
как его найти и выделить в русском языке
Все люди, которые по долгу службы или учебы работают с литературным языком, легко ответят на вопрос, что такое ключевое слово в тексте. Данные слова или даже выражения помогают лучше понять смысл текстового фрагмента, составить конспект и, соответственно, уложить в голове полученную информацию. Как найти эти «главные» слова? Подробности в данной статье.
Самые важные слова
Для лучшего понимания значения данного определения стоит прочесть фразу поэта-символиста А. Блока, который сказал о том, что текст – это по сути покрывало, растянутое на нескольких кольях. Эти «колышки» и являются такими словами. Ведь если их убрать, то весь смысл будет скомканным, подобно ткани. И напротив, если их найти, то воспроизведение текстового фрагмента не составит никакого труда.
Возьмите на заметку! Древний философ Сократ, заучивая свои речи, опирался именно на подобные слова и «расставлял» их визуально, гуляя по своему саду. Каждый куст, дерево или препятствие на дороге он нарекал тем словом, которое помогало запомниться фрагменту текста по порядку.
Каждый куст, дерево или препятствие на дороге он нарекал тем словом, которое помогало запомниться фрагменту текста по порядку.
И когда Сократ появлялся на трибуне, ему стоило только представить картину своего сада с этими кустами, и тут же речь складывалась в стройные предложения, наполненные глубоким смыслом.
Итак, что такое ключевые слова в тексте? Это опорные словоформы, которые
Самым простым примером, где можно легко потренироваться в нахождении опорных слов, будут детские сказки. Например, «Теремок». Как выделить ключевые слова в ней, чтобы правильно воспроизвести весь сюжет? Вот ответы:
- терем;
- мышка;
- зайчик;
- лягушка;
- лисичка;
- волк;
- жили не тужили;
- пришел медведь;
- раздавил;
- звери убежали.
После такого выделения ключей легко восстановить всю сюжетную составляющую.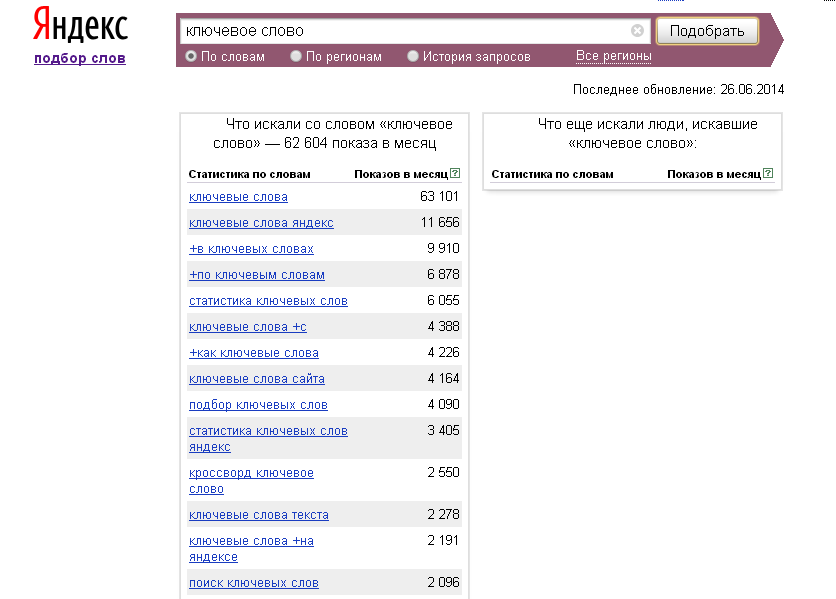
Сказка «Теремок»
Как выделить ключевые слова в любом тексте?
Чаще всего данные словоформы бывают главным членом предложения – подлежащим, либо перед нами будут слова, связанные с последующим предложением. В этом случае важно смотреть на контекст.
Самым простым способом определить ключевые слова будет выписать части основ.
Пример:
1) Детство редко дает возможность угадать что-либо о будущем ребенка. 2) Как ни пытаются папы и мамы высмотреть, что получится из их дитяти, нет, нет, не оправдывается. 3) Все они в детстве видят предисловие к взрослой жизни, подготовку. 4) На самом же деле детство – самостоятельное царство, отдельная страна, независимая от взрослого будущего, от родительских планов, она, если угодно, и есть самая главная часть жизни, она основной возраст человека. 5) Больше того, человек предназначен для детства, рожден для детства, к старости вспоминается более детство, поэтому можно сказать, что детство – это будущее взрослого человека… (По Д. А. Гранину)
А. Гранину)
Чтобы легко и просто запомнить смысл этого фрагмента, надо постараться отыскать слова, которые несут смысловую нагрузку
- Детство; угадать что-либо о будущем.
- Папы и мамы; высмотреть; не оправдываются;
- Детство; подготовка;
- ______; главная часть жизни; возраст человека;
- Рожден для ______; вспоминается; _____– это будущее.
Пропусками мы обозначаем повтор одной и той же словоформы.
Из данного анализа видно, что опорным словом для понимания смысла является именно «детство», а другие слова становятся вспомогательными элементами, которые помогут запомнить смысл данного фрагмента.
Найти ключевые слова в данном примере было легко? Конечно! Ведь, по сути, был составлен опорный конспект, передающий содержательную канву текстового фрагмента. Опорные конспекты прекрасны в ходе написания изложений.
Особенно на экзаменах о языке, типа ОГЭ, где требуется два раза прослушать аудиотекст и воспроизвести его настолько точно, насколько возможно.
[warning]Внимание! По методу восприятия действительности люди делятся на аудиалов, запоминающих лучше всего слуховую информацию; визуалов, которые воспринимают лучше зрительно всю информацию; кинестетиков, которые ориентируются на свои ощущения от тактильного контакта.[/warning]
Опорный конспект по методу «фиш-боун»
Еще одним интересным видом работы с опорными словами является конспект по методу «фиш-боун», или конспектирование по методу рыбы. Все представляют себе рыбий скелет, так вот, на каждой «косточке» располагаются те самые ключи, которые способствуют лучшему запоминанию информационной составляющей.
Это может быть речь говорящего, обычный текстовый документ или даже важный телефонный разговор.
Голова рыбины станет главным ключом, который вы заполните позднее, а косточки – это ваши основы, с помощью которых суть информации можно быстро ухватить и не искать по всему содержанию. По такому методу работают студенты высших учебных заведений, а также профессора на конференциях.
Вместо рыбьего скелета можно использовать фигуру солнца, тогда лучи – это нужные словоформы, а главный ключ – это середина. Очень удобно таким образом конспектировать лекционные материалы.
[stop]Важно! Единственным советом здесь является: никогда не сокращать подобные слова! Если вам нужно писать очень быстро, и вы способны освоить искусство стенографического письма, то все сокращения сразу помечайте и выводите на поля. Иначе простой опорный конспект превратится в расшифровывание иероглифов![/stop]
Ключевые слова в стихотворном произведении
Особенно важны ключи в стихотворных конструкциях, которые без них просто не существуют. Как искать такие слова в стихотворениях? Точно так же, как и в прозе, полностью опираясь на контекст. Помните, вам могут встретиться также контекстуальные синонимы – слова, значения которых в языке различны, но в данном тексте схожи.
Помните, вам могут встретиться также контекстуальные синонимы – слова, значения которых в языке различны, но в данном тексте схожи.
Пример:
Я вас любил,
Любовь еще быть может
В душе моей угасла не совсем.
Но не хочу напрасно вас тревожить,
И не хочу печалить вас ничем.
Я вас любил безмолвно, безнадежно,
То робостью, то ревностью томим,
Я вас любил так искренно, так нежно,
Как дай вам Бог любимой быть другим!
(По А.С. Пушкину)
Выбираем в стихотворении те опорные слова, которые, как костыли, помогают нам поддерживать содержательную часть. Какие?
Из нашего анализа видно, что слово «любил» и является главным, а сочетается оно со многими. Поэтому квинтэссенцией данного стихотворения становится следующий смысл – рассказывая про свою любовь, лирический герой сожалеет об утрате этого прекрасного чувства, однако не держит зла на свою бывшую пассию и от всей души желает ей почувствовать себя счастливой, пусть и не с ним.
Это интересно! Урок на тему: как писать сочинение ЕГЭ по русскому языку
Ключевики для поисковых систем
В нашей современности опорные слова также помогают сайтам быть в топе выдачи Гугла и Яндекса – известных поисковых систем. Ключи – это слова в тексте на сайте, которые помогают поисковикам найти ту веб-страницу, содержание которой и определяется запросом конечного пользователя.
К примеру, если на сайте осуществляется просмотр бесплатных фильмов, то, соответственно, главными ключами будут: фильмы смотреть бесплатно, фильмы в формате HD.
Ключевые слова для интернет-ресурсов могут быть, как в точном вхождении, то есть включаться в нужный текст в своем первоначальном виде, так и в разбавленном, когда ключевую фразу нужно разбавить другими словами.
Примеры для того же киносайта:
У нас вы сможете посмотреть фильмы боевики бесплатно.
У нас вы сможете посмотреть различные фильмы, в том числе и боевики, абсолютно бесплатно.
Второй вариант показывает нам, как вкрапления других слов «прячут» неестественно выглядящий на русском ключ, но также становятся своеобразным маячком для поисковых систем.
Ключевые слова. Скорочтение
Что такое ключевые слова
Вывод
Таким образом, ключевые слова – это те важные столпы, на которых держится весь смысл наших высказываний, и, теряя «золотые» ключи от текста, мы можем позабыть, где же находится та дверца, которую они открывают. Зная, как выделить главные слова в любом тексте, вы без труда поймете его смысл и воспроизведете содержание.
Самый эффективный подбор ключевых слов для научной статьи
Список ключевых слов часто оказывается последним этапом в подготовке научной публикации. Однако, он не последний по важности, и вот почему.
Однако, он не последний по важности, и вот почему.
Ключевые слова помогают находить статью в базах цитирования. Именно они делают ее видимой для других исследователей. Ведь в современном мире невозможно отследить все публикации, даже в какой-то узкой отрасли знания. Возможно, ваши коллеги не читают журнал, в котором опубликована работа или название статьи не привлекло их внимания.
В таких случаях поисковая система, которая показывает похожие статьи, может вывести из тени вашу публикацию, показать ее потенциальным читателям и повысить цитируемость.
В новых областях исследований авторские ключевые слова могут стать основой для индексирования в базах данных. Кроме того, редакция журнала может использовать список ключевых слов для определения актуальности статьи и ее соответствия профилю журнала. Хорошее совпадение уменьшает вероятность отказа в публикации.
Содержание статьи
- 1. Что такое ключевые слова и где их искать?
- 2. На что ориентироваться при выборе ключевых слов?
- 3.
 Полезные советы по выбору ключевых слов.
Полезные советы по выбору ключевых слов. - 4. Чего не следует делать при выборе ключевых слов?
- 5. Как правильно оформить список ключевых слов и перевести его на английский?
- 6. Сервисы-помощники
- 7. Как проверить релевантность ключевых слов?
- Заключение
 Полезные советы по выбору ключевых слов.
Полезные советы по выбору ключевых слов.1. Что такое ключевые слова и где их искать?
По сути, ключевые слова являются смысловым ядром текста. Они показывают читателю главное содержание статьи.
Часто авторы ограничивают поле для поиска ключевых слов аннотацией. При такой стратегии у читателя создается впечатление, что из Abstract он получил полное представление о статье. Если вы хотите, чтобы ваши коллеги ознакомились с полной версией (возможно, платной), то ключи должны отражать содержание всего исследования.
Важно: некоторые поисковые системы не выполняют поиск по всему документу, особенно, если доступ ограничен платной подпиской. В таких случаях значимость ключевых слов повышается в разы.
Чтобы выбор ключей не был случайным, действуйте в следующем порядке:
- Прежде всего ориентируйтесь на тему работы. Выделите из нее проблему исследования, это и будет первый ключ.
Важно: не используйте слова из заголовка. Это неэффективно, так как поисковая система в любом случае его покажет. Ключевое слово должно дополнять, уточнять, расшифровывать термины из названия статьи, но не дублировать их.
- Заголовки глав, разделов и подразделов. Выбирайте понятия, описывающие цель, объект и предмет исследования.
- Текст работы. Найдите самые частотные слова. Из них выбирайте те, которые описывают суть работы.
- Слова с высокой смысловой нагрузкой также будут кандидатами в ключи. Обратите внимание на раздел Materials and Methods. Наиболее важные экспериментальные методы обязательно войдут в список ключевых слов.
Важно: сверьте ваши слова-кандидаты с общепринятым словарем, списком, стандартом индексирования в вашей дисциплине, например GeoRef, ERIC Thesaurus, PsycInfo, ChemWeb, Руководство по поиску BIOSIS, MeSH Thesaurus. Убедитесь, что сами термины и их написание совпадают с приведенными в этих источниках.
Убедитесь, что сами термины и их написание совпадают с приведенными в этих источниках.
В итоге у вас должны сформироваться три группы ключевых слов:
- Опорные. Описывают область научного исследования. Например, в статье “Разработка лекарства от рака: недостающие звенья” —
- Смысловые. Раскрывают объект исследования. В упомянутой статье это “лекарства” —
- Концептуальные. Описывают предмет и методы исследования. В рассматриваемой статье к таким ключам относятся “выживаемость пациентов, доклинические испытания, клинические испытания, стоимость” — patient survival, preclinical, clinical, cost.
Чем точнее ключевые слова отражают суть работы, тем больше вероятность, что статью прочитают те из ваших коллег, кому эта тема действительно интересна.
2. На что ориентироваться при выборе ключевых слов?
По списку ключевых слов поисковая система будет выдавать статью другим читателям. Это значит, что ваша задача – предугадать, как будут сформулированы поисковые запросы других пользователей. Чтобы ключи работали эффективно, обратите внимание на следующее:
Это значит, что ваша задача – предугадать, как будут сформулированы поисковые запросы других пользователей. Чтобы ключи работали эффективно, обратите внимание на следующее:
- Существует множество инструментов для подбора ключей, но лучшим из них является ваша собственная голова. Подумайте, как вы сами сформулировали бы ключевые запросы, если бы искали материал по своей теме.
- Изучите ключевые слова в других статьях по вашей области исследований. Возможно, они помогут уточнить и дополнить собственный список.
- Эффективными ключами будут поисковые подсказки — слова, которые выдает в ответ на запрос сама поисковая система. Введите в строку поиска название своей работы или термины из нее. Посмотрите, какие подсказки при этом появляются.
Обычно научные журналы просят предоставить от 5 до 10 ключевых слов. Ваш первоначальный список может быть гораздо больше, чтобы впоследствии выбрать самые эффективные ключи.
3. Полезные советы по выбору ключевых слов.

Прежде всего нужно сказать, что под термином “ключевое слово” чаще всего понимают ключевую фразу. Отдельные слова не всегда являются хорошими ключами, так как часто имеют очень широкое значение и не позволяют читателю понять, относится ли статья к его сфере интересов.
- Используйте ключевые фразы. Например, для статьи “Тактика хирургического лечения рака толстой кишки в зависимости от локализации опухоли” подходящими ключами будут “рак толстой кишки, хирургическое лечение”. Плохие ключи — “рак, хирургия”.
- Ключевая фраза должна состоять из 2-3 слов. Слишком длинные ключи редко дают совпадения. Откажитесь от соблазна вместить все смыслы в одно большое предложение. Возможно, фраза “хирургическое лечение рака толстой кишки различной локализации” описывает содержание статьи очень точно, но по такому ключу статью, скорее всего, никогда не найдут. Эффективнее будет несколько отдельных словосочетаний, дополняющих друг друга: “хирургия рака, рак толстой кишки, локализация опухоли”.
- Используйте синонимы. Одну и ту же информацию можно искать по разным поисковым запросам. Не упускайте возможности показать свою статью всем заинтересованным читателям.
- Укажите общепринятые сокращения и аббревиатуры. Многие поисковые запросы формулируются в сокращенной форме. В списке ключевых слов нужно упомянуть как аббревиатуру, так и полный термин. Не совмещайте их в одном ключе. Лучше написать одну ключевую фразу с полным названием, а другую — с сокращением, например: “ультразвуковое сканирование, УЗС гортани”.

Важно: убедитесь, что аббревиатура не имеет омонимов и совпадений. Например, сокращение ARC используется в программировании, математике, биологии и других отраслях знания. Конкретизируйте ключ, чтобы читатель понимал, к чему он относится в вашем случае, например “формат файлов ARC”.
- Используйте
При переводе на английский используйте профессиональные словари. Проверьте какие термины и в каком написании принято использовать в вашей отрасли науки. О технических англо-русских словарях можно прочитать здесь.
4. Чего не следует делать при выборе ключевых слов?
Ключи могут быть неэффективными по разным причинам. Вот несколько рекомендаций, позволяющих этого избежать:
- Не используйте слишком абстрактные и общие понятия, такие как названия дисциплин.
- Избегайте профессионального сленга и узкоспециальных терминов.
- Не ставьте кавычки, даже в названиях организаций. Разные редакторы используют разные виды кавычек, из-за этого система может просто не распознать ключ.
- Не используйте фразы с запятыми. В поисковых системах запятая используется как разделитель. Поэтому части одной фразы система расценивает как отдельные ключи. Фразу “метод статистического анализа, используемый для оценки вероятности…” лучше разделить на два отдельных ключа: “метод статистического анализа, оценка вероятности”
- Каждое ключевое слово является самостоятельной смысловой единицей. Нельзя писать “метод ПЦР, применение его в клинической практике”. Второй ключ при такой формулировке будет бесполезен. Более эффективная формулировка “клиническое применение метода ПЦР”.
Проверьте свой список ключевых слов, прежде чем подавать рукопись в журнал. Используйте только те ключи, которые действительно приведут к вашей статье читателей.
5. Как правильно оформить список ключевых слов и перевести его на английский?
Иногда вполне релевантные ключи не работают по причине неправильного оформления. Обратите внимание на следующие правила:
- Пишите слова в единственном числе и именительном падеже. Исключением являются термины, которые не имеют формы единственного числа вообще или не используются в такой форме в вашей отрасли науки, например “инвестиции”.
- Не пишите первое слово с большой буквы. Некоторые поисковые системы распознают слова, написанные с заглавных и строчных букв как разные. В этом случае первый ключ может не давать совпадений.
- Разделяйте ключевые слова и фразы запятыми, это общепринятая практика. О правилах расстановки запятых в академическом английском можно прочитать здесь.
- Не ставьте точку в конце списка. Система может автоматически присоединить ее к последнему слову. Такой ключ не будет работать. О правилах пунктуации в академическом английском читайте в этой статье.
- Подборка ключевых слов приводиться на русском и английском языке. Не используйте машинный перевод для получения англоязычной версии. Программы-переводчики, как правило, не заточены под научную лексику и могут выдавать совершенно некорректные термины. Если вы не уверены в своем английском, лучше обратиться к специалисту в вашей научной отрасли с хорошим знанием языка.
- При переводе сверьтесь с редакционными требованиями. Если в журнале принято использовать британский или американский вариант написания, это нужно учитывать. Читайте нашу статью об особенностях американского и британского английского.
Журнал может предъявлять и другие требования к оформлению ключей. Например, регламентировать количество слов, допустимость словосочетаний, соответствие установленным спискам терминов, допустимость сокращений. Изучите редакционные требования на сайте журнала и убедитесь, что вы их выполнили. В противном случае ознакомление редактора с вашей статьей может не продвинуться дальше списка ключевых слов.
6. Сервисы-помощники
Существуют онлайн-инструменты, помогающие в выборе подходящих ключевых слов. Можно использовать генераторы ключевых слов, такие как Keyword Tool, Яндекс, Google AdWords и другие.
Важно: автоматизированная система будет выбирать ключи, опираясь на поисковые запросы. Отнеситесь к ним критически. Из предложенного списка отберите те, которые соответствуют научной специфике и содержанию вашей рукописи.
Из автоматизированных генераторов ключевых слов вариантом выбора являются те, которые созданы специально для работы с научным текстом:
- Издательство “Молодой ученый” разработало генератор ключевых слов. Поиск осуществляется по тексту статьи, который вводится в специальное поле.
- Для текстов медицинской тематики хорошим инструментом является MeSH on Demand. Он идентифицирует в тексте статьи термины, входящие в список MeSH, и выбирает похожие статьи на PubMed. О том, чем хорош сервис PubMed и как им пользоваться читайте в статье. Как уже упоминалось, просмотр списков ключевых слов в похожих публикациях может помочь с выбором подходящих ключей для собственной статьи.
Для выбора наиболее частотных слов в вашем тексте можно использовать генераторы облака слов, такие как Monkey Learn, Word Cloud Generator и Tag Crowd. Они преобразуют документ в визуальную картинку, на которой самые часто встречающиеся слова будут наиболее крупными:
С другими сервисами-помощниками можно ознакомиться здесь.
7. Как проверить релевантность ключевых слов?
Прежде чем отправлять статью в редакцию убедитесь, что выбранные ключевые слова действительно эффективны.
Вбейте свои ключи в поисковик и посмотрите, какие статьи выдаются по этому запросу. Если результат поиска имеет слабую связь с вашей темой, значит выбор ключа был неудачным.
Если поисковая система не находит по запросу ничего, то ваша статья не будет выдаваться как похожая при просмотре других публикаций.
Для поиска важно, как распределяются ключевые слова внутри документа. Нужно равномерно распределить ключи по тексту, при этом сохранив логику и академический стиль изложения. Ключевые слова должны быть естественной частью текста, а не чужеродными элементами.
Рекомендуется использовать ключи в заголовках, подзаголовках, в начале и в конце статьи.
Оптимальное количество 10–15 ключей, но это зависит также от редакционных требований.
Введение ключевых слов в текст статьи может происходить на разных этапах работы:
- По мере написания статьи. Если какие-то ключи важны, и вы хотите обязательно использовать их в работе, пишите текст сразу с этими терминами. Тогда они не будут выглядеть чужеродными вставками.
- Констатация ключевых слов при вычитке готового текста. Так происходит чаще всего. В этом случае важно понять, не упустили ли вы какой-нибудь важный ключ.
- На этапе редактирования. Это не самый лучший вариант, так как трудно вписать ключи в готовый текст так, чтобы вставки не бросались в глаза и не нарушали логику и связность изложения.
Ключевые слова должны быть запоминающимися и важными, отражающими суть работы, но не выбивающимися из текста. Вводить новые ключи на этапе редактирования разумно только в том случае, если слов, выбранных при вычитке статьи, недостаточно или при проверке они оказываются неэффективными.
Заключение
Правильный подбор ключевых слов в конечном итоге повышает индекс цитируемости статьи и автора. Они позволяют:
- быстрее найти статью в базе данных;
- увидеть работу при просмотре другой похожей публикации;
- понять, входит ли эта статья в сферу научных интересов конкретного ученого.
Выбор ключевых слов не может быть случайным, в его основе должна лежать логика и здравый смысл.
- Выбирайте в качестве ключевых слов синонимы, дополнения и уточнения к терминам из названия статьи, понятия из подзаголовков, введения, заключения и раздела “Материалы и методы”.
- Используйте ключевые фразы из 2–3 слов. Укажите общепринятые сокращения и аббревиатуры. Используйте общепринятые синонимы, чтобы охватить все возможные ключевые запросы.
- Не используйте слишком абстрактные и слишком узкие понятия. Ориентируйтесь на ключевые запросы, которые могли бы сделать в поисках информации вы и ваши коллеги.
- Берите слова из научного лексикона. Сверьтесь с общепринятыми в вашей отрасли науки списками терминов, а при переводе — со словарем по специальности.
- Убедитесь, что вы правильно оформили список ключей и выполнили требования редакции журнала.
В конце проверьте выбранные ключи на эффективность: если в ответ на введение ключа поисковая система выдает релевантные результаты, значит вы все сделали правильно.
Удачных публикаций!
Присоединяйтесь, чтобы моментально узнавать о новых статьях в нашем научном блоге, акциях и получать только полезные материалы!
Ключевые слова в Help+Manual
- Главная
- Блог
- Help+Manual
- Ключевые слова в Help+Manual
Предметный указатель — это список ключевых слов (терминов, основных понятий и т.п.), помогающий читателю быстро найти в документе нужную информацию. В печатной документации указатель содержит список страниц, на которых встречаются включенные в него термины. В электронных документах ключевые слова являются ссылками на такие страницы. В этой статье я расскажу о возможностях, предусмотренных в Help+Manual, по работе с ключевыми словами.
Сразу оговорюсь. В данной статье речь пойдет об обычных ключевых словах. Подробную информацию об ассоциативных ключевых словах (A-keywords) смотрите в статьях «Что такое ассоциативные ключевые слова» и «Ассоциативные ключевые слова в Help+Manual 7».
Содержание
В каких форматах поддерживаются ключевые слова
Ключевые слова поддерживаются в следующих форматах:
- CHM
- WebHelp
- Word
- EWriter
В форматах EPUB и MOBI ключевые слова не поддерживаются. В WebHelp и EWriter указатель можно включить или выключить.
Наверх к Содержанию
Откуда берутся ключевые слова в проекте Help+Manual
Ключевые слова добавляет в проект автор документации: либо вставляет из текста, либо вводит с клавиатуры.
Наверх к Содержанию
Как работают ключевые слова
Ключевые слова можно добавить в разделы (topics). В этом случае ключевое слово будет указывать на раздел. Для выходных форматов CHM, WebHelp и Ewriter ссылку по ключевому слову можно сделать более точной — добавить одно или несколько ключевых слов для якоря (anchor). При открытии раздела по такому ключевому слову содержимое раздела будет прокручиваться до места установки якоря.
Упорядоченный по алфавиту список ключевых слов (указатель) генерируется автоматически во время сборки документации. В форматах CHM, WebHelp и Ewriter ссылка по ключевому слову будет открывать раздел. Если ключевое слово указывает на несколько разделов, будет открыто меню для выбора раздела. В Word и PDF в предметном указателе напротив ключевого слова будет указан актуальный номер страницы раздела с ключевым словом. Если в настройках для публикации PDF выбран интерактивный документ (переключатель Similar to a Printed User Manual), то в PDF-документе номер страницы будет представлять собой ссылку на страницу.
Наверх к Содержанию
Сколько уровней ключевых слов поддерживается
В Help and Manual поддерживаются ключевые слова первого (master keywords) и второго (child keywords) уровней. Первая группа также называется простыми ключевыми словами, а вторая – дочерними.
При использовании ключевых слов второго уровня ключевое слово первого уровня будет играть роль заголовка в указателе.
При этом само ключевое слово первого уровня может и не быть ссылкой на раздел.
Ключевое слово первого уровня будет ссылкой на раздел, если оно также используется в каком-либо другом разделе как простое ключевое слово.
Наверх к Содержанию
Как добавить ключевое слово
Чтобы добавить ключевое слово в раздел, в редакторе выделите одно или несколько слов и нажмите на клавиатуре Ctrl + K (пользовательское сочетание клавиш можно задать в настройках File / Program Options / Shortcuts).
Выделенное слово или словосочетание будет добавлено как простое ключевое слово в поле Keywords на вкладке Topic Options.
В поле Keywords можно ввести любое количество ключевых слов для данного раздела, отредактировать существующие, а также удалить ненужные ключевые слова.
Наверх к Содержанию
Как добавить ключевое слово второго уровня
Установите курсор в начало строки с ключевым словом первого уровня и нажмите на клавиатуре Tab. В результате ключевое слово первого уровня станет ключевым словом второго уровня (например, documentation по отношению к projects).
Наверх к Содержанию
Как добавить ключевые слова к якорю
Одно или несколько ключевых слов первого и второго уровня можно добавить в поле Keywords: во время создания или редактирования якоря.
В этом же окне можно отредактировать ключевые слова и удалить их.
Наверх к Содержанию
Как найти и заменить ключевые слова
Функция поиска и замены в Help+Manual поддерживает работу с ключевыми словами. Для этого нужно в раскрывающемся списке поля Find Where: выбрать Topic Keywords.
Наверх к Содержанию
Как найти разделы без ключевых слов
Для поиска разделов без ключевых слов можно воспользоваться отчетом Missing Keywords.
Наверх к Содержанию
Средство для работы с ключевыми словами
В версиях Professional и Server в Help+Manual есть специальное средство для работы с ключевыми словами Index Tool. Оно представляет собой панель для работы с ключевыми словами проекта в виде списка.
Наверх к Содержанию
Как добавить алфавитные заголовки для указателя в WebHelp
Во время генерации указателя в список ключевых слов автоматически добавляются заголовки, соответствующие буквам алфавита. По умолчанию в Help+Manual заданы только буквы латинского алфавита. Чтобы в ключевые слова на русском языке были добавлены русские буквы-заголовки:
- В Project Explorer выберите Configuration \ Publishing Options \ WebHelp \ Keyword Index.
- В поле Index Separators (typically letters A-Z): после латинских букв введите заглавные буквы русского алфавита через запятую.
- Сохраните изменения.
При указанных выше настройках в указателе будут работать латинские и русские алфавитные заголовки.
Наверх к Содержанию
Как добавить алфавитные заголовки для указателя в PDF
Чтобы добавить русские буквы-заголовки в шаблон для сборки PDF документов:
- На вкладке Project выберите Templates&Skins \ Launch PDF Manual Designer.
- В окне Print Manual Designer откройте шаблон, который вы используете для генерации PDF-документов, например, Standard_manual_A4.mnl.
- В рабочей области перейдите на вкладку Keyword Index. Если данная вкладка скрыта, воспользуйтесь меню справа от вкладок.
- Выберите Pages \ Page Options.
- В окне Page Options for [Keyword Index] перейдите на вкладку Keyword Index Section.
- В поле Keyword Index Separators после латинских букв введите заглавные буквы русского алфавита через запятую.
- Нажмите на кнопку ОК.
- Сохраните отредактированный шаблон в папку с проектом.
- Во время сборки PDF выберите данный шаблон в поле Select Print Manual Template.
При указанных выше настройках в указателе будут работать латинские и русские алфавитные заголовки.
Наверх к Содержанию
Поделитесь статьей с друзьями:
- Help+Manual
Добавить комментарий
Рубрики
- Help+Manual
- Справка
- Форматы
- Программы (HAT)
- Полезные советы
- Работа с текстом
- Контроль качества
- Из книг
Илья Жуков
Технический писатель
Последние статьи
Как правильно употреблять ключевые слова
Для написания грамотного и корректного текста для сайта, необходимо четко понимать его предназначение. Он выполняет функции информатора, продавца, а также способствует продвижению ресурса в поисковых системах. На последнем остановимся подробнее. Продвижение осуществляется по ключевым словам.
Ключевые слова — это список слов, по которым сайт продвигается в поисковых системах.
Основная задача процесса продвижения — нахождение нужного нам сайта в топе выдачи поисковой системы по нужному нам запросу (ключевому слову). Для повышения релевантности сайта (меры соответствия сайта заданному запросу), а соответственно и позиций в выдаче, в текстах сайта должны присутствовать ключевые слова.
Часто приходится видеть, что некорректное употребление ключевых слов связано с непониманием их предназначения. Свой отпечаток накладывает и незнание современного положения дел в сфере поисковой оптимизации.
Чтобы внести ясность, предлагаю ответы на вопросы, которые, как мне думается, каждый автор хоть раз задавал себе при написании текста для сайта.
— Какие знаки препинания можно ставить между словами ключевого словосочетания?
Лучше не ставить вообще. Особенно если указано вполне нормальное ключевое слово, к примеру, «купить болты». Объяснение простое — ценно словосочетание, а разделенные знаками препинания слова с точки зрения русского языка таковым уже не являются.
Но, если дан ключ типа «натяжные потолки Москва», для придания тексту человеческого вида допускаются запятые. В идеале используйте предлоги, союзы. Это вполне целесообразно опять-таки с точки зрения русского языка, так как данные части речи не учитываются в подсчете слов в словосочетании. Напомню: словосочетание — сочетание двух слов, не более. Не допускаются точки, точки с запятой. Двоеточия и тире крайне нежелательны (без них вполне можно обойтись). Необходимо сказать, что уровень развития морфологии поисковых систем сегодня очень высок. Поэтому не стоит специально «корявить» тексты за счет несогласованных между собой слов в ключевом словосочетании. Пишите правильно и грамотно, но всячески избегайте знаков препинания между словами.
— Как определить оптимальное количество ключей (к примеру, на 1000 знаков), и чем это обосновано?
На этот вопрос сложно ответить. Руководствуйтесь читабельностью текста — он не должен быть спамным, но и искусственно опускать ключевое слово, к примеру, «салон красоты», если статья посвящена именно этому сервису, нет смысла. Все должно быть целесообразно и выглядеть максимально естественно.
Если текст хороший, тематический, то он в любом случае будет включать в себя слова, связанные с ключевым словом. Поисковые системы могут это учитывать за счет серьезной базы словарей. Поэтому также важным правилом является как можно большее употребление разных слов, принадлежащих данной теме. Увлекаться числом вхождений самого ключевого слово не стоит — текст должен нормально читаться. Тем более на грамотной оптимизированной странице ключевое слово будет в теге заголовка страницы TITLE, в заголовке самого текста, возможно в навигации, либо в каких-то блоках, плюс несколько раз в тексте. Этого вполне достаточно.
— Почему не нужны «кривые» вхождения — нерусское употребление ключей?
Ответ очевиден: корявые фразы недопустимы, так как текст пишется в первую очередь для человека. Плюс ко всему поисковые системы не хотят, чтобы кто-то влиял на выдачу, поэтому всякого рода некорректная оптимизация может выйти боком. На сайт могут быть наложены фильтры, которые создают существенные проблемы успешному продвижению ресурса. Текст для сайта выполняет кардинально противоположную функцию — он должен способствовать продвижению.
— Почему ключевые слова желательно употреблять в заголовках и подзаголовках?
Здесь просто: ключевые слова в заголовках имеют больший вес с точки зрения оптимизации. Плюс ко всему, куда естественнее и приятнее видеть искомую комбинацию слов в заголовках и подзаголовках, определяющих тематику текста.
— Почему оптимизаторы так бьются за прямые вхождения?
Для некоторых поисковых систем, к примеру, для Яндекса, прямые вхождения по-прежнему имеют большой вес. Однако подгонять предложения под подобное употребление ключей в ущерб читабельности — не выход.
— Почему нельзя разрывать слова ключевого словосочетания даже одним посторонним словом?
На самом деле можно, но крайне нежелательно. Однако в такой ситуации ключ будет давать меньший вес с точки зрения оптимизации. Вес падает примерно в два раза. Пробел в два слова, примерно, в 3-4 раза. Поставьте пробел более чем в три слова — и вес словосочетания падает почти до нуля. Чем слова в ключевом словосочетании ближе друг к другу, тем более связанными они считаются, и тем сильнее будет их вес по отношению к релевантности ключа.
— Почему ключи даются иногда без «-», а названия типа «Москва» пишутся с маленькой буквы?
Ключевые слова предоставляются таким образом, потому Яндекс.Директ, из которого они и берутся, опускает дефисы и заглавные буквы. Фактически ключи формируются автоматически из набора слов. Писать же важно по-русски, в противном случае тексту не поверят ни читатель, ни поисковик.
— Почему употребить один раз ключ на 2000 знаков — не значит написать оптимизированный текст?
Все очень просто. Главное правило таково — необходимо брать примерно средние значение по сайтам из топ-5 по общему объему текстов и количеству вхождений ключей. А еще лучше написать информативный текст, который сможет осветить тему в полной мере. Важно, чтобы он вам самим показался наиболее полным с точки зрения информации в сравнении с конкурентами. Ключевые слова тогда появятся «сами собой». Если же нужно будет искусственно увеличить их количество — сделать это будет нетрудно. Верно одно: единоразовое использование ключевого слова — не оптимизация.
Подводя итог, хотелось бы сказать, что оптимизация не должна вредить качеству текста. Он должен быть читабелен, интересен, соответствовать заявленным в ТЗ требованиям. Текст однозначно должен продавать — это основная задача. Но если вы пишите для сайта, а не для печатного издания, соблюдайте некоторые дополнительные требования. Использование ключевых слов как раз одно из них. Поисковые системы — все-таки машины, искусственным интеллектом пока не обладают. Поэтому надо им помогать в правильном определении темы статьи и соответствия запросам пользователей.
Но, начиная писать текст для сайта, помните: он должен быть ориентирован в первую очередь на человека, а не на робота.
редактор компании ContentRu.com
Как правильно подобрать название и ключевые слова для своей статьи?
В настоящее время исследователи уже привыкли к тому, что существуют различные базы научного цитирования и что статьи размещаются на сайтах журналов в Сети. Пользователи этих баз и сайтов, они же – потенциальные читатели, очень быстро принимают решения о том, интересен им текст или нет. Обычно это делают сразу после чтения названия статьи. Однако не каждый автор обращает должное внимание на название для статьи и выбор ключевых слов. На самом деле здесь все не так просто, как хотелось бы. Если принять необдуманное решение, то вполне возможно, что а) ваш текст никогда не найдут, б) ваш текст найдут вместе с текстами не по вашей теме, в) ваш текст найдут, но не поймут, о чем он и зачем его читать. Не нужно рассчитывать, что люди будут искать именно вашу работу, поэтому подготовьте себя к тому, что среди сотен статей выходящих в сотнях журналов, ваш текст должен правильно выделяться. Если вы можете представить кто, как и зачем будет искать написанное вами, то у вас будут надежные ориентиры для подбора названия и ключевых слов. Возможно, вы сможете скорректировать свои представления о том, в какой журнал лучше отправить текст.
Алгоритмы для выбора названия и ключевые слов
Стоит забыть о названиях вроде «К вопросу о развитии организационных форм…», поскольку оно ничего не говорит о самом главном — о содержании текста. Статья с подобным заголовком скорее всего будет проигнорирована на фоне других с более содержательными заголовками. Ваша цель, как исследователя, состоит не в том, чтобы воспроизвести словесные формулы, которые вам милы. Вы должны думать о пользе читателей.
Чтобы сформулировать правильное название статьи будет правильным сделать следующее:
1. В интернете, базах научного цитирования, репозиториях и проч. найдите тексты, которые вам нравятся, которые похожи на ваш по тематике и в ряду с которыми вам хотелось бы разместить свое произведение;
2. Прочитайте внимательно названия и ключевые слова к найденным статьям на русском и английском языках. Полная и убедительная аннотация тоже важна, однако поскольку стандартный поиск идет именно по названию и ключевым словам, для попадания в группу с нужными текстами на данном этапе вы можете меньше внимания уделять аннотации (про составление правильной аннотации вы сможете прочитать в отдельном тексте).
3. Выбирайте только то, что действительно подходит для вашей статьи. Если вы выберете модные и красивые ключевые слова, но в тексте их не проясните эти понятия, то случайный читатель быстро закроет написанное вами и в лучшем случае забудет об этом. А в худшем – запомнит и больше никогда не станет читать ваши тексты. Поскольку мы не знаем, кем может оказаться потенциальный читатель, лучше не рисковать.
4. Когда вы выбрали ключевые слова, необходимо проверить, что вы получите, если будете искать по ним в основных базах для поиска: в РИНЦ, Web of Science, Scopus, Google Scholar, – и научных социальных сетях: ResearchGate и Academia.edu. Искать лучше в каждой из них, ведь они различаются не только количеством документов, но и их типами, глубиной архива, тематической направленностью. Технологии поиска тоже различаются, поэтому лучше смотреть в каждой из информационных систем по отдельности. Результаты, которые вы будете получать, могут как различаться, так и не различаться: всё зависит от вашей тематики, языка поиска, представленности трудов вашего исследовательского сообщества в конкретной базе и научной социальной сети.
5. Если вы делаете ставку на отдельные информационные системы (например, РИНЦ), тогда лучше подстраивать название своего текста и его ключевые слова конкретно под них. Проблема заключается в том, что мы не можем предсказать, как изменятся технологии поиска, приоритеты в выдаче результатов, наполнение этих баз. Даже если вам удастся очень точно подобрать ключевые слова так, что вы будете появляться в группе с выгодными для восприятия вашей статьи текстами, никто не гарантирует, что через несколько лет результаты останутся такими же. Сложно ориентироваться на одновременно на много информационных баз, поэтому разумно смотреть на базы, в которые входит журнал, куда вы пишете.
Что делать, если заниматься поиском не хочется?
Вы можете избрать менее кропотливую стратегию. В этом случае лучше обращать внимание на формулировки, которые используют ваши коллеги. Однако сложность в том, что одни и те же явления могут описываться различными терминами, а одни и те же термины могут интерпретироваться по-разному в различных теориях. Старайтесь предотвратить подобные ошибки, особенно если вы намерены взять готовый набор ключевых слов.
Также нужно быть внимательным при выборе ключевых слов на иностранном языке. Даже русский научный язык совсем не прост и требует многих лет освоения: знающие русский язык студенты очень медленно осваивают научный стиль. А иностранный научный язык представляет двойную сложность: и с позиций владения языком вообще, и с позиций владения научным языком. Бездумный перенос ключевых слов на иностранном языке может сопровождаться переносом контекста. Поэтому лучше показать то, что вы придумали, коллеге, для которого иностранный язык – родной.
Не забывайте о классификаторах
В ряде наук популярно использовать классификаторы, которые упрощают поиск в больших массивах библиографической информации. Говорить обо всех возможных смысла не имеет, поскольку для профиля РАНХиГС подходят только два из распространенных: классификация экономической литературы (JEL) и математическая предметная классификации (MSC). Если какой-то из них имеет отношение к вашей работе, то их лучше указать. Впрочем, если вы пишете в издание, которое их использует, то это обязательно.
Многие слышали про УДК (Универсальная десятичная классификация) и ББК (Библиотечно-библиографическая классификация), рубрикатор ГРНТИ . Данные классификаторы полезны, но в основном для работы библиотек. Как правило, авторам статей в данных классификаторах разбираться не обязательно, но если понадобилось, то разумнее обратиться к библиотекарю, который занимается систематизацией. Некоторые российские журналы просят указание УДК, однако на данный момент — это требование устарело. Для статей, которые попадают в базы цитирования и другие системы, более значимыми для формирования поискового образа являются название и ключевые слова, а также аннотация. К тому же, нужно отметить, что очень многие издания отправляют информацию в РИНЦ без классификаторов, хотя могли бы это делать. И если информация о статье передается в базу Russian Science Citation Index на базе Web of Science, то там используется собственный классификатор.
Если у вас возникли вопросы, вы нашли ошибки или вы знаете, чем дополнить статью, пишите нам на Адрес электронной почты защищен от спам-ботов. Для просмотра адреса в вашем браузере должен быть включен Javascript..
На обложке использована графика с сайта Search Engine Watch.
Константин Кокарев,
заведующий отделом поддержки исследований
Научной библиотеки РАНХиГС, г. Москва
Способ, как найти ключевые слова в тексте онлайн
Home » Текстовые биржи » Находим ключевые слова в тексте через онлайн-сервис
Для людей, не разбирающихся в SEO-оптимизации и интернет-продвижении, непонятно, что значит выражение “ключевые слова”. Многие их путают с заголовками и подзаголовками, что еще больше усложняет взаимопонимание при заказе услуг SEO-продвижения. Найти ключевые слова в тексте онлайн понадобится любому человеку, который решил поднять свои сайт в ТОП поисковой выдачи Яндекса, Гугла или другой поисковой системы.
Содержание
- 1 Зачем нужны ключевые слова?
- 2 Как найти ключевые слова в тексте?
- 3 Сервисы и биржи, через которые можно проверить вхождения ключевых слов
- 4 Инструкция, как проверить вхождение ключевых слов в тексте
- 5 Как определить нужные ключевики для повышения ранжирования?
- 6 Заключение
- 6.1 Автор публикации
- 6.2 MasterCode
Зачем нужны ключевые слова?
Что же такое ключевые слова в тексте? Это наиболее часто употребляемые слова и словесные конструкции. Именно на них опираются поисковые машины при подборе сайтов по запросу пользователя. Чем больше в тексте встречается релевантных ключевых слов, тем выше будет ранжирование сайта. У ТОП-овых сайтов самый мощный поисковый трафик, ежедневно приносящий сотни и тысячи клиентов. Причем, в отличие от контекстной рекламы, трафик будет еще идти очень долго даже после того, как вы прекратите заниматься поисковой оптимизацией.
Для того чтобы понять, по каким запросам интернет-страница будет чаще всего выдаваться пользователю, необходимо определить основную словесную конструкцию.
Как найти ключевые слова в тексте?
Можно, конечно, найти все повторяющиеся конструкции самостоятельно, но этот вариант подходит только для проверки небольших отрывков. Поиск вручную в документе на 6000 символов займет не одну минуту, а что делать, если такие проверки нужно совершать по 10-20 раз в день? Тут не обойтись без специальных сервисов, которые помогут решать подобные задачи за 5-10 секунд. Рабочий интернет — вот все что для этого потребуется.
Сервисы и биржи, через которые можно проверить вхождения ключевых слов
Лучшие бесплатные сервисы для проверки вхождения ключевых слов в текст находятся на сайтах бирж копирайтинга. SEO-копирайтинг является одним из самых востребованных направлений на таких биржах. Для работы по этому направлению и нужны качественные сервисы анализа “ключей”.
Три лучших сервиса:
- Advego.
- Miratext.
- Программа Antiplagiarism.Net.
Пользоваться ими можно бесплатно и без регистрации. Программу можно скачать с сайта биржи Etxt либо с официального сайта, адрес которого является названием утилиты. Любой из этих вариантов полностью решит вопрос с поиском ключей, просто выберите, какой интерфейс вам удобней.
В Миратекст можно загрузить для анализа не только текст, но и сразу страницу сайта, что сильно ускорит и упростит работу с многостраничными порталами.
Инструкция, как проверить вхождение ключевых слов в тексте
Давайте убедимся, что определить частоту употребления слов и словесных конструкций можно быстро и легко. Для этого перейдем на Advego.
- Выбираем серую вкладку “Seo-анализ текста” в верхней шапке сайта.
- В открывшийся редактор вставляем нужный нам отрывок для проверки и запускаем процесс.
- Через несколько секунд получаем обширный отчет о предоставленном тексте. Нас интересует таблица “Семантическое ядро”. Показатель “Частота” показывает объем, который занимает то или иное слово от всего текста.
Как видите, провести моментальный поиск ключей онлайн может совершенно неподготовленный человек. Все что необходимо знать – адрес сервиса.
Как определить нужные ключевики для повышения ранжирования?
Чтобы лучше понять, какие ключевые фразы использовать, проанализируйте сайты ваших успешных конкурентов. Сняв “слепок” семантического ядра топовых сайтов, вы сможете использовать его как базу для наполнения своего интернет-проекта.
Альтернативным вариантом будет использование сервиса Yandex.WordStat, который предоставит информацию по поисковым запросам в любом регионе и за любой период. Также он подскажет аналогичные запросы, которые могут стать дополнительными ключевыми словами.
Заключение
Ключевые слова – базовый элемент для search engine optimisation. Определить их в статье на странице сайта по силу любому человеку, при помощи специальных сервисов и программ. Высокая частотность релевантных ключей повысит страницу в ранжировании, но важно не переборщить, иначе получится переспам, а заспамленные страницы быстро вылетают из Топа Yandex и Google.
Оцените текст:
Автор публикации
Обработка естественного русского языка — PrimerAI
Это стало стандартной практикой в сообществе обработки естественного языка (NLP). Выпустите хорошо оптимизированную модель английского корпуса, а затем процедурно примените ее к десяткам (или даже сотням) дополнительных иностранных языков. Эти вторичные языковые модели обычно обучаются полностью без присмотра. Они публикуются через несколько месяцев после первоначальной английской версии на ArXiv, и все это вызывает большой резонанс в технической прессе.
Например, в августе 2016 года Facebook выпустил fastText (1), быстрый инструмент для вычислений встраивания слов в вектор. В течение следующих девяти месяцев Facebook выпустил около 300 автоматически сгенерированных моделей fastText для всех языков, доступных в Википедии (2). Точно так же Google дебютировал со своим синтаксическим парсером Parsy McParseface (3) в мае 2016 года только для того, чтобы в августе того же года выпустить обновленную версию парсера, обученного для 40 различных языков (4).
Вы можете задаться вопросом, является ли таким образом многоязычное НЛП решенной проблемой. Но можно ли наивно расширить модели, обученные английскому языку, на дополнительные неанглийские языки, или перед обновлением модели требуется некоторое понимание языка на уровне носителя? Ответ особенно актуален для нас здесь, в Primer, учитывая, что наши клиенты сосредоточены на понимании и генерации текста в различных многоязычных корпусах.
Давайте начнем изучение проблемы с рассмотрения одного простого типа модели НЛП; Геометрическое вложение в стиле word2vec (5). Векторы слов полезны для обучения различных типов текстовых классификаторов, особенно когда не хватает объема должным образом помеченных обучающих данных (6). Например, мы могли бы использовать каноническую векторную модель Google, обученную новостям (7), для обучения классификатора для анализа настроений на английском языке. Затем мы расширили бы этот классификатор тональности, включив в него другие языки; таких как китайский, русский или арабский. Для этого потребуется дополнительный набор иностранных векторов, скомпилированных либо автоматически, либо путем ручной настройки носителем этого языка. Например, если бы нас интересовали эмбеддинги русских слов, мы могли бы выбирать либо из автоматических вычислений fastText Facebook, либо из результатов RusVectores для русского языка (8), которые были рассчитаны, протестированы и поддерживаются двумя русскоязычными аспирантами. . Как сравнить эти два набора векторов? Давай выясним.
RusVectores предлагает на выбор множество векторных моделей. Для нашего анализа давайте выберем их российскую новостную модель (9), которая была обучена на корпусе из почти 5 миллиардов слов из российских новостных статей за более чем три года. Несмотря на огромный размер корпуса, сам векторный файл весит всего 130 МБ, что составляет одну десятую размера канонической модели Google word2vec, обученной новостям (7). Частично несоответствие в размере связано с приведением всех русских слов к их лемматизированной эквивалентности, с добавлением признака части речи знаком подчеркивания. Эта стратегия аналогична недавно опубликованной методике Sense2Vec (10), в которой разнообразное использование слова,
, такое как, например, «утка», «утки», «пригнувшись» и «пригнувшись», заменяется одной комбинацией леммы/части речи, такой как «утка СУЩЕСТВИТЕЛЬНОЕ» или «утка ГЛАГОЛ».
Упрощение словаря с помощью лемматизации — это больше, чем просто способ уменьшить размер набора данных. Этап лемматизации на самом деле имеет решающее значение для производительности встроенного вектора на русском языке (11). Чтобы понять, зачем нужна лемматизация, достаточно взглянуть на ту необычную роль, которую играют суффиксы в русской грамматике.
Русский язык, как и большинство языков, устраняет неоднозначность использования определенных слов, изменяя их окончания в зависимости от грамматического контекста. Этот процесс известен как словоизменение, и в английском языке мы используем его, чтобы обозначить правильное время глаголов.
Перегиб — это то, откуда мы знаем, что покупка Наташей водки произошла в прошлом, а не в настоящем или будущем. Английские существительные также могут сгибаться, но только в случаях множественного числа («одна водка» vs «много водок»). Однако в русском языке флексия существительных значительно более распространена. Русские окончания слов помогают передать важную информацию, связанную с существительными, например, какие существительные являются подлежащими, а какие объектами в предложениях. В английском языке такой грамматический контекст выражается только порядком слов.
Значения этих двух предложений весьма различны, хотя слова в английских предложениях идентичны. С другой стороны, русские предложения полагаются на флексию, а не на порядок слов, чтобы передать отношения существительных. Русское предложение A является прямым переводом английского предложения A, и простая замена суффикса порождает бессмысленное предложение B. Связь между Наташей (Наташа) и водкой (водка) сигнализируется ее суффиксом, а не ее положением в предложении.
Зависимость русского языка от суффиксов приводит к большему общему количеству возможных русских слов по сравнению с английским. Например, рассмотрим следующий набор фраз: «Я люблю водку», «Дай водку», «Утопи свои печали водкой», «Водки больше нет!», «Национальная водочная компания». В английском языке слово водка осталось без изменений. Но их русские эквиваленты имеют несколько вариантов слова водка:
. Наше использование водки меняется в зависимости от контекста, и вместо одной английской водки, которую мы должны поглотить, теперь у нас есть четыре русских водки, с которыми мы должны иметь дело! Эта избыточность на основе суффиксов добавляет шума в наши векторные вычисления. Качество векторов пострадает, если мы не лемматизируем.
Имея это в виду, давайте проведем следующий эксперимент; мы загрузим модель RusVectores с помощью библиотеки python Gensim (12) (13) и выполним аналогичную функцию на слов для «водка NOUN» (водка NOUN), чтобы получить первую десятку наиболее близких слов на русском языке. векторное пространство, водке.
Мы выполняем эксперимент, используя следующий набор простых команд Python:
из gensim.models import KeyedVectors
word_vectors = KeyedVectors.load_word2vec_format('rus_vector_model.bin', binary=True)
для слова сходство в word_vectors.most_similar(u'водка_NOUN', topn=10):
напечатать слово Результаты (и их переводы) выглядят следующим образом:
Этот вывод имеет смысл. По крайней мере, большинство ближайших слов относятся к формам алкоголя. Тем не менее, в качестве проверки работоспособности, давайте сравним русский вывод с 10 наиболее близкими водочными словами в векторной модели Google, обученной новостям (7): этот упорядоченный вывод выглядит следующим образом:
Пять выделенных алкогольных напитков также фигурируют в российских результатах. Таким образом, мы добились согласованности между двумя векторными моделями. Тост за это!
А теперь давайте повторим эксперимент с русскими векторами fastText от Facebook. Первое, что мы наблюдаем, еще до загрузки модели, это то, что векторный файл Facebook (15) имеет размер 3,5 ГБ — более чем в два раза больше, чем у Google. Разница в размере файла дает о себе знать, когда мы загружаем модель в Gensim. Русскоязычные векторы Facebook загружаются на современном ноутбуке более двух минут. Для сравнения, модель RusVectores занимает менее 20 секунд.
Почему модель Facebook такая невероятно большая? Ответ становится очевидным, когда мы запрашиваем десять слов, ближайших к водке. В русской модели fastText они следующие:
Восемь из них представляют собой морфологическую вариацию водки, налитой в fastText. Кроме того, некоторые характерные для русского языка символы Unicode (например, стрелка », обозначающая конец русской цитаты) были ошибочно добавлены к просканированным словам. Таким образом, избыточность русского словаря Facebook увеличивает размер векторного набора.
Чтобы провести корректное сравнение с RusVectores, нам потребуется использовать лемматизацию для фильтрации избыточных результатов. Первая десятка неповторяющихся ближайших слов в русской модели fastText:
Поразительно, но половина этих результатов соответствует безалкогольным напиткам. Какое разочарование!
Кажется, что универсальный подход Facebook к обучению моделей довольно посредственно работает с русским текстом. Но эй, это обеспечило приличную стартовую позицию. Некоторые автоматически обучаемые векторные модели слов генерируют результаты, граничащие с абсурдом. Возьмем, к примеру, Polyglot (16), который предлагает модели, обученные на вики-дампах с 40 разных языков, и выдает следующие результаты для ближайших соседей водки:
Некоторые языковые модели не следует слепо обучать на входных данных без предварительного учета всех нюансов языка. Так что используйте и тренируйте эти модели умеренно, а не ругайте 40 языков за один раз. Такое злоупотребление моделью доставит головную боль вам и всем вашим международным клиентам. Вместо этого, пожалуйста, делайте все медленно, чтобы оценить прекрасные различия каждого языка, как ценят хорошее и пикантное вино.
Ссылки
- https://research.fb.com/fasttext/
- https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md
- https://research.googleblog.com/2016/05/announcing-syntaxnet-worlds-most.html
- https://research.googleblog.com/2016/08/meet-parseys-cousins-syntax-for-40.html
- https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
- http://nadbordrozd.github.io/blog/2016/05/20/text-classification-with-word2vec/
- http://mccormickml.com/2016/04/12/googles-pretrained-word2vec-model-in-python/
- http://rusvectores.org/ru/models/
- http://rusvectores. org/static/models/news 0 300_2.bin.gz
- https://explosion.ai/blog/sense2vec-with-spacy
- http://www.dialog-21.ru/media/1119/arefyevnvetal.pdf
- https://radimrehurek.com/gensim/
- https://radimrehurek.com/gensim/models/keyedvectors.html
- https://radimrehurek.com/gensim/models/word2vec.html#gensim.models.word2vec.Word2Vec.similar на слово
- https://s3-us-west-1.amazonaws.com/fasttext-vectors/wiki.ru.zip
- https://pypi.python.org/pypi/polyglot
Русские текстовые корпуса | Эскизный движок
Русский — один из многих языков, корпуса текстов которых включены в Sketch Engine, инструмент
для изучения того, как работает язык. Sketch Engine предназначен для лингвистов, лексикологов,
лексикографы, исследователи, переводчики, терминологи, преподаватели и студенты, работающие с
русский, чтобы легко обнаружить, что типично и часто встречается в языке, и заметить
явления, которые остались бы незамеченными без большой выборки русского текста.
В Sketch Engine есть инструменты для определения и анализа словосочетаний, синонимов и антонимов, примеры использовать в контексте, ключевых словах или терминах. Списки частотных слов русского языка, состоящих из одного или нескольких слов. могут быть созданы выражения различных типов. Даже пользователи без каких-либо технических знаний могут создавать свои собственные русские корпуса, используя интуитивно понятный встроенный инструмент Sketch Engine.
Инструменты для работы с корпусами русских текстов
Для работы с русским языком Sketch Engine предлагает следующие инструменты:
Русский Word Sketch
Word Sketch — это самый простой способ получить краткий обзор поведение слова. Словосочетания отображаются в категоризированных списках для определения сильных и слабых легко сочетается. более»
Доступные эскизы Word для корпусов пользователей: Полнофункциональная грамматика Sketch.
Word Sketch разница сравнит два словесных эскиза и укажет
которые словосочетания имеют тенденцию сочетаться с тем или иным словом. Информация может быть использована для предотвращения
ошибки в выборе слова или изучить различия между двумя словами с похожим значением.
более»
Русское согласование
Конкордансер , включенный в Sketch Engine, можно использовать для отображения списка примеров (называемых соответствием) искомого слова или фразы в русском языке языковые корпуса текстов. Поиск отобразит ключевое слово с некоторым контекстом справа и контекст слева от ключевого слова (соответствие KWIC). более»
Извлечение российского термина
Извлечение терминологии — это функция Sketch Engine, которая автоматически определяет однословные и многословные термины в тематическом русском тексте, сравнивая это к общерусскому корпусу. Инструмент предназначен для переводчиков, терминологов, преподавателей ESP. и всем, кому нужно иметь дело с доменными текстами. Экран с результатами включает ссылки на пример предложения и определения из Википедии. более»
Извлечение двуязычных терминов
Параллельные корпуса используются для извлечения терминов на двух языках
одновременно и отображать список терминологии с переводами на другой язык. более»
Русский тезаурус
Тезаурус — это функция, которая автоматически создает список слова, близкие по значению ключевому слову. более»
Списки слов на русском языке
Функция списка слов создаст частотный список всех слов, которые появляются в тексте или корпусе. Можно использовать очень большой корпус для составления списка всех слов, которые существуют в русском языке или все слова, которые начинаются, содержат или заканчиваются определенными символами. Передовой параметры могут использоваться для создания списков грамматических категорий или частей речи, используемых в корпусе вместе с их частотами. более»
N-грамм на русском языке
Формирование списка N-грамм , содержащихся в тексте, позволяет выявлять и изучать закономерности и замечать явления, связанные с многословными единицами (MWU) в русском языке которые не могут быть обнаружены другими инструментами. более»
Список доступных русскоязычных корпусов
- пробная версия – доступна как пробным пользователям, так и платным подписчикам
- основной – доступен только для платных абонентов
- по запросу – доступ к корпусу предоставляется на определенных условиях, нажмите кнопку название корпуса для деталей
| Корпус | Политика доступа | Размер прописью |
|---|---|---|
| Araneum Russicum Russicum Maius (только для России, 15. 05 G) | пробная версия | 859 319 823 |
| ДЕТСКИЙ Корпус русского языка | основной | 48 791 |
| Гутенберг Русский 2020 | основной | 13 643 |
| OpenSubtitles 2018 — Русский | основной | 180 032 832 |
| OPUS2 Русский | основной | 307 709 872 |
| РУСКЕЛЛ 1.6 | основной | 975 584 449 |
| Русские сайты в эстонской сети 2017–2021 | основной | 300 702 055 |
| Русская сеть 2006 (v2 с лемпо) | основной | 147 930 261 |
| Русская сеть 2011 (ruTenTen11) | пробная версия | 14 553 856 113 |
| Русская сеть 2017 (ruTenTen17) | основной | 9 034 837 939 |
| Веб-корпус JSI с меткой времени 2014-2016 Русский | пробная версия | 1 120 731 416 |
| Веб-корпус JSI с меткой времени 2014-2021 Русский | основной | 5 788 590 952 |
| Веб-корпус JSI с меткой времени 2021-03 Русский | основной | 150 971 438 |
| Веб-корпус JSI с меткой времени 2021-04 Русский | основной | 117 645 204 |
| Параллельный корпус Организации Объединенных Наций – русский язык | пробная версия | 529 667 487 |
Украинский и русский: насколько похожи эти два языка?
© Мальте Мюллер/Getty Images; Британская энциклопедия, Inc. Эта статья переиздана из The Conversation под лицензией Creative Commons. Читайте оригинал статьи, которая была опубликована 7 марта 2022 года.
Владимир Путин написал об «историческом единстве» украинского и русского народов, отчасти через их язык. В Украине эти утверждения опровергаются доказательствами многолетней истории украинского языка как отдельной нации и языка.
По мере того, как Путин продолжает наступление на Украину, различия между этими двумя языками стали частью публичного дискурса на Западе — посмотрите, например, на разные варианты написания украинской столицы (Киев — русская транслитерация, Киев — украинский).
Большинство людей полагают, что «отдельные» языки означают какое-то полное и четкое разделение между ними, но на самом деле все гораздо сложнее.
Украинский и русский языки принадлежат к славянской (или славянской) языковой семье. Эта группа родственных языков в Центральной и Восточной Европе также включает польский, чешский и болгарский языки. Тысячу лет назад язык, на котором говорили на территории России и Украины, был бы похож, как разные диалекты одного и того же языка. Со временем, под разными историческими влияниями, появились расхождения.
Украина стала восточной частью Речи Посполитой, вобрав в свой язык значительное количество польского языка. Москва объединила города севера и востока в независимое государство, впоследствии названное Россией. Таким образом, его язык сформировался в результате контактов и иммиграции из восточных областей, а также импорта иностранных технических и культурных терминов из западноевропейских стран, таких как Франция, Германия и Нидерланды.
К тому времени, когда Россия получила контроль над Украиной в 18 веке, носители русского и украинского языков уже не были так тесно связаны. Большие сдвиги произошли как в словарном составе языков, так и в звуках и грамматике.
Языки родные, а не двоюродные
Сегодня русский и украинский являются близкими родственниками: у них больше общего словарного запаса, грамматики и особенностей произношения друг с другом, чем с другими славянскими языками. Оба они используют кириллицу, но немного разные версии. В русском языке отсутствуют четыре буквы украинского языка (ґ, є, і, ї), а в русском языке отсутствуют четыре буквы украинского языка (ё, ъ, ы, э).
Поскольку русский и украинский языки разошлись относительно недавно (менее тысячелетия назад), у них по-прежнему много общего и ключевого словарного запаса, но недостаточно, чтобы считаться диалектами одного языка.
Одна из часто упоминаемых цифр – это то, что словарный запас украинского и русского языков составляет около 62 %. Согласно тем же расчетам, это примерно столько же общего словарного запаса, сколько в английском и голландском языках. Если вы расширите свою выборку, соскребая данные из Интернета, чтобы сравнить более широкий диапазон слов, чем только эти 200 древних «основных» слов, доля общих слов снизится. Одна вычислительная модель предполагает, что русский и украинский языки имеют примерно 55 % общего словарного запаса.
Однако, используя эту более высокую цифру в 62%, русский, не знающий украинского (или наоборот), понял бы примерно пять из восьми слов. Чтобы понять это, попросите друга вычеркнуть три из каждых восьми слов в газете и посмотреть, какую часть текста вы сможете прочитать.
«Ложные друзья» — слова, которые выглядят одинаково, но означают разные вещи — делают русский и украинский языки более похожими, чем они есть на самом деле. Украинское слово пытання (вопрос) очень похоже на русское слово пытание (попытка). У русского, который увидит пытання , это не будет ассоциироваться с русским словом вопрос, вопрос .
Принципиальные различия
Русский и украинский языки произошли от одного и того же языка-предка, и, по большому счету, не так давно. Русскому легче выучить украинский (или наоборот), чем англоговорящему, пытающемуся освоить любой из этих языков. Их общий словарный запас и тот факт, что даже слова, имеющие разное значение, могут показаться знакомыми, русско- или украиноязычным людям легче «настроиться» на другого.
Долгая история России как доминирующего политического и культурного языка Советского Союза означает, что многие граждане Украины — около 30% по данным последней переписи — являются носителями русского языка, и многие другие изучают русский язык на высоком уровне. Обратное исторически не было верным, хотя сейчас это меняется. Эти языки достаточно близки и сосуществуют достаточно долго, что у них даже есть гибрид под названием суржик, который широко используется во многих частях Украины.
Сходство между этими двумя языками не должно скрывать от нас их отчетливое существование как отдельных образований, а также политические последствия предположения, что они являются одним языком.
Около 25 лет назад название Киев начало исчезать с карт, уступая место Киеву. Последнее — просто украинская «вариант» имени, написанная латиницей, а не кириллицей. В нем изменились две гласные: в русском первая гласная -у- стала -и- после согласной к-, а в украинской исторической -е- и -о- стали -и- перед конечной согласной. Таким образом, с исторической точки зрения ни одно имя не является более «оригинальным» — каждое содержит изменения, которые вносились с течением времени.
Английская привычка использовать Киев, Харьков, Львов происходит из эпохи Российской империи и Советского Союза, когда русский язык был доминирующим письменным языком в Украине. После того, как Украина стала независимой и утвердила свою языковую идентичность, на первый план вышли украинские формы Киев, Харьков и Львов. Похожим примером являются Мумбаи и Калькутта, которые из уважения к местным нормам заменяют колониальные названия индийских городов Бомбей и Калькутта. Это изменение сейчас приходит в ближайший к вам супермаркет — до свидания, цыпленок по-киевски — здравствуй, цыпленок по-киевски.
Различия между русским и украинским языком намного больше, чем то, что Путин назвал в 2021 году «региональными языковыми особенностями». Пытаясь найти «единство» в языке между Россией и Украиной, он приводил аргумент, который давал России право вмешиваться в то, что он называл российским пространством.
Автор Нил Бермель, профессор русского и славистики Шеффилдского университета.
Русский язык | Происхождение, история, диалекты и факты
- Ключевые люди:
- Лу Синь Валерий Яковлевич Брюсов Максимус Грек Футабатей Шимей Нина Берберова
- Похожие темы:
- русская литература восточнославянские языки
Просмотреть весь связанный контент →
Популярные вопросы
Что такое русский язык?
Русский язык является основным государственным и культурным языком России. Русский язык является основным языком большинства жителей России. Он также используется в качестве второго языка в других бывших республиках Советского Союза. Он принадлежит к восточной ветви славянской семьи языков.
Кто создал русский язык?
Русский язык сформировался под влиянием нескольких основных факторов. Среди них были христианские миссионеры IX века святые Кирилл и Мефодий, которые использовали старославянский язык в своей работе среди славян, и Петр Великий (годы правления 1682–1725), чья политика вестернизации открыла русский язык для западноевропейских языков. Поэт XIX века Александр Пушкин, сочетая в своих произведениях разговорную и старославянскую дикцию, положил конец спору о том, какая форма русского языка лучше всего подходит для литературного использования.
Русский язык основан на греческом?
Сам русский язык основан не на греческом, а на его алфавите. Кириллица очень близка к греческому алфавиту, хотя содержит около дюжины дополнительных букв, которые были созданы для обозначения звуков, встречающихся в русском языке, но не в греческом.
Почему русский язык важен для космонавтов?
На борту Международной космической станции рабочим языком является английский, поэтому все астронавты должны свободно владеть этим языком или хотя бы владеть им для выполнения своих процедур. Однако одним из средств передвижения на МКС и обратно является российский космический корабль «Союз», который работает исключительно на русском языке, поэтому астронавты также должны владеть этим языком.
Русский язык , русский Русский язык , основной государственный и культурный язык России. Вместе с украинским и белорусским русский язык составляет восточную ветвь славянской семьи языков. Русский язык является основным языком подавляющего большинства людей в России, а также используется в качестве второго языка в других бывших республиках Советского Союза. Русский язык широко преподавался и в тех странах, которые находились в советской сфере влияния, особенно в Восточной Европе, во второй половине 20 века.
Русские говоры делятся на северную группу (простирающуюся от Санкт-Петербурга на восток через Сибирь), южную группу (на большей части центральной и южной части России) и центральную группу (между северной и южной). Современный литературный русский язык основан на центральном говоре Москвы, имеющем в основном систему согласных северного говора и систему гласных южного говора. Однако различий между этими тремя диалектами меньше, чем между диалектами большинства других европейских языков.
Britannica Quiz
Языки и алфавиты
Parlez-vous français? ¿Habla usted español? Посмотрите, как M-U-C-H вы знаете о ваших ABC на других языках.
Русский и другие восточнославянские языки (украинский, белорусский) не отличались заметным образом друг от друга вплоть до среднерусского периода (конец 13 — 16 вв.). Термин древнерусский обычно применяется к общему восточнославянскому языку, использовавшемуся до того времени.
Русский язык находился под сильным влиянием старославянского языка и — начиная с политики царя Петра I Великого, направленной на западничество в 18 веке — языков Западной Европы, из которых он заимствовал много слов. 19Поэт X века Александр Пушкин оказал очень большое влияние на последующее развитие языка. Его сочинения, сочетающие разговорный и церковнославянский стили, положили конец значительным спорам, возникшим по поводу того, какой стиль языка лучше всего подходит для литературного использования.
Современный язык использует шесть падежных форм (именительный, родительный, дательный, винительный, творительный, местный) в единственном и множественном числе существительных и прилагательных и выражает как вид совершенного вида (завершенное действие), так и вид несовершенного вида (процесс или незавершенное действие) ) в глаголах. В своей звуковой системе русский язык имеет множество шипящих согласных и согласных групп, а также ряд палатализованных согласных, контрастирующих с рядом непалатализованных (простых) согласных. (Небные согласные произносятся при одновременном движении лезвия языка к твердому небу или к нему; они звучат так, как если бы они сопровождались и скользят и часто называются мягкими согласными. ) Редуцированные гласные х и х исконнославянского языка были утеряны в русском языке в слабом положении в раннеисторический период. Структура предложения в русском языке в основном представляет собой субъект-глагол-объект (SVO), но порядок слов варьируется в зависимости от того, какие элементы уже знакомы в дискурсе.
Редакторы Британской энциклопедии Эта статья была недавно отредактирована и дополнена Адамом Августином.
Исследование ключевых слов на русском языке
Профессиональное исследование ключевых слов — это истинная основа любой успешной SEO-кампании!
Выполненная экспертами, она способна значительно увеличить ваш трафик. И будучи выполненным на низком уровне, это может нанести настоящий ущерб вашему сайту и ранжированию, поскольку цена оптимизации страниц вашего сайта по каждому ключевому слову высока.
- Носители языка
Выходя на российский рынок, вы встречаетесь с новой и незнакомой аудиторией. И самый сложный момент здесь — языковой барьер. Ваша новая аудитория не говорит по-английски. Все эти люди говорят по-русски! Излишне говорить, что теперь вам нужны носители русского языка SEO-специалистов. - Экспертиза
Да, Яндекс SEO отличается. И стратегия ключевых слов Яндекса тоже другая. У нас есть солидный опыт в поиске действительно прибыльных ключевых слов. - Сосредоточение внимания на ключевых словах с длинным хвостом
Поскольку мы являемся компанией, ориентированной на результат, одним из основных критериев нашей стратегии SEO является сосредоточение внимания на ключевых словах с длинным хвостом, которые легче ранжировать, менее конкурентоспособны и гораздо более прибыльны. - Источники
Мы используем широкий спектр источников для исследования и анализа ключевых слов: инструмент подсказки ключевых слов Яндекса, анализ Яндекс Метрики, поисковые подсказки, профессиональные базы данных ключевых слов и т. д.
Узнать цену
Цели исследования ключевых слов
Ключевые слова должны определять вашу общую стратегию SEO и контента. Таким образом, вы должны быть очень осторожны на этом этапе, чтобы найти возможности и не тратить свои усилия на SEO, конкурируя за краткосрочные ключевые слова.
- Найдите возможности:
Вы получите органический трафик из SE быстрее и с меньшими усилиями, если настроите таргетинг на правильные ключевые слова. - Исследование уровня сложности:
Это поможет вам правильно расставить приоритеты для ключевых слов. - Раскройте скрытые термины и тренды:
Исследование ключевых слов — это больше, чем просто ввод ключевого слова в инструмент планирования и загрузка результатов.
Как мы это делаем
Профессиональное программное обеспечение для поисковой оптимизации и специализированные онлайн-сервисы помогают нам добиваться наилучших результатов.
- Yandex Wordstat Tool:
Основы исследования ключевых слов в русском языке. - KeyCollector Tool:
Познакомьтесь с инструментом, который настоящие профессионалы используют для исследования ключевых слов. - Инструмент планирования ключевых слов Google AdWords:
Также подходит для исследования ключевых слов на русском языке. - Базы ключевых слов:
Хорошо известные на рынке проверенные базы ключевых слов. - Анализ Яндекс Метрики:
Мы анализируем рейтинг вашего сайта и историю посещаемости.
Результат
- Эффективные ключевые слова:
Ключевые слова, которые релевантны. Ключевые слова с высокой конверсией. Ключевые слова, которые легко ранжировать. Ключевые слова, которые работают. - Точные результаты:
Комбинируя данные из нескольких источников, мы формируем наиболее точные оценки и диапазоны для русских ключевых слов, как длиннохвостых, так и высококонкурентных. - Данные SEO и SERP:
Полученная таблица будет отображать не только ключевые слова, но и важные данные SEO. Мы предоставляем до 3 различных типов объема поиска, уровня сложности, KEI (индекс эффективности ключевых слов), отчет Яндекс GEO, отчет и анализ поисковой выдачи и т. д. - Исследование конкурентов:
Advanced Russian Keyword Research включает в себя анализ SEO-данных ваших конкурентов и стратегии ключевых слов.
Мы написали об этом книгу
Русское SEO в 2021-2022 годах: тенденции и особенности российского поиска
Антон Требунский, Валерия Моргачева
В настоящее время хорошая видимость в онлайн-поиске является важным элементом успешного бизнеса, особенно в зарубежных странах.
Мы создали технический документ, в котором мы рассматриваем как тенденции SEO в целом, так и некоторые специфические факторы российского поиска.
Подробнее
Цены и услуги по исследованию ключевых слов на русском языке
Вы можете найти более подробную информацию об исследовании и анализе ключевых слов на русском языке в таблице ниже.
| Features | Starter | Business | Enterprise |
| Keywords | up to 2000 | up to 5000 | up to 10000 |
| Yandex Wordstat keyword tool | |||
| Keyword databases (Semrush, MOAB, etc) | |||
| Search suggestions | — | ||
| Yandex Metrica research | — | ||
| Difficulty level research | — | ||
| Отчет Яндекс ГЕО | — | — | |
| Отчет SERP | — | — | |
| Keywords clustering | — | — | |
| Competitors research | — | up to 3 | up to 5 |
| Dedicated keyword research expert | |||
| Time to perform | 5+ рабочих дней | 9+ рабочих дней | 14+ рабочих дней |
Узнать цену
Свяжитесь с нами, мы говорим по-английски и готовы к
ответь на все твои вопросы!
Топ-5: лучшие библиотеки Python для автоматического извлечения ключевых слов из текста
Ознакомьтесь с нашей коллекцией из 5 лучших библиотек извлечения ключевых слов с открытым исходным кодом для Python.
В науке о данных извлечение ключевых слов — это метод анализа текста, с помощью которого вы можете получить важную информацию о каком-либо тексте за короткий промежуток времени. Это должно помочь получить релевантные ключевые слова из любого текста и сэкономить драгоценное время на изучение всего документа. В разных проектах есть несколько функций, где вы можете реализовать такую библиотеку, например, автоматизация извлечения ключевых слов, когда вы пишете сообщение в каком-либо блоге, поэтому, если вы чувствуете себя ленивым или менее творческим, чем обычно, вы можете автоматически генерировать их из ваш исходный текст. Еще один полезный реальный случай, когда, например, вы публикуете товар в магазине и на него приходят отзывы. Вы можете использовать эту функцию для автоматического извлечения проблем продуктов, анализируя тысячи отзывов, не изучая их все.
В этом топе я поделюсь с вами 5 наиболее полезными библиотеками Python для автоматического извлечения ключевых слов из любого текста на нескольких языках.
Реализация на Python алгоритма быстрого автоматического извлечения ключевых слов (RAKE), как описано в: Rose, S., Engel, D., Cramer, N., & Cowley, W. (2010). Автоматическое извлечение ключевых слов из отдельных документов. В MW Berry & J. Kogan (Eds.), Text Mining: Theory and Applications: John Wiley & Sons.
Онлайн-демонстрация • API
ЯКЭ! это легкий неконтролируемый автоматический метод извлечения ключевых слов, основанный на статистических характеристиках текста, извлеченных из отдельных документов, для выбора наиболее важных ключевых слов текста. Нашу систему не нужно обучать на конкретном наборе документов, она не зависит ни от словарей, ни от внешнего корпуса, ни от размера текста, ни от языка, ни от домена. Чтобы продемонстрировать достоинства и значимость нашего предложения, мы сравним его с десятью современными неконтролируемыми подходами (TF.IDF, KP-Miner, RAKE, TextRank, SingleRank, ExpandRank, TopicRank, TopicalPageRank, PositionRank и MultipartiteRank). и один контролируемый метод (KEA). Экспериментальные результаты, проведенные на двадцати наборах данных (см. ниже раздел «Эталонный анализ»), показывают, что наши методы значительно превосходят современные методы в ряде коллекций разных размеров, языков или доменов.
PKE — это набор инструментов с открытым исходным кодом на основе Python извлечения ключевых фраз , который обеспечивает сквозной конвейер извлечения ключевых фраз, в котором каждый компонент может быть легко изменен или расширен для разработки новых моделей. Он также позволяет легко сравнивать современные модели извлечения ключевых фраз и поставляется с контролируемыми моделями, обученными на наборе данных SemEval-2010. Эту библиотеку можно установить с помощью следующей команды pip (требуется Python 3.6+):
.pip установить git+https://github.com/boudinfl/pke.git
Для работы требуются дополнительные библиотеки:
python -m nltk.downloader стоп-слова python -m nltk.
PKE предоставляет стандартизированный API для извлечения ключевых фраз из документа. Его можно легко использовать, как показано в следующем скрипте:
# script.py импортировать пке # инициализируем модель извлечения ключевой фразы, здесь TopicRank экстрактор = pke.unsupervised.TopicRank() # загрузить содержимое документа, здесь ожидается, что документ будет необработанным # формат (т.е. простой текстовый файл) и предварительная обработка осуществляется с помощью spacy Extractor.load_document(input='/path/to/input.txt', language='en') # выбор кандидата ключевой фразы, в случае TopicRank: последовательности существительных # и прилагательные (например, `(существительное|прилагательное)*`) экстрактор.candidate_selection() # взвешивание кандидатов, в случае TopicRank: с использованием алгоритма случайного блуждания экстрактор.candidate_weighting() # N-лучший выбор, ключевые фразы содержат 10 кандидатов с наивысшим баллом, как # (ключевая фраза, оценка) кортежей ключевые фразы = extractor.
Чтобы использовать другую модель, просто замените pke.unsupervised.TopicRank на другую модель (список реализованных моделей).
MultiRake — это многоязычная библиотека быстрого автоматического извлечения ключевых слов (RAKE) для Python, которая включает:
- Автоматическое извлечение ключевых слов из текста, написанного на любом языке
- Нет необходимости заранее знать язык текста
- Не нужно иметь список стоп-слов
- На данный момент доступно 26 языков, для остальных — стоп-слова генерируются из предоставленного текста
- Просто настройте rake, вставьте текст и получите ключевые слова (см. подробности реализации)
Эта реализация отличается от других многоязычной поддержкой. В принципе, вы можете предоставить текст, не зная его языка (он должен быть написан кириллицей или латиницей), без явного списка стоп-слов и получить достойный результат. Хотя наилучший результат достигается при тщательно составленном списке стоп-слов. При инициализации RAKE следует использовать только код языка:
- бг — Болгарский
- cs — чешский
- да — датский
- де — немецкий
- эль — греческий
- en — Английский
- es — Испанский
- фи — финский
- фр — французский
- га — ирландский
- часов — Хорватский
- ху — Венгерский
- id — индонезийский
- это — итальянский
- лт — литовский
- лв — латышский
- nl — голландский
- нет — норвежский
- пл — польский
- pt — португальский
- ро — румынский
- ru — русский
- ск — словацкий
- св — Шведский
- т.р. — Турецкий
- Великобритания — Украинский
KeyBERT, без сомнения, является одной из самых простых в использовании библиотек среди других. KeyBERT — это минимальный и простой в использовании метод извлечения ключевых слов, который использует встраивания BERT для создания ключевых слов и фраз, наиболее похожих на документ. Эту библиотеку можно легко установить с помощью следующей команды, используя pip:
pip установить ключ
После установки вы можете использовать его в качестве библиотеки в своих сценариях со сценарием, подобным следующему, где вам нужно импортировать модель KeyBERT, после ее загрузки вы можете использовать ее для извлечения ключевых слов из переменной, содержащей простой текст :
# script.py из keybert импортировать KeyBERT документ = """ Обучение с учителем — это задача машинного обучения по обучению функции, которая сопоставляет ввод с выводом на основе примеров пар ввода-вывода. Это предполагает функцию из размеченных обучающих данных, состоящих из набора обучающих примеров. В обучении с учителем каждый пример представляет собой пару, состоящую из входного объекта (обычно вектор) и желаемое выходное значение (также называемое контрольным сигналом). Алгоритм обучения с учителем анализирует обучающие данные и выводит предполагаемую функцию.