
Яндекс отменил директиву host в файле robots.txt
В файле robots.txt содержится информация о сайте для поисковых роботов. Раньше Яндекс требовал размещения в этом файле директивы host, которая указывала на главное зеркало сайта. В 2018 году от нее решили отказаться полностью, чтобы вебмастерам было легче работать. В Google эта директива не учитывалась никогда. Чтобы изменить протокол на безопасный или переехать на другой домен, теперь используют более простой способ.
Какая команда появилась после директивы host
Раньше длительность переезда сайта на новый домен в Яндексе доходила до месяца, так как связь главного и второстепенного зеркал оказывала большое влияние на позиции в выдаче. Сейчас переезд проходит всего за несколько дней, что благоприятно сказывается на продвижении. Такое стало возможным благодаря редиректу 301, который заменил директиву хост. Теперь алгоритм смены протокола и домена ничем не отличается. Google изначально работал по такому принципу.
Для продолжения работы в обязательном порядке настраивают 301 редирект (переадресацию), директива host при переезде значение утратила полностью. Нововведения помогли ускорить и облегчить процесс перехода. Однако при переезде на новый домен или смене протокола нередко возникают непредвиденные ситуации, индивидуальные для каждого случая, поэтому алгоритм действий может отличаться. Иногда процесс затягивается, но в большинстве случаев переехать удается гораздо быстрее, чем раньше.
Нововведения помогли ускорить и облегчить процесс перехода. Однако при переезде на новый домен или смене протокола нередко возникают непредвиденные ситуации, индивидуальные для каждого случая, поэтому алгоритм действий может отличаться. Иногда процесс затягивается, но в большинстве случаев переехать удается гораздо быстрее, чем раньше.
Как проходит смена протокола или переезд на другой домен
Чтобы сменить протокол на безопасный или переехать на другой домен, убедитесь в том, что права собственности на обе версии сайта подтверждены. Затем выполните несколько простых действий:
- настройте редирект 301;
- перейдите в панель Вебмастера;
- в разделе «Переезд сайта» пропишите адрес зеркала — выберите в чек-боксе «добавить https» или «добавить www», если это необходимо.
Сразу проверять корректность переиндексации ресурса не стоит, так как для обновления требуется несколько дней. Зато команду host можно удалять, ведь она стала бесполезной как для Гугла, так и для Яндекса. Обе версии сайта должны быть доступны для поисковых роботов.
Обе версии сайта должны быть доступны для поисковых роботов.
Можно ли переехать без настройки редиректа 301
Переезд без настройки 301 редиректа возможен, однако это сопряжено с рядом проблем:
- Например, вы переезжаете с домена на домен, и у вас нет технической возможности настроить 301 редирект. В этом случае старый домен должен быть удален или скрыт от индексации. Если оставить старый домен после переезда, индексация нового будет невероятно долгой — займет даже не недели, а месяцы. Когда она будет завершена, есть вероятность, что оба домена будут признаны аффилиатами в Яндексе и приняты за дубли в Google.
Напоминаем, что оставлять открытыми для индексации старый и новый домены можно было до 2018 года, а далее директиву host отменили.
- Если вы меняете протокол http на https, но не настраиваете 301 редирект, хорошего результата ждать не стоит. Да, в панели вебмастера вы укажете Яндексу, какое зеркало — главное. Однако в индексе появятся дубли каждой страницы — одновременно на двух протоколах, и поисковые роботы сочтут их разными. Таким образом, вы задублируете весь сайт.
Настоятельно рекомендуем настраивать редиректы с http на https, все современные CMS без проблем позволяют это сделать. - Переезд на новое зеркало с www или без www в этом смысле схож со сменой протокола на https. Нужна настройка 301 редиректа, иначе вы также задублируете весь сайт.

Отметим, что переадресацию желательно было настраивать и до 2018 года, когда директива host еще учитывалась, поскольку редирект передает вес страниц, и Google никогда не «понимал» host.
Можно ли поставить редиректы, но не переезжать
Такое тоже возможно. Главное, чтобы все редиректы вели на основное зеркало. Если раньше для распознавания Яндекс изучал директиву host, то теперь поисковик определяет главный домен самостоятельно.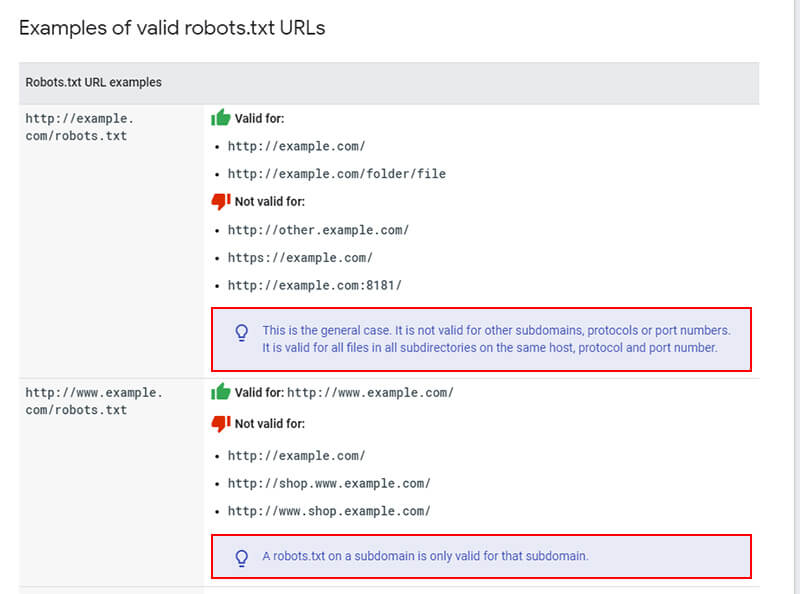
Если вы выполнили настройку редиректа, Яндекс «поймет» факт переезда. Раньше на это указывала директива host и соответствующие настройки в Вебмастере. Теперь достаточно заполнить соответствующие поля в Вебмастере. Даже если вы этого не сделаете — некритично, на возможность переезда это не повлияет. Просто переезд займет больше времени.
Что будет, если не ставить редиректы и никуда не переезжать
Если не провести процедуру переезда правильно, поисковые системы либо сочтут новый сайт дублем (либо имеющим много внутренних дублирующихся страниц), либо решат, что вы просто создали несколько одинаковых сайтов. И то и другое может повлечь негативные последствия, вплоть до наложения санкций.
Позиция «я что-то такое сделал (например переехал на https), но не выяснил, как посмотрят на это Яндекс и Google» — губительна для ранжирования нового или обновленного ресурса в рейтинге поисковых систем. Переезд должен быть обоснован, продуман, выполнен технически грамотно.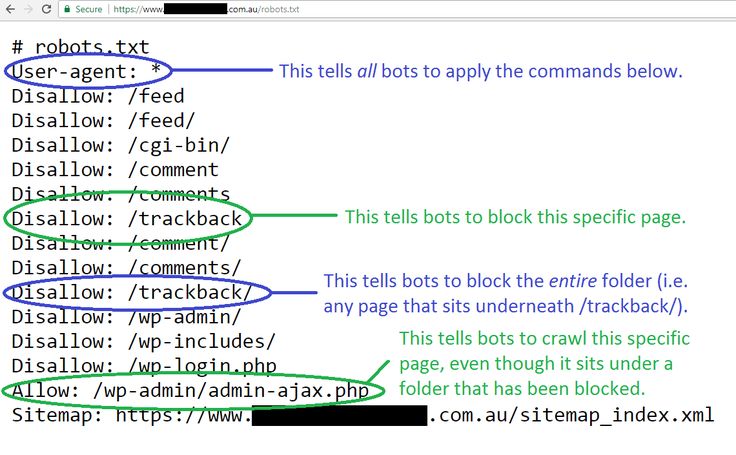 Так было и когда работала директива host, и после того, как ее упразднили, с той лишь разницей, что до 2018 года старый сайт мог оставаться в выдаче, а в директиве host мог быть прописан новый. При этом трафик в любом случае приносил только один ресурс.
Так было и когда работала директива host, и после того, как ее упразднили, с той лишь разницей, что до 2018 года старый сайт мог оставаться в выдаче, а в директиве host мог быть прописан новый. При этом трафик в любом случае приносил только один ресурс.
Если поисковик не обращает внимания на редиректы
Обычно такая ситуация возникает, когда редиректы установили с ошибками, поэтому в первую очередь проверьте корректность выполнения настроек. Остальные действия будут такими же, как и в случае со стандартным переездом или сменой протокола.
Редиректы на мобильных версиях
Директива host не требовала настройки отдельных редиректов для мобильных версий, хотя иногда поисковых роботов перенаправляли на основное зеркало. Сейчас ситуация практически не изменилась. Роботы без проблем могут исследовать любую версию сайта.
Заключение
Директиву host теперь можно смело удалять из robots.txt, ведь Яндекс тоже стал ее игнорировать. В принципе, если ее оставить, она никак не повлияет на SEO, так как стала бесполезным атрибутом. Подобные изменения Яндекс проводит для того, чтобы повысить скорость индексации и сделать процессы переезда на новый домен и смены протокола более удобными и быстрыми.
Подобные изменения Яндекс проводит для того, чтобы повысить скорость индексации и сделать процессы переезда на новый домен и смены протокола более удобными и быстрыми.
Файл robots.txt: полное руководство | CRYSTAL
Оглавление
- Зачем нужен этот файл?
- Тонкости
- Требования к robots.txt
- Как создать?
- Автогенерация
- Как проверить?
- Основные директивы
- Sitemap
- User-agent
- Disallow и Allow
- Clean-param
- Crawl-delay
- Host
- Рекомендации
- Вывод
Сеть набита информацией. Каждый в ней ищет что-то свое. Разработчиков волнует, насколько качественно проделана их работа. Пользователи хотят решить бытовые проблемы. А поисковые машины наблюдают и за первыми, и за вторыми. И тоже копят информацию.
Как они это делают? По сети ползают пауки. Они заглядывают всюду. Цель паука — проникнуть как можно дальше и понять как можно больше.
Информация от пауков, по-другому роботов, важна для поисковых систем. Она помимо прочего влияет и на ранжирование ресурсов в выдаче.
Движения пауков случайны. Это вызывает проблемы, так как они могут залезть туда, куда не следует.
Файл robots.txt прекратит лишние поползновения. Настройте его сразу. Тогда в индекс ваш сайт попадёт быстро, а сервер будет работать без перегруза.
При запуске сайта с нуля нужно сделать массу вещей. Но отладка этого инструмента сэкономит вам в будущем силы и время.
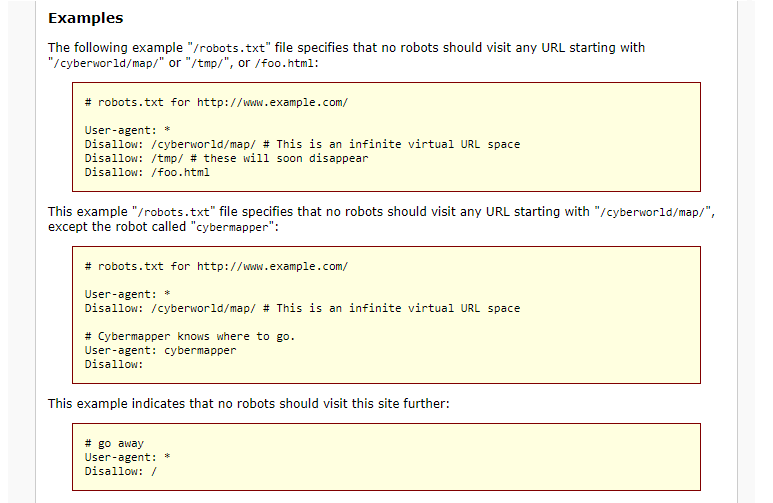
Зачем нужен этот файл?
Показать роботу, что нельзя, а что можно сканировать. Именно сканировать. Не про индексацию речь. Это разные понятия.
Файл запрещает переход робота на страницу. Но это не единственная дверь, туда ведущая. Есть и другие. Внутренние и внешние ссылки, например.
Исключить страницу из поиска этот файл может, но не всегда. Зато он не заменим, когда нужно снизить нагрузку на сервер или перераспределить ресурс роботов.
Закрывайте от сканирования:
- Административные папки
- Системные файлы сервера
- Динамические параметры адресов (не для Google)
- Медиафайлы, которые вы не хотите видеть в поиске
Не стоит заносить в файл:
- Работающие страницы сайта
- Скрипты со структурой и правилами оформления страниц (Java scripts и прочее)
- Медиафайлы, которые должны быть в выдаче
Вы можете командовать тем, какие пауки и что именно могут делать. А так же, с какой периодичностью обращаются к сайту.
Тонкости
Для Google это просто рекомендация. Логика использования — чем больше ограничений для пауков на сайте, тем меньше его загруженность.
Можно скрыть медиафайлы — чтобы в поиске не показывались картинки с вашего сайта или видео. Для этого пропишите запрет регулярными выражениями в файле.
Если нужно спрятать так, чтобы гарантированно не вылезло в поиске, действуйте иначе (мета-тег robots noindex или установка пароля).
С Яндексом ситуация другая. Он разрешает бороться с дублями с помощью файла. Просто запрещать сканирование или использовать Clean-param для меток.
По умолчанию пауки смотрят всё. Часть из них может даже игнорировать указания.
Требования к robots.txt
- Важны правильное название файла и формат. Нельзя добавлять лишние символы, менять регистр.
- Он должен лежать в корневом каталоге и только на главном зеркале. Для других субдоменов, портов и протоколов его указания не будут работать.
- Никакого русского языка в адресах внутри файла. Преобразуйте их через Punycode в допустимые — каноничные символы ASCII. Кодировка — UTF-8.
- Файл должен выдавать код доступа 200. Иначе всё равно, что его нет: сканируется всё.
Как создать?
- Напишите простой текстовый документ с директивами вручную и сохраните как . txt. В тексте не должно быть никаких служебных пометок или знаков разметки, расставленных офисными программами.
- Проверьте, что документ составлен корректно.
- Загрузите в корневой каталог.
- Убедитесь, что он доступен по ссылке: <ваш домен>/robots.txt
 txt. В тексте не должно быть никаких служебных пометок или знаков разметки, расставленных офисными программами.
txt. В тексте не должно быть никаких служебных пометок или знаков разметки, расставленных офисными программами.Автогенерация
Системы Управления Содержимым могут стать альтернативой ручному методу. Они предлагают выбрать параметры на странице с графическим интерфейсом, потом сами преобразуют их в директивы кода файла.
Есть специализированные программы. Делают они практически то же самое. Пример — PR-CY. Скопируйте получившийся текст или скачайте файл. Далее следуйте пунктам 2-4 из инструкции выше.
Как проверить?
В кабинетах Вебмастеров укажите адрес файла. После этого можно использовать их инструменты анализа.
Вебмастер Google:
- Выделит ошибки синтаксиса и логики.
- Проведёт симуляцию. Для этого выберете страницу и паука (из числа принадлежащих Google) и посмотрите, открыт ли доступ.
- Не сможет проверить субдомены и протоколы кроме тех, по которым расположен файл.
- Даст вам править текст в редакторе, но полученный результат надо будет скопировать в файл вручную.

Яндексовский проверяет только синтаксис и логику. Выведет список директив, на которые отреагирует его бот. Тут же можно задать адреса для проверки.
Этот инструмент чуть проще по функционалу, но для его использования не обязательна авторизация.
Альтернативой вебмастерам будут программы для проверки кода файла или краулеры для симуляции поведения роботов. Их легко найти в поиске.
Структура robots.txt
Директивы пишутся с новой строки. Вид такой: <directive>: <parameter>. Между группами логически связанных команд оставляют пустые строки.
Регистр не важен для <directive>, но важен для <parameter>.
В плохо организованном файле легко запутаться. Можно комментировать код — пользуйтесь этой возможностью. Всё после “#” прочтут только люди. Но помните, что файл общедоступен — любой может его открыть, зная адрес корневого каталога.
Можно комментировать код — пользуйтесь этой возможностью. Всё после “#” прочтут только люди. Но помните, что файл общедоступен — любой может его открыть, зная адрес корневого каталога.
Не допускайте противоречий. Исполнена будет команда с более длинным <parameter>.
Пробелы игнорируются роботом. Но они удобны человеку, читающему файл. Вы его не один раз и навсегда делаете. Могут потребоваться правки и не факт, что их будете делать именно вы. Пишите понятно.
Основные директивы
Директив, допускаемых файлом, не так много. Мы обсудим каждую отдельно ниже. Пока поговорим про параметр.
Параметры включают в себя указание адресов, без доменного имени (исключением будет только Sitemap).
<directive>: /pagename
По умолчанию, в конце адреса параметра может быть добавлено сколько угодно символов. На <directive>: /jewellery будет отзываться и your-address.com/jewellery и your-address. com/jewellery3f47 .
com/jewellery3f47 .
<parameter> задают регулярными выражениями. Есть два специальных символа для этого.
Знак “$” — указывает на конец адреса. На <directive>: /accessory$ будет отзываться только your-address.com/accessory .
Знак “ * ” — заменяет сколько угодно символов. На конце его ставить бессмысленно, но можно упомянуть в середине или в начале адреса параметра. <directive>: *pdf — относится ко всем адресам с _pdf_ в любом месте адреса. Обратите внимание, что для вызова именно файлов формата .pdf лучше написать так: <directive>: *.pdf$
Sitemap
Директива отличается от последующих: она не привязана к группе и исполнителю, требует указания полного адреса.
Цель — показать, где лежит карта сайта. Этот документ не дает паукам потеряться и подсказывает, куда ещё можно заглянуть.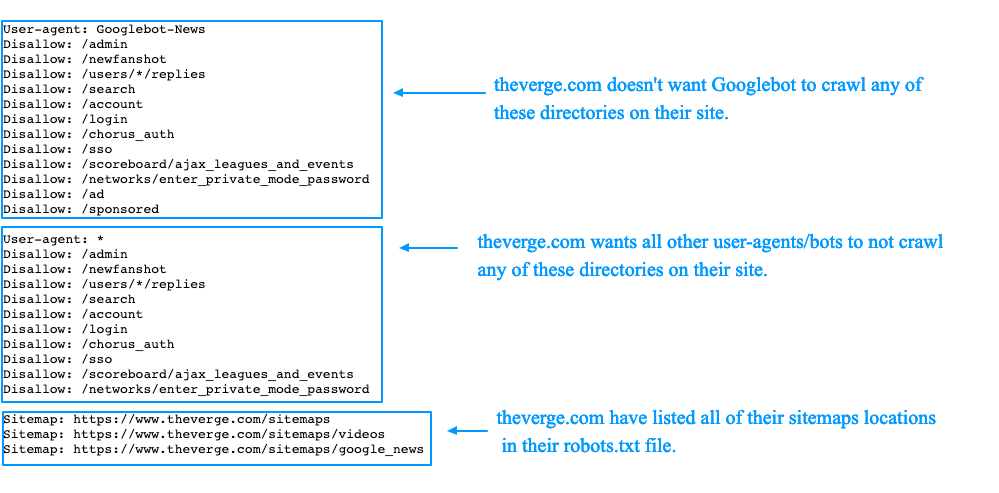
Sitemap: your-address.com/some/mysitemap.xml
Если вы ещё не создали карту, сделайте это. Не забудьте проверить, что файл с ней лежит на том же домене, что и robots.txt. Иначе, обратиться к карте паук не сможет.
User-agent
Есть в начале всех групп команд. Показывает — кто исполнитель. Прежде чем прибегать к ней, проанализируйте списки пауков целевых поисковиков. Выберите значимые.
Ею можно:
- Скомандовать любым готовым слушать: <parameter> = “ * ”
- Дать общее указание (через “ * ” ) и кому-нибудь — другое.
- Указать несколько исполнителей.
Для наглядности:
User-agent: *
<directive 1>: /mailboxUser-agent: SEbot1
User-agent: SEbot2
<directive 2>: /system-files
<directive 3>: /useless-mail
Все, кроме SEbot1 и SEbot2 выполняют предписание 1, SEbot1 и SEbot2 делают 2 и 3.
То есть, если мы специфицируем хоть один параметр для бота, то “для всех” на него больше не распространяется.
Disallow и Allow
Управляют перемещениями пауков. Они закрывают и открывают двери. Так можно контролировать сканирование. Ниже показано, как они применяются.
User-agent: * # Кто готов слушаться:
Disallow: / # Вход закрыт полностью
Allow: /fireworks/*png$ # Смотреть можно только картинки из папки “фейерверки”.User-agent: SEbot1 # Отдельно для SEbot1:
Disallow: /fireworks # Сначала сказали, что можно всё кроме “фейерверков”.
Allow: /fireworks # Теперь можно и “фейерверки” тоже.
Если параметры одинаково длинные, но приказ Allow сильнее.
Без инструкций роботы сканируют всё. Поэтому группа Яндекса в примере бессмысленна: противоречивая команда приводит к тому, что ограничений для этой ПС нет. Логичнее было бы прописать Disallow: без параметра.
Логичнее было бы прописать Disallow: без параметра.
Clean-param
Работает с метками в адресах. Они добавляются после “?” к URL и нужны для отслеживания отдельных посетителей, задания страниц каталога и тп. Эти метки — источник дублей на сайте.
Директива их скрывает и перенаправляет вес на страницу без метки. Такой способ сокрытия зеркал признаёт только Яндекс.
Метка добавляется после адреса и “?”. Состоит из “pattern1=value1&pattern1= value2…” — паттернов и их значений. Пропишите название паттерна (или нескольких). Опционально добавьте регулярное выражение для URL, по которому нужно искать.
Clean-param: pattern1&pattern2&..&patternN /directory #длина строки не больше 500 знаков.
Если вы прописываете отдельную группу для Яндекса, добавьте эту директиву туда.
Crawl-delay
Когда пауки ползают по страницам, они нагружают сервер.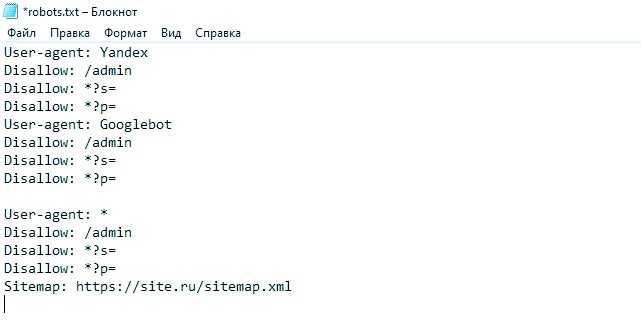 Заставить их заходить пореже может эта директива. Сайт будет работать быстрее.
Заставить их заходить пореже может эта директива. Сайт будет работать быстрее.
Неприменимо для Яндекс и Google. Они имеют встроенные инструменты для такого, а указания в файле игнорируют. Остальные поисковики правила соблюдают.
Crawl-delay: 3 #Между двумя актами сканирования мы задаем задержку 3 секунды.
Не тормозите пауков слишком сильно — это повредит вам в первую очередь. Очень долго придётся ждать индексации. Прикиньте краулинговый бюджет и объем работы, прежде чем выбирать время задержки.
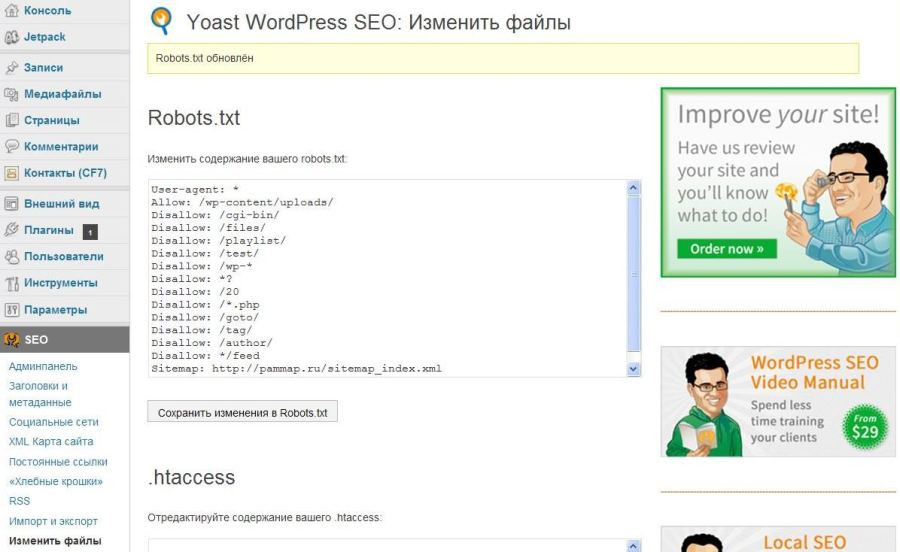
Host
Устарела. Больше не принимается роботами. Прописывать её нет необходимости.
Когда-то директива указывала на каноническое зеркало сайта и использовалась для борьбы с дублями. Сейчас лучше делать перенаправления.
Рекомендации
Пауки реагируют не на все команды. Google работает с запретом/разрешением сканирования, картой сайта и указанием исполнителя. Яндекс обрабатывает помимо их еще и запрет на индексирование меток.
Сначала дайте предписание “по умолчанию” для всех роботов.
Потом пропишите группы для каждого отдельно интересующего вас. Пауки имеют иерархию. Это упростит обращение к ним.
Большинство роботов Google отзываются на “googlebot”. Но если работающий с картинками Googlebot-Image получит отдельные предписания, то общие для своего семейства он будет игнорировать.
Не упоминайте одного и того же исполнителя в двух разных группах. Соберите вместе все директивы одному исполнителю. Это уменьшит объем файла, поможет избежать противоречивых директив.
Вывод
Сделайте короткими и простым файл robots.txt. Избавьтесь от лишних бессмысленных команд, они могут нарушить выполнение всех остальных. Проверяйте: свой код, предпочтения пауков, изменения в метриках.
Хотите сделать сайт для своего проекта?
Обратитесь к намseo — Могу ли я использовать директиву «Хост» в robots.
 txt?
txt?спросил
Изменено 1 год, 4 месяца назад
Просмотрено 9к раз
В поисках конкретной информации по robots.txt я наткнулся на справочную страницу Яндекса ‡ по этой теме. Это предполагает, что я мог бы использовать Директива хоста , сообщающая поисковым роботам мой предпочтительный зеркальный домен:
User-Agent: * Запретить: /директор/ Хост: www.example.com
Также в статье Википедии говорится, что Google тоже понимает директиву Host , но информации было немного (т.е. никакой).
На robotstxt.org я ничего не нашел по адресу Host (или Crawl-delay , как указано в Википедии).
- Рекомендуется ли вообще использовать директиву
Host? - Есть ли в Google какие-либо ресурсы по этому
robots.? - Как совместимость с другими поисковыми роботами?

‡ По крайней мере, с начала 2021 года связанная запись больше не касается рассматриваемой директивы.
- SEO
- robots.txt
3
Оригинальная спецификация robots.txt гласит:
Нераспознанные заголовки игнорируются.
Они называют это «заголовки», но этот термин нигде не определен. Но, как упоминается в разделе о формате и в том же абзаце, что и User-agent и Disallow , кажется безопасным предположить, что «заголовки» означают «имена полей».
Так что да, вы можете использовать Хост или любое другое имя поля .
- Парсеры robots.txt, которые поддерживают такие поля, ну и поддерживают.
- Парсеры robots.txt, которые не поддерживают такие поля, должны игнорировать их.
Но имейте в виду: поскольку они не указаны в проекте robots.txt, вы не можете быть уверены, что разные парсеры одинаково поддерживают это поле. Поэтому вам придется вручную проверять каждый поддерживающий парсер.
2
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Можно ли использовать домены в robots.
 txt?
txt?У нас есть сервер разработки по адресу dev.example.com, который индексируется Google. Мы используем AWS Lightsail для полного дублирования сервера разработки в нашу производственную среду — один и тот же файл robots.txt используется как на dev.example.com, так и на example.com.
В документации Google robots.txt явно не указано, можно ли определять корневые домены. Могу ли я внедрить специфичные для домена правила в файл robots.txt? Например, допустимо ли это:
Агент пользователя: * Запретить: https://dev.example.com/ Пользовательский агент: * Разрешить: https://example.com/ Карта сайта: https://example.com/sitemap.xml
Чтобы добавить, это можно решить с помощью механизма перезаписи .htaccess — мой вопрос конкретно о robots.txt.
- robots.txt
Нет, в robots.txt указать домен нельзя. Запретить: https://dev.example.com/ недействителен. На странице 6 стандарта исключения robots.txt говорится, что строка запрета должна содержать «путь», а не полный URL-адрес, включая домен.
Каждое имя хоста (домен или поддомен) имеет свой собственный файл robots.txt . Таким образом, чтобы Googlebot не сканировал http://dev.example.com/ , вам нужно будет обслуживать https://dev.example.com/robots.txt с содержимым:
User-agent: * Запретить: /
В то же время вам нужно будет обслуживать файл, отличный от http://example.com/ , возможно, с содержимым:
User-agent: * Запретить: Карта сайта: https://example.com/sitemap.xml
Если одна и та же кодовая база используется как на ваших серверах разработки, так и на рабочих серверах, вам потребуется обусловить содержание файла robots.txt в зависимости от того, работает он в рабочей среде или нет.
В качестве альтернативы вы можете разрешить роботу Googlebot сканировать и то, и другое, но включать тегов на каждую страницу, которые указывают на URL-адрес страницы на действующем сайте.