
Узнать дубли главной страницы сайта | Найти дубли онлайн
09.01.2020 12:40
Мы сделали свой сократитель ссылок
Новый инструмент поможет при составлении отчетов и аналитике переходов по сокращенным ссылкам — http://s.be1.ru/068mh
16.12.2019 18:20
Навигация по нашим инструментам стала более удобной и быстрой
Наших инструментов становится много, но у каждого пользователя есть свои часто используемые. Теперь их можно выделить и очень быстро найти — http://s.be1.ru/8qsjn
03.12.2019 13:13
Добавили возможность сохранения галочки Google в чекере позиций
Нарастив ресурсы для съема позиций в Google, теперь мы можем дать возможность сохранять проекты с галочкой — https://be1.ru/s/kdx9o
28.11.2019 18:21
Дополнили функционалом инструмент по проверке позиций сайта
Добавилась возможность выбора домена и языка результата в проверке по Google.
12.08.2019 10:00
Разработали новый SEO-инструмент, определяющий частотность запросов!
Инструмент поможет определить базовые виды частотностей поисковых запросов, данные тянутся непосредственно из Яндекс Вордстат. Ссылка на инструмент: https://be1.ru/wordstat/
02.07.2019 12:00
Обновили дизайн старого инструмента!
Мы до неузнаваемости обновили инструмент определяющий IP адрес компьютера, теперь в нем куча плюшек и современный дизайн! Ссылка на инструмент: https://be1.ru/my-ip/
13.06.2019 14:34
Добавили новый SEO-инструмент!
Он умеет быстро и бесплатно определять систему управления контентом (CMS) сайта.
07.05.2019 10:05
Мы переехали на новый сервер!
В связи с невероятной популярностью проекта, нам стало слишком тесно на нашем сервере. Смена сервера даст более стабильную и быструю работу проекта. В ближайшие дни мы будем писать сотни строк кода по 20 часов в сутки, чтобы перенастроить наши скрипты под новый сервер. Просим понять, простить и помочь найти баги, сообщить о которых Вы можете в форме связи раздела FAQ.
26.03.2019 10:47
Падение сервера 25.03.18
Остановка в работе сервиса связанна c DDoS атакой, в данный момент работа Be1 полностью восстановлена. Будем укрепляться и ждать следующую волну. Извините за временные неудобства.
19.02.2019 10:00
Новое расширение для анализа сайтов!
Наше расширение помогает бесплатно в один клик провести глубокий SEO-анализ сайта. Рекомендуем: https://be1.ru/goto/extension
Как найти дубли страниц на сайте — Devaka SEO Блог
Одна из основных причин, по которой сайт может терять позиции и трафик — возрастающее количество дублей страниц на сайте. Они могут возникать в результате особенностей работы CMS (движка), желании получить максимум трафика из поиска за счет шаблонного увеличения количества страниц на сайте, а также из-за сознательного или несознательного размещения ссылок третьими лицами на ваши дубли с других ресурсов.
Проблема дублей очень тесно перекликается с проблемой поиска канонического адреса страницы поисковым анализатором. В ряде случаев робот может определить канонический адрес, например, если в динамическом URL был изменен порядок параметров:
?&cat=10&product=25
По сути, это та же страница, что и
?product=25&cat=10
Но в большинстве случаев, особенно при использовании ЧПУ, каноническую страницу определить сложно, поэтому, полные и частичные дубли попадают в индекс.
Что интересно, для Яндекса дубли не так страшны, и даже на страницы результатов поиска по сайту (которые являются частичными дублями друг друга) он может приносить хороший трафик, но вот Google к дублям относится более критично (из-за борьбы с MFA и шаблонными сайтами).
Основные методы поиска дублей на сайте
Ниже описаны основные методы, с помощью которых можно быстро найти дубли страниц своего сайта. Используйте их периодически.
1. Гугл-вебмастер
Зайдите в панель Google для вебмастеров. Найдите раздел меню «Оптимизация» – «Оптимизация HTML». На этой странице можно увидеть количество повторяющихся мета-описаний и заголовков TITLE.

Таким способом можно найти полные копии страниц, но к сожалению, не определить частичные дубли, которые имеют уникальные, однако, шаблонные заголовки.
2. Программа Xenu
Xenu Link Sleuth — одна из популярных программ оптимизаторов, которая помогает проводить технический аудит сайта и, в том числе, находить дублирующиеся заголовки (если, например, у вас нет доступа к Google-Вебмастеру).
Подробней об этой программе написано в обзорной статье по этой ссылке. Просто просканируйте сайт, отсортируйте результаты по заголовку и ищите визуальные совпадения заголовков. При всем удобстве, данный способ имеет тот же недостаток — нет возможности найти частичные дубли страниц.
3. Поисковая выдача
Результаты поиска могут отразить не только сам сайт, а также некое отношение поисковой системы к нему. Для поиска дублей в Google можно воспользоваться специальным запросом.
site:mysite.ru -site:mysite.ru/&
Где составляющими являются:
site:mysite.ru — показывает страницы сайта mysite.ru, находящиеся в индексе Google (общий индекс).
site:mysite.ru/& — показывает страницы сайта mysite.ru, участвующие в поиске (основной индекс).
Таким образом, можно определить малоинформативные страницы и частичные дубли, которые не участвуют в поиске и могут мешать страницам из основного индекса ранжироваться выше. При поиске обязательно кликните по ссылке «повторить поиск, включив упущенные результаты», если результатов было мало, чтобы видеть более объективную картину (см. пример site:drezex.com.ua -site:drezex.com.ua/&).

Теперь, когда вы нашли все дубли страниц, можете их смело удалять, откорректировав движок сайта или добавив тег rel=canonical в заголовки страниц.
Дубли страниц на сайте
Что такое дубли страниц?
Дубли страниц на сайте — это грубая SEO-ошибка, которая характеризуется тем, что контент одной страницы полностью идентичен содержанию другой. Таким образом, они в точности копируют друг друга, но при этом доступны по разным URL-адресам.
Самые частые причины возникновения дублей:
Не сделан редирект страниц, имеющих адреса с www и без www. В этом случае каждая страница сайта будет дублироваться, так как остается доступной по двум адресам, например:
http://www.site.ru/page и http://site.ru/pageСтраницы сайта доступны по адресу со слэшем и без слэша:
http://site.ru/page/ и http://site.ru/pageТакже URL страницы может быть с .php и .html на конце либо без расширения. Как правило, это связано с особенностями cms (административной панели сайта):
http://site.ru/page.html и http://site.ru/page; http://site.ru/page.php и http://site.ru/page- Отдельно стоит выделить неполные дубли страниц. В этом случае контент на двух разных страницах не будет идентичным на 100%. Сходство и дублирование может появляться по причине того, что некоторые блоки на сайте являются сквозными — например, это может быть блок о доставке, который отображается на страницах всех товаров.
- Некоторые карточки со схожими товарами содержат идентичное описание, что также может рассматриваться как грубая ошибка.
- Постраничная пагинация каталога с товарами. В этом случае текст и МЕТА-теги на всех страницах одной категории могут быть одинаковыми.
Как дубли влияют на ранжирование?
Дубли негативно влияют на ранжирование вашего сайта — за наличие дубликатов страниц интернет-ресурс может с большой степенью вероятности подвергнуться пессимизации со стороны поисковых систем.
- Яндекс и Google очень трепетно относятся к уникальности контента на web-ресурсах. В случае, если данные на страницах дублируются, они признаются неуникальными. За это на сайт могут быть наложены санкции.
- Наличие большого количества дублей страниц сильно усложняет процесс индексации сайта и запутывает поисковых роботов.
- Затрудняется продвижение посадочных страниц, так как поисковая система не может выбрать релевантную страницу из двух одинаковых.
- Теряется «вес» страниц, поскольку распределяется между двумя одинаковыми документами.
Подробно описывается негативное влияние дублей и методы борьбы с ними в статье Google «Консолидация повторяющихся URL»
Яндекс, в свою очередь, предлагает на эту тему видеоурок «Поисковая оптимизация сайта: ищем дубли страниц», где разъясняется терминология и способы решения проблемы.
Как обнаружить дубли у себя на сайте?
С этим могут возникнуть трудности не только у обладателей больших web-ресурсов, но и у владельцев совсем небольших сайтов, так как некоторые дубли, возникающие из-за особенностей и ошибок CMS, очень сложно обнаружить. Быстро и без лишних трудозатрат найти дубли страниц можно с помощью сервиса Labrika. Для этого нужно посмотреть соответствующий отчет. Находится он в подразделе «Похожие страницы» раздела «SEO-аудит» в левом боковом меню:
В отчете вы можете увидеть следующую информацию:
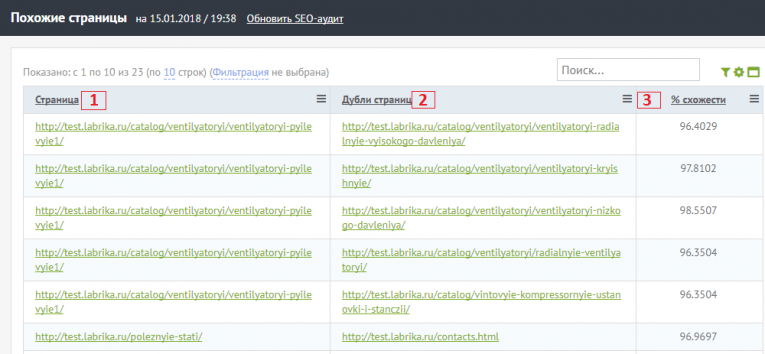
- Страница сайта, которая имеет дубль.
- Дубль этой страницы
- Процент схожести страниц. Благодаря этому проценту вы сможете определить, является ли дубль страницы полным.
Получив данные из отчета, вы сможете сэкономить время и сразу начать устранять эти ошибки.
Как устранить дубли на сайте?
В первую очередь, необходимо установить характер дубля и уже после этого выбирать способ его устранения.
- Если дублей на сайте небольшое количество и их происхождение связано с ошибками CMS (допустим, страница доступна по адресам http://site.ru/category/tovar и http://site.ru/tovar), то самым простым методом решения проблемы будет следующий. Дубль необходимо запретить для индексации поисковых систем в robots.txt (также см. информацию о robots.txt от Google). Затем воспользоваться формой удаления URL из индекса в Яндекс.Вебмастер — https://webmaster.yandex.ru/tools/del-url/ и инструментом аналогичного назначения в Google Webmaster — https://www.google.com/webmasters/tools/url-removal. Подробнее про использование инструмента от Google вы можете прочитать здесь.
- Если появление дубликатов носит системный характер и связано с такими ошибками, как, например, несклеенный домен (страница доступна по адресу с www и без www), то в таком случае необходимо выбрать главное зеркало (например, адрес сайта без www), воспользоваться командой 301 redirect (перенаправление со страниц с www на страницы без них), которая прописывается в специальном файле htaccess.
- В случае, если вы имеете дело с постраничной пагинацией товаров одной категории, Яндекс советует использовать атрибут rel=»canonical». Более подробно о применении этого атрибута на страницах с пагинацией вы можете прочитать в статье Блога Яндекс «Несколько советов интернет-магазинам по настройкам индексирования».
Удаляем дубли страниц на сайте

Когда пользователь вводит поисковые слова и начинает поиск, поисковая система в свою очередь, по определённому алгоритму начинает искать страницу, в соответствии заданным словам. В любом случае поисковой системой будет выдан конечный результат, но вот какую именно выберет система, при наличии дубликата страницы сайта, сразу узнать проблематично. Таким образом, разные поисковые системы, например как Яндекс и Google, могут выдавать различные результаты по поиску одних и тех же ключевых слов, что в свою очередь может привести к негативным результатам для владельца ресурса, у которого есть на сайте дубликаты страниц.
Основные негативные последствия для владельца сайта с дублями страниц следующие:
Происходит уменьшение семантического соответствия заданного запроса к главной странице сайта, что в свою очередь ухудшает оптимизационные свойства всего ресурса.
Позиции ключевых cлов для ресурса постоянно изменяются, всё это происходит благодаря тому, что поисковые системы выдают в результате, то одну страницу, то её дубликат.
- Ухудшается уровень ранжирования, а вместе с ним и все показатели, связанные с ним. Именно все выше перечисленные негативные последствия заставляют разработчиков и оптимизаторов веб сайтов предусмотреть их, когда происходит раскрутка ресурса и оптимизация, удалить дубликаты страниц.
Какими бывают дубликаты
Дубликаты страниц сайта бывают двух видов:
- полный. Такой вид в точности повторяет одну из страниц ресурса и находиться под другим адресом, причём количество таких страниц не ограниченно и может быть любым.
- частичный. В таком виде дубли содержат часть контента дублируемой страницы, но не являются её точной копией.
Для каждого вида дубля, процесс их поиска и удаления не много отличается.
Как появляются полные дубликаты страниц сайта
- При создании сайта не было выбрано главное зеркало сайта. В таком случае дубль страницы может быть открыт по интернет адресу без www, или с ним.
- Главная страница ресурса не была чётка заданна в параметрах хостинга или движка, на котором разрабатывался сайт.
- Разработчики ресурса не учли автоматический переход на адрес без параметра, при запросе пользователя данной страницы с параметром.
- При разработке сайта, разработчики не правильно прописали иерархические адреса страниц ресурса.
- Не правильно настроена страница с ошибкой 404, что в свою очередь приводит к появлению огромного количества дублей страниц.
Как появляются частичные дубли страниц сайта?
Частичные дубли страниц возникают также как и в случае с полными, в основном из-за различных возможностей каждого взятого движка, на котором строится ресурс. Такие дубли на много тяжелей обнаруживать, чем полные, а также тяжелей их удалять.
Приведём наиболее распространённые случаи:
- Страницы ресурса, которые содержат формы для различного рода поиска, сортировки, вывода информации по различным видам водимых параметров и тому подобное. Такое часто происходит, когда при разработке этих алгоритмов, были использованы другие возможности, отличные от скриптов.
- Страницы сайта, на которых пользователи могут оставить на ресурсе, свою информацию.
- Страницы ресурса, предоставляющие возможность пользователю увидеть определённые страницы в версии для печати, а также содержащие документы в формате *.pdf, доступные для скачивания.
- При разработке html страницы, использовалась технология AJAX.
Если полные дубли страниц сайта приводят к быстрому ухудшению ранжирования сайта по времени, то частичные дубли действуют более медленно, и создают очень много проблем оптимизаторам сайтов, в течении относительно долгого времени.
Как найти дубли страниц?
Если изучаемый ресурс содержит в себе, не большое количество страниц, то нахождение дублей можно провести в ручную.
Для ресурсов содержащих большое количество страниц, можно использовать следующие основные методы обнаружения.
C помощью специального программного обеспечения, функциональные возможности которых, позволяют выявлять дубли страниц ресурса. Основной принцип работы таких программ, состоит в том, чтобы про сканировать весь ресурс и найти на нём все ссылки. Таким образом программа находит все ссылки и потом уже легко можно будет найти дубликаты страниц.
Проверить сайт на дубли страниц онлайн можно в поисковой системе Google, в поисковой консоли(Google search console), нужно выбрать пункт меню «Оптимизация html», таким образом будут найдены страницы с повторяющимся контентом. Эти страницы и будут потенциальными дублями исследуемого ресурса.
Как предупреждать и удалять, уже имеющиеся дубли, и как происходит удаление неявных дублей ?
- Если дубли страниц находятся на статистических адресах, то у владельца ресурса, как правило имеется доступ к управлению сайтом и значит есть возможность, при обнаружении дубля на хосте, его удалить.
- В файле robots.txt запретить индексацию страниц ресурса.
- Правильная настройка и конфигурация перехода, при пере направлении 301. В зависимости от движка сайта, нужно использовать редирект страницы со слешем и без.
- Для страниц сайта, содержащих формы поиска, фильтрации и тому подобное, применить правильную установку необходимых тегов. Тоже самое относится к страницам, содержащие печатные версии, просматриваемых страниц.
- Удалить из индекса страницы, которые были про индексированы ранее поисковыми системами, но оказались дублями, достаточно просто. Так для поисковой системы Яндекс, необходимо зайти на данный адрес —
https://webmaster.yandex.ru/tools/del-url/, и с помощью инструмента для веб мастеров, удалить дублируемую страницу. Другие поисковые системы содержат подобные средства, и принцип удаления дублей аналогичен.

Как проверить сайт на дубли страниц? Основные способы
 Доброго времени суток!
Доброго времени суток!
Дубликаты страниц, или дубли — одна из тех проблем, о которой не подозревают многие вебмастера. Из-за такой ошибки, некоторые полезные WordPress-блоги теряют позиции по ряду запросов, и порою их владельцы даже не догадываются об этом. Каждый видит в статистике, что посещаемость веб-страницы упала, но разыскать и исправить ошибку могут не все. В этой статье пойдет речь о том, как найти дубли страниц сайта.
Что такое дубликаты страниц?
Дубли – это две и больше страниц с одинаковым контентом, но разными адресами. Существует понятие полных и частичных дублей. Если полные — это стопроцентный дублированный контент исходной (канонической) страницы, то частичным дублем может стать страница, повторяющая ее отдельные элементы. Причины появления дублей могут быть разными. Это могут быть ошибки вебмастера при составлении или изменении шаблона сайта. Но чаще всего дубли возникают автоматически из-за специфики работы движков, таких как WordPress и Joomla. О том, почему это происходит, и как с этим справляться я расскажу ниже. Очень важно понимать, что вебсайты с такими повторениями могут попасть под фильтры поисковых систем и понижаться в выдаче, поэтому дублей стоит избегать.
Как проверить сайт на дубли страниц?
Практика показывает, что отечественный поисковик Яндекс относится к дублям не так строго, как зарубежный Гугл. Однако и он не оставляет такие ошибки вебмастеров без внимания, поэтому для начала нужно разобраться с тем, как найти дубликаты страниц.
Во-первых, нам нужно определить, какое количество страниц нашего сайта находится в индексе поисковых систем. Для этого воспользуемся функцией site:my-site.ru, где вместо my-site.ru вам нужно подставить свой url. Покажу, как это работает на примере своего блога. Начнем с Яндекса. Вводим в строку поиска site:pro-wordpress.ru

Как видим, Яндекс нашел 196 проиндексированных страниц. Теперь проделаем то же самое с Google.

Мы получили 1400 страниц в общем индексе Гугл. Кроме основных страниц, участвующих в ранжировании, сюда попадают так называемые «сопли». Это дубли, либо малозначимые страницы. Чтобы проверить основной индекс в Google, нужно ввести другой оператор: site:pro-wordpress.ru/&

Итого в основном индексе 165 страниц. Как видим, у моего блога есть проблема с количеством дублей. Чтобы их увидеть, нужно перейти на последнюю страницу общей выдачи и нажать «показать скрытые результаты».

Снова перейдя в конец выдачи, вы увидите примерно такое:

Это и есть те самые дубли, в данном случае replycom. Такой тип дублей в WordPress создается при появлении комментариев на странице. Есть множество разных видов дублей, их названия и способы борьбы с ними, будут описаны в следующей статье.
Наверняка у вас возник вопрос, почему в Яндексе мы не увидели такого количества дублей, как в Google. Все дело в том, что в файле robots.txt (кто не знает что это, читайте «Правильный robots.txt для WordPress») на блоге стоит запрет на индексацию подобных дублей с помощью директивы Disallow (подробнее об этом в следующем посте). Для Яндекса этого достаточно, но Гугл работает по своим алгоритмам и все равно учитывает эти страницы. Но их контент он не показывает, говорит, что «Описание веб-страницы недоступно из-за ограничений в файле robots.txt».
Проверка на дубли страниц по отрывку текста, по категориям дублей
Кроме вышеописанного способа, вы можете проверять отдельные страницы сайта на наличие дублей. Для этого в окне поиска Яндекс и Google, можно указать отрывок текста страницы, после которого употребить все тот же site:my-site.ru. Например, такой текст с одной из моих страничек: «Eye Dropper — это дополнение позволяет быстро узнать цвет элемента, чем-то напоминает пипетку в Photoshop». Его вставляем в поиск Гугл, а после через пробел site:my-site

Google не нашел дублей это страницы. Для Яндекса проделываем то же самое, только текст страницы берем в кавычки «».
Кроме фрагментов текста, вы можете вставлять ключевые фразы, по которым, к примеру, у вас снизились позиции.
Есть другой вариант такой же проверки через расширенный поиск. Для Яндекса — yandex.ru/advanced.html.

Вводим тот же текст, url сайта и жмем «Найти». Получим такой же результат, как и с оператором site:my-site.
Либо такой поиск можно осуществить, нажав кнопку настроек в правой части окна Яндекс.

Для Гугла есть такая же функция расширенного поиска.

Теперь посмотрим, как можно выявить группу дублей одной категории. Возьмем, к примеру, группу tag.

И увидим на странице выдачи по данному запросу следующее:

А если попросить Гугл вывести скрытые результаты, дублей группы tag станет больше.
Как вы успели заметить, дубликатов страниц создается очень много и наша задача – предотвратить их попадание в индекс поисковиков.
Поиск дублей страниц сайта: дополнительные способы
Кроме ручных способов, есть также возможность автоматически проверить сайт на дубли страниц.
Например, это программа Xenu, предназначенная для технического аудита сайта. Кроме дубликатов страниц, она выявляет битые ссылки. Это не единственная программа для решения таких задач, но наиболее распространенная.
Также в поиске дублей страниц помогает Google Webmaster, здесь можно выявить страницы с повторяющимися мета-тегами:

Тут вы посмотрите список урлов с одинаковыми тайтлами или описанием. Часть из них может оказаться дублями.
На сегодня все. Теперь вы знаете, как найти дубликаты страниц. В следующей статье мы подробно разберем, как предотвратить их появление и удалить имеющиеся дубли.
вред сайту, или как от него избавиться
Что такое дублированный контент?
Дублированный контент или просто дубли – это страницы на вашем сайте, которые полностью (четкие дубли) или частично (нечеткие дубли) совпадают друг с другом, но каждая из них имеет свой URL. Одна страница может иметь как один, так и несколько дублей.
Как появляется дублированный контент на сайте?
Как для четких, так и для нечетких дублей есть несколько причин возникновения. Четкие дубли могут возникнуть по следующим причинам:
- Они появляются из-за CMS сайта. Например, с помощью replytocom в WordPress, когда добавление новых комментариев создает автоматом и новые страницы, отличающиеся только URL.
- В результате ошибок веб-мастера.
- Из-за изменения структуры сайта. Например, при внедрении обновленного шаблона с новыми URL.
- Делаются владельцем сайта для определенных функций. Например, страницы с версиями текста для печати.
Нечеткие дубли на вашем сайте могут появиться по следующим причинам:
- Если есть частичное повторение одинакового текста на разных страницах сайта.
На примере показан анализ текста с главной страницы сайта в программе проверки уникальности «Text.ru». На картинке видно, с какими еще страницами этого же сайта и на сколько процентов он совпадает:

- Из-за страниц пагинации, когда в одном разделе несколько страниц.
Пример страниц пагинации. Они находятся под цифрами 1, 2, 3 и т. д. Такое можно встретить, например, в блогах, где много статей или в многостраничных каталогах. И чтобы бесконечно не скролить вниз, делается их разбивка на внутренние страницы по номерам:


Почему дублированный контент вредит сайту?
- Негативно влияет на продвижение в поисковой выдаче. Поисковые роботы отрицательно относятся к дублированному контенту и могут понизить позиции в выдаче из-за отсутствия уникальности, а следовательно, и полезности для клиента. Нет смысла читать одно и то же на разных страницах сайта.
- Может подменить истинно-релевантные страницы. Робот может выбрать для выдачи дублированную страницу, если посчитает ее содержание более релевантным запросу. При этом у дубля, как правило, показатели поведенческих факторов и/или ссылочной массы ниже, чем у той страницы, которую вы целенаправленно продвигаете. А это значит, что дубль будет показан на худших позициях.
- Ведет к потере естественных ссылок. Когда пользователь делает ссылку не на прототип, а на дубль.
- Способствует неправильному распределению внутреннего ссылочного веса. Дубли перетягивают на себя часть веса с продвигаемых страниц, что также препятствует продвижению в поисковиках.
Как проверить, есть у вас дубли или нет?
Чтобы узнать, есть у страниц сайта дубли или нет, существует несколько способов.
- Проверка через расширенный поиск (например, yandex.ru/advanced.html). Для этого просто вбиваете адрес сайта и фрагмент текста со страницы, контент которой надо проверить на дубли, в соответствующие поля формы и смотрите результат. Если в выдаче появилась только одна страница, то дублей нет. Если результатов больше, это говорит о том, что у страницы сайта все такие есть дубли, и с этим надо что-то делать.
На примере показано, что у страницы сайта нашлось несколько дублей через расширенный поиск Яндекс
- Проверка через программы оценивания уникальности (например, «Text.ru»). Итоги проверки покажут вам, с какими сайтами и их внутренними страницами совпадает анализируемый текст и на сколько процентов.
На примере видно, с какими внутренними страницами и на сколько процентов совпадает контент анализируемой страницы. Анализ проводится через сайт text.ru:


Нашли дубли? Читаем, как их обезвредить:
- 301-й редирект. Этот способ считается самым надежным при избавлении от лишних дублей на вашем сайте. Суть метода заключается в переадресации поискового робота со страницы-дубля на основную. Таким образом, робот проскакивает дубль и работает только с нужной страницей сайта. Со временем, после настройки 301-ого редиректа, страницы дублей склеиваются и выпадают из индекса.
- Тег <link rel= «canonical»>. Здесь мы указываем поисковой системе, какая страница у нас основная, предназначенная для индексации. Для этого на каждом дубле надо вписать специальный код для поискового робота <link rel=»canonical» href=»http://www.site.ru/original-page.html»>, который будет содержать адрес основной страницы. Чтобы не делать подобные работы вручную, существуют специальные плагины.
- Disallow в robots.txt. Файл robots.txt – своеобразная инструкция для поискового робота, в которой указано, какие страницы нужно индексировать, а какие нет. Для запрета индексации и борьбы с дублями используется директива Disallow. Здесь, как и при настройке 301-го редиректа, важно правильно прописать запрет.
Как убрать дубли из индекса поисковых систем?
Что касается Яндекса, то он самостоятельно убирает дубли из индекса при правильной настройке файла robots.txt. А вот для Google надо прописывать правила во вкладке «Параметры URL» через Google Вебмастер.
Если у вас возникнут трудности с проверкой и устранением дублированного контента, вы всегда можете обратиться к нашим специалистам. Мы найдем все подозрительные элементы, настроим 301-й редирект, robots.txt, rel= «canonical», сделаем настройки в Google. В общем, проведем все работы, чтобы ваш сайт эффективно работал.
Как найти дубликаты страниц на сайте
Довольно часто многие веб мастера задаются вопросом про то, как найти дубликаты страниц на сайте. Ведь поисковые системы как Google, Яндекс и Bing жестко реагируют на дубликаты контента, и могут понизить сайт в результатах поиска.

Поисковая система Google в 2011 году выпустила алгоритм Google Panda, который отвечает за контент на сайте, и в случае если сайт попадет под этот фильтр, то он может сильно потерять поисковый трафик на сайт.
Для начала читаем статью: внутренняя оптимизация сайта
В ней описаны основные моменты, которые стоит оптимизировать при продвижении сайта, в том числе и обратить внимание на дублирующийся контент на сайте.
На дубликаты страниц больше реагирует Гугл, для Яндекса это важно, но не критично.
Дубликаты страниц могут быть полными и не полными:
Полный дубль страницы – это страницы на сайте или блоге, которые содержат полностью одинаковый контент, но имеют различные адрес страниц (URL).
Не полный дубликат страницы – это страницы на сайте или блоге, которые содержат много одинакового контента, но они не полностью одинаковые, а так же имею отдельные адреса страниц.
Методы поиска дублей страниц
1. Google Webmaster Tools
Заходим в Google Webmaster Tools, дальше раздел оптимизация, и нажимаем на оптимизация HTML.

Мы сможем увидеть количество повторяющихся мета описаний на сайте, а так же title (тег который очень важный при продвижении).
Дальше нажимаем на повторяющиеся страницы, смотрим, что и как, и прописываем уникальные title на них.

Как мы видим на картинке, одинаковые title у страницы услуги по аналитике, и раздела на блоге про аналитику.
2. Поисковая строка в Google
С помощью поисковой строки можно посмотреть дубли страниц, для этого необходимо использовать следующую команду:
site:moisait.com -site:moisait.com/&
В таком случае:
site:moisait.com – показывает общего индекса в Google
site:moisait.com/&- показывает страницы основного индекса в Google
С помощью данной команды можно определить частичные дубли, а так же малоинформативные страницы, которые могут мешать основным страницам, ранжироваться лучше в поиске.
Для примера смотрим такое:

Так же в Google можно использовать фрагмент текста, например:

Фрагмент может быть из пару переложений и более, или пару ключевых слов как в примере.
3. Расширенный поиск в Яндексе
В Яндексе можно использовать расширенный поиск, и искать дубликаты страниц по заданному сайту, например:

Можно использовать нужные фрагменты текста или ключевые слова и находить дубликаты страницы.
4. Xenu
Это бесплатная программа для внутренней оптимизации и внутренней перелинковки.
Читаем статью: внутренняя перелинковка сайта
Программа сканирует все страницы и файлы на сайте, выдает битые ссылки, а так же дубликаты страниц, например:

Дубли страниц плохо влияют на seo продвижение сайта, их нужно выявить, устранить или закрыть.
Следующая статья про то, как убрать или закрыть дубликаты страниц на сайте.
Оцените статью
 Загрузка…
Загрузка…