
Универсальный идентификатор ресурса — Uniform Resource Identifier
«URI» перенаправляется сюда. Для использования в других целях, см URI (значения) .Унифицированный идентификатор ресурса ( URI ) представляет собой строку из символов , однозначно идентифицирует конкретный ресурс . Для обеспечения единообразия , все идентификаторы URI следует заранее определенному набору правил синтаксиса, но и поддерживать расширяемость через отдельно определенную иерархическую схему именования (например , « http://» ).
Такая идентификация позволяет взаимодействие с представлениями ресурса по сети, как правило , в World Wide Web , с использованием специфических протоколов . Схемы с указанием конкретного синтаксиса и соответствующие протоколы определяют каждый URI. Наиболее распространенной формой URI является Uniform Resource Locator ( URL ), который часто называют неофициально в качестве веб — адреса . Более редко видели в использовании является унифицированным имя ресурса (URN), который был разработан , чтобы дополнить URL — адрес, обеспечивая механизм для идентификации ресурсов в конкретных пространствах имен .
URL-адрес и урны
Равномерное Имя ресурса (URN) является URI , который идентифицирует ресурс с помощью имени в определенном пространстве имен. Урне может быть использован , чтобы говорить о ресурсе , не подразумевая его местоположение или как получить к нему доступ. Например, в Международный стандартный номер книги (ISBN) системы, ISBN 0-486-27557-4 идентифицирует конкретный выпуск пьесы Шекспира Ромео и Джульетта . Урна для этого издания будет урна: ISBN: 0-486-27557-4 . Тем не менее, это не дает никакой информации о том, где найти копию этой книги.
Uniform Resource Locator (URL) является URI , который определяет средства воздействия на или получения представления ресурса, то есть с указанием как его механизм первичного доступа и сетевого расположения. Например, URL — адрес http://example.org/wiki/Main_Pageссылается на ресурс идентифицирован как
/wiki/Main_Pageчье представление, в виде HTML и связанный с кодом, может быть получено с помощью протокола передачи гипертекста ( HTTP: ) из сети хоста, доменное имя является example.org.Урну можно сравнить с именем человека, в то время как URL может быть по сравнению с их адрес. Другими словами, URN идентифицирует элемент, и URL-адрес предоставляет способ для нахождения его.
Технические издания, особенно стандарты , разрабатываемые в IETF и в W3C , как правило , отражают точку зрения , изложенные в Рекомендации W3C 2001 года, в котором признается приоритет термина URI , а не одобрять какое — либо формальное разделение на URL и URN.
| « | URL является полезным, но неофициальным понятием: URL является типом URI, который идентифицирует ресурс посредством представления основного механизма доступа (например, его сети «место»), а не каких-либо других признаками он может иметь. | » |
Как таковой, URL является просто URI , что происходит , чтобы указать на ресурс по сети. Однако, в нетехнических контекстах и в области программного обеспечения для World Wide Web, термин «URL» по- прежнему широко используется. Кроме того, термин «веб — адрес» (который не имеет никакого формального определения) часто встречается в нетехнических изданиях как синоним URI , который использует HTTP или HTTPS схему. Такие предположения могут привести к путанице, например, в случае пространств имен XML , которые имеют визуальное сходство с разрешимыми идентификаторами URI .
Характеристики , полученные в WHATWG предпочитают URL через URI , и поэтому новый API , HTML5 использовать URL через URI .
| « | Стандартизировать термин URL. URI и IRI [идентификатор ресурса интернационализированного] просто сбивает с толку. На практике единый алгоритм используется для обоих, так держать их отличие не помогает никому. URL также легко выигрывает конкурс популярности результатов поиска. | » |
В то время как большинство схем URI были первоначально предназначены для использования с конкретным протоколом , и часто имеет такое же имя, они семантический отличаются от протоколов. Например, схема HTTP обычно используется для взаимодействия с веб — ресурсов с использованием HTTP, но схема файла не имеет протокол.
Общий синтаксис
Определение
Каждый URI начинается с именем схемы , которая относится к спецификации для присвоения идентификаторов в пределах этой схемы. Таким образом , синтаксис URI является федеративной и расширяемой системой именования , в котором спецификация каждой схемы может дополнительно ограничивать синтаксис и семантику идентификаторов , использующих эту схему. Общий синтаксис URI является подмножеством синтаксиса всех схем URI. Впервые он был определен в запросе для комментариев (RFC) 2396, опубликованного в августе 1998 года и завершен в RFC 3986, опубликованный в январе 2005 года.
Общий синтаксис URI состоит из иерархической последовательности из пяти компонентов :
URI = scheme:[//authority]path[?query][#fragment]
где компонент власть делится на три подкомпонентов :
authority = [userinfo@]host[:port]
Это представлено в синтаксической диаграмме , как: 
URI включает в себя:
- Непустая схема компонентов с последующим двоеточием (
:), состоящий из последовательности символов , начинающихся с буквы и последующим любой комбинации букв, цифр, плюс (+), период (.) или дефис (-). Хотя схемы не чувствителен к регистру, каноническая форма в нижнем регистре и документы, определяющие схемы должны делать это с прописными буквами. Примеры популярных схем включаютhttp,https,ftp,mailto,file,data, иirc. Схемы URI должны быть зарегистрированы в Internet Assigned Numbers Authority (IANA) , хотя незарегистрированные схемы используются на практике. - Дополнительный орган компонент предшествует два косых черты (
//), включающими:- Необязательно UserInfo подкомпонент , который может состоять из имени пользователя и дополнительный пароль , которому предшествует двоеточие (
:), за которым следует символ в (@). Использование форматаusername:passwordв USERINFO подкомпоненте осуждается по соображениям безопасности. Приложения не должны оказывать в виде текста любые данные после первого двоеточия (:) найден в USERINFO подкомпоненте , если данные после двоеточия не является пустая строка (указывает на отсутствие пароля). - Дополнительный хост подкомпонент, состоящий из любого зарегистрированного имени (включая , но не ограничиваясь этим именем хоста ), или IP — адрес . IPv4 адрес должен быть в доте-числовой формате , и IPv6 — адрес должен быть заключен в скобках (
[]). - Дополнительный порт подкомпонент предшествует двоеточие (
:).
- Необязательно UserInfo подкомпонент , который может состоять из имени пользователя и дополнительный пароль , которому предшествует двоеточие (
- Путь компонент, состоящий из последовательности сегментов пути , разделенных косой чертой (
/). Путь всегда определяется для URI, хотя определенный путь может быть пустым (нулевой длины). Сегмент может также быть пустым, в результате чего два последовательных косой черты (//) в компоненте пути. Компонент пути может напоминать или карту точно на путь в файловой системе , но не всегда подразумевает отношение к одному. Если компонент власти присутствует, то компонент путь должен быть либо пустыми или начинаться с косой черты (/). Если компонент органа отсутствует, то путь не может начинаться с пустым сегментом, то есть с двумя косыми чертами (//), так как следующие символы будут интерпретироваться как компонент власти. Заключительный отрезок пути может упоминаться как « пуля ».
| Запрос разделитель | пример |
|---|---|
Амперсанд ( &) | key1=value1&key2=value2 |
Запятая ( ;) | key1=value1;key2=value2 |
- Дополнительный запрос компонент предшествует знак вопроса (
?), содержащий строку запроса неиерархических данных. Синтаксис не определена, но по соглашению чаще всего последовательность пар атрибут-значение , разделенных ограничителем . - Дополнительный фрагмент компонента предшествует хэш (
#). Фрагмент содержит идентификатор фрагмента , обеспечивающий направление вторичного ресурса, такого как раздел заголовка в статье , идентифицированной оставшейся части URI. Когда основной ресурс является HTML документ, фрагмент часто является
Строки данных октетов в пределах URI представляются в виде символов. Допустимые символы внутри URI являются ASCII — символов для строчных и заглавных букв современного русского алфавита , то арабские цифры , дефис , период , подчеркивания и тильда . Октеты , представленные любой другой символ должен быть процент-кодированные .
Из набора ASCII символов, символы : / ? # [ ] @зарезервированы для использования в качестве разделителей родовых компонентов URI и должны быть процентом кодированного — например, %3Fдля знака вопроса. Символы ! $ & ' ( ) * + , ; =разрешены общим синтаксис URI для использования неперекодированных в пользовательской информации, хост и пути в качестве разделителей. Кроме того,
:и @могут появляться незакодированной в путь, запрос и фрагмент; и ?и /может появляться незакодированным в качестве данных в рамках запроса или фрагмента.Примеры
На приведенном ниже рисунке показаны примеры URI, и их составных частей.
userinfo host port
┌─┴────┐ ┌────┴────────┐ ┌┴┐
https://john.doe@www.example.com:123/forum/questions/?tag=networking&order=newest#top
└─┬─┘ └───────┬────────────────────┘└─┬─────────────┘└──┬───────────────────────┘└┬─┘
scheme authority path query fragment
ldap://[2001:db8::7]/c=GB?objectClass?one
└─┬┘ └───────┬─────┘└─┬─┘ └──────┬──────┘
scheme authority path query
mailto:John.Doe@example.com
└──┬─┘ └─────────┬────────┘
scheme path
news:comp.infosystems.www.servers.unix
└─┬┘ └───────────────┬───────────────┘
scheme path
tel:+1-816-555-1212
└┬┘ └──────┬──────┘
scheme path
telnet://192.0.2.16:80/
└──┬─┘ └──────┬──────┘│
scheme authority path
urn:oasis:names:specification:docbook:dtd:xml:4.1.2
└┬┘ └──────────────────────┬──────────────────────┘
scheme path
ссылки URI
Определение
Ссылка URI является либо URI, или относительная ссылка , когда она не начинается с компонентом схемы следует двоеточие ( :). Сегмент путь , который содержит символ двоеточие (например, foo:bar) не может быть использован в качестве первого сегмента пути относительной ссылки , если его путь компонент не начинается с косой черты ( /), как это было бы ошибочно для компонента схемы. Такой сегмент пути должна предшествовать точка отрезка пути (например, ./foo:bar).
Веб — документ языков разметки часто используют ссылки URI , чтобы указать на другие ресурсы, например, внешние документы или отдельных частей одного и того же логического документа:
- в HTML , значение
srcатрибутаimgэлемента содержит ссылку URI, как это делает значениеhrefатрибутаaилиlinkэлемента; - в XML , то системный идентификатор появляется после
SYSTEMключевого слова в DTD является fragmentless URI — ссылка; - в XSLT , значение
hrefатрибутаxsl:importэлемента / инструкции является ссылкой URI; также первый аргументdocument()функции.
Примеры
https://example.com/path/resource.txt#fragment //example.com/path/resource.txt /path/resource.txt path/resource.txt /path/resource.txt ../resource.txt ./resource.txt resource.txt #fragment
разрешение URI
Определение
Абсолютный URI является URI , без какой — либо компоненты фрагмента.
Разрешающая ссылка URI против базы URI , приводит к цели URI . Это означает , что базовый URI существует и является абсолютной URI. Базовый URI может быть получен, в порядке очередности, из:
- ссылка сам URI, если он является URI;
- содержание представления;
- сущность герметизирующего представление;
- URI, используемый для фактического извлечения представления;
- контекст приложения.
Примеры
В представлении с хорошо определенной базовой URI из
http://a/b/c/d;p?q
относительная ссылка разрешена к своей цели URI следующим образом:
"g:h" -> "g:h" "g" -> "http://a/b/c/g" "./g" -> "http://a/b/c/g" "g/" -> "http://a/b/c/g/" "/g" -> "http://a/g" "//g" -> "http://g" "?y" -> "http://a/b/c/d;p?y" "g?y" -> "http://a/b/c/g?y" "#s" -> "http://a/b/c/d;p?q#s" "g#s" -> "http://a/b/c/g#s" "g?y#s" -> "http://a/b/c/g?y#s" ";x" -> "http://a/b/c/;x" "g;x" -> "http://a/b/c/g;x" "g;x?y#s" -> "http://a/b/c/g;x?y#s" "" -> "http://a/b/c/d;p?q" "." -> "http://a/b/c/" "./" -> "http://a/b/c/" ".." -> "http://a/b/" "../" -> "http://a/b/" "../g" -> "http://a/b/g" "../.." -> "http://a/" "../../" -> "http://a/" "../../g" -> "http://a/g"
история
Нейминг, адресации и идентификации ресурсов
URI , и URL — адрес имеют общую историю. В 1994 году Тим Бернерс-Ли предложения «S для гипертекста неявно ввел идею URL в короткой строки , представляющей собой ресурс , который является мишенью гиперссылкой . В то время люди называли его «имя гипертекстовой» или «имя документа».
В течение следующих трех с половиной лет, так как основные технологии в World Wide Web по по HTML, HTTP и веб — браузеров разработаны, необходимо выделить строку, давшую адрес ресурса из строки, просто по имени ресурс возник. Хотя формально еще не определенно, термин Uniform Resource Locator пришел представлять бывший, и тем более спорное унифицированное название ресурса стало представлять последние.
В ходе дискуссии по задающей URL , и урнам стало очевидно , что эти два понятием , воплощенных условиями были лишь аспектами фундаментального, всеобъемлющего понятия ресурса идентификации . В июне 1994 года IETF опубликовала RFC 1630 Бернерс-Ли: первый запрос на комментарии , которые признали существование URL — адресов и урн, и, что более важно, определить формальный синтаксис для универсальных идентификаторов ресурсов — URL-как строки , чьи точные Синтаксисы и семантика зависит от их схем. Кроме того, этот RFC попытался суммировать синтаксис схем URL используется в данный момент. Он также признал, но не стандартизировать, существование относительных URL — адресов и идентификаторов фрагментов.
Уточнение спецификаций
В декабре 1994, RFC 1738 формально определены относительные и абсолютные URL-адреса, усовершенствовал общий синтаксис URL, определяемый как разрешить относительные URL-адреса в абсолютной форме, и лучше перечисленных схем URL, то используется. Согласованное определение и синтаксис урн пришлось ждать до публикации RFC 2141 в мае 1997 года.
Публикация RFC 2396 в августе 1998 года увидел синтаксис URI стал отдельной спецификации и большинство частей РЛК 1630 и 1738 , связанных с URI , и URL , в общем , были пересмотрены и расширены в IETF . Новый RFC изменил значение «U» в «URI» в «Единый» от «Universal».
В декабре 1999, RFC 2732 представила небольшое обновление для RFC 2396, что позволяет URIs для размещения IPv6 — адресов. Ряд недостатков , обнаруженных в двух спецификациях привело к попытке сообщества, координируется RFC 2396 Соавтор Рой Филдинг , который завершился в публикации RFC 3986 в январе 2005 года В то время как obsoleting предварительного стандарта, он не оказывал детали существующие схемы URL устаревшие; RFC 1738 продолжает управлять такими схемами , за исключением случаев , вытесняются. RFC 2616, например, уточняет httpсхему. Одновременно IETF опубликовал содержание RFC 3986 в качестве полного стандартного STD 66, отражающий создание общего синтаксиса URI в качестве официального Интернет — протокола.
В 2001 году техническая Architecture Group стандартизованный W3C (TAG) опубликовала руководство по наилучшей практике и канонические URI , для публикации нескольких версий данного ресурса. Например, содержание может отличаться от языка или по размеру для корректировки мощности или настроек устройства , используемого для доступа к этому содержанию.
В августе 2002, RFC 3305 отметил, что термин «URL» был, несмотря на широкое общественное пользование, растворился в ближайшее устаревание, и служит лишь напоминанием , что некоторые идентификаторы URI действуют как адреса, имея схемы подразумевающей сети доступ, независимо от того, любого таких фактического использовать. Как URI на основе стандарты , такие как Resource Description Framework делают очевидными, идентификация природных ресурсов не предполагает извлечение представлений ресурсов через Интернет, и не нужна они подразумевают сетевые ресурсы на всех.
Semantic Web использует HTTP схему URI для идентификации обоих документов и понятий в реальном мире, различие , которое вызвало путаницу о том , как отличить два. TAG опубликовал электронную почту в 2005 году о том , как решить эту проблему, которая стала известна как разрешение httpRange-14 . W3C , впоследствии было опубликовано Примечание Interest Group под названием Прохладных идентификаторы URI для Semantic Web , который объясняется использование переговоров контента и HTTP 303 код ответа для перенаправления более подробно.
Отношение к XML пространств имен
В XML , пространство имен является абстрактным домена , к которому может быть присвоен набор имен элементов и атрибутов. Пространство имен является строка символов , которая должна придерживаться общего синтаксиса URI. Тем не менее, имя , как правило , не считается URI, поскольку спецификации баз URI решение не только лексических компонентов, но и от их предполагаемого использования. Имя пространства имен не обязательно подразумевает какой — либо из семантики схем URI; например, имя пространства имен , начинающееся с HTTP: может не иметь коннотации к использованию HTTP .
Первоначально имя пространства имен может соответствовать синтаксису любой непустого URI ссылки, но использование относительных ссылок URI осуждались W3C. Отдельно спецификации W3C для пространств имен XML в 1.1 разрешает интернационализирован идентификатор ресурса (IRI) ссылка , чтобы служить в качестве основы для имен пространства имен в дополнении к URI ссылкам.
Смотрите также
- КЮРИ — определяет общий, сокращенный синтаксис для выражения URI ,
- Разыменовываемый Идентификатор Uniform Resource — механизм поиска ресурсов , который использует любого из интернета — протоколов (например , HTTP) , чтобы получить копию или представление ресурса он идентифицирует
- Extensible Resource Identifier — протокол и схема разрешения для абстрактных идентификаторов совместимых с URIs
- Идентификатор интернационализированного ресурсов (IRI) — обобщение URI , что позволяет использовать Unicode
- Стойкие Uniform Resource Locator (PURL) — это URI , который используется для перенаправления на месте запрашиваемого веб — ресурса
- Единая конвенция Нейминг — общий синтаксис , используемый Microsoft для описания местоположения сетевого ресурса, такие как общий файл, каталог или принтер
- Каталог ресурсов Описание Язык — описательный язык , чтобы обеспечить машино- и читаемый человеком информации о конкретном пространстве имен , а также о документах XML , которые используют его
- UUID
Заметки
Рекомендации
Цитирование
цитируемые работы
- Филдинг, Рой Т. (18 июня 2005). «[httpRange-14] Устранено» . Проверено 24 Июлю 2009 .
- Гарольд, Эллиотт Расти (2004). XML 1.1 Bible (Third -е изд.). Wiley Publishing . п. 291. ISBN 978-0-7645-4986-1 .
- Совместный W3C / IETF URI Планирование Interest Group (21 сентября 2001). «Юрис, URL — адрес, и урны: Разъяснения и рекомендации 1.0» . Источник 2009-07-27 .
- Mealling, М .; Denenberg Р., ред. (Август 2002). «Отчет из Объединенного W3C / IETF URI планирования Interest Group: Uniform идентификаторов ресурсов (URI), URL — адрес, и Унифицированные имена ресурсов (урны): Разъяснения и рекомендация» . World Wide Web Consortium . Проверено 13 сентября 2015 года .
- Хансен, Т .; Гарди Т. (июнь 2015). Талер, D., ред. «Руководящие принципы и процедура регистрации для схем URI» . Целевая группа Internet Engineering . ISSN 2070-1721 .
- Morrison, Майкл (2006). «Час 5: Ввод пространств имен , чтобы использовать ». Sams Teach Yourself XML . Sams Publishing . п. 91.
- Палмер, Шон Б. (2001). «Ранняя история HTML» . Источник 2009-04-30 .
- URI Планирование Interest Group, W3C / IETF (21 сентября 2001). «Юрис, URL — адрес, и урны: Разъяснения и рекомендации 1.0» . Источник 2009-07-27 .
- «W3 Именование схем» . World Wide Web Consortium . 1992 . Источник 2009-07-24 .
- «О Связывание альтернативных представлений Включить обнаружение и издательство» . World Wide Web Consortium . 2006 [2001] . Источник 2012-04-03 .
- Bray, Тим ; Холландер, Дэйв; Дилетанты, Эндрю; Тобин, Ричард, ред. (16 августа 2006). «Пространства имен в XML 1.1 (Second Edition)» . World Wide Web Consortium . 2.2 Использование URI , как пространство имен имен . Проверено 31 Августа +2015 .
- Айерс, Дэнни; Volkel, Max (3 декабря 2008). Sauermann, Лео; Cyganiak, Ричард, ред. «Крутые URIs для Semantic Web» . World Wide Web Consortium . Источник 2012-04-03 .
- Bray, Тим ; Холландер, Дэйв; Дилетанты, Эндрю; Тобин, Ричард; Томпсон, Генри С., ред. (8 декабря 2009). «Пространства имен в XML 1.0 (Третье издание)» . World Wide Web Consortium . 2.2 Использование URI , как пространство имен имен . Проверено 31 Августа +2015 .
- Бернерс-Ли, Тим ; Коннолли, Дэн (ноябрь 1995). «Hypertext Markup Language — 2,0» . Целевая группа Internet Engineering . Проверено 13 сентября 2015 года .
- Бернерс-Ли, Тим ; Филдинг, Рой ; Masinter Ларри (август 1998). Унифицированные идентификаторы ресурсов (URI): общий синтаксис . Целевая группа Internet Engineering . DOI : 10,17487 / RFC2396 . RFC 2396 . Проверено 31 августа 2015 ., http://tools.ietf.org/html/rfc2396
- Бернерс-Ли, Тим ; Филдинг, Рой ; Masinter Ларри (январь 2005). Унифицированные идентификаторы ресурсов (URI): общий синтаксис . Целевая группа Internet Engineering . DOI : 10,17487 / RFC3986 . RFC 3986 . Проверено 31 августа 2015 ., http://tools.ietf.org/html/rfc3986
- Бернерс-Ли, Тим ; Филдинг, Рой ; Masinter Ларри (январь 2005). Идентификаторы Равномерного ресурса (URI): общий синтаксис, раздел 3, Синтаксис компонента . Целевая группа Internet Engineering . DOI : 10,17487 / RFC3986 . RFC 3986 . Проверено 31 августа 2015 ., https://tools.ietf.org/html/rfc3986#section-3
- Лоуренс, Эрик (6 марта 2014). «Браузер Arcana: IP литералы в URL — адресах» . IEInternals . Microsoft . Источник 2016-04-25 .
внешняя ссылка
Универсальный идентификатор ресурсов URI
⇐ ПредыдущаяСтр 45 из 57Следующая ⇒URI (Uniform Resource Identifier, Универсальный идентификатор ресурса) – компактная строка символов для идентификации абстрактного или физического ресурса. Под ресурсом понимается любой объект, принадлежащий некоторому пространству. Необходимость в URI была понятна разработчикам WWW c момента зарождения системы, т.к. предполагалось объединение в единую информационную среду средств, использующих различные способы идентификации информационных ресурсов. Была разработана спецификация, которая включала в себя обращения к FTP, Gopher, WAIS, Usenet, E–mail, Prospero, Telnet, X.500 и, конечно, HTTP (WWW). В итоге была разработана универсальная спецификация, которая позволяет расширять список адресуемых ресурсов за счет появления новых схем.
Место применения URI – гипертекстовые ссылки, которые записываются в тегах <A HREF=URI> и <LINK HREF=URI>. Встраиваемые графические объекты также адресуются по спецификации URI в тегах <IMG SRC=URI> и <FIG SRC=URI>. Реализация URI для WWW называется URL (Uniform Resource Locator). Точнее, URL – это реализация схемы URI, отображенная на алгоритм доступа к ресурсам по сетевым протоколам. Существует еще и URN (Uniform Resource Name), которое отображает URI в пространство имен на сети.
Появление URN связано с желанием адресовать части почтового сообщения MIME. Принципы построения адреса WWW. В основу URI были заложены следующие принципы:
· Расширяемость – новые адресные схемы должны легко вписываться в существующий синтаксис URI.
· Полнота – по возможности, любая из существовавших схем должна описываться посредством URI.
· Читаемость – адрес должен был быть легко читаем пользователем, что вообще характерно для технологии WWW – документы вместе с ссылками могут разрабатываться в обычном текстовом редакторе.
Прежде, чем рассмотреть различные схемы представления адресов приведем пример простого адреса URI:
http://polyn.net.kiae.su/polyn/index.html
Перед двоеточием стоит идентификатор схемы адреса – «http». Это имя отделено двоеточием от остатка URI, который называется «путь». В данном случае путь состоит из доменного адреса машины, на которой установлен сервер HTTP и пути от корня дерева сервера к файлу «index.html». Кроме представленной выше полной записи URI, существует упрощенная. Она предполагает, что к моменту ее использования многие параметры адреса ресурса уже определены (протокол, адрес машины в сети, некоторые элементы пути). При таких предположениях автор гипертекстовых страниц может указывать только относительный адрес ресурса, т.е. адрес относительно определенных базовых ресурсов.
URL (Uniform Resource Locator, Универсальный указатель ресурса), –подмножество схем URI, который идентифицирует ресурс по способу доступа к нему (например, его «местонахождению в сети») вместо того, чтобы идентифицировать его по названию или другим атрибутам этого ресурса. URL явно описывает, как добраться до объекта.
Синтаксис: <scheme>:<scheme–specific–part>, где:
scheme = «http» | «ftp» | «gopher» | «mailto» | «news» | «telnet» | «file» | «man» | «info» | «whatis» | «ldap» | «wais» | … – имя схемы
scheme–specific–part – зависит от схемы. В scheme–specific–part можно использовать шестнадцатеричные значения в виде: %5f. Обязательно должны кодироваться непечатные октеты: 00–1F, 7F, 80–FF.
Примеры URL:
· http ://www.ipm.kstu.ru/index.php
· ftp://www.ipm.kstu.ru/
URN (Uniform Resource Name, Универсальное имя ресурса) – частная URI–схема «urn:» с подмножеством «пространства имен», который должен быть уникальным и неизменным даже в том случае, когда ресурс уже не существует или недоступен.
Предполагается что, например браузер, знает, где искать этот ресурс.
Синтаксис: urn: namespace: data1.data2,more–data, где namespace (пространство имен) определяет, каким образом используются данные, указанные после второго «:».
Пример URN:
urn: ISBN: 0–395–36341–6
ISBN – тематический классификатор для издательств,
0–395–36341–6 – конкретный номер тематики книги или журнала
При получении URN клиентская программа обращается к ISBN (каталогу «тематический классификатор для издательств» в Интернете). И получает расшифровку номера тематики «0–395–36341–6» (например: «квантовая химия»). URN принят сравнительно недавно, в текущие версии HTML не включен и службы каталогов пока не развиты, поэтому URN не так широко распространен как URL.
Схемы адресации ресурсов Internet
Существует 3 схемы адресации ресурсов Internet. В схеме указывается ее идентификатор, адрес машины, TCP–порт, путь в директории сервера, переменные и их значения, метка.
Схема HTTP. Это основная схема для WWW. В схеме указывается ее идентификатор, адрес машины, TCP–порт, путь в директории сервера, поисковый критерий и метка.
Синтаксис: http://[<user>[:<password]>@]<host>[:<port>][/[<url–path>][?<query>]]
http – название схемы
user – имя пользователя
password – пароль пользователя
host – имя хоста
port – номер порта
url–path – путь к файлу и сам файл
query (<имя–поля>=<значение>{&<имя–поля>=<значение>) – строка запроса
По умолчанию, port=80.
Приведем несколько примеров URI для схемы HTTP:
http://polyn.net.kiae.su/polyn/manifest.html
Это наиболее распространенный вид URI, применяемый в документах WWW. Вслед за именем схемы (http) следует путь, состоящий из доменного адреса машины и полного адреса HTML–документа в дереве сервера HTTP.
В качестве адреса машины допустимо использование и IP–адреса:
http://144.206.160.40/risk/risk.html
Если сервер протокола HTTP запущен на другой, отличный от 80 порт TCP, то это отражается в адресе:
http://144.206.130.137:8080/altai/index.html
При указании адреса ресурса возможна ссылка на точку внутри файла HTML. Для этого вслед за именем документа может быть указана метка внутри документа:
http://polyn.net.kiae.su/altai/volume4 .html#first
Схема FTP. Данная схема позволяет адресовать файловые архивы FTP из программ–клиентов World Wide Web. При этом программа должна поддерживать протокол FTP. В данной схеме возможно указание не только имени схемы, адреса FTP–архива, но и идентификатора пользователя и даже его пароля.
Синтаксис: ftp://[<user>[:<password]>@]<host>[:<port>][/<url–path>]
ftp – название схемы
user – имя пользователя
password – пароль пользователя
host – имя хоста
port – номер порта
url–path – путь к файлу и сам файл
По умолчанию, port=21, user=anonymous, password=email–адрес.
Наиболее часто данная схема используется для доступа к публичным архивам FTP:
ftp://polyn.net.kiae.su/pub/0index.txt
В данном случае записана ссылка на архив «polyn.net.kiae.su» c идентификатором «anonymous» или «ftp» (анонимный доступ). Если есть необходимость указать идентификатор пользователя и его пароль, то можно это сделать перед адресом машины:
ftp://nobody:password@polyn.net.kiae.su/users/local/pub
В данном случае эти параметры отделены от адреса машины символом «@», а друг от друга двоеточием.
Схема TELNET. По этой схеме осуществляется доступ к ресурсу в режиме удаленного терминала. Обычно клиент вызывает дополнительную программу для работы по протоколу telnet. При использовании этой схемы необходимо указывать идентификатор пользователя, допускается использование пароля.
Синтаксис: telnet://[<user>[:<password]>@]<host>[:<port>]/
telnet – название схемы
user – имя пользователя
password – пароль пользователя
host – имя хоста
port – номер порта
По умолчанию, port=23.
Пример: telnet://name:password@ipm.kstu.ru
Реально, доступ осуществляется к публичным ресурсам, и идентификатор и пароль являются общеизвестными, например, их можно узнать в базах данных Hytelnet.
telnet://guest:password@apollo.polyn.kiae.su
Из приведенных выше примеров видно, что спецификация адресов ресурсов URI является довольно общей и позволяет проидентифицировать практически любой ресурс Internet. При этом число ресурсов может расширяться за счет создания новых схем.
Служба WWW
Служба WWW (World Wide Web) – предназначена для обмена гипертекстовой информацией, построена по схеме «клиент–сервер». Браузер (Internet Explorer, Opera …) является мультипротокольным клиентом и интерпретатором HTML. И как типичный интерпретатор, клиент в зависимости от команд (тегов) выполняет различные функции. В круг этих функций входит не только размещение текста на экране, но обмен информацией с сервером по мере анализа полученного HTML–текста, что наиболее наглядно происходит при отображении встроенных в текст графических образов.
Сервер HTTP (Apаche, IIS …) обрабатывает запросы клиента на получение файла. В начале служба WWW базировалась на трех стандартах:
· HTML (HyperText Markup Lan–guage) – язык гипертекстовой разметки документов;
· URL (Universal Resource Locator) – универсальный способ адресации ресурсов в сети;
· HTTP (HyperText Transfer Protocol) – протокол обмена гипертекстовой информацией.
Позже добавили CGI (Common Gateway Interface) – универсальный интерфейс шлюзов. Создан для взаимодействия HTTP – сервера с другими программами установленными на сервере (например, СУБД).
Схема работы WWW сервера
WWW сервер – это такая часть глобальной или внутрикорпоративной сети, которая дает возможность пользователям сети получать доступ к гипертекстовым документам, расположенным на данном сервере. Для взаимодействия с WWW сервером пользователь сети должен использовать специализированное программное обеспечение – браузер (от англ. browser) –программа просмотра.
Рассмотрим более схему работы WWW–сервера:
1. Пользователь сети запускает браузер, в функции которого входит:
· установление связи с сервером;
· получение требуемого документа;
· отображение полученного документа;
· реагирование на действия пользователя – доступ к новому документу. После запуска браузер по команде пользователя или автоматически устанавливает связь с заданным WWW – сервером и передает ему запрос-получение заданного документа.
2. WWW сервер ищет запрашиваемый документ и возвращает результаты браузеру.
3. Браузер, получив документ, отображает его пользователю и ожидает его реакции. Возможные варианты:
· ввод адреса нового документа;
· печать, поиск, другие операции над текущим документом;
· активизация (нажатие) специальных зон полученного документа, называемых связями (link) и ассоциированными с адресом нового документа. В первом и третьем случае происходит обращение за новым документом.
Универсальный идентификатор ресурсов (uri), его назначение и составные части
1.4. Универсальный идентификатор ресурса URI
Чтобы полностью понимать, как происходит взаимодействие HTML?документов, переход между страницами и откуда вообще компьютер пользователя получает данные при работе с сетью, нужно рассмотреть, как и к чему осуществляется доступ при помощи Глобальной сети.
Многие виды ресурсов, размещенных в Интернете, независимо от того, являются ли они HTML?документами, рисунками или файлами архива, чаще всего представляют собой файлы на жестком диске компьютера (сервера), подключенного к сети. С каждым ресурсом сопоставляется значение, по которому можно однозначно определить его расположение, – универсальный идентификатор ресурса или URI (Universal Resource Identifier). URI широко используются как при самостоятельном доступе пользователя к ресурсу (когда, например, пользователь сам вводит URI в адресной строке браузера), так и при переходе между веб?страницами. URI также используются в HTML?документе для указания браузеру, где искать ресурсы (например, рисунки), используемые в самом документе.
Примечание
В литературе также часто применяется обозначение URL. Следует отметить, что URI является более общим понятием, включающим в себя URL: любой URL является универсальным идентификатором ресурса и подчиняется тем же правилам, что и URI.
Идентификатор ресурса URI состоит из трех частей: из наименования механизма доступа к ресурсу, доменного имени компьютера и пути файла ресурса. Для пояснения сказанного можно рассмотреть пример:
Здесь можно увидеть, что для доступа к ресурсу, которым в данном случае является HTML?документ, используется протокол HTTP (Hyper Text Transfer Protocol). Ресурс хранится на компьютере, имеющем доменное имя somesite.com в файле ex_1.html, расположенном в папке /info/examples.
При помощи URI можно также ссылаться на части HTML?документов, например:
При использовании этого URI можно получить доступ к части HTML?документа, имеющей имя description (то, как создавать имена для фрагментов HTML?документов, будет рассмотрено в гл. 5).
URI также позволяют ссылаться на ресурсы в пределах одного компьютера. При этом указывается относительный путь ресурса. Например, чтобы из HTML?документа, расположенного в папке /info/examples, сослаться на файл /info/files/file1.jpg, достаточно задать URI /files/file1.jpg. В HTML?документах при помощи подобных ссылок указываются пути рисунков и других объектов, используемых в документах, но непосредственно не хранимых в них.
В общем случае URI считаются нечувствительными к регистру символов. Однако для полной уверенности в правильности интерпретации URI все же обращайте внимание на регистр символов в URI гиперссылок, рисунков и т. д. Это полезно для устранения таких ситуаций, когда, например, при работе сайта на компьютере под Windows все гиперссылки работают, а при помещении сайта на UNIX?сервер работать отказываются (в UNIX имена файлов чувствительны к регистру).
Работа с URI
Каждый день мы используем универсальные идентификаторы ресурса (Uniform Resource Identifiers, URI) , когда что-то ищем в WWW. URI нужны, чтобы идентифицировать и запросить новый вид ресурса. Используя URI, можно обращаться не только к Web-страницам, но и к FTP-серверу, Web-сервису и локальным файлам.
Вместо URI часто используется термин унифицированный указатель ресурса (Uniform Resource Locator, URL) . URI-общий термин, используемый для ссылок на ресурсы. URL — это URI, связанный с такими популярными схемами URI, как http, ftp и mailto. В технической документации термин URL больше не употребляется.
Еще один термин может быть вам уже известен — унифицированное имя ресурса (Uniform Resource Name, URN) . URN — это стандартизированный URI, используемый для указания ресурса независимо от его расположения в сети.
Проанализируем части URI, ссылающегося на страницу Web-сайта компании Global Knowledge:
http://www.globalknowledge.net:80/training/generic.asp?pageid=1078&country=DACH
Первая часть URI называется схемой (scheme) . Схема определяет пространство имен URI и может сузить синтаксис следующего за схемой выражения. Многие схемы названы по соответствующим протоколам (как http, ftp), которые они используют, но это не является обязательным. В нашем примере идентификатором схемы является http. Ограничитель схемы (// в этом примере) отделяет схему от остальной части URL.
После ограничителя схемы следует имя сервера или IP-адрес в десятичной записи с точками, например www.globalknowledge.net.
За именем сервера или IP-адресом находится номер порта, определяющий соединение с конкретным приложением на сервере. Если номер порта не задан, используется номер порта, устанавливаемый для этого протокола по умолчанию (например, порт 80 для HTTP).
Путь определяет страницу (и каталог) запрошенного ресурса. Он необязательно представляет физический файл на сервере, а может создаваться динамически. В данном случае путь имеет вид /training/generic.asp.
От пути символом? отделена последняя часть этого URI, называемая запросом (query) . В нашем примере запрос определен строкой pageid=1078&country=DACH. Строка запроса может состоять из нескольких компонентов, каждый из которых задает переменную и значение, объединенные символом &. Несколько компонентов запроса могут комбинироваться символом &. Так, в нашем примере первый компонент — pageid=1078 с переменной pageid и значением 1078, а второй компонент — country=DACH.
Разделы внутри ресурса можно отождествить с фрагментами. Фрагменты используются для ссылок на разделы внутри HTML-страницы. В разработке Web-страниц фрагменты также называются закладками (bookmarks). Символ # отделяет идентификатор фрагмента от пути. В URL http;//www.microsoft.com/net/basics/glossary.asp#NETFramework фрагментом является строка #NETFramework
Использование уникальных идентификаторов ресурса (URI) в AD FS
- Время чтения: 8 мин
В этой статье
(URI) универсального идентификатора ресурса — это строка символов, которая используется в качестве уникального идентификатора.A Uniform Resource Identifier (URI) is a string of characters that is used as a unique identifier. В службах AD FS коды URI используются для обозначения сетевых адресов партнеров и объектов конфигурации.In AD FS, URIs are used to identify both partner network addresses and configuration objects. При использовании для обозначения сетевых адресов партнеров URI всегда является URL-адресом.When used to identify partner network addresses, the URI is always a URL. При использовании для обозначения объектов конфигурации URI может быть URN или URL-адресом.When used to identify configuration objects, the URI may be a URN or a URL. Общие сведения о кодах URI см. в стандартах RFC 2396 и RFC 3986.For more general information about URIs, see RFC 2396 and RFC 3986.
Коды URI в качестве сетевых адресов партнеровURIs as partner network addresses
Ниже приведены сетевые URL-адреса, с которыми чаще всего сталкиваются администраторы в AD FS.The following are the network address URLs that are most often handled by administrators in AD FS.
URL-адреса служба Федерации, включая WS-Federation, SAML, WS-Trust, метаданные федерации, WS-MetadataExchange, конфиденциальность и URL-адреса Организации.The URLs of the Federation Service, including WS-Federation, SAML, WS-Trust, Federation Metadata, WS-MetadataExchange, Privacy and Organization URLs
URL-адреса отношений доверия с проверяющей стороной,-включая URL-адреса метаданных WS Federation, SAML и Federation.The URLs of a relying party trust, including WS-Federation, SAML, and Federation Metadata URLs
URL-адреса отношений доверия поставщиков утверждений, включая-URL-адреса метаданных WS Federation, SAML и Federation.The URLs of a claims provider trust, including WS-Federation, SAML, and Federation Metadata URLs
Коды URI в качестве идентификаторов объектовURIs as object identifiers
Ниже приведены идентификаторы, с которыми чаще всего сталкиваются администраторы в AD FS.The following table describes the identifiers that are most often handled by administrators in AD FS.
| ИдентификаторIdentifier name | ОписаниеDescription | СравнениеComparisons |
|---|---|---|
| Идентификатор службы федерацииFederation Service identifier | Этот идентификатор используется для обозначения службы федерации.This identifier is used to identify the Federation Service. Он используется проверяющими сторонами, использующими утверждения от этой службы федерации, а также поставщиками утверждений, выдающими утверждения для службы федерации.It is used by relying parties that use claims from this Federation Service, as well as claims providers that issue claims to this Federation Service. | Когда пользователь запрашивает у поставщика утверждений утверждения для службы федерации, идентификатор этой службы федерации будет использоваться для обозначения целевого объекта утверждений.When a user requests claims from a claims provider for this Federation Service, the Federation Service identifier will be used to identify the target for the claims. Когда служба федерации получает утверждения от поставщика утверждений, она проверяет, что утверждения относятся именно к ней, выполняя поиск своего идентификатора.When this Federation Service receives the claims from a claims provider, it will check to ensure the claims are scoped for it by looking for its Federation Service identifier. Когда проверяющая сторона получает утверждения из этой службы федерации, проверяющая сторона проверяет, что издатель утверждения соответствует идентификатору службы федерации.When a relying party is receiving claims from this Federation Service, the relying party will check that the issuer of the claims matches the Federation Service identifier. |
| Идентификатор проверяющей стороныRelying party identifier | Этот идентификатор используется для обозначения проверяющей стороны в службе федерации.This identifier is used to identify the relying party to this Federation Service. Он используется при выдаче утверждений для проверяющей стороны.It is used when issuing claims to the relying party. | Когда пользователь запрашивает утверждения от службы федерации для проверяющей стороны, идентификатор этой проверяющей стороны будет использоваться для обозначения проверяющей стороны, для которой предназначены утверждения.When a user requests claims from this Federation Service for the relying party, the relying party identifier will be used to identify the relying party for which the claims should be targeted. Это сравнение выполняется с помощью сопоставления (префиксов см. ниже.)This comparison is done using prefix matching (see below). Когда проверяющая сторона получает утверждения, она проверяет идентификатор в токене безопасности, чтобы гарантировать, что утверждения предназначены для нее.When the relying party receives the claims, it will check for its identifier in the security token to ensure the claims are targeted for it. |
| Идентификатор поставщика утвержденийClaims provider identifier | Этот идентификатор используется для обозначения поставщика утверждений в службе федерации.This identifier is used to identify the claims provider to this Federation Service. Он используется при получении утверждений от поставщика утверждений.It is used when receiving claims from the claims provider. | Когда служба федерации получает утверждения от поставщика утверждений, служба федерации проверяет, что издатель утверждений соответствует идентификатору поставщика утверждений.When this Federation Service is receiving claims from the claims provider, this Federation Service will check that the issuer of the claims matches the claims provider identifier. |
| Тип утвержденияClaim type | Этот идентификатор используется для определения типа утверждения.This identifier is used to define the type of claim. Он используется этой службой федерации, поставщиками утверждений и проверяющими сторонами при отправке и получении утверждений.It is used by this Federation Service, claims providers, and relying parties when sending and receiving claims. | Когда служба федерации получает утверждения от поставщика утверждений, правила утверждений, связанные с соответствующим отношением доверия поставщика утверждений позволяют администратору сравнивать типы утверждений и обрабатывать утверждения.When the Federation Service receives claims from a claims provider, the claim rules associated with the corresponding claims provider trust allow the administrator to compare claim types and process claims. Правила утверждения, связанные с отношением доверия с проверяющей стороной, также позволяют администратору сравнивать типы утверждений на основе утверждений, поступающих из правил отношения доверия с поставщиком утверждений, а также решать, какие утверждения выдавать.The claim rules associated with a relying party trust also allow the administrator to compare claim types from the claims coming out of the claims provider trust rules, and decide which claims to issue. |
Сопоставление префиксов URI для идентификаторов проверяющей стороныURI prefix matching for relying party identifiers
Синтаксис пути универсального кода ресурса (URI) организован иерархически и разделяются либо символами/«», либо всеми символами «:».The path syntax of a URI is organized hierarchically and is delimited by either all “/” characters or all “:”characters. Таким образом, путь может быть разбит на участки пути в зависимости от символа-разделителя. Thus the path may be split into path sections based on the delimiting character. При сопоставлении префиксов каждый раздел должен быть полным совпадением в соответствии с (правилами сопоставления, которые управляют регистром)совпадений. When prefix matching, each section must be a full match according to the matching rules (these rules govern the casing of matches). Дополнительные сведения о правилах сопоставления см. в документе RFC, упомянутом выше.For more information about matching rules, see the RFC’s mentioned above.
Когда проверяющая сторона определяется в запросе к службе федерации, службы AD FS используют логику сопоставления префиксов, чтобы определить наличие соответствующего отношения доверия с проверяющей стороной в базе данных конфигурации AD FS.When a relying party is identified in a request to the Federation Service, AD FS uses prefix matching logic to determine if there is a matching relying party trust in the AD FS configuration database.
Например, если идентификатор проверяющей стороны в базе данных (конфигурации AD FS URI1) является префиксом идентификатора проверяющей стороны во входящем запросе (URI2), то должны выполняться следующие условия.For example, if the relying party identifier in the AD FS configuration database (URI1) is a prefix to the relying party identifier in the incoming request (URI2), then the following must be true:
Замыкающие разделители () — косые черты и двоеточия для разделов пути или центров должны игнорироваться.Trailing delimiters (slashes and colons) of path sections or authorities must be ignored
Регистр частей схем и данных о пользователе и узле идентификаторов URI1 и URI2 должен строго совпадать.The scheme and authority parts of URI1 and URI2 must be a case insensitive exact match
Каждый раздел пути URI1 должен быть точным совпадением (в зависимости от регистра, выбранного) для соответствующего раздела пути в URI2Each path section of URI1 must be an exact match (based on the case sensitivity chosen) to the corresponding path section of URI2
URI2 может иметь больше участков пути, чем URI1, однако URI1 не должен иметь больше участков пути, чем URI2.URI2 may have more path sections than URI1, but URI1 must not have more path sections than URI2
URI1 не может иметь больше участков пути, чем URI2.URI1 cannot have more path sections than URI2
Если URI1 включает строку запроса, она должна строго соответствовать строке запроса URI2.If URI1 has a query string, it must match exactly to a URI2 query string
Если URI1 включает фрагмент, он должен строго соответствовать фрагменту URI2.If URI1 has a fragment, it must match exactly to a URI2 fragment
Дополнительные примеры приводятся в таблице ниже.The following table provides additional examples.
| Идентификатор проверяющей стороны в базе данных конфигурации AD FSRelying party identifier in AD FS configuration database | Идентификатор проверяющей стороны в сообщении запросаRelying party identifier in request message | Идентификатор запроса совпадает с идентификатором конфигурации?Request identifier matches the configuration identifier? | ReasonReason |
|---|---|---|---|
| http://contoso.comhttp://contoso.com | http://contoso.comhttp://contoso.com | TRUETRUE | Точно соответствуетExact match |
| http://contoso.com/http://contoso.com/ | http://contoso.comhttp://contoso.com | TRUETRUE | Конечные символы косой черты игнорируются.Trailing slashes are ignored |
| http://contoso.comhttp://contoso.com | http://contoso.com/http://contoso.com/ | TRUETRUE | Конечные символы косой черты игнорируются.Trailing slashes are ignored |
| http://contoso.comhttp://contoso.com | http://contoso.comHR/http://contoso.com/hr | TRUETRUE | URI1 не включает путь и соответствует схеме и данным о пользователе и узле для URI2.URI1 has no path and matches scheme and authority to URI2 |
| http://contoso.comHR/http://contoso.com/hr | http://contoso.comHR/Web/http://contoso.com/hr/web | TRUETRUE | Первые участки пути совпадают, в URI1 нет второго участка пути.First path sections match, URI1 has no second path section |
| http://contoso.comHR/http://contoso.com/hr | http://contoso.comHR/Web/?m=t/http://contoso.com/hr/web/?m=t | TRUETRUE | По тем же причинам строка запроса не изменяет ничегоSame reasons as above, query string doesn’t change anything |
| http://contoso.comHR//http://contoso.com/hr/ | http://contoso.comролиRunbook/Main/http://contoso.com/hrw/main | FALSEFALSE | Участок пути 1 идентификатора URI1 не соответствует участку пути 1 идентификатора URI2.URI1 path section 1 does not match URI2 path section 1 |
| http://contoso.comHR/http://contoso.com/hr | http://contoso.comhttp://contoso.com | FALSEFALSE | URI1 имеет больше участков пути, чем URI2.URI1 has more path sections than URI2 |
| http://contoso.comHR/http://contoso.com/hr | http://contoso.comHRweb/http://contoso.com/hrweb | FALSEFALSE | Первые участки пути не совпадают.First path sections do not match |
| http://contoso.com?/mt=http://contoso.com/?m=t | http://contoso.com?/mf=http://contoso.com/?m=f | FALSEFALSE | Части строки запроса не совпадают.Query string parts do not match |
| HTTPS://contoso.comhttps://contoso.com | http://contoso.comhttp://contoso.com | FALSEFALSE | Части схемы не совпадают.Scheme parts do not match |
| http://STS.contoso.comhttp://sts.contoso.com | http://contoso.comhttp://contoso.com | FALSEFALSE | Части данных о пользователе и узле не совпадают.Authority parts do not match |
| http://contoso.comhttp://contoso.com | http://STS.contoso.comhttp://sts.contoso.com | FALSEFALSE | Части данных о пользователе и узле не совпадают.Authority parts do not match |
uri Википедия
URI (/ˌjuː ɑːr ˈaɪ/ англ. Uniform Resource Identifier) — унифицированный (единообразный) идентификатор ресурса. По-русски иногда говорят [у́ри]. URI — последовательность символов, идентифицирующая абстрактный или физический ресурс. Ранее назывался Universal Resource Identifier — универсальный идентификатор ресурса.
Основы
URI — символьная строка, позволяющая идентифицировать какой-либо ресурс: документ, изображение, файл, службу, ящик электронной почты и т. д. Прежде всего, речь идёт о ресурсах сети Интернет и Всемирной паутины. URI предоставляет простой и расширяемый способ идентификации ресурсов. Расширяемость URI означает, что уже существуют несколько схем идентификации внутри URI, и ещё больше будет создано в будущем.
Связь между URI, URL и URN
URI является либо URL, либо URN, либо одновременно обоими.
URL — это URI, который, помимо идентификации ресурса, предоставляет ещё и информацию о местонахождении этого ресурса. А URN — это URI, который только идентифицирует ресурс в определённом пространстве имён (и, соответственно, в определённом контексте), но не указывает его местонахождение. Например, URN urn:ISBN:0-395-36341-1 — это URI, который указывает на ресурс (книгу) 0-395-36341-1 в пространстве имён ISBN, но, в отличие от URL, URN не указывает на местонахождение этого ресурса: в нём не сказано, в каком магазине её можно купить или на каком сайте скачать. Впрочем, в последнее время появилась тенденция говорить просто URI о любой строке-идентификаторе, без дальнейших уточнений. Так что, возможно, термины URL и URN скоро уйдут в прошлое.
Поскольку URI не всегда указывает на то, как получить ресурс, в отличие от URL, а только идентифицирует его, это даёт возможность описывать с помощью RDF (Resource Description Framework) ресурсы, которые не могут быть получены через Интернет (например, личность, автомобиль, город и проч.).
История
В 1990 году в Женеве, Швейцария, в стенах Европейского совета по ядерным исследованиям (фр. Conseil Européen pour la Recherche Nucléaire, CERN) британским учёным Тимом Бернерсом-Ли был изобретён определитель местонахождения ресурса URL. Так как URL является наиболее используемым подмножеством URI, то этот же 1990 год принято считать годом рождения URI. Но, строго говоря, концепция URI была документально оформлена лишь в июне 1994 года в документе RFC 1630.
Новая версия URI была определена в 1998 году в RFC 2396, тогда же слово Universal в названии было заменено на Uniform. В декабре 1999 года RFC 2732 ввёл в спецификацию URI небольшие изменения, обеспечив совместимость с IPv6. В августе 2002 года RFC 3305 анонсировал устаревание термина URL и приоритет URI. Текущая структура и синтаксис URI регулируется стандартом RFC 3986, вышедшим в январе 2005 года. Многие новейшие технологии семантической паутины (например, RDF) базируются на стандарте URI. Сейчас ведущая роль в развитии URI принадлежит Консорциуму Всемирной паутины.
Недостатки
URL стал фундаментальным нововведением в Интернете, поэтому принципы URI документально закреплялись так, чтобы обеспечить полную совместимость с URL. Отсюда появился и большой недостаток URI, пришедший как наследство от URL. В URI, как и в URL, можно использовать только ограниченный набор латинских символов и знаков препинания (даже меньший, нежели в ASCII). Иными словами, если мы захотим использовать в URI символы кириллицы, или иероглифы, или, скажем, специфические символы французского языка, то нам придётся кодировать URI таким же образом, каким в Википедии кодируются URL с символами Юникода. Например, строка вида:
https://ru.wikipedia.org/wiki/Кириллица
кодируется в URL как:
https://ru.wikipedia.org/wiki/%D0%9A%D0%B8%D1%80%D0%B8%D0%BB%D0%BB%D0%B8%D1%86%D0%B0
Поскольку такому преобразованию подвергаются буквы всех алфавитов, кроме используемой в английском языке латиницы, то URI со словами на других языках (даже европейских) утрачивают способность восприниматься людьми. А это входит в грубое противоречие с принципом интернационализма, провозглашаемого всеми ведущими организациями Интернета, включая W3C и ISOC. Эту проблему призван решить стандарт IRI (англ. Internationalized Resource Identifier) — международных идентификаторов ресурсов, в которых можно было бы без проблем использовать символы Юникода, и которые не ущемляли бы права других языков. Хотя заранее сложно сказать, смогут ли когда-либо идентификаторы IRI заменить URI, имеющие столь широкое употребление.
Ещё одной интересной вариацией URI является расширяемый идентификатор ресурса XRI (англ. Extensible Resource Identifier), разработанный организацией OASIS. Этот формат стремится создавать идентификаторы, которые были бы совершенно независимы от контекста, то есть не зависели бы ни от протокола, ни от домена, ни от пути, ни от приложения, ни от платформы — были бы совершенно независимыми.
Также и сам создатель URI, Тим Бернерс-Ли, говорил, что система доменных имён, лежащая в основе URL, — плохое решение, навязывающее ресурсам иерархическую архитектуру, мало подходящую для гипертекстового веба.
Структура URI
URI = [ схема ":" ] иерархическая-часть [ "?" запрос ] [ "#" фрагмент ]
В этой записи:
- схема
- схема обращения к ресурсу (часто указывает на сетевой протокол), например http, ftp, file, ldap, mailto, urn
- иерархическая-часть
- содержит данные, обычно организованные в иерархической форме, которые, совместно с данными в неиерархическом компоненте запрос, служат для идентификации ресурса в пределах видимости URI-схемы. Обычно иер-часть содержит путь к ресурсу (и, возможно, перед ним, адрес сервера, на котором тот располагается) или идентификатор ресурса (в случае URN).
- запрос
- этот необязательный компонент URI описан выше.
- фрагмент
- (тоже необязательный компонент)
RFC 3986:
позволяет косвенно идентифицировать вторичный ресурс посредством ссылки на первичный и указанием дополнительной информации. Вторичный идентифицируемый ресурс может быть некоторой частью или подмножеством первичного, некоторым его представлением или другим ресурсом, определённым или описанным таким ресурсом.
Оригинальный текст (англ.)
The fragment identifier component of a URI allows indirect identification of a secondary resource by reference to a primary resource and additional identifying information. The identified secondary resource may be some portion or subset of the primary resource, some view on representations of the primary resource, or some other resource defined or described by those representations.
Часть идентификатора URI без схемы обращения к ресурсу часто называется «ссылкой URI» (англ. URI reference). Прецеденты применения ссылок URI имеются в HTML, XHTML, XML и XSLT. Процесс превращения ссылки URI в абсолютную форму URI называют «разрешением URI» (англ. URI resolution).
Процесс разработки новых схем описан в документе RFC 2718. Новые схемы должны регистрироваться в организации IANA (англ. Internet Assigned Numbers Authority), процедура регистрации зафиксирована в RFC 2717. Оба указанных запроса комментариев (RFC) сейчас находятся в процессе переработки.
Разбор структуры URI
Для так называемого «па́рсинга» URI (англ. parsing), то есть для разложения URI на составные части и их последующей идентификации, удобнее всего использовать систему регулярных выражений, доступную почти во всех современных языках программирования. Для разбора URI в стандарте RFC 3986 рекомендуется использовать следующий шаблон:
^(([^:/?#]+):)?(//([^/?#]*))?([^?#]*)(\?([^#]*))?(#(.*))? 12 3 4 5 6 7 8 9
Этот шаблон включает в себя 9 обозначенных выше цифрами групп (подробнее о шаблонах и группах см. Регулярные выражения), которые наиболее полно и точно разбирают типичную структуру URI, где:
- группа 2 — схема,
- группа 4 — источник,
- группа 5 — путь,
- группа 7 — запрос,
- группа 9 — фрагмент.
Таким образом, если при помощи данного шаблона разобрать, например, такой типичный идентификатор URI:
http://www.ics.uci.edu/pub/ietf/uri/#Related
то 9 вышеуказанных групп шаблона дадут следующие результаты соответственно:
- http:
- http
- //www.ics.uci.edu
- www.ics.uci.edu
- /pub/ietf/uri/
- нет результата
- нет результата
- #Related
- Related
Примеры URI
Абсолютные URI
- https://ru.wikipedia.org/wiki/URI
- ftp://ftp.is.co.za/rfc/rfc1808.txt
- file://C:\UserName.HostName\Projects\Wikipedia_Articles\URI.xml
- file:///C:/file.wsdl
- file:///Users/John/Documents/Projects/Web/MyWebsite/about.html
- ldap://[2001:db8::7]/c=GB?objectClass?one
- mailto:John.Doe@example.com
- sip:911@pbx.mycompany.com
- news:comp.infosystems.www.servers.unix
- data:text/plain;charset=iso-8859-7,%be%be%be
- tel:+1-816-555-1212
- telnet://192.0.2.16:80/
- urn:oasis:names:specification:docbook:dtd:xml:4.1.2
- urn:oid:1.2.840.113549.1.1.1
Относительные URI
/relative/URI/with/absolute/path/to/resource.txt
//example.org/scheme-relative/URI/with/absolute/path/to/resource.txt
relative/path/to/resource.txt
../../../resource.txt
resource.txt
/resource.txt#frag01
#frag01
[пустая строка] — эквивалентно разбору идентификатора парсером с результатом [пустая строка], то есть ссылка ведёт на объект по умолчанию в схеме по умолчанию[источник не указан 3137 дней]
См. также
Ссылки
В чем разница между URI, URL и URN?
Содержит информацию о том, как извлечь ресурс из его местоположения. Например:
http://example.com/mypage.htmlftp://example.com/download.zipmailto:user@example.comfile:///home/user/file.txthttp://example.com/resource?foo=bar#fragment/other/link.html(Относительный URL, полезен только в контексте другого URL)
URL-адреса всегда начинаются с протокола ( http) и обычно содержат такую информацию, как имя сетевого узла ( example.com) и часто путь к документу ( /foo/mypage.html). URL могут иметь параметры запроса и идентификаторы фрагментов.
Определяет ресурс по имени. Всегда начинается с префикса. urn: Например:
urn:isbn:0451450523идентифицировать книгу по номеру ISBN.urn:uuid:6e8bc430-9c3a-11d9-9669-0800200c9a66глобально уникальный идентификаторurn:publishing:book— Пространство имен XML, которое идентифицирует документ как тип книги.
URN могут идентифицировать идеи и концепции. Они не ограничиваются идентификацией документов. Когда URN действительно представляет документ, он может быть преобразован в URL «распознавателем». Документ может быть загружен с URL.
URI охватывает как URL, URN, так и другие способы указания ресурса.
Примером URI, который не является ни URL, ни URN, может быть URI данных, например data:,Hello%20World. Это не URL или URN, потому что URI содержит данные. Он не называет его и не указывает, как найти его по сети.
Существуют также унифицированные ссылки на ресурсы (URC), которые указывают на метаданные о документе, а не на сам документ. Примером УРК будет индикатором для просмотра исходного кода веб — страницы: view-source:http://example.com/. URC — это другой тип URI, который не является ни URL, ни URN.
Я слышал, что не должен больше говорить URL, почему?
Спецификация w3 для HTML гласит, что hrefтег привязки может содержать URI, а не только URL. Вы должны быть в состоянии положить в URN, таких как <a href="urn:isbn:0451450523">. Ваш браузер затем разрешит этот URN в URL и загрузит книгу для вас.
Знают ли какие-либо браузеры, как получать документы по URN?
Не то, чтобы я знал, но современный веб-браузер реализует схему URI данных.
Может ли URI быть как URL, так и URN?
Хороший вопрос. Я видел много мест в Интернете, которые утверждают, что это правда. Я не смог найти никаких примеров чего-то, что является и URL, и URN. Я не вижу, как это возможно, потому что URN начинается с urn:недопустимого сетевого протокола.
Различие между URL и URI имеет какое-либо отношение к тому, является ли оно относительным или абсолютным?
Нет. Как относительные, так и абсолютные URL-адреса являются URL-адресами (и URI).
Разница между URL и URI имеет какое-либо отношение к тому, имеет ли он параметры запроса?
Нет. Оба URL с параметрами запроса и без них являются URL-адресами (и URI).
Разница между URL и URI имеет какое-либо отношение к тому, имеет ли он идентификатор фрагмента?
Нет. Оба URL с идентификаторами фрагментов и без них являются URL (и URI).
Является ли tel:URI URL — адрес или URN?
Например tel:1-800-555-5555. Он не начинается с urn:и имеет протокол для доступа к ресурсу через сеть. Это должен быть URL.
Но разве w3C не говорит, что URL и URI — это одно и то же?
Да. W3C осознал, что в этом есть куча путаницы. Они выпустили разъясняющий документ URI, в котором говорится, что теперь можно использовать URL и URI взаимозаменяемо. Больше не нужно строго сегментировать URI на разные типы, такие как URL, URN и URC.
Автор: Stephen Ostermiller Размещён: 04.03.2015 09:52URI — это… Что такое URI?
URI (англ. Uniform Resource Identifier) — унифицированный (единообразный) идентификатор ресурса. На английский манер произносится как [ю-ар-а́й], по-русски чаще говорят [у́ри]. URI — это последовательность символов, идентифицирующая абстрактный или физический ресурс. Ранее назывался Universal Resource Identifier — универсальный идентификатор ресурса.
Основы
URI — это символьная строка, позволяющая идентифицировать какой-либо ресурс: документ, изображение, файл, службу, ящик электронной почты и т. д. Прежде всего, речь идёт, конечно, о ресурсах сети Интернет и Всемирной паутины. URI предоставляет простой и расширяемый способ идентификации ресурсов. Расширяемость URI означает, что уже существуют несколько схем идентификации внутри URI, и ещё больше будет создано в будущем.
Подробнее см. «Структура URI» ниже.
Связь между URI, URL и URN
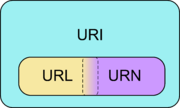
URI является либо URL, либо URN, либо одновременно обоими.
URL — это URI, который, помимо идентификации ресурса, предоставляет ещё и информацию о местонахождении этого ресурса. А URN — это URI, который только идентифицирует ресурс в определённом пространстве имён (и, соответственно, в определённом контексте), но не указывает его местонахождения. Например, URN urn:ISBN:0-395-36341-1 — это URI, который указывает на ресурс (книгу) 0-395-36341-1 в пространстве имён ISBN, но, в отличие от URL, URN не указывает на местонахождение этого ресурса: в нём не сказано, в каком магазине её можно купить, или на каком сайте скачать. Впрочем, в последнее время появилась тенденция говорить просто URI о любой строке-идентификаторе, без дальнейших уточнений. Так что, возможно, термины URL и URN скоро уйдут в прошлое.
Поскольку URI не всегда указывает на то, как получить ресурс, в отличие от URL, а только идентифицирует его, это даёт возможность описывать с помощью RDF (Resource Description Framework) ресурсы, которые не могут быть получены через Интернет (например, личность, автомобиль, город и проч.).
История
В 1990 году в Женеве, Швейцария, в стенах Европейского совета по ядерным исследованиям (фр. Conseil Européen pour la Recherche Nucléaire, CERN) британским учёным Тимом Бернерсом-Ли был изобретён определитель местонахождения ресурса URL. Так как URL является наиболее используемым подмножеством URI, то этот же 1990 год принято считать годом рождения URI. Но, строго говоря, концепция URI была документально оформлена лишь в июне 1994 года в документе RFC 1630.
Новая версия URI была определена в 1998 году в RFC 2396, тогда же слово Universal в названии было заменено на Uniform. В декабре 1999 года RFC 2732 ввёл в спецификацию URI небольшие изменения, обеспечив совместимость с IPv6. В августе 2002 года RFC 3305 анонсировал устаревание термина URL и приоритет URI. Текущая структура и синтаксис URI регулируется стандартом RFC 3986, вышедшим в январе 2005 года. Многие новейшие технологии семантической паутины (например, RDF) базируются на стандарте URI. Сейчас ведущая роль в развитии URI принадлежит Консорциуму Всемирной паутины.
Недостатки
URL стал фундаментальным нововведением в Интернете, поэтому принципы URI документально закреплялись так, чтобы обеспечить полную совместимость с URL. Отсюда появился и большой недостаток URI, пришедший как наследство от URL. В URI, как и в URL, можно использовать только ограниченный набор латинских символов и знаков препинания (даже меньший, нежели в ASCII). Иными словами, если мы захотим использовать в URI символы кириллицы, или иероглифы, или, скажем, специфические символы французского языка, то нам придётся кодировать URI таким же образом, каким в Википедии кодируются URL с символами Юникода. Например, строка вида:
http://ru.wikipedia.org/wiki/Кириллица
кодируется в URL как:
http://ru.wikipedia.org/wiki/%D0%9A%D0%B8%D1%80%D0%B8%D0%BB%D0%BB%D0%B8%D1%86%D0%B0
Поскольку такому преобразованию подвергаются буквы всех алфавитов, кроме используемой в английском языке латиницы, то URI со словами на других языках (даже европейских) утрачивают способность восприниматься людьми. А это входит в грубое противоречие с принципом интернационализма, провозглашаемого всеми ведущими организациями Интернета, включая W3C и ISOC. Эту проблему призван решить стандарт IRI (англ. International Resource Identifier) — международных идентификаторов ресурсов, в которых можно было бы без проблем использовать символы Юникода, и которые не ущемляли бы права других языков. Хотя заранее сложно сказать, смогут ли когда-либо идентификаторы IRI заменить URI, имеющие столь широкое употребление.
Ещё одной интересной вариацией URI является расширяемый идентификатор ресурса XRI (англ. Extensible Resource Identifier), разработанный организацией OASIS. Этот формат стремится создавать идентификаторы, которые были бы совершенно независимы от контекста, то есть не зависели бы ни от протокола, ни от домена, ни от пути, ни от приложения, ни от платформы — были бы совершенно независимыми.
Также и сам создатель URI, Тим Бернерс-Ли, говорил, что система доменных имён, лежащая в основе URL, — плохое решение, навязывающее ресурсам иерархическую архитектуру, мало подходящую для гипертекстового веба.
Структура URI
URI = [ схема ":" ] иер-часть [ "?" запрос ] [ "#" фрагмент ]
В этой записи:
- схема
- схема обращения к ресурсу (часто указывает на сетевой протокол), например http, ftp, file, ldap, mailto, urn
- иер-часть
- содержит данные, обычно организованные в иерархической форме, которые, совместно с данными в неиерархическом компоненте запрос, служат идентификации ресурса в пределах видимости URI-схемы. Обычно иер-часть содержит путь к ресурсу (и, возможно, перед ним, адрес сервера, на котором тот располагается) или идентификатор ресурса (в случае URN).
- запрос
- этот необязательный компонент URI описан выше.
- фрагмент
- (тоже необязательный компонент) позволяет косвенно идентифицировать вторичный ресурс посредством ссылки на первичный и указанием дополнительной информации. Вторичный идентифицируемый ресурс может быть некоторой частью или подмножеством первичного, некоторым его представлением или другим ресурсом, определённым или описанным таким ресурсом.
Цитата из RFC 3986: The fragment identifier component of a URI allows indirect identification of a secondary resource by reference to a primary resource and additional identifying information. The identified secondary resource may be some portion or subset of the primary resource, some view on representations of the primary resource, or some other resource defined or described by those representations.
Часть идентификатора URI без схемы обращения к ресурсу часто называется «ссылкой URI» (англ. URI reference). Прецеденты применения ссылок URI имеются в HTML, XHTML, XML и XSLT. Процесс превращения ссылки URI в абсолютную форму URI называют «разрешением URI» (англ. URI resolution).
Процесс разработки новых схем описан в документе RFC 2718. Новые схемы должны регистрироваться в организации IANA (англ. Internet Assigned Numbers Authority), процедура регистрации зафиксирована в RFC 2717. Оба указанных запроса комментариев (RFC) сейчас находятся в процессе переработки.
Разбор структуры URI
Для так называемого «па́рсинга» URI (англ. parsing), то есть для разложения URI на составные части и их последующей идентификации удобнее всего использовать систему регулярных выражений, доступную ныне почти во всех современных языках программирования. Для разбора URI рекомендуется[1] использовать следующий шаблон:
^(([^:/?#]+):)?(//([^/?#]*))?([^?#]*)(\?([^#]*))?(#(.*))? 12 3 4 5 6 7 8 9
Этот шаблон включает в себя 9 обозначенных выше цифрами групп (подробнее о шаблонах и группах см. Регулярные выражения), которые наиболее полно и точно разбирают типичную структуру URI, где:
- группа 2 — схема,
- группа 4 — источник,
- группа 5 — путь,
- группа 7 — запрос,
- группа 9 — фрагмент.
Таким образом, если при помощи данного шаблона разобрать, например, такой типичный идентификатор URI:
http://www.ics.uci.edu/pub/ietf/uri/#Related
то 9 вышеуказанных групп шаблона дадут следующие результаты соответственно:
- http:
- http
- //www.ics.uci.edu
- www.ics.uci.edu
- /pub/ietf/uri/
- нет результата
- нет результата
- #Related
- Related
Примеры URI
Абсолютные URI
- http://ru.wikipedia.org/wiki/URI
- ftp://ftp.is.co.za/rfc/rfc1808.txt
- file://C:\UserName.HostName\Projects\Wikipedia_Articles\URI.xml
- ldap://[2001:db8::7]/c=GB?objectClass?one
- mailto:John.Doe@example.com
- sip:911@pbx.mycompany.com
- news:comp.infosystems.www.servers.unix
- data:text/plain;charset=iso-8859-7,%be%fe%be
- tel:+1-816-555-1212
- telnet://192.0.2.16:80/
- urn:oasis:names:specification:docbook:dtd:xml:4.1.2
Ссылки URI
/relative/URI/with/absolute/path/to/resource.txt
relative/path/to/resource.txt
../../../resource.txt
resource.txt
/resource.txt#frag01
#frag01
[пустая строка] — эквивалентно разбору идентификатора парсером с результатом [пустая строка], то есть ссылка идет на объект по умолчанию в схеме по умолчанию[источник не указан 535 дней]