
Индексация сайта в поисковых системах
Представьте, что вы вводите поисковый запрос в Google и ждете, пока результаты медленно появляются на экране. Скорее всего, вы бы нажали кнопку обновления или перешли на другой сайт. В эпоху стремительно развивающегося Интернета никто не хочет тратить свое время на ожидание запроса.Этот сценарий является гипотетическим, поскольку поисковые системы сегодня работают чрезвычайно быстро. В течение нескольких секунд они выдают результаты поиска после того, как вы ввели запрос. Чтобы сделать ваш пользовательский опыт гладким, поисковики используют так называемые индексы.
Как бы мы ни привыкли к быстрым результатам в Google и других популярных поисковых системах, часто внутренний поиск на странице сайта не может предложить готовые ответы также быстро из-за очереди на запросы. Без индекса поиск отнимает ресурсы у сервера и делает работу канала медленнее. Именно поэтому он является важной частью любого хорошего варианта для сортировки информации по сайту.
Программное обеспечение автоматизирует индексирование. Если вы выполните поиск «кошка» в Google, вам будет представлено несколько страниц и URL-адресов, соответствующих вашему ключевому слову. Если книжный индекс статичен, поскольку содержание книги не меняется, то интернет-индекс динамичен, поскольку веб-сайты постоянно создаются и обновляются.
Поиск в Интернете старается включить все ключевые слова и поддерживает запросы с комбинированными поисковыми терминами. Например, вы можете искать «видео с кошкой», и поисковый индекс предложит соответствующие результаты.
Как результаты поиска возвращаются из индекса?
Когда пользователь набирает поисковый запрос, система находит документы, в которых он содержится. Например, индексация в Яндексе возвращает заголовок, краткое содержание и в редких случаях изображение.
Некоторые CMS предлагают поисковые системы, которые посещают собственную базу данных CMS.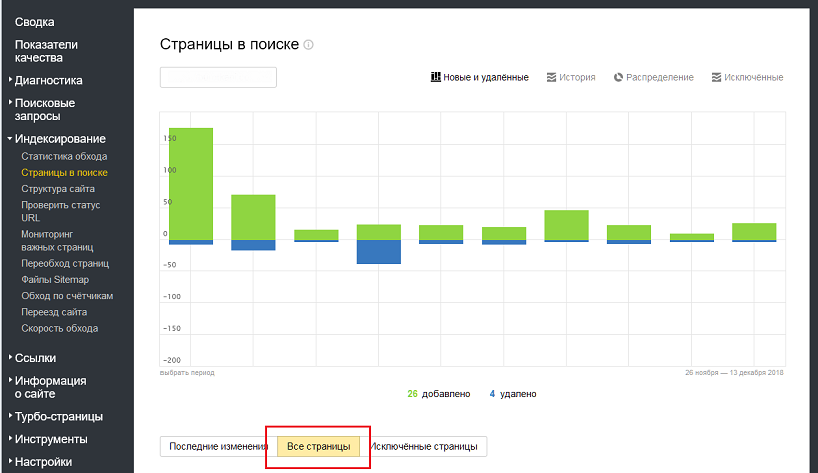
Как поисковый индекс может улучшить ваш сайт
Поисковые системы собирают содержимое вашего сайта автоматически. С помощью алгоритма результаты поиска определяются по приоритетам. Некоторым результатам придается больший вес, поэтому они появляются раньше других страниц среди результатов.
Поисковый индекс — это регулярно и автоматически обновляемая база данных всех ваших товаров и сопутствующей информации в простой форме. Он позволяет пользователям сайта осуществлять быстрый и точный поиск. Благодаря ему система может выполнять любой поиск за микросекунды, поскольку ей не нужно каждый раз просматривать сотни или тысячи страниц, достаточно провести веб-индексацию в поисковой системе.
По сути, метод схож с нумерацией в конце книги, где вы можете найти наиболее важные термины и фразы с указанием страниц, где можно узнать о них больше.
Поисковый алгоритм используется при поиске информации в Интернете. Существует два его типа: детерминированный и вероятностный. Детерминированные возвращают ответ немедленно, они не требуют вычисления вероятности. Вероятностные используют некоторую форму вычислений, чтобы определить, насколько вероятен тот или иной результат.
Вы должны обращать внимание на множество деталей: такие вещи, как предоставление правильных атрибутов и тегов, естественный язык, который используют ваши клиенты, сезонность и дизайн страниц ваших товаров. Существует множество передовых методов поиска в электронной коммерции, которые можно и нужно проиндексировать, а точная настройка — бесконечная задача.
За каждым решением о покупке стоит огромный мыслительный процесс, даже если большая его часть является подсознательной, и на вашем сайте так много мелочей, которые могут оттолкнуть возможного покупателя. Именно поэтому важно добавить правильный индекс для получения большего трафика.
Пользовательский опыт на вашем сайте является неотъемлемой частью общего впечатления клиента и, следовательно, вашего дохода. В случае с книгами индексы создаются вручную, обычно авторами и редакторами, что вполне логично: информация, размещенная на паре сотен страниц, понятна одному человеку, особенно если он составил ее.
Если же речь идет о веб-сайтах, где нередко создаются тысячи страниц для различных продуктов, атрибутов, контента и так далее, то очень важно, чтобы индексирование было автоматизировано.
Итак, веб-индексация в Интернете создается с помощью алгоритмов. Роботы, которые являются автоматизированными, регулярно посещают каждую страницу сайта, сканируют и собирают информацию о каждой из них и заносят ее в простую базу данных. В случае необходимости происходит переиндексация каждого запроса.
Конечно, это не все, поскольку современные поисковые системы сайтов должны учитывать опечатки, описки, релевантные ключевые слова, основанные на семантике и поведении пользователей, естественный язык и так далее.
Но эти алгоритмы сами себя сортируют, и, по сути, как пользователь, вы видите результаты только после того, как нажмете кнопку поиска по вашему запросу. Эти результаты обычно включают названия продуктов или заголовки контента, некоторые атрибуты или отрывок, картинку и цену.
Вы можете продвигать результаты поиска на основе определенных факторов, таких как релевантность, свежесть, проводимые акции и так далее. Это позволяет вам определить определенные параметры, которые влияют на результаты, показываемые вашим клиентам при поиске.
что это значит, как ускорить процесс
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Индексация сайта — это процесс поиска, сбора, обработки и добавления сведений о сайте в базу данных поисковых систем.
 youtube.com/embed/L6PeRqIAePU» frameborder=»0″ allowfullscreen=»allowfullscreen»>
youtube.com/embed/L6PeRqIAePU» frameborder=»0″ allowfullscreen=»allowfullscreen»> Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Индексация сайта значит, что робот поисковой системы посещает ресурс и его страницы, изучает контент и заносит его в базу данных.Впоследствии эта информация выдается по ключевым запросам. То есть, пользователи сети вводят в строку поиска запрос и получают на него ответ в виде списка проиндексированных страниц.
Если говорить простым языком, получится приблизительно так: весь интернет — это огромная библиотека. В любой уважающей себя библиотеке есть каталог, который облегчает поиск нужной информации. В середине 90-х годов прошлого века, вся индексация сводилась к такой каталогизации. Роботы находили на сайтах ключевые слова и формировали из них базу данных.
Сегодня боты собирают и анализируют информацию по нескольким параметрам (ошибки, уникальность, полезность, доступность и проч.) прежде, чем внести ее в индекс поисковой системы.
Алгоритмы работы поисковых роботов постоянно обновляются и становятся все сложнее. Базы данных содержат огромное количество информации, несмотря на это поиск нужных сведений не занимает много времени. Это и есть пример качественной индексации.
Если сайт не прошел индексацию, то информация до пользователей может и не дойти.
Как индексирует сайты Гугл и Яндекс
Яндекс и Гугл, пожалуй, самые популярные поисковики в России. Чтобы поисковые системы проиндексировали сайт, о нем нужно сообщить. Сделать это можно двумя способами:
- Добавить сайт на индексацию при помощи ссылок на других ресурсах в интернете — этот способ считается оптимальным, так как страницы, найденные таким путем, робот считает полезными и их индексирование проходит быстрее, от 12 часов до двух недель.
- Отправить сайт на индексацию путем заполнения специальной формы поисковой системы вручную с использованием сервисов Яндекс.Вебмастер, Google Webmaster Tools, Bing Webmaster Tools и др.


Второй способ медленнее, сайт встает в очередь и индексируется в течение двух недель или больше.
В среднем, новые сайты и страницы проходят индексацию за 1–2 недели.
Считается, что Гугл индексирует сайты быстрее. Это происходит потому, что поисковая система Google индексирует все страницы — и полезные, и неполезные. Однако в ранжирование попадает только качественный контент.
Яндекс работает медленнее, но индексирует полезные материалы и сразу исключает из поиска все мусорные страницы.
Индексирование сайта происходит так:
- поисковый робот находит портал и изучает его содержимое;
- полученная информация заносится в базу данных;
- примерно через две недели материал, успешно прошедший индексацию, появится в выдаче по запросу.
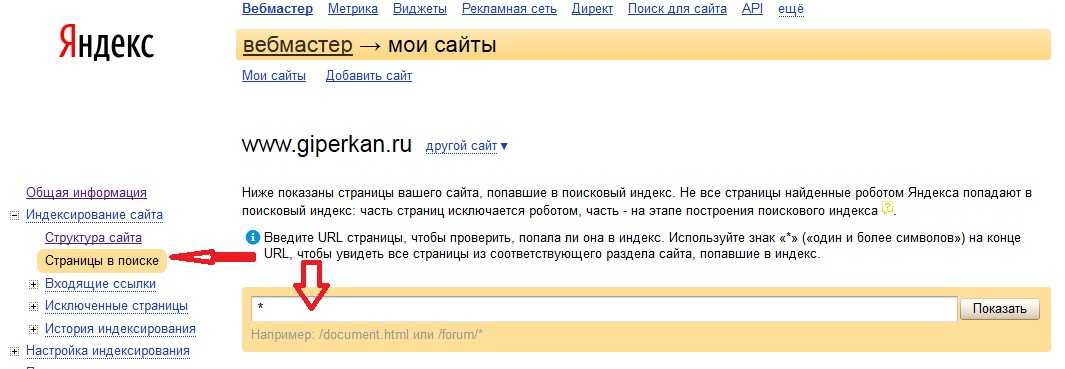
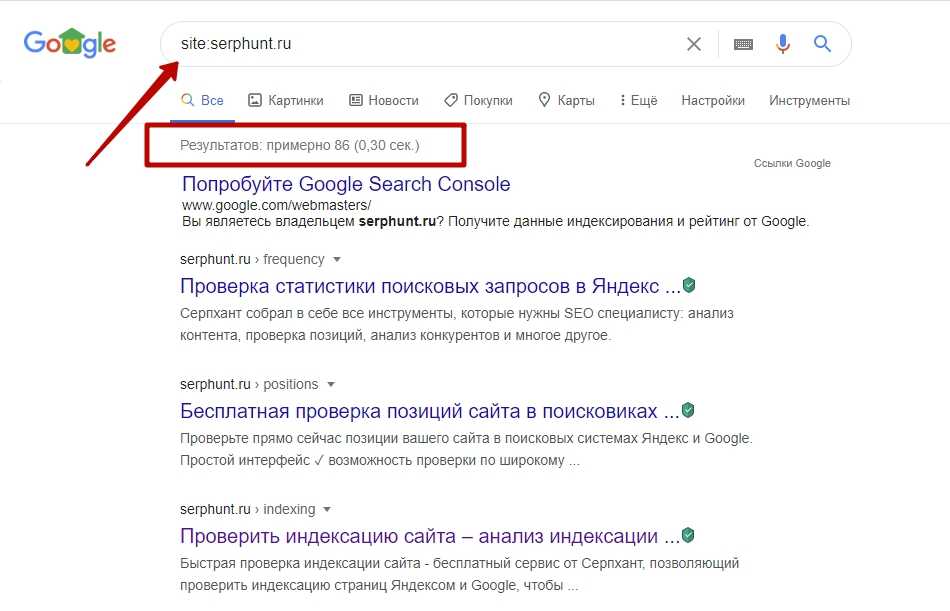
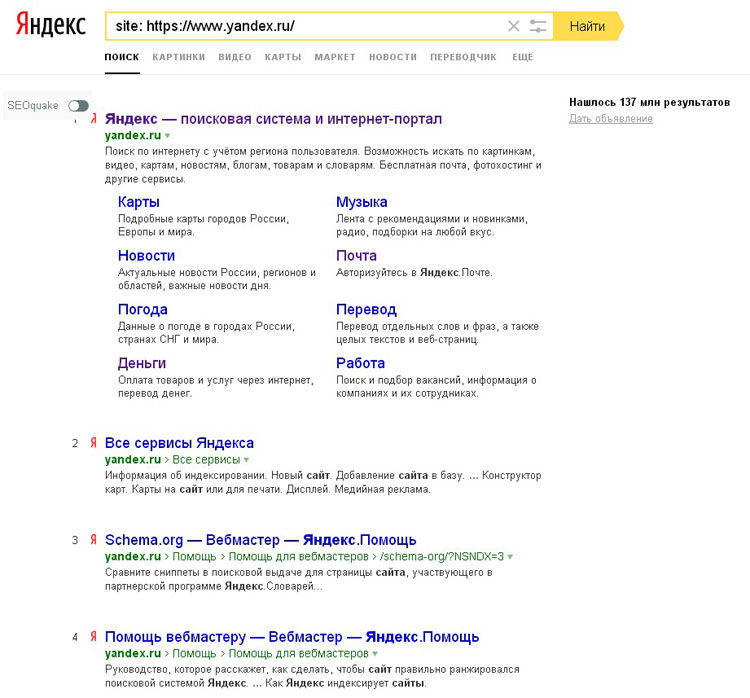
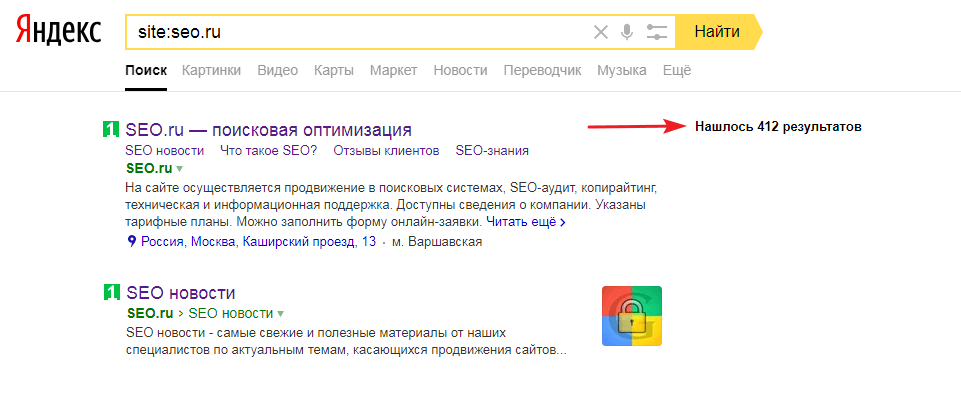
Есть 3 способа проверки индексации сайта и его страниц в Гугл и Яндексе:
- при помощи инструментов для вебмастеров — google.com/webmasters или webmaster.yandex.ru;
- при помощи ввода специальных команд в поисковую строку, команда для Яндекс будет выглядеть так: host: имя сайта+домен первого уровня; а для Гугл — site: имя сайта+домен;
- с помощью специальных автоматических сервисов.
Проверяем индексацию
Это можно сделать используя:
- операторы поисковых систем — смотрим в справке ;
- услуги специальных сервисов, например rds бар;
- Яндекс вебмастер;
- Google вебмастер.
Как ускорить индексацию сайта
От того, насколько быстро роботы проведут индексирование, зависит скорость появления нового материала в поисковой выдаче, тем быстрее на сайт придет целевая аудитория.
Для ускорения индексации поисковыми системами нужно соблюсти несколько рекомендаций.
- Добавить сайт в поисковую систему.
- Регулярно наполнять проект уникальным и полезным контентом.
- Навигация по сайту должна быть удобной, доступ на страницы не длиннее, чем в 3 клика от главной.
- Размещать ресурс на быстром и надежном хостинге.
- Правильно настроить robots.txt: устранить ненужные запреты, закрыть от индексации служебные страницы.
- Проверить на наличие ошибок, количество ключевых слов.
- Сделать внутреннюю перелинковку (ссылки на другие страницы).
- Разместить ссылки на статьи в социальных сетях, социальных закладках.
- Создать карту сайта, можно даже две, — для посетителей и для роботов.
Как закрыть сайт от индексации
Закрыть сайт от индексации — запретить поисковым роботам доступ к сайту, к некоторым его страницам, части текста или изображению. Обычно это делается для того, чтобы скрыть от публичного доступа секретную информацию, технические страницы, сайты на уровне разработки, дублированные страницы и т. п.
Сделать это можно несколькими способами:
- При помощи robots.txt можно запретить индексацию сайта или страницы. Для этого в корне веб-сайта создается текстовый документ, в котором прописываются правила для роботов поисковых систем. Эти правила состоят из двух частей: первая часть (User-agent) указывает на адресата, а вторая (Disallow) запрещает индексацию какого-либо объекта.
Например, запрет индексации всего сайта для всех поисковых ботов выглядит так:
User-agent: *
Disallow: /
- При помощи мета-тега robots, что считается наиболее правильным для закрытия одной страницы от индексирования. При помощи тегов noindex и nofollow можно запретить роботам любых поисковых систем индексировать сайт, страницу или часть текста.
 При помощи тегов noindex и nofollow можно запретить роботам любых поисковых систем индексировать сайт, страницу или часть текста.
При помощи тегов noindex и nofollow можно запретить роботам любых поисковых систем индексировать сайт, страницу или часть текста.Запись для запрета индексации всего документа будет выглядеть так:
<meta name=»robots» content=»noindex, nofollow»/>
Можно создать запрет для конкретного робота:
<meta name=»googlebot» content=»noindex, nofollow»/>
На что влияет индексация при продвижении
Благодаря индексации сайты попадают в поисковую систему. Чем чаще обновляется контент, тем быстрее это происходит, так как боты чаще приходят на сайт. Это приводит к более высокой позиции при выдаче на запрос.
Индексация сайта в поисковых системах дает приток посетителей и способствует развитию проекта.
Кроме контента, роботы оценивают посещаемость и поведение посетителей. На основании этих факторов они делают выводы о полезности ресурса, чаще посещают сайт, что поднимает на более высокую позицию в поисковой выдаче. Следовательно, трафик снова увеличивается.
Следовательно, трафик снова увеличивается.
Индексация — это важный процесс для продвижения проектов. Чтобы индексирование прошло успешно, поисковые роботы должны убедиться в полезности информации.
Алгоритмы, по которым работают поисковые машины, постоянно меняются и усложняются. Цель индексации — внесение информации в базу данных поисковых систем.
Как заставить поисковые системы индексировать нужный контент для лучшей видимости
Структура и содержание веб-сайта могут оказать значительное влияние на способность поисковых систем обеспечивать удобство поиска. В результате индустрия поисковой оптимизации эволюционировала, чтобы обеспечить лучшее понимание этих воздействий и закрыть критические пробелы. Некоторые элементы на вашем веб-сайте будут активно мешать поиску, и этот пост покажет вам, как настроить таргетинг на ценный контент и исключить отвлекающие факторы.
Мы написали статью о файлах robots.txt, в которой рассказали о высоком уровне включения и исключения контента из поисковых систем. Есть и другие ключевые инструменты, которые вы захотите использовать на своем веб-сайте для дальнейшего таргетинга контента на отдельных страницах:
Есть и другие ключевые инструменты, которые вы захотите использовать на своем веб-сайте для дальнейшего таргетинга контента на отдельных страницах:
- Элемент
- Канонические ссылки
- Метатеги роботов
- Или комбинация вышеперечисленного: Пример структуры кода для динамических списков и архивного события
<основной> элементОриентация на определенный контент на странице
Элемент  Мы рекомендуем добавить
Мы рекомендуем добавить и , чтобы разграничить эти разделы и упростить индексацию.
Элемент реализован как отдельный тег:
<тело> Избыточный код заголовка и элементы навигации, боковые панели и т. д. <основной>Это название вашей страницы
Это основной текст вашей страницы Избыточный код нижнего колонтитула Различные скрипты и т.д.
Элемент также может принимать форму Это основной текст вашей страницы
Если возможно, откройте тег Если элемент Есть две веские причины для объявления URL-адреса данной страницы: сайты CMS могут легко стать ловушками для сканеров, а списковые представления могут генерировать URL-адреса, которые бесполезны в качестве результатов поиска. Ловушка сканера возникает, когда движок попадает в цикл посещения, открытия и «обнаружения» страниц, которые кажутся новыми, но являются модификациями существующих URL-адресов. Используя каноническую ссылку, показанную выше, вы сообщаете сканеру, что это реальный URL-адрес страницы, несмотря на параметры, присутствующие в URL-адресе при открытии страницы. В приведенном выше примере, даже если сканер открыл страницу с таким URL-адресом, как Еще одним важным вариантом использования канонических ссылок является динамический список. Если приведенный выше пример представляет собой динамический список страниц по теме 1, скорее всего, внизу страницы будет нумерация страниц. Используйте каноническую ссылку, чтобы поисковая система могла индексировать только первую страницу списка, которую пользователь затем может сортировать или перемещать по своему выбору. Отдельные элементы в списке индексируются отдельно и включаются в результаты поиска. На ваших веб-сайтах есть отдельные страницы, которые не дают хороших результатов поиска. Это могут быть заархивированные страницы событий, представления списков, такие как недавние сообщения в блоге и т. Также важно отметить, что поисковые системы будут обращать внимание на директивы Чтобы добиться наилучших результатов при блокировке индексации определенных страниц, вам нужно использовать метатеги robots в В этом примере указано не индексировать страницу, но разрешается переход по ссылкам на странице: В этом примере предлагается проиндексировать страницу, но не переходить ни по одной из ссылок на странице: Этот пример указывает ботам не индексировать страницу и не переходить ни по одной из ссылок на странице: Вы также можете добавить тег X-Robots-Tag к ответу заголовка HTTP для управления индексацией данной страницы. Если у вас есть контент, который должен быть проиндексирован, когда он свежий, но его нужно удалить из индекса, как только он устарел, вам нужно выполнить несколько действий: Следующий пример кода предназначен для динамически создаваемого списка страниц на вашем сайте, где вы хотите, чтобы целевая страница списка отображалась в результатах поиска. Это вводный текст страницы. Он сообщает людям, что они здесь найдут, почему тема важна и т. д. Этот текст находится в основном элементе, поэтому он будет использоваться для извлечения этой страницы при поиске.
Динамически генерируемый список релевантных страниц
Пагинация
Различные скрипты и т.д.
Следующий пример кода предназначен для динамически генерируемого списка страниц на вашем сайте, когда вы не хотите, чтобы этот список отображался в результатах поиска. В случае страниц, помеченных определенным термином, сами страницы будут хорошими результатами поиска, но их список будет просто еще одним щелчком между пользователем и контентом. Примечание: теги описания все еще присутствуют на тот случай, если кто-то ссылается на эту страницу в другой системе, и эта система хочет отобразить сводку со ссылкой. В следующем примере страница события была опубликована в июне, а затем обновлена на следующий день после события. Это обновление добавляет метатег Это вводный текст страницы. Он сообщает людям, что они здесь найдут, почему тема важна и т. д. Этот текст находится в основном элементе, поэтому он будет использоваться для извлечения этой страницы при поиске.
Подробности о мероприятии.
Различные скрипты и т.д.
Опубликовано 21 мая 2023 г. + Подписаться В век цифровых технологий наличие веб-сайта необходимо для предприятий любого размера. Однако просто иметь сайт недостаточно. Чтобы потенциальные клиенты могли найти ваш сайт, он должен быть проиндексирован поисковыми системами, такими как Google. Но как работает индексация сайта? В этой статье мы рассмотрим все тонкости индексации веб-сайтов и предоставим вам информацию, необходимую для того, чтобы поисковые системы заметили ваш веб-сайт. Когда вы вводите запрос в поисковую систему, вы ожидаете получить релевантные результаты в течение нескольких секунд. Вы когда-нибудь задумывались, как поисковые системы могут так быстро выдавать такие точные результаты? Все упирается в индексацию сайта. Индексация веб-сайтов — это процесс, посредством которого поисковые системы собирают и сохраняют информацию о веб-страницах. Это позволяет поисковым системам быстро извлекать и отображать релевантные результаты, когда пользователь выполняет поиск по определенному запросу. Если ваш сайт не индексируется поисковыми системами, он не будет отображаться в результатах поиска. Это означает, что потенциальные клиенты не смогут найти ваш сайт, что может негативно сказаться на вашем бизнесе. Убедившись, что ваш веб-сайт правильно проиндексирован, вы можете повысить его видимость в результатах поиска и привлечь больше трафика на свой сайт. Поисковые системы используют автоматизированные программы, называемые поисковыми роботами или поисковыми роботами, для сканирования веб-сайтов и сбора информации о них. Эти программы переходят по ссылкам с одной страницы на другую и индексируют контент, который они находят по пути. Собранная информация включает URL-адрес страницы, контент, изображения и любые другие соответствующие метаданные. Существует несколько факторов, влияющих на то, как поисковые системы индексируют ваш веб-сайт. К ним относятся: Вы можете проверить, индексируется ли ваш веб-сайт поисковыми системами, выполнив поиск с использованием оператора «сайт:», за которым следует URL-адрес вашего веб-сайта. Существует несколько шагов, которые можно предпринять для улучшения индексации вашего веб-сайта, в том числе: Карта сайта — это файл, содержащий информацию о страницах, видео и других файлах на веб-сайте. Это помогает поисковым системам понять организацию веб-сайта и его содержание. Карты сайта можно создавать вручную или автоматически с помощью различных онлайн-инструментов или плагинов. Большинство систем управления контентом (CMS) предлагают плагины, которые могут автоматически создавать карты сайта. Существуют также онлайн-генераторы карт сайта, которые могут создавать карты сайта бесплатно или за плату. После создания карты сайта важно отправить ее в поисковые системы. Это можно сделать с помощью инструментов поисковой системы для веб-мастеров. Отправляя карту сайта, поисковые системы могут легче сканировать и индексировать веб-сайт, что приводит к улучшению видимости и рейтинга. Хотя индексация веб-сайтов имеет решающее значение для видимости в поисковых системах, это не всегда простой процесс. Вот некоторые распространенные проблемы, которые могут возникнуть: Поисковые системы не любят дублированный контент, и это может повредить рейтингу веб-сайта. Неработающие ссылки также могут вызвать проблемы с индексацией веб-сайта. Поисковые системы полагаются на ссылки для навигации и индексации веб-сайта. Неработающие ссылки могут помешать процессу сканирования и индексации, что приведет к плохой видимости и ранжированию. Используйте средство проверки неработающих ссылок, чтобы выявить и исправить любые неработающие ссылки на веб-сайте. Скорость веб-сайта является решающим фактором как для удобства пользователей, так и для рейтинга в поисковых системах. Низкая скорость веб-сайта может негативно повлиять на индексацию, замедляя процесс сканирования и индексации. Используйте такие инструменты, как Google PageSpeed Insights, для выявления и устранения любых проблем со скоростью веб-сайта. <тело>
Избыточный код заголовка и элементы навигации, боковые панели и т. д.
Это название вашей страницы
для заголовка вашей страницы. Если вы используете на своем сайте навигационные крошки,
Если вы используете на своем сайте навигационные крошки, , чтобы повторяющийся текст в навигационных ссылках не индексировался. и . Если ни один из них не присутствует, вся страница будет очищена. Очистка всей страницы лучше всего работает для типов файлов, отличных от HTML, включая PDF и DOC, поэтому мы рекомендуем вам реализовать эти семантические элементы в шаблонах страниц, чтобы помочь поисковым системам понять структуру вашего сайта. Объявить «настоящий» URL-адрес страницы
 Эти URL-адреса могут иметь добавленные параметры, такие как теги, ссылающиеся страницы, токены Диспетчера тегов Google, номера страниц и т. д. Ловушки сканера обычно возникают, когда ваш сайт может генерировать бесконечное количество URL-адресов. Поисковый робот в конечном итоге не может определить, что представляет собой весь сайт.
Эти URL-адреса могут иметь добавленные параметры, такие как теги, ссылающиеся страницы, токены Диспетчера тегов Google, номера страниц и т. д. Ловушки сканера обычно возникают, когда ваш сайт может генерировать бесконечное количество URL-адресов. Поисковый робот в конечном итоге не может определить, что представляет собой весь сайт. https://example.gov/topic1?sortby=desc , только https://www.example.gov/topic1 будут захвачены поисковая система. Эта разбивка на страницы динамически разделяет элементы на отдельные страницы и генерирует такие URL-адреса, как:
Эта разбивка на страницы динамически разделяет элементы на отдельные страницы и генерирует такие URL-адреса, как: https://example.gov/topic1?page=3 . Когда новые элементы добавляются в список или удаляются из него, нет никакой гарантии, что существующие элементы останутся на определенной странице. Такое поведение может расстраивать пользователей, когда на определенной странице больше нет нужного им элемента. Метатеги роботов
Исключить отдельные страницы из индексации или запретить переход по их ссылкам
 д. Заблокировать отдельные страницы в файле robots.txt будет сложно, если у вас нет простого доступа к редактированию файла. привести к неуправляемо длинному
д. Заблокировать отдельные страницы в файле robots.txt будет сложно, если у вас нет простого доступа к редактированию файла. привести к неуправляемо длинному robots.txt . Disallow в robots.txt при сканировании, но не при доступе к вашим URL-адресам из других источников, таких как ссылки с других сайтов или ваша карта сайта. Search.gov полагается на метатеги robots в каждой страницы ваших карт сайта или RSS-каналов, чтобы знать, какой контент вы хотите использовать для поиска, а какой нет. страниц, которые вы хотите исключить из поискового индекса.  Для этого требуется более глубокий доступ к серверам, чем обычно имеют сами наши клиенты, поэтому, если вы хотите узнать больше, вы можете сделать это здесь.
Для этого требуется более глубокий доступ к серверам, чем обычно имеют сами наши клиенты, поэтому, если вы хотите узнать больше, вы можете сделать это здесь. к страницы. Пример структуры кода
Динамический список 1: Тематическая целевая страница
<голова>
 example.gov/topic1" />
<тело>
example.gov/topic1" />
<тело>
Уникальный заголовок страницы
Динамический список 2: сообщения с тегами XYZ

<голова>
 example.gov/posts-tagged-xyz" />
<тело>
example.gov/posts-tagged-xyz" />
<тело>
Уникальный заголовок страницы
Динамически генерируемый список релевантных страниц
Пагинация
Различные скрипты и т.д.
Событие последнего месяца
robots , который объявляет, что страница не должна быть проиндексирована, а ссылки со страницы не должны переходить при сканировании в будущем. Опять же, метаописания сохраняются в случае ссылки из других систем. <голова>
 Это отличное место, чтобы использовать разные термины для одного и того же, что, надеюсь, является как простым языком, так и нагромождением ключевых слов в одновременно. Рекомендуемое максимальное количество символов – 175". />
<тело>
Это отличное место, чтобы использовать разные термины для одного и того же, что, надеюсь, является как простым языком, так и нагромождением ключевых слов в одновременно. Рекомендуемое максимальное количество символов – 175". />
<тело>
Уникальный заголовок страницы
Ресурсы
Индексирование веб-сайтов для поисковых систем: как это работает?
Прити Йенар Прити Йенар
SEO-менеджер в Gozoop Group
 Без индексации поисковым системам пришлось бы сканировать каждый веб-сайт в Интернете каждый раз, когда вводится поисковый запрос, что отнимало бы невероятно много времени.
Без индексации поисковым системам пришлось бы сканировать каждый веб-сайт в Интернете каждый раз, когда вводится поисковый запрос, что отнимало бы невероятно много времени.
Как проверить, индексируется ли ваш сайт поисковыми системами?  Например, если ваш веб-сайт www.example.com, вы должны ввести «site:www.example.com» в строку поиска. Если ваш сайт проиндексирован, вы должны увидеть список страниц, которые были проиндексированы поисковой системой.
Например, если ваш веб-сайт www.example.com, вы должны ввести «site:www.example.com» в строку поиска. Если ваш сайт проиндексирован, вы должны увидеть список страниц, которые были проиндексированы поисковой системой.
Роль файлов Sitemap в индексации веб-сайтов 
 Дублированный контент может возникать, когда несколько страниц веб-сайта имеют одинаковый или очень похожий контент. Чтобы избежать этой проблемы, убедитесь, что каждая страница веб-сайта содержит уникальный и ценный контент.
Дублированный контент может возникать, когда несколько страниц веб-сайта имеют одинаковый или очень похожий контент. Чтобы избежать этой проблемы, убедитесь, что каждая страница веб-сайта содержит уникальный и ценный контент.