
❶ Зачем нужны базы данных 🚩 база данных представляет собой 🚩 Компьютеры и ПО 🚩 Другое
База данных представляет собой определенным образом структурированную совокупность данных, совместно хранящихся и обрабатывающихся в соответствии с некоторыми правилами. Как правило, база данных моделирует некоторую предметную область или ее фрагмент. Очень часто в качестве постоянного хранилища информации баз данных выступают файлы.
Программа, производящая манипуляции с информацией в базе данных, называется СУБД (система управления базами данных). Она может осуществлять выборки по различным критериям и выводить запрашиваемую информацию в том виде, который удобен пользователю. Основными составляющими информационных систем, построенных на основе баз данных, являются файлы БД, СУБД и программное обеспечение (клиентские приложения), позволяющие пользователю манипулировать информацией и совершать необходимые для решения его задач действия.
Структурирование информации производится по характерным признакам, физическим и техническим параметрам абстрактных объектов, которые хранятся в данной базе. Информация в базе данных может быть представлена как текст, растровое или векторное изображение, таблица или объектно-ориентированная модель. Структурирование информации позволяет производить ее анализ и обработку: делать пользовательские запросы, выборки, сортировки, производить математические и логические операции.
Информация, которая хранится в базе данных, может постоянно пополняться. От того, как часто это делается, зависит ее актуальность. Информацию об объектах также можно изменять и дополнять.
Базы данных, как способ хранения больших объемов информации и эффективного манипулирования ею, используются практически во всех областях человеческой деятельности. В них хранят документы, изображения, сведения об объектах недвижимости, физических и юридических лицах. Существуют правовые базы данных, автомобильные, адресные и пр.
Базы данных используются в информационных системах, например, в тех, которые позволяют обеспечивать контроль и управление территориями на уровне государства. В базах данных таких систем хранятся сведения обо всех объектах недвижимости, расположенных на данных территориях: земельных участках, растительности, строениях, гидрографии, дорогах и пр. Базы данных позволяют анализировать информацию и осуществлять управление информационными потоками, использовать их для статистики, прогнозирования и учета.
Базы данных: основные понятия
База данных— организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупностьданных, характеризующая актуальное состояние некоторойпредметной областии используемая для удовлетворения информационныхпотребностейпользователей.
Централизованная, или сосредоточенная (англ. centralized database): БД, полностью поддерживаемая на одном компьютере.
Распределённая (англ. distributed database): БД, составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
Неоднородная (англ. heterogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД
Однородная (англ. homogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
Фрагментированная, или секционированная (англ. partitioned database): методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
Тиражированная (англ. replicated database): методом распределения данных является тиражирование (репликация).
→ Понятійний словник сторінки
В жизни мы часто сталкиваемся с необходимостью хранить какую-либо информацию, а потому часто имеем дело и с базами данных. Например, мы используем записную книжку для хранения номеров телефонов своих друзей и планирования своего времени. Телефонная книга содержит информацию о людях, живущих в одном городе. Все это своего рода базы данных. Ну а раз это базы данных, то посмотрим, как в них хранятся данные. Например, телефонная книга представляет собой таблицу (табл. 10.1).
В этой таблице данные – это собственно номера телефонов, адреса и ФИО., т.е. строки «Иванов Иван Иванович», «32-43-12» и т.п., а названия столбцов этой таблицы, т.е. строки «ФИО», «Номер телефона» и «Адрес» задают смысл этих данных, их семантику.
Таблица 10.1. Пример базы данных: телефонная книга | ||
ФИО | Номер телефона | Адрес |
Иванов Иван Иванович | 32-43-12 | ул. Ленина, 12, 43 |
Ильин Федор Иванович | 32-32-34 | пр. Маркса, 32, 45 |
Теперь представьте, что записей в этой таблице не две, а две тысячи, вы занимаетесь созданием этого справочника и где-то произошла ошибка (например, опечатка в адресе). Видимо, тяжеловато будет найти и исправить эту ошибку вручную. Нужно воспользоваться какими-то средствами автоматизации. Для управления большим количеством данных программисты (не без помощи математиков) придумали системы управления базами данных (СУБД). По сравнению с текстовыми базами данных электронныеСУБДимеют огромное число преимуществ, от возможности быстрого поиска информации, взаимосвязи данных между собой до использования этих данных в различных прикладных программах и одновременного доступа к данным нескольких пользователей.
Для точности дадим определение базы данных, предлагаемое Глоссарий.ру
База данных– это совокупность связанных данных, организованных по определенным правилам, предусматривающим общие принципы описания, хранения и манипулирования, независимая от прикладных программ.
База данныхявляется информационной моделью предметной области. Обращение к базам данных осуществляется с помощью системы управления базами данных (СУБД).СУБДобеспечивает поддержку создания баз данных, централизованного управления и организации доступа к ним различных пользователей.Итак, мы пришли к выводу, что хранить данные независимо от программ, так, что они связаны между собой и организованы по определенным правилам, целесообразно. Но вопрос, как хранить данные, по каким правилам они должны быть организованы, остался открытым. Способов существует множество (кстати, называются они моделями представления или хранения данных). Наиболее популярные – объектная и реляционная модели данных.
Автором реляционной моделисчитается Э. Кодд, который первым предложил использовать для обработки данных аппарат теории множеств (объединение, пересечение, разность, декартово произведение) и показал, что любое представление данных сводится к совокупности двумерных таблиц особого вида, известного в математике как отношение.
Таким образом, реляционная база данныхпредставляет собой набор таблиц (точно таких же, как приведенная выше), связанных между собой. Строка в таблице соответствует сущности реального мира (в приведенном выше примере это информация о человеке).
Примеры реляционных СУБД: MySql, PostgreSql.
В основу объектной моделиположена концепция объектно-ориентированного программирования, в которой данные представляются в виде набора объектов и классов, связанных между собой родственными отношениями, а работа с объектами осуществляется с помощью скрытых (инкапсулированных) в них методов.
Примеры объектных СУБД: Cache, GemStone (от Servio Corporation), ONTOS (ONTOS).
В последнее время производители СУБДстремятся соединить два этих подхода и проповедуют объектно-реляционную модель представления данных. Примеры такихСУБД– IBM DB2 for Common Servers, Oracle8.
Поскольку мы собираемся работать с Mysql, то будем обсуждать аспекты работы только с реляционными базами данных. Нам осталось рассмотреть еще два важных понятия из этой области: ключи и индексирование, после чего мы сможем приступить к изучению языка запросов SQL.
Ключи
Для начала давайте подумаем над таким вопросом: какую информацию нужно дать о человеке, чтобы собеседник точно сказал, что это именно тот человек, сомнений быть не может, второго такого нет? Сообщить фамилию, очевидно, недостаточно, поскольку существуют однофамильцы. Если собеседник человек, то мы можем приблизительно объяснить, о ком речь, например вспомнить поступок, который совершил тот человек, или еще как-то. Компьютер же такого объяснения не поймет, ему нужны четкие правила, как определить, о ком идет речь. В системах управления базами данных для решения такой задачи ввели понятие первичного ключа.
Первичный ключ (primary key, PK) – минимальный набор полей, уникально идентифицирующий запись в таблице. Значит, первичный ключ – это в первую очередь набор полей таблицы, во-вторых, каждый набор значений этих полей должен определять единственную запись (строку) в таблице и, в-третьих, этот набор полей должен быть минимальным из всех обладающих таким же свойством. Поскольку первичный ключ определяет только одну уникальную запись, то никакие две записи таблицы не могут иметь одинаковых значений первичного ключа.
Например, в нашей таблице (см. выше) ФИО и адрес позволяют однозначно выделить запись о человеке. Если же говорить в общем, без связи с решаемой задачей, то такие знания не позволяют точно указать на единственного человека, поскольку существуют однофамильцы, живущие в разных городах по одному адресу. Все дело в границах, которые мы сами себе задаем. Если считаем, что знания ФИО, телефона и адреса без указания города для наших целей достаточно, то все замечательно, тогда поля ФИО и адрес могут образовывать первичный ключ. В любом случае проблема создания первичного ключа ложится на плечи того, кто проектирует базу данных (разрабатывает структуру хранения данных). Решением этой проблемы может стать либо выделение характеристик, которые естественным образом определяют запись в таблице (задание так называемого логического, или естественного, PK), либо создание дополнительного поля, предназначенного именно для однозначной идентификации записей в таблице (задание так называемого суррогатного, или искусственного, PK). Примером логического первичного ключа является номер паспорта в базе данных о паспортных данных жителей или ФИО и адрес в телефонной книге (таблица выше). Для задания суррогатного первичного ключа в нашу таблицу можно добавить поле id (идентификатор), значением которого будет целое число, уникальное для каждой строки таблицы. Использование таких суррогатных ключей имеет смысл, если естественный первичный ключ представляет собой большой набор полей или его выделение нетривиально.
Кроме однозначной идентификации записи, первичные ключи используются для организации связей с другими таблицами.
Например, у нас есть три таблицы: содержащая информацию об исторических личностях (Persons), содержащая информацию об их изобретениях (Artifacts) и содержащая изображения как личностей, так и артефактов (Images) (рис 10.1).
Первичным ключом во всех этих таблицах является поле id (идентификатор). В таблице Artifacts есть поле author, в котором записан идентификатор, присвоенный автору изобретения в таблице Persons. Каждое значение этого поля является внешним ключомдля первичного ключа таблицы Persons. Кроме того, в таблицах Persons и Artifacts есть поле photo, которое ссылается на изображение в таблице Images. Эти поля также являются внешними ключами для первичного ключа таблицы Images и устанавливают однозначную логическую связь Persons-Images и Artifacts-Images. То есть если значение внешнего ключа photo в таблице личности равно 10, то это значит, что фотография этой личности имеет id=10 в таблице изображений. Таким образом,
внешние ключииспользуются для организации связей между таблицами базы данных (родительскими и дочерними) и для поддержания ограничений ссылочной целостности данных.Рис. 10.1.Пример использования первичных ключей для организации связей с другими таблицами
Одна из основных задач, возникающих при работе с базами данных, – это задача поиска. При этом, поскольку информации в базе данных, как правило, содержится много, перед программистами встает задача не просто поиска, а эффективного поиска, т.е. поиска за сравнительно небольшое время и с достаточной точностью. Для этого (для оптимизации производительности запросов) производят
Если говорить о MySQL, то там существует три вида индексов: PRIMARY, UNIQUE, и INDEX, а слово ключ (KEY) используется как синоним слова индекс (INDEX). Все индексы хранятся в памяти в виде B-деревьев.
PRIMARY – уникальный индекс (ключ) с ограничением, что все индексированные им поля не могут иметь пустого значения (т.е. они NOT NULL). Таблица может иметь только один первичный индекс, но он может состоять из нескольких полей.
UNIQUE – ключ (индекс), задающий поля, которые могут иметь только уникальные значения.
INDEX – обычный индекс (как мы описали выше). В MySqL, кроме того, можно индексировать строковые поля по заданному числу символов от начала строки.
Компьютеры были созданы для решения вычислительных задач, однако со временем они все чаще стали использоваться для построения систем обработки документов, а точнее, содержащейся в них информации. Такие системы обычно и называют информационными. В качестве примера можно привести систему учета отработанного времени работниками предприятия и расчета заработной платы, систему учета продукции на складе, систему учета книг в библиотеке и т.д. Все вышеперечисленные системы имеют следующие особенности:
Другими словами, информационная система требует создания в памяти ЭВМ динамически обновляемоймодели внешнего мира с использованием единого хранилища —базы данных. Для дальнейшего обсуждения нам необходимо ввести понятие предметной области:
Предметная область— часть реального мира, подлежащая изучению с целью организации управления и, в конечном счете, автоматизации. Предметная область представляется множествомфрагментов, например, предприятие — цехами, дирекцией, бухгалтерией и т.д. Каждый фрагмент предметной области харакетризуется множествомобъектовипроцессов, использующих объекты, а также множествомпользователей, характеризуемых различными взглядами на предметную область.
Словосочетание «динамически обновляемая» означает, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени. При этом одни и те же данные могут быть по-разному представлены в соответствии с потребностями различных групп пользователей.
Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. Независимые от программ пользователя данные обычно называются метаданными. В ряде современных систем метаданные, содержащие также информацию о пользователях, форматы отображения, статистику обращения к данным и др. сведения,хранятся в словаре базы данных.
Таким образом, система управления базой данных(СУБД) — важнейший компонент информационной системы. Для создания и управления информационной системой СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор. Основные функции СУБД:
Обычно современная СУБД содержит следующие компоненты (см. рис.):
База данных — Википедия
Ба́за да́нных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчётов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ)[1].
Многие специалисты указывают на распространённую ошибку, состоящую в некорректном использовании термина «база данных» вместо термина «система управления базами данных», и указывают на необходимость различения этих понятий[2].
 Схема базы данных движка Mediawiki
Схема базы данных движка MediawikiВ литературе предлагается множество определений понятия «база данных», отражающих скорее субъективное мнение тех или иных авторов, однако общепризнанная единая формулировка отсутствует.
Определения из международных стандартов и национальных стандартов, разработанных на основе международных:
- База данных — совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных.[3][4][5]
- База данных — совокупность данных, организованных в соответствии с концептуальной структурой, описывающей характеристики этих данных и взаимоотношения между ними, которая поддерживает одну или более областей применения[6].
Определения из авторитетных монографий:
- База данных — организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупность данных, характеризующая актуальное состояние некоторой предметной области и используемая для удовлетворения информационных потребностей пользователей[7].
- База данных — некоторый набор перманентных (постоянно хранимых) данных, используемых прикладными программными системами какого-либо предприятия[8].
- База данных — совместно используемый набор логически связанных данных (и описание этих данных), предназначенный для удовлетворения информационных потребностей организации[9].
В определениях наиболее часто (явно или неявно) присутствуют следующие отличительные признаки[10]:
- БД хранится и обрабатывается в вычислительной системе.
Таким образом, любые внекомпьютерные хранилища информации (архивы, библиотеки, картотеки и т. п.) базами данных не являются. - Данные в БД логически структурированы (систематизированы) с целью обеспечения возможности их эффективного поиска и обработки в вычислительной системе.
Структурированность подразумевает явное выделение составных частей (элементов), связей между ними, а также типизацию элементов и связей, при которой с типом элемента (связи) соотносится определённая семантика и допустимые операции[11]. - БД включает схему, или метаданные, описывающие логическую структуру БД в формальном виде (в соответствии с некоторой метамоделью).
В соответствии с ГОСТ Р ИСО МЭК ТО 10032-2007, «постоянные данные в среде базы данных включают в себя схему и базу данных. Схема включает в себя описания содержания, структуры и ограничений целостности, используемые для создания и поддержки базы данных. База данных включает в себя набор постоянных данных, определённых с помощью схемы. Система управления данными использует определения данных в схеме для обеспечения доступа и управления доступом к данным в базе данных»[3].
Из перечисленных признаков только первый является строгим, а другие допускают различные трактовки и различные степени оценки. Можно лишь установить некоторую степень соответствия требованиям к БД.
В такой ситуации не последнюю роль играет общепринятая практика. В соответствии с ней, например, не называют базами данных файловые архивы, Интернет-порталы или электронные таблицы, несмотря на то, что они в некоторой степени обладают признаками БД. Принято считать, что эта степень в большинстве случаев недостаточна (хотя могут быть исключения).
История возникновения и развития технологий баз данных может рассматриваться как в широком, так и в узком аспекте.
В широком смысле понятие истории баз данных обобщается до истории любых средств, с помощью которых человечество хранило и обрабатывало данные. В таком контексте упоминаются, например, средства учёта царской казны и налогов в древнем Шумере (4000 г. до н. э.)[12], узелковая письменность инков — кипу, клинописи, содержащие документы Ассирийского царства и т. п. Следует помнить, что недостатком этого подхода является размывание понятия «база данных» и фактическое его слияние с понятиями «архив» и даже «письменность».
История баз данных в узком смысле рассматривает базы данных в традиционном (современном) понимании. Эта история начинается с 1955 года, когда появилось программируемое оборудование обработки записей. Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. Для хранения данных использовались перфокарты[12].
Оперативные сетевые базы данных появились в середине 1960-х. Операции над оперативными базами данных обрабатывались в интерактивном режиме с помощью терминалов. Простые индексно-последовательные организации записей быстро развились к более мощной модели записей, ориентированной на наборы. За руководство работой Data Base Task Group (DBTG), разработавшей стандартный язык описания данных и манипулирования данными, Чарльз Бахман получил Тьюринговскую премию.
В это же время в сообществе баз данных Кобол была проработана концепция схем баз данных и концепция независимости данных.
Следующий важный этап связан с появлением в начале 1970-х реляционной модели данных, благодаря работам Эдгара Кодда. Работы Кодда открыли путь к тесной связи прикладной технологии баз данных с математикой и логикой. За свой вклад в теорию и практику Эдгар Ф. Кодд также получил премию Тьюринга.
Сам термин база данных (англ. database) появился в начале 1960-х годов, и был введён в употребление на симпозиумах, организованных компанией SDC в 1964 и 1965 годах, хотя понимался сначала в довольно узком смысле, в контексте систем искусственного интеллекта. В широкое употребление в современном понимании термин вошёл лишь в 1970-е годы[13].
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям. Например, в «Энциклопедии технологий баз данных»[7], по материалам которой написан данный раздел, определяются свыше 50 видов БД.
Основные классификации приведены ниже.
Классификация по модели данных[править | править код]
Примеры:
Классификация по среде постоянного хранения[править | править код]
- Во вторичной памяти, или традиционная (англ. conventional database): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — как правило жёсткий диск.
В оперативную память СУБД помещает лишь кэш и данные для текущей обработки. - В оперативной памяти (англ. in-memory database, memory-resident database, main memory database): все данные на стадии исполнения находятся в оперативной памяти.
- В третичной памяти (англ. tertiary database): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило на основе магнитных лент или оптических дисков.
Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кэш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
Классификация по содержимому[править | править код]
Примеры:
Классификация по степени распределённости[править | править код]
- Централизованная, или сосредоточенная (англ. centralized database): БД, полностью поддерживаемая на одном компьютере.
- Распределённая БД (англ. distributed database) — составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
- Неоднородная (англ. heterogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД.
- Однородная (англ. homogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
- Фрагментированная, или секционированная (англ. partitioned database): методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
- Тиражированная (англ. replicated database): методом распределения данных является тиражирование (репликация).
Другие виды БД[править | править код]
- Пространственная (англ. spatial database): БД, в которой поддерживаются пространственные свойства сущностей предметной области. Такие БД широко используются в геоинформационных системах.
- Временная, или темпоральная (англ. temporal database): БД, в которой поддерживается какой-либо аспект времени, не считая времени, определяемого пользователем.
- Пространственно-временная (англ. spatial-temporal database) БД: БД, в которой одновременно поддерживается одно или более измерений в аспектах как пространства, так и времени.
- Циклическая (англ. round-robin database): БД, объём хранимых данных которой не меняется со временем, поскольку в процессе сохранения новых данных они заменяют более старые данные. Одни и те же ячейки для данных используются циклически.
Сверхбольшая база данных (англ. Very Large Database, VLDB) — это база данных, которая занимает чрезвычайно большой объём на устройстве физического хранения. Термин подразумевает максимально возможные объёмы БД, которые определяются последними достижениями в технологиях физического хранения данных и в технологиях программного оперирования данными.
Количественное определение понятия «чрезвычайно большой объём» меняется во времени. Так, в 1997 году самой большой в мире была текстовая база данных Knight Ridder’s DIALOG объёмом 7 терабайт[14]. В 2001 году самой большой считалась база данных объёмом 10,5 терабайт, в 2003 году — объёмом 25 терабайт[15]. В 2005 году самыми крупными в мире считались базы данных с объёмом хранилища порядка сотни терабайт[16]. В 2006 году поисковая машина Google использовала базу данных объёмом 850 терабайт[17].
К 2010 году считалось, что объём сверхбольшой базы данных должен измеряться по меньшей мере петабайтами[16].
В 2011 году компания Facebook хранила данные в кластере из 2 тысяч узлов суммарной ёмкостью 21 петабайт[18]; к концу 2012 года объём данных Facebook достиг 100 петабайт[19], а в 2014 году — 300 петабайт[20].
К 2014 году по косвенным оценкам компания Google хранила на своих серверах до 10—15 эксабайт данных в совокупности[21].
По некоторым оценкам, к 2025 году генетики будут располагать данными о геномах от 100 миллионов до 2 миллиардов человек, и для хранения подобного объёма данных потребуется от 2 до 40 эксабайт[22].
В целом, по оценкам компании IDC, суммарный объём данных «цифровой вселенной» удваивается каждые два года и изменится от 4,4 зеттабайта в 2013 году до 44 зеттабайт в 2020 году[23].
Исследования в области хранения и обработки сверхбольших баз данных VLDB всегда находятся на острие теории и практики баз данных. В частности, с 1975 года проходит ежегодная конференция International Conference on Very Large Data Bases («Международная конференция по сверхбольшим базам данных»). Большинство исследований проводится под эгидой некоммерческой организации VLDB Endowment (Фонд целевого капитала «VLDB»), которая обеспечивает продвижение научных работ и обмен информацией в области сверхбольших БД и смежных областях.
- ↑ Гражданский кодекс РФ, ст. 1260
- ↑ «Следует отметить, что термин база данных часто используется даже тогда, когда на самом деле подразумевается СУБД. […]Такое обращение с терминами предосудительно». — К. Дж. Дейт. Введение в системы баз данных. — 8-е изд. — М.: «Вильямс», 2006, стр. 50.
«Этот термин (база данных) часто ошибочно используется вместо термина ‘система управления базами данных’». — Когаловский М. Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002., стр. 460.
«Среди непрофессионалов […] путаница возникает при использовании терминов „база данных“ и „система управления базами данных“. […] Мы будем строго разделять эти термины». — Кузнецов С. Д. Основы баз данных: учебное пособие. — 2-е издание, испр. — М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2007, стр. 19. - ↑ 1 2 ГОСТ Р ИСО МЭК ТО 10032-2007: Эталонная модель управления данными (идентичен ISO/IEC TR 10032:2003 Information technology — Reference model of data management)
- ↑ ГОСТ 33707-2016 (ISO/IEC 2382:2015) Информационные технологии (ИТ). Словарь
- ↑ ISO/IEC TR 10032:2003 — Information technology — Reference Model of Data Management (англ.). www.iso.org. Дата обращения 9 июля 2018.
- ↑ ISO/IEC 2382:2015 — Information technology — Vocabulary (англ.). www.iso.org. Дата обращения 9 июля 2018.
- ↑ 1 2 Когаловский М. Р., 2002.
- ↑ Дейт К. Дж., 2005.
- ↑ Коннолли Т., Бегг К., 2003.
- ↑ Мирошниченко Е. А. К формальному определению понятия «база данных» // Пробл. информатики. 2011. № 2. С. 83-87.
- ↑ Важно понимать, что структурированность базы данных оценивается не на уровне физического хранения (на котором все данные представлены совокупностями битов или байтов), а на уровне некоторой логической модели данных.
- ↑ 1 2 Грей, Дж. Управление данными: прошлое, настоящее и будущее
- ↑ Haigh T. How Data Got its Base: Information Storage Software in the 1950s and 1960s // IEEE Annals of the History of Computing. — 2009. — #4 October-December
- ↑ Very Large Database
- ↑ Riedewald M., Agrawal D., Abbadi A. Dynamic Multidimensional Data Cubes for Interactive Analysis of Massive Datasets // In: Encyclopedia of Information Science and Technology, First Edition, Idea Group Inc., 2005. ISBN 9781591405535
- ↑ 1 2 «Экстремальные» базы данных: Самые большие и самые быстрые, 2010 г.
- ↑ Alex Chitu. How Much Data Does Google Store?, 2006
- ↑ Shvachko, Konstantin. Apache Hadoop. The Scalability Update (англ.). — 2011. — Vol. 36, no. 3. — P. 7—13. — ISSN 1044-6397.
- ↑ Josh Constine. How Big Is Facebook’s Data? // TechCrunch, 23.08.2012
- ↑ Wiener, J., Bronson N. Facebook’s Top Open Data Problems, 22.10.2014
- ↑ Colin Carson. How Much Data Does Google Store? Архивная копия от 15 сентября 2016 на Wayback Machine, 2014
- ↑ Ася Горина. Увеличивающийся объем генетических данных стал проблемой для науки
- ↑ Executive Summary: Data Growth, Business Opportunities, and the IT Imperatives
- Когаловский М. Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с. — ISBN 5-279-02276-4.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. — ISBN 978-5-94774-736-2.
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: Вильямс, 2005. — 1328 с. — ISBN 5-8459-0788-8 (рус.) 0-321-19784-4 (англ.).
- Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с. — ISBN 0-201-70857-4.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс = Database Systems: The Complete Book. — Вильямс, 2003. — 1088 с. — ISBN 5-8459-0384-X.
- Date, C. J. Date on Database: Writings 2000–2006. — Apress, 2006. — 566 с. — ISBN 978-1-59059-746-0, 1-59059-746-X.
- Date, C. J. Database in Depth. — O’Reilly, 2005. — 240 с. — ISBN 0-596-10012-4.
- Beynon-Davies P. (2004). Database Systems 3rd Edition. Palgrave, Basingstoke, UK. ISBN 1-4039-1601-2
- CITForum — материалы на сайте Центра информационных технологий
- Very Large Data Base — Endowment Inc.
- ACM SIGMOD — Association for Computing Machinery: Special Interest Group On Management of Data.
Для чего нужна база данных на сайте: простое и понятное объяснение
Здравствуйте, уважаемые читатели блога start-luck. Сегодня обойдемся без шуток. Я решил написать статью на достаточно серьезную и сложную тему. Постараюсь изложить ее так, чтобы каждому было понятно. Вопрос непростой, а потому вам придется настроиться на восприятие, а мне очень постараться, чтобы дать ответы на все вопросы.
Мы поговорим о том, для чего нужна база данных на сайте. Какие преимущества она дает и как работает. Постараюсь сделать публикацию простой и не слишком нудной, но ничего обещать не могу. Итак. Приступим.
Зачем она нужна
Прежде чем создать сайт, человек в идеале сначала изучает html, затем css, ну и потом JavaScript. Первое помогает справиться с текстом, второе определяет дизайн, третье дает возможность создавать скрипты. Кстати, такой подход – явная заявка на успех в интернет-сфере.

Но многие обходятся совсем без этого, выбирая свою сферу. Сейчас эти этапы не так важны. Существует множество готовых решений и любой человек, даже без особенных навыков может просто и быстро обрести свой проект. Но мы говорим об идеальном мире.
Даже если вы все это постигли и на данный момент создали портал по всем правилам, пока его нельзя назвать динамическим. Им он станет после того, как перестанет просто лежать на сервере, а начнет обновляться.
Делать это помогает система управления или движок. По правилам, вы сами должны его спрограммировать, но сейчас существует множество готовых CMS. К примеру, WordPress, о котором я неоднократно говорил. Он-то и помогает управлять контентом и сайтом. Добавлять новые статьи и менять что-то на сайте даже без знаний кода.
Давайте предположим, вы создаете не сайт, а библиотеку. Это поможет разобраться с БД (базами данных). Вполне реальную библиотеку с полками и всем прочим. Человек приходит и видит где стоят книги, это видимая часть контента, то есть сами статьи на портале.
Как посетителю найти конкретное издание? Если вы бывали в публичных библиотеках, то возможно видели картотеки. А если писали диплом самостоятельно, то наверняка знаете, что это такое и зачем они нужны.

Картотека – это архив с небольшими записочками, в которые внесена вся основная информация о изданиях: где расположена книга, кто ее автор, в каком году он ее написал. Это и есть база данных. Только сейчас мы говорим о базе для сайта.
Когда книг не много, то можно обойтись и без архива, у вас все на виду. Вы найдете необходимый материал, но когда у вас огромный портал вы или ваш читатель потратит уйму времени, пока не отыщет нужное среди книг и полок.
Существуют движки, которые себе в преимущество ставят то, что они обходятся без Mysql. Но что это значит? По факту, где-то должен располагаться текстовый документ, в котором все равно находится информация о новых публикациях.
Вернемся к аналогии. Представьте, вы приходите в библиотеку, просите Бунина, а вам предлагают поискать его в трехметровом списке. Сначала букву нужную найди и не пропустить, затем произведение, потом нужный год выпуска. Приходится пробегать глазами от начала и до конца. Такое отношение мало кому понравится.
Реляционная база данных
Итак, с базами данных разобрались, думаю вы поняли что это такое. Но существуют разные виды хранения информации, ведь списки можно составлять по-разному. Давайте разбираться в этом.

Вообще SQL это язык программирования, свод правил, которым должна подчиняться база данных. MySQL, это программа для работы с базой данных, подчиняющаяся правилам SQL. Давайте теперь разбираться по пунктам.
Эдгар Кодд сформулировал 12 законов, на которых строится реляционная база данных SQL. Не хочу грузить вас этими правилами, они не так уж важны и я боюсь, что простым языком их никак не объяснить. В конце концов, важно лишь понять основные принципы.
Не в моих силах предоставить вам теорию в полной мере. Для этого нужны более внушительные труды. Я покажу лишь основную информацию и отличия реляционной базы на конкретном примере.
Предположим у вас есть таблица с несколькими графами: порядковый номер (код), название книги и ее расположение (слева, справа на полке).
Код является первичным ключом, а название книги и расположение – теми полезными сведениями, которые и нужно получить посредством запросов к базе. Реляционная база создана на основе взаимосвязи между несколькими таблицами.

Чтобы каждый раз не писать «слева» и «справа», ведь числа читать проще не только нам, но и машинам. Существует другая таблица, в которой обозначено лево – цифрой 1, а право – 2. В итоге, третья колонка у нас состоит только из этих обозначений: 1 и 2, но чтобы получить расшифровку, нужно обратиться к третьей таблицу, получить внешний ключ.
Именно на этом принципе и строятся реляционные таблицы. Все они взаимосвязаны. Без одной вам не получить информацию о другой.
SQL и MySQL
Из предыдущей главы, думаю, в общих чертах вы поняли, что такое SQL. Переводится эта аббревиатура как язык структурированных запросов. Создана она для того, чтобы работа с разными типами баз данных строилась по одному стандарту, а значит и управлять бы ей стало легче.
Что же можно делать при помощи этого языка? Создавать и менять структуру базы, сортировать, добавлять новые записи и так далее. Однако, не все так просто. Зная язык программирования его нужно еще и применять каким-то образом.
Зная html и css многие все равно обращаются к таким программам как Dreamweaver или Notepad++, чтобы было удобнее и быстрее работать. В конце концов они открывают хотя бы обычный блокнот, чтобы выполнять эти операции.

С SQL точно также. Для того чтобы его использовать, на хостинге устанавливается MySQL, через которую и ведется вся работа.
Поведем итоге. Существует множество типов баз данных, но самой популярной признана реляционная. Для работы с ней необходимо знать язык программирования SQL и хоть он не единственный язык, но, опять же, самый распространенный. И наконец вы можете обойтись без MySQL, в интернете достаточно и других программ, но работать с ней будет легче.
Стоит ли его изучать
Чем полезно знание этого языка? Скажу вам так, если вы знаете его и умеете пользоваться БД, то можете достичь невероятной скорости поиска нужной информации, избежать проблем с параллельным доступом, то есть вам будет совершенно все равно, когда несколько людей захочет поискать что-то одно.
Решать вам стоит ли срочно хвататься за книги. Если вы хотите научиться создавать мощные проекты с огромным бюджетом и потому по всем правилам, то да, тем более, что это не займет так уж много времени. Особенно если сравнивать с силами.
Могу предложить вам две книги для изучения языка. «SQL за 10 минут» Бена Форта. Учебник с краткой информацией и конкретными примерами. Напрягать мозг придется минимально, особенно если у вас уже есть какие-то знания, то это лучший вариант.
Второй учебник более основателен. Называется «SQL для чайников» от Аллена Тейлора. Создан он в лучших традициях издательства «Вильямс». Многим знакома эта серия хотя бы внешне. Что могу сказать о содержании? Все очень скрупулезно описано, не сомневаюсь, что поймет даже не слишком усидчивый ученик.
Ну вот и все. Теперь вы знаете что делать дальше. Подписывайтесь на рассылку и узнавайте больше о мире интернета. До новых встреч и простоты в изучении.
что это такое, зачем она нужна, почему следует делать резервные копии
Тематический трафик – альтернативный подход в продвижении бизнеса

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

База данных для сайта — это место на веб-сервере, где хранится контент веб-ресурса. Каждая база состоит из таблиц, в которой размещены записи — кортежи данных.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA

База данных по автомобилям состоит из множества таблиц. Это модели: ВАЗ, ГАЗ, FORD, VW, Ferrari и т.д. Каждая таблица имеет поля.
ВАЗ: 2101, 2104, 2105, 2107 и т.д.
В каждом поле внесены записи со значениям-характеристиками: цветовые гаммы, ЛС, мощность движка и т.д.
Таблицы связаны специальными отношениями, поэтому с записями можно работать: объединять, сортировать, делать выборку посредством указания одного запроса. Современные веб-ресурсы используют базы данных для своего функционирования.
Базы данных и организация веб-ресурса
Каждый сайт состоит из HTML-страниц. На них есть определенный каркас — то, что одинаково на любой странице. И есть контент — на каждой странице он разный.
Раньше интернет-сайты создавали на чистом HTML, и это было неудобно, так как все данные были представлены как отдельные HTML-файлы. Нельзя было осуществлять поиск, группировку, сортировку информации. К тому же, информация могла часто дублироваться. При появлении PHP у веб-мастеров появилась возможность разделения сайта на его каркас и данные в базе. Теперь структуру сайта можно хранить отдельно от контента, что позволяет быстрее и удобнее администрировать веб-ресурс, легко дорабатывать его дизайн и функционал.
Структура веб-ресурса хранится в коде или в отдельных шаблонах (специальных файлах). Контент размещается в базе данных — определенном наборе таблиц с однотипными данными.
Допустим, мы создаем обычный сайт-визитку. У нас будет отдельная структура веб-сайта и база данных. В базе будут представлены несколько таблиц: 1 — с содержимым страниц, 2 — с новостной лентой, 3 — с фотогалереей.
Преимущества использования базы банных
- Быстрое управление посредством СУБД. Любая система управления БД работает на языке запросов SQL. К примеру, для сортировки данных достаточно указать всего лишь один параметр в SQL-запросе.
- Четкое структурирование и организация логики. К примеру, можно сделать выборку и точно узнать, сколько фото размещены в альбоме “Наше производство”. Или на сайте театра можно точно узнать, в каких спектаклях работает один катер.
- С применением БД легко решаются такие вопросы как поиск, сортировка, пагинация (разбиение на материалов постранично), работа пользователей в личном кабинете.
Как работать с БД
Если вы в совершенстве владеете html и css, то все равно обращаетесь к Dreamweaver, чтобы снизить сложность работы с версткой сайта. Для работы с БД необходима также программа обработки SQL под названием MySQL. Она установлена на хостинге в оболочке phpMyAdmin.
По умолчанию сама БД сайта находится в каталоге data на веб-сервере интернет-проекта. К примеру, если БД имеет название bd, то все ее значения находятся в data/bd. Как правило, на хостинге доступ к файлам БД закрыт, их следует “вытягивать” посредством запросов SQL через консоль. Упрощает работу с запросами именно MySQL. Для того чтобы попасть в MySQL, необходимо зайти по ссылке, которую дает хостинг-провайдер, и ввести логин-пароль от базы.
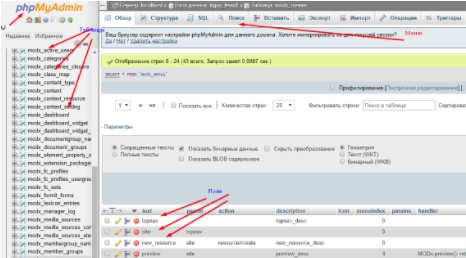
Подключение базы к сайту происходит в конфигурационном файле при помощи указания названия, пользователя и пароля. Название файла и его и месторасположение зависит от вида вашей CMS. Для MODx это config.inc по пути /core/config/.
Резервное копирование — почему оно необходимо
Необходимо периодически создавать бэкапы — резервные копии сайта и базы данных. Обычно хостинги предоставляют услуги по созданию копий сайта.
Это нужно:
- Чтобы “откатить” неудачные изменения на сайте и вернуться к предыдущей версии.
- Для восстановления веб-ресурса после вирусной атаки или взлома сайта.
- Для восстановления после сбоев.
Восстановить предыдущую версию можно с той даты, за которую сохранены база и конфигурация сайта. Легче периодически делать копии, чем восстанавливать портал с нуля.
Зачем нужна денормализация баз данных, и когда ее использовать
В нашем блоге на Хабре мы не только рассказываем о развитии своего продукта — биллинга для операторов связи «Гидра», но и публикуем материалы о работе с инфраструктурой и использовании технологий.
Недавно мы писали об использовании Clojure и MongoDB, а сегодня речь пойдет о плюсах и минусах денормализации баз данных. Разработчик баз данных и финансовый аналитик Эмил Дркушич (Emil Drkušić) написал в блоге компании Vertabelo материал о том, зачем, как и когда использовать этот подход. Мы представляем вашему вниманию главные тезисы этой заметки.
Что такое денормализация?
Обычно под этим термином понимают стратегию, применимую к уже нормализованной базе данных с целью повышения ее производительности. Смысл этого действия — поместить избыточные данные туда, где они смогут принести максимальную пользу. Для этого можно использовать дополнительные поля в уже существующих таблицах, добавлять новые таблицы или даже создавать новые экземпляры существующих таблиц. Логика в том, чтобы снизить время исполнения определенных запросов через упрощение доступа к данным или через создание таблиц с результатами отчетов, построенных на основании исходных данных.
Непременное условие процесса денормализации — наличие нормализованной базы. Важно понимать различие между ситуацией, когда база данных вообще не была нормализована, и нормализованной базой, прошедшей затем денормализацию. Во втором случае — все хорошо, а вот первый говорит об ошибках в проектировании или недостатке знаний у специалистов, которые этим занимались.
Рассмотрим нормализованную модель для простейшей CRM-системы:
Пробежимся по имеющимся здесь таблицам:
- Таблица
user_accountхранит данные о пользователях, зарегистрированных в приложении (для упрощения модели роли и права пользователей из нее исключены). - Таблица
clientсодержит некие базовые сведения о клиентах. - Таблица
product— это список предлагаемых товаров. - Таблица
taskсодержит все созданные задачи. Каждую из них можно представить в виде набора согласованных действий по отношению к клиенту. Для каждой есть список звонков, встреч, предложенных и проданных товаров. - Таблицы
callиmeetingхранят данные о заказах и встречах с клиентами и связывают их с текущими задачами. - Словари
task_outcome,meeting_outcomeиcall_outcomeсодержат все возможные варианты результата звонков, встреч и задания. product_offeredхранит список продуктов, которые были предложены клиентам;product_sold— продукты, которые удалось продать.- Таблица
supply_orderхранит информацию обо всех размещенных заказах. - Таблица
writeoffсодержит перечень списанных по каким-либо причинам товаров.
В этом примере база данных сильно упрощена для наглядности. Но нетрудно увидеть, что она отлично нормализована — в ней нет никакой избыточности, и все должно работать, как часы. Никаких проблем с производительностью не возникает до того момента, пока база не столкнется с большим объёмом данных.
Когда полезно использовать денормализацию
Прежде чем браться разнормализовывать то, что уже однажды было нормализовано, естественно, нужно четко понимать, зачем это нужно? Следует убедиться, что выгода от применения метода перевешивает возможные негативные последствия. Вот несколько ситуаций, в которых определенно стоит задуматься о денормализации.
- Сохранение исторических данных. Данные меняются с течением времени, но может быть нужно сохранять значения, которые были введены в момент создания записи. Например, могут измениться имя и фамилия клиента или другие данные о его месте жительства и роде занятий. Задача должна содержать значения полей, которые были актуальны на момент создания задачи. Если этого не обеспечить, то восстановить прошлые данные корректно не удастся. Решить проблему можно, добавив таблицу с историей изменений. В таком случае SELECT-запрос, который будет возвращать задачу и актуальное имя клиента будет более сложным. Возможно, дополнительная таблица — не лучший выход из положения.
- Повышение производительности запросов. Некоторые запросы могут использовать множество таблиц для доступа к часто запрашиваемым данным. Пример — ситуация, когда необходимо объединить до 10 таблиц для получения имени клиента и наименования товаров, которые были ему проданы. Некоторые из них, в свою очередь, могут содержать большие объемы данных. При таком раскладе разумным будет добавить напрямую поле
client_idв таблицуproducts_sold. - Ускорение создания отчетов. Бизнесу часто требуется выгружать определенную статистику. Создание отчетов по «живым» данным может требовать большого количества времени, да и производительность всей системы может в таком случае упасть. Например, требуется отслеживать клиентские продажи за определенный промежуток по заданной группе или по всем пользователям разом. Решающий эту задачу запрос в «боевой» базе перелопатит ее полностью, прежде чем подобный отчет будет сформирован. Нетрудно представить, насколько медленнее все будет работать, если такие отчеты будут нужны ежедневно.
- Предварительные вычисления часто запрашиваемых значений. Всегда есть потребность держать наиболее часто запрашиваемые значения наготове для регулярных расчетов, а не создавать их заново, генерируя их каждый раз в реальном времени.
Вывод напрашивается сам собой: не следует обращаться к денормализации, если не стоит задач, связанных с производительностью приложения. Но если чувствуется, что система замедлилась или скоро замедлится, впору задуматься о применении данной техники. Однако, прежде чем обращаться к ней, стоит применить и другие возможности улучшения производительности: оптимизацию запросов и правильную индексацию.
Не все так гладко
Очевидная цель денормализации — повышение производительности. Но всему есть своя цена. В данном случае она складывается из следующих пунктов:
- Место на диске. Ожидаемо, поскольку данные дублируются.
- Аномалии данных. Необходимо понимать, что с определенного момента данные могут быть изменены в нескольких местах одновременно. Соответственно, нужно корректно менять и их копии. Это же относится к отчетам и предварительно вычисляемым значениям. Решить проблему можно с помощью триггеров, транзакций и хранимых процедур для совмещения операций.
- Документация. Каждое применение денормализации следует подробно документировать. Если в будущем структура базы поменяется, то в ходе этого процесса нужно будет учесть все прошлые изменения — возможно, от них вообще можно будет к тому моменту отказаться за ненадобностью. (Пример: в клиентскую таблицу добавлен новый атрибут, что приводит к необходимости сохранения прошлых значений. Чтобы решить эту задачу, придется поменять настройки денормализации).
- Замедление других операций. Вполне возможно, что применение денормализации замедлит процессы вставки, модификации и удаления данных. Если подобные действия проводятся относительно редко, то это может быть оправдано. В этом случае мы разбиваем один медленный SELECT-запрос на серию более мелких запросов по вводу, обновлению и удалению данных. Если сложный запрос может серьезно замедлить всю систему, то замедление множества небольших операций не отразится на качестве работы приложения столь драматических образом.
- Больше кода. Пункты 2 и 3 потребуют добавления кода. В то же время они могут существенно упростить некоторые запросы. Если денормализации подвергается существующая база данных, то потребуется модифицировать эти запросы, чтобы оптимизировать работу всей системы. Также понадобится обновить существующие записи, заполнив значения добавленных атрибутов — это тоже потребует написания некоторого количества кода.
Денормализация на примере
В представленной модели были применены некоторые из вышеупомянутых правил денормализации. Синим отмечены новые блоки, розовым — те, что были изменены.
Что изменилось и почему?
Единственное нововведение в таблице product — строка units_in_stock. В нормализованной модели мы можем вычислить это значение следующим образом: заказанное наименование — проданное — (предложенное) — списанное (units ordered — units sold — (units offered) — units written off). Вычисление повторяется каждый раз, когда клиент запрашивает товар. Это довольно затратный по времени процесс. Вместо этого можно вычислять значение заранее так, чтобы к моменту поступления запроса от покупателя, все уже было наготове. С другой стороны, атрибут units_in_stock должен оновляться после каждой операции ввода, обновления или удаления в таблицах products_on_order, writeoff, product_offered и product_sold.
В таблицу task добавлено два новых атрибута: client_name и user_first_last_name. Оба они хранят значения на момент создания задачи — это нужно, потому что каждое из них может поменяться с течением времени. Также нужно сохранить внешний ключ, который связывает их с исходным пользовательским и клиентским ID. Есть и другие значения, которые нужно хранить — например, адрес клиента или информация о включенных в стоимость налогах вроде НДС.
Денормализованная таблица product_offered получила два новых атрибута: price_per_unit и price. Первый из них необходим для хранения актуальной цены на момент предложения товара. Нормализованная модель будет показывать лишь ее текущее состояние. Поэтому, как только цена изменится, изменится и «ценовая история». Нововведение не просто ускорит работу базы, оно улучшает функциональность. Строка price вычисляет значение units_sold * price_per_unit. Таким образом, не нужно делать расчет каждый раз, как понадобится взглянуть на список предложенных товаров. Это небольшая цена за увеличение производительности.
Изменения в таблице product_sold сделаны по тем же соображениям. С той лишь разницей, что в данном случае речь идет о проданных наименованиях товара.
Таблица statistics_per_year (статистика за год) в тестовой модели — абсолютно новый элемент. По сути, это денормализованная таблица, поскольку все ее данные могут быть рассчитаны из других таблиц. Здесь хранится информация о текущих задачах, успешно выполненных задачах, встречах, звонках по каждому заданному клиенту. В данном месте также хранится общая сумма проведенных начислений за каждый год. После ввода, обновления или удаления любых данных в таблицах task, meeting, call и product_sold приходится пересчитывать эти данные для каждого клиента и соответствующего года. Так как изменения, скорее всего, касаются лишь текущего года, отчеты за предыдущие годы теперь могут оставаться без изменений. Значения в этой таблице вычисляются заранее, поэтому мы сэкономим время и ресурсы, когда нам понадобятся результаты расчетов.
Денормализация — мощный подход. Не то чтобы к ней следует прибегать каждый раз, когда стоит задача увеличения производительности. Но в отдельных случаях это может быть лучшим или даже единственным решением.
Однако, прежде, чем принять окончательное решение об использовании денормализации, следует убедиться в том, что это действительно необходимо. Нужно провести анализ текущей производительности системы — часто денормализацию применяют уже после запуска системы в работу. Не стоит этого бояться, однако следует внимательно отслеживать и документировать все вносимые изменения, тогда проблем и аномалий данных не должно возникнуть.
Наш опыт
Мы в Латере много занимаемся оптимизацией производительности нашей биллинговой системы «Гидра», что неудивительно, учитывая объемы наших клиентов и специфику телеком-отрасли.
Один из примеров в статье предполагает создание таблицы с промежуточными итогами для ускорения отчетов. Конечно, самое сложное в этом подходе — поддерживать актуальное состояние такой таблицы. Иногда можно переложить эту задачу на СУБД — например, использовать материализованные представления. Но, когда бизнес-логика для получения промежуточных результатов оказывается чуть более сложной, актуальность денормализованных данных приходится обеспечивать вручную.
«Гидра» имеет глубоко проработанную систему привилегий для пользователей, операторов биллинга. Права выдаются несколькими способами — можно разрешить определенные действия конкретному пользователю, можно заранее подготовить роли и выдать им разные наборы прав, можно наделить определенный отдел специальными привилегиями. Только представьте, насколько медленными стали бы обращения к любым сущностям системы, если бы каждый раз нужно было пройти всю эту цепочку, чтобы убедиться: «да, этому сотруднику разрешено заключать договоры с юридическими лицами» или «нет, у этого оператора недостаточно привилегий для работы с абонентами соседнего филиала». Вместо этого мы отдельно храним готовый агрегированный список действующих прав для пользователей и обновляем его, когда в систему вносятся изменения, способные на этот список повлиять. Сотрудники переходят из одного отдела в другой намного реже, чем открывают очередного абонента в интерфейсе биллинга, а значит вычислять полный набор их прав нам приходится настолько же реже.
Конечно, денормализация хранилища — это только одна из принимаемых мер. Часть данных стоит кэшировать и непосредственно в приложении, но если промежуточные результаты в среднем живут намного дольше, чем пользовательские сессии, есть смысл всерьез задуматься о денормализации для ускорения чтения.
Другие технические статьи в нашем блоге:
Что такое база данных веб-сайта и зачем это нужно.
Любой человек, который занимается веб-разработкой рано или поздно сталкивается с таким понятием как база данных веб-сайта.
Давайте будем разбираться, что такое база данных и зачем это нужно.
Предположим, что мы решили создать какой-то свой веб-сайт. Мы создали одну страницу. Предположим, что это будет страница page.html. На этой странице находится какое-то содержимое.
С течением времени сайт начинает разрастаться. На нем начинают появляться все новые и новые материалы и страниц, на которых будут храниться эти материалы становиться все больше и больше.
Возникает вопрос, как хранить все данные, которые будут отображаться на этих веб-страницах. Какую структуру организации этих данных выбрать.
1 способ. Каждый материал (страница) — отдельный html-файл.
Как вариант, это будет работать. Но, при этом возникает ряд проблем.
Что если в этой структуре файлов, нам нужно будет добавить или изменить какой-то общий элемент? Например, нужно поменять изображение в шапке сайта.
Нужно будет открывать каждый из этих файлов и в каждом из них менять путь до картинки.
Конечно, если файлов всего 3 — это сделать довольно просто. Но, если этих файлов сотни и тысячи, могут возникнуть трудности.
А что если у нас будет стоять задача получить какую-то статистику по этим страницам? Например, нам нужно узнать сколько всего у нас есть веб-страниц и вывести это в каком-то месте веб-сайта.
Если каждая страница у нас отдельный файл, сделать это может быть трудно.
Что если нам нужно будет организовать поиск по этим файлам?
С этим тоже могут быть трудности.
Наконец, как дать доступ на редактирование созданных html-страниц человеку, который в веб-разработке ничего не понимает. Для него это тоже будут некоторые трудности.
Из-за этих проблем, что трудно обслуживать такую структуру организации данных веб-сайта, есть другой подход как можно хранить информацию, которая будет отображаться на всех этих страницах.
В этом подходе мы исходим из того, что у нас есть только один файл. Предположим, это файл page.php.
Именно этот файл будет главным для всех страниц нашего сайта. А текст всех страниц, которые будут на этом сайте. Ссылки, даты и.т.д. мы выносим в отдельную сущность, которая называется база данных.
Т.е. мы разделяем структуру веб-страницы. Разметка документа отдельно и содержимое страницы тоже отдельно.
По сути, база данных — это простые таблицы, которые содержат строки и столбцы. На пересечении этих строк и столбцов содержится какая-то информация. Каждый элемент, который будет на сайте, храниться в отдельном поле базы данных.
Каждая строка соответствует каждой странице.
При такой структуре мы можем настроить веб-сервер, чтобы при обращении по определенному url-адресу ему показывается каждый раз какая-то уникальная страница из базы данных.
Главное преимущество такой структуры в том, что нам теперь не нужно хранить на сервере огромное количество файлов.
Теперь у нас контент отдельно и разметка страницы тоже отдельно.
Какие мы теперь получаем преимущества:
1) Мы можем просто вносить изменения в содержимое страниц сайта за счет того, что контент размещается отдельно от структуры и логики.
2) Скорость и простота обработки информации в базе данных. Статистика, поиск и.т.д.
3) Возможность создания панели управления для людей, которые не знакомы с веб-разработкой.
В итоге, база данных — это то место, где храниться содержимое какой-то определенной сущности. Например, мы выбрали сущности «страница» и храним информацию в базе данных, которая к этой сущности относится.
Надеюсь, что стало понятнее что такое база данных и для чего они нужны.
Не во всех случаях оправдано их использование. Если вам приходится работать с большим объемом каких-то данных, тот первый вопрос, который вам нужно себе задать: не логичнее ли будет всю эту информацию хранить в базе данных.
На этом все, желаю вам удачно проектировать структуру своего веб-сайта и удачной работы.