
«Яндекс» научил почту писать письма под диктовку и читать их вслух
Продолжение сюжета от
Новости СМИ2
Новости
Новости
Анастасия Марьина
Руководитель новостного отдела RB.ru
Анастасия Марьина
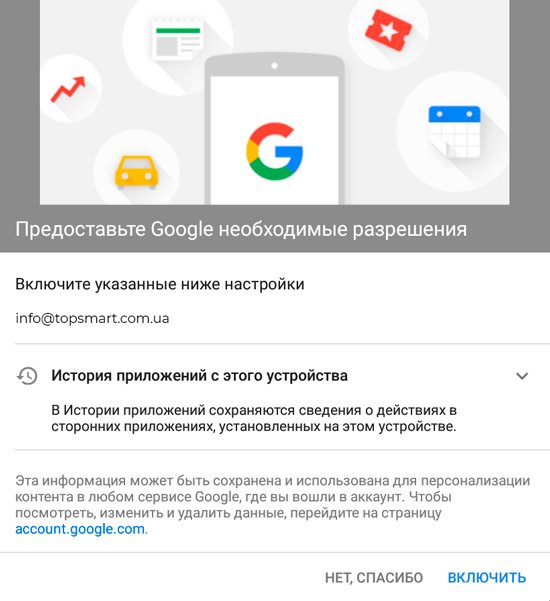
«Яндекс.Почта» запустила в приложении для iOS функцию голосового ввода текста. Об этом Rusbase рассказали в пресс-службе «Яндекса».
Анастасия Марьина
К письму также можно прикрепить аудиозапись собственного голоса — на случай, если в распознанный текст закралась ошибка, а исправлять ее не с руки.
Одновременно с голосовым вводом в почте появилось озвучивание входящих писем. Приложение может прочесть вслух тему и текст письма.
Для распознавания и озвучивания речи «Яндекс» использует комплекс технологий Yandex SpeechKit. В него входят технологии распознавания, семантического анализа и синтеза речи и технология голосовой активации. SpeechKit также используется в поиске, картах, браузере, навигаторе и других сервисах «Яндекса».
Сейчас голосовой ввод и озвучивание доступны части пользователей «Яндекс.Почты» для iOS. В течение двух недель обновление получат все пользователи iOS-приложения. О планах создать такой сервис на Android не сообщается.
Фото: Primakov / Depositphotos.
- Полезные сервисы
- Мобайл
- Технологии
- Яндекс
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Материалы по теме
- 1
И советы, и реклама: как продавать товары с высоким чеком с помощью «Яндекс.
 Дзена»
Дзена» - 2 Курьерская доставка: как настроить и использовать
- 3 Как удвоить трафик на сайт с помощью «Яндекс.Дзена»: кейс телеканала RU.TV
- 4 «Яндекс» открыл набор на оплачиваемую стажировку в Москве
- 5
Тестируем «Яндекс. Станцию Мини»: с чувством юмора все в порядке
 Дзена»
Дзена» Станцию Мини»: с чувством юмора все в порядке
Станцию Мини»: с чувством юмора все в порядкеВОЗМОЖНОСТИ
19 октября 2022
Всероссийский конкурс по агрогенетике для школьников старших классов «Иннагрика»
19 октября 2022
«Лучшие практики наставничества»
21 октября 2022
Protek Pitch Day
Все ВОЗМОЖНОСТИ
Новости
У OBI сменился собственник в результате рейдерского захвата — Forbes
Новости
ФАС проверит маркетплейсы и ритейлеров после жалоб о завышенных ценах на армейское снаряжение
Архив rb. ru
ru
Часовые пояса относительно Москвы
Новости
Германия ввела новое требование для получения шенгенских виз россиянами
Колонки
Должен ли работодатель содействовать военкоматам при вручении повестки работнику?
Как удалить Яндекс строку — подробная инструкция
ГлавнаяСофт
Яндекс.Строка – программа, разработанная одноименной корпорацией «Яндекс». Эта полезная утилита помогает пользователю находить нужную информацию как в интернете, так и в памяти самого компьютера. Ввод данных может осуществляться при помощи клавиатуры или же электроакустического прибора. Ответы на вопросы, по желанию пользователя, будут выведены на экран или же озвучены самой утилитой.
Установленная утилита Яндекс.Строка представляет собой окошко, расположенное на «Панели задач» рабочего стола. При нажатии левой кнопкой мыши на саму строку, появляется интерфейс ПО, где пользователь сможет управлять компьютером, искать информацию в интернете и пр.
При нажатии левой кнопкой мыши на саму строку, появляется интерфейс ПО, где пользователь сможет управлять компьютером, искать информацию в интернете и пр.
Многие пользователи интернета работой Яндекс.Строки остались довольны. Однако нашлись и те люди, которые утверждают, что отечественное ПО лишь отдаленно напоминает Сири. Если вы относитесь к числу последних, эта статья будет вам полезной. Здесь вы сможете узнать, как удалить эту утилиту из памяти вашего устройства.
Как удалить Яндекс строку
Содержание
- Как отключить и скрыть Яндекс.Строку
- Как удалить Яндекс.Строку
- Как скрыть Алису на «Панели задач» Windows 7, 8, 10
- Способ 1
- Способ 2
- Как видоизменить значок Алисы на «Панели задач»
- Как удалить Алису из памяти устройства
- Что такое Яндекс.Бар
- Отключение или удаление Яндекс.Элементов
- Видео — Как убрать Яндекс.строку
Как отключить и скрыть Яндекс.Строку
- Щелкните правым кликом мышки на «Панели задач» вашего рабочего стола.
Кликаем правой кнопкой мышки по «Панели задач» на рабочем столе
- Выберите пункт «Панели». Щелкните по нему.
Наводим курсор на пункт «Панели»
- Уберите отметку возле названия утилиты.
Щелчком левой кнопкой мышки снимаем галочку рядом с названием «Яндекс.Строка»

Опция строки от Яндекса отключена.
Примечание! Чтобы вновь начать работу с утилитой, включите эту опцию.
Как удалить Яндекс.Строку
- Нажмите на кнопку «Пуск».
Нажимаем на кнопку «Пуск»
- Найдите в списке, расположенном справа, строку «Программы по умолчанию». Кликните на ней. Кликаем по строке «Программы по умолчанию»
- В левом нижнем углу открывшегося окна выберите «Программы и компоненты». Щелкните по этой кнопке.
Кликаем по строке «Программы по умолчанию»
- В появившемся списке найдите нужную утилиту. Дважды кликните мышью по Яндекс.Строке.
Дважды кликаем мышью по Яндекс.
СтрокеПодтверждаем действие, нажав кнопку «Да»
 Строке
СтрокеПоздравляем! ПО удалено.
Как скрыть Алису на «Панели задач» Windows 7, 8, 10
Способ 1
- Кликните правой кнопкой устройства ввода на «Панели задач».
Щелкаем правой кнопкой мышки по «Панели задач»
- В списке выберите «Панели». Эта строка находится в самом верху появившегося окна. Щелкните мышкой.
Наводим курсор мышки на пункт «Панели»
- Уберите отметку возле фразы «Голосовой помощник».
Убираем отметку возле фразы «Голосовой помощник»
Поисковая строка на «Панели задач» отсутствует.
Примечание! При повторном использовании ПО, Алиса вновь появится на «Панели задач».
Способ 2
- Кликните левой кнопкой мыши на поисковом поле утилиты.
Кликаем левой кнопкой мыши на поисковом поле утилиты Алиса
- Найдите на «Панели инструментов» ПО значок, на котором изображена шестеренка. Нажмите на него.
Щелкаем по значку шестеренки
- В появившемся меню прокрутите страничку колесиком мышки, пока не появится фраза «Внешний вид».
Мышкой прокручиваем окошко настроек и находим опцию «Внешний вид»
- Выберите в окошке режим отображения «Скрытый».
Из списка выбираем и щелкаем по параметру «Скрытый»
Поисковое поле отсутствует. При повторном использовании ПО виджет на «Панели задач» больше не появится.
Примечание! Для удобства использования утилиты на рабочем столе можно разместить ярлык ПО: «Пуск» → «Все программы» → папка «Голосовой помощник Алиса» → файл «Голосовой помощник Алиса» (щелкните правой кнопкой мыши)→ «Отправить» → «Рабочий стол» (создать ярлык).
Как видоизменить значок Алисы на «Панели задач»
Если пользователю не нравится внешний вид Алисы, громоздкое окно на «Панели задач» можно заменить маленькой кнопкой. Удалять для этого программу не нужно.
- Щелкните левой кнопкой координатного устройства по поисковику.
Кликаем левой кнопкой мыши на поисковом поле утилиты Алиса
- Нажмите мышью на кнопку «Настройки». На таком значке нарисована шестеренка.
Щелкаем по значку шестеренки
- В открывшемся меню найдите строку «Внешний вид».
Мышкой прокручиваем окошко настроек и находим опцию «Внешний вид»
- Выберите в предложенных вариантах режим «Иконка микрофона».
Из предложенных вариантов выбираем режим «Иконка микрофона»
- Поисковое окно заменено маленьким значком.
На «Панели задач» вместо панели поиска голосового помощника Алиса появился значок микрофона
Примечание! В группе «Внешний вид» пользователь может выбрать режим «Компактный».
После чего на «Панели задач» появятся следующие значки:
Как удалить Алису из памяти устройства
- Нажмите на «Пуск».
Нажимаем на кнопку «Пуск»
- В правой колонке найдите строку «Программы по умолчанию». Кликните на ней.
Кликаем по строке «Программы по умолчанию»
- В левом нижнем углу выберите фразу «Программы и компоненты». Нажмите.
Находим в левом нижнем углу пункт «Программы и компоненты», щелкаем по нему левой кнопкой мышки
- В появившемся списке найдите нужную программу. Дважды щелкните левой кнопкой устройства ввода по утилите.
Кликаем двойным щелчком мышки по строке «Голосовой помощник Алиса»
Нажимаем «Да»
 Кликните на ней.
Кликните на ней.Поздравляем! Алиса удалена.
Примечание! После удаления строки от Яндекса в памяти устройства могут остаться ненужные документы. Чтобы избавиться от них, скачайте утилиту CCleaner.
Что такое Яндекс.Бар
Яндекс.Бар – расширение, появившееся 18 лет назад. Этот плагин представлял собой маленькую панельку. Многие пользователи обращали внимание на окошко в графическом интерфейса браузера. Этой строкой и был Яндекс.Бар, установленный пользователем по невнимательности.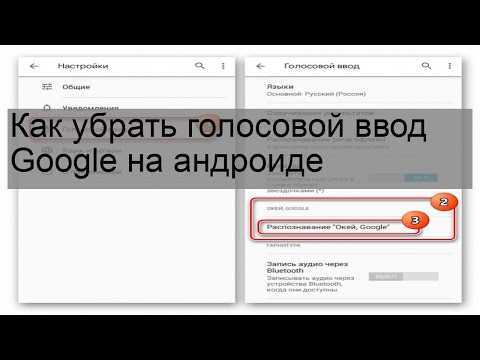
Яндекс.Бар маленькая панелька, которая отслеживала новые письма, присланные на и-мейл, показывала изменения погодных условий
Яндекс.Бар позволял находить в интернете необходимую информацию. Пользователь мог отслеживать новые письма, присланные на и-мейл, наблюдать за изменениями погодных условий и пр. В целом, Яндекс.Бар можно смело назвать «младшим братом» популярной на сегодняшний день Алисы.
В 2012 году Яндекс.Бар прекратил существование. На смену ему пришли так называемые Элементы.Яндекс.
Элементы.Яндекс это визуальные закладки, которые позволяют легко найти необходимую информацию и сохранить ее в виде превью
Это набор расширений, который упрощает работу с такими браузерами, как:
- Мозилла;
- Гугл Хром;
- Опера.
Визуальные закладки позволяют легко найти необходимую информацию и сохранить ее в виде превью. Вдобавок закладки объединяют адресную и поисковую строки и позволяют пользователю просматривать Дзен (ленту с новостями).
Если вы хотите более подробно узнать, как убрать дзен с главной страницы Яндекса, а также рассмотреть подробную инструкцию, вы можете прочитать статью об этом на нашем портале.
Отключение или удаление Яндекс.Элементов
- Откройте веб-обозреватель.
Открываем браузер Гугл Хром или другой из списка
- Вверху (справа) найдите кнопку, на которой изображены три точки. Кликните на ней.
Находим значок три точки, щелкаем по нему
- В открывшемся окне выберите строку «Настройки». Нажмите на нее.
Кликаем левой кнопкой мышки по трем горизонтальным линиям
- В левом верхнем углу вы увидите кнопку с тремя горизонтальными линиями. Кликните на ней.
Кликаем левой кнопкой мышки по трем горизонтальным линиям
- Слева появится интерфейс. В самом низу найдите строку «Расширения». Щелкните по ней.
Находим строку «Расширения», щелкаем по ней
- Откроется новая вкладка. В предложенном списке расширений найдите «Визуальные закладки».
Открываем раздел «Визуальные закладки»
- Щелкните по «Удалить», если намереваетесь избавиться от расширения.
Нажимаем по опции «Удалить»
- В противном случае передвиньте бегунок налево. Так вы расширение отключите.
Для отключения опции перемещаем бегунок налево

Читайте также полезную информацию, как удалить недавно закрытые вкладки в Яндексе, в новой статье на нашем портале.
Видео — Как убрать Яндекс.строку
Понравилась статья?
Сохраните, чтобы не потерять!
Рекомендуем похожие статьи
Голосовой ввод — определение.
Человек постоянно создаёт все новые способы, чтобы сделать свою жизнь комфортней и удобней. Это проявляется во всем — повседневности, быту, работе. Одним из последних инновационных решений стал голосовой ввод, который активно стали использовать пользователи по всему миру.
Что это такое?
Голосовой ввод — это своего рода замена стандартного ввода с клавиатуры. Данные принимаются с помощью микрофона устройства, преобразуются и отображаются в виде обычного текста.
Данные принимаются с помощью микрофона устройства, преобразуются и отображаются в виде обычного текста.
Особенно актуальна эта технология для людей с ограниченными возможностями или тем, кому постоянно приходиться работать с большими объёмами текста. Как правило, это копирайтеры, писатели, переводчики.
Средства для голосового ввода
Для распознавания речи и преобразования её в текст, используется специальное программное обеспечение. А среди его лидеров можно отметить средства от интернет-гигантов Google и «Яндекс».
Голосовой ввод «Гугл» интегрирован практически во все продукты компании. Сюда входит поиск, браузер Google Chrome, операционная система «Андроид», Google Docs. Это очень удобно — научившись пользоваться голосовым вводом в одной технологии, можно с успехом применять его и в другой.
«Андроид»
Голосовой ввод в этой операционной системе доступен «из коробки» во многих версиях. Активировать его можно через меню настроек «Язык и клавиатура» или «Язык и ввод». После этого практически во всех местах, где имеется ввод текста, будь то набор SMS или же текстовый редактор, появится иконка микрофона. Нажатие на неё запустит процесс записи, по окончании которой системе потребуется некоторое время для распознавания и возвращения результата.
После этого практически во всех местах, где имеется ввод текста, будь то набор SMS или же текстовый редактор, появится иконка микрофона. Нажатие на неё запустит процесс записи, по окончании которой системе потребуется некоторое время для распознавания и возвращения результата.
Стоит отметить, что данный функционал на некоторых последних версиях «Андроид» доступен и в режиме оффлайн. Правда, для этого придётся скачать небольшой архив для нужного языка.
Ещё один важный момент — если пользователя не устраивает штатный голосовой ввод, всегда можно установить сторонний.
Google Chrome и Google Docs
Голосовой ввод на компьютере доступен с помощью браузера Google Chrome. Так же, как и в ОС «Андроид», при посещении сайта «Гугл», в строке поиска можно увидеть иконку микрофона. Она позволяет записать звук и выполнить поиск необходимого объекта в сети, без ввода с клавиатуры.
Более расширенная версия используется в онлайн-сервисе документов Google Docs. Помимо набора текста, тут доступны функции перемещения по нему, форматирования, изменения таблиц. В общем, все, что можно сделать классическими средствами ввода — клавиатурой или мышкой.
В общем, все, что можно сделать классическими средствами ввода — клавиатурой или мышкой.
«Яндекс»
«Яндекс» не обладает таким большим набором платформ, на которых можно было бы применять голосовой ввод. Поэтому пока он представлен в продуктах «Поиск», «Разговор» и «Переводчик». Также навигаторы от «Яндекс» умеют распознавать речь и разговаривать с пользователем.
«Поиск» можно встретить в «Яндекс Браузере». Здесь он встроен по умолчанию и действует аналогично Chrome. Основана технология на собственной разработке компании, которая также доступна и для коммерческих нужд в виде Speech.Kit. Подключив его к своему проекту, можно использовать неограниченное количество запросов для распознавания. Однако услуга эта платная.
Другие продукты
Помимо средств голосового ввода от интернет-гигантов, есть и другие свободные разработчики, активно развивающие и продвигающие представленную технологию. Какие-то реализованы в виде онлайн-сервисов (например, speechpad. ru, august4u.ru, bestfree.ru), а какие-то представляют собой полноценные приложения, с возможностью установки на компьютер (speechka, realspeaker).
ru, august4u.ru, bestfree.ru), а какие-то представляют собой полноценные приложения, с возможностью установки на компьютер (speechka, realspeaker).
Несмотря на то что ресурсов у свободных разработчиков немного меньше, их решения работают ничуть не хуже. А иногда и вовсе используют API «Гугл».
Преимущества и недостатки
Голосовой ввод на компьютере обладает своими существенными плюсами и минусами:
- Это несомненно удобно. Руки могут быть свободны во время работы, а также повышается скорость набора, а вместе с этим растёт и производительность.
- В мобильных версиях голосовых средств можно работать с устройством не отрываясь, например, от управления автомобилем.
- К тому же, программы голосового ввода позволяют отказаться от использования неудобной миниатюрной клавиатуры операционной системы, что несомненно влияет на качество и скорость ввода.
Из минусов можно отметить повышенные требования к качеству микрофона. Он должен быть наиболее чувствительным. А ещё сам алгоритм распознавания работает не всегда так, как хотелось бы. Посторонние шумы и помехи могут вызвать сбой, и, как следствие, ошибки в тексте. В любом случае, его придётся редактировать после набора. Так что диктовать текст нужно тщательно и чётко. А это увеличивает время набора.
А ещё сам алгоритм распознавания работает не всегда так, как хотелось бы. Посторонние шумы и помехи могут вызвать сбой, и, как следствие, ошибки в тексте. В любом случае, его придётся редактировать после набора. Так что диктовать текст нужно тщательно и чётко. А это увеличивает время набора.
В заключение
Технология голосового ввода постоянно совершенствуется. Все чаще можно встретить людей, которые разговаривают со своим смартфоном, часами или компьютером. Голосовой ввод активно применяется в проектировании и производстве умных домов и других смежных решений на основе взаимодействия устройств с пользователями.
Возможно, в дальнейшем технология придёт к более совершенному виду, когда начнёт распознавать речь с высоким уровнем точности, вне зависимости от шумов и помех.
Медицинское программное обеспечение для распознавания голоса: типы, преимущества
Зачем использовать системы распознавания речи? Ответ на этот вопрос прост. Большинство людей говорят быстрее, чем могут печатать. Опытный оператор может напечатать сообщение из 100 слов примерно за 2 минуты. Система распознавания речи способна транскрибировать 150 слов в минуту и уже достигла точности 99%, что имеет решающее значение для медицинских работников, поскольку сэкономленное время можно потратить по-разному. Например, экономия времени на бумажной работе позволяет медицинскому персоналу сосредоточиться на выполнении своих прямых обязанностей. Кроме того, программное обеспечение для распознавания речи постоянно совершенствуется, что позволяет тратить меньше времени на одного госпитализированного пациента. Благодаря системам распознавания речи больницы сокращают свои расходы, потому что врачи могут вводить данные непосредственно в систему EHR, не прибегая к помощи медсестры или помощника для выполнения этой задачи.
Опытный оператор может напечатать сообщение из 100 слов примерно за 2 минуты. Система распознавания речи способна транскрибировать 150 слов в минуту и уже достигла точности 99%, что имеет решающее значение для медицинских работников, поскольку сэкономленное время можно потратить по-разному. Например, экономия времени на бумажной работе позволяет медицинскому персоналу сосредоточиться на выполнении своих прямых обязанностей. Кроме того, программное обеспечение для распознавания речи постоянно совершенствуется, что позволяет тратить меньше времени на одного госпитализированного пациента. Благодаря системам распознавания речи больницы сокращают свои расходы, потому что врачи могут вводить данные непосредственно в систему EHR, не прибегая к помощи медсестры или помощника для выполнения этой задачи.
В этой статье мы рассмотрим использование распознавания голоса в здравоохранении, а также его виды и основные преимущества.
Во многих медицинских учреждениях есть должность транскрипциониста или аутсорсинговые услуги транскрипции для записи всего, что врач говорит пациентам. Тем не менее, аутсорсинг или наем транскрипциониста и предоставление достаточного количества специалистов для покрытия потребностей медицинского учреждения является реальной проблемой.
Тем не менее, аутсорсинг или наем транскрипциониста и предоставление достаточного количества специалистов для покрытия потребностей медицинского учреждения является реальной проблемой.
Благодаря приложениям для распознавания голоса врачам не нужно расшифровывать аудиодиктант, а медицинским учреждениям не нужно нанимать множество медицинских транскрипционистов для сопровождения каждого врача. Текст, распознанный системой SR, поступает непосредственно в электронные медицинские карты. Не нужно беспокоиться о сложной медицинской терминологии — медицинские системы SR обучены распознавать большинство терминов.
Типы распознавания речи
Типы программного обеспечения для распознавания голоса в здравоохранении
Серверная часть. Эти системы преобразуют речь в текст только после того, как ее продиктует говорящий. Система записывает файл, обрабатывает его, а затем преобразует голос в текстовый документ. После этого документ готов для редактирования или прямого использования.
Внешний вид. В отличие от внутренних систем SR, внешние способны распознавать и преобразовывать голос в текст в режиме реального времени. Система может ошибаться в распознавании, поэтому медицинскому работнику приходится редактировать текст, то есть «научить» систему работать со своими речевыми образцами.
В зависимости от говорящего. Такое программное обеспечение запоминает уникальные характеристики голоса человека. Для корректной работы система должна быть обучена любым новым пользователем посредством разговора с ней. Часто это означает, что новые пользователи должны прочитать несколько страниц текста, чтобы система распознавания речи смогла проанализировать особенности голоса и интонации.
Независимо от динамика. Такие системы распознают любой голос пользователя, поэтому обучение не требуется. Основным недостатком программного обеспечения, независимого от говорящего, является более низкая точность по сравнению с решениями, зависящими от говорящего. Чтобы решить эту проблему, система использует ограниченную грамматику и небольшой словарный запас.
Чтобы решить эту проблему, система использует ограниченную грамматику и небольшой словарный запас.
Интерфейс управления. Системы SR с функциональностью интерфейса управления позволяют взаимодействовать с программным обеспечением с помощью различных голосовых команд. В здравоохранении такие системы, например, позволяют вводить данные в различные поля решения EMR, помогают в управлении заказами и запасами и помогают выполнять другие задачи.
Преимущества программного обеспечения для распознавания голоса в здравоохранении
Преимущества распознавания речи
Экономия времени и финансовая выгода. Программное обеспечение SR полностью устраняет необходимость транскрипции и экономит до 50 000 долларов в год на каждого врача. Внедряя EHR с обученным распознаванием голоса, поставщики медицинских услуг обычно достигают 25-процентного увеличения пропускной способности пациентов и последующего оплачиваемого дохода.
Гибкость. Большинство систем СР, используемых в здравоохранении, позволяют пользователю добавлять новые слова в словарь и тем самым адаптировать систему для работы в конкретном медицинском отделении.
Большинство систем СР, используемых в здравоохранении, позволяют пользователю добавлять новые слова в словарь и тем самым адаптировать систему для работы в конкретном медицинском отделении.
Повышение качества обслуживания. С помощью технологии распознавания речи в здравоохранении врач может по-настоящему присутствовать с пациентом, не прерывая разговор, чтобы делать какие-то заметки. В результате врач больше подключен и оказывает более качественную помощь.
Заключение
Традиционно считалось, что в больницах системы распознавания речи могут использовать только врачи, которые диктуют отчеты на компьютер. Судя по всему, современные системы СР могут оказать существенную помощь любому сотруднику учреждения здравоохранения. Такие решения сокращают время, затрачиваемое на составление и расшифровку медицинских карт, ускоряют поток информации, а также помогают медицинскому персоналу справиться с дополнительной нагрузкой.
Эффективный поставщик услуг по разработке медицинских приложений готов раскрыть потенциал распознавания голоса в здравоохранении. Свяжитесь с нами, чтобы получить цитату.
Свяжитесь с нами, чтобы получить цитату.
UMS YSR — Примечания к выпуску
3 июня 2022 г.
Выпущен плагин Yandex Speech Recognition (SR) 1.7.1 для сервера UniMRCP (UMS).
Плагин основан на следующих компонентах:
UniMRCP Server 1.7.0
Yandex SpeechKit Speech to Text API v2
gRPC 1.30.3
Protobuf 3.12.2
Libevent 2.1.9
Rapidjson 1.1.0
В настоящее время двоичные файлы доступны для следующих дистрибутивов Linux:
Red Hat/CentOS 7 (unimrcp-yandex-sr-1.7.3-1.el7.x86_64.rpm)
Red Hat/CentOS 8 (unimrcp-yandex-sr-1.7.3-1.el8.x86_64.rpm)
Ubuntu 18.04 LTS (unimrcp-yandex-sr_1.7.3-bionic_amd64.deb)
Ubuntu 20.04 LTS (unimrcp-yandex-sr_1.7.3-focal_amd64.deb)
В этом выпуске устранена возможная утечка памяти.
Ниже приводится подробный список изменений, внесенных в этот выпуск.
- Нет.
- Исправлена возможная утечка памяти, когда две записи файла (сигналы и/или RDR) имеют одинаковое время создания, что является очень редким случаем, не связанным с обычной работой.

- Нет.
- Нет.
28.12.2021
Выпущен плагин Yandex Speech Recognition (SR) 1.7.0 к UniMRCP Server (UMS).
Плагин основан на следующих компонентах:
UniMRCP Server 1.7.0
Yandex SpeechKit Speech to Text API v2
gRPC 1.30.3
Protobuf 3.12.2
Libevent 2.1.9
Rapidjson 1.1.0
В настоящее время двоичные файлы доступны для следующих дистрибутивов Linux:
Red Hat/CentOS 7 (unimrcp-yandex-sr-1.7.2-1.el7.x86_64.rpm)
Red Hat/CentOS 8 (unimrcp-yandex-sr-1.7.2-1.el8.x86_64.rpm)
Ubuntu 18.04 LTS (unimrcp-yandex-sr_1.7.2-bionic_amd64.deb)
Ubuntu 20.04 LTS (unimrcp-yandex-sr_1.7.2-focal_amd64.deb)
Этот выпуск содержит несколько исправлений и улучшений существующих функций. Релиз создан для более новых версий gRPC и API Google.
Ниже приводится подробный список изменений, внесенных в этот выпуск.
- Добавлена поддержка позднего вызова gRPC. Поздний вызов gRPC позволяет решить проблему, связанную с тем, что «чанки должны отправляться с частотой не менее одного раза в 5 секунд».
- Тайм-аут HTTP-запросов аутентификации теперь можно настраивать.
- Пропускать события, связанные с речью, когда выполняется ввод DTMF.
- Исправлена возможная ошибка сегментации при обработке поля заголовка Logging-Tag, имеющего пустое значение [no].
- Добавлен новый атрибут ‘auth-request-timeout’ в элемент ‘streaming-recognition’. По умолчанию 30 секунд.
- Записывать не только код состояния, но и текст состояния, извлеченный из полученных HTTP-ответов.
- Обновлена библиотека gRPC до версии 1.30.3.
- API Google обновлен до версии 1.5.0.
- Обновлено Руководство по использованию, чтобы отразить изменения, внесенные в этот выпуск.
20.08.2020
Выпущен плагин Yandex Speech Recognition (SR) 1..png?1662111894185) 6.0 к серверу UniMRCP (UMS).
6.0 к серверу UniMRCP (UMS).
Плагин основан на следующих компонентах:
UniMRCP Server 1.7.0
Yandex SpeechKit Speech to Text API v2
gRPC 1.30.2
Protobuf 3.12.2
Libevent 2.1.9
Rapidjson 1.1.0
В настоящее время двоичные файлы доступны для следующих дистрибутивов Linux:
Red Hat / CentOS 7 (unimrcp-yandex-sr-1.7.1-1.el7.x86_64.rpm)
Ubuntu 16.04 LTS (unimrcp-yandex-sr_1.7.1-xenial_amd64.deb)
Ubuntu 18.04 LTS (unimrcp-yandex -sr_1.7.1-bionic_amd64.deb)
Этот выпуск создан для более новых версий gRPC, Protobuf и API Яндекса/Google. В выпуске представлено множество дополнительных функций и улучшений существующей функциональности.
Ниже приводится подробный список изменений, внесенных в этот выпуск.
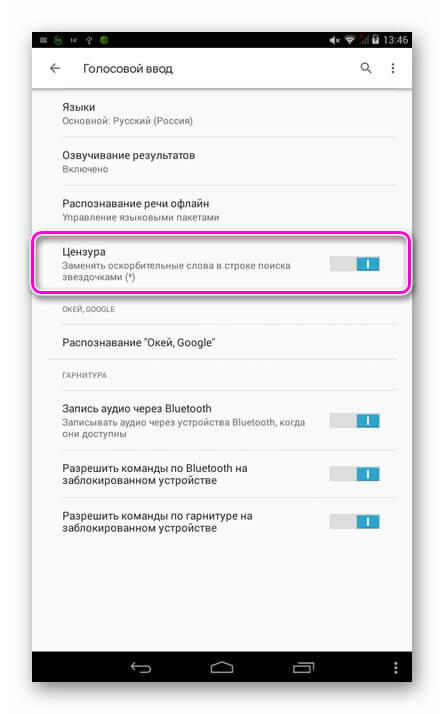
- Добавлена поддержка фильтра ненормативной лексики.
- Если для параметра конфигурации «use-logging-tag» задано значение «true», поле заголовка Logging-Tag, если оно указано, используется в качестве суффикса при составлении имен файлов высказываний и RDR.
- Если указан параметр конфигурации ‘stream-creation-timeout’, устанавливается таймер для отслеживания создания потока gRPC. Если служба недоступна или недоступна из-за проблемы с сетью, таймер позволяет своевременно ответить ошибкой, не дожидаясь истечения установленного по умолчанию срока gRPC.
- Реализовано перенаправление журналов, созданных библиотекой gRPC. Эта функция по умолчанию отключена, и ею можно управлять с помощью новых параметров конфигурации «grpc-log-redirection», «grpc-log-verbosity» и «grpc-log-trace».
- Добавлена поддержка прокси-сервера HTTP при обмене данными с серверами лицензий, доступными как услуга.
- Добавлена поддержка некоторых параметров, зависящих от поставщика, в том числе «speech-start-timeout». См. раздел 4.7 в Руководстве по использованию.
- Сделана настраиваемая область XML SRGS по умолчанию. По умолчанию область считается «строгой», но может неявно использоваться как «подсказка», если для нового параметра конфигурации «match-srgs» установлено значение «false».
- Добавлена поддержка тайм-аута между результатами. Если указанный тайм-аут истек, ввод считается завершенным. Время ожидания по умолчанию равно 0 (отключено) и может быть переопределено для каждого запроса на распознавание.

- Составьте поле заголовка Waveform-URI на основе версии протокола. Раньше безоговорочно использовался формат, определенный в MRCPv2.
- Установите параметры прокси-сервера HTTP не только для gRPC, но и для запросов аутентификации.
- Заменено «x-request-id» на «x-client-request-id» и «x-enable-data-logging-enabled» на «x-data-logging-enabled», чтобы отразить изменения в Yandex SpeechKit API.
- Изменена обработка конца высказывания с учетом изменений API Яндекса SpeechKit.
- Добавлен новый атрибут ‘match-srgs’ к элементу ‘streaming-recognition’. Атрибут по умолчанию имеет значение «истина».
- Добавлен новый атрибут «время ожидания создания потока» для элемента «распознавание потоковой передачи». Атрибут по умолчанию равен 0 (не установлен).
- Добавлены новые атрибуты «grpc-log-redirection», «grpc-log-verbosity» и «grpc-log-trace» для элемента «streaming-recognition».
- Добавлены новые атрибуты ‘http-proxy-address’ и ‘http-proxy-port’ в элемент ‘license-server’.
- Добавлен новый атрибут use-logging-tag для элементов utterance-manager и rdr-manager.
- Добавлен новый атрибут «inter-result-timeout» для элемента «streaming-recognition».
- Изменены значения по умолчанию для параметра «время ожидания неполной речи» с 3000 мс до 15000 мс, а для параметра «время ожидания ввода» — с 10000 мс до 30000 мс.
 Атрибут по умолчанию равен 0 (не установлен).
Атрибут по умолчанию равен 0 (не установлен).- Обновлена библиотека gRPC с версии 1.20.0 до версии 1.30.2.
- Обновлена библиотека Protobuf с версии 3.7.0 до версии 3.12.2.
- Добавлена зависимость от API Google, используемых внутри API Яндекса.
- Обновлено Руководство по использованию, чтобы отразить изменения, внесенные в этот выпуск.

26.08.2019
Вышел плагин Yandex Speech Recognition (SR) 1.5.0 к UniMRCP Server (UMS).
Плагин основан на следующих компонентах:
UniMRCP Server 1.6.0
Yandex SpeechKit Speech to Text API v2
gRPC 1.20.0
Protobuf 3.7.0
Libevent 2.1.9
Rapidjson 1.1.0
В настоящее время двоичные файлы доступны для следующих дистрибутивов Linux:
Red Hat / CentOS 7 (unimrcp-yandex-sr-1.6.6-1.el7.x86_64.rpm)
Ubuntu 16.04 LTS (unimrcp-yandex-sr_1.6.6-xenial_amd64.deb)
Ubuntu 18.04 LTS (unimrcp-yandex -sr_1.6.6-bionic_amd64.deb)
Этот выпуск позволяет управлять форматом элемента экземпляра в возвращаемых результатах NLSML, чтобы дополнительно включать имя записанного высказывания. Релиз также позволяет включить ведение журнала данных на стороне службы для целей отладки.
Ниже приводится подробный список изменений, внесенных в этот выпуск.
- Если для нового параметра конфигурации tag-format установлено значение «расширенный», то элемент экземпляра в результате NLSML объединяет результат транскрипции и имя записанного высказывания с использованием символа «|».
- В целях отладки включите ведение журнала данных на стороне службы, установив для нового параметра конфигурации «регистрация данных» значение «истина». По умолчанию данные не сохраняются.

- Нет.
- Добавлен новый атрибут «формат тега» к элементу «потоковое распознавание».
- Добавлен новый атрибут «регистрация данных» к элементу «потоковое распознавание».
- Руководство по использованию обновлено с учетом изменений, внесенных в этот выпуск.
09.07.2019
Вышел плагин Yandex Speech Recognition (SR) 1.4.0 к UniMRCP Server (UMS).
Плагин основан на следующих компонентах:
UniMRCP Server 1.6.0
Yandex SpeechKit Speech to Text API v2
gRPC 1.20.0
Protobuf 3.7.0
Libevent 2.1.9
Rapidjson 1.1.0
В настоящее время двоичные файлы доступны для следующих дистрибутивов Linux:
Red Hat / CentOS 7 (unimrcp-yandex-sr-1.
Ubuntu 16.04 LTS (unimrcp-yandex-sr_1.6.5-xenial_amd64.deb)
Ubuntu 18.04 LTS (unimrcp-yandex -sr_1.6.5-bionic_amd64.deb)
 6.5-1.el7.x86_64.rpm)
6.5-1.el7.x86_64.rpm) Этот выпуск был создан для более новых файлов определения proto API Яндекса Speech to Text. В выпуске также добавлена поддержка новых параметров службы.
Ниже приводится подробный список изменений, внесенных в этот выпуск.
- Добавлена поддержка нового параметра «модель».
- Добавлена поддержка нового параметра ‘raw-results’.
- Разрешить указывать все основные параметры через параметры производителя. См. раздел 4.9 в Руководстве по использованию.
- Нет.
- Добавлен новый атрибут «модель» к элементу «потоковое распознавание».
- Добавлен новый атрибут ‘raw-results’ к элементу ‘streaming-recognition’.
- Обновлены протофайлы определений Yandex Speech to Text API.
- Обновлено Руководство по использованию, чтобы отразить изменения, внесенные в этот выпуск.

04.06.2019
Вышел плагин Yandex Speech Recognition (SR) 1.3.0 к UniMRCP Server (UMS).
Плагин основан на следующих компонентах:
UniMRCP Server 1.6.0
Yandex SpeechKit Speech to Text API v2
gRPC 1.20.0
Protobuf 3.7.0
Libevent 2.1.9
Rapidjson 1.1.0
В настоящее время двоичные файлы доступны для следующих дистрибутивов Linux:
Red Hat / CentOS 7 (unimrcp-yandex-sr-1.6.4-1.el7.x86_64.rpm)
Ubuntu 16.04 LTS (unimrcp-yandex-sr_1.6.4-xenial_amd64.deb)
Ubuntu 18.04 LTS (unimrcp-yandex -sr_1.6.4-bionic_amd64.deb)
Этот выпуск создан для более новых версий библиотек gRPC и Protobuf. Релиз исправляет несколько мелких проблем.
Далее следует подробный список изменений, внесенных в этот выпуск.
- Добавлена поддержка типа контента ‘text/grammar-ref-list’.
- URI службы сделан настраиваемым в основном для того, чтобы можно было указать не только адрес, но и номер порта службы, что требуется, когда сервер UniMRCP находится за HTTP-прокси TMG.

- Не устанавливать флаг речи/результата, если детектор уже находится в завершенном состоянии. Это может привести к попытке отправить другой фрагмент аудио, когда уже было сигнализировано о завершении ввода.
- Если для одиночного высказывания задано значение false, добавьте пробел при объединении результатов транскрипции.
- Составьте поле заголовка Waveform-URI на основе версии протокола. Раньше безоговорочно использовался формат, определенный в MRCPv2.
- Добавлен новый параметр конфигурации service-uri, который по умолчанию имеет значение stt.api.cloud.yandex.net, а также может быть установлен на stt.api.cloud.yandex.net:443.
- Обновлена библиотека gRPC с версии 1.7.3 до версии 1.20.0.
- Обновлена библиотека Protobuf с версии 3.4.0 до версии 3.7.0.
- Обновлено Руководство по использованию, чтобы отразить изменения, внесенные в этот выпуск.
19.04.2019
Выпущен плагин Yandex Speech Recognition (SR) 1. 2.0 к UniMRCP Server (UMS).
2.0 к UniMRCP Server (UMS).
Плагин основан на следующих компонентах:
UniMRCP Server 1.6.0
Yandex SpeechKit Speech to Text API v2
gRPC 1.7.3
Protobuf 3.4.0
Libevent 2.1.9
Рапидджсон 1.1.0
В настоящее время двоичные файлы доступны для следующих дистрибутивов Linux:
Red Hat / CentOS 7 (unimrcp-yandex-sr-1.6.2-1.el7.x86_64.rpm)
Ubuntu 16.04 LTS (unimrcp-yandex-sr_1.6.2-xenial_amd64.deb)
Ubuntu 18.04 LTS (unimrcp-yandex -sr_1.6.2-bionic_amd64.deb)
В этом выпуске добавлена поддержка HTTP-прокси, представлены двоичные файлы для Ubuntu 18.04 LTS и исправлено несколько проблем.
Ниже приводится подробный список изменений, внесенных в этот выпуск.
- Добавлена поддержка HTTP-прокси.
- Перед отправкой RECOGNITION-COMPLETE убедитесь, что отправлено START-OF-INPUT с причиной завершения, установленной на «несоответствие» или «успех». Исправлена совместимость с медиасервером Cisco Broadworks.
- При использовании сервера лицензий исправлена обработка события разрыва соединения при отправке запроса на обновление лицензии на сервер лицензий. Это событие может привести к отключению службы на несколько секунд.
 Исправлена совместимость с медиасервером Cisco Broadworks.
Исправлена совместимость с медиасервером Cisco Broadworks.- Добавлен новый атрибут ‘http-proxy’ для элемента ‘streaming-recognition’.
- Изменено значение по умолчанию атрибута ‘speech-start-timeout’ с 300 мс до 50 мс.
- Руководство по использованию обновлено с учетом изменений, внесенных в этот выпуск.
- Исправлена библиотека Libevent для правильной поддержки связи через HTTP-прокси. Полученный пакет основан на 2.1.8 и выпущен как 2.1.9.
14 марта 2019 г.
Выпущен плагин Yandex Speech Recognition (SR) 1.1.0 к UniMRCP Server (UMS).
Плагин основан на следующих компонентах:
UniMRCP Server 1.6.0
Yandex SpeechKit Speech to Text API v2
gRPC 1.
Protobuf 3.4.0
Libevent 2.1.8
Rapidjson 1.1.0
 7.3
7.3 В настоящее время двоичные файлы доступны для следующих дистрибутивов Linux:
Red Hat/CentOS 7 (unimrcp-yandex-sr-1.6.1-1.el7.x86_64.rpm)
Ubuntu 16.04 LTS (unimrcp-yandex-sr_1.6.1-xenial_amd64.deb)
В этом выпуске исправлено использование годовых лицензий для узлов, а также внесены некоторые другие незначительные улучшения.
Ниже приводится подробный список изменений, внесенных в этот выпуск.
- Установите сигнал тревоги в файле состояния, если сервер лицензий недоступен в течение определенного периода времени, но служба еще не затронута. Снимите сигнал тревоги, как только сервер лицензий станет доступен. См. раздел 6.2 в Руководстве по использованию.
- Добавлена поддержка необязательного языкового параметра, передаваемого во встроенную грамматику.
- В запросы gRPC, отправляемые в службу, добавлены метаданные «x-request-id», которые можно использовать для сопоставления запросов при устранении возможных проблем со службой.

- Если используется годовая лицензия для узла, срок действия лицензии может быть указан неправильно, что потребует перезапуска службы для продолжения нормальной работы.
- Исправлена обработка искаженных параметров, переданных во встроенную грамматику.
- Нет.
- Исправлена ошибка, из-за которой время ответа HTTP в журналах не усекалось до мс, а представлялось в мс.
- Обновлено Руководство по использованию, чтобы отразить изменения, внесенные в этот выпуск.
24.12.2018
Выпущен плагин Yandex Speech Recognition (SR) 1.0.0 к UniMRCP Server (UMS).
Плагин основан на следующих компонентах:
UniMRCP Server 1.6.0
Yandex SpeechKit Speech to Text API v2
gRPC 1.7.3
Protobuf 3.4.0
Libevent 2.1.8
Rapidjson 1.1.0
В настоящее время двоичные файлы доступны для следующих дистрибутивов Linux:
Red Hat / CentOS 7
Ubuntu 16.
 04 LTS
04 LTSПлагин позволяет платформам IVR использовать SpeechKit Speech to Text API Яндекса через сервер UniMRCP.
Yandex SpeechKit — один из сервисов, предлагаемых Яндекс Облаком. Сервисная инфраструктура спроектирована с учетом высоких нагрузок, чтобы гарантировать доступность и безотказность системы даже при большом количестве одновременных запросов. SpeechKit — это сила Алисы, голосового помощника Яндекса.
https://cloud.yandex.com/services/speechkit
Подключение к глобально доступным сервисам осуществляется через gRPC, что обеспечивает безопасную, надежную и быструю передачу данных через Интернет.
преобразование речи в текст | Форумы 3CX
Преобразование речи в текст
Я просмотрел это руководство здесь и ознакомился с демонстрацией продукта, включенной в установку. У меня немного другой запрос от клиента, это то, что они хотят: При поступлении вызова вызывающему абоненту предлагается произнести описание своей проблемы.
Аудиоописание обрабатывается…- Крис Уолтерс
- Резьба
- конструктор потоков вызовов cfd речь до текст
- Ответов: 7
- Форум: Дизайнер потоков вызовов
Голосовой ввод клиента Сохранить в текстовый файл
Привет, Я использую «Speech to Text», чтобы получить ответ клиента для продвижения моего продукта. Теперь я хочу получить голосовой ввод клиента в текстовый документ или в виде оповещения по электронной почте. Кто сталкивался с такой ситуацией, поддержите. Или скажите мне, погода это возможно сделать .. Пример: номер сетевой карты клиента или адрес…
- Суджит Ванигасекара
- Резьба
- CFD речь до текст текст по речь
- Ответов: 6
- Форум: Дизайнер потоков вызовов
AWS против Google Cloud Точность транскрипции голоса в текст
Мигрируем с Cisco на 3CX. В нашем текущем сценарии колл-центра Cisco UCCX вызовы на нашу основную линию предоставляли бы клиентам возможность «Нажмите 1, чтобы произнести имя сотрудника», с которым вы хотели бы поговорить. Сценарий переведет вызов в AWS Transcribe и произнесет…
- амир_
- Резьба
- ох облако гугл речь до текст
- Ответов: 1
- Форум: Дизайнер потоков вызовов
Решено Где я могу найти расшифрованные текстовые данные для «записей»?
Привет Я выполнил следующие шаги и настроил API речи Google для текста.
Однако расшифрованный текст для VOICEMAIL приходит по электронной почте, но в «записях».
Где я могу найти транскрибированный текст для записи?
https://www.3cx.com/docs/voicemail-transcription/- [электронная почта защищена]
- Резьба
- запись речь до текст
- Ответов: 6
- Форум: Локальный
речь в текст
Есть ли способ заставить клиента ввести IVR 1, когда он говорит 1? Например: Когда клиент слышит IVR 1. Войдите в ОЧЕРЕДИ обслуживания продукта 2. Войдите в ОЧЕРЕДИ обслуживания продукта В это время клиент говорит 1, система автоматически оценивает то, что говорит клиент, и входит в очередь обслуживания продукта 9.0003
- ньюавеалекс
- Резьба
- речь до текст
- Ответов: 5
- Форум: Дизайнер потоков вызовов
Стереозапись MP3
Уважаемый, 3CX. Запишем разговор в MP3 24/32/64 кбит в Стерео (агент/клиент). Из-за: Службы распознавания голоса используют Stereo для создания диалога (агент/клиент). Бывший. Яндекс TextSpeechCloud (Россия, Турция). Качество преобразования голоса в текст в стерео лучше, чем в моно. Октелл, Наумен…
- ОлегОЛП
- Резьба
- мп3 речь до текст стерео
- Ответов: 3
- Форум: Сервер
Документация для голосовой почты в текст
Документация по защите ключа Google Cloud Speech to Text API устарела.
 Аудиоописание обрабатывается…
Аудиоописание обрабатывается… Однако расшифрованный текст для VOICEMAIL приходит по электронной почте, но в «записях».
Где я могу найти транскрибированный текст для записи?
https://www.3cx.com/docs/voicemail-transcription/
Однако расшифрованный текст для VOICEMAIL приходит по электронной почте, но в «записях».
Где я могу найти транскрибированный текст для записи?
https://www.3cx.com/docs/voicemail-transcription/