
что это и как использовать
Важно! Сегодня Яндекс уже не следует инструкции Crawl-delay. И теперь скорость обхода регулируется только в Яндекс Вебмастер в разделе «Индексирование — Скорость обхода».
В Google данная директива тоже не используется о чем было сказано в 2017 году в этом видео.
Видео на английском, поэтому вот перевод:
Crawl-delay — это очень давняя директива в Google. И нужна она была вебмастерам, чтобы указать период между запросами для снижения нагрузки на сервер, которые делает краулер(робот поисковой системы).
Сама по себе идея была хорошей и разумной для того времени. Но дальше стало понятно, что серверы сегодня довольно мощные, так что смыла устанавливать определенный период между запросами попросту нет.
Что же пришло в Google на смену crawl-delay директивы? Робот поисковой системы теперь автоматически регулирует скорость обхода страницы, в зависимости от реакции сервера.
Как только она замедлится или появится ошибка, обход может приостановиться. Итак, учитывая, что замена найдена и успешно нами применяется, поэтому теперь crawl-delay нами не поддерживается. И если мы обнаружим директиву в вашем robots.txt, мы на это укажем.
Стоит также отметить, что на любом сайте обязательно существуют разделы, не нуждающиеся в обходе. Вы можете сообщить нам о них, предоставив информацию в robots.txt с помощью директивы Dissalow.

Хоть и директива Crawl-delay больше не поддерживается Яндекс и Google, но вдруг вы захотите узнать, как она раньше использовалась в этих поисковых машинах, поэтому ниже мы об этом расскажем.
Crawl-delay в файле robots.txt уменьшает нагрузку на сервер, когда поисковые роботы слишком часто посещают ваш ресурс и перегружают сервер, не давая ему полноценно обрабатывать запросы бота.
Зачастую ее используют владельцы сайтов с более тысячи страниц, так как данная проблема зачастую касается крупных веб-проектов.
Посредством директивы мы просим роботов обходить страницы нашего веб-ресурса не чаще, чем один раз в три, пять и т.п. секунд. То есть, правило задает роботу поисковой системы промежуток времени, измеряющийся в секундах, между концом загрузки одной веб-страницы и началом загрузки последующей.
Есть поисковики, которые работают с форматом дробных чисел, являющихся параметром директивы Crawl-delay.
На заметку.Перед указанием новой скорости обхода ресурса роботами следует узнать, какие страницы они посещают чаще остальных.
Для этого необходимо:
- Просмотреть логи сервера.
- Проанализируйте список URL-адресов в Яндекс.Вебмастере. Сделать это можно в меню Индексирование – Статистика обхода. Не забудьте включить переключатель на “Все страницы”.
Если в результате проверки будет обнаружено, что поисковый бот в основном сканирует служебные страницы, закройте их от индексирования в файле Robots, используя директиву Disallow. Так вы существенно уменьшите количество ненужных посещений роботом.
Так вы существенно уменьшите количество ненужных посещений роботом.
Чтобы роботы поисковых систем, не всегда придерживающиеся стандарта в ходе чтения robots.txt, учитывали данное правило, его нужно включить в группу, начинающуюся с директивы User-agent, после Disallow и Allow.
Основной бот Яндекса работает с дробными значениями указания Crawl-delay, такими как 0.2 и прочими. Нет стопроцентных гарантий, что робот начнет посещать ваш ресурс 20 раз в секунду, однако обеспечить более быстрое сканирование сайта удастся.
Директива не распознается поисковым ботом, отвечающим за обход RSS-канала для создания Турбо-страниц.
На заметку. Максимальное значение директивы для роботов Яндекса – 2.0.
Чтобы выбрать необходимую скорость загрузки страниц веб-сайта, перейдите в меню Скорость обхода сайта.
Примеры:
User-agent: Yandex Crawl-delay: 2.0 # тайм-аут посещения роботом Яндекса – не чаще, чем 1 раз в 2 секунды
User-agent: * Disallow: /search Crawl-delay: 1.0 # тайм-аут посещения всеми роботами – не чаще, чем 1 раз в 1 секунду
 0 # тайм-аут посещения всеми роботами – не чаще, чем 1 раз в 1 секунду
0 # тайм-аут посещения всеми роботами – не чаще, чем 1 раз в 1 секундуЯ всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите
crawl-delay: 2 — Что за предупреждение google о robot.txt?
Ответы на пост (14) Написать ответ
Окончательный вариант, но нужно проверить, лишнее убрано, вариации адресов заменены «звездочкой».
User-Agent: Yandex
Crawl-Delay: 2
Disallow: /ajax/
Disallow: /cart/
Disallow: /register/
Disallow: /register
Disallow: /auth/
Disallow: /shop/
Disallow: /notification_request/
Disallow: /articles/root
Disallow: /guestbook/?page=1
Disallow: /blog/
Disallow: /pricelist/
Disallow: /index. php?ukey=*
php?ukey=*
Disallow: /auxpage_cjc-1295/
Disallow: /auxpage_melanotan-analiz/
Disallow: /category/*/?sort=name&direction=DESC
Disallow: /category/*/?sort=Price&direction=ASC
Disallow: /category/*/?sort=name&direction=DESC
Disallow: /articles/root
Disallow: /articles/stati/agag-melatonin
Disallow: /articles/stati/gormon-rosta-chast-1
Disallow: /articles/stati/prolongirovannye-reaktivi/offset*/
Disallow: /articles/root/melanotan-2-1_4/offset15/
Disallow: /articles/stati/offset25/
Disallow: /articles/stati/peptidnye-primesi/
Disallow: /product/765/
Disallow: /product/747/
Disallow: /product/hladogent/
Disallow: /product/aniracetam-aniracetam-30gr/reviews/
Disallow: /published/SC/html/scripts/callbackhandlers/loginza.php
Host: pepzakaz.ru
User-Agent: *
Disallow: /ajax/
Disallow: /cart/
Disallow: /register/
Disallow: /register
Disallow: /auth/
Disallow: /notification_request/
Disallow: /articles/root
Disallow: /guestbook/?page=1
Disallow: /blog/
Disallow: /pricelist/
Disallow: /index.
 php?ukey=*
php?ukey=*Disallow: /auxpage_cjc-1295/
Disallow: /auxpage_melanotan-analiz/
Disallow: /category/*/?sort=name&direction=DESC
Disallow: /category/*/?sort=Price&direction=ASC
Disallow: /category/*/?sort=name&direction=ASC
Disallow: /category/*/?sort=name&direction=DESC
Disallow: /articles/root
Disallow: /articles/stati/agag-melatonin
Disallow: /articles/stati/gormon-rosta-chast-1
Disallow: /articles/stati/prolongirovannye-reaktivi/offset*/
Disallow: /articles/root/melanotan-2-1_4/offset15/
Disallow: /articles/stati/offset25/
Disallow: /articles/stati/peptidnye-primesi/
Disallow: /product/765/
Disallow: /product/747/
Disallow: /product/hladogent/
Disallow: /product/aniracetam-aniracetam-30gr/reviews/
Disallow: /published/SC/html/scripts/callbackhandlers/loginza.php
Allow: *.js
Allow: *.
 css
cssSitemap: http://www.pepzakaz.ru/sitemap.xml
0
Решение
во! какой красивый робот стал, а не то как у меня мусорка была и постоянно приходилось удалять хлам, а тут надо было всего то сделать, что бы этот хлам если и появлялся, то не индексировался.
Crawl-Delay — это задержка между сканированием страниц сайта в целях снижения нагрузки на сайт. Яндекс «понимает» эту инструкцию, Гугл — нет. Поэтому в правилах роботс.тхт должны быть, как минимум, 2 блока, один «для всех», второй для Яндекса. Во втором также можно указать правило «host», т.к. только Яндекс его «понимает».
В данный момент у меня 2 блока User-Agent: Yandex и Host: pepzakaz.ru
в обоих есть crawl-delay: 2 , но только в блоке для яндекса есть Host: pepzakaz.ru
Получается с блока Host: pepzakaz.ru убрать crawl-delay: 2 и добавить Host: pepzakaz.ru ?
Должен быть один блок.
ах блин, опечатался. второй блок User-Agent: *
я добавил в оба блока Host: pepzakaz. ru и вылазит ошибка , что Найдено несколько директив Host
ru и вылазит ошибка , что Найдено несколько директив Host
Вот ваш правильный роботс (ниже). Где точки — это «ваши правила», весь файл по размеру в сообщение не влазит. Crawl-Delay и Host указывается только для Яндекса по 1 разу. Пустых строк между правилами для одного паука быть не должно. Пустая строка допускается только между блоками для разных пауков. Адрес сайтмап указывается 1 раз, отделяется пустой строкой.
User-Agent: Yandex
Crawl-Delay: 2
Disallow: /ajax/
Disallow: /cart/
.
.
.
.
Disallow: /pricelist/
Disallow: /published/SC/html/scripts/callbackhandlers/loginza.php
Host: pepzakaz.ru
User-Agent: *
Disallow: /ajax/
Disallow: /cart/
Disallow: /register/
.
.
.
.
Disallow: /blog/99/
Disallow: /index.php?ukey=pricelist
Disallow: /pricelist/
Disallow: /published/SC/html/scripts/callbackhandlers/loginza. php
php
Allow: *.js
Allow: *.css
Sitemap: http://www.pepzakaz.ru/sitemap.xml
Вместо закрытия кучи категорий достаточно закрыть так:
Disallow: /category/*/?sort=name&direction=DESC
Disallow: /category/*/?sort=Price&direction=ASC
а правило
Disallow: /blog/
закрывает весь каталог /blog/ и вот в этом
Disallow: /blog/100/
Disallow: /blog/101/
Disallow: /blog/103/
Disallow: /blog/104/
Disallow: /blog/105/
Disallow: /blog/106/
Disallow: /blog/27/
Disallow: /blog/39/
Disallow: /blog/78/
Disallow: /blog/85/
уже надобности нет, это лишнее.
большое спасибо!
Вот эту конструкцию
Disallow: /articles/stati/prolongirovannye-reaktivi/offset*/
Disallow: /articles/root/melanotan-2-1_4/offset15/
Disallow: /articles/stati/offset25/
можно заменить одной строкой
Disallow: */offset*/
Эта конструкция
Disallow: /category/*/?sort=name&direction=DESC
Disallow: /category/*/?sort=Price&direction=DESC
Disallow: /category/*/?sort=Price&direction=ASC
заменяется одной строкой
Disallow: */?sort=*
Сделайте правила универсальными для любого бота.
Замените все блоки одним, в котором вместо имени бота напишите зведочку, так:
User-Agent: *
Оставьте один host
crawl-delay — показывает задержку между визитами роботов в секундах.
Можно удалить. Можно оставить.
Если удалите, готовьтесь к варианту, что поисковые боты взбесятся и толпами повалят на сайт — как результат возрастет нагрузка.
Здравствуйте! Подскажите, нужно ли исправлять предупреждения (напротив каждой строки стоит предупреждение) в robots.txt:
User-agent: *
Disallow: /my/
Crawl-delay: 3
Sitemap: https://intimvalentin.ru/sitemap.1976346.xml.gz
User-Agent: Yandex
Allow: /
Disallow: /my/
Crawl-delay: 3
Host: https://intimvalentin.ru
Sitemap: https://intimvalentin.ru/sitemap.1976346.xml.gz
User-agent: msnbot
Crawl-delay: 10
User-agent: MJ12bot
Crawl-delay: 20
User-agent: AhrefsBot
Disallow: /
Каждый раз надо себе что-то делать самому.
Как настроить задержку сканирования в файле robots.txt
Задержка сканирования в файле robots.txt: что это значит?
Знаете ли вы, что поисковым системам, таким как Google, Yahoo! и Bing, необходимо регулярно сканировать ваш веб-сайт не только для поиска и индексирования вновь созданного контента, но и для того, чтобы они могли обновлять свои системы с учетом любых изменений, внесенных вами на ваш веб-сайт , такие как реструктуризация или удаление контента?
Если вы не знали, теперь знаете! Вы можете сделать это, используя специальную директиву, добавленную в ваш файл robots.txt.
Среди множества директив, которые вы можете добавить в файл robots.txt, вы можете добавить те, которые контролируют скорость индексации вашего сайта поисковыми системами. Как правило, большинству владельцев веб-сайтов не нужно настраивать задержку сканирования для своего веб-сайта, но в некоторых случаях это может быть хорошей идеей.
В этой статье базы знаний рассказывается, как создать файл robots. txt, вставить правильную директиву для ограничения скорости сканирования поисковой системы и показать, как управлять этим параметром для поисковых систем, которые не придерживаются этого параметра.
txt, вставить правильную директиву для ограничения скорости сканирования поисковой системы и показать, как управлять этим параметром для поисковых систем, которые не придерживаются этого параметра.
Как создать файл robots.txt в cPanel
Мы будем использовать файловый менеджер cPanel для создания файла. Сначала откройте свою клиентскую зону, чтобы войти на свой клиентский портал. Затем найдите оранжевый значок CP справа от службы, которую вы хотите администрировать.
Поиск вашей cPanel в личном кабинете.После открытия cPanel в области ФАЙЛЫ откройте Диспетчер файлов.
Поиск файлового менеджера в вашей cPanelПосле того, как файловый менеджер откроется, вы захотите найти свою папку public_html (Как найти корневой каталог документа в cPanel). Затем дважды щелкните значок земного шара слева от public_html, чтобы открыть папку.
Если вы дважды щелкните текст «public_html», вы можете непреднамеренно открыть опцию переименования папки. Если это произойдет, просто щелкните пустое пространство под всеми папками и повторите попытку.
После того, как папка открыта, в зависимости от того, насколько вы продвинулись в разработке своего веб-сайта, у вас могут быть или не быть какие-либо файлы/папки в папке public_html. Не волнуйтесь, если у вас есть файлы/папки, вы все равно можете пройти это руководство и не беспокоиться о том, что это сломает ваш сайт. 🙂
В нашем примере наша папка public_html пуста, за исключением папки cgi-bin.
Почти пустая папка public_html в cPanel > Диспетчер файловМы можем легко создать пустой файл robots.txt из диспетчера файлов. В верхнем левом углу файлового менеджера найдите параметр + Файл рядом с + Папка. Нажмите + Файл, и откроется модальное окно с запросом имени файла +, где вы хотите его создать:
cPanel > Диспетчер файлов > Модальное окно «Новый файл» В поле «Новое имя файла» назовите файл robots.txt, затем нажмите «Создать». Новый файл. Вы вернетесь в представление файлового менеджера в папке public_html и увидите, что файл создан.
Как настроить задержку сканирования в файле robots.txt Выход из файлового менеджера.
Чтобы начать редактирование файла, щелкните один раз файл robots.txt, чтобы он был выделен полупрозрачным голубым цветом, как показано ниже:
Выделенный файл robots.txt в cPanel > Файловый менеджерПосле выбора файл, посмотрите в верхнем меню файлового менеджера. Вверху находятся несколько опций, в том числе «+Файл», «+Папка», «Копировать», «Переместить», «Загрузить» и другие. Нам нужно использовать Edit. После того, как вы нажмете «Изменить», появится модальное окно с некоторой информацией.
Диспетчер файлов cPanel > Редактировать файлДля использования файла robots.txt вы можете игнорировать это и продолжить, нажав «Редактировать».
В вашем браузере появится новая вкладка, и вы попадете в нечто, напоминающее текстовый процессор старой школы. Для тех, кто не помнит, это то, на чем люди печатали свои письма до Интернета. 😁
😁
Важно отметить, что Google не придерживается настроек задержки сканирования, используемых в файле robots.txt. Мы поговорим о том, как настроить скорость сканирования Google позже. Эти настройки будут работать для Bing, Yahoo! и Яндекс.
Чтобы вставить задержку сканирования, скопируйте приведенный ниже текст и вставьте его в редактор:
Агент пользователя: * Crawl-delay: 1
Это попросит пауков поисковых систем, сканирующих ваш веб-сайт, ждать 1 секунду между каждой просматриваемой страницей. Если вы хотите, чтобы они ждали дольше, вы можете использовать эти две другие настройки:
User-agent: * Crawl-delay: 5
или
User-agent: * Crawl-delay: 10
Они будут просить поисковые системы ждать 5 или 10 секунд между обходами страниц.
Знаете ли вы, что скорость веб-сайта влияет на SEO и рейтинг Google? Мы используем кэширование LiteSpeed для почти мгновенной доставки контента вашим посетителям. ⚡ Ознакомьтесь с нашими планами веб-хостинга !
⚡ Ознакомьтесь с нашими планами веб-хостинга !
Ваш редактор должен выглядеть примерно так, как показано на рисунке ниже, после вставки одного из указанных выше параметров:
Диспетчер файлов cPanel > Редактор с установленными директивами robots.txtПосле ввода данных нажмите синюю кнопку «Сохранить изменения» в правом верхнем углу. . Затем нажмите кнопку «Закрыть» рядом с кнопкой «Сохранить изменения».
Вы вернетесь в диспетчер файлов cPanel, где файл robots.txt был создан и обновлен с помощью этой директивы.
Как изменить скорость сканирования Googlebot
В 2019 году Google объявил, что будет игнорировать определенные директивы в файле robots.txt, и впоследствии обновил свою консоль поиска Google, чтобы дать вам возможность контролировать скорость сканирования.
Чтобы управлять скоростью сканирования ботов Google, войдите в свою консоль поиска Google и в настройках сайта и выберите «Ограничить максимальную скорость сканирования Google», как показано ниже:
Инструменты Google для веб-мастеров > Ограничить скорость сканирования Google Если вы вносите какие-либо изменения, не забудьте нажать кнопку Сохранить.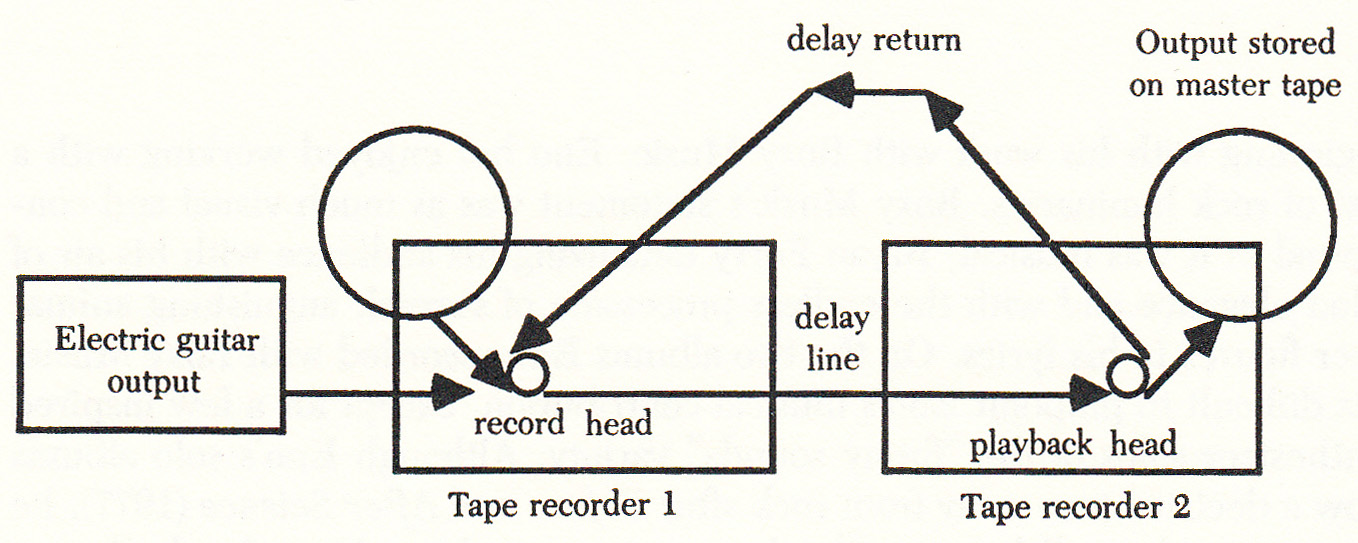
И все!
поисковых роботов. Почему Bing и SEMRushBot игнорируют задержку сканирования в моем файле robots.txt?
Спросил
Изменено 2 года, 3 месяца назад
Просмотрено 1k раз
У нас размещается большое количество сайтов с большим количеством страниц каталога. Мы хотели бы замедлить несколько ботов, потому что трафик от этих ботов довольно избыточен. В частности, мы получаем довольно много трафика от BingBot и SEMRushBot, который мы хотели бы замедлить. На информационных страницах обоих ботов указано, что они подчиняются директиве Crawl-Delay. Однако, несмотря на изменение задержек сканирования для обоих, я не вижу никаких изменений в трафике даже через несколько дней. Что-то не так с моим файлом? (Я поставил 60 в задержку SEMRushBot, но я читал, что они задерживают максимум на 10 секунд. Я не заметил никаких изменений после добавления их в файл robots.txt).
Я не заметил никаких изменений после добавления их в файл robots.txt).
Агент пользователя: * Запретить: /nobots/ Запретить: /products/features/ Запретить: /продукт/функции/ Запретить: /продукт/отзывы/ Запретить: /веб-сервисы/ajax/ Агент пользователя: yahoo-mmcrawler Запретить: /м/ Агент пользователя: MJ12bot Запретить: / Агент пользователя: AhrefsBot Запретить: / Агент пользователя: SemrushBot Задержка сканирования: 60 Агент пользователя: Bingbot Задержка сканирования: 10 Запретить: /nobots/ Запретить: /products/features/ Запретить: /продукт/функции/ Запретить: /продукт/отзывы/ Запретить: /веб-сервисы/ajax/ Агент пользователя: dotbot Задержка сканирования: 1 Агент пользователя: Goodzer Задержка сканирования: 1 Агент пользователя: rogerbot Задержка сканирования: 5 Агент пользователя: Baiduspider Запретить: / User-agent: ЯндексБот Запретить: / User-agent: YandexImages Запретить: / Агент пользователя: Linguee Bot Запретить: / Агент пользователя: Seekport Crawler Запретить: / Агент пользователя: GrapeshotCrawler Задержка сканирования: 1 Агент пользователя: istellabot Запретить: / Агент пользователя: SeznamBot Запретить: / Карта сайта:
- поисковые роботы
- robots. txt
- bing
- semrush
 txt
txt1
Ваш файл robots.txt не выполняет того, что (как мне кажется) вы намереваетесь сделать, потому что вы не используете пустые строки между разделами. Стандарт robots.txt гласит (выделено мной):
.Формат логически состоит из непустого набора или записей, разделенные пустыми строками . Записи состоят из набора строк форма:
<Поле> ":" <значение>В этом меморандуме строки с полем «foo» называются «foo lines».
Запись начинается с одной или нескольких строк User-agent, указывающих к каким роботам относится запись, а затем «Запретить» и Инструкции «Разрешить» этому роботу. Например:
Агент пользователя: webcrawler Агент пользователя: infoseek Разрешить: /tmp/ok.html Запретить: /tmp Запретить: /user/foo
Поэтому, когда у вас есть несколько разделов для разных пользовательских агентов, между ними должны быть пустые строки.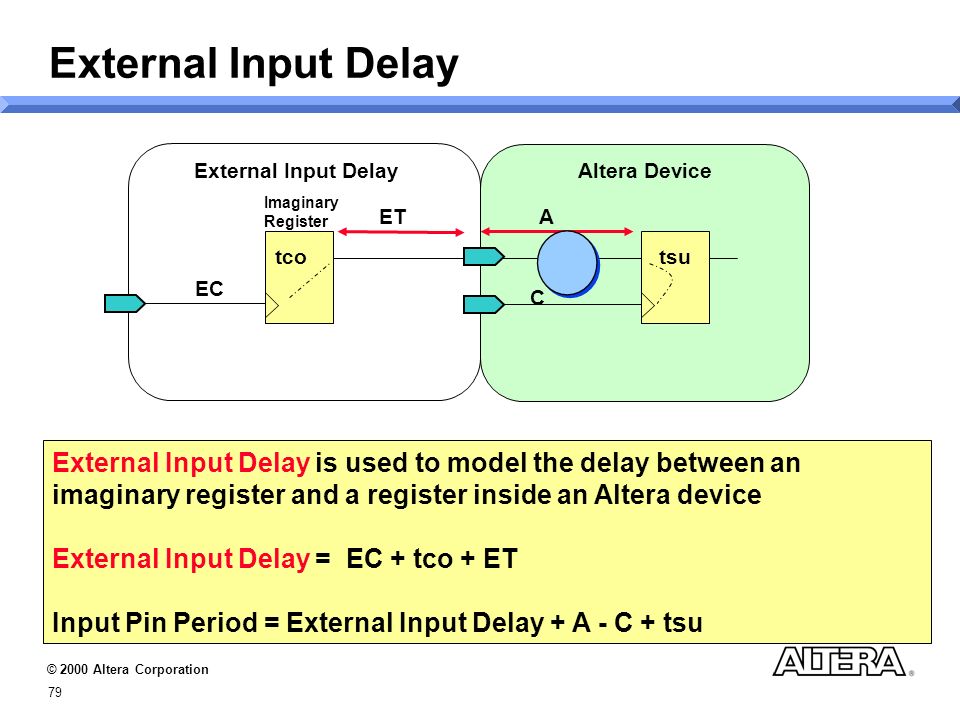 Вы также можете назначить несколько пользовательских агентов одному и тому же правилу. Ваш robots.txt должен быть:
Вы также можете назначить несколько пользовательских агентов одному и тому же правилу. Ваш robots.txt должен быть:
Агент пользователя: * Запретить: /nobots/ Запретить: /products/features/ Запретить: /продукт/функции/ Запретить: /продукт/отзывы/ Запретить: /веб-сервисы/ajax/ Агент пользователя: yahoo-mmcrawler Запретить: /м/ Агент пользователя: SemrushBot Задержка сканирования: 60 Агент пользователя: Bingbot Задержка сканирования: 10 Запретить: /nobots/ Запретить: /products/features/ Запретить: /продукт/функции/ Запретить: /продукт/отзывы/ Запретить: /веб-сервисы/ajax/ Агент пользователя: dotbot Агент пользователя: Goodzer Задержка сканирования: 1 Агент пользователя: rogerbot Задержка сканирования: 5 Агент пользователя: Baiduspider Агент пользователя: MJ12bot Агент пользователя: AhrefsBot User-agent: ЯндексБот User-agent: YandexImages Агент пользователя: Linguee Bot Агент пользователя: Seekport Crawler Агент пользователя: GrapeshotCrawler Агент пользователя: istellabot Агент пользователя: SeznamBot Запретить: /
Имейте в виду, что если вы предоставляете отдельный раздел для бота, он больше не следует директивам User-agent: * . Таким образом,
Таким образом, Semrushbot , dotbot , Goodzer и rogerbot могут сканировать весь ваш сайт, включая /nobots/ . yahoo-mmcrawler аналогичным образом позволяет сканировать почти все.
Даже задержка сканирования в 1 секунду значительно снижает скорость, с которой сканеры могут извлекать документы, до такой степени, что ваш сервер не должен замечать дополнительную нагрузку от них. Типичный сервер может обрабатывать сотни или даже тысячи запросов каждую секунду. Я бы рекомендовал поставить по умолчанию Crawl-delay: 1 и не пытаться настроить его для разных ботов. Большинство ботов полностью его игнорируют, но те, кто соблюдает его, должны иметь возможность сканировать сотни страниц с вашего сайта за разумный период времени. Я думаю, что этот файл robots.txt лучше соответствует вашим намерениям и достаточно медленным сканерам, чтобы предотвратить перегрузку сервера:
User-agent: * Задержка сканирования: 1 Запретить: /nobots/ Запретить: /products/features/ Запретить: /продукт/функции/ Запретить: /продукт/отзывы/ Запретить: /веб-сервисы/ajax/ Агент пользователя: yahoo-mmcrawler Задержка сканирования: 1 Запретить: /nobots/ Запретить: /products/features/ Запретить: /продукт/функции/ Запретить: /продукт/отзывы/ Запретить: /веб-сервисы/ajax/ Запретить: /м/ Агент пользователя: Baiduspider Агент пользователя: MJ12bot Агент пользователя: AhrefsBot User-agent: ЯндексБот User-agent: YandexImages Агент пользователя: Linguee Bot Агент пользователя: Seekport Crawler Агент пользователя: GrapeshotCrawler Агент пользователя: istellabot Агент пользователя: SeznamBot Запретить: /
1
Спасибо за вопрос и добро пожаловать в большое сообщество единомышленников. Ваш запрос сбивает с толку, но он разрешим. Я вижу несколько вещей, которые можно улучшить/изменить в вашем файле robots.txt в соответствии с документацией Bing по лучшим практикам.
Ваш запрос сбивает с толку, но он разрешим. Я вижу несколько вещей, которые можно улучшить/изменить в вашем файле robots.txt в соответствии с документацией Bing по лучшим практикам.
- Вы говорите, что размещаете большое количество сайтов. Убедитесь, что у вас есть отдельные файлы robots.txt, хранящиеся в корневой папке каждого сайта, который вы размещаете.
- Bing рекомендует размещать директиву о задержке сканирования в разделе общей директивы для всех ботов, чтобы свести к минимуму вероятность ошибок кода, которые могут повлиять на индексацию сайта конкретной поисковой системой. Я вижу, что ваши директивы о задержке сканирования предназначены для конкретных ботов. Лично я бы проигнорировал эту рекомендацию, так как вы не хотите замедлять работу робота Googlebot, так как это единственный бот, который имеет значение 😉
- Также обратите внимание, что любой набор директив задержки сканирования применим только к экземпляру веб-сервера, на котором размещен файл robots.