
Яндекс отменил директиву host в файле robots.txt
Главная » Статьи о SEO » Яндекс отменил директиву host в файле robots.txt
Просмотры: 1647
Публикация: 02 Июля 2018
Редакция: 30 Августа 2022
Прочтение ~ 5 мин.
Сложность: Продвинутый
- Какая команда появилась после директивы host
- Как проходит смена протокола или переезд на другой домен
- Можно ли переехать без настройки редиректа 301
- Можно ли поставить редиректы, но не переезжать
- Что будет, если не ставить редиректы и никуда не переезжать
- Если поисковик не обращает внимания на редиректы
- Редиректы на мобильных версиях
В файле robots. txt содержится информация о сайте для поисковых роботов. Раньше Яндекс требовал размещения в этом файле директивы host, которая указывала на главное зеркало сайта. В 2018 году от нее решили отказаться полностью, чтобы вебмастерам было легче работать. В Google эта директива не учитывалась никогда. Чтобы изменить протокол на безопасный или переехать на другой домен, теперь используют более простой способ.
txt содержится информация о сайте для поисковых роботов. Раньше Яндекс требовал размещения в этом файле директивы host, которая указывала на главное зеркало сайта. В 2018 году от нее решили отказаться полностью, чтобы вебмастерам было легче работать. В Google эта директива не учитывалась никогда. Чтобы изменить протокол на безопасный или переехать на другой домен, теперь используют более простой способ.
Какая команда появилась после директивы host
Раньше длительность переезда сайта на новый домен в Яндексе доходила до месяца, так как связь главного и второстепенного зеркал оказывала большое влияние на позиции в выдаче. Сейчас переезд проходит всего за несколько дней, что благоприятно сказывается на продвижении. Такое стало возможным благодаря редиректу 301, который заменил директиву хост. Теперь алгоритм смены протокола и домена ничем не отличается. Google изначально работал по такому принципу.
Для продолжения работы в обязательном порядке настраивают 301 редирект (переадресацию), директива host при переезде значение утратила полностью. Нововведения помогли ускорить и облегчить процесс перехода. Однако при переезде на новый домен или смене протокола нередко возникают непредвиденные ситуации, индивидуальные для каждого случая, поэтому алгоритм действий может отличаться. Иногда процесс затягивается, но в большинстве случаев переехать удается гораздо быстрее, чем раньше.
Нововведения помогли ускорить и облегчить процесс перехода. Однако при переезде на новый домен или смене протокола нередко возникают непредвиденные ситуации, индивидуальные для каждого случая, поэтому алгоритм действий может отличаться. Иногда процесс затягивается, но в большинстве случаев переехать удается гораздо быстрее, чем раньше.
Как проходит смена протокола или переезд на другой домен
Чтобы сменить протокол на безопасный или переехать на другой домен, убедитесь в том, что права собственности на обе версии сайта подтверждены. Затем выполните несколько простых действий:
- настройте редирект 301;
- перейдите в панель Вебмастера;
- в разделе «Переезд сайта» пропишите адрес зеркала — выберите в чек-боксе «добавить https» или «добавить www», если это необходимо.
Сразу проверять корректность переиндексации ресурса не стоит, так как для обновления требуется несколько дней. Зато команду host можно удалять, ведь она стала бесполезной как для Гугла, так и для Яндекса.
Можно ли переехать без настройки редиректа 301
Переезд без настройки 301 редиректа возможен, однако это сопряжено с рядом проблем:
- Например, вы переезжаете с домена на домен, и у вас нет технической возможности настроить 301 редирект. В этом случае старый домен должен быть удален или скрыт от индексации. Если оставить старый домен после переезда, индексация нового будет невероятно долгой — займет даже не недели, а месяцы. Когда она будет завершена, есть вероятность, что оба домена будут признаны аффилиатами в Яндексе и приняты за дубли в Google.
То есть, после того, как сайт переедет с домена на домен, индексироваться поисковиками должен только один — новый. Также учитывайте, что без настройки 301 редиректа произойдет неизбежная и длительная просадка трафика. Гарантия, что трафик вернется к уровню старого домена, когда работала директива host, отсутствует.
- Если вы меняете протокол http на https, но не настраиваете 301 редирект, хорошего результата ждать не стоит. Да, в панели вебмастера вы укажете Яндексу, какое зеркало — главное. Однако в индексе появятся дубли каждой страницы — одновременно на двух протоколах, и поисковые роботы сочтут их разными. Таким образом, вы задублируете весь сайт.
Настоятельно рекомендуем настраивать редиректы с http на https, все современные CMS без проблем позволяют это сделать. - Переезд на новое зеркало с www или без www в этом смысле схож со сменой протокола на https. Нужна настройка 301 редиректа, иначе вы также задублируете весь сайт.

Отметим, что переадресацию желательно было настраивать и до 2018 года, когда директива host еще учитывалась, поскольку редирект передает вес страниц, и Google никогда не «понимал» host.
Можно ли поставить редиректы, но не переезжать
Такое тоже возможно. Главное, чтобы все редиректы вели на основное зеркало. Если раньше для распознавания Яндекс изучал директиву host, то теперь поисковик определяет главный домен самостоятельно.
Если вы выполнили настройку редиректа, Яндекс «поймет» факт переезда. Раньше на это указывала директива host и соответствующие настройки в Вебмастере. Теперь достаточно заполнить соответствующие поля в Вебмастере. Даже если вы этого не сделаете — некритично, на возможность переезда это не повлияет. Просто переезд займет больше времени.
Что будет, если не ставить редиректы и никуда не переезжать
Если не провести процедуру переезда правильно, поисковые системы либо сочтут новый сайт дублем (либо имеющим много внутренних дублирующихся страниц), либо решат, что вы просто создали несколько одинаковых сайтов. И то и другое может повлечь негативные последствия, вплоть до наложения санкций.
Позиция «я что-то такое сделал (например переехал на https), но не выяснил, как посмотрят на это Яндекс и Google» — губительна для ранжирования нового или обновленного ресурса в рейтинге поисковых систем. Переезд должен быть обоснован, продуман, выполнен технически грамотно. Так было и когда работала директива host, и после того, как ее упразднили, с той лишь разницей, что до 2018 года старый сайт мог оставаться в выдаче, а в директиве host мог быть прописан новый. При этом трафик в любом случае приносил только один ресурс.
Так было и когда работала директива host, и после того, как ее упразднили, с той лишь разницей, что до 2018 года старый сайт мог оставаться в выдаче, а в директиве host мог быть прописан новый. При этом трафик в любом случае приносил только один ресурс.
Если поисковик не обращает внимания на редиректы
Обычно такая ситуация возникает, когда редиректы установили с ошибками, поэтому в первую очередь проверьте корректность выполнения настроек. Остальные действия будут такими же, как и в случае со стандартным переездом или сменой протокола.
Редиректы на мобильных версиях
Директива host не требовала настройки отдельных редиректов для мобильных версий, хотя иногда поисковых роботов перенаправляли на основное зеркало. Сейчас ситуация практически не изменилась. Роботы без проблем могут исследовать любую версию сайта.
Заключение
Директиву host теперь можно смело удалять из robots.txt, ведь Яндекс тоже стал ее игнорировать. В принципе, если ее оставить, она никак не повлияет на SEO, так как стала бесполезным атрибутом. Подобные изменения Яндекс проводит для того, чтобы повысить скорость индексации и сделать процессы переезда на новый домен и смены протокола более удобными и быстрыми.
Подобные изменения Яндекс проводит для того, чтобы повысить скорость индексации и сделать процессы переезда на новый домен и смены протокола более удобными и быстрыми.
#seo
https://blog.aventon.ru/otmena-direktivy-host
ВАМ ТАКЖЕ МОЖЕТ БЫТЬ ИНТЕРЕСНО
Использование файла robots.txt — Вебмастер. Справка
Robots.txt — это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol) с расширенными возможностями.
При очередном обходе сайта робот Яндекса загружает файл robots.txt. Если при последнем обращении к файлу, страница или раздел сайта запрещены, робот не проиндексирует их.
- Требования к файлу robots.txt
- Рекомендации по наполнению файла
- Использование кириллицы
- Как создать robots.txt
- Вопросы и ответы
Роботы Яндекса корректно обрабатывают robots. txt, если:
txt, если:
Размер файла не превышает 500 КБ.
Это TXT-файл с названием robots — robots.txt.
Файл размещен в корневом каталоге сайта.
Файл доступен для роботов — сервер, на котором размещен сайт, отвечает HTTP-кодом со статусом 200 OK. Проверьте ответ сервера
Если файл не соответствует требованиям, сайт считается открытым для индексирования.
Яндекс поддерживает редирект с файла robots.txt, расположенного на одном сайте, на файл, который расположен на другом сайте. В этом случае учитываются директивы в файле, на который происходит перенаправление. Такой редирект может быть удобен при переезде сайта.
Яндекс поддерживает следующие директивы:
| Директива | Что делает |
|---|---|
| User-agent * | Указывает на робота, для которого действуют перечисленные в robots. txt правила. txt правила. |
| Disallow | Запрещает индексирование разделов или отдельных страниц сайта. |
| Sitemap | Указывает путь к файлу Sitemap, который размещен на сайте. |
| Clean-param | Указывает роботу, что URL страницы содержит параметры (например, UTM-метки), которые не нужно учитывать при индексировании. |
| Allow | Разрешает индексирование разделов или отдельных страниц сайта. |
| Crawl-delay | Задает роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей. Рекомендуем вместо директивы использовать настройку скорости обхода в Яндекс Вебмастере. |

* Обязательная директива.
Наиболее часто вам могут понадобиться директивы Disallow, Sitemap и Clean-param. Например:
User-agent: * #указывает, для каких роботов установлены директивы Disallow: /bin/ # запрещает ссылки из "Корзины с товарами". Disallow: /search/ # запрещает ссылки страниц встроенного на сайте поиска Disallow: /admin/ # запрещает ссылки из панели администратора Sitemap: http://example.com/sitemap # указывает роботу на файл Sitemap для сайта Clean-param: ref /some_dir/get_book.pl
Роботы других поисковых систем и сервисов могут иначе интерпретировать директивы.
Примечание. Робот учитывает регистр в написании подстрок (имя или путь до файла, имя робота) и не учитывает регистр в названиях директив.
Использование кириллицы запрещено в файле robots.txt и HTTP-заголовках сервера.
Для указания имен доменов используйте Punycode. Адреса страниц указывайте в кодировке, соответствующей кодировке текущей структуры сайта.
Пример файла robots.txt:
#Неверно: User-agent: Yandex Disallow: /корзина Sitemap: сайт.рф/sitemap.xml #Верно: User-agent: Yandex Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0 Sitemap: http://xn--80aswg.xn--p1ai/sitemap.xml
В текстовом редакторе создайте файл с именем robots.txt и укажите в нем нужные вам директивы.
Проверьте файл в Вебмастере.
Положите файл в корневую директорию вашего сайта.
Пример файла. Данный файл разрешает индексирование всего сайта для всех поисковых систем.
Сайт или отдельные страницы запрещены в файле robots.txt, но продолжают отображаться в поиске
Как правило, после установки запрета на индексирование каким-либо способом исключение страниц из поиска происходит в течение двух недель. Вы можете ускорить этот процесс.
В Вебмастере на странице «Диагностика сайта» возникает ошибка «Сервер отвечает редиректом на запрос /robots. txt»
txt»
Чтобы файл robots.txt учитывался роботом, он должен находиться в корневом каталоге сайта и отвечать кодом HTTP 200. Индексирующий робот не поддерживает использование файлов, расположенных на других сайтах.
Чтобы проверить доступность файла robots.txt для робота, проверьте ответ сервера.
Если ваш robots.txt выполняет перенаправление на другой файл robots.txt (например, при переезде сайта), Яндекс учитывает robots.txt, на который происходит перенаправление. Убедитесь, что в этом файле указаны верные директивы. Чтобы проверить файл, добавьте сайт, который является целью перенаправления, в Вебмастер и подтвердите права на управление сайтом.
что это такое, что будет, если она отсутствует
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем
Заказывайте честное и прозрачное продвижение
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Директива Host – это команда или правило, сообщающее поисковой машине о том, какое зеркало веб-ресурса (с www или без) считать основным. Находится директива Host в файле Robots.txt и предназначена исключительно для Яндекса.
Часто возникает необходимость, чтобы поисковая система не индексировала некоторые страницы сайта или его зеркала. Например, ресурс находится на одном сервере, однако в интернете есть идентичное доменное имя, по которому осуществляется индексация и отображение в результатах поисковой выдачи.
Поисковые роботы Яндекса обходят страницы сайтов и добавляют собранную информацию в базу данных по собственному графику. В процессе индексации они самостоятельно решают, какую страницу необходимо обработать. К примеру, роботы обходят стороной различные форумы, доски объявлений, каталоги и прочие ресурсы, где индексация бессмысленна. Также они могут определять главный сайт и зеркала. Первые подлежат индексации, вторые – нет. В процессе часто возникают ошибки. Повлиять на это можно посредством использования директивы Host в файл Robots.txt.
Первые подлежат индексации, вторые – нет. В процессе часто возникают ошибки. Повлиять на это можно посредством использования директивы Host в файл Robots.txt.
Зачем нужен файл Robots.txt
Robots – это обычный текстовый файл. Его можно создать через блокнот, однако работать с ним (открывать и редактировать информацию) рекомендуется в текстовом редакторе Notepad++. Необходимость данного файла при оптимизации веб-ресурсов обуславливается несколькими факторами:
- Если файл Robots.txt отсутствует, сайт будет постоянно перегружен из-за работы поисковых машин.
- Существует риск, что индексироваться будут лишние страницы или сайты зеркала.
Индексация будет проходить гораздо медленнее, а при неправильно установленных настройках он вовсе может исчезнуть из результатов поисковой выдачи Google и Яндекс.
Как оформить директиву Host в файле Robots.txt
Файл Robots включает в себя директиву Host – инструкцию для поисковой машины о том, где главный сайт, а где его зеркала.
Директива имеет следующую форму написания: Host: [необязательный пробел] [значение] [необязательный пробел]. Правила написания директивы требуют соблюдения следующих пунктов:
- Наличие в директиве Host протокола HTTPS для поддержки шифрования. Его необходимо использовать, если доступ к зеркалу осуществляется только по защищенному каналу.
- Доменное имя, не являющееся IP-адресом, а также номер порта веб-ресурса.
Корректно составленная директива позволит веб-мастеру обозначить для поисковых машин, где главное зеркало. Остальные будут считаться второстепенными и, следовательно, индексироваться не будут. Как правило, зеркала можно отличить по наличию или отсутствию аббревиатуры www. Если пользователь не укажет главное зеркало веб-ресурса посредством Host, поисковая система Яндекс пришлет соответствующее уведомление в Вебмастер. Также уведомление будет выслано, если в файле Роботс задана противоречивая директива Host.
Определить, где главное зеркало сайта можно через поисковик. Необходимо вбить в поисковую строку адрес ресурса и посмотреть на результаты выдачи: сайт, где перед доменом в адресной строке стоит www, является главным доменом.
Необходимо вбить в поисковую строку адрес ресурса и посмотреть на результаты выдачи: сайт, где перед доменом в адресной строке стоит www, является главным доменом.
В случае, если ресурс не отображается на странице выдачи, пользователь может самостоятельно назначить его главным зеркалом, перейдя в соответствующий раздел в Яндекс.Вебмастере. Если веб-мастеру необходимо, чтобы доменное имя сайта не содержало www, следует не указывать его в Хосте.
Многие веб-мастера используют кириллические домены в качестве дополнительных зеркал для своих сайтов. Однако в директиве Host кириллица не поддерживается. Для этого необходимо дублировать слова на латинице, с условием, что их можно будет легко узнать, скопировав адрес сайта из адресной строки.
Хост в файле Роботс
Главное предназначение данной директивы состоит в решении проблем с дублирующими страницами. Использовать Host необходимо в случае, если работа веб-ресурса ориентирована на русскоязычную аудиторию и, соответственно, сортировка сайта должна проходить в системе Яндекса.
Не все поисковики поддерживают работу директивы Хост. Функция доступна только в Яндексе. При этом даже здесь нет гарантий, что домен будет назначен в качестве главного зеркала, но по заверениям самого Яндекса, приоритет всегда остается за именем, которое указано в хосте.
Чтобы поисковые машины правильно считывали информацию при обработке файла robots.txt, необходимо прописывать директиву Host в соответствующую группу, начинающуюся после слов User-Agent. Однако, роботы смогут использовать Host независимо от того, будет директива прописана по правилам или нет, поскольку она является межсекционной.
что это такое и для чего нужен этот файл на сайте
Robots.txt – это файл с набором инструкций для поисковых роботов, его задача – регулирование процесса индексации сайта. По своей сути это обычный файл в формате txt, который размещается в корневом каталоге. В его разделах могут быть директивы, открывающие или закрывающие доступ к разделам и страницам сайта. Но важно учитывать, что роботы разных поисковых систем используют свои алгоритмы обработки этого файла, зачастую они отличаются. В корневой каталог сайта файл robots.txt закачивается с использованием любого FTP-клиента. После его размещения необходимо проверить доступность файла по адресу site.com/robots.txt.
В корневой каталог сайта файл robots.txt закачивается с использованием любого FTP-клиента. После его размещения необходимо проверить доступность файла по адресу site.com/robots.txt.
Требования к файлу robots.txt
Если файла robots.txt нет в корневом каталоге сайта или он настроен неправильно, это создает угрозу. Сайт может быть недоступен в поиске, а значит, и его посещаемость будет крайне низкой. Все директивы в файле прописываются на латинице, использование символов кириллицы запрещено. Чтобы работать с кириллическими доменами, необходимо применять Punycode. Но важно помнить, что кодировка адресов страниц и кодировка применяемой структуры сайта должны соответствовать друг другу.
Какие функции выполняет robots.txt
Основное назначение файла – размещение указаний для поисковых роботов. Функции зависят от директив. Главные среди них – Allow и Disallow. Первая разрешает индексацию конкретной страницы или раздела. Disallow, наоборот, запрещает индексацию. Еще одна важная директива – User-agent. Она указывает на определенных роботов, к которым относятся разрешительные и запрещающие действия. У инструкций robots.txt рекомендательный характер. Это значит, что в некоторых случаях роботы могут игнорировать их.
Она указывает на определенных роботов, к которым относятся разрешительные и запрещающие действия. У инструкций robots.txt рекомендательный характер. Это значит, что в некоторых случаях роботы могут игнорировать их.
Примеры:
| User-agent: * |
| Disallow: / |
Такая запись запрещает всем роботам проводить индексацию сайта.
| User-agent: Yandex |
| Disallow: /private/ |
Данная запись применяется для запрета индексации для основного робота поисковой системы Яндекс только директории /private/.
Другие директивы файла
Помимо основных директив Allow, Disallow и User-agent, есть еще ряд других со своими важными функциями.
Host. Позволяет указать зеркало сайта (главное к индексированию) и не допустить появления дублей в выдаче. Данная директива применима для роботов всех поисковых систем.
Пример:
| User-Agent: Yandex |
| Disallow: /blog |
| Disallow: /custom |
Host: https://onesite. com com |
Так выглядит директива Host, если https://onesite.com является главным зеркалом для группы сайтов.
Если файл robots.txt содержит несколько значений директивы Host, поисковый робот обратиться только к первой, остальные он игнорирует.
Sitemap. Чтобы сделать индексацию сайта более быстрой и правильной, рекомендуется использовать файл или группу файлов Sitemap. Эта директива межсекционная, т. е. где бы она ни была расположена в robots.txt, поисковые роботы ее обязательно учтут. Как правило, ее выносят в самый конец файла.
Робот обрабатывает эту директиву, запоминает и перерабатывает данные. Полученная информация будет основой при формировании следующих сессий загрузки страниц сайта.
Пример:
| User-agent: * |
| Allow: /catalog |
| sitemap: https://mysite.com/my_sitemaps0.xml |
| sitemap: https://mysite.com/my_sitemaps1.xml |
Clean-param. Дополнительная директива, предназначенная для роботов поисковой системы Яндекс. В настоящее время у многих сайтов сложная структура названий с использованием динамических параметров.
Дополнительная директива, предназначенная для роботов поисковой системы Яндекс. В настоящее время у многих сайтов сложная структура названий с использованием динамических параметров.
Так выглядит описание стандартного синтаксиса этой директивы:
Clean-param: s0[&s1&s2&..&sn] [path]
В первом поле указаны параметры, которые не следует учитывать. Для их разделения используется символ «&». Во втором поле стоит префикс пути страниц, подпадающих под действие этого правила.
Пример:
| User-agent: * |
| Disallow: |
| Clean-param: id /forum.com/index.php |
Пример использования директивы Clean-param для некого форума, где движок сайта генерирует длинные ссылки и присваивает каждому пользователю персональный параметр id. Содержание страниц при этом остается неизменным. Данный файл robots.txt не дает попасть в индекс множеству фактически одинаковых страниц.
Crawl-delay. Эта директива задает минимальное время (в секундах) между концом загрузки страницы и обращением робота к следующей. Crawl-delay используется тогда, когда боты создают слишком высокую нагрузку на сервер сайта. Кстати, роботы поисковой системы Яндекс умеют считывать дробные значения. В Google директива не учитывается.
Эта директива задает минимальное время (в секундах) между концом загрузки страницы и обращением робота к следующей. Crawl-delay используется тогда, когда боты создают слишком высокую нагрузку на сервер сайта. Кстати, роботы поисковой системы Яндекс умеют считывать дробные значения. В Google директива не учитывается.
Пример:
| User-agent: * |
| Disallow: /cgi |
| Crawl-delay: 4.1 # таймаут 4.1 секунды для роботов |
Спецсимволы
Внесение любых директив требует по умолчанию приписывать в конце спецсимвол «*». Таким образом, действие указания будет распространяться на все страницы или разделы сайта, которые начинаются с определенной комбинации символов. Для отмены действия по умолчанию нужно использовать специальный символ «$».
Согласно стандарту использования файла robots.txt, рекомендуется вставлять пустой перевод строки после каждой группы директив User-agent. Специальный символ «#» служит для размещения комментариев в файле. Роботы не учитывают содержание строки, размещенное за символом «#» до знака пустого перевода.
Роботы не учитывают содержание строки, размещенное за символом «#» до знака пустого перевода.
Пример:
| User-agent: Googlebot |
| Disallow: /pictures$ # запрещает ‘/pictures’, # но не запрещает ‘/pictures.html’ |
Как запретить индексацию сайта или его разделов
Зачем прятать информацию от поисковых роботов? Для продвижения в поиске важно показывать только полезную информацию, от публичного просмотра лучше скрыть технические и служебные страницы, дубли, ресурсы в разработке, конфиденциальную информацию. Для этого и используется описанная в начале статьи директива Disallow.
Пример:
| User-agent: * |
| Disallow: / # блокирует доступ ко всему сайту |
| User-agent: Yandex |
| Disallow: / bin # блокирует доступ к страницам, # которые начинаются с ‘/bin’ |
Как проверить файл robots.
 txt
txtЕсли в файл robots.txt были внесены изменения, то его нужно проверить на правильность. Даже небольшая ошибка в размещении символа грозит серьезными проблемами. Для начала стоит проверить robots.txt в инструментах для веб-мастеров Яндекса, затем в Google. Предварительно необходимо авторизоваться в панели веб-мастера, после этого внести в нее данные сайта.
Файл robots.txt — зачем нужен, основные директивы, как выглядит
Многие начинающие вебмастера рано или поздно сталкиваются с понятием роботс. В этом посте я расскажу, что значит robots.txt и для чего он нужен.
Robots.txt — это файл в корневой директории сайта, который ограничивает поисковым роботам индексацию данных на сервере.
Говоря более простым языком, роботс запрещает поисковикам заходить на определенные страницы или разделы вашего сайта, например, доступ в админку сайта или личный кабинет. Обычно закрывают служебные папки или файлы, технические страницы, дубликаты и не уникальные страницы.
Если на вашем сайте отсутствует файл robots.txt или он пустой, то это дает роботам полное право индексировать весь сайт и включать в поиск все страницы, в том числе разный мусор, хлам, который там абсолютно не нужен. Для сайта это может быть чревато плохой индексацией главных продвигаемых страниц, а также наличием дублей, что в итоге скажется на общем рейтинге в глазах поисковых систем.
Еще хочу сказать такую штуку — для google роботс нахер не нужен по сути, он его игнорирует. В индексе все равно появляются страницы, закрытые в роботсе, только у них надпись, что просмотр содержимого недоступен, но сами страницы в индексе. Поэтому, если хотите закрыть от индексации гугла какой-то контент, то пользуйтесь другими способами — meta robots noindex или x-robots tag.
Содержание:
- 1 Как выглядит файл robots txt
- 2 Директивы файла robots.txt
- 2.1 User-agent
- 2.2 Allow и Disallow
- 2.3 Crawl-delay
- 2.4 Clean-param
- 2.5 Host
- 2. 6 Sitemap
- 3 Что закрывать в robots txt
Как выглядит файл robots txt
Вот как должен выглядеть пример файла для CMS WordPress
User-agent: *
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Allow: /wp-content/themes/mytheme/*
Allow: /wp-includes/js/jquery/*
Allow: /wp-content/plugins/*
Allow: /wp-content/uploads/*
Clean-Param: utm_source&utm_medium&utm_campaign
Sitemap: https://mydaoseo.ru/sitemap.xml
Как видим, содержимое robots.txt достаточно обширное. Но не нужно пугаться, все объяснимо и понятно. Давайте разберемся вместе.
Директивы файла robots.txt
Существуют определенные правила для поисковых роботов согласно спецификации W3C от 30 января 1994 года. Но поисковые системы по-разному придерживаются этих директив.
User-agent
Это главная директива, она определяет, для каких роботов прописаны правила.
Например, для всех роботов
User-agent: *
Для Яндекса
User-agent: Yandex
Для Google
User-agent: Googlebot
Allow и Disallow
Если перевести эти слова, то достаточно просто понять, что значат директивы allow и disallow в robots.txt. Allow разрешает роботу сканировать страницы или разделы, а disallow этого не позволяет.
Например, данная команда полностью запрещает весь сайт к индексации.
User-agent: *
Disallow: /
Если нужно закрыть отдельную страницу, то прописываем ее адрес (без домена)
User-agent: *
Disallow: /articles/kak-prodvinut-sait/
Директива Allow открывает нужные нам разделы или страницы сайта. Например, необходимо закрыть папку со статьями, но одну статью оставить открытой для индекса. Прописываем так:
User-agent: *
Disallow: /articles*
Allow: /articles/kak-prodvinut-sait/
Дополнительно еще нужно сказать про спецсимволы:
* — означает, что правило применимо для всех документов раздела. Выше я прописал относительный путь Disallow: /articles* — это значит, от индекса закрыты все статьи. Если бы я прописал абсолютный путь Disallow: /articles/, то закрыт был бы только раздел статей, но сами статьи продолжали бы индексироваться.
Выше я прописал относительный путь Disallow: /articles* — это значит, от индекса закрыты все статьи. Если бы я прописал абсолютный путь Disallow: /articles/, то закрыт был бы только раздел статей, но сами статьи продолжали бы индексироваться.
# — означает комментарий, все, что написано после # до перевода строки, роботом не учитывается. Например:
User-agent: *
Disallow: /articles*
# закрывает от индекса все страницы раздела статей
$ — отменяет спецсимвол * (закрывает от робота только то, что написано до спецсимвола $). Например:
User-agent: *
Disallow: /articles$
# от индекса закрыт только раздел статей, но сами статьи продолжают индексироваться.
Crawl-delay
Директива crawl-delay в robots.txt раньше применялась яндексом для регулирования частоты запросов роботов на сайт. Но в феврале 2018 года поисковик отменил директиву. Теперь вместо нее в вебмастере появился раздел «Скорость обхода».
Clean-param
Директива clean-param в robots.txt сообщает роботу, что нельзя индексировать url адрес с заданными параметрами, например, префиксы, идентификаторы сессий, utm-метки. Это нужно для того, чтобы не загружать один и тот же документ много раз и сделать индексацию сайта эффективнее.
Например, у нас есть страница https://mydaoseo.ru/articles/kak-prodvinut-sait.php и нам нужно отследить, откуда приходят на нее пользователи.
https://mydaoseo.ru/articles/kak-prodvinut-sait.php?site=1&r_id=123
https://mydaoseo.ru/articles/kak-prodvinut-sait.php?site=2&r_id=123
https://mydaoseo.ru/articles/kak-prodvinut-sait.php?site=3&r_id=123
В данном случае директива clean-param будет записана вот так:
User-agent: *
Disallow:
Clean-param: site /articles/kak-prodvinut-sait.php
В результате данной команды робот сведет все страницы к одной
https://mydaoseo.ru/articles/kak-prodvinut-sait.php?site=1&r_id=123
Host
Директива host использовалась раньше яндексом, чтобы показать роботу основное зеркало сайта (с www или без www, http или https), которое будет участвовать в поиске. Но в марте 2018 года яндекс отменил host, теперь его использовать не нужно.
Но в марте 2018 года яндекс отменил host, теперь его использовать не нужно.
Читайте также: как сделать правильный переезд сайта с http на https.
Sitemap
Директива sitemap нужна, чтобы указать путь к XML карте сайта. Обычно sitemap располгается в корне сайта по следующему адресу site.ru/sitemap.xml. Например:
User-agent: *
Disallow:
Sitemap: https://mydaoseo.ru/sitemap.xml
Директиву можно прописать несколько раз, особенно это актуально для больших интернет магазинов, где огромное количество страниц, и в один XML файл все страницы не умещаются. Расположение sitemap.xml также особого значения не имеет, но по правилам хорошего тона следует его располагать в самом низу роботса.
Это основные команды robots.txt. Есть еще и другие, но они не поддерживаются большинством поисковых систем.
Читайте также: как сделать технический аудит сайта
Что закрывать в robots txt
Роботс будет отличаться для разных сайтов, в зависимости от того, на какой платформе он разработан. Сайт может быть самописным, на платном или бесплатном движке (CMS) или сделан с помощью конструктора. В любом случае универсального варианта нет, нужно отталкиваться конкретно от вашей ситуации.
Сайт может быть самописным, на платном или бесплатном движке (CMS) или сделан с помощью конструктора. В любом случае универсального варианта нет, нужно отталкиваться конкретно от вашей ситуации.
Есть кстати, еще один способ составить роботс самому. Нужно найти несколько сайтов с такой же CMS, как у вас и составить свой роботс на их примере. Для того, чтобы найти и посмотреть файл robots.txt чужого сайта, нужно к домену прописать /robots.txt. Например:
https://mydaoseo.ru/robots.txt
Так вы можете подсмотреть, проанализировать и скомпоновать свой собственный файл. Но учтите, что можно таким способом нахватать фатальных ошибок от чужих роботсов. Будьте аккуратны при этом способе.
Итак, мы разобрались, зачем нужен файл robots txt, какие функции выполняет, основные директивы. Посмотрите также небольшое видео, чтобы закрепить материал.
P.S. Если вам понравилась статья, то поделитесь ею со своими друзьями.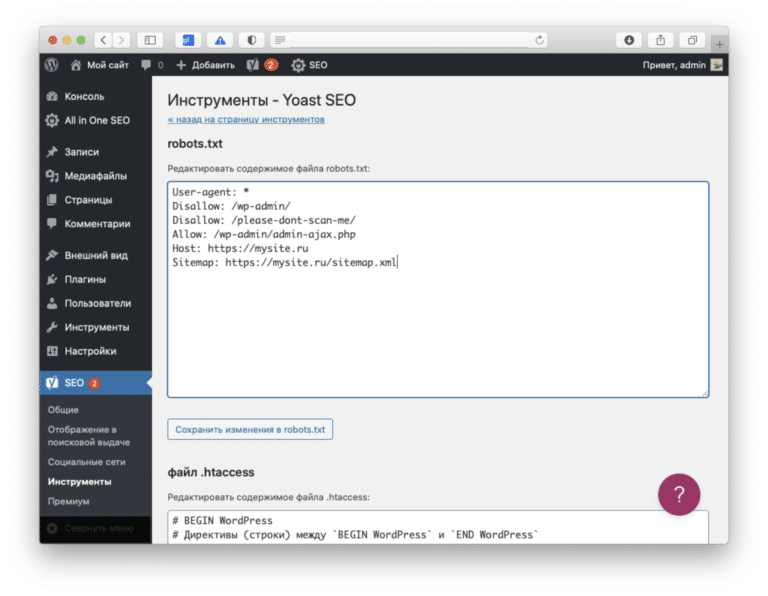 Если у вас есть вопросы или дополнения, то пишите комментарий внизу.
Если у вас есть вопросы или дополнения, то пишите комментарий внизу.
Файл robots.txt и как его правильно настроить
Robots.txt — это файл, который размещается в папке сайта на хостинге и содержит правила индексирования вашего сайта поисковыми системами. Как понятно из названия, файл имеет обычный текстовый формат. Если при обращении в браузере к вашему сайту по ссылке вида http://site.com/robots.txt корректно отображается содержимое файла — значит он будет правильно прочитан роботами поисковиков.
Зачем нужен robots.txt и как настроить robots?
Чтобы в индекс поисковых систем не попали страницы, которых там быть не должно. Если файла с настройками нет или же он пустой или настроен неправильно, то в индекс могут попасть критические данные, такие как конфигурационные файлы с паролями, ссылки на админку, какие-то системные файлы и каталоги движка сайта. В результате неправильной настройки поисковик может проиндексировать и показать всем желающим, к примеру, логин-детали для подключения к базе данных.
Страницы, которые нужно закрывать от индексации:
- Страницы поиска по сайту
- Корзина
- Сравнение, сортировка и фильтры товаров
- Теги, если их нельзя оптимизировать и модерировать
- Страницы регистрации и авторизации
- Личный кабинет и профайлы пользователей
- Системные файлы и каталоги
- Версии для печати
- Пустые страницы и т. д.
Блокировать индексацию следует для всех тех страниц, которые не несут пользу для посетителя, недоработаны, содержат чувствительные данные или являются дублями.
Как создать файл robots.txt?
Структура файла robots.txt имеет такой вид:
- Поисковый робот 1
- Инструкции для робота 1
- Дополнительные опции
- Поисковый робот 2
- Инструкции для робота 2
- Дополнительные опции
и т. д.
Порядок написания инструкций не имеет значения, поскольку обработка их происходит от менее вложенного к более вложенному. Регистр написания правил важен: cart.php и Cart.PHP — это разные страницы.
Регистр написания правил важен: cart.php и Cart.PHP — это разные страницы.
User-agent
Данная директива отвечает за имя робота, для которого будут указаны правила в этой секции. Обычно для User-agent используют два значения:
- User-agent: * — для всех роботов
- User-agent: Yandex — для всех роботов системы Yandex.
Также при необходимости можно указывать любые другие существующие user-агенты.
Disallow
Отвечает за запрет индексации указанных директорий. Нельзя указывать несколько папок в одной строке, поскольку роботы не смогут правильно интерпретировать правило. Данная директива может быть проигнорирована Googlebot, если на запрещенные к индексации директории есть ссылки на вашем сайте или других сайтах.
Если ваш сайт находится на стадии разработки и вы не хотите показывать его поисковикам, то запретить индексирование можно командами:
User-agent: *
Disallow: /Не забудьте изменить эти настройки после завершения всех работ по созданию сайта.
Allow
А эта директива, соответственно, открывает доступ роботов к указанным каталогам.
Причем указывать Allow: / не имеет смысла, поскольку по умолчанию индексация разрешена для всех каталогов, на которые не установлен запрет (Disallow).
Allow применяется обычно в комбинации с Disallow, например:
Disallow: /
Allow: /catalogЗапрет индексации корневой папки, но индексировать папку catalog можно.
Host
На данный момент директива не обрабатывается поисковыми роботами Google и Yandex (с марта 2018 года). Потому можно ее не использовать.
Ранее директива Host указывала на основное зеркало вашего сайта:
Host: https://site.comСейчас достаточно правильно настроить редиректы 301 с неосновных зеркал на основное.
Sitemap
Указывает ботам, где находится карта сайта, если это не стандартный путь https://site.com/sitemap.xml. Важно указывать полную ссылку на карту сайта, а не относительный путь:
Sitemap: https://site. com/private/sitemaps/sitemap_new.xml com/private/sitemaps/sitemap_new.xml
com/private/sitemaps/sitemap_new.xmlВы можете указывать разные карты для разных роботов при необходимости.
Crawl-Delay
Если роботы Yandex сильно нагружают хостинг, можно задать минимальный интервал между запросами. Например:
Crawl-Delay: 10 Запись означает, что роботу разрешено делать запросы не чаще, чем раз в 10 секунд.
На практике это правило не всегда соблюдается, а Googlebot и вовсе его игнорирует — скорость обхода сайта регулируется в Search Console.
Также указав интервал, например, 0.1 сек вы можете ускорить индексацию сайта. Не факт, что запросы будут приходить по 10 раз в секунду, но сайт точно будет проиндексирован быстрее. Будьте осторожны с этой настройкой, если не уверены, что ваш сервер выдержит такой большой поток запросов.
Clean-param
Эта команда используется довольно редко и призвана убрать дубли страниц, которые образуются различными utm-метками, сессиями, сортировками, фильтрами.
Например, при переходе на страницу сайта в URL подставляется referrer — сайт откуда был сделан переход:
https://site.
 com/catalog/dveri?ref=google.com.ua&model_id=125
com/catalog/dveri?ref=google.com.ua&model_id=125https://site.com/catalog/dveri?ref=yandex.ua&model_id=125
https://site.com/catalog/dveri?ref=ek.ua&model_id=125
Поисковики будут считать эту страницу как три разных. Чтобы склеить дубли, нужно добавить команду:
Clean-param: ref /catalog/dveriПодстановочные символы
Подстановочные символы в robots.txt используются для упрощения и сокращения записей.
Символ * — любая последовательность символов.
Disallow: /images/*.jpg$Запись означает: запретить индексирование всех изображений jpg в папке images.
Символ $ — конец строки. Данный символ ограничивает раскрытие содержимого каталогов, например:
Disallow: /images/$ Эта запись не позволит попасть в индекс элементам непосредственно в папке images, но элементы в папках /images/public1/, /images/public2/ и т. д. будут индексироваться.
д. будут индексироваться.
Символ # — комментирование. Все символы в строке, идущие за этим символом будут проигнорированы ботами.
Какие ошибки часто допускают при написании robots.txt?
- Имя робота в Disallow.
Неправильно:
Disallow: YandexПравильно:
User-agent: Yandex
Disallow: /2. Несколько папок в одной строке Disallow.
Неправильно:
Disallow: /admin/ /tmp/ /private/Правильно:
Disallow: /admin/
Disallow: /tmp/
Disallow: /private/3. Сам файл должен называться только robots.txt, а не Robots.txt, ROBOTS.TXT и т. д.
4. Нельзя оставлять пустым правило User-agent, нужно прописать * или имя робота, для которого далее будут прописаны правила.
5. Имена папок и доменов кириллицей. URL нужно писать в формате URL-encode, а IDN-домены в puny-code.
Неправильно:
Disallow: /корзинаПравильно:
Disallow: /%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0Неправильно:
Sitemap: https://мойсайт. com/admin/sitemap1.xml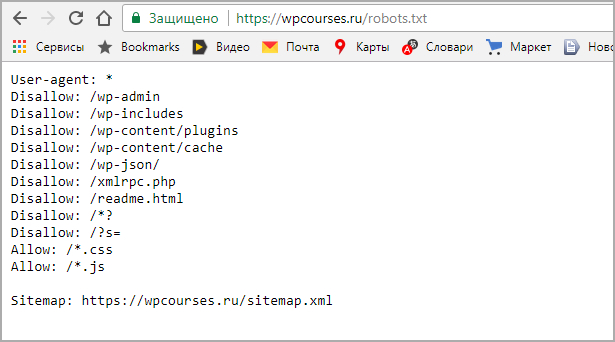 com/admin/sitemap1.xml
com/admin/sitemap1.xmlПравильно:
Sitemap: https://xn--80arbjktj.com/admin/sitemap1.xml6. Очень много правил — большой размер файла. Если файл robots.txt весит больше 32 КБ, то он не обрабатывается и считается полностью разрешающим.
Надеемся, что мы смогли ответить на некоторые вопросы о настройке robots.txt и процессе индексации в поисковых системах.
Ниже оставим ссылки с примерами файла robots.txt для популярных CMS. Если будете использовать эти файлы, не забудьте изменить имя домена на свое:
- Robots для wordpress: WordPress
- Robots для Joomla: Joomla
- Robots для OpenCart: OpenCart
- Robots для Bitrix: Bitrix
- Robots для Drupal: Drupal
- Robots для MODX Evolution: MODX Evolution
- Robots для MODX Revolution: MODX Revolution
- Robots для Webasyst: Webasyst
Robots.txt для SEO (основы SEO)
9 марта 2022 г. | Сообщение от Liraz Postan
Файлы robots.txt — это элементы на ваших веб-сайтах, которые вы не хотите выбрасывать. Они разрешают и блокируют вход нежелательным посетителям-ботам, пытающимся «подсмотреть» контент вашего сайта.
Они разрешают и блокируют вход нежелательным посетителям-ботам, пытающимся «подсмотреть» контент вашего сайта.
Это более или менее простой способ определения файлов robots.txt.
В этом посте я расскажу об основах SEO в файле robots.txt.
Вы узнаете:
- Когда их следует использовать
- Как их реализовать
- Ошибки, которых следует избегать
Боты, используемые поисковыми системами, — это пауки, которые сканируют Интернет для индексации содержимого веб-сайтов со всего Интернета. Эта информация позволяет поисковым системам узнать о содержимом веб-страниц, чтобы его можно было получить при необходимости.
Как только вы поймете процесс веб-сканирования, вы также поймете, почему файлы robots.txt полезны для вашего веб-сайта. Они здесь, чтобы защитить вас от посетителей, шныряющих вокруг. Они будут предоставлять только ту информацию, которую вы хотите показать о своем сайте.
Чтобы лучше понять файлы robots. txt, давайте подробнее рассмотрим, что они из себя представляют и как они сочетаются друг с другом.
txt, давайте подробнее рассмотрим, что они из себя представляют и как они сочетаются друг с другом.
Что такое файлы robots.txt?
Robots.txt. файлы, также известные как протокол исключения роботов, — это файлы, читаемые поисковыми системами и содержащие правила предоставления или отказа в доступе ко всем или определенным частям вашего веб-сайта. Поисковые системы, такие как Google или Bing, отправляют поисковые роботы для доступа к вашему веб-сайту и собирают информацию, которую они могут использовать, чтобы ваш контент мог отображаться в результатах поиска.
Чтобы понять, как работают файлы robot.txt, попробуйте представить ботов или маленьких пауков, ползающих по вашему сайту в поисках информации. Подумайте о тех научно-фантастических фильмах, когда миллионы роботов-пауков ползают по этому месту и вынюхивают, чтобы найти хотя бы малейшее возможное свидетельство присутствия самозванца.
через GIPHY
Эти простые текстовые файлы используются для SEO, выдавая команды индексирующим ботам поисковых систем, которые могут или не могут сканировать страницу. Файлы robots.txt в основном используются для управления бюджетом поисковых роботов и пригодятся, когда вы не хотите, чтобы эти поисковые роботы получали доступ к части вашего сайта.
Файлы robots.txt в основном используются для управления бюджетом поисковых роботов и пригодятся, когда вы не хотите, чтобы эти поисковые роботы получали доступ к части вашего сайта.
Robots.txt. файлы очень важны, потому что они сообщают поисковым системам, где им разрешено сканировать. По сути, они блокируют ваш сайт частично или полностью или индексируют ваш сайт. Другими словами, это способ сделать ваш сайт доступным для поисковых систем.
Процесс сканирования в действии
Процесс сканирования веб-сайтов в поисках контента известен как сканирование. Основная задача поисковых систем — сканировать сеть, чтобы находить и индексировать контент, переходя по миллионам ссылок. Когда робот заходит на сайт, первое, что он делает, — это ищет файлы robots.txt, чтобы получить информацию о том, сколько «отслеживания» он может сделать.0003
Поисковые системы соблюдают правила, установленные в ваших файлах robots.txt. Если файла robot.txt нет или на сайте нет запрещенной деятельности, боты будут сканировать всю информацию. Однако некоторые поисковые системы, такие как Google, не поддерживают все указанные директивы, и мы подробнее остановимся на этом ниже.
Однако некоторые поисковые системы, такие как Google, не поддерживают все указанные директивы, и мы подробнее остановимся на этом ниже.
Зачем использовать файлы robots.txt?
Файлы robots.txt позволяют веб-сайтам делать несколько вещей, например:
- блокировать доступ ко всему сайту
- Заблокировать доступ к части сайта
- Блокировать доступ к одному URL-адресу или определенным параметрам URL-адреса
- Блокировать доступ ко всему каталогу
- Позволяет устанавливать подстановочные знаки
Файлы robots.txt контролируют активность поисковых роботов на вашем сайте, предоставляя им доступ к определенным областям. Всегда есть причины, по которым вы не предоставляете Google или другим поисковым системам доступ к определенным частям вашего сайта. Одним из них может быть то, что вы все еще разрабатываете свой веб-сайт или хотите защитить конфиденциальную информацию.
Хотя веб-сайты могут работать без файла robots. txt, важно помнить о некоторых преимуществах их использования:
txt, важно помнить о некоторых преимуществах их использования:
- Предотвращение сканирования личных папок или поддоменов поисковыми системами
- Предотвращение сканирования дублированного контента и посещения страниц, которые вы считаете незначительными
- Запретить индексацию некоторых изображений на вашем сайте
- Предотвращение и управление перегрузкой сервера
- Предотвратить замедление работы сайта
Обратите внимание, что указание ботам не сканировать страницу не означает, что она не будет проиндексирована. URL-адрес появится в поисковой системе, но без мета-описания.
Как найти, создать и протестировать файлы robots.txt?
Файл robots.txt всегда находится в корневом домене веб-сайта. Например, вы можете найти его как https://www.example.com/robots.txt. Если вы хотите отредактировать его, вы можете получить доступ к диспетчеру файлов в CPanel хоста.
Если на вашем веб-сайте нет файла robots.txt, создать его довольно просто, поскольку это обычный текстовый файл, созданный в текстовом редакторе. Просто откройте пустой документ .txt и вставьте свои директивы. Когда вы закончите, просто сохраните файл как «robots.txt», и он у вас есть.
Если вы обычно делаете много ошибок при наборе текста, может быть разумно использовать генератор robots.txt, чтобы избежать SEO-катастроф и свести к минимуму синтаксические ошибки.Помните, что даже малейшая ошибка в пропущенной или добавленной букве или цифре может привести к проблемам.
После создания файла robots.txt поместите его в соответствующий корневой каталог домена. Обязательно проверьте файл перед запуском, чтобы убедиться, что он действителен. Для этого вам необходимо перейти на страницу поддержки Google и нажать кнопку «открыть тестер robots.txt». К сожалению, этот вариант тестирования доступен только в старой версии Google Search Console.
Выберите свойство, которое вы хотите проверьте, удалите все, что может быть в поле, и вставьте свой файл robots. txt. Если ваш файл получает одобрение, значит, у вас есть полнофункциональный файл robots.txt. Если нет, вам нужно вернуться и найти ошибку.
txt. Если ваш файл получает одобрение, значит, у вас есть полнофункциональный файл robots.txt. Если нет, вам нужно вернуться и найти ошибку.
Реализация директив сканирования
Каждый файл robots.txt состоит из директив, предоставляющих поисковым системам доступ к информации. Каждая директива начинается с указания пользовательского агента, а затем установки правил для этого пользовательского агента. Ниже мы составили два списка; один содержит поддерживаемые директивы, а другой не поддерживается пользовательскими агентами.
Поддерживаемые директивы
- User-agent — директива, используемая для определенных ботов. Поисковые системы ищут пользовательские агенты и блоки, которые к ним применяются. У каждой поисковой системы есть отметка user-agent. Из-за чувствительности к регистру убедитесь, что вы вводите правильную форму пользовательских агентов.
Например:
Агент пользователя: Googlebot
Агент пользователя: Bingbot
- Запретить — используйте эту директиву, если хотите, чтобы поисковые системы не сканировали определенные области веб-сайта. Вы можете сделать следующее:
 Вы можете сделать следующее:
Вы можете сделать следующее:заблокировать доступ к каталогу в целом для всех юзер-агентов:
пользовательский агент: *
Запретить: /
Заблокировать определенный каталог, в частности, для всех пользовательских агентов
пользовательский агент: *
Запретить: /portfolio
Заблокируйте доступ к PDF или любым другим файлам для всех пользовательских агентов. Просто используйте соответствующее расширение файла.
пользовательский агент: *
Disallow: *.pdf$
- Allow — эта директива позволяет поисковым системам сканировать страницу или каталог. Следует помнить, что вы можете переопределить запрещенную директиву. Допустим, вы не хотите, чтобы поисковые системы сканировали каталог портфолио, но разрешите им доступ к определенному.
агент пользователя: *
Запретить: /portfolio
Разрешить: /portfolio/allowed-portfolio
- Карта сайта — предоставление поисковым системам карты сайта облегчает их сканирование.
Неподдерживаемые директивы
- Задержка сканирования — это хорошая директива, которую можно использовать, когда вы хотите, чтобы боты замедлялись и задерживались между сканированиями, чтобы не перегружать ваши серверы. Эта директива весьма полезна для небольших веб-сайтов, а не для больших. Просто обратите внимание, что директива задержки сканирования больше не поддерживается Google и Baidu, но Яндекс и Bing все еще поддерживают ее.
- Noindex — директива, используемая для исключения веб-сайта или файла из поисковых систем. Эта команда никогда не поддерживалась Google. Итак, если вы хотите избежать поисковых систем, вам нужно использовать HTTP-заголовок x-robots или метатег robots.
- Nofollow — еще одна директива, никогда не поддерживаемая Google и используемая для указания поисковым системам не переходить по ссылкам на страницах. Используйте заголовки x-robots или роботы с метатегами, чтобы использовать директиву nofollow для всех ссылок.
- Директива хоста — используется, чтобы решить, хотите ли вы показывать www. перед URL-адресом (example.com или www.example.com). Эта директива на данный момент поддерживается только Яндексом, поэтому не рекомендуется полагаться на нее.

Использование подстановочных знаков
Подстановочные знаки — это символы, используемые для упрощения инструкций robots.txt. Подстановочные знаки могут использоваться для адресации и применения директив ко всем пользовательским агентам или для индивидуального обращения к конкретным пользовательским агентам. Вот часто используемые подстановочные знаки:
- Звездочка (*) — в директивах соответствует «применить ко всем пользовательским агентам». Также может использоваться для соответствия «соответствовать шаблонам URL или любой последовательности символов». Если у вас есть URL-адреса, которые следуют одному и тому же шаблону, это значительно облегчит вам жизнь.
- Знак доллара ($) — используется для обозначения конца URL-адреса.

Давайте посмотрим, как это будет выглядеть на примере. Если вы решили, что все поисковые системы не должны иметь доступ к вашим PDF-файлам, тогда robots.txt должен выглядеть так:
пользовательский агент: *
Disallow: /*.pdf$
Таким образом, URL-адреса, заканчивающиеся на .pdf, будут недоступны. Но обратите внимание, что если ваш URL-адрес содержит дополнительный текст после окончания .pdf, этот URL-адрес будет доступен. Таким образом, при написании файлов robots.txt убедитесь, что вы учли все аспекты.
Ошибки, которых следует избегать
Использование файлов robot.txt полезно, и существует множество способов их работы. Но давайте углубимся и рассмотрим ошибки, которых следует избегать при использовании файла robots.txt.
Преимущества огромны, но есть и много вреда, который может быть нанесен, если файлы robot.txt не используются должным образом.
- Новая строка — используйте новую строку для каждой директивы, чтобы не путать поисковые системы
- Обратите внимание на чувствительность к регистру — правильно создавайте файлы robots. txt, так как они чувствительны к регистру. Обратите на это пристальное внимание, иначе они не будут работать
- Избегайте блокировки контента. Не забудьте несколько раз просмотреть теги disallow и noindex, потому что они могут повредить результатам SEO. Будьте осторожны, чтобы не заблокировать хороший контент, который должен быть представлен публично
- Защитите личные данные — для защиты личной информации разумно попросить посетителей войти в систему. Таким образом, вы будете уверены, что PDF-файлы или другие файлы будут в безопасности
- Чрезмерное использование задержки сканирования. Небольшой совет: не злоупотребляйте никакими директивами, особенно задержкой сканирования. Если вы работаете с большим веб-сайтом, использование этой директивы может привести к обратным результатам. Вы ограничите сканирование ботов максимальным количеством URL-адресов в день, что нецелесообразно.
 txt, так как они чувствительны к регистру. Обратите на это пристальное внимание, иначе они не будут работать
txt, так как они чувствительны к регистру. Обратите на это пристальное внимание, иначе они не будут работатьДублированный контент
Существует несколько причин, по которым ваш сайт может содержать дублированный контент. Это может быть версия для печати, страница, доступная по нескольким URL-адресам, или разные страницы с похожим содержанием. Поисковые системы не могут распознать, является ли это дубликатом или нет.
Это может быть версия для печати, страница, доступная по нескольким URL-адресам, или разные страницы с похожим содержанием. Поисковые системы не могут распознать, является ли это дубликатом или нет.
В подобных случаях пользователю необходимо пометить URL-адрес как канонический. Этот тег используется для информирования поисковой системы об исходном местонахождении дубликата. Если пользователь этого не сделает, тогда пользовательский агент выберет, что является каноническим, или, что еще хуже, они могут пометить оба содержимого как канонические. Другой способ избежать этого — переписать контент.
Let Crawling Eyes Index
Когда поисковые системы сканируют или просматривают ваш веб-сайт, они просматривают все содержимое веб-сайта для его индексации. Этот процесс позволяет просканированным веб-сайтам появляться в разделе результатов поисковых систем.
Используя robots.txt, вы сообщаете поисковым системам, где у них есть или нет доступ. Вы в основном ограничиваете их, устанавливая соответствующие правила. Использование robots.txt довольно простое и полезное. Как только вы изучите правила назначения директив, вы сможете многое сделать со своим веб-сайтом.
Использование robots.txt довольно простое и полезное. Как только вы изучите правила назначения директив, вы сможете многое сделать со своим веб-сайтом.
Рекомендуется следить за файлами robots.txt, чтобы убедиться, что они настроены правильно и работают в соответствии с кодом. Если вы заметили какую-либо неисправность, реагируйте быстро, чтобы избежать катастроф.
Считайте файлы robots.txt важным инструментом для успешного управления индексацией вашего веб-сайта.
Об авторе
Лираз Постан
Follow @MordyOberstein
Лираз — международный эксперт по SEO и контенту, помогающий брендам и издателям расти с помощью поисковых систем. Она является бывшим директором по поисковой оптимизации и контенту Outbrain, а ранее более десяти лет работала в игровой индустрии, B2C и B2B.
Robots.txt для SEO: Ваше полное руководство
Что такое robots.txt и почему он важен для поисковой оптимизации (SEO)? Robots. txt — это набор необязательных директив, которые сообщают поисковым роботам, к каким частям вашего веб-сайта они могут получить доступ. Большинство поисковых систем, в том числе Google, Bing, Yahoo и Yandex, поддерживают и используют txt-роботы для определения веб-страниц, которые следует сканировать, индексировать и отображать в результатах поиска.
txt — это набор необязательных директив, которые сообщают поисковым роботам, к каким частям вашего веб-сайта они могут получить доступ. Большинство поисковых систем, в том числе Google, Bing, Yahoo и Yandex, поддерживают и используют txt-роботы для определения веб-страниц, которые следует сканировать, индексировать и отображать в результатах поиска.
Если у вас возникли проблемы с индексацией вашего веб-сайта поисковыми системами, проблема может быть в файле robots.txt. Ошибки robot.txt являются одними из наиболее распространенных технических проблем SEO, которые появляются в отчетах SEO-аудита и приводят к значительному падению поискового рейтинга. Даже опытные поставщики технических услуг SEO и веб-разработчики подвержены ошибкам robot.txt.
Таким образом, важно, чтобы вы понимали две вещи: 1) что такое robots.txt и 2) как использовать robots.txt в WordPress и других системах управления контентом (CMS). Это поможет вам создать файл robots. txt, оптимизированный для SEO, и упростит для веб-пауков сканирование и индексирование ваших веб-страниц.
txt, оптимизированный для SEO, и упростит для веб-пауков сканирование и индексирование ваших веб-страниц.
В этом руководстве мы рассмотрим:
• Что такое robots.txt?
• Что такое поисковый робот и как он работает?
• Как выглядит Robot Txt?
• Для чего используется robots.txt?
• Расположение файла robots.txt WordPress
• Где находится файл robots.txt в WordPress?
• Как найти Robots.txt в cPanel
• Как найти Magento Robots.txt
• Передовой опыт работы с Robots Txt
Давайте углубимся в основы robots.txt. Читайте дальше и узнайте, как вы можете использовать файл robots.txt для улучшения индексируемости и индексируемости вашего веб-сайта.
Что такое robots.txt?
Robots txt, также известный как стандарт или протокол исключения роботов, представляет собой текстовый файл, расположенный в корневом или основном каталоге вашего веб-сайта. Он служит инструкцией для поисковых роботов, какие части вашего сайта они могут и не могут сканировать.
Robots.Text Timeline
Текстовый файл robots.txt представляет собой стандарт, предложенный создателем Allweb Мартейном Костером для регулирования того, как различные роботы поисковых систем и поисковые роботы получают доступ к веб-контенту. Вот обзор разработки файла robots txt за последние годы:
В 1994 году Костер создал веб-паука, который вызывал вредоносные атаки на его серверы. Чтобы защитить веб-сайты от плохих поисковых роботов, Костер разработал robot.text, чтобы направлять поисковых ботов на нужные страницы и препятствовать им достигать определенных областей веб-сайта.
В 1997 году в Интернете был создан черновик для определения методов управления веб-роботами с использованием файла txt для роботов. С тех пор robot.txt использовался для ограничения или направления робота-паука для выбора частей веб-сайта.
1 июля 2019 года Google объявила, что работает над формализацией спецификаций протокола исключения роботов (REP) и превращением его в веб-стандарт — спустя 25 лет после того, как текстовый файл robots был создан и принят поисковыми системами.
Цель состояла в том, чтобы детализировать неуказанные сценарии для синтаксического анализа и сопоставления роботов txt для адаптации к современным веб-стандартам. Этот интернет-проект указывает, что:
1. Любой протокол передачи на основе универсального идентификатора ресурса (URI), такой как HTTP, протокол ограниченных приложений (CoAP) и протокол передачи файлов (FTP), может использовать robots txt.
2. Веб-разработчики должны проанализировать как минимум первые 500 кибибайт файла robot.text, чтобы уменьшить ненужную нагрузку на серверы.
3. SEO-контент robots.txt обычно кэшируется на срок до 24 часов, чтобы у владельцев веб-сайтов и веб-разработчиков было достаточно времени для обновления их файла robots.txt.
4. Запрещенные страницы не сканируются в течение достаточно длительного периода, когда текстовый файл robots становится недоступным из-за проблем с сервером.
Со временем в отрасли было предпринято несколько усилий по расширению механизмов исключения роботов. Однако не все поисковые роботы могут поддерживать эти новые текстовые протоколы для роботов. Чтобы четко понять, как работает robots.text, давайте сначала определим поисковый робот и ответим на важный вопрос: как работают поисковые роботы?
Однако не все поисковые роботы могут поддерживать эти новые текстовые протоколы для роботов. Чтобы четко понять, как работает robots.text, давайте сначала определим поисковый робот и ответим на важный вопрос: как работают поисковые роботы?
Что такое поисковый робот и как он работает?
сканер веб-сайтов , также называемый роботом-пауком , сканер или поисковый бот 9029 , обычно управляемый поисковыми системами Google и поисковыми системами , 9029 . Веб-паук сканирует сеть, чтобы анализировать веб-страницы и гарантировать, что информация может быть получена пользователями в любое время, когда они в ней нуждаются.
Что такое поисковые роботы и какова их роль в техническом SEO? Для определения поискового робота крайне важно ознакомиться с различными типами поисковых роботов в Интернете. У каждого робота-паука своя цель:
1. Боты поисковых систем
Боты поисковых систем Что такое поисковый робот? Бот поисковой системы-паука — один из наиболее распространенных поисковых роботов, используемых поисковыми системами для сканирования и очистки Интернета. Боты поисковых систем используют SEO-протоколы robots.txt, чтобы понять ваши предпочтения при сканировании веб-страниц. Зная ответ на вопрос, что такое поисковый паук? дает вам преимущество в оптимизации вашего robots.text и обеспечении его работы.
2. Коммерческий веб-паук Коммерческий сканер сайтов — это инструмент, разработанный компаниями-разработчиками программного обеспечения, чтобы помочь владельцам веб-сайтов собирать данные с их собственных платформ или общедоступных сайтов. Несколько фирм предоставляют рекомендации по созданию поискового робота для этой цели. Обязательно сотрудничайте с коммерческой компанией, занимающейся сканированием веб-страниц, которая максимизирует эффективность поискового робота для удовлетворения ваших конкретных потребностей.
Персональный поисковый робот помогает компаниям и частным лицам извлекать данные из результатов поиска и/или отслеживать эффективность своего веб-сайта. В отличие от поискового робота-паука, персональный поисковый робот имеет ограниченную масштабируемость и функциональность. Если вам интересно, как создать поисковый робот для веб-сайтов, выполняющий определенные задачи для поддержки ваших усилий по технической оптимизации, обратитесь к одному из многочисленных руководств в Интернете, в которых показано, как создать поисковый робот, работающий с вашего локального устройства.
4. Настольный сканер сайтов Настольный робот-сканер запускается локально с вашего компьютера и полезен для анализа небольших веб-сайтов. Однако поисковые роботы для настольных компьютеров не рекомендуются, если вы анализируете десятки или сотни тысяч веб-страниц. Это связано с тем, что для сканирования больших сайтов требуется специальная настройка или прокси-серверы, которые не поддерживаются ботом-обходчиком.
Поисковый робот веб-сайтов, защищающих авторские права, ищет контент, нарушающий закон об авторских правах. Поисковым ботом этого типа может управлять любая компания или лицо, владеющее материалами, защищенными авторским правом, независимо от того, знаете ли вы, как создать поисковый робот или нет.
6. Облачный краулер-роботОблачные краулер-боты используются в качестве инструмента технического SEO-сервиса. Облачный поисковый робот, также известный как «Программное обеспечение как услуга» (SaaS), работает на любом устройстве с подключением к Интернету. Этот интернет-паук становится все более популярным, потому что он сканирует веб-сайты любого размера и не требует нескольких лицензий для использования на разных устройствах.
Почему важно знать: что такое поисковые роботы? Поисковые боты обычно запрограммированы на поиск robot.text и выполнение его указаний. Однако некоторые сканирующие боты, такие как спам-боты , сборщики электронной почты и вредоносные роботы , часто игнорируют SEO-протокол robots.txt и не имеют лучших намерений при доступе к содержимому вашего сайта.
Однако некоторые сканирующие боты, такие как спам-боты , сборщики электронной почты и вредоносные роботы , часто игнорируют SEO-протокол robots.txt и не имеют лучших намерений при доступе к содержимому вашего сайта.
Что такое поведение поискового робота, если не превентивная мера, направленная на улучшение вашего присутствия в Интернете и улучшение взаимодействия с пользователем? Пытаясь понять ответ на вопрос, что такое паук поисковой системы? и чем он отличается от плохих сканеров сайта, вы можете гарантировать, что паук хорошей поисковой системы сможет получить доступ к вашему сайту и предотвратить нежелательные поисковые роботы, которые могут испортить ваш пользовательский интерфейс (UX) и поисковый рейтинг.
8-й ежегодный отчет о плохих ботах, подготовленный Imperva, показывает, что в 2020 году плохие поисковые роботы генерировали 25,6% всего трафика сайта , в то время как хорошие поисковые роботы генерировали только 15,2% трафика . Из-за множества разрушительных действий, на которые способны роботы-пауки, такие как мошенничество с кликами, захват учетных записей, очистка контента и рассылка спама, стоит знать 1) какой веб-сканер полезен для вашего сайта? и 2) каких ботов вам нужно блокировать при создании текста для роботов?
Из-за множества разрушительных действий, на которые способны роботы-пауки, такие как мошенничество с кликами, захват учетных записей, очистка контента и рассылка спама, стоит знать 1) какой веб-сканер полезен для вашего сайта? и 2) каких ботов вам нужно блокировать при создании текста для роботов?
Вам не обязательно учиться создавать поисковый робот для веб-сайтов. Оставьте технические аспекты разработки поискового робота SEO компаниям, занимающимся программными решениями, и вместо этого сосредоточьтесь на оптимизации txt для своих SEO-роботов.
Как работают поисковые роботы?Никто не создает свой собственный веб-краулер, если он специально не собирает данные с сайта», — сказал Роннел Вилориа, старший SEO-стратег Thrive по формированию спроса. «С точки зрения технического SEO инструменты для сканирования сайтов уже существуют. Только в том случае, если вы постоянно собираете десятки ГБ данных, было бы рентабельно создавать и размещать свой собственный поисковый робот».

В этом быстро меняющемся цифровом ландшафте простого знания того, что такое веб-краулер, недостаточно, чтобы оптимизировать txt для SEO-роботов. Помимо «что такое поисковые роботы?» вам также необходимо ответить на вопрос «как работают поисковые роботы?» чтобы убедиться, что вы создаете текст для робота, содержащий правильные директивы.
Поисковые пауки в основном запрограммированы на выполнение автоматических повторяющихся поисков в Интернете для создания индекса. Индекс — это место, где поисковые системы хранят веб-информацию для извлечения и отображения в релевантных результатах поиска по запросу пользователя.
Поисковый робот следует определенным процессам и политикам, чтобы улучшить процесс сканирования веб-сайта и достичь своей цели в паутине.
Итак, как именно работает поисковый робот? Давайте взглянем.
| Поиск URL-адресов | Веб-пауки начинают сканирование веб-страниц со списка URL-адресов, а затем переходят между ссылками на страницы для сканирования веб-сайтов. Чтобы улучшить возможности сканирования и индексации вашего сайта, обязательно расставьте приоритеты в отношении навигации по сайту, создайте четкую карту сайта robots.txt и отправьте файл robots.txt в Google. Чтобы улучшить возможности сканирования и индексации вашего сайта, обязательно расставьте приоритеты в отношении навигации по сайту, создайте четкую карту сайта robots.txt и отправьте файл robots.txt в Google. |
| Исследуйте список семян | Поисковые системы предоставляют своим поисковым роботам список семян или URL-адресов для проверки. Затем пауки поисковых систем посещают каждый URL-адрес в списке, определяют все ссылки на каждой странице и добавляют их в список семян для посещения. Веб-пауки используют карты сайта и базы данных ранее просканированных URL-адресов, чтобы исследовать больше веб-страниц в Интернете. |
| Добавить в индекс | Как только поисковый робот посещает URL-адреса в списке, он находит и отображает контент, включая текст, файлы, видео и изображения, на каждой веб-странице и добавляет его в список. индекс. |
| Обновление индекса | Поисковые роботы учитывают ключевые сигналы, такие как релевантность и свежесть ключевых слов и контента, при анализе веб-страницы. Как только поисковый робот обнаруживает какие-либо изменения на вашем веб-сайте, он соответствующим образом обновляет свой поисковый индекс, чтобы убедиться, что он отражает последнюю версию веб-страницы. Как только поисковый робот обнаруживает какие-либо изменения на вашем веб-сайте, он соответствующим образом обновляет свой поисковый индекс, чтобы убедиться, что он отражает последнюю версию веб-страницы. |
Согласно Google, компьютерные программы определяют, как сканировать веб-сайт. Они оценивают воспринимаемую важность и релевантность, спрос на сканирование и уровень интереса поисковых систем и онлайн-пользователей к вашему веб-сайту. Эти факторы влияют на то, как часто интернет-паук будет сканировать ваши веб-страницы.
Как работает поисковый робот и обеспечивает выполнение всех политик Google в отношении сканирования Интернета и запросов поискового робота?
Чтобы лучше сообщать поисковым системам о том, как сканировать веб-сайт, поставщики технических услуг SEO и эксперты по веб-дизайну WordPress советуют вам создать файл robots.txt, в котором четко указаны ваши предпочтения по сканированию данных. SEO robots txt — это один из протоколов, которые веб-пауки используют для управления процессом сканирования Google и данных в Интернете.
 png» nitro-lazy-empty=»» src=»data:image/svg+xml;nitro-empty-id=MTI1Mzo1NDY=-1;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMzk3IDExMSIgd2lkdGg9IjM5NyIgaGVpZ2h0PSIxMTEiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PC9zdmc+»/>
png» nitro-lazy-empty=»» src=»data:image/svg+xml;nitro-empty-id=MTI1Mzo1NDY=-1;base64,PHN2ZyB2aWV3Qm94PSIwIDAgMzk3IDExMSIgd2lkdGg9IjM5NyIgaGVpZ2h0PSIxMTEiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PC9zdmc+»/>Инструкции сканирования Spider задаются с помощью следующих директив:
User-agentДиректива user-agent относится к имени поискового робота, для которого предназначена команда. Это первая строка для любого формата robots.txt или группы правил.
Команда агента пользователя использует подстановочный знак или символ * . Это означает, что директива распространяется на всех поисковых ботов. Директивы могут также применяться к определенным пользовательским агентам.
Каждый поисковик SEO имеет свое имя. Поисковые роботы Google называются Googlebot , поисковый робот Bing идентифицируется как BingBot , а интернет-паук Yahoo называется Slurp . Вы можете найти список всех пользовательских агентов здесь.
Вы можете найти список всех пользовательских агентов здесь.
# Пример 1 |
В этом примере, с с тех пор *. все пользовательские агенты от доступа к URL-адресу. 9Пример 2 Это означает, что все поисковые роботы могут получить доступ к URL-адресу, кроме поисковых роботов Google.
# Пример 3 | 04040404040404040404040404040404040404040404040404040404040404040404040404040404040н.0002 Пример № 3 показывает, что всем агентам пользователя, кроме поискового робота Google и интернет-паука Yahoo, разрешен доступ к URL-адресу. Разрешить
 Директива разрешения Robots.txt поддерживается Google и Bing.
Директива разрешения Robots.txt поддерживается Google и Bing. # Пример 1
|
 Таким образом, сканеры Google и поисковые пауки будут сбиты с толку тем, что делать с URL-адресом http://www.yourwebsite.com/example.php . Непонятно, какому протоколу следовать.
Таким образом, сканеры Google и поисковые пауки будут сбиты с толку тем, что делать с URL-адресом http://www.yourwebsite.com/example.php . Непонятно, какому протоколу следовать.