
Как добавить новый дом в яндекс карты?
Интернет-сервисы › Яндекс › Как изменить дом в Яндекс картах?
Чтобы добавить на карту организацию:
- В правом верхнем углу экрана нажмите изображение профиля или кнопку, если вы не авторизованы.
- На открывшейся панели слева нажмите Добавить объект на карту.
- В появившемся списке нажмите Организация, укажите информацию о новой организации и установите маркер в нужном месте на карте.
- Как добавить новый дом на карты?
- Как добавить адрес дома в Яндекс?
- Как добавить строение в яндекс карты?
- Как установить номер дома на карте?
- Что делать если дом не отображается на карте?
- Как добавить несколько адресов в Яндекс карты?
- Как изменить дом на карте?
- Как в Яндексе добавить второй адрес?
- Как изменить адрес дома Яндекс карты?
- Как в Яндекс картах сделать дом?
- Как внести изменения в яндекс карты?
- Почему на картах нет номера дома?
- Как добавить место на яндекс карты?
- Как добавить место на карте?
- Как нанести адреса на карту?
- Как отметить свой магазин на карте?
- Как изменить адрес дом?
- Как подключить красивый адрес Яндекс?
- Как добавить филиал в Яндекс?
- Как создать объект в Яндекс картах?
- Как добавить адрес своего дома в 2гис?
- Как добавить здание в 2гис?
- Как называется карта на которой видно дома?
- Как оформить номер дома?
- Как найти свой дом на карте?
- Как поменять дом на карте?
- Как добавить в карты место?
- Как поменять название здания в картах?
Как добавить новый дом на карты?
Как добавить адрес:
- Откройте приложение «Google Карты» на устройстве Android.

- Нажмите «Добавить» Изменить карту Исправление адреса.
- Переместите карту таким образом, чтобы нужное строение было расположено в центре.
- Введите новый адрес.
- Нажмите Опубликовать.
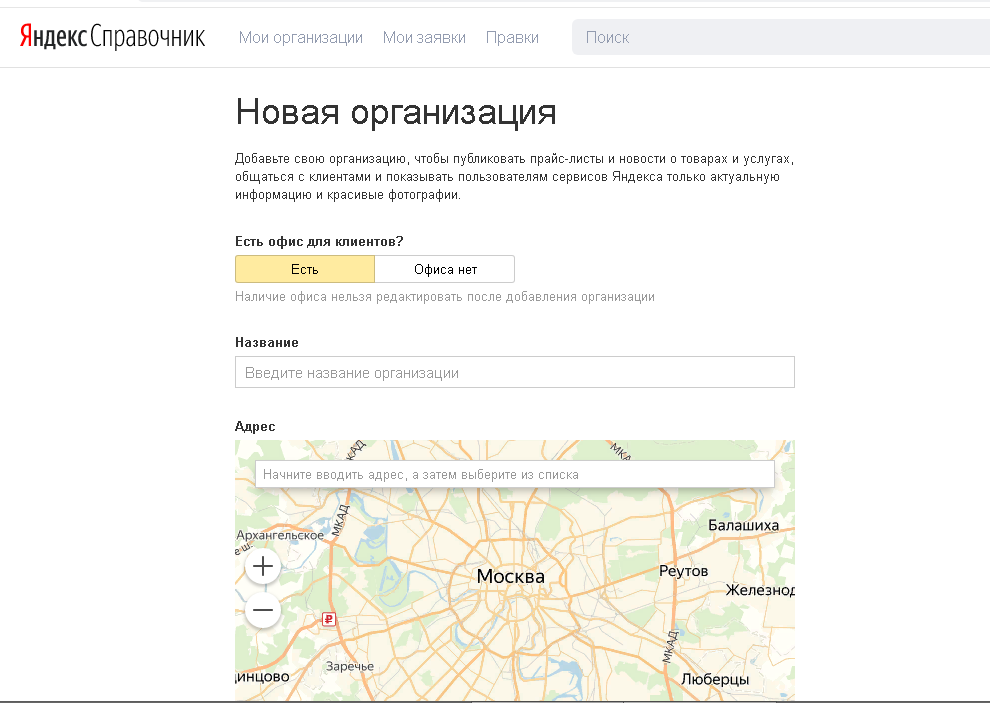
Как добавить адрес дома в Яндекс?
Зайти на сервис Яндекс Справочник, выбрать пункт «Добавить организацию» и заполнить форму. Указать все необходимые данные об организации: название, адрес (фактический) и телефон, режим работы, вид деятельности (до трех видов из рубрикатора) и ссылку на сайт или аккаунт в соцсети.
Как добавить строение в яндекс карты?
Добавить новый объект:
- Правой кнопкой мыши щёлкните по точке на карте, куда хотите добавить новый объект.
- В открывшемся меню нажмите Добавить объект.
- В появившейся панели выберите тип объекта. Если ни один из пунктов не подходит, выберите Другой объект.
- В панели нажмите кнопку Отправить.
Как установить номер дома на карте?
- Откройте приложение «Google Карты».
- Нажмите на значок «Меню» Добавить отсутствующее место.
- Выберите нужный вариант и следуйте инструкциям на экране.
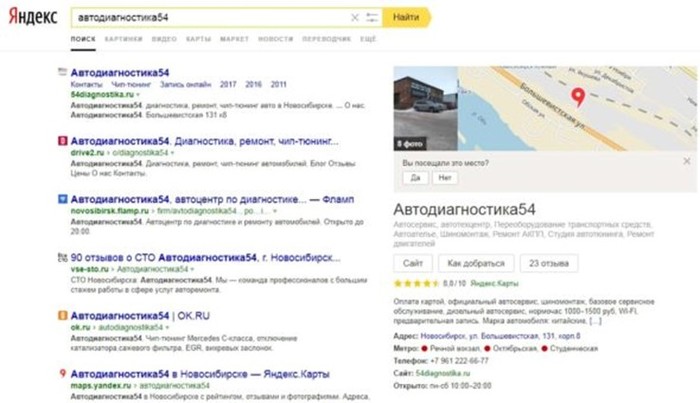
Что делать если дом не отображается на карте?
Для этого Вам необходимо обратиться к кадастровому инженеру. Он подготовит технический план для уточнения площади и местоположения границ объекта. После этого Вам необходимо подать с заявление с приложением технического плана на внесение изменений сведений в ЕГРН.
Как добавить несколько адресов в Яндекс карты?
Нажмите и удерживайте нужную точку на карте:
- В верхней части экрана нажмите Куда.
- Добавьте новую точку.
- Нажмите Готово.
Как изменить дом на карте?
Как изменить домашний или рабочий адрес:
- Откройте Google Карты и войдите в аккаунт.
- Введите дом или работа в окне поиска.
- Рядом с нужным адресом нажмите Изменить.
- Введите новый адрес и нажмите Сохранить.
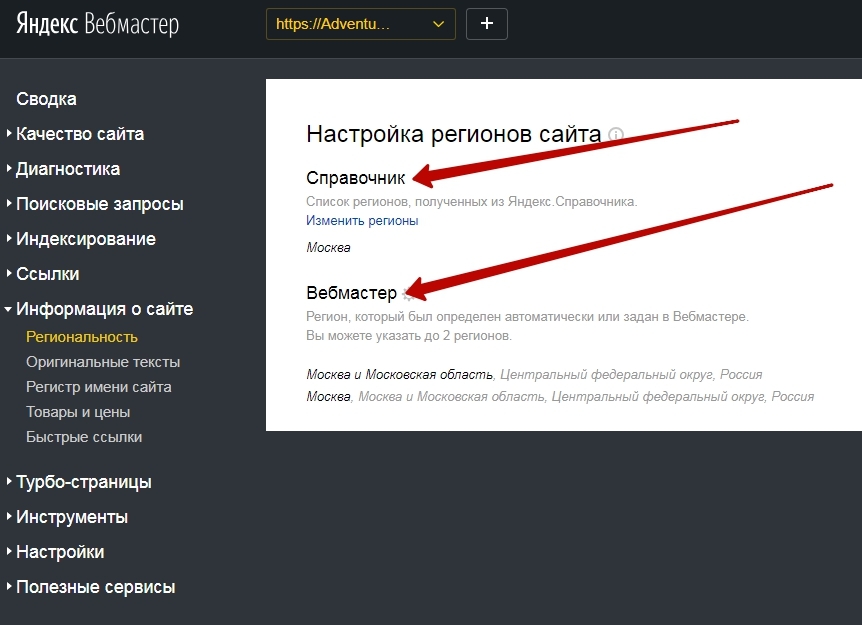
Как в Яндексе добавить второй адрес?
Для того, чтобы добавить одну или несколько точек назначения, нажмите на «плюс» в поле, куда обычно вбиваете конечную точку пути. Там же можно поменять уже указанные остановки местами. Яндекс.
Как изменить адрес дома Яндекс карты?
Исправить данные об объекте:
- Нажмите и удерживайте нужную точку карты.
- Выберите пункт Что здесь?
- В карточке объекта нажмите кнопку Исправить информацию о здании.
- Выберите пункт: Изменить адрес, чтобы исправить адрес объекта. Исправить или добавить входы, чтобы добавить на карту недостающий подъезд здания.
- Нажмите Готово.
Как в Яндекс картах сделать дом?
Добавить дом и работу:
- Нажмите кнопку.
- Выберите строку Дом или Работа и нажмите Добавить.
- Нажмите Сохранить адрес.
Как внести изменения в яндекс карты?
Изменение данных на Яндекс Картах:
- Найдите организацию на Яндекс Картах, перейдите в ее карточку и нажмите ссылку Исправить неточность.
- В открывшемся окне выберите один из вариантов изменений, исправьте данные или напишите комментарий. Нажмите Отправить. Примечание.

Почему на картах нет номера дома?
Почему нет дома на кадастровой карте Если жилой дом, здание или сооружение не отображаются на кадастровой карте и в выписке ЕГРН нет раздела со схемой расположения объекта недвижимости на участке, то это означает, что не сделан Технический План.
Как добавить место на яндекс карты?
Добавить точку в Мои места:
- Нажмите и удерживайте нужную точку на карте.
- В контекстном меню нажмите кнопку В «Мои места».
- Выберите список, в который вы хотите добавить точку, или введите название нового списка.
- Введите название точки и нажмите Сохранить.
Как добавить место на карте?
Как добавить отсутствующее место:
- Откройте приложение «Google Карты» на телефоне или планшете Android.
- Нажмите «Впечатления» Добавить место.
- Следуйте инструкциям на экране.
Как нанести адреса на карту?
На карту можно добавлять рестораны, гостиницы, музеи и другие общественные места:
- Войдите в Мои карты на компьютере.
- Откройте существующую карту или создайте новую.
- Введите в окне поиска название или адрес места.
- Найдите в результатах нужное место.
- Нажмите Добавить на карту.
Как отметить свой магазин на карте?
Как добавить компанию в Google Картах:
- Введите адрес в строке поиска. В профиле слева нажмите Добавить компанию.
- Нажмите правой кнопкой мыши в любом месте карты. Нажмите Добавить компанию.
- В левом верхнем углу нажмите на значок меню Добавить компанию.
Как изменить адрес дом?
Как изменить домашний или рабочий адрес:
- Откройте приложение «Google Карты» на смартфоне или планшете Android.
- Нажмите на значок Сохраненные.
- Рядом с пунктом «Дом» или «Работа» нажмите «Ещё» Изменить домашний адрес или Изменить рабочий адрес.
- Удалите указанный адрес и введите новый.

Как подключить красивый адрес Яндекс?
Как подключить
В правом верхнем углу нажмите значок и выберите подключение красивого адреса. Выберите понравившийся адрес или введите свой, убедившись, что адрес свободен. Примечание. Выбранный адрес не должен содержать слова, которые противоречат общественным интересам, принципам гуманности и морали.
Как добавить филиал в Яндекс?
Чтобы добавить филиал в сеть:
- Найдите филиал на Картах, перейдите в его карточку и нажмите ссылку Вы владелец этой организации?
- На странице Подтверждение прав на организацию нажмите кнопку Это моя компания.
- Получите код и укажите его для подтверждения прав.
Как создать объект в Яндекс картах?
Создание объекта:
- В окне Конструктора карт нажмите нужную кнопку под поисковой строкой или горячие клавиши, нарисуйте объект на карте и задайте значения параметров объекта:
- Любой созданный объект можно перетащить в другое место, а линию и многоугольник можно отредактировать с помощью контекстного меню.
Как добавить адрес своего дома в 2гис?
Войдите в боковое меню → «Избранное». Нажмите «Добавить адрес» в окне «Дом» или «Работа». Введите адрес.
Как добавить здание в 2гис?
Откройте боковое меню — кликните на три черты в правом верхнем углу карты. Выберите «Добавить организацию». Внесите в анкету всю известную вам информацию, указав хотя бы один контакт, чтобы наши сотрудники могли связаться с компанией. Можно добавить фотографию вывески или визитки с контактами организации.
Как называется карта на которой видно дома?
Google Maps или «Карты Google» явились настоящим открытием для пользователей интернета да и вообще всем пользователям ПК дав неслыханную и невиданную ранее возможность взглянуть на свой дом, на свою деревню, дачу, озеро или речку где они отдыхали летом — со спутника.
Как оформить номер дома?
Чтобы присвоить адрес дому или земельному участку, необходимо подать заявление в орган местного самоуправления, на территории которого он находится (образец заявления можно посмотреть здесь). К заявлению нужно приложить выписку из ЕГРН, копию паспорта, доверенность (если обращается представитель).
К заявлению нужно приложить выписку из ЕГРН, копию паспорта, доверенность (если обращается представитель).
Как найти свой дом на карте?
Откройте Google Карты. Найдите нужное место или поставьте маркер на карте. в верхнем левом углу экрана.Перейти в режим просмотра улиц можно разными способами:
- Открыв Google Карты и введя запрос о месте или адресе.
- Перетащив значок человечка в нужное место на карте.
- Введя запрос о месте или адресе в Google Поиске.
Как поменять дом на карте?
Как изменить домашний или рабочий адрес
Откройте Google Карты и войдите в аккаунт. Введите дом или работа в окне поиска. Рядом с нужным адресом нажмите Изменить. Введите новый адрес и нажмите Сохранить.
Как добавить в карты место?
Как добавить отсутствующее место:
- Откройте приложение «Google Карты» на телефоне или планшете Android.
- Нажмите «Впечатления» Добавить место.
- Следуйте инструкциям на экране.

Как поменять название здания в картах?
Как изменить название места, адрес и другую информацию:
- Откройте Google Карты.
- Выберите место на карте или найдите его с помощью поиска.
- Нажмите Предложить исправление Изменить название или другие данные.
- Следуйте инструкциям на экране.
Яндекс справочник: добавить адрес и телефон организации и компании — регистрация и редактирование в личном кабинете — помощь и поддержка пользователей
Автор Prodvigaem Team На чтение 7 мин. Просмотров 1.1k. Опубликовано
Яндекс справочник — как редактировать данные, если добавляется филиал головной компании. Для чего нужен асессор. При помощи технологий Интернета стало удобно находить информацию. Это хорошая поддержка для бизнеса. Со временем сервисы, оказывающие информационные услуги, стали удобными и начали предоставлять более полные и достоверные данные.
Содержание
- Что такое Яндекс. Справочник и для чего он нужен
- Чем еще полезна регистрация
- Правила оформления
- Правила заполнения адреса
- Правила указания сайта
- Указание видов деятельности
- Как добавить организацию
- Приоритетное размещение
- Как удалить организацию
- Причины отказа в регистрации
- Отзывы об организации
- Заключение
Что такое Яндекс. Справочник и для чего он нужен
Яндекс. Справочник является одним из таких сервисов. Это интернет–каталог официально зарегистрированных организаций.
С помощью этого каталога занесенные в него организации отображаются в виде результатов поиска в интернете. Кроме ООО, ОАО, в списке могут зарегистрироваться даже индивидуальные предприниматели.
Основной положительной стороной этой информационно-справочной системы является то, что регистрация и занесение данных фирмы совершенно бесплатны (надо лишь войти в личный кабинет).
Регистрацию в Яндекс. Справочнике считают хорошим способом продвижения своей компании в сети Интернет.
Однако пользоваться данной услугой рекомендуется, когда офис фирмы существует в реальности, имеется юридический адрес. Немаловажно наличие официальных номеров телефонов, по которым клиент может обратиться по интересующим его вопросам.
Обязательно необходимо указать режим работы.
Чем еще полезна регистрация
Вместе с тем, что зарегистрированная фирма получает возможность бесплатного продвижения в Интернете, потенциальным клиентам будет проще узнать о том, какая фирма может оказать интересующую его услугу.
При регистрации указанный адрес отмечается на карте, что упрощает задачу построения маршрута от местонахождения человека до местонахождения самой компании.
Кроме того, повышается активность на официальном сайте компании. В наше время практически необходимо, чтобы у фирмы было собственное онлайн-представительство, так что сайт обязательно должен быть. Ведь сайт является частью официального стиля любой компании, позволяет значительно облегчить задачу поисков ответов на интересующий вопрос, например, о расценках на те или иные предложения, или о том, какие услуги в целом оказываются.
Ведь сайт является частью официального стиля любой компании, позволяет значительно облегчить задачу поисков ответов на интересующий вопрос, например, о расценках на те или иные предложения, или о том, какие услуги в целом оказываются.
Благодаря некоторым модернизациям система заполнения данных о компании облегчилась и стала удобной для использования.
Кроме того, в информацию можно добавить несколько фотографий, свой логотип, ссылку на сайт. Клиенты смогут оценить качество обслуживания или добавить комментарий. Это позволит потенциальным клиентам заранее понять, что представляет собой фирма и к кому обращаться, а владельцу фирмы отслеживать качество работы сотрудников.
Правила оформления
Чтобы добавить свою фирму в список справочника, нужно знать некоторые тонкости этого процесса. Это позволит избежать лишней траты времени, а также убережет от отказа в регистрации.
Правила названия фирмы:
- Название пишется с большой буквы без указания организационно-правовой формы, за исключением ИП.
- Не стоит добавлять вид деятельности фирмы в название.
- Название не должно содержать информацию, которая говорит о местоположении фирмы, для этого есть отдельная форма заполнения.
- Запрещено вписывать в название рекламные тексты, которые перечисляют виды оказания услуг или содержат названия более известных брендов, если на самом деле фирма не является франчайзингом этого бренда на официальном уровне.
- Если слова о скидках не являются частью официально зарегистрированного названия, эту информацию указывать не стоит. К такой информации можно отнести слова «распродажи», «опт, розница», «недорого» и др.
- Строго запрещена ненормативная лексика не только в написания названия фирмы, но и в общем заполнении контактных данных.
- Представители таких компаний, как Amway, Avon и т. д. так и должны писать, что они представители фирмы.
- Частным брокерам не стоит употреблять в названии фирмы, которые являются известными страховыми компаниями.
- Высшие учебные заведения пишутся при помощи аббревиатуры.
- Если офис продаж расположен в жилом комплексе, достаточно указать ЖК и название этого комплекса в кавычках.


Правила заполнения адреса
С адресом все гораздо проще, важно, чтобы фирма была обладателем фактического адреса и была официально зарегистрирована.
Запрещено писать в строке юридический, почтовый, зарегистрированный как жилое помещение адрес. А также запрещается использовать адрес, если помещение сдано в аренду или находится на продаже. Кроме того, запрещено использовать название мест стоянок таксистов или местоположения эвакуирующих машин.
Правила указания сайта
Сайт должен иметь собственный домен, в противном случае его просто не укажут в карточке. Запрещены сайты социальных сетей, а также ссылки на скачивание какого-либо материала или содержащие порнографические материалы или нецензурные выражения.
Порталы с играми, страницы в интернете практикующих в зарегистрированных клиниках врачей также запрещаются к публикации.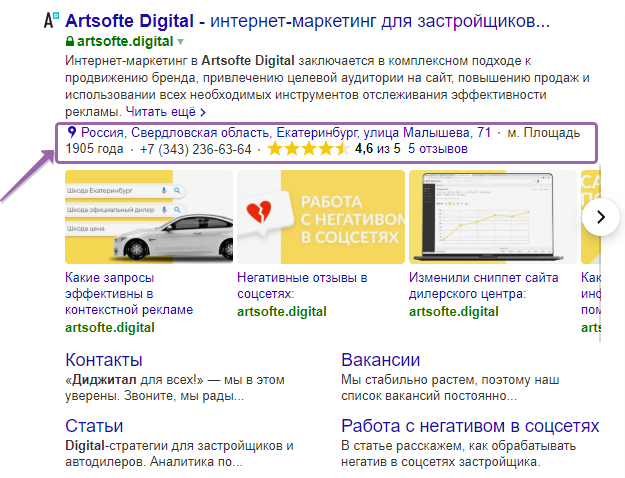
В заявке на регистрацию могут отклонить, если будет указана ссылка на чат, форум или страницу, которая не отвечает на вопросы о фирме.
Указание видов деятельности
Для регистрации потребуется всего 3 вида деятельности, но услуги как вид деятельности указывать не нужно.
Запрещено использовать в названиях видов деятельности услуги, которые считаются незаконными. Например, продажа документов, симкарт, наркотиков, или аналогичным лицензионным алкогольным напиткам.
Для шоурумов, магазинов и пунктов выдачи существует правило, чтобы указывались только официальные адреса, по которым расположен офис.
Как добавить организацию
Чтобы добавить свою организацию в каталог, достаточно зарегистрироваться и заполнить карточку своей фирмы.
В данных организации указывается название, адрес, режим работы. Также указывается ссылка на сайт и три вида деятельности, которые имеют отношение к компании. Не указываются магазины, которые работают только на платформах интернета и не имеют официального офиса.
После заполнения данных нажать «добавить организацию» и ждать звонка от менеджера, который подтвердит указанную информацию.
Приоритетное размещение
Данный способ продвижения является платным. Однако он имеет свои преимущества, так как фирма выходит в топ 5 приоритетных организаций, которые выделяются сверху списка.
Кроме того, появляется возможность добавить информацию об акциях, баннер, фотографии и прочую информацию, которая недоступна в бесплатном варианте размещения.
Расчет стоимости услуги определяется при помощи формулы, однако можно обратиться к менеджерам Яндекс. Справочник, которые помогут выполнить расчет и более развернуто ответят на все вопросы.
Как удалить организацию
Если организация перестала работать, ее можно удалить через страницу «мои организации». К сожалению, полностью удалить информацию нельзя. Можно избавиться от нее в личном кабинете или добавить пометку, в которой говорится о том, что организация больше не работает.
Причины отказа в регистрации
Отказать в регистрации могут, если данные не были подтверждены менеджером, а также если в полях регистрации недостаточно информации или она не является достоверной. В регистрации могут отказать, если поля были заполнены неправильно или использовалась запрещенная информация из вышеперечисленных списков.
Отзывы об организации
Чтобы получить информацию о рейтинге организации, Яндекс.Справочник собирает информацию с сервисов своих партнеров, и в виде цитаты отображает в разделе «Отзывы». При этом добавление отзывов четко регулируется при помощи правил и модерации.
На Яндекс.Справочнике отображаются только информативные отзывы о взаимодействии с организацией без указания сравнений с другими фирмами. Не используются отзывы, которые содержат в себе ссылки на другие сайты или вовсе не имеют прямого отношения к организации. Персональные данные лиц или отзывы с содержанием ошибок не будут добавлены на страницу.
Заключение
Благодаря созданному сервису Яндекс.Справочник стало удобно находить информацию об интересующей организации, а владельцы могут предоставить своим потенциальным клиентам развернутую информацию о своих услугах не только в качестве рекламы. Это значительно упрощает как работу самих организаций, так и их поиск потенциальными клиентами.
Для того, чтобы просто добавить информацию о своей компании, достаточно простого бесплатного размещения. При необходимости прорекламировать свою фирму можно пользоваться премиум размещением. Всегда стоит воспользоваться услугами удобного и современного сервиса для облегчения в будущем своей работы!
html — Тест микроданных: Google, Yandex или ни один из них
Я протестировал код микроданных для своего веб-сайта и получил 2 разных сообщения об ошибках в инструментах тестирования Google и Yandex.
Google говорит мне, что свойство Branchof пусто + мне нужно добавить логотип организации.
Яндекс не выделяет эти ошибки. Он говорит мне добавить адрес + номер телефона для филиала.

Должен ли я учитывать эти комментарии или игнорировать их?
Я определенно хочу соответствовать требованиям Google. Не могли бы вы помочь мне устранить ошибку в коде ниже:
Код домашней страницы:
<голова>

Код страницы продукта:
0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional .дтд"> <голова>
ИМЯ СТРАНИЦЫ
КРАТКОЕ ОПИСАНИЕ СТРАНИЦЫ

- HTML
- микроданные
1
Если вы хотите использовать микроданные, вы должны использовать (X)HTML5. Если вы хотите продолжать использовать XHTML 1.0, вы можете использовать RDFa вместо Microdata.
О предупреждениях/ошибках:
Google говорит мне, что […] мне нужно добавить логотип организации.
Google сообщает, что вам нужно добавить свойства
URLиlogoхотя вы их добавили (в первом примере). Это связано с вашими примерными значениями:URL ВЕБ-СТРАНИЦЫ ОРГАНИЗАЦИИне являются допустимыми URL-адресами, поскольку пробелы должны быть закодированы в процентах (%20).Во втором примере отсутствует
logo. У вас нет , чтобы добавить его, просто Google хотел бы его видеть, например, для показа расширенного сниппета.Google сообщает мне, что свойство Branchof пусто
Я не могу воспроизвести это с помощью (нового) инструмента тестирования Google.
Элемент не пустой, так как вы указываете
имяиописание.Яндекс […] говорит мне добавить адрес+телефон отделения.
Это просто означает, что они хотели бы видеть дополнительную информацию, например.
для отображения расширенных результатов поиска.
 для отображения расширенных результатов поиска.
для отображения расширенных результатов поиска.1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Создание воспроизводимых рабочих процессов обработки данных с помощью DVC | Глеб Ивашкевич | Яндекс школа Data Science
Фото Клинта Адэра на Unsplash Широкое внедрение машинного обучения — явление недавнее. По мере того, как область становится все более и более зрелой, типичный размер проблемы становится все больше. В то время как лучшие практики начинают появляться, с увеличением размера проблемы возникает растущая сложность и присущие структурные проблемы: беспорядочные активы, плохая воспроизводимость и фрагментарное (если таковое имеется) отслеживание экспериментов.
По мере того, как область становится все более и более зрелой, типичный размер проблемы становится все больше. В то время как лучшие практики начинают появляться, с увеличением размера проблемы возникает растущая сложность и присущие структурные проблемы: беспорядочные активы, плохая воспроизводимость и фрагментарное (если таковое имеется) отслеживание экспериментов.
Современные решения для машинного обучения требуют огромного количества файлов данных и тысяч строк кода для обработки данных и создания моделей машинного обучения. Им также требуются универсальные метаданные, которые объединяют информацию о том, как обрабатывались данные и какие артефакты или результаты были созданы.
Несмотря на то, что разработка проектов по науке о данных и машинному обучению реализована в программном обеспечении, она резко отличается от разработки программного обеспечения общего назначения: например, DS в основном ориентирован на эксперименты и имеет гораздо более высокий уровень внутренней непредсказуемости.
Чтобы проиллюстрировать предыдущий пункт, в типичном процессе разработки программного обеспечения у команды есть список функций, которые необходимо реализовать, и они проходят его, основываясь на некоторых приоритетах. Хотя этот процесс не является полностью детерминированным с точки зрения используемых ресурсов, совершенно очевидно, что если функция выбрана для разработки, она рано или поздно будет реализована.
Наука о данных и машинное обучение очень разные. Вместо функций, которые нужно реализовать, в ML у нас есть идеи, которые можно опробовать, без каких-либо гарантий успеха. Вскоре вы можете проверить несколько десятков гипотез, часто существенно различающихся по своей сложности и требуемой реализации. Большинство из них потерпят неудачу, некоторые могут выглядеть многообещающе, и, в конце концов, некоторые сложные комбинации из них могут привести к успеху.
В конце концов, вы или ваш коллега попытаетесь воспроизвести одну из этих моделей, ту, которая покажется лучшей. Вы можете обнаружить, что не можете легко восстановить, как именно была создана эта модель. Может оказаться, что параметры обучения зарыты где-то в блокноте, перезаписаны последующими экспериментами и множественными коммитами Git в нескольких ветках. Кроме того, возможно, разделение обучения/перекрестной проверки было выполнено без установки случайного начального числа. И если вы все еще недостаточно обеспокоены, вишенкой на торте является то, что при рассмотрении оказывается, что текущие функции совсем не похожи на то, что было при создании модели. Очень жаль.
Вы можете обнаружить, что не можете легко восстановить, как именно была создана эта модель. Может оказаться, что параметры обучения зарыты где-то в блокноте, перезаписаны последующими экспериментами и множественными коммитами Git в нескольких ветках. Кроме того, возможно, разделение обучения/перекрестной проверки было выполнено без установки случайного начального числа. И если вы все еще недостаточно обеспокоены, вишенкой на торте является то, что при рассмотрении оказывается, что текущие функции совсем не похожи на то, что было при создании модели. Очень жаль.
Однако есть решение. Может потребоваться некоторое время, чтобы внедрить и отшлифовать здоровые процессы и освоить необходимые инструменты, но вы быстро обнаружите, что они бесценны, как только вы это сделаете.
Нам определенно нужен какой-то способ устранить беспорядок и неразбериху. Было несколько попыток изложить принципы, лежащие в основе такого метода, и некоторые из них привели к последовательному и разумному набору эмпирических правил.
Некоторые команды используют варианты Coockiecutter Data Science, другие следуют подходу, описанному в Guerilla Analytics. Оба решают одни и те же проблемы, оба предлагают мощные инструменты, и мы рекомендуем вам попробовать их.
Скорее всего, вы или ваша команда уже используете что-то подобное. Но независимо от того, какой подход вы используете для написания воспроизводимого кода обработки данных, вам потребуются инструменты.
Минимальные требования следующие:
- способ контроля версий данных , особенно промежуточных артефактов, таких как предварительно вычисленные функции и модели,
- возможность передавать файлы данных внутри команды контролируемым и отслеживаемым способом,
- инструмент для воспроизведения любых артефактов или результатов простым и автоматизированным способом, независимо от того, как давно они были изначально созданы.
В этом руководстве мы рассмотрим, как DVC реализует все процессы, которые мы описали, и упрощает воспроизводимую науку о данных. DVC имеет открытый исходный код и пытается быть Git для машинного обучения, тесно сотрудничая с самим Git.
DVC имеет открытый исходный код и пытается быть Git для машинного обучения, тесно сотрудничая с самим Git.
DVC на самом деле довольно большой инструмент, но наиболее распространенные операции достаточно просты, точно так же, как базовые команды Git легко выучить и внедрить в повседневную практику.
DVC — не единственный инструмент для работы. Он лучше всего подходит для проектов малого и среднего размера и решает проблему, не добавляя слишком много сложности. Однако, в зависимости от ваших потребностей, размера проекта и соображений развертывания, вы можете найти Kedro или другие инструменты более подходящими. Мы рассмотрим некоторые из них в будущих уроках.
Начнем с фундаментальной задачи управления версиями данных. Давайте сначала определим, что такое контроль версий данных:
- состояние любого файла данных, исходного или производного, должно быть записано ,
- должен быть инструмент для переключения между разными версиями файлов данных.

Рассмотрим следующий сценарий: обучающие данные поступают из реляционной базы данных и хранятся в виде CSV-файла. Время от времени вы хотите обновлять набор данных последними записями из базы данных. Каждый раз, когда вы это делаете, вы записываете состояние набора данных. Если у вас есть способ переключить на любую из предыдущих версий и обратно — поздравляем, ваши данные контролируются версиями.
Git для этого не подходит, так как не предназначен для обслуживания больших или бинарных файлов, а расширения вроде Git LFS являются универсальными и могут использоваться для контроля версий данных только с некоторыми ограничениями и неудобствами. DVC предлагает более гибкий подход.
Чтобы проиллюстрировать это, мы будем использовать набор данных Titanic от Kaggle и создадим простую модель и файл представления. С помощью этого миниатюрного проекта по науке о данных мы увидим, как DVC помогает обеспечить происхождение и воспроизводимость данных.
Установите DVC
Сначала нам нужно установить DVC. Это можно сделать с помощью pip
или conda :
Обратите внимание, что вы можете настроить DVC на использование внешнего хранилища для хранения и обмена данными, и в этом случае вам также потребуется установить дополнительные зависимости. Например, если вы планируете использовать Amazon Web Services S3, вам необходимо установить
botoи некоторые другие пакеты с
Макет проекта
Наш проект начинается с набора данных Titanic, который содержит два файла (один для обучения и один для тестирования) и структуру проекта.
Может показаться заманчивым разместить все файлы данных и код в одном каталоге для такого небольшого проекта.
Однако стратегически разумнее придерживаться одной и той же структуры проекта для любого проекта, независимо от его размера. Дисциплинированный подход к структуре и операциям проекта экономит много времени и головной боли.
Давайте создадим скелет нашего проекта:
Исходные данные находятся в каталоге data . Хотя у нас есть только два исходных файла данных, для более крупных проектов могут быть десятки, тысячи или даже миллионы файлов данных, поэтому разумно иметь для них отдельный каталог.
Все файлы производных функций и промежуточных данных помещаются в каталог функций . Результаты (например, обученные модели и файлы отправки) будут храниться в каталоге результатов .
pytitanic Каталог будет содержать код Python для проекта: скрипты, модули, пакеты и т.д. Дополнительно у вас может быть каталог блокнотов и каталоги для кода на других языках (например, на R или Julia).
Сохраним README.md пустой для простоты, хотя мы все же создаем его ради общей процедуры.
Чтобы завершить настройку проекта, нам нужно добавить файлы данных и инициализировать репозиторий Git и DVC. Учитывая, что вы уже загрузили данные в виде Zip-архива в каталог
Учитывая, что вы уже загрузили данные в виде Zip-архива в каталог data :
Вы должны увидеть три новых файла ( gender_submission.csv , test.csv и train.csv ) в каталоге data сейчас. Мы не будем использовать gender_submission.csv , поэтому давайте удалим его вместе с Zip-архивом:
Обратите внимание, что мы не помещаем файлы данных под контроль Git, так как их версиями будет управлять DVC. Отныне файлы данных не будут управляться Git напрямую.
Управление данными с помощью DVC
Теперь мы готовы инициализировать DVC для нашего проекта. Для этого запустите
Когда DVC выполняет инициализацию, происходит несколько вещей. Во-первых, он создает .dvc каталог для хранения собственных файлов, необходимых для работы. 9Каталог 0049 .dvc для DVC такой же, как .git для Git.
Во-вторых, DVC инструктирует Git на , как обрабатывать вновь созданные файлы . Если вы посмотрите на текущий статус Git (со статусом
Если вы посмотрите на текущий статус Git (со статусом git ), вы увидите, что DVC подготовил свои файлы для фиксации:
.dvc/.gitignore файл указывает Git пропустить некоторые внутренние файлы DVC из . dvc , а .dvc/config содержит только что созданную конфигурацию для DVC, которая пока пуста.
DVC пытается назвать команды знакомым образом. В большинстве случаев команда DVC делает именно то, что вы ожидаете от нее, основываясь на вашем опыте работы с Git.
Кроме того, DVC — довольно многословный инструмент, и большинство команд выводят содержательные и полезные сообщения, чтобы вы могли понять, что происходит и что делать дальше.
Давайте зафиксируем изменения:
Теперь мы готовы отслеживать файлы данных с помощью DVC. Сообщить DVC о data/train.csv и data/test.csv мы будем использовать dvc add :
DVC подробно инструктирует нас о том, что произошло:
Давайте разберем это. Сначала DVC создает еще один файл
Сначала DVC создает еще один файл .gitignore , чтобы исключить исходные файлы данных из отслеживания Git.
Во-вторых, происходит нечто более важное: DVC помещает файлы данных в свой кэш и создает два метафайла ( data/train.csv.dvc и data/test.csv.dvc ) с информацией об исходных данных. файлы.
Метафайлы соответствуют стандарту YAML и имеют определенный набор атрибутов (используйте cat data/train.csv.dvc для просмотра файла):
Верхний уровень md5 атрибут содержит контрольную сумму MD5 для *.dvc содержимое файла, а md5 атрибут под outs содержит контрольную сумму самого файла данных.
Вы можете заметить, что утилита
md5sumвычисляет разные значения как для файла данных, так и для файла*.dvc. Это нормально, так как DVC вычисляет MD5 для преобразованной версии файла. Для текстовых файлов он изменяет последовательность EOL с\r\n(что имеет место для файлов набора данных Titanic) до\n.Для самого файла
*.dvcвсе еще сложнее: атрибут MD5 верхнего уровня содержит контрольную сумму не для самого файла*.dvc(задумайтесь об этом на мгновение), а для правильно закодированного строкового представления содержимого , с некоторой фильтрацией.
Теперь посмотрим на кеш. По умолчанию он расположен в .dvc/cache :
Как видите, DVC хранит файлы данных в кеше в соответствии с их MD5: первые два символа образуют имя каталога, а остальные используются в качестве имени файла кеша.
Теперь мы можем передать метафайлы DVC в Git:
Обратите внимание, что Git ничего не знает о самих файлах данных, вся информация, необходимая для их отслеживания, хранится в файлах DVC, в то время как Git служит инструментом верхнего уровня для отслеживания самого DVC .
Контролируемое перемещение данных
Поскольку файлы данных теперь находятся под контролем DVC, мы можем начать использовать его. Например, если вы случайно удалили один из файлов данных, вы можете воссоздать его из кеша с помощью
Например, если вы случайно удалили один из файлов данных, вы можете воссоздать его из кеша с помощью dvc checkout 9.0050 :
dvc checkout просматривает целевой файл ( data/train.csv.dvc в данном случае) и извлекает соответствующую версию из кэша. Это, конечно, простой пример, но он иллюстрирует закономерность.
Более сложный пример включает удаленное хранилище . DVC может хранить файлы вне рабочего каталога. Это позволяет легко обмениваться файлами с помощью инструментов DVC. DVC позволяет использовать локальный каталог, AWS S3, Azure и другие места назначения в качестве удаленных.
Давайте создадим локальное удаленное хранилище для файлов данных:
Теперь мы можем передать данные во вновь созданный удаленный:
Удаленные устройства структурированы аналогично локальному кешу:
Сами по себе удаленные устройства имеют ограниченную полезность. Однако они становятся решающими, когда вы работаете в команде . Давайте проиллюстрируем это, создав клон нашего текущего репозитория:
Исходных файлов данных там нет, но есть метафайлы DVC, поскольку они отслеживаются Git. Это позволяет нам легко извлекать файлы данных из существующего удаленного хранилища:
Информация о пультах хранится в конфигурационных файлах DVC ( .dvc/config ). Вернемся к исходному репозиторию и посмотрим, как изменился файл конфигурации:
Теперь мы можем зафиксировать изменения в конфигурации DVC:
Обратите внимание, что вновь созданный удаленный локальный , поэтому его конфигурация может быть сохранена снаружи из Git. DVC позволяет пользователю иметь несколько типов конфигурации, а тот, который называется , локальный , исключается из отслеживания Git. Чтобы использовать локальную конфигурацию при создании пультов, просто добавьте
— локальная опциядля удаленной командыdvc add. Мы добавили эту опцию для репозиторияtitanic-dvc-copyдля иллюстрации.Тот же вариант
— локальныйследует использовать при создании облачных удаленных устройств, поскольку вам потребуется добавить учетные данные для доступа к удаленным устройствам AWS S3, Azure или GCP, и не рекомендуется иметь их в Git.
Управление версиями данных
До сих пор мы использовали DVC только для добавления файлов в кэш и удаленное хранилище. Это только часть истории. Что еще более важно, файлы данных могут иметь версии. Конечно, набор данных Титаника не изменится, но реальные наборы данных могут меняться со временем.
Представьте снова набор данных, который мы обсуждали в начале раздела. Со временем в эту базу данных поступают новые записи, и вы хотите обновить набор данных последними точками данных. Очевидный (и неправильный) способ сделать это — создать новый дамп с другим именем файла. Однако это неправильно как с концептуальной, так и с организационной точек зрения.
Во-первых, концептуально это тот же набор данных, просто его новая версия.
Мы будем моделировать изменения данных, просто переименовав столбец Name в FullName в обоих файлах данных. Для наших целей этого достаточно, так как DVC не важно, что именно изменилось, он просто отслеживает изменения.
Для удобства давайте пометим последний коммит Git, чтобы мы могли легко извлекать из него файлы, не возясь с хешами:
Теперь мы можем добавить отредактированные файлы данных в DVC:
На данный момент файлы данных в рабочем каталоге содержат переименовал столбцы, и DVC добавил их в кеш (проверьте это с помощью tree .dvc/cache ) и мы отправили его на локальный пульт. На данный момент все изменения были распространены на все местоположения.
Предположим, вы хотите получить исходную версию данных. Мы намеренно пометили соответствующую фиксацию и теперь можем легко проверить метафайлы DVC для этой версии:
С метафайлами для базового набора данных мы можем легко получить исходную версию файлов данных из кэша или удаленного хранилища:
Если вы извлекаете файлы данных, вы увидите, что этот столбец называется Имя , как было в исходных файлах. Чтобы вернуть файлы данных в текущую форму с FullName вместо Name , просто сбросьте соответствующие метафайлы в Git `HEAD` и снова выполните dvc checkout .
Обратите внимание, что с DVC мы эффективно контролируем версии метафайлов. Все отслеживание фактических файлов данных выполняется DVC на основе информации в метафайлах.
Как видите, DVC достаточно удобен и прост, чтобы его можно было использовать для управления версиями данных. Это позволяет легко записывать состояние данных и переключаться между разными версиями (с помощью Git).
Это уменьшает беспорядок и помогает поддерживать согласованность данных между товарищами по команде и местоположениями. Однако DVC может больше: он может отслеживать расчеты и результаты, позволяя воссоздать любой предыдущий результат без особых проблем.
DVC имеет две основные концепции для воспроизводимых расчетов: этапов и конвейеров . Давайте начнем с более простого и создадим этап DVC, который вычисляет некоторые функции. Мы не будем заходить слишком далеко и просто сделаем некоторые столбцы категориальными (см. 9).0049 pytitanic/features.py ):
Теперь добавим код расчета характеристик в features.py :
Код прост и не требует пояснений, поэтому мы не будем его повторять. В типичной среде вы бы сразу запустили python -m pytitanic.features … , но с DVC это работает немного по-другому.
Во-первых, давайте добавим вновь созданные файлы Python в Git:
Теперь давайте создадим этап DVC :
Давайте расшифруем это. Во-первых, мы указываем DVC запустить команду и создать этап (и соответствующий файл этапа) с dvc run -f features/features.dvc . Этап в DVC — это просто часть отслеживаемых вычислений. Вся информация о том, как выполняется этап, хранится в файле этапа (в данном случае features/features.dvc ).
Чтобы сообщить DVC о зависимостях, мы используем опцию -d и перечисляем все файлы, необходимые для вычисления. С -o мы предоставляем выходы стадии. Заключительная часть — это сама команда.
Когда мы запустим приведенную выше команду, DVC создаст файл этапа, который содержит всю информацию, необходимую для воссоздания результатов этапа в любое время в будущем:
Обратите внимание, что DVC добавляет выходные файлы в кэш, поэтому вам не нужно делать это вручную. Однако нам нужно зафиксировать файл stage и .gitignore , созданный DVC в , содержит каталог (опять же, .gitignore был добавлен DVC для исключения выходных файлов из отслеживания Git) и создать тег для удобства:
You можно спросить, а при чем тут? Разве мы не можем просто поставить выходные файлы под управление DVC вручную, как мы делали раньше? Да, мы можем, но теперь мы не только храним их в кеше (и поэтому можем отправить на любой удаленный компьютер, чтобы поделиться с другими), но также можем легко воссоздать расчет с обновленным кодом.
Однако расчеты могут быть более сложными, чем просто один этап. В этом случае нам нужна некоторая модульность вместо одного монолитного вычисления.
У DVC есть инструменты и для этого. Чтобы проиллюстрировать это, мы теперь перейдем к реальным инструментам машинного обучения. Для этого мы создадим простую модель CatBoost с функциями, которые у нас есть:
Этот файл выглядит большим, но он очень простой. Во-первых, мы создаем стратифицированное случайное разделение. Мы можем стратифицировать по любому категориальному столбцу, но давайте использовать Pclass по умолчанию (задумайтесь на мгновение — зачем мы это делаем?). Затем мы выполняем вменение некоторых пропущенных значений, используя обучающий набор, и, наконец, обучаем модель. Все результаты сохраняются на диске.
Несколько замечаний:
— параметры являются явными и передаются в командной строке. Это позволяет нам иметь воспроизводимые команды без каких-либо неявных значений по умолчанию,
— этот сценарий создает так называемый файл метрик вместе с файлом модели и отправкой. Позже мы увидим, насколько это полезно в сочетании с DVC, 9.0003
— случайное состояние является явным и может быть предоставлено как параметр командной строки, который имеет значение по умолчанию. Мы не потеряем его из виду.
Теперь мы готовы обучить модель с помощью dvc run :
На самом деле мы создали конвейер DVC . Чтобы сгенерировать требуемый результат, DVC проверяет наличие всех зависимостей, поскольку features/train_features.csv и features/test_features.csv сами по себе являются результатами другого этапа ( features/festures.dvc ). Теперь, когда мы определили сцену для results/model.dvc , мы можем использовать ее с dvc repro . Кроме того, вы можете проверить конвейер:
Когда DVC пытается воспроизвести results/model.dvc , он сначала строит граф зависимостей и решает, нужно ли воспроизвести какую-либо из зависимостей. На данный момент все они обновлены, и DVC не выполняет никаких вычислений:
Однако, если мы удалим один или оба файла функций, DVC распознает это и сначала воспроизведет их:
Вы могли заметить несколько неудачное название команды
dvc repro.
Как видите, DVC проходит через все этапы, которые мы определили до сих пор, и распознает некоторые промежуточные результаты, необходимые для results/model.dvc отсутствуют. Воспроизводит этап features/features.dvc , но корректно определяет, что реально воспроизводимые файлы актуальны, поэтому нет необходимости ни сохранять их в кеш, ни воспроизводить results/model.dvc .
Другим компонентом является файл метрик. DVC может отслеживать метрики наряду с другими выходными данными. Это позволяет позже вспомнить производительность модели:
Кроме того, DVC может получать конкретные метрики напрямую:
В этом случае DVC распознает, что файл метрик находится в формате JSON, и использует путь (
-xили— xpath), чтобы найти фактическое поле внутри файла.
Теперь мы можем зафиксировать только что созданный этап:
Благодаря этапам, конвейерам и файлам метрик DVC позволяет выполнять еще более гибкие операции. Учтите следующее: после того, как вы создали основные функции и свою первую модель, вы хотите добавить некоторые дополнительные функции и переобучить модель. Вы хотите определить, лучше ли новые функции. Как бы вы этого добились?
Рабочий процесс может быть следующим:
- Создайте новый GIT Branch ,
- Добавить новый код для расчета дополнительных функций,
- Reproduce The Pipeline для
Результаты/модель. с тем, обученным новым функциям.
Давайте попробуем. Во-первых, мы создаем ветку:
Теперь мы добавляем новую функцию (хорошо известную PclassSex ) в pytitanic/features.py :
Теперь нам нужно воспроизвести results/model.dvc :
DVC сообщит, что так как одна из зависимостей изменилась, этап необходимо пересоздать и тогда запустит расчет. Оба features/features.dvc и results/model.dvc будут обновлены, и мы можем зафиксировать их сейчас:
Теперь мы можем запустить dvc metrics и посмотреть, как новая созданная модель сравнивается с предыдущей:
DVC имеет опцию для Показатели dvc показывают , чтобы показать все доступные показатели по всем ветвям, а именно -a . Это помогает нам сравнивать метрики между разными моделями внутри ветки или разными версиями одной и той же модели. Здесь мы видим, что новая модель немного лучше по точности.
Теперь мы можем решить объединить эту ветку обратно с master или отправить оба файла отправки в Kaggle для сравнения показателей таблицы лидеров.
DVC — мощный инструмент, и мы рассмотрели только его основы. DVC может быть более гибким: его можно настроить на использование ссылок между рабочим каталогом и кешем для экономии места, можно использовать любого из трех основных облачных провайдеров для удаленного хранения или даже установить Git-хуки.