
Мета тег noindex | SEO продвижение сайта в Санкт-Петербурге
Мета тег Noindex известен тем, что закрывает поисковым системам возможность осуществлять процесс индексации того фрагмента страницы сайта, который по каким-либо причинам необходимо вывести из поля зрения поисковых роботов. Иными словами, при использовании данного тега часть страницы запрещается к прочтению и обработке поисковым ботом.
Как работает мета тег noindex и где его используют
Поводов для использования мета тега Noindex множество, одна из них — наличие на странице малозначительной информации, которая используется для заполнения контента.
Под такой контент подпадает часто повторяющийся текст — объявления, формы подписки и почтовые рассылки, счетчики посещений, информация с баннеров, сайдбаров и прочее. Целесообразно использовать Noindex для того, чтобы при лавинообразном наполнении сайта «спрятать» от поискового робота копипаст.
Работает мета Тег Noindex стандартно, он имеет обычное оформление, открывающий и закрывающий теги. И все, что включено внутрь этих тегов, не попадает в индексацию роботов. К тому же этот тег не очень требователен к размещению, так как он будет выполнять свои функции и при неправильной вложенности.
Однако тег Noindex не настолько универсален, чтобы работать со всеми поисковыми системами. Noindex, как ограничивающий тег в гипертекстовой разметке HTML-страниц, предлагался для встраивания именно российской поисковой системой Яндекс.
Такая операция с окружением контента на странице тегом Noindex гарантированно сработает только лишь в случае индексации Рамблером и Яндексом. Google всемогущий и Yahoo! на такую разметку не ведутся и используют собственные инструменты управления индексацией.
Впрочем, если необходимо скрыть всю страницу полностью, то можно воспользоваться специальным мета–тегом, прописав noindex в файле robots. txt, — этот подход сработает и для российских, и для иностранных поисковиков.
txt, — этот подход сработает и для российских, и для иностранных поисковиков.
В этом случае робот того же Яндекса проиндексирует всю страницу, но затем отфильтрует значения в соответствии с проставленными тегами и робот исключит запрещенное Noindex содержание страницы.
Пример функционирования Noindex
Тег Noindex вполне может выступать как некий автоматический администратор, помогающий редактировать контент на сайте и «вычеркивать» засоряющие элементы.
Оптимизаторам приходится нелегко. Чтобы разместить внешние ссылки на свой сайт, они часто прибегают к таким «серым» методам, как выставление ссылок в блогах, электронных опросниках, энциклопедиях, статейниках и прочих посещаемых ресурсах.
Как правило, на таких ресурсах очень высокая пользовательская активность, и страницы заполняются молниеносно. Однако такие ссылки для поисковика являются спамом на публичном сайте. Чтобы избежать снижения эффективности и загрязнения своего сайта, надо использовать в ссылках тег Noindex. Этот тег избавит от необходимости ручной правки текстов и ссылок.
Этот тег избавит от необходимости ручной правки текстов и ссылок.
Есть ещё один мета тег, работа которого практически схожа с Noindex, но применяется он для других случаев. Это метатег Nofollow и подробнее о нём можно почитать здесь.
Вместо заключения
Хотите выйти в ТОП10 Яндекс и долго там оставаться? Продвигайте свои сайты и интернет-магазины исключительно белыми SEO методами! Не умеете? Могу научить! Тем, кто хочет разобраться во всех премудростях SEO, предлагаю посетить мои курсы по SEO обучению, которые я провожу индивидуально, в режиме онлайн по скайпу.
Записаться на SEO обучение
Для тех, у кого нет времени проходить обучение и самостоятельно заниматься продвижением своих интернет-магазинов, предлагаю и в этом вопросе помощь. Я могу взять ваш сайт на SEO продвижение и за несколько месяцев вывести его в ТОП10 Яндекс. Для того чтобы убедиться в моей экспертности, предлагаю ознакомиться с моими последними SEO кейсами и только после этого заказать у меня SEO продвижение. Ниже на видео один из примеров успешного продвижения строительного сайта в Санкт-Петербурге.
Я могу взять ваш сайт на SEO продвижение и за несколько месяцев вывести его в ТОП10 Яндекс. Для того чтобы убедиться в моей экспертности, предлагаю ознакомиться с моими последними SEO кейсами и только после этого заказать у меня SEO продвижение. Ниже на видео один из примеров успешного продвижения строительного сайта в Санкт-Петербурге.
Заказать SEO продвижение сайта
SEO продвижение сайта по России:
Рейтинг моего сайта в Яндекс:
noindex
- Популярные
- Последние
- Без ответа
-
Как и почему? Маил.
 Вебмастер <meta name=»robots» content=»noindex»/>
Есть решение
Вебмастер <meta name=»robots» content=»noindex»/>
Есть решение
Что за код в странице?Откуда и почему он берется?на что влияет?<meta name=»robots» content=»noindex»/>Категорически отказывается добавлять в Маил.Вебмастер сайт B-Onix.ru Начало кода несчастной главной страницы.<!DOCTYPE…
-
Заходим в витрина => шаблоны => index.
html и в head пишем <!— начало эксперимента —>
{if $smarty.server.REQUEST_URI == «`$wa->shop->productUrl($product, ‘reviews’)`»}
{$canonical_reviews =… -
noindex
Подскажите что обозначает данный синтаксис в файле index.html{if !empty($nofollow)}<meta name=»robots» content=»noindex,nofollow» />{/if}
-
Как закрыть теги в noindex в блоге?
В файле blogTag.
plugin.php нужно закрыть теги, которые отображается в блоге под новостью. В php не силен, но как не пробовал не получается.
<?php
class blogTagPlugin extends blogPlugin
{
public function postSearch($options)
{…
 org/Question»>
org/Question»>
Доброго времени суток, поясните пожалуйста код (самый последний), что он делает? На сколько я могу понять, то он судя по этой строке: <meta name=»robots» content=»noindex,nofollow» /> <meta name=»robots»…
 Вебмастер <meta name=»robots» content=»noindex»/>
Есть решение
Вебмастер <meta name=»robots» content=»noindex»/>
Есть решение
 html и в head пишем <!— начало эксперимента —>
{if $smarty.server.REQUEST_URI == «`$wa->shop->productUrl($product, ‘reviews’)`»}
{$canonical_reviews =…
html и в head пишем <!— начало эксперимента —>
{if $smarty.server.REQUEST_URI == «`$wa->shop->productUrl($product, ‘reviews’)`»}
{$canonical_reviews =… org/Question»>
org/Question»>
Необходимо добавить <meta name=»robots» content=»noindex, follow» > на некоторые служебные страници, такие как «Доставка» «Оплата» «О нас»Может это можно сделать в дополнительных параметрах…
 plugin.php нужно закрыть теги, которые отображается в блоге под новостью. В php не силен, но как не пробовал не получается.
<?php
class blogTagPlugin extends blogPlugin
{
public function postSearch($options)
{…
plugin.php нужно закрыть теги, которые отображается в блоге под новостью. В php не силен, но как не пробовал не получается.
<?php
class blogTagPlugin extends blogPlugin
{
public function postSearch($options)
{…Файл robots.txt, теги noindex и nofollow, а также настройка sitemap.xml (карты сайта)
- Главная
- Оптимизация сайта в деталях
- Сопутствующие настройки сайта
Файл robots.txt
Файл robots.txt – это текстовый файл, который находится в корневой директории сайта и используется для того, чтобы управлять страницами, индексируемыми поисковым роботом. Robots.txt может запрещать поисковому роботу двигаться по сайту и индексировать содержимое сайта.
Работа с данным файлом требует определенных знаний, но отказываться от его использования нельзя. Роботы поисковых систем обычно следуют директивам, расположенным в robots.
Чтобы проверить наличие файла robots.txt, наберите в браузере следующий URL (вместо site.ru – название вашего домена):
Если по этому адресу выдается какое-либо другое содержание, помимо текстового файла с директивами для поисковых роботов, это означает, что файл отсутствует на сайте и следует загрузить файл robots.txt в корневую директорию сайта, прописав для него корректное содержание.
Неграмотно составленный файл robots.txt ограничивает поисковому роботу доступ к релевантной информации и сокращает количество проиндексированного контента на сайте, что противоречит основной цели оптимизации: позволить роботу проиндексировать как можно больше полезного и качественного контента.
Самый простой способ закрыть сайт от индексации – прописать в файле robots.txt «Disallow: /». Часто данной конструкцией пользуются при редизайне или создании сайта, когда не нужно, чтобы поисковый робот проиндексировал недоделанные страницы. Но обязательно после завершения всех работ нужно снять это ограничение. Чтобы проверить свой сайт на предмет запрета индексации, необходимо зайти по адресу www.site.ru/robots.txt (вместо site.ru ваш сайт) и посмотреть содержание директивы Disallow.
Конструкцию «Disallow: /» следует заменить на «Аllow: /» или «Disallow: ».
При помощи различных конструкций можно закрывать от индексации одни разделы сайта, открывать другие и даже работать с отдельными страницами. Однако при работе с robots.txt следует быть предельно внимательным: неверно используя конструкции «Allow-Disallow», можно случайно закрыть от индексации раздел с полезной и уникальной информацией.
Рассмотрим ситуацию, при которой может возникнуть ошибка с использованием конструкции «Allow- Disallow».
На сайте есть раздел, посвященный технике. Он не полностью готов, и мы не хотим, чтобы он индексировался. Для этого мы закрываем его индексацию: «Disallow: / catalog». Но из-за этой конструкции мы закрываем от индексации отлично работающий и полный раздел про автомобили (/catalog/ auto). Правильно было бы закрыть раздел «Disallow: /catalog/ tech».
Чтобы проверить, индексируется какой-либо раздел сайта или нет, можно воспользоваться сервисами «Проверить URL» или «Проверить robots.txt». При использовании инструмента «Проверить URL» необходимо ввести адрес любой страницы из проверяемого раздела в соответствующую строку. Если раздел запрещен к индексации, то появится оповещение. При использовании инструмента «Проверить robots.txt» следует указать, с какого сайта загрузить robots.txt. Затем через ссылку «Добавить» нужно указать список URL для проверки. После нажатия на кнопку «Проверить» по каждому введенному адресу будет указан результат проверки. Рассмотрим на следующей странице пример.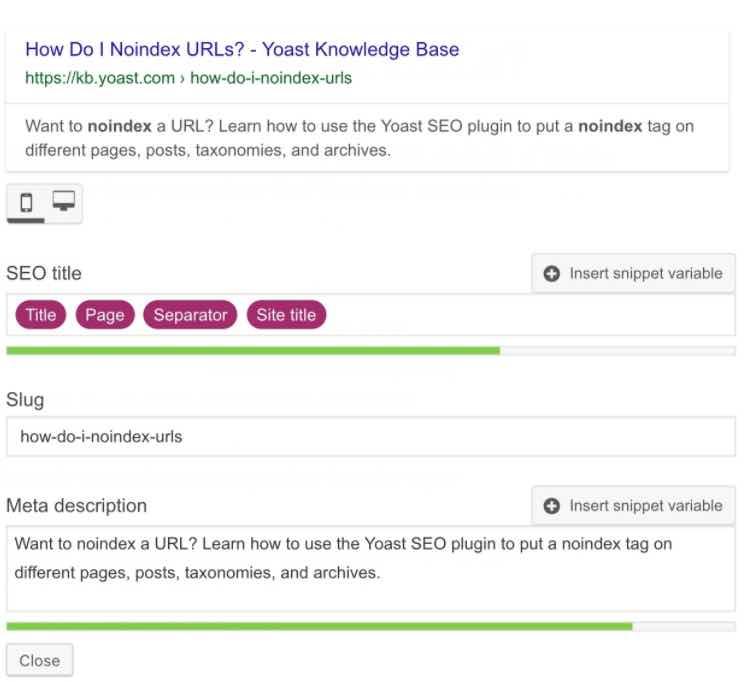
Полезными для посетителя являются такие страницы, как новости, галереи, разного рода статьи. Даже если информация не уникальна, мы её не закрываем от индексации. Закрываем от индексации только пустые страницы, на которых нет контента, кроме основного дизайна сайта, дорвеи, полный дубль внутри сайта.
При составлении технического задания на доработки сайта обязательным шагом является проверка файла robots.txt. Нужно посмотреть, какие каталоги и страницы закрыты от индексации директивой Disallow. По возможности нужно зайти на эти страницы и оценить, насколько их содержание полезно для пользователя и для поисковых роботов. Если закрытые каталоги и страницы представляют ценность для пользователя и для поисковых роботов и не являются служебными каталогами и дубликатами страниц, нужно открыть их для индексации, изменив содержание директивы Disallow.
Noindex и nofollow
Запретить индексировать ту или иную страницу можно не только с помощью файла robots. txt, но и с помощью мета-тега «ROBOTS» в заголовках каждой страницы. Данному мета-тегу могут соответствовать 4 значения, которые указываются в атрибуте CONTENT:
txt, но и с помощью мета-тега «ROBOTS» в заголовках каждой страницы. Данному мета-тегу могут соответствовать 4 значения, которые указываются в атрибуте CONTENT:
- index — индексировать,
- noindex — не индексировать,
- follow — следовать по ссылкам,
- nofollow — не следовать по ссылкам.
Если «index» и «follow» навредить не могут (их необходимо использовать только при открытии какой-то страницы для индексации и учета ссылок), то неверно расставленные «noindex» и «nofollow» могут представлять угрозу.
Если на странице присутствует следующий код, то данная страница будет недоступна для поискового робота, и она не будет участвовать в ранжировании.
Если мы хотим, чтобы страница индексировалась, но не передавала вес ни по одной ссылке, чтобы робот не переходил по ссылкам с данной страницы, то следует использовать следующий код.
Если же требуется применить оба правила, то в атрибуте «content» через запятую указываются два параметра.
Если с файлом robots.txt все в порядке, но страница никак не хочет индексироваться, следует проверить мета-теги «robots» на ней. Это можно сделать как вручную, так и с помощью Яндекс.Вебмастер. В разделе «Исключенные страницы» будет указана категория «Документ содержит мета-тег noindex».
А что делать, если требуется запретить к индексации не всю страницу, а отдельные фрагменты кода? Например, если они содержат бесполезный или неуникальный контент? Поможет тег <noindex></noindex>.
Работать с ним просто – в коде сайта необходимо заключить соответствующий текст между этими тегами. Например,
Перебарщивать с данным тегом нельзя. Поисковая система будет видеть несвязный текст или его отсутствие в зависимости от закрытия, и данная страница может посчитаться спамной.
Атрибут rel ссылки со значением «nofollow» сообщает поисковой системе, что данную гиперссылку не следует учитывать при индексировании страницы. Например,
Поисковые системы не учитывают ссылки с таким атрибутом при расчёте индекса цитирования веб-ресурсов. Закрывая таким образом ссылки, мы сохраняем вес страницы на сайте, не передавая его внешним сайтам.
Настройка sitemap.xml
Sitemap.xml – это файл формата xml, содержащий ссылки на все страницы сайта, подлежащие индексации поисковыми системами. С помощью этого файла можно указать роботу-индексатору, какие страницы следует индексировать, как часто это стоит делать и какие страницы имеют наибольшее значение. Поэтому помимо адресов страниц сайта в xml карте сайта также могут содержаться относящиеся к ним данные:
Sitemap.xml особенно актуален для крупных ресурсов, содержащих большое количество страниц (например, для интернет-магазинов). Ведь поисковому роботу уже не нужно будет ходить по сайту, фиксируя адреса страниц и прочую информацию – он может обратиться к xml карте сайта и взять готовую структуру ресурса.
- <lastmod> — время последнего обновления страницы,
- <changefreq> — частота обновления,
- <proirity> — важность данной страницы относительно других.
Чтобы указать поисковой системе на xml карту сайта, следует воспользоваться сразу двумя способами (для подстраховки):
1) Указать в Яндекс.Вебмастер адрес sitemap.xml в соответствующем разделе
2) Указать путь в файле robots.txt. По умолчанию sitemap.xml располагается в корневой директории сайта
Для генерации карты сайта sitemap.xml существуют различные веб-сервисы. Например, если ваш сайт содержит не более 500 страниц, можно воспользоваться сервисом для генерации xml карты — http://www.xml-sitemaps.com/. Для более крупных ресурсов (от 10 тысяч страниц), как правило, пишется специальный программный модуль, автоматически генерирующий карту сайта в xml формате.
Карта сайта
Помимо карты сайта sitemap.xml, которая важна для поисковых систем, следует также составлять карту сайта в виде HTML-страницы непосредственно на сайте – для посетителей и для поисковых систем.
Карта сайта – это страница, содержащая полный каталог всех разделов сайта, представленный в древовидной структуре. Она подобна оглавлению книги, посмотрев на которое каждый пользователь может быстро найти необходимую информацию, сориентироваться в структуре и разделах сайта. Желательно, чтобы карта сайта содержала все страницы ресурса. Но перегружать её излишним количеством ссылок (например, для интернет-магазинов – ссылками на каждый товар) также не стоит – все-таки пользователь должен быстро и легко в ней ориентироваться.
Поисковым системам карта сайта также помогает быстрее индексировать сайт: ведь в этом случае робот находит ссылки на все страницы сайта на одной странице! Отсутствие карты сайта может затруднить индексацию. По опыту, поисковые системы ценят сайты с навигационными картами. Они отвечают требованиям юзабилити, которые Яндекс стал учитывать в ранжировании.
Рассмотрим пример карты сайта интернет-магазина на следующей странице.
Правила создания карты сайта:
Карта сайта должна быть выполнена в дизайне сайта, чтобы не нарушать его концепцию, не дезориентировать посетителя и максимально соответствовать его ожиданиям.
Нежелательно использовать графические элементы, чтобы не сместить акцент с полезности данной страницы на ее «украшательство».
Структура карты сайта должна соответствовать иерархии сайта – посетитель, посмотрев на карту, должен без труда сориентироваться в разделах веб-ресурса, это увеличит его лояльность.
Ссылку на карту сайта размещайте на главной странице так, чтобы пользователь мог легко её найти при необходимости.
Вернуться назад: Настройка редиректов и статус-кодовЧитать далее: Внутренние корректировки страниц сайта
Noindex, nofollow — чек лист для работы
Главная / Блог / Noindex, nofollow — чек лист для работыNoindex и nofollow зачастую называют некорректно: тегами, метатегами, атрибутами. На самом деле noindex — это тег, а nofollow — атрибут внутри тега.
Метатеги — это теги, которые относятся ко всей странице: <meta name=»robots» content=»noindex, nofollow» />
Тег <noindex> создает конструкцию: <noindex> … </noindex>;
атрибут rel=”nofollow” может появляться в конструкции тега.
С помощью этих параметров можно и нужно указывать поисковым роботам Google, Яндекс или других систем, как именно нужно взаимодействовать с контентом, находящимся внутри этих параметров.
Где и как использовать noindex и nofollow
Эти атрибуты могут располагаться в заголовке страницы, и тогда они будут правилом для всего контента. А могут ограждать конкретный текстовый фрагмент, ссылку или изображение.
Для страниц метатеги noindex и nofollow закрывают от индексации:
- страницы регистрации;
- служебные страницы;
- страницы авторов комментариев;
- другие «вредные» для индексации страницы;
Для контента теги noindex и атрибут nofollow закрывают от индексации:
- «вредные» ссылки;
- цитаты из различных источников;
- повторяющийся контент
Чтобы закрыть от индексации страницы — метатеги noindex и nofollow
Когда нужно чтобы страница и контент на ней индексировались, а поисковый робот не переходил по ссылкам. В таком случае используем конструкцию:
<meta name="robots" content="index, nofollow"/>
Когда надо закрыть страницу от индексации, а переходы по ссылкам разрешить, вставляем
<meta name="robots" content="noindex, follow"/>
Чтобы индексировались и ссылки, и сама страница, в заголовке применяем метатег
<meta name="robots" content="index, follow"/>
Для полного закрытия страницы и ссылок на ней от индексации:
<meta name="robots" content="noindex, nofollow"/>
Для примера приведем заголовок страницы, в которой используются метатеги с полным закрытием страницы и ссылок для индексации ее роботом поисковой системы (noindex, nofollow):
<html> <head> <meta name="robots" content="noindex,nofollow"> <meta name="description" content="Description для данной странички"> <title>…</title> </head> <body>
Для контента и ссылок тег noindex и атрибут nofollow
Чтобы скрыть от индексации фрагмент текста (работает только для Яндекс и Рамблер), используем следующее решение:
<!--noindex--> (текст, который нужно скрыть) <!--/noindex-->
Чтобы скрыть от индексации ссылку, используем:
<a href="https://mysite.
Чтобы скрыть ссылку от индексации и Яндекс, и Google, применяем
<noindex><a href="http://mysite.com/" rel="nofollow">текст ссылки</a></noindex>
Google в данной конструкции принимает только rel=»nofollow», а для Яндекса действуют и noindex, и rel=»nofollow».
<noindex> — неофициальный тег
<noindex>…</noindex> используется поисковыми системами Яндекс и Rambler. Цель — скрыть от индексации указанный контент.
Google на данный тег не обращает внимание, ибо он не является принятым тегом разметки html.
rel=”nofollow” — атрибут внутри тега ссылки
rel=”nofollow” запрещает поисковым системам переходить по указанной ссылке. Конструкция:
<a href="signin.php" rel="nofollow">Войти</a>
Как сообщается в ответе поддержки Google для веб-мастеров, поисковая система не переходит по ссылке и не использует для перехода по ней краулинговый бюджет. Но это не значит, что робот туда не заглянет и не проверит. То есть дальнейшая судьба данной ссылки такая: мы про тебя знаем, но молчим, пока это безопасно.
Если нужно скрыть от индексации страницы только для Google, можно использовать <meta name=»googlebot» content=»noindex» />.
Если нужно закрыть от индексации только для Яндекс – <meta name=»yandex» content=»noindex»/>.
Закрытие индексации через файл robots.txt
Метатеги, описанные ранее <meta name=»robots» content=»noindex, nofollow»> появляются только после открытия роботом страницы и прочтения заголовка.
Закрытие же страницы через файл robots.txt запрещает даже заходить на страницу.
Если поисковая система раньше проиндексировала эту страницу, то она будет находится в индексе поисковых систем (даже после закрытия в файле robots.txt). А в description нам сообщат, что описание для данной страницы отобразить невозможно, ведь она закрыта от индексации в файле robots. txt.
# robots.txt for http://www.w3.org/ User-agent: W3C-gsa Disallow: /Out-Of-Date User-agent: W3T_SE Disallow: /Out-Of-Date User-agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT; MS Search 4.0 Robot) Disallow: / # W3C Link checker User-agent: W3C-checklink Disallow: User-agent: Applebot Disallow: /People/domain/ # the following settings apply to all bots User-agent: * # Blogs - WordPress # https://codex.wordpress.org/Search_Engine_Optimization_for_WordPress#Robots.txt_Optimization Disallow: /*/wp-admin/ Disallow: /*/wp-includes/ Disallow: /*/wp-content/plugins/ Disallow: /*/wp-content/cache/ Disallow: /*/wp-content/themes/ Disallow: /blog/*/trackback/ Disallow: /blog/*/feed/ Disallow: /blog/*/comments/ Disallow: /blog/*/category/*/* Disallow: /blog/*/*/trackback/ Disallow: /blog/*/*/feed/ Disallow: /blog/*/*/comments/ Disallow: /blog/*/*?
Поэтому для непроиндексированных страниц можно использовать как вариант закрытия через метатеги в заголовке, так и через файл роботс. тхт.
Если страница уже была проиндексирована, рекомендуем вставить в заголовок, в секцию <head> метатег <meta name=»robots» content=»noindex, nofollow» />. Это исключит ее из индексации и предотвратит последующее попадание в нее.
В данном файле есть несколько блоков. Первый — User-agent — команда для определения робота, к которому относится последующие директивы. В коде файла роботс.тхт, что представлен выше — для робота W3C-gsa, W3T_SE, Mozilla/4.0, W3C-checklink, Applebot. А звездочка ( * ) после команды User-agent — говорит что последующие директивы относятся ко всем поисковым роботам.В большинстве случаев нам понадобиться заголовок в файле robots.txt следующего стандартного вида:
User-agent: * # applies to all robots
Последующие директивы позволяют исключить как отдельные страницы, так и целые папки со страницами. Код будет выглядеть так:
Disallow: / # disallow indexing of all pages
В случае, если в данной папке есть одна или несколько страниц, которые должны быть проиндексированы поступаем следующим образом:
User-agent: * Disallow: /help #запрещает страницы к индексированию, которые находятся в каталоге, например: /help.
В файле robots.txt обязательно должно быть хотя бы одно поле Disallow. Как же поступить если нам не нужно закрывать ни одной страницы? Оставляем поле пустым:
Disallow: #если после директивы оставить поле пустым - считается что все страницы сайта остаются открытыми для индексирования
Распространенные ошибки:
- Попытка закрыть от индексации ссылку следующей комбинацией: <nofollow><a href=»index.php»>Перейти</a></nofollow>
- Попытка закрыть ссылку от индексации с помощью тега <noindex>. Таким образом можно закрыть только анкор (текст ссылки, а не саму ссылку), и только для Яндекс.
Тег <noindex> для разметки html является неофициальным; в официальной разметке есть только атрибут rel или метатег со значением nofollow.
Выводы
Для экономии краулингового бюджета важно закрывать от индексации лишние ссылки, вес которых не существенен для продвижения.
Для поисковых систем ссылки nofolow выглядят естественно, а их наличие является нормальным. Однако большое количество исходящих ссылок на сайте может оказаться и минусом, несмотря на то, что они были закрыты от индексации.
Заказать сайт
Популярное
09 сен 2020
психология
7 реальных идей для быстрого бизнеса в 2020 году
09 сен 2020
психология
7 реальных идей для быстрого бизнеса в 2020 году
09 сен 2020
психология
7 реальных идей для быстрого бизнеса в 2020 году
09 сен 2020
психология
7 реальных идей для быстрого бизнеса в 2020 году
09 сен 2020
психология
7 реальных идей для быстрого бизнеса в 2020 году
Давайте
сотрудничать!
Разработка логотипаФирменный стильРазработка сайтаРазработка упаковки / этикеткиМаркетинговое исследованиеБрендинг или РебрендингРозничная торговля или Pos-материалы
Отправить
сообщение
Вечные вопросы о мета-теге «robots noindex» или что означает «грустная мордочка» • ПРОДЗЕН
Опубликовано 18. 05.2021 ·
Комментарии: 0
·
На чтение: 9 мин
·
Просмотры:
4 333
Грустный робот, грустная (или красная) мордочка, робот, ноиндекс, алл или нон — это неполный список того, как блогеры называют явление, связанное с тем, что иногда публикации могут быть отмечены мета-тегом <meta name=»robots» content=»noindex» />. Далее, когда в статье будет употребляться термин мета-тег, будет подразумеваться именно он.
Когда автор обнаруживает этот мета-тег у себя на канале, то начинает беспокоиться, рвать на себе волосы, и задавать вопросы, на которые я попытаюсь ответить.
Каждый раз мне приходится писать одно и то же, и наконец-то я решил, что надо написать одну большую и подробную статью, чтобы просто ссылаться на неё.
Если вам не терпится прочитать, как связаны мета-теги с ограничениями каналов можно перейти сразу сюда.
Как выглядит мета-тег и где его посмотреть
Вообще мета-тег — это обычный тег html, который используется при создании веб-страниц для хранения информации, предназначенной для браузеров и поисковых систем. Теоретически в мета-теге может содержаться абсолютно любая информация, но в контексте публикаций в Дзене обычно имеются в виду мета-теги <meta name=»robots» content=»noindex» /> или <meta property=»robots» content=»none» />.
Чтобы посмотреть, есть ли мета-тег на обычной странице, нужно кликнуть правой кнопкой мыши в любом месте страницы, и в меню выбрать пункт «Просмотр кода страницы».
Откроется окно с исходным кодом страницы, где среди множества понятных и не очень строчек можно найти нужные нам мета-теги.
Здесь немного другой мета-тег — видите «all»? Об этом поговорим чуть ниже.Мета-тега на странице может и не быть или он может быть немного другим, и это может менять его значение.
Что означают мета-теги «robots»
<meta name=»robots» content=»noindex» />
Этот мета-тег является командой поисковому роботу (это программа поисковых систем, которая собирает информацию о страницах на различных сайтах). Обнаружив этот мета-тег, поисковый робот понимает, что эта страница не предназначена для включения её в поисковую базу данных и пропускает страницу.
В итоге страница не попадает в поисковую базу (или если она там уже есть — исключается), после чего поисковик не будет включать эту страницу в результаты поиска.
Подробнее об этом можно прочитать в инструкции Google для веб-разработчиков.
В Дзене этот мета-тег может встречаться на страницах конкретных публикаций (статьи, галереи, видео). И означает лишь то, что по каким-то причинам Дзен решил, что эту статью не должны находить в поиске.
Если этого мета-тега нет, это значит публикация не исключена из поисковой индексации, значит на неё могут (теоретически) приходить читатели, которые ищут статьи в Яндексе или Google.
<meta property=»robots» content=»none» />
Этот мета-тег является, скорее всего, внутренним тегом Дзена. Он может встречается на главной странице канала, это означает, что у всех публикаций канала отключена индексация — т.е. в коде каждой публикации будет встречаться <meta name=»robots» content=»noindex» />.
В нормальном состоянии мета-тег канала должен выглядеть немного иначе — <meta property=»robots» content=»all» />.
Важно. В настоящее время на новых каналах всегда присутствует мета-тег <meta property=»robots» content=»none» />. После прохождения проверки этот мета-тег снимается (точнее в нём значение «none» меняется на «all»).
Примечание. Кроме этого, сейчас можно встретить мета-тег <meta name=»robots» content=»max-image-preview:large»/>. Этот мета-тег ничему не угрожает, он просто сообщает поисковикам изображения какого размера показывать на странице поиска. Подробнее об этом можно прочитать здесь.
Почему мета-теги называют «мордочками» или «рожицами»
Это связано с браузерным расширением «ПРОДЗЕН». В нём на страницах публикаций отображается пиктограмма «грустный робот», которую в итоге стали называть «красной мордой», «грустной мордочкой» и т.д.
Как с помощью расширения обнаружить статьи с мета-тегом?
Значок грустного робота на странице канала
При установленном расширении проверка главной страницы канала производится автоматически. Если канал отмечен как неиндексируемый, то в меню расширения пункт «Неиндексируемые» заменяется значением «Канал не индексируется».
Ещё раз подчеркну, что наличие этого кода, а значит и соответствующего оповещения в меню — норма для новых каналов.
Значок «грустного робота» на странице публикации
При установленном расширении на странице публикации может отображаться значок грустного робота.
Если в публикации есть такой значок, значит в коде страницы есть <meta name=»robots» content=»noindex» />Соответственно, для того чтобы его увидеть нужно зайти на страницу публикации. Но зато не нужно изучать исходный код страницы.
Поиск публикаций с мета-тегом
Если вы решите проверить не одну, а десяток публикаций, то придётся заходить в каждую и проверять наличие мета-тега в каждой из них. Вручную это неудобно, поэтому в расширении предусмотрена возможность автоматической проверки.
Правда, этот пункт меню будет недоступен, если весь канал отмечен, как неиндексируемый — нет смысла запускать проверку, теги будут обнаружены на всех публикациях.
При первом запуске будет отображено большое страшное предупреждение о том, что процедура поиска производится на страх и риск пользователя.
Дело в том, что стандартной процедуры поиска публикаций с мета-тегом в Дзене не предусмотрено, и расширению приходится буквально открывать каждую проверяемую публикацию и заглядывать в код страницы.
Теоретически это может быть воспринято как DDOS-атака или как попытка накрутить просмотры. На практике с этим проблем не было, но предупредить я вас обязан.
Можно проверить все публикации на канале, а можно проверить лишь 20 последних.Процедура поиска может занять продолжительное время, по завершении вы получите список публикаций, на которых обнаружен мета-тег.
На моём канале только на одной публикации есть этот мета-тег.На мой странице (не) обнаружен мета-тег, а страница (не) видна в поиске
Действительно, так бывает, что статью из Дзена не удаётся найти в поиске, хотя на ней нет зловредного мета-тега; или наоборот — тег есть, но и на статью есть переходы из поиска.
Всё дело в том, что поисковики работают с определённой задержкой, кроме того у них свои алгоритмы, определяющие, отвечает ли статья на поисковый запрос и насколько она релевантна ему.
Статья, которая отлично чувствуют себя в Дзене, собирает сотни тысяч и миллионы показов, поисковику может показаться неинтересной, и тогда он не будет показывать ссылку на неё на первых страницах поиска.
Кроме того, индексирование может занимать продолжительное время, это значит, что после появления (или удаления мета-тега), должно пройти какое-то время, прежде чем изменение будет учтено поисковыми системами.
Как мета-теги связаны с ограничениями канала или публикации
Официально связь мета-тега с ограничениями публикаций не подтверждается. Если написать в техническую поддержку, то вам скорее всего посоветуют не обращать на него внимание.
Тем не менее, наличие мета-тега может говорить о следующих ситуациях:
- Канал новый, все статьи отмечены мета-тегом. Переживать не стоит, ждите проверки.
- Статья недавно опубликована или отредактирована. Сразу после публикации на статье установлен мета-тег, через некоторое время он пропадает.
- Мета-тег появился по непонятным причинам и говорит о каком-то сбое.
- Статья ограничена или находится в каком-то статусе, которые сводится к тому что статья не получает показов.
Важно. Публикация может быть ограничена, но при этом на ней будет установлен мета-тег.
Т.е. отсутствие мета-тега не говорит о том, что с публикацией всё в порядке. А вот наличие мета-тега говорит о том, что с публикацией что-то не так.
Специалисты поддержки часто на обращение с вопросом о мета-тегах могут говорить, что на мета-тег не нужно обращать внимания, а с публикацией всё хорошо (а то что показов всего лишь 9 штук, так это просто статья никому не интересна).
При этом, мне неизвестны такие случаи, чтобы статья с мета-тегом успешно транслировалась в ленту и получала показы.
Что делать если вы обнаружили на статье мета-тег
Ещё раз подчеркну, что наличие мета-тега — норма на новых, не прошедших модерацию каналов. Проверка (или, как говорят, «выход на алл») может занять какое-то время. Иногда каналы успевают достигнуть порога монетизации, в этом случае монетизация не будет подключена до прохождения проверки.
Если канал не новый, то возможны разные ситуации:
- Иногда мета-тег снимается простым переопубликованием (т.е. нужно отредактировать и снова её опубликовать, ничего не меняя).
- Если это не помогло, то высока вероятность того, что статья ограничена (возможно ошибочно). В этом случае поможет только обращение в службу поддержки Дзена, правда добиться этого не всегда бывает просто.
Как общаться с технической поддержкой о мета-тегах
Чтобы не тратить зря время, не упоминайте расширение ПРОДЗЕН и термины «красная рожица», «грустная мордочка», «значок робота» и т. п.
Сотрудники ТП не могут комментировать то, как работает расширение, не знают и не должны знать, что оно показывает и т.п. Поэтому упомянув расширение, вы гарантированно получите отказ его обсуждать, иногда даже с советом его не использовать.
Не ссылайтесь только лишь на наличие самого мета-тега.
Если статья новая и не получает показов — так и напишите.
Если публикация опубликована больше суток назад, успешно набирала просмотры, а потом внезапно получила мета-тег, посмотрите график конкретной статьи в метрике — там будет видно, что в какой-то момент резко прекратились просмотры. Приведите скриншот этого графика.
Т.е. основным в вашем письме должно быть то, что возникли проблемы с публикацией. Про мета-тег можно вообще не упоминать, или упоминать в качестве дополнения.
К сожалению, это может не помочь. Если менеджеры, помогающие участникам программы Нирвана, ещё готовы разбираться с проблемами, то сотрудники обычной поддержки очень часто начинают писать стандартные отписки, не сильно вникая в их смысл.
Иногда можно подождать, пока ваше обращение будет отмечено как завершённое и написать ещё раз — если повезёт, вам ответит сотрудник, настроенный как-то помочь вам.
Так же можно обратиться за помощью в официальные группы Дзена в ВК или в телеграме.
Если ничего добиться не удастся, то остаётся только грустить вместе с грустным роботом.
Нужно ли удалять публикации, отмеченные мета-тегом с канала
Итак, вы обнаружили мет-тег, но обращение в техподдержку не помогло.
Давайте рассуждать логически:
- Если статья не получает показы, то её никто не увидите в Дзене.
- Если статья не индексируется поисковыми системами, то на неё не будут переходить из поиска.
Т.е. фактически статья не существует. Удалять её или нет — это ваше личное решение.
Но если у вас есть свой сайт или блог на другой платформе, то я бы рекомендовал перенести статью туда. И удалить. Зачем ей бессмысленно болтаться там, где ей не рады.
Если какой-то трафик на статье есть (а, вдруг?!), то имеет смысла подождать пока ей не исполнится три месяца и тогда удалить.
Собственно, я стал активно публиковать статьи на prozen.ru после того, как мне пришлось перенести несколько статей, получивших «ноиндекс» в Дзене.
Метки: noindex, букварь дзена, мета-тег, робот
Основы тегов Noindex — все, что вам нужно знать
Предотвращение появления определенных страниц в результатах поиска является неотъемлемой частью вашей стратегии индексации.
Одним из важнейших методов управления индексацией вашего сайта является директива noindex в метатегах robots или x-robots-tags.
Тег noindex можно использовать, чтобы сообщить ботам, что страницу не следует индексировать, если вы все еще хотите, чтобы они сканировали данную страницу и переходили по ссылкам на ней.
Неправильная реализация директивы noindex может привести к тому, что ваш контент будет удален из индекса Google.
Убедитесь, что этого не происходит — следуйте моему руководству , чтобы узнать, когда использовать тег noindex, как его реализовать и какие рекомендации использовать.
Что такое тег noindex?
Тег noindex — это тег HTML, используемый для управления тем, как боты обрабатывают определенную страницу или файл на вашем сайте, и запрещает им индексировать эту страницу или файл.
Вы можете указать поисковым системам не индексировать страницу , добавив директиву noindex в метатег robots — просто добавьте следующий код в раздел
HTML:Кроме того, тег noindex может быть добавлен в качестве тега x-robots в заголовок HTTP :
тег x-robots: noindex
Когда бот поисковой системы, такой как Googlebot, сканирует страницу с тегом noindex, он не будет ее индексировать. Если страница ранее была проиндексирована, а тег был добавлен позже, Google удалит ее из результатов поиска, даже если на нее ссылаются другие сайты.
Как правило, сканеры поисковых систем не обязаны следовать метадирективам , поскольку они служат скорее предложениями, чем правилами, которые они должны соблюдать. Некоторые сканеры поисковых систем могут по-разному интерпретировать мета-значения роботов.
Однако большинство поисковых роботов, таких как Googlebot, подчиняются директиве noindex.
Noindex vs nofollow
Существуют и другие директивы мета-роботов, которые поддерживает Google — самые популярные из них включают nofollow и follow. Однако тег Follow является настройкой по умолчанию, если метатеги robots не добавлены, поэтому Google считает его ненужным.
Тег nofollow не позволяет поисковым системам сканировать ссылки на странице. В результате ранжирующие сигналы этой страницы не будут передаваться страницам, на которые она ссылается.
Директиву noindex можно использовать отдельно, но ее также можно комбинировать с другими директивами. Например, вы можете добавить тег noindex и nofollow , если вы не хотите, чтобы роботы поисковых систем индексировали страницу и переходили по ссылкам на ней.
Если вы внедрили тег noindex, но ваша страница по-прежнему появляется в результатах поиска, вероятно, Google просто не сканировал страницу с момента добавления тега. Чтобы запросить у Google повторное сканирование страницы, вы можете использовать инструмент проверки URL.
Когда следует использовать тег noindex?
Вы должны использовать тег noindex для предотвращения индексации страниц Google.
Запрещение индексации менее важных страниц имеет решающее значение, поскольку у Google недостаточно ресурсов для сканирования и индексации каждой страницы, которую он находит в Интернете. В то же время вам необходимо определить свои ценные страницы, которые следует проиндексировать, и расставить приоритеты в их оптимизации.
Давайте посмотрим, на какие типы страниц следует добавить тег noindex, чтобы сделать их неиндексируемыми.
Поместите тег noindex на:
- Страницы для товаров, которых нет в наличии и которые больше не будут доступны.
- Страницы с дублирующимся содержимым, которые часто преобладают на веб-сайтах электронной коммерции. Также рекомендуется использовать канонические теги, чтобы указать поисковым системам на основные версии ваших страниц и предотвратить дублирование контента.
- Страницы, которые не должны быть доступны в результатах поиска, например, промежуточные среды или защищенные паролем страницы.
- Страницы, ценные для поисковых систем, но не для пользователей, например страницы, содержащие ссылки, которые помогают ботам находить другие страницы.
Запрещение индексации страниц должно быть частью хорошо зарекомендовавшей себя стратегии индексации.
Никогда не добавляйте noindex на ценные страницы, например:
- Страницы самых популярных товаров,
- статей в блогах (если они не устарели),
- Страницы обо мне и контакты,
- страниц с описанием предлагаемых вами услуг.
Как правило, никогда не размещайте noindex на страницах, которые, как вы ожидаете, будут генерировать значительный органический трафик.
Как реализовать тег noindex
Тег noindex можно поместить в HTML-код сайта или в заголовки ответа HTTP.
Некоторые плагины CMS, такие как Yoast, позволяют автоматически не индексировать публикуемые вами страницы.
Давайте шаг за шагом рассмотрим два основных метода реализации и проанализируем их плюсы и минусы.
Вставьте тег noindex в HTML-код страницы.
Тег noindex можно реализовать как метатег robots в HTML-кода страницы.
Метатеги роботов — это коды, используемые для управления сканированием и индексированием веб-сайта. Пользователи их не видят, но боты находят их при сканировании страницы.
Вот как реализовать код:
<голова> <тело>
Давайте поясним, как устроен метатег robots.
Внутри метатега есть пары атрибутов и значений:
Метатег Robots имеет два атрибута:
- name — указывает имя бота поисковой системы,
- content — содержит директивы для ботов.
Для обоих атрибутов требуются разные значения в зависимости от того, что вы хотите, чтобы боты делали. Кроме того, атрибуты name и content не чувствительны к регистру.
Атрибут имени обычно принимает значение «роботы», указывая, что директива предназначена для всех ботов.
Вместо этого также можно использовать имя конкретного бота, например «googlebot», хотя такое встречается гораздо реже. Если вы хотите обращаться к разным ботам, вам нужно будет создать отдельные метатеги для каждого из них.
Имейте в виду, что поисковых систем имеют разные сканеры для разных целей — ознакомьтесь со списком сканеров Google.
Между тем, атрибут содержимого содержит директиву для ботов. В нашем случае это «noindex». Вы можете поместить туда более одного значения и разделить атрибуты запятыми.
Плюсы и минусы метатегов robots
Метод HTML легче реализовать и изменить, чем метод заголовка HTTP. Это также не требует, чтобы у вас был доступ к вашему серверу.
Однако внедрение тега noindex в ваш HTML может занять много времени — вам придется добавлять его вручную на каждую страницу, которую вы хотите запретить индексировать.
Добавить тег noindex в заголовки HTTP
Другое решение — указать директиву noindex в теге x-robots.
Это элемент ответа заголовка HTTP. HTTP-заголовки используются для связи между сервером и клиентом (браузером или ботом поисковой системы).
Вы можете настроить его на веб-сервере HTTP. Код будет выглядеть немного по-разному в зависимости от того, какой сервер вы используете — например, Apache, Nginx или другие.
Вот пример того, как может выглядеть ответ HTTP с тегом x-robots:
HTTP/1.1 200 OK (…) тег x-роботов: noindex (…)
Сервер Apache
Если у вас Сервер на основе Apache и хотите запретить индексацию всех файлов, заканчивающихся на «.pdf», вам следует добавить директиву к файлу .htaccess .
Вот пример кода:
В заголовке установлен x-robots-tag "noindex"
Сервер Nginx
Если у вас есть сервер на основе Nginx , внедрите директиву в файл . conf :
location ~* \.pdf$ {
add_header x-robots-tag "noindex";
} Плюсы и минусы использования HTTP-заголовков
Одним из существенных преимуществ использования noindex в HTTP-заголовках является то, что вы можете использовать его в веб-документах, которые не являются HTML-страницами , например в файлах PDF, видео или изображениях. Кроме того, этот метод позволяет настроить таргетинг на определенную часть страницы.
Кроме того, тег x-robots поддерживает использование регулярных выражений (RegEx). Другими словами, вы можете настроить таргетинг на страницы, которые не должны индексироваться, указав, что у них общего. Например, вы можете настроить таргетинг на страницы с URL-адресами, которые содержат определенные параметры или символы.
С другой стороны, вам нужен доступ к вашему серверу для реализации тега x-robots.
Добавление тега также требует технических навыков и является более сложным, чем добавление метатегов robots в HTML-код веб-сайта.
Как проверить реализацию тега noindex?
Если вы хотите проверить, реализованы ли noindex или другие метадирективы robots, вы можете сделать это в зависимости от того, как они были добавлены на страницу.
Итак, если тег noindex был добавлен в HTML страницы, вы можете проверить ее исходный код, а для заголовков HTTP вы можете использовать тег Опция проверки в Chrome . Эти инструменты покажут вам, какие директивы были распознаны на данной странице.
Другие варианты включают ввод URL-адреса в инструмент проверки URL-адресов Google Search Console или использование расширения Link Redirect Trace.
Дополнительная информация об использовании тега noindex
Вот некоторые дополнительные рекомендации по использованию тега noindex и сведения о его характеристиках:
- Когда вы не включаете noindex в свой код, вариант по умолчанию — боты могут индексировать твоя страница .
- Следите за любыми ошибками в коде, такими как запятые в нужных местах — боты не поймут ваши команды, если синтаксис неправильный.
- Добавьте теги в код HTML или заголовки ответа HTTP, но не в оба одновременно. Это может иметь преимущественно негативные последствия, если директивы в соответствующих местах противоречат друг другу. В этом случае Googlebot выберет директиву, ограничивающую индексацию.
- Вы можете использовать директиву noimageindex, которая будет работать аналогично noindex, но только предотвратит индексацию изображений на данной странице.
- Через некоторое время боты начинают рассматривать noindex как nofollow. Многие люди отключают индексирование страниц с помощью noindex, но комбинируют его с директивой follow, чтобы роботы по-прежнему сканировали ссылки на странице. Но Google объяснил , что директива noindex, follow в конечном итоге будет рассматриваться как noindex, nofollow , потому что в какой-то момент они перестают сканировать ссылки на неиндексированных страницах. В результате страницы назначения ссылок могут не индексироваться и получать сигналы пониженного ранжирования, что может негативно сказаться на их ранжировании.
- Не используйте noindex в файлах robots.txt. Хотя это и некоторые другие правила официально не поддерживались, поисковые роботы следовали директивам noindex в файлах robots.txt. Однако в сентябре 2019 года Google объявил об удалении кода, который обрабатывал неподдерживаемые и неопубликованные правила в файлах robots.txt, таких как noindex, в сентябре 2019 года.
Сравнение тегов noindex, файлов robots.txt и канонических тегов
тегов noindex, файлы robots.txt и канонические теги связаны — они могут использоваться для управления сканированием и/или индексацией страниц .
Однако у них есть некоторые отличительные характеристики, которые делают их пригодными для использования в различных ситуациях.
Мы установили, что теги noindex определяют, следует ли индексировать определенные страницы веб-сайта, и они действуют на уровне страниц.
Давайте посмотрим, как это соотносится с файлами robots. txt и каноническими тегами.
Файлы robots.txt
Файлы robots.txt могут использоваться для управления тем, как роботы поисковых систем сканируют части вашего веб-сайта на уровне каталогов.
В частности, файлы robots.txt содержат директивы для ботов поисковых систем, в которых основное внимание уделяется либо «запрещению», либо «разрешению» их поведения. Если боты будут следовать директиве, они не будут сканировать запрещенные страницы, и страницы не будут проиндексированы.
Директивы robots.txt широко используются для сохранения 9 веб-сайтов.0004 краулинговый бюджет.
Будьте осторожны при реализации тегов noindex и настройке правил в файлах robots.txt. Чтобы директива noindex была эффективной, данная страница должна быть доступна для сканирования, а это означает, что она не может быть заблокирована файлом robots.txt.
Если сканер не может получить доступ к странице, он не увидит тег noindex и не будет его учитывать. Затем страницу можно просканировать и она появится в результатах поиска, например, если на нее ссылаются другие страницы.
Чтобы не индексировать страницу, разрешите ее сканирование в файле robots.txt и используйте метатег noindex , чтобы заблокировать ее индексацию — тогда Googlebot будет следовать директиве noindex.
Канонические теги
Канонические теги — это элементы HTML, которые сообщают поисковым системам, какая страница из нескольких похожих является основной версией и должна быть проиндексирована. Они размещаются на второстепенных страницах и указывают канонический URL — в результате эти второстепенные страницы не должны включаться в индекс.
Канонические теги могут ограничивать индексацию неканонических страниц, но Google не всегда будет учитывать эти теги . Например, если Google находит больше ссылок на другую страницу, он может рассматривать ее как более важную, чем указанный канонический URL-адрес, и считать ее основной версией.
Кроме того, канонические теги могут быть обнаружены ботами только во время сканирования. В отличие от файлов robots.txt, их нельзя использовать для остановки сканирования страницы.
Существенное различие между каноническими тегами и тегами noindex заключается в том, что канонизированных страниц объединяют сигналы ранжирования под одним URL. Между тем, непроиндексированные страницы не будут передавать сигналы ранжирования , что очень важно для внутренних ссылок — они не будут передавать сигналы ранжирования URL-адресам, на которые они ссылаются.
Подведение итогов
Запрещение индексации некачественных страниц — один из лучших методов SEO для оптимизации вашей стратегии индексации, а использование метатега noindex — один из наиболее оптимальных способов не допустить страницы в индекс Google .
Используя этот тег, вы можете заблокировать индексацию неважных страниц и впоследствии помочь роботам поисковых систем сфокусироваться на наиболее ценном контенте.
Эффективное сканирование и индексация вашего веб-сайта являются ключом к максимальному использованию органического трафика, который ценные страницы могут привести на ваш сайт. Чтобы узнать больше о процессе индексации, обязательно прочитайте наше руководство по индексации SEO дальше!
Noindex пост в WordPress, простой способ! • Йост
Некоторые сообщения и страницы не должны отображаться в результатах поиска. Чтобы были уверены, что они не отображаются, вы должны попросить поисковые системы исключить их. Вы делаете это с помощью метатега robots noindex . Установив для страницы значение noindex , вы гарантируете, что поисковые системы никогда не отобразят ее в своих результатах. Здесь мы объясним, как легко не индексировать запись в WordPress, если вы используете Yoast SEO.
Зачем удалять пост из результатов поиска?
Почему вы НЕ хотите, чтобы страница отображалась в результатах поиска? Что ж, на большинстве сайтов есть страницы, которые не должны отображаться в результатах поиска. Например, вы можете не захотеть, чтобы люди попадали на страницу «спасибо», на которую вы перенаправляете людей, когда они связывались с вами. Или ваша страница «успешная оплата». Поиск этих страниц в Google никому не нужен.
Для таких страниц вам нужно «не индексировать».
Для каких типов страниц я могу установить значение noindex?
Авторские архивы в блоге с одним автором
Если вы единственный человек, который пишет для своего блога, ваши авторские страницы, вероятно, на 90% совпадают с главной страницей вашего блога. Это не ценная страница и может рассматриваться как дублированный контент. Чтобы предотвратить это, вы можете полностью отключить авторский архив — вот как легко включить или отключить его с помощью Yoast SEO. Если по какой-то причине вы хотите оставить его на своем сайте, но вне результатов поиска, вы можете noindex ит. К счастью, с Yoast SEO это тоже не очень сложно; просто проверьте, как не индексировать авторский архив.
Определенные (настраиваемые) типы сообщений
Иногда плагин или веб-разработчик добавляет настраиваемый тип сообщений, который вы не хотите индексировать. Например, музыкальный блог может захотеть проиндексировать 90 323 исполнителя 90 324 и 90 323 альбомов 90 324, но не 90 323 отдельных песен 90 324 .
Страницы благодарности
Эти страницы обычно малосодержательны и не обеспечивают хорошего входа на сайт. Если вы используете аналитику на своем сайте или размещаете рекламу, входы на эти страницы также могут вызывать конверсии и искажать ваши данные!
Страницы администратора и входа
Большинство страниц входа не должны быть в Google. К счастью, если вы используете WordPress, вы в безопасности, поскольку страница входа на ваш сайт автоматически не индексируется.
Внутренние результаты поиска
Внутренние результаты поиска в значительной степени являются последними страницами, на которые Google хотел бы отправить своих посетителей. Если вы хотите испортить впечатление от поиска, вы ссылаетесь на другие страницы поиска, а не на фактический результат. Но ссылки на странице результатов поиска по-прежнему очень ценны, вы определенно хотите, чтобы Google следовал за ними. Итак, все ссылки должны быть пройдены, а мета-настройка robots должна быть:
Yoast SEO гарантирует, что ваши страницы внутреннего поиска по умолчанию настроены на noindex. Это одна из скрытых функций Yoast SEO. Это не редактируемый параметр, потому что это просто то, как это должно быть сделано в соответствии с рекомендациями Google, и мы полностью с ними согласны.
Только для разработчиков: если вы хотите изменить это, это можно сделать с помощью одного из наших фильтров. Пример можно найти здесь.
Как сделать публикацию без индекса с помощью Yoast SEO
Установить для публикации или страницы значение без индекса просто, если вы используете Yoast SEO. Под вашим сообщением в мета-поле Yoast SEO просто нажмите на вкладку «Дополнительно»:
На вкладке «Дополнительно» вы увидите несколько вопросов. Первый: «Разрешить поисковым системам показывать этот пост в результатах поиска?» Если вы выберете «Да», ваш пост появится в Google. Если вы выберете «Нет», вы установите публикацию на без индекса . Это означает, что он не будет отображаться в результатах поиска.
Обратите внимание, что если сообщение, которое вы устанавливаете на noindex уже находится в результатах поиска, может пройти некоторое время, прежде чем страница исчезнет. Сначала поисковым системам придется повторно просканировать страницу, чтобы найти тег noindex . И не стоит легкомысленно не индексировать посты: если раньше они получали трафик, вы теряете этот трафик.
Вы собирались использовать файл robots.txt, чтобы исключить что-либо из результатов поиска? Узнайте, почему для этого не следует использовать файл robots.txt.
Имеют ли ценность ссылки на непроиндексированных страницах?
Когда вы устанавливаете для сообщения значение noindex , Yoast SEO автоматически предполагает, что вы хотите установить для него значение noindex, следуйте . Это означает, что поисковые системы по-прежнему будут переходить по ссылкам на этих страницах. Если вы делаете , а не , чтобы поисковые системы переходили по ссылкам, ваш ответ на следующий вопрос должен быть « Нет» :
Это установит мета-роботов на nofollow , что изменит поведение поисковых систем. Теоретически это означает, что они будут игнорировать все ссылки на странице, хотя Google по-прежнему может сканировать их, чтобы обнаружить новые URL-адреса.
Начиная с Yoast SEO 14.4, вы также можете установить отдельные ссылки на nofollow в редакторе блоков. Вы даже можете пометить коммерческую ссылку как спонсируемую , что также автоматически добавит атрибут nofollow . Просто нажмите на ссылку и настройте параметры для этой конкретной ссылки.
nofollow в редакторе блоков WordPressPS. Вы не проиндексировали запись или страницу в WordPress, хотя и не собирались этого делать? Не беспокойтесь, так как вы можете легко исправить случайный noindex!
Подробнее: Полное руководство по тегу meta robots »
Йост де Валк
Йост де Валк является основателем Yoast. После продажи Yoast он перестал быть активным на постоянной основе и теперь выступает в качестве советника компании. Он интернет-предприниматель, который вместе со своей женой Марике активно инвестирует и консультирует несколько стартапов. Его основная специализация — разработка программного обеспечения с открытым исходным кодом и цифровой маркетинг.
Далее!
- Событие
День участника Yoast
14 сентября 2022 г. Команда Yoast организует день участников Yoast. Нажмите, чтобы узнать, что мы собираемся делать, кто будет там и многое другое! Узнайте, где вы можете найти нас дальше » - SEO-вебинар
Новостной вебинар Yoast SEO — 27 сентября 2022 г.
27 сентября 2022 г. Наш глава SEO, Джоно Алдерсон, будет держать вас в курсе всего, что происходит в мире SEO и WordPress. Все вебинары Yoast SEO »
Теги Noindex: что нужно знать для SEO в электронной торговле
Главная > Блог > Теги без индекса: что нужно знать для SEO в электронной торговле
Бренды электронной коммерции сталкиваются с уникальной задачей SEO, связанной с управлением тысячами страниц продуктов и страниц категорий. При работе с таким большим объемом веб-страниц становится жизненно важным использовать все имеющиеся в вашем распоряжении инструменты, чтобы помочь вашим наиболее ценным страницам ранжироваться и быть замеченными вашими клиентами.
Канонические ссылки, файлы robots.txt и XML-карты сайта — все это инструменты в нашем контрольном списке SEO 101 для электронной коммерции, которые могут помочь выполнить эту задачу. Теги Noindex — это еще один мощный инструмент SEO для электронной коммерции, который можно использовать для оптимизации вашего сайта и повышения его рейтинга, органического трафика и продаж.
Проще говоря, метатеги noindex сообщают поисковым системам, как сканировать и индексировать ваш сайт. В частности, они используются для сообщения о том, какие страницы следует и не следует индексировать.
Это важно, потому что каждая поисковая система назначила вашему сайту электронной коммерции уникальный краулинговый бюджет, то есть максимальное количество URL-адресов, которые их боты будут сканировать, прежде чем перейти на другой сайт. Если вы сообщите ботам игнорировать определенные страницы с низкой ценностью, ваш краулинговый бюджет может быть потрачен на страницы с высокой ценностью, приносящие доход.
Однако тегами noindex можно легко злоупотребить. В этом руководстве рассказывается все, что вам нужно знать об использовании тегов noindex для SEO электронной коммерции, включая рекомендации и распространенные ошибки, которых следует избегать.
Что такое поисковые метатеги?Метатеги — это фрагменты данных, которые предоставляют важную информацию о веб-странице поисковым системам. Эта информация, известная как метаданные, не отображается на странице; скорее, он добавляется в исходный код страницы. Метаданные используются поисковыми системами для принятия решений о ранжировании страницы или о том, какой контент должен отображаться в результатах поиска.
Существует множество различных типов метатегов, каждый из которых имеет свою функцию и назначение. Тег заголовка, метаописание и тег alt изображения являются одними из самых известных метатегов, используемых брендами электронной коммерции и цифровыми маркетологами. Метатег robots — это еще один тип метатега, который мы рассмотрим более подробно в следующих разделах.
Метатег robots — это директива, сообщающая роботам поисковых систем, какие веб-страницы следует сканировать и индексировать, а какие — игнорировать. Основные директивы, связанные с метатегами robots: index или noindex , а следует за или nofollow .
По умолчанию, если вы не укажете метатег robots для своей веб-страницы, сканеры поисковых систем будут читать это как индекс , затем следует . Это позволяет поисковым системам добавлять страницу в свой индекс, чтобы пользователи могли ее обнаружить, и переходить по ссылкам на странице для обнаружения других страниц.
Если вы хотите указать поисковым системам поступать иначе, веб-разработчик должен поместить соответствующие метатеги robots в исходный код вашей страницы. Например, допустим, вы хотите, чтобы боты переходили по ссылкам на странице, но не индексировали ее. Тег robots для этой директивы будет выглядеть так:
или
Опять же, поскольку индекс , следуйте по умолчанию следует за и может быть добавлено или нет; роботы поисковых систем будут одинаково читать оба вышеуказанных метатега. Noindex или noindex, затем — наиболее часто используемый тег.
Если вы хотите, чтобы боты деиндексировали страницу из поиска и игнорировали все ссылки на странице, применяется следующий тег robots:
В следующем разделе мы приведем конкретные примеры того, как теги noindex влияют на поисковую оптимизацию электронной торговли.
Как использовать метатеги Noindex на моем сайте электронной торговли?Теги Noindex — один из единственных надежных способов гарантировать, что поисковые системы будут игнорировать живые страницы на вашем сайте и не отображать их в поисковой выдаче.
Почему бренд электронной коммерции хочет, чтобы деиндексировал свои веб-страницы? Ниже приведены некоторые сценарии, в которых метатег noindex может быть полезен для SEO вашего сайта:
Ваша страница имеет дублированный контент (например, целевая страница Google Ad имеет тот же контент, что и одна из страниц вашей категории; определенные отфильтрованные страницы категорий, которые полезны для пользователя, но не стоят краулингового бюджета вашего сайта); или страница продукта, которая очень похожа на другую страницу продукта, например тот же продукт другого цвета или размера).
Во всех вышеперечисленных сценариях метатеги noindex используются для указания роботам поисковых систем игнорировать определенные малоценные страницы, освобождая краулинговый бюджет для более важных страниц.
Теги Noindex: Предупреждения и что нужно знатьПоскольку метатеги noindex — это гарантированный способ исключить страницу из поиска, вам следует соблюдать осторожность при их использовании. Случайное добавление этой директивы на важную страницу, которую вы хотите просканировать и проиндексировать, может иметь катастрофические последствия для SEO вашей электронной коммерции.
Страницы с тегами noindex должны быть удалены из карты сайта XML, если это возможно. Если оставить слишком много деиндексированных страниц в карте сайта, поисковые системы могут запутаться в том, какие страницы действительно важны для сканирования, а какие следует игнорировать.
То же самое касается верхней навигации; в соответствии с передовой практикой SEO страницы с тегами noindex следует удалять, чтобы не создавать путаницы для поисковых роботов.
Когда дело доходит до SEO для электронной коммерции, теги robots являются одним из самых важных инструментов в вашем наборе инструментов. Тем не менее, в то время как правильно примененный тег noindex может высвободить ваш краулинговый бюджет и повысить рейтинг вашего сайта, неправильно примененный метатег может нанести ущерб вашему органическому трафику.
В качестве наилучшей практики мы всегда рекомендуем нанять квалифицированного технического эксперта по SEO для оценки вашего сайта перед внедрением метатегов noindex.
Нужна помощь в оценке того, являются ли теги noindex правильным SEO-решением для электронной коммерции для вашего сайта? Свяжитесь с Whitecap SEO для получения дополнительной информации и бесплатного предложения.
Что такое теги Noindex| Как они могут помочь SEO в электронной коммерции?
06 Май
Что такое неиндексные теги| Как они могут помочь SEO в электронной коммерции?
Мета-теги являются основной частью обеспечения бесперебойной работы вашего веб-сайта и правильного ранжирования страниц Google. Если вы управляете интернет-магазином, скорее всего, у вас есть как минимум несколько десятков страниц продуктов. Эти страницы продуктов могут отображаться в результатах поиска Google с правильными тегами, направляя вашу аудиторию к лучшим продуктам для их нужд.
Однако иногда вам может потребоваться убедиться, что веб-страница на вашем сайте электронной электронной коммерции не отображается в Google. Вот для чего нужны теги noindex. В этой статье будет рассказано, что такое теги noindex, как они работают и как они могут улучшить SEO для вашей электронной коммерции.
Описание метатегов роботов
Правильно функционирующий веб-сайт электронной коммерции включает множество элементов, таких как сертификаты SSL, ссылки на другие страницы и метатеги.
Чтобы понять теги noindex, вам нужно сначала понять метатеги robots. В двух словах, метатеги роботов (также известные как просто метатеги) — это директивы кода, которые инструктируют роботов поисковых систем. В частности, они говорят роботам:
- Какие веб-страницы следует сканировать и индексировать
- Какие веб-страницы следует игнорировать
Роботы поисковых систем просматривают многие миллиарды страниц в Интернете и индексируют их для отображения в результатах поиска или игнорируют их по указанию. Основные теги робота, о которых следует помнить:
- Index, который указывает роботу поисковой системы индексировать определенную страницу
- Noindex, который сообщает роботу поисковой системы не индексировать определенную страницу
- Follow, который сообщает роботу поисковой системы переходить по ссылкам на данной странице, чтобы обнаружить другие страницы
- Nofollow, который сообщает роботу поисковой системы не переходить по ссылкам на данной странице
В метакодировании поисковой системы «следовать» является кодом по умолчанию. Например, представьте, что вы используете строку кода, подобную этой:
Робот поисковой системы читает это, как будто добавлено «follow». после «без индекса». Вы должны указать, что вы не хотите, чтобы поисковые роботы переходили по ссылкам на странице, а не наоборот. Это может быть полезно, если вы все еще создаете страницу и на ней есть несколько неработающих ссылок, которые нужно исправить.
Объяснение тегов Noindex
Как видно из приведенной выше разбивки, теги noindex сообщают роботам поисковых систем, что им не следует индексировать определенную веб-страницу. Это означает, что бот поисковой системы может обнаружить веб-страницу, но не добавит ее в индексы поисковых систем.
Когда кто-то ищет ключевые слова, связанные с этой страницей, она не будет отображаться в поисковой выдаче. Обратите внимание, что теги noindex не мешают роботам находить страницы. Роботы по-прежнему сканируют страницы и отмечают их содержимое и теги — они просто не добавляют их в публичный индекс для обнаружения поисковиками.
Как теги Noindex улучшают SEO сайта?
Хотя теги noindex важны для правильной работы и функциональности сайта, владельцы онлайн-бизнеса могут обоснованно спросить, зачем им вообще их использовать. Разве не всегда лучше для клиента найти страницу на веб-сайте электронной коммерции, особенно если там есть сотни различных продуктов для просмотра?
Не всегда. Есть много ситуаций, когда отображение всех страниц вашего сайта может навредить вашему SEO. Давайте посмотрим, как теги noindex могут помочь избежать проблем с SEO.
Предотвратить дублирование контента на вашем сайте
Во-первых, теги noindex позволяют запретить ботам поисковых систем индексировать или каталогизировать дублированный контент. Допустим, у вас есть целевая страница Google Ad для вашего небольшого ортодонтического бизнеса, на которой много скопированного и вставленного контента со страниц категорий или статей на вашем веб-сайте.
Если бот поисковой системы обнаружит целевую страницу, а также другие страницы, с которых он заимствует копию, это может привести к штрафным санкциям в отношении SEO-оптимизации вашего ортодонтического бизнеса. Боты поисковых систем Google не любят дублированный контент, поэтому владельцы сайтов электронной коммерции могут использовать тег noindex на определенных страницах, чтобы предотвратить это наказание.
Запретить покупателям находить товары с малым запасом
Далее, теги noindex полезны, если вы хотите, чтобы покупатели не находили страницы товаров с товарами, которых нет в наличии. Если люди постоянно посещают страницу продукта, но не совершают покупку, потому что в вашем магазине недостаточно этого продукта, Google может обнаружить это и оштрафовать эту страницу.
Вы можете использовать метки noindex в качестве временной меры, пока товар не пополнится (они не являются постоянными метками; вы можете использовать их при необходимости). Лучше всего рассматривать теги noindex как инструменты, которые можно использовать, когда это уместно. Вы даже можете регулярно просматривать теги страниц и решать, фильтровать ли страницы в обращении или из обращения по прошествии времени.
Экспериментируйте со страницами, не влияя на поисковую оптимизацию
Время от времени вам может понадобиться поэкспериментировать или обновить свой сайт электронной коммерции. Это означает запуск веб-страниц для таких мер, как A/B-тестирование. Единственная проблема заключается в том, что вы не хотите, чтобы Google проиндексировал эти тестовые страницы, прежде чем вы будете к этому готовы.
Теги Noindex — идеальное решение. Эти теги позволяют вам тестировать разные веб-страницы на предмет функциональности или неработающих ссылок, не индексируя их до того, как они будут готовы. Как только веб-страницы готовы к работе, вы можете запустить их и сделать их «живыми» для поиска Google, изменив тег noindex на тег index в коде страницы.
Сообщите ботам двигателя игнорировать малоценные страницы
Ваш сайт электронной коммерции имеет общий балл, и некоторые страницы имеют более высокую ценность, чем другие. Если вы удалите страницы с низкой ценностью со своего сайта, Google вознаградит вас более высоким рейтингом в поисковой системе, что может помочь вам привлечь больше трафика на ваш сайт.
Но что, если по той или иной причине вы не хотите удалять малоценные страницы? Вместо этого вы можете использовать теги noindex, чтобы сообщить ботам игнорировать эти страницы с низкой ценностью и перейти к страницам с высокой ценностью. Соедините эти теги с тегами nofollow для еще более высокого рейтинга.
Оптимизация сайта для пользователей, осуществляющих поиск
Наконец, вы можете оптимизировать свой сайт электронной коммерции для пользователей, выполняющих поиск Google. Теги Noindex предотвращают появление в Google загроможденных страниц или страниц, не предназначенных для обычных пользователей. Таким образом, когда люди ищут ваш бренд, они направляются либо на одну целевую страницу, либо на несколько высококачественных страниц. Это, в свою очередь, позволяет вам лучше направлять трафик на лучшие части вашего сайта или воронки продаж.
Резюме
Теги Noindex — это важные инструменты, которые вы можете и должны использовать для своего сайта электронной коммерции. При правильном применении теги noindex могут улучшить рейтинг вашего сайта в поисковых системах и привести к увеличению трафика и продаж. Попробуйте использовать теги noindex на благо вашего SEO уже сегодня!
Как не индексировать страницу в WordPress?
Содержание
Когда речь идет о создании веб-сайта или блога, вы наверняка слышали о WordPress и SEO. WordPress — это крупнейшая платформа для создания веб-сайтов, а SEO — это правильный способ получить на ваш веб-сайт и страницы необходимый трафик. Даже если вы еще не очень хорошо знакомы с WordPress, не будет ошибкой предположить, что вы немного его видели. Он прост в использовании, но как бы он ни был прост, он также имеет слишком много настроек, которые вы можете настроить, что иногда может привести к путанице. Например, вы могли слышать о страницах «noindex». А может и не знать, что это такое.
Не нужно беспокоиться, как и другие функции WordPress, это в значительной степени говорит само за себя, и вы сможете обойти его, как только прочитаете эту статью. Давайте начнем с выяснения того, что означает noindex и как это сделать.
Что означает Noindex?
Итак, чтобы начать легко и гладко, давайте начнем с того, что означает noindex. Поисковые системы просматривают вашу страницу, чтобы увидеть, когда ее ранжировать в результате, что называется «индексированием» или «индексной страницей». Это означает, что noindex — это когда ваша страница не появляется в результатах поиска. Это также называется «сканированием», когда поисковые системы «сканируют» вашу страницу и добавляют ее в свои результаты. Мы поговорим о том, почему вам нужно запретить индексацию некоторых страниц. Но сначала давайте поговорим о том, как бы вы это сделали.
Как не индексировать страницу?
Есть несколько способов запретить индексацию сообщений; мы собрали их всех здесь.
Когда вы публикуете что-то через WordPress и запускаете плагин Yoast SEO, под своим сообщением WordPress вы увидите мета-окно Yoast SEO. Это одно из мест настройки этого плагина.
Итак, из мета-поля Yoast SEO все, что вам нужно сделать, это:
- Нажмите кнопку «Дополнительно» под мета-полем.
- При выборе ответа «нет» на вопрос «Разрешить поисковым системам показывать этот пост в результатах поиска?» ваш пост будет считаться постом без индекса и не будет отображаться в результатах.
После этого можно сделать еще один выбор. Когда вы не индексируете страницу в Yoast SEO , для нее автоматически устанавливается статус «следить». Это означает, что поисковые системы по-прежнему будут переходить по ссылкам на вашей странице или в публикации WordPress. Если вы этого не хотите, вы можете установить «nofollow». Это будет игнорировать ВСЕ ссылки на вашей странице. Тем не менее, есть еще одна настройка, в которой вы можете настроить каждую ссылку для подписки, nofollow или спонсорства в сообщении. Вы можете установить и решить действие для каждой ссылки с помощью редактора блоков, нажав на ссылку. Вариант спонсируемой ссылки предназначен для ваших коммерческих ссылок и также будет добавлен в nofollow.
Существуют также способы запретить индексацию ваших страниц без использования плагина Yoast SEO. Это делается путем добавления тега в раздел заголовка HTML-кода вашей страницы.
Для этого добавьте: в раздел.
В качестве альтернативы вы можете пометить в программе чтения HTTP тег X-Robots-Tag
Например; X-Robots-Tag: noindex
Тег noindex в вашем файле robots.txt также сообщит поисковым системам, что они не должны показываться на вашей странице.
- Вы не можете индексировать URL в файл robots.txt следующим образом: Noindex: /robots-txt-noindexed-page/
Примечание. Сохранить в Имейте в виду, что Google не рекомендует использовать этот метод, если вы не индексируете.
Почему вы не должны индексировать страницу?
Мы выяснили, как не индексировать страницу, объясняя условия nofollow и сканирования. Но почему кто-то хочет, чтобы его страница не отображалась в результатах поиска?
Разве весь смысл SEO и оптимизации не в ранжировании страницы результатов?
ПОСЛЕДНИЕ ПОСТЫ
PDF известен как формат, используемый для обмена документами во многих областях, таких как результаты опросов и учебная информация. Если у вас есть сайт и вы хотите…
Когда вы управляете веб-сайтом WordPress, вы должны помнить о надлежащем измерении вовлеченности пользователей, потому что важно разработать стратегию роста и определить…
На этот вопрос есть простой, но важный ответ. Конечно, вы хотели бы, чтобы ваша страница отображалась, но не все страницы — это только ваши записи в блоге и так далее. Например, страница оформления заказа на веб-сайтах интернет-магазинов или страницы «спасибо», которые вы получаете после посещения веб-сайта, в конце концов, также являются веб-страницами. И вы бы не хотели, чтобы страница оформления заказа отображалась в результатах поиска. Это не только не имело бы никакого смысла, но и смутило бы зрителей. Таким образом, приняв соответствующие меры, вы можете решить, какие страницы вашего веб-сайта должны попасть в список nofollow и noindex.
Заключение — отсутствие индексации в WordPress
В заключение мы помогли вам освоить несколько новых терминов WordPress и узнать, как не индексировать страницу в WordPress. Надеюсь, мы смогли помочь.
Если вы хотите узнать больше о таких темах, ознакомьтесь с нашими соответствующими статьями для получения дополнительной информации.
Часто задаваемые вопросы
Как проверить мои неиндексированные страницы?
После завершения индексации вы можете проверить, работает ли она, с помощью веб-сайтов или инструментов Google. Просто выполните поиск noindex checker и вставьте свой помеченный URL, HTML или способ, который вы использовали.
Как изменить случайно установленный noindex?
Если вы передумали или случайно установили страницу без индексации, вы можете исправить это, удалив тег или выбрав ответ «да» на настройку Yoast SEO.
Нужно ли загружать Yoast SEO в noindex?
Нет, вы не можете, как мы упоминали, вы не можете индексировать страницы тремя другими способами, но рекомендуется загрузить Yoast SEO для более простого и более настраиваемого опыта работы с WordPress.
Тег Noindex: определение и принцип работы
Без индекса | SEO словарь
Существуют различные способы предотвращения индексации страницы Google или другими поисковыми системами. От настройки команды disallow в файле robots.txt до использования тега nofollow в ссылках, до использования метатега HTML Noindex.
С помощью метатега noindex можно избежать индексации самой страницы, добавив к ней HTML-код, и нет необходимости использовать другие внешние методы, чтобы избежать ее индексации.
Содержание
Что такое метатег noindex?
Метатег noindex — это тег, который вставляется в HTML-код страницы, чтобы указать Google и другим поисковым системам, что им не следует индексировать страницу .
Основная особенность этого метатега заключается в том, что он не блокирует доступ к нему для поисковых систем (как это делает тег nofollow или команда disallow в robots.txt), но предотвращает его индексацию в рейтинге их веб-сайтов.
Использование рекомендаций follow и nofollow расширяет возможности использования мета-noindex, позволяя настраивать блок индексирования и сканирования в соответствии с потребностями каждой страницы.
¿Por Qué es Importante для SEO?
Метатег noindex является очень полезным инструментом для SEO, поскольку он позволяет контролировать некоторые аспекты, связанные с индексацией контента, такие как:
- Не индексировать страницы с некачественным контентом, который вы не собираетесь удалять или улучшать. (тонкое содержание).
- Избегайте индексации страниц категорий с небольшой ценностью для пользователя
- Не индексируйте страницы с некачественным контентом, который вы не собираетесь удалять или улучшать (некачественный контент).
- Избегайте дублирования контента, не индексируя страницу с наименьшим ранжированием.
- Избегайте индексации результатов внутреннего поиска.
- Избегайте индексации результатов внутреннего поиска.
- Избегайте индексации результатов внутреннего поиска.
- Позволяет роботам Googlebot сканировать все ссылки на странице без необходимости индексации.
При проведении SEO-аудита часто обнаруживаются важные страницы веб-сайта, которые даже не проиндексированы в Google, в большинстве случаев из-за неправильной настройки метатега noindex или других инструментов, таких как robots.txt. файл.
Существуют инструменты, которые позволяют вам анализировать веб-сайт, чтобы увидеть, активирован ли на его URL-адресах этот метатег и блокируется ли его индексация, как в случае с Screaming SEO Frog Spider. С помощью этого приложения вы можете сканировать веб-сайт, как если бы это был бот поисковой системы, впоследствии получая доступ к большому количеству важной информации.
На вкладке директив приложения ( директивы ) вы можете отфильтровать результаты, чтобы увидеть, какие страницы заблокированы от индексации с метаданными noindex и nofollow.
Как поставить страницу в noindex?
Давайте посмотрим, как тег noindex реализован на странице, чтобы избежать индексации поисковыми системами.
1. Установка noindex в HTML
Это метатег HTML, который должен быть включен в раздел или заголовок кода. Этот код очень прост, в отличие от других тегов и параметров HTML.
Должна быть включена в заголовок HTML:
Эта строка запрещает любому боту, будь то роботы Googlebot или другие сканеры поисковых систем, индексировать эту страницу в своих базах данных сайта.
Этот код можно настроить для обозначения определенного бота. Например, если мы хотим, чтобы Google-image не индексировал изображения URL-адреса, мы должны указать:
Еще одна интересная особенность этого метатега заключается в том, что на одну и ту же страницу можно вставить несколько метатегов для выполнения настраиваемых ограничений индексации.
2. Настройка noindex в WordPress
Как это часто бывает, в WordPress еще проще работать с метатегом noindex. С помощью плагинов , таких как Yoast SEO или Rank Math SEO , просто перейдите на страницу или запись в блоге, которую вы хотите избежать индексации, и установите флажок No Index . Таким образом, плагин автоматически добавляет метатег noindex в HTML страницы.
Директивы Follow и nofollow, сопровождающие noindex
Этот метатег обеспечивает еще большую степень персонализации, используя атрибуты Follow и nofollow в зависимости от поставленной цели.
без индекса, следуйте
Используя эту комбинацию, вы сообщаете поисковым системам, что они не должны индексировать страницу в своей базе данных, но должны сканировать все ссылки , содержащиеся в ней.
Это один из наиболее распространенных вариантов использования этого метатега в SEO. Способ добавления его в HTML следующий:
Очень простой процесс, требующий только добавления к noindex атрибута follow, разделенного запятой.
noindex, nofollow
Эта комбинация noindex и nofollow предотвращает индексацию веб-сайта поисковыми системами, а также предотвращает сканирование содержащихся на нем ссылок. Для его реализации используется тот же простой и легкий процесс, что и в предыдущем случае объединения noindex с follow.
Распространенные ошибки при использовании тега noindex
При использовании этого типа метатегов совершается много ошибок, многие из которых отмечаются самой Google Search Console при их обнаружении.
Среди основных ошибок при внедрении тегов noindex на страницу у нас есть:
Карты сайта с URL-адресами, содержащими тег noindex
Обычно, когда файл карты сайта создается со списком URL-адресов сайта, подлежащего индексации , те страницы, которые имеют метатег noindex, не учитываются. Бредовая ситуация ( через карту сайта отправляется URL-адрес, помеченный тегом «не индексировать» ) обнаруживается Google Search Console и помечает его как ошибку.
Решение этой проблемы довольно простое и заключается в удалении URL-адреса из карты сайта или в удалении самого тега noindex с этой страницы , если вы действительно хотите, чтобы она была проиндексирована.
Забудьте о теге noindex
Хотя это может показаться несколько абсурдной ошибкой, это происходит регулярно. По определенной причине этот метатег используется для предотвращения индексации контента в Google, но когда проблема или причина решена, забывается, что тег все еще активен, предотвращая индексацию, поэтому страница все равно не будет отображаться в результатах поиска Google. .
Чтобы устранить этот тип ошибки, лучше всего всегда иметь хорошую организацию, отмечая те страницы, которые не проиндексированы с помощью этого тега (а также те, которые включены в robots.txt или использовать тег nofollow в ссылки).
Метатег noindex — очень интересная альтернатива контролю того, какой контент индексировать, а какой исключить из базы данных Google и других поисковых систем.