
Как легко повысить уникальность текста самому. Примеры и советы
Сложность обхода программ, проверяющих текст на уникальность, зависит от нескольких факторов: требований преподавателя, начальной уникальности и темы диплома или курсовой работы. К примеру, если написать курсовую работу, текст которой собран из нескольких источников и уникален на 40%, а преподавателю нужно как минимум 70%, повысить оригинальность будет несложно.
1. Лучший способ обойти антиплагиат — полная перестройка текста.
Если вы хорошо владеете словом или не понаслышке знакомы с темой магистерской диссертации или курсовой, можно попробовать обойти антиплагиат, переделав текст из источников таким образом, чтобы получился абсолютно другой документ. Составьте план и подробно распишите каждый из его пунктов, изменив структуру исходного текста. Если у вас хорошая память, прочитайте исходную статью или учебник, а затем перепишите своими словами. Так можно добиться максимального результата и поднять оригинальность.
2. Перестановка частей текста, предложений и абзацев поможет немного повысить оригинальность.
Программа Антиплагиат проверяет текст по частям, разбивая его на словесные конструкции и находя совпадения с источниками. Если поменять структуру документа, есть шанс повысить процент уникальности.
3. Легкий синонимайзинг.
Иногда можно обойтись без полного пересказа источника – достаточно заменить несколько слов в предложении на другие, схожие по смыслу. Этот способ повысит уникальность, однако сильно увлекаться этим не стоит.
4. Использование новых и иностранных источников.
Чем новее научный труд или статья, откуда берется информация, тем меньше шансов, что их уже использовал кто-то другой. Чтобы отыскать «свежие» тексты, можно почитать новости по теме диплома или курсовой, анонсы статей, или просто отправиться в библиотеку за еще не оцифрованными журналами.
Если вы хорошо владеете иностранными языками, поищите работы на похожую тему на зарубежных порталах. Даже если просто воспользоваться Гугл-переводчиком, подправив автоматически созданный текст, можно написать реферат или курсовую работу с высокой оригинальностью.
Читайте также: Как сделать презентацию для защиты диплома на «отлично»
Как исправить антиплагиат в тексте бесплатно
Практически ни одно написание курсовой или дипломной работы не обходится без рерайта одного или нескольких источников. Рерайт – это своеобразное перефразирование начального текста, в результате которого выходит работа с таким же смыслом, но написанная в другой манере, что поможет пройти антиплагиат.
Рерайт бывает двух видов: глубокий и поверхностный. Первый вариант сложнее, но зато он позволяет получить связный текст с показателем оригинальности 90% и выше. Для этого Вам придется самостоятельно поработать над источниками: прочитать несколько статей по теме курсовой или диплома, составить предварительный план будущей структуры работы и пересказать своими словами основные мысли по теме. После этого можно сделать текст более развернутым, дополнить его фактами, примерами, цитатами и т. д. В результате получится действительно качественная работа, при сдаче которой можно надеяться на максимально высокую оценку.
С поверхностным рерайтом дело обстоит несколько иначе. Он подойдет разве что для троечников и лентяев, зато не потребует большой умственной нагрузки и пропускания через себя значительного объема информации. Прочитайте предложение из источника и перефразируйте его – и так с каждым по порядку. Структура исходного текста не изменится, но предложения будут достаточно уникальными.
Пример поверхностного рерайта с синонимайзингом: «Нужно ли говорить, что достижения в сфере информационных технологий затрагивают каждого из нас?» – «Всем известно, что развитие компьютерных технологий важно для каждого человека».
Вам может быть интересно: Как написать рецензию на дипломную работу (ВКР)
Устаревшие способы обойти антиплагиат
Раньше, чтобы обойти антиплагиат, было возможно просто заменить повторяющиеся русские буквы в словах на буквы английского алфавита (вроде «а», «о», «р») и так, схитрив, повысить уникальность работы. Сейчас нет такой программы, которая не смогла бы вычислить подобные манипуляции. То же касается и других устаревших фишек:
- Сплошной синонимайзинг. Полученная таким способом дипломная работа может разве что повеселить преподавателя своей несуразностью. Синонимизированные тексты звучат не просто фальшиво, а совсем бессмысленно. Робот не может понять смысловые различия в словах, которые на первый взгляд кажутся синонимами – и в результате вы получите оригинальный, но несвязный текст, напоминающий бред сумасшедшего.
- Захламление предложений вводными конструкциями. Как бы много слов по типу «таким образом», «хотелось бы сказать, что», «конечно» не добавили в курсовую работу, уникальность повысится максимум на 1-2 процента. Излишне водная теория не придется по вкусу преподавателю – никому не захочется искать смысл в дипломной работе, как иголку в стоге сена.
- Вставка символов в белом цвете. Раньше любили повышать уникальность таким методом: в пустые места на страницах курсовых и дипломов вставлялись случайные наборы символов, затем цвет «ненужного» фрагмента заменялся белым. В итоге работа выглядела хорошо, невнимательные преподаватели могли не заметить подвоха в программах антиплагиата. Однако и этот способ был обречен на провал – простое копирование в блокнот или в окошко программы антиплагиат текста курсовой выдавало нечестные манипуляции. Сейчас этим преподавателей не удивишь.

- Замена знаков препинания. Современные антиплагиаты не обращают внимания на подмены точек, запятых, тире и т. д. Даже вставка точек вместо пробелов не поможет исправить ситуацию, и повысить уникальность готовых и оформленных рефератов.

Технические способы повысить оригинальность самостоятельно
Если до достаточной уникальности Вам не хватает совсем немного (2-7%), воспользуйтесь встроенной в Word функцией автоматического переноса слов. Из-за того, что слово разделяется на две строки, робот воспринимает его как два отдельных слова. В некоторых случаях это помогает добиться чуть более высокой уникальности.
Вставка картинок. Если преподаватель требует наглядной подачи информации – добавления таблиц, формул, диаграмм с подписями и т. д., не стоит пытаться сделать все это уникальным. В любом случае вряд ли у Вас получиться переписать формулу бинома Ньютона так, чтобы она была не только правильной, но и уникальной. Просто сделайте скриншот и вставьте его в текст документа – при печати качество не изменится, и антиплагиат не найдет неуникальных фрагментов. То же с таблицами – создайте нужную таблицу в Word или Excel, сделайте снимок экрана и вставьте его в работу.
Вместо подмены русских букв латинскими попробуйте подходящие литеры греческого алфавита – программы антиплагиата пока еще не научились их распознавать как неуникальные части текста. Если греческих букв недостаточно, попробуйте вставлять символы из формул. Единственный минус такого способа – при открытии документа в Ворде все подправленные места будут отмечены как орфографические ошибки. Чтобы система не подчеркивала слова красной линией, отключите эту опцию в стандартных настройках программы.
Вставка оригинальных фрагментов за пределы видимости. При распечатке документа не будут видны вставленные в свободном пространстве надписи мелким шрифтом белого цвета, а также примечания. Таким образом, можно попытаться обойти антиплагиат, если вы не смогли написать дипломную работу с высокой оригинальностью, но опытные преподаватели уже сами в курсе подобных фишек, и обмануть их не так просто.
Технические способы повышения оригинальности текста
//Технические способы повышения оригинальности текста. Технический АнтиплагиатПродолжая рассмотрение вопросов о способах повышения оригинальности текста, остановимся на второй группе таких способов, которые мы обозначили как «технические» (первая группа – «честные» способы повышения оригинальности текста описана здесь).
Все технические способы обхода системы Антиплагиат можно подразделить на 2 группы. К первой можно отнести обман самой системы проверки текста, ко второй обман скрипта, который передает текст для проверки.
Давайте остановимся на указанных способах более подробно.
- 1. Наверное, самым первым способом обхода системы Антиплагиат является способ замены русских (кириллических) букв на схожие по написанию иные буквы (латинские). Наиболее распространенными буквами для замены оказались буквы: а, о, м, р, к, х, и, с. Автор в Word выбирал замену символов по всему документу и получал, хоть и не читаемый в нормальном понимании текст, но «смотрящимся» вполне допустимо. Немаловажной особенностью была необходимость отключения проверки правописания во всем документе, так как для текстового редактора текст содержал очень много ошибок. Примерно через 2 года после начала работы системы Антиплагиат данную особенность разработчики исправили. Хотя стоит отметить, что до сих пор некоторые сервисы по проверке уникальности текста можно обойти таким образом.
- 2. Вторым этапом развития технических способов стало отыскание и замена русских букв на греческие и иные, схожие по написанию. Например, очень схожи по написанию буквы «О» в кириллице и «Омега» в греческом алфавите. Какое-то время данный способ также работал.
- 3. Помимо замены букв, достаточно часто применялись способы, связанные со вставкой невидимых для системы Антиплагиат специальных символов, начиная от пробела и заканчивая различными иероглифами в других системах исчисления.
- 4. После того, как на основном сайте по проверке студенческих работ Антиплагиат – www.Antiplagiat.ru была введена система проверки правописания и выделения всех слов, содержащих ошибки, а также пометкой всего документа красным восклицательным знаком, данный способ, в принципе, перестал быть актуальным. Хотя наличие восклицательного знака не говорит о применении технических способов обхода антиплагиата – он лишь рекомендует преподавателю более подробно ознакомиться с отчетом, так как во многих научных сферах такой знак возможен. К примеру, это иностранные языки, информатика, математика и т.д.
- 5. Самым простым и в то же время, самым доступным способом, который используется в настоящее время, является способ добавления оригинального текста к документу. А чтобы данный текст не был виден, его прячут в «Надписи», выводят за видимость экрана, делают белым цветом, устанавливает размер на 1 кегль. Большая часть сервисов в Интернете поступают именно данным образом. О данном способе, конечно же, знают все преподаватели и стараются выявить в отчете текст, который не соответствует содержанию работы. Гораздо более перспективно вставлять в работу не любой текст, а блоки из той же самой работы, которые являются оригинальными и преподавателю будет уже гораздо сложнее увидеть подвох.
- 6. Еще одним способом технического обхода системы Антиплагиат является подмена содержимого текста, который виден на экране, не отправляется корректно на проверку. Самой простой иллюстрацией этого метода является вставка вместо букв картинок – в Word все видно нормально, а вот при проверке на оригинальность эти буквы (цифры) пропадают. Замена отдельных букв эффекта не даст, так как таким образом значительно ухудшается орфография текста. Есть смысл менять слова целиком и приводить их к виду, который не воспринимается сервисом Антиплагиат. К примеру, можно заменить какой-нибудь символ, который теряется при проверке на какое-нибудь слово, и внести изменения в сам шрифт документа, чтобы он понимал под этим символом целое слово. Выявить такой способ технического повышения оригинальности не так сложно – нужно просто скопировать документ в любой текстовой редактор, лучше в блокнот и посмотреть – пропали ли символы, буквы, слова и т.д. Надо сверить идентичность проверяемого текста и текста, который содержится в работе, так как это все равно будет видно в расширенном отчете системы «Антиплагиат-ВУЗ».

 Выявить такой способ технического повышения оригинальности не так сложно – нужно просто скопировать документ в любой текстовой редактор, лучше в блокнот и посмотреть – пропали ли символы, буквы, слова и т.д. Надо сверить идентичность проверяемого текста и текста, который содержится в работе, так как это все равно будет видно в расширенном отчете системы «Антиплагиат-ВУЗ».
Выявить такой способ технического повышения оригинальности не так сложно – нужно просто скопировать документ в любой текстовой редактор, лучше в блокнот и посмотреть – пропали ли символы, буквы, слова и т.д. Надо сверить идентичность проверяемого текста и текста, который содержится в работе, так как это все равно будет видно в расширенном отчете системы «Антиплагиат-ВУЗ».Безусловно, есть и иные технические способы повышения оригинальности текста, но самый лучший способ, это конечно копирайт, ну на крайний случай, рерайт.
Если у вас имеются какие-то вопросы — позвоните нам, у нас круглосуточная поддержка клиентов!
8-800-550-55-87 звонок бесплатный
Загрузить работу
Сегодня 59 студентов повысили уникальность своих работ. А всего — 512826 студентов
Повысить антиплагиат (оригинальность) текста
Для того чтобы повысить оригинальность (уникальность) текста для антиплагиата, Вам нужно обладать глубокими знаниями в области рерайта и разбираться в тематике текста. Но порой такими знаниями не обладают студенты и выход один обратится к специалистам, которые хорошо знают, как это делать.
На первый взгляд всё кажется просто и потратив несколько дней у Вас получится добиться нужного процента оригинальности текста в своей курсовой или дипломной работе. Поверьте, это не так. И некоторые студенты по не знанию ищут дешевые способы повысить уникальность текста. Вы просто выкинете деньги и не пройдете проверку. Мало кто знает, что система антиплагиат с каждым годом усовершенствуется и те методы, что ранее работали уже не помогают. Вы только добавите себе проблем, так как преподаватель при проверке обнаружит скрытое повышение и не допустит Вас до защиты.
Мы занимаемся повышением процента оригинальности для прохождения антиплагиата уже более 5 лет и с 100% уверенностью можем Вам сказать, что единственный способ, который работает — это академический рерайт.
За время работы и личного опыта мы усовершенствовали данный метод и добились 100% результата. У нас есть правило, если мы не помогли, то деньги возвращаются заказчику.
5 причин обратиться к нам:
- У нас дешевле, чем у других.
- Мы делаем за 1-3 дня.
- Вы получаете отчет о проценте уникальности Вашей работы (после чего можете сами перепроверить).
- Всегда есть выбор метода повышения уникальности текста (программный и ручной).
- Мы всегда на связи — онлайн.
Помните – даже если у Вас % оригинальности текста равен 14%, мы можем сделать текст уникальностью более 72%.
Для примера поднятия оригинальности мы выложили картинку, где из плагиатной работы, сделали уникальную. Работа была в первоначальном виде 15.02%, после нашей обработки, стала 83.45%.
И заметьте, нет, не каких значков о предупреждении, что в работе есть подозрения на искусственное завышение оригинальности!
Как обмануть проверку на плагиат
Большинство студентов хоть раз слышали слово «антиплагиат» — это означает, что диплом или курсовая работа, прежде чем быть принятыми, должны пройти проверку оригинальности. Требования к проверке обычно довольно стандартные – уникальность текста должна составлять от 60% до 90%.
Антиплагиат – это сервис или программа, которая сличает загруженный текст с теми текстами, которые уже есть в интернете и проиндексированы поисковыми системами. Для проверки чаще всего используются популярные антиплагиат-сервисы (Advego. Etxt, text.ru), в некоторых случаях проверка может вестись через узкоспециализированные сервисы, заточенные под анализ студенческих работ (например, Антиплагиат ВУЗ – в базе этого сервиса имеются тексты уже сданных ранее дипломов и курсовых работ, что существенно затрудняет прохождение проверки).
Что такое уникальность текста?
Уникальный текст – это текст, который нигде ранее не встречался. Если в тексте присутствуют цитаты, скопированные термины и определения, отрывки из электронных учебных пособий или статей, фрагменты работ других авторов – обмануть проверку на плагиат не получится.
Если в тексте присутствуют цитаты, скопированные термины и определения, отрывки из электронных учебных пособий или статей, фрагменты работ других авторов – обмануть проверку на плагиат не получится.
Как поступить? Рассмотрим основные способы обойти антиплагиат.
1. Искусственно повысить процент уникальности, используя специальные сервисы. Обработка текста занимает 4-5 минут, а перекодированный файл распознается программами антиплагиата как уникальный. Этот способ хорош, если преподаватель не дотошный и не будет изучать электронную копию работы – потому что в перекодированном файле все слова будут восприниматься текстовым редактором как ошибки.
2. Автозамена синонимов. Этим способом (так же, как и синонимайзерами) все еще пользуются некоторые ленивые студенты. Автозамена хороша для уникализации небольших отрывков текста, но для всей работы этот способ бесполезен – слишком сильно снижается качество результата.
3. Рерайтинг (переписывание, изложение своими словами) неоригинальных отрывков. Этот способ работает всегда и на 100%, но у него есть огромный минус: трудоемкость. По сути, вся работа пишется заново, с той лишь разницей, что студент не вкладывает в нее свои мысли и выводы, а пересказывает чужие. Сложность рерайтинга меняется в зависимости от того, по какому сервису проверяется текст. Так, чтобы обмануть проверку на плагиат в сервисе antiplagiat.ru, достаточно переписать фразу своими словами. Для сервиса etxt придется дополнительно поменять местами предложения. Text.ru требует еще более тщательной проработки, вплоть до изменения структуры всей работы.
4. Если студент понимает суть предмета, он может использовать для своей работы машинный перевод и адаптацию с иноязычных источников..jpg)
5. Чтобы обмануть проверку на плагиат, пригодятся и маленькие хитрости – например, оформление цитат непрямой речью, использование инфографики и иллюстраций вместо таблиц и описаний, добавление в работу графиков с подписями на самом графике, а не отдельным текстом. Такие моменты лучше заранее обсудить с преподавателем, и если он не против – использование графических объектов существенно увеличит шансы обмануть антиплагит, ведь в антиплагиат-сервисах пока не существует алгоритмов, проверяющих рисунки.
Повысить уникальность текстовой работы. Обойти антиплагиата онлайн
Как проверить диплом, реферат или курсовую работу на уровень плагиата (Antiplagiat.ru, Антиплагиат ВУЗ, Etxt антиплагиат, РУКОНТекст)
Каждый студент прекрасно знает, что такое плагиат. Уровень плагиата – едва ли не главное требование к студенческим работам в большинстве российских ВУЗов.
Чтобы выявить заимствования в тексте документа, преподаватели пользуются рядом сервисов. Наиболее популярные – Антиплагиат ВУЗ, Antiplagiat.ru, ETXT и РУКОНТекст.
Как они работают?
Большинство таких сервисов используют схожий алгоритм. А именно – сравнивают загружаемый текст с базой документов, которая постоянно пополняется. Есть и небольшие отличия – Антиплагиат ВУЗ, например, имеет доступ к огромной базе статей и научных работ.
Антиплагиат (Antiplagiat.ru, Антиплагиат ВУЗ)
База системы Антиплагиат насчитывает более 90 миллионов документов, включая тексты диссертаций, авторефератов, научных статей, юридических документов. Разработчики Антиплагиата утверждают, что система умеет эффективно выявлять рерайтинг – помечать как плагиат синонимы, выявлять замену символов и знаков препинания и др. В самом деле — практика показывает, что обойти Антиплагиат можно, если выполнить глубокий рерайтинг вручную.
В самом деле — практика показывает, что обойти Антиплагиат можно, если выполнить глубокий рерайтинг вручную.
Etxt антиплагиат
Etxt – онлайн-сервис и приложение для ПК, известные одновременно и умением выявлять перефразированные фрагменты, и возможностью проведения четырех различных проверок: на рерайтинг, экспресс-проверки, стандартной и глубокой. В ВУЗах обычно требуют проверять документ последним способом.
РУКОНТекст
Руконтекст заслуживает особого внимания. В некоторых ВУЗах эта платная система принята как аналог Антиплагиат ВУЗ и широко используется. В первую очередь – потому, что в 2017 году разработчики Руконтекста проанализировали основные методы обмана и ввели проверку на попытки искусственно повысить уникальность работы. Поэтому, если система получает документ с искусственно завышенной уникальностью, вместо результата проверки появится сообщение о попытке обмана.
Руконтекст – наиболее защищенная система, обойти ее очень сложно. Даже выполнение ручного рерайтинга не гарантирует успех.
Как поднять процент уникальности и пройти проверку?
Самый простой способ – честно написать работу самостоятельно. Но не у всех на это есть время, особенно если приходится сдавать по 4-5 рефератов за семестр. Будем честны – мало кто из преподавателей читает студенческие работы, поэтому стараться и писать все рефераты и курсовые с нуля особого смысла нет.
Можно поручить эту задачу специалистам – опытный исполнитель напишет реферат, курсовую или даже диплом и гарантирует, что работа успешно пройдет проверку на плагиат. Но данный вариант весьма дорогой и затратный по времени.
Но данный вариант весьма дорогой и затратный по времени.
Самый простой и в тоже время достаточно эффективный способ повысить уникальность документа — это воспользоваться сервисом технического повышения уникальности. Данный способ самый экономичный, а само повышение уникальности займет не более 3-х минут.
Как повысить уникальность текста и пройти проверку на антиплагиат
К несчастью для студентов, теперь в каждом ВУЗе, чтобы сдать курсовую или дипломную работу необходимо пройти проверку на антиплагиат, понятное дело, что даже те, кто пишет диплом сам, берет информацию из открытых источников, а значит работа получается не уникальной. Как с этим бороться и о том, как же повысить уникальность работы мы поговорим в нашей статье.
Начнем с того, что у вас всегда есть выбор, вы можете купить уже уникальный диплом, заказать повышение уникальности платно или повысить уникальность самостоятельно.
Какой способ выбрать решать только Вам. Но у каждого есть свои плюсы и недостатки, о которых стоит знать заранее.
1. Повышение уникальности бесплатно онлайн. Даже не теряйте свое время на поиск таких сайтов, как вы знаете бесплатный сыр бывает только в мышеловки. Либо Вам не повысят уникальность, либо повышение составит 1-3%. Либо попросят заплатить.
2. Повышение уникальности самостоятельно – самый трудоемкий и эффективный способ, который я вам советую использовать, почему?
Во-первых, если вы пишите и сдаете диплом сами, это будет плюсом, пока вы будете увеличивать уникальность, вы выучите свой диплом на зубок.
Во-вторых Вы будете уверенны, что повышение уникальности – это естественный процесс, а не применение технических средств, будете уверены в том, что программа не выдаст в последний момент ошибку, типа «использованы технические средства обхода программы».
В третьих, самый очевидный плюс, это экономия, да сил и труда потребуется много, но вы добьетесь результата бесплатно.
3. Заказать повышение уникальности у специалистов, тут стоит оговорится, что такую услугу вам готовы предложить сотни сайтов, но 99% из них повышают уникальность средствами технических уловок, и тут идет борьба современных программ и поиска из уязвимостей.
Если Вам предложат хорошую низкую цену, то будьте уверенны уникальность будет повышена искусственно и вас легко раскусят. Даже если изначально вы сможете пройти проверку не факт, что перед итоговой сдачей, программы не обновят и ваш трюк будет не обнародован.
Если вы решили, что самостоятельное повышение уникальности – точно не для Вас. Не пожалейте денег для реального рерайта Вашей работы.
Если вы решили повысить уникальность самостоятельно в помощь Вам будет эта статья.
Заказать повышение уникальности дипломной/курсовой работы вы можете и у нас. Мы не предложим вам дешевую цену – но мы сделаем качественную работу. Чтобы оставить заявку нажмите на кнопку. В нашей группе вы сможете почитать отзывы и задать все интересующие Вас вопросы.
Может еще поучимся? Загляни сюда!
Как повысить уникальность текста самостоятельно
Приветствую вас, дорогие читатели! На связи Павел Ямб. Продолжим разговор об уникальности. Написали вы статью, и все замечательно, но она неуникальна, и поисковикам не понравится. Как повысить уникальность текста самостоятельно?
Убираем сходство с публикациями на других сайтах
Первое – уничтожаем шаблонные фразы. Строим предложения так, чтобы не получить публикации-двойника с уже имеющимися в сети. Заменить похожие слова синонимами, перестроить предложения, изменить стиль написания, наконец, если это не повредит изложению – все доступно.
Только не нужно чересчур увлекаться синонимайзингом. Постоянное пользование сервисами замены имеет смысл, когда необходимо найти синоним к профессиональному термину, но не когда подыскать подходящее слово можно в памяти или посмотреть по смыслу.
Если заменять все слова синонимами, то в итоге мы получим нечитабельное нечто.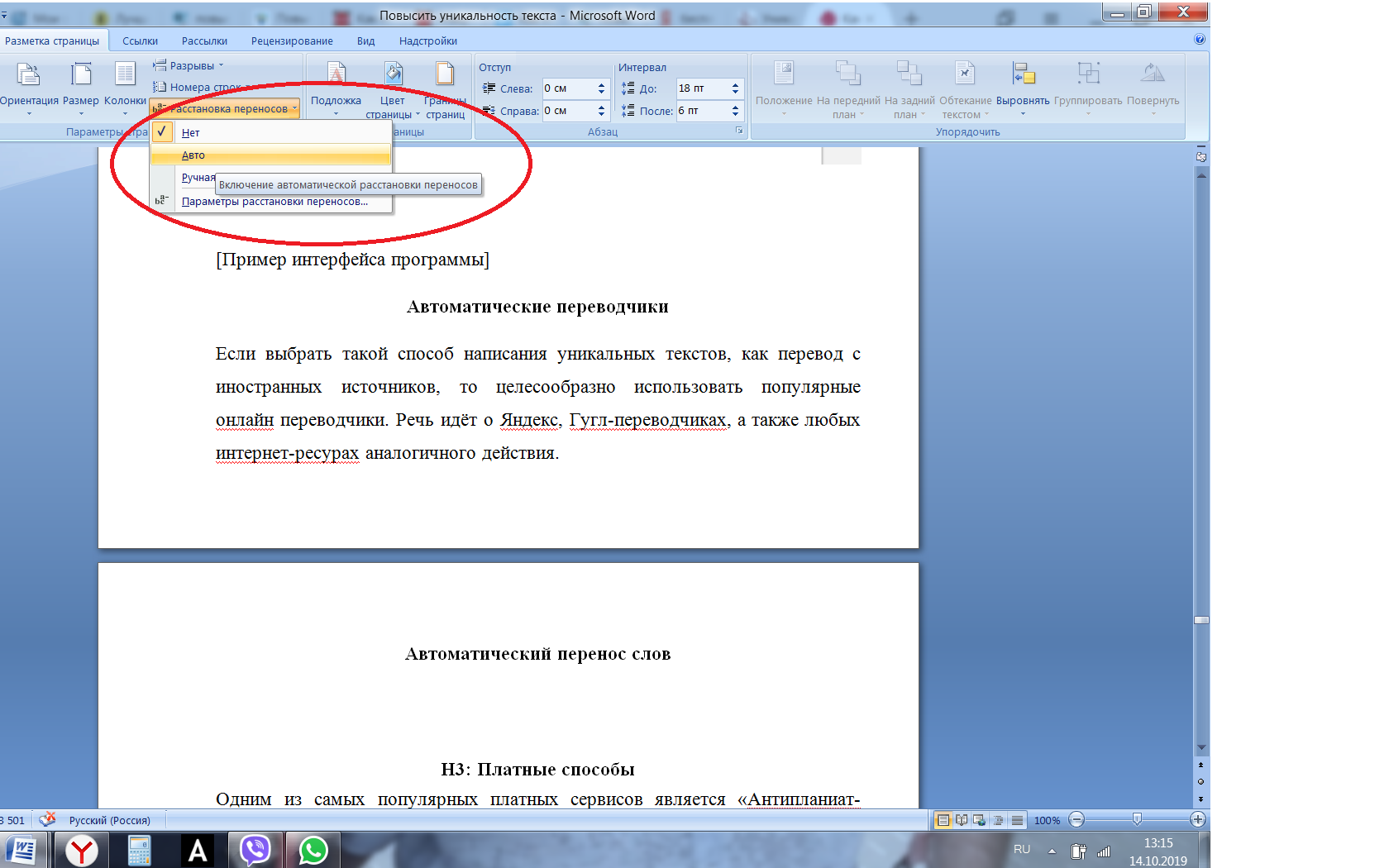 А такое читатели не оценят, разве что поисковый робот уникальность поставит высокую. Но и они научились определять искусственную генерацию. Так что делаем выводы.
А такое читатели не оценят, разве что поисковый робот уникальность поставит высокую. Но и они научились определять искусственную генерацию. Так что делаем выводы.
Взгляд на вопрос с новой точки зрения
Предлагаемая тема «заиграна до дыр»? Если вам она интересна, то почему бы не посмотреть на материал по-новому? Не так, как все, а иначе, свежо, оригинально? Это возможно, если тема – ваша. Предлагаем различные варианты решения вопроса.
Без внимания читателей ваши предложения не останутся. Да и поисковые системы относятся к таким публикациям благосклонно. Полезно? Конечно. Интересно? Безусловно! Значит, ни что не станет препятствием на пути процветания блога!
Польза и информация – главные движущие силы
Если в публикации нет смысла, то и высокая уникальность не спасет. Посетители не станут читать такой материал. Поисковые системы отметят уменьшение интереса, сайт понизят в выдаче… Продолжать не будем. А будем писать полезные и интересные статьи.
Идеи найти можно повсюду, даже пообщавшись на форуме. Разумеется, прежде, чем предлагать что-то необходимо проверить все факты. Подтвердили? Можем писать! Полезность и информационность поисковые роботы учитывают.
Размер имеет значение
Для повышения уникальности можно воспользоваться некоторыми «техническими хитростями». Чем больше размер статьи, тем выше ее уникальность. Расхожие фразы в таком объеме останутся, но понижение «уника» будет меньше. Вывод – пишем объемные тексты.
Не списываем, а пишем. То есть, излагаем своими словами, из головы, придумываем, строим повествование… Как ни скажи, главное – свои мысли, а не списанные.
Хорошо включать собственные мысли вместо цитат: размер текста увеличивается, значит, растет и уникальность. Пересказывать авторские высказывания не нужно, но добавления своих наблюдений способствует повышению ценности публикации. Такой метод, конечно, не подойдет, если объем статьи заранее оговорен заказчиком.
Создаем собственную структуру предложений
При написании текста, некоторых слов и оборотов лучше избегать. Заменим «во-первых», «во-вторых» и так далее списками – уникальность повысится. Не будем увлекаться сложными и длинными предложениям: короткие фразы воспринимаются легче.
Обороты «похоже», «вроде» убираем: обороты не повысят уника. Изменение порядка фраз без потери смысла повышает ценность текста.
Все материалы, на основании которых пишем статью, изучаем подробно и сразу. Для переработки авторских мыслей собственными приемами стилистики и лексики это не6обходимо. Построение предложений желательно сделать не похожим ни на одно произведение.
Включать в публикацию малоизвестные данные, опираться на книги, во Всемирной паутине не выложенные – отличный способ повышения уникальности. Лучше понять вашу статью помогут таблицы, списки и иллюстрации.
Используем эпитеты
К каждому слову русского языка есть немало синонимов и эпитетов. Так почему бы не воспользоваться этим? По страницам толстенных словарей «бродить» в мучительных поисках не придется: есть специальные программы-синонимайзеры.
Но бездумное использование программы может больше навредить: такие замены способны навредить читабельности и смыслу текста и понизить публикацию в выдаче. Если с первым все понятно и определить все довольно просто, то с поисковиками сложнее. И Яндекс, и Гугл «поумнели»: замену слов на синонимы они распознают сразу. Так что копирование с заменой слов пользы не приносит: статья оценивается как неуникальная.
Фразеологизмы освежат публикацию и добавят ей выразительности. Пример: не «тратил время зря», а «бил баклуши». Смысл не изменится, а проверка не покажет, что слово заменили синонимом. При удачной замене система решит, что исходный и авторский текст разные.
Повысить своими силами уникальность нетрудно. Сложно не перестараться. Есть ситуации, когда уникальность лучше оставить на прежнем уровне. Бессмысленно переделывать текст, заполненный терминами более чем наполовину.
Когда уникальность лучше не повышать
Узкоспециализированные тексты, наполненные спецтерминами, переделать невозможно: смысл искажается, а задача автора – дать качественную и достоверную информацию. Замена терминов в инструкции способна нанести вред здоровью человека. Разве стоит уник такой цены? Не нужно забывать об ответственности за каждое слово своей публикации.
Замена терминов в инструкции способна нанести вред здоровью человека. Разве стоит уник такой цены? Не нужно забывать об ответственности за каждое слово своей публикации.
Нормативные документы не рерайтят, как и авторские произведения. Читателю об уникальности неизвестно, а вот ваше посягательство на классику он оценит негативно.
Даже для достижения стопроцентной уникальности искажать текст до безобразия нельзя. Вы же не терминатор, любой ценой добивающийся результата! Задача копирайтера – думать и анализировать.
Во время работы важно думать о читателе, а не об оценке работы Гуглом или Яндексом. Вот потому материал необходимо подготовить достоверный. А как по-вашему: стоит жертвовать смыслом ради уникальности?
С вами был Павел Ямб. До связи!
что делать с плохим текстом
Подробно Создано: 21.03.2017 11:01 Обновлено: 17.05.2019 20:30 Опубликовано: 21.03.2017 11:01
«Все новое хорошо забыто старым.» Так было, есть и будет. Все произведения мира по большей части неуникальны, повторяются. Но рассерженные учителя (или заказчики) вынуждены сдавать свои работы со стопроцентным результатом. Для этого используются специальные программы тестирования на плагиат, которые, к счастью, можно обойти.Но, согласитесь, не всегда есть время или желание пересказывать чужие мысли, никому от этого не пойдет. А в Интернете есть масса способов повысить уникальность текста, и о них пойдет речь в статье.
В некоторых случаях может потребоваться усиление антиплагиата:
- Необходимо повысить уникальность эссе;
- Необходимо повысить уникальность курса;
- Необходимо повысить оригинальность диплома;
- Для повышения уникальности собственного текста для доставки заказчику;
- Уникальность в текстовых документах в форматах: docx, doc, rtf или pdf.
Конечно, есть и другие варианты, когда вы хотите повысить уникальность, но это самые основные.
Основные программы антиплагиата и проверки уникальности
Самый популярный сервис копирайтинга в Рунете. В нем есть свой модуль проверки, который жестче всех остальных, довольно заметно переписан (о нем поговорим чуть позже). Текст считается уникальным при 100% производительности на этом сервисе.
Advego plagiatus
Самая жесткая программа поиска антиплагиата.Обойти это довольно сложно. Программа загружается в компьютер и проверяет каждое предложение текста в Интернете. Антивирус на нее часто ругается. Уникальность текста считается высокой с более чем 90% антиплагиата.
Антиплагиат.ру — сервис, позволяющий проверить бесплатно
Основная программа проверки на антиплагиат в вузах. Именно по нему будут проверяться все курсовые работы и диссертации.Имеет возможность подключения всех научных работ из библиотеки Elibrary.ru. Он находит много общего, поэтому процент более 70% считается хорошим.
и т. Д. — Антиплагиат
Принцип действия аналогичен Advego Plagiatus. Однако он имеет более улучшенный интерфейс и расширенный набор функций, улучшающих проверки. Уникальность текста считается высокой при достижении 100%.
Способы повышения оригинальности текста
Сегодня существуют следующие способы повышения уникальности текста онлайн:
- Переписывание;
- Специальные программы, повышающие антиплагиат;
- Специализированные сайты;
- Собственный пересказ произведения, чтобы в файле был высокий процент.
Это все методы, но в будущем, скорее всего, появятся новые.
Переписывание — как действенный метод повышения оригинальности текста Для одних это форма заработка в Интернете, а для других — отличная возможность повысить уникальность текста. Суть данной работы в том, что исполнитель переписывает фрагменты текста, заменяет слова синонимами и схожими по смыслу.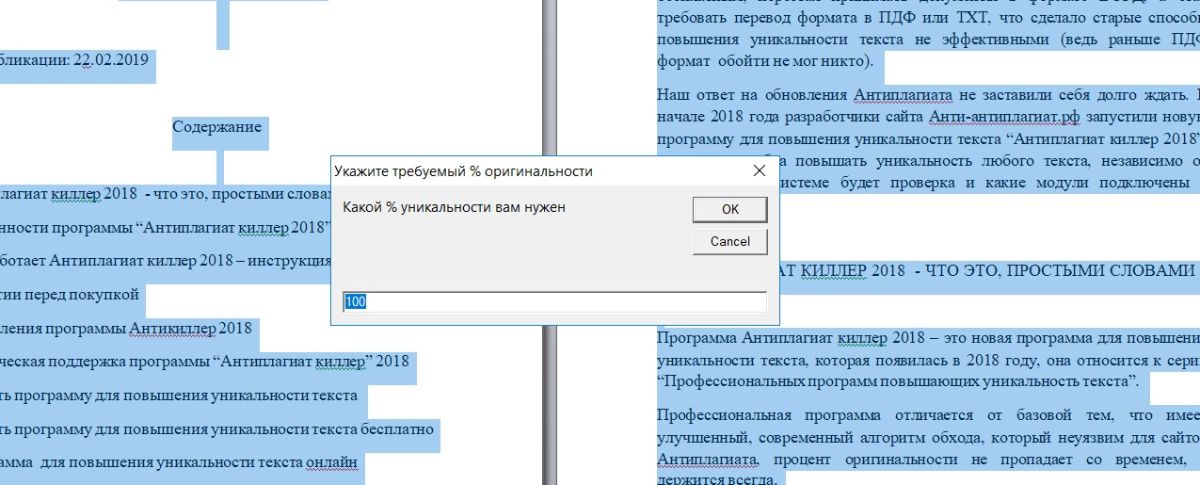 Конечно, эта услуга платная.Цена за тысячу знаков в среднем составляет 25-40 рублей в зависимости от профессионализма исполнителя. Вы можете найти художников на популярных биржах Рунета Text.ru, Etxt и Advego.
Конечно, эта услуга платная.Цена за тысячу знаков в среднем составляет 25-40 рублей в зависимости от профессионализма исполнителя. Вы можете найти художников на популярных биржах Рунета Text.ru, Etxt и Advego.
+ Уникальный артикул, документ;
+ Полностью сохраненный смысл;
+ Довольно низкая заработная плата.
— Оплата все еще есть;
— Ориентировочное время выполнения заказа — 2 дня.
Программы, специализирующиеся на повышении уникальности текстаЕсть варианты как для программ, повышающих уникальность текста бесплатно, так и для платных версий, которые работают немного лучше.Суть этих программ заключается в замене слов синонимами, добавлении слов в предложения, замене русских символов на английские, тем самым пытаясь повысить процент оригинальности документа. Все это сказывается на увеличении и увеличивает оригинальность, однако некоторые программы замечают замену букв. При загрузке таких программ нужно быть максимально осторожными, вы довольно легко можете заразиться вирусом.
Однако их работа заключается в использовании специальных онлайн-алгоритмов, которые легко обнаруживают антиплагиат и обманывают его до отказа.Поэтому повысить уникальность текста в сети не получится, их использование лучше всего подходит для слабых антиплагиаторов, а не таких мощных акул этого дела, которые представлены выше.
Две наиболее распространенные программы борьбы с плагиатом:
Antiplagiat killer
Плюсы и минусы этой опции для увеличения антиплагиата:
+ Самый дешевый вариант из всех;
+ Скорость работы, все происходит онлайн;
— Их работа легко быть антиплагиаторами;
— Есть возможность подбирать вирусы
Сайты помогают повысить оригинальность В Интернете также есть сайты, специализирующиеся на повышении уникальности текста в Интернете. Таких сайтов достаточно; убедитесь, что он не создан мошенниками. Обычно они берут деньги, но не делают работы. Пользуйтесь только проверенными сервисами и понимайте, как повысить уникальность.
Таких сайтов достаточно; убедитесь, что он не создан мошенниками. Обычно они берут деньги, но не делают работы. Пользуйтесь только проверенными сервисами и понимайте, как повысить уникальность.
Обычно существует два алгоритма работы сайтов:
- Использование программ, повышающих оригинальность текста;
- Перепишите.
Программы таких сайтов отличаются от тех, что находятся в открытом доступе.Они используют свои собственные, специальные алгоритмы в программах, которые обычно программа проверки не может найти, и они могут легко помочь повысить оригинальность.
Сайты, использующие перезапись, чем-то похожи на биржи. Обычно у них есть собственный штат рерайтеров, которые переделывают уникальность текста и могут повысить оригинальность на 100%.
Самый популярный и надежный онлайн-сервис, который поможет:
Конечно, вы можете найти множество сервисов, повышающих оригинальность в поисковике, но это проверено временем и удобно, вы можете проверить работу на нем и при необходимости сразу же отправить для увеличения уникальности.Часто наивные мошенники зарабатывают легкие деньги. Не поддавайтесь на уловки.
Эти сайты предоставляют возможность повысить уникальность текста онлайн бесплатно, но только в первый раз в пробной версии. Обычно первое использование ограничено 2000 символами. После вам придется заплатить деньги. Примерная цена 150 руб. за документ. К тому же крупные сайты быстро выполняют заказы, максимум — за сутки. Это может быть удобно при сжатых сроках.
Плюсы и минусы этого метода:
+ Высокая оригинальность;
+ Скорость работы;
— Не бесплатно;
— На мошенников можно наткнуться.
Самосовершенствование оригинальности Обычно учителя хотят, чтобы вы сами увеличили оригинальность текста, переделали несколько источников. Это должно помочь усвоению материала, расширить ваши знания и т. Д. Что ж, если у вас есть свободное время, вы можете сделать это сами. Так вы приобретете знания, не потратите деньги и, возможно, получите удовольствие от работы. А представленные ниже советы помогут вам повысить оригинальность.
Д. Что ж, если у вас есть свободное время, вы можете сделать это сами. Так вы приобретете знания, не потратите деньги и, возможно, получите удовольствие от работы. А представленные ниже советы помогут вам повысить оригинальность.
Гонт Правило
Готовы ли вы получить уникальный текст за 30 минут?
Здравствуйте мой дорогой гость.Сегодня я расскажу о принципе, позволяющем повысить уровень антиплагиатной оценки в выпускной квалификационной работе.
В результате довольно простых и логичных манипуляций вы получите заготовку с высоким уровнем антиплагиата.
В этом примере я повысил уникальность материала из Интернета с уникальности с 0% до 64% всего за пару минут. Естественно, после этого материал нужно отредактировать, но редактирование одного не является уникальным, а совсем другое — что уже можно опробовать.
Уверен, что после прочтения этой статьи вам станет намного проще редактировать свою работу)
Если вы не хотите самостоятельно поднимать собственный антиплагиат, но ищете где его заказать, предлагаю свой услуги по ручному переписыванию произведений (по экономике или юриспруденции) до желаемого уровня уникальности.
С вопросами обращайтесь сюда: vk.com/diplom35. Отзывы клиентов, которые работали со мной, внизу этой статьи.
Весной 2018 года компания ЗАО «Антиплагиат» предложила использовать новые модули поиска плагиата: Интернет и ЭЛЕКТРОННАЯ БИБЛИОТЕКА.RU модули поиска перефразирования.
Способы повышения оригинальности, описанные в этой статье, сейчас немного помогают, хотя если ваша работа проверена без этих модулей, то в принципе они помогут. Вы также можете прочитать эту статью, чтобы понять, как вообще работает антиплагиат.
Программы для ручной уникальности
Что нужно для исправления вашей уникальности? Только Ворд и др. Антиплагиат.
Пример повышения уникальности текста
Так как я финансист и близок к финансовому анализу, я взял из Интернета отрывок текста по финансовому анализу.
Но поскольку программа делает выборки и определяет по ним, заимствован ли текст, решение задачи оказывается элементарным. И это не совет многих учителей «пользоваться журналами» и тому подобным. Программе все равно, откуда берется материал. Если выбор совпадает, текст будет помечен как заимствованный. Поэтому постоянно возникают ситуации, когда вы пишете работы по учебникам, журналам, лекциям и т. Д., И в итоге они показывают вам 40% уникальности или меньше.
Ну а как тогда обойти антиплагиат? Да элементарно. Вам просто нужно разбить эти образцы. Для этого после каждого 3-4-5-го слова нужно поставить любое слово размером более 4 букв. Я выбрал слово «сложный», хотя слово может быть любым. Хотя бы слово «лохматый» или «табурет».
А просто вставьте это слово в текст. После вставки нажмите кнопку проверки.
Вот, собственно, и все. Затем читаем этот файл, исправляем в нем косяки, согласовываем слова.Слово подчеркивает все. И в то же время вы уже точно знаете, что ваша работа отличается высокой оригинальностью. Да, работа довольно муторная, но что поделать.
Хотя при желании можно заказать на любой бирже студенческие работы. На таких биржах ваши работы будут переписаны для любого уровня уникальности. Но обязательно укажите в том порядке, что вам нужна перезапись, а не какая-то обработка. Так как от недобросовестного исполнителя может быть сюрприз. А если вы указали это прямо в заказе, то в случае возникновения спора вас просто заменит исполнитель или вернут деньги.
Ссылка на биржу с наибольшим количеством исполнителей: author24.ru. Зарегистрируйтесь, разместите заказ и дождитесь, пока подрядчик (или несколько) исправят вашу работу за вас)
Если у вас хозяйственная или юридическая работа — предлагаю вам свои услуги по рерайтингу — подробнее в конце статьи.
Ну или если будет время — отредактируй сам. И не бойтесь, что вас заворачивают из-за антиплагиата. Поправлю на пару дней. При этом материал вы будете знать лучше)
Обратите внимание, я копирую не всю работу сразу, а по частям..jpg) Например, от начала раздела к таблице, затем от таблицы к рисунку и так далее. Потому что форматирование таблиц в программе не сохраняется. Поэтому оставляю их в Ворде как есть, а когда вся работа завершена, добавляю слова в таблицы.
Например, от начала раздела к таблице, затем от таблицы к рисунку и так далее. Потому что форматирование таблиц в программе не сохраняется. Поэтому оставляю их в Ворде как есть, а когда вся работа завершена, добавляю слова в таблицы.
Основные ошибки, которые вы можете сделать при усилении антиплагиата:
1. Отредактируйте антиплагиат в исходном файле Word. Не делайте этого. Необходимо повысить уникальность в окне антиплагиат etxt, потому что оно показывает, где именно нужно вставить слова, или слово из этого окна копируется в отдельный документ, чтобы не потерять работу при случайном закрытии программы.
2. Перепишите своими словами. Не делайте этого. Вполне вероятно, что кто-то с такими же словами что-то уже написал. Экономисты каждый год выпускают облака. Необходимо разбивать фразы дополнительными словами
3. Необязательно вставлять бессмысленное слово (как в примере). Основная логика повышения уникальности — разорвать цепочки слов. Вы можете заменить каждое четвертое на пятое слово: вместо существительного сделать местоимение прилагательным, изменить части речи, вы можете размещать фразы внутри абзаца и т. Д.И опять же, в etxt antiplagiat это удобно делать, потому что там выделены заимствованные фрагменты. И новые слова и фразы будут на белом фоне. Вы можете очень ясно увидеть, разорвали ли вы цепи или нет.
Какие слова я могу вставить? Самый простой вариант — это название организации, которой вы пишете работу. Эта фраза неизменна. Например, ПАО «Сбербанк России» — может вам помочь — пример на рисунке. Затраченное время — 30 секунд.
На мой взгляд, первые 3 пункта для повышения уникальности нет смысла использовать, а вот остальные вам полностью помогут.
Удачи. С уважением, Александр Крылов.
Ваши вопросы и мысли — в комментариях.
Помощь в повышении уникальности работы в хозяйстве.
Предлагаю Вашему вниманию свой сервис по рерайтингу на предмет антиплагиата.
Естественно, без всякой техники, кодировок и тупой замены синонимами (синонимизация). Просто переписать.
Стоимость и сроки зависят от количества страниц и размера, на который нужно поднять уникальность работы.По порядку и вопросам — стучите, пожалуйста.
Подробно Создано: 21.03.2017 15:09 Обновлено: 17.05.2019 20:32 Опубликовано: 21.03.2017 15:09
Очень часто преподавателям разных учебных заведений приходится перечитывать полностью идентичные главы в произведениях своих учеников. Студенты не придают особого значения бездумному копированию информации из Интернета, забывая, что она доступна практически каждому пользователю глобальной сети. Теперь, чтобы учитель принял диплом или курсовую работу, она должна пройти обязательный тест на уникальность.Во избежание подобных эксцессов с 2006 года в учебный процесс введена программа тестирования на антиплагиат. Студенты, естественно, совсем не довольны этим типом проверки работы на уникальность и поэтому ищут способы обойти антиплагиат без ущерба для содержания или семантической составляющей.
Студентам, которым необходимо проверять текстовые произведения с помощью общей программы, следует более подробно изучить материал, в котором представлены наиболее популярные методы обхода системы проверки на уникальность.
Определение плагиата
Чтобы разобраться в сути вопроса, необходимо разобраться в этимологии слова «плагиат». Подразумевает заимствование или присвоение информационных данных без разрешения автора, так как сам плагиат можно рассматривать с двух сторон:
- Сохранение основной структуры с изменением словесного содержания;
- Копирование всей информации без изменений.
Как пройти антиплагиат: жгучие секреты
Проверить текстовую информацию на уникальность с помощью бесплатных утилит Большинство этих программ работают на определенном сайте. К наиболее распространенным сервисам онлайн-проверки относятся:
К наиболее распространенным сервисам онлайн-проверки относятся:
Exchange Text.ru , который быстро и точно выявляет не только повторяющийся текст, но и выполняет поиск ошибок и уровней спама.
Ресурс Антиплагиат.ру
Сайт профессионалов Content-watch.ru , которые автоматически сканируют целые веб-страницы и документы.
Компьютерные утилиты включают:
Ett , можно скачать с сайта биржи;
Advego , продается на одноименной бирже.
Они используют такие сложные системы проверки, что пройти антиплагиат становится все труднее. Антиплагиат.ру считается самым распространенным и надежным сервисом, и именно его используют большинство учителей для определения антиплагиата.
Т.к. основной целью аудита является определение максимального количества заимствований. Поэтому программа дает полный отчет об уровне уникальности и количестве использованных источников. Благодаря получению подробной информации возможно усиление антиплагиата, что в последнее время сделали все студенты средних и высших учебных заведений.Преимущество этой работы заключается в том, что во время активного поиска приходят необходимые знания, навыки, которые можно использовать в будущем для написания собственных работ. Правда, единственным существенным нюансом программы является то, что она указывает только объем заимствованного текста, без акцента на специально включенные цитаты, вроде плагиата.
Для пополнения сбора информации сервисы проверки уникальности используют базы данных как с открытым, так и с закрытым кодом. Естественно, об алгоритме проверки никто не распространяет, поэтому можно только догадываться, как работает система.Однако, несмотря на такую секретность, многие люди методом проб и ошибок выявляют методы, с помощью которых можно повысить уникальность текстов.
Как работает система проверки уникальности антиплагиата?
Если вы понимаете общую схему работы механизма антиплагиата, то можете определиться со способами его обхода. Фрагмент текста, добавленный в систему проверки уникальности, определяется как набор отдельных предложений, которые, в свою очередь, делятся на фразы и отдельные слова.Первоначально система ищет похожие предложения, обычно ориентируясь на их отдельные фрагменты. Программа проводит семантический и синтаксический анализ, при нахождении большого количества совпадений приходит сообщение о наличии плагиата в тексте.
Теперь становится понятно, как повысить уникальность текста, используя синонимичные слова или словосочетания в любом порядке, не меняя смысла взятого текста. Поскольку на это часто уходит много времени, есть несколько способов ускорить работу.
Методы, которые уже нельзя обойти с антиплагиатом:
Методы, которые уже неэффективны, их использование можно только потратить впустую:
- Исправление букв кириллицы и латинского алфавита;
- Перенос абзацев из одной части в другую;
- Простая перегруппировка слов в одном предложении;
- Объединение простых предложений в сложные и наоборот;
- Замена знаков препинания;
- Использование белых символов вместо пробелов;
- Простая замена синонимами.
- Уникальность не может быть увеличена путем добавления скрытых символов.
Разработчики ежегодно обновляют модули верификации, доводя свою работу до совершенства, поэтому такие примитивные методы больше не помогают. Даже если работа написана самостоятельно, то есть устойчивые фразы, без которых невозможно написать курсовой или дипломный проект, поэтому учебные заведения ставят допустимую уникальность выше 70%, и студенту придется повышать свою оригинальность до порога, требуемого Университет.
Но есть еще действенные способы повысить процент уникальности текста без ущерба для смыслового наполнения.
Как обмануть систему? Самые актуальные секреты и рабочие варианты обхода антиплагиата в 2018 г.
Самым эффективным методом на сегодняшний день является самостоятельная презентация выбранного материала на доступном языке с изменением словоформ или синонимов. Конечно, с помощью этого метода получить 100% уникальность тоже довольно сложно, нужно будет приложить максимум усилий.
Людям с ограниченным количеством свободного времени стоит обратиться за помощью к грамотным специалистам, которые точно знают, как обмануть антиплагиат в 2018 году. Это будет отличным решением для тех, у кого достаточно денег.
Копирайтеры, предпочитающие самостоятельную работу, могут использовать несколько простых приемов, которые были успешно протестированы многими людьми:
- Форматирование текста в Word с добавлением специальных символов, скрытых под белой краской. Из-за таких изменений текст больше не будет адекватно восприниматься Антиплагиатом;
- Уникальный фрагмент текста, многократно скопированный и введенный в поле «надпись».Правда, система увидит гораздо большее количество символов, и это может вызвать подозрение у инспектора;
- Выбор сложных и менее популярных тем для курсовых работ, дипломов или рефератов значительно повысит уникальность за счет меньшего количества копий;
- Можно использовать множество выдержек из бумажных изданий последних выпусков, в том числе статьи из журналов, информационные видеоролики онлайн-конференций, вероятность попадания в общую базу антиплагиата значительно снижена;
- При отсутствии проблем с грамматикой и лексикой можно использовать сложную перифразу с изменением семантического и синтаксического ядра с сохранением литературной формы и читабельности.
- Зарубежные печатные издания станут большим подспорьем в уникальном произведении.
- При использовании синонимических словоформ и фразеологизмов необходимо внимательно следить за отсутствием стилистических недостатков, обусловленных незнанием этимологии того или иного употребляемого слова;
- Вы можете значительно увеличить объем работы, добавив «воды», что снижает процент нахождения похожих предложений или фраз. Это актуально для филологов, чьи работы наполнены большим количеством цитируемого текста.
Все эти методы требуют от человека времени, усидчивости и начитанности, но есть решения для людей, творческие способности которых не выходят за рамки обычного. Чтобы упростить работу, вы можете использовать программные средства для прохождения антиплагиата.
Программные способы повышения антиплагиата бесплатно
- Word считается наиболее распространенным с возможностью создания макросов или областей невидимого текста, поскольку макросы позволяют повысить уровень антиплагиата, добавляя в текст левые символы Юникода.
- Использование изображений некоторых фрагментов текста, что повысит уникальность, скрывая при этом неуникальные фрагменты. Этот метод работает для таблиц и формул, которых в диссертациях очень много, особенно по техническим специальностям.
- Воспользуйтесь онлайн-сервисом, который заменяет часто встречающиеся слова синонимичными формами или фразами. Он хорошо работает, когда у вас много времени и вы можете вычитать полученный текст, исправлять дефекты и изменять синонимы, которые не были заменены вручную.Этот метод не подходит для технических и медицинских работ, так как к ним просто не найдешь синонимов.
Мошенничество с антиплагиатом: внимание, есть риск, что учитель сожжет
Большинство инструментов повышения уникальности платные и не всегда эффективные, поэтому вам следует несколько раз подумать, прежде чем повышать оригинальность. В противном случае все придется переделывать самостоятельно и в спешке. Часто большинство программных инструментов нацелены на выявление пробелов в программах борьбы с плагиатом.Поэтому, получив отличную уникальность в рамках одной услуги, не факт, что она останется после тщательной проверки на платных ресурсах. Если есть возможность, желательно сразу доверить работу профессионалу, чтобы потом не беспокоиться об избавлении от повторяющихся фрагментов.
Несколько советов о том, как бесплатно обойти систему антиплагиата
Эти советы особенно важны для студентов и студентов, которые решили самостоятельно корректировать работу.
- В каждом учебном заведении есть базовая программа для проверки уникальности, ее необходимо скачать;
- Проверьте готовый текстовый файл, чтобы получить информацию о его уникальности;
- Выберите один из предложенных вариантов повышения уникальности;
- Внесите свои собственные настройки. Желательно сделать копию с оригинала, чтобы все можно было исправить в случае неудачи;
- Довести работу до необходимого уровня уникальности с запасом 5-6%;
- Сохраните результат.
Все подсказки помогут решить главный вопрос школьника, как самостоятельно обойти антиплагиат, и при этом сохранить семантическую начинку.
- Опытный и высококвалифицированный преподаватель без проблем сочтет неправильным то, что в работе много плагиата и она скачивается из Интернета. Можно обойти программы антиплагиата, но профессионального преподавателя в своей области нет. За годы своей работы он просмотрел сотни работ по разным темам и сразу же раскроет ранее сданные работы, если они не будут существенно обработаны профессионалами.
- Все темы курсовых и дипломных работ в старших классах не меняются годами. Все они так много раз сдавались, что не знать прошлогодней работы очень проблематично. Те учителя, которые вообще не читают работу, не заметят, что работа не уникальна и, возможно, тупо скачана из Интернета.
- Когда учитель сбрасывает форматирование, он видит, что все слова в работе подчеркнуты красным и ученик пытался пройти антиплагиат, а соответственно и он сам.Учитель может просто выборочно взять несколько произведений из работы и набрать их вручную в любой поисковой системе и узнать, откуда работа была скачана.
Как бы ученик ни пытался самостоятельно обмануть систему антиплагиата — результат всегда печальный, поэтому — творчески переписать текст работы с сохранением смысла и ни один преподаватель не сможет ничего доказать и не принять работу !
Наш сайт предоставляет услуги по повышению уникальности вашей студенческой работы по Антиплагиату. ru система, антиплагиат. Университет, RUKONText, Etxt, Advego, Text ru. Если описанные выше действия кажутся вам очень сложными и трудоемкими, или у вас совсем нет на это времени, доверьте эту работу профессионалам! Заполните форму на нашем сайте, выбрав интересующую вас систему проверки уникальности, и наши специалисты оперативно свяжутся с вами!
ru система, антиплагиат. Университет, RUKONText, Etxt, Advego, Text ru. Если описанные выше действия кажутся вам очень сложными и трудоемкими, или у вас совсем нет на это времени, доверьте эту работу профессионалам! Заполните форму на нашем сайте, выбрав интересующую вас систему проверки уникальности, и наши специалисты оперативно свяжутся с вами!
Не всегда удается добиться высокой (разумеется, по антиплагиатным системам) оригинальности произведения, так как в Интернете уже размещено огромное количество различных работ и текстов.Этот вопрос очень популярен среди студентов и авторов, пишущих на заказ, поскольку приходится использовать информацию из Интернета, а она редко бывает оригинальной и уникальной.
В нашем обзоре мы собрали советы, которые могут помочь авторам и студентам повысить процент оригинальности своих работ.
Итак, вы написали работу (неважно, курсовую это или статью), вы проверили ее через службу проверки заемщиков, например, «Антиплагиат» и ох … эта система говорит, что текст на 60% не уникален.Это происходит и будет с каждым годом все больше и больше.
2. При переписывании читайте сразу несколько предложений, это позволит не потерять основную идею, выраженную в тексте;
3. поменять местами абзацы;
4. в обязательном порядке менять заголовки;
5. взять материалы из нескольких источников;
6. Не копируйте даже предложение целиком;
7. использовать синонимайзеры;
8. использовать программы для проверки уровня заимствований; они выделяют неоригинальный текст.
Повысить оригинальность курсовых и диссертационных работ описанными выше способами крайне сложно, так как часто приходится использовать устоявшиеся выражения, обоснования и т. Д. Также практически невозможно добиться высокой оригинальности работы, если работа написана. по технической теме.
Если вам нужно сделать работу оригинальной для службы проверки на плагиат, вы можете обойтись без всех описанных выше уловок, наш сайт онлайн-сервиса вам в этом поможет
сайт — без изменения текста, повысит оригинальность текста любой работы до нужного вам процента всего за несколько минут. И ни одна программа или сервис не усомнятся в оригинальности и уникальности вашего текста.
На все вопросы о нашем онлайн-сервисе вы можете получить ответы в разделе часто задаваемых вопросов.
Прежде чем приступить к работе с оптимизацией, следует запомнить главное правило современного SEO-продвижения — вся информация должна быть для людей! Не должно быть бесполезной информации и «московские двери дешевы», что нигде не будет смотреться естественно. В Яндексе вы не найдете в ТОП-100 таких сайтов — они ушли в прошлое.Ниже мы расскажем, как составить необходимую комбинацию из сложного «ключа».
Опытный автор, который обычно пользуется спросом у клиентов:
⦁ Подписан на список рассылки авторитетных источников, следит за новой информацией, знает, как выбираются ключи и строится сайт.
⦁ Имеет навыки продавца автоответчика, интригует без вопросов клиента.
⦁ Идеально — подбирает «ключи» для статьи, опытной рукой соединяет их между собой.
Список необходим для эффективного продвижения сайта. Если все будет сделано правильно, к нему обратятся новые клиенты. Без работы опытного автора сайт не сможет найти своих клиентов.
Даже если нанять дизайнеров и создать красочную комфортную атмосферу, это не поможет увеличить количество пользователей. Один из важнейших критериев — уникальность текста на Яндексе или Гугле.
В чем уникальность артикула?
Это основной инструмент для качественного содержания сайта.Каждая новая статья регистрируется в поисковой системе как принадлежащая определенному сайту. Вы не можете сделать копию — контент не может быть размещен, так как он будет дубликатом существующего. Это невыгодно ни поисковой системе, ни людям, ищущим ответ на вопрос.
Где проверить текст на уникальность
Для этого существуют специальные сервисы, отслеживающие повторяющиеся статьи. Самые большие — это текст ru () и. Во втором% будет немного ниже, в первом — выше.Где лучше проверить уникальность текста? Однозначного ответа нет, но большинство предпочитает text. ru, он более лоялен к статьям, а его алгоритмы наиболее близки к поисковым системам.
ru, он более лоялен к статьям, а его алгоритмы наиболее близки к поисковым системам.
- Какой должна быть уникальность копирайтинга на text.ru
Действительно минимум 95%, в идеале 100%. Номер указан чуть выше скопированной статьи. Копирайтинг — это информация, основанная на личном опыте.
- Какой должна быть уникальность перезаписи текста.ru
Если заказчик указывает в тех. Переписывание задания — это означает, что вам нужно сделать точную копию существующей статьи. Допустимое значение — 90-95%. Но повысить уникальность текста с 95% до 100% не составит труда (см. Ниже), поэтому часто можно соблюсти требуемые 100%.
В чем должна быть уникальность копирайтинга на advego.ru? Добиться 100% уникальности текста намного сложнее, чем в text.ru. Поэтому клиенты часто устанавливают стоимость копирайтинга 95-97%.
- Какой должна быть уникальность переписывания на advego.ru
Значение может варьироваться от 85 до 95 процентов. Но этот сервис не так популярен, как text.ru из-за немного завышенного алгоритма. Уникальность Advego нужна требовательному заказчику и опытному, крепкому нервному автору, хорошо разбирающемуся в тематике.
Где еще проверить текст на уникальность? Сервисов много, а точнее сколько бирж копирайтинга — столько версий документов.На старых% будет меньше, на новых — больше. Часто их алгоритмы не соответствуют действительности, они могут приукрашивать или наоборот — слишком высокие критерии. Лучший ответ на вопрос, где «проверить текст на уникальность?» Есть сайт text.ru.
Как добиться хорошей уникальности документа
Правило №1 — прежде чем проверять тексты на уникальность, нужно хоть немного разобраться в теме статьи. Новичкам не хватает словарного запаса синонимов, чтобы сделать точную копию существующей статьи.Если сравнить тексты — они будут очень похожи, но с переставленными словами, что не увеличивает%.
- Как написать продающий текст для сайта
Для этого необходимо обладать навыком «глухого продавца», то есть самостоятельно угадывать мысли читателей без их вопросов. Последний не станет листать до конца и слушать глухого продавца, чтобы узнать информацию, если ему это не интересно. Автор должен уметь преподавать информацию, чтобы клиент не задавал ни единого вопроса и не уходил от скуки.
Последний не станет листать до конца и слушать глухого продавца, чтобы узнать информацию, если ему это не интересно. Автор должен уметь преподавать информацию, чтобы клиент не задавал ни единого вопроса и не уходил от скуки.
Приходит только с опытом и качественно, продающая статья считается верхушкой айсберга копирайтинга. Добиться уникальности текста удастся, если у вас будет достаточно знаний в данной теме или достаточный запас синонимов для выделенных неуникальных фраз.
- Как определить уникальность текста
Для этого необходимо скопировать написанную статью в специальное поле, указанное на сайте text.ru.
После этого фиолетовым цветом выделяются неуникальные фрагменты.Замените их синонимами, тогда вам нужно будет сравнить тексты. Если выделение пропадает, значит, мы все сделали правильно.
Как повысить уникальность документа
- Как увеличить процент уникальности текста в сервисе text.ru
Для этого с помощью сервиса http://jeck.ru/tools/SynonymsDictionary вы можете искать подходящие синонимы для выбранных слов. Так вы сможете быстро и качественно повысить уникальность документа.Также еще один ответ на вопрос «Как добиться или как сделать хорошую уникальность» может быть перефразированием предложения с конца.
Перед тем, как увеличить процент уникальности, вы можете заранее ознакомиться с предложением. Таким образом можно повысить уникальность документа.
- Как повысить уникальность текста с помощью субтитров
Необходимо ввести их в поиск, сравнить между собой, выбрать наиболее подходящий синоним для совпадений.
Какова роль субтитров в статье
Они играют главную роль, так как поисковые системы проверяют на уникальность между собой все аналоги. Часто покупатели задаются вопросом «Как повысить уникальность текста?» указывают в задаче придумать уникальные подзаголовки.
- Какой должна быть уникальность текста при использовании выдающихся неуникальных ключей
До 90%, если ниже, сообщить заказчику о необходимости уменьшения ключей.
Следует использовать менее часто используемые слова («свяжитесь с нашим консультантом»).
- Как сделать фрагмент документа, который никоим образом не становится уникальным, уникальным
Разбавляем его вставкой слова / фразы в середине предложения.
Еще один способ из категории «как увеличить процент уникальности» — это встраивать неуникальные фрагменты в списки.
В документах в формате Word есть специальные символы вверху, маркированные и нумерованные списки:
Таким образом, вы можете сами повысить оригинальность текста в антиплагиате.Опытные копирайтеры не рекомендуют использовать программы для автоматического повышения уникальности. Для удобства ввода одних и тех же ключей допускается использование макросов, находящихся в Word во вкладке «Вид» справа.
- Как определить уникальность текста в Advego Plagiatus
Перед проверкой необходимо скачать программу с сайта advego.ru. Затем скопируйте статью в поле и щелкните значок Инь-Ян вверху, указывающий на глубокую проверку:
- Что должно быть уникального при копирайтинге в программе Advego Plagiatus
- Что должно быть уникального при выполнении перезаписи?
В пределах 90-95% при выполнении задачи лучше всего уточнять детали с заказчиком, чтобы не было инцидентов и изменений.
- Какой должен быть процент уникальности текста при воспроизведении статей
В пределах 90-95%, так как это глубокая перезапись. При этом уникальность текста на сайте text.ru должна быть в пределах 93-97%. При том, что при воспроизведении статей появляется много персонажей, которые нигде не встречаются.
При копирайтинге уникальность текста на сайте text.ru должна быть не менее 95%. Теперь, изучив материал, можно довести его до совершенства.
Все дело в словах. Почему искусственный интеллект может улучшить ваш текстовый контент
Написание вдохновляет, но это также трудоемкое занятие, которое может утомлять. К счастью для всех писателей в мире, искусственный интеллект может помочь сделать ваше письмо быстрее, эффективнее и даже интереснее для вашей аудитории .
К счастью для всех писателей в мире, искусственный интеллект может помочь сделать ваше письмо быстрее, эффективнее и даже интереснее для вашей аудитории .
Эксперты говорят, что робот сам напишет статью только тогда, когда он сможет пройти тест Тьюринга, и ни одна машина еще не достигла этой цели.
Тем не менее, , даже если он еще не может стать следующим Хемингуэем, искусственный интеллект может — как это часто бывает — изменить ситуацию на . Неспособность конкурировать с писателями-людьми на равных не означает, что у технологий искусственного интеллекта нет потенциала.
Сегодня мы увидим, как ИИ может улучшить написание текста и выделить ваш контент.
Как ИИ может улучшить ваше профессиональное письмо
Всегда была проблема, которая заключалась в точности и эффективном использовании инструментов .Некоторые профессиональные писатели, такие как Джордж Р. Мартин — автор знаменитой саги A Song of Ice and Fire — говорят, что инструменты бесполезны для людей с уже хорошо развитыми письменными навыками.
Написать привлекательный и привлекательный контент — трудный, но увлекательный занятие. Каждый, кто пишет о работе, прекрасно знает , как это делать и насколько это может быть сложно . Если вы профессиональный писатель, вы также знаете, что вам нужно выиграть несколько испытаний, чтобы ваша работа продолжалась.
Прежде всего, вам нужно выбрать и идея — хорошая . Затем вы просматриваете веб-страницы, чтобы убедиться, что эта небольшая подсказка ценна и что исходных материалов достаточно. Может быть, вы даже могли бы подчеркнуть пару многообещающих предложений. Опять же, вы пишете стиль , систематизируйте свои идеи в связную статью .
Только после этого вы можете положить руки на клавиатуру и начать строить свой кусок письма . Вам нужно будет найти лучший способ сформулировать свое сообщение, и это может занять некоторое время. Вы должны учитывать такие элементы, как стиль, целевая аудитория, SEO (для цифровых публикаций) и качество вашего контента.
Вы должны учитывать такие элементы, как стиль, целевая аудитория, SEO (для цифровых публикаций) и качество вашего контента.
Конечно, это еще не конец. Вы перечитаете свою работу, и вы, вероятно, что-то измените — например, слишком сложное предложение. И последнее, но не менее важное: вы загрузите его на свой веб-сайт и будете продвигать в социальных сетях с помощью спонсорства и рекламы.
Это долгий и сложный процесс. Есть что-нибудь, чтобы упростить? Это и есть Искусственный интеллект .ИИ может помочь всему процессу написания разными способами, от поиска источников до проверки того, насколько свободно написана ваша статья. Он может сделать это самостоятельно практически в кратчайшие сроки, позволяя вам писать более конкретный, лучше написанный контент за меньшее время, чем когда-либо.
AI также становится лучше в распознавании контекста и понимании смысла написанного текста. Мы увидим пару ситуаций, в которых ИИ потенциально может спасти ваш синдром белой страницы.
- Проверка качества контента .Как узнать, настолько ли хороша ваша статья, как вы надеетесь? Если у вас нет никого, кто мог бы это проверить, вы можете попросить ИИ помочь. Многие инструменты могут делать именно это; они проверяют качество вашего письма и даже его читаемость . Если вы обеспокоены неправильным словом или написали слишком длинное предложение, они помогут вам облегчить беспокойство. Грамматика — один из самых важных инструментов для этого. Еще один инструмент, который может помочь вам достичь поставленных целей по качеству контента, — это Hemingway. Это онлайн-редактор письма, который использует ИИ для выявления проблем с письмом с помощью НЛП, а также ошибок и элементов цветовой кодировки до совершенства.
- Найдите идеальный источник . Если вы когда-либо что-то писали, вы прекрасно знаете, насколько болезненным может быть прокрутка веб-страниц в поисках ценных источников. AI может помочь вам сэкономить времени и энергии и найти именно тот товар, который вам нужен . Как это сделать? Это может быть сделано разными способами, например, путем составления краткого изложения темы конкретной статьи. Воспитывайте свое вдохновение, выбирая для вас тематические сообщения и новости.
- Упрощение написания контента .Может ли ИИ ускорить написание контента? Да, оно может! Content Creator — это инструмент GhostwriterAI, разработанный, чтобы помочь вам создавать новый текстовый контент за половину времени . Он использует искусственный интеллект для извлечения ценных фрагментов контента из выбранных вами источников, поэтому вам не нужно начинать с нуля. Более того, он изучает ваш стиль письма. Чем больше вы напишете, тем больше это поможет вам автоматизировать написание.
- Больше никакого плагиата . Плагиат — одно из худших вещей, которые могут случиться с писателем.Иногда это даже бессознательно или непреднамеренно, но бывает. Вы можете скопировать предложение из этой интересной статьи и забыть вставить источник, или сделать это намеренно. Неважно, действуете ли вы добросовестно, это все равно неправильно и наказывается за вашу статью. Как этого избежать? Программное обеспечение AI может анализировать предложения, которые вы пишете, и сканировать Интернет, чтобы выяснить, есть ли подозрительное совпадение с чьей-то бумагой .
 AI может помочь вам сэкономить времени и энергии и найти именно тот товар, который вам нужен . Как это сделать? Это может быть сделано разными способами, например, путем составления краткого изложения темы конкретной статьи. Воспитывайте свое вдохновение, выбирая для вас тематические сообщения и новости.
AI может помочь вам сэкономить времени и энергии и найти именно тот товар, который вам нужен . Как это сделать? Это может быть сделано разными способами, например, путем составления краткого изложения темы конкретной статьи. Воспитывайте свое вдохновение, выбирая для вас тематические сообщения и новости.
Freepik
Почему ИИ не заменит писателей-людей (пока)
Даже если использовать ИИ для написания необычных звуков, мы должны помнить, что маловероятно, что робот когда-либо полностью возьмет на себя работу журналиста.
Как мы уже говорили, это потому, что ни одна машина никогда не проходила тест Тьюринга, но есть еще . Искусственный интеллект и машинное обучение — два удивительных метода, которые иногда могут показаться волшебными. Однако они по-прежнему машины, подчиняющиеся приказам.
Это означает, что им не хватает одного фундаментального качества навсегда писателя, которым является творчество . Эмоции и навыки рассказывания историй имеют решающее значение для создания значимой истории, которая поражает сердца людей, и в настоящее время только люди могут это делать.
Теперь ясно, что AI — не угроза для вашего профессионального писателя, а ресурс , который может облегчить вашу работу. Как с этим справляются технологии? Есть ли уже книги, написанные искусственным интеллектом? Может ли машина написать вдохновляющее эссе, захватывающий роман или захватывающую сагу? Как мы уже говорили, это маловероятно, но ИИ значительно продвинулся в понимании и написании текста. Давайте посмотрим на пару таких потрясающих примеров.
- Книги СБ Эхада .Книги этого загадочного автора месяцами остаются бестселлерами. Неудивительно, что публика в восторге от того, что писатель впервые проявил себя на Оксфордском литературном фестивале. Все звучит захватывающе, но сюрприз был еще больше, потому что фактическим автором был… компьютер с именем 3B1 (на иврите это можно перевести как Шалош Б. Эхад). Рядом с ним — программист Математического института Оксфордского университета, который дал ему жизнь. Код позволял компьютеру просматривать все книги в Бодлианской библиотеке.Результат был невероятным, потому что ноутбук развивался сам по себе и понимал, что люди ценят больше всего.
- AI напишет следующую книгу о Гарри Поттере . Есть роман Роальда Даля «Великий автоматический грамматизатор», в котором суперкомпьютер может сам писать романы для массового производства. По сюжету машина используется для шантажа известных авторов, но, к счастью, реальность немного иная.
Группа программистов создала коллектив под названием Ботник и решила выпускать литературу на основе ИИ .Программа проанализировала семь книг JKR и подготовила первые три страницы новой книги о Гарри Поттере.
Название? «Гарри Поттер и портрет, похожий на большую кучу пепла». Продукт оказался на удивление убедительным, хотя и не безупречным. - AI в журналистике . ИИ становится огромным подспорьем в журналистике. Например, Forbes использует AI, чтобы предоставить журналистам и репортерам шаблоны и первые черновики для написания следующей статьи . ИИ работает путем преобразования данных в реальном времени в беглое повествование.
 Название? «Гарри Поттер и портрет, похожий на большую кучу пепла». Продукт оказался на удивление убедительным, хотя и не безупречным.
Название? «Гарри Поттер и портрет, похожий на большую кучу пепла». Продукт оказался на удивление убедительным, хотя и не безупречным. Что дальше? Вероятно, следующей революцией станет NLU (понимание естественного языка), которая заставит людей и компьютеры понимать друг друга.
Мы не знаем, что произойдет, но нам не терпится увидеть это!
Выводы
- Написание текста — важная задача для маркетолога, но это может быть тяжелая работа. AI может помочь вам сделать это проще и быстрее.
- AI становится лучше в распознавании контекста и понимании смысла написанного текста.Это может помочь писателю во многих отношениях, от предотвращения плагиата до проверки источников.
- AI может помочь вам писать, но у него нет (пока?) Творческих способностей для создания оригинального и связного текста самостоятельно.
Источники
Представляем DeepText: механизм распознавания текста Facebook
Текст — распространенная форма общения на Facebook. Понимание различных способов использования текста на Facebook может помочь нам улучшить взаимодействие людей с нашими продуктами, независимо от того, просматриваем ли мы больше контента, который люди хотят видеть, или отфильтровываем нежелательный контент, такой как спам.
С этой целью мы создали DeepText, основанный на глубоком обучении механизм понимания текста, который может понимать текстовое содержание нескольких тысяч сообщений в секунду на более чем 20 языках с точностью, близкой к человеческой.
DeepText использует несколько архитектур глубоких нейронных сетей, включая сверточные и рекуррентные нейронные сети, и может выполнять обучение на уровне слов и символов. Мы используем FbLearner Flow и Torch для обучения модели. Обученные модели обслуживаются одним нажатием кнопки через платформу FBLearner Predictor, которая обеспечивает масштабируемую и надежную инфраструктуру распределения моделей.Инженеры Facebook могут легко создавать новые модели DeepText с помощью архитектуры самообслуживания, которую предоставляет DeepText.
Почему глубокое обучение
Понимание текста включает в себя несколько задач, таких как общая классификация, чтобы определить, о чем пост — например, о баскетболе — и распознавание сущностей, таких как имена игроков, статистика игры и другая значимая информация. Но чтобы приблизиться к тому, как люди понимают текст, нам нужно научить компьютер понимать такие вещи, как сленг и определение смысла слов.Например, если кто-то говорит: «Мне нравится ежевика», это означает фрукт или устройство?
Понимание текста на Facebook требует решения сложных задач масштабирования и языковых проблем там, где традиционные методы НЛП неэффективны. Используя глубокое обучение, мы можем лучше понимать текст на нескольких языках и использовать помеченные данные намного эффективнее, чем традиционные методы НЛП. DeepText основывается на идеях глубокого обучения, которые изначально были разработаны в статьях Ронана Коллобера и Яна ЛеКуна из Facebook AI Research.
Понимание большего количества языков быстрее
Сообщество Facebook действительно глобально, поэтому DeepText важно понимать как можно больше языков. Традиционные методы НЛП требуют обширной логики предварительной обработки, основанной на сложной инженерии и знании языков. Существуют также вариации внутри каждого языка, поскольку люди используют сленг и разные варианты написания, чтобы передать одну и ту же идею. Используя глубокое обучение, мы можем уменьшить зависимость от языковых знаний, поскольку система может учиться на тексте без предварительной обработки или с небольшой предварительной обработкой.Это помогает нам быстро охватить несколько языков с минимальными инженерными усилиями.
Более глубокое понимание
В традиционных подходах НЛП слова преобразуются в формат, который может выучить компьютерный алгоритм. Слову «брат» может быть присвоен целочисленный идентификатор, например 4598, в то время как слово «брат» становится другим целым числом, например 986665. Это представление требует, чтобы каждое слово было видно с точным написанием в обучающих данных, чтобы его можно было понять.
При глубоком обучении мы можем вместо этого использовать «вложения слов», математическую концепцию, которая сохраняет семантические отношения между словами.Итак, при правильном расчете мы видим, что вложения слов «брат» и «брат» близки в пространстве. Этот тип представления позволяет нам уловить более глубокое семантическое значение слов.
Используя встраивание слов, мы также можем понять одну и ту же семантику на нескольких языках, несмотря на различия в поверхностной форме. Например, для английского и испанского языков слова «с днем рождения» и «feliz cumpleaños» должны располагаться очень близко друг к другу в общем пространстве для встраивания. Сопоставляя слова и фразы с общим пространством встраивания, DeepText может создавать модели, не зависящие от языка.
Маркированная нехватка данных
Письменный язык, несмотря на упомянутые выше вариации, имеет большую структуру, которая может быть извлечена из немаркированного текста с помощью обучения без учителя и зафиксирована во вложениях. Глубокое обучение предлагает хорошую основу для использования этих встраиваний и их дальнейшего совершенствования с использованием небольших помеченных наборов данных. Это значительное преимущество перед традиционными методами, которые часто требуют больших объемов данных, помеченных людьми, которые неэффективны для создания и трудно адаптировать к новым задачам.Во многих случаях эта комбинация обучения без учителя и обучения с учителем значительно повышает производительность, поскольку компенсирует нехватку помеченных наборов данных.
Изучение DeepText на Facebook
DeepText уже тестируется на некоторых платформах Facebook. В случае Messenger, например, DeepText используется командой AML Conversation Understanding, чтобы лучше понять, когда кто-то может захотеть куда-то пойти. Он используется для обнаружения намерений, что помогает понять, что человек не ищет такси, когда он или она говорит что-то вроде «Я только что вышел из такси», а не «Мне нужно подвезти».”
Мы также начинаем использовать высокоточные многоязычные модели DeepText, чтобы помочь людям найти подходящие инструменты для их целей. Например, кто-то может написать сообщение: «Я хотел бы продать свой старый велосипед за 200 долларов, кому интересно?» DeepText сможет обнаружить, что сообщение о продаже чего-либо, извлечь значимую информацию, такую как продаваемый объект и его цена, и побудить продавца использовать существующие инструменты, которые упрощают эти транзакции через Facebook.
DeepText имеет потенциал для дальнейшего улучшения взаимодействия с Facebook за счет лучшего понимания сообщений для извлечения намерений, настроений и сущностей (например, людей, мест, событий), использования сигналов смешанного контента, таких как текст и изображения, и автоматизации удаления нежелательного контента, такого как спам. . Многие знаменитости и общественные деятели используют Facebook, чтобы начать общение с общественностью. Эти разговоры часто вызывают сотни или даже тысячи комментариев. Поиск наиболее релевантных комментариев на нескольких языках при сохранении качества комментариев в настоящее время является сложной задачей.Еще одна проблема, которую DeepText может решить, — это поиск наиболее актуальных или высококачественных комментариев.
Следующие шаги
Мы продолжаем развивать технологию DeepText и ее приложения в сотрудничестве с исследовательской группой Facebook AI Research. Вот несколько примеров.
Лучшее понимание интересов людей
Частью персонализации опыта людей в Facebook является рекомендация контента, который соответствует их интересам. Для этого мы должны иметь возможность сопоставить любой заданный текст с определенной темой, что требует огромных объемов помеченных данных.
Для этого мы должны иметь возможность сопоставить любой заданный текст с определенной темой, что требует огромных объемов помеченных данных.
Хотя такие наборы данных сложно создать вручную, мы тестируем возможность создания больших наборов данных с частично контролируемыми метками с использованием общедоступных страниц Facebook. Разумно предположить, что сообщения на этих страницах будут представлять отдельную тему — например, сообщения на странице Steelers будут содержать текст о футбольной команде Steelers. Используя этот контент, мы обучаем классификатор общих интересов, который мы называем PageSpace, который использует DeepText в качестве базовой технологии. В свою очередь, это могло бы еще больше улучшить систему понимания текста в других приложениях Facebook.
Совместное понимание текстового и визуального контента
Часто люди публикуют изображения или видео, а также описывают их с помощью связанного текста. Во многих из этих случаев понимание намерения требует совместного понимания как текстового, так и визуального контента. Например, друг может опубликовать фотографию своего новорожденного ребенка с текстом «День 25». Комбинация изображения и текста дает понять, что цель здесь — поделиться семейными новостями. Мы работаем с группами понимания визуального контента Facebook над созданием новых архитектур глубокого обучения, которые учат намерения совместно с текстовыми и визуальными входами.
Новые архитектуры глубоких нейронных сетей
Мы продолжаем разрабатывать и исследовать новые архитектуры глубоких нейронных сетей. Двунаправленные рекуррентные нейронные сети (BRNN) показывают многообещающие результаты, поскольку они стремятся уловить как контекстные зависимости между словами посредством повторения, так и позиционно-инвариантную семантику посредством свертки. Мы заметили, что BRNN достигают более низкого уровня ошибок, чем обычные сверточные или рекуррентные нейронные сети для классификации; в некоторых случаях частота ошибок составляет всего 20 процентов.
Хотя применение методов глубокого обучения для понимания текста продолжит улучшать продукты и возможности Facebook, верно и обратное. Неструктурированные данные на Facebook предоставляют уникальную возможность для систем распознавания текста автоматически учиться на языке, поскольку они естественным образом используются людьми, говорящими на нескольких языках, что будет способствовать дальнейшему развитию современного состояния обработки естественного языка.
Инструмент перефразирования | Бесплатный редактор статей, чтобы переписывать предложения.
Article Spinner (инструмент для перефразирования), A Luxury
Переписывание статей связано с восприятием информации и ее выражением по-новому. И это требует комплексного словаря, исследования, времени и напряженной работы.
Перезапись содержимого вручную может занять несколько часов. Что ж, сейчас не тот досуг. Усердный труд, безусловно, окупается, но на это уходит много времени, и производство контента становится меньше. Например, если вы используете инструмент перефразирования, чтобы переписать эссе или статью, сначала вы должны внимательно прочитать это содержание.Затем найдите подходящие слова, чтобы заменить исходное содержание, сохраняя целостность темы. Для этого вам понадобится хорошо развитый словарный запас и много свободного времени. Таким образом, люди, которые невероятно свободны, могут заниматься этим делом, но те, у кого в руках ограниченные ресурсы, могут найти переписывание обременительной работы.
Студенты часто сталкиваются с проблемой переписывания или перефразирования.
Они очень много работают, но не могут передать истинную суть темы.Они стараются написать диссертацию, чтобы избежать плагиата. Более того, это отнимает их драгоценное время и может даже не оправдать ожиданий учителей. Это приводит к их разочарованию. Учителя часто сталкиваются с трудностями при подготовке лекций и конспектов для студентов.
Иногда они не могут предоставить своим ученикам правильный контекст. Владельцы веб-сайтов и создатели нового веб-контента также регулярно сталкиваются со многими проблемами, связанными с производством контента, потому что они не могут позволить себе профессиональных писателей.Иногда новостным авторам приходится переписывать рассказы, делая акцент на другом аспекте события или преподнося его по-другому. Блоггеры должны очень тщательно выбирать то, что они пишут, из-за огромной конкуренции в Интернете. Таким образом, им приходится тратить часы на исследования, чтобы улучшить качество контента и избежать плагиата.
Владельцы веб-сайтов и создатели нового веб-контента также регулярно сталкиваются со многими проблемами, связанными с производством контента, потому что они не могут позволить себе профессиональных писателей.Иногда новостным авторам приходится переписывать рассказы, делая акцент на другом аспекте события или преподнося его по-другому. Блоггеры должны очень тщательно выбирать то, что они пишут, из-за огромной конкуренции в Интернете. Таким образом, им приходится тратить часы на исследования, чтобы улучшить качество контента и избежать плагиата.
Избегайте плагиата, цитируя и перефразируя
Редактор статей DupliChecker готов спасти положение
В наши дни очень сложно найти идеальный инструмент для перезаписи текста.Итак, если вы ищете счетчик текста, попробуйте наш инструмент и почувствуйте разницу. Онлайн-редактор статей — идеальное место для вас, чтобы переписать или перефразировать статьи. Время и качество контента являются наиболее важными факторами для любого человека, работающего над написанием контента. Учителя и студенты могут извлечь из этого пользу, сводя к минимуму все риски плагиата и грамматических ошибок. Писатели сталкиваются с большими трудностями при переписывании статей. Им приходится часами искать возможные ошибки в своем содержании.На это уходит большая часть их драгоценного времени, в течение которого они могли бы написать что-нибудь еще. Владельцы веб-сайтов сталкиваются с нехваткой времени и денег, поэтому они не могут нанять профессиональных писателей для редактирования своего контента. Они должны быть особенно осторожны с контентом, потому что объем трафика на их веб-сайте зависит от качества их контента. Итак, они обращаются к этим инструментам прядильщика статей в Интернете.
Инструмент перефразирования, динамический инструмент для SEO
В Интернете доступен ряд инструментов для прядения статей, большинство из которых очень медленно обрабатываются.Некоторые предлагают бесплатную пробную версию на два-три дня, но после этого вам придется покупать их, что очень дорого. Так что, если вы студент или новичок в SEO-бизнесе, этот вариант может оказаться для вас неприемлемым. Мы всегда учитываем потребности тех, кто не может себе позволить.
Так что, если вы студент или новичок в SEO-бизнесе, этот вариант может оказаться для вас неприемлемым. Мы всегда учитываем потребности тех, кто не может себе позволить.
Вы будете рады узнать, что наш редактор статей не только эффективен и быстр, но и совершенно бесплатен. У нас также есть дополнительная опция проверки грамматики, которая также совершенно бесплатна. Все, что вам нужно сделать, это перенести свой контент на наш сайт и позволить Rewriter’у контента делать работу, а вы расслабляетесь и мгновенно получать результат.Есть еще один важный фактор, который превосходит результаты нашего переписчика, — это использование передового искусственного интеллекта. У нас есть лучший ИИ и серверы, которые могут обрабатывать огромный контент и несколько статей одновременно.
Кроме того, у нас есть обширная библиотека слов и их синонимов, которые вам помогут. Соедините это с нашими вариантами проверки орфографии и проверки грамматики и вуаля! у вас будет окончательное решение ваших проблем с письмом. Это сэкономит вам не только время, но и много денег, которые в противном случае вы бы заплатили на других сайтах.
Тот факт, что наш прядильщик текста предпочитают как студенты, так и учителя, объясняется тем, что он производит качественный контент. Это действительно помогает студентам в выполнении заданий и диссертаций. Это также позволяет учителям готовить материал для обучения учащихся. Блогеры могут проверять свой контент на нашем сайте, чтобы уберечь его от плагиата и грамматических ошибок. Использование наших бесплатных инструментов действительно помогло многим SEO-авторам сохранить свой бизнес, сохранив при этом посещаемость своих веб-сайтов.
Наш мотив — эффективно и действенно предоставлять эти услуги, не эксплуатируя людей.
Как использовать редактор статей (перефразируйте онлайн)?
Еще никогда не было так просто использовать редактор статей. Вы можете использовать наш редактор контента как профессионал. Все, что вам нужно сделать, это следовать приведенным ниже инструкциям:
Все, что вам нужно сделать, это следовать приведенным ниже инструкциям:
- Чтобы начать, нажмите здесь
- Когда вы откроете страницу редактора статьи, вы увидите белое прямоугольное поле, как показано на рисунке ниже.
- В появившемся выше поле вы можете вставить скопированный абзац или нажать кнопку «Загрузить файл сюда» , которая откроет окно, в котором вы можете выбрать желаемый текстовый файл для загрузки.
- Вы заметите, что когда вы вставили свой контент в поле, в нем отображаются некоторые подчеркнутые красным цветом слова, красные подчеркивания указывают на орфографические ошибки, а выделенный текст указывает на грамматические.
- После вставки или загрузки вашего контента в поле вам нужно будет выбрать опцию «Далее», чтобы обработать контент для повторной записи, или нажать кнопку «Проверить грамматику» для исправления грамматических ошибок.
DupliChecker.com Полный пакет
Как я уже упоминал ранее, наш инструмент абсолютно бесплатный. Это полный пакет инструментов для перезаписи статей (инструмент перефразирования), проверки орфографии, проверки на плагиат и проверки грамматики. Другие сайты той же категории заставят вас платить за свои услуги даже за такие простые задачи, как проверка орфографии. Мы хотим, чтобы у вас были лучшие впечатления от использования нашего веб-сайта, потому что мы понимаем, что вам нужно. Таким образом, вам даже не нужно регистрироваться, чтобы использовать какие-либо наши бесплатные инструменты.Так что просто бродите по нашему сайту и используйте наши инструменты наилучшим образом.
Как искусственный интеллект изменит будущее маркетинга
Адами, К. (2015). Искусственный интеллект: роботы с инстинктами. Nature, 521 (7553), 426–427.
Google Scholar
Агравал, А., Ганс, Дж. С., и Гольдфарб, А. (2018). Машины предсказания: простая экономика искусственного интеллекта. Пресса Гарвардской школы бизнеса.
Агирре, Э., Мар, Д., Греваль, Д., де Рюйтер, К., и Ветцельс, М. (2015). Разоблачение парадокса персонализации: влияние стратегии сбора информации и укрепления доверия на эффективность онлайн-рекламы. Журнал розничной торговли, 91 (1), 34–49.
Артикул Google Scholar
Андре К., Кармон З., Вертенброх К., Крам А., Франк Д., Гольдштейн В. и др. (2018). Выбор потребителей и автономия в эпоху искусственного интеллекта и больших данных. Потребности клиентов и решения, 5 (1–2), 28–37.
Google Scholar
Эндрюс, Т. (2016). Познакомьтесь с роботом-монахом, распространяющим учение буддизма по Китаю. Washington Post, 27 апреля. Получено 11 февраля 2019 г. с сайта https://www.washingtonpost.com/news/morning-mix/wp/2016/04/27/meet-the-robot-monk-spreading-the-teachings- буддизма вокруг Китая /? utm_term = .fed52d90bff3. По состоянию на 11 февраля 2019 г.
Antonio, V.(2018). Как ИИ меняет продажи. Harvard Business Review, 30 июля. Получено 11 февраля 2019 г. с сайта https://hbr.org/2018/07/how-ai-is-changing-sales.
Авалос, Г. (2018). Walmart тестирует роботов для сканирования полок в районе залива. The Mercury News, 20 марта. Получено 11 февраля 2019 г. с https://www.mercurynews.com/2018/03/20/walmart-tests-shelf-scanning-robots-bay-area/.
Барро С. и Дэвенпорт Т. Х. (2019). Люди и машины: партнеры в области инноваций. MIT Sloan Management Review, 60 (4), 22–28.
Google Scholar
Баум, С. Д., Гертцель, Б., и Герцель, Т. Г. (2011). Как долго до ИИ человеческого уровня? Результаты экспертной оценки. Технологическое прогнозирование и социальные изменения, 78 (1), 185–195.
Google Scholar
Беттман Дж. (1973). Воспринимаемый риск и его компоненты: модель и эмпирический тест. Маркетинговый журнал, 10 (2), 184–190.
(1973). Воспринимаемый риск и его компоненты: модель и эмпирический тест. Маркетинговый журнал, 10 (2), 184–190.
Google Scholar
Бисвас, А., Бховмик, С., Гуха, А., и Гревал, Д. (2013). Потребительские оценки продажных цен: роль принципа вычитания. Маркетинговый журнал, 77 (4), 49–66.
Google Scholar
Бойд Р. и Холтон Р. Дж. (2018). Технологии, инновации, занятость и власть: действительно ли робототехника и искусственный интеллект означают социальную трансформацию? Социологический журнал, 54, (3), 331–345.
Google Scholar
Берроуз, Л. (2019). Наука об искусственном. Получено 12 июня 2019 г. с сайта https://www.seas.harvard.edu/news/2019/05/science-of-artificial.
Бирнс, Дж. П., Миллер, Д. К., & Шафер, В. Д. (1999). Гендерные различия в принятии риска: метаанализ. Психологический бюллетень, 125 (3), 367.
Google Scholar
Карпентер, Дж.(2015). Вирджиния Рометти из IBM говорит выпускникам Университета: технологии улучшат нас. Получено 11 февраля 2019 г. с сайта https://www.chicagotribune.com/bluesky/originals/ct-northwestern-virginia-rometty-ibm-bsi-20150619-story.html.
Каштелу, Н. (2019). Стирание границы между человеком и машиной: маркетинг искусственного интеллекта (докторская диссертация). Получено из Академического сообщества Колумбийского университета. https://doi.org/10.7916/d8-k7vk-0s40.
Кастело, Н., & Уорд, А. (2016). Политическая принадлежность снижает отношение к искусственному интеллекту. В П. Моро и С. Пунтони (ред.), NA — достижения в исследовании потребителей (стр. 723–723). Дулут, Миннесота: Ассоциация потребительских исследований.
Google Scholar
Кастело, Н. , Бос, М., и Леман, Д. (2018). Принятие потребителями алгоритмов, стирающих грань между человеком и машиной . Высшая школа бизнеса: Рабочий документ Колумбийского университета.
, Бос, М., и Леман, Д. (2018). Принятие потребителями алгоритмов, стирающих грань между человеком и машиной . Высшая школа бизнеса: Рабочий документ Колумбийского университета.
Google Scholar
Чуй, М., Маньяка, Дж., Миремади, М., Хенке, Н., Чунг, Р., Нел, П., и Малхотра, С. (2018). Заметки из области искусственного интеллекта: приложения и ценность глубокого обучения. Дискуссионный документ глобального института McKinsey, апрель 2018 г. Получено 12 июня 2019 г. по адресу https://www.mckinsey.com/featured-insights/artificial-intelligence/notes-from-the-ai-frontier-applications-and-value-of -глубокое обучение.
Колсон, Э.(2018). Наука о данных, ориентированная на любопытство. Harvard Business Review, 27 ноября. Получено 11 февраля 2019 г. с сайта https://hbr.org/2018/11/curiosity-driven-data-science.
Колумбус, Л. (2019). 10 диаграмм, которые изменят ваш взгляд на ИИ в маркетинге. Forbes , 7 июля. Получено 9 июля 2019 г. по адресу https://www.forbes.com/sites/louiscolumbus/2019/07/07/10-charts-that-will-change-your-perspective-of-. ai-in-marketing / amp /
Давенпорт, Т.Х. (2018). Преимущество искусственного интеллекта: как заставить революцию искусственного интеллекта работать. MIT Press.
Давенпорт, Т. Х., и Кирби, Дж. (2016). Насколько умны умные машины? MIT Sloan Management Review, 57 (3), 21–25.
Google Scholar
Давенпорт, Т. Х., и Ронанки, Р. (2018). Искусственный интеллект для реального мира. Harvard Business Review, 96 (1), 108–116.
Google Scholar
Давенпорт, Т.Х., Далле Мул, Л., и Лакер, Дж. (2011). Знайте, чего хотят ваши клиенты, прежде чем они это сделают. Harvard Business Review, 89 (12), 84–92.
Google Scholar
Дедехайир, О.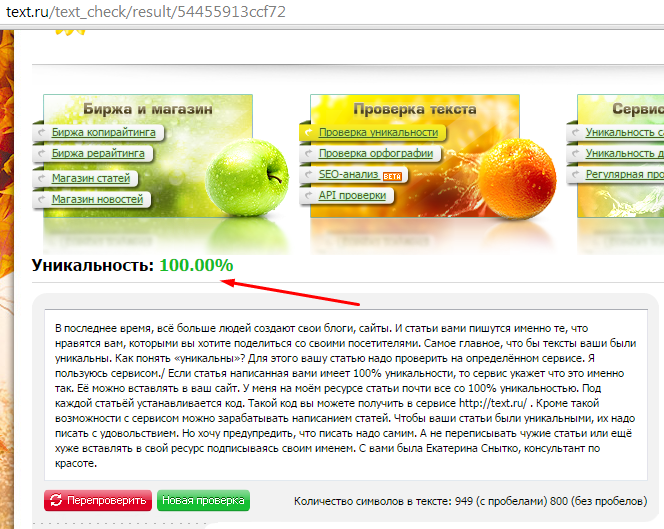 , и Стейнерт, М. (2016). Модель цикла шумихи: обзор и направления на будущее. Технологическое прогнозирование и социальные изменения, 108 , 28–41.
, и Стейнерт, М. (2016). Модель цикла шумихи: обзор и направления на будущее. Технологическое прогнозирование и социальные изменения, 108 , 28–41.
Google Scholar
Флеминг, П.(2019). Роботы и исследования организаций: почему роботы могут не захотеть украсть вашу работу. Исследования организации, 40 (1), 23–38.
Google Scholar
Фаулер, Г. (2019). У дверных звонков есть глаза: битвы за конфиденциальность назревают из-за домашних камер безопасности. Получено 11 февраля 2019 г. с сайта https://www.sltrib.com/news/business/2019/02/01/doorbells-have-eyes/.
Френч, К. (2018). Ваш новый лучший друг: чат-бот AI.Получено 13 февраля 2019 г. с сайта https://futurism.com/ai-chatbot-meaningful-conversation.
Ганс, Дж., Агравал, А., и Гольдфарб, А. (2017). Как ИИ изменит стратегию: мысленный эксперимент. Обзор бизнеса Гарварда онлайн. Получено 11 февраля 2019 г. с сайта https://hbr.org/product/how-ai-will-change-strategy-a-aught-experiment/H03XDI-PDF-ENG.
Годен, С. (2016). Специалисты по обработке данных и а.И. стать личным стилистом. Получено 11 февраля 2019 г. с сайта https: // www.computerworld.com/article/3067264/artificial-intelligence/at-stitch-fix-data-scientists-and-ai-become-personal-stylists.html.
Гахрамани, З. (2015). Вероятностное машинное обучение и искусственный интеллект. Nature, 521 (7553), 452–459.
Google Scholar
Гибельхаузен, М., Робинсон, С. Г., Сирианни, Н. Дж., И Брэди, М. К. (2014). Сенсор против технологий: когда технология выступает в качестве барьера или преимущества для обслуживания. Маркетинговый журнал, 78 (4), 113–124.
Google Scholar
Голдфарб, А., & Такер, К. (2013). Почему управление конфиденциальностью потребителей может быть выгодным. MIT Sloan Management Review, 54 (3), 10–12.
MIT Sloan Management Review, 54 (3), 10–12.
Google Scholar
Грей, К. (2017). AI может быть неприятным товарищем по команде. Harvard Business Review, 20 июля. Получено 11 февраля 2019 г. с сайта https: // hbr.org / 2017/07 / ai-может-быть-неприятным-товарищем по команде.
Грей К. и Вегнер Д. М. (2012). Чувствующие роботы и человеческие зомби: восприятие разума и зловещая долина. Познание, 125 (1), 125–130.
Google Scholar
Грум, В., Сринивасан, В., Бетел, К. Л., Мерфи, Р., Доул, Л., и Насс, К. (2011, май). Ответы на социальные роли роботов и формирование социальных ролей. В материалах Международной конференции IEEE по технологиям и системам для совместной работы (CTS ) (стр.194-203).
Guha, A., Biswas, A., Grewal, D., Verma, S., Banerjee, S., & Nordfält, J. (2018). Переосмысление скидки как сравнения с продажной ценой: делает ли скидка более привлекательной? Журнал маркетинговых исследований, 55 (3), 339–351.
Google Scholar
Густавсод, П. Э. (1998). Гендерные различия в восприятии риска: теоретические и методологические перспективы. Анализ рисков, 18 (6), 805–811.
Google Scholar
Хардинг, К. (2017). Искусственный интеллект и машинное обучение для прогнозной оценки данных. Получено 11 февраля 2019 г. с сайта https://www.objectiveit.com/blog/use-ai-and-machine-learning-for-predictive-lead-scoring за 13 февраля 2019 г.
Haslam, N., Bain , П., Дуг, Л., Ли, М., и Бастиан, Б. (2005). Более человечен, чем вы: приписывание человечности себе и другим. Журнал личности и социальной психологии, 89 (6), 937–950.
Google Scholar
Хасслер, К. А. (2018). Познакомьтесь с Репликой, роботом с искусственным интеллектом, который хочет стать вашим лучшим другом.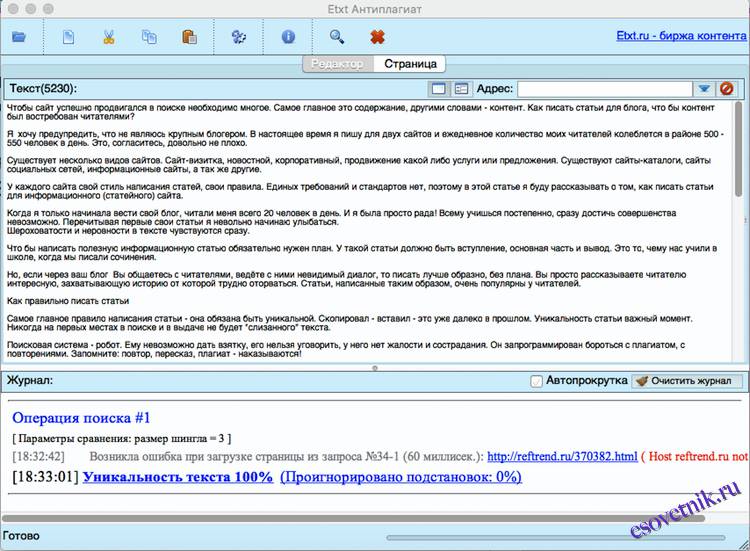 Получено 11 февраля 2019 г. с сайта https://www.popsugar.com/news/Replika-Bot-AI-App-Review-Interview-Eugenia-Kuyda-44216396.
Получено 11 февраля 2019 г. с сайта https://www.popsugar.com/news/Replika-Bot-AI-App-Review-Interview-Eugenia-Kuyda-44216396.
Хокинс, А. (2019). Нет, Илон, функция навигации на автопилоте не является «полностью самостоятельным вождением». Получено 11 февраля 2019 г. с сайта https://www.theverge.com/2019/1/30/18204427/tesla-autopilot-elon-musk-full-self-driving-confusion.
Хейс, А. (2015). Непредвиденные последствия беспилотных автомобилей. Получено 11 февраля 2019 г. с сайта https://www.investopedia.com/articles/investing/0
/unintended-consequences-selfdriving-cars.asp.Хохман Д. (2018). Эта роботизированная рука за 25000 долларов хочет вывести из бизнеса вашего бариста Starbucks. Получено 11 февраля 2019 г. с https://www.cnbc.com/2018/05/08/this-25000-robot-wants-to-put-your-starbucks-barista-out-of-business.html.
Хоффман, Д.Л., и Новак, Т. П. (2018). Потребительский и объектный опыт в Интернете вещей: подход теории сборки. Журнал потребительских исследований, 44 (6), 1178–1204.
Google Scholar
Хуанг, М. Х., & Раст, Р. Т. (2018). Искусственный интеллект на службе. Журнал сервисных исследований, 21 (2), 155–172.
Google Scholar
Халлингер, Дж.(2016). Что сделает для вас робот Lowe’s — и будущее розничной торговли. Получено 11 февраля 2019 г. с веб-сайта http://campfire-capital.com/retail-innovation/sales-channel-innovation/what-the-lowes-robot-will-do-for-you-and-the-future-of-. розничная торговля/.
Каплан, А., & Хенлейн, М. (2019). Сири, Сири, в моей руке: кто самый красивый в стране? Об интерпретации, иллюстрациях и значениях искусственного интеллекта. Business Horizons, 62 (1), 15–25.
Google Scholar
Кидд, К.Д., и Бризил С. (2008, сентябрь). Роботы дома: понимание долгосрочного взаимодействия человека и робота. В материалах Международной конференции IEEE по интеллектуальным робототехническим системам (стр. 3230–3235).
В материалах Международной конференции IEEE по интеллектуальным робототехническим системам (стр. 3230–3235).
Ким Т. и Духачек А. (2018). Влияние искусственных агентов на убеждение: отчет на конструктивном уровне. ACR Asia-Pacific Advances .
Найт, W. (2017). Забудьте о роботах-убийцах — предвзятость — настоящая опасность для ИИ. Получено 11 февраля 2019 г. с сайта https: // www.technologyreview.com/s/608986/forget-killer-robotsbias-is-the-real-ai-danger/.
Кобер, Дж., Багнелл, Дж. А., и Петерс, Дж. (2013). Обучение с подкреплением в робототехнике: обзор. Международный журнал исследований робототехники, 32 (11), 1238–1274.
Google Scholar
Квак, С., Ким, Ю., Ким, Э., Шин, К., и Чо, К. (2013). Что заставляет людей сопереживать эмоциональному роботу? Влияние свободы воли и физического воплощения на человеческое сочувствие роботу.В протоколе Proceedings of the IEEE International. Симпозиум Сообщество взаимодействия роботов и людей ( стр. 180–185).
Ламмер, Л., Хубер, А., Вайс, А., Винче, М. (2014). Взаимопомощь: как пожилые люди реагируют, когда им следует помочь своему роботу по уходу. В Труды Международного симпозиума социальных исследований AI Simulation Behavior (стр. 3-4).
Ларсон, К. (2019). Конфиденциальность данных и этика искусственного интеллекта вышли на первый план в 2018 году. Получено 11 февраля с https: // medium.com / @ Smalltofeds / data-privacy-and-ai-ethics-step-to-the-fore-in-2018-4e0207f28210.
Лашинский, А. (2019). Искусственный интеллект: отделить шумиху от реальности. Получено от 11 февраля 2019 г. с веб-сайта http://fortune.com/2019/01/22/artificial-intelligence-ai-reality/.
ЛеКун, Ю., Бенжио, Ю., и Хинтон, Г. (2015). Глубокое обучение. Nature, 521 (7553), 436–444.
Google Scholar
Ли, А. Ю., Келлер, П. А., и Стернтал, Б. (2009). Ценность нормативного конструктивного соответствия: убедительное влияние соответствия между целями потребителя и конкретностью сообщения. Журнал потребительских исследований, 36 (5), 735–747.
Ю., Келлер, П. А., и Стернтал, Б. (2009). Ценность нормативного конструктивного соответствия: убедительное влияние соответствия между целями потребителя и конкретностью сообщения. Журнал потребительских исследований, 36 (5), 735–747.
Google Scholar
Леунг, Э., Паолаччи, Г., и Пунтони, С. (2018). Человек против машины: сопротивление автоматизации в поведении потребителей на основе идентичности. Журнал маркетинговых исследований, 55 (6), 818–831.
Google Scholar
Левин С. (2017). Новый ИИ может угадать, гей ты или прямо по фотографии. Получено 11 февраля 2019 г. с сайта https://www.theguardian.com/technology/2017/sep/07/new-artificial-intelligence-can-tell-whether-youre-gay-or-straight-from-a-photograph.
Ли Д., Рау П. П. и Ли Ю. (2010). Межкультурное исследование: влияние внешнего вида робота и задачи. Международный журнал социальной робототехники, 2 (2), 175–186.
Google Scholar
Лонгони, К., Бонецци, А., и Морведж, К. К. (2019). Устойчивость к медицинскому искусственному интеллекту. Журнал потребительских исследований (готовится к печати).
Лоуи, Дж. (2016). Беспилотные автомобили «абсолютно не готовы» к развертыванию. Получено 11 февраля 2019 г. с сайта https://www.pbs.org/newshour/science/self-driving-cars-are-absolutely-not-ready-for-deployment.
Луо, Х., Тонг, С., Фанг, З. и Чжэ, К. (2019). Машины против людей: влияние раскрытия информации о чат-ботах на покупки потребителей. Неопубликованный рабочий документ.
Мандель, Н., Рукер, Д. Д., Левав, Дж., И Галински, А. Д. (2017). Компенсаторная модель поведения потребителей: как несоответствия между собой определяют поведение потребителей. Журнал потребительской психологии, 27 (1), 133–146.
Google Scholar
Марр Б. (2019).Как роботы, Интернет вещей и искусственный интеллект меняют способы занятия сексом у людей. Получено 12 июня 2019 г. с https://www.forbes.com/sites/bernardmarr/2019/04/01/how-robots-iot-and-artificial-intelligence-are-changing-how-humans-have-sex/. # 3679d398329c.
(2019).Как роботы, Интернет вещей и искусственный интеллект меняют способы занятия сексом у людей. Получено 12 июня 2019 г. с https://www.forbes.com/sites/bernardmarr/2019/04/01/how-robots-iot-and-artificial-intelligence-are-changing-how-humans-have-sex/. # 3679d398329c.
Мартин, К. Д., и Мерфи, П. Э. (2017). Роль конфиденциальности данных в маркетинге. Журнал Академии маркетинговых наук, 45 (2), 135–155.
Google Scholar
Мартин, К.Д., Бора А. и Палматье Р. В. (2017). Конфиденциальность данных: влияние на работу клиентов и компаний. Маркетинговый журнал, 81 (1), 36–58.
Google Scholar
Мехта, Н., Детройа, П., и Агаше, А. (2018). Amazon меняет цены на свои товары примерно каждые 10 минут — вот как и почему они это делают. Получено 11 февраля 2019 г. с сайта https://www.businessinsider.com/amazon-price-changes-2018-8?international=true&r=US&IR=T.
Mende, M., Scott, M. L., van Doorn, J., Grewal, D., & Shanks, I. (2019). Рост сервисных роботов: как гуманоидные роботы влияют на качество обслуживания и потребление пищи. Журнал маркетинговых исследований, 56 (4), 535–556.
Google Scholar
Мец, К. (2018). Марк Цукерберг, Илон Маск и вражда из-за роботов-убийц. Получено 11 февраля 2019 г. с сайта https://www.nytimes.com/2018/06/09/technology/elon-musk-mark-zuckerberg-artificial-intelligence.html.
Милграм П., Такемура Х., Утсуми А. и Кишино Ф. (1995, декабрь). Дополненная реальность: класс дисплеев в континууме реальность-виртуальность. Телеманипуляторы и технологии телеприсутствия, 2351 , 282–293.
Google Scholar
Миллер, Г. (2016). Боты, чат-боты и искусственный интеллект — в чем суть эволюции (aBot). Получено 12 июня 2019 г. с сайта https: // chatbotnewsdaily. com / bots-chatbots-and-искусственный интеллект-какая-эволюция-это-все-abot-about-a7e148dd067d.
com / bots-chatbots-and-искусственный интеллект-какая-эволюция-это-все-abot-about-a7e148dd067d.
Мних, В., Кавукчуоглу, К., Сильвер, Д., Русу, А. А., Венесс, Дж., Беллемар, М. Г. и др. (2015). Контроль на уровне человека посредством глубокого обучения с подкреплением. Nature, 518 (7540), 529–533.
Google Scholar
Мун, Ю. (2003). Не вините компьютер: когда самораскрытие уменьшает корыстную предвзятость. Журнал потребительской психологии, 13 (1–2), 125–137.
Google Scholar
Мори, М. (1970). Жуткая долина. Энергия, 7 (4), 33–35.
Google Scholar
Motyka, S., Grewal, D., Puccinelli, N. M., Roggeveen, A. L., Avnet, T., Daryanto, A., et al. (2014). Соответствие нормативным требованиям: метааналитический синтез. Журнал потребительской психологии, 24 (3), 394–410.
Google Scholar
Мюллер В. К. и Бостром Н. (2016). Будущий прогресс в области искусственного интеллекта: обзор мнения экспертов. В Фундаментальные вопросы искусственного интеллекта (стр. 555–572). Спрингер, Чам.
Парех, Дж. (2018). Почему алгоритмические продажи обеспечивают лучший ландшафт цифрового маркетинга. Получено 13 февраля 2019 г. с сайта https://www.adweek.com/programmatic/why-programmatic-provides-a-better-digital-marketing-landscape/.
Педерсен, И., Рид, С., и Аспевиг, К. (2018). Разработка социальных роботов для стареющего населения: обзор литературы последних академических источников. Социологический компас, 12 (6).
Пауэр, Б. (2017). Как ИИ оптимизирует маркетинг и продажи. Harvard Business Review, 12 июня. Получено 11 февраля 2019 г. с сайта https://hbr.org/2017/06/how-ai-is-streamlining-marketing-and-sales.
Рахван, И. , Цебриан, М., Обрадович, Н., Bongard, J., Bonnefon, J.F., Breazeal, C., et al. (2019). Поведение машины. Nature, 568 (7753), 477–486.
Google Scholar
Риз Б. (2018). Четвертая эпоха: умные роботы, сознательные компьютеры и будущее человечества . Нью-Йорк, Нью-Йорк: Книги Атрии.
Google Scholar
Робинсон, М. (2017). Технические гиганты Кремниевой долины начинают полагаться на роботов для борьбы с преступностью для обеспечения безопасности.Получено 11 февраля 2019 г. с веб-сайта https://www.businessinsider.com/knightscope-security-robots-microsoft-uber-2017-5.
Сандовал, Э. Б., Брандштеттер, Дж., Обейд, М., и Бартнек, К. (2016). Взаимность взаимодействия человека и робота: количественный подход через дилемму заключенного и игру в ультиматум. Международный журнал социальной робототехники, 8 (2), 303–317.
Google Scholar
Щацкий, Д., Катял, В., Айенгар, С., и Чаухан, Р. (2019). Почему предприятиям не следует ждать регулирования ИИ. Получено 11 июля 2019 г. с сайта https://www2.deloitte.com/insights/us/en/focus/signals-for-strategists/ethical-artificial-intelligence.html.
Шрифт, Р. Ю., Вертенброх, К., Андре, К., и Франк, Д. Х. (2017). Угрожая свободе воли. Презентация на симпозиуме по отчуждению и значению в производстве и потреблении , Технический университет Мюнхена.
Шанкар, В.(2018). Как искусственный интеллект (ИИ) меняет розничную торговлю. Журнал розничной торговли, 94 (4), vi – xi.
Google Scholar
Шервуд, Х. (2017). Робот-священник представлен в Германии в ознаменование 500-летия Реформации. The Guardian , 20 мая. Получено 11 февраля 2019 г. по адресу https://www.theguardian.com/technology/2017/may/30/robot-priest-blessu-2-germany-reformation-exhibition.
Шум, П., И Лин, Г. (2007). Модель передового опыта в области разработки новых продуктов мирового класса. Международный журнал производственных исследований, 45 (7), 1609–1629.
Google Scholar
imşek, Ö. Ф. и Ялинчетин Б. (2010). Я чувствую себя уникальным, поэтому я: Разработка и предварительная проверка шкалы личного чувства уникальности (PSU). Личность и индивидуальные различия, 49 (6), 576–581.
Google Scholar
Сингх, Дж., Flaherty, K., Sohi, R. S., Deeter-Schmelz, D., Habel, J., Le Meunier-FitzHugh, K., et al. (2019). Торговые профессии и профессионалы в эпоху цифровизации и технологий искусственного интеллекта: концепции, приоритеты и вопросы. Журнал личных продаж и управления продажами , 1–21.
Смит, К. (2019) Понимание конфуцианства Китая в глобальной гонке ИИ, Quillette , 14 февраля 2019 г., Получено с https://quillette.com/2019/02/14/understanding-chinas -confucian-edge-in-the-global-ai-race / 6 июля 2019 г.
Стали, Л., и Брукс, Р. (2018). Путь от искусственной жизни к искусственному интеллекту: создание воплощенных агентов . Рутледж.
Сям, Н., и Шарма, А. (2018). В ожидании возрождения продаж в четвертой промышленной революции: машинное обучение и искусственный интеллект в исследованиях и практике продаж. Управление промышленным маркетингом, 69 , 135–146.
Google Scholar
Такер, К.(2018). Конфиденциальность, алгоритмы и искусственный интеллект. В Экономика искусственного интеллекта: повестка дня . Издательство Чикагского университета.
ван Ленте, Х., Спиттерс, К., и Пайн, А. (2013). Сравнение технологических циклов ажиотажа: к теории. Технологическое прогнозирование и социальные изменения, 80 (8), 1615–1628.
Google Scholar
Верхоф, П. К., Стивен, А. Т., Каннан, П.К., Луо, X., Абхишек, В., Эндрюс, М., и др. (2017). Подключение потребителей в сложном, технологичном и ориентированном на мобильные устройства мире с помощью интеллектуальных продуктов. Журнал интерактивного маркетинга, 40 , 1–8.
К., Стивен, А. Т., Каннан, П.К., Луо, X., Абхишек, В., Эндрюс, М., и др. (2017). Подключение потребителей в сложном, технологичном и ориентированном на мобильные устройства мире с помощью интеллектуальных продуктов. Журнал интерактивного маркетинга, 40 , 1–8.
Google Scholar
Вилласенор, Дж. (2019). Искусственный интеллект и предвзятость: четыре ключевые проблемы. Получено 11 февраля 2019 г. с сайта https://www.brookings.edu/blog/techtank/2019/01/03/artificial-intelligence-and-bias-four-key-challenges/.
Wainer, J., Feil-Seifer, D. J., Shell, D. A., & Mataric, M. J. (2006, сентябрь). Роль физического воплощения во взаимодействии человека и робота. В Протоколах Международного симпозиума IEEE по взаимодействию между роботами и людьми, общение (стр. 6-8).
Ван, Ю., и Косински, М. (2018). Глубокие нейронные сети точнее людей определяют сексуальную ориентацию по изображениям лиц. Журнал личности и социальной психологии, 114 (2), 246–257.
Google Scholar
Вайсман, Дж. (2018). Amazon создала инструмент найма, используя A.I. тут же началась дискриминация женщин. 10 октября. Получено 11 февраля 2019 г. с сайта https://slate.com/business/2018/10/amazon-artificial-intelligence-hiring-discrimination-women.html.
Уилсон, С. (2018). Большая конфиденциальность: компактная конфиденциальность данных в эпоху больших данных и искусственного интеллекта. Получено 11 февраля 2019 г. с сайта https: // www.zdnet.com/article/big-privacy-the-data-privacy-compact-for-the-era-of-big-data-and-ai/.
Уилсон Дж., Догерти П. и Шукла П. (2016). Как одна компания по производству одежды сочетает искусственный интеллект и человеческий опыт. Harvard Business Review, 21 ноября. Получено 11 февраля из .
https://hbr.org/2016/11/how-one-clothing-company-blends-ai-and-human-expertise.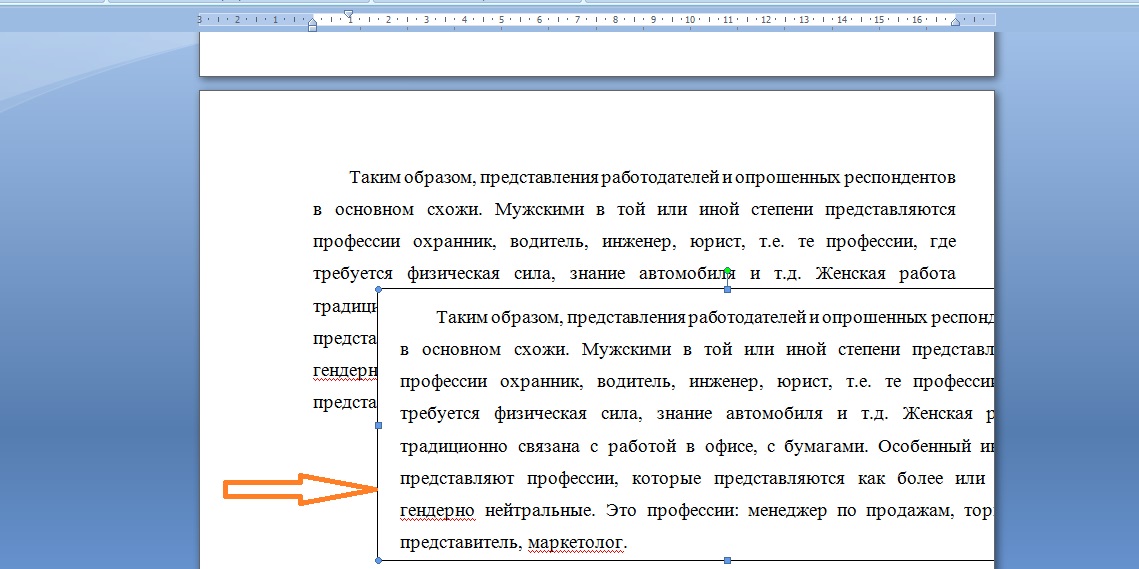
Виртц, Дж., Паттерсон, П. Г., Кунц, В. Х., Грубер, Т., Лу, В. Н., Палуч, С., и Мартинс, А. (2018).Дивный новый мир: сервисные роботы на передовой. Журнал управления услугами, 29 (5), 907–931.
Google Scholar
Ю, К., Джин, Х., Ван, З., Фанг, К., и Луо, Дж. (2016). Подписи к изображениям с семантическим вниманием. В Труды конференции IEEE по компьютерному зрению и распознаванию образов (стр. 4651-4659).
Чжао, М., Хёффлер, С., и Даль, Д. В. (2012). Сложность воображения и оценка нового продукта. Журнал управления инновационными продуктами, 29 (S1), 76–90.
Google Scholar
Практическая классификация текста с помощью Python и Keras — Real Python
Представьте, что вы можете узнать настроение людей в Интернете. Может быть, вас интересует не все, но только если люди сегодня счастливы в вашей любимой социальной сети. После этого урока у вас будет все необходимое для этого. Делая это, вы получите представление о текущих достижениях (глубоких) нейронных сетей и о том, как их можно применить к тексту.
Чтение настроения из текста с помощью машинного обучения называется анализом настроений, и это один из наиболее заметных вариантов использования при классификации текста. Это относится к очень активной области исследований обработки естественного языка (NLP). Другие распространенные варианты использования классификации текста включают обнаружение спама, автоматическую пометку запросов клиентов и категоризацию текста по определенным темам. Так как же это сделать?
Бесплатный бонус: 5 мыслей о Python Mastery, бесплатный курс для разработчиков Python, который показывает вам план действий и образ мышления, которые вам понадобятся, чтобы вывести свои навыки Python на новый уровень.
Выбор набора данных
Прежде чем мы начнем, давайте посмотрим, какие данные у нас есть. Скачайте набор данных из набора данных Sentiment Labeled Sentences Data Set из репозитория машинного обучения UCI.
Скачайте набор данных из набора данных Sentiment Labeled Sentences Data Set из репозитория машинного обучения UCI.
Между прочим, этот репозиторий — прекрасный источник наборов данных машинного обучения, когда вы хотите опробовать некоторые алгоритмы. Этот набор данных включает помеченные обзоры от IMDb, Amazon и Yelp. Каждый отзыв получает оценку 0 за отрицательное мнение или 1 за положительное мнение.
Извлеките папку в папку данных и загрузите данные с помощью Pandas:
импортировать панд как pd
filepath_dict = {'yelp': 'данные / sentiment_analysis / yelp_labelled.txt',
'amazon': 'data / sentiment_analysis / amazon_cells_labelled.txt',
'imdb': 'data / sentiment_analysis / imdb_labelled.txt'}
df_list = []
для источника путь к файлу в filepath_dict.items ():
df = pd.read_csv (путь к файлу, names = ['предложение', 'метка'], sep = '\ t')
df ['source'] = source # Добавить еще один столбец, заполненный именем источника
df_list.добавить (df)
df = pd.concat (df_list)
печать (df.iloc [0])
Результат будет следующим:
предложений Ничего себе ... Мне очень понравилось это место.
этикетка 1
исходный визг
Имя: 0, dtype: объект
Выглядит примерно правильно. С помощью этого набора данных вы можете обучить модель предсказывать тональность предложения. Найдите минутку, чтобы подумать, как вы будете прогнозировать данные.
Один из способов сделать это — подсчитать частоту каждого слова в каждом предложении и связать этот счет со всем набором слов в наборе данных.Вы должны начать с сбора данных и создания словарного запаса из всех слов во всех предложениях. Сборник текстов также называется корпусом в НЛП.
Словарь в данном случае — это список слов, которые встречаются в нашем тексте, где каждое слово имеет свой индекс. Это позволяет вам создать вектор для предложения. Затем вы берете предложение, которое хотите векторизовать, и подсчитываете каждое вхождение в словарном запасе. Результирующий вектор будет с длиной словаря и счетчиком для каждого слова в словаре.
Результирующий вектор будет с длиной словаря и счетчиком для каждого слова в словаре.
Результирующий вектор также называется вектором признаков . В векторе признаков каждое измерение может быть числовым или категориальным признаком, таким как, например, высота здания, цена акций или, в нашем случае, количество слов в словаре. Эти векторы функций являются важной частью науки о данных и машинного обучения, поскольку от них зависит модель, которую вы хотите обучить.
Давайте быстро проиллюстрируем это. Представьте, что у вас есть следующие два предложения:
>>> >>> предложения = ['Джон любит мороженое', 'Джон ненавидит шоколад.']
Затем вы можете использовать CountVectorizer , предоставленный библиотекой scikit-learn, для векторизации предложений. Он берет слова из каждого предложения и создает словарь всех уникальных слов в предложениях. Затем этот словарь можно использовать для создания вектора признаков количества слов:
>>> from sklearn.feature_extraction.text import CountVectorizer
>>> векторизатор = CountVectorizer (min_df = 0, нижний регистр = False)
>>> векторизатор.подходят (предложения)
>>> vectorizer.vocabulary_
{'Джон': 0, 'шоколад': 1, 'сливки': 2, 'ненавидит': 3, 'лед': 4, 'любит': 5}
Этот словарь служит также указателем каждого слова. Теперь вы можете взять каждое предложение и получить количество вхождений слов на основе предыдущего словаря. Словарь состоит из всех пяти слов в наших предложениях, каждое из которых представляет одно слово в словаре. Когда вы возьмете два предыдущих предложения и преобразуете их с помощью CountVectorizer , вы получите вектор, представляющий количество каждого слова предложения:
>>> векторизатор.преобразовать (предложения) .toarray ()
array ([[1, 0, 1, 0, 1, 1],
[1, 1, 0, 1, 0, 0]])
Теперь вы можете увидеть результирующие векторы признаков для каждого предложения на основе предыдущего словаря. Например, если вы посмотрите на первый элемент, вы увидите, что оба вектора имеют там
Например, если вы посмотрите на первый элемент, вы увидите, что оба вектора имеют там 1 . Это означает, что оба предложения имеют одно вхождение Иоанна , что стоит на первом месте в словаре.
Это считается моделью мешка слов (BOW), которая является обычным способом в НЛП для создания векторов из текста.Каждый документ представлен в виде вектора. Теперь вы можете использовать эти векторы в качестве векторов признаков для модели машинного обучения. Это подводит нас к следующей части, определяющей базовую модель.
Определение базовой модели
Когда вы работаете с машинным обучением, одним из важных шагов является определение базовой модели. Обычно это включает простую модель, которая затем используется для сравнения с более продвинутыми моделями, которые вы хотите протестировать. В этом случае вы будете использовать базовую модель, чтобы сравнить ее с более продвинутыми методами, включающими (глубокие) нейронные сети, мясо и картошку из этого руководства.
Во-первых, вы собираетесь разделить данные на набор для обучения и тестирования, который позволит вам оценить точность и посмотреть, хорошо ли обобщается ваша модель. Это означает, может ли модель хорошо работать с данными, которые она раньше не видела. Это способ увидеть, не переоснащается ли модель.
Переобучение — это когда модель слишком хорошо обучена на обучающих данных. Вы хотите избежать переобучения, так как это будет означать, что модель в основном просто запоминает данные обучения.Это объясняет большую точность обучающих данных, но низкую точность данных тестирования.
Мы начинаем с набора данных Yelp, который мы извлекаем из нашего объединенного набора данных. Оттуда мы берем предложения и ярлыки. .values возвращает массив NumPy вместо объекта Pandas Series, с которым в этом контексте легче работать:
>>> from sklearn.model_selection import train_test_split
>>> df_yelp = df [df ['source'] == 'yelp']
>>> предложения = df_yelp ['предложение']. значения
>>> y = df_yelp ['label']. values
>>> предложения_поездка, предложения_тест, y_train, y_test = train_test_split (
... предложения, y, test_size = 0,25, random_state = 1000)
 значения
>>> y = df_yelp ['label']. values
>>> предложения_поездка, предложения_тест, y_train, y_test = train_test_split (
... предложения, y, test_size = 0,25, random_state = 1000)
значения
>>> y = df_yelp ['label']. values
>>> предложения_поездка, предложения_тест, y_train, y_test = train_test_split (
... предложения, y, test_size = 0,25, random_state = 1000)
Здесь мы снова будем использовать предыдущую модель BOW для векторизации предложений. Вы можете снова использовать CountVectorizer для этой задачи. Поскольку данные тестирования могут быть недоступны во время обучения, вы можете создать словарь, используя только данные обучения. Используя этот словарь, вы можете создать векторы признаков для каждого предложения набора для обучения и тестирования:
>>> из sklearn.feature_extraction.text импорт CountVectorizer
>>> векторизатор = CountVectorizer ()
>>> vectorizer.fit (предложения_поездка)
>>> X_train = vectorizer.transform (предложения_поезд)
>>> X_test = vectorizer.transform (предложения_тест)
>>> X_train
<Разреженная матрица 750x2505 типа ''
с 7368 сохраненными элементами в формате сжатой разреженной строки>
Вы можете видеть, что в результирующих векторах признаков есть 750 выборок, которые представляют собой количество обучающих выборок, которые мы имеем после разделения на поезд-тест.Каждый образец имеет 2505 измерений, что составляет размер словаря. Также вы можете видеть, что мы получаем разреженную матрицу. Это тип данных, оптимизированный для матриц с несколькими ненулевыми элементами, который отслеживает только ненулевые элементы, уменьшая нагрузку на память.
CountVectorizer выполняет разметку, которая разделяет предложения на набор из токенов , как вы видели ранее в словаре. Он дополнительно удаляет знаки препинания и специальные символы и может применять другую предварительную обработку к каждому слову.Если вы хотите, вы можете использовать настраиваемый токенизатор из библиотеки NLTK с CountVectorizer или использовать любое количество настроек, которые вы можете изучить, чтобы улучшить производительность вашей модели.
Примечание: Существует множество дополнительных параметров для CountVectorizer () , которые мы здесь не используем, например, добавление нграмм , поскольку цель состоит в том, чтобы сначала построить простую базовую модель. Сам шаблон токена по умолчанию равен token_pattern = ’(? U) \ b \ w \ w + \ b’ , который является шаблоном регулярного выражения, который говорит: «Слово — это 2 или более символа слова Unicode, окруженные границами слова.».
Модель классификации, которую мы собираемся использовать, представляет собой логистическую регрессию, которая представляет собой простую, но мощную линейную модель, которая с математической точки зрения фактически представляет собой форму регрессии между 0 и 1 на основе входного вектора признаков. При указании порогового значения (по умолчанию 0,5) для классификации используется регрессионная модель. Вы можете снова использовать библиотеку scikit-learn, которая предоставляет классификатор LogisticRegression :
>>> из sklearn.linear_model импорт LogisticRegression
>>> classifier = LogisticRegression ()
>>> classifier.fit (X_train, y_train)
>>> score = classifier.score (X_test, y_test)
>>> print ("Точность:", оценка)
Точность: 0,796
Вы можете видеть, что логистическая регрессия достигла впечатляющих 79,6%, но давайте посмотрим, как эта модель работает с другими наборами данных, которые у нас есть. В этом скрипте мы выполняем и оцениваем весь процесс для каждого набора данных, который у нас есть:
для источника в df ['source'].уникальный():
df_source = df [df ['источник'] == источник]
предложения = df_source ['предложение']. значения
y = df_source ['label']. values
предложения_поездка, предложения_тест, y_train, y_test = train_test_split (
предложения, y, test_size = 0,25, random_state = 1000)
vectorizer = CountVectorizer ()
vectorizer. fit (предложения_поезд)
X_train = vectorizer.transform (предложения_поезд)
X_test = vectorizer.transform (предложения_тест)
classifier = LogisticRegression ()
classifier.fit (X_train, y_train)
оценка = классификатор.оценка (X_test, y_test)
print ('Точность для {} данных: {: .4f}'. формат (источник, оценка))
Вот результат:
Точность отображения данных: 0,7960
Точность для данных Amazon: 0,7960
Точность для данных IMDB: 0,7487
Отлично! Вы можете видеть, что эта довольно простая модель обеспечивает довольно хорошую точность. Было бы интересно посмотреть, сможем ли мы превзойти эту модель. В следующей части мы познакомимся с (глубокими) нейронными сетями и их применением для классификации текста.
Учебник по (глубоким) нейронным сетям
Возможно, вы испытали волнение и страх, связанные с искусственным интеллектом и глубоким обучением. Возможно, вы наткнулись на какую-то запутанную статью или обеспокоенные разговоры на TED о приближающейся сингулярности, или, может быть, вы увидели падающих назад роботов и задаетесь вопросом, кажется ли жизнь в лесу разумной в конце концов.
В более легкой ноте, все исследователи ИИ согласились, что они не согласны друг с другом, когда ИИ превысит производительность человеческого уровня.Согласно этой статье, у нас еще должно быть время.
Возможно, вам уже интересно, как работают нейронные сети. Если вы уже знакомы с нейронными сетями, не стесняйтесь переходить к частям, связанным с Керасом. Кроме того, есть замечательная книга Яна Гудфеллоу по глубокому обучению, которую я настоятельно рекомендую, если вы хотите глубже погрузиться в математику. Вы можете прочитать всю книгу онлайн бесплатно. В этом разделе вы получите обзор нейронных сетей и их внутреннего устройства, а позже вы узнаете, как использовать нейронные сети с выдающейся библиотекой Keras.
В этой статье вам не нужно беспокоиться о сингулярности, но (глубокие) нейронные сети играют решающую роль в последних разработках в области искусственного интеллекта. Все началось с известной статьи Джеффри Хинтона и его команды в 2012 году, которая превзошла все предыдущие модели в знаменитом ImageNet Challenge.
Все началось с известной статьи Джеффри Хинтона и его команды в 2012 году, которая превзошла все предыдущие модели в знаменитом ImageNet Challenge.
Задачей можно считать чемпионат мира по компьютерному зрению, который включает в себя классификацию большого набора изображений на основе заданных ярлыков. Джеффри Хинтону и его команде удалось превзойти предыдущие модели с помощью сверточной нейронной сети (CNN), которую мы также рассмотрим в этом руководстве.
С тех пор нейронные сети переместились в несколько областей, включая классификацию, регрессию и даже генеративные модели. Наиболее распространенные области включают компьютерное зрение, распознавание голоса и обработку естественного языка (НЛП).
Нейронные сети, или иногда называемые искусственными нейронными сетями (ИНС) или нейронными сетями прямого распространения, представляют собой вычислительные сети, которые смутно вдохновлены нейронными сетями в человеческом мозгу. Они состоят из нейронов (также называемых узлами), которые связаны, как показано на графике ниже.
Вы начинаете со слоя входных нейронов, куда вы вводите свои векторы признаков, а затем значения передаются на скрытый слой. При каждом подключении вы передаете значение вперед, в то время как значение умножается на вес, а к значению добавляется смещение. Это происходит при каждом соединении, и в конце вы попадаете на выходной слой с одним или несколькими выходными узлами.
Если вы хотите иметь двоичную классификацию, вы можете использовать один узел, но если у вас несколько категорий, вы должны использовать несколько узлов для каждой категории:
Модель нейронной сети Вы можете иметь сколько угодно скрытых слоев.Фактически нейронная сеть с более чем одним скрытым слоем считается глубокой нейронной сетью. Не волнуйтесь: я не буду вдаваться в математические подробности, касающиеся нейронных сетей. Но если вы хотите получить интуитивное визуальное представление о задействованной математике, вы можете проверить плейлист YouTube Гранта Сандерсона. Формула перехода от одного слоя к другому — это короткое уравнение:
Формула перехода от одного слоя к другому — это короткое уравнение:
Давайте потихоньку разберемся, что здесь происходит. Понимаете, мы имеем дело только с двумя слоями.Слой с узлами a служит входом для слоя с узлами o . Чтобы вычислить значения для каждого выходного узла, мы должны умножить каждый входной узел на вес w и добавить смещение b .
Все они затем должны быть суммированы и переданы в функцию f . Эта функция считается функцией активации, и существуют различные функции, которые могут использоваться в зависимости от уровня или проблемы. Обычно используется выпрямленный линейный блок (ReLU) для скрытых слоев, сигмоидальная функция для выходного слоя в задаче двоичной классификации или функция softmax для выходного уровня задач мультиклассовой классификации.
Возможно, вы уже задаетесь вопросом, как рассчитываются веса, и это, очевидно, самая важная часть нейронных сетей, но также и самая сложная часть. Алгоритм начинается с инициализации весов случайными значениями, а затем они обучаются методом обратного распространения ошибки.
Это делается с помощью методов оптимизации (также называемых оптимизатором), таких как градиентный спуск, для уменьшения ошибки между вычисленным и желаемым выходными данными (также называемыми целевым выходом).Ошибка определяется функцией потерь, потери которой мы хотим минимизировать с помощью оптимизатора. Весь процесс слишком обширен, чтобы описывать его здесь, но я снова вернусь к плейлисту Гранта Сандерсона и книге Яна Гудфеллоу по глубокому обучению, о которой я упоминал ранее.
Что вам нужно знать, так это то, что вы можете использовать различные методы оптимизации, но наиболее распространенный оптимизатор, используемый в настоящее время, называется Adam, который имеет хорошую производительность при решении различных задач.
Вы также можете использовать различные функции потерь, но в этом руководстве вам понадобится только функция потери перекрестной энтропии или, более конкретно, двоичная перекрестная энтропия, которая используется для задач двоичной классификации.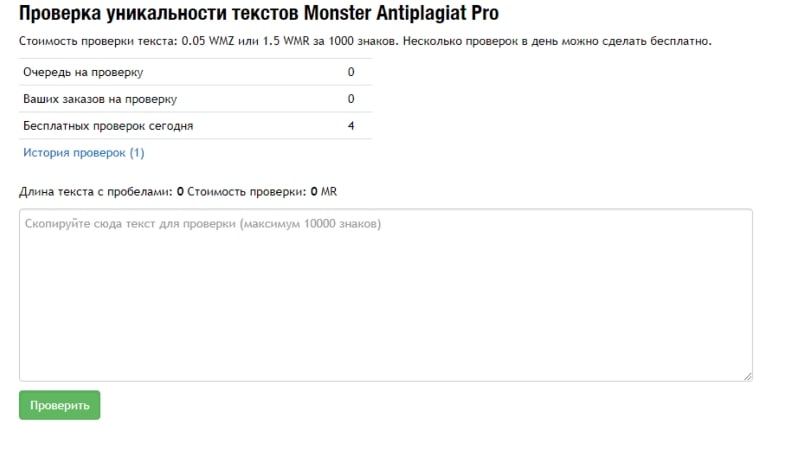 Обязательно поэкспериментируйте с различными доступными методами и инструментами. Некоторые исследователи даже утверждают в недавней статье, что выбор наиболее эффективных методов граничит с алхимией. Причина в том, что многие методы плохо объяснены и состоят из множества настроек и тестирования.
Обязательно поэкспериментируйте с различными доступными методами и инструментами. Некоторые исследователи даже утверждают в недавней статье, что выбор наиболее эффективных методов граничит с алхимией. Причина в том, что многие методы плохо объяснены и состоят из множества настроек и тестирования.
Представляем Keras
Keras — это API глубокого обучения и нейронных сетей от Франсуа Шолле, который может работать поверх Tensorflow (Google), Theano или CNTK (Microsoft). Процитируем замечательную книгу Франсуа Шоле, Deep Learning with Python :
Keras — это библиотека на уровне модели, предоставляющая стандартные блоки высокого уровня для разработки моделей глубокого обучения.Он не обрабатывает низкоуровневые операции, такие как манипулирование тензором и дифференцирование. Вместо этого он полагается на специализированную, хорошо оптимизированную библиотеку тензоров для этого, выступающую в качестве внутреннего механизма Keras (Источник)
.
Это отличный способ начать экспериментировать с нейронными сетями без необходимости реализовывать каждый слой и элемент самостоятельно. Например, Tensorflow — отличная библиотека для машинного обучения, но вам нужно реализовать много шаблонного кода, чтобы модель работала.
Установка Keras
Перед установкой Keras вам понадобится Tensorflow, Theano или CNTK.В этом руководстве мы будем использовать Tensorflow, поэтому ознакомьтесь с их руководством по установке здесь, но не стесняйтесь использовать любой из фреймворков, который лучше всего подходит для вас. Keras можно установить с помощью PyPI с помощью следующей команды:
Вы можете выбрать нужный бэкэнд, открыв файл конфигурации Keras, который вы можете найти здесь:
Если вы являетесь пользователем Windows, вам необходимо заменить $ HOME на % USERPROFILE% . Файл конфигурации должен выглядеть следующим образом:
{
"image_data_format": "каналы_последний",
"эпсилон": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
Вы можете изменить поле backend на theano , tenorflow или cntk , если вы установили backend на свой компьютер. Для получения дополнительной информации ознакомьтесь с документацией по бэкэндам Keras.
Для получения дополнительной информации ознакомьтесь с документацией по бэкэндам Keras.
Вы могли заметить, что мы используем данные float32 в файле конфигурации. Причина этого в том, что нейронные сети часто используются в графических процессорах, а вычислительным узким местом является память. Используя 32-битную версию, мы можем уменьшить нагрузку на память и не терять слишком много информации в процессе.
Ваша первая модель Keras
Теперь вы, наконец, готовы экспериментировать с Керасом. Keras поддерживает два основных типа моделей.У вас есть API-интерфейс последовательной модели, который вы собираетесь использовать в этом руководстве, и функциональный API-интерфейс, который может выполнять все функции последовательной модели, но его также можно использовать для расширенных моделей со сложной сетевой архитектурой.
Последовательная модель представляет собой линейный стек слоев, в котором вы можете использовать большое количество доступных слоев в Keras. Самый распространенный слой — это плотный слой, который представляет собой ваш обычный плотно связанный слой нейронной сети со всеми весами и смещениями, с которыми вы уже знакомы.
Давайте посмотрим, сможем ли мы добиться улучшения нашей предыдущей модели логистической регрессии. Вы можете использовать массивы X_train и X_test , которые вы построили в нашем предыдущем примере.
Прежде чем мы построим нашу модель, нам нужно знать входное измерение наших векторов признаков. Это происходит только в первом слое, так как следующие слои могут автоматически определять форму. Чтобы построить последовательную модель, вы можете добавлять слои один за другим в следующем порядке:
>>> >>> из кераса.модели импортируют Последовательный
>>> из слоев импорта keras
>>> input_dim = X_train.shape [1] # Количество функций
>>> модель = Последовательный ()
>>> model.add (Layers.Dense (10, input_dim = input_dim, Activation = 'relu'))
>>> model. add (Layers.Dense (1, Activation = 'sigmoid'))
Использование бэкэнда TensorFlow.
 add (Layers.Dense (1, Activation = 'sigmoid'))
Использование бэкэнда TensorFlow.
add (Layers.Dense (1, Activation = 'sigmoid'))
Использование бэкэнда TensorFlow.
Прежде чем вы сможете начать обучение модели, вам необходимо настроить процесс обучения. Это делается с помощью метода .compile () .Этот метод определяет оптимизатор и функцию потерь.
Кроме того, вы можете добавить список показателей, которые впоследствии можно будет использовать для оценки, но они не влияют на обучение. В этом случае мы хотим использовать двоичную кросс-энтропию и оптимизатор Adam, который вы видели в упомянутом выше учебнике. Keras также включает удобную функцию .summary () для обзора модели и количества параметров, доступных для обучения:
>>> модель.компилировать (потеря = 'binary_crossentropy',
... optimizer = 'адам',
... метрики = ['точность'])
>>> model.summary ()
_________________________________________________________________
Слой (тип) Параметр формы вывода #
================================================== ===============
плотный_1 (плотный) (нет, 10) 25060
_________________________________________________________________
плотный_2 (плотный) (нет, 1) 11
================================================== ===============
Всего параметров: 25071
Обучаемые параметры: 25071
Необучаемые параметры: 0
_________________________________________________________________
Вы могли заметить, что у нас есть 25060 параметров для первого слоя и еще 11 — для второго.Откуда они взялись?
Видите ли, у нас есть 2505 измерений для каждого вектора признаков, а затем у нас есть 10 узлов. Нам нужны веса для каждого измерения функции и каждого узла, который составляет 2505 * 10 = 25050 параметров, а затем у нас есть еще 10-кратное добавленное смещение для каждого узла, что дает нам 25060 параметров. В последнем узле у нас есть еще 10 весов и одно смещение, что дает нам 11 параметров. Это всего 25071 параметр для обоих слоев.
Аккуратно! Вы почти там.Пришло время начать обучение с функции .. fit ()
fit ()
Поскольку обучение в нейронных сетях — это итеративный процесс, обучение не останавливается сразу после его завершения. Вы должны указать количество итераций, которые вы хотите, чтобы модель обучалась. Эти завершенные итерации обычно называют эпохами . Мы хотим запустить его в течение 100 эпох, чтобы увидеть, как потери при обучении и точность меняются после каждой эпохи.
Еще один параметр, который вы должны выбрать, — это размер партии .Размер пакета отвечает за то, сколько семплов мы хотим использовать за одну эпоху, что означает, сколько семплов используется в одном прямом / обратном проходе. Это увеличивает скорость вычислений, поскольку для выполнения требуется меньше эпох, но также требуется больше памяти, и модель может ухудшиться с увеличением размера пакета. Поскольку у нас есть небольшой обучающий набор, мы можем оставить его маленьким размером партии:
>>> >>> history = model.fit (X_train, y_train,
... эпох = 100,
... verbose = False,
... validation_data = (X_test, y_test)
... batch_size = 10)
Теперь вы можете использовать метод .evaluate () для измерения точности модели. Вы можете сделать это как для данных обучения, так и для данных тестирования. Мы ожидаем, что данные обучения имеют более высокую точность, чем данные тестирования. Чем дольше вы тренируете нейронную сеть, тем больше вероятность, что она начнет переобучаться.
Обратите внимание, что если вы повторно запустите .fit () , вы начнете с вычисленных весов из предыдущего обучения. Обязательно вызовите clear_session () , прежде чем снова начинать обучение модели:
>>> из keras.backend import clear_session
>>> clear_session ()
А теперь оценим точность модели:
>>> >>> потеря, точность = model.evaluate (X_train, y_train, verbose = False)
>>> print ("Точность обучения: {:.4f} ". Формат (точность))
>>> потеря, точность = model. evaluate (X_test, y_test, verbose = False)
>>> print ("Проверка точности: {: .4f}". формат (точность))
Точность обучения: 1.0000
Точность тестирования: 0,7754
 evaluate (X_test, y_test, verbose = False)
>>> print ("Проверка точности: {: .4f}". формат (точность))
Точность обучения: 1.0000
Точность тестирования: 0,7754
evaluate (X_test, y_test, verbose = False)
>>> print ("Проверка точности: {: .4f}". формат (точность))
Точность обучения: 1.0000
Точность тестирования: 0,7754
Вы уже можете видеть, что модель переобучалась, поскольку она достигла 100% точности для обучающего набора. Но это было ожидаемо, так как количество эпох для этой модели было довольно большим. Однако точность набора тестов уже превзошла нашу предыдущую логистическую регрессию с моделью BOW, что является большим шагом вперед с точки зрения нашего прогресса.
Чтобы облегчить себе жизнь, вы можете использовать эту небольшую вспомогательную функцию для визуализации потерь и точности данных обучения и тестирования на основе обратного вызова History. Этот обратный вызов, который автоматически применяется к каждой модели Keras, записывает потери и дополнительные метрики, которые можно добавить в метод .fit () . В этом случае нас интересует только точность. Эта вспомогательная функция использует библиотеку построения графиков matplotlib:
импортировать matplotlib.pyplot как plt
plt.style.use ('ggplot')
def plot_history (история):
acc = history.history ['acc']
val_acc = history.history ['val_acc']
loss = history.history ['потеря']
val_loss = history.history ['val_loss']
x = диапазон (1, len (acc) + 1)
plt.figure (figsize = (12, 5))
plt.subplot (1, 2, 1)
plt.plot (x, acc, 'b', label = 'Training acc')
plt.plot (x, val_acc, 'r', label = 'Validation acc')
plt.title ('Точность обучения и проверки')
plt.legend ()
plt.subplot (1, 2, 2)
plt.plot (x, loss, 'b', label = 'Training loss')
plt.plot (x, val_loss, 'r', label = 'Validation loss')
plt.title ('Потеря обучения и проверки')
plt.legend ()
Чтобы использовать эту функцию, просто вызовите plot_history () с собранной точностью и потерями внутри истории словаря:
>>> сюжет_история (история)
Точность и потери для базовой модели Вы можете видеть, что мы тренировали нашу модель слишком долго, так как обучающая выборка достигла 100% точности. Хороший способ увидеть, когда модель начинает переобучаться, — это когда снова начинает расти потеря данных проверки. Это хороший момент, чтобы остановить модель. Вы можете увидеть это около 20-40 эпох на этом тренинге.
Примечание: При обучении нейронных сетей следует использовать отдельный набор для тестирования и проверки. Обычно вы берете модель с наивысшей точностью проверки, а затем тестируете ее с помощью набора для тестирования.
Это гарантирует, что вы не переобьете модель.Использование набора проверки для выбора наилучшей модели — это форма утечки данных (или «обман»), чтобы выбрать результат, который дал лучший результат теста из сотен из них. Утечка данных происходит, когда в модели используется информация за пределами обучающего набора данных.
В этом случае наши наборы для тестирования и проверки совпадают, поскольку у нас меньший размер выборки. Как мы уже говорили ранее, (глубокие) нейронные сети работают лучше всего, когда у вас очень большое количество выборок.В следующей части вы увидите другой способ представления слов в виде векторов. Это очень увлекательный и эффективный способ работы со словами, в котором вы увидите, как представлять слова в виде плотных векторов.
Что такое встраивание слова?
Текст считается формой данных последовательности, аналогичных данным временных рядов, которые могут быть у вас в данных о погоде или финансовых данных. В предыдущей модели BOW вы видели, как представить всю последовательность слов как единый вектор признаков. Теперь вы увидите, как представить каждое слово в виде векторов.Существуют различные способы векторизации текста, например:
- слов, представленных каждым словом в виде вектора
- Символы, представленные каждым символом в виде вектора
- N-грамм слов / символов, представленных в виде вектора (N-граммы представляют собой перекрывающиеся группы из нескольких следующих друг за другом слов / символов в тексте)
В этом руководстве вы увидите, как работать с представлением слов в виде векторов, что является распространенным способом использования текста в нейронных сетях.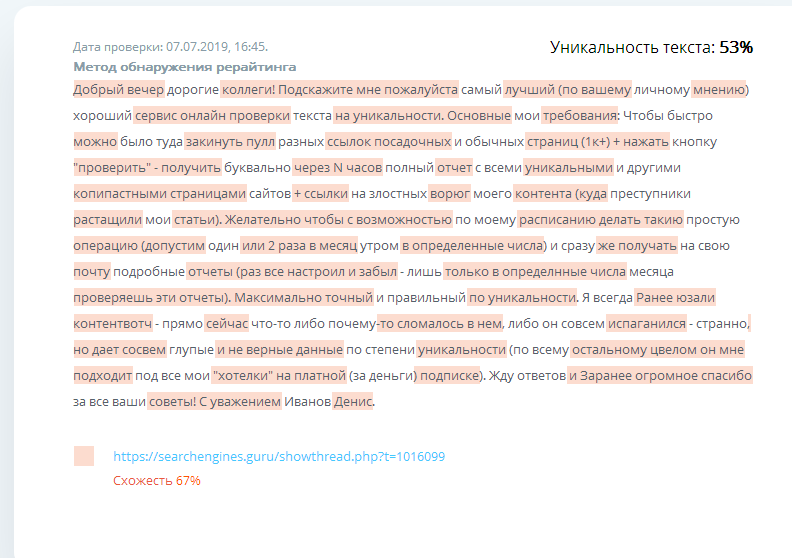 Два возможных способа представления слова в виде вектора — это быстрое кодирование и встраивание слов.
Два возможных способа представления слова в виде вектора — это быстрое кодирование и встраивание слов.
Горячее кодирование
Первый способ представить слово как вектор — это создать так называемое горячее кодирование, которое просто выполняется путем взятия вектора длины словаря с записью для каждого слова в корпусе.
Таким образом, у вас есть для каждого слова, если у него есть место в словарном запасе, вектор с нулями повсюду, кроме соответствующего места для слова, которое установлено в единицу. Как вы можете себе представить, это может стать довольно большим вектором для каждого слова и не дает никакой дополнительной информации, такой как отношения между словами.
Допустим, у вас есть список городов, как в следующем примере:
>>> >>> cities = ['Лондон', 'Берлин', 'Берлин', 'Нью-Йорк', 'Лондон']
>>> города
["Лондон", "Берлин", "Берлин", "Нью-Йорк", "Лондон"]
Вы можете использовать scikit-learn и LabelEncoder для кодирования списка городов в категориальные целочисленные значения, как здесь:
>>> из sklearn.preprocessing import LabelEncoder
>>> кодировщик = LabelEncoder ()
>>> city_labels = кодировщик.fit_transform (города)
>>> city_labels
массив ([1, 0, 0, 2, 1])
Используя это представление, вы можете использовать OneHotEncoder , предоставленный scikit-learn, для кодирования категориальных значений, которые мы получили ранее, в числовой массив с горячим кодированием. OneHotEncoder ожидает, что каждое категориальное значение будет в отдельной строке, поэтому вам нужно будет изменить форму массива, затем вы можете применить кодировщик:
>>> from sklearn.preprocessing import OneHotEncoder
>>> encoder = OneHotEncoder (sparse = False)
>>> city_labels = city_labels.изменить форму ((5, 1))
>>> encoder.fit_transform (city_labels)
массив ([[0., 1., 0.],
[1., 0., 0.],
[1., 0., 0.],
[0. , 0., 1.],
[0., 1., 0.]])
 , 0., 1.],
[0., 1., 0.]])
, 0., 1.],
[0., 1., 0.]])
Вы можете видеть, что категориальное целочисленное значение представляет позицию массива: 1 , а остальное — 0 . Это часто используется, когда у вас есть категориальная функция, которую вы не можете представить в виде числового значения, но вы все равно хотите использовать ее в машинном обучении. Один из вариантов использования этой кодировки — это, конечно, слова в тексте, но чаще всего она используется для категорий.Такими категориями могут быть, например, города, подразделения или другие категории.
Вложения слов
Этот метод представляет слова в виде плотных векторов слов (также называемых вложениями слов), которые обучаются в отличие от жестко запрограммированного однократного кодирования. Это означает, что слово «встраивание» собирает больше информации в меньшее количество измерений.
Обратите внимание, что вложения слов не понимают текст так, как это сделал бы человек, а скорее отображают статистическую структуру языка, используемого в корпусе.Их цель — отобразить семантическое значение в геометрическом пространстве. Это геометрическое пространство называется пространством вложения .
Это отобразит семантически похожие слова, близкие к пространству вложения, такие как числа или цвета. Если вложение хорошо улавливает отношения между словами, должны стать возможными такие вещи, как векторная арифметика. Известным примером в этой области исследований является способность сопоставить король — мужчина + женщина = королева.
Как можно получить такое вложение слов? У вас есть два варианта для этого.Один из способов — тренировать вложения слов во время обучения нейронной сети. Другой способ — использовать предварительно обученные вложения слов, которые вы можете напрямую использовать в своей модели. Здесь у вас есть возможность либо оставить эти вложения слов неизменными во время обучения, либо вы их тоже обучите.
Теперь вам нужно токенизировать данные в формате, который можно использовать для встраивания слов. Keras предлагает несколько удобных методов предварительной обработки текста и предварительной обработки последовательности, которые вы можете использовать для подготовки своего текста.
Вы можете начать с использования служебного класса Tokenizer , который может векторизовать текстовый корпус в список целых чисел. Каждое целое число сопоставляется со значением в словаре, которое кодирует весь корпус, причем ключи в словаре сами являются терминами словаря. Можно добавить параметр num_words , который отвечает за установку размера словаря. После этого будут сохранены наиболее распространенные num_words слово. У меня есть данные для тестирования и обучения, подготовленные из предыдущего примера:
>>> из кераса.preprocessing.text import Tokenizer
>>> tokenizer = Токенизатор (num_words = 5000)
>>> tokenizer.fit_on_texts (предложения_поезд)
>>> X_train = tokenizer.texts_to_sequences (предложения_поездка)
>>> X_test = tokenizer.texts_to_sequences (предложения_тест)
>>> vocab_size = len (tokenizer.word_index) + 1 # Добавление 1 из-за зарезервированного индекса 0
>>> print (предложения_поезд [2])
>>> print (X_train [2])
Из всех блюд лосось был лучшим, но все были великолепны.[11, 43, 1, 171, 1, 283, 3, 1, 47, 26, 43, 24, 22]
Индексирование производится после наиболее употребительных слов в тексте, которые можно увидеть по словам и с индексом 1 . Важно отметить, что индекс 0 зарезервирован и не присваивается никакому слову. Этот нулевой индекс используется для заполнения, о котором я расскажу чуть позже.
Неизвестные слова (слова, которых нет в словаре) обозначаются в Keras с помощью word_count + 1 , поскольку они также могут содержать некоторую информацию.Вы можете увидеть индекс каждого слова, взглянув на словарь word_index объекта Tokenizer :
>>> по слову в ['the', 'all', 'happy', 'sad']:
. .. print ('{}: {}'. format (word, tokenizer.word_index [слово]))
: 1
всего: 43
счастливы: 320
грустно: 450
 .. print ('{}: {}'. format (word, tokenizer.word_index [слово]))
: 1
всего: 43
счастливы: 320
грустно: 450
.. print ('{}: {}'. format (word, tokenizer.word_index [слово]))
: 1
всего: 43
счастливы: 320
грустно: 450
Примечание: Обратите особое внимание на разницу между этим методом и X_train , созданным scikit-learn CountVectorizer .
В CountVectorizer у нас были штабелированные векторы количества слов, и каждый вектор имел одинаковую длину (размер всего словарного запаса корпуса). С Tokenizer результирующие векторы равны длине каждого текста, а числа не обозначают счетчики, а соответствуют значениям слов из словаря tokenizer.word_index .
Одна из наших проблем заключается в том, что каждая текстовая последовательность в большинстве случаев имеет разную длину слов. Чтобы противостоять этому, вы можете использовать pad_sequence () , который просто дополняет последовательность слов нулями.По умолчанию он добавляет нули, но мы хотим их добавить. Обычно не имеет значения, добавляете ли вы нули в начале или в конце.
Кроме того, вы можете добавить параметр maxlen , чтобы указать длину последовательности. Это вырезает последовательности, превышающие это число. В следующем коде вы можете увидеть, как дополнять последовательности с помощью Keras:
>>> from keras.preprocessing.sequence import pad_sequences
>>> maxlen = 100
>>> X_train = pad_sequences (X_train, padding = 'post', maxlen = maxlen)
>>> X_test = pad_sequences (X_test, padding = 'post', maxlen = maxlen)
>>> print (X_train [0,:])
[1 10 3 282 739 25 8 208 30 64 459 230 13 1 124 5 231 8
58 5 67 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
Первые значения представляют индекс в словаре, как вы узнали из предыдущих примеров.Вы также можете видеть, что результирующий вектор признаков содержит в основном нули, поскольку у вас довольно короткое предложение. В следующей части вы узнаете, как работать с вложениями слов в Keras.
В следующей части вы узнаете, как работать с вложениями слов в Keras.
Слой вложения Keras
Обратите внимание, что на данный момент наши данные все еще жестко закодированы. Мы не говорили Керасу изучать новое пространство встраивания с помощью последовательных задач. Теперь вы можете использовать слой внедрения Keras, который берет ранее вычисленные целые числа и сопоставляет их с плотным вектором вложения.Вам потребуются следующие параметры:
-
input_dim: размер словаря -
output_dim: размер плотного вектора -
input_length: длина последовательности
С слоем Embedding у нас теперь есть несколько вариантов. Один из способов — взять результат слоя внедрения и подключить его к слою Dense . Для этого вам нужно добавить промежуточный слой Flatten , который подготавливает последовательный ввод для слоя Dense :
от keras.модели импортируют Последовательный
из слоев импорта keras
embedding_dim = 50
model = Последовательный ()
model.add (Layers.Embedding (input_dim = vocab_size,
output_dim = размер_встраивания,
input_length = maxlen))
model.add (Layers.Flatten ())
model.add (Layers.Dense (10, Activation = 'relu'))
model.add (Layers.Dense (1, Activation = 'sigmoid'))
model.compile (optimizer = 'adam',
loss = 'binary_crossentropy',
метрики = ['точность'])
model.summary ()
Результат будет следующим:
_________________________________________________________________
Слой (тип) Параметр формы вывода #
================================================== ===============
embedding_8 (Встраивание) (Нет, 100, 50) 87350
_________________________________________________________________
flatten_3 (Flatten) (Нет, 5000) 0
_________________________________________________________________
плотный_13 (Плотный) (Нет, 10) 50010
_________________________________________________________________
плотный_14 (плотный) (нет, 1) 11
================================================== ===============
Всего параметров: 137 371
Обучаемые параметры: 137 371
Необучаемые параметры: 0
_________________________________________________________________
Теперь вы можете видеть, что у нас есть 87350 новых параметров для обучения. Это число получается из
Это число получается из vocab_size , умноженное на embedding_dim . Эти веса слоя внедрения инициализируются случайными весами, а затем корректируются посредством обратного распространения ошибки во время обучения. Эта модель принимает слова в порядке их поступления в качестве входных векторов. Вы можете тренировать его со следующим:
history = model.fit (X_train, y_train,
эпох = 20,
verbose = False,
validation_data = (X_test, y_test),
batch_size = 10)
потеря, точность = модель.оценить (X_train, y_train, verbose = False)
print ("Точность обучения: {: .4f}". формат (точность))
потеря, точность = модель. оценка (X_test, y_test, verbose = False)
print ("Проверка точности: {: .4f}". формат (точность))
plot_history (история)
Результат будет следующим:
Точность обучения: 0,5100
Точность тестирования: 0,4600
Точность и потери для первой моделиЭто обычно не очень надежный способ работы с последовательными данными, как вы можете видеть по производительности.При работе с последовательными данными вы хотите сосредоточиться на методах, которые рассматривают локальную и последовательную информацию, а не абсолютную позиционную информацию.
Другой способ работы с внедрением — использование слоя MaxPooling1D / AveragePooling1D или GlobalMaxPooling1D / GlobalAveragePooling1D после внедрения. Вы можете думать о слоях пула как о способе субдискретизации (способ уменьшить размер) входящих векторов признаков.
В случае максимального объединения вы берете максимальное значение всех функций в пуле для каждого измерения функции.В случае среднего пула вы берете среднее значение, но, похоже, чаще используется максимальный пул, поскольку он выделяет большие значения.
Глобальный максимальный / средний пул принимает максимальное / среднее значение всех функций, тогда как в другом случае вам необходимо определить размер пула. У Кераса снова есть собственный слой, который вы можете добавить в последовательную модель:
У Кераса снова есть собственный слой, который вы можете добавить в последовательную модель:
из keras.models импорт Последовательный
из слоев импорта keras
embedding_dim = 50
model = Последовательный ()
model.add (Layers.Embedding (input_dim = vocab_size,
output_dim = размер_встраивания,
input_length = maxlen))
модель.добавить (слои.GlobalMaxPool1D ())
model.add (Layers.Dense (10, Activation = 'relu'))
model.add (Layers.Dense (1, Activation = 'sigmoid'))
model.compile (optimizer = 'adam',
loss = 'binary_crossentropy',
метрики = ['точность'])
model.summary ()
Результат будет следующим:
_________________________________________________________________
Слой (тип) Параметр формы вывода #
================================================== ===============
embedding_9 (Встраивание) (Нет, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_5 (Glob (Нет, 50) 0
_________________________________________________________________
плотный_15 (плотный) (нет, 10) 510
_________________________________________________________________
плотный_16 (плотный) (нет, 1) 11
================================================== ===============
Всего параметров: 87 871
Обучаемые параметры: 87 871
Необучаемые параметры: 0
_________________________________________________________________
Порядок обучения не меняется:
история = модель.подходят (X_train, y_train,
эпох = 50,
verbose = False,
validation_data = (X_test, y_test),
batch_size = 10)
потеря, точность = модель. оценка (X_train, y_train, verbose = False)
print ("Точность обучения: {: .4f}". формат (точность))
потеря, точность = модель. оценка (X_test, y_test, verbose = False)
print ("Проверка точности: {: .4f}". формат (точность))
plot_history (история)
Результат будет следующим:
Точность обучения: 1. 0000
Точность тестирования: 0,8050
Точность и потери для модели максимального объединения 0000
Точность тестирования: 0,8050
0000
Точность тестирования: 0,8050
. Вы уже можете увидеть некоторые улучшения в наших моделях. Далее вы увидите, как мы можем использовать предварительно обученные вложения слов и помогут ли они нам с нашей моделью.
Использование предварительно обученных вложений слов
Мы только что видели пример совместного обучения встраиванию слов, включенный в более крупную модель, которую мы хотим решить.
Альтернативой является использование предварительно вычисленного пространства для вложения, которое использует гораздо больший корпус.Можно предварительно вычислить вложения слов, просто обучив их на большом корпусе текста. Среди наиболее популярных методов — Word2Vec, разработанный Google, и GloVe (глобальные векторы для представления слов), разработанный Stanford NLP Group.
Обратите внимание, что это разные подходы с одной и той же целью. Word2Vec достигает этого с помощью нейронных сетей, а GloVe достигает этого с помощью матрицы совместного появления и использования факторизации матрицы. В обоих случаях вы имеете дело с уменьшением размерности, но Word2Vec более точен, а GloVe быстрее вычисляет.
В этом руководстве вы увидите, как работать с встраиваемыми словосочетаниями GloVe от Stanford NLP Group, поскольку их размер более управляем, чем встраивания слов Word2Vec, предоставляемые Google. Скачайте отсюда 6B (обучено 6 миллиардам слов) вложения слов ( glove.6B.zip , 822 МБ).
Вы можете найти другие вложения слов также на главной странице GloVe. Вы можете найти предварительно обученные вложения Word2Vec от Google здесь. Если вы хотите обучить собственные вложения слов, вы можете сделать это эффективно с помощью пакета gensim Python, который использует Word2Vec для вычислений.Подробнее о том, как это сделать, можно узнать здесь.
Теперь, когда мы разобрались с вами, вы можете начать использовать слово «встраивание» в своих моделях. В следующем примере вы можете увидеть, как можно загрузить матрицу внедрения. Каждая строка в файле начинается со слова, за которым следует вектор встраивания для конкретного слова.
В следующем примере вы можете увидеть, как можно загрузить матрицу внедрения. Каждая строка в файле начинается со слова, за которым следует вектор встраивания для конкретного слова.
Это большой файл с 400000 строками, каждая из которых представляет слово, за которым следует его вектор в виде потока с плавающей запятой. Например, вот первые 50 символов первой строки:
$ голова -n 1 данные / glove_word_embeddings / glove.6B.50d.txt | вырезать -c-50
0,418 0,24968 -0,41242 0,1217 0,34527 -0,04445
Поскольку вам не нужны все слова, вы можете сосредоточиться только на тех словах, которые есть в нашем словаре. Поскольку в нашем словарном запасе лишь ограниченное количество слов, мы можем пропустить большую часть из 40000 слов в предварительно обученных вложениях слов:
импортировать numpy как np
def create_embedding_matrix (путь к файлу, word_index, embedding_dim):
Dictionary_size = len (word_index) + 1 # Повторное добавление 1 из-за зарезервированного индекса 0
embedding_matrix = np.нули ((размер_круга, размер_встраивания))
с открытым (путь к файлу) как f:
для строки в f:
слово, * вектор = line.split ()
если слово в word_index:
idx = word_index [слово]
embedding_matrix [idx] = np.array (
вектор, dtype = np.float32) [: embedding_dim]
вернуть embedding_matrix
Теперь вы можете использовать эту функцию для получения матрицы вложения:
>>> >>> embedding_dim = 50
>>> embedding_matrix = create_embedding_matrix (
... 'data / glove_word_embeddings / glove.6B.50d.txt',
... tokenizer.word_index, embedding_dim)
Замечательно! Теперь вы готовы использовать матрицу внедрения в обучении. Давайте продолжим и воспользуемся предыдущей сетью с глобальным максимальным пулом и посмотрим, сможем ли мы улучшить эту модель. Когда вы используете предварительно обученные вложения слов, у вас есть выбор: разрешить вложение обновляться во время обучения или использовать только результирующие векторы встраивания, как они есть.
Во-первых, давайте быстро посмотрим, сколько векторов внедрения отличны от нуля:
>>> >>> nonzero_elements = np.count_nonzero (np.count_nonzero (embedding_matrix, axis = 1))
>>> nonzero_elements / vocab_size
0,95077275326
Это означает, что 95,1% словарного запаса покрывается предварительно обученной моделью, что является хорошим охватом нашего словарного запаса. Давайте посмотрим на производительность при использовании слоя GlobalMaxPool1D :
модель = Последовательная ()
model.add (Layers.Embedding (vocab_size, embedding_dim,
веса = [embedding_matrix],
input_length = maxlen,
trainable = Ложь))
модель.добавить (слои.GlobalMaxPool1D ())
model.add (Layers.Dense (10, Activation = 'relu'))
model.add (Layers.Dense (1, Activation = 'sigmoid'))
model.compile (optimizer = 'adam',
loss = 'binary_crossentropy',
метрики = ['точность'])
model.summary ()
Результат будет следующим:
_________________________________________________________________
Слой (тип) Параметр формы вывода #
================================================== ===============
embedding_10 (Встраивание) (Нет, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_6 (Glob (Нет, 50) 0
_________________________________________________________________
плотный_17 (плотный) (нет, 10) 510
_________________________________________________________________
плотный_18 (плотный) (нет, 1) 11
================================================== ===============
Всего параметров: 87 871
Обучаемые параметры: 521
Необучаемые параметры: 87 350
_________________________________________________________________
история = модель.подходят (X_train, y_train,
эпох = 50,
verbose = False,
validation_data = (X_test, y_test),
batch_size = 10)
потеря, точность = модель. оценка (X_train, y_train, verbose = False)
print ("Точность обучения: {: .4f}". формат (точность))
потеря, точность = модель. оценка (X_test, y_test, verbose = False)
print ("Проверка точности: {: .4f}". формат (точность))
plot_history (история)
Результат будет следующим:
Точность обучения: 0.7500
Точность тестирования: 0,6950
Точность и потери для необученных встраиваний слов Поскольку вложения слов дополнительно не обучаются, ожидается, что они будут ниже. Но давайте теперь посмотрим, как это работает, если мы разрешим обучение встраиванию с помощью trainable = True :
модель = Последовательная ()
model.add (Layers.Embedding (vocab_size, embedding_dim,
веса = [embedding_matrix],
input_length = maxlen,
обучаемый = True))
модель.добавить (слои.GlobalMaxPool1D ())
model.add (Layers.Dense (10, Activation = 'relu'))
model.add (Layers.Dense (1, Activation = 'sigmoid'))
model.compile (optimizer = 'adam',
loss = 'binary_crossentropy',
метрики = ['точность'])
model.summary ()
Результат будет следующим:
_________________________________________________________________
Слой (тип) Параметр формы вывода #
================================================== ===============
embedding_11 (Встраивание) (Нет, 100, 50) 87350
_________________________________________________________________
global_max_pooling1d_7 (Glob (Нет, 50) 0
_________________________________________________________________
плотный_19 (плотный) (нет, 10) 510
_________________________________________________________________
плотный_20 (плотный) (нет, 1) 11
================================================== ===============
Всего параметров: 87 871
Обучаемые параметры: 87 871
Необучаемые параметры: 0
_________________________________________________________________
история = модель.подходят (X_train, y_train,
эпох = 50,
verbose = False,
validation_data = (X_test, y_test),
batch_size = 10)
потеря, точность = модель. оценка (X_train, y_train, verbose = False)
print ("Точность обучения: {: .4f}". формат (точность))
потеря, точность = модель. оценка (X_test, y_test, verbose = False)
print ("Проверка точности: {: .4f}". формат (точность))
plot_history (история)
Результат будет следующим:
Точность обучения: 1.0000
Точность тестирования: 0,8250
Точность и потеря для предварительно обученных встраиваний словКак видите, наиболее эффективно позволить обучать вложениям. При работе с большими тренировочными наборами это может ускорить тренировочный процесс, чем без него. В нашем случае это помогло, но не сильно. Это не должно быть из-за предварительно обученных встраиваний слов.
Теперь пришло время сосредоточиться на более продвинутой модели нейронной сети, чтобы увидеть, можно ли улучшить модель и дать ей преимущество по сравнению с предыдущими моделями.
Сверточные нейронные сети (CNN)
Сверточные нейронные сетиили также называемые свёрточными сетями — одно из самых интересных достижений в области машинного обучения за последние годы.
Они произвели революцию в классификации изображений и компьютерном зрении, получив возможность извлекать элементы из изображений и использовать их в нейронных сетях. Свойства, которые сделали их полезными при обработке изображений, также делают их удобными для обработки последовательностей. Вы можете представить CNN как специализированную нейронную сеть, способную обнаруживать определенные закономерности.
Если это просто еще одна нейронная сеть, что отличает ее от того, что вы узнали ранее?
CNN имеет скрытые слои, которые называются сверточными слоями. Когда вы думаете об изображениях, компьютер должен иметь дело с двумерной матрицей чисел, и поэтому вам нужен какой-то способ обнаружить особенности в этой матрице. Эти сверточные слои способны обнаруживать края, углы и другие виды текстур, что делает их таким особенным инструментом. Сверточный слой состоит из нескольких фильтров, которые скользят по изображению и могут обнаруживать определенные особенности.
Это самая суть техники, математический процесс свертки. С каждым сверточным слоем сеть способна обнаруживать более сложные шаблоны. В визуализации функций Криса Олаха вы можете получить хорошее представление о том, как могут выглядеть эти функции.
Когда вы работаете с последовательными данными, такими как текст, вы работаете с одномерными свертками, но идея и приложение остаются неизменными. Вы по-прежнему хотите улавливать шаблоны в последовательности, которые усложняются с каждым добавленным сверточным слоем.
На следующем рисунке вы можете увидеть, как работает такая свертка. Он начинается с того, что берется патч входных функций с размером ядра фильтра. С помощью этого патча вы берете скалярное произведение умноженных весов фильтра. Одномерная свертка инвариантна к переводам, что означает, что определенные последовательности могут быть распознаны в другом месте. Это может быть полезно для определенных шаблонов в тексте:
1D Convolution (Источник изображения) Теперь давайте посмотрим, как можно использовать эту сеть в Keras.Керас снова предлагает различные сверточные слои, которые вы можете использовать для этой задачи. Вам понадобится слой Conv1D . Этот слой снова имеет различные параметры на выбор. На данный момент вас интересуют количество фильтров, размер ядра и функция активации. Вы можете добавить этот слой между слоем Embedding и слоем GlobalMaxPool1D :
embedding_dim = 100
model = Последовательный ()
model.add (sizes.Embedding (vocab_size, embedding_dim, input_length = maxlen))
модель.добавить (Layers.Conv1D (128, 5, активация = 'relu'))
model.add (слои.GlobalMaxPooling1D ())
model.add (Layers.Dense (10, Activation = 'relu'))
model.add (Layers.Dense (1, Activation = 'sigmoid'))
model.compile (optimizer = 'adam',
loss = 'binary_crossentropy',
метрики = ['точность'])
model.summary ()
Результат будет следующим:
_________________________________________________________________
Слой (тип) Параметр формы вывода #
================================================== ===============
embedding_13 (Встраивание) (Нет, 100, 100) 174700
_________________________________________________________________
conv1d_2 (Conv1D) (Нет, 96, 128) 64128
_________________________________________________________________
global_max_pooling1d_9 (Glob (Нет, 128) 0
_________________________________________________________________
плотный_23 (плотный) (нет, 10) 1290
_________________________________________________________________
плотный_24 (плотный) (нет, 1) 11
================================================== ===============
Всего параметров: 240,129
Обучаемые параметры: 240,129
Необучаемые параметры: 0
_________________________________________________________________
история = модель.подходят (X_train, y_train,
эпох = 10,
verbose = False,
validation_data = (X_test, y_test),
batch_size = 10)
потеря, точность = модель. оценка (X_train, y_train, verbose = False)
print ("Точность обучения: {: .4f}". формат (точность))
потеря, точность = модель. оценка (X_test, y_test, verbose = False)
print ("Проверка точности: {: .4f}". формат (точность))
plot_history (история)
Результат будет следующим:
Точность обучения: 1.0000
Точность тестирования: 0,7700
Точность и потери для сверточной нейронной сети. Вы можете видеть, что точность 80% кажется трудным препятствием для преодоления этого набора данных, а CNN может быть плохо оборудована. Причина такого плато может заключаться в следующем:
- Не хватает обучающих выборок
- Имеющиеся у вас данные плохо обобщают
- Отсутствует внимание к настройке гиперпараметров CNN
лучше всего работают с большими обучающими наборами, где они могут находить обобщения, в которых простая модель, такая как логистическая регрессия, не сможет.
Оптимизация гиперпараметров
Одним из важнейших шагов глубокого обучения и работы с нейронными сетями является оптимизация гиперпараметров.
Как вы видели в моделях, которые мы использовали до сих пор, даже с более простыми, у вас было большое количество параметров для настройки и выбора. Эти параметры называются гиперпараметрами. Это наиболее трудоемкая часть машинного обучения, и, к сожалению, пока нет готовых универсальных решений.
Если вы посмотрите на соревнования на Kaggle, одном из крупнейших мест, где можно соревноваться с другими коллегами по анализу данных, вы увидите, что многие из команд-победителей и моделей прошли через множество настроек и экспериментов, пока не достигли своего пика. .Так что не расстраивайтесь, когда становится трудно и вы выходите на плато, а лучше подумайте о том, как можно оптимизировать модель или данные.
Одним из популярных методов оптимизации гиперпараметров является поиск по сетке. Что делает этот метод, так это то, что он принимает списки параметров и запускает модель с каждой комбинацией параметров, которую он может найти. Это наиболее тщательный, но также и наиболее сложный в вычислительном отношении способ сделать это. Другой распространенный способ, случайный поиск , который вы увидите здесь в действии, просто использует случайные комбинации параметров.
Чтобы применить случайный поиск с Keras, вам нужно будет использовать KerasClassifier, который служит оболочкой для scikit-learn API. С помощью этой оболочки вы можете использовать различные инструменты, доступные в scikit-learn, такие как перекрестная проверка. Вам нужен класс RandomizedSearchCV, который реализует случайный поиск с перекрестной проверкой. Перекрестная проверка — это способ проверить модель, взять весь набор данных и разделить его на несколько наборов данных для тестирования и обучения.
Существуют различные типы перекрестной проверки.Один тип — это k-кратная перекрестная проверка , которую вы увидите в этом примере. В этом типе набор данных разделен на k наборов одинакового размера, где один набор используется для тестирования, а остальные разделы используются для обучения. Это позволяет запускать k различных запусков, где каждый раздел один раз используется в качестве набора для тестирования. Таким образом, чем выше значение k , тем точнее будет оценка модели, но тем меньше будет каждый набор для тестирования.
Первым шагом для KerasClassifier является создание функции, которая создает модель Keras.Мы будем использовать предыдущую модель, но мы позволим устанавливать различные параметры для оптимизации гиперпараметров:
def create_model (num_filters, kernel_size, vocab_size, embedding_dim, maxlen):
model = Последовательный ()
model.add (sizes.Embedding (vocab_size, embedding_dim, input_length = maxlen))
model.add (Layers.Conv1D (num_filters, kernel_size, Activation = 'relu'))
model.add (слои.GlobalMaxPooling1D ())
model.add (Layers.Dense (10, Activation = 'relu'))
model.add (слои.Плотный (1, активация = 'сигмовидная'))
model.compile (optimizer = 'adam',
loss = 'binary_crossentropy',
метрики = ['точность'])
модель возврата
Затем вы хотите определить сетку параметров, которую хотите использовать при обучении. Он состоит из словаря с каждым параметром, названным как в предыдущей функции. Количество пробелов в сетке — 3 * 3 * 1 * 1 * 1 , где каждое из этих чисел представляет собой количество различных вариантов выбора для данного параметра.
Вы можете видеть, как это может очень быстро стать вычислительно дорогостоящим, но, к счастью, и поиск по сетке, и случайный поиск поразительно параллельны, а классы поставляются с параметром n_jobs , который позволяет вам тестировать пространства сетки параллельно. Сетка параметров инициализируется следующим словарем:
param_grid = dict (num_filters = [32, 64, 128],
kernel_size = [3, 5, 7],
voiceab_size = [5000],
embedding_dim = [50],
maxlen = [100])
Теперь вы уже готовы начать случайный поиск.В этом примере мы перебираем каждый набор данных, а затем вы хотите предварительно обработать данные так же, как и раньше. После этого вы берете предыдущую функцию и добавляете ее в класс-оболочку KerasClassifier , включая количество эпох.
Результирующий экземпляр и сетка параметров затем используются в качестве средства оценки в классе RandomSearchCV . Кроме того, вы можете выбрать количество сверток при перекрестной проверке k-кратностей, которое в данном случае равно 4. Вы уже видели большую часть кода в этом фрагменте ранее в наших предыдущих примерах.Помимо RandomSearchCV и KerasClassifier , я добавил небольшой блок кода, обрабатывающий оценку:
из keras.wrappers.scikit_learn import KerasClassifier
из sklearn.model_selection import RandomizedSearchCV
# Основные настройки
эпох = 20
embedding_dim = 50
maxlen = 100
output_file = 'данные / output.txt'
# Запускаем поиск по сетке для каждого источника (yelp, amazon, imdb)
для источника кадр в df.groupby ('source'):
print ('Выполняется поиск по сетке для набора данных:', источник)
предложения = df ['предложение'].значения
y = df ['label']. values
# Поезд-тестовый сплит
предложения_поездка, предложения_тест, y_train, y_test = train_test_split (
предложения, y, test_size = 0,25, random_state = 1000)
# Токенизация слов
tokenizer = Токенизатор (num_words = 5000)
tokenizer.fit_on_texts (предложения_поезд)
X_train = tokenizer.texts_to_sequences (предложения_поезд)
X_test = tokenizer.texts_to_sequences (предложения_тест)
# Добавление 1 из-за зарезервированного индекса 0
Dictionary_size = len (tokenizer.word_index) + 1
# Закладывать последовательности нулями
X_train = pad_sequences (X_train, padding = 'сообщение', maxlen = maxlen)
X_test = pad_sequences (X_test, padding = 'сообщение', maxlen = maxlen)
# Сетка параметров для поиска по сетке
param_grid = dict (num_filters = [32, 64, 128],
kernel_size = [3, 5, 7],
Vocalab_size = [vocab_size],
embedding_dim = [embedding_dim],
maxlen = [maxlen])
model = KerasClassifier (build_fn = create_model,
epochs = эпохи, batch_size = 10,
verbose = False)
сетка = RandomizedSearchCV (оценка = модель, param_distributions = param_grid,
cv = 4, verbose = 1, n_iter = 5)
grid_result = сетка.подходят (X_train, y_train)
# Оценить набор для тестирования
test_accuracy = grid.score (X_test, y_test)
# Сохранить и оценить результаты
prompt = input (f'finished {source}; записать в файл и продолжить? [y / n] ')
если prompt.lower () не входит в {'y', 'true', 'yes'}:
перерыв
с open (output_file, 'a') как f:
s = ('Текущий {} набор данных \ nНаилучшая точность:'
'{: .4f} \ n {} \ nТочность теста: {: .4f} \ n \ n')
output_string = s.format (
источник,
grid_result.best_score_,
grid_result.best_params_,
test_accuracy)
печать (output_string)
f.write (строка_вывода)
Это займет некоторое время, а это отличный шанс выйти на улицу, чтобы подышать свежим воздухом или даже отправиться в поход, в зависимости от того, сколько моделей вы хотите запустить. Посмотрим, что у нас получилось:
Запуск набора данных Amazon
Лучшая точность: 0,8122
{'vocab_size': 4603, 'num_filters': 64, 'maxlen': 100, 'kernel_size': 5, 'embedding_dim': 50}
Точность теста: 0,8457
Запуск набора данных imdb
Лучшая точность: 0.8161
{'vocab_size': 4603, 'num_filters': 128, 'maxlen': 100, 'kernel_size': 5, 'embedding_dim': 50}
Точность теста: 0,8210
Запуск набора данных yelp
Лучшая точность: 0,8127
{'vocab_size': 4603, 'num_filters': 64, 'maxlen': 100, 'kernel_size': 7, 'embedding_dim': 50}
Точность теста: 0,8384
Интересно! По какой-то причине точность тестирования выше, чем точность обучения, что может быть связано с большим разбросом оценок во время перекрестной проверки. Мы видим, что нам все еще не удалось пробить ужасные 80%, что кажется естественным пределом для этих данных с заданным размером.Помните, что у нас небольшой набор данных, и сверточные нейронные сети, как правило, лучше всего работают с большими наборами данных.
Другой метод для CV — это вложенная перекрестная проверка (показана здесь), которая используется, когда гиперпараметры также необходимо оптимизировать. Это используется потому, что результирующая невложенная модель CV имеет смещение в сторону набора данных, что может привести к чрезмерно оптимистичной оценке. Видите ли, при оптимизации гиперпараметров, как мы делали в предыдущем примере, мы выбираем лучшие гиперпараметры для этого конкретного обучающего набора, но это не означает, что эти гиперпараметры обобщают лучшее.
Заключение
Вот и все: вы научились работать с классификацией текста с помощью Keras, и мы перешли от модели набора слов с логистической регрессией к все более продвинутым методам, ведущим к сверточным нейронным сетям.
Теперь вы должны быть знакомы с вложениями слов, почему они полезны, а также как использовать предварительно обученные вложения слов для своего обучения. Вы также узнали, как работать с нейронными сетями и как использовать оптимизацию гиперпараметров, чтобы добиться большей производительности от вашей модели.
Одна большая тема, которую мы здесь не затронули, оставила на другой раз, это повторяющиеся нейронные сети, в частности LSTM и GRU. Это другие мощные и популярные инструменты для работы с последовательными данными, такими как текст или временные ряды. Другие интересные разработки в настоящее время связаны с нейронными сетями, которые привлекают внимание, которые активно исследуются и кажутся многообещающим следующим шагом, поскольку LSTM, как правило, требует больших вычислений.
Теперь у вас есть понимание важнейшего краеугольного камня обработки естественного языка, который вы можете использовать для классификации текста любого рода.Наиболее ярким примером этого является анализ тональности, но он включает и многие другие приложения, такие как:
- Обнаружение спама в электронных письмах
- Автоматическая разметка текстов
- Категоризация новостных статей с заранее определенными темами
Вы можете использовать эти знания и модели, которые вы обучили в продвинутом проекте, как в этом руководстве, чтобы применить анализ тональности в непрерывном потоке данных Twitter с Kibana и Elasticsearch. Вы также можете комбинировать анализ тональности или классификацию текста с распознаванием речи, как в этом удобном руководстве, используя библиотеку SpeechRecognition в Python.
Дополнительная литература
Если вы хотите глубже разобраться в различных темах этой статьи, вы можете взглянуть на эти ссылки:
Ваш путеводитель по обработке естественного языка (NLP) | Диего Лопес Исе
Как машины обрабатывают и понимают человеческий язык
Все, что мы выражаем (устно или письменно), несет в себе огромное количество информации. Тема, которую мы выбираем, наш тон, наш выбор слов — все это добавляет какой-то тип информации, которую можно интерпретировать и извлечь из нее ценность.Теоретически мы можем понять и даже предсказать поведение человека, используя эту информацию.
Но есть проблема: один человек может генерировать сотни или тысячи слов в объявлении, причем каждое предложение имеет соответствующую сложность. Если вы хотите масштабировать и анализировать несколько сотен, тысяч или миллионов людей или деклараций в данной географии, тогда ситуация неуправляема.
Данные, полученные из разговоров, заявлений или даже твитов, являются примерами неструктурированных данных. Неструктурированные данные не вписываются в традиционную структуру строк и столбцов реляционных баз данных и представляют собой подавляющее большинство данных, доступных в реальном мире. Это грязно, и им сложно манипулировать. Тем не менее, благодаря достижениям в таких дисциплинах, как машинное обучение, в этой теме происходит большая революция. В настоящее время речь идет уже не о попытках интерпретировать текст или речь на основе его ключевых слов (старомодный механический способ), а о понимании значения этих слов (когнитивный способ).Таким образом можно обнаружить такие речевые образы, как иронию, или даже провести анализ настроений.
Обработка естественного языка или НЛП — это область искусственного интеллекта, которая дает машинам возможность читать, понимать и извлекать значение из человеческих языков.
Это дисциплина, которая фокусируется на взаимодействии между наукой о данных и человеческим языком и распространяется во многих отраслях. Сегодня НЛП переживает бум благодаря огромным улучшениям в доступе к данным и увеличению вычислительной мощности, которые позволяют практикам достигать значимых результатов в таких областях, как здравоохранение, СМИ, финансы и человеческие ресурсы, среди прочих.
Проще говоря, НЛП представляет собой автоматическую обработку естественного человеческого языка, такого как речь или текст, и, хотя сама концепция увлекательна, реальная ценность этой технологии исходит из вариантов использования.
NLP может помочь вам с множеством задач, и области применения, кажется, увеличиваются с каждым днем. Приведем несколько примеров:
- NLP позволяет распознавать и прогнозировать заболевания на основе электронных медицинских карт и собственной речи пациента.Эта способность исследуется при состояниях здоровья, которые варьируются от сердечно-сосудистых заболеваний до депрессии и даже шизофрении. Например, Amazon Comprehend Medical — это сервис, который использует NLP для извлечения болезненных состояний, лекарств и результатов лечения из записей пациентов, отчетов о клинических испытаниях и других электронных медицинских записей.
- Организации могут определять, что клиенты говорят об услуге или продукте, идентифицируя и извлекая информацию из таких источников, как социальные сети.Этот анализ настроений может предоставить много информации о выборе клиентов и их факторах принятия решений.
- Изобретатель из IBM разработал когнитивного помощника , который работает как персонализированная поисковая машина, узнавая все о вас, а затем напоминая вам имя, песню или что-нибудь, что вы не можете вспомнить, в тот момент, когда вам это нужно.
- Такие компании, как Yahoo и Google, фильтруют и классифицируют ваши электронные письма с помощью NLP, анализируя текст в электронных письмах, которые проходят через их серверы, и останавливает спам еще до того, как они попадут в ваш почтовый ящик.
- Чтобы помочь идентифицировать фальшивые новости , NLP Group в Массачусетском технологическом институте разработала новую систему для определения того, является ли источник точным или политически предвзятым, определяя, можно ли доверять источнику новостей или нет.
- Amazon Alexa и Apple Siri являются примерами интеллектуальных голосовых интерфейсов , которые используют NLP для ответа на голосовые подсказки и делают все, например, найти конкретный магазин, сообщить нам прогноз погоды, предложить лучший маршрут до офиса или включить огни дома.
- Понимание того, что происходит и о чем говорят люди, может быть очень ценным для финансовых трейдеров . NLP используется для отслеживания новостей, отчетов, комментариев о возможных слияниях компаний, все это затем может быть включено в торговый алгоритм для получения огромной прибыли. Помните: покупайте слухи, продавайте новости.
- NLP также используется на этапах поиска и отбора набора талантов , выявляя навыки потенциальных сотрудников, а также выявляя потенциальных клиентов до того, как они станут активными на рынке труда.
- На основе технологии IBM Watson NLP LegalMation разработала платформу для автоматизации рутинных судебных задач и помогает юридическим группам сэкономить время, сократить расходы и сместить стратегический фокус.
НЛП особенно быстро развивается в отрасли здравоохранения . Эта технология улучшает оказание медицинской помощи, диагностику заболеваний и снижает расходы, в то время как медицинские организации все больше внедряют электронные медицинские карты. Тот факт, что клиническая документация может быть улучшена, означает, что пациентов можно лучше понять и получить пользу от лучшего здравоохранения.Цель должна заключаться в оптимизации их опыта, и несколько организаций уже работают над этим.
Количество публикаций, содержащих предложение «обработка естественного языка» в PubMed за период 1978–2018 гг. По состоянию на 2018 год PubMed содержит более 29 миллионов ссылок на биомедицинскую литературу.Компании, такие как Winterlight Labs, значительно улучшают лечение болезни Альцгеймера, отслеживая когнитивные нарушения с помощью речи, а также могут поддерживать клинические испытания и исследования для широкого круга центральных расстройства нервной системы.Следуя аналогичному подходу, Стэнфордский университет разработал Woebot, чат-бота-терапевта с целью помочь людям с тревогой и другими расстройствами.
Но по этому поводу ведутся серьезные разногласия. Пару лет назад Microsoft продемонстрировала, что, анализируя большие выборки поисковых запросов, они могут идентифицировать интернет-пользователей, страдающих от рака поджелудочной железы, еще до того, как им поставят диагноз. Как пользователи отреагируют на такой диагноз? А что было бы, если бы у вас был ложноположительный результат? (это означает, что у вас может быть диагностирована болезнь, даже если у вас ее нет).Это напоминает случай с Google Flu Trends, который в 2009 году был объявлен способным прогнозировать грипп, но позже исчез из-за его низкой точности и неспособности соответствовать прогнозируемым показателям.
НЛП может стать ключом к эффективной клинической поддержке в будущем, но в краткосрочной перспективе еще предстоит решить множество проблем.
Основные недостатки, с которыми мы сталкиваемся в наши дни с НЛП, связаны с тем фактом, что язык очень сложен. Процесс понимания и манипулирования языком чрезвычайно сложен, и по этой причине принято использовать разные методы для решения различных задач, прежде чем связывать все вместе.Языки программирования, такие как Python или R, широко используются для выполнения этих методов, но прежде чем углубляться в строки кода (это будет темой другой статьи), важно понять концепции, лежащие в основе них. Давайте подытожим и объясним некоторые из наиболее часто используемых алгоритмов в НЛП при определении словаря терминов:
Набор словЭто широко используемая модель, которая позволяет вам подсчитывать все слова в фрагменте текста. По сути, он создает матрицу вхождений для предложения или документа, игнорируя грамматику и порядок слов.Эти частоты или встречаемости слов затем используются в качестве признаков для обучения классификатора.
Чтобы привести короткий пример, я взял первое предложение песни «Через Вселенную» из The Beatles:
Слова текут, как бесконечный дождь в бумажный стаканчик,
Они скользят, когда проходят, они ускользают через вселенную
Теперь давайте посчитаем слова:
Этот подход может отражать несколько недостатков, таких как отсутствие семантического значения и контекста, а также факты, которые останавливают слова (например, «the» или «a»), добавляют шум в анализ. и некоторые слова не имеют соответствующего веса («вселенная» весит меньше, чем слово «они»).
Чтобы решить эту проблему, один из подходов состоит в том, чтобы изменить масштаб частоты слов в зависимости от того, как часто они появляются во всех текстах (а не только в том, который мы анализируем), чтобы оценки для часто встречающихся слов, таких как «the», также часто встречаются во всех текстах. другие тексты наказываются. Этот подход к оценке называется «Частота термина — обратная частота документа» (TFIDF) и улучшает набор слов по весам. Через TFIDF часто встречающиеся в тексте термины «вознаграждаются» (например, слово «они» в нашем примере), но они также «наказываются», если эти термины часто встречаются в других текстах, которые мы также включаем в алгоритм.Напротив, этот метод выделяет и «награждает» уникальные или редкие термины с учетом всех текстов. Тем не менее, у этого подхода нет ни контекста, ни семантики.
ТокенизацияЭто процесс сегментации текущего текста на предложения и слова. По сути, это задача разрезать текст на части, называемые токенами , и в то же время отбросить определенные символы, такие как знаки препинания. Следуя нашему примеру, результат токенизации будет:
Довольно просто, не так ли? Что ж, хотя в этом случае это может показаться довольно простым, а также в таких языках, как английский, где слова разделяются пробелом (так называемые сегментированные языки), не все языки ведут себя одинаково, и, если подумать, одних пробелов недостаточно. даже для английского, чтобы выполнить правильную токенизацию.Разделение на пробелы может разбить то, что следует рассматривать как один токен, как в случае определенных имен (например, Сан-Франциско или Нью-Йорк) или заимствованных иностранных фраз (например, laissez faire).
Токенизация может также удалить знаки препинания , облегчая путь к правильной сегментации слов, но также вызывая возможные осложнения. В случае точек, следующих за аббревиатурой (например, dr.), Точка, следующая за этой аббревиатурой, должна рассматриваться как часть того же символа и не удаляться.
Процесс токенизации может быть особенно проблематичным при работе с биомедицинскими текстовыми доменами, которые содержат множество дефисов, скобок и других знаков препинания.
Более подробные сведения о токенизации можно найти в этой статье.
Удаление стоп-словВключает в себя избавление от общеязыковых статей, местоимений и предлогов, таких как «и», «the» или «to» в английском языке. В этом процессе некоторые очень распространенные слова, которые, по-видимому, не имеют большого значения для цели НЛП или не имеют никакого значения, фильтруются и исключаются из обрабатываемого текста, тем самым удаляя широко распространенные и часто встречающиеся термины, которые не информативны для соответствующего текста.
Стоп-слова можно безопасно игнорировать, выполняя поиск в заранее определенном списке ключевых слов, освобождая место в базе данных и сокращая время обработки.
Универсального списка стоп-слов не существует. Их можно выбрать заранее или создать с нуля. Потенциальный подход — начать с принятия заранее определенных стоп-слов и добавить слова в список позже. Тем не менее, похоже, что в последнее время общая тенденция заключалась в том, чтобы перейти от использования больших стандартных списков стоп-слов к использованию вообще без списков.
Дело в том, что удаление стоп-слов может стереть релевантную информацию и изменить контекст в данном предложении. Например, если мы выполняем анализ настроений, мы можем сбить наш алгоритм с пути, если удалим стоп-слово, например «не». В этих условиях вы можете выбрать минимальный список стоп-слов и добавить дополнительные термины в зависимости от вашей конкретной цели.
ОснованиеОтносится к процессу разрезания конца или начала слова с целью удаления аффиксов (лексических добавлений к корню слова).
Аффиксы, которые добавляются в начале слова, называются префиксами (например, «astro» в слове «астробиология»), а аффиксы, прикрепленные в конце слова, называются суффиксами (например, «ful» в слове «полезный»).
Проблема в том, что аффиксы могут создавать или расширять новые формы одного и того же слова (так называемые флективные аффиксы ) или даже сами создавать новые слова (так называемые деривационные аффиксы ). В английском языке префиксы всегда являются производными (аффикс создает новое слово, как в примере с префиксом «eco» в слове «экосистема»), но суффиксы могут быть производными (аффикс создает новое слово, как в примере с суффикс «ist» в слове «гитарист») или словоизменительный (аффикс создает новую форму слова, как в примере с суффиксом «er» в слове «быстрее»).
Итак, как мы можем определить разницу и нарезать нужный кусок?
Возможный подход состоит в том, чтобы рассмотреть список общих аффиксов и правил (языки Python и R имеют разные библиотеки, содержащие аффиксы и методы) и выполнить основание на них, но, конечно, этот подход имеет ограничения. Поскольку стеммеры используют алгоритмические подходы, результатом процесса стемминга может быть не реальное слово или даже изменение значения слова (и предложения). Чтобы компенсировать этот эффект, вы можете редактировать эти предопределенные методы, добавляя или удаляя аффиксы и правила, но вы должны учитывать, что вы можете улучшать производительность в одной области, производя ухудшение в другой.Всегда смотрите на картину целиком и проверяйте работоспособность своей модели.
Итак, если у стемминга есть серьезные ограничения, почему мы его используем? Прежде всего, его можно использовать для исправления орфографических ошибок токенов. Стеммеры просты в использовании и работают очень быстро. (они выполняют простые операции со строкой), и если скорость и производительность важны в модели НЛП, то стемминг, безусловно, лучший вариант. Помните, мы используем его с целью повышения производительности, а не как упражнение по грамматике.
ЛемматизацияИмеет цель свести слово к его основной форме и сгруппировать различные формы одного и того же слова. Например, глаголы в прошедшем времени меняются на настоящее (например, «пошел» заменен на «идти»), а синонимы унифицированы (например, «лучший» заменен на «хороший»), таким образом стандартизируя слова со схожим значением их корня. Хотя это кажется тесно связанным с процессом выделения корней, лемматизация использует другой подход для поиска корневых форм слов.
Лемматизация преобразует слова в их словарную форму (известную как лемма ), для чего требуются подробные словари, в которых алгоритм может искать и связывать слова с соответствующими леммами.
Например, слова « бег», «бег» и «бег» — все формы слова « бег» , поэтому « бег» — это лемма всех предыдущих слов.
Лемматизация также принимает во внимание контекст слова, чтобы решить другие проблемы, такие как устранение неоднозначности , что означает, что она может различать идентичные слова, которые имеют разные значения в зависимости от конкретного контекста.Подумайте о таких словах, как «летучая мышь» (что может соответствовать животному или металлической / деревянной клюшке, используемой в бейсболе) или «банк» (что соответствует финансовому учреждению или земле рядом с водоемом). Предоставляя параметр части речи слову (будь то существительное, глагол и т. Д.), Можно определить роль этого слова в предложении и устранить неоднозначность.
Как вы уже могли представить, лемматизация — это гораздо более ресурсоемкая задача, чем выполнение процесса стемминга.В то же время, поскольку для этого требуется больше знаний о структуре языка, чем для подхода с выделением корней, он требует большей вычислительной мощности , чем установка или адаптация алгоритма выделения остатков.
Тематическое моделированиеИспользуется как метод обнаружения скрытых структур в наборах текстов или документов. По сути, он группирует тексты, чтобы обнаруживать скрытые темы на основе их содержания, обрабатывая отдельные слова и присваивая им значения на основе их распределения.Этот метод основан на предположении, что каждый документ состоит из смеси тем и что каждая тема состоит из набора слов, а это означает, что если мы сможем обнаружить эти скрытые темы, мы сможем раскрыть смысл наших текстов.
Из вселенной методов тематического моделирования, Latent Dirichlet Allocation (LDA) , вероятно, является наиболее часто используемым. Этот относительно новый алгоритм (изобретенный менее 20 лет назад) работает как метод обучения без учителя, который раскрывает различные темы, лежащие в основе набора документов.В методах неконтролируемого обучения , подобных этому, нет выходной переменной, которая бы направляла процесс обучения, и данные исследуются алгоритмами для поиска закономерностей. Чтобы быть более конкретным, LDA находит группы связанных слов по:
- Назначая каждое слово случайной теме, где пользователь определяет количество тем, которые он хочет раскрыть. Вы не определяете сами темы (вы определяете только количество тем), и алгоритм будет сопоставлять все документы с темами таким образом, чтобы слова в каждом документе в основном захватывались этими воображаемыми темами.
- Алгоритм итеративно перебирает каждое слово и переназначает слово теме, принимая во внимание вероятность того, что слово принадлежит теме, и вероятность того, что документ будет создан темой.