
Парсер / wiki ТопЭксперт
Парсер (граббер) — это скрипт, предназначенный для автоматического наполнения сайтов текстовым контентом. Парсер в автоматическом режиме ищет в сети нужную текстовую информацию и, находя её, копирует на сайт, принадлежащий владельцу данного парсера. Таким образом, использование парсеров или грабберов избавляет веб-мастеров от рутинной работы по ручному наполнению своих ресурсов. Новый текстовый контент появляется на сайте автоматически, без вмешательства специалиста.
Примеры использования парсеров
- Актуальность и свежесть информации.
- Полное или частичное копирование материалов сайта и размещение этих материалов на своих ресурсах.
- Объединение потоков информации из разных источников в одном месте и ее постоянное обновление.
Главные требования поисковых систем к текстовому контенту:
- Актуальность
- Уникальность
Использование парсеров представляет собой беспроигрышный вариант. Качественно написанный и правильно настроенный скрипт обеспечивает наполнение сайта самыми свежими текстами. Речь идёт о новостях, но парсеры активно используются и для ведения блогов, где важным является постоянное обновление. С точки зрения актуальности у поисковых систем вопросов к сайтам не возникает.
Речь идёт о новостях, но парсеры активно используются и для ведения блогов, где важным является постоянное обновление. С точки зрения актуальности у поисковых систем вопросов к сайтам не возникает.
А вот об уникальности материалов, получаемых методом парсинга, говорить не приходится. Граббер не обрабатывает текст подобно тому, как это происходит при рерайтинге, а просто-напросто копирует чужой текст на страницы своего сайта. И вот здесь поисковые системы стоят на страже. Сайт, который пусть и совсем немного, но наполняется заимствованным контентом, никогда не получит сколько-нибудь значимых позиций в выдаче. Если же каждая страница ресурса будет содержать ворованные тексты, сайт могут даже исключить из поисковой базы.
Выделяют два вида парсинга в интернете, которые пользуются наибольшей популярностью:
- парсинг контента
- парсинг результатов выдачи поисковых систем.
Программы-парсеры:
Выделяют следующие основные программы-парсеры:
- Универсальный парсер Datacol
Выполняет следующие функции:
- Результаты поисковой выдачи
- Сбор контента с заданных сайтов
- Сбор внутренних и внешних ссылок для интернет сайта
- Сбор графической информации, аудио контента, видео материалов
- Парсинг СЕО показателей сайтов с различных сервисов
- Различная информация с интернет ресурсов
Выполняет следующие функции:
- Парсер товаров
- Парсер интернет-магазинов
- Парсер картинок
- Парсер видео
- RSS парсер
- Парсер ссылок
- Парсер новостей
Выполняет следующие функции:
- Парсер выдачи любых поисковых систем по ключевым запросам
- Парсер контента с любого сайта
- Парсер контента по ключевым запросам из выдачи любой поисковой системы
- Парсер контента по списку URLов
- Парсер внутренних ссылок
- Парсер внешних ссылок
Выполняет следующие функции:
- Парсер поисковых систем.


Как работает парсер Mediawiki / Хабр
Перевод статьи The MediaWiki parser, uncovered.
Актуальность перевода статьи 2009 года в том, что, во-первых, костяк парсера с тех пор существенно не поменялся, и во-вторых, с ним приходится ежедневно сталкиваться тем, кто пишет расширения для Mediawiki, на котором крутятся их корпоративные сайты.
Парсер Mediawiki — фундаментальная часть кода движка Mediawiki. Без него вы бы не смогли вставлять в свои статьи Википедии различные метки: секции, ссылки или картинки. Вы даже не смогли бы увидеть или быстро изменить разметку других статей. Вики-разметка достаточно гибка, чтобы дать возможность одинаково легко писать статьи как новичкам, так и HTML-экспертам. Из-за этого код парсера несколько сложноват, и с годами проходил через множество попыток его улучшить. Тем не менее, даже сегодня он все еще достаточно быстро работает для Википедии, одного из самых больших веб-сайтов в мире. Давайте взглянем на внутренности этого ценного (но чуть-чуть заумного) куска кода.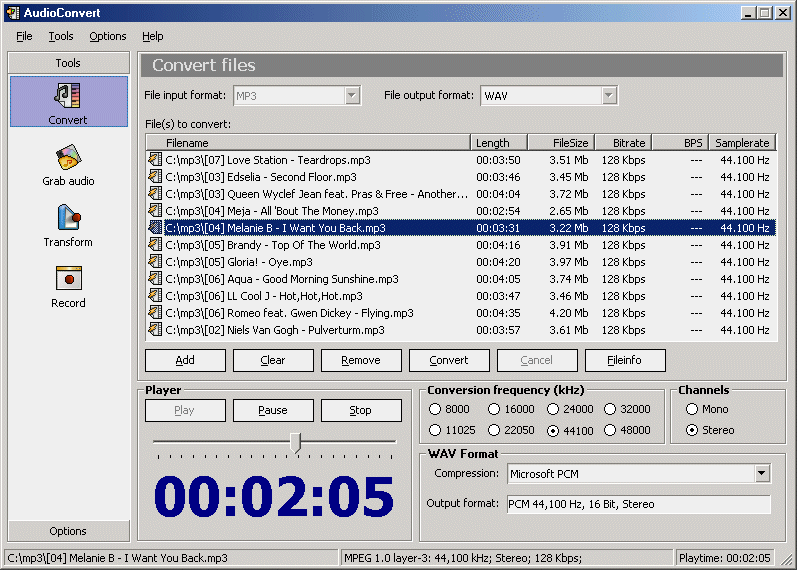
Краткая история
Дисклеймер. Эта история, как я ее понимаю, в основном почерпнута из обсуждений, в которых я участвовал в течение долгих лет в рассылке Викимедии, а также из обсуждений на конференции Викимания 2006. До 2008 года парсер Mediawiki сильно страдал от необычайной сложности, которая проистекала из необходимости уложиться в один проход (для скорости), но также и из-за того, что в существующий код всё время добавляли новые правила. С течением времени код парсера стал настоящим спагетти-кодом, который было очень сложно отлаживать, и еще сложнее улучшать. Переписать его было практически невозможно, т.к. он относится к ядру движка. Миллионы страниц Википедии могли полететь в один момент, если бы в каком-то месте нового кода произошла ошибка.
Что делать
Разразилось множество дискуссий о том, как решить эту проблему. Кто-то предлагал переписать парсер на C, который бы сделал парсер быстрее, что позволило бы разрешить парсеру разбирать текст не за один проход, а в цикле — этого требовало нарастающее число шаблонов и подшаблонов, которые включались на страницах Википедии. Были также и предложения изменить синтаксис Mediawiki так, чтобы устранить неопределенности при разборе некоторых конструкций (как, например, »»’жирный или курсив?»жирный или курсив?»»’ или отношения между тройными и двойными фигурными скобками в шаблонах).
Были также и предложения изменить синтаксис Mediawiki так, чтобы устранить неопределенности при разборе некоторых конструкций (как, например, »»’жирный или курсив?»жирный или курсив?»»’ или отношения между тройными и двойными фигурными скобками в шаблонах).
Препроцессор
В папке исходников Mediawiki вы найдете две версии препроцессора, версию Hash и DOM, их можно найти соответственно по адресам /includes/parser/Preprocessor_Hash.
Мы сконцентрируемся на DOM-версии, так как она практически идентична Hash-версии, но работает быстрее, потому что пользуется PHP XML-поддержкой, опциональной компонентой PHP. Самая важная функция в классе препроцессора назвается preprocessToObj(). Внутри файла Preprocessor_DOM.php лежат несколько других важных классов, которые использует препроцессор: PPDStack, PPDStackElement, PPDPart, PPFrame_DOM и PPNode_DOM.
Препроцессор делает меньше, чем вы думаете
Итак, на что же походит Mediawiki XML? Вот пример того, как викитекст «{{МойШаблон}} это [[тест]]» выглядит в XML-представлении:
<root>
<template>
<title>mytemplate</title>
</template>
this is a [[test]]
</root>
Заметим. что внутренняя ссылка вообще не обрабатывается. Код препроцессора избегает той работы, которую можно сделать на более позднем этапе (и у него есть для этого основания), так что единственной настоящей работой препроцессора является создание XML элементов для шаблонов и парочки других вещей.
Если вы когда-либо работали с викитекстом, то уже знаете, какая разметка соответствует этим базовым узлам. На всякий случай, вот она:
- template = двойные фигурные скобки {{…}}
- tplarg = тройные фигурные скобки {{{…}}}
- comment = HTML-комментарий любого типа
- ext = Всё, что должно разбираться в отдельном расширении
- ignore = теги типа noinclude, а также теги includeonly и содержимое внутри них
- h = секции
Вот и все. Все остальное игнорируется и возвращается как исходный викитекст в парсер.
Как работает препроцессор
Тут нет ничего особенного, но стоит сказать несколько слов. Для того, чтобы получить XML-представление, нужное нам, препроцессор проходит викитекст в цикле столько раз, сколько символов содержит этот текст. Нет другого способа для корректной обработки рекурсивных шаблонов, которые могут быть представлены как угодно в тексте благодаря синтаксису. Так что, если статья в Википедии содержит 40 000 знаков, то вероятно, что цикл будет состоять из 40 000 итераций. Теперь понятно, почему скорость так важна для парсера.
Нет другого способа для корректной обработки рекурсивных шаблонов, которые могут быть представлены как угодно в тексте благодаря синтаксису. Так что, если статья в Википедии содержит 40 000 знаков, то вероятно, что цикл будет состоять из 40 000 итераций. Теперь понятно, почему скорость так важна для парсера.
Собственно парсинг
Пропустим остальные детали препроцессора и дополнительные классы, которые используются для генерации XML-кода. Обратим наше внимание на сам парсер и взглянем на типичный случай работы парсера при клике на статью Википедии. Здесь, правда, не следует забывать, что вики-страницы кешируются любыми возможными способами, так что вряд ли вы каждый раз при клике на страницу вызовете разбор парсером страницы.
Вот типичное дерево вызовов парсера для текущей версии страницы, начиная от объекта Article.
| 01. Article->view |
| 02. —Article->getContent |
03. —-Article->loadContent —-Article->loadContent |
| 04. ——Article->fetchContent->возвращает викитекст, извлеченный из БД |
| 05. —Article->outputWikiText->prepare for the parse |
| 06. —-Parser->parse |
| 07. ——Parser->internalParse |
| 08. ———Parser->replaceVariables |
| 09. ———-Parser->preprocessToDom |
| 10. ————Preprocessor->preprocessToObj |
| 11. ———-Frame->expand |
| 12. ———Parser->doTableStuff |
| 13. ———Parser->replaceInternalLinks |
| 14. ———Parser->replaceExternalLinks |
| 15. ——Parser->doBlockLevels |
| 16. ——Parser->replaceLinkHolders |
Давайте взлянем на эти функции. Снова, это главные функции, а не все, которые вызываются в данном примере. Пункты 2-4 извлекают и возвращают викитекст статьи из базы данных. Этот текст передается объекту outputWikiText, который подготавливает его для передачи функции Parser::parse().
Пункты 2-4 извлекают и возвращают викитекст статьи из базы данных. Этот текст передается объекту outputWikiText, который подготавливает его для передачи функции Parser::parse().
Далее снова интересно становится на пунктах 8-11. Внутри функции replaceVariables текст превращается в представление DOM, в цикле по каждому символу статьи ищутся начальные и конечные метки шаблонов, подшаблонов и других узлов, упомянутых выше.
Пункт номер 11 — интересный шаг, который я сейчас пропущу, потому что он требует некоторых знаний о других классах из файла Preprocessor_DOM.php (упомянутых выше). Expand — очень важная функция, делает кучу вещей (среди которых её рекурсивный вызов), но достаточно сказать, что она выполняет работу по фактическому извлечению текста из узлов DOM (мы помним. что шаблоны могут быть вложенными — так что вы не всегда получите полный текст из каждой включенной статьи) и воврату валидного HTML-текста, в котором раскрыты все вики-метки, за исключением трех видов: таблиц, ссылок и списков. Так что, в примере выше, «{{МойШаблон}} это [[тест]]» expand() вернет текст вида:
Так что, в примере выше, «{{МойШаблон}} это [[тест]]» expand() вернет текст вида:
«Я включил [[текст]] из моего шаблона, это [[тест]]»
Как вы можете видеть из этого простого примера, на данном этапе разбирается все, за исключением таблиц, ссылок и списков.
Ссылки — это особенный случай
Да, у ссылок есть своя отдельная секция. И не только потому, что они, пожалуй, самая существенная часть того, что делает из wiki её саму (помимо возможности редактирования). Но еще и потому, что они разбираются совершенно особенным от всей остальной разметки образом в коде парсера. Особенными их делает то, что они обрабатываются в два этапа: на первом этапе каждой ссылке присваивается уникальный id, а на втором этапе её валидный HTML вставляется на место «заместителя ссылки» (link holder). В нашем примере вот какой результат получается после первого этапа:
«Я включил <!—LINK 0—> из моего шаблона, это <!—LINK 1—>».
Как вы можете представить, существует также массив, который сопоставляет текст ссылок с их ID вида LINK #ID, это переменная класса Parser с именем mLinkHolders. Помимо сопоставления, эта переменная также хранит объекты Title для каждой ссылки.
Помимо сопоставления, эта переменная также хранит объекты Title для каждой ссылки.
Так что на втором этапе разбора ссылок мы используем этот массив для простого поиска и замены. Теперь всё! Отправляем готовый текст за дверь!
Следующий этап
В следующем посте я сконцентрируюсь больше на препроцессоре и деталях классов из файла Preprocessor__DOM.php, а именно как они используются для построения первоначального дерева DOM XML. Я также расскажу о том, как я воспользовался ими для кеширования инфобоксов в расширении Unbox.
Граббер | Dead Space Wiki
Захват
Описание:
Внутренне мутировавшее неподвижное тело; чрезвычайно длинная, мускулистая шея; челюстная голова; длинный, зазубренный корешок
Атака(-и):
Хватает игрока за голову и притягивает его к зазубренному позвоночнику, чтобы убить им
Граббер — некроморф из Dead Space: Extraction и анимационного фильма Dead Space: Aftermath 9. 0019 .
0019 .
Содержание
- 1 Обзор
- 2 Стратегия
- 3 Общая информация
- 4 Галерея
- 5 выступлений
- 6 источников
Обзор[]
Граббер — некроморф, чей дизайн был в конечном итоге утилизирован для включения в Dead Space . Состоящий из, казалось бы, неприметного человеческого трупа, хотя и слегка поврежденного, Граббер использует элемент неожиданности, вытягивая голову мутировавшего трупа на невероятно большое расстояние по направлению к игроку и цепляясь за него, чтобы либо удерживать его на месте, либо отвлекать (не говоря уже о беспокоить их) или тянуть их к телу Граббера, в то время как зазубренное лезвие (бывший позвоночник трупа) вырывается из того же отверстия, чтобы убить игрока.
В этом случае большая часть основной массы тела была преобразована для создания и хранения чрезвычайно длинной, мускулистой шеи и хребтового лезвия Граббера. Хотя этих тревожных существ не было в Dead Space , они появляются в Dead Space: Extraction . Похоже, они продолжают ту цель, которую должны были иметь в Dead Space .
Похоже, они продолжают ту цель, которую должны были иметь в Dead Space .
Впервые они появляются в главе 6 задания «Эвакуация », когда Натан подходит к трупу, частично погруженному в воду, который, похоже, не заражен. Однако, как только он оказывается ближе, голова Некроморфа начинает трястись, а затем резко поднимается вверх и пугает выживших. Затем Граббер раскалывает свою человеческую голову пополам и начинает яростно трясти головой Макнила, размахивая языком. После отправки Уоррен Экхардт заявляет, что существа приспосабливаются к окружающей среде. Еще несколько Грабберов можно найти по всей дренажной системе, удивив команду тем, что они подстерегают, прежде чем выпрыгнуть из-под поверхности мутной воды. Неясно, были ли тела заражены в канализации и просто мутировали, чтобы наилучшим образом удовлетворить их потребности, или они были заражены где-то еще, а затем перемещены в канализацию другими некроморфами. Хотя кажется, что они не могут двигаться в игре, вполне возможно, что они смогут занять подходящие позиции для засады.
Стратегия[]
- Учитывая небольшой размер Граббера, такие виды оружия, как плазменный резак и заклепочный пистолет, не очень эффективны.
- Грабберы могут появиться из любого трупа, находящегося в воде. Следите за телами, у которых нет головы, или голова странно подперта/повернута под странным углом, так как они, скорее всего, повернутся.
- Самая большая цель Граббера — его голова. При использовании высокоточного оружия, такого как импульсная винтовка и контактный луч, это лучшее место для прицеливания.
- Оружие, покрывающее большие площади, такое как Force Gun, Line Gun и Flamethrower, является лучшим оружием для использования против Grabbers. Из этого оружия лучшее место для прицеливания — шея, особенно для Line Gun. Force Gun и Flamethrower достаточно просты, просто прицеливайтесь и стреляйте, но Line Gun, если хорошо прицелиться, может уничтожить сразу несколько Grabbers, если они появятся перед игроком в количестве.
- В качестве альтернативы вы можете стазисировать голову, что сделает ее легкой мишенью.

Общая информация[]
- Граббер все еще мог присутствовать на Ишимуре в Dead Space, но из-за того, что Исаак никогда не спускался в обширную канализационную систему корабля, он никогда не встречался с ним.
- Граббер должен был схватить Исаака своими челюстями и притянуть его к себе, после чего выпотрошить Исаака своим длинным хребтовым лезвием.
- Граббер выглядит как водный некроморф.
- Из-за сильно вытянутой шеи Граббер напоминает Рокурокуби из японского фольклора.
- В Dead Space: Extraction Граббер появляется только в канализации Ишимуры , поскольку он описывается как «адаптирующийся».
- Граббер — один из немногих некроморфов, сохранивших волосы, наряду с Флаером, Гнездом и некоторыми вариантами Слэшера.
- Анатомия Граббера очень похожа на Делителя. Возможно, это результат трупов очень поврежденных тел.
- Граббер появляется в Dead Space: Aftermath 9.0019 . Grabber находит соседка по комнате его хозяина, Лана, которая называет ее «Дженни». Когда Лана приближается к Грабберу, он поднимает голову и плюет кислотой на лицо Ланы, полностью растворяя всю кожу и волосы на ее голове. Затем его уничтожают зажигательной гранатой. Интересно отметить, что этот Grabber может двигаться, черта, которой, кажется, нет у других (или, по крайней мере, у Extraction Grabbers, которые все время были неподвижны). Это может быть вовсе не Граббер, так как фильм содержит странные вариации/комбинации разных некроморфов.
- В Извлечение нижняя часть тела Граббера почти никогда не видна, так как Грабберы встречаются только в канализации. На самом деле, нижнюю часть тела Граббера можно увидеть только дважды, включая первый раз, когда он встречается в начале Главы 6: Негде спрятаться.
- В Dead Space: Extraction The Spine по прозвищу «Striker» так и не попал в финальную версию игры.
- Глава Граббера имеет прозвище «Искатель»
- Интересен тот факт, что в Dead Space: Aftermath Граббер не плюется кислотой и не находится ни в какой воде, потому что некроморф по своей природе водный.


Галерея[]
Граббер вцепляется в Макнила, болтая языком.
Граббер в Dead Space: Aftermath .
Граббер, притворяющийся мертвым.
Голова набрасывается.
Голова вот-вот вцепится в Макнила.
«Искатель»
Эскиз граббера.
Эскиз граббера.
Ранний концепт граббера.
То же самое
Концепт-арт Grabber
Еще один концепт-арт с описанием.
Внешний вид[]
- Dead Space (Вырезано)
- Dead Space: Извлечение
- Dead Space: Aftermath
Источники[]
Контент сообщества доступен по лицензии CC-BY-SA, если не указано иное.
Руководство:Грабберы — MediaWiki
На этой странице описывается серия скриптов грабберов, предназначенных для получения содержимого вики без прямого доступа к базе данных. Если у вас нет дампа базы данных или доступа к базе данных, и вам нужно переместить/создать резервную копию вики, API MediaWiki предоставляет доступ, чтобы получить почти все, что вам нужно. Для этих скриптов также требуется MediaWiki 1.35+, так как Gerrit изменился 816349.. Скрипты также были протестированы в MediaWiki 1.39.
Если у вас нет дампа базы данных или доступа к базе данных, и вам нужно переместить/создать резервную копию вики, API MediaWiki предоставляет доступ, чтобы получить почти все, что вам нужно. Для этих скриптов также требуется MediaWiki 1.35+, так как Gerrit изменился 816349.. Скрипты также были протестированы в MediaWiki 1.39.
Для получения личных или удаленных данных требуется соответствующий доступ к целевой вики, но большинство сценариев будут работать без такого доступа. Этот документ изначально был скомпилирован, а скрипты собраны для перемещения Uncyclopedia; потому что общая цель состояла в том, чтобы просто сдвинуть эту чертову штуку, слова «красиво» не было точно в нашем лексиконе, когда мы это настраивали, поэтому некоторые из них все еще представляют собой ужасный беспорядок. Однако с тех пор многие из них были пересмотрены и сделаны более надежными, и они успешно использовались для переноса нескольких вики с викии на новый хост.
Принцип работы этих сценариев заключается в репликации базы данных с теми же общедоступными идентификаторами (идентификатором редакции, идентификатором журнала, идентификатором статьи), поэтому большинство из них необходимо использовать в чистой, пустой базе данных (только со структурой таблицы) или в база данных с теми же идентификаторами, что и у удаленной реплицируемой вики.
Вещи, которые нужно получить[править]
Если вы перемещаете всю вики, возможно, вам нужно получить это. Дополнительную информацию о таблицах можно найти в Руководстве: макет базы данных, но вторичные таблицы можно перестроить на их основе. В противном случае вы, вероятно, знаете, чего хотите.
- Редакции : текст, редакция, страница, page_restrictions, protected_titles, архив (большинство хостов предоставляют XML-дамп, по крайней мере, таблиц текста, редакций и страниц, которые составляют большую часть вики)
- Журналы : регистрация
- Интервики : Интервики
- Файлы (включая удаленные) и данные файлов : изображение, старое изображение, файловый архив
- Пользователи : пользователь, пользовательские_группы, пользовательские_свойства, список наблюдения, ipblocks
- Вероятно, другие вещи (это просто ядро; расширения часто добавляют другие таблицы и прочее).

Скрипты[править]
- Файлы php должны находиться в репозитории кода (GitHub). В репозиторий также добавлено
- файлов Python.
- Рубин не используется. До сих пор.
PHP-скрипты[править]
Это скрипты обслуживания, которые выводят прямо в базу данных вики. Чтобы «установить» их:
- получить ядро MediaWiki,
- по тому же пути, скачайте скрипты, т.е. с клоном
git https://gerrit.wikimedia.org/r/mediawiki/tools/grabbers.gitили скачать с GitHub.
Примечания:
- Требуется рабочий LocalSettings.php с учетными данными базы данных и работающая база данных MediaWiki, поэтому сначала убедитесь, что вы настроили вики
- Вы можете быстро создать его, запустив
php Maintenance/install.php --server="http://dummy/" --dbname=grabber --dbserver="localhost" --installdbuser=root --installdbpass=rootpassword --lang=en --pass=aaaaa --dbuser=grabber --dbpass=grabber --scriptpath=/ GrabberWiki Admin - Некоторые переменные конфигурации в LocalSettings. php, поддерживаемые этими сценариями: $wgDBtype, Manual:$wgCompressRevisions, внешнее хранилище.
- Вы можете быстро создать его, запустив
- If you’re importing all the contents with grabText.php, be sure to remove all rows from
page,revision,revision_actor_temp,revision_comment_temp,ip_changes,slots,contentandtextтаблиц перед запуском скрипта.- Вам также следует удалить строки из таблиц
пользователяиактера, чтобы предотвратить конфликт с пользователями с одинаковым идентификатором или именем, например, с первым пользователем, который создается при первой установке вики.
- Вам также следует удалить строки из таблиц
- Если вы импортируете все журналы с помощью grabLogs.php, обязательно удалите все строки из таблиц
loggingиlog_searchперед запуском скрипта. - Если вам нужно войти в целевую вики в последних версиях MediaWiki (что иногда требуется при захвате удаленного текста или желательно из-за более высоких ограничений API), вам нужно установить пароль бота на внешней вики.
 php, поддерживаемые этими сценариями: $wgDBtype, Manual:$wgCompressRevisions, внешнее хранилище.
php, поддерживаемые этими сценариями: $wgDBtype, Manual:$wgCompressRevisions, внешнее хранилище.
Эти сценарии требуют, чтобы у вас было достаточно прав для создания файлов в каталоге, из которого вы их выполняете. Это связано с тем, что curl пытается записать файл cookie в текущий каталог, и невыполнение этого требования приведет к неудачной попытке входа в систему без какого-либо другого объяснения того, что происходит.
Если вы войдете в целевую вики, файл cookie, созданный curl, не будет удален после завершения сценария. Файл cookie содержит идентификаторы сеансов, которые в случае утечки могут использоваться для входа в систему от имени того же пользователя и доступа ко всем его привилегиям. Из-за этого после успешного входа в систему вам больше не нужно вводить учетные данные, но это может вызвать проблемы, если вы нацелитесь на несколько вики. В случае проблем со входом в систему удалите файл cookie с именем 9.0234 куки.tmp . Не забудьте удалить файл cookie или убедитесь, что он недоступен из Интернета.
| Скрипт | Цель | Таблицы | Примечания | |||
|---|---|---|---|---|---|---|
грабитьтекст. php php | Содержимое страницы (живое). |
|
| |||
| грабитьNewText.php | Новый контент для заполнения правок после создания и импорта дампа. |
|
# Захватить только основное пространство имен grabText.php --namespaces=0 --enddate=t1 # Обновление основного пространства имен через несколько дней (это можно повторить, соответственно обновив t1 и t2) grabNewText.php --namespaces=0 --startdate=t1 --enddate=t2 # Захватите новое пространство имен, используйте дату окончания из предыдущего grabNewText.php grabText.php --namespaces="14|6" --enddate=t2 # Теперь в файле grabNewText.php должны быть указаны все ранее импортированные пространства имен, начиная с предыдущей даты окончания grabNewText.php --namespaces="0|14|6" --startdate=t2 --enddate=t3
| |||
| грабитьDeletedText.php | Удаленный контент. |
|
| |||
| грабитьNamespaceInfo.php | Пространства имен | н/д |
| |||
| Материал, который появляется в журнале Special:Log. |
|
| ||||
| Поддерживаемые ссылки интервики — отображаются на Special:Interwiki, если установлено расширение:Interwiki. |
|
| ||||
| грабитьFiles.php | Файлы и информация о файлах, включая старые версии (описания являются содержимым страницы). |
|
| Файлы и информация о файлах для обновления сайта, на котором уже использовался файл grabFiles.php. |
|
|
| грабитьИзображения.php | Текущие версии файлов без информации о базе данных | н/д |
| |||
| грабитьDeletedFiles.php | Удаленные файлы и информация о файлах. |
|
| |||
| грабитьUserBlocks.php | Пользовательские блоки. |
|
| |||
| грабитьUserGroups.php | Группы, к которым принадлежат пользователи. |
|
| |||
| грабитьProtectedTitles.php | Страницы защищены от создания. |
|
| |||
| грабитьAbuseFilter.php | Фильтры злоупотреблений. |
|
| |||
| populateUserTable.php | пользователей. |
|
|
 20, и наверное еще есть). Отсутствующие элементы обычно включают в себя удаленные ревизии (архив), информацию о защите (page_restrictions, protected_titles) и, очевидно, все, что изменилось с момента создания дампа.
20, и наверное еще есть). Отсутствующие элементы обычно включают в себя удаленные ревизии (архив), информацию о защите (page_restrictions, protected_titles) и, очевидно, все, что изменилось с момента создания дампа.
 php
php 

 php ...
php ...  Имейте в виду, что вы можете потерять некоторые файлы. Вы можете запустить этот запрос, чтобы получить отсутствующие файлы со страницей описания файла:
Имейте в виду, что вы можете потерять некоторые файлы. Вы можете запустить этот запрос, чтобы получить отсутствующие файлы со страницей описания файла: 


Скрипты Python
Рекомендуется использовать Python 2.7.2+. Вам нужно будет установить наш SQL и запросы.
Вам необходимо отредактировать settings.py и указать сайт, с которого вы хотите импортировать, и информацию о вашей базе данных.
Самый простой способ запустить все это просто $ python python_all.py , который выполняет все четыре отдельных скрипта. Вы также можете запускать каждый сценарий по отдельности, если хотите (чтобы вы могли запускать их одновременно).
Примечание. Автоблокировки не будут импортированы, так как у нас нет данных о том, какой IP-адрес фактически блокируется.
Дополнительные параметры ID как оригинальная вики. Используйте это расширение для заполнения пользовательской таблицы строками-заглушками, которые не будут содержать информацию о пароле. Затем настройте расширение как PasswordAuthenticationProvider, как описано в руководстве по расширению.
 Если пользователь пытается войти в систему, а пользователь все еще является заглушкой в таблице пользователей, вместо этого расширение выполнит вход в удаленную вики. Если вход в систему выполнен успешно, будет создан новый хэш пароля и сохранен в базе данных. Любые дальнейшие входы в систему будут производиться только локально.
Если пользователь пытается войти в систему, а пользователь все еще является заглушкой в таблице пользователей, вместо этого расширение выполнит вход в удаленную вики. Если вход в систему выполнен успешно, будет создан новый хэш пароля и сохранен в базе данных. Любые дальнейшие входы в систему будут производиться только локально.Это рекомендуется вместо Extension:MediaWikiAuth, поскольку все идентификаторы пользователей уже будут правильными.
Скачать исходный код: https://github.com/ciencia/mediawiki-extensions-StubUserWikiAuth
Импорт учетных записей пользователей при входе в систему. Обратите внимание, что для этого требуется, чтобы сайт, с которого вы копируете, был активен, чтобы использовать свою аутентификацию.
Влияет на пользователей, user_properties, список наблюдения таблиц
- Использует скриншоты, а также API из-за неполной функциональности.
- Обновляет идентификаторы пользователей в большинстве других таблиц, чтобы они соответствовали импортированному идентификатору, хотя, по-видимому, не userid log_params для записей о создании пользователей.
