
Индексация, наукометрия — Университет Лобачевского
Данные становятся информацией, если есть основания считать их достоверными. Абсолютное большинство открытых материалов Интернет (как и многие книги) не проходят независимой экспертизы. Оценка достоверности содержащихся в них данных – проблема пользователя.
Применительно к научным публикациям оценка достоверности (независимая экспертиза) осуществляется в форме рецензирования (single blind или double blind) на стадии приёмки статьи. Её уровень (симулятивный, формальный, содержательный, профессиональный, жёсткий), главным образом, и определяет научный авторитет журнала. Формализованным измерителем авторитета журнала является цитирование опубликованных в нём статей. Корректный учёт цитирований статьи (научного документа) предполагает наличие представительной по отношению ко всему множеству научных документов базы, которая содержит, как минимум, библиографические данные этих документов (индексирует их).
Наукометрия – это, в сущности, система показателей, построенная на сопоставлении библиографических данных: количества публикаций и их цитирований. Такие формализованные показатели, разумеется, не являются исчерпывающими, но в современной массовой и коммерциализованной науке их важность общепризнана.
Индексация научных документов, БАЗЫ, наукометрия
|
Научные библиографические базы индексируют некоторое множество источников (оно может быть замкнутым, как в Web of Science Core Collection и Scopus, или открытым, как Google Scolar и РИНЦ). Авторитет таких баз определяется и поддерживается качеством индексируемых ими документов (контента базы). Библиографичеcкие базы не включают полных текстов документов (поэтому не связаны проблемами copyright), а содержат лишь их метаданные (библиографическую запись).  |
| Вопрос о значимости того или иного показателя (и, соответственно, той или иной базы) при решении конкретных вопросов относится к сфере административной, а не наукометрической.
Поскольку любая система, будучи формализована алгоритмически (с открытым кодом), в естественных условиях замусоривается и допускает манипуляции (термин predator journals прочно вошёл в мировую практику), необходимы дополнительные меры по отбору источников и их фильтрации (экспертные или алгоритмы с закрытым кодом) для поддержания качества контента. Такие меры применяются в авторитетных библиографических базах при индексации источников (журналов и книг). |
|
РИНЦ (общедоступна) – российская библиографическая база, созданная с целью максимально ПОЛНО отразить все публикации РОССИЙСКИХ УЧЁНЫХ. 1) весь контент eLibrary, 2) контент РИНЦ (где сохранены все издания, претендующие на научность), 3) ядро РИНЦ. Ядро РИНЦ – на данный момент более 700 российских журналов, первоначально отобранных в 2015 году в результате вполне разумной, хотя и небесспорной (смешанной формализованно-экспертной) процедуры. Причём сделано это с возможностью исключения/дополнения журналов по результатам мониторинга. Все наукометрические показатели вычисляются отдельно по ядру РИНЦ. Авторитет базы (по определению – только внутри страны) и рассчитываемых по ней показателей может выявить лишь время и российская административная практика. В качестве иллюстрации можно привести примеры, когда авторский индекс Хирша по РИНЦ равен 31, а по ядру РИНЦ – единице, импакт-фактор журнала по РИНЦ равен 0,879, а по ядру РИНЦ — 0,050. Отметим, что бедность статистики цитирований по сравнительно небольшой (даже качественной по контенту базе) – одна из угроз для представительности (востребованности) этой базы. Косвенно авторитет базы повышает то, что на её основе формируется отражаемая на портале Web of Science база RSCI (см. |
|
Авторитетные библиографические базы призваны ответить на три группы вопросов:
В силу международного характера науки для корректного ответа на эти вопросы авторитетная база должна быть полидисциплинарной по содержанию и мировой по охвату. Современная авторитетная база (а это коммерческое предприятие) формируется на основе компромиссного разрешения противоречия между качественным отбором источников и объёмом контента базы. Пренебрежение первым ведёт к потере авторитета, сужение контента ведёт к уменьшению востребованности. Авторитетность базы не гарантирует отсутствия в ней мусора, шума (или ложной информации). Последнее возможно на уровне отдельных статей (например, отзыв статей, в том числе, из весьма престижных журналов происходит как по инициативе издателей, так и авторов). Но именно в виде исключений, так как качество журналов является в такой базе предметом мониторинга (формализованного и экспертного). |
|
Web of Science Core Collection (доступна в ННГУ), отображаемая на портале Web of Science – исторически первая (идущая от «отца» наукометрии Ю. Гарфилда) авторитетная мировая библиографическая база, обладающая наиболее глубоким архивом и изначально проводившая НАИБОЛЕЕ ЖЁСТКИЙ качественный отбор источников (разумеется, не бесспорный). Она индексирует научные журналы, выходящие во всех странах мира и по всем областям знания. Журналы, не имеющие англоязычных версий (в частности, российские гуманитарные), представлены слабо. |
|
При оценке глубины архива базы следует различать собственный и доступный конкретному пользователю архивы. Глубина собственного архива по указанным выше журнальным подбазам – 1970 г. и 1975 г., по конференциям – 1990 г., по книгам – 2005 г. Глубина же доступного архива определяется условиями подписки. Ясно, что вычисленные на основе собственного и доступного архивов интегральные наукометрические показатели, например, индекса Хирша, могут существенно различаться. |
|
Наукометрический инструментарий, относящийся к журналам, выделен на портале Web of Science в отдельный сервис – Journal Citation Reports (недоступен в ННГУ), из которого в базу Web of Science Core Collection по результатам запроса конкретной статьи подгружаются лишь двух- и пятилетние импакт-факторы и квартиль журнала с данной статьёй. Journal Citation Reports – единственная мировая база импакт-факторов  Контент, для которого в Journal Citation Reports рассчитываются наукометрические показатели, также расширяется: число журналов, имеющих импакт-факторы, увеличилось в 2017-2018 гг. с 11300 до 13500. Контент, для которого в Journal Citation Reports рассчитываются наукометрические показатели, также расширяется: число журналов, имеющих импакт-факторы, увеличилось в 2017-2018 гг. с 11300 до 13500.
|
|
При этом из входящих в Web of Science Core Collection 7 подбаз:
— импакт-факторы вычисляются только для журналов, индексируемых в первых двух подбазах (соответственно, только у этих журналов в JCR есть определённый квартиль). Поисковый инструментарий в базе Web of Science Core Collection – более мощный, чем для других интегрированных на портале Web of Science региональных и национальных баз, среди которых:
Импакт-факторы для входящих в эти базы журналов в Journal Citation Reports не вычисляются, как и для 5 из 7 подбаз в Core Collection. |
|
SCOPUS (доступна в ННГУ) – более молодая авторитетная мировая библиографическая база, индексирующая НАИБОЛЬШЕЕ ЧИСЛО источников. Здесь индексируются научные журналы, выходящие во всех странах мира и по всем областям знания, книги, труды международных конференций. |
|
Scimago Journal & Country Rank (общедоступна) – рейтинговая база журналов (и стран), в которой сходный с импакт-фактором показатель (SJR) рассчитывается на контенте SCOPUS по алгоритму взвешенного цитирования. В соответствии с величиной SJR и предметной областью определяется квартиль журнала. |
|
MEDLINE (доступна в ННГУ) – библиографическая база Национальной медицинской библиотеки США. Отражается на портале Web of Science. Индексирует около 5000 научных журналов из всех стран мира (а также книги) по медицине, живым системам, биофизике и биохимии. Chinese Science Citation Database (CSCD) (недоступна в ННГУ) – первая не англоязычная база, интегрированная на портале Web of Science. Формируется Академией наук КНР и индексирует более 1200 национальных научных журналов по всем отраслям знания с 1989 года. |
|
|
Russian Science Citation Index (RSCI) (доступна в ННГУ) – близкая по контенту к ядру РИНЦ национальная библиографическая база, интегрированная на портале Web of Science с 2015 года (RSCI-2015) и индексирующая входящие в неё журналы с 2005 года.. Библиографические записи даются в двуязычном виде. Поисковые запросы, вводимые прямым набором, могут делаться как в англоязычном, так и в русскоязычном виде. По версии RSCI-2015 в базу входило 653 журнала, отобранных в результате упомянутой выше процедуры для ядра РИНЦ. Обновлённая (после исключения/добавления журналов) версия RSCI-2018 включает 743 журнала (с англоязычными названиями). Русскоязычный список журналов RSCI можно посмотреть здесь. |

 Поэтому (при соблюдении чисто формальных требований при загрузке) входной отбор источников и их фильтрация не проводится. Индексируются более 2600 текущих российских журналов, книги, сборники, труды конференций любого уровня. Данные по публикациям российских учёных в зарубежных журналах экспортируются из Scopus. Наукометрический инструментарий базы по разнообразию выводимых показателей является, пожалуй, беспрецедентным, поскольку строится параллельно на трёх подмножествах
Поэтому (при соблюдении чисто формальных требований при загрузке) входной отбор источников и их фильтрация не проводится. Индексируются более 2600 текущих российских журналов, книги, сборники, труды конференций любого уровня. Данные по публикациям российских учёных в зарубежных журналах экспортируются из Scopus. Наукометрический инструментарий базы по разнообразию выводимых показателей является, пожалуй, беспрецедентным, поскольку строится параллельно на трёх подмножествах
 ниже).
ниже).



 Неплохо представлены журналы, не имеющие англоязычных версий (в частности, российские). В отличие от Web of Science Core Collection собственный архив при наличии подписки доступен целиком и не делится на подбазы, но его глубина меньше и он довольно «неровный» – сейчас с почти полным охватом по индексируемым журналам это примерно 1980 г. (по значительному числу источников – 1960 г., по единичным – середина XIX в.). Тем не менее имеются отдельные журналы, для которых глубина архива – лишь 1996 г. Вследствие автоматизированной процедуры загрузки данных в базу архивные записи для «старых» статей далеко не всегда полные: в некоторых присутствуют лишь название журнала и статьи с фамилиями авторов. Поэтому поисковый запрос будет выводить на эти статьи лишь по указанным атрибутам. В процессе формирования контента в базу попало некоторое количество мусорных источников (predator journals), которые в последние годы фильтруются (индексация их в Scopus прекращается). Наукометрический инструментарий применительно к журналам представлен показателем прямого цитирования (CiteScore), по алгоритму близкого к импакт-фактору, взвешенного цитирования (SJR) и контент-обусловленного цитирования (SNIP), а также процентилем журнала (по данным SJR).
Неплохо представлены журналы, не имеющие англоязычных версий (в частности, российские). В отличие от Web of Science Core Collection собственный архив при наличии подписки доступен целиком и не делится на подбазы, но его глубина меньше и он довольно «неровный» – сейчас с почти полным охватом по индексируемым журналам это примерно 1980 г. (по значительному числу источников – 1960 г., по единичным – середина XIX в.). Тем не менее имеются отдельные журналы, для которых глубина архива – лишь 1996 г. Вследствие автоматизированной процедуры загрузки данных в базу архивные записи для «старых» статей далеко не всегда полные: в некоторых присутствуют лишь название журнала и статьи с фамилиями авторов. Поэтому поисковый запрос будет выводить на эти статьи лишь по указанным атрибутам. В процессе формирования контента в базу попало некоторое количество мусорных источников (predator journals), которые в последние годы фильтруются (индексация их в Scopus прекращается). Наукометрический инструментарий применительно к журналам представлен показателем прямого цитирования (CiteScore), по алгоритму близкого к импакт-фактору, взвешенного цитирования (SJR) и контент-обусловленного цитирования (SNIP), а также процентилем журнала (по данным SJR). Эти показатели вычисляются для ВСЕХ журналов, включённых в базу, и ежемесячно пересчитываются на меняющемся (загруженном) контенте. Из-за естественного запаздывания загрузки, показатели последних двух лет сравнивать некорректно (особенно в начале года): например, для журнала Chemical Reviews отражаемый базой в феврале 2018 года CiteScore 2016 равен 42,79, тогда как CiteScore 2017 того же журнала показывается равным лишь 15,38 (заметим, что в Journal Citation Reports все выводимые наукометрические показатели разных лет сопоставимы, так как рассчитываются один раз в год).
Эти показатели вычисляются для ВСЕХ журналов, включённых в базу, и ежемесячно пересчитываются на меняющемся (загруженном) контенте. Из-за естественного запаздывания загрузки, показатели последних двух лет сравнивать некорректно (особенно в начале года): например, для журнала Chemical Reviews отражаемый базой в феврале 2018 года CiteScore 2016 равен 42,79, тогда как CiteScore 2017 того же журнала показывается равным лишь 15,38 (заметим, что в Journal Citation Reports все выводимые наукометрические показатели разных лет сопоставимы, так как рассчитываются один раз в год).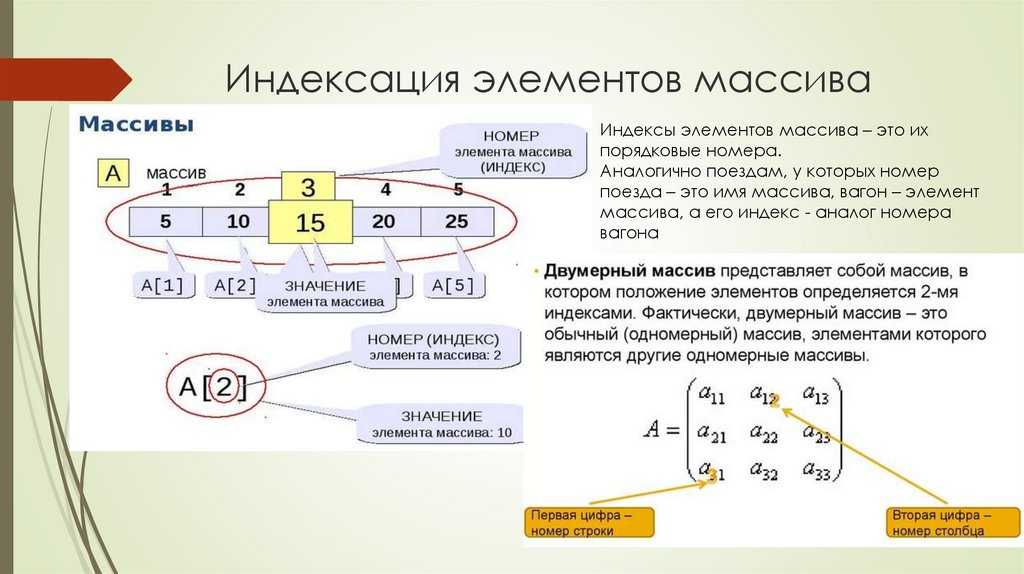 Естественно, квартили многих журналов отличаются от определяемых Journal Citation Reports (иной контент, иное разбиение на предметные области, иной алгоритм учёта цитирований). Показатель SJR экспортируется и отображается в базе SCOPUS.
Естественно, квартили многих журналов отличаются от определяемых Journal Citation Reports (иной контент, иное разбиение на предметные области, иной алгоритм учёта цитирований). Показатель SJR экспортируется и отображается в базе SCOPUS.
 Предполагается включение в базу журналов из Украины, Беларуси, Молдовы, Казахстана и Армении, в результате чего база из национальной превратится в региональную.
Предполагается включение в базу журналов из Украины, Беларуси, Молдовы, Казахстана и Армении, в результате чего база из национальной превратится в региональную.Нашли ошибку в тексте?
Выделите ее и нажмите Ctrl + Enter
Индексация зарплаты
Индексация заработной платы — это механизм ее повышения, дающий возможность частично или полностью возместить подорожание потребительских товаров и услуг (Закон Украины «Об индексации денежных доходов населения» от 03.07.1991 № 1282).
Порядок проведения индексации денежных доходов населения утвержден постановлением КМУ от 17.07.2003 № 1078.
Расчет самой индексации, поскольку она призвана защитить доходы населения от инфляции, основывается на индексе потребительских цен (индексе инфляции), ежемесячно публикуемом Держстатом Украины.
Напомним вкратце основные принципы индексации зарплаты.
Для индексации заработной платы необходимо определить два показателя: базовый месяц и коэффициент индексации.
- Базовый месяц — это месяц последнего повышения окладов.
- Коэффициент индексации вычисляется на основе ежемесячных индексов инфляции.
Расчет ведется нарастающим итогом путем перемножения индексов инфляции (деленных на 100), начиная с месяца, следующего за базовым — до превышения порога индексации
с января 2016 порог индексации равен 1,03 (или 103%), до этого он составлял 1,01 (или 101%)
Полученный коэффициент индексации умножается на размер зарплаты в пределах прожиточного минимума для трудоспособных граждан (т.е., фактически на размер прожиточного минимума). Если же заработная плата меньше прожиточного минимума, коэффициент следует умножать на величину зарплаты.
Начисление индексации осуществляется с первого числа месяца, следующего за месяцем, в котором Держстатом опубликован индекс инфляции.
Необходимо учесть, что в текущем месяце публикуется индекс инфляции за предыдущий месяц.
Например: в марте публикуется индекс за февраль и, если порог индексации превышен по итогам февраля, то индексироваться с учетом полученного индекса будет заработная плата за апрель.
Для проведения последующей индексации (т.е., для расчета индексированной зарплаты на очередные месяцы) расчет коэффициента индексации продолжается со следующего месяца за тем, в котором был превышен порог индексации. Не будем вдаваться в дальнейшие подробности расчета, поскольку результат можно быстро получить с помощью нашего калькулятора:
Калькулятор индексации зарплаты| Базовый месяц | январьфевральмартапрельмайиюньиюльавгустсентябрьоктябрьноябрьдекабрь | |
| Размер зарплаты | грн. | |
| Месяц индексации | январьфевральмартапрельмайиюньиюльавгустсентябрьоктябрьноябрьдекабрь | |
- См. также:
- Средняя заработная плата в Украине
- Средняя заработная плата в различных странах мира
- Индекс реальной заработной платы
- Индексация зарплаты
- Минимальная заработная плата в Украине
- Единый социальный взнос (ЕСВ)
- Прожиточный минимум в Украине
- Индекс инфляции
Определение и использование в экономике и инвестировании
Что такое индексация?
Индексирование в широком смысле относится к использованию некоторого эталонного индикатора или меры в качестве эталона или эталона. В финансах и экономике индексация используется в качестве статистической меры для отслеживания экономических данных, таких как инфляция, безработица, рост валового внутреннего продукта (ВВП), производительность и рыночная доходность.
В финансах и экономике индексация используется в качестве статистической меры для отслеживания экономических данных, таких как инфляция, безработица, рост валового внутреннего продукта (ВВП), производительность и рыночная доходность.
Индексация может также относиться к пассивным инвестиционным стратегиям, которые воспроизводят эталонные индексы. Инвестирование в индексы становится все более популярным в последние десятилетия.
Ключевые выводы
- Индексация — это практика объединения экономических данных в единый показатель или сравнения данных с таким показателем.
- В финансах существует множество индексов, которые отражают экономическую активность или обобщают рыночную активность — они становятся контрольными показателями, по которым оцениваются портфели и управляющие фондами.
- Индексация также используется для обозначения пассивного инвестирования в рыночные индексы для воспроизведения широкой рыночной доходности, а не активного выбора отдельных акций.


Понимание индексации
Индексация используется на финансовом рынке как статистическая мера для отслеживания экономических данных. Индексы, созданные экономистами, являются одними из ведущих рыночных индикаторов экономических тенденций. Экономические индексы, за которыми внимательно следят на финансовых рынках, включают Индекс менеджеров по закупкам (PMI), Производственный индекс Института управления поставками (ISM) и Сводный индекс ведущих экономических индикаторов. Эти индексы отслеживаются для измерения изменений с течением времени.
Статистические индексы также могут использоваться в качестве меры для связывания значений. Корректировка стоимости жизни (COLA) — это статистическая мера, полученная путем анализа индекса потребительских цен (ИПЦ), который индексирует цены в зависимости от инфляции. Многие пенсионные планы и страховые полисы используют COLA и индекс потребительских цен в качестве меры для корректировки пенсионных выплат с корректировкой с использованием мер индексации на основе инфляции.
Индексация на финансовых рынках
Индекс — это метод стандартизированного отслеживания производительности группы активов. Индексы обычно измеряют эффективность корзины ценных бумаг, предназначенных для воспроизведения определенной области рынка. Это может быть широкомасштабный индекс, охватывающий весь рынок, например, индекс Standard & Poor’s 500 или промышленный индекс Доу-Джонса (DJIA). Индексы также могут быть более специализированными, например индексы, отслеживающие определенную отрасль или сегмент. Промышленный индекс Доу-Джонса — это взвешенный по цене индекс, что означает, что больший вес придается акциям в индексе с более высокой ценой. Индекс S&P 500 является взвешенным по рыночной капитализации индексом, что означает, что он придает больший вес акциям в индексе S&P 500 с более высокой рыночной капитализацией.
У поставщиков индексов есть множество методологий построения индексов инвестиционного рынка. Инвесторы и участники рынка используют эти индексы в качестве эталонов производительности. Например, если управляющий фондом в долгосрочной перспективе отстает от S&P 500, ему будет трудно привлечь инвесторов в фонд.
Например, если управляющий фондом в долгосрочной перспективе отстает от S&P 500, ему будет трудно привлечь инвесторов в фонд.
Также существуют индексы, которые отслеживают рынки облигаций, товаров и деривативов.
Индексирование и пассивное инвестирование
Индексация широко известна в инвестиционной индустрии как пассивная инвестиционная стратегия для получения целевого доступа к определенному сегменту рынка. Большинство активных инвестиционных менеджеров, как правило, не всегда превосходят контрольные показатели индексов. Кроме того, инвестирование в целевой сегмент рынка для прироста капитала или в качестве долгосрочного вложения может быть дорогостоящим, учитывая торговые издержки, связанные с покупкой отдельных ценных бумаг. Поэтому индексация является популярным вариантом для многих инвесторов.
Инвестор может достичь того же риска и доходности целевого индекса, инвестируя в индексный фонд. Большинство индексных фондов имеют низкие коэффициенты расходов и хорошо работают в пассивно управляемом портфеле. Индексные фонды могут быть созданы с использованием отдельных акций и облигаций для воспроизведения целевых индексов. Они также могут управляться как фонд фондов с взаимными фондами или биржевыми фондами в качестве их базовых активов.
Индексные фонды могут быть созданы с использованием отдельных акций и облигаций для воспроизведения целевых индексов. Они также могут управляться как фонд фондов с взаимными фондами или биржевыми фондами в качестве их базовых активов.
Поскольку при инвестировании в индексы используется пассивный подход, индексные фонды обычно имеют более низкие комиссии за управление и коэффициенты расходов (ER), чем активно управляемые фонды. Простота отслеживания рынка без портфельного менеджера позволяет провайдерам поддерживать скромные комиссии. Индексные фонды также имеют тенденцию быть более эффективными с точки зрения налогообложения, чем активные фонды, потому что они совершают менее частые сделки.
Фонды индексирования и отслеживания
Более сложные стратегии индексации могут быть направлены на то, чтобы воспроизвести активы и доходность настроенного индекса. Индивидуальные фонды отслеживания индексов превратились в недорогой вариант инвестирования в проверенное подмножество ценных бумаг. Эти фонды отслеживания, по сути, пытаются выбрать лучших из лучших в категории акций — например, лучшие энергетические компании в индексах, которые отслеживают энергетическую отрасль. Эти фонды отслеживания основаны на ряде фильтров, включая основные принципы, дивиденды, характеристики роста и многое другое.
Эти фонды отслеживания, по сути, пытаются выбрать лучших из лучших в категории акций — например, лучшие энергетические компании в индексах, которые отслеживают энергетическую отрасль. Эти фонды отслеживания основаны на ряде фильтров, включая основные принципы, дивиденды, характеристики роста и многое другое.
Как работает индексация | Учебное пособие от Chartio
Что делает индексация?
Индексация — это способ привести неупорядоченную таблицу в порядок, максимально повышающий эффективность запроса при поиске.
Когда таблица не проиндексирована, порядок строк, скорее всего, не будет различим для запроса как оптимизированного каким-либо образом, и поэтому вашему запросу придется искать строки линейно. Другими словами, запросы должны будут выполнять поиск по каждой строке, чтобы найти строки, соответствующие условиям. Как вы понимаете, это может занять много времени. Просмотр каждой строки не очень эффективен.
Например, в таблице ниже представлена таблица в вымышленном источнике данных, которая полностью неупорядочена.
| компания_id | блок | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 16 | 12 | 1,31 |
| 10 | 12 | 1,15 |
| 12 | 24 | 1,3 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1,36 |
| 12 | 12 | 1,05 |
| 20 | 6 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 14 | 24 | 1,05 |
Если бы мы выполнили следующий запрос:
SELECT Идентификатор компании, единицы измерения, себестоимость единицы продукции ОТ index_test ГДЕ идентификатор_компании = 18
База данных должна будет выполнить поиск по всем 17 строкам в порядке их появления в таблице, сверху вниз, по одной за раз. Таким образом, для поиска всех потенциальных экземпляров
Таким образом, для поиска всех потенциальных экземпляров company_id число 18, база данных должна просмотреть всю таблицу на наличие всех вхождений 18 в столбце company_id .
Это будет занимать все больше и больше времени по мере увеличения размера таблицы. По мере усложнения данных в конечном итоге может произойти следующее: таблица с одним миллиардом строк соединяется с другой таблицей с одним миллиардом строк; запрос теперь должен выполнять поиск в удвоенном количестве строк, что требует в два раза больше времени.
Вы можете видеть, как это становится проблематичным в нашем вечно насыщенном данными мире. Таблицы увеличиваются в размерах, а время выполнения поиска увеличивается.
Запрос к неиндексированной таблице, если он представлен визуально, будет выглядеть так:
Что делает индексация, так это настраивает столбец, в котором находятся условия поиска, в отсортированном порядке, чтобы помочь оптимизировать производительность запроса.
С индексом в столбце company_id таблица будет, по существу, «выглядеть» так:
| company_id | блок | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 10 | 12 | 1,15 |
| 11 | 24 | 1,15 |
| 11 | 24 | 1,15 |
| 12 | 12 | 1,05 |
| 12 | 24 | 1,3 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1,31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1,05 |
| 16 | 12 | 1,31 |
| 18 | 18 | 1,34 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 18 | 18 | 1,34 |
| 20 | 6 | 1,31 |
| 21 | 18 | 1,36 |
Теперь база данных может искать company_id номер 18 и возвращать все запрошенные столбцы для этой строки, а затем переходить к следующей строке. Если в следующей строке
Если в следующей строке comapny_id номер также равен 18, тогда он вернет все столбцы, запрошенные в запросе. Если в следующей строке company_id равен 20, запрос знает, что поиск нужно прекратить, и запрос завершится.
Как работает индексация?
На самом деле таблица базы данных не переупорядочивается каждый раз при изменении условий запроса для оптимизации производительности запроса: это было бы нереалистично. На самом деле происходит то, что индекс заставляет базу данных создавать структуру данных. Тип структуры данных, скорее всего, B-Tree. Несмотря на множество преимуществ B-дерева, основное преимущество для наших целей заключается в том, что его можно сортировать. Когда структура данных отсортирована по порядку, это делает наш поиск более эффективным по очевидным причинам, которые мы указали выше.
Когда индекс создает структуру данных для определенного столбца, важно отметить, что никакой другой столбец не сохраняется в структуре данных. Наша структура данных для приведенной выше таблицы будет содержать только номера
Наша структура данных для приведенной выше таблицы будет содержать только номера company_id . Units и unit_cost не будут храниться в структуре данных.
Откуда база данных узнает, какие еще поля в таблице нужно вернуть?
Индексы базы данных также будут хранить указатели, которые являются просто справочной информацией о расположении дополнительной информации в памяти. В основном индекс держит company_id и домашний адрес этой конкретной строки на диске памяти. На самом деле индекс будет выглядеть так:
| company_id | указатель |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
С помощью этого индекса запрос может искать только строки в столбце company_id , которые имеют 18, а затем с помощью указателя можно перейти в таблицу, чтобы найти конкретную строку, в которой находится этот указатель.