
Что такое документная база данных?
Документная база данных – это тип нереляционных баз данных, предназначенный для хранения и запроса данных в виде документов в формате, подобном JSON. Документные базы данных позволяют разработчикам хранить и запрашивать данные в БД с помощью той же документной модели, которую они используют в коде приложения. Гибкий, полуструктурированный, иерархический характер документов и документных баз данных позволяет им развиваться в соответствии с потребностями приложений. Документная модель хорошо работает в таких примерах использования, как каталоги, пользовательские профили и системы управления контентом, где каждый документ уникален и изменяется со временем. Документные базы данных обеспечивают гибкость индексации, производительность выполнения стандартных запросов и аналитику наборов документов.
В следующем примере документ в формате, подобном JSON, описывает книгу.
[
{
"year" : 2013,
"title" : "Turn It Down, Or Else!",
"info" : {
"directors" : [ "Alice Smith", "Bob Jones"],
"release_date" : "2013-01-18T00:00:00Z",
"rating" : 6.
2,
"genres" : ["Comedy", "Drama"],
"image_url" : "http://ia.media-imdb.com/images/N/O9ERWAU7FS797AJ7LU8HN09AMUP908RLlo5JF90EWR7LJKQ7@@._V1_SX400_.jpg",
"plot" : "A rock band plays their music at high volumes, annoying the neighbors.",
"actors" : ["David Matthewman", "Jonathan G. Neff"]
}
},
{
"year": 2015,
"title": "The Big New Movie",
"info": {
"plot": "Nothing happens at all.",
"rating": 0
}
}
]
Управление контентом
Документная база данных – отличный выбор для приложений управления контентом, таких как платформы для блогов и размещения видео. При использовании документной базы данных каждая сущность, отслеживаемая приложением, может храниться как отдельный документ. Документная база данных позволяет разработчику с удобством обновлять приложение при изменении требований. Кроме того, если необходимо изменить модель данных, то требуется обновление только затронутых этим изменением документов. Для внесения изменений нет необходимости обновлять схему и прерывать работу базы данных.
Для внесения изменений нет необходимости обновлять схему и прерывать работу базы данных.
Каталоги
Документные базы данных эффективны для хранения каталожной информации. Например, в приложениях для интернет‑коммерции разные товары обычно имеют различное количество атрибутов. Управление тысячами атрибутов в реляционных базах данных неэффективно. Кроме того, количество атрибутов влияет на производительность чтения. При использовании документной базы данных атрибуты каждого товара можно описать в одном документе, что упрощает управление и повышает скорость чтения. Изменение атрибутов одного товара не повлияет на другие товары.
Amazon DocumentDB (совместима с MongoDB)
Amazon DocumentDB (совместима с MongoDB) — это быстрая, масштабируемая, высокодоступная и полностью управляемая документная база данных, которая поддерживает рабочие нагрузки MongoDB. Разработчики могут использовать в Amazon DocumentDB такой же код приложения, драйверы и инструменты для запуска, управления и масштабирования рабочей нагрузки, что и в MongoDB, при этом получая высокопроизводительную, масштабируемую и готовую к работе базу данных и не тратя время на управление базовой инфраструктурой.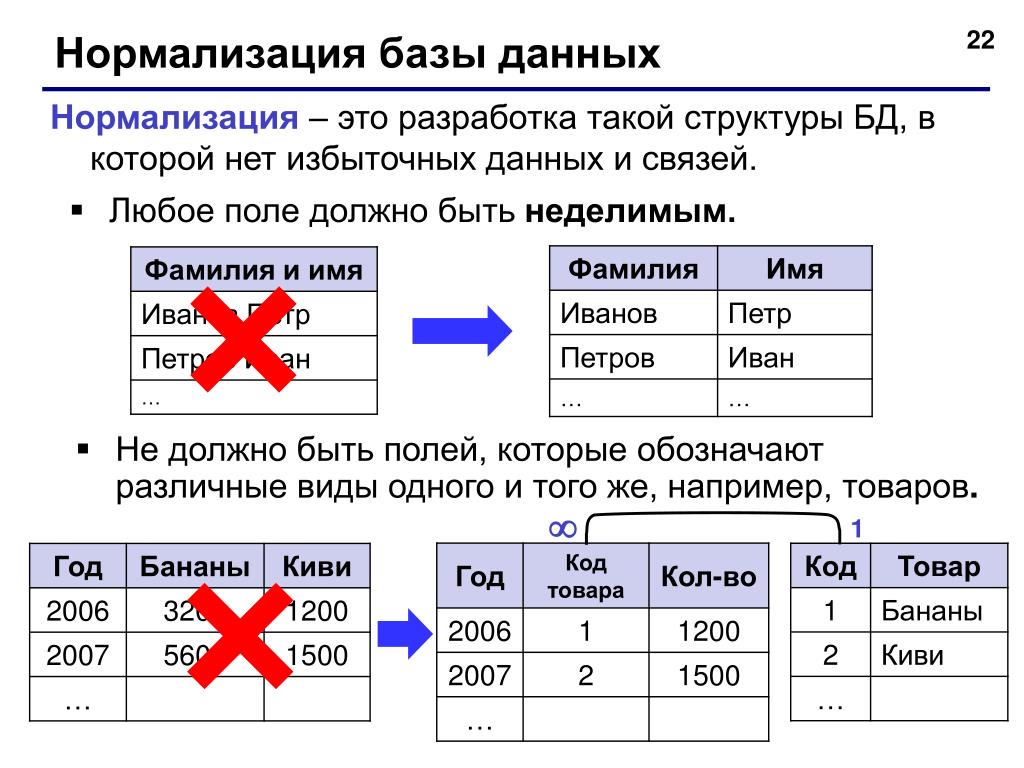
Начать работу с Amazon DocumentDB сегодня.
Вход в Консоль
Подробнее об AWS
- Что такое AWS?
- Многообразие, равенство и инклюзивность AWS
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Безопасность облака AWS
- Новые возможности
- Блоги
- Пресс‑релизы
Ресурсы для работы с AWS
- Начало работы
- Обучение и сертификация
- Библиотека решений AWS
- Центр архитектуры
- Вопросы и ответы по продуктам и техническим темам
- Аналитические отчеты
- Партнеры AWS
Разработчики на AWS
- Центр разработчика
- Пакеты SDK и инструментарий
- .NET на AWS
- Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
Поддержка
- Свяжитесь с нами
- Обратиться в службу поддержки
- Центр знаний
- AWS re:Post
- Обзор AWS Support
- Юридическая информация
- Работа в AWS
Amazon. com – работодатель равных возможностей. Мы предоставляем равные права представителям меньшинств, женщинам, лицам с ограниченными возможностями, ветеранам боевых действий и представителям любых гендерных групп любой сексуальной ориентации независимо от их возраста.
com – работодатель равных возможностей. Мы предоставляем равные права представителям меньшинств, женщинам, лицам с ограниченными возможностями, ветеранам боевых действий и представителям любых гендерных групп любой сексуальной ориентации независимо от их возраста.
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari. Подробнее »
Нереляционные данные и базы данных NoSQL — Azure Architecture Center
Нереляционная база данных — это база данных, в которой в отличие от большинства традиционных систем баз данных не используется табличная схема строк и столбцов. В этих базах данных применяется модель хранения, оптимизированная под конкретные требования типа хранимых данных. Например, данные могут храниться как простые пары «ключ — значение», документы JSON или граф, состоящий из ребер и вершин.
Все эти хранилища данных не используют реляционную модель. Кроме того, они, как правило, поддерживают определенные типы данных. Процесс запроса данных также специфический. Например, хранилища данных временных рядов рассчитаны на запросы к последовательностям данных, упорядоченных по времени. В свою очередь хранилища данных графов рассчитаны на анализ взвешенных связей между сущностями. Ни один из форматов не подходит в полней мере при выполнении задач управления данными о транзакциях.
Процесс запроса данных также специфический. Например, хранилища данных временных рядов рассчитаны на запросы к последовательностям данных, упорядоченных по времени. В свою очередь хранилища данных графов рассчитаны на анализ взвешенных связей между сущностями. Ни один из форматов не подходит в полней мере при выполнении задач управления данными о транзакциях.
Термин NoSQL применяется к хранилищам данных, которые не используют язык запросов SQL. Вместо этого они запрашивают данные с помощью других языков программирования и конструкций. На практике NoSQL означает «нереляционная база данных», даже несмотря на то, что многие из этих баз данных под держивают запросы, совместимые с SQL. Однако базовая стратегия выполнения запросов SQL обычно значительно отличается от применяемой в системе управления реляционной базой данных (реляционная СУБД).
В разделах ниже описаны основные категории нереляционных баз данных или баз данных NoSQL.
Хранилища данных документов
Хранилище данных документов управляет набором значений именованных строковых полей и данных объекта в сущности, которая называется документом.
Как правило, документ содержит все данные для сущности. Элементы, составляющие сущность, зависят от конкретного приложения. Например, сущность может содержать сведения о клиенте, заказе или их сочетание. Один документ может содержать сведения, которые в реляционной СУБД обычно распределяются по нескольким реляционным таблицам. Хранилище документов не требует, чтобы все документы имели одинаковую структуру. Такой свободный подход к форме обеспечивает большую гибкость. Например, приложения могут хранить в документах разные данные в соответствии с текущими требованиями компании.
Приложение может получать документы по ключу документа. Ключ — это уникальный идентификатор документа. Часто к нему применяется хэширование для равномерного распределения данных. Некоторые базы данных документов автоматически создают ключ документа. Другие позволяют указать атрибут документа, который будет использоваться в качестве ключа. Приложение также может запрашивать документы на основе значения одного или нескольких полей. Некоторые базы данных документов поддерживают индексирование, чтобы облегчить быстрый поиск документов по одному или нескольким индексированным полям.
Многие базы данных документов поддерживают обновления «на месте», то есть позволяют приложению изменять значения отдельных полей без перезаписи всего документа. Операции чтения и записи в нескольких полях одного документа обычно являются атомарными.
Соответствующие службы Azure:
- Azure Cosmos DB
Столбчатые хранилища данных
Столбчатое хранилище данных или хранилище семейств столбцов упорядочивает данные по столбцам и строкам.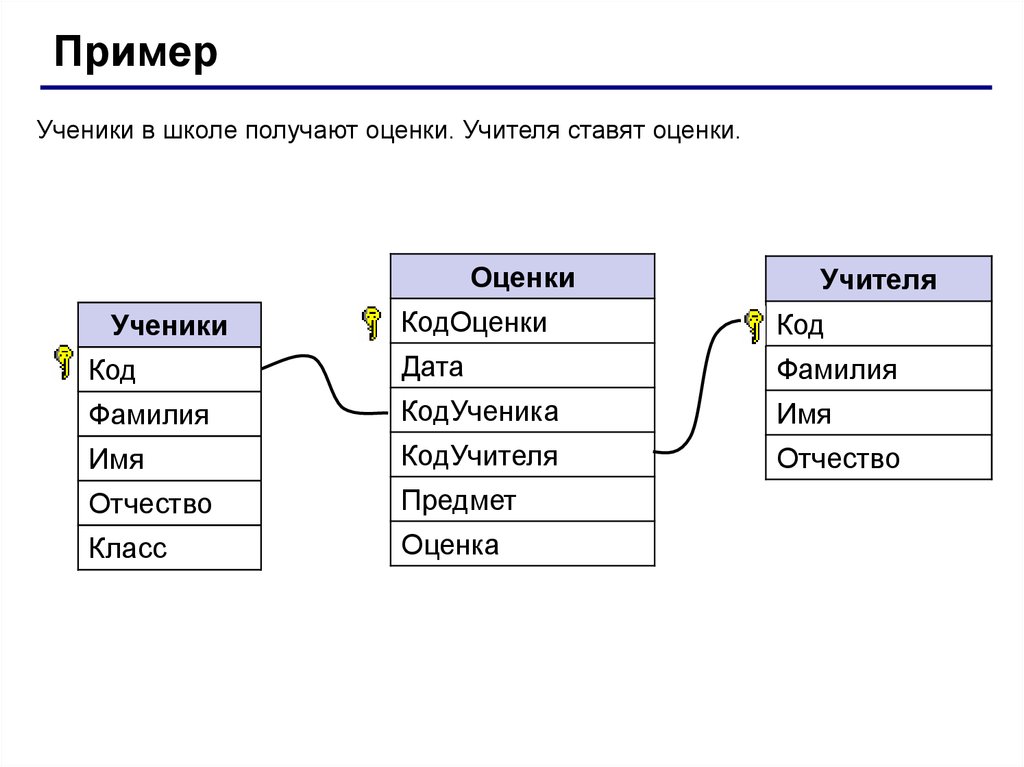 Столбчатое хранилище данных в простейшей форме почти неотличимо от реляционной базы данных, по крайней мере организационно. Настоящее преимущество столбчатого хранилища данных заключается в способности денормализованно структурировать разреженные данные, что связано со столбцово-ориентированным методом хранения данных.
Столбчатое хранилище данных в простейшей форме почти неотличимо от реляционной базы данных, по крайней мере организационно. Настоящее преимущество столбчатого хранилища данных заключается в способности денормализованно структурировать разреженные данные, что связано со столбцово-ориентированным методом хранения данных.
Столбчатое хранилище данных можно представить как набор табличных данных со строками и столбцами, в которых столбцы разделяются на определенные группы или семейства столбцов. Каждое семейство столбцов включает набор логически связанных столбцов, которые обычно извлекаются или управляются как единое целое. Другие данные, которые используются в других процессах, хранятся отдельно в других семействах столбцов. В семейство столбцов можно динамически добавить новые столбцы, а строки могут быть разреженными (то есть строки не обязаны иметь значение для каждого столбца).
На следующей диаграмме представлен пример таблицы с двумя семействами столбцов: Identity и Contact Info. Данные одной сущности имеют одинаковые ключи строк во всех семействах столбцов. Такая структура, в которой строки любого объекта в семействе столбцов могут динамически изменяться, определяет важное преимущество этой категории хранилищ. Семейства столбцов очень хорошо подходят для хранения данных с различными схемами.
Данные одной сущности имеют одинаковые ключи строк во всех семействах столбцов. Такая структура, в которой строки любого объекта в семействе столбцов могут динамически изменяться, определяет важное преимущество этой категории хранилищ. Семейства столбцов очень хорошо подходят для хранения данных с различными схемами.
В отличие от хранилища пар «ключ — значение» и баз данных документов, большинство столбчатых баз данных упорядочивают хранимые данные с помощью самих значений ключей, а не хэш-кодов от них. Ключ строки рассматривается как первичный индекс и обеспечивает доступ на основе определенного ключа или их диапазона. Некоторые реализации позволяют создавать вторичные индексы по определенным столбцам в семействе столбцов. Вторичные индексы позволяют получать данные по значениям столбцов, а не ключам строки.
Все столбцы одного семейства хранятся на диске в одном файле. Каждый файл содержит определенное число строк. При использовании больших наборов данных этот подход позволяет повысить производительность за счет снижения объема данных, которые необходимо считывать с диска, когда отправляется запрос на получение нескольких столбцов за раз.
Чтение и запись строки из одного семейства столбцов — это обычно атомарные операции. Однако некоторые реализации поддерживают атомарность всей строки, распределенной по нескольким семействам столбцов.
Соответствующие службы Azure:
- Azure Cosmos DB для Apache Cassandra
- Использование HBase в HDInsight
Хранилище пар «ключ — значение»
Хранилище пар «ключ — значение» по сути представляет собой большую хэш-таблицу. Каждое значение сопоставляется с уникальным ключом, и хранилище ключей использует этот ключ для хранения данных, применяя к нему некоторую функцию хэширования. Выбор функции хэширования должен обеспечить равномерное распределение хэшированных ключей по хранилищу данных.
Большинство хранилищ пар «ключ — значение» поддерживают только самые простые операции запроса, вставки и удаления. Чтобы частично или полностью изменить значение, приложение всегда перезаписывает существующее значение целиком. В большинстве реализаций атомарной операцией считается чтение или запись одного значения.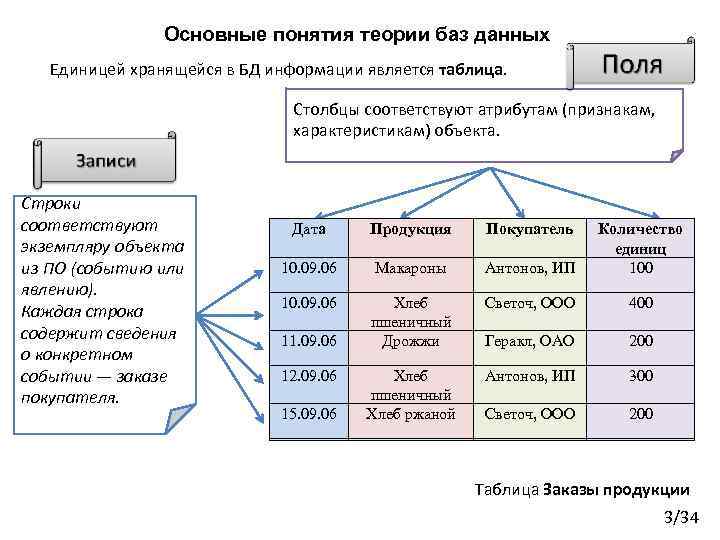
Приложение может хранить в наборе значений произвольные данные, но некоторые хранилища пар «ключ — значение» накладывают ограничения на максимальный размер значений. Программное обеспечение хранилища ничего не знает о значениях, которые в нем хранятся. Все сведения о схеме поддерживаются и применяются на уровне приложения. Эти значения по существу являются большими двоичными объектами, которые хранилище извлекает и сохраняет по соответствующему ключу.
Хранилища пар «ключ — значение» рассчитаны на приложения, выполняющие простые операции поиска на основе значения ключа или диапазона ключей, но не очень подходят для систем, которым нужно запрашивать данные из нескольких таблиц хранилищ пар «ключ — значение», например присоединенные данные в нескольких таблицах.
Кроме того, хранилища пар «ключ — значение» неудобны в сценариях, где могут выполняться запросы или фильтрация по значению, а не только по ключам. Например, в реляционной базе данных вы можете найти определенную запись с помощью предложения WHERE и отфильтровать ее по неключевым столбцам, но хранилища пар «ключ-значение» обычно не поддерживают такую возможность поиска значений или же этот процесс выполняется медленно.
Например, в реляционной базе данных вы можете найти определенную запись с помощью предложения WHERE и отфильтровать ее по неключевым столбцам, но хранилища пар «ключ-значение» обычно не поддерживают такую возможность поиска значений или же этот процесс выполняется медленно.
Одно хранилище пар «ключ — значение» очень легко масштабируется, поскольку позволяет удобно распределить данные среди нескольких узлов на разных компьютерах.
Соответствующие службы Azure:
- Azure Cosmos DB для таблицы
- Кэш Azure для Redis
- хранилище таблиц Azure
Хранилища данных графов
Хранилища данных графов управляют сведениями двух типов: узлами и ребрами. Узлы в этом случае представляют сущности, а ребра определяют связи между ними. Узлы и грани имеют свойства, которые предоставляют сведения о конкретном узле или грани, примерно как столбцы в реляционной таблице. Грани могут иметь направление, указывающее на характер связи.
Хранилища данных графов позволяют приложениям эффективно выполнять запросы, которые проходят через сеть узлов и ребер, а также анализировать связи между сущностями. На схеме ниже представлены данные персонала организации, структурированные в виде графа. Сущностями здесь являются сотрудники и отделы, а грани определяют отношения подчинения и отдел, в котором работает каждый сотрудник. Стрелки на ребрах этого графа показывают направление связей.
На схеме ниже представлены данные персонала организации, структурированные в виде графа. Сущностями здесь являются сотрудники и отделы, а грани определяют отношения подчинения и отдел, в котором работает каждый сотрудник. Стрелки на ребрах этого графа показывают направление связей.
Такая структура позволяет легко выполнять такие запросы, как «найти всех сотрудников, которые прямо или косвенно подчиняются Светлане» или «найти всех, кто работает в одном отделе с Дмитрием». Процессы сложного анализа выполняются быстро даже на больших графах с большим количеством сущностей и связей. Многие базы данных графов предоставляют язык запросов, который можно использовать для эффективного обхода сети связей.
Соответствующие службы Azure:
- API Graph в Azure Cosmos DB
Хранилища данных временных рядов
Данными временных рядов называются наборы значений, которые упорядочены по времени. Соответственно хранилища данных временных рядов оптимизированы для хранения данных именно такого типа. Хранилища данных временных рядов должны поддерживать очень большое число операций записи, так как обычно в них в режиме реального времени собирается большой объем данных из большого количества источников. Эти хранилища также хорошо подходят для хранения данных телеметрии. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.
Хранилища данных временных рядов должны поддерживать очень большое число операций записи, так как обычно в них в режиме реального времени собирается большой объем данных из большого количества источников. Эти хранилища также хорошо подходят для хранения данных телеметрии. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.
Размер отдельных записей в базе данных временных рядов обычно невелик, но их очень много, а значит общий размер данных быстро увеличивается. Хранилища данных временных рядов также обрабатывают данные, полученные вне очереди или несвоевременно, автоматически индексируют точки данных и оптимизируют запросы, полученные в течение определенного промежутка времени. Эта последняя возможность позволяет быстро выполнять запросы к миллионам точек данных и нескольким потокам данных, что, в свою очередь, обеспечивает поддержку визуализации временных рядов (стандартный способ потребления данных временных рядов).
Дополнительные сведения см. в статье Решения для временных рядов.
Соответствующие службы Azure:
- Аналитика временных рядов Azure
- OpenTSDB с HBase в HDInsight
Хранилище данных объектов
Хранилища данных объектов оптимизированы для хранения и извлечения больших двоичных объектов, например изображений, текстовых файлов, видео- и аудиопотоков, объектов данных и документов приложений большого размера, образы дисков виртуальных машин. Объект состоит из сохраненных данных, метаданных и уникального идентификатора доступа к объекту. Хранилища объектов поддерживают отдельные большие файлы, а также позволяют управлять всеми файлами за счет внушительного общего объема хранилища.
Некоторые хранилища данных объектов реплицируют определенный большой двоичный объект между несколькими узлами кластера, что обеспечивает быстрое параллельное чтение. Этот процесс, в свою очередь, позволяет реализовать масштабируемую архитектуру запроса данных, хранящихся в больших файлах, так как несколько процессов, обычно выполняющихся на разных серверах, могут одновременно запрашивать большие файлы данных.
Часто хранилища данных объектов используют как сетевые общие папки. Доступ к файлам, хранящимся в этих папках, можно получить через компьютерную сеть с использованием стандартных сетевых протоколов, например SMB. Если созданы необходимые механизмы поддержки безопасности и одновременного доступа, такое совместное использование данных позволяет распределенным службам с высокой степенью масштабируемости предоставлять доступ к данным для базовых низкоуровневых операций, то есть для простых запросов на чтение и запись.
Соответствующие службы Azure:
- Хранилище BLOB-объектов Azure
- Azure Data Lake Storage
- Хранилище файлов Azure
Хранилища данных внешних индексов
Хранилища данных внешних индексов позволяют искать информацию, содержащуюся в других хранилищах данных и службах. Внешний индекс выступает в роли вторичного индекса любого хранилища данных. Кроме того, с его помощью можно индексировать большие объемы данных и предоставлять доступ к этим индексам почти в реальном времени.
Например, в файловой системе могут храниться текстовые файлы. По пути файл можно найти быстро, но поиск на основе содержимого выполняется медленно, так как сканируются все файлы. Внешний индекс позволяет создавать вторичные индексы, а затем быстро искать путь к файлам, соответствующим заданным условиям. Рассмотрим еще один пример использования внешнего индекса. Предположим, что хранилища пар «ключ — значение» поддерживают индексирование только по ключу. Вы можете создать вторичный индекс на основе значений данных и быстро найти ключ, однозначно определяющий каждый соответствующий элемент.
Индексы создаются в процессе индексирования, который может выполняться по модели извлечения, то есть по требованию хранилища данных, или по модели передачи, то есть по команде из кода приложения. В некоторых системах поддерживаются многомерные индексы и полнотекстовый поиск по большим объемам текстовых данных.
Часто хранилища данных внешних индексов используют для реализации полнотекстового поиска и поиска в Интернете. В этих случаях поддерживается точный или нечеткий поиск. Нечеткий поиск находит документы, которые соответствуют набору условий, и вычисляет для них коэффициент совпадения с этим набором. Некоторые внешние индексы также поддерживают лингвистический анализ, который возвращает соответствия с учетом синонимов, категорий (например, при поиске по запросу «собаки» соответствием считается «питомцы») и морфологии (например, при поиске по запросу «бег» соответствием считается «бегущий»).
В этих случаях поддерживается точный или нечеткий поиск. Нечеткий поиск находит документы, которые соответствуют набору условий, и вычисляет для них коэффициент совпадения с этим набором. Некоторые внешние индексы также поддерживают лингвистический анализ, который возвращает соответствия с учетом синонимов, категорий (например, при поиске по запросу «собаки» соответствием считается «питомцы») и морфологии (например, при поиске по запросу «бег» соответствием считается «бегущий»).
Соответствующие службы Azure:
- Поиск Azure
Стандартные требования
Часто архитектура нереляционных хранилищ данных отличается от архитектуры реляционных баз данных. В частности эти хранилища, как правило, не имеют фиксированной схемы, а также не поддерживают транзакции или ограничивают их область. Из соображений масштабируемости они обычно не включают вторичные индексы.
В таблице ниже приведено сравнение требований каждого нереляционного хранилища данных.
| Требование | Хранилище данных документов | Столбчатое хранилище данных | Хранилище данных пар «ключ — значение» | Хранилище данных графов |
|---|---|---|---|---|
| Нормализация | Денормализированные данные | Денормализированные данные | Денормализированные данные | Нормализированные данные |
| схема | Схема при чтении | Семейства столбцов, определенные при записи, схема столбца при чтении | Схема при чтении | Схема при чтении |
| Согласованность (между параллельными транзакциями) | Настраиваемый уровень согласованности, гарантии на уровне документа | Гарантии на уровне семейства столбцов | Гарантии на уровне ключей | Гарантии на уровне графа |
| Атомарность (область транзакции) | Коллекция | Таблица | Таблица | График |
| Стратегия блокировки | Оптимистичная (без блокировки) | Пессимистичная (блокировка строк) | Оптимистичная (ETag) | |
| Шаблон доступа | Прямой доступ | Статистические выражения на основе данных большого формата | Прямой доступ | Прямой доступ |
| Индексация | Первичный и вторичные индексы | Первичный и вторичные индексы | Только первичный индекс | Первичный и вторичные индексы |
| Форма представления данных | Документ | Таблица с семействами столбцов | Ключ и значение | Граф с ребрами и вершинами |
| разреженные; | Да | Да | Да | Нет |
| Масштабность (большое количество столбцов и атрибутов) | Да | Да | Нет | Нет |
| Размер данных | От малого (КБ) до среднего (несколько МБ) | От среднего (МБ) до большого (несколько ГБ) | Небольшой (КБ) | Небольшой (КБ) |
| Общий максимальный масштаб | Очень большой (ПБ) | Очень большой (ПБ) | Очень большой (ПБ) | Большой (ТБ) |
| Требование | Данные временных рядов | Хранилище данных объектов | Хранилище данных внешних индексов |
|---|---|---|---|
| Нормализация | Нормализированные данные | Денормализированные данные | Денормализированные данные |
| схема | Схема при чтении | Схема при чтении | Схема при записи |
| Согласованность (между параллельными транзакциями) | Н/Д | Н/Д | Н/Д |
| Атомарность (область транзакции) | Н/Д | Объект | Н/Д |
| Стратегия блокировки | Н/Д | Пессимистичная (блокировка больших двоичных объектов) | Н/Д |
| Шаблон доступа | Прямой доступ и агрегирование | Последовательный доступ | Прямой доступ |
| Индексация | Первичный и вторичные индексы | Только первичный индекс | Н/Д |
| Форма представления данных | Таблица | Большой двоичный объект и метаданные | Документ |
| разреженные; | нет | Н/Д | Нет |
| Масштабность (большое количество столбцов и атрибутов) | Нет | Да | Да |
| Размер данных | Небольшой (КБ) | От большого (ГБ) до очень большого (ТБ) | Небольшой (КБ) |
| Общий максимальный масштаб | Большой (несколько ТБ) | Очень большой (ПБ) | Большой (несколько ТБ) |
Соавторы
Эта статья поддерживается Майкрософт. Первоначально она была написана следующими авторами.
Первоначально она была написана следующими авторами.
Основной автор:
- | Зойнер Теджада Генеральный директор и архитектор
Дальнейшие действия
- Реляционные и Данные NoSQL
- Общие сведения о распределенных базах данных NoSQL
- Основы данных в Microsoft Azure: изучение нереляционных данных в Azure
- Реализация нереляционной модели данных
- Разработка архитектуры баз данных
- Основные сведения о моделях хранилищ данных
- Масштабируемая обработка заказов
- Обработка данных Lakehouse практически в реальном времени
Bd Определение и значение — Merriam-Webster
1 из 2
1
баррелей в сутки
4
граница
5
пачка
БД
2 из 2
1
бакалавр богословия
2
банковская тратта
3
купюры со скидкой
4
обезвреживание бомб
5
сбиты
История слов
Словарные статьи рядом с
bdБД
бд
бдэ
Посмотреть другие записи поблизости
Процитировать эту запись «Бд.
 » Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/bd. По состоянию на 27 января 2023 г.
» Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/bd. По состоянию на 27 января 2023 г.Ссылка на копию
Медицинское определение
bd.
сокращение
два раза в день
— используется при выписывании рецептов
История и этимология bd
Latin bis die
Подпишитесь на крупнейший словарь Америки и получите тысячи дополнительных определений и расширенный поиск без рекламы!
Merriam-Webster без сокращений
вилять
См. Определения и примеры »
Определения и примеры »
Получайте ежедневно по электронной почте Слово дня!
Большая британская викторина по словарному запасу
- Названный в честь сэра Роберта Пиля, как называется британская полиция?
- Робби Пилхеды
- Бобби Берти
Проверьте свои знания и, возможно, узнаете что-нибудь по ходу дела.
ПРОЙДИТЕ ТЕСТ
Сможете ли вы составить 12 слов из 7 букв?
ИГРАТЬ
Слова в игре
14 слов, вдохновленных собаками
Лучший друг лексикографа
Большой список красивых и бесполезных слов, Vol.
4Больше слов, больше красивых, больше бесполезных
«Серый» и «серый»: в чем разница?
Орфография не всегда однозначна.
Когда впервые были использованы слова?
Найдите любой год, чтобы узнать
 4
4Спросите у редакторов
Странные множественные числа
Один гусь, два гуся. Один лось, два… лось. Чт…
независимо
На самом деле это настоящее слово (но это не значит…
Принести или взять
Оба слова означают движение, но разница может быть.
..Дефенестрация
Увлекательная история любимых многими людей…
 ..
..Игра слов
Что было первым?
«Леггинсы» или «мамины джинсы»? «Chillax» или «мусорный контейнер»…
Пройди тест
Мегавикторина «Назови эту вещь»: Vol. 4
Проверьте свой визуальный словарный запас!
Пройди тест
Правда или ложь?
Проверьте свои знания и, возможно, узнаете что-то новое…
Пройдите тест
Орфографическая викторина
Сможете ли вы превзойти прошлых победителей национального конкурса Spelli.
..Примите участие в викторине
 ..
..Что означает BD? Бесплатный словарь
Также найдено в: Словарь, Тезаурус, Медицина, Финансы, Энциклопедия, Википедия.
Фильтр категорий: Показать все (140)Наиболее распространенные (5)Технологии (21)Правительство и военные (19)Наука и медицина (37)Бизнес (22)Организации (19)Сленг / жаргон (35)
| Акроним | Определение | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BD | Доска | |||||||||||||
| BD | День рождения | |||||||||||||
BD 66| BD | Baud | BD | Bachelor of Divinity | BD | Bangladesh (top-level domain name) | BD | Bermuda | BD | Blu -ray Disc | BD | Bound | BD | Base de Datos (испанский: База данных) | |
| BD | Broker Dealer (securities firm) | |||||||||||||
| BD | Band (German: Volume [books]) | |||||||||||||
| BD | Bob Dylan (singer) | |||||||||||||
| BD | Belly Dance | |||||||||||||
| BD | Bis in Die (Latin: twice a day) | |||||||||||||
| BD | Break Down | |||||||||||||
| BD | Business Development | |||||||||||||
| BD | Boulevard | |||||||||||||
| BD | Bipolar Disorder | |||||||||||||
| BD | Block Diagram | |||||||||||||
| BD | Bass Drum | |||||||||||||
| BD | Business Day | |||||||||||||
| BD | Bundle | |||||||||||||
| BD | Bradford (почтовый индекс, Великобритания) | |||||||||||||
| BD | Blue Diamond | BD10226 | Breaking Dawn | |||||||||||
| BD | Black Dog (White-Wolf’s game studio) | |||||||||||||
| BD | La Bande Dessinee | |||||||||||||
| BD | Boundary | |||||||||||||
| BD | Bank Draft | |||||||||||||
| BD | Black Dragon (gaming) | |||||||||||||
| BD | Back Door | |||||||||||||
| BD | Beaver Dam | |||||||||||||
| BD | Brain Damage (Pink Floyd song/fanzine) | |||||||||||||
| BD | Bandes Dessinées (French: Comic Books) | |||||||||||||
| BD | Becton Dickinson and Company | |||||||||||||
| BD | Birth Defect | |||||||||||||
| BD | Бородатый дракон | .|||||||||||||
| BD | Blue Devils (Drum and Bugle Corps; Concord, CA) | |||||||||||||
| BD | ||||||||||||||
| BD | ||||||||||||||
| BD | ||||||||||||||
| BD | ||||||||||||||
| BD | ||||||||||||||
| BD) | Bile Duct | |||||||||||||
| BD | Bone Dry | |||||||||||||
| BD | British Midland (IATA airline code) | |||||||||||||
| BD | Barrels per Day | |||||||||||||
| BD | Bob Dole | |||||||||||||
| BD | Building Department | |||||||||||||
| BD | Barndoor | |||||||||||||
| BD | Binomial Distribution | |||||||||||||
| BD | BlueDragon (computer parsing engine) | |||||||||||||
| BD | Устройство Bluetooth | |||||||||||||
| BD | Расстройство поведения | |||||||||||||
| BD | Брейк-данс | |||||||||||||
| BD | Ben Drowned (Creepypasta) | |||||||||||||
| BD | Blowdown | |||||||||||||
| BD | Bomb Disposal | |||||||||||||
| BD | Bastardidentro (Italian video) | |||||||||||||
| BD | Bondage & Discipline | |||||||||||||
| BD | Двоично-десятичный | |||||||||||||
| BD | Beedi (индийская сигара) | Словарь 6 BD | 0226 | |||||||||||
| BD | Body Development (gaming) | |||||||||||||
| BD | Behcet’s Disease | |||||||||||||
| BD | Birth Doula (childbirth) | |||||||||||||
| BD | Big Dawg | |||||||||||||
| BD | Black Disciples (банда; Чикаго, Иллинойс) | |||||||||||||
| BD | Барон Дэвис (игрок НБА) | |||||||||||||
| 0258 (electronics) | ||||||||||||||
| BD | Brought Down | |||||||||||||
| BD | Base de Donnée (French: Database) | |||||||||||||
| BD | budget deficit | |||||||||||||
| BD | Binary Digit | |||||||||||||
| BD | Плотность тела (Анализ композиций тела) | |||||||||||||
| BD | Дисконтированные | 25 BDS | 25 BD. |
 0258 (Бостон, Массачусетс, США)
0258 (Бостон, Массачусетс, США)