
Кодирование и декодирование / Хабр
Причиной разобраться в том, как же работает UTF-8 и что такое Юникод заставил тот факт, что VBScript не имеет встроенных функций работы с UTF-8. А так как ничего рабочего не нашел, то пришлось писть/дописывать самому. Опыт на мой взгляд полезный в любом случае. Для лучшего понимания начну с теории.
О Юникоде
До появления Юникода широко использовались 8-битные кодировки, главные минусы которых очевидны:
- Всего 255 символов, да и то часть из них не графические;
- Возможность открыть документ не с той кодировкой, в которой он был создан;
- Шрифты необходимо создавать для каждой кодировки.
Так и было решено создать единый стандарт «широкой» кодировки, которая включала бы все символы (при чем сначала хотели в нее включить только обычные символы, но потом передумали и начали добавлять и экзотические). Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
Юникод использует 1 112 064 кодовых позиций (больше чем 16 бит). Начало дублирует ASCII, а дальше остаток латиницы, кирилица, другие европейские и азиатские символы. Для обозначений символов используют шестнадцатеричную запись вида «U+xxxx» для первых 65k и с большим количеством цифр для остальных.
О UTF-8
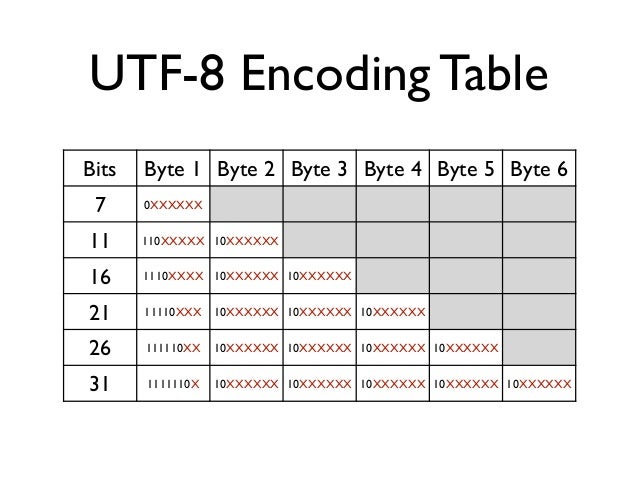
UTF-8 является лишь представлением Юникода в 8-битном виде. Символы с кодами меньше 128 представляются одним байтом, а так как в Юникоде они повторяют ASCII, то текст написанный только этими символами будет являться текстом в ASCII. Символы же с кодами от 128 кодируются 2-мя байтами, с кодами от 2048 — 3-мя, от 65536 — 4-мя. Так можно было бы и до 6-ти байт дойти, но кодировать ими уже ничего.
0x00000000 — 0x0000007F: 0xxxxxxx 0x00000080 — 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 — 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 — 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Кодируем в UTF-8
Порядок действий примерно такой:
- Каждый символ превращаем в Юникод.

- Проверяем из какого символ диапазона.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.

Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h50
b2 = (c - b1) / &h50
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h50
b2 = ((c - b1) / &h50) Mod &h50
b3 = (c - b1 - (&h50 * b2)) / &h2000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < 0 Then
ToLong = CLng(intVal) + &h20000
Else
ToLong = CLng(intVal)
End If
End Function
Декодируем UTF-8
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Юникода.

Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h4F
b2 = c and &h2F
c = b1 + b2 * &h50
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h4F
b2 = asc(mid(s,i+1,1)) and &h4F
b3 = c and &h0F
c = b3 * &h2000 + b2 * &h50 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function
Ссылки
Юникод на Википедии
Исходник для ASP+VBScript
UPD: Обработка ошибочных последовательностей и ошибка с типом Integer, который возвращает AscW.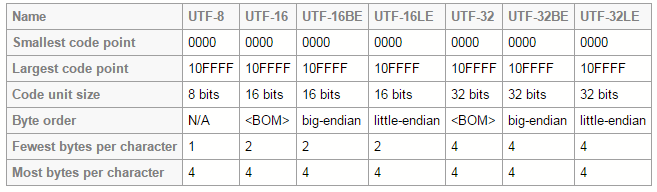
UTF8 | это… Что такое UTF8?
ТолкованиеПеревод
- UTF8
UTF-8 (от англ. Unicode Transformation Format — формат преобразования Юникода) — в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста.
Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст байт со значением меньше 128 изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байтов (реально только до 4 байт, поскольку использование кодов больше 2
21 не планируется), в которых первый байт всегда имеет вид11xxxxxx, а остальные —10xxxxxx.Проще говоря, в формате UTF-8 символы латинского алфавита, знаки препинания и управляющие символы ASCII записываются кодами US-ASCII, a все остальные символы кодируются при помощи нескольких октетов со старшим битом 1.
Это приводит к двум эффектам.- Даже если программа не распознаёт Юникод, то латинские буквы, арабские цифры и знаки препинания будут отображаться правильно.
- В случае, если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объём текста, UTF-8 даёт выигрыш по объёму по сравнению с [1][2]
- На первый взгляд может показаться, что UTF-16 удобнее, так как в ней большинство символов кодируется ровно двумя байтами. Однако это сводится на нет необходимостью поддержки суррогатных пар, о которых часто забывают при использовании UTF-16, реализовывая лишь поддержку символов UCS-2.
Формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9[3]. Сейчас стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
Символы UTF-8 получаются из Unicode следующим образом:
Unicode UTF-8 0x00000000—0x0000007F0xxxxxxx0x00000080—0x000007FF110xxxxx 10xxxxxx0x00000800—0x0000FFFF1110xxxx 10xxxxxx 10xxxxxx0x00010000—0x001FFFFF11110xxx 10xxxxxx 10xxxxxx 10xxxxxxТакже теоретически возможны, но не включены в стандарты:
Unicode UTF-8 0x00200000—0x03FFFFFF111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx0x04000000—0x7FFFFFFF1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxxЗамечание: Символы, закодированные в UTF-8, могут быть длиной до шести байтов, однако стандарт Unicode не определяет символов выше
0x10ffff, поэтому символы Unicode могут иметь максимальный размер в 4 байта в UTF-8.Содержание
- 1 Неиспользуемые значения байтов
- 2 Примечания
- 3 Ссылки
- 4 См. также
Неиспользуемые значения байтов
В тексте UTF-8 принципиально не может быть байтов со значениями 254 (0xFE) и 255 (0xFF). Поскольку в Юникоде не определены символы с кодами выше 221, то в UTF-8 оказываются неиспользуемыми также значения байтов от 248 до 253 (0xF8—0xFE). Если запрещены искусственно удлинённые (за счёт добавления ведущих нулей) последовательности UTF-8, то не используются также байтовые значения 192 и 193 (0xC0 и 0xC1).
Примечания
- ↑ 1 2 Well, I’m Back String Theory (англ.). Robert O’Callahan (2008-03-01). Проверено 1 марта 2008.
- ↑ Ростислав Чебыкин Всем кодировкам кодировка. UTF‑8: современно, грамотно, удобно.. HTML и CSS. Проверено 22 марта 2009.
- ↑ http://www.cl.cam.ac.uk/~mgk25/ucs/utf-8-history.txt (англ.)
Ссылки
- UTF-8 encoding table and Unicode characters
См. также
- Юникод в GNU/Linux
- Юникод в FreeBSD
- Plan 9
 Это приводит к двум эффектам.
Это приводит к двум эффектам.

Wikimedia Foundation. 2010.
Игры ⚽ Нужна курсовая?
- UTF-16 Big Endian
- UTF-32
Полезное
Что такое кодировка UTF-8? Руководство для непрограммистов
Текст: его важность в Интернете очевидна. Это первая буква «Т» в «HTTP», единственная «Т» в «HTML», и практически каждый веб-сайт так или иначе использует ее, будь то URL-адрес, маркетинговая копия, обзор продукта, вирусный твит или Сообщение блога. (Привет!)
Но веб-текст на самом деле может быть не таким простым, как вы думаете. Подумайте о тысячах языков, на которых говорят сегодня, или обо всех знаках препинания и символах, которые мы можем добавить, чтобы улучшить их, или о том факте, что новые смайлики создаются для того, чтобы запечатлеть каждую человеческую эмоцию.
Правда в том, что даже такая простая вещь, как текст, требует хорошо скоординированной, четко определенной системы для отображения в веб-браузерах. В этом посте я объясню основы одной технологии, занимающей центральное место в тексте в Интернете, UTF-8 . Мы изучим основы хранения и кодирования текста и обсудим, как это помогает размещать привлекательные слова на вашем сайте.
Прежде чем мы начнем, вы должны быть знакомы с основами HTML и готовы погрузиться в несложную компьютерную науку.
Что такое UTF-8?
UTF-8 означает «Формат преобразования Unicode — 8 бит». Нам это пока не помогло, так что давайте вернемся к основам.
Двоичный: как компьютеры хранят информацию
Для хранения информации компьютеры используют двоичную систему. В двоичном формате все данные представлены в виде последовательностей 1 и 0. Самая основная единица двоичного кода — это бит , который представляет собой всего одну единицу или 0.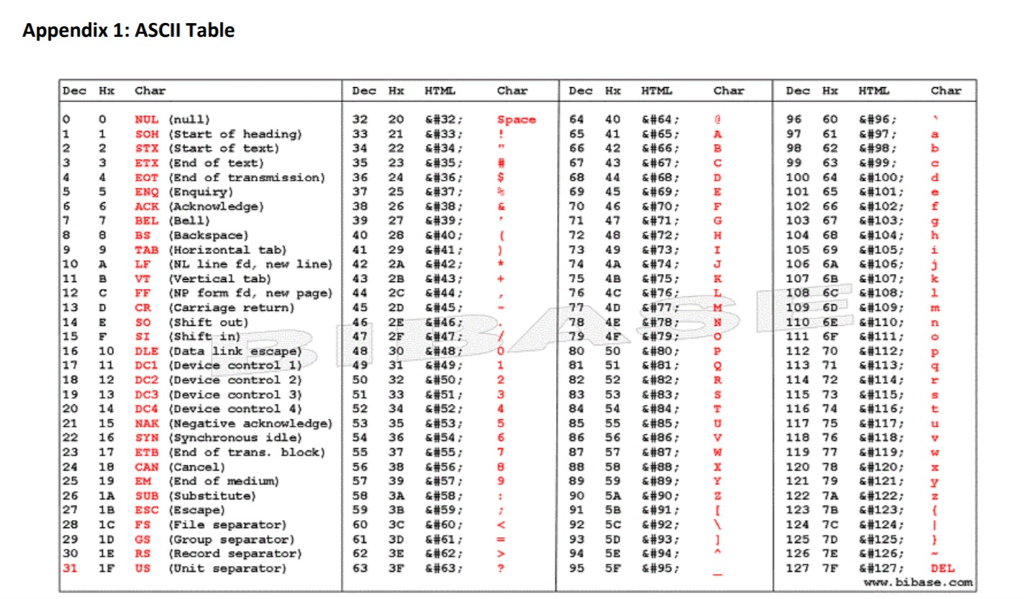 Следующая по величине единица двоичного кода, байт, состоит из 8 бит. Пример байта: «01101011».
Следующая по величине единица двоичного кода, байт, состоит из 8 бит. Пример байта: «01101011».
Каждый цифровой актив, с которым вы когда-либо сталкивались, — от программного обеспечения до мобильных приложений, веб-сайтов и историй в Instagram — построен на этой системе байтов, которые связаны друг с другом таким образом, который имеет смысл для компьютеров. Когда мы говорим о размерах файлов, мы имеем в виду количество байтов. Например, килобайт — это примерно тысяча байтов, а гигабайт — примерно один миллиард байтов.
Текст является одним из многих активов, которые компьютеры хранят и обрабатывают. Текст состоит из отдельных символов, каждый из которых представлен в компьютере строкой битов. Эти строки собираются для формирования цифровых слов, предложений, абзацев, любовных романов и так далее.
ASCII: преобразование символов в двоичные
Американский стандартный код для обмена информацией (ASCII) был ранней стандартизированной системой кодирования текста. Кодирование — это процесс преобразования символов человеческого языка в двоичные последовательности, которые могут обрабатываться компьютером.
Кодирование — это процесс преобразования символов человеческого языка в двоичные последовательности, которые могут обрабатываться компьютером.
Библиотека ASCII включает все прописные и строчные буквы латинского алфавита (A, B, C…), все цифры от 0 до 9 и некоторые распространенные символы (такие как /, ! и ?). Он присваивает каждому из этих символов уникальный трехзначный код и уникальный байт.
В таблице ниже показаны примеры символов ASCII с соответствующими кодами и байтами.
| Символ | Код ASCII | БАЙТ |
| А | 065 | 01000001 |
| и | 097 | 01100001 |
| Б | 066 | 01000010 |
| б | 098 | 01100010 |
| З | 090 | 01011010 |
| с | 122 | 01111010 |
| 0 | 048 | 00110000 |
| 9 | 057 | 00111001 |
| ! | 033 | 00100001 |
| ? | 063 | 00111111 |
Так же, как символы объединяются в слова и предложения в языке, двоичный код делает то же самое в текстовых файлах.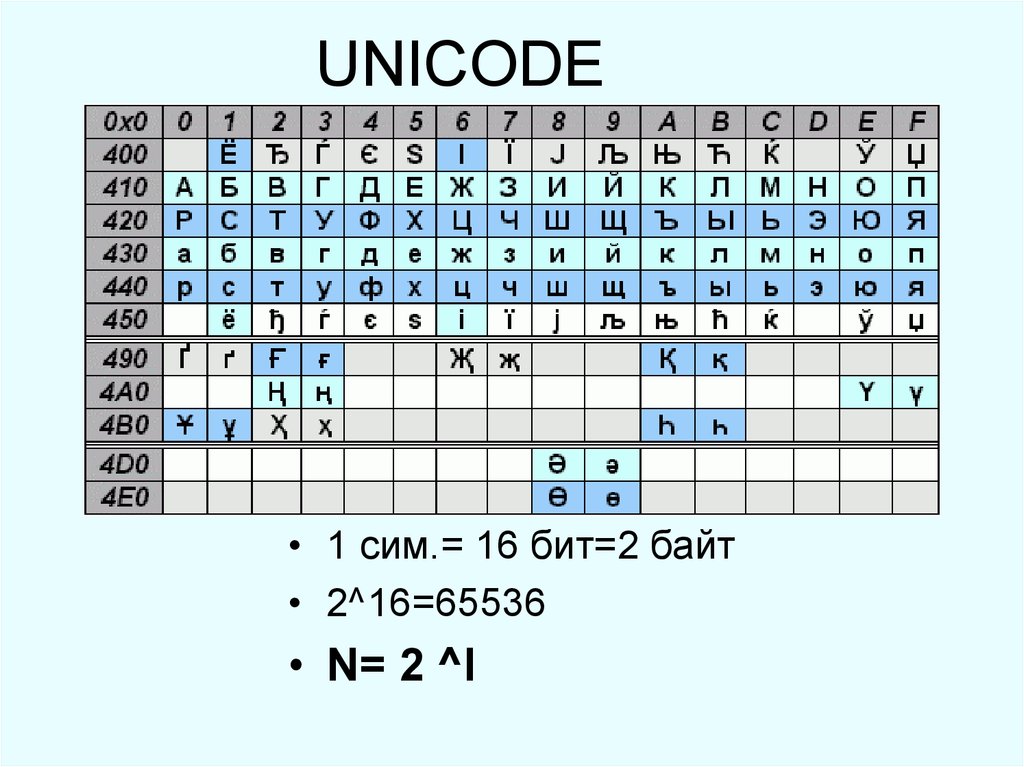 Итак, предложение «Быстрая коричневая лиса перепрыгивает через ленивую собаку». представленный в двоичном формате ASCII, будет:
Итак, предложение «Быстрая коричневая лиса перепрыгивает через ленивую собаку». представленный в двоичном формате ASCII, будет:
01010100 01101000 01100101 00100000 01110001
01110101 01101001 01100011 01101011 00100000
01100010 01110010 01101111 01110111 01101110
00100000 01100110 01101111 01111000 00100000
01101010 01110101 01101101 01110000 01110011
00100000 01101111 01110110 01100101 01110010
00100000 01110100 01101000 01100101 00100000
01101100 01100001 01111010 01111001 00100000
01100100 01101111 01100111 00101110
Это мало что значит для нас, людей, но это хлеб с маслом для компьютера.
Количество символов, которые может представлять ASCII, ограничено количеством доступных уникальных байтов, поскольку каждый символ занимает один байт. Если вы посчитаете, то обнаружите, что существует 256 различных способов сгруппировать восемь единиц и нулей вместе. Это дает нам 256 различных байтов или 256 способов представления символа в ASCII. Когда в 1960 году была введена ASCII, это было нормально, поскольку разработчикам требовалось всего 128 байт для представления всех нужных им английских букв и символов.
Когда в 1960 году была введена ASCII, это было нормально, поскольку разработчикам требовалось всего 128 байт для представления всех нужных им английских букв и символов.
Но по мере глобального распространения вычислительной техники компьютерные системы стали хранить текст на других языках, помимо английского, многие из которых использовали символы, отличные от ASCII. Были созданы новые системы для сопоставления других языков с одним и тем же набором из 256 уникальных байтов, но наличие нескольких систем кодирования было неэффективным и запутанным. Разработчикам нужен был лучший способ кодировать все возможные символы с помощью одной системы.
Unicode: способ хранения всех символов, всегда
Введите Unicode, систему кодирования, которая решает проблему пробелов в ASCII. Подобно ASCII, Unicode присваивает уникальный код, называемый 9.0019 кодовая точка для каждого символа. Однако более сложная система Unicode может создавать более миллиона кодовых точек, чего более чем достаточно для учета каждого символа любого языка.
Unicode теперь является универсальным стандартом для кодирования всех человеческих языков. И да, он даже включает смайлики.
Ниже приведены некоторые примеры текстовых символов и соответствующие им кодовые точки. Каждая кодовая точка начинается с «U» для «Unicode», за которой следует уникальная строка символов для представления символа.
| Символ | Кодовая точка |
| А | U+0041 |
| и | U+0061 |
| 0 | U+0030 |
| 9 | U+0039 |
| ! | U+0021 |
| Ø | U+00D8 |
| ڃ | U+0683 |
| ಚ | У+0С9А |
| 𠜎 | У+2070Е |
| 😁 | У+1Ф601 |
Если вы хотите узнать, как генерируются кодовые точки и что они означают в Unicode, ознакомьтесь с этим подробным объяснением.
Итак, теперь у нас есть стандартизированный способ представления каждого символа, используемого каждым человеческим языком, в одной библиотеке. Это решает проблему множественных систем маркировки для разных языков — любой компьютер на Земле может использовать Unicode.
Но Unicode сам по себе не хранит слова в двоичном виде. Компьютерам нужен способ перевода Unicode в двоичный код, чтобы его символы можно было хранить в текстовых файлах. Вот тут-то и появляется UTF-8.
UTF-8: последняя часть головоломки
UTF-8 — это система кодирования для Unicode. Он может преобразовать любой символ Unicode в соответствующую уникальную двоичную строку, а также может преобразовать двоичную строку обратно в символ Unicode. В этом смысл «UTF» или «формата преобразования Unicode».
Помимо UTF-8, для Unicode существуют и другие системы кодирования, но UTF-8 уникальна, поскольку представляет символы в однобайтовых блоках. Помните, что один байт состоит из восьми битов, отсюда и «-8» в его названии.
В частности, UTF-8 преобразует кодовую точку (которая представляет один символ в Unicode) в набор от одного до четырех байтов. Первые 256 символов в библиотеке Unicode, включая символы, которые мы видели в ASCII, представлены как один байт. Символы, которые появляются позже в библиотеке Unicode, кодируются как двухбайтовые, трехбайтовые и, возможно, четырехбайтовые двоичные единицы.
Ниже приведена та же таблица символов, что и выше, с выводом UTF-8 для каждого добавленного символа. Обратите внимание, что некоторые символы представлены одним байтом, в то время как другие используют больше.
| Символ | Кодовая точка | Двоичная кодировка UTF-8 |
| А | U+0041 | 01000001 |
| и | U+0061 | 01100001 |
| 0 | U+0030 | 00110000 |
| 9 | U+0039 | 00111001 |
| ! | U+0021 | 00100001 |
| Ø | U+00D8 | 11000011 10011000 |
| ڃ | U+0683 | 11011010 10000011 |
| ಚ | U+0C9A | 11100000 10110010 10011010 |
| 𠜎 | У+2070Е | 11110000 10100000 10011100 10001110 |
| 😁 | У+1Ф601 | 11110000 10011111 10011000 10000001 |
Почему UTF-8 преобразовывает одни символы в один байт, а другие в четыре байта? Короче, для экономии памяти. Используя меньше места для представления более распространенных символов (например, символов ASCII), UTF-8 уменьшает размер файла, позволяя использовать гораздо большее количество менее распространенных символов. Эти менее распространенные символы кодируются двумя или более байтами, но это нормально, если они хранятся экономно.
Используя меньше места для представления более распространенных символов (например, символов ASCII), UTF-8 уменьшает размер файла, позволяя использовать гораздо большее количество менее распространенных символов. Эти менее распространенные символы кодируются двумя или более байтами, но это нормально, если они хранятся экономно.
Пространственная эффективность — ключевое преимущество кодировки UTF-8. Если бы вместо этого каждый символ Unicode был представлен четырьмя байтами, текстовый файл, написанный на английском языке, был бы в четыре раза больше размера того же файла, закодированного с помощью UTF-8.
Еще одним преимуществом кодировки UTF-8 является ее обратная совместимость с ASCII. Первые 128 символов в библиотеке Unicode совпадают с символами в библиотеке ASCII, и UTF-8 переводит эти 128 символов Unicode в те же двоичные строки, что и ASCII. В результате UTF-8 может взять текстовый файл, отформатированный в ASCII, и без проблем преобразовать его в удобочитаемый текст.
Символы UTF-8 в веб-разработке
UTF-8 является наиболее распространенным методом кодирования символов, используемым сегодня в Интернете, и является набором символов по умолчанию для HTML5. Более 95% всех веб-сайтов, включая ваш собственный, хранят символы таким образом. Кроме того, распространенные методы передачи данных через Интернет, такие как XML и JSON, кодируются стандартами UTF-8.
Поскольку теперь это стандартный метод кодирования текста в Интернете, все страницы вашего сайта и базы данных должны использовать кодировку UTF-8. Система управления контентом или конструктор веб-сайтов по умолчанию сохраняет ваши файлы в формате UTF-8, но все же рекомендуется убедиться, что вы придерживаетесь этой передовой практики.
Текстовые файлы, закодированные с помощью UTF-8, должны указать это программе, обрабатывающей их. В противном случае программное обеспечение не сможет правильно преобразовать двоичный файл обратно в символы. В файлах HTML вы можете увидеть строку кода, подобную следующей, вверху:
.<метакодировка="UTF-8">
Это сообщает браузеру, что файл HTML закодирован в UTF-8, чтобы браузер мог преобразовать его обратно в разборчивый текст.
UTF-8 против UTF-16
Как я уже упоминал, UTF-8 — не единственный метод кодирования символов Юникода — существует также UTF-16. Эти методы различаются количеством байтов, необходимых для хранения символа. UTF-8 кодирует символ в двоичную строку из одного, двух, трех или четырех байтов. UTF-16 кодирует символ Unicode в строку из двух или четырех байтов.
Это различие очевидно из их имен. В UTF-8 наименьшее двоичное представление символа составляет один байт или восемь бит. В UTF-16 наименьшее двоичное представление символа составляет два байта или шестнадцать бит.
Как UTF-8, так и UTF-16 могут преобразовывать символы Unicode в двоичные файлы, удобные для компьютера, и обратно. Однако они не совместимы друг с другом. Эти системы используют разные алгоритмы для сопоставления кодовых точек с двоичными строками, поэтому двоичный вывод для любого заданного символа будет выглядеть по-разному для обоих методов:
| Символ | Двоичная кодировка UTF-8 | Двоичная кодировка UTF-16 |
| А | 01000001 | 01000001 11011000 00001110 11011111 |
| 𠜎 | 11110000 10100000 10011100 10001110 | 01000001 11011000 00001110 11011111 |
Кодировка UTF-8 предпочтительнее UTF-16 на большинстве веб-сайтов, поскольку она использует меньше памяти. Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы двумя или четырьмя байтами. Это означает, что текстовый файл на английском языке, закодированный с помощью UTF-16, будет как минимум вдвое больше того же файла, закодированного с помощью UTF-8.
Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы двумя или четырьмя байтами. Это означает, что текстовый файл на английском языке, закодированный с помощью UTF-16, будет как минимум вдвое больше того же файла, закодированного с помощью UTF-8.
UTF-16 эффективнее, чем UTF-8, только на некоторых веб-сайтах, отличных от английского. Если веб-сайт использует язык с более ранними символами в библиотеке Unicode, UTF-8 будет кодировать все символы как четыре байта, тогда как UTF-16 может кодировать многие из тех же символов только как два байта. Тем не менее, если ваши страницы заполнены буквами ABC и 123, придерживайтесь UTF-8.
Расшифровка мира кодировки UTF-8
Это было много слов о словах, так что давайте подытожим то, что мы рассмотрели:
- Компьютеры хранят данные, включая текстовые символы, в двоичном виде (1 и 0).
- ASCII был ранним способом кодирования или преобразования символов в двоичный код, чтобы компьютеры могли их хранить. Однако ASCII не предоставлял достаточно места для представления нелатинских символов и чисел в двоичном виде.
- Unicode был решением этой проблемы. Unicode присваивает уникальный «код» каждому символу в каждом человеческом языке.
- UTF-8 — это метод кодирования символов Unicode. Это означает, что UTF-8 берет кодовую точку для данного символа Unicode и переводит ее в двоичную строку. Он также делает обратное, читая двоичные цифры и преобразовывая их обратно в символы.
- UTF-8 в настоящее время является самым популярным методом кодирования в Интернете, поскольку он может эффективно хранить текст, содержащий любой символ.
- UTF-16 — это еще один метод кодирования, но он менее эффективен для хранения текстовых файлов (за исключением тех, которые написаны на некоторых языках, отличных от английского).
 Однако ASCII не предоставлял достаточно места для представления нелатинских символов и чисел в двоичном виде.
Однако ASCII не предоставлял достаточно места для представления нелатинских символов и чисел в двоичном виде. Перевод Unicode — это не то, о чем большинству из нас нужно думать при просмотре или разработке веб-сайтов, и это как раз то, что нужно — создать единую систему обработки текста, которая работает для всех языков и веб-браузеров.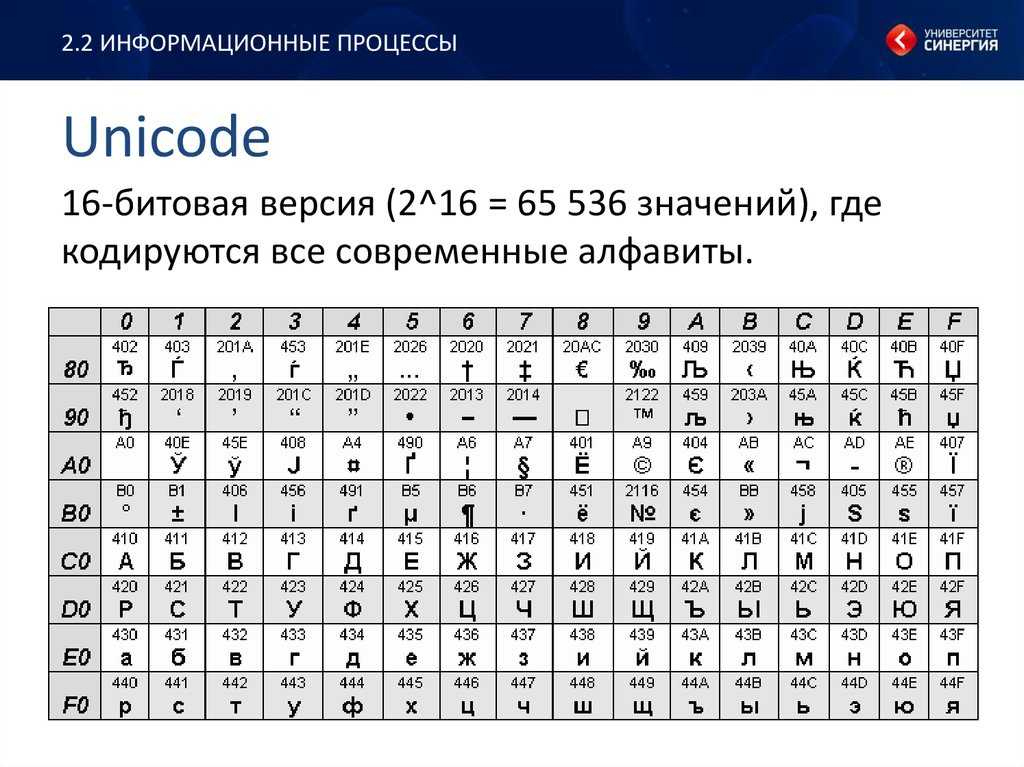 Если он работает хорошо, вы этого не заметите.
Если он работает хорошо, вы этого не заметите.
Но если вы обнаружите, что страницы вашего веб-сайта занимают слишком много места или если ваш текст замусорен ▢s и s, пришло время применить ваши новые знания UTF-8 на практике.
Темы: Дизайн сайта
Не забудьте поделиться этим постом!
Кодировка UTF-8
Сводка
UTF-8 — компромиссная кодировка символов, которая может быть как ASCII (если файл представляет собой простой текст на английском языке), но также может содержать любые символы Юникода (с некоторым увеличением размера файла).
UTF означает формат преобразования Unicode. «8» означает, что он использует 8-битные блоки для представлять персонажа. Количество блоков, необходимых для представления символа, варьируется от от 1 до 4.
Одной из действительно приятных особенностей UTF-8 является то, что она совместима со строками, оканчивающимися нулем.
Ни один символ не будет иметь нулевой (0) байт при кодировании. Это означает, что код C, который имеет дело с
char[] будет «просто работать».
Это означает, что код C, который имеет дело с
char[] будет «просто работать».
Вы можете попробовать тестовую страницу UTF-8, чтобы увидеть, насколько хорошо ваш браузер (и шрифт по умолчанию) поддерживают UTF-8.
Если вы разработчик приложений, эта статья Joel On Software о Unicode довольно хорошее резюме всего, что вам нужно знать.
Дополнительные ссылки:
- Если вас интересуют кровавые подробности, официальная спецификация — RFC 3629 .
- Часто задаваемые вопросы Маркуса Куна
- Рассказ Роба Пайка об его изобретении
Подробности
Для любого символа, равного или меньшего 127 (шестнадцатеричный 0x7F), представление UTF-8 составляет один байт. Это всего лишь младшие 7 бит полного значения Unicode. Это также то же самое, что и значение ASCII.
Для символов, равных или меньше 2047 (шестнадцатеричный 0x07FF), представление UTF-8
распределяется по двум байтам. В первом байте будут установлены два старших бита и
третий бит очищен (т. е. от 0xC2 до 0xDF). Второй байт будет иметь
установлен верхний бит, а второй бит очищен (т. е. от 0x80 до 0xBF).
е. от 0xC2 до 0xDF). Второй байт будет иметь
установлен верхний бит, а второй бит очищен (т. е. от 0x80 до 0xBF).
Для всех символов, равных или превышающих 2048, но менее 65535 (0xFFFF), представление UTF-8 распределяется по трем байтам.
В следующей таблице показан формат таких последовательностей байтов UTF-8 (где «свободные биты», обозначенные крестиками в таблице, объединяются в порядок показан и интерпретирован от наиболее значимого к наименее значимому).
Двоичный формат байтов в последовательности
| 1-й байт | 2-й байт | 3-й байт | 4-й байт | Количество бесплатных битов | Максимальное выражаемое значение Unicode |
|---|---|---|---|---|---|
| 0ххххххх | 7 | 007F шестигранник (127) | |||
| 110xxxxx | 10ххххххх | (5+6)=11 | 07FF шестигранник (2047) | ||
| 1110хххх | 10ххххххх | 10ххххххх | (4+6+6)=16 | Шестигранник FFFF (65535) | |
| 11110xxx | 10ххххххх | 10ххххххх | 10ххххххх | (3+6+6+6)=21 | 10FFFF шестнадцатеричный (1 114 111) |
Значение каждого отдельного байта указывает его функцию UTF-8 следующим образом:
- 00–7F hex (0–127): первый и единственный байт последовательности.
