
Какие метатеги использовать в вебе в 2017 году
Метатеги в контексте веб-страниц — HTML-теги, которые размещаются в разделе <head> веб-страницы. Браузеры интерпретируют их, чтобы правильно отобразить сайт, а поисковые системы используют при выборке информации о странице. Некоторые теги могут влиять на позиции сайта в результатах поиска.
Рассмотрим метатеги, которые стоит использовать в 2017 году. Стандарты взаимодействия развиваются, и теги — вместе с ними. Поэтому те теги, которые здесь не описаны, с большой вероятностью уже бесполезны.
Основные
Определяет кодировку веб-страницы:
<meta charset="utf-8">
Определяет заголовок веб-страницы, который также отображается в результатах поиска Google, Яндекс, Bing и др. Длину заголовка стоит уместить в 70 символов, так как остальное будет отсечено при отображении:
<title>Заголовок страницы</title>
Определяет краткое описание содержания веб-страницы, которое также может быть использовано в выдаче поисковых систем. Длину описания стоит уместить в 150 символов, так как остальное будет отсечено при отображении:
Длину описания стоит уместить в 150 символов, так как остальное будет отсечено при отображении:
<meta name="description" content="[описание страницы]">
Известен как метатег адаптивного дизайна, потому что описывает, как разметка и контент изменяются в зависимости от размера области просмотра устройства. Атрибут content принимает различные значения, однако указанный выше вариант можно назвать стандартным:
<meta name="viewport" content="width=device-width, initial-scale=1">
Определяет базовый URL-адрес для ссылок на внешние файлы, такие, как CSS, Javascript и изображения. В результате браузер найдёт файл независимо от размещения текущей веб-страницы. Это не самый полезный тег, но если его указать, то объём исходного кода страницы уменьшится, а перенос сайта на другой домен принесёт меньше головной боли разработчику:
<base href="//cdn.example.com/">
Определяет «Имя приложения», которое появляется под иконкой страницы на мобильных устройствах, когда пользователь использует функцию «Добавить на главный экран» в веб-браузере:
<meta name="application-name" content="[имя приложения]">
Взаимодействие с поисковыми системами
Иногда требуется запретить или разрешить роботам поисковых систем обрабатывать ту или иную страницу. Метатег
Метатег robots определяет политику обработки страницы поисковыми роботами. Вот несколько примеров:
<meta name="robots" content="all"/>— разрешено индексировать текст и ссылки на странице, аналогично<meta name="robots" content="index, follow"/>;<meta name="robots" content="noindex"/>— не индексировать текст страницы;<meta name="robots" content="nofollow"/>— не переходить по ссылкам на странице;<meta name="robots" content="none"/>— запрещено индексировать текст и переходить по ссылкам на странице, аналогично<meta name="robots" content="noindex, nofollow"/>;<meta name="robots" content="noarchive"/>
Как и предыдущий тег, определяет политику обработки страницы поисковым роботом, но только для Google:
<meta name="googlebot" content="index,follow">
Проверяет веб-сайт на наличие доступа к панели веб-мастера Google (Google Webmaster Tools):
<meta name="google-site-verification" content="[код верификации]">
Отключает панель поиска ссылок Google:
<meta name="google" content="nositelinkssearchbox">
Запрещает браузеру Google Chrome переводить веб-страницу:
<meta name="google" content="notranslate">
Подробности работы с Google описаны в Справочном центре.
Яндекс
Определяет политику обработки страницы роботом Яндекс:
<meta name="yandex" content="index,follow">
Проверяет веб-сайт на наличие доступа к сервису Яндекс.Вебмастер:
<meta name="yandex-verification" content="[код верификации]">
Подробности работы с Яндекс описаны на странице помощи для веб-мастеров.
Взаимодействие с социальными сетями
Метатеги социальных медиа необязательны, но помогают поделиться ссылкой на веб-страницу в таком виде, чтобы привлечь внимание читателей, увеличить количество лайков и репостов.
Текст адаптируется для поста, картинка создаётся специально под площадку. Причём они могут даже не отображаться в веб-версии сайта.
Open Graph (Facebook, Pinterest, Вконтакте, Одноклассники)
Open Graph — разработанная Facebook разметка, позволяющая настраивать превью страницы, ссылка на которую размещена в социальной сети. Open Graph поддерживают социальные сети вроде Вконтакте, Одноклассники, Google+, Twitter и LinkedIn.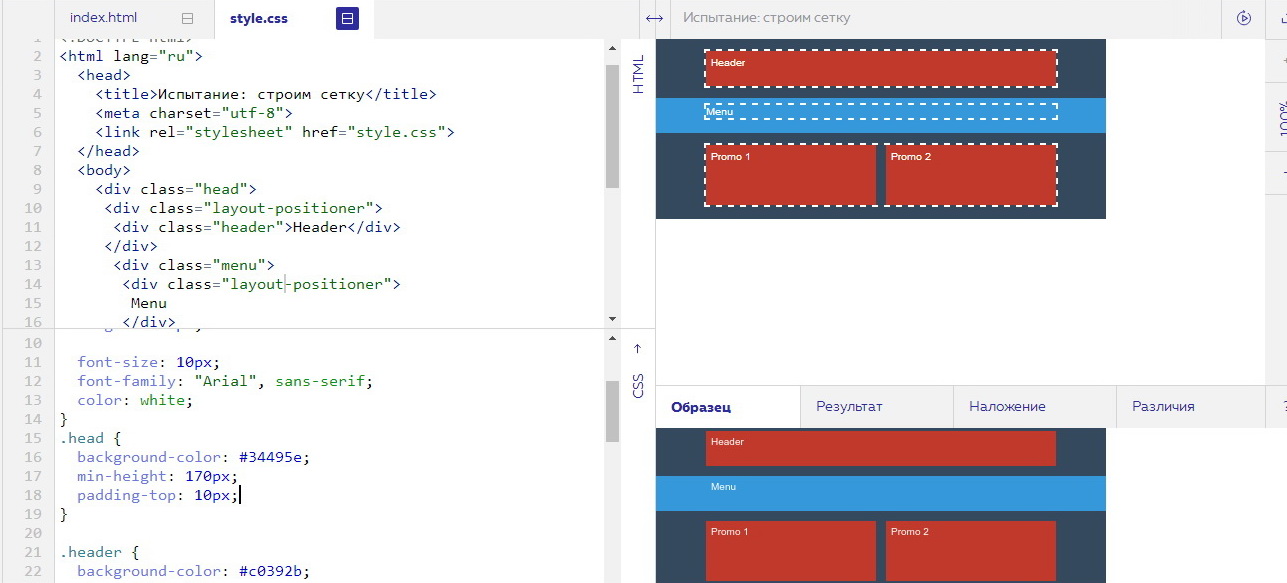 Как основную используют Facebook и Pinterest.
Как основную используют Facebook и Pinterest.
Стандартный сниппет выглядит так:
<meta property="og:url" content="[ссылка]"> <meta property="og:type" content="article"> <meta property="og:title" content="[заголовок]"> <meta property="og:description" content="[описание]"> <meta property="og:image" content="[ссылка на изображение]"> <meta property="article:author" content="[ссылка на аккаунт Facebook"> <meta property="og:site_name" content="[название сайта]"> <meta property="article:published_time" content="2014-08-12T00:01:56+00:00">
Facebook поддерживает дополнительные метатеги для изображений и видео.
Для Pinterest в article:author указывается имя автора или название сайта, но это противоречит требованиям Open Graph на Facebook. Для программистов создано интересное решение. В противном случае используйте более выгодный вариант или разметку Schema вместе с Open Graph.
Чтобы запретить пользователям пинить свой контент, используйте следующий код:
<meta name="pinterest" content="nopin" description="[нет!]">
Стандартные метатеги (Twitter)
Twitter поддерживает некоторые элементы Open Graph, но в основном использует стандартные метатеги для определения расшаренного контента. Проверить описание, или карту, как называет его Twitter, можно с помощью валидатора карт.
Вот пример описания:
<meta name="twitter:card" content="описание"> <meta name="twitter:site" content="[@websitetwitter]"> <meta name="twitter:creator" content="[@yourtwitter]"> <meta property="og:url" content="[ссылка]"> <meta property="og:title" content="[заголовок]"> <meta property="og:description" content="[описание]"> <meta property="og:image" content="[ссылка на изображение]">Примечание
twitter:site — ссылка на аккаунт сайта в Twitter, twitter:creator — ссылка на аккаунт автора.
Schema (Google+ и Pinterest)
Разметка Schema — продукт совместной работы крупнейших поисковых систем, преимущественно используемый в Google+. В Pinterest Schema поддерживается как альтернатива Open Graph, но не в полной мере: рекомендуется использовать обе. Разметка Schema громоздкая и менее привлекательная, чем Open Graph, но её словарь описания связанного контента богаче.
Вот сниппет для Google+:
<meta itemscope itemtype="http://schema.org/Article"> <meta itemprop="headline" content="[заголовок]"> <meta itemprop="description" content="[описание]"> <meta itemprop="image" content="[ссылка на изображение]">
Google+ использует Open Graph как резервную разметку, у Pinterest используются дополнительные метатеги Schema, поэтому разумно использовать все три описанные разметки.
Разные полезности
Передача реферальных данных
<meta name="referrer" content="unsafe-url">
При использовании HTTPS реферальные данные по умолчанию не передаются. Это улучшает защиту сайта, но мешает собирать веб-аналитику. С помощью метатега
Это улучшает защиту сайта, но мешает собирать веб-аналитику. С помощью метатега referrer определяется политика передачи реферальных данных. Атрибут content принимает различные значения. unsafe-url, например, указывает, что передаётся полная ссылка на страницу.
Исключение дублированного контента
<link rel="canonical" href="https://example.com/2010/06/9-things-to-do.html">
Если при анализе сайта Google находит две версии одной страницы, каждая из которых имеет свой URL-адрес, будет применён штраф за дублирование контента (duplicate content). Используя canonical, вы говорите поисковикам: «Эй, это наше художественное видение!». Таким образом, штрафных мер не будет.
<link rel="amphtml" href="https://example.com/path/to/amp-version.html">
Ссылка на AMP-версию страницы.
<link rel="alternate" href="https://es.example.com/" hreflang="es">
Ссылка на версию веб-страницы, которая переведена на другой язык. Язык текущей страницы указывается следующим образом:
Язык текущей страницы указывается следующим образом:
<html lang="es">
RSS
<link rel="alternate" href="https://feeds.feedburner.com/example" type="application/rss+xml" title="RSS">
С помощью alternate также указывается RSS-версия страницы.
<link rel="alternate" href="https://example.com/feed.atom" type="application/atom+xml" title="Atom 0.3">
Аналогично на примере канала Atom.
Favicon
<link rel="icon" href="favicon-16.png" type="image/png"> <link rel="icon" href="favicon-32.png" type="image/png"> <link rel="icon" href="favicon-48.png" type="image/png"> <link rel="icon" href="favicon-62.png" type="image/png"> <link rel="icon" href="favicon-192.png" type="image/png">
Ссылки на иконки веб-страницы в нескольких размерах. Проверить правильность описания иконок сайта или сгенерировать новое на основе готового изображения можно на специальных сайтах, таких как realfavicongenerator. net. Обратите внимание, что некоторые новые браузеры требуют иной способ указания этой опции. Например:
net. Обратите внимание, что некоторые новые браузеры требуют иной способ указания этой опции. Например:
Apple Touch
<link rel="apple-touch-icon" href="older-iPhone.png"> // 120px <link rel="apple-touch-icon" href="iPhone-6-Plus.png"> <link rel="apple-touch-icon" href="iPad-Retina.png"> <link rel="apple-touch-icon" href="iPad-Pro.png">
Windows Metro
<?xml version="1.0" encoding="utf-8"?>
<browserconfig>
<msapplication>
<tile>
<square70x70logo src="https://cdn.yourwebsite.com/mstile-70x70.png"/>
<square150x150logo src="https://cdn.yourwebsite.com/mstile-270x270.png"/>
<square310x310logo src="https://cdn.yourwebsite.com/mstile-310x310.png"/>
<wide310x150logo src="https://cdn.yourwebsite.com/mstile-310x150.png"/>
<TileColor>#2b5797</TileColor>
</tile>
</msapplication>
</browserconfig> Код для Metro, в отличие от предыдущих случаев, требуется сохранить в файл browserconfig. в корне сайта. xml
xml
Предварительная загрузка
Применение метатега link с опцией предварительной загрузки (dns-prefetch, prefetch, preconnect, subresource, prerender и preload) поможет увеличить скорость работы веб-сайта. Они дают знать браузеру, какие ресурсы понадобятся пользователю в будущем, чтобы подготовиться к загрузке в фоновом режиме.
<link rel="dns-prefetch" href="//example.com">
Браузер определяет в фоновом режиме IP-адрес указанного домена и, когда потребуется запросить что-либо с ресурса на этом домене, сэкономит время на выполнении DNS lookup.
<link rel="preconnect" href="https://www.example.com/">
Похож на dns-prefetch, но, кроме запроса DNS, браузер предварительно устанавливает TCP и TLS соединение.
<link rel="prefetch" href="https://www.example.com/image.png">
Указывает браузеру ресурс, который требуется сохранить в кэш. Однако загрузка выполняется с низким приоритетом и может быть проигнорирована. Это зависит от обстоятельств. Например, от качества сетевого соединения или для Firefox наличия достаточного для загрузки времени простоя браузера.
Однако загрузка выполняется с низким приоритетом и может быть проигнорирована. Это зависит от обстоятельств. Например, от качества сетевого соединения или для Firefox наличия достаточного для загрузки времени простоя браузера.
<link rel="subresource" href="styles.css">
Делает то же, что и prefetch, но приоритет у операции высокий. Если ресурс понадобится на текущей странице или в ближайшее время, то разумно использовать subresource. В остальных случаях лучше, конечно, применить prefetch.
<link rel="prerender" href="https://example.com/">
Браузер загружает указанную страницу, строит DOM, применяет CSS и выполняет JavaScript. Как если бы мы открыли её в скрытой вкладке. Но при использовании требуется уверенность, что указанная страница будет загружена, иначе перечисленные операции будут выполнены зря.
<link rel="preload" href="image.png">
По сути, это аналог prefetch, но с гарантированной загрузкой. Уже описан в спецификации, но поддерживается пока не всеми браузерами. На момент публикации этой статьи есть поддержка в Firefox, Chrome, Safari, Opera и Android Browser. Проверить актуальность информации можно на сайте caniuse.com.
Уже описан в спецификации, но поддерживается пока не всеми браузерами. На момент публикации этой статьи есть поддержка в Firefox, Chrome, Safari, Opera и Android Browser. Проверить актуальность информации можно на сайте caniuse.com.
Разные бесполезности
Давайте поговорим начистоту. Ничего страшного не случится, если использовать устаревшие метатеги, но они занимают место в разметке, и их никто не обрабатывает. Долой лишнее из раздела <head>!
Примеры таких метатегов:
Author/web author— определяет имя автора страницы. Указывать бессмысленно, так как не используется.Revisit after— указывает поисковым роботам время, через которое требуется зайти на страницу снова. Поисковые системы вроде «Яндекс» и Google не учитывают этот параметр.Rating— обозначает возрастную категорию контента. Чтобы пометить страницу, на которой размещены изображения для взрослых, требуется пройти запутанную процедуру. Проще отметить «плохие» изображения, разместить в отдельной директории на сайте и сообщить об этом поисковым системам.
Проще отметить «плохие» изображения, разместить в отдельной директории на сайте и сообщить об этом поисковым системам.Expiration/date— указывает дату создания и срок актуальности страницы. Если страницы уже не нужны, просто удалите. Дату создания же лучше указать в XML sitemap.Copyright— описывает авторские права. Посмотрите на нижний колонтитул сайта. Наверняка там размещена фраза вроде Copyright 20xx. Не стоит дублировать описание ещё в теги.Abstract— содержит аннотацию к содержанию страницы и чаще используется на образовательных ресурсах.Distribution— описывает права доступа к странице. Как правило, содержит значениеglobal. Изначально задумывалось, что если страница открыта (не защищена паролем), то предназначена для всего мира. Смиритесь и уберите со страницы.Generator— указывает, с помощью какой программы создана страница. Как иauthor, это бесполезно.Cache control— указывает, когда и как часто страница кэшируется в браузере. Лучше это определить в заголовке HTTP.Resource type— указывает тип ресурса страницы, например, document. Не тратьте на это время, так как это работа DTD.
 Проще отметить «плохие» изображения, разместить в отдельной директории на сайте и сообщить об этом поисковым системам.
Проще отметить «плохие» изображения, разместить в отдельной директории на сайте и сообщить об этом поисковым системам.
Эта шпаргалка поможет понять, что происходит в мире метатегов. Если считаете, что нужно что-то добавить или удалить — пишите в комментарии.
При подготовке использовались материалы:
«Which Meta Tags Should You Be Using in 2017?»,
«The Wonderful World of SEO Meta Tags»,
«How to Boost Social Media Engagement with Meta Tags».
Автор иллюстрации с буханкой — Boryaspec.
Зачем запрещать индексацию страниц благодарности в поисковиках?
Источник изображения
Индексация страниц сайта в поисковиках – основа SEO. Чем больше страниц проиндексировано, тем больше релевантного трафика, все верно; тем не менее существуют страницы, которые нежелательно показывать пользователям, не прошедшим воронку конверсии на вашем ресурсе или на автономных целевых страницах.
Как следует из заголовка поста, речь сегодня пойдет о запрете индексации страниц благодарности или Tnank You Pages.
- 11 способов увеличения ROI с помощью страницы благодарности (Thank You Page)
- Новые возможности создания страниц благодарности от LPgenerator
Итак, предположим, вы направляете посетителя на посадочную страницу в воронку конверсии, в качестве «добавочной приманки» обещая ему некий дополнительный приз, ожидающий его на странице благодарности после завершения процесса конвертации – «получите в подарок книгу в формате PDF!». Однако, оставляя страницу Tnank You Page в SERP (ранжирование результатов поиска), вы увеличиваете вероятность перехода пользователя на страницу благодарности «через черный ход».
Мы, как маркетологи, хотим избегать таких вот случайных «попаданий в цель» по двум причинам:
-
Пользователь, не став лидом, получает доступ к закрытой или, скажем так, более «привилегированной» информации.
- Такие действия «портят» чистую статистику.

Эти страницы благодарности вполне могут занимать верхние позиции рейтинга по низкочастотным запросам и генерировать какой-либо трафик. В любом случае, мы рекомендуем закрыть автономные лендинги и страницы вашего ресурса от индексации.
Как запретить индексацию Tnank You Page, пользуясь редактором LPgenerator
Выберите инструмент «Мета-теги» в основном меню редактора:
Для запрета индексации страницы поставьте галочки в соответствующие чек-боксы «Robots noindex» и «Robots nofollow»:
Как запретить индексацию страниц своего сайта
Существуют также 2 способа запрета индексации страниц «вручную».
Вариант 1: через файл robots.txt
Первый способ заключается в добавлении файла robots.txt на ваш сайт. Преимуществом данного метода является возможность получить максимальный уровень контроля над тем, что вы позволяете (или не позволяете) индексировать поисковым ботам. В файле robots.txt вы можете указать, хотите ли вы блокировать ботам доступ к одной отдельной странице, целому каталогу сайта или же к одному-единственному изображению или файлу. О тонкостях создания и настройки файла robots.txt можно узнать здесь.
В файле robots.txt вы можете указать, хотите ли вы блокировать ботам доступ к одной отдельной странице, целому каталогу сайта или же к одному-единственному изображению или файлу. О тонкостях создания и настройки файла robots.txt можно узнать здесь.
Вариант 2: через метатег «noindex»
Использование метатега noindex – самый простой и эффективный способ удаления страницы из результатов поиска (SERP). При использовании на вашем сайте той или иной системы управления контентом (CMS), от вас потребуется лишь минимальное владение «искусством копипасты» (copy/paste). Итак, вот как это делается.
Для начала скопируйте этот тег:
<META NAME=»robots» content=»noindex»>
Затем вставьте его в начало новой строки в разделе <head> HTML-верстки вашей страницы (этот раздел называется header, хедер). На скриншотах ниже представлено, как это выглядит на практике.
Вот здесь начинается хедер:
Вот метатег noindex в хедере:
А здесь хедер заканчивается:
Вот и все! Теперь метатег «прикажет» поисковым роботам «развернуться и уйти», удалив тем самым страницу из результатов поиска.
Нужно только помнить вот о чем: результат запрета индексирования проявится не мгновенно. Изменения станут заметны только тогда, когда поисковые машины в очередной раз проиндексируют ваш сайт.
- Целевые страницы и SEO
- Поисковая оптимизация и целевые страницы (продолжение)
- Активный контент-маркетинг – приоритет маркетологов в 2013 году
- Если контент – король, то многоканальность – королева! – подтверждает новое исследование Google
- Что любит Google на завтрак, обед и ужин?
Высоких вам конверсий!
12-04-2013
Понравилась статья? Поделитесь впечатлениями или расскажите о вашем опыте.
Комментироватьhtml — В чем разница между «индексировать, следовать» или «следовать»
спросил
Изменено 6 месяцев назад
Просмотрено 18 тысяч раз
чем отличаются списки ниже:
- html
- SEO
- без индекса
Во-первых, знаете ли вы о тегах Meta Robots?
Теги Meta Robots сообщают пауку или поисковому роботу, какую страницу сканировать или индексировать, а какую нет.
Следовать означает : страница будет просканирована.
No Follow означает : страница не будет просканирована.
Индекс означает : ваша страница показывается в результатах поиска.
Без индекса означает : ваша страница не отображается в результатах поиска.
Этот тег сообщает поисковому роботу, что все страницы будут проиндексированы, и сканировать их.
Этот тег используется, чтобы сообщить поисковому роботу, что все страницы будут просканированы и проиндексированы.
Этот тег используется для того, чтобы указать сканеру отслеживать, но не индексировать страницу в вашей базе данных.
Сообщить веб-сканеру, что страницы не сканируются, а индексируются.
To указывает веб-сканеру не индексировать и не сканировать.
Паук проиндексирует весь ваш сайт. Паук будет индексировать не только первую веб-страницу вашего веб-сайта, но и все остальные ваши веб-страницы, когда он просматривает ссылки с этой страницы.
Сообщает поисковым системам, что они могут переходить по ссылкам на странице для обнаружения других страниц. (оба действия по умолчанию)
Паук теперь будет индексировать весь ваш сайт. Паук не будет индексировать веб-страницу, но он может перейти по ссылкам на странице, чтобы обнаружить другие страницы.
Паук проиндексирует эту страницу, но не будет переходить по ссылкам на этой странице на новые страницы.
Паук вообще не будет индексировать эту страницу и не будет переходить по ссылкам на этой странице на какие-либо другие страницы.
Источники :
https://www.metatags.org/meta_name_robots
https://yoast.com/robots-meta-tags/
https://developer.mozilla.org/en-US/docs/Web/HTML/Element/meta#attr-name
Основное различие между этими тегами, если говорить очень простыми словами:
noindex Страница не должна отображаться в списке результатов таких страниц, как google, yahoo и так далее. индекс означает обратное и допускает это.
nofollow Запрещает сканерам/роботам вызывать (переходить) ссылки, которые встроены в/найдены на страницах, имеющих этот флаг в своих метаданных. следовать означает обратное и разрешает это.
Теперь вы можете сами понять, к чему приводит каждая комбинация обоих. 😉
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаОбязательно, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
поисковых роботов. В чем разница в порядке «следить» и «индексировать» в метатеге robots?
спросил
Изменено 2 года, 3 месяца назад
Просмотрено 100 раз
В чем разница между
ии
Будет ли создаваться проблема для индексации или сканирования?
- поисковые роботы
- поисковая индексация
- метатеги
- метароботы
Нет никакой разницы между подписка, индекс и индекс , следуйте . Оба они позволили бы роботам до индекс содержание и следуйте ссылкам *1 . Однако это действие по умолчанию для всех ботов, поэтому элемент совершенно лишний.
Однако это действие по умолчанию для всех ботов, поэтому элемент совершенно лишний.
( *1 Но не потому, что он содержит ключевые слова индекс и следуют за , а потому что не содержит ключевые слова noindex и/или no следуйте .)
На самом деле, Google просто проигнорирует этот элемент, так как индекс и следуют за , не являются одним из перечисленных значений, которые он поддерживает (и не упоминает эти значения в своем справочном документе). Bingbot упоминает, что вы можете использовать эти значения, но снова заявляет, что это действие по умолчанию, поэтому они излишни. Google упоминает значение all (чтобы указать «нет ограничений для индексации или обслуживания»), если вы хотите явно поместить что-то в тег, однако он также заявляет, что это «значение по умолчанию и не имеет никакого эффекта», так что опять же совершенно лишнее.
Однако, если вы также обслуживаете HTTP-заголовок X-Robots-Tag , это переопределит метатег robots в документе HTML.