
Про директиву Disallow из robots.txt / Оптимизация и продвижение / LiveStreet CMS
Навеяно яростно обсуждавшейся заметкой господина Znayka .
Disallow из robots.txt ( как и гаубица М-30 ) — самая лучшая и старейшая из систем. SEO, правда, но тоже штука массового поражения. На данный момент, это единственный 100%-ый способ закрыть от всех поисковиков линки на сайте. Ибо rel=«nofollow», то ли вообще не работает, то ли работает оригинальным образом, но точно больше не работает так, как раньше. А noindex принимается во внимание не всеми поисковиками (Яндекс — точно понимает, а Google — точно нет).
Чем опасно? robots.txt — самый высоко приоритетный файл для веб краулеров. Изменения в нём учитываются очень быстро. Одно не верное движение — и N тысяч ваших страниц будут выкинуты из поисковых систем. И очень не скоро вернуться обратно, даже после исправления. Особенно в отношении Яндес верно. Google — он пошустрее.
Зачем вообще линки от поисковиков закрывать? Основных причин три:
Во-первых — достоверно известно что, мистический, статический вес страницы(который непосредственно влияет на ранк страницы в поисковой системе) тем больше, чем меньше на ней видимых поисковикам линков. Т.е. убираем линки — поднимаем страницу в поиске. Профит.
Т.е. убираем линки — поднимаем страницу в поиске. Профит.
Во-вторых — чтобы ускорить скорость индексирования ценного. Краулер заходит на сайт эпизодически и обходит его понемногу. Незачем нам, чтоб он свои заходы на всякую малоценную ерунду тратил. Пусть ходит по тем страницам, которые мы жаждем в поиске увидеть.
Ну и в-третьих — это самый простой способ борьбы с дублированием контента (Duplicate content).
Замечание: Но нужно иметь в виду, что для борьбы с дублированием контента есть и другие, не столь кровожадные методы.
Что стоит, а чего не стоит закрывать с помощью robots.txt в контексте LiveStreet — это тема изрядно субъективная, так что рецепта от всех болезней у меня нет. Но есть личное мнение, и некоторый (не очень приятный местами) опыт, которым и хочу поделиться.
I. Стоит закрыть линки-входы в закрытую (не публичную) часть сайта. Краулеры в закрытую часть сайта все равно не попадут, а по входящим линкам ничего достойного индексирования нет.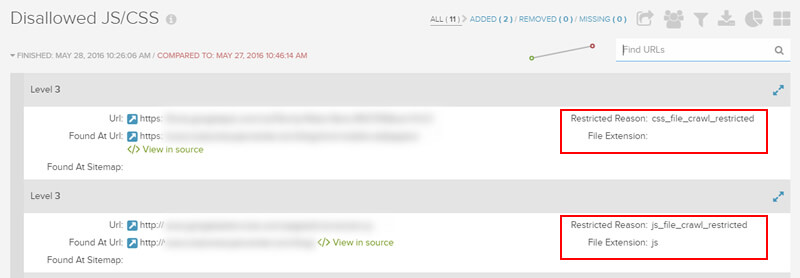 Для LiveStreet — это /login/ и /registration/.
Для LiveStreet — это /login/ и /registration/.
Замечание: Подобные линки могут появляться в результате использования плагинов. /openid_login/, например.
I.a. Стоит также, на всякий случай, закрыть линки которые однозначно могут существовать только в закрытой части сайта: /feed/, /admin/. По идее, подобные линки вообще не встречаются на странице для не залогиненного пользователя и/или не админа. Но мало ли, какой косяк в шаблоне, разработанном фирмой «Вася Пупкин & co.».
II. Стоит закрыть «технические» страницы. Что-то, на что ценные страницы вашего сайта почти или совсем не ссылаются, и где мало чего ценного для индексирования. В моем понимании, в контексте LiveStreet, примером такого является раздел «Активность», и соответствующий ему
III. Стоит закрыть от поисковиков то, что всегда, однозначно и без сомнений будет трактоваться поисковиками как дублирующийся контент. Они это не любят. В LiveStreet это RSS /rss. (Поисковики уже давным давно прекрасно понимают XML, если вы вдруг не знали.)
Они это не любят. В LiveStreet это RSS /rss. (Поисковики уже давным давно прекрасно понимают XML, если вы вдруг не знали.)
Замечание: RSS, ещё и из-за «во-вторых» причин использования robots.txt, стоит пустить под нож.
IV. Поиск. Нормальный линк на поиск выглядит примерно так: livestreet.ru/search/topics/?q=%D0%92%D0%B0%D1%81%D1%8F+%D0%9F%D1%83%D0%BF%D0%BA%D0%B8%D0%BD+%D0%B8+co. И такой линк не очень хочется блокировать. Потому, что он может расплодиться в сети, и поднять соответствующую страницу высоко в поисковом ранке. Особенность, однако, заключается в том, что такие линки встречаются на сайте крайне не часто: изредка в тексте заметок и комментариев. Очень изредка. Т.е. на сайте краулер такие линки не найдет. Зато, почти на каждой странице, найдётся несколько «технических», не несущих никакой пользы для индексирования, поисковых линков:
livestreet.ru/search/topics/
livestreet.ru/search/opensearch/
Стандартное лекарство: /search/ в robots.
 txt — редкие «правильные» линки тоже пострадают, но не велика потеря, ибо их очень мало. Однако, можно действовать тоньше и закрыть только гадость:
txt — редкие «правильные» линки тоже пострадают, но не велика потеря, ибо их очень мало. Однако, можно действовать тоньше и закрыть только гадость:/search/$
/search/topics/$
/search/opensearch/$
Замечание: Такие конструкции c $ (и с *
V. НЕ стоит закрывать облако тегов /tag/. Теги, во-первых, сильно способствуют внутренней перелинковке ( линки на теги, у нас же, вокруг любой заметки ). Во-вторых теги имеют вирусную природу, в гораздо большей степени, чем поиск: поиск же надо открыть, набрать там что-то. А теги вот они — кликнул, и вуаля.
Замечание: Много споров вокруг закрытия облака тегов потому, что они же частенько порождают проблему дублирующегося контента. Тема такая есть, но решать её с помощью Disallow это слишком кардинальный метод в стиле «Виноват один — расстрелять всех, на всякий случай»
VI. НЕ стоит закрывать пользователей /profile/. Опять же перелинковка. Потом люди у себя в профайлах такое пишут иногда, что вполне достойно индексирования. Ну и напоследок — успешные авторы/редакторы могут двигать ваш сайт своим именем похлеще статей. У нас, собственно, такой пример есть.
НЕ стоит закрывать пользователей /profile/. Опять же перелинковка. Потом люди у себя в профайлах такое пишут иногда, что вполне достойно индексирования. Ну и напоследок — успешные авторы/редакторы могут двигать ваш сайт своим именем похлеще статей. У нас, собственно, такой пример есть.
VII. CSS-ы. Google мягко намекает, что делать это незачем: www.youtube.com/watch?v=PNEipHjsEPU. Однако, существует несколько недоказанных утверждений связанных с CSS:
- Поисковики могут счесть некоторые стили крамолой и наказать за это: «Например, Вы сделали бледно-серые буквы на белом фоне и они плохо видны — может повлечь за собой санкции. Далее Вы в стиле для h3 прописали размер больше, чем для h2, что также противоречит нормам.» ©
- запрет на индексацию CSS файлов ускоряет индексацию самого сайта
Правда всё это или нет — вопрос открытый, но я лично скорее верю, чем нет. Правильный способ закрыть их: /*.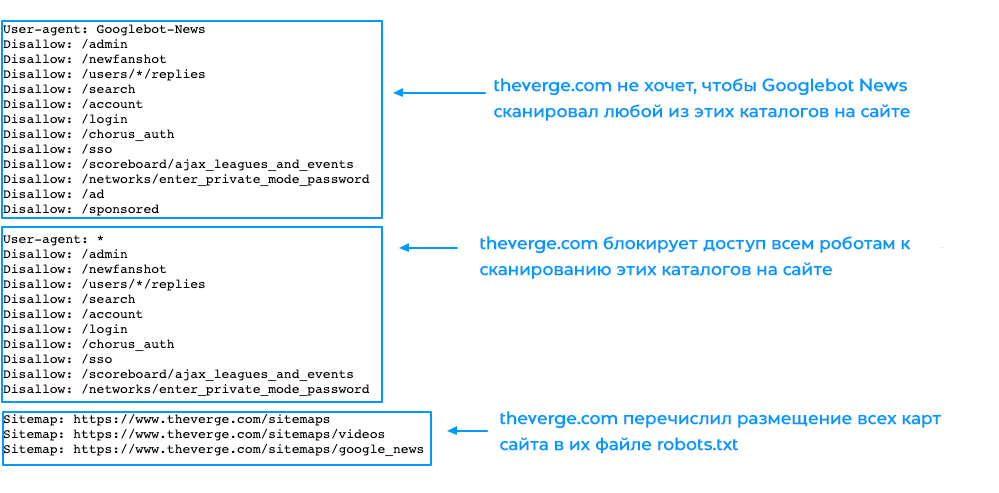 css$
css$
Замечание: Имейте ввиду, что часто встречающийся вариант «/css/» может не закрыть их все. У LiveStreet полно css из других директорий, которые могут вылезти, в зависимости от конфигурации или особенностей шаблонов от «Вася Пупкин & co.»
VIII. JS-ы. Да, они могут быть проблемным источником не нужных линков, но блокировать я бы их не стал из боязливых соображений :). Много всякого черного SEO связанно с JavaScript, и его блокировка в robots.txt, на мой взгляд, очень подозрительна. Но если сильно хотите — способ тот же, что и с CSS.
IX. Всякая хрень, которая всплывает непонятно откуда, и оставляет за собой грязные следы в виде «404 в Webmaster Tools». Такое вот, например: livestreet.ru/blog/questions/13601.html. Такое, однозначно, надо душить на корню. Способ тот же что и с поиском.
На этом, пожалуй, всё. Буду благодарен за любые интересные идеи по теме.
P.S. Если сомневаетесь, что все эти эксперименты где-то реально запущены — можете убедиться сами: robots.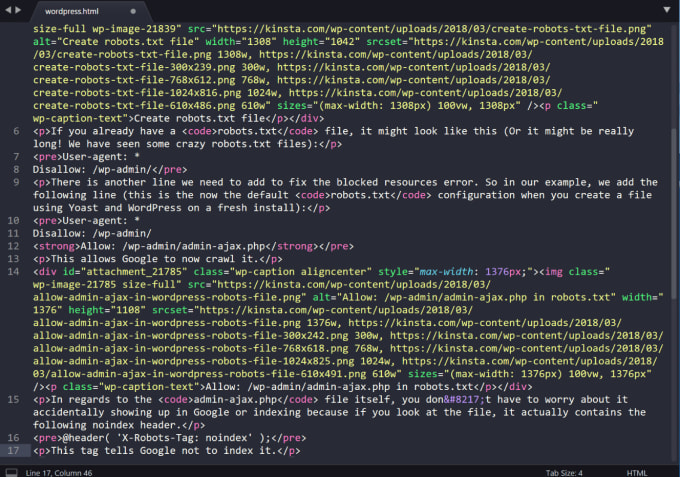
Как использовать robots.txt для разрешения или запрета всего
Файл robots.txt — это файл, расположенный в корневом домене.
Это простой текстовый файл, основной целью которого является указание поисковым роботам и поисковым роботам файлов и папок, от которых следует держаться подальше.
Роботы поисковых систем — это программы, которые посещают ваш сайт и переходят по ссылкам на нем, чтобы узнать о ваших страницах. Примером может служить поисковый робот Google, который называется Googlebot.
Обычно боты проверяют файл robots.txt перед посещением вашего сайта. Они делают это, чтобы узнать, разрешено ли им сканировать сайт и есть ли вещи, которых следует избегать.
Файл robots.txt следует поместить в каталог верхнего уровня вашего домена, например, example.com/robots.txt.
Лучший способ отредактировать его — войти на свой веб-хост через бесплатный FTP-клиент, такой как FileZilla, а затем отредактировать файл с помощью текстового редактора, такого как Блокнот (Windows) или TextEdit (Mac).
Если вы не знаете, как войти на свой сервер через FTP, обратитесь в свою хостинговую компанию за инструкциями.
Некоторые плагины, такие как Yoast SEO, также позволяют редактировать файл robots.txt из панели управления WordPress.
Как запретить всем использовать robots.txt
Если вы хотите, чтобы все роботы держались подальше от вашего сайта, то этот код вы должны поместить в свой robots.txt, чтобы запретить все:
User-agent: * Disallow: /
Часть «User-agent: *» означает, что применяется ко всем роботам. Часть «Запретить: /» означает, что она применяется ко всему вашему сайту.
По сути, это сообщит всем роботам и поисковым роботам, что им не разрешен доступ к вашему сайту или его сканирование.
Важно: Запрет всех роботов на действующем веб-сайте может привести к удалению вашего сайта из поисковых систем и потере трафика и доходов. Используйте это, только если вы знаете, что делаете!
Как разрешить все
Robots.
Если вы хотите, чтобы боты могли сканировать весь ваш сайт, вы можете просто иметь пустой файл или вообще не иметь файла.
Или вы можете поместить это в свой файл robots.txt, чтобы разрешить все:
Агент пользователя: * Disallow:
Это интерпретируется как запрещение ничего, поэтому фактически разрешено все.
Как запретить определенные файлы и папки
Вы можете использовать команду «Запретить:», чтобы заблокировать отдельные файлы и папки.
Вы просто помещаете отдельную строку для каждого файла или папки, которые хотите запретить.
Вот пример:
User-agent: * Запретить: /topsy/ Запретить: /crets/ Запретить: /hidden/file.html
В этом случае разрешено все, кроме двух подпапок и одного файла.
Как запретить определенным ботам
Если вы просто хотите заблокировать сканирование одного конкретного бота, сделайте это следующим образом:
Агент пользователя: Bingbot Запретить: / Пользовательский агент: * Disallow:
Это заблокирует поисковый робот Bing от сканирования вашего сайта, но другим ботам будет разрешено сканировать все.
Вы можете сделать то же самое с Googlebot, используя «User-agent: Googlebot».
Вы также можете запретить определенным ботам доступ к определенным файлам и папкам.
Хороший файл robots.txt для WordPress
Следующий код — это то, что я использую в своем файле robots.txt. Это хорошая настройка по умолчанию для WordPress.
Агент пользователя: * Запретить: /wp-admin/ Разрешить: /wp-admin/admin-ajax.php Карта сайта: https://searchfacts.com/sitemap.xml
Этот файл robots.txt сообщает ботам, что они могут сканировать все, кроме папки /wp-admin/. Однако им разрешено сканировать один файл в папке /wp-admin/ с именем admin-ajax.php.
Причиной этого параметра является то, что Google Search Console раньше сообщала об ошибке, если не могла просканировать файл admin-ajax.php.
Googlebot — единственный бот, который понимает «Разрешить:» — он используется для разрешения обхода определенного файла внутри запрещенной папки.
Вы также можете использовать строку «Карта сайта:», чтобы сообщить ботам, где найти вашу XML-карту сайта.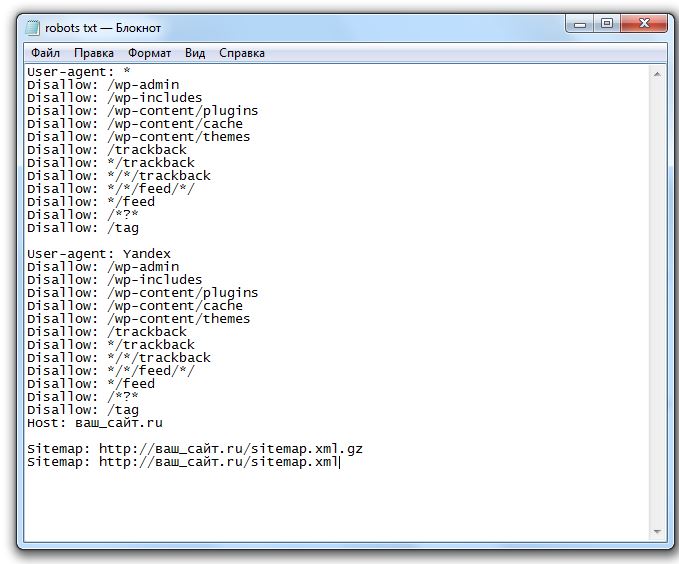 Эта карта сайта должна содержать список всех страниц вашего сайта, чтобы поисковым роботам было легче найти их все.
Эта карта сайта должна содержать список всех страниц вашего сайта, чтобы поисковым роботам было легче найти их все.
Когда использовать noindex вместо robots
Если вы хотите заблокировать показ всего сайта или отдельных страниц в поисковых системах, таких как Google, то robots.txt — не лучший способ сделать это.
Поисковые системы по-прежнему могут индексировать файлы, заблокированные роботами, просто они не будут показывать некоторые полезные метаданные.
Вместо этого в описании результатов поиска будет указано: «Описание этого результата недоступно из-за файла robots.txt этого сайта».
Источник: Круглый стол поисковой системыЕсли вы скрываете файл или папку с robots.txt, но потом кто-то ссылается на него, Google, скорее всего, покажет его в результатах поиска, но без описания.
В этих случаях лучше использовать тег noindex, чтобы запретить поисковым системам отображать его в результатах поиска.
В WordPress, если вы перейдете в «Настройки» -> «Чтение» и отметите «Запретить поисковым системам индексировать этот сайт», на все ваши страницы будет добавлен тег noindex.
Выглядит так:
Вы также можете использовать бесплатный SEO-плагин, такой как Yoast или The SEO Framework, чтобы не индексировать определенные сообщения, страницы или категории на вашем сайте.
В большинстве случаев noindex лучше блокирует индексирование, чем robots.txt.
Когда вместо этого заблокировать весь сайт
В некоторых случаях может потребоваться заблокировать доступ ко всему сайту как для ботов, так и для людей.
Лучше всего для этого установить пароль на свой сайт. Это можно сделать с помощью бесплатного плагина WordPress под названием «Защищено паролем».
Важные факты о файле robots.txt
Имейте в виду, что роботы могут игнорировать ваш файл robots.txt, особенно вредоносные боты, такие как те, которыми управляют хакеры, ищущие уязвимости в системе безопасности.
Кроме того, если вы пытаетесь скрыть папку со своего веб-сайта, просто поместить ее в файл robots. txt может быть неразумным подходом.
txt может быть неразумным подходом.
Любой может увидеть файл robots.txt, если введет его в свой браузер, и может понять, что вы пытаетесь скрыть таким образом.
На самом деле, вы можете посмотреть на некоторых популярных сайтах, как настроены их файлы robots.txt. Просто попробуйте добавить /robots.txt к URL-адресу домашней страницы ваших любимых веб-сайтов.
Если вы хотите убедиться, что ваш файл robots.txt работает, вы можете протестировать его с помощью Google Search Console. Вот инструкции.
Сообщение на вынос
Файл robots.txt сообщает роботам и поисковым роботам, какие файлы и папки они могут и не могут сканировать.
Его использование может быть полезно для блокировки определенных областей вашего веб-сайта или для предотвращения сканирования вашего сайта определенными ботами.
Если вы собираетесь редактировать файл robots.txt, то будьте осторожны, ведь небольшая ошибка может иметь катастрофические последствия.
Например, если вы неправильно поместите одну косую черту, она может заблокировать всех роботов и буквально удалить весь ваш поисковый трафик, пока это не будет исправлено.
Я работал с большим сайтом до того, как однажды случайно поставил «Disallow: /» в их живой файл robots.txt. Из-за этой маленькой ошибки они потеряли много трафика и доходов.
Файл robots.txt очень мощный, поэтому обращайтесь с ним с осторожностью.
Как запретить всем использовать robots.txt?
Если вы хотите, чтобы все роботы держались подальше от вашего сайта, то этот код вы должны поместить в свой robots.txt, чтобы запретить все:
User-agent: *
Disallow: /
Как разрешить все с помощью robots.txt?
Если вы хотите, чтобы боты могли сканировать весь ваш сайт, вы можете просто иметь пустой файл или вообще не иметь файла.
Или вы можете поместить это в свой файл robots.txt, чтобы разрешить все:
User-agent: *
Disallow:
Как запретить определенные файлы и папки с robots.txt?
Вы просто помещаете отдельную строку для каждого файла или папки, которые хотите запретить.
Вот пример:
User-agent: *
Disallow: /topsy/
Disallow: /crets/
Disallow: /hidden/file.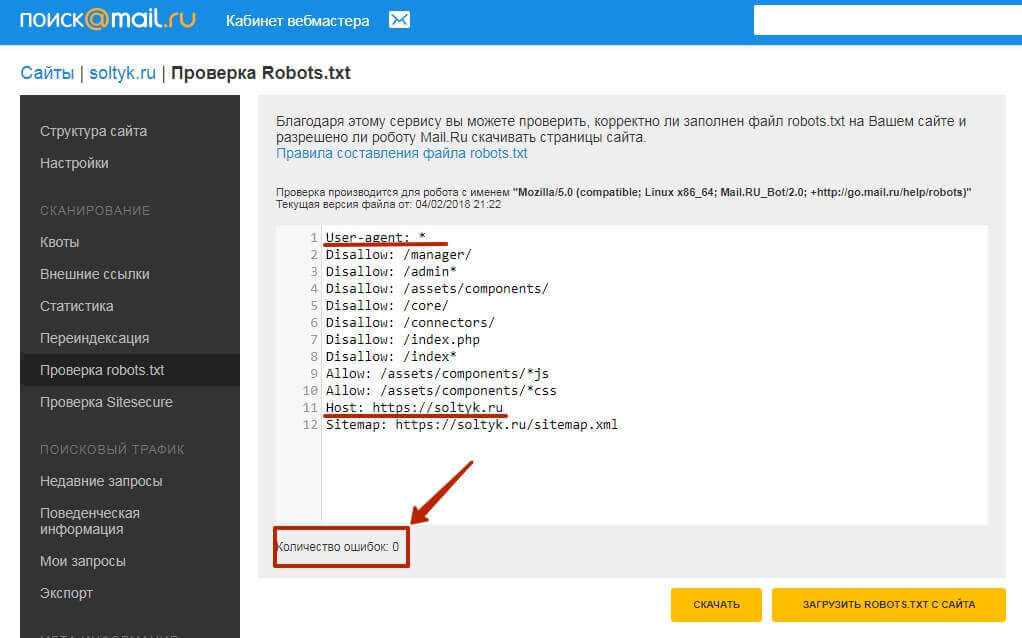 html
html
Как запретить определенных ботов с помощью robots.txt?
Если вы просто хотите заблокировать сканирование одного конкретного бота, например Bing, то вы делаете это так:
User-agent: Bingbot
Disallow: /
Какой файл robots.txt подходит для WordPress?
Следующий код — это то, что я использую в своем файле robots.txt. Это хорошая настройка по умолчанию для WordPress.
Агент пользователя: *
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax.php
Карта сайта: https://searchfacts.com/sitemap.xml
Запрещенный контент — документация CKEditor 4
Функция запрещенного содержимого была введена в CKEditor 4.4 как часть системы расширенного фильтра содержимого, которая была представлена в CKEditor 4.1 .
Функция «Запрещенный контент» дополняет существующую функцию «Разрешенный контент» тем, что позволяет явно заносить в черный список элементы, которые вы не хотите иметь в своем контенте CKEditor 4.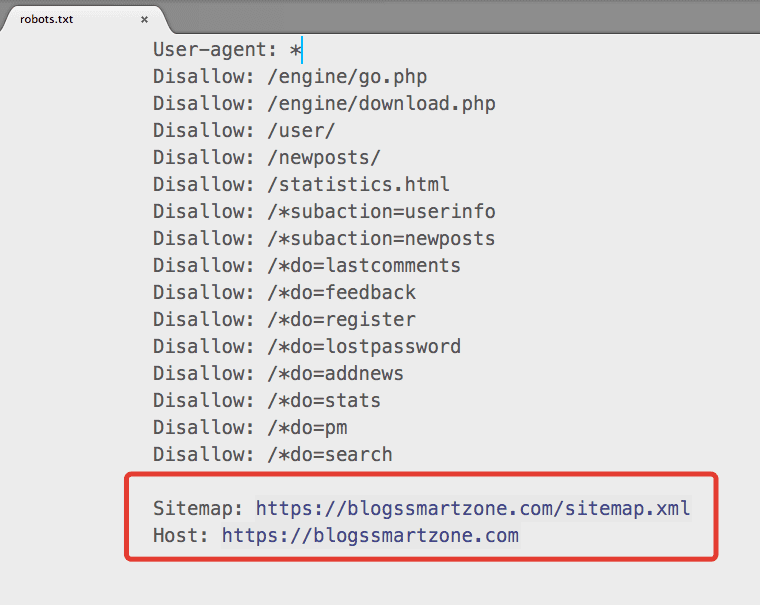 Вы можете использовать его, чтобы ограничить функции, которые в противном случае были бы доступны в полностью автоматическом режиме Advanced Content Filter.
Вы можете использовать его, чтобы ограничить функции, которые в противном случае были бы доступны в полностью автоматическом режиме Advanced Content Filter.
Запрещенное содержимое можно определить в параметре CKEDITOR.config.disallowedContent или добавить динамически с помощью метода CKEDITOR.filter.disallow. Он имеет более высокий приоритет, чем контент, разрешенный автоматически или настройкой CKEDITOR.config.allowedContent, поэтому можно исправить автоматические настройки или добиться более сложных результатов, таких как «разрешить все атрибуты, кроме тех, которые начинаются с 9».0186 по *».
Невозможно запретить содержимое, если расширенный фильтр содержимого отключен путем установки для CKEDITOR.config.allowedContent значения true . Аналогичного решения можно достичь, разрешив все элементы HTML.
Правила запрещенного содержимого
Правила запрещенного содержимого очень похожи на правила разрешенного содержимого. Их можно указать в двух форматах (строковый и объектный), однако указать требуемые свойства нельзя (что в данном случае просто не имело бы никакого смысла).
Когда определены только имена элементов, правило запрещает целые элементы (и, таким образом, эти элементы будут удалены). Когда правило также содержит имена свойств, будут удалены только эти свойства (атрибуты, стили, классы), а не элементы (если не было удалено какое-либо требуемое свойство).
Лучше всего смотреть на примерах.
Запрет целых элементов.
config.allowedContent = 'h2 h3 h4 p'; config.disallowedContent = 'h3 h4'; // Ввод:
Foo
Bar
Bom
// Отфильтровано:Foo
Bar
Bom
Запрещение атрибутов, классов и стилей.
config.allowedContent = 'p[*]{*}(foo,bar)'; config.disallowedContent = 'p[on*](foo)'; // Вход:Foo
Bar
// Отфильтровано:Foo
Bar
Запрещение обязательного свойства.
config.allowedContent = 'p; img[!src,alt]'; config.disallowedContent = 'img[src]'; // Ввод:
// Отфильтровано: ./assets/img/..." alt="..."/>
./assets/img/..." alt="..."/>Запрет свойств для всех элементов.
config.allowedContent = 'p em{*}'; config.disallowedContent = '*{шрифт*}'; // Ввод:Фу
// Отфильтровано:Foo
Настройка автоматически разрешенного контента.
// Включенные плагины: изображение и таблица. config.disallowedContent = 'img{граница*,маржа*}; таблица[граница]{*}';После реализации этого кода откройте диалоговое окно «Свойства изображения» и убедитесь, что поля «Граница», «HSpace» и «VSpace» скрыты. Вы также можете открыть диалоговое окно «Таблица» и увидеть, что поля «Граница», «Ширина» и «Высота» также скрыты.
Как разрешить все, кроме…
Популярным требованием является разрешение всех функций HTML, кроме нескольких определенных. В этом случае установка для CKEDITOR.config.allowedContent значения true не является решением, поскольку это полностью отключает расширенный фильтр содержимого, поэтому CKEDITOR.