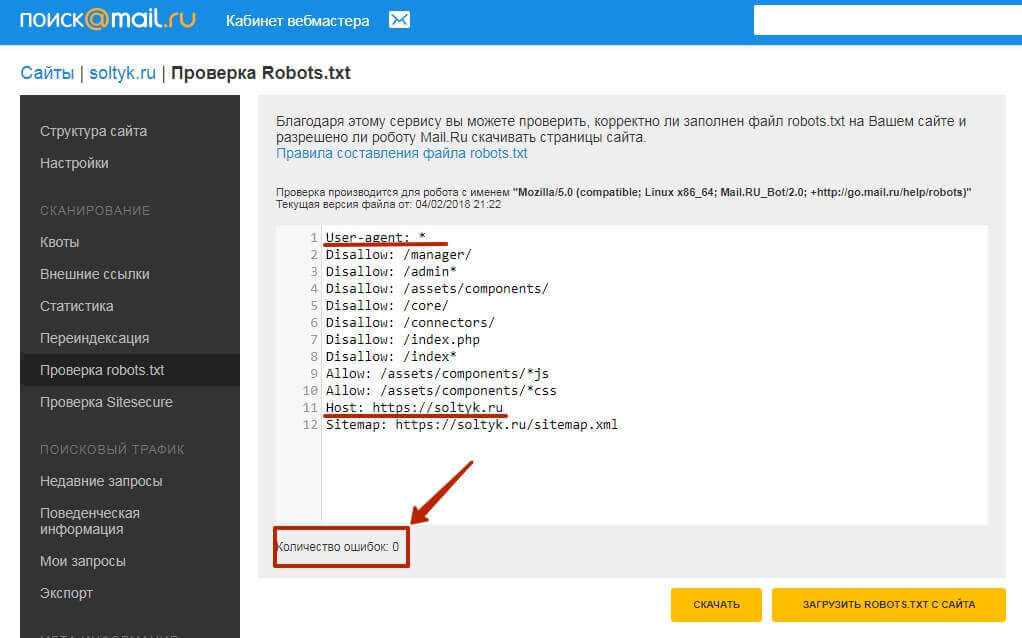
Яндекс отменил директиву host в файле robots.txt
В файле robots.txt содержится информация о сайте для поисковых роботов. Раньше Яндекс требовал размещения в этом файле директивы host, которая указывала на главное зеркало сайта. В 2018 году от нее решили отказаться полностью, чтобы вебмастерам было легче работать. В Google эта директива не учитывалась никогда. Чтобы изменить протокол на безопасный или переехать на другой домен, теперь используют более простой способ.
Какая команда появилась после директивы host
Раньше длительность переезда сайта на новый домен в Яндексе доходила до месяца, так как связь главного и второстепенного зеркал оказывала большое влияние на позиции в выдаче. Сейчас переезд проходит всего за несколько дней, что благоприятно сказывается на продвижении. Такое стало возможным благодаря редиректу 301, который заменил директиву хост. Теперь алгоритм смены протокола и домена ничем не отличается. Google изначально работал по такому принципу.
Для продолжения работы в обязательном порядке настраивают 301 редирект (переадресацию), директива host при переезде значение утратила полностью. Нововведения помогли ускорить и облегчить процесс перехода. Однако при переезде на новый домен или смене протокола нередко возникают непредвиденные ситуации, индивидуальные для каждого случая, поэтому алгоритм действий может отличаться. Иногда процесс затягивается, но в большинстве случаев переехать удается гораздо быстрее, чем раньше.
Нововведения помогли ускорить и облегчить процесс перехода. Однако при переезде на новый домен или смене протокола нередко возникают непредвиденные ситуации, индивидуальные для каждого случая, поэтому алгоритм действий может отличаться. Иногда процесс затягивается, но в большинстве случаев переехать удается гораздо быстрее, чем раньше.
Как проходит смена протокола или переезд на другой домен
Чтобы сменить протокол на безопасный или переехать на другой домен, убедитесь в том, что права собственности на обе версии сайта подтверждены. Затем выполните несколько простых действий:
- настройте редирект 301;
- перейдите в панель Вебмастера;
- в разделе «Переезд сайта» пропишите адрес зеркала — выберите в чек-боксе «добавить https» или «добавить www», если это необходимо.
Сразу проверять корректность переиндексации ресурса не стоит, так как для обновления требуется несколько дней. Зато команду host можно удалять, ведь она стала бесполезной как для Гугла, так и для Яндекса.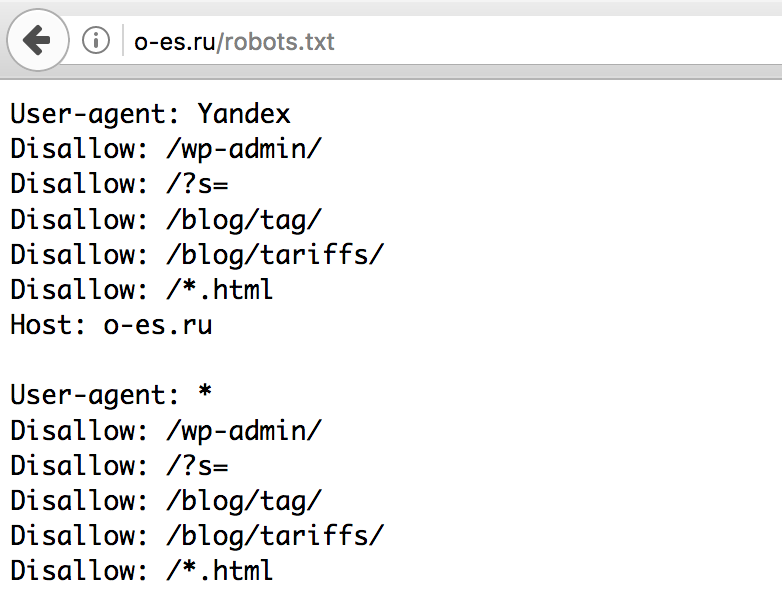 Обе версии сайта должны быть доступны для поисковых роботов.
Обе версии сайта должны быть доступны для поисковых роботов.
Можно ли переехать без настройки редиректа 301
Переезд без настройки 301 редиректа возможен, однако это сопряжено с рядом проблем:
- Например, вы переезжаете с домена на домен, и у вас нет технической возможности настроить 301 редирект. В этом случае старый домен должен быть удален или скрыт от индексации. Если оставить старый домен после переезда, индексация нового будет невероятно долгой — займет даже не недели, а месяцы. Когда она будет завершена, есть вероятность, что оба домена будут признаны аффилиатами в Яндексе и приняты за дубли в Google.
Напоминаем, что оставлять открытыми для индексации старый и новый домены можно было до 2018 года, а далее директиву host отменили.
- Если вы меняете протокол http на https, но не настраиваете 301 редирект, хорошего результата ждать не стоит. Да, в панели вебмастера вы укажете Яндексу, какое зеркало — главное. Однако в индексе появятся дубли каждой страницы — одновременно на двух протоколах, и поисковые роботы сочтут их разными. Таким образом, вы задублируете весь сайт.
Настоятельно рекомендуем настраивать редиректы с http на https, все современные CMS без проблем позволяют это сделать. - Переезд на новое зеркало с www или без www в этом смысле схож со сменой протокола на https. Нужна настройка 301 редиректа, иначе вы также задублируете весь сайт.

Отметим, что переадресацию желательно было настраивать и до 2018 года, когда директива host еще учитывалась, поскольку редирект передает вес страниц, и Google никогда не «понимал» host.
Можно ли поставить редиректы, но не переезжать
Такое тоже возможно. Главное, чтобы все редиректы вели на основное зеркало. Если раньше для распознавания Яндекс изучал директиву host, то теперь поисковик определяет главный домен самостоятельно.
Если вы выполнили настройку редиректа, Яндекс «поймет» факт переезда. Раньше на это указывала директива host и соответствующие настройки в Вебмастере. Теперь достаточно заполнить соответствующие поля в Вебмастере. Даже если вы этого не сделаете — некритично, на возможность переезда это не повлияет. Просто переезд займет больше времени.
Что будет, если не ставить редиректы и никуда не переезжать
Если не провести процедуру переезда правильно, поисковые системы либо сочтут новый сайт дублем (либо имеющим много внутренних дублирующихся страниц), либо решат, что вы просто создали несколько одинаковых сайтов. И то и другое может повлечь негативные последствия, вплоть до наложения санкций.
Позиция «я что-то такое сделал (например переехал на https), но не выяснил, как посмотрят на это Яндекс и Google» — губительна для ранжирования нового или обновленного ресурса в рейтинге поисковых систем. Переезд должен быть обоснован, продуман, выполнен технически грамотно. Так было и когда работала директива host, и после того, как ее упразднили, с той лишь разницей, что до 2018 года старый сайт мог оставаться в выдаче, а в директиве host мог быть прописан новый. При этом трафик в любом случае приносил только один ресурс.
Так было и когда работала директива host, и после того, как ее упразднили, с той лишь разницей, что до 2018 года старый сайт мог оставаться в выдаче, а в директиве host мог быть прописан новый. При этом трафик в любом случае приносил только один ресурс.
Если поисковик не обращает внимания на редиректы
Обычно такая ситуация возникает, когда редиректы установили с ошибками, поэтому в первую очередь проверьте корректность выполнения настроек. Остальные действия будут такими же, как и в случае со стандартным переездом или сменой протокола.
Редиректы на мобильных версиях
Директива host не требовала настройки отдельных редиректов для мобильных версий, хотя иногда поисковых роботов перенаправляли на основное зеркало. Сейчас ситуация практически не изменилась. Роботы без проблем могут исследовать любую версию сайта.
Заключение
Директиву host теперь можно смело удалять из robots.txt, ведь Яндекс тоже стал ее игнорировать. В принципе, если ее оставить, она никак не повлияет на SEO, так как стала бесполезным атрибутом. Подобные изменения Яндекс проводит для того, чтобы повысить скорость индексации и сделать процессы переезда на новый домен и смены протокола более удобными и быстрыми.
Подобные изменения Яндекс проводит для того, чтобы повысить скорость индексации и сделать процессы переезда на новый домен и смены протокола более удобными и быстрыми.
Sprinthost — robots.txt
robots.txt — текстовый файл, в котором указаны правила индексации сайта. С его помощью можно регулировать частоту обращений поисковых роботов, запретить индексирование отдельных страниц или всего сайта.
Разместите файл c именем robots.txt в корневой директории вашего сайта и наполните его правилами. Рассмотрим основные.
User-agent
В первой строке укажите директиву User-agent. Она определяет имена роботов, для которых составлены правила. Например: User-agent: Yandex только для ботов Яндекса; User-agent: * для всех существующих ботов.
Список имен поисковых роботов есть в документации Яндекса и Google.
Disallow, Allow
Директивы Disallow и Allow ограничивают доступ роботов к определенным страницам. С их помощью вы можете закрыть от индексирования административную часть и другие разделы сайта.
Disallow запрещает индексацию, Allow разрешает индексировать отдельные ссылки внутри запрещенных. Например: Allow: /public Правило запрещает индексировать все, кроме страниц вида domain.ru/public
Disallow: /
Директивы работают со специальными символами «*» и «$». Символ «*» задает последовательность из неограниченного количества символов (0 и более): Disallow: /catalog/*.html Правило запрещает доступ роботам ко всем страницам из раздела catalog с расширением .html.
При этом идентичными будут правила: Disallow: /catalog/*Disallow: /catalog/
Символ «$» жестко указывает на конец правила: Disallow: /catalog/boxs$ Такое правило запрещает индексирование страницы domain.ru/catalog/boxs , в то же время доступ к domain.ru/catalog/boxs.html роботы получить смогут.
Crawl-delay
Директива Crawl-delay определяет максимальное число запросов к сайту от робота. Она помогает избежать повышенного потребления ресурсов из-за активности поисковых ботов.
Достаточно направлять один запрос в 7 секунд: Crawl-delay: 7
Не все роботы следуют этому правилу. Для Яндекса и Google скорость обхода указывается в кабинете вебмастера.
Clean-param
Порой в ссылках содержатся параметры (идентификаторы сессий, пользователей), которые не влияют на содержимое страницы.
Например, на странице domain.ru/catalog есть каталог товаров, которые можно отфильтровать. После применения фильтра получится следующий набор ссылок: domain.ru/catalog
domain.ru/catalog? =1domain.ru/catalog?product=2
Первый URL включает в себя весь каталог продуктов, индексация этой же страницы с параметрами не нужна. Используйте Clean-param, чтобы убрать лишние ссылки из поисковой выдачи: Clean-param: product /catalog
Указать несколько параметров можно через символ «&»: Clean-param: product&price /catalog
Clean-param ускоряет обход сайта поисковыми роботами и снижает нагрузку на сервер.
Host
Если ваш сайт имеет несколько доменов (алиасов), укажите основное имя с помощью директивы Host: Host: domain.ru
Sitemap
Sitemap указывает роботу расположение карты сайта: Sitemap: http://domain.ru/sitemap.xml
Как отключить индексацию
Если вы не хотите, чтобы сайт индексировался, укажите правило: User-agent: *
Disallow: /
При составлении файла robots.txt рекомендуем ознакомиться со справочной информацией поисковиков: некоторые правила могут не поддерживаться или игнорироваться роботами.
Была ли эта инструкция полезной?
seo — Могу ли я использовать директиву «Хост» в robots.txt?
спросил
Изменено 1 год, 2 месяца назад
Просмотрено 9к раз
В поисках конкретной информации по robots. я наткнулся на справочную страницу Яндекса ‡ по этой теме. Это предполагает, что я мог бы использовать 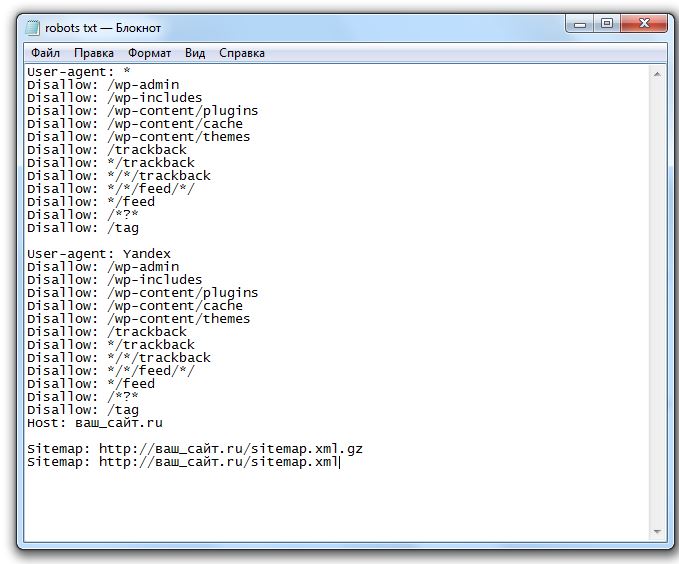 txt
txt Директива хоста , сообщающая поисковым роботам мой предпочтительный зеркальный домен:
User-Agent: * Запретить: /директор/ Хост: www.example.com
Также в статье Википедии говорится, что Google тоже понимает директиву Host , но информации было немного (т.е. никакой).
На robotstxt.org я ничего не нашел по адресу Host (или Crawl-delay , как указано в Википедии).
- Рекомендуется ли вообще использовать директиву
Host? - Есть ли в Google какие-либо ресурсы по этому
robots.txt? - Как совместимость с другими поисковыми роботами?
‡ По крайней мере, с начала 2021 года связанная запись больше не касается рассматриваемой директивы.
- SEO
- robots.txt
3
Оригинальная спецификация robots. txt гласит:
txt гласит:
Нераспознанные заголовки игнорируются.
Они называют это «заголовки», но этот термин нигде не определен. Но, как упоминается в разделе о формате и в том же абзаце, что и User-agent и Disallow , кажется безопасным предположить, что «заголовки» означают «имена полей».
Так что да, вы можете использовать Хост или любое другое имя поля .
- Парсеры robots.txt, которые поддерживают такие поля, ну и поддерживают.
- Парсеры robots.txt, которые не поддерживают такие поля, должны игнорировать их.
Но имейте в виду: поскольку они не указаны в проекте robots.txt, вы не можете быть уверены, что разные парсеры одинаково поддерживают это поле. Поэтому вам придется вручную проверять каждый поддерживающий парсер.
2
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью GoogleЗарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Можно ли использовать домены в robots.
 txt?
txt?У нас есть сервер разработки по адресу dev.example.com, который индексируется Google. Мы используем AWS Lightsail для полного дублирования сервера разработки в нашу производственную среду — один и тот же файл robots.txt используется как на dev.example.com, так и на example.com.
В документации Google robots.txt явно не указано, можно ли определять корневые домены. Могу ли я внедрить специфичные для домена правила в файл robots.txt? Например, допустимо ли это:
Агент пользователя: * Запретить: https://dev.example.com/ Пользовательский агент: * Разрешить: https://example.com/ Карта сайта: https://example.com/sitemap.xml
Чтобы добавить, это можно решить с помощью механизма перезаписи .htaccess — мой вопрос конкретно о robots.txt.
- robots.txt
Нет, в robots.txt указать домен нельзя. Запретить: https://dev.example.com/ недействителен. На странице 6 стандарта исключения robots.txt говорится, что строка запрета должна содержать «путь», а не полный URL-адрес, включая домен.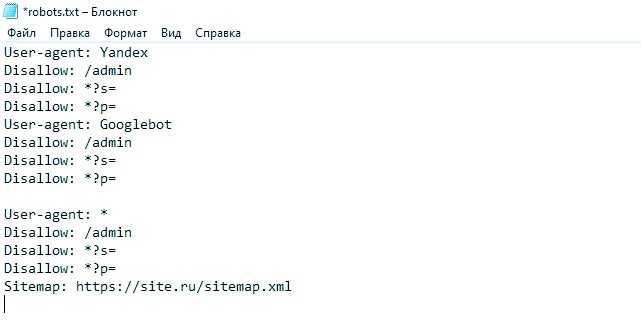
Каждое имя хоста (домен или субдомен) имеет свой
собственный файл robots.txt . Таким образом, чтобы Googlebot не сканировал http://dev.example.com/ , вам нужно будет обслуживать https://dev.example.com/robots.txt с содержимым:User-agent: * Запретить: /
В то же время вам нужно будет обслуживать файл, отличный от http://example.com/ , возможно, с содержимым:
User-agent: * Запретить: Карта сайта: https://example.com/sitemap.xml
Если одна и та же кодовая база используется как на ваших серверах разработки, так и на рабочих серверах, вам потребуется обусловить содержание файла robots.txt в зависимости от того, работает он в рабочей среде или нет.
В качестве альтернативы вы можете разрешить роботу Googlebot сканировать и то, и другое, но включать тегов на каждую страницу, которые указывают на URL-адрес страницы на действующем сайте.