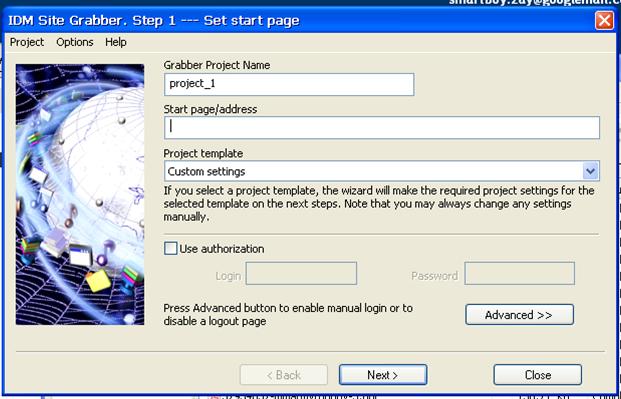
Делаем парсер, чтобы массово тянуть с сайтов что угодно
Однажды мы рассказывали, как утащить что угодно с любого сайта, — написали свой парсер и забрали с чужого сайта заголовки статей. Теперь сделаем круче — покажем на примере нашего сайта, как можно спарсить вообще весь текст всех статей.
Простая работа с исключениями
Парсинг — это когда вы забираете какую-то конкретную информацию с сайта в автоматическом режиме. Для этого пишется софт (скрипт или отдельная программа), софт настраивается под конкретный сайт, и дальше он ходит по нужным страницам и всё оттуда забирает.
После парсинга полученный текст можно передать в другие программы — например подстроить свои цены под цены конкурентов, обновить информацию на своём сайте, проанализировать текст постов или собрать бигдату для тренировки нейросетей.
Что делаем
Сегодня мы спарсим все статьи «Кода» кроме новостей и задач, причём сделаем всё так:
- Научимся обрабатывать одну страницу.

- Сделаем из этого удобную функцию для обработки.
- Найдём все адреса всех нужных страниц.
- Выберем нужные нам рубрики.
- Для каждой рубрики создадим отдельный файл, в который добавим всё текстовое содержимое всех статей в этой рубрике.

Чтобы потом можно было нормально работать с текстом, мы не будем парсить вставки с примерами кода, а ещё постараемся избавиться от титров, рекламных баннеров и плашек.
Будем работать поэтапно: сначала научимся разбирать контент на одной странице, а потом подгрузим в скрипт все остальные статьи.
Выбираем страницу для отладки
Технически самый простой парсинг делается двумя командами в Python, одна из которых — подключение сторонней библиотеки. Но этот код не слишком полезен для нашей задачи, сейчас объясним.
from urllib.request import urlopen
inner_html_code = str(urlopen('АДРЕС СТРАНИЦЫ').read(),'utf-8')Когда мы заберём таким образом страницу, мы получим сырой код, в котором будет всё: метаданные, шапка, подвал и т. д. А нам нужно не только достать информацию из самой статьи (а не всей страницы), а ещё и очистить её от ненужной информации.
д. А нам нужно не только достать информацию из самой статьи (а не всей страницы), а ещё и очистить её от ненужной информации.
Чтобы скрипт научился отбрасывать ненужное, придётся ему прописать, что именно отбрасывать. А для этого нужно знать, что нам не нужно. А значит, нам нужно взять какую-то старую статью, в которой будут все ненужные элементы, и на этой одной странице всё объяснить.
Для настройки скрипта мы возьмём нашу старую статью. В ней есть всё нужное для отладки:
- текст статьи,
- подзаголовки,
- боковые ссылки,
- кат с кодом,
- просто вставки кода в текст,
- титры,
- рекламный баннер.
Получаем сырой текст
Вот что мы сейчас сделаем:
- Подключим библиотеку urlopen для обработки адресов страниц.
- Подключим библиотеку BeautifulSoup для разбора исходного кода страницы на теги.
- Получим исходный код страницы по её адресу.
- Распарсим его по тегам.
- Выведем текстовое содержимое распарсенной страницы.

На языке Python это выглядит так:
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSoup
from bs4 import BeautifulSoup
# получаем исходный код страницы
inner_html_code = str(urlopen('https://thecode.media/parsing/').read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# выводим содержимое страницы
print(inner_soup.get_text())Если посмотреть на результат, то видно, что в вывод пошло всё: и программный код из примеров, и текст статьи, и служебные плашки, и баннер, и ссылки с рекомендациями. Такой мусорный текст не годится для дальнейшего анализа:
Чистим текст
Так как нам требуется только сама статья, найдём раздел, в котором она лежит. Для этого посмотрим исходный код страницы, нажав Ctrl+U или ⌘+⌥+U. Видно, что содержимое статьи лежит в блоке <div>, причём такой блок на странице один.
Чтобы из всего исходного кода оставить только этот блок, используем команду find() с параметром 'div', {"class": 'article-content'} — она найдёт нужный нам блок, у которого есть характерный признак класса.
Добавим эту команду перед выводом текста на экран:
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
Стало лучше: нет мусора до и после статьи, но в тексте всё ещё много лишнего — содержимое ката с кодом, преформатированный код ( вот такой), вставки с кодом, титры и рекламный баннер.
Чтобы избавиться и от этого, нам нужно знать, в каких тегах или блоках это лежит. Для этого нам снова понадобится заглянуть в исходный код страницы. Логика будет такая: находим фрагмент текста → смотрим код, который за него отвечает, → удаляем этот код из нашей переменной.Например, если мы хотим убрать титры, то находим блок, где они лежат, а потом в цикле удаляем его командой decompose().
Сделаем функцию, которая очистит наш код от любых разделов и тегов, которые мы укажем в качестве параметра:
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code. find_all(tag, arg):
# и удаляем их из кода
div.decompose()
А теперь добавим такой код перед выводом содержимого:
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})Титры исчезли, но реклама осталасьТочно так же проанализируем исходный код и добавим циклы для удаления остального мусора:
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры, перебирая все их возможные индексы в цикле (потому что баннеры в коде имеют номера от 1 до 99)
for i in range(99):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')Теперь всё в порядке: у нас есть только текст статьи, без внешнего обвеса, лишнего кода и ссылок. Можно переходить к массовой обработке.
Собираем функцию
У нас есть скрипт, который берёт одну конкретную ссылку, идёт по ней, чистит контент и получает очищенный текст. Сделаем из этого функцию — на вход она будет получать адрес страницы, а на выходе будет давать обработанный и очищенный текст. Это нам пригодится на следующем шаге, когда будем обрабатывать сразу много ссылок.
Если запустить этот скрипт, получим тот же результат, что и в предыдущем разделе.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code.find_all(tag, arg):
# и удаляем их из кода
div.decompose()
# очищаем текст по указанному адресу
def clear_text(url):
# получаем исходный код страницы
inner_html_code = str(urlopen(url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html. parser")
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры
for i in range(11):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')
# возвращаем содержимое страницы
return(inner_soup.get_text())
print(clear_text('https://thecode.media/parsing/')) 
Получаем адреса всех страниц
Одна из самых сложных вещей в парсинге — получить список адресов всех нужных страниц. Для этого можно использовать:
- карту сайта,
- внутренние рубрикаторы,
- разделы на сайте,
- готовые страницы со всеми ссылками.

В нашем случае мы воспользуемся готовой страницей — там собраны все статьи с разбивкой по рубрикам: https://thecode.media/all. Но даже в этом случае нам нужно написать код, который обработает эту страницу и заберёт оттуда только адреса статей. Ещё нужно предусмотреть, что нам не нужны ссылки из новостей и задач.
Идём в исходный код общей страницы и видим, что все ссылки лежат внутри списка:
При этом каждая категория статей лежит в своём разделе — именно это мы и будем использовать, чтобы обработать только нужные нам категории. Например, вот как рубрика «Ахах» выглядит на странице:
А вот она же — но в исходном коде. По названию легко понять, какой блок за неё отвечает:
Чтобы найти раздел в коде по атрибуту, используем команду find() с параметром attrs — в нём мы укажем название рубрики. А чтобы найти адрес в ссылке — используем команду select(), в которой укажем, что ссылка должна лежать внутри элемента списка.
Теперь логика будет такая:
- Создаём список с названиями нужных нам рубрик.
- Делаем функцию, куда будем передавать эти названия.
- Внутри функции находим рубрику по атрибуту.
- Перебираем все элементы списка со ссылками.
- Находим там адреса и записываем в переменную.
- Для проверки — выводим переменную с адресами на экран.

def get_all_url(data_title):
html_code = str(urlopen('https://thecode.media/all').read(),'utf-8')
soup = BeautifulSoup(html_code, "html.parser")
# находим рубрику по атрибуту
s = soup.find(attrs={"data-title": data_title})
# тут будут все найденные адреса
url = []
# перебираем все теги ссылок, которые есть в списке
for tag in s.select("li:has(a)"):
# добавляем адрес ссылки в нашу общую переменную
url.append(tag.find("a")["href"])
# выводим найденные адреса
print(url)
# названия рубрик, которые нам нужны
division = ['Ахах','Не стыдно','Это баг','Это как']
# перебираем все рубрики
for el in division:
# и обрабатываем каждую рубрику отдельно
get_all_url(el)На выходе у нас все адреса страниц из нужных рубрик. Теперь объединим обе функции и научим их сохранять текст в файл.
Теперь объединим обе функции и научим их сохранять текст в файл.
Сохраняем текст в файл
Единственное, чего нам сейчас не хватает, — это сохранения в файл. Чтобы каждая рубрика хранилась в своём файле, привяжем имя файла к названию рубрики. Дальше логика будет такая:
- Берём функцию get_all_url(), которая формирует список всех адресов для каждой рубрики.
- В конец этой функции добавляем команду создания файла с нужным названием.
- Открываем файл для записи.
- Перебираем в цикле все найденные адреса и тут же отправляем каждый адрес в функцию clear_text().
- Результат работы этой функции — готовый контент — записываем в файл и переходим к следующему.
Так у нас за один прогон сформируются адреса, и мы получим содержимое страницы, которые сразу запишем в файл. Читайте комментарии, чтобы разобраться в коде:
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code. find_all(tag, arg):
# и удаляем их из кода
div.decompose()
# очищаем текст по указанному адресу
def clear_text(url):
# получаем исходный код страницы
inner_html_code = str(urlopen(url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры
for i in range(11):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')
# возвращаем содержимое страницы
return(inner_soup. get_text())
# формируем список адресов для указанной рубрики
def get_all_url(data_title):
# считываем страницу со всеми адресами
html_code = str(urlopen('https://thecode.media/all').read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим рубрику по атрибуту
s = soup.find(attrs={"data-title": data_title})
# тут будут все найденные адреса
url = []
# перебираем все теги ссылок, которые есть в списке
for tag in s.select("li:has(a)"):
# добавляем адрес ссылки в нашу общую переменную
url.append(tag.find("a")["href"])
# имя файла для содержимого каждой рубрики
content_file_name = data_title + '_content.txt'
# открываем файл и стираем всё, что там было
file = open(content_file_name, "w")
# перебираем все адреса из списка
for x in url:
# сохраняем обработанный текст в файле и переносим курсор на новую строку
file.write(clear_text(x) + '\n')
# закрываем файл
file. close()
# названия рубрик, которые нам нужны
division = ['Ахах','Не стыдно','Это баг','Это как']
# перебираем все рубрики
for el in division:
# и обрабатываем каждую рубрику отдельно
get_all_url(el)Содержимое файла с рубрикой «Ахах» find_all(tag, arg):
# и удаляем их из кода
div.decompose()
# очищаем текст по указанному адресу
def clear_text(url):
# получаем исходный код страницы
inner_html_code = str(urlopen(url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры
for i in range(11):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')
# возвращаем содержимое страницы
return(inner_soup.
find_all(tag, arg):
# и удаляем их из кода
div.decompose()
# очищаем текст по указанному адресу
def clear_text(url):
# получаем исходный код страницы
inner_html_code = str(urlopen(url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры
for i in range(11):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')
# возвращаем содержимое страницы
return(inner_soup. get_text())
# формируем список адресов для указанной рубрики
def get_all_url(data_title):
# считываем страницу со всеми адресами
html_code = str(urlopen('https://thecode.media/all').read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим рубрику по атрибуту
s = soup.find(attrs={"data-title": data_title})
# тут будут все найденные адреса
url = []
# перебираем все теги ссылок, которые есть в списке
for tag in s.select("li:has(a)"):
# добавляем адрес ссылки в нашу общую переменную
url.append(tag.find("a")["href"])
# имя файла для содержимого каждой рубрики
content_file_name = data_title + '_content.txt'
# открываем файл и стираем всё, что там было
file = open(content_file_name, "w")
# перебираем все адреса из списка
for x in url:
# сохраняем обработанный текст в файле и переносим курсор на новую строку
file.write(clear_text(x) + '\n')
# закрываем файл
file.
get_text())
# формируем список адресов для указанной рубрики
def get_all_url(data_title):
# считываем страницу со всеми адресами
html_code = str(urlopen('https://thecode.media/all').read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим рубрику по атрибуту
s = soup.find(attrs={"data-title": data_title})
# тут будут все найденные адреса
url = []
# перебираем все теги ссылок, которые есть в списке
for tag in s.select("li:has(a)"):
# добавляем адрес ссылки в нашу общую переменную
url.append(tag.find("a")["href"])
# имя файла для содержимого каждой рубрики
content_file_name = data_title + '_content.txt'
# открываем файл и стираем всё, что там было
file = open(content_file_name, "w")
# перебираем все адреса из списка
for x in url:
# сохраняем обработанный текст в файле и переносим курсор на новую строку
file.write(clear_text(x) + '\n')
# закрываем файл
file. close()
# названия рубрик, которые нам нужны
division = ['Ахах','Не стыдно','Это баг','Это как']
# перебираем все рубрики
for el in division:
# и обрабатываем каждую рубрику отдельно
get_all_url(el)
close()
# названия рубрик, которые нам нужны
division = ['Ахах','Не стыдно','Это баг','Это как']
# перебираем все рубрики
for el in division:
# и обрабатываем каждую рубрику отдельно
get_all_url(el)Что дальше
Теперь у нас есть все тексты всех статей. Как-нибудь проанализируем частотность слов в них (как в проекте с текстами Льва Толстого) или научим нейросеть писать новые статьи на основе старых.
Objective-C | Урок 4 Часть 1 — Создаем парсер новостей из сайта-блога для iPhone.
- Главная >
- Видео канал >
 org/ListItem»>
Objective-C | Урок 4 Часть 1 — Создаем парсер новостей из сайта-блога для iPhone.
org/ListItem»>
Objective-C | Урок 4 Часть 1 — Создаем парсер новостей из сайта-блога для iPhone.
УЛУЧШАЙТЕ НАВЫКИ С ПОМОЩЬЮ ПРАКТИКУМА
СЛЕДУЮЩЕЕНа данном уроке, рассматривается тема — «Создание парсера новостей из сайта-блога для iPhone». Пример создания программы-парсер новостей с вашего сайта/блога в приложение для iPhone. Реализация будет состоять из двух частей. Еще больше полезной информации на ITVDN.
Please enable JavaScript to view the comments powered by Disqus.Регистрация через
✖или E-mail
Нажав на кнопку «Зарегистрироваться»,
Вы соглашаетесь с условиями использования.
Уже есть аккаунт
Получите курс бесплатно
✖
Вы выбрали курс для изучения
«»
Чтобы получить доступ к курсу, зарегистрируйтесь на сайте.
РЕГИСТРАЦИЯ
Спасибо за регистрацию
✖
Перейдите на почту и подтвердите Ваш аккаунт,
чтобы получить доступ ко всем
бесплатным урокам и вебинарам на сайте ITVDN.com
ПОДТВЕРДИТЬ ПОЧТУ НАЧАТЬ ОБУЧЕНИЕ
Спасибо за регистрацию
✖
Ваш аккаунт успешно подтвержден.
Начать обучение вы можете через Личный кабинет
пользователя или непосредственно на странице курса.
НАЧАТЬ ОБУЧЕНИЕ
Подтверждение аккаунта
На Ваш номер телефона было отправлено смс с кодом активации аккаунта. Пожалуйста, введите код в поле ввода.
Пожалуйста, введите код в поле ввода.
Отправить код еще раз
Изменить номер телефона
Ошибка
✖Что такое веб-риппер и лучшие бесплатные рипперы веб-сайтов
Есть три возможные причины, по которым вы читаете эту статью:
👉 1. Вы активно ищете веб-риппер.
👉 2. Некоторые друзья-гики упомянули веб-рипперы, а вы постеснялись признаться в своем невежестве, поэтому погуглили.
👉 3. Вы начали копаться в одной из этих печально известных кроличьих нор в Интернете, и к настоящему времени вы не помните, как начался этот веб-поиск, где вы живете или как вас зовут.
Какой бы ни была причина, по которой вы здесь оказались, мы ответим на ваши вопросы о рипперах веб-сайтов. Таким образом, вы либо:
A. Найдёте то, что ищете,
B. Почувствуете себя в состоянии поговорить с друзьями о веб-рипперах, не выглядя при этом идиотом, или
C. Наконец-то выберетесь из этой кроличьей норы и вернётесь в цивилизацию. .
.
Что такое риппер сайта?
Программа для копирования веб-сайтов — это программа, которая копирует весь веб-сайт или его части, чтобы вы могли загрузить его для чтения и анализа в автономном режиме. Вы можете копировать и извлекать данные, изображения, файлы и ссылки и загружать эти данные на свой компьютер. Но зачем кому-то это может понадобиться? Вот четыре причины скачать веб-сайт:
- Вы можете просматривать сайт без подключения к Интернету
- Вы можете сохранить загруженную копию своего веб-сайта в качестве резервной копии
- Вы можете загрузить исходные файлы и перенести свой сайт на новый сервер
- Вы можете использовать веб-данные для в образовательных целях, таких как изучение исходного кода
Как скопировать веб-сайт?
Это что и почему из пути, но как вы копируете веб-сайт? Для этого вам понадобится программное обеспечение для извлечения данных. Существует несколько инструментов для копирования веб-сайтов, которые могут выполнить эту работу, но чтобы помочь вам выбрать, мы сузили список до пяти (в пятом вас ждет приятный сюрприз) 😉
HTTrack
HTTrack — мощный инструмент, позволяющий загружать веб-сайты для просмотра в автономном режиме. Начните с Мастера 🧙♂️ и выберите необходимое количество подключений и элементы, которые вы хотите извлечь. Инструмент создаст каталог веб-сайта с HTML-кодом, файлами и изображениями сервера и передаст его на ваш компьютер. Когда вы откроете страницу скопированного веб-сайта, вы сможете просматривать ее так же, как в Интернете.
Начните с Мастера 🧙♂️ и выберите необходимое количество подключений и элементы, которые вы хотите извлечь. Инструмент создаст каталог веб-сайта с HTML-кодом, файлами и изображениями сервера и передаст его на ваш компьютер. Когда вы откроете страницу скопированного веб-сайта, вы сможете просматривать ее так же, как в Интернете.
Основные недостатки: Не позволяет скачать ни одну страницу сайта; требует времени и усилий, чтобы исключить ненужные типы файлов
SiteSucker
SiteSucker может показаться оскорблением, но на самом деле это очень полезный веб-риппер. Однако это только для компьютеров Mac. SiteSucker копирует отдельные веб-страницы, таблицы стилей, изображения и PDF-файлы и позволяет загружать их на локальный жесткий диск. Все, что вам нужно сделать, это ввести URL-адрес веб-сайта и нажать Enter. Вы можете приостанавливать и возобновлять загрузку, а также доступен ряд языков: французский, испанский, немецкий, итальянский и португальский.
Вы можете приостанавливать и возобновлять загрузку, а также доступен ряд языков: французский, испанский, немецкий, итальянский и португальский.
Основные недостатки: Только для Mac
Cyotek WebCopy
Cyotek WebCopy — это бесплатный инструмент, который может частично или полностью копировать веб-сайты на ваш локальный жесткий диск, сканируя указанный сайт и загружая его на твой компьютер. Он переназначает ссылки на изображения, видео и таблицы стилей, чтобы они соответствовали локальным путям. Он имеет сложную конфигурацию, которая позволяет вам определить, какие части веб-сайта следует копировать.
Основные достоинства: Сложная конфигурация, позволяющая копировать веб-сайты частично или полностьюОсновные недостатки: Не может обрабатывать сайты, использующие JavaScript или динамические функции; может очищать только то, что появляется в браузере
Getleft
Getleft — бесплатная загружаемая программа для Windows. При этом вы можете загружать полные веб-сайты, просто указав URL-адрес. Он поддерживает 14 языков и редактирует исходные страницы и ссылки на внешние сайты, чтобы вы могли эмулировать онлайн-просмотр на своем жестком диске. Вы также можете возобновить прерванную загрузку и использовать фильтры, чтобы выбрать файлы для загрузки.
При этом вы можете загружать полные веб-сайты, просто указав URL-адрес. Он поддерживает 14 языков и редактирует исходные страницы и ссылки на внешние сайты, чтобы вы могли эмулировать онлайн-просмотр на своем жестком диске. Вы также можете возобновить прерванную загрузку и использовать фильтры, чтобы выбрать файлы для загрузки.
Основные недостатки: Может обрабатывать только HTML; не могу скачать файлы, встроенные в JavaScript
Универсальные парсеры
Теперь пришло время раскрыть тот сюрприз, который мы скрывали! Наша пятая запись на самом деле представляет собой список из 5 парсеров. Все веб-рипперы используют веб-сканирование и сбор данных, поэтому эти инструменты очень пригодятся, если вы хотите извлечь и загрузить веб-данные. Пять парсеров ниже — самые мощные инструменты на платформе Apify. С их помощью вы можете извлекать практически любые данные (при условии, что это законно) с любого веб-сайта в любом масштабе.
С их помощью вы можете извлекать практически любые данные (при условии, что это законно) с любого веб-сайта в любом масштабе.
Универсальные веб-скраперы · Apify
Счищайте любой веб-сайт с помощью универсальных скребков. Puppeteer или Playwright Scraper для полных браузерных задач или Vanilla JS и Cheerio Scraper, если нет динамического контента.
ApifyЧтобы начать работу с любым из следующих инструментов, вам нужно только указать парсеру, какие страницы он должен загружать и как извлекать данные с каждой страницы. Парсеры начинают с загрузки страниц, указанных с помощью URL-адресов, и могут переходить по ссылкам страниц для рекурсивного сканирования целых веб-сайтов.
Web Scraper
Web Scraper — универсальный простой в использовании инструмент для сканирования веб-страниц и извлечения из них структурированных данных с помощью нескольких строк кода JavaScript. Он загружает веб-страницы в браузере Chromium и отображает динамический контент.
Cheerio Scraper
Cheerio Scraper — это готовое решение для сканирования веб-сайтов с использованием простых HTTP-запросов. Быстрая и легкая альтернатива Web Scraper, веб-скрапинг Cheerio подходит для веб-сайтов, которые не отображают контент динамически. Он извлекает HTML-страницы, анализирует их с помощью библиотеки Cheerio Node.js и позволяет быстро извлекать из них любые данные.
Vanilla JS Scraper
Vanilla JS Scraper — это не-jQuery альтернатива Cheerio Scraper, которая хорошо подходит для парсинга веб-страниц, которые не полагаются на клиентский JavaScript для обслуживания своего контента. Это может быть до 20 раз быстрее, чем полнобраузерное решение, такое как Puppeteer.
Puppeteer Scraper
Puppeteer Scraper — это полнофункциональное браузерное решение, поддерживающее вход на веб-сайт, рекурсивное сканирование и пакетные URL-адреса в Chrome. Как следует из названия, этот инструмент использует библиотеку Puppeteer для программного управления безголовым браузером Chrome и может заставить его делать практически все что угодно. Puppeteer — это библиотека Node.js, поэтому для использования этого мощного инструмента требуется знание Node.js и его парадигм.
Puppeteer — это библиотека Node.js, поэтому для использования этого мощного инструмента требуется знание Node.js и его парадигм.
Playwright Scraper
Драматургический аналог Puppeteer Scraper, Playwright Scraper отлично подходит для создания решений для парсинга и веб-автоматизации. Он поддерживает функции помимо браузеров на основе Chromium, обеспечивая полный программный контроль над Firefox и Safari. Как и в случае с Puppeteer Scraper, этот инструмент требует знания Node.js.
Решение для кроличьей норы
Если ни один из вышеперечисленных инструментов не соответствует вашим требованиям, или если они кажутся вам слишком сложными, вместо того, чтобы спускаться в другую кроличью нору через постоянно расширяющуюся вселенную сети за этим неуловимым идеальное решение, у нас есть идея получше. Свяжитесь с нами в Apify и дайте нам знать, что вам нужно. Мы будем рады обсудить ваш случай и разработать инструмент или решение именно для вас!
Загрузчик веб-сайтов | Копир сайта | Загрузчик сайта
Загрузчик сайта | Копир сайта | Загрузчик сайта | Website RipperЭто приложение лучше всего работает с включенным JavaScript.
6k
Акции
Загрузите весь исходный код и активы любого веб-сайта
Основные преимущества
Самый простой способ
загрузить веб-сайт .Независимая от платформы
Веб-интерфейс позволяет использовать риппер веб-сайтов прямо в браузере в любой операционной системе, без загрузки или настройки какого-либо программного обеспечения. Используйте его, когда вам нужно быстро скачать сайт .
Fast Previews
Website Downloader предлагает быстрый предварительный просмотр результатов загрузки, размещенных на наших серверах, без использования драгоценного дискового пространства вашего компьютера. После предварительного просмотра вы можете загрузить веб-страницу или загрузить весь сайт .
Простота
Загрузчик веб-сайтов очень прост и удобен в использовании, но обладает расширенными функциями, такими как загрузка только подкаталога или определенных страниц с веб-сайта (как загрузчик веб-страниц ). Веб-граббер — это самый простой способ загрузить веб-сайт .
Веб-граббер — это самый простой способ загрузить веб-сайт .
Что люди говорят о нас
Опыт работы с лучшим
Копир веб-сайтов . Реувен Коэн@rUv
Украсть полный исходный код любого веб-сайта? Websitedownloader.io pic.twitter.com/ko6KO9T1eF
6 20:55 — 12 августа 2016 г. justin barbour@jus10barbour
Полезный инструмент для работы с локальными копиями сайтов: DL всего исходного кода HTML и ресурсов любого сайт с WebsiteDownloader.io bit.ly/website-downloader
5 10:05 — 11 августа 2016 Raul L Cruz@iamRaulCruz
Быстро загружайте исходный код любого веб-сайта в легко редактируемый формат (включая все активы) | Websitedownloader.io
4 8:19 — 9 августа 2016 Тиффани Уордл@typegirl
Еще один полезный способ недорого получить визуальный архив вашей учетной записи @flickr. Websitedownloader. io
io
@AMDesignlovin
Нашел этот классный инструмент для загрузки ресурсов веб-страницы. bit.ly/website-downloader
4 16:00 — 9 августа 2016 Кейси Оуэнс@clowens3
Ознакомьтесь с этим новым загрузчиком веб-сайтов – buff.ly/2aZufqw #web #design #dev #FrontEnd #css #html #js #php pic.twitter.com/K2W4JAfljJ
1 16:54 — 19 августа 2016 Джонатан Паски@jonathanpasky
Очень круто: загрузите исходный код и активы любого веб-сайта: bit.ly/ загрузчик веб-сайтов
2 9:53:00 — 11 августа 2016 г. John-Bunya Klutse@JBKlutse
Ищете инструмент для загрузки всего исходного кода HTML и ресурсов любого веб-сайта. Попробуйте Websitedownloader.io #jbklutse #websitedownloader
2 9:43 — 11 августа 2016 Ben Novak@novakben
Загрузите весь исходный HTML-код и активы любого веб-сайта с WebsiteDownloader. io, посетите bit.ly/website -downloader
io, посетите bit.ly/website -downloader
@larrysivitz
Вы не работаете со службой, которая загружает весь исходный код HTML и активы любого веб-сайта? Websitedownloader.io
2 17:46 — 8 августа 2016 Цезарь Разури@CeaseTheDay
Довольно изящно: новый загрузчик веб-сайтов Websitedownloader.io
3 8:18 — 9 августа 2016 Сурадж Барти@ surajbarthy
Исходный код кто-нибудь? fb.me/1lG7V0FyX
2 22:00 — 8 августа 2016Нравится Загрузчик веб-сайтов? Голосуйте за нас на RankedByVotes
Особенности загрузчика веб-сайтов
Загрузчик веб-сайтов,
Копир веб-сайтов или Ripper веб-сайтов позволяет загружать веб-сайты из Интернета на локальный жесткий диск вашего компьютера. Загрузчик веб-сайтов упорядочивает загруженный сайт по исходной относительной структуре ссылок веб-сайтов. Загруженный веб-сайт можно просмотреть, открыв одну из HTML-страниц в браузере.
HTML
Веб-граббер берет каждый HTML-файл, загружает и клонирует его на локальный жесткий диск. Вы можете использовать HTML-редактор для внесения изменений в каждый HTML-файл локально или использовать онлайн-редактор HTML. Если вы не кодер, вы можете вместо этого использовать редактор WYSIWYG-HTML.
Преобразование ссылок
Мы преобразуем все ссылки в HTML-файлах, чтобы они работали локально, в автономном режиме, а не указывали на онлайн-сайт.
CSS и JavaScript
Файлы CSS и JavaScript загружаются в простую структуру папок и правильно ссылаются в файлах HTML.
Изображения
Как и другие ресурсы, изображения также загружаются и используются локально.
Варианты использования популярного загрузчика веб-сайтов
После клонирования веб-сайта на жесткий диск вы можете открыть исходный код веб-сайта с помощью редактора кода или просто просмотреть его в автономном режиме с помощью выбранного вами браузера.
 Site Downloader можно использовать для разных целей. Это действительно просто использовать программное обеспечение для загрузки веб-сайта , ничего не загружая.
Site Downloader можно использовать для разных целей. Это действительно просто использовать программное обеспечение для загрузки веб-сайта , ничего не загружая.Резервные копии
Если у вас есть веб-сайт, у вас всегда должна быть свежая резервная копия веб-сайта на случай, если сервер сломается или вас взломают. Загрузчик веб-сайтов — это самый быстрый и простой способ сделать резервную копию вашего веб-сайта, он позволяет вам загрузить весь веб-сайт .
Автономный загрузчик веб-сайтов
Загрузите веб-сайт в автономном режиме для дальнейшего использования, к которому вы можете получить доступ, скажем, даже без подключения к Интернету. когда вы в полете или на отдыхе на острове!
Миграция сайта
Если вы привязаны к своему хостинг-провайдеру или по какой-либо другой причине не имеете доступа к исходным файлам вашего веб-сайта, просто используйте копировальный аппарат веб-сайта , чтобы загрузить файлы и перенести свой веб-сайт на новый сервер. Не забудьте установить правильные права доступа к файлам с помощью калькулятора chmod при миграции.
Не забудьте установить правильные права доступа к файлам с помощью калькулятора chmod при миграции.
Learning
Если вы веб-дизайнер или разработчик, поднимите свои навыки на новый уровень путем обратного проектирования исходного кода веб-сайта по номеру , загрузите полный веб-сайт и изучите новые шаблоны UX и передовые методы кодирования. Загрузите полную версию веб-сайта , чтобы начать обучение.
Очистка экрана
Онлайн-загрузчик веб-сайтов позволяет извлекать полезные данные, информацию и знания из содержимого веб-страницы. Запуская ваши алгоритмы парсинга локально, они работают быстрее и плавнее!
Интернет-архив
Забыли оплатить продление хостинга? Не волнуйтесь, ваш сайт не потерян. Вы можете восстановить свои веб-сайты из Интернет-архива с помощью Wayback Machine Downloader
Машинное обучение
Интеллектуальный анализ веб-контента: вы можете получать несколько веб-сайтов и запускать текстовый анализ или алгоритмы машинного обучения на локальных данных вместо того, чтобы каждый раз извлекать новую веб-страницу.