от сервисов Яндекса. Прямо в подсказках, не переходя на страницу поиска, можно узнать ситуацию на дорогах города, курсы валют, перевод слова или, например, высоту Останкинской телебашни.
Самые посещаемые пользователем сайты вынесены на специальное Табло. Оно появляется всякий раз, когда человек собирается открыть новую страницу. С его помощью можно в один клик перейти на нужный ресурс, не набирая его адрес вручную. Сайты представлены на Табло логотипом или иконкой — мы считаем, что так узнать сайт гораздо легче, чем по скриншоту. Кроме того, на Табло можно получить свежую информацию от любимых сайтов — например, количество новых сообщений в почте или уведомления от социальной сети.
Браузер позволяет путешествовать по сети, не беспокоясь за безопасность компьютера. Программа предупредит о страницах и файлах, которые лучше не открывать. Веб-страницы проверяет антивирусная технология Яндекса, скачиваемые файлы — система «Лаборатории Касперского».
Yandex поможет сориентироваться и на сайтах на незнакомом языке. Он умеет переводить как отдельные слова или фразы, так и целые веб-страницы с девяти языков, в том числе английского, немецкого и французского. Для перевода текстов и слов используется облачная технология машинного перевода Яндекса.
Теперь о том, что внутри. В качестве движка был выбран WebKit, который поддерживается многими разработчиками. Интерфейс базируется на открытом исходном коде Chromium. В платформе Яндекса WebKit расширен решениями компании Opera Software — в частности, технологией Opera Turbo. Она позволяет быстро загружать страницы даже при низкой скорости соединения. Режим Turbo появится уже в следующей версии продукта. Кроме того, в программу добавлены компоненты, без которых современный браузер был бы неполным. Так, в него встроена свежая версия Adobe Flash и программа для просмотра PDF-файлов.
Обычно в браузере накапливается много персональных настроек: закладки, настройки, посещенные страницы. Yandex легко перенесет все данные из вашего старого браузера, и переезд никак не помешает работе. Программа умеет импортировать информацию из любых популярных браузеров.
Загрузить браузер Yandex вы сможете сегодня после 17:00 по адресу
Наполнение страницы: как работают браузеры — Производительность в Интернете
Пользователи хотят работать в Интернете с контентом, который быстро загружается и с которым легко взаимодействовать. Поэтому разработчик должен стремиться к достижению этих двух целей.
Чтобы понять, как улучшить производительность и воспринимаемую производительность, нужно понять, как работает браузер.
Быстрые сайты обеспечивают лучший пользовательский опыт. Пользователи хотят и ожидают веб-интерфейса с контентом, который быстро загружается и с которым легко взаимодействовать.
Две основные проблемы с веб-производительностью — это проблемы, связанные с задержкой, и проблемы, связанные с тем фактом, что по большей части браузеры являются однопоточными.
Задержка — самая большая угроза нашей способности обеспечить быструю загрузку страницы. Цель разработчиков — сделать так, чтобы сайт загружался как можно быстрее — или, по крайней мере, отображалось как для сверхбыстрой загрузки — чтобы пользователь как можно быстрее получал запрошенную информацию. Сетевая задержка — это время, необходимое для передачи байтов по воздуху на компьютеры. Веб-производительность — это то, что мы должны сделать, чтобы страница загружалась как можно быстрее.
По большей части браузеры считаются однопоточными. То есть они выполняют задачу от начала до конца, прежде чем приступить к другой задаче. Для плавного взаимодействия цель разработчика — обеспечить эффективное взаимодействие с сайтом, от плавной прокрутки до отклика на прикосновение. Время рендеринга является ключевым моментом, так как главный поток может завершить всю работу, которую мы на него возлагаем, и при этом всегда быть доступным для обработки взаимодействий с пользователем. Веб-производительность может быть улучшена за счет понимания однопоточной природы браузера и сведения к минимуму обязанностей основного потока, где это возможно и уместно, чтобы обеспечить плавность рендеринга и немедленные ответы на взаимодействия.
Навигация — это первый шаг в загрузке веб-страницы. Это происходит всякий раз, когда пользователь запрашивает страницу, вводя URL-адрес в адресную строку, щелкая ссылку, отправляя форму, а также выполняя другие действия.
Одна из целей веб-производительности — свести к минимуму время, необходимое для завершения навигации. В идеальных условиях это обычно не занимает много времени, но задержка и пропускная способность — враги, которые могут вызвать задержки.
DNS-поиск
Первым шагом при переходе на веб-страницу является определение местоположения ресурсов этой страницы. Если вы перейдете к https://example.com , HTML-страница расположена на сервере с IP-адресом 93.184.216.34 . Если вы никогда не посещали этот сайт, необходимо выполнить поиск DNS.
Ваш браузер запрашивает поиск DNS, который в конечном итоге обрабатывается сервером имен, который, в свою очередь, отвечает IP-адресом. После этого первоначального запроса IP-адрес, скорее всего, будет кэшироваться на некоторое время, что ускоряет последующие запросы за счет извлечения IP-адреса из кэша вместо повторного обращения к серверу имен.
DNS-запросы обычно нужно выполнять только один раз для каждого имени хоста для загрузки страницы. Однако поиск DNS должен выполняться для каждого уникального имени хоста, на которое ссылается запрошенная страница. Если ваши шрифты, изображения, сценарии, реклама и метрики имеют разные имена хостов, для каждого из них необходимо выполнить поиск в DNS.
Это может отрицательно сказаться на производительности, особенно в мобильных сетях. Когда пользователь находится в мобильной сети, каждый поиск DNS должен идти с телефона на вышку сотовой связи, чтобы достичь авторитетного DNS-сервера.
Расстояние между телефоном, вышкой сотовой связи и сервером имен может увеличить задержку.
TCP-рукопожатие
Как только IP-адрес известен, браузер устанавливает соединение с сервером через трехстороннее TCP-рукопожатие. Этот механизм разработан таким образом, что два объекта, пытающиеся установить связь, — в данном случае браузер и веб-сервер — могут согласовать параметры сетевого TCP-сокета перед передачей данных, часто по протоколу HTTPS.
Метод трехэтапного квитирования TCP часто называют «SYN-SYN-ACK» — или, точнее, SYN, SYN-ACK, ACK — потому что TCP передает три сообщения для согласования и начала сеанса TCP между двумя компьютерами. Да, это означает еще три сообщения взад и вперед между каждым сервером, и запрос еще не сделан.
Согласование TLS
Для безопасных соединений, установленных через HTTPS, требуется еще одно «рукопожатие». Это рукопожатие или, скорее, согласование TLS определяет, какой шифр будет использоваться для шифрования связи, проверяет сервер и устанавливает наличие безопасного соединения перед началом фактической передачи данных. Это требует еще пяти обращений к серверу, прежде чем запрос контента будет фактически отправлен.
Хотя обеспечение безопасности соединения увеличивает время загрузки страницы, безопасное соединение стоит затрат на задержку, поскольку данные, передаваемые между браузером и веб-сервером, не могут быть расшифрованы третьей стороной.
После восьми обращений к серверу браузер, наконец, может выполнить запрос.
Как только мы установили соединение с веб-сервером, браузер отправляет начальный HTTP-запрос GET от имени пользователя, который для веб-сайтов чаще всего представляет собой HTML-файл. Как только сервер получит запрос, он ответит соответствующими заголовками ответа и содержимым HTML.
Этот ответ на этот первоначальный запрос содержит первый байт полученных данных. Время до первого байта (TTFB) — это время между тем, когда пользователь сделал запрос — скажем, нажав на ссылку — и получением этого первого пакета HTML. Первый фрагмент контента обычно составляет 14 КБ данных.
В нашем примере выше размер запроса определенно меньше 14 КБ, но связанные ресурсы не запрашиваются до тех пор, пока браузер не обнаружит ссылки во время синтаксического анализа, описанного ниже.
Контроль перегрузки/медленный старт TCP
TCP-пакеты во время передачи разбиваются на сегменты. Поскольку TCP гарантирует последовательность пакетов, сервер должен получить подтверждение от клиента в виде пакета ACK после отправки определенного количества сегментов.
Если сервер ожидает ACK после каждого сегмента, это приведет к частым ACK от клиента и может увеличить время передачи даже в случае малонагруженной сети.
С другой стороны, одновременная отправка слишком большого количества сегментов может привести к тому, что в загруженной сети клиент не сможет получить сегменты и будет просто отвечать ACK в течение длительного времени, а серверу придется постоянно пересылать сегменты.
Чтобы сбалансировать количество передаваемых сегментов, используется алгоритм медленного старта TCP для постепенного увеличения объема передаваемых данных до тех пор, пока не будет определена максимальная пропускная способность сети, а также для уменьшения объема передаваемых данных в случае высокой нагрузки на сеть.
Количество передаваемых сегментов контролируется значением окна перегрузки (CWND), которое может быть инициализировано равным 1, 2, 4 или 10 MSS (MSS составляет 1500 байт по протоколу Ethernet). Это значение представляет собой количество байтов для отправки, после получения которых клиент должен отправить ACK.
Если получен ACK, то значение CWND будет удвоено, и сервер сможет отправить больше сегментов в следующий раз. Если вместо этого ACK не получен, значение CWND будет уменьшено вдвое. Таким образом, этот механизм обеспечивает баланс между отправкой слишком большого количества сегментов и отправкой слишком малого количества сегментов.
Как только браузер получит первый фрагмент данных, он может начать анализ полученной информации. Синтаксический анализ — это шаг, который браузер выполняет, чтобы преобразовать данные, которые он получает по сети, в DOM и CSSOM, которые используются визуализатором для отображения страницы на экране.
DOM — это внутреннее представление разметки для браузера. Модель DOM также открыта, и ею можно манипулировать с помощью различных API-интерфейсов в JavaScript.
Даже если HTML-код запрошенной страницы больше исходного пакета размером 14 КБ, браузер начнет синтаксический анализ и попытается отобразить интерфейс на основе имеющихся у него данных. Вот почему для оптимизации веб-производительности важно включить все, что нужно браузеру для начала рендеринга страницы, или, по крайней мере, шаблон страницы — CSS и HTML, необходимые для первого рендеринга — в первые 14 КБ. Но прежде чем что-либо отобразится на экране, необходимо проанализировать HTML, CSS и JavaScript.
Построение дерева DOM
Мы описываем пять шагов критического пути рендеринга.
Первым шагом является обработка разметки HTML и построение дерева DOM. Парсинг HTML включает в себя токенизацию и построение дерева. Маркеры HTML включают начальный и конечный теги, а также имена и значения атрибутов. Если документ правильно сформирован, его разбор выполняется просто и быстро. Синтаксический анализатор анализирует токенизированный ввод в документ, создавая дерево документа.
Дерево DOM описывает содержимое документа. элемент — это первый элемент и корневой узел дерева документа. Дерево отражает отношения и иерархии между различными элементами. Элементы, вложенные в другие элементы, являются дочерними узлами. Чем больше количество узлов DOM, тем больше времени требуется для построения дерева DOM.
Когда синтаксический анализатор находит неблокирующие ресурсы, такие как изображение, браузер запрашивает эти ресурсы и продолжает синтаксический анализ. Синтаксический анализ может продолжаться при обнаружении файла CSS, но 9Элементы 0025 будет анализировать доступный контент и запрашивать высокоприоритетные ресурсы, такие как CSS, JavaScript и веб-шрифты. Благодаря сканеру предварительной загрузки нам не нужно ждать, пока парсер найдет ссылку на внешний ресурс, чтобы запросить его. Он будет извлекать ресурсы в фоновом режиме, поэтому к тому времени, когда основной анализатор HTML достигнет запрошенных ресурсов, они уже могут быть загружены или загружены. Оптимизации, которые обеспечивает сканер предварительной загрузки, уменьшают блокировки.
<ссылка rel="stylesheet" href="styles.css" />
В этом примере, пока основной поток анализирует HTML и CSS, сканер предварительной загрузки найдет сценарии и изображение и также начнет их загрузку. Чтобы сценарий не блокировал процесс, добавьте атрибут async или атрибут defer 9.0026, если важен разбор и порядок выполнения JavaScript.
Ожидание получения CSS не блокирует синтаксический анализ или загрузку HTML, но блокирует JavaScript, поскольку JavaScript часто используется для запроса влияния свойств CSS на элементы.
Построение дерева CSSOM
Вторым шагом критического пути рендеринга является обработка CSS и построение дерева CSSOM. Объектная модель CSS похожа на DOM. DOM и CSSOM — это деревья. Это независимые структуры данных. Браузер преобразует правила CSS в карту стилей, которую он может понять и с которой может работать. Браузер просматривает каждый набор правил в CSS, создавая дерево узлов с родительскими, дочерними и одноуровневыми отношениями на основе селекторов CSS.
Как и в случае с HTML, браузеру необходимо преобразовать полученные правила CSS во что-то, с чем он сможет работать. Следовательно, он повторяет процесс преобразования HTML в объект, но для CSS.
Дерево CSSOM включает стили из таблицы стилей пользовательского агента. Браузер начинает с наиболее общего правила, применимого к узлу, и рекурсивно уточняет вычисленные стили, применяя более конкретные правила. Другими словами, он каскадирует значения свойств.
Создание CSSOM выполняется очень быстро и не отображается уникальным цветом в текущих инструментах разработчика. Скорее, «Пересчитать стиль» в инструментах разработчика показывает общее время, необходимое для синтаксического анализа CSS, построения дерева CSSOM и рекурсивного вычисления вычисляемых стилей. С точки зрения оптимизации веб-производительности, есть более низкие висящие плоды, так как общее время для создания CSSOM, как правило, меньше, чем время, необходимое для одного поиска DNS.
Другие процессы
Компиляция JavaScript
Во время анализа CSS и создания CSSOM другие активы, включая файлы JavaScript, загружаются (благодаря сканеру предварительной загрузки). JavaScript анализируется, компилируется и интерпретируется. Сценарии анализируются в виде абстрактных синтаксических деревьев. Некоторые браузерные движки берут абстрактные синтаксические деревья и передают их компилятору, выводя байт-код. Это известно как компиляция JavaScript. Большая часть кода интерпретируется в основном потоке, но есть исключения, такие как код, выполняемый в веб-воркерах.
Построение дерева специальных возможностей
Браузер также строит дерево специальных возможностей, которое вспомогательные устройства используют для анализа и интерпретации содержимого. Объектная модель доступности (AOM) похожа на семантическую версию DOM. Браузер обновляет дерево специальных возможностей при обновлении DOM. Дерево специальных возможностей не может быть изменено самими вспомогательными технологиями.
Пока AOM не будет построен, содержимое недоступно для программ чтения с экрана.
Шаги рендеринга включают стиль, компоновку, рисование и, в некоторых случаях, композитинг. Деревья CSSOM и DOM, созданные на этапе синтаксического анализа, объединяются в дерево рендеринга, которое затем используется для вычисления макета каждого видимого элемента, который затем отображается на экране. В некоторых случаях содержимое можно перенести на отдельный уровень и скомпоновать, повышая производительность за счет рисования частей экрана на графическом процессоре, а не на ЦП, освобождая основной поток.
Стиль
Третий шаг критического пути рендеринга — объединение DOM и CSSOM в дерево рендеринга. Вычисленное дерево стилей или дерево рендеринга начинается с корня дерева DOM, обходя каждый видимый узел.
Элементы, которые не будут отображаться, например элемент и его дочерние элементы, а также любые узлы с display: none , например скрипт { display: none; } , которые вы найдете в таблицах стилей пользовательского агента, не включены в дерево рендеринга, поскольку они не будут отображаться в выводе рендеринга. Узлы с 9Видимость 0025: скрытые примененные включены в дерево рендеринга, так как они занимают место. Поскольку мы не дали никаких директив для переопределения значения по умолчанию для пользовательского агента, узел сценария в нашем примере кода выше не будет включен в дерево рендеринга.
К каждому узлу применяются свои правила CSSOM. Дерево рендеринга содержит все видимые узлы с содержимым и вычисленными стилями — все соответствующие стили сопоставляются с каждым видимым узлом в дереве DOM и определяются на основе каскада CSS, какие вычисленные стили предназначены для каждого узла.
Макет
Четвертый этап критического пути рендеринга — запуск макета в дереве рендеринга для вычисления геометрии каждого узла. Макет — это процесс, посредством которого определяются размеры и расположение всех узлов в дереве рендеринга, а также определяется размер и положение каждого объекта на странице. Reflow — любое последующее определение размера и положения любой части страницы или всего документа.
После построения дерева рендеринга начинается компоновка. Дерево рендеринга определило, какие узлы отображаются (даже если они невидимы) вместе с их вычисленными стилями, но не размерами или расположением каждого узла. Чтобы определить точный размер и положение каждого объекта, браузер начинает с корня дерева рендеринга и просматривает его.
На веб-странице почти все представляет собой коробку. Разные устройства и разные настройки рабочего стола означают неограниченное количество разных размеров области просмотра. На этом этапе, принимая во внимание размер области просмотра, браузер определяет размеры всех различных полей, которые будут отображаться на экране. Принимая за основу размер окна просмотра, компоновка обычно начинается с тела, задавая размеры всех потомков тела, со свойствами блочной модели каждого элемента, предоставляя пространство-заполнитель для замененных элементов, размеры которых неизвестны, например нашего изображения.
При первом определении размера и положения каждого узла называется макет . Последующие пересчеты называются перерасчетами . В нашем примере предположим, что первоначальный макет происходит до того, как изображение будет возвращено. Поскольку мы не объявляли размеры нашего изображения, после того, как размеры изображения станут известны, произойдет перекомпоновка.
Отрисовка
Последним шагом критического пути отрисовки является отрисовка отдельных узлов на экране, первое вхождение которого называется первой осмысленной отрисовкой. На этапе рисования или растеризации браузер преобразует каждое поле, рассчитанное на этапе макета, в фактические пиксели на экране. Рисование включает в себя отрисовку каждой визуальной части элемента на экране, включая текст, цвета, границы, тени и замененные элементы, такие как кнопки и изображения. Браузер должен делать это очень быстро.
Чтобы обеспечить плавную прокрутку и анимацию, все, что занимает основной поток, включая вычисление стилей, а также перекомпоновку и отрисовку, должно выполняться браузером менее чем за 16,67 мс. При разрешении 2048 x 1536 iPad имеет более 3 145 000 пикселей, которые нужно отобразить на экране. Это очень много пикселей, которые нужно очень быстро закрашивать. Чтобы гарантировать, что перерисовка может быть выполнена даже быстрее, чем первоначальная краска, рисунок на экране обычно разбивается на несколько слоев. Если это происходит, то необходимо композитинг.
Рисование может разбить элементы в дереве макета на слои. Продвижение содержимого по слоям на графическом процессоре (вместо основного потока на ЦП) повышает производительность рисования и перерисовки. Существуют определенные свойства и элементы, которые создают экземпляр слоя, в том числе и , а также любой элемент, который имеет свойства CSS opacity , 3D transform , will-change и некоторые другие. Эти узлы будут прорисованы на своем собственном слое вместе со своими потомками, если только потомку не потребуется собственный слой по одной (или нескольким) из вышеперечисленных причин.
Слои действительно повышают производительность, но требуют больших затрат, когда речь идет об управлении памятью, поэтому не следует злоупотреблять ими в рамках стратегий оптимизации веб-производительности.
Композитинг
Когда части документа отрисовываются в разных слоях, перекрывая друг друга, компоновка необходима для обеспечения того, чтобы они отображались на экране в правильном порядке и содержимое отображалось правильно.
Поскольку страница продолжает загружать активы, может произойти перекомпоновка (вспомните наш пример изображения, которое прибыло с опозданием). Переплавка вызывает перерисовку и повторную композицию. Если бы мы определили размеры нашего изображения, перекомпоновка не потребовалась бы, и только тот слой, который нужно было перерисовать, был бы перерисован и, при необходимости, скомпонован. Но мы не включили размеры изображения! Когда изображение получено с сервера, процесс рендеринга возвращается к шагам компоновки и перезапускается оттуда.
Когда основной поток закончит рисовать страницу, можно подумать, что все готово. Это не обязательно так. Если загрузка включает в себя JavaScript, который был правильно отложен и выполняется только после срабатывания события onload , основной поток может быть занят и недоступен для прокрутки, касания и других взаимодействий.
Время до интерактивности (TTI) – это измерение того, сколько времени прошло от первого запроса, который привел к поиску DNS и TCP-подключению, до момента, когда страница стала интерактивной. Под интерактивностью понимается момент времени после первой отрисовки содержимого, когда страница отвечает на действия пользователя в течение 50 мс. Если основной поток занят синтаксическим анализом, компиляцией и выполнением JavaScript, он недоступен и, следовательно, не может своевременно (менее 50 мс) реагировать на действия пользователя.
В нашем примере, возможно, изображение загрузилось быстро, но, возможно, файл Anotherscript. js весил 2 МБ, а сетевое соединение нашего пользователя было медленным. В этом случае пользователь увидит страницу очень быстро, но не сможет прокручивать ее без помех, пока скрипт не будет загружен, проанализирован и выполнен. Это не очень хороший пользовательский опыт. Не занимайте основной поток, как показано в этом примере WebPageTest:
.
В этом примере выполнение JavaScript заняло более 1,5 секунд, и все это время основной поток был полностью занят, не реагируя на события кликов или касания экрана.
Веб-производительность
Обнаружили проблему с содержанием этой страницы?
Отредактируйте страницу на GitHub.
Сообщить о проблеме с содержимым.
Просмотрите исходный код на GitHub.
Хотите принять участие? Узнайте, как внести свой вклад.
Последний раз эта страница была изменена участниками MDN.
Сегодня я узнал: почему некоторые сайты работают неправильно в разных браузерах
Сегодня я узнал: почему некоторые сайты работают неправильно в разных браузерах
0
Независимо от того, какой браузер вы используете или насколько он современен, неизбежно вы обнаружите, что веб-сайт работает неправильно.
Многие проблемы, с которыми вы сталкиваетесь, могут вызывать проблемы с печатью, интерактивностью или анимацией.
ПОЧЕМУ ЕСТЬ ПРОБЛЕМЫ С РАЗНЫМИ БРАУЗЕРАМИ
Веб-страницы программируются с использованием нескольких разных языков. Эти языки имеют стандарты, которым должны следовать производители и разработчики, чтобы их продукты были совместимы с браузером. Большинство этих стандартов введены после инноваций, и они могут изменить способ работы браузера. Эти стандарты различны для каждого языка, и это по-разному влияет на браузеры, будь то Firefox, Internet Explorer или Chrome.
У каждого браузера разные движки. Эти механизмы обрабатывают код, написанный для различных веб-сайтов, которые вы можете посещать. Механизм каждого браузера интерпретирует и отображает веб-страницу по-своему. Это означает, что один и тот же веб-сайт может выглядеть и функционировать по-разному в разных браузерах.
Из-за этого разработчики балансируют на натянутой веревке. Они пытаются найти компромисс при кодировании, основываясь на относительной популярности браузера, которым пользуется большинство их клиентов. Из-за этого в разных браузерах возникает множество мелких проблем.
Что еще хуже, могут быть проблемы с веб-сайтом в разных версиях одних и тех же браузеров. Например, если Chrome добавит новый стандарт в свой движок, это может привести к поломке веб-сайта, который когда-то работал в Chrome. Разработчики должны попытаться уловить эти изменения и обновить свои веб-сайты до того, как клиент заметит проблемы.
Все это вызовет сбои в работе; однако FIS предоставляет доступ к нескольким браузерам для решения этой проблемы. Если веб-сайт не работает в одном браузере, есть большая вероятность, что он был создан для следующего.
ЧЕМ МЫ МОЖЕМ ПОМОЧЬ
Если на вашем веб-сайте используется Java, не используйте Chrome. Chrome не поддерживает интеграцию Java с их браузером. Например, PRISM использует Java и не будет корректно работать в Chrome.
Поддержка Internet Explorer прекращена. Поскольку Microsoft переходит на Edge в качестве браузера по умолчанию, поддержка и обновления Internet Explorer прекращены. Это означает, что вы можете заметить снижение функциональности этого браузера, особенно при просмотре сайтов, которые регулярно обновляются.
Мы столкнулись с большим количеством проблем с производительностью печати в Firefox, чем в других браузерах, поэтому, если вы печатаете отчеты из PeopleSoft. Возможно, вы захотите использовать другой браузер.
Используйте предпочитаемый браузер. В вашем выборе нет правильного или неправильного. Некоторые люди предпочитают Chrome, потому что он синхронизируется с вашей учетной записью Gmail, а другие используют Firefox, потому что он наиболее настраиваемый.
Создайте избранное для нужных вам веб-сайтов, которые работают в каждом браузере, это поможет запомнить, для работы каких веб-сайтов требуется определенный браузер, и вы сможете быстро получить к ним доступ.




 Именно в этом направлении будут сосредоточены многие наши усилия.
Именно в этом направлении будут сосредоточены многие наши усилия.
 Так, в него встроена свежая версия Adobe Flash и программа для просмотра PDF-файлов.
Так, в него встроена свежая версия Adobe Flash и программа для просмотра PDF-файлов.
 Веб-производительность может быть улучшена за счет понимания однопоточной природы браузера и сведения к минимуму обязанностей основного потока, где это возможно и уместно, чтобы обеспечить плавность рендеринга и немедленные ответы на взаимодействия.
Веб-производительность может быть улучшена за счет понимания однопоточной природы браузера и сведения к минимуму обязанностей основного потока, где это возможно и уместно, чтобы обеспечить плавность рендеринга и немедленные ответы на взаимодействия. Если вы никогда не посещали этот сайт, необходимо выполнить поиск DNS.
Если вы никогда не посещали этот сайт, необходимо выполнить поиск DNS.
 Это требует еще пяти обращений к серверу, прежде чем запрос контента будет фактически отправлен.
Это требует еще пяти обращений к серверу, прежде чем запрос контента будет фактически отправлен.
 com/about">ссылкой
com/about">ссылкой

 Если вместо этого ACK не получен, значение CWND будет уменьшено вдвое. Таким образом, этот механизм обеспечивает баланс между отправкой слишком большого количества сегментов и отправкой слишком малого количества сегментов.
Если вместо этого ACK не получен, значение CWND будет уменьшено вдвое. Таким образом, этот механизм обеспечивает баланс между отправкой слишком большого количества сегментов и отправкой слишком малого количества сегментов. Но прежде чем что-либо отобразится на экране, необходимо проанализировать HTML, CSS и JavaScript.
Но прежде чем что-либо отобразится на экране, необходимо проанализировать HTML, CSS и JavaScript. Синтаксический анализ может продолжаться при обнаружении файла CSS, но 9Элементы 0025 будет анализировать доступный контент и запрашивать высокоприоритетные ресурсы, такие как CSS, JavaScript и веб-шрифты. Благодаря сканеру предварительной загрузки нам не нужно ждать, пока парсер найдет ссылку на внешний ресурс, чтобы запросить его. Он будет извлекать ресурсы в фоновом режиме, поэтому к тому времени, когда основной анализатор HTML достигнет запрошенных ресурсов, они уже могут быть загружены или загружены. Оптимизации, которые обеспечивает сканер предварительной загрузки, уменьшают блокировки.
Синтаксический анализ может продолжаться при обнаружении файла CSS, но 9Элементы 0025 будет анализировать доступный контент и запрашивать высокоприоритетные ресурсы, такие как CSS, JavaScript и веб-шрифты. Благодаря сканеру предварительной загрузки нам не нужно ждать, пока парсер найдет ссылку на внешний ресурс, чтобы запросить его. Он будет извлекать ресурсы в фоновом режиме, поэтому к тому времени, когда основной анализатор HTML достигнет запрошенных ресурсов, они уже могут быть загружены или загружены. Оптимизации, которые обеспечивает сканер предварительной загрузки, уменьшают блокировки.
 Браузер просматривает каждый набор правил в CSS, создавая дерево узлов с родительскими, дочерними и одноуровневыми отношениями на основе селекторов CSS.
Браузер просматривает каждый набор правил в CSS, создавая дерево узлов с родительскими, дочерними и одноуровневыми отношениями на основе селекторов CSS.

 Узлы с 9Видимость 0025: скрытые примененные включены в дерево рендеринга, так как они занимают место. Поскольку мы не дали никаких директив для переопределения значения по умолчанию для пользовательского агента, узел сценария
Узлы с 9Видимость 0025: скрытые примененные включены в дерево рендеринга, так как они занимают место. Поскольку мы не дали никаких директив для переопределения значения по умолчанию для пользовательского агента, узел сценария 
 Последующие пересчеты называются перерасчетами . В нашем примере предположим, что первоначальный макет происходит до того, как изображение будет возвращено. Поскольку мы не объявляли размеры нашего изображения, после того, как размеры изображения станут известны, произойдет перекомпоновка.
Последующие пересчеты называются перерасчетами . В нашем примере предположим, что первоначальный макет происходит до того, как изображение будет возвращено. Поскольку мы не объявляли размеры нашего изображения, после того, как размеры изображения станут известны, произойдет перекомпоновка. При разрешении 2048 x 1536 iPad имеет более 3 145 000 пикселей, которые нужно отобразить на экране. Это очень много пикселей, которые нужно очень быстро закрашивать. Чтобы гарантировать, что перерисовка может быть выполнена даже быстрее, чем первоначальная краска, рисунок на экране обычно разбивается на несколько слоев. Если это происходит, то необходимо композитинг.
При разрешении 2048 x 1536 iPad имеет более 3 145 000 пикселей, которые нужно отобразить на экране. Это очень много пикселей, которые нужно очень быстро закрашивать. Чтобы гарантировать, что перерисовка может быть выполнена даже быстрее, чем первоначальная краска, рисунок на экране обычно разбивается на несколько слоев. Если это происходит, то необходимо композитинг.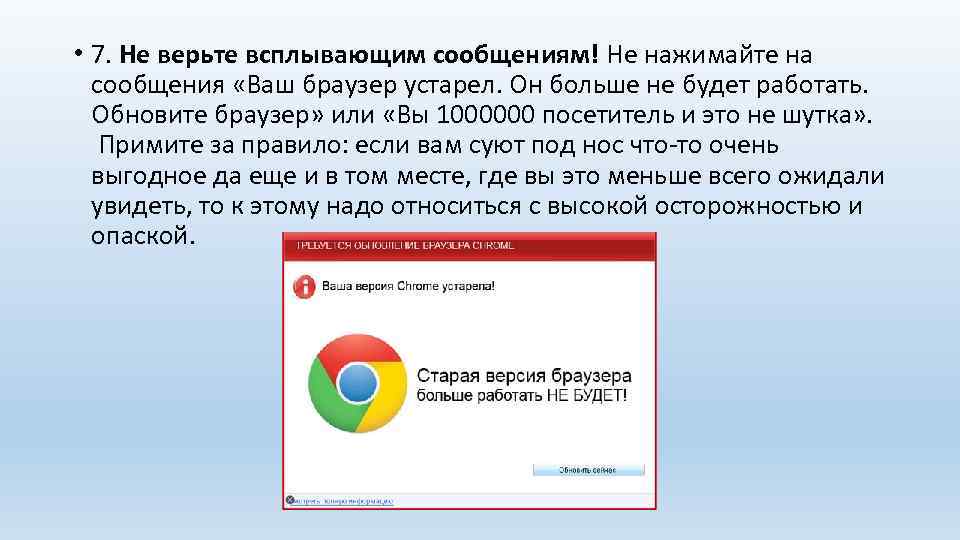

 js
js  Многие проблемы, с которыми вы сталкиваетесь, могут вызывать проблемы с печатью, интерактивностью или анимацией.
Многие проблемы, с которыми вы сталкиваетесь, могут вызывать проблемы с печатью, интерактивностью или анимацией. Они пытаются найти компромисс при кодировании, основываясь на относительной популярности браузера, которым пользуется большинство их клиентов. Из-за этого в разных браузерах возникает множество мелких проблем.
Они пытаются найти компромисс при кодировании, основываясь на относительной популярности браузера, которым пользуется большинство их клиентов. Из-за этого в разных браузерах возникает множество мелких проблем.
