
Что такое Robots.txt? | Глоссарий Интернет-маркетинга
Что такое Robots.txt?
Robots.txt — это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем.
После создания файла robots.txt, его нужно поместить в корневой каталог сайта. Поисковый робот всегда обращается к файлу по URL /robots.txt.
После того, как сайт загружен на хостинг и прописаны DNS, роботы поисковых систем получают возможность для обхода сайта и индексации его страниц. Отсутствие файла robots.txt может служить поводом для возникновения проблем со скоростью обхода сайта и присутствия мусора в индексе. А неправильная настройка приводит к исключению из индекса важных частей ресурса или присутствию в выдаче ненужных страниц. Это способствует трудностям с продвижением сайта.
Функции robots.txt
Основная задача этого файла — информирование роботов индексации. Главные указания или директивы robots. txt — это:
txt — это:
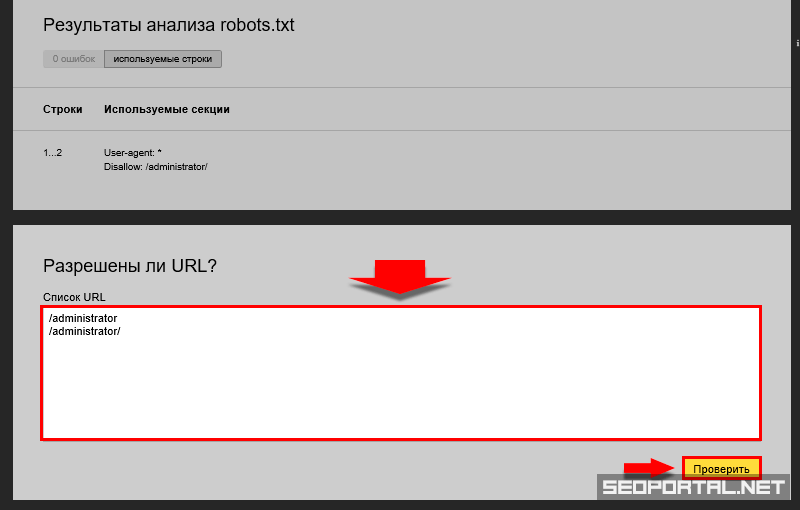
- «Allow» (отвечает за разрешение индексации определенного раздела или файла).
- «Disallow» (соответственно, запрещает индексацию),
- «User-agent» (определяет, к каким именно роботам относятся разрешительные и запрещающие директивы).
Но следует знать, что указания robots.txt носят рекомендательный характер. Это значит, что при определенных условиях робот может проигнорировать их.
Символы в robots.txt
Символы, которые чаще всего используют в данном файле — «/, *, $, #».
С помощью «/» можно показать, что нужно закрыть от индексации. Например, если поставить один слеш в правиле Disallow, то он будет означать запрет на сканирование всего сайта. Применив два знака, запрещают сканирование отдельного раздела, например: /tovary/. Такая запись говорит, что запрещена индексация всего содержимого папки tovary. Но если прописать /tovary, то запрет распространится на все ссылки на сайте, которые будут начинаться на /tovary.
Звездочка «*» имеет значение любой последовательности символов в файле. Ее ставят после каждого правила.
Эта запись говорит, что все роботы не должны индексировать любые файлы с расширением .gif в папке /catalog/
Знак доллара «$» нужен для ограничения знака «*». Если нужно запретить все содержимое папки catalog, но при этом нельзя запретить url-адреса, которые содержат /catalog, то запись в индексном файле будет такой:
Решетка «#» используется для комментариев, которые веб-мастер оставляет для себя или других веб-мастеров. Робот не будет их учитывать при сканировании сайта.
Требования к файлу robots.txt
Веб-мастер всегда должен помнить, что отсутствие в корневом каталоге сайта файла robots.txt или его неправильная настройка потенциально угрожают посещаемости сайта и доступности в поиске.
По стандартам, в файле robots.txt запрещено использование кириллических символов.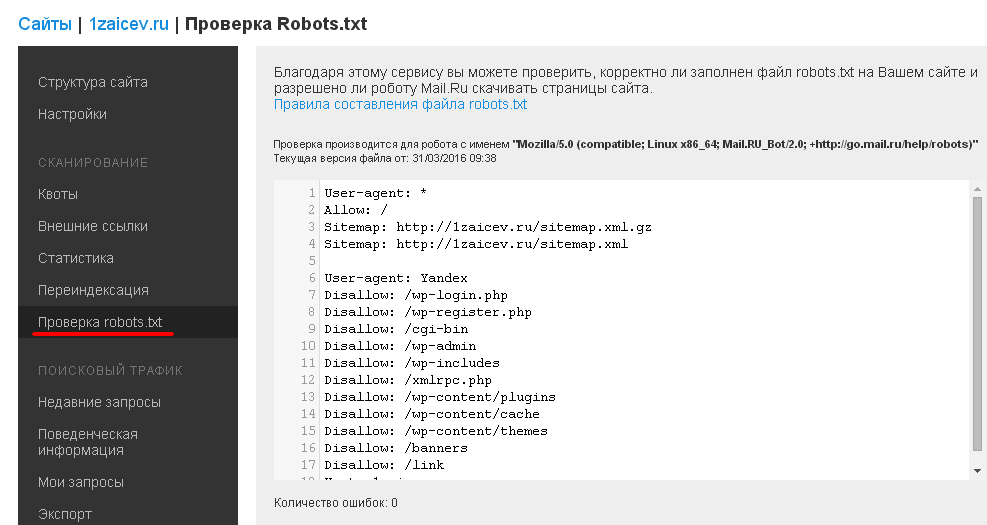 Поэтому для работы с кириллическими доменами нужно применять Punycode. При этом кодировка адресов страниц должна соответствовать кодировке применяемой структуры сайта.
Поэтому для работы с кириллическими доменами нужно применять Punycode. При этом кодировка адресов страниц должна соответствовать кодировке применяемой структуры сайта.
См. также
Индексация
Ранжирование
Уровень вложенности
Анкор
Disavow
Для чего нужен и как правильно составить файл robots.txt?
- Термины и определения
- Что такое домен
- Что такое хостинг
- Что такое ISPmanager
- Что такое время ответа сервера?
- Что такое RDP
- Что такое CMS
- Что такое выделенный сервер
- Что такое PhpMyAdmin
- Что такое MySQL
- Что такое VDS
- Что такое php.ini
- Что такое DNS
- Что такое PHP
- Что такое FTP
- Что такое NS-сервера
- Что такое трансфер
- Что такое POP3
- Что такое протокол IMAP
- Что такое SMTP
- Что такое SSH
- Что такое WWW-домен
- Что такое CRON
- Что такое VNC
- Что такое SSL
- Что такое WHOIS
- Что такое IP
- Что такое DDoS
- Что такое Спам
- Что такое HTML
- Что такое CSS
- Что такое JavaScript
- Что такое Apache
- Биллинг (личный кабинет)
- Финансовые вопросы
- Домены и поддомены
- Виртуальный хостинг
- SSL-сертификаты
- Конструктор сайтов
- VPS и выделенные серверы
- Полезные статьи
- Утилиты
- Помощь
- Термины и определения
 org/BreadcrumbList»>
org/BreadcrumbList»>Содержание:
- Что такое robots.txt?
- Как выглядит robots.txt?
- Как создать robots.txt?
Что такое файл robots.txt?
Файл robots.txt — это документ состоящий из латинских символов, хранящийся на сервере и предназначенный для рекомендации поисковым системам, какие страницы стоит сканировать.
Для чего нужен файл robots.txt?
- определение страниц для индексации
- снижение нагрузки на сервер за счет запрета доступа к сайту для поисковых систем
- определение пути к карте сайта и основного зеркала
- указание правил для обхода определенного ресурса
Как выглядит файл robots.
 txt?
txt?Представим пример базового файла robots.txt:
Sitemap: http://www.mysite.ru
User-agent:*
Allow: /admin/
Allow: /home/
1. Sitemap — это URL карты сайта. Для всех User-agent действует один адрес. В файле robots.txt можно указать количество карт сайтов, которое Вам требуется.
2. User-agent — обращение к поисковым ботам. Указывается список ботов, к которым применяются следующие правила, например:
- «*» — обозначает инструкции ко всем поисковым ботам
- «Googlebot» — обозначает инструкции только к Google
- «Yandex
3. Директивы — инструкции, прописанные для User-agent, которым он должен следовать.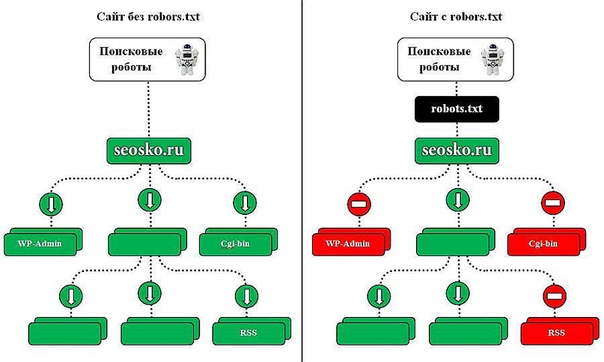 Перечислим некоторые директивы:
Перечислим некоторые директивы:
- Disallow — используется для того, чтобы ограничить доступ к ресурсу по какому-либо пути
- Allow — используется для того, чтобы открыть доступ к ресурсу
- Crawl-delay — используется для задержки сканирования. Не поддерживается для Google
- Noindex — запрещает индексацию ресурса и исключает его из поисковых систем
- Nofollow — запрещает переходить по всем ссылкам на странице
- Host — указывает основное зеркало
- Clean-param — запрещает индексировать параметры адреса страницы. Работает исключительно для Яндекса.
Как создать файл robots.txt ?
Файл robots.txt — это тестовый файл txt с названием robots.txt. Его можно написать, например в блокноте. Знак «$» используется для того, чтобы сохранить окончание URL. Отдельная директива должна начинаться с новой строки. В файл можно вписать комментарий для веб-мастеров, он должен начинаться с новой строки, со знака «#».
Отдельная директива должна начинаться с новой строки. В файл можно вписать комментарий для веб-мастеров, он должен начинаться с новой строки, со знака «#».
Также существуют онлайн сервисы, которые генерируют robots.txt по заданным параметрам. Например SEOlib (https://seolib.ru/tools/generate/robots).
Файл robots.txt должен быть размещен в корневом каталоге субдомена, в рамках которого он должен действовать и должен открываться по адресу сайта. Допустим сайт имеет адрес:
Как закрыть сайт для индексации от поисковых ботов Вы можете узнать на нашем сайте.
В файле robots использование кириллицы запрещено. Поэтому нужно преобразовывать кириллицу в PunyCode, а адреса страниц указывать в кодировке, которая соответствует структуре ресурса.
Существует сервис по преобразованию URL на кириллице — Simple Seo Solutions (https://www.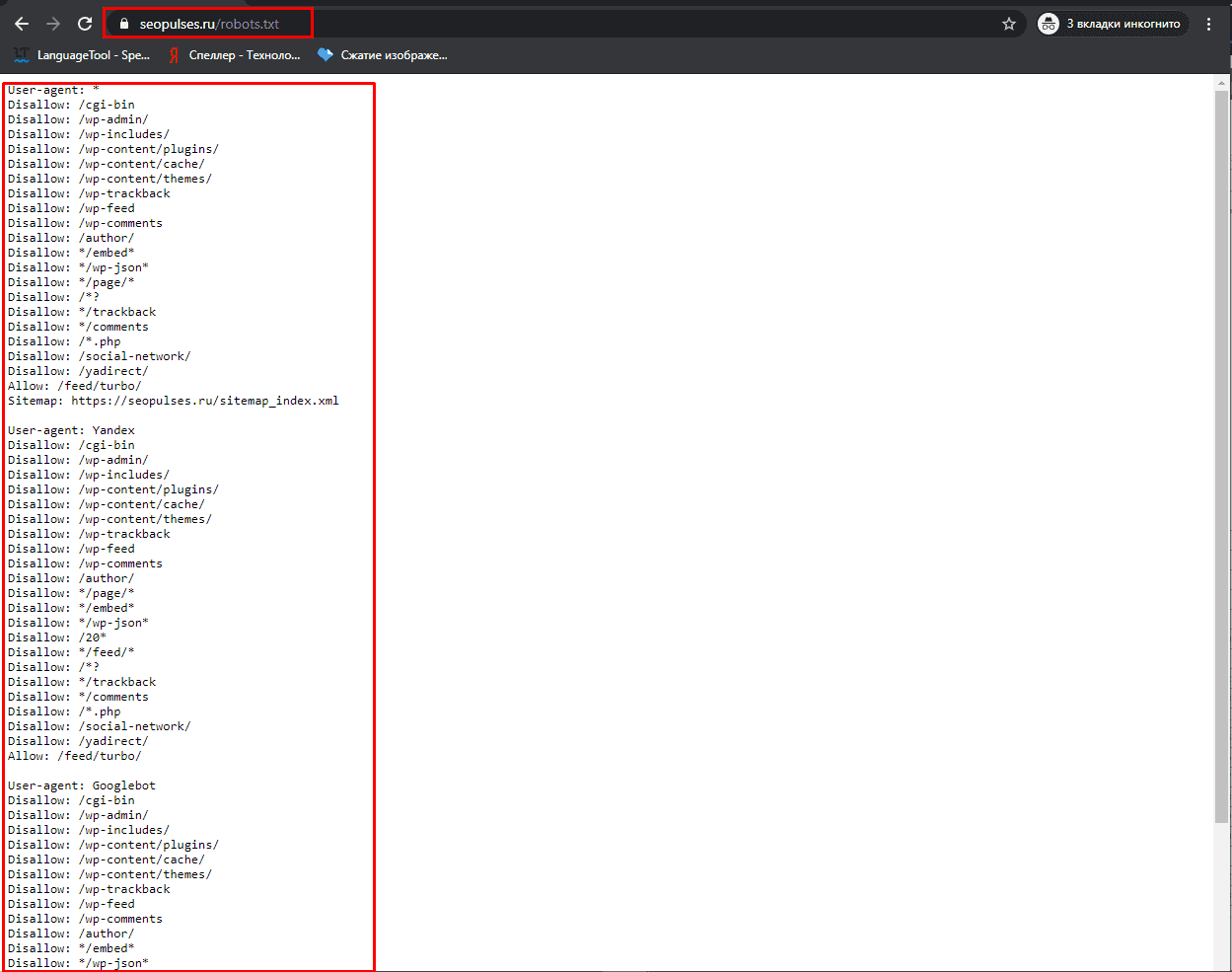 design-sites.ru/utility/url-encoding.php).
design-sites.ru/utility/url-encoding.php).
Неверно:User-agent: Yandex
Disallow: /магазин
Sitemap: http://первыйсайт.рф/sitemap.xml
Верно:User-agent: Yandex
Disallow: /xn—80aairftm
Sitemap:http://%D0%BF%D0%B5%D1%80%D0%B2%D1%8B%D0%B9%D1%81%D0%B0%D0%B9%D1%82.%D1%80%D1%84/sitemap.xml
Что такое robots.txt? Руководство для начинающих с примерами
А, robots.txt — один крошечный файл с большими последствиями. Это один технический элемент SEO, в котором вы не хотите ошибиться, ребята.
В этой статье я объясню, почему каждому веб-сайту нужен файл robots.txt и как его создать (без проблем для SEO). Я отвечу на часто задаваемые вопросы и приведу примеры того, как правильно выполнить это для вашего сайта. Я также дам вам загружаемое руководство, которое охватывает все детали.
Содержание:
- Что такое robots.txt?
- Почему файл robots.
 txt важен?
txt важен? - Но нужен ли файл robots.txt?
- Какие проблемы могут возникнуть с robots.txt?
- Как работает файл robots.txt?
- Советы по созданию файла robots.txt без ошибок
- Тестер robots.txt
- Руководство по протоколу исключения роботов (скачать бесплатно)
 txt важен?
txt важен? Что такое robots.txt?
Robots.txt — это текстовый файл, который издатели веб-сайтов создают и сохраняют в корне своего веб-сайта. Его цель — сообщить автоматическим веб-краулерам, таким как боты поисковых систем, какие страницы на веб-сайте не сканировать. Это также известно как протокол исключения роботов.
Robots.txt не гарантирует, что исключенные URL-адреса не будут проиндексированы для поиска. Это потому, что пауки поисковых систем все еще могут узнать, что эти страницы существуют, через другие веб-страницы, которые ссылаются на них.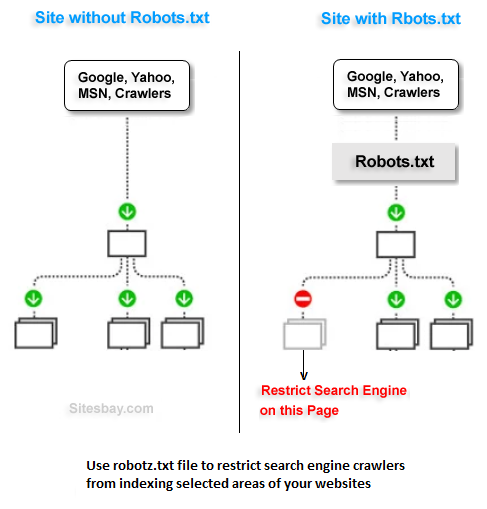 Или страницы все еще могут быть проиндексированы из прошлого (подробнее об этом позже).
Или страницы все еще могут быть проиндексированы из прошлого (подробнее об этом позже).
Robots.txt также не гарантирует, что бот не будет сканировать исключенную страницу, поскольку это добровольная система. Боты основных поисковых систем редко не придерживаются ваших указаний. Но другие, которые являются плохими веб-роботами, такие как спам-боты, вредоносные программы и программы-шпионы, часто не следуют приказам.
Помните, что файл robots.txt общедоступен. Вы можете просто добавить /robots.txt в конец URL-адреса домена, чтобы увидеть его файл robots.txt (как у нас здесь). Поэтому не включайте никакие файлы или папки, которые могут содержать важную для бизнеса информацию. И не полагайтесь на файл robots.txt для защиты личных или конфиденциальных данных от поисковых систем.
Хорошо, с учетом этих предостережений, давайте продолжим…
Почему robots.txt важен?
Боты поисковых систем имеют директиву сканировать и индексировать веб-страницы. С помощью файла robots.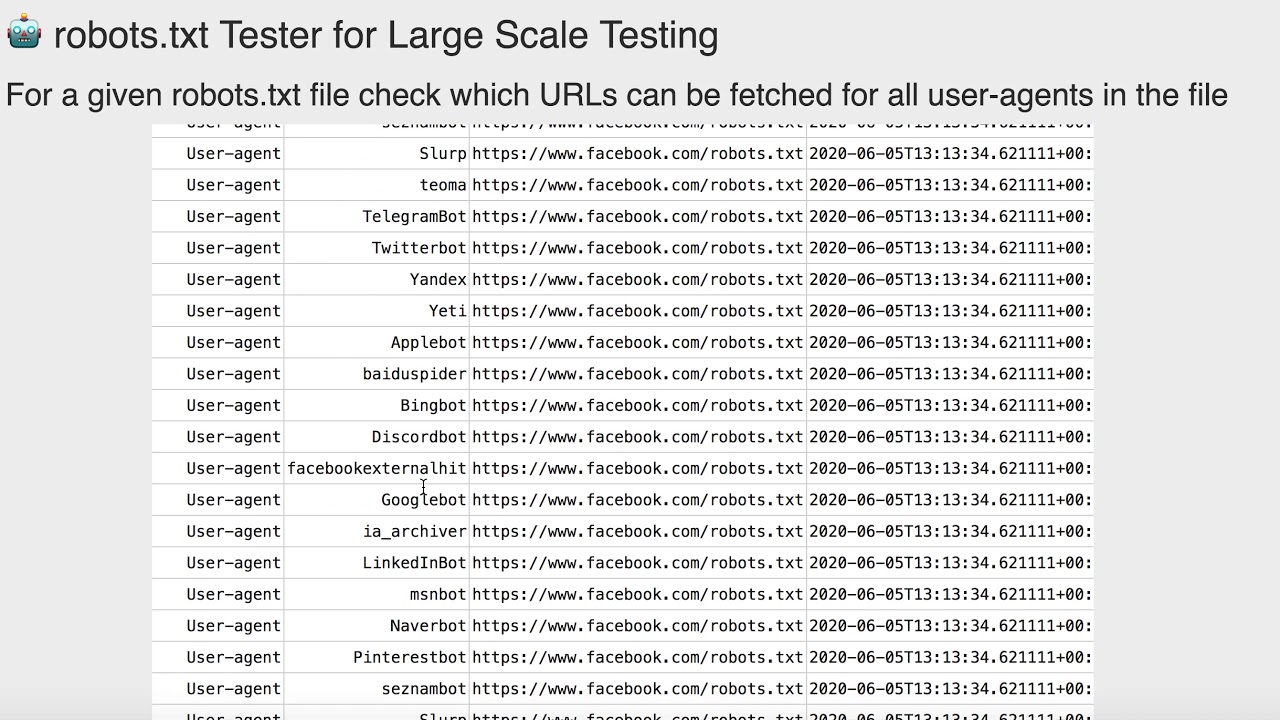 txt вы можете выборочно исключить страницы, каталоги или весь сайт из сканирования.
txt вы можете выборочно исключить страницы, каталоги или весь сайт из сканирования.
Это может быть удобно во многих различных ситуациях. Вот некоторые ситуации, в которых вы можете использовать файл robots.txt:
- Для блокировки определенных страниц или файлов, которые не следует сканировать/индексировать (например, неважные или похожие страницы)
- Чтобы прекратить сканирование определенных частей веб-сайта, пока вы их обновляете
- Чтобы сообщить поисковым системам о расположении вашей карты сайта
- Чтобы указать поисковым системам игнорировать определенные файлы на сайте, такие как видео, аудиофайлы, изображения, PDF-файлы и т. д., чтобы они не отображались в результатах поиска
- Чтобы ваш сервер не был перегружен запросами*
*Использование robots.txt для блокировки ненужного сканирования — один из способов снизить нагрузку на сервер и помочь ботам более эффективно находить ваш хороший контент. Google предоставляет удобную диаграмму здесь.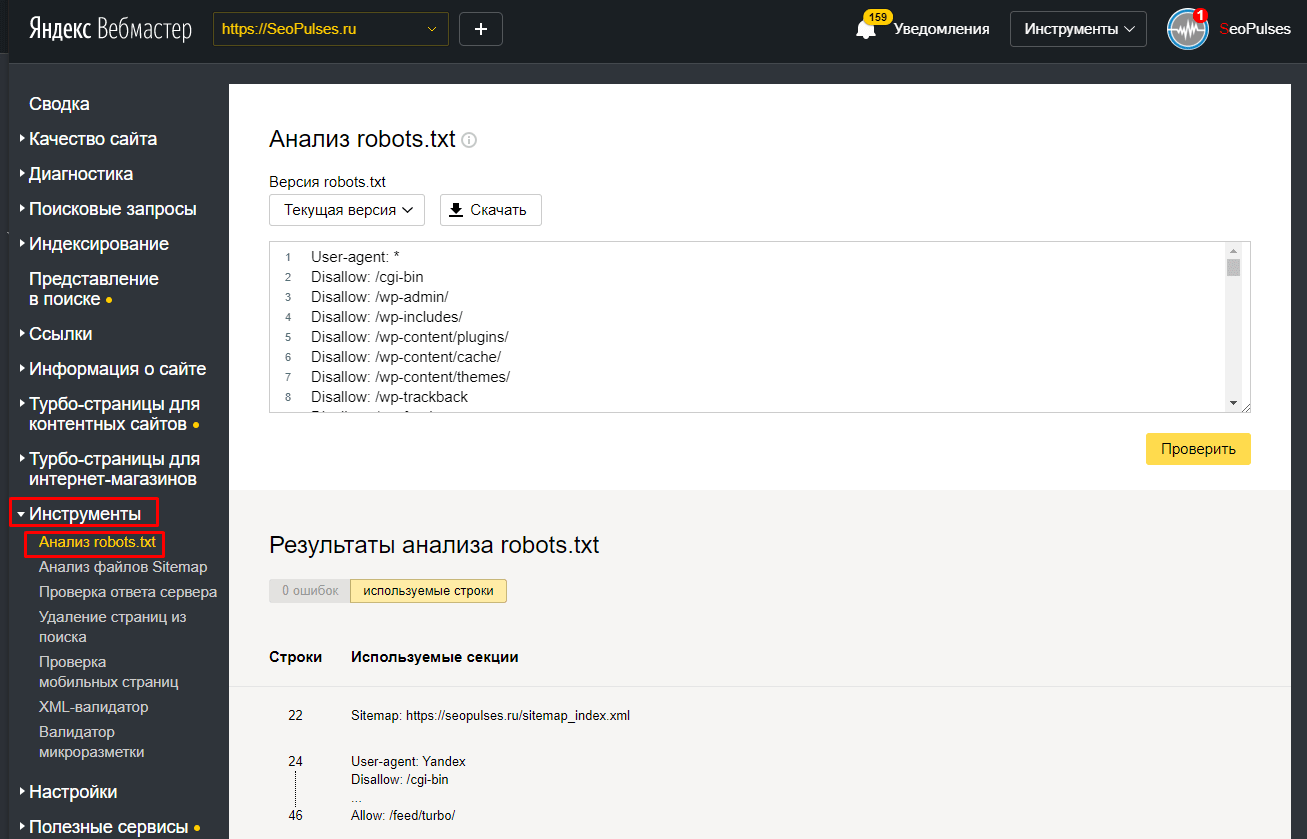 Кроме того, Bing поддерживает директиву Crawl-Delay, которая может помочь предотвратить слишком много запросов и избежать перегрузки сервера.
Кроме того, Bing поддерживает директиву Crawl-Delay, которая может помочь предотвратить слишком много запросов и избежать перегрузки сервера.
Конечно, у файла robots.txt есть много применений, и я расскажу о них в этой статье.
Но нужен ли файл robots.txt?
На каждом веб-сайте должен быть файл robots.txt, даже если он пустой. Когда поисковые роботы заходят на ваш сайт, первое, что они ищут, это файл robots.txt.
Если ничего не существует, поисковые роботы получают ошибку 404 (не найдено). Хотя Google утверждает, что Googlebot может продолжать сканировать сайт, даже если файла robots.txt нет, мы считаем, что лучше иметь первый файл, который бот запрашивает, а не выдавать ошибку 404.
Какие проблемы могут возникнуть с robots.txt?
Этот простой маленький файл может создать проблемы для SEO, если вы не будете осторожны. Вот несколько ситуаций, на которые стоит обратить внимание.
1. Случайная блокировка всего вашего сайта
Эта ошибка случается чаще, чем вы думаете. Разработчики могут использовать robots.txt, чтобы скрыть новый или измененный раздел сайта во время его разработки, но затем забыть разблокировать его после запуска. Если это уже существующий сайт, эта ошибка может привести к внезапному падению рейтинга в поисковых системах.
Разработчики могут использовать robots.txt, чтобы скрыть новый или измененный раздел сайта во время его разработки, но затем забыть разблокировать его после запуска. Если это уже существующий сайт, эта ошибка может привести к внезапному падению рейтинга в поисковых системах.
Удобно иметь возможность отключать сканирование на время подготовки нового сайта или раздела сайта к запуску. Просто не забудьте изменить эту команду в файле robots.txt, когда сайт заработает.
2. Исключение уже проиндексированных страниц
Блокировка проиндексированных страниц robots.txt приводит к тому, что они застревают в индексе Google.
Если исключить страницы, которые уже есть в индексе поисковой системы, они останутся там. Чтобы действительно удалить их из индекса, вы должны установить на самих страницах мета-тег robots «noindex» и позволить Google просканировать и обработать его. Как только страницы будут удалены из индекса, заблокируйте их в robots.txt, чтобы Google не запрашивал их в будущем.
Как работает robots.txt?
Чтобы создать файл robots.txt, вы можете использовать простое приложение, такое как Блокнот или TextEdit. Сохраните его с именем файла robots.txt и загрузите его в корень вашего веб-сайта как www.domain.com/robots.txt — здесь его будут искать пауки.
Простой файл robots.txt будет выглядеть примерно так:
User-agent: *
Disallow: /directory-name/
Google дает хорошее объяснение того, что означают разные строки в группе в файле robots.txt файл в своем файле справки по созданию robots.txt:
Каждая группа состоит из нескольких правил или директив (инструкций), по одной директиве в строке.
Группа предоставляет следующую информацию:
- К кому относится группа (пользовательскому агенту)
- К каким каталогам или файлам может получить доступ агент
- К каким каталогам или файлам этот агент не имеет доступа
Я объясню подробнее о различных директивах в файле robots.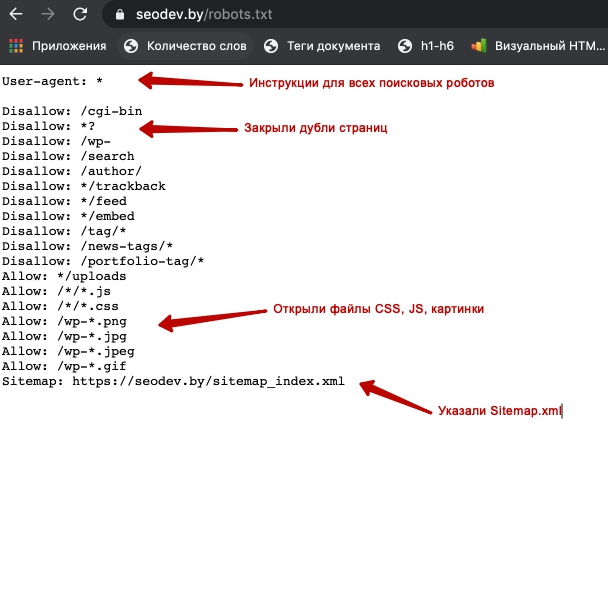 txt далее.
txt далее.
Директивы robots.txt
Общий синтаксис, используемый в файле robots.txt, включает следующее:
User-agent
User-agent относится к боту, которому вы отдаете команды (например, Googlebot или Bingbot). У вас может быть несколько директив для разных пользовательских агентов. Но когда вы используете символ * (как показано в предыдущем разделе), это означает все пользовательские агенты. Вы можете увидеть список пользовательских агентов здесь.
Запретить
Правило Запретить указывает папку, файл или даже весь каталог для исключения из доступа веб-роботов. Примеры включают следующее:
Разрешить роботам сканировать весь сайт:
User-agent: *
Disallow:
Запретить всем роботам со всего сайта:
User-agent: *
Disallow: /
Запретить всем роботам из «/myfolder /» и все подкаталоги «myfolder»:
User-agent: *
Disallow: /myfolder/
Запретить всем роботам доступ к любому файлу, начинающемуся с «myfile. html»:
html»:
User-agent: *
Disallow: /myfile.html
Запретить роботу Googlebot доступ к файлам и папкам, начинающимся с «мой»:
User-agent: googlebot
Disallow: /my
Allow
Эта команда применима только к Googlebot и сообщает ему, что он может получить доступ к подкаталогу или веб-странице, даже если его родительский каталог или веб-страница запрещены.
Возьмем следующий пример: Запретить всех роботов из папки /scripts/, кроме page.php:
Запретить: /scripts/
Разрешить: /scripts/page.php
Crawl-delay
Это сообщает ботам, как долго подождите, чтобы просканировать веб-страницу. Веб-сайты могут использовать это для сохранения пропускной способности сервера. Googlebot не распознает эту команду, и Google просит вас изменить скорость сканирования через консоль поиска. По возможности избегайте задержки сканирования или используйте ее с осторожностью, так как она может существенно повлиять на своевременное и эффективное сканирование веб-сайта.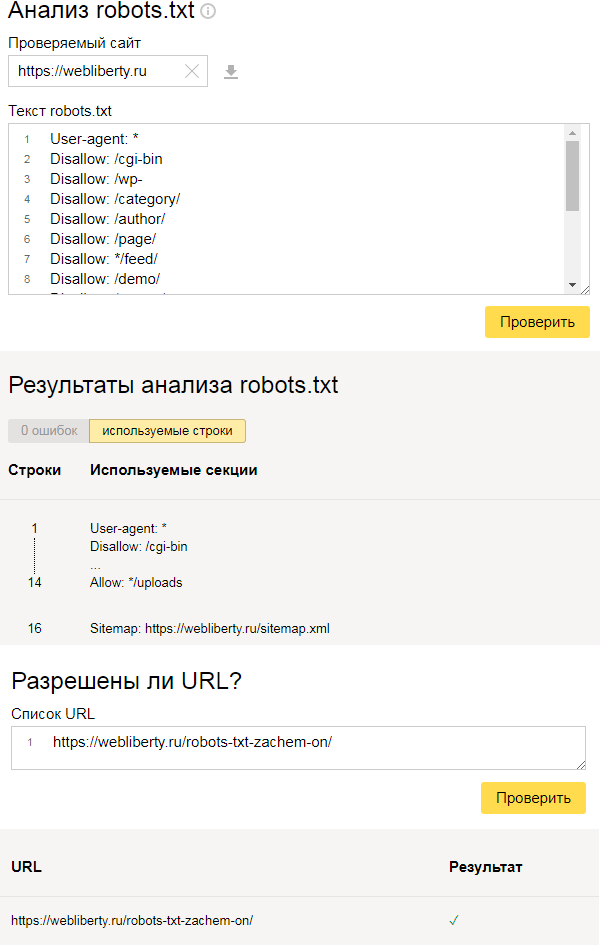
Карта сайта
Сообщите роботам поисковых систем, где в файле robots.txt найти XML-карту сайта. Пример:
User-agent: *
Disallow: /directory-name/
Карта сайта: https://www.domain.com/sitemap.xml
Чтобы узнать больше о создании XML-карт сайта, см. это: Что такое Карта сайта в формате XML и как ее создать?
Подстановочные знаки
Есть два символа, которые могут указывать роботам, как обрабатывать определенные типы URL:
Символ *. Как упоминалось ранее, он может применять директивы к нескольким роботам с одним набором правил. Другое использование — сопоставление последовательности символов в URL-адресе, чтобы запретить эти URL-адреса.
Например, следующее правило запрещает роботу Googlebot доступ к любому URL-адресу, содержащему «страницу»:
Агент пользователя: googlebot
Запретить: /*page
Символ $. Символ $ сообщает роботам, что нужно сопоставить любую последовательность в конце URL-адреса. Например, вы можете заблокировать сканирование всех PDF-файлов на веб-сайте:
Например, вы можете заблокировать сканирование всех PDF-файлов на веб-сайте:
User-agent: *
Disallow: /*.pdf$
Обратите внимание, что вы можете комбинировать подстановочные знаки $ и *, и их можно комбинировать для разрешающих и запрещающих директив.
Например, Запретить все файлы asp:
Агент пользователя: *
Запретить: /*asp$
- Это не будет исключать файлы со строками запроса или папками из-за символа $, обозначающего конец
- Исключено из-за подстановочный знак перед asp – /pretty-wasp
- Исключено из-за подстановочного знака перед asp – /login.asp
- Не исключено из-за $ и URL-адреса, включающего строку запроса (?forgotten-password=1) – /login.asp?forgotten-password=1
Не сканируется и не индексируется
Если вы не хотите Google для индексации страницы, для этого есть другие средства, кроме файла robots.txt. Как указывает здесь Google:
Какой метод следует использовать для блокировки сканеров?
- robots.
- : используйте его, если вам нужно контролировать, как отдельная HTML-страница отображается в результатах поиска (или убедиться, что она не отображается).
- X-Robots-Tag HTTP-заголовок: используйте его, если вам нужно контролировать, как контент, отличный от HTML, отображается в результатах поиска (или убедиться, что он не отображается).
 txt: используйте его, если сканирование вашего контента вызывает проблемы на вашем сервере. Например, вы можете запретить сканирование бесконечных сценариев календаря. Вы не должны использовать robots.txt для блокировки частного контента (вместо этого используйте аутентификацию на стороне сервера) или обработки канонизации. Чтобы убедиться, что URL-адрес не проиндексирован, используйте метатег robots или HTTP-заголовок X-Robots-Tag. 9Метатег robots 0013
txt: используйте его, если сканирование вашего контента вызывает проблемы на вашем сервере. Например, вы можете запретить сканирование бесконечных сценариев календаря. Вы не должны использовать robots.txt для блокировки частного контента (вместо этого используйте аутентификацию на стороне сервера) или обработки канонизации. Чтобы убедиться, что URL-адрес не проиндексирован, используйте метатег robots или HTTP-заголовок X-Robots-Tag. 9Метатег robots 0013А вот еще руководство от Google:
Блокировка Google от сканирования страницы, скорее всего, приведет к удалению страницы из индекса Google.
Однако запрет в robots.
 txt не гарантирует, что страница не будет отображаться в результатах: Google может решить, основываясь на внешней информации, такой как входящие ссылки, что она релевантна. Если вы хотите явно заблокировать страницу от индексации, вам следует вместо этого использовать метатег noindex robots или HTTP-заголовок X-Robots-Tag. В этом случае не следует запрещать страницу в robots.txt, потому что страницу необходимо просканировать, чтобы тег был виден и подчинялся.
txt не гарантирует, что страница не будет отображаться в результатах: Google может решить, основываясь на внешней информации, такой как входящие ссылки, что она релевантна. Если вы хотите явно заблокировать страницу от индексации, вам следует вместо этого использовать метатег noindex robots или HTTP-заголовок X-Robots-Tag. В этом случае не следует запрещать страницу в robots.txt, потому что страницу необходимо просканировать, чтобы тег был виден и подчинялся.Советы по созданию файла robots.txt без ошибок
Вот несколько советов, которые следует учитывать при создании файла robots.txt:
- Команды чувствительны к регистру. Например, вам нужна заглавная буква «D» в Disallow.
- Всегда добавляйте пробел после двоеточия в команду.
- При исключении всего каталога поставьте косую черту до и после имени каталога, например: /имя-каталога/
- Все файлы, не исключенные специально, будут включены для сканирования ботами.
Тестер robots.
 txt
txtВсегда проверяйте файл robots.txt. Чаще всего вы думаете, что издатели веб-сайтов ошибаются, что может разрушить вашу стратегию SEO (например, если вы запретите сканирование важных страниц или всего веб-сайта).
Используйте инструмент Google robots.txt Tester. Вы можете найти информацию об этом здесь.
Руководство по протоколу исключения роботов
Если вам нужна более подробная информация, чем эта статья, загрузите нашу Руководство по протоколу исключения роботов . Это бесплатный PDF-файл, который вы можете сохранить и распечатать для справки, чтобы получить подробную информацию о том, как создать файл robots.txt.
Заключительные мысли
Файл robots.txt на первый взгляд кажется простым, но он позволяет издателям веб-сайтов давать сложные указания о том, как они хотят, чтобы боты сканировали веб-сайт. Правильное получение этого файла имеет решающее значение, так как оно может уничтожить вашу программу SEO, если все сделано неправильно.
Поскольку существует множество нюансов использования robots.txt, обязательно прочитайте введение Google в robots.txt.
У вас есть проблемы с индексацией или другие вопросы, требующие технических знаний SEO? Если вы хотите получить бесплатную консультацию и расценки на услуги, свяжитесь с нами сегодня.
Брюс Клэй является основателем и президентом Bruce Clay Inc., глобальной фирмы цифрового маркетинга, предлагающей поисковую оптимизацию, оплату за клик, маркетинг в социальных сетях, оптимизированную для SEO веб-архитектуру, а также инструменты SEO и обучение. Свяжитесь с ним через LinkedIn или через веб-сайт BruceClay.com.
На странице автора Брюса есть ссылки для связи в социальных сетях.
Что такое robots.txt в WordPress?
акции 48 Делиться Твитнуть Делиться Facebook-мессенджер WhatsApp Электронная почта
Robots.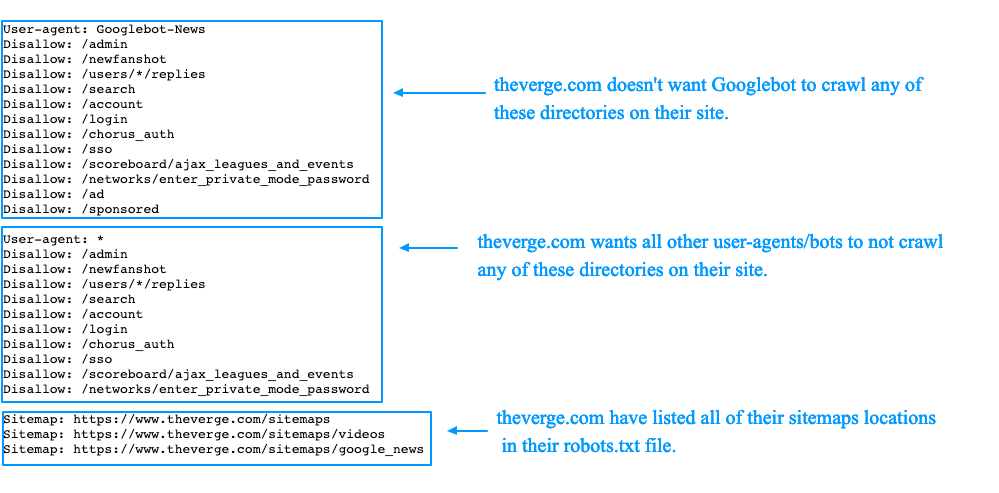 txt — это текстовый файл, который позволяет веб-сайту давать инструкции роботам, сканирующим веб-страницы.
txt — это текстовый файл, который позволяет веб-сайту давать инструкции роботам, сканирующим веб-страницы.
Поисковые системы, такие как Google, используют эти поисковые роботы, иногда называемые веб-роботами, для архивирования и категоризации веб-сайтов. Большинство ботов настроены на поиск файла robots.txt на сервере, прежде чем он прочитает любой другой файл с веб-сайта. Это делается для того, чтобы узнать, есть ли у владельца веб-сайта какие-либо специальные инструкции о том, как сканировать и индексировать его сайт.
Файл robots.txt содержит набор инструкций, которые требуют от бота игнорировать определенные файлы или каталоги. Это может быть сделано в целях конфиденциальности или потому, что владелец веб-сайта считает, что содержимое этих файлов и каталогов не имеет отношения к классификации веб-сайта в поисковых системах.
Если веб-сайт имеет более одного субдомена, для каждого субдомена должен быть свой файл robots.txt. Важно отметить, что не все боты поддерживают файл robots.