Как закрыть индексацию сайта через robots, htaccess, метатеги
Пошаговая инструкция как закрыть сайт на wordpress (и другие) от индексации.
Приятного чтения!
Закажите создание сайта, или продвижение, или контекстную рекламу у нас
Есть несколько вариантов:
I. Через файл robots.txt;
II. Через файл .htaccess;
III. Через метатеги noindex, nofollow;
IV. Через панель администратора wordpress;
Закрываем индексацию сайта через файл robots.txt:1.1 Для начала проверим есть ли такой файл. Для этого зайдем на сервере в папку с файлами сайта, обычна она называется также как доменное имя:
1.2 Если такого файла нет:
1.2.1 На рабочем столе компьютера нажимаем правой кнопкой мыши, в выпавшем меню выбираем «Создать», далее выбираем «Текстовый документ»:
1.
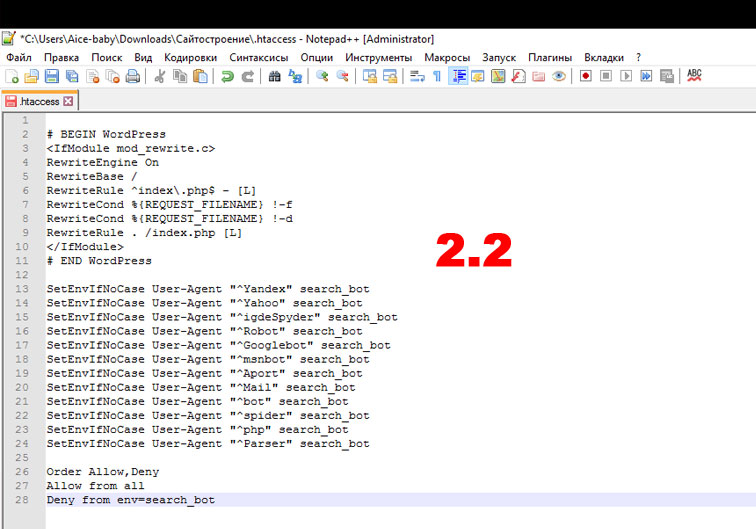
Так как у меня сайт на CMS WordPress, то мой файл будет выглядеть вот так:
2.3 Сохраняем файл .htaccess и закачиваем его обратно в корневую папку сайта, замещая старый файл;
Запрещаем индексацию через метатеги noindex, nofollow
Для этого нужно знать, в каком из файлов лежит шаблон header для страниц вашего сайта. Ниже я опишу вариант для WordPress
3.1 Для вордпресса вы должны зайти на сервере по директории /ДОМЕННОЕ ИМЯ ВАШЕГО САЙТА/wp-content/themes/ВАША ТЕМА. Ниже приведен пример для сайта frez.by с используемой темой astra:
3.2 Находим файл «header.php»:
3.3 Скачиваем это файл себе на компьютер с сервера и открываем в текстовом редакторе. После чего находим тег «<head>», после которого сразу вставляет метагег:
<meta name="robots" content="noindex, nofollow">
3.4 Сохраняем файл и не забываем закачать обратно на сервер;
Как закрыть сайт от индексации wordpress через панель управления
4. 1 Заходим в административную панель сайта, в боков меню ищем раздел «Настроки» (4.1), далее выбираем подраздел «Чтение» (4.2), далее в низу страницы находим предложение «Попросить поисковые системы не индексировать сайт» и ставим галочку (4.3) и не забываем сохранить (4.4):
1 Заходим в административную панель сайта, в боков меню ищем раздел «Настроки» (4.1), далее выбираем подраздел «Чтение» (4.2), далее в низу страницы находим предложение «Попросить поисковые системы не индексировать сайт» и ставим галочку (4.3) и не забываем сохранить (4.4):
Все, готово!
Теперь вы знаете как закрыть сайт от индексации.
Надеюсь статья была вам полезна.
Если есть вопросы — задавайте в комментариях
Закажите создание сайта, или продвижение, или контекстную рекламу у нас
Похожие
- Добавление товаров Woocommerce
- Перенос сайта wordpress на другой домен sql
- Как установить joomla
Как закрыть сайт от индексации в robots.
 txt, через htaccess и мета-теги
txt, через htaccess и мета-тегиПривет уважаемые читатели seoslim.ru! Некоторые пользователи интернета удивляются, какими же быстродействующими должны быть компьютеры Яндекса, чтобы в несколько секунд просмотреть все сайты в глобальной сети и найти ответ на вопрос?
Но на самом деле за пару секунд изучить все данные WWW не способна ни одна современная, даже самая мощная вычислительная машина.
Содержание:
Как поисковые системы индексируют сайты
Как поставить запрет на индексацию с помощью:
— robots.txt
— htaccess
— админ панели WordPress
— метатегов
Давайте сегодня пополним наши знания о всемирной сети и разберемся, как поисковые машины ищут и находят ответы на вопросы пользователей и каким образом можно им запретить это делать.
Что такое индексация сайта
Опубликованный на страницах сайтов контент собирается заранее и хранится в базе данных поисковой системы.
Называется эта база данных Индексом (Index), а собственно процесс сбора информации в сети с занесением в базу ПС называется «индексацией».
Продвинутые пользователи мгновенно сообразят, получается, что если текст на странице сайта не занесен в Индекс поисковика, так эта информация не может быть найдена и контент не станет доступен людям?
Так оно и есть. Каждый день тысячи веб-мастеров публикуют на своих площадках новые статьи. Однако доступными для поиска эти новые публикации становятся далеко не сразу.
Это полезно знать: Какую роль в работе сайта играют DNS-сервера
В плане индексации Google работает несколько быстрее нашего Яндекса.
- Публикация на сайте станет доступна в поиске Гугл через несколько часов. Иногда индексация происходит буквально в считанные минуты.
- В Яндексе процесс сбора информации относительно нового контента в интернете происходит значительно медленнее. Иногда новая публикация на сайте или блоге появляется в Яндексе через две недели.
Чтобы ускорить появление вновь опубликованного контента, администраторы сайтов могут вручную добавить URL новых страниц в инструментах Яндекса для веб-мастеров. Однако и это не гарантирует, что новая статья немедленно появится в интернете.
Однако и это не гарантирует, что новая статья немедленно появится в интернете.
С другой стороны, бывают ситуации, когда веб-страница или отдельная часть контента уже опубликованы на сайте, но вот показывать этот контент пользователям нежелательно по каким-либо причинам.
- Страница еще не полностью доработана, и владелец сайта не хочет показывать людям недоделанный продукт, поскольку это производит негативное впечатление на потенциальных клиентов.
- Существует разновидностей технического контента, который не предназначен для широкой публики. Определенная информация обязательно должна быть на сайте, но вот видеть ее обычным людям пользователям не нужно.
- В статьях размещаются ссылки и цитаты, которые необходимы с информационной точки зрения, но вот находиться в базе данных поисковой системы они не должны. Например, эти ссылки выглядят как неестественные и за их публикацию в проект может быть подвергнут штрафным санкциям.
В общем, причин, почему веб-мастеру не хотелось бы, чтобы целые веб-страницы или отдельные блоки контента, ссылки не были занесены в базы поисковиков, может существовать много.
Давайте разберемся, как задачу управления индексацией решить практически.
Как скрыть сайт от индексации поисковыми системами
Сбором информации в интернете и занесением его в базу данных поисковой системы занимаются автоматические программы, называемые роботами-индикаторами. Веб-мастера часто называют этих роботов сокращенно «ботами».
Слово «боты» вы могли уже встречать в различных мессенджерах. В этих системах быстрой коммуникации боты тоже являются компьютерными программами, выполняющими определенные функции или задачи.
Так вот, для того, чтобы роботы-индексаторы не занесли определенные веб-страницы или контент в Index поисковика, следует сформировать специальные команды, которые указывают ботам, что некоторые страницы на сайте посещать запрещено, а некоторый контент не следует заносить в поисковые базы.
Настроить команды запрета индексации можно несколькими способами, которые мы и рассмотрим ниже.
Запрет в robots.txt
В корневой папке сайта на удаленном сервере хостинг-провайдера имеется файл с именем robots.
- Что такое корневая папка сайта? Корневая папка или каталог – это то место, которому в первую очередь производится запрос из браузера, когда пользователь обращается к какому-нибудь ресурсу в интернете. То есть, это исходная папка с которой начинаются все запросы к веб-ресурсу.
- Файл robots.txt – это пакетный командный файл, в котором содержатся директивы для ПС, ответственных за индексацию контента.
Говоря простыми словами, robots.txt это специальный файл, предназначенный для поисковых роботов. Что, собственно, понятно из самого имени документа – Robots, что означает «роботы».
Отредактировать файл с командами для роботов ПС можно вручную в простом текстовом редакторе, добавить или удалить команды, изменить отдельные записи.
У каждой поисковой системы действует множество роботов, которые ответственны за индексацию разного рода контента. Отдельные роботы ищут и заносят в базу изображения, текст, скрипты и все остальное, что только может иметь значение для нормальной работы интернет-проекта.
Роботов индексаторов довольно много, перечислим только некоторых из них:
- Yandex – главный робот, ответственный за индексацию проекта в поисковой системе Яндекс.
- YaDirectBot – робот, ответственный за индексацию веб-страниц, на которых опубликована реклама контекстной системы Яндекс Директ.
- Yandex/1.02.000 (F) – робот, занимающийся индексации фавиконов, иконок сайта, которые пользователь видит во вкладках браузера и в сниппетах на странице выдачи.
- Yandex Images – индексация изображений.
Как вы понимаете, директивы или команды следует задавать для каждого конкретного робота в том случае, если вы желаете задать правила поведения индексация индексируемых роботов в отношении определенного типа контента.
Если же необходимо задать правила индексации для всей поисковой системы, тогда в файле robots.txt прописывается директива для главного робота.
В поисковой системе Google работают свои роботы:
- Googlebot – основной бот Google.

- Googlebot Video – сбор информации о видеороликах, размещенных на площадке.
- Googlebot Images – индексация картинок.
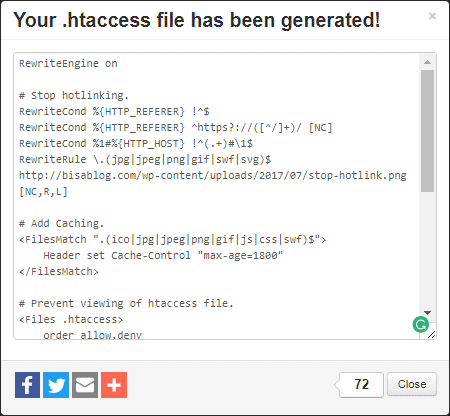
А теперь давайте рассмотрим, как выглядят сами директивы или команды для поисковых роботов.
- Команда User-agent: определяет, какому конкретному роботу предназначена директива. Если в этой команде указана звездочка * – это означает что команда предназначена для всех, любых поисковых роботов.
- Команда Disallow означает запрет индексации, а команда Allow означает разрешение индексации.
Например, команда User-agent: Yandex задает правила поведения для всех поисковых роботов Яндекса. Если юзер-агент не задан, то команды будут действовать для всех поисковых систем.
В общем-то, для того, чтобы вручную редактировать файл robot.txt, не нужно быть опытным программистам.
В профессиональных конструкторах сайтов и системах управления контентом обычно предусмотрен отдельный интерфейс для настройки файла robots.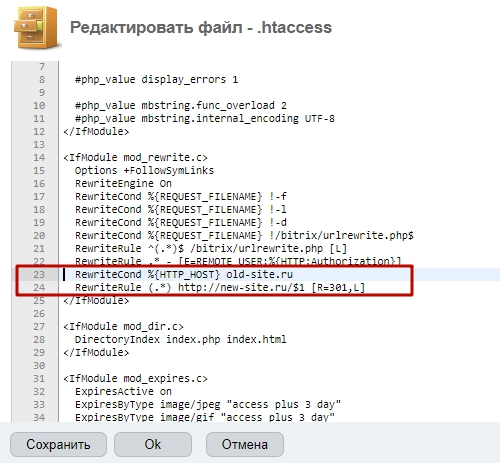 txt. Знать конкретные названия поисковых роботов и разбираться в директивах необходимости нет. Достаточно указать то, что вам нужно в самом файле.
txt. Знать конкретные названия поисковых роботов и разбираться в директивах необходимости нет. Достаточно указать то, что вам нужно в самом файле.
Рассмотрим для примера некоторые команды.
- User-agent: *
- Disallow: /
Эта директива запрещает обход проекта любым роботам всех поисковых систем. Если же будет указана директива Allow — сайт открыт для индексации.
Следующая команда запрещает обход всем поисковым системам, кроме Яндекса.
- User-agent: *
- Disallow: /
- User-agent: Yandex
- Allow: /
Чтобы запретить индексацию только отдельных страниц, создается вот такая команда – запрет на обход страниц «Контакты» и «О компании».
- User-agent: *
- Disallow: /contact/
- Disallow: /about/
Закрыть целый отдельный каталог сайта:
- User-agent: *
- Disallow: /catalog/
Закрыть папку с картинками:
- Disallow: /images/
Не индексировать файлы с указанным расширением:
- User-agent: *
- Disallow: /*. jpg
 jpg
jpgРазличных команд, с помощью которых можно управлять поисковыми роботами, существует достаточно много. Веб-мастер может в широких пределах регулировать схему индексации веб-страниц и отдельных типов контента.
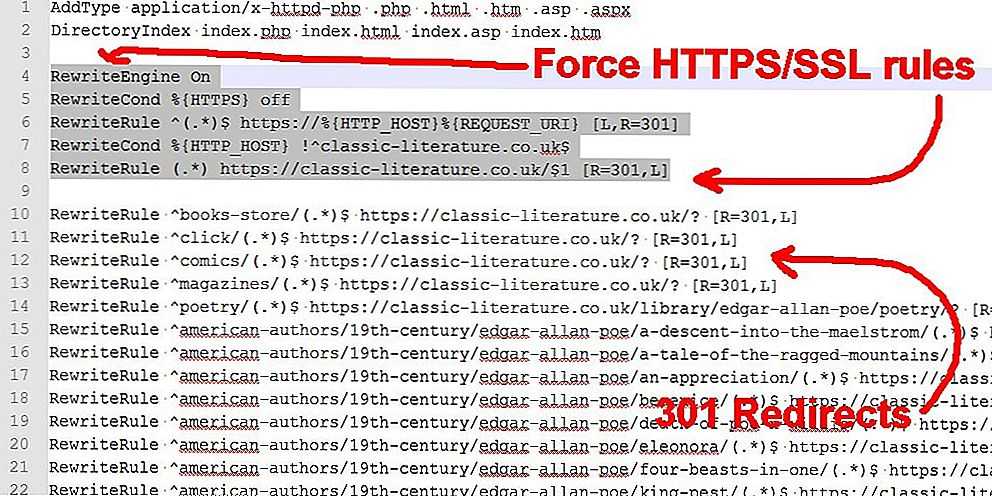
Запрет индексации через htaccess
На серверах Apache для управления доступом используется файл .htaccess (hypertext access).
Особенностью функционирования этого файла является то, что его команды распространяются только на папку или каталог, в которых этот файл размещен. Если этот файл помещается в корневой каталог, то его директивы будут действовать на весь ресурс.
Возникает логичный вопрос, зачем использовать более сложный .htaccess, если задать порядок индексации можно в файле robots.txt?
Дело в том, что далеко не все роботы не всех поисковых систем подчиняются команда файла robots.txt. Зачастую поисковые роботы просто игнорируют этот файл.
С другой стороны, директивы .htaccess являются всеобъемлющими по отношению к сайтам, размещенным на серверах типа Apache.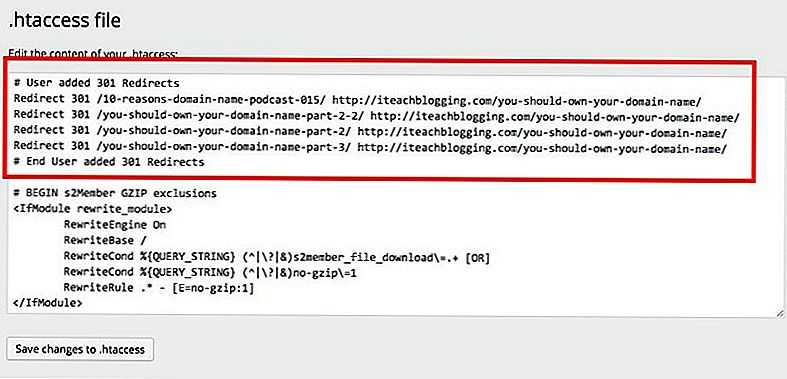 Googlebot» search_bot
Googlebot» search_bot
Как вы могли заметить, хотя .htaccess является простым текстовым файлом, он не имеет расширения txt, а должен иметь именно указанный формат, в противном случае сервер его не распознает.
С помощью админ панели WordPress
Зайдите в административную панель своего блога на WordPress и выберите раздел «Настройки». Нажмите на пункт Меню «Чтение».
После перехода в интерфейс «Чтение», вы найдете следующие возможности для настройки индексации.
Отметьте пункт «Попросить поисковые системы не индексировать сайт», если не хотите, чтобы контент был доступен в открытом интернете. Не забудьте сохранить изменения.
Как видите, при помощи админ панели WordPress можно сделать только общие запреты или разрешения. Для более тонких настроек индексации следует использовать файл robots.txt и .htaccess.
С помощью meta-тега
Управлять индексацией можно и с помощью тегов в HTML-документе веб-страницы.
Директивы добавляются в файле header.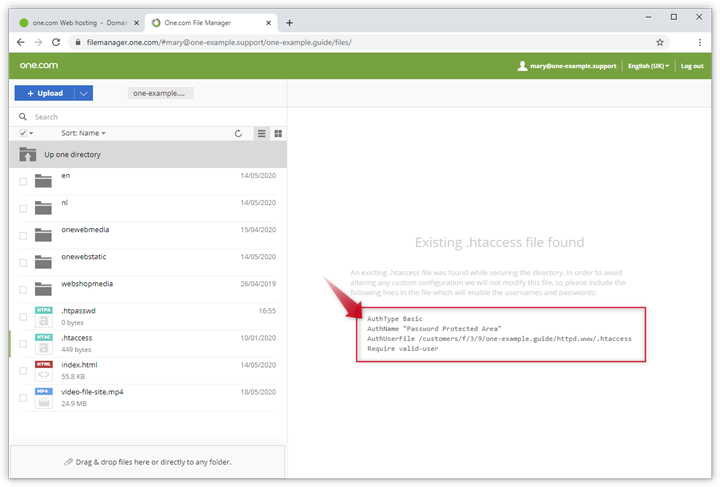 php в контейнере <head> … </head>.
php в контейнере <head> … </head>.
Команда выглядит следующим образом:
<meta name=”robots” content=”noindex, nofollow”/>
Это означает, что поисковым роботам запрещается индексация контента. Если вместо robots указа точное имя бота определенной поисковой машины, то запрет будет касаться только ее роботов.
На этом все, как видите существует много методов, которые позволят скрыть площадку от поисковых систем. Какой использовать вам, решайте сами.
Только помните, что проанализировать правильность директив относительно индексации сайта можно с помощью инструментов Яндекса для веб-мастеров либо через SEO-сервисы.
htaccess — Как предотвратить индексацию определенного PDF-файла поисковыми системами в WordPress?
спросил
Изменено 2 года, 4 месяца назад
Просмотрено 1к раз
В многосайтовой установке WordPress я хотел бы заблокировать индексацию определенного файла PDF с помощью заголовка ответа HTTP X-Robots-Tag с использованием файла htaccess.
Ни одно из указаний, найденных в предыдущих связанных вопросах (например, в этом), не сработало в моем случае.
Я использовал инструкции, но все проверки и все онлайн-проверки не показывают заголовки, которые мне нужны
Это мои конфиги htaccess
Это настоящие заголовки в инспекторе браузера
- htaccess
- поисковая индексация
8
<Файлы> 9Директива 0030 применяется только к именам файлов , а не к путям к файлам, поэтому ваша директива никогда не будет совпадать, и заголовок не будет установлен.
Чтобы установить этот заголовок для определенного файла (а не для всех файлов .pdf - как в связанных вопросах/ответах) в корневом файле .htaccess , вы можете установить переменную среды, когда этот файл запрашивается и условно установите заголовок на основе этой env var.
Например:
SetEnvIf Request_URI "/path/to/example.
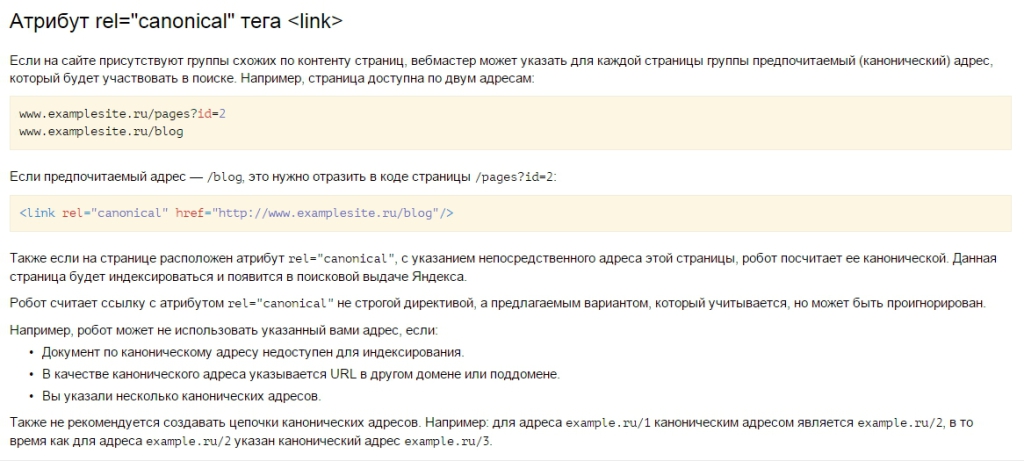 pdf" NOINDEX
Набор заголовков X-Robots-Tag "noindex, nofollow" env=NOINDEX
pdf" NOINDEX
Набор заголовков X-Robots-Tag "noindex, nofollow" env=NOINDEX
В качестве альтернативы, если вы можете поместить дополнительный файл .htaccess в каталог, содержащий файл PDF, который вы хотите настроить, то вы можете использовать директиву в этом файле .htaccess :
< Файлы "пример.pdf"> Набор заголовков X-Robots-Tag "noindex, nofollow"
Вы можете использовать тот же метод в корневом файле .htaccess , но он также добавит заголовок к all example.pdf файловых запросов в системе - хотя, я думаю, маловероятно, что у вас есть более одного файла с одинаковым именем, так что в конце концов это может быть лучшим решением.
2
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
.
 htaccess — Как запретить поисковым системам индексировать все URL-адреса, начинающиеся с origin.domainname.com
htaccess — Как запретить поисковым системам индексировать все URL-адреса, начинающиеся с origin.domainname.comспросил
Изменено 4 года, 1 месяц назад
Просмотрено 19 тысяч раз
У меня есть www.domainname.com, origin.domainname.com, указывающие на одну и ту же кодовую базу. Есть ли способ предотвратить индексацию всех URL-адресов с базовым именем origin.domainname.com.
В файле robot.txt есть какое-то правило для этого. Оба URL-адреса указывают на одну и ту же папку. Кроме того, я попытался перенаправить origin.domainname.com на www.domainname.com в файле htaccess, но это, похоже, не работает. 9robots.txt$ - [L]
Вместо того, чтобы просить поисковые системы заблокировать все страницы для страниц, отличных от www.