
Google и Яндекс не индексируют сайт: причины, руководство что делать
Форумы вебмастеров пестрят грустными постами по поводу того, что сайт плохо индексируется поисковыми системами. А ведь это основа SEO-продвижения, без которой популяризация интернет-ресурса практически невозможна.
Обидней всего, когда над созданием web-проекта трудился дорогостоящий программист, а на его наполнение контентом ежемесячно тратится внушительная сумма.
Однако Яндекс и Гугл не спешат индексировать отдельные страницы или даже целый сайт. Почему так происходит?
На этот вопрос нет однозначного ответа: существует множество причин.
Важно выявить конкретную проблему (технические ошибки, дубляж страниц, нестабильную работу хостинга или санкции поисковиков) и сделать все для ее решения. Есть хорошая новость — ситуацию можно исправить. Хотите, знать как? Читайте дальше!
Нормы индексации сайтов
В Яндекс
Yandex сканирует и добавляет новые страницы примерно два-четыре раза в месяц. Попасть в поисковую выдачу раньше способны лишь трастовые и часто обновляемые порталы — внушающие доверие сайты индексируются быстроботом Яндекса ежедневно.
Попасть в поисковую выдачу раньше способны лишь трастовые и часто обновляемые порталы — внушающие доверие сайты индексируются быстроботом Яндекса ежедневно.
В Google
Что касается Гугла, обновления могут занять от одного дня до двух недель. Здесь многое зависит от категории вашего сайта. Например, ресурсы с актуальными новостями и живые форумы роботы проверяют с завидной регулярностью.
Материалы часто обновляемых порталов обычно сканируются в тот же день или на следующий. Индексация блога, в котором каждую неделю появляется новый контент, нередко задерживается на 2–4 дня.
Совсем печально обстоит дело с третьесортными сайтами, а также совсем молодыми веб-проектами, только что появившимися в Сети. Поисковые роботы могут игнорировать их в течение месяца.
Важно! Вышеописанные данные актуальны при добавлении малого количества страниц в индекс. При добавлении большого количества страниц одномоментно, скорость индексации может увеличиться в несколько раз.
Особенно долго будут индексироваться страницы с малой ценностью для посетителей.
Что делать, если новый сайт не индексируется поисковиками?
Под это определение подходит ресурс с возрастом домена до полугода, который не имеет обратных ссылок и ранее не продвигался.
Добавить сайт в панели вебмастеров
Вы только что создали сайт и ждете чуда под названием «быстрая индексация»? Такая стратегия ошибочная, ведь в первое время Гугл и Яндекс не обращают на новый сайт внимание. Помогите своему проекту заинтересовать роботов — сделать это достаточно просто: надо лишь добавить сайт в поисковые системы.
Важно! Использование сервиса Яндекс. Вебмастер и Google Webmaster не только ускорит добавление страниц в индекс, но и позволит эффективнее работать над оптимизацией сайта. Представленные инструменты бесплатно открывают вебмастерам множество возможностей для диагностики, получения рекомендованных для продвижения запросов и привязки сайта к конкретному региону.
Улучшить сайт
Пора заняться внутренней оптимизацией: систематически создавать первоклассный контент, улучшить юзабилити, сделав удобные рубрики, а также позаботиться об адаптивности и перелинковке. После этого следует задуматься о внешнем продвижении. Оно включает в себя работу с социальными факторами и размещение естественных ссылок у надежных доноров.
Если сайт все так же не индексируется Яндексом, необходимо написать в техническую поддержку поисковика. В результате вашего запроса вы получите информацию о наличии бана, фильтра или установите другую объективную причину возникшей проблемы.
Как проверить индексацию сайта?
Используйте в запросе оператор Site
Узнайте количество просканированных и добавленных в индекс страниц путем введения в строку поиска Гугл и Яндекс «site: url вашего сайта». Благодаря дополнительным настройкам легко получить данные о произошедших за конкретный промежуток времени изменения.
К примеру, сегодняшняя проверка российской версии Википедии показала, что за последние 2 недели на этом сайте появилось 143 новых материалов.
Учтите! Разница между показателями разных поисковых систем является поводом для тревоги. Чаще всего это свидетельствует о возможном попадании под фильтр Гугла или Яндекса.
Введите в поисковик url страницы
Этот способ идеален для проверки индексации отдельно выбранной страницы.
Для Google
url:https://ru.wikipedia.org/
Для Яндекс
info:https://ru.wikipedia.org/
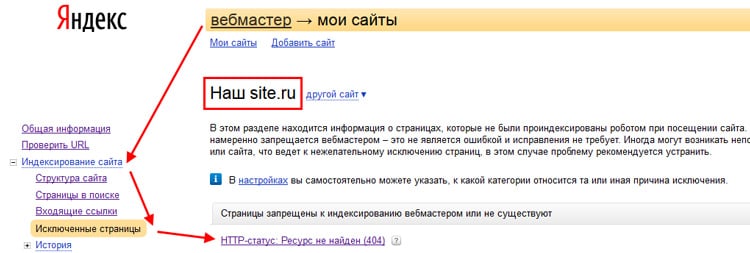
Через панель вебмастеров
Если вы ранее уже зарегистрировались в Яндекс. Вебмастер, то при переходе на данный сервис сразу увидите число загруженных материалов и тех, что находятся в поиске. В идеале их количество должно совпадать или быть похожим на реальное количество страниц сайта.
Более детальную информацию вы получите при переходе на основную панель, после чего необходимо нажать «Индексирование» и «Страницы в поиске».
Анализируя полученный отчет и ищите страницы, которые не индексируются.
В новом Google вебмастере также есть инструмент для анализа индексации.
С помощью Key Collector проверяем индексацию большого количества страниц
Скачанный и установленный на компьютере многофункциональный инструмент облегчит работу любому оптимизатору. Он позволяет автоматизировать процесс, значит, вам не придется вручную проверять сотни, а то и тысячи документов.
Чтобы воспользоваться этим методом, требуется собрать парсером список всех страниц, а затем добавить перед каждым адресом оператор url для Google или info для Яндекс. Хотите сэкономить время и нервы — воспользуйтесь для этого автозаменой в блокноте. Дальше надо загрузить полученные данные в Key Collector, не забыв о настройке XML для быстрого анализа результатов.
Также, нужно настроить правильно поисковые системы, для корректного парсинга. URL лучше добавлять без смены регистра.
У проиндексированных материалов в графе «Позиция по запросу» будет стоять единица. Сверьте ваш URL со страницей на первом месте. Они должны совпадать.
Это метод не идеален, но имеет право жизнь.
Как решить проблемы индексации?
Вариант 1: Сайт долго не индексируется, роботы не видят свежие материалы — в индекс попадает мало новых страниц, процесс осуществляется медленно.
Узнайте далее, что может быть причиной столь плачевной ситуации.
Редкое обновление контента
Для SEO-продвижения нужно вовремя подкармливать роботов новой порцией качественного контента, тогда они будут чаще заходить на ваш сайт. Причем на поведение поисковиков положительно влияют даже незначительные улучшения старых статей в виде более удачных иллюстраций, обновлений даты публикации или добавления цитаты эксперта.
А вот если робот приходит и видит, что за период его последнего посещения ничего не изменилось, сайт не будет нормально индексироваться в будущем. Более того, ждите ухудшения позиций в выдаче: ресурс, остановившийся в развитии, опережают конкуренты.
То есть
Если вы публикуете не регулярно — это может быть причиной. Если это не ваша ситуация, то читайте далее.
Если это не ваша ситуация, то читайте далее.
Плохое качество контента
За последние годы и читатели, и роботы стали более требовательными к размещенной в Рунете информации. Важную роль играет не только техническая, но и смысловая уникальность / полнота статей, картинок, видео.
При этом ключевые слова должны вписываться в текст естественно, а за переспам есть шанс попадания под фильтры поисковиков.
То есть
Если публикуемый контент малополезен или состоит из 100 слов, то вряд ли он попадет в индекс. Необходимо менять подход к написанию контента или качеству страниц.
Заинтересованы в генерации отличного контента?
Возьмите на вооружение LSI-копирайтинг, который сейчас в почете у поисковых систем. При качественном оформлении, полном раскрытии темы с использованием ключей и списка дополнительных синонимов, ассоциаций вам не придется беспокоиться о том, что страница не будет индексироваться в поисковых системах.
Наличие дубликатов
Секретом успешной технической оптимизации является отсутствие одинаковых мета-тегов и текстов; полных копий страниц. Если таковые имеются, закройте лишние данные от индекса при помощи meta name=«robots» content=«noindex, nofollow» или пропишите на них 301 редирект.
Если таковые имеются, закройте лишние данные от индекса при помощи meta name=«robots» content=«noindex, nofollow» или пропишите на них 301 редирект.
В противном случае поисковики запутаются в похожих документах и удалят их из выдачи.
Проблемы с краулинговым бюджетом
Существует определенный лимит на количество страниц, индексируемых роботом за единицу времени.
Краулинговый бюджет Google напрямую зависит от PageRank ресурса. Чем выше данный показатель, тем большее число документов будет проиндексировано. Соответственно, для масштабных сайтов крайне важно повышать критерий своей ценности путем регулярных обновлений, увеличения посещаемости и приобретения ссылок. Иначе некоторые страницы могут не индексироваться в Гугле.
То есть
Если сайт молодой, то у него низкий краулинговый бюджет. И если вы хотите проиндексировать большое количество страниц, то эта процедура может занять на порядок больше времени.
Технические нюансы для ускорения сканирования
Добавление sitemap.
 xml
xmlЭта карта, созданная для поисковых систем, дает роботам возможность быстро найти все страницы, независимо от их числа и уровней вложенности. Кроме того, она повышает доверие к вашему сайту, позволяет указывать дату обновления и расставлять приоритеты.
Алгоритм действий следующий: сгенерируйте sitemap.xml с учетом стратегии продвижения, загрузите карту в корень сайта и добавьте в панели вебмастеров.
Обновление http-заголовков Last-Modified и If-Modified-Since.
Last-Modified сообщает поисковикам о последних изменениях в документе, направляя роботов сразу к обновленным страницам и свежим материалам.
Ответ сервера на запрос If-Modified-Since снижает нагрузку на краулинговый бюджет, к тому же улучшает позиции контента при сортировке по дате.
Проверить этот заголовок можно тут — https://last-modified.com/ru/if-modified-since.html
Вариант 2: Сайт вообще не индексируется в Яндексе и Гугле, страницы выпадают из индекса.
Код ответа сервера
Убедитесь, что страница содержит код сервера 200 ОК — это означает: она действительно существует, доступна к просмотру для пользователей и поисковых систем.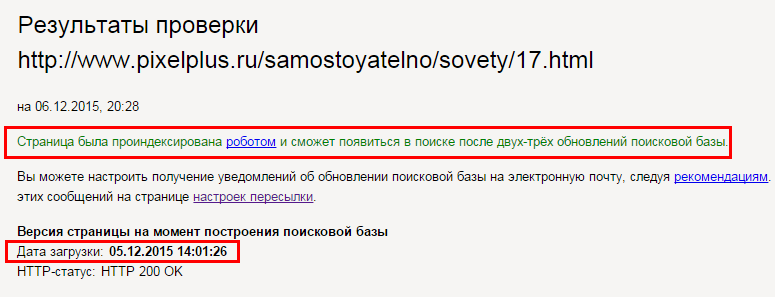
Проверка осуществляется при помощи специальных сервисов.
Например, http://www.bertal.ru/index.php?a1910327/
Если код ответа не 200 ОК, то именно в этом может быть причина не индексации страницы.
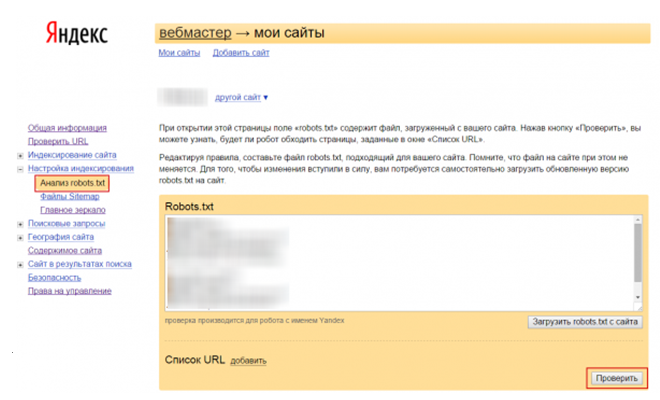
Robots.txt
В файле robots.txt недопустимы запреты на индексацию сайта и отдельных страниц, а также работу конкретного поисковика.
Важно! Обязательно проверьте сформированный robots.txt на ошибки. Сделать это можно в Google Вебмастер: нажмите на «Сканирование», а затем на «Инструмент проверки файла robots.txt».
Meta Robots
Часто сайт не индексируется в Гугле, если добавление сведений в базу данных запрещено в мета-тегах. Обязательно удалите в HTML-коде строкии если они есть на важных страницах.
Чтобы проверить откройте код страницы и сделайте поиск строки.
Либо используйте плагины для браузера, такие как расширение Seo Meta in 1 Click для Google Chrome.
Rel Canonical
Многие неопытные оптимизаторы неверно настраивают атрибут rel=canonical.
Хотите, чтобы страница попала в индекс поисковика? Тогда она не должна ссылаться на другой канонический документ.
Чтобы проверить откройте код страницы и сделайте поиск строки.
Либо через тот же плагин
Вебмастера
Используйте Google Webmaster Tools для выявления ошибок сканирования, из-за которых роботы не получают ответы на запросы.
Перейдите в раздел «Просмотреть как Googlebot» введите адрес страницы, и нажмите кнопку «Получить и отобразить».
Когда получите результат, сравните, что видит Google и пользователь. Картинки должны быть одинаковыми. Если нет, то ищите причины блокировки файлов.
Протестируйте скорость загрузки и время ответа сервера. Убедитесь, что выбранный вами хостинг работает стабильно.
Файл .htaccess
Если сайт не индексируется, он может быть заблокирован в файле .htaccess.
Проверьте .htaccess на наличие таких строк:
RewriteCond %{USER_AGENT} Googlebot
RewriteRule. * — [F]
* — [F]
Либо такой вариант, который будет отдавать роботу Google 404 ошибки.
RewriteCond %{USER_AGENT} Googlebot
RewriteRule.* — [R=404]
Поищите в файле другие варианты блокировок с использованием USER_AGENT или названия поисковых ботов: googlebot, yandex и т. д.
AJAX и JavaScript
Распространены проблемы с языками AJAX и JavaScript. Блог Яндекса для вебмастеров рекомендует создать в структуре ресурса определенную схему, которая сообщит поисковым системам о необходимости индексации.
Санкции
Еще одна серьезная проблема — наложение санкций на страницу или даже весь сайт. Узнайте в техподдержке поисковой системы (только Яндекс), за что именно (ссылки, переспам, неуникальный контент) вас наказали, после чего оперативно исправьте ситуацию.
Как уже говорилось ранее, причиной отсутствия внимания к странице часто является низкокачественный и дублированный контент.
Вряд ли робот будет заинтересован в ваших материалах, если в выдаче уже имеются похожие документы, продвигаемые по тому же семантическому ядру.
Негативно влияет на скорость индексирования незрелый возраст домена, а также забаненный ранее б/у домен. В таком случае стоит написать запрос на пересмотр в Яндекс.
Итоги
Если сайт не индексируется Яндексом или Гуглом, значит, на то есть объективная причина. Ваша цель — выявить и решить проблему. Спустя некоторое время необходимо снова проверить индексацию страницы. Если вы все сделаете правильно, положительные изменения не заставят себя долго ждать!
Если у вас сложный случай, рекомендую обратиться за консультацией к специалистам. Команда Livepage проконсультирует и выполнит SEO-аудит, который решит все проблемы с индексацией в поисковых системах.
Почему Яндекс не индексирует сайт
Прежде чем сеять панику, необходимо понять следующую вещь. Индексация в яндексе зачастую происходит дольше, чем в Google. Поэтому, если ваш сайт совсем новый, и вы только недавно отправили его на индексацию, то следует немного подождать. Средний срок индексации в Яндексе составляет около 2-3х недель.
Если Яндекс не индексирует сайт в течение месяца
Если же проблема не решается в течение месяца, то необходимо рассмотреть следующие варианты:
Закрыт вход на ваш сайт
Вероятность данной ситуации, крайне мала, однако существует, поэтому в первую очередь рекомендуется проверить файл Robots.txt на предмет открытия доступа к сайту.
Неправильный тег <noindex>
Использование данного тега, связано с тем, чтобы определенный код не попал в индекс Яндекса. На некоторых сайтах наблюдается такая ошибка: открытый тег <noindex> в начале сайта в шапке забывали закрыть, в конечном итоге весь код страницы «прячется» от робота.
Иностранный язык на сайте
Система Яндекс предрасположена к использованию на просторах рунета, в связи с чем, возникают трудности индексации, если используемый язык на сайте отличен от языков стран СНГ. Решить данную проблему можно путем обращения в службу поддержки.
Что делать если сайт не индексируется ни одной системой
Заметив данную проблему, следует обратить внимание на следующее:
Мета-тег Robots
При наличии на странице подобного тега <meta name=»robots» content=»noindex, nofollow»> приведет к не индексации.
Плохая HTML-разметка
Неправильно вложенные теги, могут создать проблемы для роботов в процессе разбора страницы. Конечным результатом ошибки в разметке может стать либо полная не индексация, либо ухудшение ее ранжирования.
Медленная загрузка сайта
В каждой поисковой системе у роботов существует лимит времени, за который они обращаются к веб – страницам. Если страница не открылась после нескольких запросов, робот не сможет узнать какую информацию необходимо поместить в свой индекс. Довести загрузку страницы до времени в доли секунд не является необходимым, достаточно 3-4 секунд, это будет приемлемо. В основном время загрузки сайта зависит от хостинга, поэтому данному вопросу необходимо уделять особое внимание, чтобы не столкнуться с массой возможных проблем.
Возникновение ошибок сервера с кодами 4хх и 5хх
Вместе со страницей, которую мы видим, когда заходим на сайт, сервер отдает и код этой страницы. Часто возникает внутренняя ошибка сервера, которая имеет код 500. Возникает данная ошибка не из-за плохого качества хостинга, а из-за неправильных серверных скриптов, которые написал владелец сайта. Ошибка 404 так же достаточно распространена, она сообщает о том, что страница не найдена, при этом вместо страницы выводится специальная страница с сообщением «Страница не найдена». В обоих случаях поисковый робот не индексирует полученную страницу, так как её код говорит о проблемах на данной странице.
Возникает данная ошибка не из-за плохого качества хостинга, а из-за неправильных серверных скриптов, которые написал владелец сайта. Ошибка 404 так же достаточно распространена, она сообщает о том, что страница не найдена, при этом вместо страницы выводится специальная страница с сообщением «Страница не найдена». В обоих случаях поисковый робот не индексирует полученную страницу, так как её код говорит о проблемах на данной странице.
Отсутствует настройки домена с www и без www
Это не распространенная причина, но она все же встречается. Правильным подходом является настройка работы сайта на каком-нибудь одном домене:
http://blog.ru
http://www.blog.ru
Для поисковой системы Яндекс настроить эту функцию можно с помощью файла Robots.txt либо же нужно указать главное зеркало в панели вебмастера. Самым лучшим вариантом, является настройка 301-го редиректа в .htaccess.
Худший вариант – домен имеющий “плохую” историю
Вероятнее всего вы подобрали доменное имя, которое раньше имело плохую репутацию у поисковых роботов. К примеру, это мог быть дорвей или adult-ресурс. Либо же данный сайт занимался активной продажей ссылок с автобирж, за это и получил бан в поисковых системах. Если на данном домене имело место злоупотребление черными SEO методами, то к новому ресурсу поисковые роботы определенное время будут относиться особенно, и нормальной индексации необходимо будет подождать.
К примеру, это мог быть дорвей или adult-ресурс. Либо же данный сайт занимался активной продажей ссылок с автобирж, за это и получил бан в поисковых системах. Если на данном домене имело место злоупотребление черными SEO методами, то к новому ресурсу поисковые роботы определенное время будут относиться особенно, и нормальной индексации необходимо будет подождать.
Bing против Google: какая поисковая система индексирует больше контента?
Поисковые системы не могут обнаружить и проиндексировать каждую страницу в Интернете — им нужно сделать выбор в этом отношении. И хотя все поисковые системы служат одной и той же цели, они используют разные критерии индексации страниц.
При этом, как правило, хорошо, если поисковая система может сканировать и индексировать как можно больше ценного контента — это увеличивает вероятность того, что она покажет пользователям то, что они ищут.
Мне было любопытно, какая поисковая система — Bing или Google — в целом индексирует больше контента.
В этой статье описываются различные аспекты моего исследования, и хотя мне нужно больше данных, чтобы сделать определенные выводы, мне все же удалось собрать много уникальных и ценных идей.
Вот что я узнал о том, как Bing и Google индексируют веб-страницы.
1.1 Покрытие индекса случайной выборки сайтов WordPress
1,2 Сканирование данных для выборки наших клиентов
1,3 Индекс Покрытие выборки популярных сайтов
2 Bing против индексации Google — первоначальные наблюдения
2.1 Представляем IndexNow
2.2 Оптимизация сканирования и индексации страниц
3 Подведение итогов
Анализ данных об индексации: методология и результаты
Покрытие индексом случайной выборки сайтов WordPress
Первым шагом моего исследования был сбор выборки страниц для проверки статистики их индексации.
Я решил, что хорошей отправной точкой будет использование образца веб-сайтов с плагином Yoast SEO для WordPress. Выбор этого плагина был обусловлен практической причиной: он делит карту сайта по разделам, что позволяет мне анализировать, какие разделы индексируются больше всего.
Я нашел список веб-сайтов, использующих плагин Yoast SEO, на сайте buildwith.com, который сообщает о веб-сайтах, использующих определенные технологии или инструменты. Я выбрал случайную выборку из 200 веб-сайтов из списка сайтов, использующих Yoast SEO.
Затем я проверил статистику индексации этих веб-сайтов с помощью ZipTie.dev, и полученные данные оказались очень интересными.
Bing проиндексировал больше веб-страниц, чем Google.
Взгляните на приведенные ниже диаграммы, которые показывают статистику индексации для заданных категорий карты сайта:
Покрытие индекса одинаково для Bing и Google для категорий историй и прессы. Более того, Google проиндексировал больше контента в путеводителях и локациях. Однако во всех остальных категориях карты сайта индексация Bing превосходит индексацию Google, включая важные категории, такие как сообщения, продукты и изображения.
Однако во всех остальных категориях карты сайта индексация Bing превосходит индексацию Google, включая важные категории, такие как сообщения, продукты и изображения.
Но означает ли это, что Bing также может сканировать больше страниц, чем Google? Или они сканируют одинаковое количество контента, но имеют разные предпочтения в отношении индексации?
Сканирование данных для выборки наших клиентов
Чтобы расширить свои выводы, я проверил данные для нескольких наших клиентов как в Bing Webmaster Tools, так и в Google Search Console.
Эти инструменты показывают страницы, о которых знает соответствующая поисковая система для данного домена.
В консоли поиска Google я просмотрел все известные страницы, отображаемые в отчете о покрытии индекса, и проверил количество URL-адресов для всех четырех статусов (ошибки, действительные, действительные с предупреждениями и исключенные).
В инструментах Bing для веб-мастеров в разделе Site Explorer, который содержит данные об индексации страниц в данном домене, я отфильтровал представление, чтобы отобразить все URL-адреса.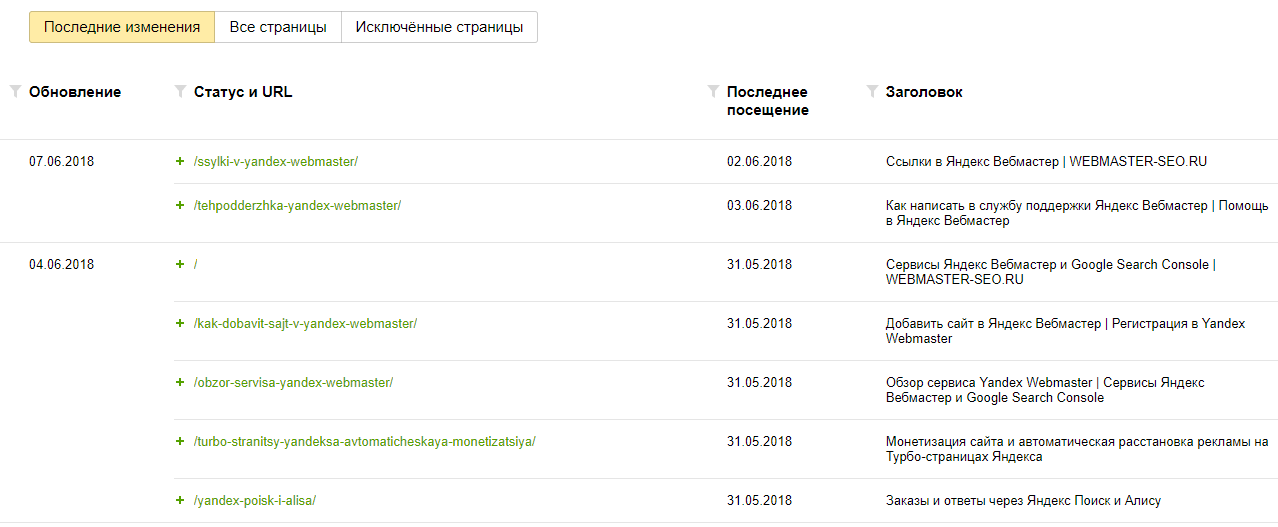
Это показало мне все обнаруженные URL-адреса для каждого домена, который я проанализировал.
Сравнив данные, полученные в обоих этих инструментах, я заметил, что Google обнаружил больше страниц, чем Bing.
С другой стороны (при условии, что эти результаты совпадают для обоих протестированных образцов веб-сайтов), мы уже знаем, что Google и Bing обнаружили 9 страниц.0003 с большей вероятностью будет проиндексирован Bing.
Имейте в виду, что эти результаты относятся только к небольшой выборке сайтов и могут не отражать всю сеть.
Покрытие индекса выборки популярных сайтов
Третьим аспектом моего исследования было проверить статус индексирования нескольких популярных веб-сайтов с помощью ZipTie , чтобы увидеть, как он различается между Bing и Google.
Я узнал, что Bing гораздо активнее индексирует эти сайты, чем Google. Это подтвердило мои более ранние выводы для выборки веб-сайтов WordPress, использующих YoastSEO.
Взгляните на данные, которые я получил:
Bing по сравнению с индексированием Google – первые наблюдения
Можем ли мы сказать, что Bing лучше поисковой системы на основе данных?
Хотя Bing индексирует больше контента, мы не можем выделить одного победителя, просто взглянув на статистику индексации. Мы не знаем, почему Bing индексирует больше, чем Google.
Моя гипотеза состоит в том, что Google может быть «более разборчивым», чем Bing. Нет ничего удивительного в том, что выбор индекса существует.
Мы говорили об этом в течение многих лет – индексировать Google становится все труднее.
Мы также знаем, что поисковых системы сканируют страницы с разной скоростью.
Вот что сказал Джон Мюллер о том, как часто Googlebot сканирует страницы:
Я думаю, что сложность здесь в том, что мы не сканируем URL-адреса с одинаковой частотой все время. Поэтому некоторые URL-адреса мы будем сканировать ежедневно.
Некоторые URL-адреса могут быть еженедельными. Другие URL-адреса каждые пару месяцев, может быть, даже раз в полгода или около того. Так что это то, для чего мы пытаемся найти правильный баланс, чтобы не перегружать ваш сервер. […] Так что, в частности, если вы делаете такие вещи, как запросы к сайту, есть шанс, что вы увидите те URL-адреса, которые сканируются примерно раз в полгода. Они все еще будут там через пару месяцев. […] если вы считаете, что эти URL-адреса вообще не должны индексироваться, то, возможно, вы можете поддержать это и сказать: ну, вот файл карты сайта с датой последней модификации, чтобы Google отключился и попытался удвоить- проверьте это немного быстрее, чем в противном случае.
источник: Джон Мюллер
 Некоторые URL-адреса могут быть еженедельными. Другие URL-адреса каждые пару месяцев, может быть, даже раз в полгода или около того. Так что это то, для чего мы пытаемся найти правильный баланс, чтобы не перегружать ваш сервер. […] Так что, в частности, если вы делаете такие вещи, как запросы к сайту, есть шанс, что вы увидите те URL-адреса, которые сканируются примерно раз в полгода. Они все еще будут там через пару месяцев. […] если вы считаете, что эти URL-адреса вообще не должны индексироваться, то, возможно, вы можете поддержать это и сказать: ну, вот файл карты сайта с датой последней модификации, чтобы Google отключился и попытался удвоить- проверьте это немного быстрее, чем в противном случае.
Некоторые URL-адреса могут быть еженедельными. Другие URL-адреса каждые пару месяцев, может быть, даже раз в полгода или около того. Так что это то, для чего мы пытаемся найти правильный баланс, чтобы не перегружать ваш сервер. […] Так что, в частности, если вы делаете такие вещи, как запросы к сайту, есть шанс, что вы увидите те URL-адреса, которые сканируются примерно раз в полгода. Они все еще будут там через пару месяцев. […] если вы считаете, что эти URL-адреса вообще не должны индексироваться, то, возможно, вы можете поддержать это и сказать: ну, вот файл карты сайта с датой последней модификации, чтобы Google отключился и попытался удвоить- проверьте это немного быстрее, чем в противном случае.Я также нашел несколько интересных идей в документации Bing:
Чтобы оценить, насколько интеллектуален наш поисковый робот, мы измеряем эффективность сканирования bingbot. Эффективность сканирования — это то, как часто мы сканируем и обнаруживаем новый и свежий контент на просканированную страницу.
источник: Серия Bingbot: максимальная эффективность сканирования»
 Наша северная звезда эффективности сканирования заключается в том, чтобы сканировать URL-адрес только тогда, когда контент был добавлен (URL-адрес не сканировался ранее), обновлен (свежий контекст на странице или полезные исходящие ссылки). Чем больше мы сканируем дублированный, неизменный контент, тем ниже наш показатель эффективности сканирования.
Наша северная звезда эффективности сканирования заключается в том, чтобы сканировать URL-адрес только тогда, когда контент был добавлен (URL-адрес не сканировался ранее), обновлен (свежий контекст на странице или полезные исходящие ссылки). Чем больше мы сканируем дублированный, неизменный контент, тем ниже наш показатель эффективности сканирования.Bing может не захотеть углубляться при сканировании веб-сайтов, поскольку это может принести мало пользы и привести к снижению их KPI.
Мы знаем, что Bing работает над повышением эффективности сканирования. Например, Bing попытался оптимизировать сканирование статического контента и определить шаблоны, которые уменьшили бы частоту сканирования на многих веб-сайтах.
Также обратите внимание на различия в том, как Google и Bing индексировали случайные сайты WordPress — они были намного меньше. В случае очень популярных веб-сайтов они гораздо более значимы.
Это наводит меня на мысль, что в соответствии с тем фактом, что Bing открыто признает, что использует данные о поведении пользователей в своих алгоритмах,
Представляем IndexNow
Недавно Bing сделал еще один шаг вперед, приняв протокол IndexNow. Вы можете использовать IndexNow, чтобы информировать Bing и Яндекс о новом или обновленном контенте.
В ходе наших тестов мы обнаружили, что Bing обычно начинает сканировать страницу в промежутке от 5 секунд до 5 минут с момента ее отправки с помощью IndexNow.
IndexNow — это инициатива по повышению эффективности Интернета: сообщая поисковым системам, был ли изменен URL-адрес, владельцы веб-сайтов дают четкий сигнал, помогая поисковым системам расставить приоритеты при сканировании этих URL-адресов, тем самым ограничивая потребность в исследовательском сканировании для проверки содержимого.
изменилось […].Мы продолжим учиться и совершенствоваться в [a] большем масштабе и корректировать скорость сканирования для сайтов, использующих IndexNow. Наша цель — предоставить каждому пользователю максимальную выгоду с точки зрения индексации, управления нагрузкой при сканировании и актуальности контента для искателей.
источник: Блог Bing, «IndexNow — Мгновенное индексирование вашего веб-контента в поисковых системах»

IndexNow позволяет веб-сайтам быстрее индексировать свой контент и использовать меньше ресурсов для сканирования. В результате предприятия могут повысить качество обслуживания своих клиентов, предоставив им доступ к наиболее актуальной информации.
Мы создали инструмент, который поможет вам отправлять URL-адреса или карты сайта в IndexNow еще быстрее и проще.
Важно отметить, что IndexNow дает небольшим поисковым системам, таким как Bing и Yandex, возможность добавлять в свои индексы обширную базу данных контента.
Время покажет, примет ли Google протокол IndexNow или создаст альтернативное решение, которое позволит владельцам сайтов отправлять страницы для индексации.
Оптимизация обхода и индексации страниц
Еще один вывод из моего анализа индексации заключается в том, насколько важно упростить сканирование и индексирование для поисковых систем.
Во-первых, вам нужно создать и поддерживать карты сайта, которые включают ваши ценные URL-адреса. Файлы Sitemap полезны для Bing и Google для обнаружения контента, который они должны проиндексировать.
Поисковые системы будут изо всех сил пытаться определить, какие страницы релевантны и должны быть проиндексированы, если вы не отправите оптимизированную карту сайта. Для получения более подробной информации о настройке карты сайта и о том, какие страницы включать, прочитайте наше Полное руководство по файлам Sitemap в формате XML.
Кроме того, у вас должен быть файл robots.txt , содержащий правильные директивы для ботов и правильно реализованные теги noindex на страницах, которые не должны быть проиндексированы.
Чтобы определить четкую закономерность в индексации Bing и Google, мне пришлось бы изучить гораздо больше веб-сайтов, но есть определенные идеи, которые мы можем почерпнуть из моих образцов данных:
- Bing индексирует больше контента, чем Google.
- Google обнаруживает больше контента, чем Bing, что позволяет предположить, что Google более требователен к индексации. Руководящий принцип Bing — меньше сканировать и сосредоточиться на добавленном или обновленном содержимом.
- Bing отдает приоритет индексированию популярных веб-сайтов, в то время как популярность не имеет для Google большого значения.
Мы также видим, что качество контента и оптимизация сканирования и индексации вашего сайта являются жизненно важными аспектами SEO, , и их нельзя недооценивать или пренебрегать ими.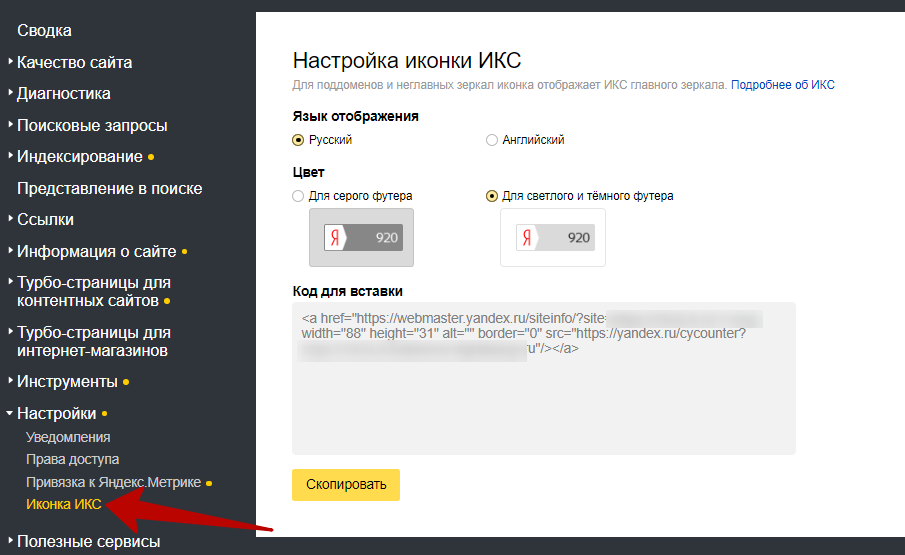 Более того, эти факторы, вероятно, будут продолжать играть решающую роль по мере роста Интернета и усложнения алгоритмов поисковых систем.
Более того, эти факторы, вероятно, будут продолжать играть решающую роль по мере роста Интернета и усложнения алгоритмов поисковых систем.
Что такое веб-краулер? Все, что вам нужно знать от TechTarget.com
К
- Александр С. Гиллис, Технический писатель и редактор
Поисковый робот, поисковый робот или веб-паук — это компьютерная программа, которая используется для поиска и автоматического индексирования содержимого веб-сайтов и другой информации в Интернете. Эти программы или боты чаще всего используются для создания записей для индекса поисковой системы.
Веб-сканеры систематически просматривают веб-страницы, чтобы узнать, о чем каждая страница на веб-сайте, поэтому эту информацию можно индексировать, обновлять и извлекать, когда пользователь выполняет поисковый запрос. Другие веб-сайты используют роботов для сканирования веб-страниц при обновлении собственного веб-контента.
Другие веб-сайты используют роботов для сканирования веб-страниц при обновлении собственного веб-контента.
Поисковые системы, такие как Google или Bing, применяют алгоритм поиска к данным, собранным поисковыми роботами, для отображения релевантной информации и веб-сайтов в ответ на поисковые запросы пользователей.
Если организация или владелец веб-сайта хочет, чтобы его веб-сайт занимал высокие позиции в поисковой системе, его необходимо сначала проиндексировать. Если веб-страницы не просканированы и не проиндексированы, поисковая система не сможет найти их естественным образом.
Поисковые роботы начинают сканирование определенного набора известных страниц, а затем переходят по гиперссылкам с этих страниц на новые страницы. Веб-сайты, которые не хотят, чтобы их сканировали или находили поисковые системы, могут использовать такие инструменты, как файл robots.txt, чтобы попросить ботов не индексировать веб-сайт или индексировать только его части.
Проведение аудита сайта с помощью инструмента сканирования может помочь владельцам веб-сайтов выявить неработающие ссылки, дублированный контент и повторяющиеся, отсутствующие или слишком длинные или короткие заголовки.
работают, начиная с исходного кода или списка известных URL-адресов, просматривая и затем классифицируя веб-страницы. Перед просмотром каждой страницы поисковый робот просматривает файл robots.txt веб-страницы, в котором указаны правила для ботов, обращающихся к веб-сайту. Эти правила определяют, какие страницы можно сканировать и по каким ссылкам можно переходить.
Чтобы перейти на следующую веб-страницу, сканер находит гиперссылки и переходит по ним. По какой гиперссылке следует сканер, зависит от определенных политик, которые делают его более избирательным в отношении порядка следования сканера. Например, определенные политики могут включать следующее:
- сколько страниц ссылаются на эту страницу;
- количество просмотров страниц; и
- авторитет бренда.

Эти факторы означают, что страница может содержать более важную информацию для индексации.
Находясь на веб-странице, сканер сохраняет копию и описательные данные, называемые метатегами, а затем индексирует их для поисковой системы для поиска ключевых слов. Затем этот процесс решает, будет ли страница отображаться в результатах поиска по запросу, и если да, то возвращает список проиндексированных веб-страниц в порядке важности.
Если владелец веб-сайта не отправляет карту своего сайта поисковым системам для сканирования сайта, поисковый робот все равно может найти веб-сайт, перейдя по ссылкам с проиндексированных сайтов, которые связаны с ним.
Примеры поисковых роботовБольшинство популярных поисковых систем имеют собственные поисковые роботы, которые используют определенный алгоритм для сбора информации о веб-страницах. Инструменты веб-краулера могут быть настольными или облачными. Некоторые примеры поисковых роботов, используемых для индексации поисковыми системами, включают следующее:
- Amazonbot — поисковый робот Amazon.
- Bingbot — поисковый робот Microsoft для Bing.
- DuckDuckBot — сканер для поисковой системы DuckDuckGo.
- Googlebot – это поисковый робот Google.
- Yahoo Slurp — поисковый робот Yahoo.
- Yandex Bot — поисковый робот Яндекс.

Поисковая оптимизация (SEO) — это процесс улучшения веб-сайта с целью повышения его видимости, когда люди ищут товары или услуги. Если на веб-сайте есть ошибки, которые затрудняют его сканирование, или он не может быть просканирован, его рейтинг страницы результатов поисковой системы (SERP) будет ниже или он не будет отображаться в результатах обычного поиска. Вот почему важно следить за тем, чтобы на веб-страницах не было неработающих ссылок или других ошибок, а также позволять ботам-сканерам получать доступ к веб-сайтам, а не блокировать их.
Аналогично, страницы, которые не сканируются регулярно, не будут отражать никаких обновленных изменений, которые в противном случае могли бы повысить SEO.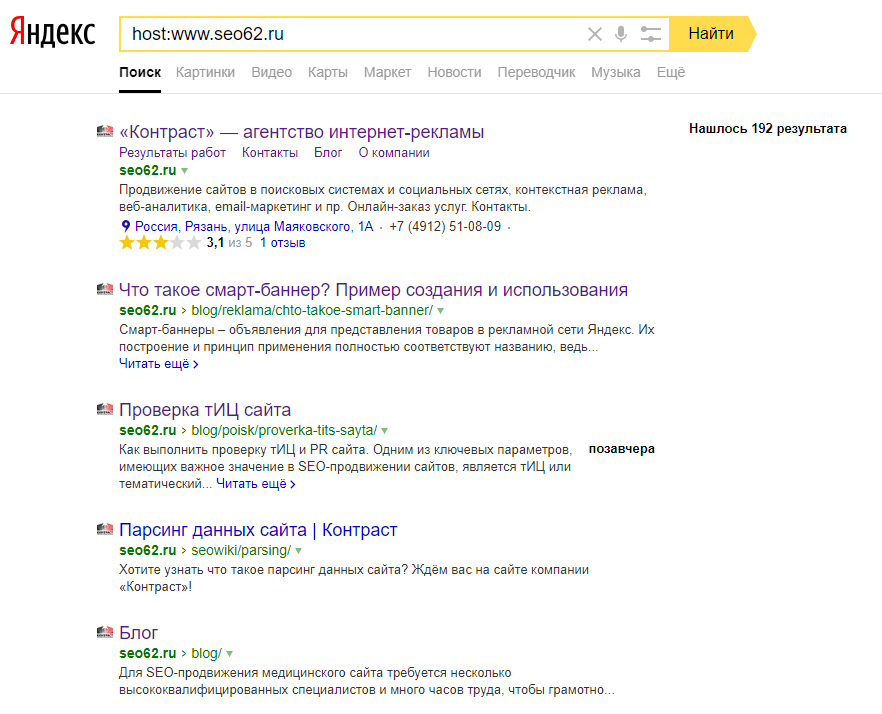 Регулярное сканирование и обновление страниц могут помочь улучшить поисковую оптимизацию, особенно в отношении срочного контента.
Регулярное сканирование и обновление страниц могут помочь улучшить поисковую оптимизацию, особенно в отношении срочного контента.
Веб-сканирование и веб-скрапинг — это два схожих понятия, которые легко спутать. Основное различие между ними заключается в том, что в то время как веб-сканирование связано с поиском и индексированием веб-страниц, веб-скрапинг — это извлечение данных, найденных на одной или нескольких веб-страницах.
Веб-скрапинг включает в себя создание бота, который может автоматически собирать данные с различных веб-страниц без разрешения. В то время как поисковые роботы постоянно переходят по ссылкам на основе гиперссылок, веб-скрапинг обычно является гораздо более целенаправленным процессом и может выполняться только после определенных страниц.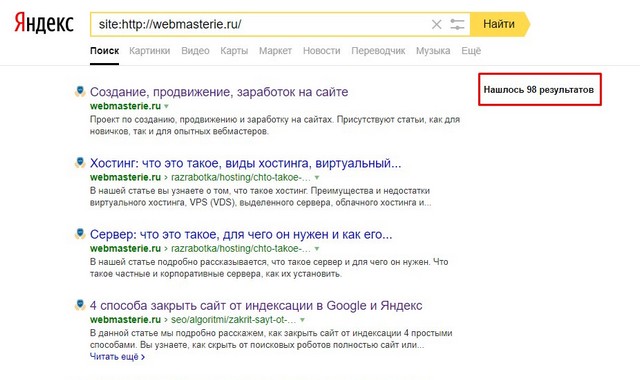
В то время как веб-сканеры следуют файлу robots.txt, ограничивая запросы, чтобы избежать перегрузки веб-серверов, веб-скраперы игнорируют любую нагрузку, которую они могут вызвать.
Веб-скрапинг может использоваться для целей аналитики — сбора данных, их хранения и последующего анализа — для создания более целевых наборов данных.
Простые боты могут использоваться для парсинга веб-страниц, но более сложные боты используют искусственный интеллект для поиска соответствующих данных на странице и копирования их в нужное поле данных для обработки аналитическим приложением. Варианты использования ИИ на основе веб-скрапинга включают электронную коммерцию, исследования рынка труда, аналитику цепочки поставок, сбор корпоративных данных и исследования рынка.
Коммерческие приложения используют парсинг веб-страниц для анализа настроений при запуске новых продуктов, отбора структурированных наборов данных о компаниях и продуктах, упрощения интеграции бизнес-процессов и предиктивного сбора данных.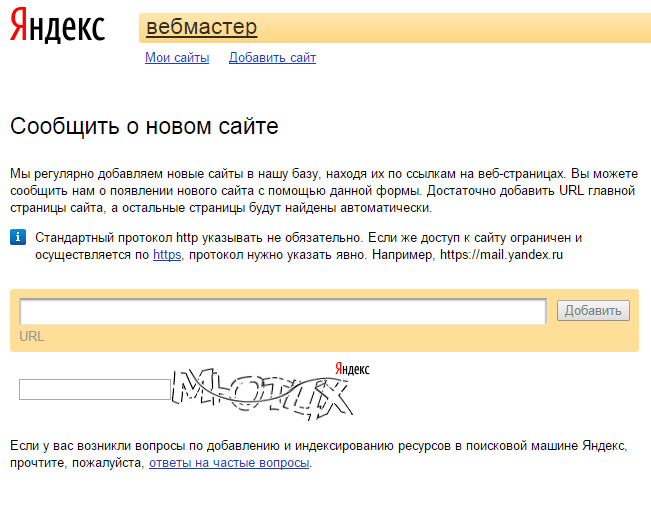
Узнайте больше о четырех других стратегиях SEO, включая создание лучших тематических кластеров и стратегий обратных ссылок.
Последнее обновление: сентябрь 2022 г.
Продолжить чтение О веб-сканере- 5 бесплатных инструментов для исследования ключевых слов SEO
- Фишинговые атаки с использованием сомнительных методов SEO
- Борьба с плохими ботами — как избежать большой очистки данных
- 6 бесплатных инструментов для парсинга веб-страниц, упрощающих сбор данных
- Технологии Cisco Talos обнаруживают сайты программ-вымогателей в даркнете
устойчивый AI
Устойчивый ИИ — это использование систем искусственного интеллекта, которые работают в соответствии с устойчивой деловой практикой.
Сеть
- полоса (полоса частот)
В телекоммуникациях полоса частот, иногда называемая полосой частот, относится к определенному диапазону частот в .
.. - HAProxy
HAProxy — это высокопроизводительный балансировщик нагрузки с открытым исходным кодом и обратный прокси-сервер для приложений TCP и HTTP.
- ACK (подтверждение)
В некоторых протоколах цифровой связи ACK — сокращение от «подтверждение» — относится к сигналу, который устройство посылает, чтобы указать…
 ..
..Безопасность
- постквантовая криптография
Постквантовая криптография, также известная как квантовое шифрование, представляет собой разработку криптографических систем для классических компьютеров…
- деинициализация
Деинициализация — это часть жизненного цикла сотрудника, в ходе которой лишаются прав доступа к программному обеспечению и сетевым службам.
- Требования PCI DSS 12
Требования PCI DSS 12 представляют собой набор мер безопасности, которые предприятия должны внедрить для защиты данных кредитных карт и соблюдения .
..
 ..
..ИТ-директор
- Agile-манифест
The Agile Manifesto — это документ, определяющий четыре ключевые ценности и 12 принципов, в которые его авторы верят разработчикам программного обеспечения…
- Общее управление качеством (TQM)
Total Quality Management (TQM) — это система управления, основанная на вере в то, что организация может добиться долгосрочного успеха, …
- системное мышление
Системное мышление — это целостный подход к анализу, который фокусируется на том, как взаимодействуют составные части системы и как…
HRSoftware
- вовлечения сотрудников
Вовлеченность сотрудников — это эмоциональная и профессиональная связь, которую сотрудник испытывает к своей организации, коллегам и работе.
- кадровый резерв
Кадровый резерв — это база данных кандидатов на работу, которые могут удовлетворить немедленные и долгосрочные потребности организации.
