
подробное руководство по настройке и использованию
Содержание [показать]
Facebook Conversions API – что это такое?
Conversions API (раньше называемое Server-Side API) – это функционал Facebook, который позволяет передавать данные напрямую со своего сервера на сервер Facebook.
Conversions API представляет собой в некотором роде альтернативу более привычному client-side подходу, при котором для отправки данных о событиях, совершенных пользователями на сайте, используется размещение на страницах сайта js-кода пикселя Facebook.
С помощью Conversions API можно настроить отслеживание события, которое происходит за пределами сайта, например, звонок. Также, используя Conversions API, можно отправлять в Facebook данные о переводе заявки из лида в клиента на основании этапов воронки в CRM-системе или факт реальной оплаты покупки, а не отправки транзакции на сайте.
На основании событий Conversions API, так же как и событий пикселя, можно проводить дальнейшую оптимизацию рекламных кампаний.
Особенно актуальным становится освоение Conversions API сейчас, когда ужесточается политика отслеживания данных пользователей (наверняка, уже все, кто работает в рекламном кабинете Facebook, столкнулись с оповещением об изменениях подхода Apple в отношении сбора данных пользователей устройств с iOS 14).
Подготовка к настройке Conversions API
Перед тем, как приступить к настройке, убедитесь, что у вас есть бизнес-менеджер (Business Manager) и пиксель Facebook.
Business Manager – это инструмент Facebook, позволяющий централизованно управлять различными рекламными объектами: кабинетами, страницами, каталогами и др. Если бизнес-менеджера нет, создайте его (инструкция).
Пиксель Facebook (Facebook Pixel) – это код отслеживания (фрагмент кода JavaScript), с помощью которого можно собирать информацию о посетителях сайта и использовать ее для создания аудиторий ремаркетинга и оптимизации рекламы в Facebook/Instagram. Если пикселя нет, необходимо его создать и установить на сайт (инструкция).
Если пикселя нет, необходимо его создать и установить на сайт (инструкция).
Настройка Conversions API
В разделе Events Manager
нужно добавить новое событие, выбрав в выпадающем списке «Использование API Conversions».
Далее появится окно с выбором способа настройки Conversions API – вручную или с использованием партнерской интеграции:
Проверить, доступна ли интеграция для нужной вам платформы, можно по этой ссылке. Если такой нет, выбираем «Внедрение API вручную». Далее пошагово нужно указать, какие события и какие параметры с этими событиями вы хотите отправлять в Facebook.
На последнем шаге вы можете выбрать отправить инструкции разработчику либо выполнить настройку самостоятельно.
При выборе самостоятельной настройки откроется руководство по реализации:
Генерация маркера доступа
Для реализации API запросов нам понадобится сгенерировать маркер доступа. Маркер доступа предоставляет доступ к Conversions API. Его нужно использовать при каждом вызове API.
Маркер доступа предоставляет доступ к Conversions API. Его нужно использовать при каждом вызове API.
Сгенерируйте маркер доступа, а затем скопируйте его и сохраните, так как маркер доступа в Facebook не сохраняется.
Если вдруг вы закрыли руководство или не сохранили маркер, ничего страшного, в меню генерации маркера можно перейти также в разделе «Events Manager» – «Настройки» – блок «API Conversions».
Отправка событий через API
Чтобы отправить свое первое тестовое событие, перейдите в Facebook Graph API Explorer.
Graph API Explorer – это инструмент Facebook, с помощью которого можно выполнять API запросы и проверять ответы на них. Руководство по работе с Graph API Explorer
Для отправки события нужно создать новый POST запрос.
Далее следует указать актуальную версию API (обычно она уже выбрана по умолчанию).
После версии API добавляем идентификатор пикселя и после него сегмент /events:
Идентификатор пикселя можно посмотреть в разделе настроек.
В поле «Маркер доступа» вставляем сгенерированный на прошлом шаге маркер:
Чтобы сформировать тело запроса, нужно переключиться на JSON
и в поле для ввода текста вставить свои данные. Чтобы не ошибиться при составлении тела запроса, удобно использовать Payload Helper. В меню слева можно указывать необходимые для вашего события параметры, а в меню справа автоматически будет формироваться нужный код в формате JSON.
Кроме того, в Payload Helper очень удобно, что при клике на «Получить код» открываются сгенерированные варианты кода на разных языках.
Сформированный JSON нужно скопировать в поле Graph API Explorer.
И, чтобы информация об отправленном событии отобразилась в режиме тестирования в Events Manager, после закрывающей квадратной скобки нужно добавить параметр «test_event_code» со значением, которое сгенерировано на вкладке тестирования серверных событий в Events Manager.
В моем случае:
Кликаем на «Отправить».
Если запрос составлен корректно, то в окошке посредине появится информация о том, что событие получено.
Также тестовое событие появится на вкладке «Тестирование событий» в Events Manager
После того, как вы создали и протестировали отправку нужного события, вы можете реализовать отправку данных на реальном проекте сами либо составить ТЗ для разработчика, который поддерживает ваш проект.
Важно: для событий на сайте, передаваемых через API Conversions, обязательно указывать параметры client_user_agent, action_source и event_source_url. Для остальных типов событий достаточно указания параметра action_source.
С примерами отправки события покупки, реализованными на разных серверных языках, можно ознакомиться в этом разделе developers.
Полезные ссылки со справочной информацией по событиям и параметрам:
- Перечень всех стандартных событий
- Перечень параметров событий
- Параметры данных о клиенте
- Параметры пользовательских данных
- О настройке передачи параметров fbp and fbc
Дедупликация событий
Если с помощью пикселя Facebook и с помощью Conversions API отправляются одинаковые события, системой выполняется дедупликация, то есть удаление дубликатов. То, что события являются совпадающими, определяется на основании параметров «название события» и «ID события», поэтому во избежание дублирования данных, следует передавать эти параметры.
То, что события являются совпадающими, определяется на основании параметров «название события» и «ID события», поэтому во избежание дублирования данных, следует передавать эти параметры.
При отправке события, идентичного тому, что уже было отправлено, дубль будет удален, в режиме тестирования вы можете увидеть такое оповещение:
О дедупликации событий
Об обязательных для дедупликации параметрах
Полезные материалы по Facebook Conversions API
Инструкция по использованию Conversions API + описание обязательных параметров
Инструкция по настройке + пример кода отправки события покупки на Python
Внедрение Conversions API с помощью серверного Google Tag Manager
Что такое Facebook conversion API (CAPI)? Инструкция по подключению к Shopify — Маркетинг на vc.ru
5173 просмотров
Цифровой мир активно меняется. Ранее при работе с таргетированной рекламой в Facebook достаточно было установить пиксель, который помогал отслеживать все активные события на Facebook. К сожалению, после выхода обновления Apple iOS 14 данные на Facebook стали отслеживаться значительно хуже. Это связано с ужесточением закона о конфиденциальности и политики браузеров в отношении файлов cookie. Теперь у пользователей iPhone есть больше контроля над данными, которыми они делятся с рекламодателями.
К сожалению, после выхода обновления Apple iOS 14 данные на Facebook стали отслеживаться значительно хуже. Это связано с ужесточением закона о конфиденциальности и политики браузеров в отношении файлов cookie. Теперь у пользователей iPhone есть больше контроля над данными, которыми они делятся с рекламодателями.
Facebook оперативно нашел выход из данной ситуации и запустил Facebook Conversions API – инструмент, который предоставляет рекламодателям новый, а главное – конфиденциальный способ отслеживания рекламных данных.
В данной статье мы поговорим о Facebook Conversions API, его преимуществах над пикселем, а также поделимся лайфхаками подключения к интернет-магазину на Shopify.
Что такое Facebook Conversions API (CAPI)
Facebook Conversions API (CAPI) – это инструмент, который позволяет получать данные о действиях пользователей на вашем сайте, а на их основе – анализировать статистику и оптимизировать рекламные кампании. В отличие от установки и настройки пикселя, интеграция с API Conversions обеспечивает более надежное соединение для передачи данных, в рамках которого веб-события отправляются на Facebook не из браузера, а прямо с сервера. В последствии использование CAPI помогает увеличить эффективность вашей рекламы, т. к. ее будут видеть те люди, которые с большей вероятностью заинтересуются рекламным предложением.
В последствии использование CAPI помогает увеличить эффективность вашей рекламы, т. к. ее будут видеть те люди, которые с большей вероятностью заинтересуются рекламным предложением.
Отличительная особенность API Conversions в том, что данный инструмент предоставляет дополнительный контроль над передаваемыми данными и оптимизирует процесс их отправки на Facebook. В отличие от пикселя, CAPI меньше подвержен всевозможным проблемам, связанными со сбоями браузера или подключением. Это означает, что при его использовании вы сможете получить гораздо больше информации о целевой аудитории и событиях, которые пиксель может не фиксировать. Но, конечно же, при всем этом CAPI не является заменой пикселя. Почему? Ответим далее в статье.
Существует несколько разных способов настройки API Conversions. Тот, который подойдет вам, зависит от CMS-системы, которую вы используете. Множество платформ, такие как Shopify, Woocommerce, Magento, Tilda и другие предоставляют готовые интеграции, с помощью которых вы сможете настроить API Conversions всего за несколько кликов.
Преимущества использования CAPI
Когда система рекламного аккаунта получает информацию по конверсиям (событиям), то источником этих данных является не что иное, как Facebook Pixel. Он является браузерным источником данных, иными словами web-трекером, инструментом трекинга от самого Facebook. Далее, в опции Event Manager отражаются все данные по браузерным событиям или по событиям пикселя, которые вы настроили.
К сожалению, как мы уже говорили ранее, Facebook Pixel может потерять или не учесть пользователя, что, в свою очередь, повлияет на отображение произошедшей конверсии. Следовательно, он может не добавить пользователя в аудиторию ретаргетинга, что приводит к потере потенциальных клиентов. Это не значит, что пиксель больше не полезен. Он просто работает по-другому. На самом деле, лучше сначала настроить и запустить свой Facebook пиксель, прежде чем начинать настройку CAPI.
У использования Facebook Conversions API есть весомые преимущества, которые повышают эффективность работы рекламы на FB.
- Отслеживание эффективности рекламы. Это преимущество является одним из самых важнейших. С CAPI у вас будет доступ к данным не только пользователей IPhone, но и тех, кто пользуется системами блокировки рекламы, что снизит риск потери 10-20% данных, как при работе с одним пикселем. CAPI собирает все данные по рекламе, что поможет вам повышать ее эффективность.
- Снижение стоимости за действие в связи с улучшением связи. Как уже говорилось выше, ошибки при загрузке браузера, проблемы с подключением и блокировщики рекламы оказывают меньшее влияние на данные API Conversions, чем на данные пикселя. Использование API Conversions предоставляет более качественную связь, что помогает системе показа снизить цену за действие.
- Повышение точности измерений. CAPI помогает точнее измерять результативность и атрибуцию рекламы на всех этапах пути клиента: от знакомства с брендом до конверсии. Это позволит вам точнее оценить влияние цифровой рекламы на результаты вашего бизнеса.

Система API на основе собираемых данных находит подходящих пользователей, и чем больше данных вы передаете системе, тем лучше работает поиск нужной аудитории.
Использование API Conversions с пикселем Facebook
Как вы уже поняли, CAPI имеет отличный функционал. Стоит отметить, что Conversion API не заменяет стандартный Facebook Pixel, который вы устанавливаете для сбора различных данных о пользователях и их взаимодействии с вашим сайтом. Facebook предлагает запуск вашего настроенного пикселя параллельно с их API для максимально эффективной работы обоих инструментов.
Вот несколько преимуществ совместной работы CAPI и пикселя Facebook:
Во-первых, вы устраняете 10-20% разрыва между фактическими целевыми действиями (например, заказами в магазине) и отображаемыми покупками в Facebook.
Во-вторых, так как браузеры все больше и больше начинают блокировать файлы cookie (Safari уже это делает, Chrome планирует), а пользователи все чаще начинают использовать AdBlock (блокировка и фильтрация рекламы), то становится все более важным использовать расширенные функции, такие как CAPI, чтобы иметь возможность полностью отслеживать эффективность вашей рекламы.
Получается, Conversion API – это не новый инструмент, заменяющий пиксель, а некое дополнение к нему. CAPI должен работать параллельно с вашим пикселем для обеспечения максимальной точности отчетов о всех событиях. Пока оба этих инструмента включены в преобразование на стороне пикселя и на стороне сервера, вы можете быть спокойны и не сомневаться в успешности рекламы. Используя API в сочетании с пикселем Facebook, вы получаете больше информации о реальных взаимодействиях с вашим сайтом.
Как подключить CAPI к интернет-магазину на Shopify?
Интеграция API Conversions и Shopify позволяет повысить качество полученных данных. Они будут передаваться из онлайн-магазина непосредственно в ваш аккаунт.
Кроме этого, подключить CAPI к вашему магазину на Shopify очень просто. Это не займет у вас много времени, зато принесет огромную выгоду, так как Facebook Pixel не передает часть событий по некоторым причинам, о которых мы говорили выше. Мы подготовили пошаговую инструкцию по его подключению:
Мы подготовили пошаговую инструкцию по его подключению:
1. Перейдите в Интернет-магазин Shopify > Preferences > прокрутите вниз до раздела Facebook Pixel.
2. После того, как вы нажмете «Настроить Facebook», вы увидите новое приложение и Facebook как канал продаж появится на левой панели навигации. Настройки не займут много времени, просто выполняйте следующие шаги.
3. Сначала подключите свою учетную запись Facebook. После этого, выберите вкладку Business Manager.
4.Далее нужно выбрать вашу действующую страницу в Facebook.
5. Затем выберите свой рекламный аккаунт. До выбора обязательно убедитесь, что выбрали правильный, если у вас их несколько.
6. Теперь самое важное – вкладка «Обмен данными». Здесь нужно выбрать подходящий для вас уровень отслеживания. Есть три уровня: Стандартный, Расширенный и Максимальный:
Стандартный (Standart Tracking) поддерживает только пиксель Facebook. Блокировщики рекламы могут помешать пикселю собирать данные.
Второй вариант – расширенное отслеживание (Enhanced Tracking) – сочетает в себе пиксель и расширенный поиск совпадений.
Максимальное отслеживание (Maximum Tracking) – это уровень, который объединяет пиксель, расширенный поиск совпадений и активирует CAPI Facebook. Эта функция предназначена для получения максимального количества данных, максимальной атрибуции и улучшения общих результатов от ваших рекламных кампаний.
Если вы решили использовать Расширенное или Максимальное отслеживание, обязательно зайдите в Менеджер событий в настройках Facebook и включите расширенную настройку соответствия и событий (Advanced Matching).
Как убедиться, что все настроено корректно?
Вам необходимо загрузить расширение Pixel Helper для Chrome, чтобы убедиться, что CAPI и пиксель настроены правильно. Здесь вы можете посмотреть срабатывает ли пиксель корректно. Кроме этого, просмотрите поток данных и убедитесь, что события, которые вы хотите отслеживать, запускаются правильно.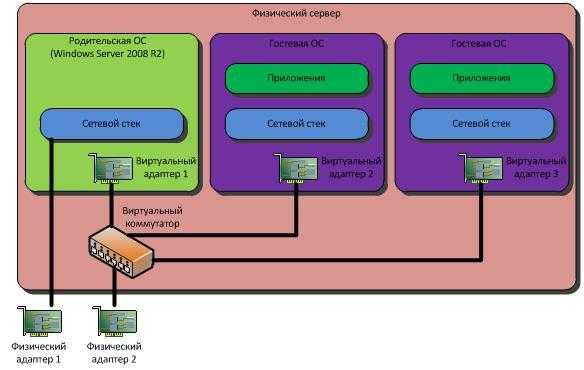
Кроме этого, можно установить Payload Helper (помощник по полезным данным) для того, чтобы проверить запуск CAPI. Проверка через Payload Helper обеспечивает правильную передачу событий обратно в Facebook.
Используя данную инструкцию, вы с легкостью подключите Facebook Conversion API к вашему интернет-магазину на Shopify, сэкономив время и силы. Со списком других сервисов, для которых имеются готовые интеграции, можно ознакомиться по ссылке.
Отслеживание эффективности рекламы в Facebook с помощью API Conversions
Как уже говорилось выше, нужно учитывать, что обновление iOS 14 сильно ограничивает использование файлов cookie для отслеживания на мобильных устройствах Apple. Это означает, что при использовании исключительно пикселя, вы получите гораздо меньше информации о том, как пользователи iOS взаимодействуют с вашим бизнесом. Например, если кто-то перейдет на ваш сайт с Facebook, вы можете этого и не узнать, что приведет к потере потенциального клиента.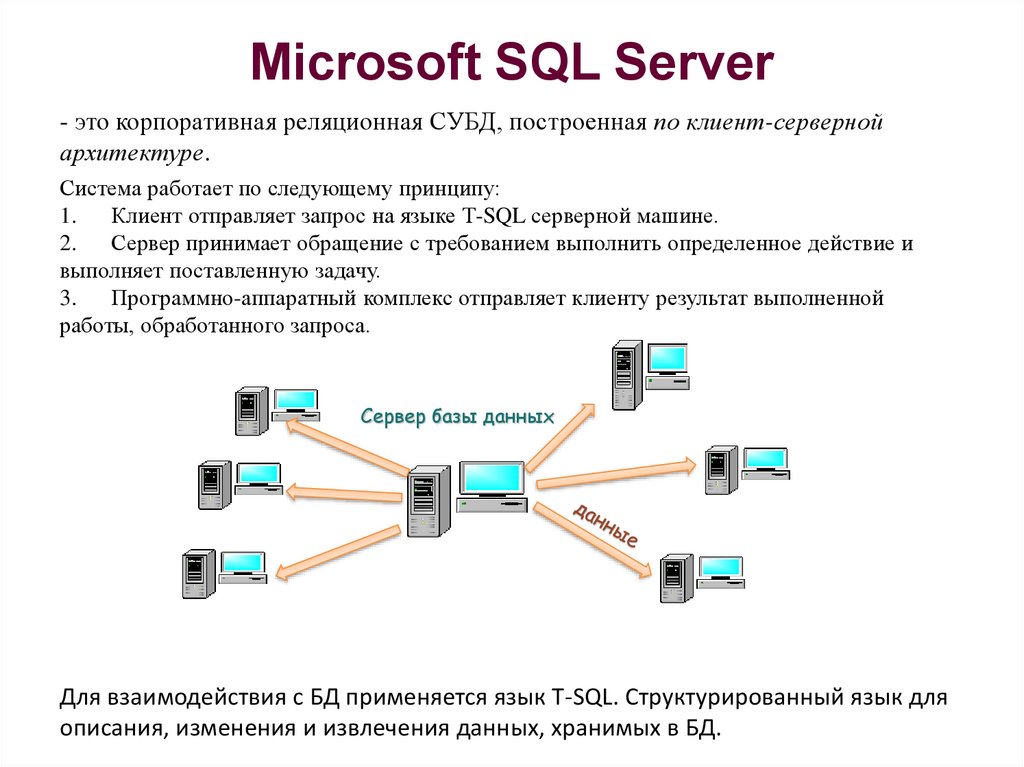
Стоит отметить, что в настоящее время работа с аккаунтами Facebook – достаточно трудоемкий и проблематичный процесс в связи с частыми случаями блокировок. Покупка социального аккаунта или верифицированного бизнес-менеджера – это отличный вариант для запуска в случае, если на ваш аккаунт наложен запрет рекламной деятельности (ЗРД).
Поделитесь в комментариях вашим мнением о данной статье, нам будет очень приятно узнать обратную связь 🙂
И еще кое-что…
Наша команда действительно старается публиковать самые интересные и актуальные материалы , которые помогут вам быть в курсе текущих трендов и новостей в сфере eCommerce. Мы всегда рады новым читателям и с радостью продолжим делиться своими наблюдениями и наработками. Если статья была полезна, то мы будем благодарны, если вы поддержите наш канал подпиской и комментарием:)
Новый интерфейсный сервер Facebook обеспечивает высокую производительность без потребления энергии
- Одной из основных целей эффективной инфраструктуры центра обработки данных является извлечение максимального количества вычислительных ресурсов при минимальном потреблении энергии.
- В Facebook наши веб-серверы должны обрабатывать все большее количество запросов одновременно, отвечая на каждый отдельный запрос как можно быстрее. Чтобы не отставать от растущего спроса на производительность, в течение последних 10 лет мы использовали процессоры с возрастающей мощностью.
- Учитывая конечную мощность, эту тенденцию больше нельзя было масштабировать, и нам требовалось другое решение. Поэтому мы перепроектировали наши веб-серверы, чтобы вместить в каждую стойку более чем вдвое большую вычислительную мощность, сохранив при этом бюджет мощности стойки. Мы также тесно сотрудничали с Intel над новым процессором, который будет встроен в эту конструкцию.
- Эта конструкция обеспечивает значительное улучшение производительности на ватт по сравнению с предыдущей траекторией поколения за поколением. Благодаря внедрению этой системы сегодня мы можем достичь той же производительности на ватт, которая в противном случае потребовала бы нескольких новых поколений серверов.


Масштабирование вычислительной инфраструктуры Facebook, чтобы сделать ее максимально эффективной и рентабельной, было постоянным фокусом наших инженерных усилий. За последние несколько лет мы переосмыслили практически каждый компонент наших центров обработки данных — от специально разработанных серверов и стоек до программного обеспечения, которое работает на них, — и мы сделали наши проекты открытыми для других в отрасли через Open Вычислительный проект.
Одна вещь, которая остается неизменной в наших центрах обработки данных, — это использование двухпроцессорных серверов со все более мощными процессорами Intel. Примерно каждые два года Intel выпускала новое поколение более мощных чипов, производительность которых постоянно улучшалась по сравнению с предыдущим поколением. Но стремление к более высокой производительности в отрасли подтолкнуло процессоры Intel к работе с растущим пределом мощности, что становилось все более сложной проблемой с каждым поколением и в конечном итоге переставало быть масштабируемым.
Вместо того, чтобы оставить эту проблему исключительно в руках Intel и принять тот факт, что наша траектория повышения производительности со временем будет выравниваться, мы обратились к Intel с предложением о совместной работе над поиском решения. Мы тесно сотрудничали с ними при разработке нового процессора и параллельно перепроектировали нашу серверную инфраструктуру, чтобы создать систему, которая удовлетворит наши потребности и будет широко применяться в остальной отрасли. В результате получился однопроцессорный сервер с процессорами меньшей мощности, который работал лучше, чем двухпроцессорный сервер, для нашей веб-рабочей нагрузки и в целом лучше подходил для рабочих нагрузок центра обработки данных. С помощью этой новой системы мы не только смогли избежать снижения производительности, но и смогли резко увеличить темпы производительности, на которых мы работали в течение последних пяти поколений серверов. Система также работает в пределах того же бюджета мощности стойки, что делает наши центры обработки данных более эффективными, чем когда-либо прежде.
Определение проблемы: увеличение нагрузки на веб-сервер
В кластерной архитектуре Facebook каждый кластер состоит из более чем 10 000 серверов. Большая часть нашего пользовательского трафика проходит через внешние кластеры, а веб-серверы составляют основную часть внешнего кластера. На этих веб-серверах работает HHVM, виртуальная машина с открытым исходным кодом, предназначенная для выполнения программ, написанных на Hack и PHP. HHVM использует метод своевременной компиляции для достижения превосходной производительности при сохранении гибкости разработки, которую обеспечивает PHP.
На высоком уровне эта рабочая нагрузка одновременно чувствительна к задержкам и ограничена пропускной способностью. Каждый веб-сервер должен быстро реагировать на данный запрос пользователя, а также параллельно обслуживать запросы от нескольких пользователей. С точки зрения ЦП нам требуется хорошая однопоточная производительность и отличная пропускная способность с большим количеством одновременных потоков. Мы спроектировали эту рабочую нагрузку таким образом, чтобы можно было распараллелить запросы, используя модель выполнения PHP без сохранения состояния. Между запросами на данном веб-сервере не так много взаимодействия, что позволяет нам эффективно масштабироваться на большом количестве машин.
Мы спроектировали эту рабочую нагрузку таким образом, чтобы можно было распараллелить запросы, используя модель выполнения PHP без сохранения состояния. Между запросами на данном веб-сервере не так много взаимодействия, что позволяет нам эффективно масштабироваться на большом количестве машин.
Однако, поскольку у нас большая кодовая база и каждый запрос обращается к большому объему данных, рабочая нагрузка, как правило, связана с пропускной способностью памяти, а не с емкостью памяти. Объем кода достаточно велик, поэтому мы видим нагрузку на переднюю часть ЦП (инструкции по выборке и декодированию). Это требует особого внимания к конструкции кэш-памяти в процессоре. Частые пропуски инструкций в l-кэше приводят к зависаниям интерфейса, что влияет на задержку и количество выполняемых инструкций в секунду.
Мы используем традиционные двухпроцессорные серверы уже более пяти поколений серверов в Facebook. Поскольку наши веб-серверы сильно привязаны к вычислительным ресурсам и не требуют большого объема памяти, у двухпроцессорных серверов, которые у нас были в производстве, было несколько ограничений. У сервера есть ссылка QPI, которая соединяет процессоры, что создало проблему NUMA. Для этого также требуется сопутствующий набор микросхем, который требует большей мощности. Мы продолжали расширять границы производительности (и, следовательно, мощности). Intel предоставила нам 95 Вт, затем 115 Вт, а теперь 120–130 Вт для достижения наших целевых показателей производительности. Учитывая бюджет мощности на уровне стойки в 11 кВт, расширение пределов мощности ЦП было не масштабируемым, и мы не видели, чтобы производительность соответствовала увеличению мощности.
У сервера есть ссылка QPI, которая соединяет процессоры, что создало проблему NUMA. Для этого также требуется сопутствующий набор микросхем, который требует большей мощности. Мы продолжали расширять границы производительности (и, следовательно, мощности). Intel предоставила нам 95 Вт, затем 115 Вт, а теперь 120–130 Вт для достижения наших целевых показателей производительности. Учитывая бюджет мощности на уровне стойки в 11 кВт, расширение пределов мощности ЦП было не масштабируемым, и мы не видели, чтобы производительность соответствовала увеличению мощности.
Наши нынешние процессоры Haswell производятся на основе 14-нм техпроцесса Intel, а следующее поколение техпроцессов — 10-нм. На протяжении нескольких десятилетий улучшения производительности Intel неуклонно соответствовали закону Мура, но в последнее время их цикл «тик-так», включающий переход на новую архитектуру и процессы, замедлился.
Создать ЦП серверного класса сложно, и мы считаем это само собой разумеющимся. Технологические переходы также сложны, особенно при таких крошечных размерах. Мы знали, что Intel решает сложную проблему, но, поскольку наше программное обеспечение параллельно развивалось быстрыми темпами, мы хотели взяться и за эту проблему и посмотреть на дизайн нашей системы через новую призму.
Технологические переходы также сложны, особенно при таких крошечных размерах. Мы знали, что Intel решает сложную проблему, но, поскольку наше программное обеспечение параллельно развивалось быстрыми темпами, мы хотели взяться и за эту проблему и посмотреть на дизайн нашей системы через новую призму.
Строительство ветряных мельниц, а не стен
«Когда дует ветер перемен, одни люди строят стены, а другие предпочитают строить ветряные мельницы». — Китайская пословица
Поскольку веб-серверы составляют основную часть интерфейсного кластера, мы решили сосредоточить наши усилия по оптимизации на этом компоненте нашего парка. Три года назад мы начали работать с Intel, чтобы определить детали нового процессора под названием Broadwell-D, входящего в линейку процессоров Intel Xeon, который лучше подходил для рабочих нагрузок центров обработки данных, а не предприятий. Мы минимизировали ЦП именно до того, что нам требовалось. Мы убрали ссылки QPI, что снизило затраты для Intel и устранило проблему NUMA для нас, учитывая, что все серверы будут односокетными.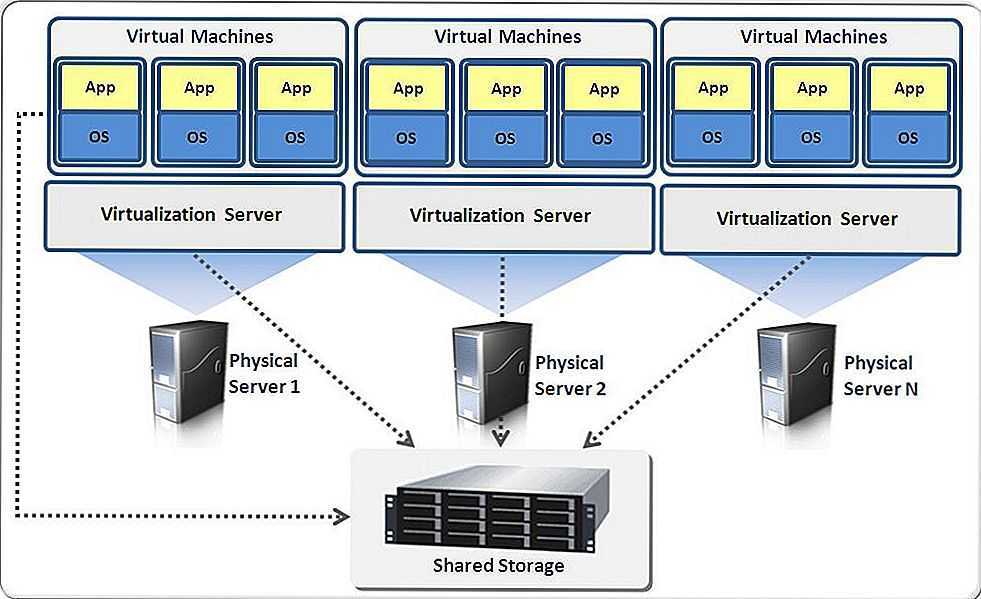 Мы разработали его как систему на кристалле (SOC), которая интегрирует набор микросхем, создавая тем самым более простую конструкцию. Этот односокетный ЦП также имеет более низкую расчетную тепловую мощность (TDP).
Мы разработали его как систему на кристалле (SOC), которая интегрирует набор микросхем, создавая тем самым более простую конструкцию. Этот односокетный ЦП также имеет более низкую расчетную тепловую мощность (TDP).
В то же время мы перепроектировали нашу серверную инфраструктуру, чтобы вместить удвоенное количество ЦП на стойку в той же инфраструктуре питания. Вместе мы разработали сервер с 4 процессорами на салазках и процессором мощностью 65 Вт, который идеально подходит с точки зрения производительности и энергопотребления. Facebook ограничен бюджетом мощности стойки в 11 кВт. У нас 30 серверов в стойке. При 120 Вт на ЦП это позволяло использовать 60 ЦП, а 65 Вт — 120 ЦП на стойку в той же инфраструктуре питания. Хотя математика может показаться простой, для разработки этой новой части потребовался значительный пересмотр дорожной карты Intel.
Изменение дорожной карты — непростой процесс, учитывая сложность проектирования и производства процессора. Intel называет эту новую линейку продуктов линейкой Xeon-D и сделала эту линейку деталей рекордным планом для более широкого внедрения на рынке. Здесь мы взаимозаменяемо используем Xeon-D и Broadwell-D (BW-D).
Здесь мы взаимозаменяемо используем Xeon-D и Broadwell-D (BW-D).
Mono Lake
Мы хотели построить инфраструктуру, состоящую из ряда простых модульных строительных блоков, которые позволили бы нам в будущем использовать другую вычислительную логику (FPGA или GPU). Mono Lake — это серверное воплощение Xeon-D и строительный блок для наших серверов на основе SOC. Это очень упрощенная плата, которая позволяет размещать SOC с соответствующей памятью и хранилищем для загрузки и журнала. В настоящее время он имеет 32 ГБ ОЗУ и 128 ГБ памяти (загрузочная и журнал), связанных с одним процессором Xeon-D. Будущие проекты могут иметь увеличенную память и хранилище, если это необходимо.
Yosemite
Миграция процессов и выделение памяти снижают производительность системы. Это становится все труднее и неэффективнее, поскольку серверы отправляют запросы данных нижестоящим службам. После многих лет попыток исправить это в программном обеспечении, мы решили исправить это в аппаратном обеспечении и упростить дизайн в процессе.
Yosemite — это салазки, включающие четыре платы Mono Lake и соответствующую сетевую карту, в которой процессоры подключены к сетевой карте через линии PCIe, а каждый сервер имеет независимый IP-адрес. Эта конструкция требовала использования сетевого адаптера с несколькими хостами для объединения пропускной способности четырех серверов. Выход NIC в настоящее время рассчитан на скорость 2×25 Гбит/с, которая динамически распределяется между четырьмя процессорами. Объединение портов на уровне салазок обеспечивает более эффективное использование портов верхней части стойки (TOR).
Учитывая, что между серверами нет прямой связи, проблема с NUMA устранена конструктивно. ЦП на данном салазках могут взаимодействовать друг с другом через простой коммутатор в сетевой карте, а не через коммутатор TOR.
Обзор производительности
Процессор Xeon-D обеспечивает значительное повышение производительности на ватт. Это позволяет нам отойти от траектории, по которой мы шли, и показывает преимущества работы в оптимальном режиме, а не просто раздвигает границы производительности одного процессора. Производительность одного процессора мощностью 65 Вт снижается по сравнению с процессором мощностью 120 Вт, но незначительно, учитывая, что процессор работает в момент эффективного выполнения процесса. Выигрыш от удвоения числа ЦП в стойке намного перевешивает потерю производительности одного процессора. Снижение TDP ниже 65 Вт снизило производительность на процессор до неприемлемого уровня. Это одна из причин, по которой процессоры класса Atom не закрепились в крупномасштабных распределенных рабочих нагрузках.
Производительность одного процессора мощностью 65 Вт снижается по сравнению с процессором мощностью 120 Вт, но незначительно, учитывая, что процессор работает в момент эффективного выполнения процесса. Выигрыш от удвоения числа ЦП в стойке намного перевешивает потерю производительности одного процессора. Снижение TDP ниже 65 Вт снизило производительность на процессор до неприемлемого уровня. Это одна из причин, по которой процессоры класса Atom не закрепились в крупномасштабных распределенных рабочих нагрузках.
Мы обнаружили, что для нашей сетевой рабочей нагрузки однопроцессорная система имеет лучшую производительность на ватт, чем двухпроцессорный сервер. Это привело к значительному повышению производительности и увело нас от постепенного повышения производительности от поколения к поколению, по которому мы шли в течение последних пяти поколений серверов.
Существенным ограничением текущего процессора Xeon-D является ограниченное количество каналов памяти. В настоящее время он имеет два канала памяти, что приемлемо для нашего текущего поколения веб-серверов. Будущие SOC должны будут решить проблемы с объемом памяти и пропускной способностью за счет увеличения количества каналов.
Будущие SOC должны будут решить проблемы с объемом памяти и пропускной способностью за счет увеличения количества каналов.
Разбиение кэша LLC — это функция, над которой мы тесно сотрудничали с Intel. Учитывая размер нашего кода, мы планируем создать соответствующие разделы для горячих инструкций и часто используемых данных, тем самым снизив пропускную способность памяти и повысив производительность. Это все еще реализуется в нашей инфраструктуре, и мы очень рады потенциальным преимуществам этой функции.
Все это стало возможным благодаря тесному сотрудничеству и неустанной работе инженеров Facebook и наших отраслевых партнеров, но наше путешествие выполнено только на 1 процент. Впереди интересные времена!
Как Facebook поддерживает свою крупномасштабную инфраструктуру в рабочем состоянии
Службы Facebook опираются на парк серверов в центрах обработки данных по всему миру — все приложения работают и обеспечивают производительность, необходимую нашим службам. Вот почему мы должны убедиться, что наше серверное оборудование надежно и что мы можем управлять сбоями серверного оборудования в нашем масштабе с минимальным нарушением работы наших сервисов.
Вот почему мы должны убедиться, что наше серверное оборудование надежно и что мы можем управлять сбоями серверного оборудования в нашем масштабе с минимальным нарушением работы наших сервисов.
Компоненты оборудования сами по себе могут выйти из строя по ряду причин, включая разрушение материала (например, механические компоненты вращающегося жесткого диска), использование устройства за пределами его предела прочности (например, устройства флэш-памяти NAND), воздействие окружающей среды (например, , коррозия из-за влажности) и производственные дефекты.
В целом, мы всегда ожидаем некоторую степень отказа оборудования в наших центрах обработки данных, поэтому мы внедряем такие системы, как наша система управления кластером, чтобы свести к минимуму перерывы в обслуживании. В этой статье мы представляем четыре важных методологии, которые помогают нам поддерживать высокую степень доступности оборудования. Мы создали системы, которые могут обнаруживать и устранять проблемы. Мы отслеживаем и исправляем аппаратные события, не оказывая отрицательного влияния на производительность приложений. Мы применяем упреждающие подходы к ремонту оборудования и используем методологию прогнозирования для устранения неполадок. Кроме того, мы автоматизируем анализ первопричин аппаратных и системных сбоев в масштабе, чтобы быстро разобраться в сути проблем.
Мы применяем упреждающие подходы к ремонту оборудования и используем методологию прогнозирования для устранения неполадок. Кроме того, мы автоматизируем анализ первопричин аппаратных и системных сбоев в масштабе, чтобы быстро разобраться в сути проблем.
Как мы проводим восстановление оборудования
Мы периодически запускаем инструмент под названием MachineChecker на каждом сервере для обнаружения сбоев оборудования и подключения. Как только MachineChecker создает оповещение в централизованной системе обработки оповещений, инструмент под названием Facebook Auto-Remediation (FBAR) получает оповещение и выполняет настраиваемые исправления для исправления ошибки. Чтобы обеспечить достаточную мощность для сервисов Facebook, мы также можем установить ограничения скорости, чтобы ограничить количество серверов, ремонтируемых в любой момент времени.
Если FBAR не может вернуть сервер в работоспособное состояние, ошибка передается инструменту под названием Cyborg. Cyborg может выполнять исправления более низкого уровня, такие как обновление прошивки или ядра, а также повторное создание образа. Если проблема требует ручного ремонта техническим специалистом, система создает заявку в нашей системе заявок на ремонт.
Если проблема требует ручного ремонта техническим специалистом, система создает заявку в нашей системе заявок на ремонт.
Мы подробно рассмотрим этот процесс в нашей статье «Масштабное восстановление оборудования».
Процесс обнаружения и устранения аппаратных сбоев.Как мы минимизируем негативное влияние отчетов об ошибках на производительность сервера
MachineChecker обнаруживает аппаратные сбои, проверяя различные журналы сервера на наличие отчетов об ошибках. Как правило, когда возникает аппаратная ошибка, она обнаруживается системой (например, сбой проверки четности), и на ЦП отправляется сигнал прерывания для обработки и регистрации ошибки.
Поскольку эти сигналы прерывания считаются сигналами с высоким приоритетом, ЦП остановит свою нормальную работу и сосредоточит свое внимание на обработке ошибки. Но это отрицательно сказывается на производительности сервера. Например, для регистрации исправимых ошибок памяти традиционное прерывание управления системой (SMI) остановит все ядра ЦП, в то время как исправимое прерывание машинной проверки (CMCI) остановит только одно из ядер ЦП, оставив остальные ядра ЦП доступными. для нормальной работы.
для нормальной работы.
Хотя задержки ЦП обычно длятся всего несколько сотен миллисекунд, они все же могут нарушить работу служб, чувствительных к задержке. В масштабе это означает, что прерывания на нескольких машинах могут иметь каскадное негативное влияние на производительность на уровне обслуживания.
Чтобы свести к минимуму влияние отчетов об ошибках на производительность, мы внедрили гибридный механизм отчетов об ошибках памяти, который использует как CMCI, так и SMI без потери точности с точки зрения количества исправимых ошибок памяти.
В нашей статье «Оптимизация производительности обработки прерываний при сбоях памяти в крупных центрах обработки данных» это подробно обсуждается.
Время простоя ЦП, вызванное сообщениями SMI об ошибках памяти по сравнению с CMCI.Как мы используем машинное обучение для прогнозирования ремонта
Поскольку мы часто внедряем новые аппаратные и программные конфигурации в наши центры обработки данных, нам также необходимо создать новые правила для нашей системы автоматического восстановления.
Если автоматизированная система не может исправить аппаратный сбой, проблеме назначается тикет для ручного устранения. Новое аппаратное и программное обеспечение означает новые типы потенциальных отказов, которые необходимо устранять. Но может возникнуть разрыв между внедрением нового оборудования или программного обеспечения и моментом, когда мы сможем внедрить новые правила исправления. В течение этого промежутка некоторые заявки на ремонт могут быть классифицированы как «недиагностированные», что означает, что система не предложила действие по ремонту, или как «неправильно диагностированные», что означает, что предложенное действие по ремонту неэффективно. Это означает больше труда и время простоя системы, в то время как технические специалисты должны самостоятельно диагностировать проблему.
Чтобы заполнить пробел, мы создали платформу машинного обучения, которая учится на том, как сбои были устранены в прошлом, и пытается предсказать, какой ремонт потребуется для текущих недиагностированных или неправильно диагностированных заявок на ремонт. Основываясь на стоимости и выгоде от неверных и правильных прогнозов, мы назначаем порог достоверности прогноза для каждого действия по ремонту и оптимизируем порядок действий по ремонту. Например, в некоторых случаях мы бы предпочли сначала попробовать перезагрузку или обновление прошивки, потому что такие виды ремонта не требуют физического ремонта оборудования и занимают меньше времени, поэтому алгоритм должен сначала рекомендовать такие действия. Проще говоря, машинное обучение позволяет нам не только предсказывать, как исправить недиагностированную или неправильно диагностированную проблему, но и расставлять приоритеты среди наиболее важных.
Основываясь на стоимости и выгоде от неверных и правильных прогнозов, мы назначаем порог достоверности прогноза для каждого действия по ремонту и оптимизируем порядок действий по ремонту. Например, в некоторых случаях мы бы предпочли сначала попробовать перезагрузку или обновление прошивки, потому что такие виды ремонта не требуют физического ремонта оборудования и занимают меньше времени, поэтому алгоритм должен сначала рекомендовать такие действия. Проще говоря, машинное обучение позволяет нам не только предсказывать, как исправить недиагностированную или неправильно диагностированную проблему, но и расставлять приоритеты среди наиболее важных.
Подробнее об этом можно прочитать в нашей статье «Прогнозирование устранения сбоев оборудования в крупных центрах обработки данных».
Процесс восстановления аппаратного обеспечения с прогнозами восстановления.Как мы автоматизировали анализ первопричин на уровне парка
В дополнение к журналам серверов, в которых регистрируются перезагрузки, паника ядра, нехватка памяти и т.