
Проверка файла robots.txt | REG.RU
Файл robots.txt — это инструкция для поисковых роботов. В ней указывается, какие разделы и страницы сайта могут посещать роботы, а какие должны пропускать. В фокусе этой статьи — проверка robots.txt. Мы рассмотрим советы по созданию файла для начинающих веб-разработчиков, а также разберем, как делать анализ robots.txt с помощью стандартных инструментов Яндекс и Google.
Зачем нужен robots.txt
Поисковые роботы — это программы, которые сканируют содержимое сайтов и заносят их в базы поисковиков Яндекс, Google и других систем. Этот процесс называется индексацией.
robots.txt содержит информацию о том, какие разделы нельзя посещать поисковым роботам. Это нужно для того, чтобы в выдачу не попадало лишнее: служебные и временные файлы, формы авторизации и т. п. В поисковой выдаче должен быть только уникальный контент и элементы, необходимые для корректного отображения страниц (изображения, CSS- и JS-код).
Если на сайте нет robots. txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
txt, роботы заходят на каждую страницу. Это занимает много времени и уменьшает шанс того, что все нужные страницы будут проиндексированы корректно.
Если же файл есть в корневой папке сайта на хостинге, роботы сначала обращаются к прописанным в нём правилам. Они узнают, куда нельзя заходить, а какие страницы/разделы обязательно нужно посетить. И только после этого начинают обход сайта по инструкции.
Веб-разработчикам следует создать файл, если его нет, и наполнить его правильными директивами (командами) для поисковых роботов. Ниже кратко рассмотрим основные директивы для robots.txt.
Основные директивы robots.txt
Структура файла robots.txt выглядит так:
- Директива User-agent. Обозначает, для каких поисковых роботов предназначены правила в документе. Здесь можно указать все поисковые системы (для этого используется символ «*») или конкретных роботов (Yandex, Googlebot и другие).
- Директива Disallow (запрет индексации). Указывает, какие разделы не должны сканировать роботы.
 Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами. - Директива Allow (разрешение). Указывает, какие разделы или файлы должны просканировать поисковые роботы. Здесь не нужно указывать все разделы сайта: все, что не запрещено к обходу, индексируется автоматически. Поэтому следует задавать только исключения из правила Disallow.
- Sitemap (карта сайта). Полная ссылка на файл в формате .xml. Sitemap содержит список всех страниц, доступных для индексации, а также время и частоту их обновления.
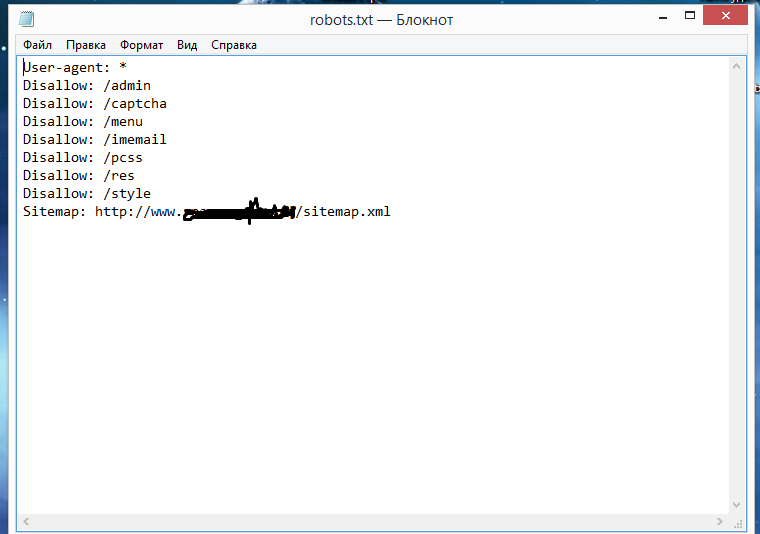 Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.
Даже если на сайте нет служебного контента, который необходимо закрыть от индексации, директиву нужно прописывать (не указывая значение). Если не сделать этого, robots.txt может некорректно читаться поисковыми роботами.Пример простого файла robots.txt (после # указаны пояснительные комментарии к директивам):
User-agent: * # правила ниже предназначены для всех поисковых роботов Disallow: /wp-admin # запрет индексации служебной папки со всеми вложениями Disallow: /*? # запрет индексации результатов поиска на сайте Allow: /wp-admin/admin-ajax.
 php # разрешение индексации JS-скрипты темы WordPress
Allow: /*.jpg # разрешение индексации всех файлов формата .jpg
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайта
php # разрешение индексации JS-скрипты темы WordPress
Allow: /*.jpg # разрешение индексации всех файлов формата .jpg
Sitemap: http://site.ru/sitemap.xml # адрес карты сайта, где вместо site.ru — домен сайтаСоветы по созданию robots.txt
Для того чтобы файл читался поисковыми программами корректно, он должен быть составлен по определенным правилам. Даже детали (регистр, абзацы, написание) играют важную роль. Рассмотрим несколько основных советов по оформлению текстового документа.
Группируйте директивы
Если требуется задать различные правила для отдельных поисковых роботов, в файле нужно сделать несколько блоков (групп) с правилами и разделить их пустой строкой. Это необходимо, чтобы не возникало путаницы и каждому роботу не нужно было сканировать весь документ в поисках подходящих инструкций. Если правила сгруппированы и разделены пустой строкой, робот находит нужную строку User-agent и следует директивам. Пример:
User-agent: Yandex # правила только для ПС Яндекс Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов # пустая строка User-agent: Googlebot # правила только для ПС Google Disallow: # раздел, файл или формат файлов Allow: # раздел, файл или формат файлов Sitemap: # адрес файла
Учитывайте регистр в названии файла
Для некоторых поисковых систем не имеет значение, какими буквами (прописными или строчными) будет обозначено название файла robots. txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
txt. Но для Google, например, это важно. Поэтому желательно писать название файла маленькими буквами, а не Robots.txt или ROBOTS.TXT.
Не указывайте несколько каталогов в одной директиве
Для каждого раздела/файла нужно указывать отдельную директиву Disallow. Это значит, что нельзя писать Disallow: /cgi-bin/ /authors/ /css/ (указаны три папки в одной строке). Для каждой нужно прописывать свою директиву Disallow:
Disallow: /cgi-bin/ Disallow: /authors/ Disallow: /css/
Убирайте лишние директивы
Часть директив robots.txt считается устаревшими и необязательными: Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующегося контента). Вы можете удалить эти директивы, чтобы не «засорять» файл.
Как проверить robots.txt онлайн
Чтобы убедиться в том, что файл составлен грамотно, можно использовать веб-инструменты Яндекс, Google или онлайн-сервисы (PR-CY, Website Planet и т. п.). В Яндекс и Google есть собственные правила для проверки robots.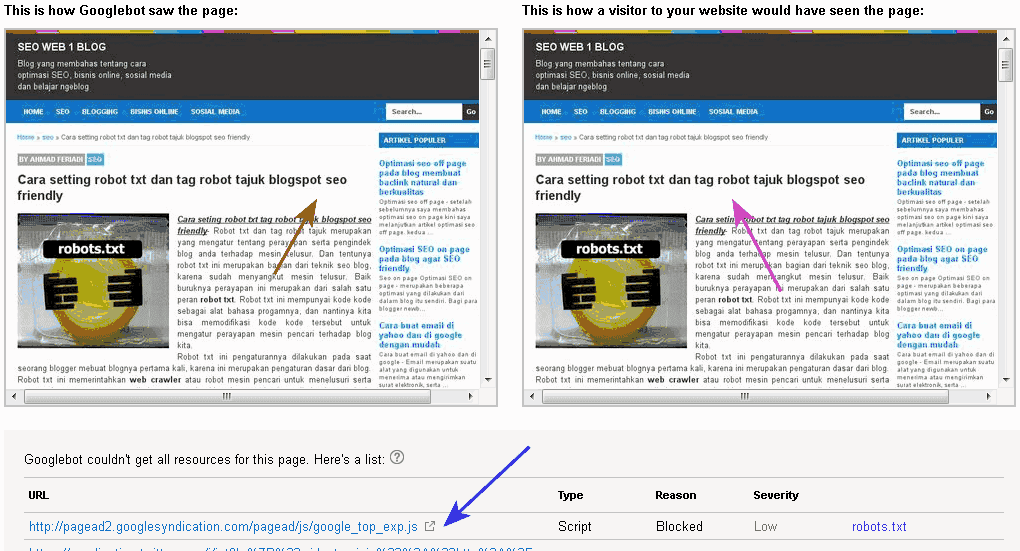
Яндекс.Вебмастер
Если вы впервые пользуетесь сервисом Яндекс.Вебмастер, сначала добавьте свой сайт и подтвердите права на него. После этого вы получите доступ к инструментам для анализа SEO-показателей сайта и продвижения в ПС Яндекс.
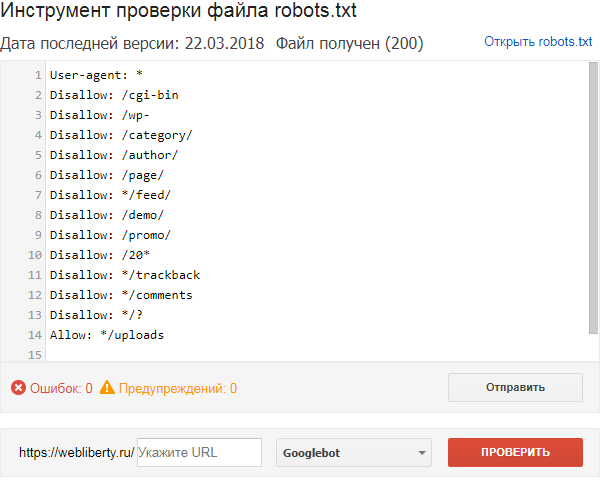
Чтобы проверить robots.txt с помощью валидатора Яндекс:
- 1.
Зайдите в личный кабинет Яндекс.Вебмастер.
- 2.
Выберите в левом меню раздел Инструменты → Анализ robots.txt.
- 3.
Содержимое нужного файла подставиться автоматически. Если по какой-то причине этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:
 org/HowToStep»>
4.
org/HowToStep»>
4.Ниже будут указаны результаты проверки. Если в директивах есть ошибки, сервис покажет, какую строку нужно поправить, и опишет проблему:
Google Search Console
Чтобы сделать проверку с помощью Google:
- 1.
Перейдите на страницу инструмента проверки.
Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку Отправить и следуйте инструкциям Google:
- 3.
Через несколько минут вы можете обновить страницу. В поле будут отображаться актуальные директивы. Предупреждения/ошибки (если система найдет их) будут перечислены под кодом.
Проверка robots.txt Google не выявила ошибок
Обратите внимание: правки, которые вы вносите в сервисе проверки, не будут автоматически применяться в robots.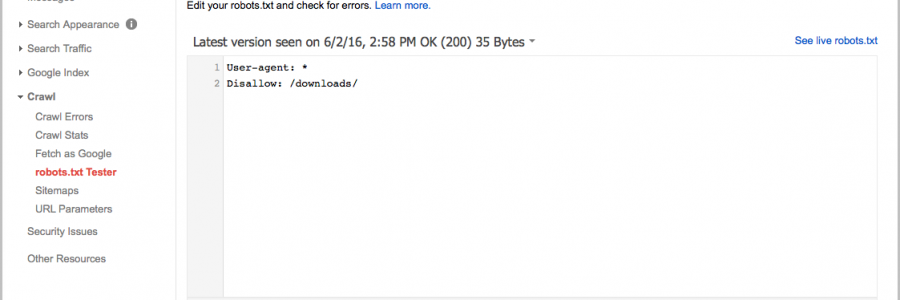 txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
txt. Вам нужно внести исправленный код вручную на хостинге или в административной панели CMS и сохранить изменения.
Помогла ли вам статья?
Да
раз уже
помогла
Robots.txt — как настроить и загрузить на сайт
Михаил Шумовский
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
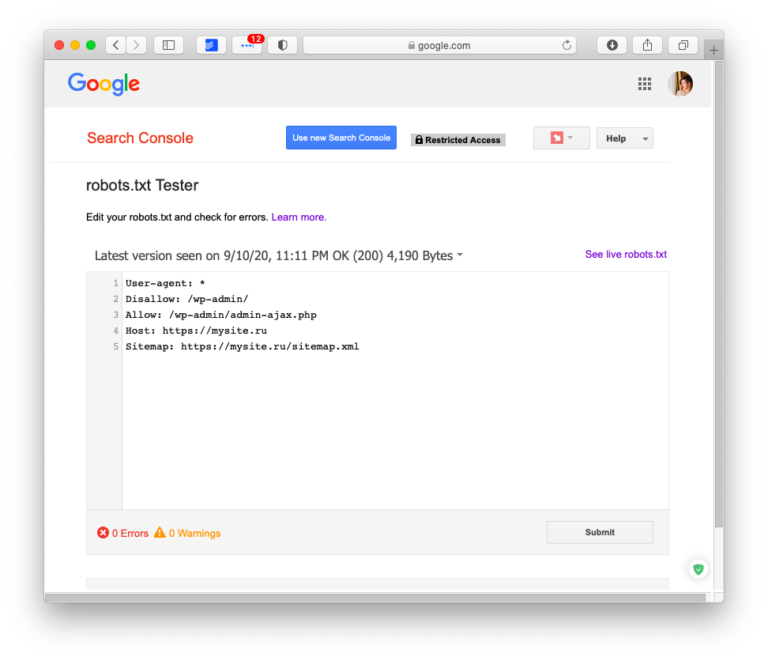
Robots.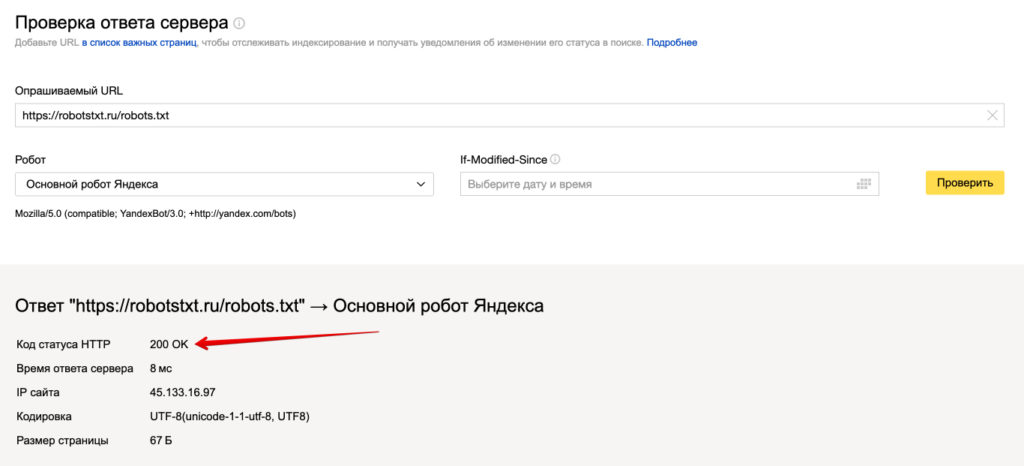 txt — документ, который нужен для индексирования и продвижения сайта. С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
txt — документ, который нужен для индексирования и продвижения сайта. С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т. д.
 д.
д.Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Googlebot. Основной робот Google.
- Googlebot-Image. Индексирует изображения.
 Индексирует изображения.
Индексирует изображения.Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.
Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *. js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой.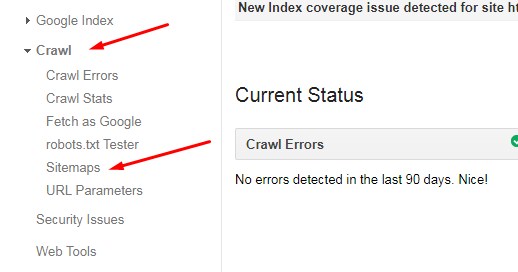 Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
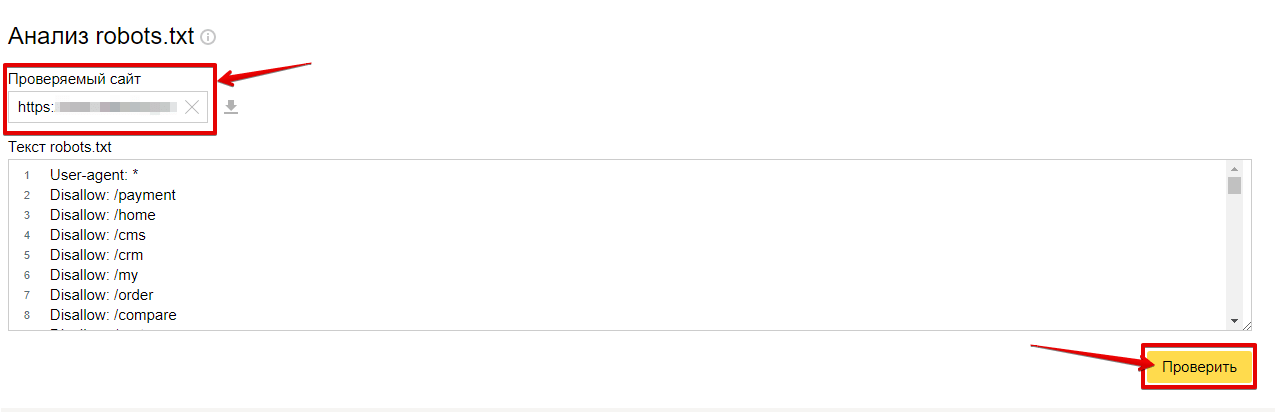
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы и интервью с экспертами диджитала.
Свежие статьи из блога. Эксклюзивные кейсы и интервью с экспертами диджитала.
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
Как исправить ошибку «Отправленный URL-адрес заблокирован robots.
 txt» в Google Search Console? » Rank Math
txt» в Google Search Console? » Rank MathЕсли вы когда-либо видели ошибку «Отправленный URL-адрес заблокирован robots.txt» в вашей консоли поиска Google и в отчете о статусе индекса аналитики Rank Math, вы знаете, что это может быть довольно неприятно. В конце концов, вы соблюдали все правила и позаботились о том, чтобы ваш сайт был оптимизирован для поисковых систем, таких как Google или Bing. Так почему это происходит?
В этой статье базы знаний мы покажем вам, как исправить ошибку «Отправленный URL-адрес заблокирован robots.txt», а также объясним, что означает эта ошибка и как предотвратить ее повторение в будущем.
Начнем!
Содержание
- Что означает ошибка?
- Как найти ошибку «Отправленный URL-адрес заблокирован robots.txt»?
- Как исправить ошибку «Отправленный URL-адрес, заблокированный robots.txt»?
- Как предотвратить повторение ошибки
- Заключение
1 Что означает ошибка?
Ошибка «Отправленный URL-адрес заблокирован robots. txt» означает, что файл robots.txt вашего веб-сайта блокирует сканирование страницы роботом Googlebot. Другими словами, Google пытается получить доступ к странице, но ему мешает файл robots.txt.
txt» означает, что файл robots.txt вашего веб-сайта блокирует сканирование страницы роботом Googlebot. Другими словами, Google пытается получить доступ к странице, но ему мешает файл robots.txt.
Это может произойти по ряду причин, но наиболее распространенной причиной является неправильная настройка файла robots.txt. Например, вы могли случайно заблокировать роботу Googlebot доступ к странице или включить директиву disallow в файл robots.txt, которая не позволяет роботу Googlebot сканировать страницу.
2 Как найти ошибку «Отправленный URL-адрес заблокирован robots.txt»?
К счастью, ошибку «Отправить URL-адрес, заблокированный robots.txt» довольно легко найти. Вы можете использовать консоль поиска Google или отчет о статусе индекса в аналитике Rank Math, чтобы найти эту ошибку.
2.1 Используйте консоль поиска Google для поиска ошибки
Чтобы проверить наличие этой ошибки в консоли поиска Google, просто перейдите на вкладку Покрытие и найдите ошибку в разделе Ошибка , как показано ниже:
Затем нажмите на ошибку Submitted URL Blocked by robots. txt , как показано ниже:
txt , как показано ниже:
Если вы нажмете на ошибку, вы увидите список страниц, заблокированных вашим файлом robots.txt:
2.2 Использование аналитики Rank Math для выявления проблемных страниц
Вы также можете использовать отчет о состоянии индекса в аналитике Rank Math, чтобы определить страницы с проблемой.
Для этого перейдите к Rank Math > Analytics на панели управления WordPress. Затем перейдите на вкладку Состояние индекса . На этой вкладке вы получите реальные данные/статус ваших страниц, а также их присутствие в Google.
Кроме того, вы можете отфильтровать статус индекса сообщения, используя раскрывающееся меню. Когда вы выбираете определенный статус, например «Отправленный URL-адрес заблокирован robot.txt», вы сможете увидеть все сообщения, которые имеют один и тот же статус индекса.
Получив список страниц, которые возвращают этот статус, вы можете приступить к устранению неполадок и устранению проблемы.
3 Как исправить ошибку «Исправить отправленный URL, заблокированный robots.txt»?
Чтобы исправить это, вам нужно убедиться, что файл robots.txt вашего веб-сайта настроен правильно. Вы можете использовать инструмент тестирования robots.txt от Google, чтобы проверить файл и убедиться в отсутствии директив, которые блокируют доступ робота Googlebot к вашему сайту.
Если вы обнаружите, что в вашем файле robots.txt есть директивы, которые блокируют доступ робота Googlebot к вашему сайту, вам нужно будет удалить их или заменить более либеральными.
Давайте посмотрим, как вы можете проверить файл robots.txt и убедиться, что никакие директивы не блокируют доступ робота Googlebot к вашему сайту.
3.1 Откройте тестер robots.txt
Сначала перейдите к тестеру robots.txt. Если ваша учетная запись Google Search Console связана с несколькими веб-сайтами, выберите свой веб-сайт из списка сайтов, показанного в правом верхнем углу. Теперь Google загрузит файл robots. txt вашего сайта.
txt вашего сайта.
Вот как это будет выглядеть.
3.2 Введите URL-адрес вашего сайта
В нижней части инструмента вы найдете возможность ввести URL-адрес вашего веб-сайта для тестирования.
3.3 Выберите агент пользователя
В раскрывающемся списке справа от текстового поля выберите агент пользователя, который вы хотите имитировать (в нашем случае Googlebot).
3.4 Проверить Robots.txt
Наконец, нажмите кнопку Проверить .
Сканер немедленно проверит, есть ли у него доступ к URL-адресу на основе конфигурации robots.txt, и, соответственно, тестовая кнопка окажется ПРИНЯТ или ЗАБЛОКИРОВАН .
Редактор кода, доступный в центре экрана, также выделит правило в файле robots.txt, которое блокирует доступ, как показано ниже.
3.5 Редактирование и отладка
Если тестер robots.txt обнаружит какое-либо правило, запрещающее доступ, вы можете попробовать отредактировать правило прямо в редакторе кода, а затем снова запустить тест.
Вы также можете обратиться к нашей специальной статье базы знаний о robots.txt, чтобы узнать больше о принятых правилах, и было бы полезно изменить правила здесь.
Если вам удастся исправить правило, то это здорово. Но обратите внимание, что это инструмент отладки, и любые внесенные вами изменения не будут отражены в robots.txt вашего веб-сайта, если вы не скопируете и не вставите содержимое в robots.txt своего веб-сайта.
3.6 Редактирование файла robots.txt с помощью Rank Math
Для этого перейдите к файлу robots.txt в Rank Math, который находится в разделе Панель управления WordPress > Rank Math > Общие настройки > Редактировать robots.txt , как показано ниже:
Примечание: Если этот параметр недоступен для вас, убедитесь, что вы используете расширенный режим в Rank Math.
В редакторе кода, расположенном посередине экрана, вставьте код, скопированный из robots.txt. Tester, а затем нажмите кнопку Сохранить изменения , чтобы отразить изменения.
Предупреждение: Будьте осторожны, внося какие-либо существенные или незначительные изменения на свой веб-сайт с помощью файла robots.txt. Хотя эти изменения могут улучшить ваш поисковый трафик, они также могут принести больше вреда, чем пользы, если вы не будете осторожны.
Чтобы узнать больше, смотрите скриншоты ниже:
Вот и все! После внесения этих изменений Google сможет получить доступ к вашему веб-сайту, и ошибка «Отправленный URL-адрес заблокирован robots.txt» будет исправлена.
4 Как предотвратить повторное появление ошибки
Чтобы предотвратить повторение ошибки «Отправленный URL-адрес, заблокированный robots.txt» в будущем, мы рекомендуем регулярно просматривать файл robots.txt вашего веб-сайта. Это поможет убедиться, что все директивы точны и что ни одна страница не будет случайно заблокирована для сканирования роботом Googlebot.
Мы также рекомендуем использовать такие инструменты, как Инструменты Google для веб-мастеров, которые помогут вам управлять файлом robots. txt вашего веб-сайта. Инструменты для веб-мастеров позволят вам легко редактировать и обновлять файл robots.txt, а также отправлять страницы для индексации, просматривать ошибки сканирования и многое другое.
txt вашего веб-сайта. Инструменты для веб-мастеров позволят вам легко редактировать и обновлять файл robots.txt, а также отправлять страницы для индексации, просматривать ошибки сканирования и многое другое.
5 Заключение
В конце концов, мы надеемся, что эта статья помогла вам узнать, как исправить ошибку «Отправленный URL-адрес, заблокированный robots.txt» в Google Search Console и в отчете о статусе индекса аналитики Rank Math. Если у вас есть какие-либо сомнения или вопросы, связанные с этим вопросом, пожалуйста, не стесняйтесь обращаться в нашу службу поддержки. Мы доступны 24×7, 365 дней в году и будем рады помочь вам с любыми проблемами, с которыми вы можете столкнуться.
6 Распространенные проблемы с файлом robots.txt и способы их устранения
Robots.txt — это полезный и относительно мощный инструмент для указания поисковым роботам того, как вы хотите, чтобы они сканировали ваш сайт.
Он не всемогущ (по словам самого Google, «это не механизм для защиты веб-страницы от Google»), но может помочь предотвратить перегрузку вашего сайта или сервера запросами сканера.
Если на вашем сайте установлена эта блокировка сканирования, вы должны быть уверены, что она используется правильно.
Это особенно важно, если вы используете динамические URL-адреса или другие методы, которые теоретически генерируют бесконечное количество страниц.
В этом руководстве мы рассмотрим некоторые из наиболее распространенных проблем с файлом robots.txt, их влияние на ваш веб-сайт и ваше присутствие в поиске, а также способы устранения этих проблем, если вы считаете, что они возникли.
Но сначала давайте кратко рассмотрим файл robots.txt и его альтернативы.
Что такое robots.txt?
Robots.txt использует формат обычного текстового файла и размещается в корневом каталоге вашего веб-сайта.
Он должен находиться в самом верхнем каталоге вашего сайта; если вы поместите его в подкаталог, поисковые системы просто проигнорируют его.
Несмотря на свои огромные возможности, robots.txt часто представляет собой относительно простой документ, и простой файл robots.![]() txt можно создать за считанные секунды с помощью редактора, например Блокнота.
txt можно создать за считанные секунды с помощью редактора, например Блокнота.
Существуют и другие способы достижения тех же целей, для которых обычно используется файл robots.txt.
Отдельные страницы могут включать метатег robots в самом коде страницы.
Вы также можете использовать HTTP-заголовок X-Robots-Tag, чтобы повлиять на то, как (и будет ли) отображаться контент в результатах поиска.
Что может robots.txt?
Robots.txt может дать различные результаты для различных типов контента:
Веб-страницы могут быть заблокированы от сканирования .
Они могут по-прежнему появляться в результатах поиска, но не будут иметь текстового описания. Содержимое страницы, отличное от HTML, также не будет сканироваться.
Медиафайлы могут быть заблокированы от появления в результатах поиска Google.
Сюда входят изображения, видео- и аудиофайлы.
Если файл является общедоступным, он по-прежнему будет «существовать» в сети, и его можно будет просмотреть и связать с ним, но этот частный контент не будет отображаться в результатах поиска Google.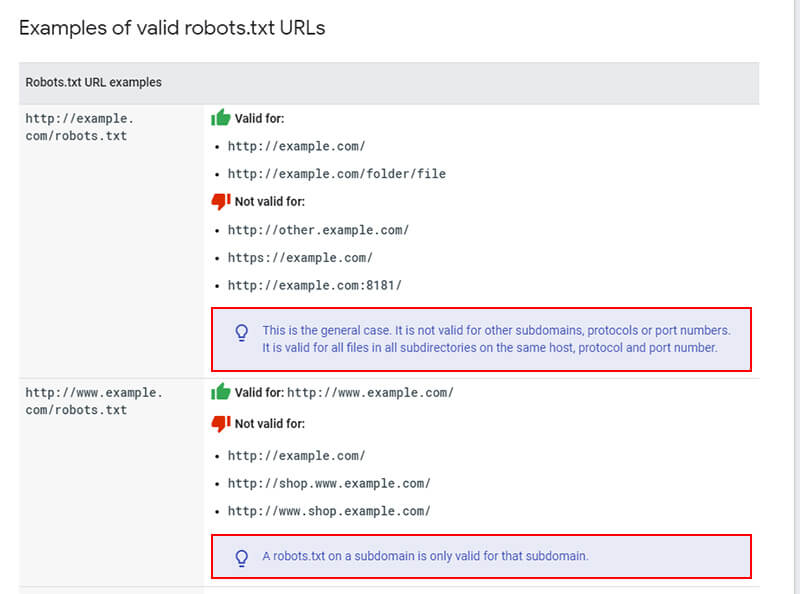
Файлы ресурсов, такие как неважные внешние скрипты, могут быть заблокированы .
Но это означает, что если Google просканирует страницу, для загрузки которой требуется этот ресурс, робот Googlebot «увидит» версию страницы, как если бы этот ресурс не существовал, что может повлиять на индексацию.
Вы не можете использовать robots.txt, чтобы полностью заблокировать появление веб-страницы в результатах поиска Google.
Чтобы добиться этого, вы должны использовать альтернативный метод, такой как добавление метатега noindex в начало страницы.
Насколько опасны ошибки robots.txt?
Ошибка в robots.txt может иметь непредвиденные последствия, но зачастую это не конец света.
Хорошая новость заключается в том, что, исправив файл robots.txt, вы сможете быстро и (как правило) полностью восстановиться после любых ошибок.
Руководство Google для веб-разработчиков говорит следующее об ошибках robots.txt:
«Веб-сканеры, как правило, очень гибкие и обычно не реагируют на незначительные ошибки в файле robots.
Имейте в виду, что Google не может читать мысли при интерпретации файла robots.txt; мы должны интерпретировать полученный нами файл robots.txt. Тем не менее, если вы знаете о проблемах в файле robots.txt, их обычно легко исправить».
 txt. В общем, худшее, что может случиться, это то, что некорректные [или] неподдерживаемые директивы будут проигнорированы.
txt. В общем, худшее, что может случиться, это то, что некорректные [или] неподдерживаемые директивы будут проигнорированы.6 Распространенные ошибки в файле robots.txt
- Robots.txt не находится в корневом каталоге.
- Неправильное использование подстановочных знаков.
- Noindex в файле robots.txt.
- Заблокированные скрипты и таблицы стилей.
- Нет URL-адреса карты сайта.
- Доступ к сайтам разработки.
Если ваш веб-сайт ведет себя странно в результатах поиска, ваш файл robots.txt — это хорошее место для поиска любых ошибок, синтаксических ошибок и превышения правил.
Давайте рассмотрим каждую из вышеперечисленных ошибок более подробно и посмотрим, как убедиться, что у вас есть действительный файл robots. txt.
txt.
1. Robots.txt не находится в корневом каталоге
Поисковые роботы могут обнаружить файл только в том случае, если он находится в корневом каталоге.
Вот почему между .com (или эквивалентным доменом) вашего веб-сайта и именем файла robots.txt в URL-адресе вашего файла robots.txt должна быть только косая черта.
Если там есть подпапка, ваш файл robots.txt, вероятно, не виден поисковым роботам, и ваш сайт, вероятно, ведет себя так, как будто файла robots.txt вообще нет.
Чтобы решить эту проблему, переместите файл robots.txt в корневой каталог.
Стоит отметить, что для этого вам потребуется root-доступ к вашему серверу.
Некоторые системы управления контентом по умолчанию загружают файлы в подкаталог «media» (или что-то подобное), поэтому вам может потребоваться обойти это, чтобы получить файл robots.txt в нужном месте.
2. Неправильное использование подстановочных знаков
Robots.txt поддерживает два подстановочных знака:
- Звездочка * , который представляет любые экземпляры допустимого символа, например Джокера в колоде карт.
- Знак доллара $ , обозначающий конец URL-адреса, что позволяет применять правила только к последней части URL-адреса, например к расширению типа файла.

Разумно использовать минималистский подход к использованию подстановочных знаков, поскольку они могут налагать ограничения на гораздо более широкую часть вашего веб-сайта.
Также относительно легко заблокировать доступ роботов со всего вашего сайта с помощью неудачно расположенной звездочки.
Чтобы решить проблему с подстановочными знаками, вам нужно найти неправильный подстановочный знак и переместить или удалить его, чтобы файл robots.txt работал должным образом.
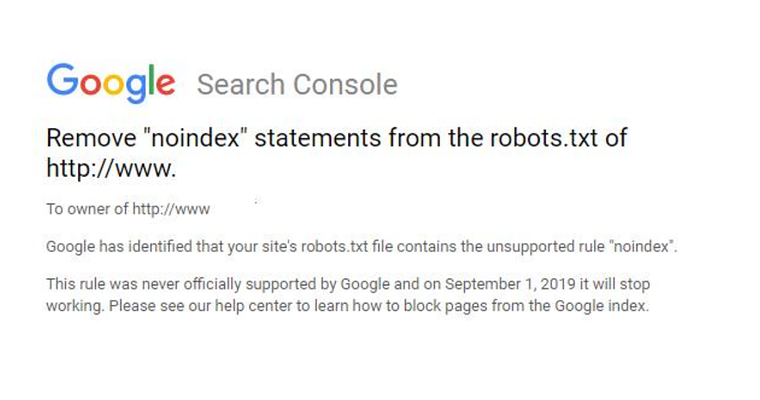
3. Noindex In Robots.txt
Это чаще встречается на веб-сайтах, которым больше нескольких лет.
Компания Google перестала соблюдать правила noindex в файлах robots.txt с 1 сентября 2019 г. результаты поиска.
Решение этой проблемы заключается в реализации альтернативного метода noindex.
Одним из вариантов является метатег robots, который можно добавить в заголовок любой веб-страницы, которую вы хотите предотвратить от индексации Google.
4. Заблокированные сценарии и таблицы стилей
Может показаться логичным заблокировать доступ сканера к внешним сценариям JavaScript и каскадным таблицам стилей (CSS).
Однако помните, что роботу Googlebot требуется доступ к файлам CSS и JS, чтобы правильно «видеть» ваши HTML- и PHP-страницы.
Если ваши страницы странно отображаются в результатах Google или кажется, что Google не видит их правильно, проверьте, не блокируете ли вы доступ сканера к необходимым внешним файлам.
Простое решение этой проблемы — удалить из файла robots.txt строку, блокирующую доступ.
Или, если у вас есть файлы, которые нужно заблокировать, вставьте исключение, которое восстанавливает доступ к необходимым CSS и JavaScript.
5. Нет URL карты сайта
Это больше касается SEO, чем что-либо еще.
Вы можете включить URL-адрес вашей карты сайта в файл robots.txt.
Поскольку это первое, на что обращает внимание робот Googlebot при сканировании вашего веб-сайта, это дает ему преимущество в знании структуры и основных страниц вашего сайта.
Хотя это не является строго ошибкой, так как отсутствие карты сайта не должно отрицательно влиять на фактическую основную функциональность и внешний вид вашего веб-сайта в результатах поиска, все же стоит добавить URL-адрес вашей карты сайта в robots.txt, если вы хотите дать свой SEO усилие.
6. Доступ к сайтам разработки
Блокировать поисковые роботы на вашем действующем веб-сайте нельзя, как и разрешать им сканировать и индексировать ваши страницы, которые все еще находятся в стадии разработки.
Рекомендуется добавить инструкцию о запрете в файл robots.txt веб-сайта, находящегося в стадии разработки, чтобы широкая публика не увидела его, пока он не будет завершен.
Точно так же очень важно удалить команду запрета при запуске готового веб-сайта.
Забыть удалить эту строку из robots.txt — одна из самых распространенных ошибок среди веб-разработчиков, которая может помешать правильному сканированию и индексированию всего вашего веб-сайта.
Если кажется, что ваш сайт разработки получает реальный трафик или ваш недавно запущенный веб-сайт совсем не работает в поиске, найдите универсальное правило запрета пользовательского агента в файле robots.txt:
User-Agent : *
Disallow: /
Если вы видите это, когда не должны (или не видите, когда должны), внесите необходимые изменения в файл robots.txt и убедитесь, что ваш сайт отображается в результатах поиска. обновления соответственно.
Как исправить ошибку robots.txt
Если ошибка в robots.txt оказывает нежелательное влияние на внешний вид вашего веб-сайта в результатах поиска, самым важным первым шагом является исправление файла robots.txt и проверка того, что новые правила имеют желаемое значение.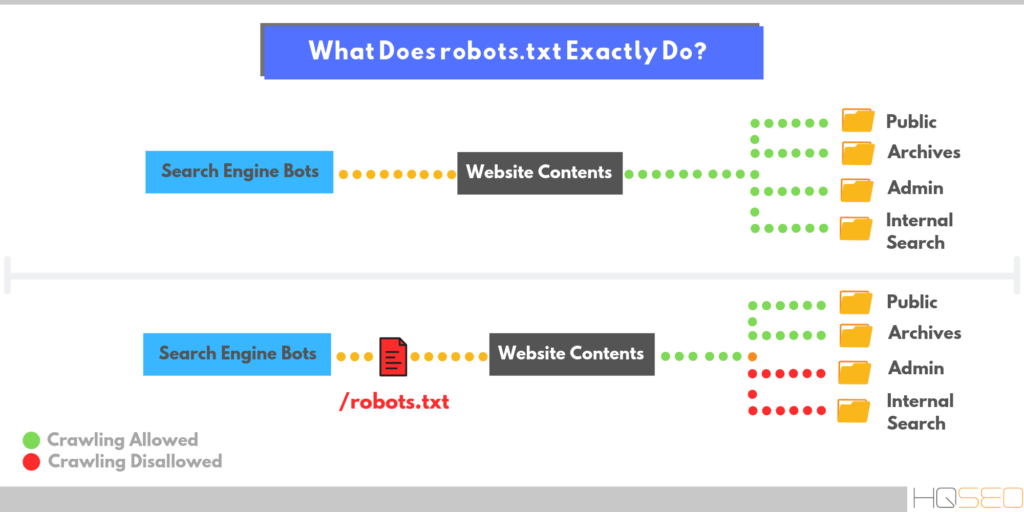 эффект.
эффект.
В этом могут помочь некоторые инструменты SEO-сканирования, поэтому вам не нужно ждать, пока поисковые системы снова просканируют ваш сайт.
Если вы уверены, что robots.txt ведет себя должным образом, вы можете попытаться повторно просканировать свой сайт как можно скорее.
Могут помочь такие платформы, как Google Search Console и Bing Webmaster Tools.
Отправьте обновленную карту сайта и запросите повторное сканирование любых страниц, которые были неправомерно удалены из списка.
К сожалению, вы попали в прихоть робота Googlebot — нет никаких гарантий относительно того, сколько времени потребуется, чтобы отсутствующие страницы снова появились в поисковом индексе Google.
Все, что вы можете сделать, это предпринять правильные действия, чтобы максимально сократить это время, и продолжать проверку до тех пор, пока робот Googlebot не внедрит исправленный файл robots.txt.
Заключительные мысли
Если речь идет об ошибках robots.