
делаем валидный код на сайте
Привет. Сразу отвечу на ваш вопрос: стоит ли читать Вам этот урок? Перейдите на весьма полезный и бесплатный сервис validator.w3.org, вбейте туда адрес своего сайта и, если вы видите, что на Вашем сайте есть ошибки, то урок прочитать стоит. Примеры отображения ошибок с помощью данного онлайн валидатора:
На моем же блоге сейчас нет подобных ошибок, я от них избавился (всего было более 70 ошибок и более 80-ти предупреждений). Чтобы внести ясность, расскажу, что такое валидный код и зачем он нам необходим.
Валидный код — это код, который соответствует стандартам.
На валидность можно проверить HTML, CSS, всяческие микроразметки и другое. Сегодня я расскажу про валидность в HTML.
- Валидный код необязателен, но количество ошибок должно быть минимальным, иначе ваш сайт не будет кроссбраузерным. Валидность кода нужна в прежде всего для того, чтобы ваш сайт отображался правильно во всех браузерах.

- Поисковые роботы «разговаривают» с вашим сайтом на языке HTML, поэтому важно отдавать четко и ясно контент на сайте со всеми «закрытыми тегами» и прочее.
- Валидность HTML влияет на SEO, но довольно незначительно (если, конечно, у вас не сотни, а то и тысячи ошибок). Рекомендую почитать интересные наблюдения Деваки «Влияние качества HTML на их ранжирование».
- Когда я делал на своем сайте код валидным, я нашел и исправил свои глупые ошибки (повторение тегов, пропущенная буква и т.п.).
- Не стоит «рвать себе *опу», если какую-то ошибку сложно исправить, либо ее исправление принесет вред функциональности сайта. Главное, чтобы было удобно пользователю.

Ниже я разберу основные ошибки, на которые указывал валидатор. Если вдруг в списке ниже не окажется вашей ошибки, впишите ее в комментариях, попробуем вместе разобраться и я добавлю решение данной проблемы в данный урок. Кстати, да, ошибки, на которые указывает валидатор w3c смотрим тут:
В каждой ошибке есть подсказка — это номер строки в исходном коде странице, а из нее уже можно определить примерно в каком файле темы расположена данная строка. Исходный код страницы смотрим с помощью CTRL+U (в основных браузерах).
Исходный код страницы смотрим с помощью CTRL+U (в основных браузерах).
Перед тем, как приступить к работе, сделайте резервную копию шаблона вашего сайта.
Также для упрощения нахождения ошибок в исходном коде, можете использовать HTML валидатор для Mozilla Firefox. Установив его, перейдя в исходный код страницы, вы увидите те же самые ошибки, что указывает сервис validator.w3.org. Кликнув по названию ошибки (в левом нижнем углу), вас автоматически перебросит на ту строчку, где находится данный невалидный код.
Нахождение ошибок в HTML с помощью валидатора w3c и их исправление
Ищите в списке ниже свою ошибку и кликнуть по ней, вас автоматически «прокрутит» куда надо.
- No space between attributes.
- The width attribute on the td element is obsolete. Use CSS instead.
- An img element must have an alt attribute, except under certain conditions. For details, consult guidance on providing text alternatives for images.
- Section lacks heading. Consider using h3-h6 elements to add identifying headings to all sections.
- The hgroup element is obsolete. To mark up subheadings, consider either just putting the subheading into a p element after the h2-h6 element containing the main heading, or…
- Element «noindex» undefined.
- End tag for element «div» which is not open
- Document type does not allow element «li» here; missing one of «ul», «ol», «menu», «dir» start-tag.
- End tag for «div» omitted, but OMITTAG NO was specified.
- There is no attribute «border».
- Character «<» is the first character of a delimiter but occurred as data.
- Saw » when expecting an attribute name. Probable cause: = missing immediately before.
- The align attribute on the img element is obsolete. Use CSS instead.
- Bad value Блог Алексея Смирнова for attribute href on element link: Illegal character in path segment: not a URL code point.
 Consider using h3-h6 elements to add identifying headings to all sections.
Consider using h3-h6 elements to add identifying headings to all sections.1. No space between attributes.

…rel=»shortcut icon» href=»http://arbero.ru/favicon.ico» ; type=»image/x-icon» Просто убираем «точку с запятой».
2. The width attribute on the td element is obsolete. Use CSS instead.
td valign=»center» width=»80″ height=»80″ >
Подобное преобразуем к виду
td style=»align:center; width:80; height: 80;»>
3. An img element must have an alt attribute, except under certain conditions. For details, consult guidance on providing text alternatives for images.
Одна из самых частых ошибок. Просто не хватает альтернативного текста для картинки. Прописываем тег alt.
4. Section lacks heading. Consider using h3-h6 elements to add identifying headings to all sections.
section id=»comments» >
Внутри блока section должны содержаться что-то из тегов h3-h6, если их нет, просто переименовываем слово section на div
5. The hgroup element is obsolete. To mark up subheadings, consider either just putting the subheading into a p element after the h2-h6 element containing the main heading,
or else putting the subheading directly within the h2-h6 element containing the main heading, but separated from the main heading by punctuation and/or within, for example, a span class=»subheading» element with differentiated styling. To group headings and subheadings, alternative titles, or taglines, consider using the header or div elements.
To group headings and subheadings, alternative titles, or taglines, consider using the header or div elements.
Аналогично предыдущему пункту. Просто меняем фразу hgroup на div. Вы можете использовать инструмент «Найти/заменить все» в текстовом редакторе, чтобы ускорить подобные процессы.
6. Element «noindex» undefined
Чтобы тег noindex стал валидным, пишем его в виде комментирования, то есть так:
<!--noindex-->Неиндексируем<!--/noindex-->
7. End tag for element «div» which is not open
Закрывающий тег div лишний. Убираем его.
Неправильное использование тега «li»: отсутствует тег «ul», «ol» и др. Проверьте.
9. End tag for «div» omitted, but OMITTAG NO was specified
Не хватает закрывающего тега div.
10. There is no attribute «border»
alt=»» width=»1″ height=»1″ border=«0″/>
Просто удаляем фразу border=»0″.
11. Character «<» is the first character of a delimiter but occurred as data
Не используйте тег «<» перед обычными словами, используйте лучше разные кавычки.
12. Saw » when expecting an attribute name. Probable cause: = missing immediately before.
Лишняя кавычка, удалите ее.
13. The align attribute on the img element is obsolete. Use CSS instead.
Не используйте значение align внутри тега img. Пропишите ее отдельно, в таком виде:
<div align='center'>тут картинка (img src)</div>
14. Bad value for attribute href on element link: Illegal character in path segment: not a URL code point.
То, что идет в href должно быть ссылкой, начинаться с http, но никак не слово.
Заключение
Если у вас на сайте есть какая-то ошибка, которой нет в этом списке — пишите в комментариях. Разберемся, а я дополню статью. Повторюсь, если какую-то ошибку не получается исправить, не стоит заморачиваться.
У меня на блоге осталась ошибка (хотя еще вчера почему-то код был без ошибок):
The text content of element script was not in the required format: Expected space, tab, newline, or slash but found < instead.
Если в курсе, как исправить ее, буду признателен. Я немножко перфекционист. 🙂
Будете ли вы делать HTML код сайта валидным?
Пожелаю вам получить валидный HTML код на вашем сайте, уведомление которого выглядит так:
P.s. Вы часто перегружаете свой организм? Тогда вам нужна программа детоксикации. Восстановите силы и энергетический баланс.
HTML/Элемент var
Синтаксис
(X)HTML
<var> ... </var>
Описание
Элемент var (от англ. «variable» ‒ «переменная») обозначает переменную в тексте. Под переменной в данном случае может пониматься переменная из математического выражения или кода программы, математическая (или другая) постоянная, физическая величина, параметр функции или просто термин (слово-заменитель), используемый в качестве альтернативы чему-нибудь в тексте.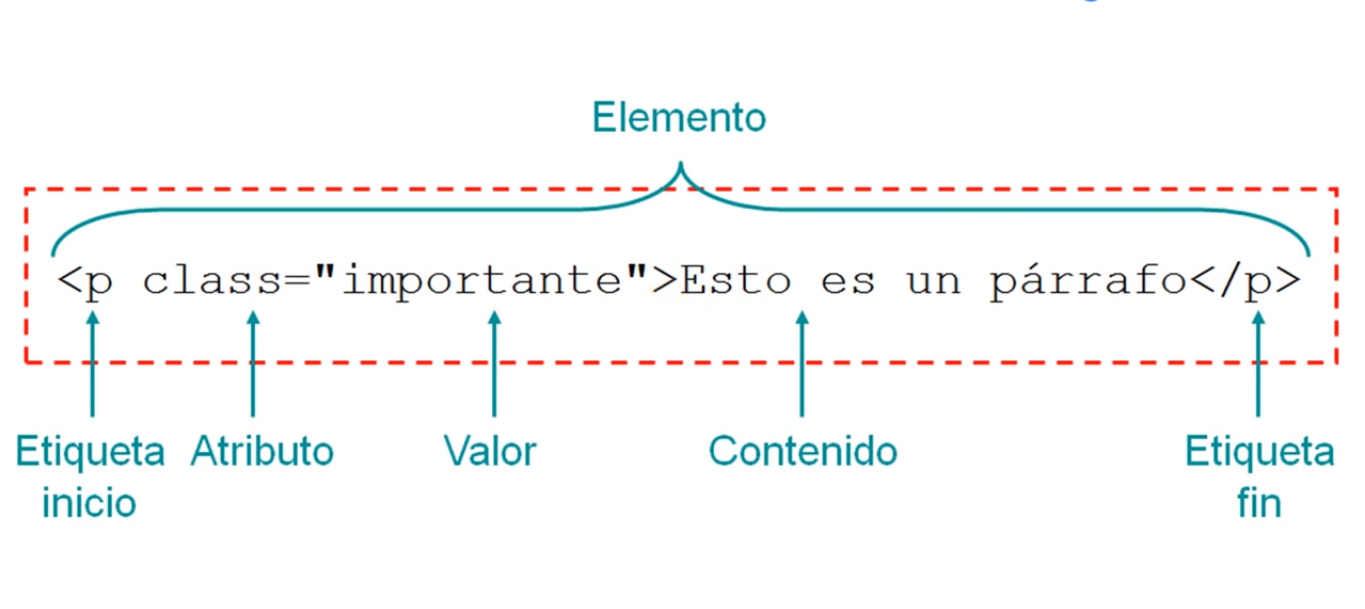
Примечание
Текст, вкладываемый в данный элемент, большинство браузеров по умолчанию отображают ‘курсивом’.
Совет
В случае использования в документе раздела/блока с математическим языком разметки MathML, например, для написания формулы, в описании к формуле можно использовать данный элемент для выделения из текста конкретных переменных формулы.
Поддержка браузерами
Chrome
Поддерж.
Firefox
Поддерж.
Opera
Поддерж.
Maxthon
Поддерж.
IExplorer
Поддерж.
Safari
Поддерж.
iOS
Поддерж.
Android
Поддерж.
Спецификация
| Верс. | Раздел | |
|---|---|---|
| HTML | ||
| 2.0 | Variable: VAR | Перевод |
3. 2 2 | Phrase Elements | |
| 4.01 | 9.2.1 Phrase elements: EM, STRONG, DFN, CODE, SAMP, KBD, VAR, CITE, ABBR, and ACRONYM DTD: Transitional
Strict
Frameset | |
| 5.0 | 4.5.13 The var element | |
| 5.1 | 4.5.18. The var element | |
| XHTML | ||
| 1.0 | Extensible HyperText Markup Language DTD: Transitional
Strict
Frameset | |
| 1.1 | Extensible HyperText Markup Language | |
Атрибуты
- Глобальные атрибуты
- accesskey, class, contenteditable, contextmenu, data-*, dir, draggable, dropzone, hidden, id, inert, lang, spellcheck, style, tabindex, title, translate, xml:lang
Пример использования
Листинг кода
<!DOCTYPE html>
<html>
<head>
<meta charset=»utf-8″>
<title>Элемент var</title>
</head>
<body>
<h2>Пример использования элемента «var»</h2>
<h3>Пример 1</h3>
<p>Если переменная <var>box</var> возвращает значение «<samp>undefined</samp>», значит она не определена. </p>
</p>
</body>
</html>
Элемент var
Политики индексирования Azure Cosmos DB
- Статья
ПРИМЕНЯЕТСЯ К: NoSQL
В Azure Cosmos DB у каждого контейнера есть политика индексирования, определяющая, как следует индексировать элементы контейнера. Политика индексирования по умолчанию для вновь созданных контейнеров индексирует каждое свойство каждого элемента и применяет индексы диапазона для любой строки или числа. Это позволяет получить хорошую производительность запросов, не задумываясь заранее об индексировании и управлении индексами.
В некоторых ситуациях вы можете захотеть переопределить это автоматическое поведение, чтобы оно лучше соответствовало вашим требованиям.
Примечание
Метод обновления политик индексирования, описанный в этой статье, применим только к API Azure Cosmos DB для NoSQL. Узнайте об индексировании в API Azure Cosmos DB для MongoDB
Режим индексирования
Azure Cosmos DB поддерживает два режима индексирования:
- Непротиворечивый : Индекс обновляется синхронно при создании, обновлении или удалении элементов. Это означает, что согласованность ваших запросов на чтение будет согласованностью, настроенной для учетной записи.
- Нет : Индексирование контейнера отключено. Этот режим обычно используется, когда контейнер используется как чистое хранилище ключей и значений без необходимости использования вторичных индексов. Его также можно использовать для повышения производительности массовых операций. После завершения массовых операций режим индекса можно установить на «Согласованный», а затем отслеживать с помощью IndexTransformationProgress до завершения.
 После завершения массовых операций режим индекса можно установить на «Согласованный», а затем отслеживать с помощью IndexTransformationProgress до завершения.
После завершения массовых операций режим индекса можно установить на «Согласованный», а затем отслеживать с помощью IndexTransformationProgress до завершения.Примечание
Azure Cosmos DB также поддерживает режим отложенного индексирования. Ленивая индексация выполняет обновления индекса с гораздо более низким уровнем приоритета, когда механизм не выполняет никакой другой работы. Это может привести к несогласованным или неполным результатам запроса. Если вы планируете запрашивать контейнер Azure Cosmos DB, не следует выбирать отложенное индексирование. Новые контейнеры не могут выбирать ленивую индексацию. Вы можете запросить исключение, обратившись по адресу [email protected] (за исключением случаев, когда вы используете учетную запись Azure Cosmos DB в бессерверном режиме, который не поддерживает отложенное индексирование).
По умолчанию политика индексирования установлена на автоматически . Это достигается установкой для свойства Automatic в политике индексирования значения true . Установка для этого свойства значения
Установка для этого свойства значения true позволяет Azure Cosmos DB автоматически индексировать элементы по мере их записи.
Размер индекса
В Azure Cosmos DB общий потребляемый объем хранилища представляет собой комбинацию размера данных и размера индекса. Ниже приведены некоторые особенности размера индекса:
- Размер индекса зависит от политики индексирования. Если все свойства проиндексированы, то размер индекса может быть больше, чем размер данных.
- При удалении данных индексы уплотняются почти непрерывно. Однако при небольшом удалении данных вы можете не сразу заметить уменьшение размера индекса.
- Размер индекса может временно увеличиваться при разделении физических разделов. Пространство индекса освобождается после завершения разделения раздела.
Включая и исключая пути свойств
Настраиваемая политика индексирования может указывать пути к свойствам, которые явно включаются или исключаются из индексации. Оптимизируя количество индексируемых путей, вы можете существенно сократить задержку и затраты на RU при операциях записи. Эти пути определяются в соответствии с методом, описанным в разделе обзора индексации, со следующими дополнениями:
Оптимизируя количество индексируемых путей, вы можете существенно сократить задержку и затраты на RU при операциях записи. Эти пути определяются в соответствии с методом, описанным в разделе обзора индексации, со следующими дополнениями:
- путь, ведущий к скалярному значению (строка или число), заканчивается
/? - элемента массива адресуются вместе через
/[]обозначение (вместо/0,/1и т.д.) - подстановочный знак
/*может использоваться для соответствия любым элементам ниже узла .
Снова тот же пример:
{
"Места": [
{ "страна": "Германия", "город": "Берлин" },
{ "страна": "Франция", "город": "Париж" }
],
«штаб-квартира»: { «страна»: «Бельгия», «сотрудники»: 250 },
"экспорт": [
{ "город": "Москва" },
{ "город": "Афины" }
]
}
штаб-квартира
сотрудниковпуть/штаб-квартира/сотрудники/?мест‘странапуть/места/[]/страна/?путь к чему-либо под
штаб-квартирой— это/штаб-квартира/*
Например, мы могли бы включить /headquarters/employees/? путь. Этот путь гарантирует, что мы проиндексируем свойство сотрудников, но не будем индексировать дополнительный вложенный JSON в этом свойстве.
Этот путь гарантирует, что мы проиндексируем свойство сотрудников, но не будем индексировать дополнительный вложенный JSON в этом свойстве.
Стратегия включения/исключения
Любая политика индексирования должна включать корневой путь /* либо как включенный, либо как исключенный путь.
Включите корневой путь, чтобы выборочно исключить пути, которые не нужно индексировать. Этот подход рекомендуется, поскольку он позволяет Azure Cosmos DB заблаговременно индексировать любое новое свойство, которое может быть добавлено в вашу модель.
Исключить корневой путь, чтобы выборочно включить пути, которые необходимо проиндексировать. Путь к свойству ключа секции не индексируется по умолчанию с помощью стратегии исключения и должен быть явно включен при необходимости.
Для путей с обычными символами, которые включают: буквенно-цифровые символы и _ (подчеркивание), вам не нужно экранировать строку пути в двойных кавычках (например, «/path/?»).
Для путей с другими специальными символами необходимо заключить строку пути в двойные кавычки (например, «/»path-abc»/?»). Если вы ожидаете, что на вашем пути появятся специальные символы, вы можете избежать каждого пути в целях безопасности. Функционально не имеет значения, избежите ли вы всех путей или только тех, которые содержат специальные символы.Системное свойство
_etagпо умолчанию исключено из индексации, если только etag не добавлен к включенному пути для индексации.Если для режима индексации установлено значение последовательный , системные свойства
idи_tsиндексируются автоматически.Если в элементе не существует явно проиндексированного пути, к индексу будет добавлено значение, указывающее, что путь не определен.
 Для путей с другими специальными символами необходимо заключить строку пути в двойные кавычки (например, «/»path-abc»/?»). Если вы ожидаете, что на вашем пути появятся специальные символы, вы можете избежать каждого пути в целях безопасности. Функционально не имеет значения, избежите ли вы всех путей или только тех, которые содержат специальные символы.
Для путей с другими специальными символами необходимо заключить строку пути в двойные кавычки (например, «/»path-abc»/?»). Если вы ожидаете, что на вашем пути появятся специальные символы, вы можете избежать каждого пути в целях безопасности. Функционально не имеет значения, избежите ли вы всех путей или только тех, которые содержат специальные символы. Все явно включенные пути будут иметь значения, добавленные к индексу для каждого элемента в контейнере, даже если путь для данного элемента не определен.
В этом разделе приведены примеры политик индексации для включения и исключения путей.
Приоритет включения/исключения
Если включенные и исключенные пути конфликтуют, приоритет имеет более точный путь.
Вот пример:
Включенный путь : /пища/ингредиенты/питание/*
Исключенный путь : /food/ingredients/*
В этом случае включенный путь имеет приоритет над исключенным путем, поскольку он более точен. На основе этих путей любые данные в пути food/ingredients или вложенные в него будут исключены из индекса. Исключение составляют данные по включенному пути: /food/ingredients/nutrition/* , которые будут проиндексированы.
Вот некоторые правила приоритета включенных и исключенных путей в Azure Cosmos DB:
Более глубокие пути более точны, чем более узкие. например:
/а/б/?точнее/a/?./?точнее, чем/*. Например /а/?точнее, чем/a/*, значит,/a/?имеет приоритет.Путь
/*должен быть включенным или исключенным путем.
 Например
Например Пространственные индексы
Когда вы определяете пространственный путь в политике индексирования, вы должны указать, какой тип индекса следует применять к этому пути. Возможные типы пространственных индексов включают:
Point
Полигон
Мультиполигон
LineString
Azure Cosmos DB по умолчанию не создает пространственные индексы. Если вы хотите использовать встроенные пространственные функции SQL, вам следует создать пространственный индекс для необходимых свойств. В этом разделе приведены примеры политик индексирования для добавления пространственных индексов.
Составные индексы
Запросы, содержащие предложение ORDER BY с двумя или более свойствами, требуют составного индекса. Вы также можете определить составной индекс, чтобы улучшить производительность многих запросов на равенство и диапазон. По умолчанию составные индексы не определены, поэтому их следует добавлять по мере необходимости.
Вы также можете определить составной индекс, чтобы улучшить производительность многих запросов на равенство и диапазон. По умолчанию составные индексы не определены, поэтому их следует добавлять по мере необходимости.
В отличие от включенных или исключенных путей, вы не можете создать путь с подстановочным знаком /* . Каждый составной путь имеет неявный /? в конце пути, который указывать не нужно. Составные пути ведут к скалярному значению, которое является единственным значением, включенным в составной индекс. Если путь в составном индексе не существует в элементе, к индексу будет добавлено значение, указывающее, что путь не определен.
При определении составного индекса укажите:
Примечание
При добавлении составного индекса запрос будет использовать существующие диапазонные индексы, пока не будет завершено добавление нового составного индекса. Поэтому, когда вы добавляете составной индекс, вы можете не сразу заметить улучшения производительности. Ход преобразования индекса можно отслеживать с помощью одного из SDK.
Ход преобразования индекса можно отслеживать с помощью одного из SDK.
Запросы ORDER BY для нескольких свойств:
При использовании составных индексов для запросов с предложением ORDER BY с двумя или более свойствами используются следующие соображения:
Если пути составного индекса не соответствуют последовательности свойств в предложении
ORDER BY, составной индекс не может поддерживать запрос.Порядок путей составного индекса (по возрастанию или по убыванию) также должен соответствовать
заказв пунктеORDER BY.Составной индекс также поддерживает предложение
ORDER BYс противоположным порядком на всех путях.
Рассмотрим следующий пример, в котором составной индекс определен для свойств name, age и _ts:
| Составной индекс | Образец ORDER BY Запрос | Поддерживается составным индексом? |
|---|---|---|
(имя АСЦ, возраст АСЦ) | ВЫБЕРИТЕ * ИЗ c ORDER BY c. | Да |
(имя ASC, возраст ASC) | ВЫБЕРИТЕ * ИЗ c ORDER BY c.age ASC, c.name asc | № |
(имя ASC, возраст ASC) | ВЫБЕРИТЕ * ИЗ c ORDER BY c.name DESC, c.age DESC | Да |
(имя ASC, возраст ASC) | ВЫБЕРИТЕ * ИЗ c ORDER BY c.name ASC, c.age DESC | № |
(имя ASC, возраст ASC, отметка времени ASC) | ВЫБЕРИТЕ * ИЗ c ORDER BY c.name ASC, c.age ASC, отметка времени ASC | Да |
(имя ASC, возраст ASC, отметка времени ASC) | ВЫБЕРИТЕ * ИЗ c ORDER BY c.name ASC, c.age ASC | № |
 name ASC, c.age asc
name ASC, c.age asc Вам следует настроить политику индексирования, чтобы вы могли обслуживать все необходимые запросы ORDER BY .
Запросы с фильтрами по нескольким свойствам
Если в запросе есть фильтры по двум или более свойствам, может оказаться полезным создать составной индекс для этих свойств.
Например, рассмотрим следующий запрос, который имеет фильтр равенства и диапазон:
SELECT * ОТ С ГДЕ c.name = "Джон" И c.age > 18
Этот запрос будет более эффективным, займет меньше времени и потребует меньше RU, если он сможет использовать составной индекс для (имя ASC, возраст ASC) .
Запросы с несколькими фильтрами диапазонов также можно оптимизировать с помощью составного индекса. Однако каждый отдельный составной индекс может оптимизировать только один диапазонный фильтр. Фильтры диапазона включают > , < , <= , >= и != . Фильтр диапазона должен быть определен последним в составном индексе.
Рассмотрим следующий запрос с фильтром равенства и двумя фильтрами диапазона:
SELECT * ОТ С ГДЕ c.
 name = "John" И c.age > 18 И c._ts > 1612212188
name = "John" И c.age > 18 И c._ts > 1612212188
Этот запрос будет более эффективным с составным индексом (имя ASC, возраст ASC) и (имя ASC, _ts ASC) . Однако запрос не будет использовать составной индекс для (возраст ASC, имя ASC) , поскольку свойства с фильтрами равенства должны быть определены в составном индексе первыми. Требуются два отдельных составных индекса вместо одного составного индекса на (имя ASC, возраст ASC, _ts ASC) , так как каждый составной индекс может оптимизировать только один фильтр диапазона.
При создании составных индексов для запросов с фильтрами по нескольким свойствам учитываются следующие соображения.
- Выражения фильтра могут использовать несколько составных индексов.
- Свойства в фильтре запроса должны совпадать со свойствами составного индекса. Если свойство находится в составном индексе, но не включено в запрос в качестве фильтра, запрос не будет использовать составной индекс.
- Если у запроса есть другие свойства в фильтре, которые не определены в составном индексе, то для оценки запроса будет использоваться комбинация составного и диапазонного индексов. Для этого потребуется меньше единиц запроса, чем при использовании исключительно индексов диапазонов.
- Если у свойства есть фильтр диапазона (
>,<,<=,>=или!=), то это свойство должно быть определено последним в составном индексе. Если запрос имеет более одного фильтра диапазона, он может выиграть от нескольких составных индексов. - При создании составного индекса для оптимизации запросов с несколькими фильтрами
ORDERсоставного индекса не повлияет на результаты. Это свойство является необязательным.

Рассмотрим следующие примеры, в которых составной индекс определен для имени свойства, возраста и отметки времени:
| Составной индекс | Пример запроса | Поддерживается составным индексом? |
|---|---|---|
(имя ASC, возраст ASC) | SELECT * FROM c WHERE c. | Да |
(имя ASC, возраст ASC) | SELECT * FROM c WHERE c.name = "John" AND c.age > 18 | Да |
(имя ASC, возраст ASC) | SELECT COUNT(1) FROM c WHERE c.name = "John" AND c.age > 18 | Да |
(имя DESC, возраст ASC) | SELECT * FROM c WHERE c.name = "John" AND c.age > 18 | Да |
(имя ASC, возраст ASC) | SELECT * FROM c WHERE c.name != "John" AND c.age > 18 | № |
(имя ASC, возраст ASC, отметка времени ASC) | SELECT * FROM c WHERE c.name = "John" AND c.age = 18 AND c.timestamp > 123049923 | Да |
(имя ASC, возраст ASC, отметка времени ASC) | SELECT * FROM c WHERE c. | № |
(имя ASC, возраст ASC) и (имя ASC, отметка времени ASC) | SELECT * FROM c WHERE c.name = "John" AND c.age < 18 AND c.timestamp > 123049923 | Да |
 name = "John" AND c.age = 18
name = "John" AND c.age = 18  name = "John" AND c.age < 18 AND c.timestamp = 123049923
name = "John" AND c.age < 18 AND c.timestamp = 123049923 Запросы с фильтром и ORDER BY
Если запрос фильтрует одно или несколько свойств и имеет разные свойства в предложении ORDER BY, может быть полезно добавить свойства в фильтре в предложение ORDER BY .
Например, добавив свойства фильтра в предложение ORDER BY , можно переписать следующий запрос для использования составного индекса:
Запрос с использованием индекса диапазона:
SELECT * ОТ С ГДЕ c.name = "Джон" ЗАКАЗАТЬ ПО c.timestamp
Запрос с использованием составного индекса:
SELECT * ОТ С ГДЕ c.name = "Джон" ЗАКАЗАТЬ ПО c.name, c.timestamp
Те же оптимизации запросов можно обобщить для любых запросов ORDER BY с фильтрами, учитывая, что отдельные составные индексы могут поддерживать не более одного фильтра диапазона.
Запрос с использованием индекса диапазона:
SELECT * ОТ С ГДЕ c.name = "John" И c.age = 18 И c.timestamp > 1611947901 ЗАКАЗАТЬ ПО c.timestamp
Запрос с использованием составного индекса:
SELECT * ОТ С ГДЕ c.name = "John" И c.age = 18 И c.timestamp > 1611947901 ЗАКАЗАТЬ ПО c.name, c.age, c.timestamp
Кроме того, вы можете использовать составные индексы для оптимизации запросов с системными функциями и ORDER BY:
Запрос с использованием индекса диапазона:
SELECT * ОТ С ГДЕ c.firstName = "Джон" И Содержит (c.lastName, "Смит", правда) ЗАКАЗАТЬ ПО c.lastName
Запрос с использованием составного индекса:
SELECT * ОТ С ГДЕ c.firstName = "Джон" И Содержит (c.lastName, "Смит", правда) ЗАКАЗАТЬ ПО c.firstName, c.lastName
Следующие соображения применимы при создании составных индексов для оптимизации запроса с фильтром и предложением ORDER BY :
- Если вы не определяете составной индекс для запроса с фильтром по одному свойству и отдельному
ORDER Если в предложении BYиспользуется другое свойство, запрос все равно будет выполнен успешно. Однако стоимость RU запроса может быть уменьшена с помощью составного индекса, особенно если свойство в предложении ORDER BYимеет большое количество элементов. - Если запрос фильтрует свойства, эти свойства должны быть сначала включены в предложение
ORDER BY. - Если запрос фильтрует несколько свойств, фильтры равенства должны быть первыми свойствами в предложении
ORDER BY. - Если запрос фильтрует несколько свойств, вы можете использовать не более одного фильтра диапазона или системной функции для каждого составного индекса. Свойство, используемое в фильтре диапазона или системной функции, должно быть определено последним в составном индексе.
- Все рекомендации по созданию составных индексов для запросов
ORDER BYс несколькими свойствами, а также запросов с фильтрами по нескольким свойствам остаются в силе.
 Однако стоимость RU запроса может быть уменьшена с помощью составного индекса, особенно если свойство в предложении
Однако стоимость RU запроса может быть уменьшена с помощью составного индекса, особенно если свойство в предложении | Составной индекс | Образец ORDER BY Запрос | Поддерживается составным индексом? |
|---|---|---|
(имя ASC, метка времени ASC) | SELECT * FROM c WHERE c. | Да |
(имя ASC, отметка времени ASC) | SELECT * FROM c WHERE c.name = "John" AND c.timestamp > 1589840355 ЗАКАЗАТЬ ПО c.name ASC, c.timestamp ASC | Да |
(метка времени ASC, имя ASC) | ВЫБЕРИТЕ * ИЗ c, ГДЕ c.timestamp > 1589840355 И c.name = "John" ЗАКАЗАТЬ ПО c.timestamp ASC, c.name ASC | № |
(имя ASC, отметка времени ASC) | SELECT * FROM c WHERE c.name = "John" ORDER BY c.timestamp ASC, c.name ASC | № |
(имя ASC, отметка времени ASC) | SELECT * FROM c WHERE c.name = "John" ORDER BY c.timestamp ASC | № |
(возраст ASC, имя ASC, отметка времени ASC) | ВЫБЕРИТЕ * ИЗ c, ГДЕ c. | Да |
(возраст ASC, имя ASC, отметка времени ASC) | SELECT * FROM c WHERE c.age = 18 and c.name = "John" ORDER BY c.timestamp ASC | № |
 name = "John" ORDER BY c.name ASC, c.timestamp ASC
name = "John" ORDER BY c.name ASC, c.timestamp ASC  age = 18 и c.name = "John" ORDER BY c.age ASC, c.name ASC, c.timestamp ASC
age = 18 и c.name = "John" ORDER BY c.age ASC, c.name ASC, c.timestamp ASC Запросы с фильтром и агрегатом
Если запрос фильтрует одно или несколько свойств и имеет агрегатную системную функцию, может быть полезно создать составной индекс для свойств в фильтре и агрегатной системной функции. Эта оптимизация применяется к системным функциям SUM и AVG.
Следующие соображения применимы при создании составных индексов для оптимизации запроса с помощью системной функции фильтрации и агрегирования.
- Составные индексы необязательны при выполнении запросов с агрегатами. Однако стоимость запросов на единицу запросов часто можно значительно снизить с помощью составного индекса.
- Если запрос фильтрует несколько свойств, фильтры равенства должны быть первыми свойствами в составном индексе.
- У вас может быть не более одного фильтра диапазона для каждого составного индекса, и он должен быть в свойстве в агрегированной системной функции.
- Свойство в агрегированной системной функции должно быть определено последним в составном индексе.
- Заказ
ASCилиDESC) не имеет значения.

| Составной индекс | Пример запроса | Поддерживается составным индексом? |
|---|---|---|
(имя ASC, метка времени ASC) | ВЫБЕРИТЕ AVG(c.timestamp) FROM c WHERE c.name = "John" | Да |
(метка времени ASC, имя ASC) | ВЫБЕРИТЕ AVG(c.timestamp) FROM c WHERE c.name = "John" | № |
(имя ASC, отметка времени ASC) | ВЫБЕРИТЕ AVG(c. | № |
(имя ASC, возраст ASC, отметка времени ASC) | ВЫБЕРИТЕ AVG(c.timestamp) FROM c WHERE c.name = "John" AND c.age = 25 | Да |
(возраст ASC, отметка времени ASC) | SELECT AVG(c.timestamp) FROM c WHERE c.name = "John" AND c.age > 25 | № |
 timestamp) FROM c WHERE c.name > "John"
timestamp) FROM c WHERE c.name > "John" Изменение политики индексирования
Политику индексирования контейнера можно обновить в любое время с помощью портала Azure или одного из поддерживаемых пакетов SDK. Обновление политики индексирования инициирует преобразование старого индекса в новый, которое выполняется онлайн и на месте (поэтому во время операции не используется дополнительное пространство для хранения). Старая политика индексирования эффективно преобразуется в новую политику, не влияя на доступность для записи, доступность для чтения или пропускную способность, выделенную для контейнера. Преобразование индекса — это асинхронная операция, и время, необходимое для ее завершения, зависит от подготовленной пропускной способности, количества элементов и их размера.
Преобразование индекса — это асинхронная операция, и время, необходимое для ее завершения, зависит от подготовленной пропускной способности, количества элементов и их размера.
Важно
Преобразование индекса — это операция, которая использует единицы запроса. Единицы запроса, использованные при преобразовании индекса, в настоящее время не оплачиваются, если вы используете бессерверные контейнеры. Плата за эти единицы запросов будет выставлена после того, как бессерверные технологии станут общедоступными.
Примечание
Ход преобразования индекса можно отслеживать на портале Azure или с помощью одного из пакетов SDK.
Никакого влияния на доступность записи во время любых преобразований индекса нет. Преобразование индекса использует подготовленные вами ЕЗ, но с более низким приоритетом, чем операции или запросы CRUD.
Добавление новых индексированных путей не влияет на доступность для чтения. Запросы будут использовать новые индексированные пути только после завершения преобразования индекса. Другими словами, при добавлении нового индексированного пути запросы, использующие этот индексированный путь, будут иметь одинаковую производительность до и во время преобразования индекса. После завершения преобразования индекса механизм запросов начнет использовать новые индексированные пути.
Другими словами, при добавлении нового индексированного пути запросы, использующие этот индексированный путь, будут иметь одинаковую производительность до и во время преобразования индекса. После завершения преобразования индекса механизм запросов начнет использовать новые индексированные пути.
При удалении индексированных путей следует сгруппировать все изменения в одно преобразование политики индексирования. Если вы удалите несколько индексов и сделаете это одним изменением политики индексирования, обработчик запросов предоставит согласованные и полные результаты на протяжении всего преобразования индекса. Однако если вы удаляете индексы посредством нескольких изменений политики индексирования, обработчик запросов не будет предоставлять согласованные или полные результаты, пока не будут завершены все преобразования индексов. Большинство разработчиков не удаляют индексы, а затем сразу же пытаются выполнять запросы, использующие эти индексы, поэтому на практике такая ситуация маловероятна.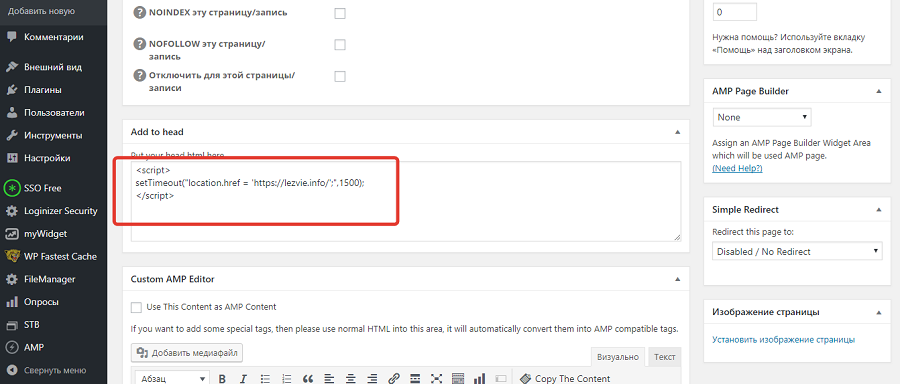
Когда вы удаляете проиндексированный путь, обработчик запросов немедленно прекращает его использование и вместо этого выполняет полное сканирование.
Примечание
По возможности всегда следует пытаться сгруппировать несколько изменений индексирования в одно изменение политики индексирования
Политики индексирования и TTL
Использование функции Time-to-Live (TTL) требует индексирования. Это означает, что:
- невозможно активировать TTL для контейнера, где режим индексации установлен на
нет, - невозможно установить режим индексирования None для контейнера, в котором активирован TTL.
В сценариях, где не нужно индексировать путь к свойству, но требуется TTL, вы можете использовать политику индексирования с режимом индексирования, установленным на согласованный , без включенных путей и /* в качестве единственного исключенного пути.
Дальнейшие действия
Узнайте больше об индексации в следующих статьях:
- Обзор индексации
- Как управлять политикой индексации
SEO и метаданные · Начните работу с Nuxt
Улучшите SEO своего приложения Nuxt с помощью мощной конфигурации головы, компоновок и компонентов.
По умолчанию Nuxt предоставляет разумные значения по умолчанию, которые при необходимости можно переопределить.
-
кодировка:utf-8 -
окно просмотра:ширина = ширина устройства, начальный масштаб = 1
экспорт по умолчанию defineNuxtConfig({
приложение: {
голова: {
кодировка: 'utf-8',
область просмотра: 'ширина = ширина устройства, начальный масштаб = 1',
}
}
}) Предоставление свойства app.head в вашем nuxt.config.ts позволяет настроить заголовок для всего приложения.
Этот метод не позволяет предоставлять реактивные данные. Мы рекомендуем использовать useHead() в app. . vue
vue
Для облегчения настройки доступны ярлыки: charset и viewport . Вы также можете указать любой из ключей, перечисленных ниже в Типы.
Компонуемая функция useHead позволяет управлять тегами заголовков программным и реактивным способом,
питание от Unhead.
Как и все составные компоненты, его можно использовать только с компонентами , настройкой и крючками жизненного цикла.
<настройка скрипта lang="ts">
использоватьголову({
заголовок: «Мое приложение»,
мета: [
{ name: 'description', content: 'Мой замечательный сайт.' }
],
атрибуты тела: {
класс: «тест»
},
сценарий: [ { innerHTML: 'console.log(\'Привет, мир\')' } ]
})
Рекомендуем обратить внимание на компонуемые useHead и useHeadSafe .
Компоненты useSeoMeta и useServerSeoMeta позволяют определять метатеги SEO вашего сайта в виде плоского объекта с полной поддержкой TypeScript.
Это поможет вам избежать опечаток и распространенных ошибок, таких как использование имя вместо свойство .
<настройка скрипта lang="ts">
использоватьSeoMeta({
title: 'Мой удивительный сайт',
ogTitle: «Мой удивительный сайт»,
description: 'Это мой удивительный сайт, позвольте мне рассказать вам все о нем.',
ogDescription: 'Это мой удивительный сайт, позвольте мне рассказать вам все о нем.',
ogImage: 'https://example.com/image.png',
twitterCard: 'summary_large_image',
})
Подробнее о составных компонентах useSeoMeta и useServerSeoMeta .
Nuxt предоставляет {{название}}
 head
head  например,добавив название вашего сайта в заголовок каждой страницы.
например,добавив название вашего сайта в заголовок каждой страницы.  Вы также можете передать
Вы также можете передать  vue
vue 