
что это за тег для Яндекса
Для того чтобы сайт или отдельные его страницы попадали в выдачу поисковых машин, они должны проходить индексацию. Однако зачастую не весь текстовый контент должен индексироваться, так как на любом ресурсе могут присутствовать не несущие полезной нагрузки для SEO данные. Тег noindex позволяет скрывать ненужные фрагменты текста, в результате чего они не проходят индексацию, так как поисковик их игнорирует. Этот инструмент ввели специалисты «Яндекса», значительно упростив задачи для веб-разработчиков.
Также noindex позволяет блокировать индексацию целых страниц. Чаще всего это необходимо для того, чтобы в поисковом продвижении не участвовал пользовательский контент, например комментарии, сообщения или отзывы. Это снимает нагрузку с модераторов и позволяет без помех проводить кампании по SEO-продвижению.
На текущий момент этот тег работает только для поисковой машины «Яндекса», а Google игнорирует его и индексирует весь контент сайта, поэтому при ориентировании на него необходимо использовать файл robots.
Что дает использование тега noindex?
- Обеспечивает максимальную релевантность страниц за счет исключения из индексации второстепенного текстового контента, способного изменить плотность ключевых слов и смысловое содержание в целом;
- Позволяет избежать блокировок или игнорирования ресурса, которые могут возникнуть по причине дублируемого на страницах текста. Его можно просто скрыть от поисковой машины;
- Исключает вероятность попадания в сниппеты ненужной информации – каких-либо технических, служебных данных.
Как это работает?
Каждая страница построена на основе HTML-кода с различными уровнями вложенности. Тег может быть прописан абсолютно в любом месте, и правильный формат его вставки будет таким:
<!—noindex—>Неиндексируемый контент<!—/noindex—>
Изначально этот тег был внедрен специалистами «Яндекса» для облегчения задач веб-разработчикам, но нередко он используется в качестве инструмента для так называемой «серой» оптимизации. То есть некоторые веб-мастера применяют его для сокрытия контента, который предназначен для прочтения пользователем, но при этом не содержит ключевых слов. Причем это может быть неуникальный контент или копипаст, использование которого в обычном режиме может привести к утрате позиций в поисковой выдаче и к блокировке ресурса. А для SEO на сайте оставляют оптимизированный фрагмент уникального текста, который остается видимым для робота.
То есть некоторые веб-мастера применяют его для сокрытия контента, который предназначен для прочтения пользователем, но при этом не содержит ключевых слов. Причем это может быть неуникальный контент или копипаст, использование которого в обычном режиме может привести к утрате позиций в поисковой выдаче и к блокировке ресурса. А для SEO на сайте оставляют оптимизированный фрагмент уникального текста, который остается видимым для робота.
В связи с этим «Яндекс» усовершенствовал алгоритм работы с тегом noindex, и сейчас его содержимое также проходит первичную индексацию, но впоследствии при отсутствии проблем со скрытым контентом он просто игнорируется. Если же машина сочтет, что разработчик использовал тег для «серого» продвижения, найдет признаки нерелевантности ресурса используемым запросам, то сайт будет заблокирован и не попадет в выдачу.
SEO-wiki – Что такое Noindex
SEO-wiki – Что такое Noindex × Алфавитный указательNoindex
Тегом noindex отмечается часть содержимого веб-страницы, которая запрещена к индексации поисковым роботом. Мотивация для применения этого тега может быть разной, к примеру, веб-мастер может пойти на использование тега noindex, чтобы закрыть от индексации неуникальный контент, дублированные фрагменты и тексты, которые встречаются на других страницах ресурса, технический контент и т. п. Оформляется тег следующим образом: <noindex>фрагмент текста, запрещенный для индексации</noindex>.
Мотивация для применения этого тега может быть разной, к примеру, веб-мастер может пойти на использование тега noindex, чтобы закрыть от индексации неуникальный контент, дублированные фрагменты и тексты, которые встречаются на других страницах ресурса, технический контент и т. п. Оформляется тег следующим образом: <noindex>фрагмент текста, запрещенный для индексации</noindex>.
Спасибо!
Скоро мы свяжемся с Вами!
Спасибо!
Скоро мы свяжемся с Вами!
Спасибо!
Скоро мы свяжемся с Вами!
×
Продолжая использовать наш сайт, вы даете согласие на обработку файлов cookie, пользовательских данных (сведения о местоположении; тип и версия ОС; тип и версия Браузера; тип устройства и разрешение его экрана; источник откуда пришел на сайт пользователь; с какого сайта или по какой рекламе; язык ОС и Браузера; какие страницы открывает и на какие кнопки нажимает пользователь; ip-адрес) в целях функционирования сайта, проведения ретаргетинга и проведения статистических исследований и обзоров.
× Продолжая использовать наш сайт, вы даете согласие на обработку файлов cookie, пользовательских данных (сведения о местоположении; тип и версия ОС; тип и версия Браузера; тип устройства и разрешение его экрана; источник откуда пришел на сайт пользователь; с какого сайта или по какой рекламе; язык ОС и Браузера; какие страницы открывает и на какие кнопки нажимает пользователь; ip-адрес) в целях функционирования сайта, проведения ретаргетинга и проведения статистических исследований и обзоров. Если вы не хотите, чтобы ваши данные обрабатывались, покиньте сайт.
Noindex определение | Что такое Noindex термины
Что такое noindex
Noindex – тэг, который запрещает роботу индексировать часть страницы. Если вы продвигаете свой сайт в Google, используйте robots. Кроме всего прочего, он способен обработать всю веб-страницу.
Тег noindex Яндекс ввел по собственной инициативе, которую до сегодняшнего дня разделяет лишь Рамблер.
Поэтому при использовании тега noindex, Google не будет обращать на него внимания.
 Поэтому при использовании тега noindex, Google не будет обращать на него внимания.
Поэтому при использовании тега noindex, Google не будет обращать на него внимания.Также noindex и его постоянный спутник nofollow могут использоваться совершенно в ином виде – как значения атрибута content в составе мета-тега robots.
Noindex – это тег, с помощью которого можно управлять функцией индексации поискового робота. Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш.
Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы. alt= Что такое noindex термин определение
Noindex определение
Вторая, не менее важная функция тега noindex, состоит в том, чтобы блокировать индексацию отдельных страниц сайта, предназначенных для публикации пользовательского контента. К таким относятся страницы с отзывами, комментариями, сообщениями и др.
Noindex термин
Тег noindex учитывает только Яндекс. Google игнорирует его присутствие и проводит полную индексацию текстового содержания страницы. Для задействования блокировки индексации, актуальной для всех поисковиков, следует прописывать соответствующий метатег для отдельных страниц или всего сайта в файле robots.txt.
Стань эффективным интернет-маркетологом — запишись к нам на курсы! Школа Интернет Маркетинга Онлайн.
имя не входящего в официальную спецификацию тега языка гипертекстовой разметки веб-страниц HTML, предназначенного для включения в него частей веб-стра
Пользователи также искали:
a href noindex,
googlebot noindex,
noindex google,
noindex, nofollow,
noindex тег,
noindex yandex,
проверить noindex,
rel=noindex,
noindex,
Noindex,
googlebot,
проверить,
href,
yandex,
nofollow,
google,
googlebot noindex,
проверить noindex,
a href noindex,
relnoindex,
noindex тег,
noindex yandex,
noindex nofollow,
noindex google,
микроформаты.
что это такое и как использовать
- – Автор: Игорь (Администратор)
В рамках данного обзора, я расскажу вам что такое Nofollow и Noindex, а так же ряд связанных с ними особенностей.
Раньше текст веб-страницы полностью формировался только ее автором. Однако, со временем появилась возможность влиять на содержимое текста обычными читателями. Это комментарии, темы в блогах, посты и тому подобное. Кроме того, сайты стали большими и появилась необходимость в страницах, которые бесполезны для поисковых систем, но нужны пользователям. Это дубликаты страниц, расположенных в разных разделах, автогенерируемые страницы с кусками текста и тому подобное.
Поэтому появилась необходимость как-то сигнализировать поисковым системам, таким как Яндекс и Google, о том, какой текст необходимо индексировать и какие ссылки учитывать в ссылочной массе. Этими сигналами стали специальные слова Nofollow и Noindex.
Но, обо всем по порядку.
Nofollow, Noindex это
Nofollow — это атрибут, который указывается в определенных ссылках или же мета-теге robots для запрета индексации ссылок и передачи по ним веса.
Noindex — это атрибут, который указывается в мета-теге robots для закрытия текста от индексации. Так же может быть представлен в виде отдельного тега, но учитывается только поисковыми системами Яндекс и Рамблер.
Как используется атрибут nofollow в ссылке:
<a href="/[адрес сайта]" <strong>rel="nofollow"</strong>>Текст</a>
Часть rel=»nofollow» информирует поисковые системы, что поисковым ботам нет необходимости переходить по данной ссылке.
Как используются атрибуты nofollow и noindex в мета-теге robots:
1. Индексировать и переходить по ссылкам в странице
<meta name="robots" <strong>content="index, follow"</strong> />
Если мета-тега в странице нет, то по умолчанию считается, что страницу можно индексировать и поисковому боту необходимо переходить по ссылкам (если они не запрещены атрибутом).
2. Не индексировать текст и переходить по ссылкам в странице
<meta name="robots" <strong>content="noindex, follow"</strong> />
Так же можно не указывать follow, так как поисковики считают по умолчанию, что индексация текста и переход по ссылкам разрешены.
3. Индексировать текст и не переходить по ссылкам в странице
<meta name="robots" <strong>content="index, nofollow"</strong> />
Так же можно не указывать index, так как поисковики считают по умолчанию, что индексация текста и переход по ссылкам разрешены.
4. Не индексировать текст и не переходить по ссылкам в странице
<meta name="robots" <strong>content="noindex, nofollow"</strong> />
5. Не индексировать текст и не переходить по ссылкам в странице с помощью none
<meta name="robots" <strong>content="none"</strong> />
Однако, стоит учитывать, что в мета-теге robots поддерживаются иные вариант специальных директив. Например, noarchive означает не сохранять копию странице в кэше поисковых систем. Поэтому применять none стоит с осторожностью.
Как выглядят тег noindex в поисковых системах Яндекс и Рамблер:
1. <noindex>Неиндексируемый кусок кода</noindex>
2. <!—noindex—>Неиндексируемый кусок кода<!—/noindex—>
Читателю стоит знать, что приоритетным считается второй вариант (в виде html комментария), так как тег из первого варианта корректно воспринимается только поисковыми системами Яндекс и Рамблер (для остальных же это наличие невалидного тега в коде html).
Для чего нужны Nofollow и Noindex?
Для чего применяется Nofollow:
1. Закрытие лишних ссылок.
2. Распределение веса. Открытые ссылки передают больше веса (подробнее об этом чуть далее).
3. Скрытие технических ссылок и передачи веса по ним.
4. Не передавать вес для отдельных сайтов. Например, сомнительные ссылки.
5. Чтобы избежать спама. Площадки с возможностью публиковать открытые ссылки часто становятся объектами для спама.
6. Рекламный контент.
7. Чтобы избежать большого числа внешних открытых ссылок.
8. Приоритет сканирования. Если nofollow ссылки и будут просканированы ботом, то только после открытых.
Для чего применяется Noindex:
1. Данные не статичны, поэтому нет смысла их индексировать.
2. Данные динамически генерируются, поэтому нет смысла индексировать такие страницы. Особенно, если речь о подгрузке данных с помощью ajax.
3. Закрытие информации, которую не хотелось бы, чтобы она отображалась в поиске. Например, личные контактные данные.
Например, личные контактные данные.
4. Технические блоки (в случае тега noindex), такие как счетчики.
5. Дубликаты страниц. Как альтернативу, лучше использовать canonical, но все же.
6. Защита от спама. Обычно применяется к тем разделам, в которых часто публикуют информацию для продвижения иных проектов.
7. Цитаты и копипаст (в случае тега noindex) для увеличения уникальности текста.
8. Яндексу отображать одно, для Google другое (в случае тега noindex).
9. Чтобы текст не оказался в сниппете (в случае тега noindex).
Особенности nofollow и noindex
Вот несколько особенностей использования Nofollow и Noindex:
1. Из-за того, что ажиотаж с использованием ссылок с nofollow порой доходит до абсурда, поисковые системы все же учитывают подобные ссылки, но с меньшим весом. Например, в большинстве социальных сетей, внешние ссылки автоматически закрываются в nofollow, какого бы качества не были сайты акцепторы.
2. Если внутри тега noindex находятся ссылки без nofollow, то они будут учитываться поисковыми системами. Для Яндекса они будут безанкорными, ну а остальные системы и вовсе игнорируют тег noindex. Поэтому, если необходимо так же скрывать ссылки, то в них необходимо задавать nofollow.
Для Яндекса они будут безанкорными, ну а остальные системы и вовсе игнорируют тег noindex. Поэтому, если необходимо так же скрывать ссылки, то в них необходимо задавать nofollow.
3. Поисковые системы Яндекс и Google по разному воспринимают nofollow. Яндекс не учитывает ссылки, но индексирует текст. Google же не только не учитывает ссылку, но и ее текст. Это важная особенность, так как если внутри текста ссылки был адрес сайта, то Яндекс увидит его, а Google нет. Но, как уже говорилось, помните про первую особенность.
4. Учтите, что если в мета-теге robots закрыть только индексацию текста, то ссылки будут учтены.
5. Так же поисковые системы учитывают специальный HTTP заголовок «X-Robots-Tag». Например, «X-Robots-Tag: noindex, nofollow» аналогичен мета-тегу с noindex и nofollow.
6. Если вы используете несколько мета-тегов, то поисковые системы могут по разному их интерпретировать (тем более, что механизмы постоянно корректируются). Поэтому старайтесь задавать необходимое в одном мета-теге.
7. Стоит помнить, что файл «robots.txt» предполагает более высокий приоритет, чем мета-теги. Логика в том, что если страница запрещена в файле, то поисковая система проигнорирует страницу, как и ее мета-теги. Хотя, отмечу, что в интернете порой упоминается, что далеко не всегда страницы, запрещенные к индексации в файле robots, не попадают в индекс. Например, если на страницу была внешняя ссылка.
8. Поисковые системы поддерживают собственный набор мета-тегов и вариаций их представления, более подробно о них лучше смотреть в справке необходимого поисковика. Сделано это для того, чтобы разным поисковым системам можно было указывать разные ограничения.
Теперь, вы знаете что такое nofollow и noindex, а так же некоторые важные особенности.
☕ Хотите выразить благодарность автору? Поделитесь с друзьями!
- Редирект (redirect) что это и зачем он нужен?
- Что такое карта сайта (sitemap)?
Добавить комментарий / отзыв
Зачем в SEO использовать noindex и nofollow
Первое на что стоит обратить внимание, это на то, что существует несколько разных понятий: атрибут – rel=”nofollow”, тег – <noindex> и метатег – <meta name=”robots” content=”noindex, nofollow” />.
Ниже в статье мы подробнее разберёмся с определениями и предназначениями данных понятий.
Тег noindex
С помощью тега noindex можно выделить отдельный фрагмент текста и закрыть его от индексации робота поисковой системы. Также с его помощью, можно блокировать индексацию отдельных страниц сайта, которые предназначены для публикации пользовательского контента например, страницы с отзывами или комментариями и пр.
Данный тег в HTML-коде может прописываться где угодно вне зависимости от уровня вложенности. Пример написания тега выглядит следующим образом:
- < !—noindex— >текст, который мы хотим скрыть от индексации<!—/noindex— >
- <noindex>ссылка, которою необходимо скрыть от индексации</noindex>
Важно знать, что тег noindex не учитывается ПС Google. Система попросту игнорирует его присутствие и проводит полную индексацию текстового содержания на страницах сайта.
Атрибут nofollow
В HTML-коде nofollow, является одним из множества значений, которое способно принимать атрибут rel.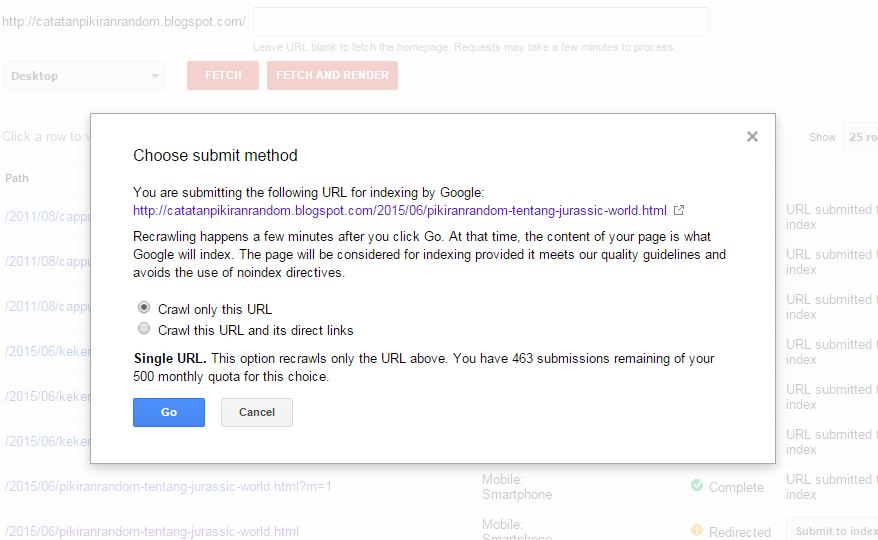 Использование данного атрибута rel=”nofollow” полагается в том, что бы запрещать роботам ПС индексировать и переходить по активной ссылке, на которой стоит данный атрибут.
Использование данного атрибута rel=”nofollow” полагается в том, что бы запрещать роботам ПС индексировать и переходить по активной ссылке, на которой стоит данный атрибут.
В коде, rel=”nofollow” выглядит следующим образом:
<a href=»https://site.com/» rel=»nofollow»>текст ссылки</a>
Причины, по которым стоит пользоваться атрибутом nofollow
На самом деле есть множество причин, по которым стоит запрещать индексацию ссылок, перечислим самые актуальные и важные из них.
- Ссылка на некачественный или нетематический сайт.
- Огромное количество ссылок ведущие на сторонние ресурсы.
- Защита от тех ссылок, что оставили пользователи в комментариях или отзывах.
- Перераспределение и сохранение веса страниц.
- Потребность в создании естественного ссылочного профиля.
Также, можно использовать одновременно тех noindex и атрибут nofollow, выглядеть данное сочетание будет так:
<noindex><a href=»http://site. com/» rel=»nofollow»>текст ссылки</a></noindex>
com/» rel=»nofollow»>текст ссылки</a></noindex>
Что правда, такой метод работать полноценно не будет для роботов ПС Google, так как они понимают только атрибут – rel=»nofollow».
Мета-тег <meta name=”robots” content=”noindex, nofollow” />
Для начала рассмотрим, что такое метатег robots и зачем он нужен. Мета-тег robots – это код гипертекстовой разметки, который позволяет контролировать индексирование и показ страниц веб-сайта в результатах поиска. Метатег, можно писать на любой странице ресурса в специально отведённом для него месте в HTML-коде в теге <head>. Во время индексирования, Поисковые роботы будут читать значение мета-тега robots и учитывать его в дальнейшей работе над ресурсом.
Выглядит метатег robots следующим образом:
<meta name=»robots» content=» » />
Между кавычек content указываются следующие команды для поисковых роботов:
- Index;
- Noindex;
- Follow;
- Nofollow и пр.

Суть значений в мета-теге robots команд noindex и nofollow
- запрещать индексацию на уровне страницы, при этом не запрещать роботам посещать её и переходить по ссылкам.
- запрещать роботам ПС переходить по внешним и внутреннем ссылкам.
На практике комбинация <meta name=”robots” content=”noindex, nofollow” />, используются в случае, когда нужно запретить поисковым роботом индексировать контент на странице сайта и переходить по ссылкам.
Noindex, nofollow для Google — как и когда использовать с пользой для SEO продвижения
Noindex – это директива для поисковых систем, которая запрещает отображать страницу либо часть текста в результатах поиска. Давайте рассмотрим подробнее – где и в каких случаях используется эта директива?
Mетатег “robots” со значением “noindex”
Чтобы не допустить определенную страницу к индексированию поисковыми системами используется метатег robots с добавлением значения “noindex”.
В разделе <head> страницы размещается следующая конструкция:
<head>
<meta name="robots" content="noindex" />
…
</head>
Данный метатег распространяется на всех роботов поисковых систем. Но иногда может использоваться только для определенных роботов, в зависимости от целей. Например, можно запретить индексацию только лишь определенной поисковой системе, указав в значении для атрибута “name” название робота (например – Googlebot, для Google):
<meta name="googlebot" content="noindex" />
Пример: Вы не хотите, чтобы ваши изображения были найдены через поиск по изображениям и использованы кем-то в личных целях.
Решение: Можно запретить индексацию страницы с данными изображениями только в поиске по изображениям, используя робот Googlebot-Image:
<meta name="googlebot-image" content="noindex" />
Таким образом, страница появится в результатах обычного поиска, но её содержимое не будет индексироваться для поиска по изображениям.
Тег <noindex> – для закрытия от индексации части контента
Для того, чтобы закрыть от индексации часть текста используется тег <noindex>, который может быть помещен в любые элементы html-кода страницы:
<noindex>текст, который будет запрещен к индексированию</noindex>
Однако, данный тег будет восприниматься только поисковиком Яндекс, так как он не является стандартизированным и был введен только этой поисковой системой.
Если мы разместим текст внутрь тега, то он не будет индексироваться при сканировании роботом Яндекс и при этом будет попадать в индекс всех остальных поисковиков.
Валидность
Так как тег <noindex> не является стандартизированным, то могут возникать ошибки валидации. Чтобы код оставался валидным, рекомендуется использование тега в таком виде:
<!--noindex-->текст, который будет запрещен к индексированию<!--/noindex-->
Варианты использования meta robots noindex
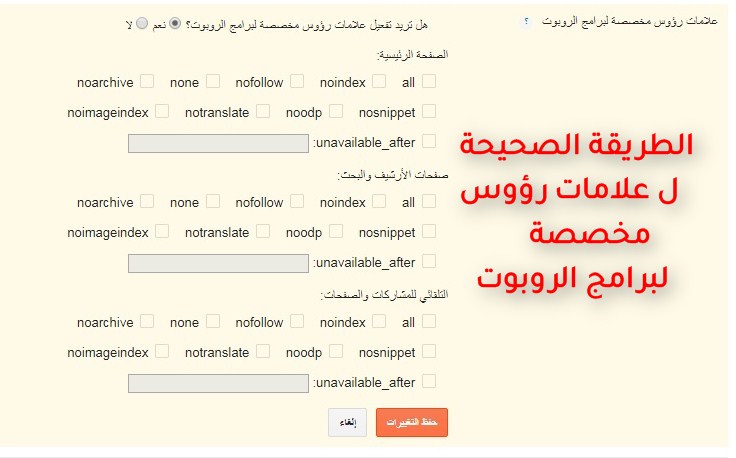
Мета-тег “Robots” содержит директивы, разделенные запятыми:
- Index/Noindex задает правило индексации страницы;
- Follow/Nofollow разрешает или запрещает переходить по ссылкам со страницы. Значения по умолчанию – Index и Follow.
 Значения по умолчанию – Index и Follow.
Значения по умолчанию – Index и Follow.Существуют следующие варианты использования метатега:
| <meta name=“robots” content=“index,follow”> | Разрешено индексировать страницу и переходить по ссылкам на ней. |
| <meta name=“robots” content=“noindex,follow”> | Запрещено индексировать страницу, но можно переходить по ссылкам на ней. |
| <meta name=“robots” content=“index,nofollow”> | Разрешено индексировать страницу, но нельзя переходить по ссылкам на странице. |
| <meta name=“robots” content=“noindex,nofollow”> | Запрещено индексировать страницу и переходить по ссылкам на ней. |
Как показывает практика (см. эксперимент С. Кокшарова), Google обычно корректно воспринимает данные правила. Что касается Яндекс, то он может не всегда следовать правилу “noindex, nofollow” и переходит по ссылкам, чтобы проверить их качество (под такими директивами иногда прячутся недобросовестные сайты).
Отличия meta robots noindex от noindex в robots.txt
Есть 2 способа скрыть страницу от индексирования:
- Закрыть страницу в robots.txt с помощью Disallow.
- Добавить на страницу в <head> метатег:
<meta name="robots" content="noindex" />
Основные отличия:
- В robots.txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
- <meta name=”robots” content=”noindex, follow”> позволяет закрывать страницы точечно, а также передавать ссылочный вес.
Если необходимо закрыть определенную страницу, лучше все-же воспользоваться метатегом чтобы не перегружать robots.txt лишними строками. Кроме того, выше вероятность того, что правило сработает (по сравнению с robots.txt).
Помните, что robots.txt – это всего лишь рекомендации, то есть поисковые системы могут игнорировать его — индексировать и сканировать запрещенные URL. Поэтому, если вы хотите скрыть URL с гарантией, лучше это сделать через метатег. А если уж наверняка – то можно, например, закрыть директории паролем.
Поэтому, если вы хотите скрыть URL с гарантией, лучше это сделать через метатег. А если уж наверняка – то можно, например, закрыть директории паролем.
Распространенные ошибки
Страница закрыта через метатег, но все равно находится в поиске
Возможные причины:
- Страница закрыта также robots.txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
- Робот еще не успел посетить страницу (на сайте много страниц).
Решение: Чтобы закрыть страницу через метатег, необходимо, чтобы она была открыта в robots.txt. Если на сайте много страниц, а страницу нужно срочно закрыть – лучше воспользоваться панелью вебмастера.
Внедрение одновременно noindex и rel canonical на страницах (например, пагинации)
Это частая ошибка вебмастеров, ведь эти два тега противоречат друг другу. Google дает четкий ответ по этому поводу тут: https://www. seroundtable.com/noindex-canonical-google-18274.html .
seroundtable.com/noindex-canonical-google-18274.html .
Решение для страниц пагинации:
- canonical не использовать,
- на страницах пагинации прописать: <meta name=”robots” content=”noindex, follow” />, а также link rel=”prev” и link rel=”next”.
На сайте есть не закрытые метатегом служебные страницы – версии страниц «для печати», а также служебные/шаблонные страницы, которые создаются динамически. Это частая проблема, так как в индекс могут попасть сотни ненужных страниц. В дальнейшем эти «мусорные» страницы могут ранжироваться в поиске вытесняя полезные продвигаемые страницы. Закрытие через robots.txt может не решить проблему.
Решение: Google советует закрыть такого рода страницы через метатег <meta name="robots" content="noindex, nofollow" />.
Атрибут rel-nofollow
Значение rel=”nofollow” запрещает поисковой системе переходить по конкретной ссылке.
Пример использования: <a href="test.com" rel="nofollow">Ссылка</a>
Google утверждает: «…Как правило, переход не производится. Это означает, что по этим ссылкам Google не передает ни PageRank, ни текст ссылки…»
Однако, «как правило» предполагает, что бывают исключения. Также, например, ссылки с nofollow могут быть проиндексированы, если на страницу ссылаются другие сайты без использования nofollow, либо страница есть в Sitemap.
Как и где использовать
Рекомендуется использовать rel=”nofollow”:
- для закрытия ссылок на некачественный контент или контент, которому вы не доверяете,
- для закрытия неуникального контента,
- для закрытия платных ссылок,
- для корректной индексации (например, чтобы скрыть технические страницы и не тратить ресурсы робота на их сканирование).
Помимо этих случаев, многие оптимизаторы используют rel=”nofollow”, когда хотят, чтобы внешняя ссылка не передавала вес.
Передает ли nofollow вес
По словам Google, rel=”nofollow” не передает ссылочный вес. Однако, есть свидетельства, что Google учитывает ссылки социальных сетей Facebook, Twitter не смотря на nofollow.
Что касается Яндекс, то с 2010 года он не учитывает ссылки с nofollow и, соответственно ссылка не передает вес. Это официальная версия Яндекс. Однако, есть подтверждения экспериментов, что Яндекс учитывает анкоры таких ссылок.
Как бы там ни было, ваш ссылочный профиль должен быть разнообразным и рекомендуется разбавлять анкор-лист ссылками с rel=”nofollow”.
Распространенные ошибки
Использование rel=”nofollow” для внутренней перелинковки.
Google так делать не советует (https://www.searchengines.ru/mett_katts_ne_nofollow_int_links.html )
Использовать rel nofollow на каждый язык языковой версии чтобы «сегментировать» их, не передавая вес друг-другу.
Не нужно с помощью rel nofollow пытаться манипулировать весом. Если сайт целостный, все равно в рамках внутренней перелинковки вес будет переходить. Как уже говорилось выше – Google не приветствует rel nofollow для внутренней перелинковки. Но не забудьте об использовании hreflang.
Использовать rel nofollow для ссылок на страницы фильтра.
Рекомендуется не использовать атрибут nofollow, а реализовать фильтры с помощью JS или закрывать страницы метатегом noindex, nofollow.
Надеемся, что данная статья ответила на основные вопросы по использованию тегов noindex, nofollow. Желаем успешного продвижения!
Какие страницы на вашем сайте использовать noindex или nofollow? • Yoast
Мишель ХеймансМихиэль был одним из наших первых сотрудников и раньше был партнером Yoast. Начните оптимизацию своего сайта с его статей!
Некоторые страницы вашего сайта служат определенной цели, но не для ранжирования в поисковых системах и даже не для привлечения трафика на ваш сайт. Эти страницы должны быть там, как клей для других страниц или просто потому, что правила требуют, чтобы они были доступны на вашем веб-сайте.Если вы регулярно читаете наш блог, вы знаете, как noindex или nofollow могут помочь вам справиться с этими страницами. Однако, если вы новичок в этих условиях, пожалуйста, продолжайте читать и позвольте мне объяснить, что они из себя представляют и к каким страницам они могут применяться!
Эти страницы должны быть там, как клей для других страниц или просто потому, что правила требуют, чтобы они были доступны на вашем веб-сайте.Если вы регулярно читаете наш блог, вы знаете, как noindex или nofollow могут помочь вам справиться с этими страницами. Однако, если вы новичок в этих условиях, пожалуйста, продолжайте читать и позвольте мне объяснить, что они из себя представляют и к каким страницам они могут применяться!
Что такое noindex nofollow?
noindex означает, что веб-страница не должна индексироваться поисковыми системами и, следовательно, не должна отображаться на страницах результатов поиска. nofollow означает, что пауки поисковых систем не должны переходить по ссылкам на этой странице.Вы можете добавить эти значения в свой метатег robots. Мета-тег robots — это фрагмент кода в разделе заголовка веб-страницы. Он сообщает поисковым системам, как сканировать и индексировать ли страницу.
Наше полное руководство по метатегу robots — отличное чтение, если вы хотите немного глубже погрузиться в эту тему.
Вкратце:
- Мета-тег robots в большинстве случаев выглядит следующим образом:
- VALUE1 и VALUE2 имеют индекс
, по умолчанию используется, что означает данная страница может быть проиндексирована поисковыми системами, и по ссылкам на этой странице можно будет сканировать страницы, на которые они ссылаются. - VALUE1 и VALUE2 могут быть установлены на
noindex, nofollowили другую комбинацию, например индекс, nofollow.
Но пусть вас не пугает этот код. Yoast SEO поможет вам! Если вы хотите узнать, как noindex пост в WordPress супер-простым способом, вам следует прочитать этот пост: Как noindexing пост в WordPress: простой способ.
Но когда какое значение использовать?
Страниц для установки noindex
Авторский архив в блоге одного автора
Если вы единственный, кто пишет для своего блога, страницы ваших авторов, вероятно, на 90% совпадают с домашней страницей вашего блога. Это бесполезно для Google и может рассматриваться как дублированный контент. Чтобы предотвратить такое дублирование контента, вы можете полностью отключить авторский архив. Вот как легко включить или отключить его с помощью Yoast SEO. Если по какой-то причине вы хотите сохранить его на своем сайте, но не в результатах поиска, вы можете
Это бесполезно для Google и может рассматриваться как дублированный контент. Чтобы предотвратить такое дублирование контента, вы можете полностью отключить авторский архив. Вот как легко включить или отключить его с помощью Yoast SEO. Если по какой-то причине вы хотите сохранить его на своем сайте, но не в результатах поиска, вы можете noindex . К счастью, с Yoast SEO это тоже не сложно; просто проверьте, как не индексировать архив автора.
Определенные (настраиваемые) типы сообщений
Иногда плагин или веб-разработчик добавляют пользовательский тип сообщения, который вы не хотите индексировать.Например, в Yoast мы используем настраиваемые страницы для наших продуктов, поскольку мы не являемся типичным интернет-магазином, продающим физические продукты. Таким образом, нам не нужно изображение продукта, фильтры, такие как размеры и технические характеристики, на вкладке рядом с описанием. Поэтому мы не индексируем обычные страницы продуктов, которые выводит WooCommerce, и используем наши собственные страницы. Действительно, у нас
Действительно, у нас noindex тип сообщения о продукте.
Соответственно, мы видели решения для электронной коммерции, которые также добавляли такие характеристики, как размеры и вес, в качестве настраиваемого типа сообщений.Эти страницы считаются некачественным контентом. Вы поймете, что эти страницы не нужны ни посетителям, ни Google, поэтому их тоже нужно держать подальше от страниц результатов поиска.
Страницы благодарности
Эта страница не служит никакой другой цели, кроме как поблагодарить вашего клиента / подписчика на новостную рассылку / впервые комментирующего. Эти страницы, как правило, представляют собой страницы с тонким контентом, с возможностью дополнительных продаж и социальных сетей, но они не представляют ценности для тех, кто использует Google для поиска полезной информации. Следовательно, этих страниц не должно быть на страницах результатов поиска.
Страницы администратора и входа в систему
Большинство страниц входа не должны находиться в Google. Но это так. Не допускайте попадания своего в индекс, добавив к нему
Но это так. Не допускайте попадания своего в индекс, добавив к нему noindex . Исключением являются страницы входа, которые обслуживают сообщество, например Dropbox или аналогичные службы. Просто спросите себя, стали бы вы гуглить одну из своих страниц входа в систему, если бы вы не работали в своей компании. Если нет, то можно с уверенностью сказать, что Google не нужно индексировать эти страницы входа. К счастью, если вы используете WordPress, вы в безопасности, поскольку CMS автоматически не индексирует страницу входа на ваш сайт.
Результаты внутреннего поиска
Результаты внутреннего поиска — это в значительной степени последние страницы, на которые Google хотел бы отправлять своих посетителей. Если вы хотите испортить поиск, вы ссылаетесь на другие страницы поиска вместо фактического результата. Но ссылки на странице результатов поиска по-прежнему очень ценны, вы определенно хотите, чтобы Google следил за ними. Таким образом, необходимо переходить по всем ссылкам, а мета-настройка роботов должна быть:
Yoast SEO следит за тем, чтобы для ваших внутренних поисковых страниц по умолчанию было установлено значение noindex. Это одна из скрытых функций Yoast SEO. Это не редактируемый параметр, потому что это просто то, как это должно быть сделано в соответствии с рекомендациями Google, и мы полностью с ними согласны.
Это одна из скрытых функций Yoast SEO. Это не редактируемый параметр, потому что это просто то, как это должно быть сделано в соответствии с рекомендациями Google, и мы полностью с ними согласны.
Только для разработчиков: если вы действительно хотите изменить это, это можно сделать с помощью одного из наших фильтров. Пример можно найти здесь.
Страниц для установки на nofollow
Для всех примеров, упомянутых выше, нет необходимости nofollow для всех ссылок на этих страницах.Вы не хотите отображать их в результатах поиска, но хотите, чтобы Google переходил по ссылкам на странице. Теперь, когда должен , вы добавляете nofollow в метатег роботов?
Если вы установите для страницы значение nofollow с метатегом robots, ни одна из ссылок на этой странице не будет переходить. Google придумал nofollow, чтобы иметь возможность различать ссылки на ненадежный контент (или, позже, оплаченный, например, рекламу). На обычном веб-сайте, вероятно, очень мало страниц, на которых вы бы хотели, чтобы Google не переходил по по любой ссылке .
На обычном веб-сайте, вероятно, очень мало страниц, на которых вы бы хотели, чтобы Google не переходил по по любой ссылке .
Пример: если у вас есть страница со списком книг по SEO с избытком партнерских ссылок Amazon, они могут быть полезны для вашего сайта для ваших пользователей. Но я бы дал nofollow всю страницу, если на странице нет ничего важного. Однако вы могли бы проиндексировать его. Просто убедитесь, что вы правильно скрываете свои ссылки.
Одинарные ссылки Nofollow
Если у вас есть сообщение или страница с несколькими ссылками, вы можете помочь поисковым системам квалифицировать их.В настоящее время вы можете nofollow для одной ссылки или даже установить для нее спонсируемый или пользовательский контент. Добавление правильных атрибутов rel к вашей ссылке позволяет вам это сделать. Например, ссылка на рекламу будет выглядеть так: пример ссылки . С Yoast SEO настроить эти атрибуты rel очень просто, как вы можете видеть в этом видео:
С Yoast SEO настроить эти атрибуты rel очень просто, как вы можете видеть в этом видео:
Заключение
Как мы видели, независимо от того, будет ли ссылка на noindex на страницу или на nofollow на ссылку сводится к двум вопросам: хотите ли вы, чтобы эта страница отображалась на страницах результатов поиска и , если поисковые системы переходят по ссылкам на эта страница? Например, для страниц с благодарностью или страниц входа в систему ответ на первый вопрос — «нет».Для страницы с множеством партнерских ссылок ответ на второй вопрос — «нет». Помните о примерах из этого поста, и у вас больше не будет проблем с поиском ответов для вашего собственного сайта!
PS. Вы
Вы noindex пост или страницу, хотя не хотели? Не беспокойтесь, вы легко можете исправить случайную ошибку noindex !
Подробнее: Как не индексировать сообщение »
noindex vs. nofollow — Справочный центр Siteimprove
Модуль Siteimprove SEO уведомляет пользователей о страницах, исключенных с помощью noindex / nofollow.Эта статья предназначена для объяснения разницы между метатегами noindex и nofollow, когда их использовать и как эти теги влияют на веб-индексирование и страницы результатов поиска (SERP).
И noindex, и nofollow являются частью протокола исключения роботов (REP) , стандарта для управления индексацией веб-страниц на вашем сайте. Давайте рассмотрим несколько примеров noindex и nofollow и то, как они контролируют доступ и индексацию вашего веб-сайта Google и другими поисковыми системами.
Что такое noindex и когда его использовать?
Обычно, когда робот Googlebot находит страницу, он читает все ссылки на этой странице, а затем выбирает эти страницы и индексирует их.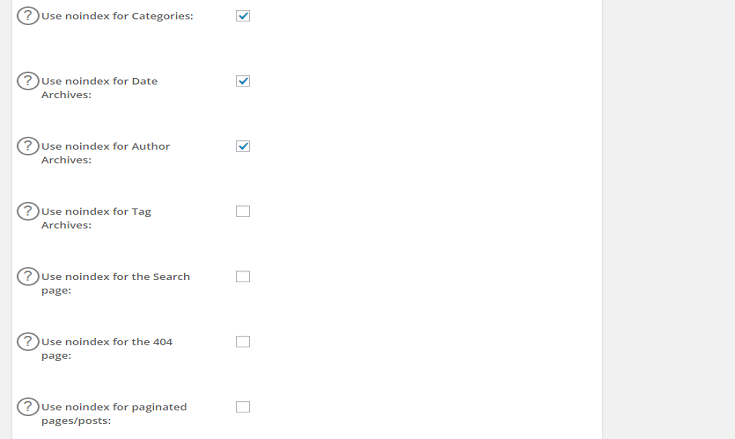 Это основной процесс, с помощью которого робот Googlebot «сканирует» Интернет. Это полезно, поскольку позволяет Google включать все страницы вашего сайта, если они связаны друг с другом. Что делать, если вы не хотите, чтобы некоторые страницы вашего сайта отображались в индексе Google? Здесь применяется метатег noindex.
Это основной процесс, с помощью которого робот Googlebot «сканирует» Интернет. Это полезно, поскольку позволяет Google включать все страницы вашего сайта, если они связаны друг с другом. Что делать, если вы не хотите, чтобы некоторые страницы вашего сайта отображались в индексе Google? Здесь применяется метатег noindex.
Когда вы добавляете метатег «noindex» к веб-странице, он сообщает поисковой системе, что она не может добавить страницу в свой поисковый индекс, даже если поисковая система может сканировать страницу.
Пример Noindex
статей в разделе «Последние новости» CNN могут появиться только на несколько часов, прежде чем они будут обновлены и перенесены в раздел «Статьи». В этом случае CNN захочет проиндексировать полные статьи, а не раздел последних новостей с короткой частью полной статьи.
Таким образом, вы можете добавить тег noindex к статьям, находящимся в настоящее время в разделе «Последние новости», и удалить этот тег, как только статья больше не будет актуальной.
Чтобы превратить обычные ссылки в ссылки noindex, добавьте «noindex» в HTML-код:
Текст ссылки
Что такое nofollow и когда его использовать?
Nofollow — это атрибут HTML, который предписывает большинству поисковых систем воздерживаться от перехода по ссылке и тем самым передавать значение на страницу, на которую ведет ссылка. Некоторые эксперты по SEO интерпретируют это как способ сообщить поисковым системам, что вы не доверяете или не можете поручиться за содержание ссылки, на которую ведет ссылка. Короче говоря, если вы хотите, чтобы поисковая машина проиндексировала вашу веб-страницу в поиске, но вы, , не хотите, чтобы переходила по ссылкам на этой странице; добавьте на свою страницу тег nofollow.
Чтобы превратить обычные ссылки в ссылки nofollow, добавьте «nofollow» в HTML-код *:
Текст ссылки
* Вы можете добавить код вручную, но многие CMS автоматически вставляют его при необходимости. Обратитесь к своему веб-мастеру за советом.
Обратитесь к своему веб-мастеру за советом.
Пример Nofollow
Когда пользователи ищут в Google фразы, связанные с новостями, CNN хочет, чтобы разделы их статей (со статьями) находились в первых строчках поисковой выдачи, потому что статьи являются наиболее ценным активом CNN.
Не имеет смысла располагать их раздел входа наверху.
Таким образом, чтобы сообщить Google, что статьи важнее входа в систему, CNN добавит тег nofollow к своей ссылке для входа.
Примечание. Сканер Siteimprove не учитывает «noindex» или «nofollow» при определении содержания для сканирования. Сканируем на основе настроек сканирования.
Блочная индексация поиска с помощью ‘noindex’ | Центр поиска Google
Вы можете предотвратить появление страницы в поиске Google, включив метатег noindex в HTML-код страницы или вернув заголовок noindex в HTTP-запросе. Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, он полностью исключит эту страницу из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты.
Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, он полностью исключит эту страницу из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты.
noindex вступила в силу, страница не должна блокироваться файлом robots.txt. Если страница заблокирована файлом robots.txt, сканер никогда не увидит директиву noindex , и страница все равно может отображаться в результатах поиска, например, если на нее ссылаются другие страницы. Использование noindex полезно, если у вас нет root-доступа к вашему серверу, так как он позволяет вам контролировать доступ к вашему сайту на постраничной основе.
Реализация noindex
Существует два способа реализовать noindex : как метатег и как заголовок ответа HTTP. У них такой же эффект; выберите способ, более удобный для вашего сайта.
У них такой же эффект; выберите способ, более удобный для вашего сайта.
Тег
Чтобы запретить большинству поисковых роботов индексировать страницу на вашем сайте, поместите следующий метатег в раздел своей страницы:
Чтобы запретить только веб-сканерам Google индексировать страницу:
Вы должны знать, что некоторые поисковые роботы могут по-разному интерпретировать директиву noindex .В результате возможно, что ваша страница все еще будет отображаться в результатах других поисковых систем.
Подробнее о метатеге noindex .
Помогите нам определить ваши метатеги
Нам необходимо просканировать вашу страницу, чтобы увидеть ваши метатеги. Если ваша страница по-прежнему отображается в результатах, возможно, мы не сканировали ваш сайт с тех пор, как вы добавили тег. Вы можете запросить у Google повторное сканирование вашей страницы с помощью инструмента проверки URL. Другая причина также может заключаться в том, что ваш файл robots.txt блокирует этот URL для поисковых роботов Google, поэтому мы не видим тег. Чтобы разблокировать свою страницу от Google, вы должны отредактировать файл robots.txt. Вы можете редактировать и тестировать свой robots.txt с помощью инструмента robots.txt Tester .
Вместо метатега вы также можете вернуть заголовок X-Robots-Tag со значением noindex или none в своем ответе. Вот пример ответа HTTP с X-Robots-Tag , инструктирующим сканеры не индексировать страницу:
HTTP / 1.
 1 200 ОК
(…)
X-Robots-Тег: noindex
(…)
1 200 ОК
(…)
X-Robots-Тег: noindex
(…) Подробнее о заголовке ответа noindex .
Что это такое и как их использовать?
Три слова, приведенные выше, могут звучать как SEO gobbledegook, но эти слова стоит знать, поскольку понимание того, как их использовать, означает, что вы можете управлять роботом Googlebot. Это весело.
Итак, начнем с основ: есть три способа контролировать, какие части вашего сайта будут сканироваться поисковыми системами:
- Noindex: указывает поисковым системам не включать ваши страницы в результаты поиска.
- Disallow: указывает им не сканировать ваши страницы.
- Nofollow: говорит им не переходить по ссылкам на вашей странице.
Что такое метатег Noindex?
Тег noindex указывает поисковым системам не включать страницу в результаты поиска.
Самый распространенный метод запрета индексирования страницы — это добавить тег в заголовок HTML или в заголовки ответов. Чтобы поисковые системы могли видеть эту информацию, страница не должна быть заблокирована (запрещена) в файле robots.txt файл. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
Чтобы поисковые системы не индексировали вашу страницу, просто добавьте в раздел следующее:
Вторая часть тега содержимого указывает, что необходимо переходить по всем ссылкам на этой странице, которые мы обсудим ниже.
В качестве альтернативы тег noindex можно использовать в теге X-Robots-Tag в заголовке HTTP:
X-Robots-Tag: noindex
Дополнительную информацию см. В сообщении разработчиков Google о спецификациях метатега Robots и HTTP-заголовка X-Robots-Tag.
Как использовать Noindex в файле robots.txt?
Тег noindex в файле robots.txt также сообщает поисковым системам не включать страницу в результаты поиска, но это более быстрый и простой способ не индексировать сразу много страниц, особенно если у вас есть доступ к вашему robots.txt. файл. Например, вы не можете индексировать любые URL-адреса в определенной папке.
Вот пример директивы noindex, которую можно поместить в файл robots.txt:
Noindex: / robots-txt-noindexed-page /
Однако Google не рекомендует использовать этот метод: Джон Мюллер заявил, что «не следует полагаться на него».
Что такое запретительная директива?
Запрещение страницы означает, что вы даете поисковым системам указание не сканировать ее, что должно быть выполнено в файле robots.txt вашего сайта. Это полезно, если у вас много страниц или файлов, которые бесполезны для читателей или поискового трафика, поскольку это означает, что поисковые системы не будут тратить время на сканирование этих страниц.
Чтобы добавить запрет, просто добавьте в файл robots.txt следующую строку:
Запретить: / your-page-url /
Если на странице есть внешние ссылки или канонические теги, указывающие на нее, ее все равно можно проиндексировать и ранжировать, поэтому важно сочетать запрет с тегом noindex, как описано ниже.
Предупреждение: запрещая страницу, вы фактически удаляете ее со своего сайта.
Запрещенные страницы не могут передавать PageRank где-либо еще — поэтому любые ссылки на этих страницах фактически бесполезны с точки зрения SEO — а запрет на включение страниц, которые должны быть включены, может иметь катастрофические последствия для вашего трафика, поэтому будьте особенно осторожны при написании запрещающих директив.
Как объединить Noindex и Disallow?
Noindex (страница) + Disallow: Disallow не может сочетаться с noindex на странице, потому что страница заблокирована, и поэтому поисковые системы не будут сканировать ее, чтобы знать, что они не должны оставлять страницу вне индекс.
Noindex (robots.txt) + Disallow : предотвращает появление страниц в индексе, а также предотвращает сканирование страниц. Однако помните, что через эту страницу не может пройти PageRank.
Чтобы объединить запрет с noindex в файле robots.txt, просто добавьте обе директивы в файл robots.txt:
Запрещено: / example-page-1/
Запрещено: / example-page-2/
Noindex: / example-page-1/
Noindex: / example-page-2/
Что такое тег Nofollow?
Тег nofollow в ссылке указывает поисковым системам не использовать ссылку для определения важности связанных страниц (PageRank) или обнаружения дополнительных URL-адресов на том же сайте.
Обычно nofollows использует ссылки в комментариях и другом контенте, который вы не контролируете, платные ссылки, встраиваемые элементы, такие как виджеты или инфографику, ссылки в гостевых сообщениях или что-нибудь не по теме, на которое вы все еще хотите связывать людей.
Исторически сложилось так, что оптимизаторы поисковых систем также избирательно исключали переход по ссылкам, чтобы направлять внутренний PageRank на более важные страницы.
Теги Nofollow могут быть добавлены в одном из двух мест:
- страницы (чтобы nofollow все ссылки на этой странице):
- Код ссылки (для nofollow отдельной ссылки): пример страницы
nofollow не предотвратит полное сканирование связанной страницы; он просто предотвращает сканирование по этой конкретной ссылке. Наши и другие тесты показали, что Google не будет сканировать URL-адрес, который он находит в ссылке nofollowed.
Google заявляет, что если другой сайт ссылается на ту же страницу без использования тега nofollow или страница отображается в файле Sitemap, эта страница все равно может отображаться в результатах поиска. Точно так же, если это URL, о котором уже знают поисковые системы, добавление ссылки nofollow не удалит его из индекса.
В сентябре 2019 года Google объявил об обновлении своей директивы nofollow и представил два новых атрибута ссылки, а именно:
- rel = «sponsored» — атрибут sponsored следует использовать для идентификации ссылок, предназначенных для рекламных целей, при наличии соглашений о спонсорстве и компенсации.
- rel = «ugc» — В качестве атрибута для пользовательского содержимого это значение рекомендуется для ссылок на сайтах с пользовательским содержимым, например для сообщений на форумах и комментариев в блогах.
Кроме того, все ссылки, помеченные как nofollow, sponsored или ugc, теперь рассматриваются как подсказки относительно того, какие ссылки следует учитывать при поиске и сканировании, а не просто как сигнал, как раньше использовалось для nofollow. Вы можете узнать больше об этом обновлении в нашем посте, который также охватывает их влияние и мнения экспертов.
Что такое Noindex Nofollow?
Как упоминалось выше, добавление тега nofollow к странице не препятствует ее полному сканированию. Следовательно, чтобы предотвратить его индексирование, вам также необходимо не индексировать страницу. Это позволит Google по-прежнему сканировать страницу, но она не будет отображаться в индексе. Страницы, которые вы, вероятно, захотите включить в noindex; страницы администратора / входа, внутренние результаты поиска и страницы регистрации. Чтобы Google полностью прекратил сканирование страницы, вам также следует запретить это (см. Выше).
Следовательно, чтобы предотвратить его индексирование, вам также необходимо не индексировать страницу. Это позволит Google по-прежнему сканировать страницу, но она не будет отображаться в индексе. Страницы, которые вы, вероятно, захотите включить в noindex; страницы администратора / входа, внутренние результаты поиска и страницы регистрации. Чтобы Google полностью прекратил сканирование страницы, вам также следует запретить это (см. Выше).
Другие директивы: Canonical Tags, Pagination и Hreflang
Есть и другие способы сообщить Google и другим поисковым системам, как обрабатывать URL-адреса:
- Канонические теги сообщают поисковым системам, какую страницу из группы похожих страниц следует проиндексировать.Канонизированные (то есть вторичные страницы, которые направляют поисковые системы к первичной версии) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на свои настольные.
- Pagination группирует несколько страниц вместе, чтобы поисковые системы знали, что они являются частью набора. Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
- Hreflang сообщает поисковым системам, какие международные версии одного и того же контента предназначены для какого региона, чтобы они могли определить приоритетность правильной версии для каждой аудитории.Все эти версии останутся в индексе.
Сколько времени вам следует потратить на сокращение краулингового бюджета?
Вы можете услышать много разговоров на форумах SEO о том, насколько важны эффективность сканирования и бюджет сканирования для SEO, и, хотя обычной практикой является запрет и noindex для больших групп страниц, которые не имеют никакой пользы для поисковых систем или читателей (например, back -end кода, который используется только для работы сайта или некоторых типов дублированного контента), решение о том, скрывать ли много отдельных страниц, вероятно, не лучший вариант использования времени и усилий.
Google любит индексировать как можно больше URL-адресов, поэтому, если нет особой причины скрыть страницу от поисковых систем, обычно можно оставить решение на усмотрение Google. В любом случае, даже если вы скроете страницы от поисковых систем, Google все равно будет проверять, изменились ли эти URL-адреса. Это особенно актуально, если есть ссылки, указывающие на эту страницу; даже если Google забыл об URL-адресе, он все равно может снова обнаружить его, когда на него будет найдена ссылка.
Тестирование с помощью Search Console, DeepCrawl и Robotto
Тестовые роботы.txt с помощью Search Console
Тестер robots.txt в Search Console (в разделе «Сканирование») — популярный и в значительной степени эффективный способ проверить новую версию файла на наличие ошибок до того, как он будет опубликован, или протестировать конкретный URL, чтобы убедиться, что он заблокирован:
Однако этот инструмент не работает точно так же, как Google, с некоторыми небольшими различиями в конфликтующих правилах разрешения / запрета, которые имеют одинаковую длину.
Инструмент тестирования robots.txt сообщает, что они разрешены, однако Google сказал: «Если результат не определен, robots.txt могут разрешить или запретить сканирование. По этой причине не рекомендуется полагаться на то, что какой-либо из результатов будет использоваться повсеместно ».
Подробнее см. В этом обсуждении на справочном форуме в Центре веб-мастеров.
Найти все неиндексируемые страницы с помощью DeepCrawl
Запустите универсальное сканирование без каких-либо ограничений (но с применением условий robots.txt), чтобы DeepCrawl мог вернуть все ваши URL-адреса и показать вам все индексируемые / неиндексируемые страницы.
Если у вас есть параметры URL, которые были заблокированы для робота Google с помощью Search Console, вы можете имитировать эту настройку для сканирования, используя поле «Удалить параметры» в разделе Дополнительные настройки> Перезапись URL .
Затем вы можете использовать следующие отчеты, чтобы убедиться, что сайт настроен так, как вы ожидали при первом сканировании, а затем объединить их со встроенными журналами изменений при последующих сканированиях.
Индексация> Страницы Noindex
В этом отчете будут показаны все страницы, содержащие тег noindex в метаинформации, HTTP-заголовке или файле robots.txt файл.
Индексация> Запрещенные страницы
Этот отчет содержит все URL-адреса, сканирование которых невозможно из-за запрещающего правила в файле robots.txt. На панели управления вашего отчета есть цифры для обоих этих отчетов:
Используйте наши интуитивно понятные отчеты в каждом из наших отчетов, чтобы проверять определенные папки и выявлять шаблоны в URL-адресах, которые в противном случае вы могли бы пропустить:
Протестируйте новый файл robots.txt с помощью DeepCrawl
Используйте роботов DeepCrawl.txt Функция перезаписи в дополнительных настройках для замены живого файла на пользовательский.
Затем при следующем запуске сканирования вы можете использовать тестовую версию вместо активной.
В отчетах о добавленных и удаленных запрещенных URL-адресах будет показано, какие именно URL-адреса были затронуты измененным файлом robots. txt, что упростит оценку.
txt, что упростит оценку.
Для получения дополнительной информации прочтите наше руководство по управлению изменениями robots.txt с помощью DeepCrawl.
Хотите больше такого?
Мы надеемся, что этот пост был полезен для вас, когда вы узнали больше о noindex, nofollow и disallow для управления сканированием вашего сайта.
Вы можете узнать больше об этих темах в нашей Технической библиотеке SEO или, если вы хотите узнать, как проводить технический SEO-аудит, прочтите наше руководство.
Кроме того, если вы заинтересованы в том, чтобы быть в курсе последних обновлений Google и рекомендациями по передовому опыту, почему бы не заглянуть в наши электронные письма?
Зайди меня!
Автор
Сэм Марсден
Сэм Марсден — менеджер по поисковой оптимизации и контенту DeepCrawl.Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых публикаций, таких как Search Engine Journal и State of Digital.
Теги
Управление роботами
В чем разница между NoIndex и NoFollow?
В чем разница между NoFollow и NoIndex?
Цифровые маркетологи тратят много времени и энергии на совершенствование каждой страницы контента на веб-сайте.У каждой страницы есть цель, с хорошо проработанным и стратегически сформулированным содержанием, ориентированным на целевого пользователя. Контент создается для привлечения потенциальных клиентов и повышения авторитета веб-страниц и их соответствующих доменов. Затем эти страницы отправляются для индексации поисковым системам, чтобы их можно было сканировать и в конечном итоге сохранять для того, чтобы их нашел конечный пользователь.
Однако есть страницы, сканирование которых запрещено. Эти страницы могут помешать вашей тяжелой работе по созданию этого красивого и индивидуального контента.Имея это в виду, вам нужно знать, как правильно сообщить сканерам поисковых систем, что вы не хотите, чтобы ваш контент индексировался или сканировался.
Что такое NoIndex?
NoIndex — это метатег, который добавляется в код заголовка веб-страницы, чтобы сообщить поисковым системам, что, хотя они могут сканировать страницу, чтобы понять ее содержание, они не могут проиндексировать страницу, чтобы она отображалась в результатах поиска. Это пример того, как NoIndex отображается в исходном коде веб-страницы:
Что такое NoFollow?
NoFollow — это метатег, добавляемый в код заголовка веб-страницы, который сообщает поисковым системам не переходить по ссылкам на этой странице.По сути, это дезавуирует ссылки на этой странице и информирует поисковую систему, чтобы она не передавала никаких полномочий или «ссылочного веса» страницам, на которые есть ссылки в вашем контенте. Это пример того, как NoFollow отображается в исходном коде веб-страницы:
Чем они отличаются?
NoIndex и NoFollow сильно различаются по полезности. Вы будете использовать NoIndex при указании поисковой системе не сохранять вашу веб-страницу для отображения в результатах поиска, в то время как вы будете использовать NoFollow, когда вы дадите указание сканерам поисковой системы не переходить по ссылкам на вашей странице.Следовательно, NoIndex предназначен для вашей веб-страницы , а NoFollow — для ссылок , которые существуют на вашей веб-странице.
Вы будете использовать NoIndex при указании поисковой системе не сохранять вашу веб-страницу для отображения в результатах поиска, в то время как вы будете использовать NoFollow, когда вы дадите указание сканерам поисковой системы не переходить по ссылкам на вашей странице.Следовательно, NoIndex предназначен для вашей веб-страницы , а NoFollow — для ссылок , которые существуют на вашей веб-странице.
Когда следует использовать каждый?
Примером метатега NoIndex является страница с благодарностью. Вы бы не хотели, чтобы поисковая система отображала страницу с благодарностью на странице результатов поисковой системы, поскольку это обычно страница, на которую пользователь попадает после того, как он заполнил вашу форму генерации лидов. Чтобы поисковые системы знали, что эту страницу хранить нельзя, вы должны указать метатег NoIndex в коде заголовка вашей веб-страницы.Другие примеры страниц, которые вы не хотели бы индексировать поисковыми системами, включают Политику конфиденциальности, Положения и условия и страницы Страница не найдена.
Примером метатега NoFollow также является целевая страница. Если ваша целевая страница содержит ссылку на ваше предложение, скажем, электронную книгу «10 советов, как максимально использовать ваши усилия в цифровом маркетинге», вы должны убедиться, что сканер поисковой системы не просканирует эту ссылку и не начнет индексировать этот контент.
Изучение ресурсов для защиты и оптимизации вашего контента для поисковых систем является важной частью вашего контент-маркетинга и инициатив по привлечению потенциальных клиентов.Правильное использование метатегов NoFollow и NoIndex поможет вам максимально использовать вашу контент-стратегию и убедиться, что вы не теряете ценных потенциальных клиентов.
Как мне реализовать NoIndex или NoFollow на моем веб-сайте?
Если вы используете WordPress, мы рекомендуем бесплатный инструмент Yoast SEO для управления вашими усилиями по SEO на странице. Чтобы активировать функции NoIndex и NoFollow, вы должны включить «расширенные настройки» на панели настроек Yoast.
Оттуда вы найдете варианты для реализации правил NoIndex и NoFollow на каждой странице вашего веб-сайта.
Легко, как пирог!
Что такое Noindex и как он работает?
В то время как тег noindex сообщает боту или сканеру не добавлять страницу в индекс результатов поиска, директива disallow предписывает поисковым системам вообще не сканировать страницу. Это должно быть сделано через файл robots.txt и иногда используется вместе с noindex.
Тег disallow — полезный инструмент, но при использовании директивы disallow важно соблюдать особую осторожность.Запрещая страницу, вы, по сути, удаляете ее со своего сайта в отношении поиска, а также лишаете ее возможности передавать PageRank — значение, присвоенное веб-странице поисковой системой, которая позволяет ей появляться в результатах поиска. Случайный запрет ошибочной страницы — например, страницы, которая привлекает трафик на ваш сайт — может иметь катастрофические последствия для трафика и вашей тактики SEO.
Почему я должен запретить страницу?
Запрещение страниц, которые не имеют ценности для читателей или SEO, может ускорить сканирование и индексирование вашего сайта ботами.Примером может служить функция поиска на сайте электронной коммерции. Хотя функция поиска представляет ценность для пользователя, различные страницы, которые она извлекает, не обязательно являются страницами, которые повышают ценность вашего сайта для SEO.
Объединение Noindex и Disallow
Если есть внешние ссылки или канонические теги — теги, которые сообщают ботам, какую страницу из группы похожих страниц следует проиндексировать — указывающие на страницу, которая была запрещена, ее все равно можно проиндексировать и ранжировать, даже если ее нельзя сканировать.Это означает, что он все еще может отображаться в поисковой выдаче.
Чтобы применить обе директивы, добавьте их обе в файл robot.txt. Например:
- Запретить: /example-folder/example-page.html
- Noindex: /example-folder/example-page. html
 html
htmlЧто такое метатег Nofollow?
Тег nofollow используется для указания поисковым системам не оценивать достоинства ссылок (или конкретной ссылки), существующих на странице. Мета-директивы Nofollow также предписывают ботам не открывать больше URL-адресов на сайте, устанавливая для всех ссылок значение «nofollow» — по умолчанию все ссылки на странице настроены на переход.Вы можете добавить тег nofollow к отдельным ссылкам или скрыть их с помощью метатега robots в заголовке HTML страницы. Ссылки Nofollow могут использоваться в качестве тактики SEO, чтобы иметь возможность ссылаться на страницы, которые они хотят предоставить читателю, без связывания ботом или поисковым роботом этой страницы со своей собственной.
Например, одиночная ссылка nofollowed может выглядеть так:
< a href = ”https://example.com/” rel = ”nofollow”>
В то время как метатег nofollow в заголовке будет выглядеть так:
< meta name = «robots» content = «nofollow»>
Когда мне следует использовать ссылки Nofollow?
Теги Nofollow полезны при применении к ссылкам, которые вы не можете напрямую контролировать, например, ссылкам в разделах комментариев, неорганическим или нерелевантным платным ссылкам, гостевым сообщениям, ссылкам на что-то не по теме на веб-сайте или странице, или к встраиваемым таким как виджет или инфографику.
Что такое Noindex Nofollow?
Добавление тега nofollow к ссылке не препятствует сканированию или индексированию связанной страницы, хотя предотвращает ассоциацию или передачу полномочий между связанными страницами.
Чтобы одновременно дать команду ботам не индексировать страницу и не переходить по ссылкам на ней, вы должны просто объединить определения noindex, nofollow в один метатег. Например:
< meta name = «robots» content = «noindex, nofollow»>
Если вы не хотите, чтобы Google сканировал страницу полностью, вам все равно необходимо запретить это.
Что такое Noindex и для чего он нужен? с Гэри Иллисом
В нашем втором виртуальном выступлении с аналитиком Google Webmaster Trends Гэри Иллисом Эрик Эндж спросил его о том, как Google обрабатывает различные теги SEO. В этом посте я резюмирую то, что Гэри сказал о теге noindex.
Вы можете посмотреть отрывок, в котором происходит это обсуждение, в этом видео:
Что такое тег noindex?
По словам Эрика Энджа, «Тег NoIndex — это инструкция для поисковых систем, что вы не хотите, чтобы страница оставалась в их результатах поиска.Вам следует использовать это, если вы считаете, что у вас есть страница, которую поисковые системы сочтут некачественной ».
Что делает тег noindex?
- Это директива, а не предложение. То есть Google будет подчиняться ему, а не индексировать страницу.
- Страница все еще может сканироваться Google.
- Страница все еще может накапливать PageRank.
- Страница все еще может передавать PageRank через любые ссылки на странице.
[Твитнуть: «Страницы Noindex по-прежнему собирают и передают PageRank (Гэри Иллис).См. »]
(Гэри отметил, что, хотя Эрик упомянул PageRank, на самом деле существует множество других сигналов, которые потенциально могут передаваться через любую ссылку. Лучше сказать« сигналы пройдены », чем« PageRank пройдены ».)
Лучше сказать« сигналы пройдены », чем« PageRank пройдены ».)
Уменьшается ли частота сканирования страницы noindex со временем?
Частота сканирования — это то, как часто Google возвращается на страницу, чтобы проверить, существует ли еще страница, есть ли какие-либо изменения, накоплены или нет сигналы.
Обычно частота сканирования снижается для любой страницы, которую Google не может проиндексировать по какой-либо причине.Google попытается выполнить повторное сканирование несколько раз, чтобы проверить, исчезли ли или исправлены ли noindex, ошибка или что-то, что блокировало сканирование.
Если инструкция noindex останется, Google начнет постепенно увеличивать время до следующей попытки сканирования страницы, в конечном итоге сокращаясь до проверки примерно каждые два-три месяца, чтобы увидеть, есть ли еще тег noindex.
Эрик отметил, что это означает, что тег noindex — это способ контролировать, как Google сканирует ваш сайт, и Гэри согласился.
[Твитнуть: «Тег Noindex постепенно снижает частоту сканирования страницы Google» (Гэри Илес).См. »]
Узнайте, как реализовать тег noindex на своем сайте.
Узнайте, что Perficient Digital может сделать для SEO вашей компании.
Об авторе
Эрик Энге возглавляет отдел цифрового маркетинга Perficient.Он разрабатывает исследования и проводит отраслевые исследования, чтобы помочь доказать, опровергнуть или развить предположения о методах цифрового маркетинга и их ценности. Эрик — писатель, блоггер, исследователь, преподаватель, основной докладчик и участник крупных отраслевых конференций. В партнерстве с несколькими другими экспертами Эрик был ведущим автором книги «Искусство SEO».
Больше от этого автора
.