
Как просмотреть старые или удаленные веб-страницы или более раннюю версию? Пошаговое руководство
Если вы миллениал, скорее всего, вы не знакомы с такими сайтами, как GeoCities , Hotmail или что ты думаешь что WhatsApp была первой чат-платформой. Причина, по которой вы не знаете этих имен, в том, что они больше не существуют или они принадлежат другим доменам .
Если вы знаете, о чем все эти сайты, в вас пробудится небольшая ностальгия. Хотя он больше невозможно использовать их как раньше , это существует онлайн-приложение, которое может показать вам, как они выглядели много лет назад.
С его помощью вы запомните страницы, на которых наверняка провели часы. Вы также можете взглянуть на ce à как выглядели самые популярные сайты сегодня, когда они только начинали . Чтобы узнать, о каком инструменте идет речь, предлагаем вам прочитать эту статью.
The Wayback Machine Инструмент, который позволяет нам путешествовать во времени в Интернете!
Это не Делориан, и при этом он не создаст парадокса в пространстве и времени. Однако вы можете увидеть, как веб-сайты, которые вы посещали чаще всего, выглядели в прошлом. Это инструмент, который функционирует как электронная библиотека веб-сайтов. . Его база данных содержит копии огромного количества страниц с течением времени.
Таким образом можно найти сайт, который был удален с сервера или это было изменено. Хотя некоторые адреса могут быть недоступны, потому что они не индексируются. На сервисе хранится более 11 900 терабайт информации.
Библиотека сохраняет страницы с 1996 года , накапливая миллионы гигабайт данных на тысячах серверов. Интересен тот факт, что резервные копии этих дисков уже созданы и отправлены в библиотеку как этот исторический архив . Система работает за счет сохранения HTML-содержимого исходного кода. из URL записано в Интернете. По этой причине изображения, которые были удалены с исходного сервера, не отображаются через Машина Wayback .
из URL записано в Интернете. По этой причине изображения, которые были удалены с исходного сервера, не отображаются через Машина Wayback .
Что-то интересное происходит с этим сайтом: с момента последнего обновления вы можете сотрудничать с ним . Речь идет о возможности сохранения веб-страницы для потомков. Введя его адрес на web.archive.org/save/ , платформа таким образом сохранит всю информацию HTML , а также скриншот и все сопутствующие ресурсы.
Шаги по просмотру старой версии удаленного веб-сайта или страницы с помощью The Wayback Machine
Этот грозный инструмент не только считается оплотом для веб-историков. , очень проста в использовании . Даже если языковой барьер для вас непрактичен, он настолько интуитивно понятен, что ты не заблудишься в кратчайшие сроки . Вы можете получить доступ к сайту со своего компьютера, мобильного телефона или планшета.
«ОБНОВЛЕНИЕ ✅ Вы хотите просматривать старый или уже не существующий веб-сайт со своего компьютера или мобильного телефона? ⭐ ВОЙДИТЕ ЗДЕСЬ ⭐ и узнайте, как это сделать С ЦЕПИ! »
Вам просто нужно выполнить следующие действия:
- Доступ к web.archive.org .
- В главной строке поиска введите адрес, который вы хотите учиться.
- Нажимая «Вход», сайт вернет результаты
- Выберите год на шкале времени. Каждый из них будет содержать черную графику, отображающую объем информации, имеющейся на сайте. под вопросом Если у вас его нет, значит, нечего показывать.
- Наведите указатель мыши на нужную дату. Он должен быть окруженный кругом цветные, этот и его размер указывают на количество уловов, сделанных в этот день.
 Comme в течение многих лет календарные точки, не содержащие информации, не имеют этой отметки.
Comme в течение многих лет календарные точки, не содержащие информации, не имеют этой отметки. - Внутри небольшого окна, которое появляется при наведении указателя мыши , отображается время захвата сайта . Выберите один из этих вариантов.
 Comme в течение многих лет календарные точки, не содержащие информации, не имеют этой отметки.
Comme в течение многих лет календарные точки, не содержащие информации, не имеют этой отметки.- Платформа покажет вам, как выглядел портал на дату, когда вы вошли . В некоторых случаях в этом интерфейсе можно перемещаться.
Важно отметить, что некоторые URL-адреса не отображают весь контент , хотя вы всегда можете выбрать другую дату, чтобы изучить как можно больше. La подключение через этот инструмент также отключено . Что ж, для этого мы бы изменили исторический документ.
Wayback Machine также имеет другие утилиты, такие как расширения браузера et приложение для Android и iOS . Что касается первых, то они доступно в Chrome, Firefox и Safari. Они предлагают гораздо более простой способ сохранять страницы и перемещаться по более ранним версиям. Даже удаленные файлы, такие как PDF и изображения доступны
Даже удаленные файлы, такие как PDF и изображения доступны
Quant à их мобильные приложения , они все еще не так эффективны, как расширения а в некоторых случаях в них есть определенные ошибки. Однако он предлагает те же услуги, что и сайт, и можно скачать бесплатно в магазине для каждой операционной системы.
Если у вас есть какие-либо вопросы, оставляйте их в комментариях, мы свяжемся с вами как можно скорее, и это будет большим подспорьем для большего числа участников сообщества. Je Vous remercie!
report this ad
Как посмотреть старую версию сайта в гугле
Как посмотреть старую версию сайта: полезные советы
Предположим, вы нашли в Интернете очень интересную статью, но времени прочитать ее не нашлось, и вы решили отложить этот вопрос на вечер. Придя домой, вы обнаружили, что статья была удалена — что делать? Хорошая новость — информация в Интернете хорошо сохраняется. Но как посмотреть старую версию сайта?
Придя домой, вы обнаружили, что статья была удалена — что делать? Хорошая новость — информация в Интернете хорошо сохраняется. Но как посмотреть старую версию сайта?
Используем кэш Google
Поисковая система Google регулярно кэширует веб-страницы, попадающие в поисковую выдачу. Это значит, что в определенный момент времени снимается резервная копия информации, содержавшейся на ресурсе, и сохраняется в базах данных поисковика. Если сайт в определенный момент станет недоступен, можно посмотреть старую версию сайта. Как это сделать? Существует два способа, с помощью которых можно узнать, какие данные были когда-то на ресурсе.
Первый способ — это использование ссылки на последнюю сохраненную версию сайта. Выглядеть она будет следующим образом:
В эту строку вместо «адрес_сайта» впишите название ресурса, и вы попадете на последнюю сохраненную версию веб-страницы.
Сверху будет служебная информация, которая поможет сориентироваться — дата последнего сохранения страницы, возможность переключаться между текстовой и полной версиями сайта (в текстовой версии будут недоступны изображения и другой медиа-контент, а также стили оформления).
Второй способ того, как посмотреть старую версию сайта, будет доступен в том случае, если ресурс отображается в поисковой выдаче. Если он по каким-либо причинам не индексируется поисковой системой Google, посмотреть его не удастся.
Итак, в строку поиска введите адрес сайта, который вы разыскиваете. В поисковой выдаче отобразятся соответствующие результаты. Обратите внимание — справа от каждой ссылки расположена маленькая зеленая стрелка. Нажав на нее, выберите пункт «Сохраненная копия» или Cached, и вы попадете на сохраненную копию страницы.
Ищем старую версию в «Яндексе»
Интересуясь, как посмотреть старую версию страницы сайта, нельзя обойти вниманием один из самых популярных поисковиков в нашей стране.
В целом механизм использования кэша «Яндекса» ничем существенно не отличается от тех же возможностей в Google.
Нужно зайти в сам поисковик, ввести в строку поиска адрес сайта и по знакомой вам уже схеме нажать на зеленую стрелку справа от ссылки на ресурс.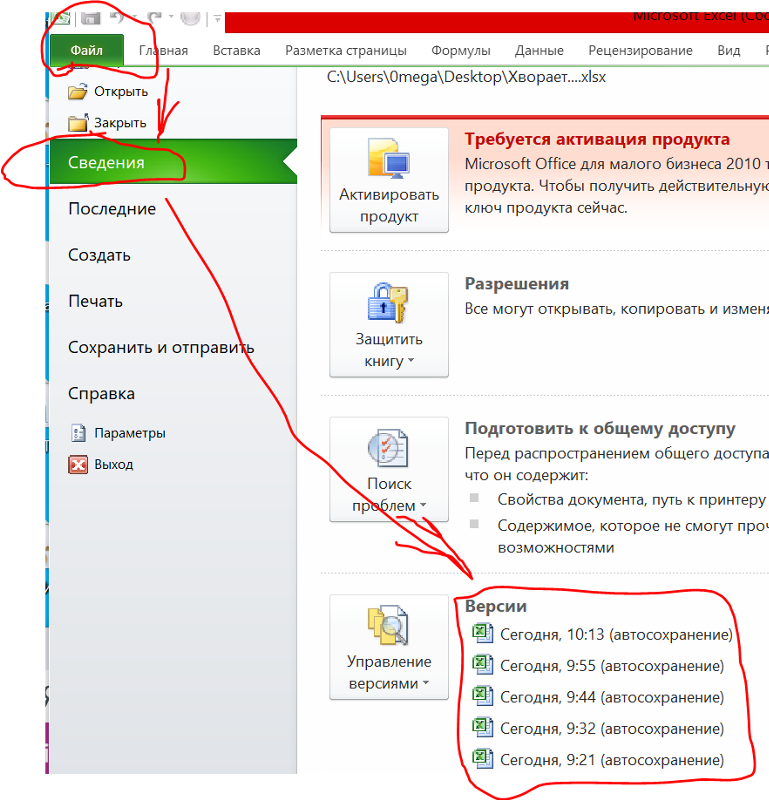 Нажмите на меню «Сохраненная копия». Вы попадете на нужную страницу.
Нажмите на меню «Сохраненная копия». Вы попадете на нужную страницу.
Меню сверху будет практически идентично тому, что было в Google — можно посмотреть текстовую версию сайта, воспользоваться поиском и узнать, каким числом была сделана резервная копия страницы.
Использование сервиса WebArchive
Всем, кто задается вопросом, где посмотреть старые версии сайтов, можно порекомендовать воспользоваться таким интересным сервисом как WebArchive.
Его функционал гораздо шире, чем у кэша поисковиков, можно просмотреть, как видоизменялся сайт за месяцы и годы своего существования, а также воспользоваться поиском по конкретному числу, когда была сохранена копия содержимого страницы.
Для того, чтобы воспользоваться сервисом, в поиске на сайте WebArchive введите адрес искомой страницы. Также поддерживается поиск по ключевым словам, относящимся к тематике ресурса — можно воспользоваться им. Как только вы это сделаете, появится статистика по годам. Черным цветом отмечено, в какое время создавалась резервная копия сайта, сохраненная в архиве.
Как только вы выберете нужный год и перейдете на него, откроется календарь, в котором можно выбрать число, за которое была сохранена резервная копия страницы сайта.
Зеленым и синим цветом отмечены даты, когда поисковые роботы заархивировали страницу и добавили ее к просмотру.
Как правило, возможность просмотра изображений отсутствует, однако текст сохраняется в полном объеме. А если вы ищете какую-либо конкретную статью на определенном ресурсе, есть вероятность, что ссылка на нее могла сохраниться.
В заключение
Интернет — это динамично развивающаяся структура, в нее регулярно поступает новая информация, но данные также могут быть и удалены. Мы надеемся, что эта статья помогла вам узнать, как посмотреть старую версию сайта, чтобы не потерять важную и интересную информацию.
Как посмотреть старые версии страниц в поиске Google
Кэшированные ссылки позволяют увидеть, как выглядела конкретная веб-страница, когда она последний раз сканировалась Google.
О кешированных ссылках
Google сохраняет снимки всех веб-сайтов, чтобы их можно было просматривать, когда текущие версии недоступны. Эти страницы сохраняются в кеше Google. Если вы нажмете ссылку «Копировать», вы увидите предыдущую сохраненную версию страницы.
Если веб-страница, которую вы хотите посетить, работает медленно или не отвечает, вы можете воспользоваться закешированной ссылкой.
Как посмотреть и восстановить старые изменения в документах Google
Те, кто активно пользуются облачным хранилищем Google наверняка хоть раз сталкивались с ситуацией, когда в документе что-то нужное случайно удалили, исправили или вовсе очистили по ошибке весь документ. И тут если информация была действительно важная, да ещё и документ был в одном экземпляре, наступает печалька. «Ёёёмаё!! И чё теперь делать??», такие мысли обычно в голове. Чаще с нецензурной лексикой 🙂
Если удалили что-то и сразу опомнились, не закрывая документ в гугле, то ситуация, конечно, решается очень просто — функцией отмены действия. Т.е. через меню «Правка» — «Отменить», либо быстрыми клавишами Ctrl+Z.
Т.е. через меню «Правка» — «Отменить», либо быстрыми клавишами Ctrl+Z.
А вот если документ уже закрыли, то такой вариант не поможет. В этом случае на помощь придёт только восстановление старой версии документа. Как это сделать рассмотрим ниже.
На самом деле с восстановлением документов в гугле я уже сталкивался неоднократно, обучая людей компьютерной грамотности через интернет и в некоторых других областях. Бывают случаи, человек по неопытности просто берёт и удаляет всё к едрени фени из документа, забывает про клавиши отмены действия и закрывает в панике документ 🙂 Вот в таких случаях восстановление в Google — самое настоящее спасение!
ПРОСМОТР СТАРЫХ ВЕРСИЙ ДОКУМЕНТОВ GOOGLE
Сервис Google очень хорош помимо всего прочего ещё и тем, что сам хранит все версии каждого документа длительное время. Сколько конкретно, информации не накопал, но сам видел сохранённые копии за несколько месяцев! Вероятно сервис хранит вообще все версии каждого документа. Эта функция никак не настраивается, то есть этим управляет сам гугл.
Итак, что нужно для восстановления старых версий.
Для начала откройте в гугле тот документ, старые версии которого хотели бы посмотреть и какую-то из них, вероятно, восстановить.
В самом верху, над панелью инструментов редактора, обычно сразу отображается ссылка «Последнее изменение . » и указан пользователь, который последним вносил в документ какие-то правки. Пример:
В Google диске с одним документом могут работать несколько пользователей сразу. Те, которым вы предоставляете доступ для редактирования.
Так вот, кликнув по этой ссылке, вы сможете сразу перейти к просмотру версий текущего документа и восстановлению нужной в случае необходимости.
Но бывает так, что такой ссылки вверху не отображается. Тогда есть второй вариант попасть на страницу просмотра версий документа: меню «Файл» — «История версий» — «Смотреть историю версий».
На странице справа будут списком отображены все версии данного документа с указанием даты и времени изменений.
Кликнув на нужную версию, информация в открытом документе в предпросмотре изменится на ту, что соответствует выбранной версии. Пролистывая документ, вы увидите изменения в нём, например, текст, который ранее присутствовал и потом был удалён или наоборот. Эти изменения обозначаются различными способами, например, информация, которой в более свежих версиях документа уже нет, будет перечёркнута [1]:
Можно перемещаться по изменениям в документе, пользуясь стрелками вверху [2], где указано общее количество правок.
Далеко не всегда удобно смотреть версии документа с включенным отображением сделанных изменений. К примеру, мне это совсем неудобно 🙂 Мне хочется видеть чистый документ за выбранную дату и время, безо всяких вычёркиваний и прочей лабуды, которая чаще только мешается. Чтобы эти изменения не отображались, нужно отключить опцию «Показать изменения» внизу:
Теперь будете видеть документы без отображения правок.
Таким вот образом, можете перемещаться по разным версиям документа в поисках нужной.
Чтобы восстановить нужную версию документа, открыв её, нажмите вверху соответствующую кнопку «Восстановить эту версию».
В результате ваш текущий документ будет заменён на выбранную вами версию. Помните, что не всегда имеет смысл восстанавливать таким образом документ, порой достаточно открыть нужную версию для просмотра и просто скопировать какую-то информацию, которую ранее потеряли. Зависит от ситуации.
Для удобства, можно присваивать нужным версиям свои названия, чтобы затем легко их найти по своим названиям, не блуждая по всему списку с указанием только дат и времени. Чтобы версии задать название, щёлкните по кнопке меню рядом с ней (её называю ещё «гамбургер» 🙂 ) и выберите «Указать название версии».
Теперь вместо даты укажите своё название. Пример:
В итоге вы будете видеть вместо даты и времени заданное вами название данной версии документа.
Если хотите, чтобы Google отобразил только версии с названиями, то активируйте вверху опцию «Только версии с названиями»:
Также указать название версии можно прямо во время работы над документом, выбрав меню «Файл» — «История версий» — «Указать название текущей версии».
ЗАКЛЮЧЕНИЕ
Возможность посмотреть и восстановить старые версии документов Google порой очень важна и может в некоторых ситуациях спасти нас, например, от повторного внесения правок, часть из которых могли уже и позабыть 🙂 Конечно, никогда не стоит рассчитывать только на то, что Google хранит старые версии. Нужно всегда самостоятельно делать резервные копии любых важных для вас данных!
А вы знали о возможности восстановления старых версии документов в гугле, пользовались ей когда-либо ? 🙂 Поделитесь в комментариях, буду рад обратной связи! 🙂
Как посмотреть кэшированную версию сайта
Хотите посмотреть старые веб-страницы или сайт, который сейчас недоступен? В этой статье мы расскажем, как получить доступ к кэшу веб-страниц при помощи Google, Яндекс, Wayback Machine и других инструментов.
- Поиск Google
- Поиск Яндекс
- Wayback Machine
- Archive.Today
- Расширения для браузеров
- Веб-инструменты
Легко забыть о том, что интернет является весьма непостоянной средой. Страницы могут быть отредактированы без предупреждения, сайты исчезнуть навсегда.
Страницы могут быть отредактированы без предупреждения, сайты исчезнуть навсегда.
Существует несколько причин, по которым теряется доступ к сайтам и их страницам. Может быть, не работают серверы, на которых они размещены. Владелец сайта может изменить или удалить содержимое, которое вы пытаетесь найти. В таком случае на помощь приходит кэшированная версия.
Роботы Google и Яндекс постоянно обходят новые страницы и выполняют их индексирование. При этом также сохраняются резервные копии посещённых страниц. Тем же занимаются веб-браузеры, чтобы ускорить загрузку страниц.
Копии сохраняются в кэш. Это раздел вашего накопителя, который временно доступен, если сайт или часть его содержимого недоступны в интернете. Не все сайты индексируются Google или сохраняются в кэш. Если это происходит, давайте узнаем, как получить к ним доступ.
Поиск Google
Просмотр сохранённых в кэше Google страниц начинается так же, как и любой другой поиск Google. Когда вы ввели поисковый запрос и видите результаты, нажмите на стрелку рядом с URL-адресом и выберите опцию «Сохранённая копия» для просмотра последних сохранённых в Google версий страниц.
Когда вы ввели поисковый запрос и видите результаты, нажмите на стрелку рядом с URL-адресом и выберите опцию «Сохранённая копия» для просмотра последних сохранённых в Google версий страниц.
Когда сайт загрузился, Google уведомляет, что это устаревшая версия, и указывает дату её создания. Также есть опция просмотра только текстового варианта страница и исходного кода. Вы не сможете переходить на другие страницы и при этом оставаться в кэш-версии. Если вы попытаетесь перейти по ссылке, откроется действующая версия сайта.
Поиск Яндекс
Просмотр сохранённых в кэше Яндекса страниц делается так же, как и у Google. Когда вы ввели поисковый запрос и видите результаты, нажмите на стрелку рядом с URL-адресом и выберите опцию «Сохранённая копия».
Wayback Machine
Существуют организации, которые пытаются сохранить историю интернета. Самой известной такой организацией является некоммерческая Internet Archive, где хранятся веб-сайты, текст, видео, аудиозаписи, программное обеспечение и изображения, которые трудно найти где-то ещё. Старые версии веб-сайта вы можете посмотреть также на Wayback Machine.
Старые версии веб-сайта вы можете посмотреть также на Wayback Machine.
Введите URL-адрес и движок архивного поиска покажет календарь, где отображается, когда Wayback Machine сохранила эту страницу. Нажмите на дату в календаре для просмотра того, как сайт выглядел в этот день. Wayback Machine и является отличным способом изучения истории интернета.
Archive.Today
Сайт архивирования Archive.Today позволяет пользователям сохранять текущие веб-страницы и искать ранее сохранённые. Введите URL-адрес для сохранения или для просмотра сохранённых страниц, которые также можно скачивать на компьютер.
Если вы хотите посмотреть архивные версии веб-сайта, введите его адрес в поисковую панель и появятся результаты с домашней страницей и связанными отдельными страницами. Если есть больше одной версии одной страницы, они будут показываться все вместе для упрощения просмотра.
Расширения для браузеров
Существуют расширения для браузеров на все случаи жизни, в том числе и для доступа к кэшированной версии сайта.
Добавьте в Chrome расширение Web Cache Viewer и нажмите правой кнопкой мыши на любой странице для просмотра версии из Google или Wayback Machine. Расширение под названием View Page Archive & Cache для Chrome или Firefox идёт ещё дальше и позволяет смотреть кэшированные версии веб-страниц из многочисленных поисковых движков, таких как Bing, Baidu, Yandex.
Веб-инструменты
Из других онлайн-инструментов для просмотра кэшированных страниц стоит отметить Cached Page. Он ищет определённый URL-адрес в кэше Google, Internet Archive и сервисе WebCite.
Как посмотреть старую версию страницы?
1. ОПРЕДЕЛЕНИЕ ТЕРМИНОВ
1.1. В настоящей Политике конфиденциальности используются следующие термины:
1.1.1. «Администрация сайта» – уполномоченные сотрудники на управления сайтом, действующие от имени ООО
«Третий Путь», которые организуют и (или) осуществляет обработку персональных данных, а также определяет цели
обработки персональных данных, состав персональных данных, подлежащих обработке, действия (операции),
совершаемые с персональными данными.
1.1.2. «Персональные данные» — любая информация, относящаяся прямо или косвенно к определяемому физическому лицу (субъекту персональных данных).
1.1.3. «Обработка персональных данных» — любое действие (операция) или совокупность действий (операций), совершаемых с использованием средств автоматизации или без использования таких средств с персональными данными, включая сбор, запись, систематизацию, накопление, хранение, уточнение (обновление, изменение), извлечение, использование, передачу (распространение, предоставление, доступ), обезличивание, блокирование, удаление, уничтожение персональных данных.
1.1.4. «Конфиденциальность персональных данных» — обязательное для соблюдения Организацией или иным получившим доступ к персональным данным лицом требование не допускать их распространения без согласия субъекта персональных данных или наличия иного законного основания.
1.1.5. «Пользователь сайта (далее Пользователь)» – лицо, имеющее доступ к Сайту, посредством сети Интернет и
использующее Сайт Организации.
1.1.6. «IP-адрес» — уникальный сетевой адрес узла в компьютерной сети, построенной по протоколу IP.
1.1.7. «Cookies» — небольшой фрагмент данных, отправленный веб-сервером и хранимый на компьютере пользователя, который веб-клиент или веб-браузер каждый раз пересылает веб-серверу в HTTP-запросе при попытке открыть страницу соответствующего сайта.
2. ОБЩИЕ ПОЛОЖЕНИЯ
2.1. Порядок ввода в действие и изменения Политики конфиденциальности:
2.1.1. Настоящая Политика конфиденциальности (далее – Политика конфиденциальности) вступает в силу с момента его утверждения приказом Руководителей Организации и действует бессрочно, до замены его новой Политикой конфиденциальности.
2.1.2. Изменения в Политику конфиденциальности вносятся на основании Приказов Руководителей Организации.
2.1.3. Политика конфиденциальности персональных данных действует в отношении информации, которую ООО «Третий
Путь» (далее – Организация) являясь владельцем сайтов, находящихся по адресам: 3put. ru, а также их поддоменах
(далее – Сайт и/или Сайты), может получить от Пользователя Сайта при заполнении Пользователем любой формы на
Сайте Организации. Администрация сайта не контролирует и не несет ответственность за сайты третьих лиц, на
которые Пользователь может перейти по ссылкам, доступным на Сайтах.
ru, а также их поддоменах
(далее – Сайт и/или Сайты), может получить от Пользователя Сайта при заполнении Пользователем любой формы на
Сайте Организации. Администрация сайта не контролирует и не несет ответственность за сайты третьих лиц, на
которые Пользователь может перейти по ссылкам, доступным на Сайтах.
2.1.4. Администрация сайта не проверяет достоверность персональных данных, предоставляемых Пользователем.
2.2. Порядок получения согласия на обработку персональных данных и их обработки:
2.2.1. Заполнение любой формы Пользователем на Сайте означает дачу Организации согласия на обработку его персональных данных и с настоящей Политикой конфиденциальности и условиями обработки персональных данных Пользователя, так как заполнение формы на Сайте Пользователем означает конклюдентное действие Пользователя, выражающее его волю и согласие на обработку его персональных данных.
2.2.2. В случае несогласия с условиями Политики конфиденциальности и отзывом согласия на обработку
персональных данных Пользователь должен направить на адрес эл.
2.2.3. Согласие Пользователя на использование его персональных данных может храниться в Организации в бумажном и/или электронном виде.
2.2.4. Согласие Пользователя на обработку персональных данных действует в течение 5 лет с даты поступления персональных данных в Организацию. По истечении указанного срока действие согласия считается продленным на каждые следующие пять лет при отсутствии сведений о его отзыве.
2.2.5. Обработка персональных данных Пользователя без их согласия осуществляется в следующих случаях:
- Персональные данные являются общедоступными.
- По требованию полномочных государственных органов в случаях, предусмотренных федеральным законом.
- Обработка персональных данных осуществляется для статистических целей при условии обязательного
обезличивания персональных данных.
- В иных случаях, предусмотренных законом.

2.2.6. Кроме персональных данных при посещении Сайта собираются данные, не являющиеся персональными, так как
их сбор происходит автоматически веб-сервером, на котором расположен сайт, средствами CMS (системы управления
сайтом), скриптами сторонних организаций, установленными на сайте. К данным, собираемым автоматически,
относятся: IP адрес и страна его регистрации, имя домена, с которого Пользователь осуществил перехода на сайты
организации, переходы посетителей с одной страницы сайта на другую, информация, которую браузер Посетителя
предоставляет добровольно при посещении сайта, cookies (куки), фиксируются посещения, иные данные, собираемые
счетчиками аналитики сторонних организаций, установленными на сайте. Эти данные носят неперсонифицированный
характер и направлены на улучшение обслуживания Пользователя, улучшения удобства использования сайта, анализа
посещаемости.
2.2.7. Порядок обработки персональных данных:
К обработке персональных данных Пользователей могут иметь доступ только сотрудники Организации, допущенные к работе с персональными данными Пользователей и подписавшие соглашение о неразглашении персональных данных Пользователей. Перечень сотрудников Организации, имеющих доступ к персональным данным Пользователей, определяется приказом Руководителей Организации. Обработка персональных данных Пользователей может осуществляться исключительно в целях установленных настоящей политикой и при условии соблюдения законов и иных нормативных правовых актов Российской Федерации.
3. ПРЕДМЕТ ПОЛИТИКИ КОНФИДЕНЦИАЛЬНОСТИ
3.1. Настоящая Политика конфиденциальности устанавливает обязательства Администрации сайта по неразглашению и
обеспечению режима защиты конфиденциальности персональных данных, которые Пользователь предоставляет при
заполнении любой формы на Сайте.
3.2. Персональные данные, разрешённые к обработке в рамках настоящей Политики конфиденциальности, предоставляются Пользователем путём заполнения регистрационной формы на Сайте и включают в себя следующую информацию:
3.2.1. фамилию, имя, отчество Пользователя.
3.2.2. контактный телефон Пользователя.
3.2.3. адрес электронной почты (e-mail).
3.3. Любая иная персональная информация неоговоренная выше подлежит надежному хранению и нераспространению, за исключением случаев, предусмотренных п. 2.5. настоящей Политики конфиденциальности.
4. ЦЕЛИ СБОРА ПЕРСОНАЛЬНОЙ ИНФОРМАЦИИ ПОЛЬЗОВАТЕЛЯ
4.1. Персональные данные Пользователя Администрация сайта может использовать в целях:
4.1.1. Установления с Пользователем обратной связи, включая направление уведомлений, запросов, касающихся использования Сайта, оказания услуг, обработка запросов и заявок от Пользователя.
4.1.2. Осуществления рекламной деятельности с согласия Пользователя.
4.1.3. Регистрации Пользователя на Сайтах Организации для получения индивидуальных сервисов и услуг.
4.1.4. Совершения иных сделок, не запрещенных законодательством, а также комплекс действий с персональными данными, необходимых для исполнения данных сделок.
5. СПОСОБЫ И СРОКИ ОБРАБОТКИ ПЕРСОНАЛЬНОЙ ИНФОРМАЦИИ
5.1. Обработка персональных данных Пользователя осуществляется без ограничения срока, любым законным способом, в том числе в информационных системах персональных данных с использованием средств автоматизации или без использования таких средств.
5.2. При утрате или разглашении персональных данных Администрация сайта информирует Пользователя об утрате или разглашении персональных данных.
5.3. Администрация сайта принимает необходимые организационные и технические меры для защиты персональной
информации Пользователя от неправомерного или случайного доступа, уничтожения, изменения, блокирования,
копирования, распространения, а также от иных неправомерных действий третьих лиц.
6. ОБЯЗАТЕЛЬСТВА СТОРОН
6.1. Пользователь обязан:
6.1.1. Предоставить информацию о персональных данных, необходимую для пользования Сайтом.
6.1.2. Обновить, дополнить предоставленную информацию о персональных данных в случае изменения данной информации.
6.2. Администрация сайта обязана:
6.2.1. Использовать полученную информацию исключительно для целей, указанных в п. 4 настоящей Политики конфиденциальности.
6.2.2. Обеспечить хранение конфиденциальной информации в тайне, не разглашать без предварительного письменного разрешения Пользователя, а также не осуществлять продажу, обмен, опубликование, либо разглашение иными возможными способами переданных персональных данных Пользователя, за исключением случаев, указанных в п. 2.5. настоящей Политики Конфиденциальности.
6.2.3. Принимать меры предосторожности для защиты конфиденциальности персональных данных Пользователя
согласно порядку, обычно используемого для защиты такого рода информации в существующем деловом обороте.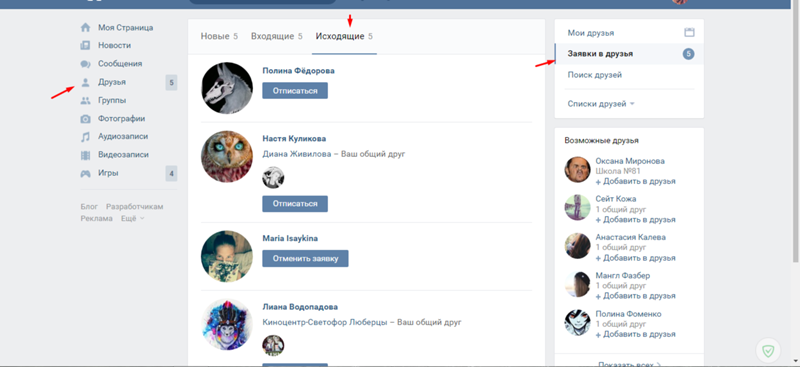
6.2.4. Осуществить блокирование и/или удаления персональных данных, относящихся к соответствующему Пользователю, с момента обращения или запроса Пользователя или его законного представителя либо уполномоченного органа по защите прав субъектов персональных.
7. ОТВЕТСТВЕННОСТЬ СТОРОН
7.1. Администрация сайта, не исполнившая свои обязательства, несёт ответственность в соответствии с действующим законодательством Российской Федерации, за исключением случаев, предусмотренных п.2.5. и 7.2. настоящей Политики
Конфиденциальности.
7.2. В случае утраты или разглашения Конфиденциальной информации Администрация сайта не несёт ответственность, если данная конфиденциальная информация:
7.2.1. Стала публичным достоянием до её утраты или разглашения.
7.2.2. Была получена от третьей стороны до момента её получения Администрацией сайта.
7.2.3. Была разглашена с согласия Пользователя.
8. РАЗРЕШЕНИЕ СПОРОВ
8. 1. До обращения в суд с иском по спорам, возникающим из отношений между Пользователем сайта и
Администрацией сайта, обязательным является предъявление претензии (письменного предложения о добровольном
урегулировании спора).
1. До обращения в суд с иском по спорам, возникающим из отношений между Пользователем сайта и
Администрацией сайта, обязательным является предъявление претензии (письменного предложения о добровольном
урегулировании спора).
8.2. Получатель претензии в течение 30 календарных дней со дня получения претензии, письменно уведомляет заявителя претензии о результатах рассмотрения претензии.
8.3. При не достижении соглашения спор будет передан на рассмотрение в судебный орган в соответствии с действующим законодательством Российской Федерации.
8.4. К настоящей Политике конфиденциальности и отношениям между Пользователем и Администрацией сайта применяется действующее законодательство Российской Федерации.
9. ДОПОЛНИТЕЛЬНЫЕ УСЛОВИЯ
9.1. Администрация сайта вправе вносить изменения в настоящую Политику конфиденциальности без согласия Пользователя.
9.2. Новая Политика конфиденциальности вступает в силу с момента ее размещения на Сайте, если иное не
предусмотрено новой редакцией Политики конфиденциальности.
9.3. Действующая Политика конфиденциальности размещена на страницах сайтов находящихся по адресам: 3put.ru, а также на их поддоменах.
ВЕБ-архив — история сайтов интернета, как посмотреть старую версию страниц сайта
Команда AskUsers
2021-06-29 • 9 мин читать
Читать позже
WebArchive — огромная бесплатная библиотека, в которой хранятся web-архивы сайтов — миллиарды страниц, в том числе те, которых уже нет в Яндекс и Google. Это живая история интернета, поскольку в Web-архиве можно посмотреть старую версию сайта, узнать, какой контент размещался на интересующем домене и даже восстановить удаленные документы.
Что такое веб-архив?
Организатор и идейный вдохновитель веб-архива сайтов — американец Брюстер Кейл. Internet Archive («Архив интернета») — некоммерческий проект, его цель — сохранить мировое культурное и интеллектуальное наследие. По данным Википедии, этот сервис был создан в 1996 году. Во всемирном архиве интернета хранятся литературные произведения, видеозаписи, изображения, которые свободно публикуются в Сети. Это один из разделов огромного сервиса archive.org.
По данным Википедии, этот сервис был создан в 1996 году. Во всемирном архиве интернета хранятся литературные произведения, видеозаписи, изображения, которые свободно публикуются в Сети. Это один из разделов огромного сервиса archive.org.
Боты постоянно сканируют всемирный интернет и пополняют библиотеку. Роботам помогают живые сотрудники и партнеры. Добавить копии страничек в веб-архив интернета может любой желающий. Конечно, в библиотеке невозможно найти абсолютно все страницы, которые когда-то были созданы. Но их там очень много — более 580 миллиардов.
Просмотреть архив «машины времени» («Wayback Machine» — второе название web-архива сайтов) можно бесплатно. При этом пользователям предлагают перейти по ссылке «Пожертвовать» и перевести создателям уникального сервиса посильную сумму.
Возможности сервиса
Для вебмастера и SEO-специалиста бесплатные всемирные архивы открывают ряд полезных возможностей.
- Если планируется купить домен или интернет-проект, важно посмотреть историю сайта. В ней могут быть «криминальные» эпизоды. Например, распространение пиратских видеозаписей, продажа запрещенных товаров или адалт-контент. «Темное прошлое» может негативно сказаться на продвижении проекта в поисковых системах.
- Архив веб-страниц поможет при выборе дроп-домена. В сервисе можно посмотреть бесплатно, какой проект на нем располагался (коммерческий, информационный) и как он выглядел.
- Можно узнать историю конкурентов. Сравнивая архивы сайтов с их современной версией, легко понять, как менялась ниша, как трансформировались проекты.
- Есть возможность проследить и проанализировать изменения на собственном сайте и даже восстановить измененный по ошибке URL.
- С помощью дополнительных сервисов можно восстановить удаленный ресурс или отдельные страницы.
- А также найти контент по интересующей теме, которого уже нет в глобальной сети.
 В ней могут быть «криминальные» эпизоды. Например, распространение пиратских видеозаписей, продажа запрещенных товаров или адалт-контент. «Темное прошлое» может негативно сказаться на продвижении проекта в поисковых системах.
В ней могут быть «криминальные» эпизоды. Например, распространение пиратских видеозаписей, продажа запрещенных товаров или адалт-контент. «Темное прошлое» может негативно сказаться на продвижении проекта в поисковых системах.Как посмотреть архивные страницы?
Откройте в браузере https://web. archive.org/. В строке для поиска укажите URL главной или любой другой страницы нужного сайта.
archive.org/. В строке для поиска укажите URL главной или любой другой страницы нужного сайта.
Сервис покажет график сохранений и календарь, в котором обведены даты сканирований. Эти даты не связаны с датами обновления контента. Боты работают по собственному графику.
Если кликнуть на нужный год и дату, сервис покажет web-версию старых страниц. Обычно сохраняется не весь контент, часть документов недоступна, отображаются не все фотографии и картинки. Часть ссылок кликабельны, можно погулять по интернет-площадке, перейти в другие разделы.
Если вы не знаете точный адрес нужного ресурса или хотите изучить целую нишу, нужно набрать в поисковой строке главные ключевые слова. Архив бесплатно найдет сайты нужной тематики. Перейдите по ссылкам этого списка и изучайте историю интересующего проекта.
Существует приложение Wayback Machine («Машина времени») для iOS и Android. Приложение скачивают на мобильное устройство. В нем заложен тот же функционал, что и в десктопной версии.
Как добавить страницу в сервис?
Боты обходят интернет по собственному графику. Не все проекты попадают в историю «Машины времени». Молодые площадки с небольшим трафиком редко оказываются в библиотеке. А если и попадают туда, то частота сканирований очень низкая — раз в несколько месяцев.
Сохранять копии сайта в WebArchive можно самостоятельно. Для этого нужно открыть сервис, найти поле «Сохранить страницу» и добавить туда URL. Снимки появятся в библиотеке через пару минут.
Эту операцию можно периодически повторять.
В будущем эти копии будут полезны, чтобы отслеживать изменения в дизайне, структуре, контенте. Если страницы будут по ошибке удалены, а бэкапы не делались или были утеряны, архивные снимки помогут восстановить документ.
Как удалить копии страниц своего проекта?
Не всем и не всегда хочется выкладывать историю своей веб-площадки на всеобщее обозрение. Например, на сайте могла быть выложена ошибочная, некорректная или противозаконная информация. Даже если удалить страницу или файл, они сохранятся в библиотеке.
Даже если удалить страницу или файл, они сохранятся в библиотеке.
Архивом страниц могут заинтересоваться конкуренты и недоброжелатели. Поэтому многим хочется удалить копии веб-документов из сервиса.
Раньше вебмастера вписывали в robots.txt запрещающую директиву для ботов. Но сейчас это уже не работает.
Убрать страницы из библиотеки можно только через саппорт. Для этого нужно написать письмо на info@archive.org. Писать нужно по-английски, с указанием реальных имени, фамилии, физического адреса. Чтобы подтвердить, что вы владелец ресурса, отправлять письмо лучшего с почтового ящика, указанного на сайте. Еще один способ подтвердить свои права — написать через регистратора домена или через хостинг. Иногда саппорт просит прислать копию паспорта.
Через поддержку можно навсегда запретить делать копии своего проекта.
Как восстановить сайт из архива?
Если вы сами загрузили копию страницы, ее можно найти в своем аккаунте в разделе «Мой архив».
Чтобы скачать страницу, найдите ее в списке, кликните по виджету справа и сохраните документ в виде html-файла.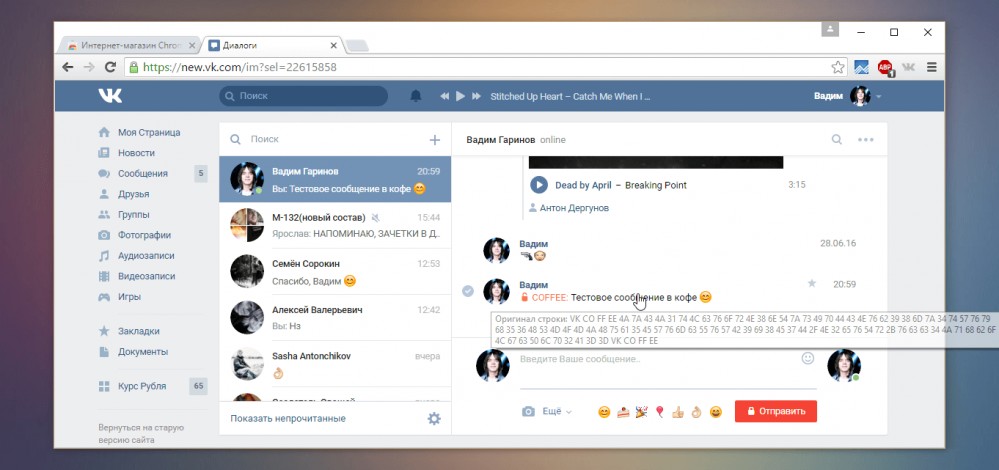
С чужими сайтами действуют примерно так же: открывают копию в архиве, через панель разработчика копируют html-код, стили, изображения.
Файлы заливаются по FTP в корневую директорию домена на хостинге.
Но ручной способ слишком долгий и трудоемкий. Автоматизировать процесс можно через платные онлайн сервисы: Archivarix, waybackmachinedownloader, r-tools, rush-analytics и другие. Здесь можно не только скачать файлы, но и оптимизировать их: убрать битые ссылки, неработающие скрипты и так далее. Некоторые сервисы умеют импортировать файлы в WordPress.
Другие полезные опции
WebArchive умеет не только сохранять копии и показывать старую версию страниц сайта. Здесь есть несколько полезных инструментов аналитики.
- Сводка. Сервис показывает, какие данные содержит сайт: сколько на нем текстов, изображений, приложений. Можно открыть и просмотреть список всех URL.
- Изменения. Инструмент поможет выявить изменения в URL-адресах. Для этого надо выбрать архивы на разные даты и сравнить старшие копии с младшими. Изменения будут выделены цветом.
- Карта сайта. Группирует данные по годам и строит карту в виде круговой диаграммы для каждого года.
 Для этого надо выбрать архивы на разные даты и сравнить старшие копии с младшими. Изменения будут выделены цветом.
Для этого надо выбрать архивы на разные даты и сравнить старшие копии с младшими. Изменения будут выделены цветом.В центре диаграммы корень сайта, а кольца — это разделы и страницы. Диаграмма кликабельна, она позволяет перейти на копию нужного URL.
Читайте на Askusers
Как быстро и правильно провести A/B-тестирование в маркетинге и SEO? Что можно тестировать, какие инструменты использовать и как замерять результат?
Что такое коммерческие факторы ранжирования, как они влияют на трафик и конверсию и как их улучшить?
Если страницы выпали из индекса поисковых систем — это тревожный признак, надо срочно искать причину. Подробный алгоритм проверки.
Закажи юзабилити-тестирование прямо сейчас
Заказать услугу
Старые версии сайтов вебархив
Содержание
Что такое веб-архив
21 октября 2017 года. Опубликовано в разделах: Азбука терминов. 30445
Опубликовано в разделах: Азбука терминов. 30445
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Это настоящая библиотека, в которой каждый желающий может открыть интересующий его веб-ресурс, и посмотреть на его содержимое, на ту дату, в которую вебархив посетил сайт и сохранил копию.
Знакомство с archive org или как Валерий нашел старые тексты из веб-архива
В 2010-м году, Валерий создал сайт, в котором он писал статьи про интернет-маркетинг. Одну из них он написал о рекламе в Гугл (AdWords) в виде краткого конспекта. Спустя несколько лет ему понадобилась эта информация. Но страница с текстами, некоторое время назад, была им ошибочно удалена. С кем не бывает.
Однако, Валерий знал, как выйти из ситуации. Он уверенно открыл сервис веб-архива, и в поисковой строке ввел нужный ему адрес. Через несколько мгновений, он уже читал нужный ему материал и еще чуть позже восстановил тексты на своем сайте.
История создания Internet Archive
В 1996 году Брюстер Кайл, американский программист, создал Архив Интернета, где он начал собирать копии веб-сайтов, со всей находящейся в них информацией. Это были полностью сохраненные в реальном виде страницы, как если бы вы открыли необходимый сайт в браузере.
Данными веб-архива может воспользоваться каждый желающий совершенно бесплатно. Создавая его, у Брюстера Кайла была основная цель – сохранить культурно-исторические ценности интернет-пространства и создать обширную электронную библиотеку.
В 2001 году был создан основной сервис Internet Archive Wayback Machine, который и сегодня можно найти по адресу https://archive.org . Именно здесь находятся копии всех веб-сервисов в свободном доступе для просмотра.
Чтобы не ограничиваться коллекцией сайтов, в 1999 году начали архивировать тексты, изображения, звукозаписи, видео и программные обеспечения.
В марте 2010 года, на ежегодной премии Free Software Awards, Архив Интернета был удостоен звания победителя в номинации Project of Social Benefit.
С каждым годом библиотека разрастается, и уже в августе 2016 года объем Webarchive составил 502 миллиарда копий веб-страниц. Все они хранятся на очень больших серверах в Сан-Франциско, Новой Александрии и Амстердаме.
Все про archive.org: как пользоваться сервисом и как достать сайт из веб-архива
Брюстер Кайл создал сервис Internet Archive Wayback Machine, без которого невозможно представить работу современного интернет-маркетинга. Посмотреть историю любого портала, увидеть, как выглядели определенные страницы раньше, восстановить свой старый веб-ресурс или найти нужный и интересный контент — все это можно сделать с помощью Webarchive.
Как на archive.org посмотреть историю сайта
Благодаря веб-сканеру, в библиотеке веб-архива, хранится большая часть интернет-площадок со всеми их страницами. Также, он сохраняет все его изменения. Таким образом, можно просмотреть историю любого веб-ресурса, даже если его уже давно не существует.
Для этого, необходимо зайти на https://web. archive.org/ и в поисковой строке ввести адрес веб-ресурса.
archive.org/ и в поисковой строке ввести адрес веб-ресурса.
После, некоторого времени, веб-архив выдаст календарь с датами изменений данной страницы и информацию о его создании и количестве изменений за весь период.
Согласно полученной информации, можно узнать, что главная страница нашего сайта была впервые найдена сервисом 24 мая 2014 года. И, с этого времени, по сегодняшний день, ее копия сохранялась 38 раз. Даты изменений на странице отмечены на календаре голубым цветом. Для того, чтобы посмотреть историю изменений и увидеть как выглядел определенный участок веб-ресурса в интересующий вас день, следует выбрать нужный период в ленте с предыдущими годами, и дату в календаре из тех, что предлагает сервис.
Через мгновение, веб-архив откроет запрашиваемую версию на своей платформе, где можно увидеть как выглядел наш сайт в самом первоначальном виде.
Далее, с помощью календаря со стрелками, в самом верху экрана, можно перелистывать страницы, по хронологии их изменений, чтобы отследить, как изменялся внешний вид и их содержание.
Таким образом, можно нырнуть в прошлое и увидеть все его перемены, которые с ним происходили за все время его существования.
Почему вы можете не узнать на Webarchive, как выглядел сайт раньше
Случается такое, что веб-площадка не может быть найден с помощью сервиса Internet Archive Wayback Machine. И происходит это по нескольким причинам:
- правообладатель решил удалить все копии;
- веб-ресурс закрыли, согласно закону о защите интеллектуальной собственности;
- в корневую директорию интернет-площадки, внесен запрет через файл robots.txt
Для того, чтобы сайт в любой момент был в веб-архиве, рекомендуется принимать меры предосторожности и самостоятельно сохранять его в библиотеке Webarchive. Для этого в разделе Save Page Now введите адрес веб-ресурса, который нужно заархивировать, нажмите кнопку Save Page.
Таким образом, для безопасности и сохранности всей информации, необходимо такую процедуру повторять с каждым изменением. Это даст 100% гарантию сохранения ваших страниц на долгое время.
Как недействующий сайт восстановить из веб-архива
Бывают разные ситуации, когда браузер выдает, что такого-то веб-сервиса больше нет. Но данные нужно извлечь. Поможет Webarchive.
И для этого существует два варианта. Первый подходит для старых площадок небольшого размера и хорошо проиндексированных. Просто извлеките данные нужной версии. Далее просматривается код страницы и дошлифовываются вручную ссылки. Процесс несколько трудозатратный по времени и действиям. Поэтому существует другой, более оптимальный способ.
Второй вариант идеален для тех, кто хочет сэкономить время и решить вопрос скачивания, максимально быстро и легко. Для этого нужно открыть сервис восстановления сайта из Webarchive – RoboTools. Ввести доменное имя интересующего портала и указать дату сохраненной его версии. Через некоторое время, задача будет выполнена в полном объеме, с наполнением всех страниц.
Как найти контент из веб-архива
Webarchive является замечательным источником для наполнения полноценными текстами веб-ресурсов. Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Есть множество площадок, которые по ряду причин прекратили свое существование, но содержат в себе полезную и нужную информацию. Которая не попадает в индексы поисковых систем, и по сути есть неповторяющейся.
Так, существует свободные домены, которые хранят много интересного материала. Все что нужно, это найти подходящее содержание, и проверить его уникальность. Это очень выгодно, как финансово – ведь не нужно будет оплачивать работу авторов, так и по времени – ведь весь контент уже написан.
Как сделать так, чтобы сайт не попал в библиотеку веб-архива
Случаются такие ситуации, когда владелец интернет-площадки дорожит информацией, размещенной на его портале, и он не хочет, чтобы она стала доступной широкому кругу. В таких ситуациях есть один простой выход – в файле robots.txt, прописать запретную директиву для Webarchive. После этого изменения в настройках, веб-машина больше не будет создавать копии такого веб-ресурса.
– Только качественный трафик из Яндекса и Google
– Понятная отчетность о работе и о планах работ
– Полная прозрачность работ
Как скачать сайт из вебархива
Обращаю ваше внимание на то, что все операции производятся в операционной системе Ubuntu (Linux). Как все это провернуть на Windows я не знаю. Если хотите все проделать сами, а у вас Windows, то можете поставить VirtualBox, а на него установить ту же Ubuntu. И приготовьтесь к тому, что сайт будет качаться сутки или даже двое. Однажды один сайт у меня скачивался трое суток.
Как все это провернуть на Windows я не знаю. Если хотите все проделать сами, а у вас Windows, то можете поставить VirtualBox, а на него установить ту же Ubuntu. И приготовьтесь к тому, что сайт будет качаться сутки или даже двое. Однажды один сайт у меня скачивался трое суток.
По сути, на текущий момент мы имеем два сервиса с архивом сайтов. Это российский сервис web-archiv.ru и зарубежный archive.org. Я скачивал сайты с обоих сервисов. Только вот в случае с первым, тут не все так просто. Для этого был написан скрипт, который требует доработки, но поскольку мне он более не требуется, соответственно я не стал его дорабатывать. В любом случае его вполне достаточно на то, что бы скачать страницы сайта, но приготовьтесь к ошибкам, поскольку очень велика вероятность появления непредусмотренных особенностей того или иного сайта.
Первым делом я расскажу о том, как скачать сайт с web.archive.org, поскольку это самый простой способ. Вторым способом имеет смысл воспользоваться если по каким-то причинам копия сайта на web. archive.org окажется неполной или её не окажется совсем. Но скорее всего вам вполне хватит первого способа.
archive.org окажется неполной или её не окажется совсем. Но скорее всего вам вполне хватит первого способа.
Принцип работы веб-архива
Прежде чем пытаться восстанавливать сайт из веб-архива, необходимо понять принцип его работы, который является не совсем очевидным. С особенностями работы сталкиваешься только тогда, когда скачаешь архив сайта. Вы наверняка замечали, попадая на тот или иной сайт, сообщение о том, что домен не продлен или хостинг не оплачен. Поскольку бот, который обходит сайты и скачивает страницы, не понимает что подобная страница не является страницей сайта, он скачивает её как новую версию главной страницы сайта.
Таким образом получается если мы скачаем архив сайта, то вместо главной страницы будем иметь сообщение регистратора или хостера о том, что сайт не работает. Чтобы этого избежать, нам необходимо изучить архив сайта. Для этого потребуется просмотреть все копии и выбрать одну или несколько где на главной странице страница сайта, а не заглушка регистратора или хостера.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
- http://web.archive.org/web/ 20180330034350 /http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
- wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Качаем сайт с web-arhive.ru
Это самый геморройный вариант ибо у данного сервиса нет возможности скачать сайт как у описанного выше. Соответственно пользоваться этим вариантом есть смысл пользоваться только в случае если нужно скачать сайт, которого нет на web.archive.org. Но я сомневаюсь что такое возможно. Этим вариантом я пользовался по причине того, что не знал других вариантов,а поискать поленился.
В итоге я написал скрипт, который позволяет скачать архив сайта с web-arhive.ru. Но велика вероятность того, что это будет сопровождаться ошибками, поскольку скрипт сыроват и был заточен под скачивание определенного сайта. Но на всякий случай я выложу этот скрипт.
Пользоваться им довольно просто. Для запуска скачивания необходимо запустить этот скрипт все в той же командной строке, где в качестве параметра вставить ссылку на копию сайта. Должно получиться что-то типа такого:
- php get_archive.php “http://web-arhive.ru/view2?time=20160320163021&url=http%3A%2F%2Fremontistroitelstvo. ru%2F”
 ru%2F”
ru%2F”Заходим на сайт web-arhive.ru, в строке указываем домен и жмем кнопку «Найти». Ниже должны появится года и месяцы в которых есть копии.
Обратите внимание на то, что слева и справа от годов и месяцев есть стрелки, кликая которые можно листать колонки с годами и месяцами.
Остается найти дату с нужной копией, скопировать ссылку из адресной строки и отдать её скрипту. Не забывает помещать ссылку в кавычки во избежание ошибок из-за наличия спецсимволов.
Мало того, что само скачивание сопровождается ошибками, более того, в выбранной копии сайта может не быть каких-то страниц и придется шерстить все копии на предмет наличия той или иной страницы.
Помощь в скачивании сайта из веб-архива
Если у вас вдруг возникли трудности в том, что бы скачать сайт, можете воспользоваться моими услугами. Буду рад помочь. Для начала заполните и отправьте форму ниже. После этого я с вами свяжусь и мы все обсудим.
Как посмотреть удаленную страницу ВКонтакте
Для многих пользователей, ВК – это хранилище личной информации. Фотографии с памятными моментами, видео с прогулки вашей компании, члены которой уже давно разъехались по разным городам и странам. Вы хранили это в социальной сети, а вашу страницу заблокировали? А может друг удалил свой профиль с ценной информацией. Не огорчайтесь! Не все еще потеряно. Можно использовать веб архив ВКонтакте.
Фотографии с памятными моментами, видео с прогулки вашей компании, члены которой уже давно разъехались по разным городам и странам. Вы хранили это в социальной сети, а вашу страницу заблокировали? А может друг удалил свой профиль с ценной информацией. Не огорчайтесь! Не все еще потеряно. Можно использовать веб архив ВКонтакте.
Существует выражение «Все, что попадает в интернет, остается там навсегда». Оно очень близко к истине, ведь даже удаленные страницы в ВК и других соц. сетях можно просмотреть. Для этой цели используется три рабочих инструмента.
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
Для этого необходимо выполнить следующие действия.
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.
Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.
Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.
Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.
Попытайте удачу в поисках архивной версии профиля на этих сайтах:
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Справка. Веб-архивы сохраняют всю информацию, которая попадает в интернет без разбора. Видимо по этой причине, доступ к большинству существующих сервисов заблокирован на территории России Роскомнадзором. Чтобы работать с этими сайтами, воспользуйтесь анонимайзером или прокси-сервером.
Просмотр копии страницы в поисковиках
Зная алгоритмы работы поисковых роботов, можно использовать их возможности в своих целях. Каждый созданный сайт, попадает в Яндекс и Гугл не сразу. Он размещается на специальном сервере и ждет, пока поисковик найдет его и добавит в свою базу. Такие обходы поисковые системы выполняют в среднем один раз в 14 дней. Во время этого процесса они не только добавляют в свою базу новые сайты, но удаляют неработающие. Это значит, что если страничка ВКонтакте была удалена совсем недавно, то возможно ее копия еще сохранилась на серверах поисковиков.
Он размещается на специальном сервере и ждет, пока поисковик найдет его и добавит в свою базу. Такие обходы поисковые системы выполняют в среднем один раз в 14 дней. Во время этого процесса они не только добавляют в свою базу новые сайты, но удаляют неработающие. Это значит, что если страничка ВКонтакте была удалена совсем недавно, то возможно ее копия еще сохранилась на серверах поисковиков.
- Скопируйте адрес страницы, которую нужно найти, из адресной строки браузера.
- Вставьте эту ссылку в поисковую строку Яндекса или Гугла и нажмите «Поиск».
- Если страница все еще храниться в поисковике, то она будет первой в результатах выдачи. Справа от ссылки находится еле заметный треугольник. Нажмите на него.
- В открывшемся меню выберите «Сохранённая копия».
Перед вами откроется последняя версия страницы, которую сохранил Яндекс или Гугл. Сохраните фото, видео и всю прочую необходимую информацию себе на компьютер, так как совсем скоро сохраненная копия будет удалена с серверов поисковых машин.
Справка. Страница должна быть открыта для индексирования поисковиками в настройках аккаунта ВКонтакте. Если она была скрыта от них, то, соответственно, и сохраненной копии вы найти не сможете.
Кэш браузера
Если ни один из представленных ваше способов не помог вам найти нужную страницу, остается надеяться только на то, что копия уже сохранена на вашем компьютере. Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
В браузере Mozilla Firefox это делается следующим образом:
- зайдите в меню, нажав кнопку в виде трех горизонтальных полос;
- выберите пункт «Веб-разработка»;
- в этом подменю нажмите «Работать автономно».
Когда вы перешли в автономный режим, браузер не сможет загружать никакую информацию из интернета. Он будет использовать только те данные, которые сохранил на компьютере. Введите в адресную строку адрес нужной вам страницы и нажмите «Enter». Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Важно! После проведенного эксперимента не забудьте отключить автономный режим. Если этого не сделать, браузер не сможет подключиться к интернету.
Как видите, даже из самых, казалось бы, безвыходных ситуаций можно найти выход. Если же ни один из способов вам не помог, то позвоните другу и попросите восстановить страницу. А также отправьте ему ссылку на сайт vkbaron.ru, чтобы он видел, сколько всего интересного можно делать в социальной сети Вконтакте. В случае если вы пытаетесь сохранить информацию со своей страницы, которую кому-то удалось взломать, обязательно ознакомьтесь со статьей о составлении пароля, который не сможет подобрать ни один хакер.
Как работать с WebArchive: инструкция
Интернет появился около 37 лет назад, за этот период он все время менялся — что-то совершенствовалось, что-то убиралось, а что-то наоборот появлялось. Сайты постоянно меняли оформление, контент, кнопки и т.д. Для того, чтобы отследить эти изменения в целом или же какой-то конкретной нише, просмотреть сайт конкурентов, который уже не ведется или просмотреть историю интересующего вас сайта/домена — существует Web Archive.
Сайты постоянно меняли оформление, контент, кнопки и т.д. Для того, чтобы отследить эти изменения в целом или же какой-то конкретной нише, просмотреть сайт конкурентов, который уже не ведется или просмотреть историю интересующего вас сайта/домена — существует Web Archive.
Что такое Web Archive
WebArchive — бесплатный сервис, так называемая машина времени, которая ориентирована исключительно на сайты. Данный сервис хранит архивные данные с историей каждого ресурса, которые включают в себя целые страницы с контентом, заголовками, ссылками, изображениями и т.д.
Отслеживание истории домена необходимо не только в целях интересного времяпровождения, но и позволит вам узнать необходимую для продвижения вашего сайта информацию, такую как:
- Возраст домена, здесь мы уже описывали зачем вам нужны эти данные;
- Тематичность домена — WebArchive позволит вам узнать, не менялась ли тематика данного домена за время его существования, а если менялась, то когда и на какую;
- Увидеть, как сайт выглядел раньше — такая информация будет полезна при покупке б/у доменов;
- Просмотреть удаленный контент на сайте;
- Проверить домен на “чистоту” перед покупкой;
- Восстановить сайт, если до этого вы не сделали резервную копию;
- Отыскать уникальный контент с ресурсов в необходимой для вас нише.

Машина времени сайтов (англ. Wayback Machine) — один из главных проектов archive.org. Данный сервис не является коммерческим и был создан в 1996 году американским программистом Брюстером Кейлом. Архив сайтов имеет четкую цель — искать и собирать копии ресурсов вместе с изображениями, ссылками и контентом для дальнейшей возможности свободного просматривания информации любыми пользователями.
База web archive собиралась на протяжении 20 лет, в ней находится 280 миллиардов страницы, 12 миллионов статей и книг, миллион картинок, а также 100 тысяч программ.
Как пользоваться WebArchive
Сервис крайне прост и удобен в использовании. Приведем пошаговую инструкцию:
1. Заходим на главную страницу сайта — https://web.archive.org/
2. Введите в поиск интересующий вас сайт или же ключевое слово в нужном вам нише и нажмите Enter(подойдет для тех, кто хочет просмотреть все сайты, которые подходят для введенного КС)
3. Появится информация о ресурсе: сколько было сделано резервных копий сайта и с какой даты хранится информация о данном сайте
4. Внизу также будет календарь с отметками по годам, вы можете выбрать интересующий вас год
Внизу также будет календарь с отметками по годам, вы можете выбрать интересующий вас год
Проверьте позиции своего сайта прямо сейчас!
После этого на календаре голубым цветом будут выделены отметки, которые указывают на создание копий, вы можете выбрать любую из этих отметок.
5. После выбора отметки вас перебросит на копию сайта в выбранную вами дату. Например, вот так выглядел ресурс Liveinternet 27 марта 2012 года
6. Также вы можете получить общие статистические данные о нужном вам проекте. Для этого под строкой ввода нужно нажать Summary of
7. Еще вы можете ознакомиться с картой сайта, для этого необходимо нажать на кнопку Site Map под строкой ввода сайта
Алгоритм действий прост, а работа с сайтом не займет более 10-ти минут.
Как исключить свой сайт из WebArchive
Если вы по определенным причинам не хотите, чтобы ваш сайт попал в веб архив, то можно прописать запретную директиву в robots.txt вашего сайта, она должна выглядеть так:
После изменений в robots. txt машина времени перестанет делать резервные копии на ваш сайт, а уже имеющиеся сохранения будут удалены. Однако не забывайте, что данные изменения работают только тогда, когда есть доступ к robots.txt вашего сайта и если вы не будете продлевать использование вашего домена, то все изменения будут аннулированы и ваш сайт снова появится на WebArchive для просмотра всех желающих.
txt машина времени перестанет делать резервные копии на ваш сайт, а уже имеющиеся сохранения будут удалены. Однако не забывайте, что данные изменения работают только тогда, когда есть доступ к robots.txt вашего сайта и если вы не будете продлевать использование вашего домена, то все изменения будут аннулированы и ваш сайт снова появится на WebArchive для просмотра всех желающих.
Похожие статьи
Руководство по созданию и внедрению микроразметки для вашего сайта
Как использовать микроразметку, чтобы выделить свой сайт в результате поиска и пользователи чаще переходили на него. Самый действенный метод достижения этой цели – работа со структурированными данными. В этой статье мы постараемся разобраться, что же такое структурированные данные и как их можно внедрить на свой сайт.
Микроразметка Schema.org: как использовать для SEO-продвижения
Schema.org — это стандарт семантической разметки (микроразметки) данных на сайтах в сети Интернет. В этой статье мы рассмотрим, что из себя представляет микроразметка, как она позволяет передавать поисковикам основную информацию со страницы, а также в чем её польза для SEO-оптимизации.
12 уникальных SEO-инструментов для эффективных заголовков
Существует огромное количество инструментов, которые помогут вам создать идеальное название страницы. Выбор зависит только от ваших целей и предпочитаемых методов.
Программа для восстановления сайтов из
вебархива.WebArchive Downloader 6.0 – профессиональное программное обеспечение для скачивания сайта и страниц из интернет архива web.archive.org.
Основные преимущества программы:
- Сохраняет все файлы — стили CSS, скрипты, изображения, страницы
- Создает внутреннюю перелинковку страниц сайта
- Возможны два вида внутренних ссылок: файловые и доменные
- Удаляет из текста страниц всю служебную информацию
- Восстанавливать сайт из вебархива на конкретную дату
- Поддерживает три вида кодировки страниц
- Автоматический процесс закачки контента сайта
- Сохраняет полную навигацию по сайту
Применяя WebArchive Downloader 6.
 0 вы выбираете:
0 вы выбираете:Экономию
денег
Не нужно платить каждый раз за скачивание сайта из web архива. Достаточно один раз просто купить программу.
Автоматизацию
процесса
WebArchive Downloader 6.0 автоматизирует процесс сохранения страниц сайта, изображений и прочего контента.
Больше
времени
Ручной метод сохранения страниц из вебархива очень нудный и занимает много времени. WebArchive Downloader делает это пока вы отдыхаете.
Готовый
сайт
Скачанный сайт, при нормальном его качестве, практически сразу можно размещать на хостинг.
Уникальный
контент
Найдите брошенный домен и получите уникальные статьи и материал для своего сайта.
Веб архив — как пользоваться и открыть Web Archive Org, что это такое за сайт
- SEO-оптимизация
- 17 октября 2021
- 8 мин.

Руководитель Rush Analytics Дмитрий Цытрош
Обновлено 03 июля 2022 Что изменено?
навигация по статье
- Что такое веб-архив
- Зачем нужен web archive и как его можно использовать
- Как просмотреть старые версии сайтов на Wayback Machine
- Как добавить современную версию сайта в веб-архив Wayback Machine и выполнить другие действия
- Уникальный контент из веб-архива
Создание и наполнение онлайн-ресурса — это многоэтапный системный процесс. Контент фирменного сайта, интернет-магазина, лэндинга или портала должен постоянно обновляться с учетом целей и задач компании, изменений предпочтений целевой аудитории и алгоритмов поисковых систем. Но иногда старые тексты могут пригодиться, и тогда их можно найти на веб-архивах.
Но иногда старые тексты могут пригодиться, и тогда их можно найти на веб-архивах.
Что такое веб-архив
Веб-архив (web archive, internet archive) — это онлайн-платформа Wayback Machine, созданная в 1996 году. Здесь хранятся копии контента сайтов, интернет-магазинов, блогов, информационных и развлекательных порталов и других интернет-ресурсов, которые разрешены для сохранения. Это бесплатная онлайн-библиотека web.archive.org, где можно найти разные версии всех веб-ресурсов и просмотреть, как выглядел их контент, сохраненный на дату посещения сайта роботом сервиса.
Со времени создания веб-архива, здесь накопилось и на данный момент хранится больше 330 миллиардов файлов:
- интернет-страниц;
- аудио;
- видео;
- электронных книг и пр.
Зачем нужен web archive и как его можно использовать
Веб-архивирование нужно для того, чтобы можно было восстановить важную утерянную информацию с сайта, которая может не сохраниться из-за технических проблем или повреждения вирусом.
Например, владелец сайта создал его и наполнил описанием продукции, полезными статьями и изображениями по тематике. Через время веб-ресурс был обновлен и тексты заменены на новые. А еще через время понадобились именно старые тексты. В таких случаях и нужен открытый интернет-архив, в котором можно найти десятки сохраненных версий сайта на разные даты.
Предназначение веб-архивов:
- Возможность восстановления собственного контента в случае повреждения или удаления старых текстов и изображений.
- Просмотр старых файлов на других работающих веб-сайтах.
- Анализ изменений наполнения онлайн-ресурсов (собственных и конкурентных).
Сохранение авторского контента — это важная функция. Намного проще корректировать уже имеющиеся тексты, чем писать новые с нуля. Можно сделать рерайт (переписывание текста другим словами с сохранением смысла и структуры). Особенности использования резервных копий приведены в Табл. 1.
Табл. 1. Для каких целей можно использовать более ранний контент
| Цели | Особенности применения |
| Восстановление сайта | Бывают случаи непоправимого повреждения онлайн-ресурса — из-за вирусов, хакерских атак. Если не было проведено резервное копирование на своем хостинге, то можно будет найти свои тексты в веб-архиве Если не было проведено резервное копирование на своем хостинге, то можно будет найти свои тексты в веб-архиве |
| Наполнение сайта по похожей тематике | Старый экспертный текст по своей тематике может понадобиться при создании лэндинга, вспомогательного онлайн-ресурса. Если тексты неуникальны, их нужно рерайтить |
| Ведение блога | Для привлечения трафика на профильный сайт нужно вести блог с текстами узкой тематики. Это могут быть советы по выбору товаров, использованию продукции и другой контент. Для написания таких текстов может потребоваться информация со старых копий веб-ресурса |
| Публикации на странице в социальных сетях | Бизнес-аккаунт в соцсетях помогает поднять узнаваемость бренда и компании, привлечь новых покупателей, расширить рынки сбыта. Для постов в социальных сетях можно использовать тексты, которые ранее были опубликованы на сайте (если они не дублируются с новыми) |
Как просмотреть старые версии сайтов на Wayback Machine
Если вам необходимо найти старую версию страниц какого-либо веб сайта, выполните следующие действия:
- Наберите в поисковой строке адрес https://web. archive.org/.
- С главной страницы архива сайтов перейдите по ссылке на нужный раздел (файлы, видео, изображения и пр.), укажите адрес домена и нажмите «BROWSE HISTORY».
- Во временной шкале будут отображены все копии сайтов. Словно с помощью машины времени, здесь можно найти любую созданную ранее архивную копию и даже скачать ее при помощи специальных инструментов.
- В открывшемся календаре можно выбрать дату, отмеченную зеленым или голубым кружком (диаметр этого кружка зависит от числа обращений робота сервиса к онлайн-проекту в указанный день). Зеленым кружком обозначены редиректы.
 archive.org/.
archive.org/.Важно! Если веб-страницу через некоторое время не удается просмотреть, это может быть вызвано несколькими причинами:
- Правообладатель обратился на платформу архива интернета с требованием удалить копии.
- Сам веб-проект был закрыт из-за нарушения авторских прав и закона об использовании интеллектуальной собственности.
- Разработчики закрыли страницы своего онлайн-ресурса от индексации роботами поисковых систем.

Если вы хотите посмотреть, как выглядел веб-сайт, но на сохраненной копии нет изображений или других элементов дизайна (иногда они не сохраняются), нужно открыть другую версию, которую веб-архив сохранил в другой день.
Как добавить современную версию сайта в веб-архив Wayback Machine и выполнить другие действия
Онлайн-платформа по веб-архивированию сайтов предоставляет множество возможностей разработчикам и владельцам ресурсов (Табл. 2).
Табл. 2. Как работать с веб-архивом
| Возможности | Особенности выполнения |
| Сохранение нужной версии сайта на платформе интернет-архива | Нужно самостоятельно инициировать сохранение. В разделе платформы «Save Page Now» нужно забить домен онлайн-ресурса и нажать «Save page». Такую процедуру рекомендуется повторять каждый раз, когда в контент были внесены исправления или дополнения |
| Запрет на добавление интернет-ресурса в память веб-архива | Для запрета добавления нужно прописать это в файле robots. txt. В панелях хостеров есть корневой каталог, в котором предусмотрена возможность редактирования файлов. При введении кода User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: / файл будет скрыт от копирования. При введении такого кода из веб-архива удаляется и текущая версия сайта и не осуществляется системное копирование (до тех пор, пока в файле robots.txt есть такие настройки или пока не закончится срок регистрации домена) txt. В панелях хостеров есть корневой каталог, в котором предусмотрена возможность редактирования файлов. При введении кода User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: / файл будет скрыт от копирования. При введении такого кода из веб-архива удаляется и текущая версия сайта и не осуществляется системное копирование (до тех пор, пока в файле robots.txt есть такие настройки или пока не закончится срок регистрации домена) |
| Восстановление веб-сайта из интернет-архива | Если сайт был поврежден вирусами или есть другие технические проблемы, из-за которых контент был нарушен, можно восстановить файлы из онлайн-хранилища. Для этого применяются специальные сервисы. Есть платные и бесплатные варианты, которые выбираются с учетом количества страниц для восстановления |
Уникальный контент из веб-архива
Многие коммерческие сайты через некоторое время существования закрываются. Если на них был опубликован полезный контент (экспертные статьи, аналитические обзоры и другая важная информация), то после закрытия первоисточника они могут быть востребованными. То есть, сайт уже не работает и ранее написанные статьи могут использоваться на информационных порталах (если они уникальны).
То есть, сайт уже не работает и ранее написанные статьи могут использоваться на информационных порталах (если они уникальны).
Веб-архив является очень полезным сервисом, который может пригодиться в различных ситуациях. Быстрое восстановление потерянных данных может значительно сэкономить время и финансы, если сайт подвергнется хакерской атаке или же перестанет работать из-за серьезной технической проблемы. Веб-архив дает возможность не только просматривать старые версии своего сайта, но и анализировать контент конкурентов, сохраненный в разные периоды времени.
Просмотров
7240
Рейтинг
4,0/5
Оценить
Комментариев
Комментировать
Другие наши статьи
На страницу статей- Контент
Верстка и оформление статей на сайте
Вы можете написать интересный текст, придумать цепляющий заголовок, но если статью будет сложно читать, то вы рискуете потерять своих посетителей.
- Valeriy London
- 17 октября 2021
- 6 мин.
- Копирайтинг
Работаем с Текстовым Анализатором в Rush Analytics
Сегодня, когда контент играет все большую роль в продвижении сайтов, найти инструмент с помощью которого можно качественно оптимизировать текст под поисковые машины — цель каждого оптимизатора или seo-копирайтера.
- Дмитрий Цытрош
- 17 октября 2021
- 10 мин.
Получите 7 дней бесплатного доступа
Здесь вы можете собрать поисковые подсказки из Яндекс, Google или YouTube
Зарегистрироваться
Нужны доказательства по вашему делу? 7 способов найти старые версии веб-сайтов на предмет стертого контента
Что делать, если вы обращаетесь в суд, думая, что ваши доказательства есть на веб-сайте, но сайт их стер? Вот 7 способов поиска старых версий веб-сайтов.
Учитывая огромное количество веб-сайтов, которые сегодня находятся в сети, и всю информацию, которую они хранят, само собой разумеется, что время от времени юридической фирме может потребоваться извлечь информацию с сайта для доказательства. Проблема в том, что как только ответчик узнает о том, что вы собираетесь подать в суд, он может отредактировать свой веб-сайт так, как ему выгодно.
Когда это происходит, вы можете подумать, что потеряли ключевую информацию для поддержки вашего дела. К счастью, вам еще не повезло!
К счастью, вам еще не повезло!
Современный Интернет, к лучшему или к худшему, создает резервные копии старых версий веб-сайтов. Они делают это, заставляя свои инструменты «сканировать» Интернет и фотографировать все, что они видят.
Между этим и некоторыми другими творческими средствами вы можете откопать нужные вам удаленные веб-страницы. Вот несколько советов по лучшим вариантам восстановления.
1. Подайте юридический запрос
Хотя мы можем лично говорить об эффективности этого, теоретически ваша фирма может обратиться к ответчику с юридическим запросом о передаче старых версий веб-сайта. Этот запрос может быть связан с вашим обвинением в заговоре с целью уничтожения улик.
Защищающие юридические группы могут иметь другую точку зрения, что может привести к тупиковой ситуации. Тем не менее, вы ничего не теряете, делая запрос.
Возможно, вы обнаружите, что напуганные ответчики, которые не спешат получить юридическую консультацию, быстро подчиняются.
2. Загляните в кеш вашего браузера
Кэш — это сохраненная информация с посещенных вами сайтов, которая хранится на вашем локальном компьютере. Цель кеша — позволить людям, которые посещали сайты раньше, быстро загружать страницы, а не загружать их заново с нуля.
В зависимости от настроек вашего браузера на вашем компьютере может быть сохранен кеш сайта. Получив доступ к этому кешу, вы теоретически могли видеть старые версии веб-сайтов. Ваша способность сохранять кеш страницы частично зависит от настроек кеша рассматриваемого сайта.
3. Проверьте кэш Google
Когда Google сканирует веб-сайты для своей поисковой системы, он сохраняет кешированные версии страниц. К этим кэшированным страницам можно получить доступ через результаты поиска, чтобы просмотреть исторические версии веб-сайта.
Чтобы просмотреть кэшированную версию страницы результатов поиска Google, просто щелкните стрелку раскрывающегося списка рядом с адресом веб-сайта, наведите указатель мыши на «кэшировано» и щелкните по нему.
4. Попробуйте кэш других поисковых систем
Хотя может показаться, что это так, Google, безусловно, не единственная поисковая система в городе. Другие движки, такие как Yahoo и Bing, также сканируют и индексируют страницы. Поэтому, если кеш Google не показывает вам результаты, которые вы хотите найти, возможно, воля Bing или Yahoo.
Перейдите к этим движкам, просмотрите разделы их кэшированных страниц и посмотрите, что доступно.
5. Попробуйте Wayback Machine
Одним из самых популярных способов просмотра старых версий веб-сайтов является использование Wayback Machine. Эта «машина» на самом деле является веб-сайтом, созданным Интернет-архивом.
Целью Wayback Machine является просмотр веб-страниц для сохранения страниц и создания сжатой цифровой записи. Затем эти страницы индексируются в календаре, который позволяет пользователям быстро и легко просматривать исторические версии страниц и понимать, когда эти страницы были активны.
Например, вот сохраненная на Wayback Machine версия старой версии Amazon. com.
com.
Wayback Machine не является надежной, поскольку пользователи могут размещать указания в файле «robots.txt» своего сайта, который сообщает Wayback Machine не сохранять свои страницы. Инструмент должен выполнять такие запросы, учитывая, что сохранение работы других людей, защищенной авторским правом, является средством нарушения.
6. Перейдите на веб-сайт
Когда интернет-авторы цитируют источники в Интернете, исходные материалы часто меняются. Это создает условия, при которых авторы перезванивают на страницы, на которых больше нет приемлемой информации.
Например, предположим, что учитель должен был предложить веб-сайт, который ему понравился, и поделиться ссылкой на него. Если этот веб-сайт позже превратится во что-то неуместное, у этого учителя могут быть проблемы. Чтобы решить эту проблему, Webcite решил архивировать старые версии страниц, чтобы люди могли ссылаться на эти архивы, а не на динамические исходные страницы.
Возможно, на Webcite есть архивная копия страницы, на которую нужно ссылаться.
7. Сохранение сайта на локальном компьютере
Чтобы использовать этот способ доступа к старым версиям веб-сайтов, вам потребуется предусмотрительность. Однако, если вы все еще в состоянии это сделать, сохранить сайт для поддержки импичмента подсудимых (прочитайте это, чтобы узнать больше) или что-то еще так же просто, как нажать «Ctrl + S» на ПК.
При этом ваш браузер предложит загрузить текущую версию страницы, на которой вы находитесь. В этот момент поиск нужного вам контента можно выполнить, зайдя в каталог сохранения вашего браузера.
Доступ к старым версиям веб-сайтов проще, чем когда-либо
Если вы узнали что-то из нашего краткого руководства по поиску старых версий веб-сайтов, мы надеемся, что доступ к архивным данным веб-сайтов прост! Все, что вам нужно сделать, это пройтись по вариантам, доступным вам онлайн и оффлайн.
Когда вы это сделаете, скорее всего, вы сможете получить данные, необходимые для создания дела, над которым вы работаете.
Интернет может быть непростым местом, даже для юристов (иногда особенно для юристов)! Если вы нуждаетесь в цифровом руководстве или хотите получить информацию по другим темам, относящимся к праву, просмотрите больше контента в нашей онлайн-публикации.
Просмотры сообщений: 12,276
3 способа просмотра старых версий веб-сайтов в браузере
Иногда вам может понадобиться посмотреть, как выглядела старая версия определенного сайта. Что ж, это было бы невозможно, если бы кто-то не додумался создать архив на заре Интернета. К счастью, у нас есть несколько вариантов посещения веб-страниц с предыдущей даты. Вот три способа посетить и просмотреть старые версии веб-сайтов в вашем браузере.
Связанные | 3 способа узнать, безопасно ли посещать веб-страницу в Chrome
Содержание
Посещение и просмотр старых версий веб-страниц или веб-сайтов
предыдущая дата. Это может быть развлечение, вдохновение в дизайне, сохранение старых изображений или обход цензуры. Какой бы ни была причина, если вы хотите просмотреть старую версию веб-сайта, вам помогут указанные ниже интернет-библиотеки.
Какой бы ни была причина, если вы хотите просмотреть старую версию веб-сайта, вам помогут указанные ниже интернет-библиотеки.
1. Используйте Интернет-архив для посещения старой версии сайта
Когда дело доходит до посещения веб-страниц из прошлого, одно имя, которое встречается во всех рекомендациях, — это Интернет-архив. Это некоммерческая организация, предлагающая бесплатную Wayback Machine, которая хранит более 591 миллиарда веб-страниц в Интернете.
Не только старые версии веб-сайтов, но и Интернет-архив также хранит обширную библиотеку миллионов бесплатных изображений, видео, программного обеспечения, музыки, электронных книг и т. д. Выполните следующие шаги, чтобы посетить старые версии ваших любимых веб-сайтов через Интернет. Машина обратного пути архивов.
Шаг 1 : Посетите InternetArchive в любом браузере.
Шаг 2 : Прямо в верхней части главной страницы вы найдете Wayback Machine вместе с окном поиска.
Шаг 3 : Введите URL-адрес веб-сайта, на котором вы хотите увидеть старую версию. На следующем экране Wayback Machine покажет номер, под которым этот конкретный веб-сайт сохранен в своем архиве.
Шаг 4 : На той же странице появится представление календаря — вы можете нажать на конкретный год, месяц и дату, чтобы увидеть старую версию. Как видите, это показывает, что сайт GadgetsToUse.com был сохранен 460 раз за последние десять лет.
Шаг 5 : Как только вы выберете конкретную дату, InternetArchive покажет вам, как сайт выглядел в прошлом.
Шаг 6 : Не только домашняя страница, но и можно щелкнуть по статьям, чтобы увидеть их содержание. Все комментарии к изображениям будут доступны.
2. Использование Библиотеки Конгресса
Следующей в нашем списке является Библиотека Конгресса. Это одна из лучших альтернатив Интернет-архиву. Это может быть полезно, если искомый веб-сайт не сохранен в Wayback Machine.
В прошлом я сталкивался с несколькими случаями, когда Интернет-архив не сохранял определенную веб-страницу, но копия была в Библиотеке Конгресса. Выполните следующие шаги, чтобы использовать его.
Шаг 1 : Отправляйтесь в Библиотеку Конгресса.
Шаг 2 : Прямо на странице вы найдете окно поиска, чтобы ввести URL-адрес веб-страницы, которую вы хотите просмотреть.
Шаг 3 : Теперь будет показано, сколько раз веб-сайт сохраняется в библиотеке. Вы можете выбрать конкретный год или месяц в представлении календаря, аналогично Wayback Machine.
Шаг 4 : Я выбрал 9 декабря 2001 года, когда веб-сайт CNET был сохранен в первый раз. Вы можете увидеть результат ниже — именно так сайт выглядел в то время.
3. OLD.WEB.TODAY — Эмулировать устаревшие браузеры
Два вышеприведенных варианта показывают старые версии веб-сайтов, но в Chrome, но что, если кто-то захочет увидеть то же самое через браузеры того времени? Например, поколение Z могло никогда не использовать NCSA Mosaic 2, Navigator, IE 4 или другие устаревшие браузеры.
OLD.WEB.TODAY делает то же самое, эмулируя старую версию веб-сайта в браузере. Он использует библиотеку интернет-архивов, но добавляет дополнительные возможности для эмуляции веб-страниц в старом веб-браузере. Выполните следующие шаги, чтобы использовать его.
Шаг 1 : Прежде всего, зайдите на OLD.WEB.TODAY в любом браузере.
Шаг 2 : Выберите браузер, в котором вы хотите увидеть старую версию веб-сайта. Он позволяет выбрать NCSA Mosaic, Navigator, старые версии Internet Explorer, Firefox и т. д., как показано ниже.
Шаг 3 : После выбора браузера введите URL-адрес веб-сайта и дату, когда вы хотите просмотреть веб-сайт.
Шаг 4 : На следующем экране OLD.WEB.TODAY откроет страницу на компьютере со старой операционной системой, выбранным браузером и, конечно же, старой версией веб-сайта.
Повторное посещение старых веб-сайтов
Забавно видеть и посещать старые версии веб-сайтов, которыми мы пользуемся сегодня. Все три упомянутых выше инструмента отлично работают при показе сотен копий веб-сайтов. Большую часть времени с этой задачей справится Интернет-архив. Но если вы обнаружите, что он не сохранил веб-сайт в течение определенного периода времени, дайте шанс Библиотеке Конгресса. Наконец, Old.Web.Today можно использовать для просмотра старой версии веб-сайта в устаревших браузерах того времени.
Все три упомянутых выше инструмента отлично работают при показе сотен копий веб-сайтов. Большую часть времени с этой задачей справится Интернет-архив. Но если вы обнаружите, что он не сохранил веб-сайт в течение определенного периода времени, дайте шанс Библиотеке Конгресса. Наконец, Old.Web.Today можно использовать для просмотра старой версии веб-сайта в устаревших браузерах того времени.
Как просмотреть старые версии веб-сайтов: подробное руководство
В этой статье мы покажем вам, как можно просмотреть старые версии веб-сайтов с помощью бесплатных онлайн-ресурсов.
В этой статье мы покажем вам, как посмотреть старые версии сайтов с помощью бесплатных онлайн-ресурсов.
После того, как веб-страница была закрыта, больше недоступна или изменена, вы можете захотеть просмотреть старые версии веб-сайтов по разным причинам. Вы можете путешествовать во времени и получить заархивированную версию веб-сайта, на который вы хотите ссылаться, или просмотреть его более старый контент, или получить вдохновение от предыдущего дизайна страницы. Исторические онлайн-базы данных позволят вам увидеть старые версии веб-сайтов, созданные в определенные моменты времени.
Исторические онлайн-базы данных позволят вам увидеть старые версии веб-сайтов, созданные в определенные моменты времени.
К счастью, есть много онлайн-инструментов, которые помогут вам в этом, и в этой статье мы покажем вам все наиболее полные базы данных, чтобы увидеть старые версии веб-сайтов с использованием различных ресурсов. Возможность восстановить старые веб-сайты, которые больше не существуют, окажется более полезной, чем просто путешествие по переулку памяти. Давайте подробно рассмотрим, почему и как вы можете увидеть старые версии веб-сайтов всего за несколько кликов.
Зачем находить и просматривать старые версии веб-сайтов?
Говорят, что интернет вечен, значит, так оно и есть. Даже если ваш веб-сайт может выйти из строя или вы можете удалить веб-сайт, все еще есть способы найти эти старые версии веб-сайтов и просмотреть их кэшированные версии с помощью различных инструментов и ресурсов.
Существует несколько причин, по которым вам может понадобиться искать и извлекать кешированные версии веб-сайтов, среди них: ищут вдохновение для дизайна на определенном веб-сайте.
Как просмотреть кэшированную версию веб-сайта с помощью Google Cache
Google сканирует веб-страницы и сохраняет HTML-копию веб-сайта, которые обычно называются кэшированными страницами. Просматривать кэшированные веб-сайты с помощью Google в качестве инструмента довольно просто. Вы сможете просмотреть веб-сайт, который работает медленно или не отвечает.
Это может помочь специалистам по поисковой оптимизации рассчитать проблемы индексации. В тот момент, когда Google сканирует веб-сайт, он делает снимок экрана веб-страницы и индексирует содержимое для будущих ссылок. Используя метод, который мы покажем ниже, вы сможете увидеть дату, когда Google проиндексировал страницу. Вы также можете использовать Google Cache, чтобы узнать, когда в последний раз определенный веб-сайт или страницу посещали боты Google.
В тот момент, когда Google сканирует веб-сайт, он делает снимок экрана веб-страницы и индексирует содержимое для будущих ссылок. Используя метод, который мы покажем ниже, вы сможете увидеть дату, когда Google проиндексировал страницу. Вы также можете использовать Google Cache, чтобы узнать, когда в последний раз определенный веб-сайт или страницу посещали боты Google.
Сначала введите имя веб-сайта или страницы, кэшированную версию которой вы пытаетесь просмотреть. Вы можете просто сделать это из окна поиска Google. Рядом с URL-адресом вы увидите маленькую стрелку, указывающую вниз, нажмите на нее, а затем нажмите «Кэшировано».
Google перенаправит вас на кешированную версию этого конкретного веб-сайта.
На верхней панели вы можете найти ценную информацию о том, когда Google в последний раз индексировал страницу, а также точную дату и время создания снимка экрана. Кроме того, у вас есть возможность просмотреть текстовую версию страницы. Вы сможете нормально взаимодействовать со страницей.
Другой вариант просмотра кэшированных веб-сайтов, который намного проще, — это ввести cache: в адресной строке, а затем ввести URL-адрес веб-сайта, который вы хотите посетить. Это создаст кешированную версию этого конкретного веб-сайта.
4 Инструменты, которые можно использовать для просмотра старых версий веб-сайтов
В Интернете доступно несколько инструментов и ресурсов, которые помогут вам просматривать старые версии веб-сайтов в определенный момент времени. Эти инструменты делают снимки веб-сайтов в виде кэшированной версии с разными отметками времени. Затем они архивируют эти веб-страницы, что позволяет вам легко получить к ним доступ.
Эти инструменты работают примерно так же, как процесс резервного копирования вашего веб-сайта, с той лишь разницей, что эти старые версии веб-сайтов доступны для просмотра всем, а не только вам, владельцу сайта. Обычно вы можете найти копии и снимки различных кешированных версий веб-сайтов, но результаты зависят от популярности конкретного веб-сайта и трафика, который он генерирует.
Wayback Machine
Сначала мы познакомим вас с наиболее полным веб-архивом, в котором хранится более 554 миллиардов заархивированных веб-страниц. Интернет-архив — это цифровая библиотека Интернета, содержащая веб-сайты, книги, аудиозаписи, записи и даже программное обеспечение.
Wayback Machine — это продукт Internet Archive, который предоставляет вам миллионы скриншотов веб-сайтов из разных временных интервалов. Wayback Machine — отличный инструмент для просмотра старых или даже живых веб-сайтов.
Чтобы найти старую версию веб-сайта с помощью Wayback Machine, просто введите URL-адрес веб-сайта в специальное поле, например, как здесь.
На следующем экране будет сгенерирован график, содержащий копии веб-сайтов, распределенных по годам. Чтобы просмотреть, каким был веб-сайт в определенный период времени, просто щелкните год на графике, показанном ниже.
Здесь вы можете увидеть подробный календарь, содержащий снимки этого конкретного веб-сайта и того, каким он был раньше. На каждой дате вы можете увидеть синий или зеленый кружок. Чем больше круг, тем больше кешированных версий этой веб-страницы вы можете найти. Нажмите на кружок с определенной датой, и там вы увидите снимки соответствующего веб-сайта.
На каждой дате вы можете увидеть синий или зеленый кружок. Чем больше круг, тем больше кешированных версий этой веб-страницы вы можете найти. Нажмите на кружок с определенной датой, и там вы увидите снимки соответствующего веб-сайта.
Щелкнув по снимку, вы сможете просматривать веб-сайт и взаимодействовать с ним, как обычно. Вы можете нажимать на ссылки, просматривать изображения, переходить со страницы на страницу. Все доступно.
Wayback Machine — отличный инструмент для просмотра старых версий веб-сайтов, которые больше не доступны или не существуют, но вы также можете выполнить поиск существующего веб-сайта, если вам интересно, какими они были в прошлом. Вы должны иметь в виду, что не каждая ссылка будет работать, и не каждая страница будет доступна для навигации из-за того, что страница не кэшируется.
Архив.Сегодня
Архив.Сегодня — это отличный инструмент, который также представляет время для хранения веб-сайтов в Интернете навсегда. Он будет делать снимки веб-сайтов и сохранять их в своей базе данных. Эти снимки навсегда останутся в сети, даже если самого веб-сайта больше не существует. Через надежную ссылку вы сможете получить доступ к неизменяемой версии страницы. Он также сохраняет текстовую и графическую копию страницы для большей гибкости.
Эти снимки навсегда останутся в сети, даже если самого веб-сайта больше не существует. Через надежную ссылку вы сможете получить доступ к неизменяемой версии страницы. Он также сохраняет текстовую и графическую копию страницы для большей гибкости.
Archive.Today предлагает возможность сохранить ваш веб-сайт и его содержимое, а также выполнить поиск и найти существующие веб-сайты, которые были ранее сохранены. Вы можете легко просмотреть старые версии веб-сайтов, просмотреть веб-страницу в том виде, в каком она есть на данный момент, сохранить ее и загрузить страницу на свой компьютер.
Это так же просто, как ввести URL-адрес во втором поле, где вы ищете в архиве сохраненные снимки.
Сначала вы можете увидеть самую старую и самую новую версии веб-сайта определенного домена. Когда вы нажимаете на определенное изображение или ссылку, она перенаправляет вас на кешированную версию веб-сайта, и вы можете легко взаимодействовать со страницей. Хотя не все взаимодействия будут доступны.
Oldweb.today
Один из самых уникальных инструментов в списке, Oldweb.today — это удивительная машина с инкапсуляцией во времени, которая позволяет вам находить и просматривать старые версии веб-сайтов с помощью старых браузеров, которые функционировали в то время.
Этот инструмент вызовет у вас мурашки по коже и перенесет вас в прошлое, где вы сможете работать со старыми веб-страницами. Oldweb.today извлекает старые версии веб-сайтов, используя цифровые библиотеки, такие как Интернет-архив, и другие ресурсы в Интернете.
Обратите внимание, что процесс доставки может быть медленным и занять некоторое время, но он будет эмулировать старые браузеры, такие как Intern Explorer и Netscape. После того, как вы попали на целевую страницу oldweb.today, чтобы найти кешированную версию определенного веб-сайта, вам нужно будет сначала выбрать браузер из раскрывающегося списка. Затем введите URL-адрес веб-сайта, который вы хотите изучить, и убедитесь, что выбран параметр «Просматривать архивы на».
Нажмите Enter и дождитесь отображения результатов. Как только процесс извлечения старых версий веб-сайта будет завершен, вы сможете увидеть отображение веб-сайта. Вы можете, конечно, перемещаться по сайту, легко нажимать на ссылки или копировать текст с сайта.
Веб-архив Библиотеки Конгресса
Веб-архив Библиотеки Конгресса — это комплексный и мощный инструмент, который управляет, сохраняет и предоставляет цифровую коллекцию заархивированных веб-сайтов, газет, книг, аудиозаписей и книг. Вы можете без проблем выполнять поиск в обширной библиотеке и просматривать старые версии веб-сайтов. Этот инструмент разработан, чтобы помочь исследователям находить контент, доступный сегодня и в будущем, даже если такой контент будет удален.
Мы знаем, что новые веб-сайты появляются с очень высокой скоростью из-за чрезвычайной доступности Интернета, изменения URL-адресов, изменения контента, поэтому веб-архив Библиотеки Конгресса хранит общедоступный контент, который позволяет вам искать в нем. легко. Чтобы начать изучение этого инструмента, все, что вам нужно сделать, это указать URL-адрес веб-сайта, на котором вы хотите найти его старый контент, и нажать кнопку поиска.
легко. Чтобы начать изучение этого инструмента, все, что вам нужно сделать, это указать URL-адрес веб-сайта, на котором вы хотите найти его старый контент, и нажать кнопку поиска.
Результаты поиска будут аналогичны результатам поиска Wayback Machine, то есть функциональность будет такой же. Выберите конкретный год, за который вы хотите увидеть старые версии веб-сайтов, а затем снова щелкните конкретную дату, чтобы отобразить данные, и это приведет к кэшированию веб-сайта.
Обратите внимание, что некоторые веб-сайты будут находиться за пределами Библиотеки Конгресса. Для низкопрофильных веб-сайтов обязательно используйте три других представленных решения, которые лучше подходят для работы.
Расширения и веб-инструменты
Расширения браузера также могут получать доступ к кэшированным веб-сайтам и позволяют просматривать старые версии веб-сайтов. Одним из таких инструментов может быть расширение Chrome Web Cache Viewer. Добавьте расширение в свой браузер, и всякий раз, когда вы хотите просмотреть кешированную версию веб-сайта, просто щелкните правой кнопкой мыши страницу, и вы сможете увидеть результаты с помощью Google Cache или Wayback Machine.
Существует также онлайн-инструмент Cached Page, который предлагает возможность просмотра кэшированных версий и страниц Google, просто вставив URL-адрес определенного веб-сайта. Он работает аналогично Google Cache. Он отображает всю кэшированную информацию в верхней части страницы, включая отметку времени сделанного снимка.
Заключительные мысли
В этом исчерпывающем руководстве мы поделились всеми нашими секретами, как научить вас просматривать старые версии веб-сайтов, и дали руководство по всем наиболее используемым и эффективным инструментам, доступным в Интернете. Если вы ищете старый контент или просто хотите найти старую кешированную версию веб-сайта, это так же просто, как ввести URL-адрес и начать исследование.
Вы можете использовать различные инструменты, представленные по нескольким причинам, как указано выше. Не стесняйтесь поделиться своими секретами поиска и поиска старого контента в Интернете, который в настоящее время недоступен.
Сноуи Смит
Директор по дизайну, Freehand
Связанные статьи
Как и где просматривать старые версии веб-сайтов
Ищете старые записи в Интернете или хотите просмотреть старые версии веб-сайтов? По данным IACP, за одну минуту в мире создается почти 580 новых веб-сайтов.
Служба поддержки Easylinehost
28.03.2021
Служба поддержки Easylinehost
Ищете старые записи в Интернете или хотите просмотреть старые версии веб-сайтов? Что ж, это очень даже возможно. По данным IACP, за одну минуту в мире создается почти 580 новых веб-сайтов. Но не многие служат годами. Если быть точным, средний срок жизни веб-страницы составляет от 40 до 44 дней.
Тем не менее, есть несколько ценных инструментов и веб-сайтов, которые позволяют вам просматривать и извлекать старый контент, к которому вы не можете получить доступ через URL или поисковые системы. Посмотрите:
Посмотрите:
Wayback Machine
Благодаря своей привлекательности Wayback Machine стала спасением для тысяч пользователей за последние двадцать лет. Это сокровище старого содержания. Проще говоря, это библиотека, содержащая 450 миллиардов веб-страниц, причем сервис бесплатный!
Чтобы получить доступ и использовать старые версии веб-сайта через Wayback Machine, просто зайдите на сайт и вставьте URL-адрес сайта, который вы хотите получить или просмотреть в старой версии. После ввода URL-адреса нажмите Enter, и ниже вы увидите календарь. Нажав на даты, вы можете просмотреть старую версию выбранного веб-сайта.
Google Cache
Еще один удобный вариант, когда дело доходит до просмотра старых версий веб-сайтов. Опция кеша Google содержит запись обо всех просканированных и проиндексированных веб-страницах, к которым вы можете легко получить доступ.
Использование Google Cache также не требует усилий. Введите URL-адрес в поиске Google, как обычно, и тогда вы увидите небольшую нисходящую ошибку справа от введенного URL-адреса в результатах поиска. Затем Google предоставит вам кешированную копию этой веб-страницы.
Затем Google предоставит вам кешированную копию этой веб-страницы.
Другой способ использовать эту функцию Google:
Введите «кеш» в строке поиска/адреса, а затем введите URL-адрес желаемого веб-сайта, который вы ищете.
Например: в адресной строке: « cache:www.websitename.com» .
Web Cache Viewer
Далее у нас есть расширение, которое вы можете установить в браузере Chrome для просмотра старых веб-страниц. После установки расширения щелкните правой кнопкой мыши ссылку, которую вы хотите просмотреть, и вы найдете два варианта просмотра старых веб-страниц. Расширение позволяет просматривать старые версии через Wayback Machine или Google Cache.
WebCite
WebCite — еще один полезный способ доступа к старым веб-страницам и старым версиям веб-сайтов. Архивный сайт не нов, он был представлен в 2005 году. Заархивированные веб-страницы перечислены в разделе ссылок или иногда в статьях. Это отличный способ исследовать тему или если вы ищете фактический источник любого чтения. Получив доступ к WebCite, вы не можете искать определенные ключевые слова, но вы можете проверить конкретный URL-адрес.
Получив доступ к WebCite, вы не можете искать определенные ключевые слова, но вы можете проверить конкретный URL-адрес.
Bing, Yahoo или Ask Cache
Если по какой-то причине Google не найдет искомую веб-страницу, она может быть в других поисковых системах. Таким образом, нет ничего плохого в том, чтобы попробовать другие поисковые системы для кешированных версий веб-сайтов, таких как Bing, Yahoo или Ask Cache.
16.05.2022
Служба поддержки Easylinehost
Лучшие ключевые слова Canva
Canva упрощает создание дизайна. В этой статье рассказывается о лучших и уникальных ключевых словах Canva для создания привлекательных дизайнов.
Подробнее
7.4.2022
Служба поддержки Easylinehost
Семь шагов, чтобы начать свой экологически чистый блог о путешествиях
Ведение блога — лучший способ изложить свои идеи, распространить информацию и помочь людям. Ознакомьтесь с семью шагами, чтобы начать свой собственный блог.
Ознакомьтесь с семью шагами, чтобы начать свой собственный блог.
Подробнее
28.03.2022
Служба поддержки Easylinehost
Как убрать фон с картинки в Canva
Canva — отличный инструмент для дизайна. Одно замечательное приложение, которое предлагает Canva, — это возможность удалить фон с изображения одним щелчком мыши.
Подробнее
4.3.2022
Служба поддержки Easylinehost
Сторонние файлы cookie скоро станут историей
Google Chrome готовится к окончательному удалению сторонних файлов cookie. Новая политика Google предлагает новые альтернативные решения.
Подробнее
23.02.2022
Служба поддержки Easylinehost
Как изменить размер изображения с помощью бесплатных инструментов
Вам нужно изменить размер изображения на веб-странице? Изменение размера изображений помогает увеличить скорость загрузки веб-страницы и улучшить общий индекс SEO.
Подробнее
8.12.2021
Служба поддержки Easylinehost
Должен ли я создать блог компании?
Есть ли смысл заводить корпоративный блог? Блог помогает вам установить авторитет на рынке вашего бизнеса.
Подробнее
4.10.2021
Служба поддержки Easylinehost
Как начать блог о зеленой жизни?
Блог о зеленой жизни может быть чем угодно: от еды, которую мы потребляем, до технологий, транспорта или всего, что влияет на климат и окружающую среду.
Подробнее
18.9.2021
Служба поддержки Easylinehost
Как управлять адресами электронной почты с помощью Plesk Panel
Вы можете легко управлять своими учетными записями электронной почты через панель управления Plesk. Прочтите наши пошаговые инструкции по управлению собственными учетными записями электронной почты.
Прочтите наши пошаговые инструкции по управлению собственными учетными записями электронной почты.
Подробнее
18.9.2021
Служба поддержки Easylinehost
Как изменить записи DNS в панели управления Plesk
Вы можете легко изменить запись DNS своего домена через панель управления Plesk. Узнайте, как изменить старую запись DNS или создать новую.
Подробнее
Веб-сайт и SEO
Как просмотреть старые версии любого сайта WordPress (3 инструмента)
Хотите просмотреть старые версии любого сайта WordPress?
Просмотр старой версии сайта WordPress не только доставляет удовольствие, но и может вдохновить вас на дизайн и предоставить вам доступ к контенту и мультимедиа, которые больше не доступны в Интернете.
В этой статье мы покажем вам, как вы можете просто увидеть старые версии любого веб-сайта WordPress.
Зачем смотреть старые версии сайтов WordPress?
Интернет движется на гиперскорости. Помимо прогулки по переулку памяти, есть много веских причин для просмотра старой версии веб-сайта WordPress.
Большинство элементов веб-сайта со временем будут меняться. Веб-сайты подвергаются редизайну, контент удаляется, а иногда целые сайты перестают работать.
Возможность поиска старой версии веб-сайта может быть очень полезной во многих ситуациях.
- Вам необходимо получить старый контент с веб-сайта
- Вы хотите воссоздать ресурс, который больше не в сети
- Вам нужны скриншоты для редизайна сайта до и после
- Вы ищете вдохновение для дизайна на старых веб-сайтах
С учетом сказанного давайте посмотрим, как просмотреть старые версии любого веб-сайта.
Как просмотреть старые версии любого веб-сайта (3 инструмента)
Существует несколько различных онлайн-инструментов для создания архивов веб-сайтов. Эти инструменты делают снимки в разные моменты времени и архивируют эти страницы веб-сайта.
Эти инструменты делают снимки в разные моменты времени и архивируют эти страницы веб-сайта.
Он работает аналогично вашим собственным резервным копиям WordPress, за исключением того, что они доступны для всего Интернета.
Обычно эти инструменты делают архивы по популярности и посещаемости. На некоторых сайтах со временем будут храниться тысячи копий, в то время как другие будет невозможно найти.
Тем не менее, вот 3 различных инструмента, которые вы можете использовать для поиска старых версий любого веб-сайта в Интернете.
1. Wayback Machine
Интернет-архив — это цифровая библиотека Интернета. У него есть инструмент под названием Wayback Machine, который содержит более 554 миллиардов заархивированных веб-страниц.
Wayback machine — это веб-архив, позволяющий находить скриншоты старых веб-сайтов в разные моменты времени.
Чтобы использовать этот инструмент, перейдите на веб-сайт Wayback Machine, введите URL-адрес веб-сайта, который вы хотите проверить, и нажмите «Просмотреть историю».
Затем он покажет вам график разных дат, когда были сделаны копии веб-сайта.
Вы можете щелкнуть верхнюю панель для сортировки по годам.
Ниже вы увидите разбивку календаря по месяцам.
Затем нажмите на конкретный день, и появится всплывающее окно для выбора времени.
Вам нужно щелкнуть нужное время, и он загрузит кешированную копию веб-сайта. Вы можете щелкнуть правой кнопкой мыши, чтобы просмотреть сайт в новой вкладке.
После загрузки страницы вы сможете нормально с ней взаимодействовать.
Вы можете переходить со страницы на страницу, просматривать изображения, переходить по ссылкам и т. д.
Имейте в виду, что не все ссылки будут работать, и вы не сможете перейти на каждую страницу, так как не каждая страница будет кэшироваться.
Обычно это проблема, когда сайты очень большие и содержат тысячи страниц контента.
2. Oldweb.today
Oldweb.today — это уникальный инструмент, позволяющий просматривать старые версии веб-сайтов с помощью старых веб-браузеров, существовавших в то время.
Это дает вам опыт, аналогичный тому, как это было при использовании некоторых веб-сайтов в прошлом.
Этот инструмент извлекает копии веб-сайтов из сторонних архивов, таких как Интернет-архив, и национальных цифровых библиотек со всего мира.
Имейте в виду, что этому инструменту потребуется некоторое время для загрузки старых веб-сайтов. Он эмулирует браузеры старой школы, такие как Internet Explorer и Netscape navigator, но сначала должен найти и загрузить веб-сайты.
Чтобы использовать этот инструмент, перейдите на сайт oldweb.today. Затем выберите «Браузер» из раскрывающегося списка и введите URL-адрес веб-сайта.
Убедитесь, что установлен флажок «Просматривать архивы в» и введите дату.
Как только вы нажмете Enter, инструмент автоматически начнет генерировать результаты.
Затем, после загрузки, вы сможете просматривать и перемещаться по блогу WordPress, как если бы он был заморожен во времени.
Вы можете перемещаться, щелкать ссылки и даже копировать текст.
3. Интернет-архив Библиотеки Конгресса
Библиотека Конгресса имеет обширную цифровую коллекцию газет, книг, аудиозаписей и веб-сайтов.
У них также есть инструмент поиска по архивам веб-сайтов, который работает аналогично Wayback Machine, упомянутой выше. Однако результаты будут немного отличаться от результатов двух других инструментов.
Если вы не можете найти старую версию веб-сайта раньше, попробуйте этот инструмент.
Чтобы использовать этот инструмент, перейдите в веб-архивы Библиотеки Конгресса. После этого введите URL-адрес веб-сайта и нажмите значок поиска.
Страница результатов также похожа на Wayback Machine.
Сначала выберите год в верхнем меню.
Затем выберите дату и щелкните время для доступного моментального снимка.
Этот инструмент обычно дает вам только один раз на выбор.
Когда вы нажмете на дату, откроется заархивированный веб-сайт.
Вы также можете щелкнуть правой кнопкой мыши, чтобы открыть страницу в новой вкладке.
Надеемся, что один из этих трех инструментов помог вам найти старый веб-сайт, который вы искали.
Если вы хотите воссоздать старую страницу на любом сайте, лучшим инструментом для этой работы является SeedProd. Это лучший конструктор страниц с перетаскиванием для WordPress, который позволяет легко создавать веб-сайты любого типа без редактирования кода.
Мы надеемся, что эта статья помогла вам узнать, как просмотреть старые версии любого сайта WordPress. Вы также можете ознакомиться с нашим руководством о том, как создать информационный бюллетень по электронной почте для увеличения трафика, и нашим сравнением лучших плагинов членства в WordPress для создания и продажи онлайн-курсов.
Если вам понравилась эта статья, подпишитесь на наш канал YouTube для видеоуроков по WordPress. Вы также можете найти нас в Twitter и Facebook.
Простые инструменты для обнаружения старых версий веб-сайтов
Перейти к содержимому
Если вы ищете более старые версии некоторых веб-сайтов или ищете важные данные, которые больше не доступны, то вы попали по адресу. В этой статье мы порекомендуем несколько простых инструментов для обнаружения старых версий веб-сайтов.
В этой статье мы порекомендуем несколько простых инструментов для обнаружения старых версий веб-сайтов.
Почему так важно найти старую версию веб-сайта
Поскольку технологии развиваются быстрее, а веб-сайты обновляются, иногда старый дизайн и информация о сайте становятся недоступными. Таким образом, с помощью некоторых инструментов вы можете просматривать старые версии сайтов, которые помогут вам даже сделать ценный обзор информации и функциональности сайта.
Таким образом, у вас могут быть следующие причины для просмотра старых версий сайта:
- Для просмотра старого дизайна
- Доступ к важным данным, которые больше не существуют got updated
- Доступ к недоступным медиафайлам
Подводя итог, можно сказать, что эти интернет-архивы похожи на библиотеки для ваших старых записей на ваших архивных веб-сайтах .
Итак, мы собираемся обсудить и объяснить тему на примере нескольких платформ. И первый — Wayback Machine . Это интернет-архив , который включает 588 миллиардов живых веб-страниц и более 52 миллионов других программ и файлов, таких как книги, тексты, видео, аудиозаписи, изображения и т. д.
И первый — Wayback Machine . Это интернет-архив , который включает 588 миллиардов живых веб-страниц и более 52 миллионов других программ и файлов, таких как книги, тексты, видео, аудиозаписи, изображения и т. д.
Он был создан в 1996 году и позволяет каждому загружать медиафайлы. файлы в интернет-архив. Поскольку это в основном архив цифровой библиотеки, Wayback Machine уделяет большое внимание библиотекам. Итак, он является членом:
- Califa
- Internation Federation of Library Associations and Institutions
- Music Library Association
- Boston Library Consortium
- Digital Preservation Coalition
- American Library Association
- Digital Library Federation
- Biodiversity Heritage Library
- ReShare
- Internation Internet Консорциум по сохранению и т. д.
Работа с WayBack Machine
А теперь пришло время показать инструменты Wayback Machine .
- Чтобы увидеть старую версию вашего веб-сайта, вам нужно ввести URL-адрес в поле поиска.
- After you enter the URL of the website, you will see the results in 6 separate sections:
- Calendar
- Collections
- Changes
- Summary
- Site Map
- URLs
So, let Начнем с « Календарь ». Здесь вы можете увидеть снимки сайта, сделанные этим архивом с года основания WordPress. Есть два типа календарей. Один показывает годовую временную шкалу, а другой показывает точные дни, когда были сделаны снимки.
Здесь вы можете запутаться, увидев черные, синие, зеленые метки и отсутствие цветовых меток. Давайте проверим, что обозначают эти цвета:
- Черный — обозначает годовую временную шкалу, в которой были сделаны снимки.
- Синий — показывает, что сайт был сохранен в точную дату.
- Зеленый — указывает на редиректы.
Итак, чтобы увидеть обновления и снимки, вам нужно будет удерживать курсор мыши на точной дате.
Как видите, просмотреть старую версию сайта с помощью этого веб-архива довольно просто.
Но со временем вы можете забыть тот или иной URL. Тем не менее, с помощью этого метода вы даже можете найти сайт, URL-адрес которого вы забыли. Вы можете искать его по ключевым словам в поле «Расширенный поиск». Также этот веб-архив позволяет сохранить тот или иной URL, чтобы не потерять его.
Помимо всего вышеперечисленного, Wayback Machine предлагает расширение для браузера, а также приложение для частого использования.
Вот второй рекомендуемый сервис. OldWeb — уникальная платформа, на которой можно найти не только старые версии сайтов, но и сравнить браузеры между собой.
На этой платформе вы можете обнаружить даже старые версии Internet Explorer . Все данные включают Интернет-архив и различные библиотеки.
Хотя он дает вам широкие возможности для глубокого погружения в старый веб-сайт, он загружается медленно.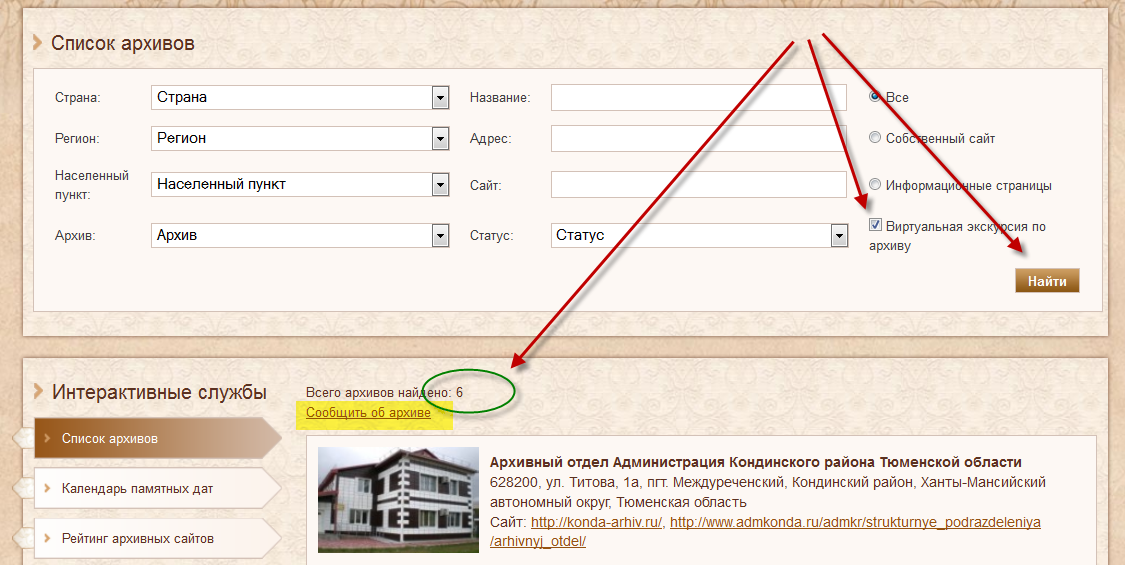 Получение результатов может занять даже несколько минут.
Получение результатов может занять даже несколько минут.
Итак, чтобы увидеть результаты, вы должны:
- Скопировать и вставить URL-адрес веб-сайта, старую версию которого вы хотите просмотреть.
- Choose a browser from the browser list:
- NCSA Mosaic 2
- NCSA Mosaic 3
- MacLynx 2
- Navigator 3 (Shockwave 3, Java 1.0)
- Navigator 4 (Shockwave 3)
- IE 4
- Navigator 4 (Flash 8, Java 1.1.5)
- IE 5
- IE 6
- Firefox 10
- Opera 12
- Ruffle (Flash)
- Напишите ниже период времени и подайте заявку, чтобы увидеть результат:
Это третий архив из нашего списка. Снимки, сделанные им, остаются в сети, даже если веб-сайт отключается. Archive.today имеет простой интерфейс . Тем не менее, он содержит огромную библиотеку веб-сайтов , собранную за эти годы.
Чтобы использовать его, вы должны скопировать URL-адрес веб-сайта и вставить его в строку поиска.
Результаты появятся немедленно, отображая снимки веб-сайта в хронологическом порядке. Этот инструмент позволяет загрузить zip-файл веб-страницы. Вы также можете поделиться страницей.
Одной из наиболее ценных функций этого инструмента является то, что вы можете отправить запрос на захват того или иного веб-сайта, чтобы не потерять его. Кроме того, вы можете найти Archive.today как расширение Chrome .
Этот инструмент отличается от других. Это архив Конгресса США . Он содержит огромное количество книг, изображений, веб-страниц, газет и т. д.
Библиотека Конгресса является важным источником, предоставляющим пользователям достоверную информацию о старых веб-страницах и других материалах, включенных в этот архив.
После того, как вы скопируете и вставите URL-адрес в строку поиска, вы получите Календарь для просмотра архива. Есть два типа календарей . Их интерфейс и функциональность немного похожи на предыдущие или другие варианты машин Wayback. Черный цвет показывает период времени, в течение которого были сделаны эти снимки. А синий показывает точные снимки.
Есть два типа календарей . Их интерфейс и функциональность немного похожи на предыдущие или другие варианты машин Wayback. Черный цвет показывает период времени, в течение которого были сделаны эти снимки. А синий показывает точные снимки.
Кроме того, поиск по URL-адресу или другим ключевым словам, этот инструмент дает вам широкие возможности поиска. Таким образом, вы можете просматривать прямо на платформе, используя множество категорий, предлагаемых инструментом Библиотеки Конгресса.
Если Библиотека Конгресса предлагает архив, созданный Конгрессом США, то этот инструмент предлагает вам получить доступ к веб-сайтам Великобритании . Благодаря этой платформе все веб-сайты Великобритании сохраняются как минимум один раз в течение года.
Вы можете поиск по ключевым словам, различным связанным фразам, URL-адресам . Некоторые материалы доступны только в библиотеке. Тем не менее, вы можете получить доступ к огромным данным, которые вам могут понадобиться.
Здесь вы найдете отдельные категории и интересы. Эти опции облегчат вам процесс поиска. В дополнение к упомянутому варианту вы можете запросить захват нужного вам сайта в Великобритании. И если вы намерены посетить особенно Правительственные страницы Великобритании , то это ваш правильный выбор.
Следующий инструмент — это Memento. Это один из веб-архивов с десятками веб-страниц, сохраненных на тот момент . Чтобы посетить старые версии определенных веб-сайтов, вам просто нужно ввести URL-адрес и ввести период времени , который вам нужно просмотреть.
Итак, проделав эти простые шаги, вы сразу увидите результаты.
Еще одна важная особенность Memento заключается в том, что она также предлагает расширение Google Chrome . Кроме того, вы можете вставлять веб-страницы в формате HTML.
Вот последний инструмент. Но в отличие от других инструментов, это расширение Google Chrome. Чтобы просматривать старые веб-сайты с помощью этого расширения, вам нужно сначала добавить его в свой браузер . После этого перейдите на страницу, на которой вы хотите увидеть старую версию, и нажмите, чтобы сразу подключить расширение.
Чтобы просматривать старые веб-сайты с помощью этого расширения, вам нужно сначала добавить его в свой браузер . После этого перейдите на страницу, на которой вы хотите увидеть старую версию, и нажмите, чтобы сразу подключить расширение.
С этим расширением вы получите архивные заметки Wayback Machine и Google Cache . Потому что он не предоставляет свой собственный архив. Тем не менее, и Wayback Machine, и Google Cache предоставляют всю необходимую информацию о ваших архивах.
Резюме
В заключение хотелось бы, чтобы вы обратили внимание на важность обнаружения старой версии сайта. Учитывая, что вы можете забыть информацию, которую получаете каждый день, и захотеть повторить или использовать ее сейчас, но ее больше нет. Таким образом, старая версия веб-сайтов может быть очень полезна для тех, кто ищет очень нужные и важные данные, которые больше не доступны. Или они могут захотеть сравнить старый/новый интерфейсы, чтобы сделать сайт максимально привлекательным для поисковых систем.
В любом случае, возможность увидеть старую версию сайта очень эффективна. А для того, чтобы получить информацию или веб-сайт, который в настоящее время находится в автономном режиме после длительного существования, вы можете использовать инструменты, предлагаемые ниже. Каждая из упомянутых платформ уникальна. Некоторые из них создаются и используются для определенной цели, например веб-архив Великобритании или Библиотека Конгресса. А некоторые другие могут включать в себя самое огромное количество архивных материалов, как это делает Wayback Machine. Но они исключительно необходимы на вашем пути к поиску веб-сайтов и их данных, которые вам не удалось сохранить. Кроме того, они могут служить большим хранилищем для сохранения нужных вам веб-страниц, чтобы не потерять их в будущем.
Итак, чтобы получить хороший результат, мы рекомендуем вам использовать один из этих супер инструментов.
Если вам понравилась статья, не стесняйтесь найти нас на Facebook и Twitter.
