
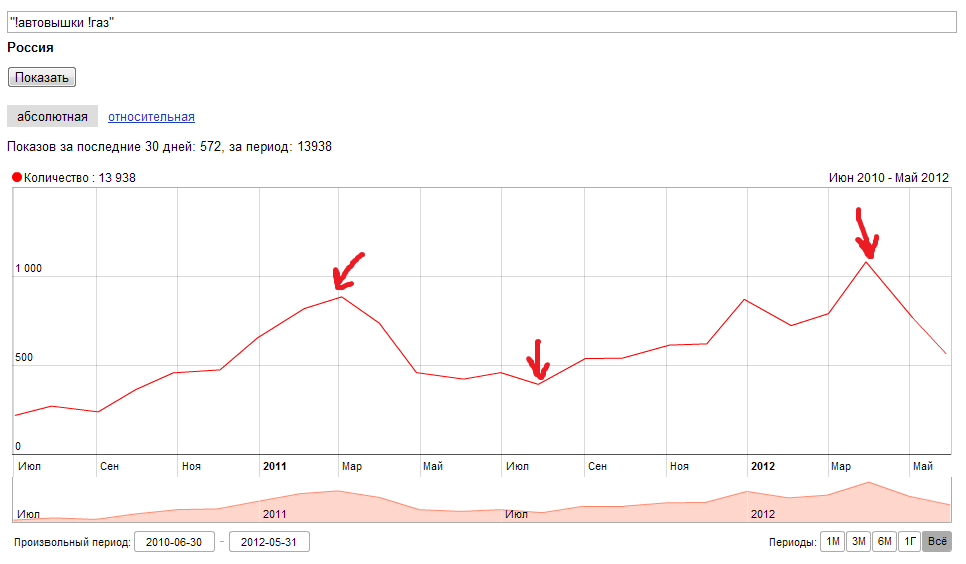
инструкция подбора ключевых слов для сайта
Грамотный подбор поисковых запросов поможет быстро получить обширную базу ключевых слов (семантическое ядро) для дальнейшего создания релевантных им, востребованных у пользователей материалов.
Узнав частотность запроса в Google, вы сможете создать сайт с правильной структурой и улучшить позиции уже имеющихся страниц. Кроме того, полученная в ходе исследования статистика даст возможность настроить контекстную рекламу с минимальными затратами и максимальной конверсией.
Секрет успеха в том, что нужно не только провести анализ ниши и понять свою целевую аудиторию, но и подобрать популярные запросы с помощью специальных сервисов.
Хотите создать эффективное семантическое ядро без услуг агентств и оптимизаторов? Тогда вам жизненно необходимо прочитать данную статью!
Как узнать статистику запросов в «Гугл»?
Если вы нацелены на завоевание симпатий пользователей Рунета, профессиональные инструменты от поисковой системы Google — именно то, что вам надо.
Планировщик ключевых слов AdWords
Google AdWords это основная бесплатная платформа с интуитивно-понятным интерфейсом наподобие Yandex WordStat, но с предусмотренной оценкой конкуренции. Сервис ориентирован на выдачу и фильтрацию запросов от «Гугл», которые можно использовать для SEO-раскрутки сайтов и каналов на YouTube, а также настройки рекламных объявлений.
Инструмент планировщика ключевых слов показывает сведения и по отдельным ключевым словам, и по целым фразам, выдает всю связанную с ними информацию — сведения пригодятся для успешной стратегии проекта. К достоинствам подобного варианта относится мощный функционал для аналитики эффективности продвижения с учетом не только частотности, но и конкуренции ключей. Помимо прочего, Google AdWords выдает предварительную цену (ставку) по запросам.
Минус один — вы получаете не точные, средние данные с учетом результатов поиска. Служба поддержки «Гугл» акцентирует внимание на том, что общее число выбранных запросов для отдельных регионов редко соответствует сумме их ключей.
Внимание! AdWords показывает не более 800 запросов, значит, придется вводить каждую интересующую вас фразу отдельно. Например, сначала «купить женскую одежду», а затем «купить женское платье».
Статистика поисковых запросов Google Keywords Planner
Функционал инструмента «Планировщик ключевых слов» совмещает возможности Traffic Estimator и канувшего в небытие Keyword Tool — он предоставляет новые идеи для ключей и объявлений, определяет бюджет и ставки, которые подходят конкретно для вашей кампании. Все сведения оформляются в удобных таблицах и графиках, при этом пользоваться Keyword Planner Tool можно бесплатно (надо лишь иметь аккаунт в «Гугл Адвордс»).
Недостатки сервиса: нет сортировки запросов по типу устройства, результаты выводятся лишь по точному соответствию ключевого слова.
Cкриншот интерфейса Google Keywords PlannerGoogle Trends
Инструмент «Гугл Тренды» показывает уровень спроса коммерческого или информационного ключа на данный момент, динамику его востребованности.
Кстати говоря, на SEO-форумах новички часто задают вопрос: «В чем ценность и польза Google Trends?»
Ответ простой: эта платформа является маркетинговым способом отслеживания главных событий и трендов. Полученная информация адаптируется под особенности кампании, давая возможность сайту шагать в ногу со временем.
Еще один плюс «Гугл Трендс» — благодаря функции «Прогноз» вы поймете, стоит ли активно инвестировать в рекламу или от подобных действий целесообразнее отказаться. Конечно, такой прогноз нельзя расценивать как данность, он не гарантирует 100% точности.
Читайте подробнее о том, как работать с Google Trends.
Инструкция по подбору запросов в Google AdWords
Алгоритмы работы с этим сервисом невероятно простые:
1. Создайте единый для всех информеров аккаунт «Гугл».
2. Зайдите на ресурс Google AdWords и подключите к нему свой профиль.
3. Найдите раздел «Инструменты и анализ», после чего перейдите в «Планировщик ключевых слов».
4. Заполните простую форму (с выбранными фразами, местоположением и минус-словами) — и вы получите нужную вам информацию.
Это интересно! В 2017 году «Гугл» изменил серый интерфейс с неоправданными подменю на более современный и привлекательный аналог. Теперь работать в системе стало еще удобней и приятнее.
Ручной метод подбора ключей
В отличие от автоматического способа работы с сервисом, ручное управление осуществляется через браузер без таких вспомогательных инструментов, как «Словоеб», «Магадан» или Key Collector.
Для начала сбора семантического ядра вам требуется перейти по ссылке https://adwords.google.com/KeywordPlanner, после чего зайти в подраздел «Поиск новых ключевых слов по фразе, сайту или категории».
Чтобы начать подбор ключевых слов в Гугл Кейвордс Пленэре, необходимо вбить одну-две фразы из вашего предварительного списка, отрегулировав настройки выдачи с помощью фильтров по региону, языку и диапазону дат. Затем следует нажать кнопку «Получить варианты», осуществить экспорт полученных запросов в CSV и дальше продолжить работу со следующими поисковыми фразами.
Затем следует нажать кнопку «Получить варианты», осуществить экспорт полученных запросов в CSV и дальше продолжить работу со следующими поисковыми фразами.
Подбор ключей для существующей целевой страницы
Вы имеете возможность посмотреть статистику поисковых запросов в Google, исходя от первоначального списка приоритетных фраз или от конкретной посадочной страницы. Таким способом несложно проанализировать, а затем улучшить главные элементы веб-проекта. Можно пойти дальше — изучить под микроскопом особенности сайта конкурента, сделать выводы и пересмотреть собственную стратегию.
Для этого заходим в «Планировщик ключевых слов», вводим адрес на интересующую страницу и настраиваем инструмент в соответствии с личными предпочтениями.
Представленный метод анализа покажет как частоту запросов, так и уровень их конкуренции, рекомендованную сервисом ставку для запуска платной рекламы.
Как пользоваться Google Keywords Planner Tool
Интерфейс видоизмененного сервиса впечатляет продуманностью. Сверху имеется строка для названия продукта или услуги, рядом находится кнопка «Получить варианты» и «Изменить критерии поиска». Ниже два подраздела: один для работы с группами объявлений, другой — для вычисления ключевых слов.
Сверху имеется строка для названия продукта или услуги, рядом находится кнопка «Получить варианты» и «Изменить критерии поиска». Ниже два подраздела: один для работы с группами объявлений, другой — для вычисления ключевых слов.
Во второй категории доступны показатели частотности, уровень конкуренции, а также средняя цена за клик и показатель отказа каждого объявления. В самом низу можно увидеть релевантные фразы — они пригодятся для расширения семантического ядра.
Порядок слов в запросе
В отличие от Yandex WordStat, инструмент подбора запросов от «Гугл» способен отличить одну и ту же ключевую фразу с той или иной очередностью слов. Статистика и ставка по таким ключам будут иметь разные показатели — это касается точного и фразового соответствия.
Если вы не желаете вписывать, по сути, одинаковые запросы с разным порядком слов, а хотите сразу ознакомиться со всеми данными, воспользуйтесь модификатором широкого соответствия (+). Он покажет синонимы и похожие ключи.
Поиск фраз по регионам
Планируете продвигать сайт в области? Тогда необходимо воспользоваться вкладкой «Местоположение» и задать нужный город — вы получите список запросов, которые пользуются популярностью у целевой аудитории.
Кроме того, можно выбрать «Все местоположения», а затем исключить из результатов фразы с лишними городами и регионами.
Совет! Если требуется обширный начальный список, советуем использовать минимум фильтров. Так вы соберете максимальное количество целевых фраз и лучше поймете тему, потребности своих потенциальных клиентов. Но приготовьтесь к тому, что дальнейшая чистка и подготовка ключей потребует немало усилий и времени.
Удобный анализ сезонности
Инструмент подбора ключевых слов в Google показывает динамику поисковых запросов по неделям и месяцам. Информация из этого раздела пригодится информационному сайту с новогодней тематикой, предлагающему свои услуги туристическому агентству, интернет-магазину по продаже купальников или семян цветов.
Полученные сведения помогут прогнозировать спад и рост числа посетителей по конкретным ключам.
Программы и сервисы поиска запросов для «Гугл»
1. «Словоеб» — многофункциональный бесплатный инструмент, который дает возможность автоматически сгенерировать большой список ключей с анализом региона и времени, необходимого для продвижения.
2. Keyword Tool — удобный сервис, поддерживающий более 80 языков. Для большинства запросов подбирает свыше 750 ключей, к тому же выдает поисковые подсказки.
3. SEMrush.com — платформа радует понятным интерфейсом и хорошим функционалом. Позволяет определить ключевые слова, по которым продвигаются ваши конкуренты.
4. Key Collector — платный, но очень удобный и мощный вариант для тех, кто хочет получить максимум информации при минимальных усилиях.
5. SerpStat.com — демонстрирует подсказки для улучшения списка ключей, позволяет собрать длинный хвост, который быстро приведет первых клиентов.
Протестировав каждый из представленных инструментов, вы наверняка найдете тот, что поможет вам сформировать идеальное семантическое ядро. В результате сайт привлечет новых посетителей, а значит, увеличит продажи или доходы с монетизации.
В результате сайт привлечет новых посетителей, а значит, увеличит продажи или доходы с монетизации.
Google Trends — зачем нужен и как пользоваться
Анастасия
Чирво, специалист по контекстной рекламеМаркетологам и специалистам по рекламе важно знать, что происходит с покупательским спросом: какие события или факты на него влияют, насколько активны и популярны конкуренты. Ответить на эти вопросы поможет Google Trends — сервис, который собирает и оценивает популярные поисковые запросы и распределяет их категориям.
С Google Trends можно оставаться в курсе главных событий в мире и стране и понимать, чем интересуются пользователи. Информация собирается из поисковых запросов, выполненных пользователями Google, а статистика обновляется автоматически.
Важно понимать, что Google Trends — это не замена Wordstat от Яндекса. Основная функция Wordstat — сбор ключевых запросов и их частотности для семантического ядра, что особенно помогает при SEO-продвижении сайта.
Google Trends учитывает только высокочастотные фразы, анализирует популярность запросов и оценивает ее по стобалльной шкале, где 100 баллов — максимальный интерес к теме.
Что можно сделать в Google Trends
- Определить популярность темы, события или поискового запроса.
- Посмотреть динамику поисковых запросов.
- Провести анализ сезонности этих запросов.
- Выявить конкурентов и оценить популярность в нише.
- Узнать влияние географических данных на поисковые запросы.
Подробнее о Google Trends
Google Trends состоит из пяти разделов:
- Главная,
- Анализ,
- Популярные запросы,
- Год в поиске,
- Подписки.
Найти их можно в меню в левом верхнем углу.
На главной странице находится строка поиска. После того как вы введете поисковой запрос, сервис автоматически перенаправит вас в раздел «Анализ».
Раздел «Анализ» показывает популярность темы, ее сезонность, динамику поискового запроса и наличие конкурентов. С помощью фильтров можно выбрать регион, период, категорию и тип поиска.
С помощью фильтров можно выбрать регион, период, категорию и тип поиска.
В разделе «Популярные запросы» отображаются самые важные темы и запросы за последние сутки. Здесь можно узнать инфоповод и подумать, как на него отреагировать. Данные обновляются каждый час.
Вкладка «Год в поиске» показывает самые значимые события за этот и прошлые годы для разных стран. Статистика доступна с 2008 года.
Инструмент «Подписки» позволяет подписаться на интересующую тему и получать на почту обновления с выбранной периодичностью — раз в неделю или раз в месяц. Также можно подписаться на раздел «Популярные запросы», тогда уведомления о новых запросах будут приходить на вашу почту.
Как Google Trends подсчитывает популярность запроса
Сервис делит частоту запроса на общее число поисковых запросов, при этом учитывает конкретный регион и выбранный период. Исходя из этих данных система оценивает уровень интереса по шкале от 0 до 100 баллов.
Оценку 100 получает самый популярные за этот период запрос или тема — совокупность похожих запросов. Остальные распределяются в зависимости от отношения к этому числу. Оценка 0 означает, что запрос не популярен.
Остальные распределяются в зависимости от отношения к этому числу. Оценка 0 означает, что запрос не популярен.
Как работать с Google Trends
Разберем на примере интернет-магазина электроники. Допустим, нужно узнать динамику поисковых запросов двух популярных моделей телефонов. Мы вводим два поисковых запроса — они должны быть высокочастотными — и смотрим статистику:
По статистике, в последние 90 дней пользователей чаще интересовали телефоны фирмы Samsung.
Теперь можно узнать, в каких регионах какая марка телефона пользуется большей популярностью.
Выборку можно сортировать по городам или по регионам, фильтр находится в правом верхнем углу.
Важно: Google Trends показывает популярность запроса относительно других запросов в каждом отдельно взятом регионе, а затем сортирует их в порядке убывания. Это не значит, что частотность запроса в республике Тува будет больше, чем в Москве.
Также можно увидеть, какие именно модели телефонов популярны в регионах.
Динамика популярности показывает, есть ли сезонный спрос на товар или услугу.
На скрине видно, что спрос на iPhone растет каждый год в сентябре, как раз когда Apple выпускает новую модель телефона. Кроме того, спрос на телефоны растет на Новый год. Эти знания помогут маркетологу или владельцу бизнеса спланировать продажи и перераспределить бюджет в рекламных кампаниях.
Также можно узнать динамику популярности конкретной модели телефона.
С помощью фильтров можно узнать, какие темы в тренде у пользователей и самые популярные запросы по теме.
Чтобы данные были точнее, в Google Trends можно использовать три логических оператора: минус, плюс и кавычки.
- Минус (—). Этот фильтр удаляет из запроса нерелевантные нам слова, например «купить айфон -мини».
- Плюс (+). С помощью этого оператора, наоборот, можно уточнить запрос и добавить разные написания продукта, например «купить айфон 13 +iphone».
- Кавычки (» «).
 Этот оператор показывает запросы без изменения окончаний и порядка слов. Например, при запросе статистики для фразы «купить айфон», будет показана статистика и для поисковых запросов «купить айфон красный», «купить айфон 13» и т. д.
Этот оператор показывает запросы без изменения окончаний и порядка слов. Например, при запросе статистики для фразы «купить айфон», будет показана статистика и для поисковых запросов «купить айфон красный», «купить айфон 13» и т. д.
 Этот оператор показывает запросы без изменения окончаний и порядка слов. Например, при запросе статистики для фразы «купить айфон», будет показана статистика и для поисковых запросов «купить айфон красный», «купить айфон 13» и т. д.
Этот оператор показывает запросы без изменения окончаний и порядка слов. Например, при запросе статистики для фразы «купить айфон», будет показана статистика и для поисковых запросов «купить айфон красный», «купить айфон 13» и т. д.Что важно помнить при работе с инструментом
- Вводить в строку поиска нужно только высокочастотные запросы, по низкочастотным данных не будет.
- Для более точной статистики по поисковым запросам стоит использовать операторы: плюс, минус и компьютерные кавычки.
- В сервисе можно подписаться на рассылку популярных запросов по вашей тематике. Это поможет оставаться в теме трендов и новостей.
- Предпочтения пользователей могут быть разными в зависимости от региона. Учитывайте это при работе с Google Trends: это поможет вам выделить перспективные регионы для продвижения и масштабирования рекламных кампаний.
Google Trends — один из лучших бесплатных универсальных инструментов для анализа сезонности, трендов и прогнозирования спроса.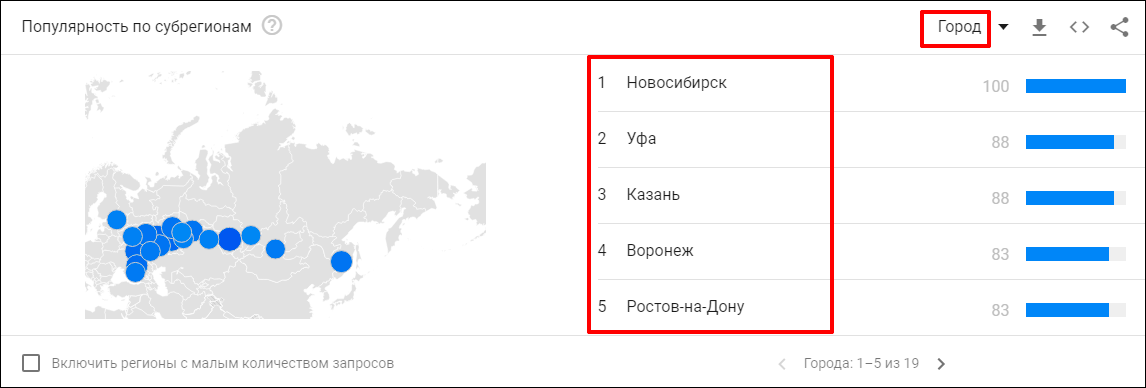 Он поможет узнать потребности и интересы аудитории и определить время, когда лучше сделать выгодное предложение целевой аудитории.
Он поможет узнать потребности и интересы аудитории и определить время, когда лучше сделать выгодное предложение целевой аудитории.
Акции для любых бюджетов и задач
Бонусы на первый запуск рекламы, возврат комиссии за первый месяц и бесплатные кампании для старта
К акциям
руководство по работе с сервисом
Автор Сергей Шевченко На чтение 9 мин Просмотров 397 Опубликовано
Содержание
- Что такое Google Trends?
- Для чего нужен сервис Google Trends?
- Принцип работы Google Trends
- Как правильно работать с сервисом Google Trends?
- Актуальные тенденции
- Популярность запроса
- Сезонность
- Сравнение популярности запросов
- География спроса
- Похожие запросы пользователей
- Популярные запросы за год
- Поисковые операторы
- Руководство по использованию Google Trends с примерами
- Как определить сезонность спроса?
- Узнайте спрос в определенном регионе
- Как найти похожие запросы?
- Узнайте своих конкурентов
- Определите частотность ключевых слов
- Выберите самый востребованный товар в нише
- Спрогнозируйте популярность видеоролика на YouTube
- Найдите популярную тему для статьи или видео
Узнать интересы потенциальных клиентов, оценить спрос на определённые продукты, проанализировать существующие и уже неактуальные тренды, узнать объём запросов по популярным фразам в поиске, которые вводят пользователи разных стран и регионов, — это далеко не вся информация, которую можно получить с помощью сервиса Google Trends.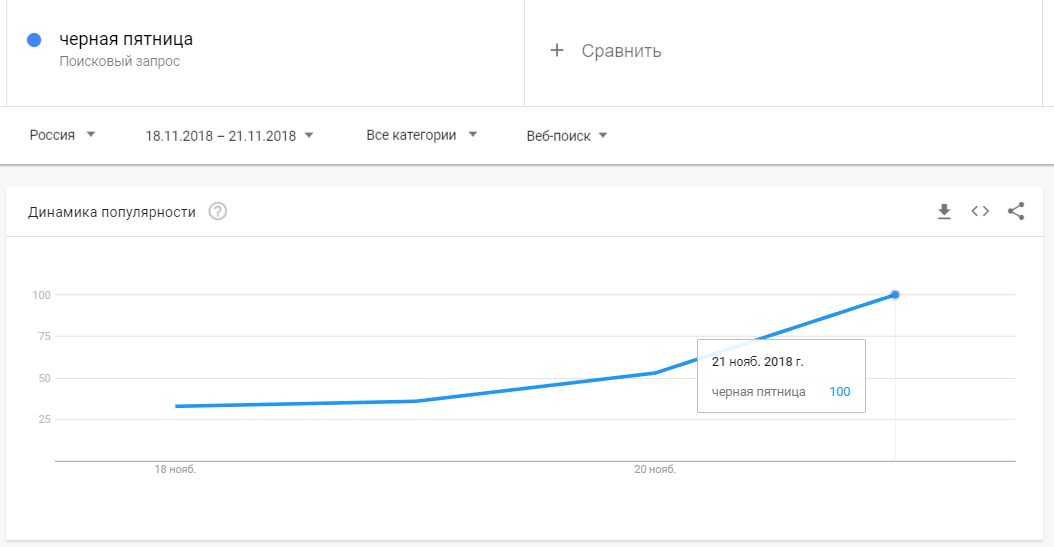
Если хотите детальнее познакомиться с возможностями этого инструмента, а также понять, почему он необходим каждому, кто продвигает свой продукт в сети, читайте эту статью. В дополнение к перечисленному Вы узнаете, как работать с системой.
Что такое Google Trends?
Google Trends — это онлайн-инструмент, применение которого открывает возможность использовать огромный массив данных, где содержится информация о востребованности любого запроса или явления в заданной точке планеты в определённый интервал времени.
Сервис позволяет получить сведения о динамике числа поисковых запросов, увидеть снижение или рост. В накопленной базе можно найти данные о демографических особенностях спроса в определённой сфере деятельности, уловить популярные тенденции и изменения в приоритетах потребителей.
С помощью этого инструмента вы соберёте ценные сведения для принятия решения о масштабировании бизнеса и лучше поймёте потребности и желания Вашей аудитории. Дополнительно Google Trends позволяет прогнозировать рентабельность продаж.
Для чего нужен сервис Google Trends?
Пользоваться Google Trends удобно, если Вам необходимо:
- Найти дополнительные рынки сбыта или новые сферы деятельности. Вы сможете получить информацию об уровне популярности продукта в текущий момент времени, а также оценить динамику интереса потребителей к нему;
- Проанализировать сезонность в определённой сфере. С помощью сервиса легко оценивать изменение спроса во времени и выявлять сезонные отклонения;
- Выявить самые перспективные для развития бизнеса регионы. Вы сможете определить территории, где масштабировать бизнес целесообразнее всего;
- Иметь актуальную информацию о трендах в вашей сфере. Такие данные помогают создавать востребованный контент для веб-ресурса, публиковать новости на важные для аудитории темы, снимать интересное видео;
- Оценить известность бренда. Сервис позволяет получить вполне достоверную оценку уровня известности товарной марки, компании или бренда и сопоставить её с аналогичным показателем конкурентов.
Принцип работы Google Trends
Числовые величины для определённого временного интервала или географического положения рассчитываются по следующим правилам:
- Определяется относительный рейтинг конкретного ключевого слова как доля в суммарном количестве всех поисковых запросов на заданной территории за определённый временной интервал. Если бы в основу ранжирования были положены абсолютные величины, то первые места списка всегда занимали бы регионы с наиболее активными пользователями;
- Полученные показатели выстраиваются по возрастанию или убыванию с использованием 100-бальной шкалы, отражающей востребованность тематики в сравнении с запросами на любые другие темы;
- В регионах, где число запросов по заданному словосочетанию одинаковое, суммарный объём остальных запросов может сильно отличаться;
- Система не выдаёт информацию по редко употребляемым ключевым фразам, поступившим в большом количестве от одного и того же пользователя за непродолжительный период времени.

Как правильно работать с сервисом Google Trends?
Интерфейс сервиса интуитивно понятен и не перегружен лишней информацией. Чтобы понять, как работать с Google Trends, рассмотрим наиболее популярные его инструменты:
Актуальные тенденции
В модуле «Актуальные», расположенном на стартовой странице, отображаются самые востребованные темы за прошедший час. Такие сведения дают представление об общих тенденциях в поведении онлайн-аудитории, помогают использовать популярные инфоповоды для создания креативной рекламы.
Модуль «Популярные запросы» настраивается — Вы можете выбрать отображение поисковых трендов на текущий момент и за один день, определить регион для поиска актуальных новостей:
Подписавшись на рассылку и указав её периодичность в настройках (сутки, неделя или по факту изменения тренда), Вы будете получать новости по интересующей Вас тематике на e-mail.
Популярность запроса
Среди сведений, доступ к которым реализован в модуле «Анализ», — данные о поисковых запросах по определённому продукту и динамике изменения их востребованности, информация о рентабельности медийных кампаний и популярности бренда.
Инструмент позволяет сравнивать тренды с учётом территориальной привязки и проводить анализ в разных интервалах времени и пр. Есть возможность выгрузки данных в файл с расширением .csv.
В качестве показателей для ранжирования не используются абсолютные величины. Алгоритм присваивает значение 100 самому большому числу за период, а остальные вычисляет как их отношение к максимуму. В параметрах можно задать регион, анализируемый интервал времени, категорию и тип поиска.
Сезонность
При продаже некоторых товаров и услуг нельзя не учитывать фактор сезонности. Используя модуль «Анализ», можно проследить динамику изменения популярности по времени, подтвердить или опровергнуть гипотезу о цикличности изменения спроса на продукт.
Важно! Период для анализа сезонности должен быть достаточно продолжительным — в идеале несколько лет. Тогда на графике можно будет увидеть всплески популярности по тому или иному товару или услуге.
В случае, если спрос на продукцию носит сезонный характер, рационально запланировать маркетинговые активности на периоды подъёма. Используя инструмент Google Trends, Вы также сможете выявить лидирующие тренды.
Используя инструмент Google Trends, Вы также сможете выявить лидирующие тренды.
Сравнение популярности запросов
С помощью инструментария сервиса можно провести сравнительную аналитику востребованности разных словосочетаний (до 5 одновременно). Этим способом можно сопоставить товары-субституты и аналоги, конкурирующие организации и торговые марки за определённый временной промежуток с территориальной привязкой и выбором категорий. В поле запроса фильтрация настраивается быстро и просто:
География спроса
Анализировать данные можно в нескольких срезах: по странам, регионам и даже районам одного населённого пункта. Этот функционал полезен как крупным компаниям, рассматривающим в качестве одной из своих основных стратегий возможность территориальной экспансии, так и для небольших организаций, рынок сбыта которых располагается в границах одного географического положения:
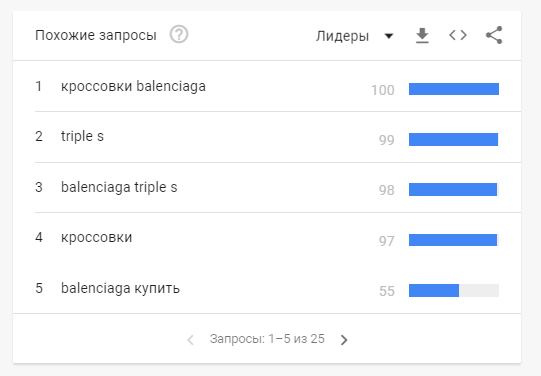
Похожие запросы пользователей
В Google Trends можно получить информацию о похожих или смежных ключевых словах, разных вариантах написания определённых фраз для качественного формирования семантического ядра в SEO-продвижении:
Перечень альтернативных формулировок, которые используются для поиска бренда или товара, появляется при переключении параметра «В тренде» на «Лидеры».
Популярные запросы за год
«Год в поиске» — функционал, с помощью которого можно отследить наиболее востребованные запросы по каждом году, начиная с 2001. Этот инструмент интересен тем, кто ищет новые идеи для маркетинговых кампаний и анализирует изменения пользовательских предпочтений:
Выборка самых популярных тем отображается на отдельной странице и сопровождается рядом видеороликов, повествующих о важнейших медийных событиях периода.
Поисковые операторы
Для удобства использования в Google Trends можно добавлять к запросу операторы поиска. Система поддерживает:
- «+» — с помощью плюса можно узнать популярность сразу нескольких поисковых запросов. Особенно актуально, когда пользователь может вводить ключевое слово на различных языках или в разных словоформах. Например, «Facebook + Фейсбук + FB».
- «-» — позволяет исключить из результатов запрос, который расположен после знака минус. Например, требуется получить статистику популярности Samsung Galaxy по всей Украине, исключая Киев. Тогда запрос должен выглядеть так «Samsung Galaxy — Киев».
- «“”» — с помощью кавычек можно зафиксировать порядок слов в запросе и словоформу (по аналогии с фразовым соответствием в Google Ads). Однако, для не слишком популярных ключевых слов Гугл Тренды могут отдавать результат «недостаточно данных» в случае применения кавычек.
 Тогда запрос должен выглядеть так «Samsung Galaxy — Киев».
Тогда запрос должен выглядеть так «Samsung Galaxy — Киев».Руководство по использованию Google Trends с примерами
На коротких примерах покажем, как можно использовать сервис Google Trends для оценки поисковых запросов.
Как определить сезонность спроса?
В модуле «Анализ» вводим словосочетание «солнцезащитные очки» для региона «Украина» и задаём границы анализируемого временного интервала. На появившемся графике невооружённым глазом видно, что спрос достигает своего максимума в мае-июне. Разумно предположить, что наиболее эффективными будут вложения в рекламу в самые популярные месяцы. Это явление необходимо принимать в расчёт SEO-специалистам и администраторам онлайн-магазинов при составлении графика работ по оптимизации веб-ресурса, а также PPC-специалистам для вычисления даты начала рекламной кампании:
Узнайте спрос в определенном регионе
Проанализируем распределение популярности запроса по региональному признаку. Этот инструмент позволяет проводить более комплексную сравнительную фильтрацию на уровне нескольких стран одновременно, а также по субрегионам и городам. Чтобы увидеть степень заинтересованности по определённому субъекту, наведите курсор на соответствующую область карты:
Этот инструмент позволяет проводить более комплексную сравнительную фильтрацию на уровне нескольких стран одновременно, а также по субрегионам и городам. Чтобы увидеть степень заинтересованности по определённому субъекту, наведите курсор на соответствующую область карты:
Как найти похожие запросы?
Аналитический инструмент с широким функционалом в Google Trends позволяет задавать таргетинг по интересам при настройке рекламы. Информация представлена в виде кластеров, которые включают в себя данные о том, чем ещё интересуются пользователи, осуществлявшие поиск определённого товара или услуги. Перечень похожих ключевых фраз может стать базой для наполнения семантического ядра.
Информация! При росте популярности запроса, превышающем 5000 %, вместо числового значения показателя высвечивается пометка «Сверхпопулярность».
Использовать ключевые слова на стадии роста их популярности для SEO-оптимизации и в рекламе — рациональное решение, которое позволяет монетизировать тренд.
Узнайте своих конкурентов
Статистика связанных тем и похожих запросов помогает оценить конкурентов, интересных Вашим потенциальным покупателям. Используя эту информацию, Вы сможете выделить свои сильные стороны на страницах сайта.
Определите частотность ключевых слов
Ещё одно применение инструментария Google Trends для целей поисковой оптимизации и при составлении семантического ядра. Среди нескольких слов-синонимов можно выбрать наиболее популярное используя показатель его частотности:
Выберите самый востребованный товар в нише
Для решения данной задачи используется тот же функционал сравнения, что и в предыдущем варианте. Инструмент даёт возможность тратить маркетинговый бюджет рационально, сделав упор на наиболее востребованный продукт. В качестве примера рассмотрим частотность запросов, связанных с разными типами спортивных тренажеров:
Очевидно, что лидирует беговая дорожка, поэтому именно на неё должна быть распределена большая часть рекламного бюджета.
Спрогнозируйте популярность видеоролика на YouTube
С помощью Google Trends Вы сможете оценить, какие темы для видео являются наиболее востребованными за последнее время на Ютубе.
В поисковой выдаче всё чаще демонстрируется видеоконтент. Он представляет собой расширенный сниппет над результатами поиска. Правильно подобранная тематика и оптимизация видео может увеличить трафик не только с видео-хостинга YouTube, но также из органической выдачи.
Найдите популярную тему для статьи или видео
В некоторых источниках, описывающих, как пользоваться Google Trends, этот инструмент упоминается только в связи с частным использования блогерами, отслеживающими темы, на которых можно сделать хайп.
Но для качественного SMM-продвижения также необходима информация о сенсациях и событиях, имеющих отношение к медийным персонам. Таким образом можно привлечь внимание своей аудитории, опубликовав пост на актуальную тему.
Как узнать точное количество запросов в гугл
Google Trends: сервис, который помогает маркетологам ориентироваться в быстро меняющейся обстановке
Рынок очень непостоянен, и маркетологам зачастую трудно следить за тем, как меняются потребности потенциальных клиентов. Сайт Google Trends позволяет узнать, какие темы в данный момент вызывают интерес у пользователей, а какие – нет. Например, в марте 2020 года в США буквально за несколько дней стал очень популярен запрос «virtual birthday party ideas» (как провести виртуальный день рождения). Благодаря таким данным вы будете в курсе, что сейчас интересует целевую аудиторию, и сможете скорректировать рекламные кампании в соответствии с ожиданиями потребителей. Из этой статьи вы узнаете, как находить в сервисе Google Trends статистику, которая поможет обеспечить стабильность вашего бизнеса в этот трудный период и предлагать клиентам именно то, что им нужно.
Сайт Google Trends позволяет узнать, какие темы в данный момент вызывают интерес у пользователей, а какие – нет. Например, в марте 2020 года в США буквально за несколько дней стал очень популярен запрос «virtual birthday party ideas» (как провести виртуальный день рождения). Благодаря таким данным вы будете в курсе, что сейчас интересует целевую аудиторию, и сможете скорректировать рекламные кампании в соответствии с ожиданиями потребителей. Из этой статьи вы узнаете, как находить в сервисе Google Trends статистику, которая поможет обеспечить стабильность вашего бизнеса в этот трудный период и предлагать клиентам именно то, что им нужно.
Моментально узнавайте о том, какие поисковые запросы сейчас популярны
Просматривайте страницы сайта Google Trends с подборками статистики по определенным темам, например по поисковым запросам о коронавирусе, чтобы быть в курсе последних тенденций.
Анализируйте статистику на важные для вас темы
Помимо тематических подборок на главной странице, вы можете изучать статистику практически на любые темы. При поиске в Google Trends можно посмотреть график изменений популярности запроса с течением времени. Наведите курсор на график, чтобы увидеть число, характеризующее, как часто выполнялся поиск по этому запросу относительно всех запросов в Google.
При поиске в Google Trends можно посмотреть график изменений популярности запроса с течением времени. Наведите курсор на график, чтобы увидеть число, характеризующее, как часто выполнялся поиск по этому запросу относительно всех запросов в Google.
- Сравнение поисковых запросов. Чтобы добавить поисковый запрос для сравнения, нажмите «+ Сравнить» и введите текст запроса.
Если выбрать в раскрывающемся меню вариант «В тренде», то появятся похожие запросы с наибольшим ростом популярности за выбранный период. Для каждого запроса будет указан процент роста популярности по сравнению с предыдущим периодом. Если термин стал популярнее более чем на 5000 %, то вместо числа вы увидите надпись «Сверхпопулярность».
Просматривайте статистику по разным странам
- Поиск с учетом географического местоположения. Если у вас международная компания, вы можете просматривать статистику по разным странам, выбирая их в раскрывающемся меню слева над графиком. Так вы узнаете, как различается интерес пользователей из разных стран к определенной теме. Это поможет оптимизировать вашу рекламную стратегию и адаптировать маркетинговые материалы для соответствующих рынков.
 Так вы узнаете, как различается интерес пользователей из разных стран к определенной теме. Это поможет оптимизировать вашу рекламную стратегию и адаптировать маркетинговые материалы для соответствующих рынков.
Так вы узнаете, как различается интерес пользователей из разных стран к определенной теме. Это поможет оптимизировать вашу рекламную стратегию и адаптировать маркетинговые материалы для соответствующих рынков.Если навести курсор на область карты, появится окно со сравнительной статистикой количества запросов для этого региона. Справа от карты приводится список регионов или городов, в которых поисковый запрос наиболее популярен. Для некоторых стран также приводится статистика по агломерациям.
Выполняйте детальный анализ
- Фильтрация по разным сервисам Google. Вы можете анализировать популярность поисковых запросов конкретно в Google Поиске, Поиске картинок, Поиске новостей, Покупках и YouTube.
- Если указать ключевые слова без пунктуации, то появятся результаты, содержащие все ключевые слова в любом порядке, а также любые другие слова. Например, по запросу «список продуктов» (без кавычек) появятся результаты «список продуктов для карантина», «коронавирус список продуктов», «список продуктов для магазинов» и т. д. Варианты с опечатками, словоформами и синонимами представлены не будут.
- Если заключить ключевые слова в кавычки, появятся результаты, содержащие ключевую фразу в точности, но до или после нее могут быть другие слова. Например, по запросу «список продуктов» (с кавычками) может быть показан результат «список продуктов самое важное».
- По запросу «еда + рецепты» (без кавычек) будут показаны результаты, содержащие хотя бы одно из этих слов.
- С помощью запроса «йогурт + ёгурт + егурт» (без кавычек) можно охватить типичные ошибочные формы написания этого слова.
- По запросу «завтрак — контейнер» (без кавычек) будут появляться результаты, в которых есть слово «завтрак», но нет слова «контейнер». Так вы можете исключить поисковые фразы, которые популярны, но не имеют отношения к вашему бизнесу (в нашем примере – «контейнеры для завтраков»).
 д. Варианты с опечатками, словоформами и синонимами представлены не будут.
д. Варианты с опечатками, словоформами и синонимами представлены не будут.- Фильтрация результатов по категориям. При поиске слова, имеющего несколько значений, вы можете отфильтровать результаты, указав подходящую категорию.

Автоматизируйте поиск
Чтобы экономить свое время, подпишитесь на уведомления от Google Trends. Вы будете автоматически получать по электронной почте статистику популярных поисковых запросов и тем в вашем регионе.
Как узнать частоту ключевого запроса в Яндекс и Google
164
Эта статья рассчитана на новичков в SEO, а также на владельцев сайтов, которые выбрали себе запросы для продвижения, но не знают, частотные ли это запросы.
Частотность запроса — это количество запросов или фраз, набранных пользователем в поисковой системе в определённый промежуток времени. Способы определения частотности запроса в поисковых системах отличаются. В этой статье мы рассмотрим частотность запросов в самых популярных поисковых системах — в Google и Яндексе.
Из этой статьи мы узнаем следующее:
1. Как определять частотность запросов в Яндексе
1.1. Сервис подбора слов в Яндексе
Для определения частоты запросов в Яндексе есть простой и удобный «Сервис подбора слов в Яндексе» или, как его ещё называют, Яндекс Wordstat..png)
Вбивая запрос в строку подбора, мы получаем следующую картину:
Мы видим, что по запросу [пластиковые окна] было 1 006 660 показов в месяц — это и есть его частота. То, что находится ниже, — это «Статистика по запросу» + «Словосочетания с этим запросом, которые также искали люди». Эти данные необходимы при сборе семантического ядра. Об этом есть статья в нашем блоге «Семантическое ядро: как правильно подобрать ключевые фразы для продвижения сайта».
Примечательно, что сейчас мы видим общую картину по показам в месяц, но можно посмотреть частоту запроса отдельно по виду устройств (планшеты, мобильные телефоны, компьютеры), с которых пользователи искали запрос.
Так, мы видим, что 269 733 показа от общего количества пришлись на телефоны.
1.2. Виды частотности в Яндексе
Итак, мы узнали, что у запроса [пластиковые окна] было 1 006 660 показов в месяц — это будет базовая частота запроса.
Всего в Яндекс Wordstat выделяют три вида частоты:
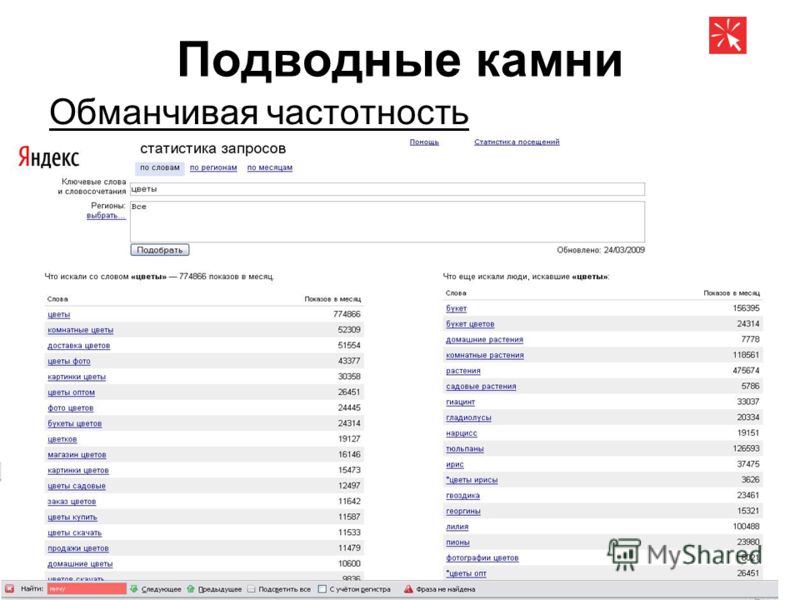
- Базовая частота — обозначает число показов по всем запросам с нужным ключевым запросом. В нашем случае это запрос [пластиковые окна]. При сборе базовой частоты по этому запросу были учтены все возможные словоформы, а также варианты запросов [купить пластиковые окна], [цены на пластиковые окна] и т. д.
- Фразовая частота — для её определения нужно взять запрос в кавычки. Это позволит нам узнать частоту запроса по интересующей нас фразе.
 В нашем случае это запрос [пластиковые окна]. При сборе базовой частоты по этому запросу были учтены все возможные словоформы, а также варианты запросов [купить пластиковые окна], [цены на пластиковые окна] и т. д.
В нашем случае это запрос [пластиковые окна]. При сборе базовой частоты по этому запросу были учтены все возможные словоформы, а также варианты запросов [купить пластиковые окна], [цены на пластиковые окна] и т. д.Как видно по скриншоту, фразовая частота значительно ниже базовой, так как во фразовой частоте могут учитываться словоформы, падежи, разные окончания, но игнорируются добавочные слова (например, запрос [купить пластиковые окна] при сборе фразовой частоты не учитывается).
- Точная частота — для её определения нужно взять запрос в кавычки и перед каждым словом в запросе поставить восклицательный знак.
В таком виде мы узнаем количество показов в месяц конкретно по этому запросу.
1.3. Геозависимость
Помимо различной частоты запроса, мы можем узнать частоту по запросам в разных регионах. Для этого нужно вместо пункта «По словам» отметить пункт «По регионам».
Для этого нужно вместо пункта «По словам» отметить пункт «По регионам».
На скриншоте видно общее число запросов, а также их количество конкретно по регионам. К примеру, в регионе «Москва» 13 847 показов, региональная популярность составляет 206%.
Что такое региональная популярность? Ответ Яндекса:
«Региональная популярность» — это доля, которую занимает регион в показах по данному слову, делённая на долю всех показов результатов поиска, пришедшихся на этот регион. Популярность слова/словосочетания, равная 100%, означает, что данное слово в данном регионе ничем не выделено. Если популярность более 100%, это означает, что в данном регионе существует повышенный интерес к этому слову, если меньше 100% — пониженный. Для любителей статистики можем заметить, что региональная популярность – это affinity index.
Также можно задать регион при сборе частоты. По умолчанию установлен сбор по всем регионам.
Таким образом, при поиске точной частоты запроса по конкретному региону можно узнать, какое количество людей ищут интересующий вас запрос в указанном регионе.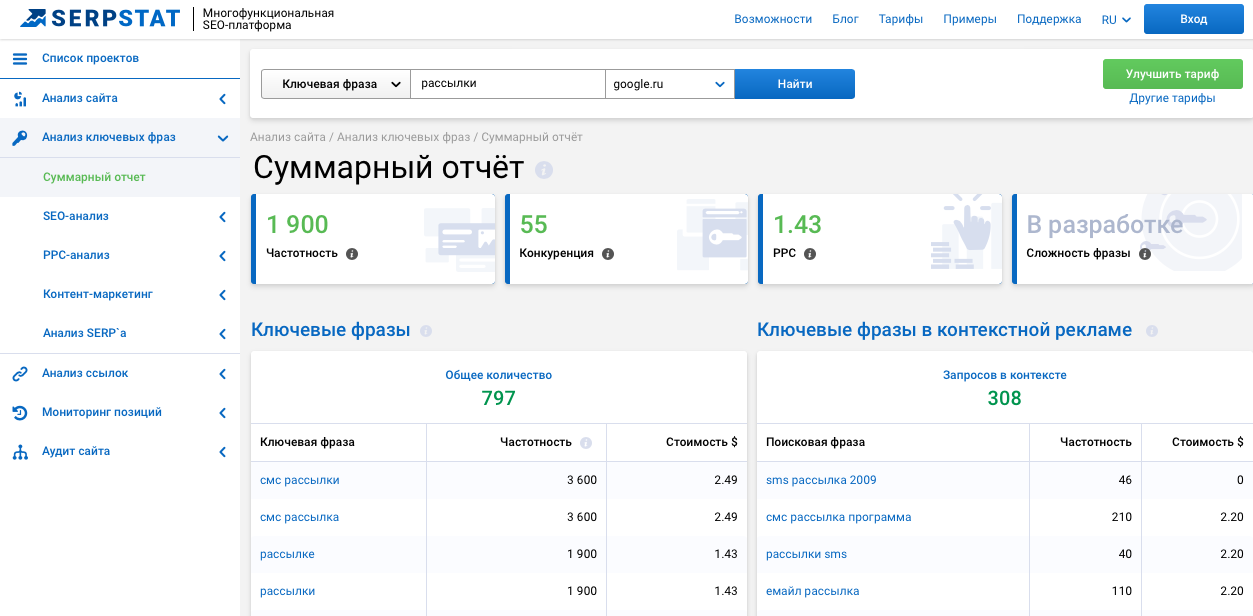
1.4. Как определить сезонность запроса
В Яндекс Wordstat есть ещё одна интересующая нас функция. Для её использования нужно отметить пункт «История запросов».
Таким образом, мы видим, какой была частота запроса по месяцам в разные периоды. С помощью этой информации можно примерно спрогнозировать падения/подъёмы трафика на сайте.
1.5. Плагины для удобства пользования сервисом
Сервис Wordstat полезный, но не очень удобный, поэтому для того чтобы облегчить себе жизнь, при работе с ним я использую плагин Yandex Wordstat Assistant.
Вот так он выглядит в окне Вордстата:
Первое, что бросается в глаза, — это плюсы около запросов. Нажимая на них, мы добавляем запросы в колонку слева:
Это очень удобно, так как обычно нужно выделять каждый запрос и его частоту, чтобы его скопировать. Более того, можно спокойно переключаться на другие запросы, и список запросов, добавленных в колонку, сохранится.
Также этот плагин позволяет сортировать запросы прямо в колонке по частоте или алфавиту, а после — копировать эти запросы с частотой в нужный вам документ. Рекомендую использовать плагин для браузера Chrome, так как там более свежая версия, которая постоянно обновляется. Для FireFox тоже есть плагин, но он не обновлялся с апреля 2015 года, так что не все функции работают корректно.
2. Как определять частотность запросов в Google?
Если с Яндексом всё относительно просто, то узнать частоту запроса в Google будет сложнее. У Google нет сервиса вроде Яндекс Wordstat, поэтому приходится использовать сервис контекстной рекламы Google AdWords. Вам нужно будет зарегистрироваться в нём. После регистрации перед вами появится панель.
Откройте вкладку меню «Инструменты» и в выпавшем меню найдите «Планировщик ключевых слов».
После этого откроется страница планировщика. На этой странице нужно выбрать «Получение статистики запросов и трендов». Там вбейте интересующий вас запрос и укажите регион.
Нажмите на кнопку «Узнать количество запросов». Вы получите такой результат:
Из-за ограничений AdWords у запроса среднее число запросов в месяц колеблется от 1000 до 10 000. Чтобы получить более подробную информацию, нужно создать и запустить кампанию.
При запущенной платной кампании частота запроса будет выглядеть следующим образом:
3. Программный сбор частоты запросов
Выше были описаны способы ручного сбора частоты запросов. При большом количестве запросов собирать их частоту вручную очень неудобно, поэтому я использую специальные программы.
3.1. Программа «Словоёб»
В статье в нашем блоге «Два подхода к подбору семантического ядра» подробно описано, как с помощью «Словоёба» парсить ключевые слова (скачать его можно бесплатно с сайта). Но программа будет полезна и в том случае, если у вас уже есть запросы и вам нужно только собрать частоту.
Обратите внимание: программа парсит данные из Яндекс Wordstat, следовательно, частоту запросов можно узнать только по Яндексу.
Чтобы собрать частоту по определённому списку запросов, нужно сделать следующее:
- Добавить запросы в программу, вызвать контекстное меню в окне программы и выбрать функцию «Добавить фразы»;
- В появившемся окне вставить списком запросы и нажать «Добавить в таблицу»;
- Указать «Регион» и в верхнем меню выбрать вид частоты.
Как я уже говорил выше, программа парсит Яндекс Wordstat, так что в настройках меню Yandex. Direct нужно будет добавить любой аккаунт Яндекса. Также в настройках можно указать ключ для Антикапчи. Настроек немного, так что разобраться несложно. Программа бесплатная, потому воспользоваться ею может любой желающий.
3.2. Программа Key Collector
Ещё одна программа, которую я хочу упомянуть, — это знаменитый Key Collector. Этой программой я пользуюсь регулярно и рекомендую всем, кто связан с SEO и постоянно работает с запросами.
Чтобы собрать частоту, нужно для начала настроить программу. О настройке программы Key Collector написано в статье «Как составить ТЗ копирайтеру, чтобы статья попала в ТОП без ссылок?».
О настройке программы Key Collector написано в статье «Как составить ТЗ копирайтеру, чтобы статья попала в ТОП без ссылок?».
После настройки программы нужно запустить её и так же, как и в случае со «Словоёбом», добавить запросы, указать «Регион» и нажать на «Сбор статистики Yandex. Direct».
Key Collector, в отличие от «Словоёба», парсит данные, используя Яндекс. Директ, что значительно ускоряет процесс парсинга. Жмём «Получить данные» и получаем результат:
Программа позволяет собирать частоту и для Google, используя Google AdWords. Для этого нужно её настроить. Настройки можно посмотреть на официальном сайте Key Collector. Затем нужно будет нажать на кнопку «Сбор статистики Google. Adwords», которая находится рядом с кнопкой «Сбор статистики Yandex.Direct».
4. Онлайн-сбор частоты запросов
Иногда бывают ситуации, когда любимого инструмента нет под рукой, а частоту собрать нужно. В этом случае можно воспользоваться онлайн-сервисами для сбора частоты.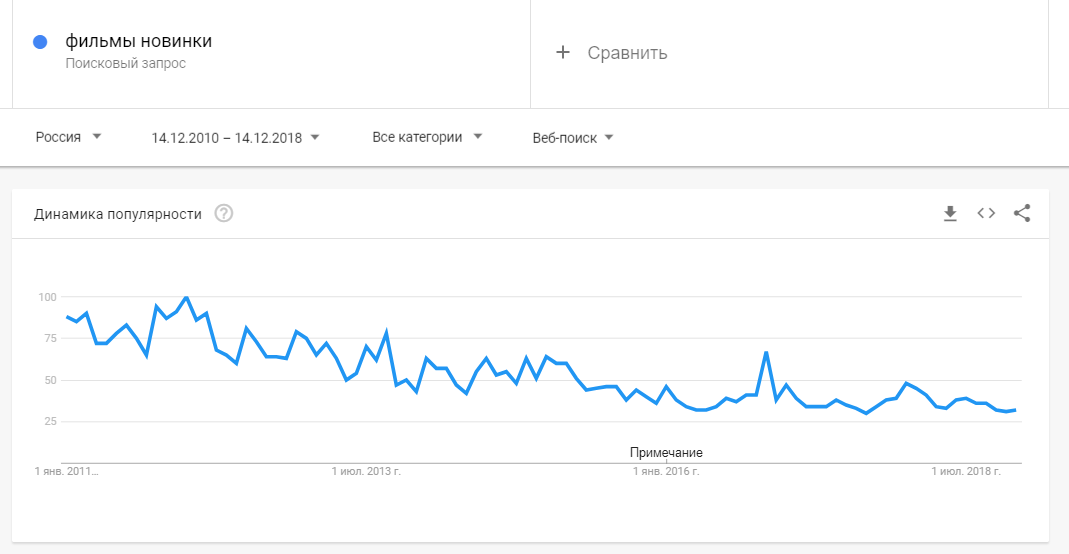 Я рассмотрю 2 сервиса, которые использую сам. Один будет под Яндекс, другой — под Google.
Я рассмотрю 2 сервиса, которые использую сам. Один будет под Яндекс, другой — под Google.
4.1. Онлайн-инструмент для сбора частоты от SeoLib для Яндекса
У сервиса SeoLib есть множество удобных инструментов. Один из таких инструментов — «Подбор ключевых слов».
Всё, что нужно сделать, — это открыть вкладку «Анализ ключевых фраз» и скопировать в форму для запросов или прикрепить отдельным файлом список интересующих запросов. После этого нужно выбрать необходимую частоту и регион, при необходимости указать дополнительные параметры. После нажать на «Начать анализ».
Инструмент платный, но цены демократичные. К примеру, список из этих 7 запросов по всем видам частотности обошёлся мне в 5,3 рубля.
4.2. Онлайн-инструмент для сбора частоты от Ahrefs для Google
Сервис Ahrefs популярен тем, что через него удобно анализировать ссылочную массу сайта. В нашем блоге сервису посвящена отдельная статья «Как проанализировать ссылочную массу сайта с помощью Ahrefs».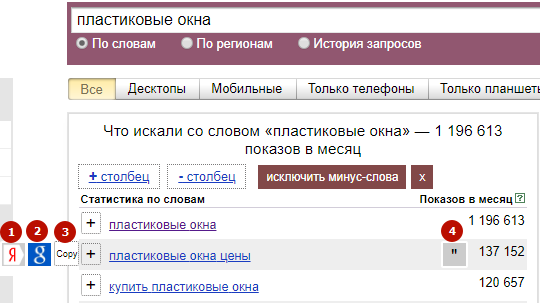
В сервисе есть инструмент «Анализ ключевых слов».
В форму нужно через запятую добавить ключевые слова и указать регион около кнопки «Пояса».
Переходим во вкладку «Метрики»:
Отчёты содержат большое количество полезной информации для анализа. Сервис платный, но есть 2 недели пробного доступа для знакомства с функционалом.
Итоги
Работа с Яндексом:
- Если запросов несколько, можно смотреть их вручную через Яндекс Wordstat. В таком случае я настоятельно рекомендую поставить плагин Yandex Wordstat Assistant — он заметно облегчает процесс;
- Если у вас есть список запросов и вам необходима быстрая разовая проверка, используйте онлайн-инструмент «Подбора ключевых слов» от SeoLib;
- Если вы постоянно работаете с запросами, рекомендую купить Key Collector. «Словоёб» хоть и бесплатный, но парсит слишком медленно, а время, которое вы сэкономите на парсинге запросов в Key Collector, с лихвой отобьёт затраты. «Словоёб» можно использовать, если вы работаете с небольшим списком запросов и пользуетесь им нечасто. Я сам им пользовался, когда начинал работу в SEO, но когда приобрёл Key Collector, пожалел, что не купил его раньше.
 «Словоёб» можно использовать, если вы работаете с небольшим списком запросов и пользуетесь им нечасто. Я сам им пользовался, когда начинал работу в SEO, но когда приобрёл Key Collector, пожалел, что не купил его раньше.
«Словоёб» можно использовать, если вы работаете с небольшим списком запросов и пользуетесь им нечасто. Я сам им пользовался, когда начинал работу в SEO, но когда приобрёл Key Collector, пожалел, что не купил его раньше.Работа с Google:
- Если запросов несколько, используйте Google AdWords;
- Если у вас есть список запросов, то удобнее будет воспользоваться онлайн-сервисом Ahrefs или настроить Key Collector.
Я перечислил сервисы, которые сам использую для сбора частоты запросов. Возможно, вы пользуетесь другими сервисами? Тогда укажите их в комментариях, буду рад ознакомиться с ними!
На этом пока всё, желаю вам хороших позиций по частотным запросам!
Всегда знал, что моя работа будет связана с интернетом и компьютером. Начал самостоятельно учить HTML и пробовать себя в верстке. HTML давался легко, но верстать сайты было скучно. Тогда я и узнал о SEO.
С отличием завершил мастер-класс по обучению и управлению персоналом.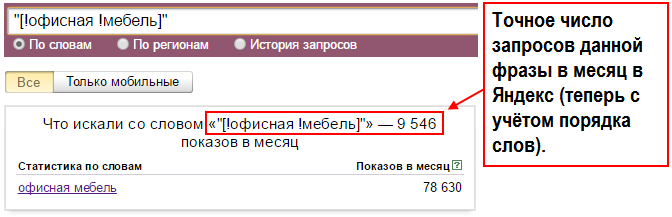 Сдал письменный тест по английскому языку в Лондонской школе на 98%. Написал более десятка развивающих статей по SEО.
Сдал письменный тест по английскому языку в Лондонской школе на 98%. Написал более десятка развивающих статей по SEО.
Работаю SEO-специалистом в компании SiteClinic, пишу статьи для блога. В свободное время хожу в походы.
Как узнать точное количество запросов в гугл
В этой статье мы расскажем, как вам узнать количество поисковых запросов в Google, чтобы правильно запустить рекламную кампанию в Google Ads.
В частности, речь пойдет про ТОП-7 самых распространенных и популярных способов, которые должен знать каждый арбитражник.
Статистика поисковых запросов Google доступна в инструментах поисковой системы и сторонних сервисах.
С их помощью можно собрать или расширить семантическое ядро, провести анализ популярности ключевых фраз в конкретном регионе, а также создать эффективную рекламную кампанию с учетом стоимости клика.
Как узнать частотность запроса в Serpstat
С помощью инструментов Serpstat можно собрать ключевые слова для семантического ядра сайта, узнать уровень конкуренции ключевых фраз в контекстной рекламе, а также быстро определить их частотность в поисковой выдаче и расставить приоритеты уже на этапе сбора ключевых фраз.
Статистика запросов Google Ads
Для начала работы с ключевыми запросами необходимо зарегистрировать рекламную кампанию в Google Ads.
Этот процесс происходит в несколько этапов.
После введения личных данных требуется написать название рекламного объявления, его примерный текст, указать информацию о компании.
Запускать и оплачивать рекламу не обязательно, использовать Планировщик ключевых запросов можно на бесплатной основе.
Но при неоплаченной рекламной кампании сервис показывает неточные данные.
Чтобы запустить планировщик, зайдите в Google Рекламу и найдите в инструментах соответствующий раздел.
Допустим, необходимо собрать базу запросов на тему «доставка цветов».
Нужно перейти в раздел новых ключевых слов и ввести искомую фразу в первое поле.
Разрешается вводить сразу несколько словосочетаний для подбора более обширного списка.
Вот что получается в итоге.
Первыми указаны фразы, которые были введены в предыдущем окне.
Дальше подобраны варианты запросов, которые дополнительно ищут пользователи.
В левой части окна доступны базовые функции для работы с подобранными запросами.
Справа сверху можно установить временной период и настроить фильтры.
В таблице справа от ключевых фраз описан диапазон показов, минимальная и максимальная стоимость клика.
Через планировщик Google невозможно узнать точное количество показов, но можно оценить уровень конкуренции.
Принимая во внимание эти факторы, интернет-маркетолог делает выводы о целесообразности создания контекстной рекламы по определенному запросу.
Если в аккаунте не подключена рекламная кампания, в выдаче отобразятся фразы из органического поиска и контекста.
Для получения более точных сведений из поисковой системы необходимо подключить свою рекламную кампанию.
Google Trends
Google Trends не показывает частотность запросов в абсолютном значении, но отображает динамику роста и падения популярности конкретного запроса.
Это хорошо заметно по кривой изменения спроса на шубы.
Уже с начала осени кривая заметно ползет вверх.
В этом инструменте можно уточнить данные, указав геолокацию, диапазон времени, категории и источники поиска.
Выставить нужные параметры можно над окном с графиком.
Из приведенного примера следует вывод, что запускать рекламную кампанию можно уже в сентябре.
Статистика ключевых слов Google Analytics
С помощью этого инструмента можно проследить, какие источники трафика дают максимальную конверсию, а также отследить действия посетителей сайта.
Собрать ключевые фразы через Analytics не удастся.
Через этот сервис можно проследить целесообразность их использования, чтобы сделать выводы о потребности расширения или изменения семантического ядра.
Он показывает набор данных из Google Search Console.
Slovoeb
Бесплатный парсер Slovoeb показывает количество запросов Google, разделяет их по регионам, частотности, конкуренции, сезонности. Инструмент выдает подсказки поисковых фраз для сбора максимального количества запросов смежных тематик.
Инструмент выдает подсказки поисковых фраз для сбора максимального количества запросов смежных тематик.
Key Сollector
Платная программа для сбора и анализа ключевых запросов — Key Collector, помогает собрать максимум данных по ключевым фразам.
Она определяет позиции, конкурентность, цену одного клика, частотность, показывает релевантность страниц и дает советы относительно перелинковки страниц сайта.
Keyword Tool
Еще один бесплатный инструмент для сбора семантического ядра — Keyword Tool.
Он подбирает до 800 запросов к одной прописанной ключевой фразе и выдает поисковые подсказки.
Однако для того, чтобы увидеть частотность найденных ключевых слов, придется купить платную версию (от $69 в месяц).
Выводы
Для сбора и анализа ключевых запросов можно использовать разные инструменты, такие как Google Ads, Analytics, Trends и другие.
Все это позволит вам более детально проанализировать поисковые запросы по выбранному вами офферу для правильного и прибыльного запуска вашей рекламной кампании.
Оставайтесь с нами, и вы всегда будете в курсе самых актуальных возможностей для заработка на арбитраже трафика!
Google.Ads – Key Collector
Программа поддерживает работу с сервисом Google.Ads. Данные извлекаются из раздела планировщика ключевых слов.
- Пакетный сбор фраз
- Сбор статистики
- Сбор истории частот
- Устранение неполадок
Настройка сбора и требования к аккаунтам
Для доступа к планировщику, как правило, требуется наличие в аккаунте хотя бы 1 рекламной кампании (активной или приостановленной).
Если после создания аккаунта Google.Ads система не пускает дальше шага создания новой кампании, не позволяет пропустить этот шаг, то собирать данные не получится до тех пор, пока кампания не будет создана.
В зависимости от рекламных расходов в аккаунте система будет выдавать в ответе либо точные данные статистики (показы), либо приближенные значения в диапазонах с кратными 10 границами: 10-100, 100-1000, 1000-10 000 и т.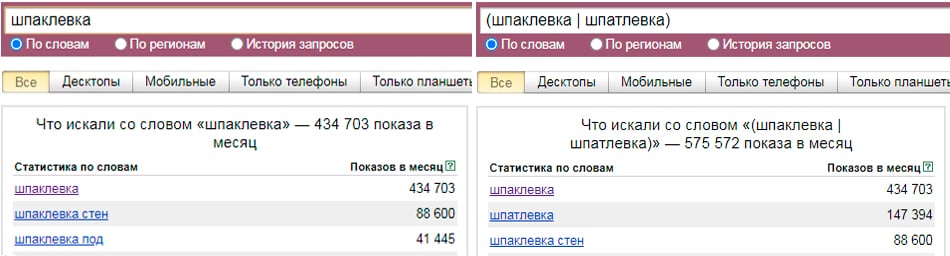 д. Также аккаунты без расходов не имеют доступа к историческим данным (график популярности запросов).
д. Также аккаунты без расходов не имеют доступа к историческим данным (график популярности запросов).
В отчете (выгрузке), которую скачивает и исследует программа, эти диапазоны усредняются, и в ответе получается 50, 500, 5 000 и т.д.
Таким образом, если вы хотите получать более точные значения, вы должны выполнять предъявляемые Google.Ads требования в части рекламных расходов. Сумма расходов рассчитывается индивидуально, мы на нее никак не влияем.
Для работы программы необходимо указать учетную запись в настройках. Пожалуйста, изучите описание настроек, чтобы узнать об ограничениях и поддерживаемых типах аккаунтов.
Пакетный сбор фраз
Пакетный сбор позволяет собрать новые фразы по списку запросов или URL.
Сбор выполняется из планировщика ключевых слов. В процессе сбора в таблицу записываются фразы вместе со статистикой.
По непопулярным запросам, а также по запросам некоторых тематик может не быть выдачи, поэтому если в журнале событий вы не наблюдаете ошибок, настройки не ограничивают добавлений фраз, а результатов нет, то можно проверить любой из проблемных запросов вручную через браузер, чтобы убедиться, что проблема не на стороне программы.
Вы можете вводить ключевые запросы в текстовом виде или URL. При введении текстового запроса программа получает выдачу со вкладки «Ввести свои варианты ключевых слов» (1), а при введении URL — со вкладки «Указать сайт» (2). При этом при введении http://site.com данные будут снимать в режиме всего сайта, а при введении «http://site.com» (в кавычках) — в режиме отдельной страницы.
Инструмент поддерживает стандартные функции окна пакетного сбора фраз.
Выдача по запросу не всегда содержит исходный запрос. Включите опцию принудительного добавления запросов, если хотите добавлять в выдачу исходный запрос.
Параметры сбораМестоположение
Вы можете задать таргетинг.
В процессе сбора данных программа введет в поле поиска локации указанное значение и выберет первый вариант в выпадающем списке найденных совпадений.Если нужного региона в списке нет, введите регион без ошибок вручную.
Как правило, для максимального охвата выдачи рекомендуется не использовать настройки региональности. Выбор региона может потребоваться при оценке нишевого спроса в каком-либо регионе.
При введении некоторых регионов, особенно зарубежных, на первом месте может оказаться не та локация, которая вас интересует. Например, при введении «Нью-Йорк» будет найден штат Нью-Йорк, а для поиска города Нью-Йорк нужно ввести «Нью-Йорк, Нью-Йорк» (см. скриншот).
Выбор каждого указанного региона в процессе сбора данных занимает время! Старайтесь не указывать регионы без необходимости, рассмотрите использование опции «Не менять настройки аккаунта».
Опция «Не менять настройки аккаунта» позволяет пропустить этап выбора региона и сокращает время обработки запросов.
Однако, сам Google.Ads может сбрасывать последнее выбранное в аккаунте местоположение на регион по умолчанию. Будьте внимательны.Период
Программа может собирать статистику за различные периоды. Вы можете указать предпочтительный источник данных.
Смена периода со стандартного занимает дополнительное время при обработке запросов. Включите опцию «Не менять настройки аккаунта», если хотите сократить время сбора информации.
Язык запросов
Вы можете указать предпочтительный язык запросов в отчете. Это напрямую скажется на составе и количестве выдачи по запросу.
Смена языка со стандартного занимает дополнительное время при обработке запросов. Включите опцию «Не менять настройки аккаунта», если хотите сократить время сбора информации.
Настройки фильтрации
Здесь вы можете указать дополнительные фильтры, которые будут применены при сборе запросов.
Использование каждого из фильтров занимает время при обработке запросов, поэтому старайтесь не использовать условия без необходимости.
Собирать только тесно связанные запросыИногда выдача по запросу содержит побочные запросы и запросы из смежных тематик. Использование этой опции уточняет результаты, одновременно с этим уменьшая количество запросов в выдаче.
Например, при поиске резиновых ковров в машину могут быть предложены держатели для телефонов.
Исключить варианты для взрослыхИспользование этой опции убирать из выдачи результаты с возрастными ограничениями (для взрослых).
Использовать автофильтр по тексту фразПри активации опции программа будет замыкать выдачу на исследуемый запрос, добавляя текстовый фильтр «содержит» с текстом самого запроса в качестве условия.
Опция является альтернативной режиму «Собирать только тесно связанные запросы», сильно сокращает выдачу по запросам, занимает время. Используйте с осторожностью.
Уровень конкуренцииЕсли вы не хотите ограничить выдачу определенным уровнем конкуренции (хотите получить все варианты), то не включайте данный фильтр в принципе.
 В процессе сбора данных программа введет в поле поиска локации указанное значение и выберет первый вариант в выпадающем списке найденных совпадений.
В процессе сбора данных программа введет в поле поиска локации указанное значение и выберет первый вариант в выпадающем списке найденных совпадений.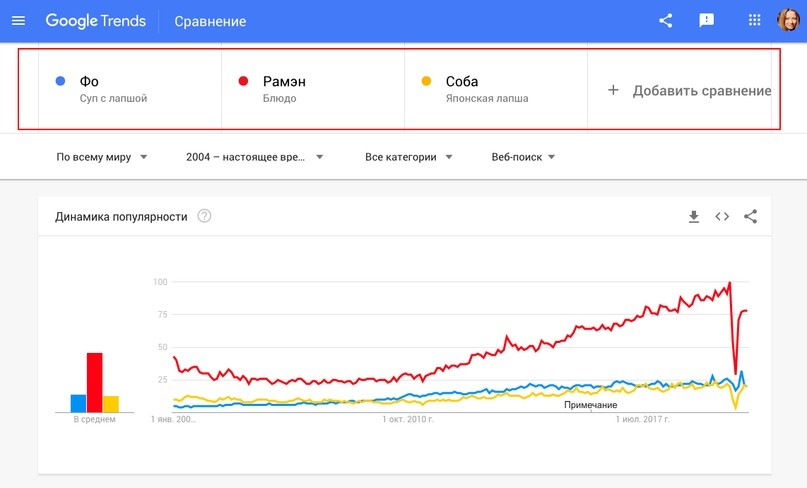 Однако, сам Google.Ads может сбрасывать последнее выбранное в аккаунте местоположение на регион по умолчанию. Будьте внимательны.
Однако, сам Google.Ads может сбрасывать последнее выбранное в аккаунте местоположение на регион по умолчанию. Будьте внимательны.

Записывать {доп. значение} для добавляемых фраз и их расширений
В процессе сбора фраз вы можете использовать разные или общие целевые группы для добавления результатов.
Программа позволяет указать произвольное дополнительное значение, которое будет добавляться в указанную текстовую колонку для всех результатов, относящихся к тому или иному запросу.
Например, в качестве доп.
значения можно указать сам исходный запрос или страницу сайта. В дальнейшем по этому значению можно выполнить поиск, сортировку и фильтрацию, определять, откуда пришел запрос и т.п.- газовая сварка {газовая сварка}
- рецепт соленых огурцов {https://ru.wikipedia.org/wiki/Солёные_огурцы}
Не забывайте заключить доп. значение в фигурные скобки { }
Разрешить пакетную отправку фраз
Обработка запросов в Google.Ads занимает довольно много времени. В некоторых случаях вы можете существенно сократить время сбора, разрешив программе отправлять на исследования пакеты из нескольких фраз.
Программа не может всегда отправлять запросы пакетно, т.к. выдача ограничена определенным кол-вом фраз в отчете. Поэтому группируются только потенциально низкочастотные запросы с небольшой выдачей.
Программа определяет возможность группировки автоматически. На это нельзя повлиять вручную.
 значения можно указать сам исходный запрос или страницу сайта. В дальнейшем по этому значению можно выполнить поиск, сортировку и фильтрацию, определять, откуда пришел запрос и т.п.
значения можно указать сам исходный запрос или страницу сайта. В дальнейшем по этому значению можно выполнить поиск, сортировку и фильтрацию, определять, откуда пришел запрос и т.п.
Сбор статистики
Сбор статистики позволяет оценить популярность запросов.
Данные загружаются из планировщика ключевых слов. Источником могут являться прогнозные значения (планирование) или прежние значения (исторические данные).
Параметры сбораПараметры сбора идентичны параметрам пакетного сбора фраз. Дополнительно вы можете указать раздел сбора статистики: прежние результаты (исторические данные) или прогноз (прогнозные значения).
Настройки
Записывать в колонки 0 вместо «—» (нет данных)
Для низкочастотных запросов Google.Ads может не иметь статистики. В таких случаях он выдает прочерк «—» вместо числовых значений статистики.
При использовании этой опции вместо прочерков программа будет записывать 0 в ячейки колонок Google.Ads. Это может потребоваться, например, для более удобной фильтрации и сортировки значений.
Пропускать фразы с «—» в режиме необработанных фраз
Использование данной опции разрешает программе пропускать фразы с «—» в колонках Google.Ads.
В режиме сбора «Для несобранных» программа по умолчанию расценивает прочерк «—» в колонках Google.Ads как отсутствующее значение, которое необходимо попробовать получить.
Некоторые запросы не имеют полезной статистики, и планировщик запросов выдает «—» в результатах.
В этом случае программа может начать циклично пытаться получить статистику для запросов, которые ее в принципе не имеют.
Игнорировать недопустимые символы
Планировщик ключевых слов имеет ряд ограничений для исследуемых фраз.
Например, запросы, содержащие запрещенные символы, приведут к ошибке.При использовании этой опции программа будет автоматически заменять известные ей недопустимые символы на символ пробела.
Это помогает избежать ошибок при сборе статистики и собрать данные для некорректно введенных фраз.
 Например, запросы, содержащие запрещенные символы, приведут к ошибке.
Например, запросы, содержащие запрещенные символы, приведут к ошибке.Сбор истории частот
Сбор истории частот выполняется автоматически при сборе статистики Google.Ads. Однако исторические данные доступны только на аккаунтах, которые по мнению Google.Ads имеют достаточные рекламные расходы.
Величина необходимых трат рассчитывается Google.Ads индивидуально. Мы не имеем к этому никакого отношения.
Вкладка дополнительной статистики
Для просмотра расширенной статистики активируйте вкладку дополнительной статистики Google.Ads (1) и выберите фразу в таблице (2).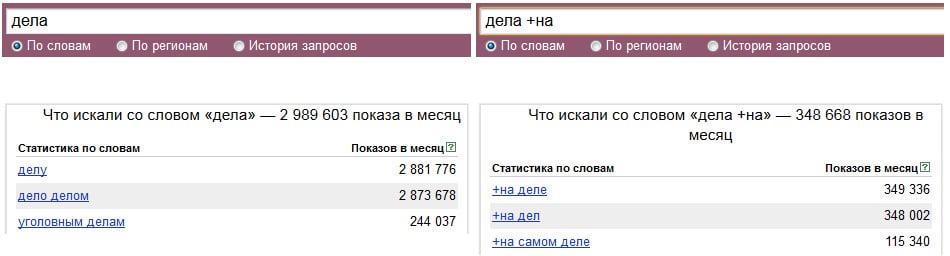
Панель идентична панели дополнительной статистики Yandex.Wordstat, поэтому скриншот приведен для Yandex.Wordstat. Принципы взаимодействия с панелью совпадают.
Панель содержит график истории показов, табличное представление данных с возможностью копирования в буфер обмена.
Если панель скрыта, вы можете вернуть ее на вкладке инструментов «Вид — Дополнительные панели».
Слишком большое кол-во открытых вкладок дополнительной статистики может привести к замедлению работы интерфейса программы. Рекомендуем закрывать ненужные вкладки и открывать их при необходимости.
Устранение неполадок
Сбор статистики Google.Ads является технически сложным процессом. Иногда могут возникать ошибки или неисправности.
Здесь вы можете ознакомиться с описанием и решением наиболее часто встречающихся проблем.
- Ошибка «Не удалось подключиться к сервису-помощнику парсинга»
Статистика запросов Google Adwords
Здравствуйте!
Чтобы получить данные по частотности запросов в Яндексе, достаточно обратиться к Вордстату, но чтобы узнать аналогичную информацию в Гугле, нужна статистика запросов Google Ads (ex. Adwords) и далеко не все знают, как её посмотреть. А эта информация крайне важна для SEO-продвижения, написания статей и для запуска контекстной рекламы.
Adwords) и далеко не все знают, как её посмотреть. А эта информация крайне важна для SEO-продвижения, написания статей и для запуска контекстной рекламы.
В этой статье мы разберём, как посмотреть статистику запросов в Google Ads и с помощью каких сервисов можно автоматизировать сбор данных.
2 способа посмотреть статистику запросов в Google Adwords
Посмотреть статистику ключевых слов в Google Adwords можно двумя способами: в планировщике ключевых слов и в статистике показов по ключевым фразам (для работающей рекламной компании).
Поочерёдно рассмотрим оба способа и разберём реальный пример. Но для начала потребуется зарегистрировать аккаунт в Гугл Эдвордс.
Зайдите на adwords.google.com и нажмите «Начать».
Затем внесите все данные, необходимые для регистрации и укажите сайт, который теоретически хотели бы прорекламировать. Пополнять бюджет и запускать рекламы при этом НЕ ТРЕБУЕТСЯ, мы просто воспользуемся необходимым инструментарием.
В планировщике ключевых слов
Шаг 1. По завершении регистрации заходим на главную страницу, жмём «Инструменты и настройки» и в выпавшем списке выбираем «Планировщик ключевых слов».
Шаг 2. На открывшейся странице кликаем «Найдите новые ключевые слова».
Далее вводим запросы, по которому хотим проверить частотность. Пусть это будет [купить ноутбук], [заказать ноутбук] — для разделения ключевых слов используйте запятые. Под полем со словами выбираем русский язык и указываем нужную геолокацию. В завершении кликаем «Показать результаты».
Шаг 3. Откроется страница, где мы можем ознакомиться со статистикой и узнать среднее число запросов в месяц по заданным фразам.
Здесь же доступны дополнительные инструменты для анализа ключевых фраз.
Таргетинг. Здесь можно задать регион, по которому требуется статистика, язык запросов, минус-слова, а так же добавить поисковых партнёров Google (сайта на которых размещён поиск от гугла). Например, давайте посмотрим статистику запросов по Москве (можно выбрать любой другой регион) и добавим минус-слово «бу».
Например, давайте посмотрим статистику запросов по Москве (можно выбрать любой другой регион) и добавим минус-слово «бу».
Диапазон дат. Здесь можно выбрать временной период, за который будут анализироваться данные. Рекомендуем поставить последний календарный год.
Параметры поиска.
- Фильтры ключевых слов. В этом пункте настроек можно задать, чтобы не показывались запросы, по которым частотность, рекомендуемая ставка и процент полученных показов объявлений, больше или меньше определённой цифры. Например, пусть это будет не менее 100 запросов в месяц с рекомендуемой ставкой не более 1 доллара. Также внизу можно указать желаемый уровень конкуренции.
- Варианты ключевых слов. Здесь можно включить или отключить показ ключевых слов схожих по смыслу по различным параметрам: наиболее тесно связанные с запросом, из рекламного аккаунта, из плана или вариант только для взрослых. Рекомендуем оставить по умолчанию.
- Рассматриваемые ключевые слова. Введите слова, чтобы посмотреть запросы, включающие их в себя.
 Введите слова, чтобы посмотреть запросы, включающие их в себя.
Введите слова, чтобы посмотреть запросы, включающие их в себя.В итоге мы получили вот такие данные. Динамика объёма запросов по месяцам. Эта диаграмма поможет выявить сезонность спроса, а так же самый «горячий» в году.
Чуть ниже мы видим статистику, показывающую в среднем 4400 запросов в месяц (на основе показателей за последние 12 месяцев), уровень конкуренции и рекомендуемая ставка. Это крайне полезная информация для запуска рекламной компании в Google Adwords.
Статистика поисковых запросов на основе показов рекламы
Если у Вас была ранее запущена рекламная компания, то дополнительную информацию по статистике запросов в Google Adwords, можно посмотреть промониторив по каким запросам была показана ваша реклама.
Для этого, зайдите в раздел «Отчёты» и создайте новый в виде таблице.
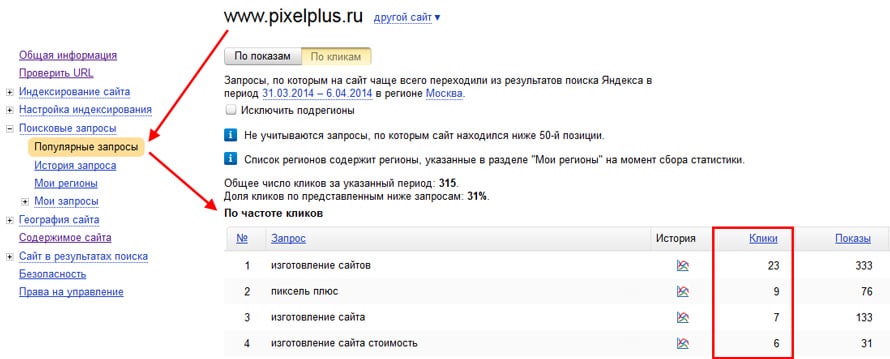
Затем в разделе «Таргетинг» найдите Поисковый запрос и перетащите в поле таблицы. Далее полученные таким образом данные, в любом удобном формате, в том числе экселевском файле, можно сохранить на своём компьютере, а затем кластеризовать или сделать интересующую выборку. На рисунке ниже приведены реальные данные по одному нашему клиенту, где собрано 1894 уникальных запроса! Круто же?
На рисунке ниже приведены реальные данные по одному нашему клиенту, где собрано 1894 уникальных запроса! Круто же?
Среди этих запросов, можно выделить все запросы, в которых указывается названия компаний, номера телефонов или адреса сайтов конкурентов, и добавить эти ключевики в свои компании в КМС и/или на поиске.
Так же данная статистика, поможет определить реальные потребности пользователей:
- собирается покупать, но не скоро;
- оценивает предложения разных компаний;
- готов купить прямо сейчас;
- не будет покупать, ищет общую информацию.
Ещё один пример сбора статистики по запросам
Например, наша компания занимается ремонт компьютеров и «железа» в городе Москва. При этом мы имеем достаточно ограниченный бюджет на рекламу, поэтому хотим найти ключевые слова, по которым наиболее низкая конкуренция (мало рекламодателей), чтобы в рекламе быть приоритетным выбор для пользователей и таким образом с минимального охвата получить максимальное количество конверсий.
Запрос по которому будут собираться слова: «ремонт ноутбуков».
- Регион: Москва.
- Уровень конкуренции: низкая.
Вот несколько ключевиков из 300, которые показала нам система, среди которых очень перспективно выглядит запрос «ремонт планшетов».
На рекомендуемой уровень ставки здесь можно не ориентироваться, так как по факту она может значительно отличаться от реальной, как со знаком «+», так и со знаком «-«.
Проверив запрос «ремонт планшетов в Москве» мы не обнаружили ни одного рекламного объявления.
Поэтому можно заключить, что статистика запросов Google Adwords — это кладезь полезной информации, при правильном использовании, обладающая огромным потенциалом. А вот будете ли Вы её использовать или нет, целиком и полностью зависит от Вас.
До новых встреч!
Примеры запросов в Ads Data Hub
Примечание. Дополнительные примеры запросов доступны через шаблоны запросов в пользовательском интерфейсе. Подробнее
ПодробнееЭти примеры запросов предполагают наличие практических знаний SQL и BigQuery. Узнайте больше о SQL в BigQuery.
Запросы на передачу данных Campaign Manager 360
Сопоставление переменных Floodlight с временными таблицами
Создание соответствия между user_id и пользовательскими переменными Floodlight в таблице действий. Затем это можно использовать для объединения собственных данных с данными Менеджера кампаний 360. 9;]*)’) AS u1_val ИЗ adh.cm_dt_activities_attributed ГРУППА ПО 1, 2 ) /* Сопоставление с данными о показах Менеджера кампаний 360 */ ВЫБРАТЬ imp.event.campaign_id, темп.u1_val, COUNT(*) КАК центов ИЗ adh.cm_dt_impressions AS имп. ПРИСОЕДИНИТЬСЯ tmp.temp_table AS temp USING (user_id) ГРУППА ПО 1, 2
Выдача показов
Этот пример удобен для управления показами и показывает, как найти количество показов, которые были выполнены с превышением частоты показов или если определенные потенциальные клиенты не были показаны рекламе.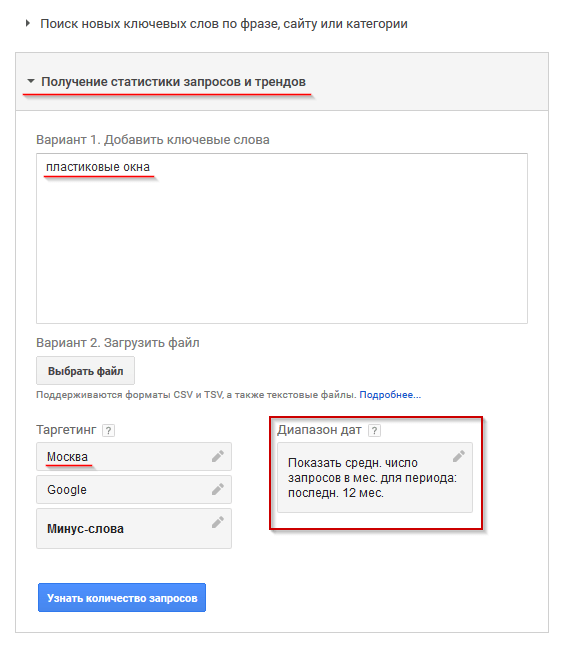 Используйте эти знания для оптимизации своих сайтов и тактики, чтобы получить нужное количество показов выбранной аудитории.
Используйте эти знания для оптимизации своих сайтов и тактики, чтобы получить нужное количество показов выбранной аудитории.
/* Для выполнения этого запроса @advertiser_ids и @campaigns_ids
должны быть заменены фактическими идентификаторами. Например [12345] */
С filtered_uniques AS (
ВЫБРАТЬ
ID пользователя,
COUNT(event.placement_id) частота AS
ОТ adh.cm_dt_impressions
ГДЕ user_id! = '0'
И event.advertiser_id В UNNEST(@advertiser_ids)
И event.campaign_id В UNNEST(@campaign_ids)
И event.country_domain_name = 'США'
СГРУППИРОВАТЬ ПО user_id
)
ВЫБРАТЬ
частота,
COUNT(*) AS уникальных
ОТ filtered_uniques
СГРУППИРОВАТЬ ПО частоте
ЗАКАЗАТЬ ПО частоте
;
Общее количество уникальных файлов cookie / частота
Этот пример помогает определить тактику и форматы рекламы, которые приводят к увеличению или уменьшению количества или частоты уникальных файлов cookie.
/* Для выполнения этого запроса @advertiser_ids и @campaigns_ids и @placement_ids должны быть заменены фактическими идентификаторами.
 Например [12345] */
ВЫБРАТЬ
COUNT(DISTINCT user_id) AS total_users,
COUNT(DISTINCT event.site_id) AS total_sites,
COUNT(DISTINCT device_id_md5) AS total_devices,
COUNT(event.placement_id) КАК показы
ОТ adh.cm_dt_impressions
ГДЕ user_id! = '0'
И event.advertiser_id В UNNEST(@advertiser_ids)
И event.campaign_id В UNNEST(@campaign_ids)
И event.placement_id В UNNEST(@placement_ids)
И event.country_domain_name = 'США'
;
Например [12345] */
ВЫБРАТЬ
COUNT(DISTINCT user_id) AS total_users,
COUNT(DISTINCT event.site_id) AS total_sites,
COUNT(DISTINCT device_id_md5) AS total_devices,
COUNT(event.placement_id) КАК показы
ОТ adh.cm_dt_impressions
ГДЕ user_id! = '0'
И event.advertiser_id В UNNEST(@advertiser_ids)
И event.campaign_id В UNNEST(@campaign_ids)
И event.placement_id В UNNEST(@placement_ids)
И event.country_domain_name = 'США'
;
Вы также можете включить идентификаторы сайта или места размещения в предложение WHERE, чтобы сузить запрос.
Общее количество уникальных файлов cookie и средняя частота по штатам
Этот пример объединяет таблицу cm_dt_impressions и таблицу метаданных cm_dt_state , чтобы показать общее количество показов, количество файлов cookie по штатам и среднее количество показов по пользователям, сгруппированных по географическим штатам Северной Америки.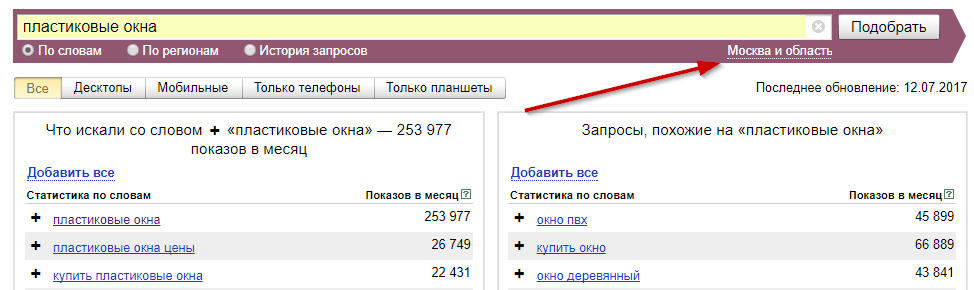 или провинция.
или провинция.
С Impression_stats КАК (
ВЫБРАТЬ
event.country_domain_name КАК страна,
CONCAT(event.country_domain_name, '-', event.state) Состояние AS,
COUNT(DISTINCT user_id) КАК пользователей,
COUNT(*) КАК показы
ОТ adh.cm_dt_impressions
ГДЕ event.country_domain_name = 'США'
ИЛИ event.country_domain_name = 'CA'
СГРУППИРОВАТЬ ПО 1, 2
)
ВЫБРАТЬ
страна,
IFNULL(имя_состояния, состояние) КАК имя_состояния,
пользователи,
впечатления,
ФОРМАТ(
'%0.2f',
ЕСЛИ(
IFNULL(показы, 0) = 0,
0,
показы / пользователи
)
) AS avg_imps_per_user
ИЗ Impression_stats
LEFT JOIN adh.cm_dt_state USING (состояние)
;
Аудитории Дисплея и Видео 360
В этом примере показано, как анализировать аудитории Дисплея и Видео 360. Узнайте, какой аудитории достигаются показы, и определите, работают ли одни аудитории лучше, чем другие. Эти знания могут помочь сбалансировать количество уникальных файлов cookie (показ рекламы большому количеству пользователей) и качество (узкий таргетинг и видимые показы) в зависимости от ваших целей.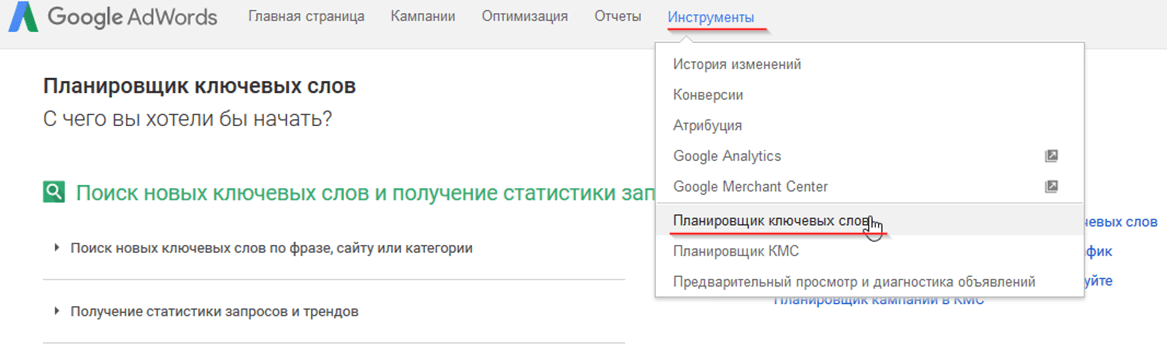
/* Для выполнения этого запроса @advertiser_ids и @campaigns_ids и @placement_ids
должны быть заменены фактическими идентификаторами. Например [12345] */
С отфильтрованными_показами КАК (
ВЫБРАТЬ
event.event_time как дата,
КЕЙС
КОГДА (event.browser_enum IN ('29', '30', '31')
ИЛИ event.os_id IN
(501012, 501013, 501017, 501018,
501019, 501020, 501021, 501022,
501023, 501024, 501025, 501027))
ТОГДА «Мобильный»
ЕЩЕ 'Рабочий стол'
КОНЕЦ КАК устройство,
event.dv360_matching_targeted_segments,
event.active_view_viewable_impressions,
event.active_view_measurable_impressions,
ID пользователя
ОТ adh.cm_dt_impressions
ГДЕ event.dv360_matching_targeted_segments != ''
И event.advertiser_id в UNNEST(@advertiser_ids)
И event.campaign_id В UNNEST(@campaign_ids)
И event.dv360_country_code = 'США'
)
ВЫБРАТЬ
id_аудитории,
устройство,
COUNT(*) КАК показы,
COUNT(DISTINCT user_id) КАК уникальных,
ОКРУГЛ(COUNT(*) / COUNT(DISTINCT user_id), 1) частота AS,
SUM(active_view_viewable_impressions) AS viewable_impressions,
SUM(active_view_measurable_impressions) КАК измеряемые_показы
ИЗ отфильтрованных_показов
ПРИСОЕДИНЯЙТЕСЬ К UNNEST(SPLIT(dv360_matching_targeted_segments, ' ')) КАК Audience_id
СГРУППИРОВАТЬ ПО 1, 2
;
Видимость
В этом примере показано, как измерять показатели видимости Active View Plus.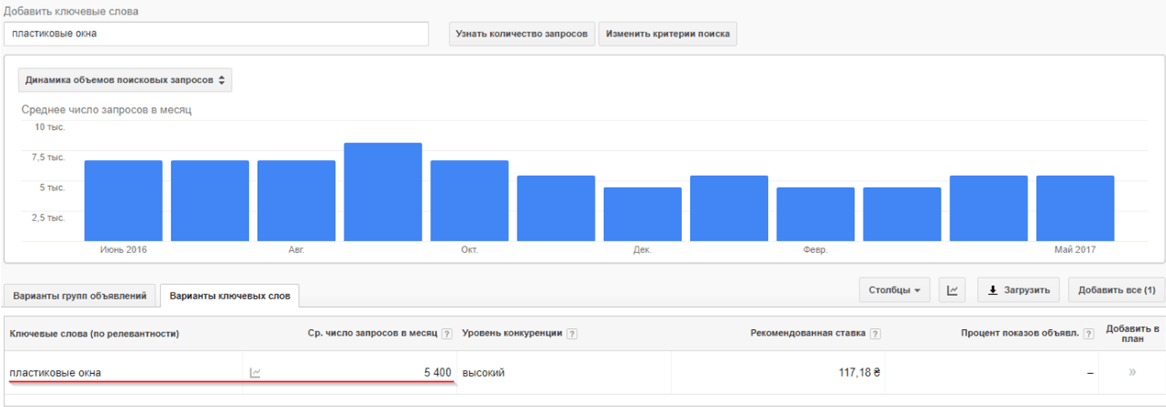
С Т КАК (
ВЫБЕРИТЕ cm_dt_impressions.event.impression_id КАК показ,
cm_dt_impressions.event.active_view_measurable_impressions AS AV_Measurable,
SUM(cm_dt_active_view_plus.event.active_view_plus_measurable_count) AS AVP_Measurable
ОТ adh.cm_dt_impressions
ПОЛНОЕ ПРИСОЕДИНЕНИЕ adh.cm_dt_active_view_plus
ВКЛ (cm_dt_impressions.event.impression_id =
cm_dt_active_view_plus.event.impression_id)
СГРУППИРОВАТЬ ПО показу, AV_Measurable
)
ВЫБЕРИТЕ COUNT(показ), SUM(AV_Measurable), SUM(AVP_Measurable)
ОТ Т
;
С сырым КАК (
ВЫБРАТЬ
event.ad_id КАК Ad_Id,
SUM(event.active_view_plus_measurable_count) AS avp_total,
СУММ(event.active_view_first_quartile_viewable_impressions) AS avp_1st_quartile,
СУММ(event.active_view_midpoint_viewable_impressions) AS avp_2nd_quartile,
СУММ(event.active_view_ Third_quartile_viewable_impressions) AS avp_3rd_quartile,
SUM(event. active_view_complete_viewable_impressions) AS avp_complete
ИЗ
adh.cm_dt_active_view_plus
ГРУППА ПО
1
)
ВЫБРАТЬ
Ad_Id,
avp_1st_quartile / avp_total AS Viewable_Rate_1st_Quartile,
avp_2nd_quartile / avp_total AS Viewable_Rate_2nd_Quartile,
avp_3rd_quartile / avp_total AS Viewable_Rate_3rd_Quartile,
avp_complete / avp_total AS Viewable_Rate_Completion_Quartile
ИЗ
Сырой
КУДА
авп_тотал > 0
СОРТИРОВАТЬ ПО
Viewable_Rate_1st_Quartile DESC
;
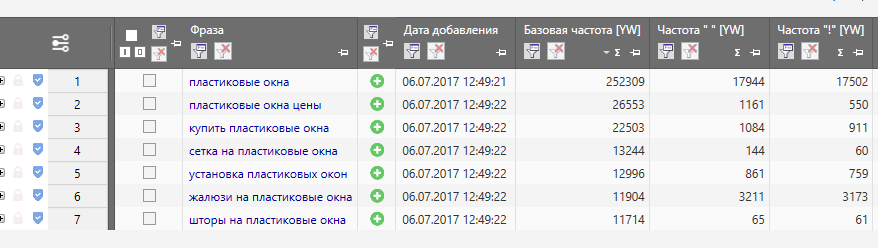 active_view_complete_viewable_impressions) AS avp_complete
ИЗ
adh.cm_dt_active_view_plus
ГРУППА ПО
1
)
ВЫБРАТЬ
Ad_Id,
avp_1st_quartile / avp_total AS Viewable_Rate_1st_Quartile,
avp_2nd_quartile / avp_total AS Viewable_Rate_2nd_Quartile,
avp_3rd_quartile / avp_total AS Viewable_Rate_3rd_Quartile,
avp_complete / avp_total AS Viewable_Rate_Completion_Quartile
ИЗ
Сырой
КУДА
авп_тотал > 0
СОРТИРОВАТЬ ПО
Viewable_Rate_1st_Quartile DESC
;
active_view_complete_viewable_impressions) AS avp_complete
ИЗ
adh.cm_dt_active_view_plus
ГРУППА ПО
1
)
ВЫБРАТЬ
Ad_Id,
avp_1st_quartile / avp_total AS Viewable_Rate_1st_Quartile,
avp_2nd_quartile / avp_total AS Viewable_Rate_2nd_Quartile,
avp_3rd_quartile / avp_total AS Viewable_Rate_3rd_Quartile,
avp_complete / avp_total AS Viewable_Rate_Completion_Quartile
ИЗ
Сырой
КУДА
авп_тотал > 0
СОРТИРОВАТЬ ПО
Viewable_Rate_1st_Quartile DESC
;
Динамические данные в Campaign Manager 360 Data Transfer
Количество показов на динамический профиль и фид
ВЫБРАТЬ событие.динамический_профиль, фид_имя, COUNT(*) как показы ОТ adh.cm_dt_impressions ПРИСОЕДИНЯЙТЕСЬ к UNNEST (event.feed) как feed_name СГРУППИРОВАТЬ ПО 1, 2;
Количество показов на ярлык динамической отчетности в фиде 1
ВЫБРАТЬ event.
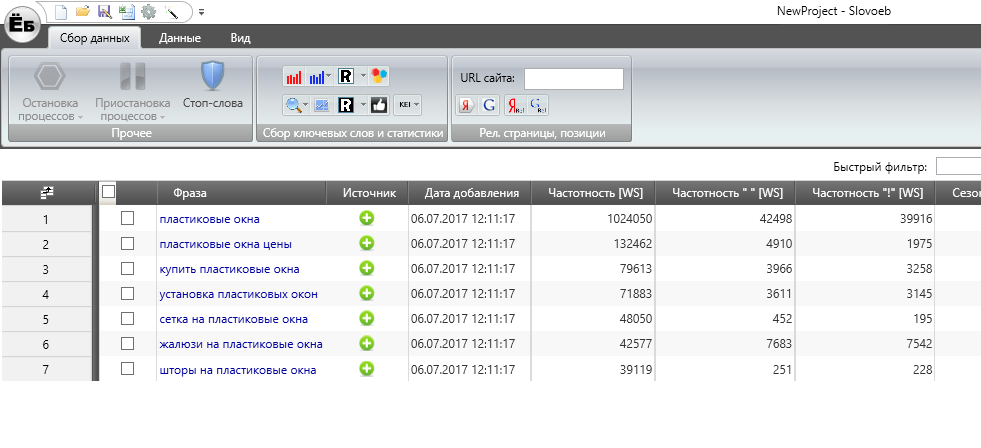 feed_reporting_label[SAFE_ORDINAL(1)] feed1_reporting_label,
COUNT(*) как показы
ОТ adh.cm_dt_impressions
WHERE event.feed_reporting_label[SAFE_ORDINAL(1)] <> "" # где у вас установлена хотя бы одна метка отчетности
СГРУППИРОВАТЬ ПО 1;
feed_reporting_label[SAFE_ORDINAL(1)] feed1_reporting_label,
COUNT(*) как показы
ОТ adh.cm_dt_impressions
WHERE event.feed_reporting_label[SAFE_ORDINAL(1)] <> "" # где у вас установлена хотя бы одна метка отчетности
СГРУППИРОВАТЬ ПО 1;
Количество показов, для которых метка отчета = «красный» в фиде 2
ВЫБЕРИТЕ event.feed_reporting_label[SAFE_ORDINAL(2)] AS feed1_reporting_label, COUNT(*) как показы ОТ adh.cm_dt_impressions ГДЕ event.feed_reporting_label[SAFE_ORDINAL(2)] = «красный» СГРУППИРОВАТЬ ПО 1;
Количество показов, для которых параметр_1 = «красный» и параметр_2 = «автомобиль» в фиде 1
ВЫБЕРИТЕ event.feed_reporting_label[SAFE_ORDINAL(1)] AS feed1_reporting_label, event.feed_reporting_dimension1[SAFE_ORDINAL(1)] AS feed1_reporting_dimension1, event.
 feed_reporting_dimension2[SAFE_ORDINAL(1)] AS feed2_reporting_dimension1,
event.feed_reporting_dimension3[SAFE_ORDINAL(1)] AS feed3_reporting_dimension1,
event.feed_reporting_dimension4[SAFE_ORDINAL(1)] AS feed4_reporting_dimension1,
event.feed_reporting_dimension5[SAFE_ORDINAL(1)] AS feed5_reporting_dimension1,
event.feed_reporting_dimension6[SAFE_ORDINAL(1)] AS feed6_reporting_dimension1,
COUNT(*) как показы
ОТ adh.cm_dt_impressions
ГДЕ event.feed_reporting_dimension1[SAFE_ORDINAL(1)] = «красный»
И event.feed_reporting_dimension2[SAFE_ORDINAL(1)] = «автомобиль»
СГРУППИРОВАТЬ ПО 1,2,3,4,5,6,7;
feed_reporting_dimension2[SAFE_ORDINAL(1)] AS feed2_reporting_dimension1,
event.feed_reporting_dimension3[SAFE_ORDINAL(1)] AS feed3_reporting_dimension1,
event.feed_reporting_dimension4[SAFE_ORDINAL(1)] AS feed4_reporting_dimension1,
event.feed_reporting_dimension5[SAFE_ORDINAL(1)] AS feed5_reporting_dimension1,
event.feed_reporting_dimension6[SAFE_ORDINAL(1)] AS feed6_reporting_dimension1,
COUNT(*) как показы
ОТ adh.cm_dt_impressions
ГДЕ event.feed_reporting_dimension1[SAFE_ORDINAL(1)] = «красный»
И event.feed_reporting_dimension2[SAFE_ORDINAL(1)] = «автомобиль»
СГРУППИРОВАТЬ ПО 1,2,3,4,5,6,7;
Форматы объявлений в Campaign Manager 360 Data Transfer
В этих примерах показано, как определить, какие форматы объявлений обеспечивают максимальное количество уникальных файлов cookie или частоту показов. Используйте эти знания, чтобы сбалансировать общее количество уникальных файлов cookie и воздействие рекламы на пользователей.
Доставка показов
/* Для выполнения этого запроса @advertiser_ids и @campaigns_ids
должны быть заменены фактическими идентификаторами. Например [12345]. YOUR_BQ_DATASET должен быть
заменено фактическим именем вашего набора данных.*/
С filtered_uniques AS (
ВЫБРАТЬ
ID пользователя,
КЕЙС
WHEN creative_type LIKE '%Video%' THEN 'Video'
КОГДА creative_type равен NULL, ТОГДА "Неизвестно"
ИНАЧЕ 'Показать'
КОНЕЦ КАК creative_format,
COUNT(*) КАК показы
ОТ показов adh.cm_dt_impressions
LEFT JOIN YOUR_BQ_DATASET.campaigns креатив
ON creative.rendering_id = Impression.event.rendering_id
ГДЕ user_id! = '0'
И event.advertiser_id В UNNEST(@advertiser_ids)
И event.campaign_id В UNNEST(@campaign_ids)
И event.country_domain_name = 'США'
СГРУППИРОВАТЬ ПО user_id, creative_format
)
ВЫБРАТЬ
частота показов AS,
креатив_формат,
COUNT(DISTINCT user_id) КАК уникальных,
СУММ(показы) КАК показы
ОТ filtered_uniques
СГРУППИРОВАТЬ ПО частоте, креатив_формат
ЗАКАЗАТЬ ПО частоте
;
Количество и частота уникальных файлов cookie
/* Для выполнения этого запроса @advertiser_ids и @campaigns_ids должны быть заменены фактическими идентификаторами.
 Например [12345]. YOUR_BQ_DATASET должен быть
заменено фактическим именем вашего набора данных. */
С отфильтрованными_показами КАК (
ВЫБРАТЬ
event.campaign_id КАК кампания_id,
event.rendering_id КАК rendering_id,
ID пользователя
ОТ adh.cm_dt_impressions
ГДЕ user_id! = '0'
И event.advertiser_id В UNNEST(@advertiser_ids)
И event.campaign_id В UNNEST(@campaign_ids)
И event.country_domain_name = 'США'
)
ВЫБРАТЬ
Кампания,
КЕЙС
WHEN creative_type LIKE '%Video%' THEN 'Video'
КОГДА creative_type равен NULL, ТОГДА "Неизвестно"
ИНАЧЕ 'Показать'
КОНЕЦ КАК creative_format,
COUNT(DISTINCT user_id) КАК пользователей,
COUNT(*) КАК показов
ИЗ отфильтрованных_показов
ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ К YOUR_BQ_DATASET.campaigns, ИСПОЛЬЗУЯ (campaign_id)
ОСТАЛОСЬ ПРИСОЕДИНИТЬСЯ К YOUR_BQ_DATASET.creatives, ИСПОЛЬЗУЯ (rendering_id)
СГРУППИРОВАТЬ ПО 1, 2
;
Например [12345]. YOUR_BQ_DATASET должен быть
заменено фактическим именем вашего набора данных. */
С отфильтрованными_показами КАК (
ВЫБРАТЬ
event.campaign_id КАК кампания_id,
event.rendering_id КАК rendering_id,
ID пользователя
ОТ adh.cm_dt_impressions
ГДЕ user_id! = '0'
И event.advertiser_id В UNNEST(@advertiser_ids)
И event.campaign_id В UNNEST(@campaign_ids)
И event.country_domain_name = 'США'
)
ВЫБРАТЬ
Кампания,
КЕЙС
WHEN creative_type LIKE '%Video%' THEN 'Video'
КОГДА creative_type равен NULL, ТОГДА "Неизвестно"
ИНАЧЕ 'Показать'
КОНЕЦ КАК creative_format,
COUNT(DISTINCT user_id) КАК пользователей,
COUNT(*) КАК показов
ИЗ отфильтрованных_показов
ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ К YOUR_BQ_DATASET.campaigns, ИСПОЛЬЗУЯ (campaign_id)
ОСТАЛОСЬ ПРИСОЕДИНИТЬСЯ К YOUR_BQ_DATASET.creatives, ИСПОЛЬЗУЯ (rendering_id)
СГРУППИРОВАТЬ ПО 1, 2
;
Google Ads
Показы мобильного приложения с таблицами _rdid
Запрос 1:
ВЫБРАТЬ идентификатор_кампании, COUNT(*) КАК имп.
 ,
COUNT(DISTINCT user_id) AS пользователей
ОТ adh.google_ads_impressions
ГДЕ is_app_traffic
СГРУППИРОВАТЬ ПО 1
;
,
COUNT(DISTINCT user_id) AS пользователей
ОТ adh.google_ads_impressions
ГДЕ is_app_traffic
СГРУППИРОВАТЬ ПО 1
;
Запрос 2:
ВЫБРАТЬ идентификатор_кампании, COUNT(DISTINCT device_id_md5) AS device_ids ОТ adh.google_ads_impressions_rdid СГРУППИРОВАТЬ ПО 1 ;
Результаты могут быть объединены с использованием идентификатора кампании.
Демографический охват
В этом примере показано, как определить, какие кампании охватывают данную демографическую группу.
/* Для выполнения этого запроса @customer_id
должен быть заменен фактическим идентификатором. Например [12345] */
С Impression_stats КАК (
ВЫБРАТЬ
идентификатор_кампании,
demographics.gender КАК гендерный_ид,
demographics.age_group AS age_group_id,
COUNT(DISTINCT user_id) КАК пользователей,
COUNT(*) КАК показов
ОТ adh.google_ads_impressions
ГДЕ customer_id = @customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3
)
ВЫБРАТЬ
Название кампании,
пол_имя,
возрастная_группа_название,
пользователи,
впечатления
ИЗ Impression_stats
НАЛЕВО ПРИСОЕДИНЯЙТЕСЬ к adh. google_ads_campaign, ИСПОЛЬЗУЯ (campaign_id)
LEFT JOIN adh.gender ИСПОЛЬЗОВАНИЕ (gender_id)
ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ к adh.age_group, ИСПОЛЬЗУЯ (age_group_id)
ПОРЯДОК ПО 1, 2, 3
;
 google_ads_campaign, ИСПОЛЬЗУЯ (campaign_id)
LEFT JOIN adh.gender ИСПОЛЬЗОВАНИЕ (gender_id)
ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ к adh.age_group, ИСПОЛЬЗУЯ (age_group_id)
ПОРЯДОК ПО 1, 2, 3
;
google_ads_campaign, ИСПОЛЬЗУЯ (campaign_id)
LEFT JOIN adh.gender ИСПОЛЬЗОВАНИЕ (gender_id)
ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ к adh.age_group, ИСПОЛЬЗУЯ (age_group_id)
ПОРЯДОК ПО 1, 2, 3
;
Вычитание одной группы пользователей из другой
В этом примере показано, как вычесть одну группу пользователей из другой. Этот метод имеет широкий спектр применений, включая подсчет несовершивших конверсию, пользователей без показов в видимой области экрана и пользователей без кликов.
С исключить КАК (
ВЫБЕРИТЕ РАЗЛИЧНЫЙ user_id
ОТ adh.google_ads_impressions
ГДЕ кампания_id = 123
)
ВЫБРАТЬ
COUNT(DISTINCT imp.user_id) -
COUNT(DISTINCT exclude.user_id) КАК пользователей
ОТ показов adh.google_ads_impressions
ЛЕВОЕ СОЕДИНЕНИЕ исключить
ИСПОЛЬЗОВАНИЕ (user_id)
ГДЕ imp.campaign_id = 876
;
Видимость
В этом примере показано, как выполнить простой запрос видимости. Видимость дает сигнал о том, насколько вероятно, что пользователь действительно увидел ваше объявление.
С
active_view_metrics КАК (
ВЫБРАТЬ
SUM(imp.num_active_view_eligible_impression) AS Допустимые показы,
SUM(imp.num_active_view_measurable_impression) КАК измеряемые показы,
SUM(view.num_active_view_viewable_impression) AS ViewableImpressions,
SUM(IF(imp.num_active_view_eligible_impression > 0 AND (ctv.template_id IN (213) ИЛИ ctv.creative_type в (84)), 1, 0)) AS EligibleSkippableImpressions
ОТ показов adh.google_ads_impressions
LEFT JOIN adh.google_ads_active_views view ON view.impression_id = imp.impression_id
LEFT JOIN adh.google_ads_adgroupcreative agc ON imp.ad_group_creative_id = agc.ad_group_creative_id
ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ adh.google_ads_creative КАК ctv ON agc.creative_id = ctv.creative_id
ГДЕ (imp.active_view_type = 'VIDEO_MEASURABLE' ИЛИ imp.active_view_type = 'VIDEO_ENABLED')
И imp.customer_id = @customer_id И imp. campaign_id = @campaign_id
)
ВЫБРАТЬ
Соответствующие показы,
Измеримые показы,
показов в видимой области экрана,
Допустимые показы с возможностью пропуска
ОТ active_view_metrics
;
Настройки часового пояса рекламодателя Google Ads
ВЫБРАТЬ
Пользовательский ИД,
клиент_часовой пояс,
подсчитывать(1) как показы
ОТ adh.google_ads_impressions i
ВНУТРЕННЕЕ СОЕДИНЕНИЕ adh.google_ads_customer c
ВКЛ c.customer_id = i.customer_id
ГДЕ TIMESTAMP_MICROS(i.query_id.time_usec) >= CAST(DATETIME(@date, c.customer_timezone) AS TIMESTAMP)
AND TIMESTAMP_MICROS(i.query_id.time_usec) < CAST(DATETIME_ADD(DATETIME(@date, c.customer_timezone), INTERVAL 1 DAY) AS TIMESTAMP)
СГРУППИРОВАТЬ ПО customer_id, customer_timezone
Запросы рекламных блоков YouTube
Рекламные блоки группируют 2 объявления в одну рекламную паузу во время длительных сеансов просмотра YouTube. (Вспомните рекламную паузу, но не более 2 объявлений.) Рекламу в рекламных блоках по-прежнему можно пропустить. Однако, если пользователь пропускает первое объявление, второе объявление также пропускается.
Показы кампании GoogleAds Trueview Instream и просмотры TrueView
ВЫБРАТЬ cmp.имя_кампании, imp.is_app_traffic, COUNT(*) AS total_impressions, СЧЁТЕСЛИ(clk.click_id НЕ NULL) AS total_trueview_views ОТ показов adh.google_ads_impressions ПРИСОЕДИНЯЙТЕСЬ к adh.google_ads_campaign cmp, ИСПОЛЬЗУЯ (campaign_id) ПРИСОЕДИНЯЙТЕСЬ к объявлению adh.google_ads_adgroup, ИСПОЛЬЗУЯ (adgroup_id) НАЛЕВО ПРИСОЕДИНЯЙТЕСЬ adh.google_ads_clicks нажмите ВКЛ. imp.impression_id = clk.impression_id КУДА imp.customer_id В UNNEST(@customer_ids) И adg.adgroup_type = 'VIDEO_TRUE_VIEW_IN_STREAM' И cmp.advertising_channel_type = 'ВИДЕО' СГРУППИРОВАТЬ ПО 1, 2
Показатели видимости в Медийная и видеореклама 360 по позициям
С
imp_stats КАК (
ВЫБРАТЬ
имп. line_item_id,
count(*) как total_imp,
SUM(num_active_view_measurable_impression) AS num_measurable_impressions,
SUM(num_active_view_eligible_impression) AS num_enabled_impressions
ОТ adh.dv360_youtube_impressions имп
КУДА
imp.line_item_id В UNNEST(@line_item_ids)
СГРУППИРОВАТЬ ПО 1
),
av_stats КАК (
ВЫБРАТЬ
имп.line_item_id,
SUM(num_active_view_viewable_impression) AS num_viewable_impressions
ОТ adh.dv360_youtube_impressions имп
ЛЕВОЕ СОЕДИНЕНИЕ
adh.dv360_youtube_active_views ав.
ON imp.impression_id = av.impression_id
КУДА
imp.line_item_id В UNNEST(@line_item_ids)
СГРУППИРОВАТЬ ПО 1
)
ВЫБРАТЬ
li.line_item_name,
SUM(imp.total_imp) как num_impressions,
SUM(imp.num_measurable_impressions) AS num_measurable_impressions,
SUM(imp.num_enabled_impressions) AS num_enabled_impressions,
SUM(IFNULL(av.num_viewable_impressions, 0)) AS num_viewable_impressions
ИЗ imp_stats как имп
LEFT JOIN av_stats AS av USING (line_item_id)
ПРИСОЕДИНЯЙТЕСЬ к adh. dv360_youtube_lineitem li ON (imp.line_item_id = li.line_item_id)
СГРУППИРОВАТЬ ПО 1
Запросы YouTube Reserve
Количество показов рекламодателем
Этот запрос измеряет количество показов и отдельных пользователей на одного рекламодателя. Вы можете использовать эти цифры для расчета среднего количества показов на пользователя (или «частоты показов рекламы»).
ВЫБОР имя_рекламодателя, COUNT(*) КАК имп., COUNT(DISTINCT user_id) AS пользователей ОТ adh.yt_reserve_impressions КАК показов ПРИСОЕДИНЯЙТЕСЬ к заказу adh.yt_reserve_order ON impressions.order_id = order.order_id СГРУППИРОВАТЬ ПО 1 ;
Пропуски объявлений
Этот запрос измеряет количество пропусков объявлений для каждого клиента, кампании, группы объявлений и креатива.
ВЫБОР Impression_data.customer_id, Impression_data.
Общие запросы
Пользовательское перекрытие
Этот запрос измеряет перекрытие двух или более кампаний. Его можно настроить для измерения перекрытия на основе произвольных критериев.
/* Для выполнения этого запроса @campaign_1 и @campaign_2 должны быть заменены на фактические идентификаторы кампании. */ С помеченными_показами КАК ( ВЫБРАТЬ ID пользователя, SUM(IF(campaign_ID в UNNEST(@campaign_1), 1, 0)) AS C1_impressions, SUM(IF(campaign_ID в UNNEST(@campaign_2), 1, 0)) AS C2_impressions ОТ adh.cm_dt_impressions СГРУППИРОВАТЬ ПО user_ID ВЫБЕРИТЕ СЧЁТЕСЛИ(C1_impressions > 0) как C1_cookie_count, СЧЁТЕСЛИ(C2_impressions > 0) как C2_cookie_count, СЧЁТЕСЛИ(C1_показы > 0 и C2_показы > 0) как перекрытие_cookie_count FROM отмеченных_показов ;
Продажи партнеров — перекрестные продажи
Этот запрос измеряет количество показов и переходов по ссылкам на ресурсы, продаваемые партнерами.
ВЫБОР
a.record_date КАК record_date,
a.line_item_id КАК line_item_id,
a.creative_id КАК creative_id,
a.ad_id КАК ad_id,
a.impressions КАК показы,
a.click_through КАК click_through,
a.video_skiped КАК video_skiped,
b.pixel_url КАК pixel_url
ИЗ
(
ВЫБРАТЬ
FORMAT_TIMESTAMP('%D', TIMESTAMP_MICROS(i.query_id.time_usec), 'Etc/UTC') AS record_date,
i.line_item_id как line_item_id,
i.creative_id как creative_id,
i.ad_id как ad_id,
COUNT(i.query_id) как показы,
COUNTIF(c.label='video_click_to_advertiser_site') КАК переход по клику,
СЧЁТЕСЛИ(c.label='видеопропущено') КАК видео_пропущено
ИЗ
adh.partner_sold_cross_sell_impressions КАК я
ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ к adh.partner_sold_cross_sell_conversions AS c
ВКЛ i.impression_id = c.impression_id
ГРУППА ПО
1, 2, 3, 4
) Как
ПРИСОЕДИНЯЙТЕСЬ к adh.partner_sold_cross_sell_creative_pixels AS b
ВКЛ (a.ad_id = b.ad_id)
;
Показы магазина приложений
Следующий запрос подсчитывает общее количество показов, сгруппированных по магазину приложений и приложению.
ВЫБРАТЬ app_store_name, app_name, COUNT(*) AS number ОТ adh.google_ads_impressions КАК имп. ПРИСОЕДИНЯЙТЕСЬ к adh.mobile_app_info ИСПОЛЬЗОВАНИЕ (app_store_id, app_id) ГДЕ imp.app_id НЕ NULL СГРУППИРОВАТЬ НА 1,2 ЗАКАЗАТЬ ПО 3 DESC
Как Google может выбирать ответы на запросы с инструкциями
Как Google может отвечать на запросы с инструкциями
https://gofishdigital.com/google-how-to-queries/
Компания Google опубликовала патент на то, как они могут обрабатывать запросы с практическими рекомендациями.
Не забудьте также прочитать страницу разработчиков Google о том, как использовать структурированные данные с инструкциями, чтобы получить информацию о том, как Google рекомендует разработчикам внедрять структурированную разметку с инструкциями. Эта страница определяет цель разметки с практическими рекомендациями для нас:
С практическими рекомендациями пользователи проходят ряд шагов для выполнения задачи и могут содержать видео, изображения и текст.
Компания Google получила патент на запросы с инструкциями, которыми, похоже, стоило поделиться, чтобы показать, что они думают о демонстрации ответов на запросы с инструкциями.
Как нам сразу говорит описание патента:
Данная спецификация направлена в основном на предоставление пошаговых инструкций по выполнению задачи на основе анализа множества источников.
Страница разработчика не содержит некоторой информации, которую содержит патент, рассказывая нам о том, как Google может анализировать множество источников, чтобы предоставить «пошаговые инструкции для выполнения задачи на основе анализа этих источников».
Это руководство, лежащее в основе процесса ответа на запрос Google:
- Запрос с инструкциями, связанный с выполнением задачи, и источники, связанные с запросом с инструкциями, могут быть идентифицированы
- Могут быть определены шаги, которые могут позволить пользователю выполнить задачу
- Определение шагов может быть основано на анализе источников, связанных с запросом с инструкциями .
- Меры доверия могут быть определены для источников
- Шаги могут быть связаны с практическими запросами в базе данных
- Эти шаги могут быть предоставлены искателю в ответ на запрос с инструкциями (или аналогичный запрос), отправленный искателем
- Анализ источников, связанных с запросом с инструкциями, может включать сравнение компонентов различных наборов шагов и выявление общих элементов для определения набора шагов
Более подробно шаги процесса запроса с инструкциями включают:
- Определение запроса с инструкциями, связанного с выполнением задачи
- Идентификация источников, отвечающих на запрос с практическими рекомендациями
- Определение меры достоверности для одного или нескольких из множества идентифицированных источников, при этом мера достоверности данного источника указывает на эффективность данного источника при предоставлении шагов для задачи запроса с инструкциями
- Определение шагов для выполнения задачи на основе мер достоверности для идентифицированных источников
- Связывание шагов с запросом с инструкциями и сохранение шагов, которые должны быть предоставлены в ответ на запрос с инструкциями
Некоторые дополнительные функции, лежащие в основе этого процесса, могут включать:
При поиске источников одним из них может быть руководство пользователя, и это руководство пользователя может считаться одним из источников. Набор шагов для выполнения задачи может основываться на руководстве пользователя.
Шаги, лежащие в основе ответа на запрос с инструкциями
Метод ответа на запрос с инструкциями может дополнительно включать:
- Идентификацию шагов из ряда источников
- Идентификация шагов из каждой группы шагов
- Определение шагов для выполнения задачи на основе этих шагов
- Определение мер подобия между шагами из источников
- Определение шагов для отображения на основе показателей сходства
Меры сходства могут быть основаны на:
- Соответствии ключевых слов
- Сопоставление фраз
- Соответствие дерева разбора
- Показатели сходства распределения
- Редактировать показатели расстояния
В некоторых реализациях метод может дополнительно включать:
- Определение для каждого шага в каждой группе шагов оценки релевантности, указывающей уровень достоверности шага
- Идентификация одного или нескольких шагов из группы шагов на основе оценок релевантности
Как выбираются шаги в ответе на запрос с инструкциями
Шаги, показанные для выполнения задачи, могут быть выбраны из источника на основе меры достоверности источника.
Мера достоверности для источника может основываться на:
- Рейтинг данного источника
- Частота посещения данного источника
- Количество ссылок на данный источник
- Связность данного источника
- Отзывы пользователей, относящиеся к данному источнику
Мера качества может быть определена для набора шагов, которые могут быть предоставлены в ответ на отправленный запрос.
Оценка запроса также может быть определена для отправленного запроса на основе уверенности в том, что запрос искателя указывает на желание получить шаги для выполнения задачи, указанной в запросе; и решение о том, что показ шагов в ответ на запрос удовлетворит потребности искателя.
Способ может дополнительно включать:
- Определение одного или нескольких уровней навыков, необходимых для выполнения задачи
- Продолжительность выполнения задачи
- Список инструментов, необходимых для выполнения задачи
- Список материалов, необходимых для выполнения задания.
Этот патент об ответах на запросы с практическими рекомендациями можно найти по адресу:
Определение набора шагов в ответ на запрос с практическими рекомендациями
Изобретатели: Кервелл Ляо, Нихил Шарма, ЛаДоун Ризенмай Дженцш и Дженнифер Эллен Фернквист
Правопреемник: GOOGLE LLC
Патент США: 10 585 927
Выдан: 10 марта 2020 г.
Подана: 2 марта 2017 г.
Abstract
Методы и устройства, связанные с предоставлением шагов для выполнения задачи на основе анализа нескольких источников. Могут быть идентифицированы запрос с инструкциями, относящийся к выполнению задачи, и множество источников, связанных с запросом с инструкциями. Набор шагов, связанных с выполнением задачи, может быть определен на основе анализа множества источников, которые относятся к запросу с инструкциями, необязательно включая определение меры достоверности для множества источников. Набор шагов может быть связан с практическим запросом в базе данных.
Условия задачи и условия запросов в запросах с инструкциями
В патенте указаны некоторые примеры того, что они называют условиями задач и условиями запроса:
- «как удалить смолу с одежды» — это запрос с инструкциями который включает в себя условия задачи («удалить смолу с одежды»), которые определяют задачу удаления смолы с одежды, а также термины запроса («как»), указывающие на потребность в информации, которая может быть использована при удалении смолы с одежды.
- «Как мне заменить автомобильную шину» — это запрос с практическими рекомендациями, который включает термины задачи («заменить автомобильную шину»), которые определяют задачу по замене автомобильной шины, и включает термины запроса («как мне сделать»), указывающие на желание получить информацию, которая может быть использована при замене автомобильной шины.
Как Google может идентифицировать запросы с инструкциями
1. Использование ключевых терминов или ключевых фраз. Они могут быть включены в запрос. Например, префикс запроса может быть сопоставлен с одним или несколькими терминами запроса, такими как:
- «как»
- «как мне быть»
- «как поживает»
- «кто-нибудь знает»
- «где найти инструкции»
- «где я могу получить инструкции»
- «может кто-нибудь сказать мне»
- «научи меня»
- «скажи мне, как»
- «как»
- «где»
- «инструкции»
- «?»
2. Использование префикса с условиями запроса и дополнительными условиями, следующими за префиксом, что может включать сопоставление условий запроса с условиями запроса, а также сопоставление условий запроса с условиями задачи. Например:
- Запрос «заменить спущенную шину?» может быть идентифицирован как запрос с инструкциями, основанный на сопоставлении терминов «заменить спущенную шину» с фразой задачи «замена спущенной шины» и сопоставлением термина «?» к термину запроса «?»
- Запрос «инструкции по удалению tar» может быть идентифицирован как запрос с практическими рекомендациями на основании соответствия терминов «удалить tar» фразе задачи «удаление tar» и соответствия термина «инструкции» термину запроса «инструкции».
3. Может использоваться точное соответствие и/или мягкое соответствие между условиями запроса и условиями запроса и/или условиями задачи.
Ключевые термины и ключевые фразы (включая термины задач и/или термины запросов), которые могут часто включаться в запросы с практическими рекомендациями, могут храниться в базе данных контента.
Термины задач могут быть идентифицированы на основе:
- Тегирования части речи
- Семантический анализ
- Синтаксический анализ
- Другие методы
4. Частота терминов запроса и условий задачи, включенных в запрос, может использоваться для определения того, является ли запрос запросом с инструкциями.
Данные, относящиеся к частоте ключевых терминов в запросах и/или частоте в другом корпусе документов, могут дополнительно храниться в базе данных контента и использоваться для принятия решения о том, является ли запрос практическим запросом.
- «как сделать торт с нуля» может быть идентифицирован как запрос с инструкциями только в том случае, если термины задачи «сделать торт с нуля» встречаются как минимум с пороговым уровнем частоты в прошлых запросах.
5. Частота отправки запроса может быть использована для принятия решения о том, является ли запрос практическим.
Эта частота может храниться в базе данных контента. Запрос может быть идентифицирован как запрос с практическими рекомендациями, если он был отправлен как минимум с пороговым уровнем частоты.
- «как сделать торт с нуля» можно рассматривать как запрос с практическими рекомендациями, если он и его варианты соответствуют пороговому уровню запросов в нескольких прошлых запросах.
6. Похожие запросы с инструкциями могут быть связаны друг с другом
IСвязи между похожими запросами с инструкциями могут храниться в базе данных контента. Подобные запросы с практическими рекомендациями — это запросы, указывающие на желание получить информацию для выполнения аналогичных задач, например:
- «как удалить смолу с одежды»
- «Как удалить смолу с одежды?»
- «Как удалить смолу с ткани»
- «удаление пятен смолы»
- «Пятновыводитель-смола»
Подобные запросы с практическими рекомендациями можно определить, сравнив соответствующие условия запроса и/или условия задачи из них.
7. Анализ результатов поиска и/или документов результатов поиска, связанных с запросом с инструкциями .
Таким образом, первые N результатов поиска с самым высоким рейтингом могут быть проанализированы, чтобы определить, содержат ли пороговое число из них шаги по выполнению задачи, указанной в запросе.
Страница в этих результатах поиска может быть определена как имеющая наивысший рейтинг выбора для запроса, который также может быть проанализирован, чтобы увидеть, предоставляет ли он шаги для выполнения задачи, указанной в запросе.
8. Аналогичные запросы могут использовать некоторые дополнительные методы
Они могут включать:
- Соответствие ключевым словам
- Сопоставление фраз
- Сопоставление фраз по контекстному сходству
9. Сходство между терминами можно определить другими способами
Сюда могут входить:
Семантическое расстояние или длина пути по краям между терминами во внешнем ресурсе, таком как лексическая база данных.
Некоторые другие типы запросов с практическими рекомендациями
В патенте описаны некоторые другие случаи, когда поисковые запросы могут выполнять поиск запросов с практическими рекомендациями. Сюда могут входить:
- Установка запасной части на транспортное средство
- Установка сложного программного обеспечения
- Выполнение задания, связанного с поиском («как найти новый дом в Городе?»)
- Запрос местоположения, связанный с картой
Меры доверия, связанные с источниками
Мера достоверности для источника может указывать на эффективность этого источника в предоставлении правильных шагов для выполнения конкретного запроса с инструкциями.
Мера достоверности для источника может быть основана на:
- Своевременности данного источника (отметка времени, указывающая время последнего обновления источника.)
- Количество документов, ссылающихся на данный источник (с указанием популярности или авторитетности источника
- Количество исходящих ссылок из данного источника (с указанием полноты источника.)
- Если он основан на исходящих ссылках, он также может быть основан на коэффициенте выбора исходящих ссылок
- Анализ связности данного источника
- Насколько близко данный источник относится к задаче, указанной в запросе с практическими рекомендациями
- Свидетельство анкорного текста (если страница содержит ссылки с анкорным текстом, похожим на информацию о задаче, описанной на странице.)
- Частота посещения данного источника
- Анализ отношения информации к шуму данного источника. Этот шум может включать в себя такие вещи, как HTML-теги, пустое пространство, нерелевантные ссылки, спонсируемую рекламу или контент, закрывающий нерелевантный контент 9. 0192
- Количество шагов, предусмотренных для выполнения задачи запроса с инструкциями (большее количество шагов может указывать на полноту).
- На основе автора и/или издателя, связанного с данным источником (например, если запрос с инструкциями относится к технической задаче, является ли автор и/или издатель признанным авторитетом для такой технической задачи?)
- На основе автора источника и атрибутов автора, таких как соответствующая техническая квалификация и/или опыт для предоставления достоверной информации, связанной с запросом с инструкциями)
- Обсуждаемые здесь методы могут быть дополнительно объединены
Другие подходы
- В запросе с инструкциями может использоваться ответ, найденный в инструкции по выполнению задачи, и это руководство может иметь наивысшую меру достоверности в качестве источника шагов для выполнения задачи
- Один или несколько источников (источников с высоким рейтингом) могут использоваться для включения шагов для выполнения задачи с некоторыми шагами из одного источника и некоторыми из другого
- Некоторые дополнительные шаги могут быть включены как необязательные
- Некоторые этапы могут быть показаны и помечены как далекие от идеальных
- Информация могла отображаться в абзаце, а не в наборе шагов
- Методы обработки естественного языка могут использоваться для разделения абзаца или другого текстового сегмента на шаги, которые выполняют по крайней мере часть задачи
Патент также предоставляет информацию о рассмотрении сходства шагов, которые могут быть включены в выполнение задач в ответ на запрос с инструкциями, а также об оценках релевантности шагов. Оценка релевантности для шага может быть частично основана на доверительной мере для источников, в которых идентифицирован этот шаг. Таким образом, шаг из высоко оцененного технического руководства может иметь более высокий балл релевантности.
Оценка релевантности для группы шагов может основываться на количестве источников, которые определяют шаг, соответствующий группе шагов, необходимых для выполнения задачи.
Отдельные шаги, необходимые для выполнения задачи, могут быть основаны на оценках достоверности, таких как «высокая достоверность», «средняя достоверность». и «низкая достоверность». (в зависимости от того, как часто эти шаги появляются в источниках, указывающих, что шаг является обязательным.
Таким образом, релевантность шагов может основываться как на показателях достоверности из источников, так и на количестве источников, которые включают эти шаги.
Шаги должны соответствовать пороговому показателю релевантности, чтобы их можно было включить в базу данных контента как шаги, из которых могут поступать ответы на запросы с инструкциями.
Атрибуты для ответов на запросы с инструкциями
Атрибуты, связанные с набором шагов, могут быть идентифицированы и отображены вместе с этими шагами в ответ на запрос с инструкциями. Примеры могут включать:
- Название набора шагов (например, «Как заменить автомобильную шину»)
- Уровень квалификации (например, водительский возраст)
- Примерное необходимое время (например, двадцать пять минут)
- Необходимые инструменты (например, домкрат и гаечный ключ)
- Материалы, необходимые для выполнения задания
- Один или несколько источников (например, руководство пользователя), связанных с определенным набором шагов
- Одно или несколько предупреждений (например, припаркуйте автомобиль на ровной поверхности, поместите стопоры за колесами, чтобы предотвратить скатывание, включите ручной тормоз).
Источники могут включать источники, на которых основан набор шагов и/или которые определены как соответствующие одному или нескольким шагам.
Патент включает более подробную информацию об атрибутах, которые могут быть связаны с этапами, а также меры качества для каждого шага и каждого атрибута, который может быть связан с набором шагов.
Он также сообщает нам о метках, которые могут быть связаны с шагами, например, «наилучшее предположение» и «самая высокая достоверность» или «самая низкая достоверность».
Выводы с практическими рекомендациями
Я включил много разных аспектов этого патента, но в нем много подробностей, и я не все уловил.
Прочтите патент, чтобы понять, какие из них рекомендуются, и, надеюсь, этот пост облегчит вам изучение патента.
Один из моментов, который мне показался очень интересным в процессе оформления патента, заключался в том, сколько усилий требуется для сравнения различных источников информации о задачах и шагов для выполнения этих задач.
Я думаю, это помогает понять, почему некоторые ответы могут быть лучше, чем другие, для запросов с практическими рекомендациями.
Поиск новостей прямо в папку "Входящие"
*Обязательно
О Билле Славски
Обладая более чем 26-летним опытом работы в области SEO и степенью доктора юридических наук, Билл Славски является ведущим экспертом по патентам Google, связанным с SEO. Patent Exploration — один из самых быстрых и подробных способов найти новую информацию о SEO. Билл является редактором SEO by the Sea, известного блога по поисковой оптимизации, где он является автором более 1300 сообщений. Опыт Билла включает бренды из списка Fortune 500 и некоторые из крупнейших веб-сайтов в мире. Билл является автором для Moz, Search Engine Land и Search Engine Journal. В 2014–2021 годах он выступал на ведущих в отрасли международных конференциях по таким темам, как алгоритмы поисковых систем, универсальный и смешанный поиск, персонализация в поиске, поиск и социальные сети, а также проблемы дублированного контента, структурированные данные и схема 9.0005Обмен информацией о кампании в режиме реального времени с использованием Google Ads Data Hub | Саптасва Пал | MiQ Tech and Analytics
Понимание функций конфиденциальности при выполнении запроса с определенной частотой в Ads Data Hub
В нашем предыдущем блоге мы представили и объяснили важность решения Google для хранилища данных, ориентированного на конфиденциальность — Ads Data Hub (АДГ). ADH обеспечивает чистую среду, в которой рекламодатели могут продолжать использовать свои возможности моделирования данных в огороженном саду Google, а также получать информацию для оптимизации кампании.
Тем не менее, ADH не является идеальным решением для хранилища данных. Его ориентированный на конфиденциальность характер может вызвать проблемы с получением динамических данных для активной кампании, если целью является обновление данных каждые 2 или 3 дня. Нам в MiQ нужно было придумать решение, позволяющее получать детальную информацию о кампании в реальном времени с использованием источников данных ADH, а также обновлять данные для этой информации с определенной периодичностью. В этом блоге мы попытаемся понять проблемы, с которыми столкнулись, и необходимость дискретного решения.
Каждый раз, когда мы пишем запрос в ADH и устанавливаем контекст в этом блоге, нам нужно помнить о 3 проверках конфиденциальности, предоставляемых ADH, т. е.:
- Статическая проверка конфиденциальности — забота о конфиденциальности в наших запросах еще до того, как мы сможем запустить ее с помощью пользовательского интерфейса ADH или API (мгновенное исключение).
- Проверка конфиденциальности агрегирования — Это гарантирует, что каждая строка результата запроса ADH включает достаточно пользователей для защиты конфиденциальности конечных пользователей. По большинству запросов мы получаем только агрегированные данные по 50 и более пользователям. Однако запросы, извлекающие клики и конверсии, можно использовать для агрегирования данных по 10 и более пользователям. Любая строка, не соответствующая проверке агрегации, отфильтровывается.
- Дифференциальная проверка конфиденциальности — Это не позволяет нам собирать информацию об отдельных пользователях, выполняя один и тот же запрос несколько раз для близкого или перекрывающегося диапазона дат, тем самым предотвращая сравнение данных от нескольких наборов пользователей. Поэтому, когда какой-либо запрос пытается агрегировать один и тот же набор пользователей в одновременных заданиях на определенном уровне (скажем, агрегирование на уровне даты!!), тогда несколько строк могут быть отфильтрованы в нашем текущем задании и могут не отображаться в наборе результатов. если мы не упомянем Сводка отфильтрованных строк’ для нашего запроса.
Поскольку Ads Data Hub записывает результаты в таблицу BigQuery (BQ), иногда нам может понадобиться преобразовать эти результаты в презентабельный формат, прежде чем делиться ими с нашими командами/клиентами. Это можно сделать следующим образом:
- Либо путем прямого совместного использования таблицы BQ, если выходные данные из запроса ADH уже обеспечивают желаемую степень детализации.
- Или путем визуализации данных из таблицы BQ в инструменте визуализации данных или бизнес-аналитики.
А вот и Google Data Studio (GDS), который служит отличным инструментом визуализации данных и является частью Google Marketing Platform (GMP). Это помогает в создании интерактивных информационных панелей и настраиваемых красивых отчетов. Мы в MiQ используем GDS для отслеживания ключевых показателей эффективности для клиентов, визуализации тенденций и сравнения производительности с течением времени. Чтобы этот блог был кратким и лаконичным, мы больше не будем обсуждать GDS.
Запуск запроса ADH один раз и получение результатов в BigQuery
Рисунок 1. Идеальный поток для визуализации данных из ADH Представьте, что вы — рекламное агентство, проводящее кампанию для клиента/рекламодателя, и учетная запись рекламодателя в DV360 связана с вашей учетной записью ADH. Для кампании вы создали один заказ на размещение (IO) с набором из 5 позиций (LI) и хотите получить информацию обо всех 5 позициях (рис. 2), написав запрос ADH. Источники данных ADH-DV360 можно использовать, как показано на рис. 3, для создания необходимого запроса. Рисунок 3: Запрос ADH Кроме того, рекомендуется всегда упоминать сводку отфильтрованных строк (FRS) перед выполнением нашего запроса. В этом случае, чтобы указать FRS, 'Line_Item' и ' LINE_ITEM_ID' можно сохранить как - 848484' 848484 ' 848484' ' ' ' ' ' ' ' ' ' ' ' ' ' и . Вуаля!! Это было довольно просто, так как это было одноразовое задание, и, если вам повезет, ни одна из строк не будет отфильтрована из-за проверок агрегации. Выполнение запроса ADH с частотой обновления и получение результатов в BigQuery 'Constant' и 'Iffments' 84848484 ' 'media_cost' можно сохранить как - 'Сумма' . После завершения выполнения запроса ADH данные сбрасываются в BQ, откуда их можно легко отобразить на панели мониторинга GDS с помощью коннектора BQ.
Понимание постановки задачи
Давайте попробуем запустить тот же запрос, который мы написали выше, на следующий день, и вы можете получить результат, похожий на рисунок 4. Теперь, если мы попытаемся получить информацию, используя эту таблицу BQ, будет довольно вводящее в заблуждение. Итак, что пошло не так во втором запуске, когда три позиции не отображались по отдельности, а вместо этого были отфильтрованы?
Что вызвало проблему?
Это связано с тем, что ADH не является идеальным решением для хранилища данных, в котором данные можно было бы просто запрашивать и извлекать. Во втором сценарии задания из-за дифференциальных проверок конфиденциальности ADH мог обнаружить некоторые уязвимости на уровне отдельных пользователей при сравнении результатов задания с предыдущими результатами, поскольку может быть большое количество перекрывающихся пользователей, и, следовательно, несколько позиций получают отфильтровано. Обычные блокираторы, с которыми пользователи сталкиваются на данный момент:
- Данные отфильтровываются при каждом последующем запуске, оставляя несколько или ноль строк в выходной таблице.
- Если один и тот же запрос выполняется несколько раз, пользователю может быть заблокировано выполнение этих запросов на некоторое время (обычно 6–7 часов, что может увеличиться в зависимости от случая).
Как мы решили проблему?
На данный момент мы понимаем ограничения получения данных из одного и того же запроса ADH путем его многократного выполнения. Итак, что можно сделать, чтобы получать данные практически в режиме реального времени для понимания текущей кампании с частотой обновления 2 или 3 дня и получать большую часть данных из сводки отфильтрованных строк?
Рисунок 5: Архитектура потока данных Мы в MiQ попытались устранить это ограничение, включив отдельную архитектуру потока данных (рис. 5) в наш рабочий процесс , начиная со 2-го запуска .
- Начнем с того, что назовем таблицу BQ из 1-го прогона как основную таблицу . Мы начнем с резервного копирования основной таблицы из 1-го запуска или предыдущего запуска в новую таблицу, которая называется Backup Table .
- Затем мы продолжаем выполнять тот же запрос ADH с датой начала в качестве дня 1 кампании и , где дата окончания является последним допустимым днем в календаре (вчера), который заполнит результат в новую таблицу с именем Temporary Table .
- Затем мы полностью усекаем основную таблицу и записываем в нее все строки из временной таблицы.
- Следующим шагом является вставка строк из резервной таблицы с любыми уникальными строками (в нашем случае уникальными элементами строк), которые могли быть отфильтрованы во временной таблице из-за проверок конфиденциальности.
Теперь окончательная главная таблица во втором прогоне может выглядеть примерно так, как показано на рис. 6, где отсутствующие строки заполнены.
Объяснение очень простое.
Допустим, если «Идентификатор позиции 3» будет отфильтровано во 2-м запуске. Таким образом, эти конкретные данные будут частью сводки отфильтрованных строк. Затем та же позиция снова появляется при третьем запуске, после чего вы можете просто сложить такие параметры, как « показа» , « конверсии», и « media_cost» . Теперь эти данные будут вводить в заблуждение, поскольку данные для этой позиции не включают цифры из 2-го прогона . Таким образом, идея просто группировать данные и суммировать измерения не очень хороша.
Рисунок 7: Данные таблицы BQ на уровне даты Хотя приведенный выше аргумент в пользу выполнения запроса ADH за последние 1 или 2 дня вместо запуска его с первого дня кампании, может работать лучше, когда мы пытаемся получить информацию для конкретная дата.
Допустим, у нас уже есть запрос ADH и основная таблица с трендами на уровне дат с 1 по 3 января 21 года. Теперь мы хотим получить данные за 4 и 5 января, затем мы можем попробовать выполнить запрос ADH только за эти 2 дня, а затем объединить результат с главной таблицей (рис. 7).
Затем информация на уровне даты также поможет нам с информацией на другом уровне (например: «день недели» на уровне ), которую можно обсудить в другой раз!! 🙂
Заключение
Рисунок 8: Панель инструментов Data Studio с использованием главной таблицы Предложенное выше решение во всех наших будущих запусках может убедиться, что все новые строки обновлены, а строки, которые не обновлены, будут содержать данные из предыдущих бежит. Это дает нам еще одно представление о строках, которые не обновляются в течение длительного времени: позиции могут работать плохо или могут быть деактивированы. Приведенный выше алгоритм поможет получить максимальное количество деталей, запустив один и тот же запрос ADH с определенной частотой. Даже если строки будут отфильтрованы, у нас будет моментальный снимок старых данных, который будет отображаться на панели инструментов.
Главную таблицу (рис. 6), которая обновляется после каждого запуска, можно использовать на панели инструментов Data Studio (рис. 8) для отслеживания KPI клиента и визуализации тенденций. Каждый раз, когда обновляется главная таблица, мы можем обновить панель инструментов, чтобы отобразить свежие данные (выделено красным цветом ). В зависимости от того, какие важные решения могут быть приняты между кампаниями, чтобы оптимизировать их, чтобы повысить производительность и, следовательно, максимизировать прибыль.
Ориентация на окно ответов Google [Исследование включено]
Что такое блок ответов Google? В ходе обновленного исследования выборки из 6,3 миллиона ключевых слов мы обнаружили более 2100 уникальных возможных функций в поисковой выдаче Google (страницы результатов поисковой системы). Поле ответов Google — это один уникальный результат поисковой выдачи, основанный на графе знаний или полученный с сайта, который дает адекватный ответ на запрос пользователя.
Также известный как Featured Snippet, он обычно отображается в верхней части страницы результатов Google над обычными результатами. Избранные фрагменты обычно отображаются в виде поля с кратким текстовым ответом и исходным URL-адресом. Это попытка Google быстро отвечать на вопросы, при этом пользователю не нужно находить и нажимать на результат поиска Google.
На самом деле функции SERP — это способ Google улучшить взаимодействие с пользователем.
Вот пример для поискового запроса Google «внутренние и внешние ссылки» и соответствующего окна ответов:
сайт. Единственное, что отличается, — это представление списка веб-страниц в поисковой выдаче.
Featured Snippet также может представлять собой список или таблицу, в зависимости от запроса.
Взгляните на этот список лучших потоковых сервисов:
Взлет и падение ящика для ответов
Для некоторых контент-маркетологов победа в ящике для ответов является конечной целью. Но прежде чем вы сосредоточите всю свою SEO-стратегию на ее защите, важно знать, что в США «Ящик ответов» оказался нестабильным.
Несколько лет назад казалось, что рост окна ответов не остановить: в начале 2018 года 23% всех поисковых запросов вызывали его. И вдруг цифры упали.
(Обновления алгоритма и другие факторы могут изменить внешний вид поисковой выдачи.)
После достижения минимума в 8% частота окна ответов снова начала медленно увеличиваться, но, скорее всего, она не достигнет прежних уровней. . В конце лета 2020 года произошло еще одно снижение, и оно продолжало снижаться вплоть до марта 2021 года. Эти цифры основаны на выборке нашего набора данных Research Grid в США — мы рассмотрели более 100 миллионов ключевых слов.
Отрасль имеет большое значение
Колебания в окне ответов не должны отвлекать вас от его поиска, но вы должны знать, что распространенность окна ответов зависит от отрасли.
Помните о приведенных ниже цифрах, прежде чем ставить своей конечной целью получение избранного фрагмента.
Мы разделили наш набор данных на несколько отраслевых категорий, и неудивительно, что индустрия здравоохранения лидирует. В конце концов, WebMD был оригиналом, из которого все узнали о блоках ответов.
Поэтому, прежде чем приложить все усилия для защиты ящика для ответов, поймите, что — в зависимости от вашей отрасли — это может быть не самая ценная стратегия цифрового маркетинга.
Как выиграть ящик для ответов?
Существует несколько рекомендаций, которым следует следовать, чтобы увеличить свои шансы на получение ящика ответов Google.
1. Сосредоточьтесь на короткой продолжительности концентрации внимания Для вас очень важно связаться с клиентами в нужный момент. Google выделяет следующие моменты, с которыми должен быть знаком каждый цифровой маркетолог: момент «Я хочу знать»; момент «хочу пойти»; момент «я хочу сделать»; Я хочу купить момент.
Будьте ясны и лаконичны и дайте пользователям то, что они хотят!
2. Проверьте своих конкурентовПросмотрите, где конкуренты выиграли поле для ответов, чтобы получить ценные возможности для вас написать контент, за который вы хотите ответить. Информация о конкурентах раскрывает большие возможности Feature Snipple. Как и в любом контент-маркетинге, требуется надлежащее исследование ключевых слов.
3. Создайте страницу часто задаваемых вопросовВаша страница часто задаваемых вопросов должна содержать ответы на распространенные вопросы, которые могут задавать ваши пользователи. Выяснив, какие вопросы задают ваши клиенты, вы можете создать тип контента, который они, скорее всего, сочтут полезным.
4. Ответьте на пять букв W и H Подумайте о том, как пользователи используют Google. Есть несколько вопросов, которые используют все: кто, что, где, когда, почему и как! Поэтому прямо ответьте на эти вопросы в своем контенте. Данные также показали некоторые другие важные триггерные слова, включая Best, Can, Is и Top.
Сосредоточьтесь на содержании, в котором подробно описаны шаги и способы выполнения задач, связанных с вашим продуктом или услугой. «Как» и «Что есть» значительно опережают другие триггерные слова.
6. Выделите лучшие варианты для клиентовСоздавайте руководства по покупке, которые помогут в процессе принятия решений в формате списка и маркеров, чтобы продемонстрировать лучшие варианты для клиентов.
7. Включите формулировку определенияРазмещение предложения, отвечающего на вопрос, в верхней части вашего контента, отвечающего на вопрос «Что», помогает Google автоматически находить ответы.
8. Сосредоточьтесь на структурировании контента таким образом, чтобы он соответствовал намерениям потребителей Используйте форматы, удобные для ваших клиентов, и структурируйте контент в соответствии с намерениями. Рассмотрите возможность использования таблиц, упорядоченных списков, маркеров и видео.
Всегда используйте лучшие методы поисковой оптимизации, размещая ключевые слова и ключевые фразы в заголовке, метаданных, структурах URL и тегах alt. Также рассмотрите разметку Schema. Структурированные данные схемы помогают выделить конкретную информацию для поисковых систем. Он сообщает Google, что означает информация, а не только то, что она говорит.
10. Создавайте подробный контентВ своих усилиях по поисковой оптимизации вы никогда не должны забывать, что контент — это самое важное. Обязательно создавайте соответствующий контент, который дает подробные ответы на вопросы, которые задает ваша целевая аудитория.
11. Используйте исследовательскую сетку seoClarity Чтобы помочь нашим клиентам изучить и понять все возможности контента, мы представили исследовательскую сетку. Это самое современное и всестороннее решение, позволяющее получить информацию о пробелах в контенте, возможностях и производительности для любого домена, поддомена и URL-адреса.
Он предназначен для оптимизации и создания проверенного контента. Построенный на базе Clarity Grid, он обеспечивает мгновенный доступ к триллионам точек данных. Также доступна бесплатная версия для мгновенного доступа.
12. Используйте анализ возможностей окна для ответов seoClarity
Единственный в своем роде на рынке, наш вариант "Ящик для ответов" позволяет вам увидеть сайт, который в настоящее время владеет ящиком для ответов в вашей отрасли. Используйте полученные знания и поймите возможности легкого создания и оптимизации контента, который может конкурировать за этот блок ответов.
13. Понимание цели поиска
Важно понимать цель запросов, которые запускают универсальный тип ранжирования, включая видео, PLA, люди также спрашивают и локальные. Посмотрите на страницы с высоким рейтингом для ключевых слов, которые имеют намерение осведомленности и внимания от имени человека, проводящего поиск.
Думая об этапах осознания и рассмотрения на пути покупателя, а также оптимизируя контент, чтобы отвечать на эти вопросы или реагировать на проблемы, которые испытывает ваша аудитория, вы сможете получить окно ответов для настольного и голосового поиска.
14. Отслеживание эффективностиКак всегда, очень важно отслеживать эффективность в соответствии со своей стратегией и целями.
Чтобы узнать больше об оптимизации ящиков для ответов, перейдите к разделу «Как отслеживать возможности ящиков для ответов с помощью стратегии ящиков для ответов»
:
Google отвечает на ваш запрос Чтобы узнать больше об этих крупицах знаний, мы просмотрели более 40 миллионов (!) ключевых слов. В этом наборе мы сосредоточились на результатах настольных ПК в США. Из них чуть менее 4 миллионов вернули ящики для ответов.
Это соответствует примерно 9,5%, поэтому процент результатов поиска с окнами ответов, безусловно, значителен. Это дает прекрасную возможность для всех сайтов, поскольку рейтинг кликов (CTR) и трафик с них кажутся выше, чем с первой позиции.
Статистика блоков ответов
Неудивительно, что когда дело доходит до результатов блоков ответов, Википедия лидирует с большим отрывом — 15,4% из почти 4 миллионов блоков ответов. Отрасль здравоохранения хорошо представлена между WebMD, Mayoclinic и Healthline, что в совокупности составляет 4,8%.
Google сообщает нам, что для мобильных устройств с ответами на вопросы о состоянии здоровья будет еще много интересного. Финансы имеют некоторое представительство в Investopedia, и в этой отрасли есть много возможностей для расширения в будущем.
Все эти 10 основных доменов узнаваемы и, по мнению большинства, являются логичным выбором в качестве ресурсов в своих уважаемых областях. Один из основных способов, с помощью которого поисковая система может определить это, — это связывание данных и метрик, подобных PageRank.
Взглянув на показатели оценки Majestic для этих доменов, мы лучше понимаем, почему эти домены появляются в окнах ответов чаще, чем другие. Среднее значение потока доверия и потока цитирования для этих ведущих доменов ящиков для ответов составляет более 80 из 100 возможных. Это означает, что отношение потока (CF/TF) примерно в два раза лучше, чем в среднем.
Визуализация примерно 4 миллионов ключевых слов, вызывающих окна ответов, по группам объема поиска показывает сильно логарифмическую диаграмму. Мы наблюдали появление 56 уникальных экземпляров примерно 85 сегментов объема поиска по ключевым словам. Этот график показывает, что окна ответов чаще появляются для ключевых слов со средним и длинным хвостом или для тех, где диапазон объема поиска составляет менее 1000.
Чтобы получить более четкое представление об этом, мы можем взглянуть на количество слов в запросе. Это показывает нам, что подавляющее большинство, более 65% запросов, которые отображают окна ответов, содержат от 3 до 5 слов. Эта несовершенная колоколообразная кривая дает представление о том, какова длина (в словах) запросов, которые вызывают окна ответов.
Почти четверть всех блоков ответов содержат конкретные вопросы, такие как: кто, где, когда, почему, что и как. Эти любознательные слова обычно рассматривались как начальные слова запроса (первые 2 слова в запросе).
10 наиболее часто встречающихся начальных слов и их процент от общего числа запросов можно увидеть ниже:
Некоторые из них были более распространены в доменах в сфере здравоохранения, таких как WebMD, где большинство запросов следуют образец выше, где их главными стартовыми словами были «как» и «что есть».
Однако не все домены следовали этому шаблону. Например, в финансовой сфере Investopedia увидела, что большинство ее запросов начинаются с «что есть», а затем с «определения». Это делает очевидным, что некоторые фразы более специфичны для определенных отраслей, что логично.
Мобильные блоки ответов
Являются ли блоки ответов одинаковыми на разных устройствах? Мгновенный ответ: Не всегда. Когда окна ответов появляются для запроса как на мобильном, так и на настольном компьютере, чаще всего они идентичны. Но есть и исключения, как например с поиском по запросу "seo и sem".
В окне ответов на рабочем столе отображается URL-адрес источника с сайта www.reliablesoft.net, тогда как в окне ответов на мобильном устройстве отображается URL-адрес источника с сайта blog.hubspot.com. Первые 3 результата (на изображении рабочего стола) идентичны для разных устройств. Это потому, что надежный софт не подходит для мобильных устройств?
Не в этом случае, так как оба URL-адреса прошли тест для мобильных устройств, основанный на инструменте Google для мобильных устройств. Что делает это более интересным, так это то, что HubSpot цитирует статью из Википедии.
Наблюдения за блоком ответов
В то время как все URL-адреса YouTube для настольных компьютеров отображаются с использованием HTTPS, URL-адрес YouTube для мобильных устройств (m.youtube.com) отображается как HTTP в 99% случаев. Однако все они перенаправляют на свои аналоги HTTPS, указывая на то, что окна ответов могут обновляться нечасто. Поскольку на большинстве устройств на базе Android предустановлен YouTube, это не так часто встречается.
Кроме того, в URL-адресе окна ответов используется несколько экземпляров протокола FTP. Так обстоит дело в Государственном университете Сан-Диего, где отображаемый URL-адрес — ftp://rohan.sdsu.edu/ для «введите трансмиссионную жидкость» (Google, США).
Существуют также случаи использования IP-адресов в качестве URL-адреса окна ответов. Это случай Канадского агентства по доходам, чье веб-представительство расположено по адресу 198.103.185.80, и его можно увидеть при поиске «netfilecanada» в Google Canada (Google. ca).
Ответы на вопросы по исследованиям — TL; DR
В конце концов, у Google есть логика, определяющая, какие запросы отображают блоки ответов. Однако определить, что это такое и как оно обрабатывается, не так просто, как можно подумать.
Эта логика, как мы видели, различается между настольными и мобильными устройствами. Это также не обязательно должен быть традиционный веб-URL, такой как IP-адрес или местоположение FTP. Также можно использовать описания видео, например, найденные на YouTube. Частота обновлений окна ответов, таких как отображение URL-адреса, кажется разной.
- Частота зависит от отрасли
- Тип устройства играет роль
- Блоки ответов не застаиваются, но могут отображать старые URL-адреса
- Ящики для ответов различаются в зависимости от отрасли, когда речь идет о типах запросов
- Полномочные домены более распространены, чем Featured Snippet
- Окна ответов появляются чаще для 3-5 запросов с ключевыми словами
- Большинство запросов в окне ответов имеют средний объем поиска менее 1000
В целом их следует рассматривать в первую очередь как возможность для запросов, ответы на которые носят описательный характер и требуется больше информации, чем можно найти в 2-3 предложениях (с учетом вашей отрасли).
И наоборот, упрощенные по своей природе ответы, скорее всего, не будут привлекать трафик, если ответ можно будет просмотреть и понять в поисковой выдаче. Это означает, что необходимо немного изучить поисковый запрос, чтобы получить представление о намерениях.
Хотите узнать, какие ключевые слова ранжируются в вашем домене, чтобы вызвать окна для ответов? Запросить демо!
-- Райан Хойзер, Менеджер по продуктам и техническим услугам, seoClarity
Какова распространенность запросов о здоровье во всемирной паутине? Качественный и количественный анализ поисковых запросов в Интернете
- Список журналов
- AMIA Annu Symp Proc
- v.2003; 2003 г.
- PMC1480194
AMIA Annu Symp Proc. 2003 г.; 2003: 225–229.
1), 2) и 2)
Информация об авторе Информация об авторских правах и лицензии Отказ от ответственности
Хотя часто говорят, что информация о здоровье является наиболее востребованной информацией в Интернете, эмпирические данные о фактической частоте поисковых запросов, связанных со здоровьем, в Интернете отсутствуют. В настоящем исследовании мы стремились определить распространенность поисковых запросов, связанных со здоровьем, в Интернете, анализируя поисковые запросы, вводимые людьми в популярные поисковые системы. Мы также предприняли некоторые предварительные попытки качественно описать и классифицировать эти поиски. Периодические трудности с определением того, что представляет собой поиск, связанный со здоровьем, побудили нас предложить и проверить простой метод автоматической классификации строки поиска как «связанной со здоровьем». Этот метод основан на определении доли страниц в Интернете, содержащих строку поиска и слово «здоровье», как доли от общего количества страниц, содержащих только строку поиска. Используя человеческие коды в качестве золотого стандарта, мы построили кривую ROC и эмпирически определили, что если эта «коэффициент встречаемости» превышает 35%, можно сказать, что строка поиска связана со здоровьем (чувствительность: 85,2%, специфичность 80,4%). . Результаты нашего «человеческого» кодирования поисковых запросов определили, что около 4,5% всех поисков «связаны со здоровьем». По нашим оценкам, во всем мире каждый день в Интернете выполняется не менее 6,75 миллионов поисковых запросов, связанных со здоровьем, что примерно равно количеству поисковых запросов, которые выполнялись в системе NLM Medlars за 19 годов.96 за полный год.
Часто говорят, что наиболее распространенной причиной, по которой люди выходят в интернет, является поиск медицинской информации. Это утверждение, по-видимому, основано в первую очередь на результатах опросов, таких как Pew Internet Survey, в котором утверждается, что 55% тех, у кого есть доступ в Интернет, использовали Интернет для получения информации о здоровье или медицинской информации 1 . Однако неясно, каковы фактический объем и распространенность поисковых запросов, связанных со здоровьем, в Интернете по отношению к общему количеству поисковых запросов, проводимых ежедневно в Интернете. Учитывая богатый источник данных, который представляет собой Интернет для изучения поведения, связанного с поиском личной информации о здоровье, наблюдается удивительная нехватка данных о том, что потребители ищут в Интернете и как потребители это делают 9.1033 2 . Подобно тому, как Дайана Форсайт когда-то утверждала, что «разработка и внедрение соответствующих автоматизированных решений предполагает знание информационных потребностей врачей» 3 , и впервые применила метод этнографических методов для облегчения непосредственного наблюдения за общением об информационных потребностях врачей, мы считаем, что понимание здоровья потребителей потребности в информации являются необходимым условием для создания решений в области информатики для здоровья потребителей 4 ; 5 и, в свою очередь, требует прямого наблюдения за информационным поведением потребителей. Наша собственная предыдущая работа в этой области включает полуколичественный контент-анализ электронных писем пациентов, обращающихся к врачам 9.1033 6 , качественное исследование с фокус-группами и прямое наблюдение лаборатории юзабилити о том, как потребители ищут в Интернете 7 . В настоящем исследовании мы стремились определить фактическую распространенность запросов, связанных со здоровьем, в Интернете путем анализа поисковых запросов, введенных людьми в популярные поисковые системы, и сделать некоторые предварительные попытки качественно описать и классифицировать эти запросы.
Исследования, изучающие распространенность запросов, связанных со здоровьем (или связанные исследования, пытающиеся определить, например, количество веб-сайтов, связанных со здоровьем), осложняются трудностью определения того, что означает «связанный со здоровьем». Определение ВОЗ здоровья как «состояния полного физического, душевного и социального благополучия, а не просто отсутствия болезней или физических дефектов» (Преамбула к Уставу Всемирной организации здравоохранения) настолько широкое, что даже финансовая информация может быть оспорена. быть «связанным со здоровьем».
Трудности определения того, что является «связанным со здоровьем» (и трудоемкий процесс ручного кодирования), побудили нас разработать и проверить простой алгоритм для автоматического определения запросов, связанных со здоровьем. Этот метод также предлагает рабочее определение того, что представляет собой «связанная со здоровьем» информация или поисковое выражение.
Сбор поисковых запросов
Поисковые термины были собраны из двух поисковых систем, которые позволяют «заглянуть» в поиск, т. е. пользователи могут видеть, какие запросы в настоящее время вводят другие пользователи. Двумя используемыми поисковыми системами были Metaspy (http://www.metaspy.com/), в которой перечислены поисковые запросы из Metacrawler и AskJeeves (http://www.ask.com/docs/peek/). В то время как Metaspay перечисляет традиционные условия поиска, запросы Askjeeves имеют форму вопросов, например «Где я могу найти информацию о морских растениях и водорослях?». Был разработан временной скрипт, который периодически посещал и «счищал» эту информацию, т. е. HTML анализировался, из него извлекалась соответствующая информация (поисковый запрос) и записывалась в базу данных. 29В период с февраля 2001 г. по апрель 2002 г. в MetaSpy было получено 85 поисковых запросов, а в период с февраля 2001 г. по апрель 2001 г. — 475 поисковых запросов. Это должна быть случайная выборка поисковых запросов, введенных пользователями.
Кодирование поисковых запросов человеком
Был разработан веб-интерфейс, позволяющий кодировщикам классифицировать запросы. Меташпионские поиски были классифицированы как «не связанные со здоровьем», «отчасти связанные со здоровьем» и «явно связанные со здоровьем». Последние две категории позже были объединены для анализа в одну категорию запросов, связанных со здоровьем. Вопросы AskJeeves также были классифицированы как «не связанные со здоровьем» или «связанные со здоровьем», а запросы из последней категории также были закодированы с помощью таксономии Ely, которая была разработана для классификации информационных потребностей врачей и предлагает в общей сложности 66 различных кодов. 8 . Одним из аспектов этого исследования было изучение того, в какой степени эта таксономия будет полезна и применима к вопросам кодирования потребителей. Все запросы были закодированы двумя кодерами независимо друг от друга, и был рассчитан межнаблюдательный коэффициент надежности.
Автоматизированный метод классификации запросов, связанных со здоровьем
Высокая изменчивость разных наблюдателей в определении того, что связано со здоровьем, и трудоемкое ручное кодирование послужили мотивом для разработки и проверки автоматического метода классификации поисковых терминов и запросов как «связанных со здоровьем». .
Наш метод автоматической классификации предлагает использовать допущение о том, что поисковые термины, связанные со здоровьем, должны встречаться на результирующих веб-страницах вместе со словом «здоровье» чаще, чем поисковые термины, не связанные со здоровьем. Мы используем поисковую систему (google) для определения количества страниц, найденных с поисковым запросом И словом «здоровье», по отношению к количеству страниц, найденных только с поисковым запросом. Эта пропорция, которую в дальнейшем мы называем «коэффициентом совпадения» (с), показывает, насколько часто поисковые запросы встречаются на одной странице со словом «здоровье», и может рассматриваться как метрика того, как здоровье связано с поиском. запрос:
Если страницы (запрос)=0, то c:= 0.
Если c>=? тогда говорят, что запрос связан со здоровьем, иначе не связан со здоровьем.
Где
c := коэффициент совпадения
Запрос := поисковый термин(ы) в вопросе
Pages() := количество совпадений (страниц), полученных Google
?:= порог [0,1 ]
Для поисковых запросов или терминов, не связанных со здоровьем (например, «Лондон»), с должно быть маленьким, что означает, что очень небольшая часть страниц, содержащих поисковые термины, также содержит слово «здоровье». Напротив, для запросов, связанных со здоровьем, этот показатель должен быть ближе к 1, что указывает на высокую степень совпадения со словом «здоровье». Если c больше или равно порогу? тогда поисковый запрос можно считать связанным со здоровьем. Оптимальный порог? который делит поисковые термины, связанные со здоровьем, от поисковых терминов, не связанных со здоровьем, был эмпирически определен как 0,35 (см. ниже), т. е. если более 35% страниц с поисковыми терминами также содержат слово «здоровье», то можно сказать, что поисковый запрос является связанные со здоровьем.
Например, если мы хотим узнать, связан ли поисковый запрос «кисты яичников» со здоровьем, мы вводим этот поисковый запрос в Google и записываем количество найденных страниц (59100 просмотров), затем вводим поисковый запрос «кисты яичников». здоровье» (обратите внимание, что Google использует неявный оператор И), который вызвал 49 800 обращений, в результате чего частота совпадений составила 49 800/59 100 = 84,2%. Напротив, такой поисковый запрос, как «Regents Park London», дает коэффициент совпадения только 59 600/10 800 = 18,1% и, следовательно, может быть исключен как «не связанный со здоровьем».
Для автоматического определения c для каждого из 2985 поисковых терминов из Metaspy мы разработали компьютерный скрипт, который использует Google API (http://www. google.com/apis/) для автоматического запроса к базе данных Google страниц, содержащих поиск запрос – сначала вводится сам по себе, а затем в сочетании со словом здоровье. Скрипт считывал количество обращений (страниц), найденных по этим двум запросам, результаты записывались в базу данных, а коэффициент совпадения для каждого запроса рассчитывался путем деления цифр по приведенной выше формуле. Если исходный поисковый запрос имеет 0 совпадений (что произошло 113 раз), коэффициент совпадения (COR) устанавливается равным нулю.
Проверка метода автоматической классификации
Мы проверили описанный выше автоматический метод на соответствие кодированию поисковых запросов человеком, сведя в таблицу коэффициенты совпадений в сравнении с консенсусной классификацией человека для каждого поискового запроса. Мы нарисовали кривую рабочих характеристик приемника (ROC) и кривую точности-отзыва, чтобы определить чувствительность (=отзыв), специфичность и точность (=положительное прогностическое значение) этого метода для различных точек отсечки?.
Ручное кодирование условий поиска метакраулера
2985 поисковых выражений, собранных из Metacrawler, были закодированы двумя авторами (GE, CK) независимо друг от друга как «связанные со здоровьем» (включая «отчасти связанные со здоровьем») или «не связанные со здоровьем». 108 (3,6%) запросов были закодированы обоими кодировщиками как «связанные со здоровьем», 2827 (94,7%) запросов были согласованно классифицированы как не связанные со здоровьем, а 50 (1,7%) получили несогласную классификацию. Поисковые выражения, которые были закодированы несогласованно, включали, например, «лечение зависимости от порнографии», «транссексуал», «прекратите сосать палец», «статистика подростковых самоубийств», «кристаллы кальция» и т. д. Эти запросы иллюстрируют иногда трудности с определением того, что « связанные со здоровьем». Мы еще раз прошлись по всем несогласованным поисковым выражениям, чтобы определить консенсусное кодирование. Большинство поисковых запросов, закодированных одним из кодировщиков как связанные со здоровьем, в конечном итоге получили консенсусное кодирование как «связанное со здоровьем». Согласно итоговому консенсус-рейтингу, 135 (4,5%) всех поисковых запросов можно считать «связанными со здоровьем». Хотя формально они не были закодированы, большинство оставшихся поисковых запросов оказались связанными с порнографическими материалами.
Ручное кодирование вопросов AskJeeves
475 вопросов AskJeeves были закодированы двумя кодировщиками независимо друг от друга (). Два кодировщика определили 48 и 45 (10,1% и 9,5%) вопросов, связанных со здоровьем, соответственно. 44 вопроса (9,3%) были последовательно закодированы как «связанные со здоровьем» (дискордантно закодированные вопросы включают, например, «Что нужно каждому ребенку для полноценного развития?», «Как долго я буду жить?», «Где я могу увидеть фотографии ДНК ?» и «Где я могу найти ресурсы от Britannica.com по апатии?»). 36 из них были закодированы с использованием согласующихся кодов Эли, а 8 вопросов были закодированы несогласованно. Подавляющее большинство вопросов (22) были закодированы как «немедицинские – образование – пациент». Таксономия Эли, первоначально разработанная для классификации информационных потребностей врачей, оказалась не очень полезной для кодирования вопросов потребителей. Поэтому в настоящее время мы разрабатываем новую систему кодирования вопросов о здоровье потребителей.
Table 1
Codings of the AskJeeves questions with the Ely classification 8
| Coder 1 | Coder 2 | n |
|---|---|---|
| Not health related | Не связанный со здоровьем | 426 |
| Не связанный со здоровьем | Эпидемиология - не классифицированная в других рубриках | 1 |
| Диагноз - причина/интерпретация клинического симптома | 4 | |
| Диагностика - Ориентация - Состояние | 1 | |
| Лечение - лекарственное средство - побочные эффекты - результаты, вызванные лекарственным препаратом. состав | 1 | |
| Лечение – назначение лекарств – механизм действия | Лечение – назначение лекарств/состав | 1 |
| Лечение – не ограничивается, но может включать назначение лекарств – как это делать | Не связанное со здоровьем | 1 |
| Лечение – не ограничивается, но может включать назначение лекарств – как это делать | 2 | 3 Лечение – не классифицированное в других рубриках | 1 |
| Ведение (без уточнения диагностики или терапии) – не классифицировано в других рубриках | 1 | |
| Ведение (без уточнения диагностики или терапии) – не классифицировано в других рубриках | Epidemiology - not else-where classified | 1 |
| nonclinical - education- patient | Not health related | 3 |
| nonclinical - education- patient | Diagnosis - orientation - condition | 6 |
| неклинические - обучение - пациент | лечение - не классифицированное в других рубриках | 1 |
| неклиническое - обучение - пациент | 22 | |
| nonclinical - education- patient | nonclinical - not elsewhere classified | 1 |
| nonclinical - education- patient | nonclinical - legal | 1 |
| 475 | ||
Open в отдельном окне
Во время кодирования также стало ясно, что вопросы, предоставленные AskJeeves как «то, что люди спрашивают прямо сейчас», вряд ли были реальными вопросами, заданными людьми. Скорее, большинство вопросов, казалось, были «предварительно подготовленными» вопросами, предоставленными AskJeeves, которые были сопоставлены с запросами, введенными пользователями. Кроме того, вопросы, похоже, были отфильтрованы, так как не отображались вопросы сексуальной направленности (которые в меташпионском анализе составляли большинство поисковых запросов). Таким образом, отображаемые вопросы AskJeeves, вероятно, дают предвзятое и нерепрезентативное представление об информационных потребностях людей. Это объясняет более высокую распространенность запросов, связанных со здоровьем, по сравнению с поисками Metaspy.
Валидация метода автоматической классификации
«Коэффициенты совпадения» для каждого поискового запроса поисковых запросов метакраулера как метрики их связи со здоровьем были рассчитаны, как описано выше (как соотношение между страницами с поисковым запросом и здоровье на страницы только с поисковым запросом). показывает распределение частоты совпадений во всем наборе данных Metacrawler.
Открыть в отдельном окне
Распределение «коэффициентов совпадения» поисковых запросов от метакраулера. Чем выше показатель, тем выше доля страниц, на которых поисковый запрос и слово «здоровье» встречаются вместе, и, предположительно, тем больше поисковый запрос связан со здоровьем. Коэффициент сочетанности можно рассматривать как «индекс связанности со здоровьем».
Чтобы найти оптимальный порог? (точка отсечки для частоты совпадений), которая позволяет оптимально различать связанные со здоровьем и не связанные со здоровьем поисковые запросы, мы нарисовали кривую рабочих характеристик приемника (ROC) с различными пороговыми параметрами? (), показывая характеристики теста как компромисс между специфичностью и чувствительностью, с человеческим кодированием в качестве золотого стандарта и автоматической классификацией с порогом? как тест на то, насколько поиск связан со здоровьем. Другой способ оценить метод — посмотреть на кривую точность-отзыв ().
Открыть в отдельном окне
Кривая ROC (рабочие характеристики приемника)
Кривая ROC показывает, что точка отсечки ? =35% имеет оптимальный компромисс между чувствительностью 85,2% (115/135, т. е. доля терминов, связанных со здоровьем, правильно подобранных этим методом) и специфичностью 80,4% (2292/2850 поисковых терминов, не связанных со здоровьем). были отфильтрованы) (см. ).
Таблица 2
Таблица непредвиденных обстоятельств с истинными положительными результатами (TP), ложными положительными результатами (FP), ложноотрицательными результатами (FN) и истинно отрицательными результатами (TN) для метода автоматической классификации с порогом? = 0,35 для частоты встречаемости
| Manual coding | |||
|---|---|---|---|
| Auto-coding | Health-related | Non-health | |
| c >= . 35 | 115 (TP) | 558 (FP ) | 673 |
| c < .35 | 20 (FN) | 2292 (TN) | 2312 |
| 135 | 2850 | 2985 | |
Открыть в отдельном окне
Автоматический метод можно сделать более чувствительным (в ущерб специфичности) если порог ниже? выбран. Например, если качественный исследователь хочет сделать предварительный выбор всех возможных поисковых запросов, связанных со здоровьем, не рискуя отфильтровать слишком много истинных терминов, связанных со здоровьем, он / она выберет более низкий порог. Например, с? из 20% метод по-прежнему выявляет 123/135 запросов, связанных со здоровьем (чувствительность 91,1%), со специфичностью 58,7% (отфильтровано 1673/2850 терминов, не связанных со здоровьем). Чтобы не пропустить много терминов, связанных со здоровьем, исследователю достаточно просмотреть менее половины (45,6%) первоначальных поисковых запросов.
Для других приложений может быть уместна очень конкретная классификация. Например, если порог установлен на 80 %, всего остается только 56 поисковых запросов, а метод является максимально точным с точностью (= положительное прогностическое значение) 66 % (это означает, что 66 % из 56 поисковых терминов на самом деле связаны со здоровьем). Специфика 99,3%, но чувствительность (отзыв) составляет 27,4% (это означает, что в окончательный набор входят только 37/135 терминов, связанных со здоровьем).
Основываясь на нашем анализе, мы подсчитали, что примерно 4,5% всех поисковых запросов в Интернете могут быть связаны со здоровьем. Хотя запросы, связанные со здоровьем, составляют относительно небольшую часть поисковых запросов в Интернете, абсолютные цифры по-прежнему впечатляют: Google сообщает о 150 миллионах поисковых запросов в день на всех региональных партнерских сайтах вместе взятых, что означает, что около 6,75 миллионов поисковых запросов, связанных со здоровьем в день только в Google ведется. Для сравнения, в 1996 году NLM сообщила о 7 миллионах поисковых запросов в системе MEDLARS (Medline) в год .
Хотя наша оценка распространенности в 4,5% основана на данных одной поисковой системы (MetaCrawler), мало оснований полагать, что более часто используемая поисковая система, такая как Google, имеет другую распространенность запросов, связанных со здоровьем. Более высокая распространенность запросов, связанных со здоровьем, на AskJeeves, вероятно, является результатом предвзятого (отфильтрованного) отображения запросов на этом сайте.
Мы считаем, что прямой анализ поисковых запросов дает гораздо более точную картину того, что люди делают и что ищут в Интернете, чем, например, данные опросов, таких как Pew Internet Survey, которые в настоящее время доминируют в литературе. Мало того, что людям трудно вспомнить в ходе опроса, какую информацию они чаще всего находят в Интернете, точность данных опроса также страдает от предвзятости социальной желательности — редко люди, например, признаются, что ищут порнографические материалы, хотя такие поиски, по-видимому, являются наиболее распространенными.
Чтобы упростить дальнейшие исследования и классификацию поисковых запросов, мы также разработали и утвердили автоматический метод выявления запросов, связанных со здоровьем. Этот метод, который рассматривает совпадения терминов со словом «здоровье», может быть расширен, чтобы классифицировать любые короткие фразы или тексты как связанные со здоровьем. Потенциальные приложения включают автоматический анализ электронных писем и классификацию на связанные со здоровьем и не связанные со здоровьем, чтобы автоматически направлять входящие электронные письма техническому или медицинскому персоналу. Каждое предложение электронной почты может быть подвергнуто анализу совпадений, и может быть рассчитана средняя частота совпадений. В настоящее время проводится валидация этого метода.
Джим Лай запрограммировал сценарии, Дэвид Мейсон обеспечил техническую поддержку.
1. Проект Pew Internet and American Life. Революция в области онлайн-здравоохранения: как Интернет помогает американцам лучше заботиться о себе. 26.11.2000.
2. Ставри ПЗ. Поиск информации о личном здоровье: качественный обзор литературы. Мединфо. 2001; 10:1484–8. [PubMed] [Google Scholar]
3. Forsythe DE, Buchanan BG, Osheroff JA, Miller RA. Расширение концепции медицинской информации: наблюдательное исследование информационных потребностей врачей. Компьютер Биомед Рез. 1992;25:181–200. [PubMed] [Google Scholar]
4. Эйзенбах Г. Информатика здоровья потребителей. БМЖ. 2000;320:1713–6. [Бесплатная статья PMC] [PubMed] [Google Scholar]
5. Хьюстон Т.К., Чанг Б.Л., Браун С., Кукафка Р. Информатика здоровья потребителей: согласованное описание и комментарии членов Американской ассоциации медицинской информатики. Proc AMIA Symp. 2001: 269–73. [Бесплатная статья PMC] [PubMed] [Google Scholar]
6. Eysenbach G, Diepgen TL. Пациенты ищут информацию в Интернете и обращаются за телеконсультацией: мотивация, ожидания и неправильные представления, выраженные в электронных письмах, отправленных врачам. Арка Дерматол. 1999;135:151–156. [PubMed] [Google Scholar]
7. Эйзенбах Г., Келер К. Как потребители ищут и оценивают информацию о здоровье во всемирной паутине? Качественное исследование с использованием фокус-групп, юзабилити-тестов и глубинных интервью. БМЖ. 2002; 324: 573–7. [Бесплатная статья PMC] [PubMed] [Google Scholar]
8. Ely JW, Osheroff JA, Gorman PN, Ebell MH, Chambliss ML, Pifer EA, et al. Таксономия общих клинических вопросов: классификационное исследование. БМЖ. 2000;321:429–32. [Бесплатная статья PMC] [PubMed] [Google Scholar]
Материалы ежегодного симпозиума AMIA предоставлены здесь с разрешения Американской ассоциации медицинской информатики
Частота поисковых запросов, связанных со здоровьем, в Интернете | Образ жизни | JAMA
Письмо об исследовании
5 ноября 2003 г.
Джордж Филиппов, доктор философии 1 ; Патрик Дж. Филлипс, FRACP 1
Принадлежность автораИнформация о статье
1 Отделение эндокринологии, Больница и служба здравоохранения королевы Елизаветы, Вудвилл, Австралия
ДЖАМА. 2003;290(17):2258-2259. дои: 10.1001/jama.290.17.2258
Редактору: Wolfe et al 1 недавно сообщили, что 53% взрослого населения США используют Интернет для поиска информации, связанной со здоровьем. Однако измерение использования Интернета, как правило, проводилось на основе самоотчетов, а не на основе оценки фактического поискового поведения. 1 ,2 Поскольку поисковые системы представляют собой основной метод поиска информации в Интернете, 3 мы проанализировали частоту использования ключевых слов поисковых систем для вопросов, связанных со здоровьем.
Методы
В период с 9 сентября 2001 г. по 20 июля 2002 г. мы оценили 300 наиболее распространенных запросов в отчете Wordtracker Top 500 Keyword Report, который публикуется по электронной почте каждую субботу. 4 Мы изучили в общей сложности 39 еженедельных отчетов, каждый из которых включал список 300 самых популярных запросов и общее количество запросов за исследуемый 24-часовой период. Средняя (SD) частота запросов за 24 часа составила 5 100 000 (900 000) и учитывала все запросы от двух крупных интернет-метакраулеров, Metacrawler и Dogpile. Хотя 300 самых популярных списков, которые мы оценили, были отфильтрованы, чтобы исключить большую часть запросов, связанных с порнографией, такие запросы не были исключены из общих показателей активности за 24 часа. Wordtracker утверждает, что от 20% до 25% всех поисковых запросов относятся к порнографии. 4
Чтобы стандартизировать различия в общем количестве запросов между отдельными отчетами, 300 самых популярных ключевых слов в каждом отчете были разделены на общий уровень активности за 24 часа, а результат умножен на 1 миллион, что дало показатель «количество обращений на миллион запросов». " Из-за потенциально большого количества возможных поисковых терминов, связанных со здоровьем, они были классифицированы как связанные со здоровьем на интуитивной основе. Из нашей первоначальной проверки неотфильтрованных 300 лучших отчетов маловероятно, что термины, связанные со здоровьем, будут удалены порнографическими фильтрами. Кроме того, нефильтрованные списки 300 лучших, которые содержали много высокопоставленных терминов, связанных с порнографией, значительно уменьшили появление большинства терминов, связанных со здоровьем.
Полученные результаты
Количество идентифицированных терминов, связанных со здоровьем, было небольшим. Такие термины появлялись нечасто, и каждый из них обычно занимал низкие места в топ-300 списков (таблица 1). Чтобы представить эти оценки в перспективе, максимальная частота запросов за 24 часа для термина в течение периода исследования составляла 3409 на миллион запросов ( Хэллоуин , 11 марта 2001 г. ), в то время как запросы по гороскопам ранжировались во всех отчетах и усреднялись. 180 за миллион запросов. Многие из терминов, связанных со здоровьем, по-видимому, связаны с преходящей рекламой в средствах массовой информации или отражают другую краткосрочную рекламу. Например, чрезвычайно высокий уровень запросов об анорексии 8 декабря 2001 г. (таблица 1) последовал за телешоу на интернет-сайтах, выступающих за анорексию, 5 , в то время как единственное появление акриламида в топ-300 появилось одновременно с сообщениями СМИ о высоких уровнях этого потенциального канцерогена в жареных продуктах. 6 Общие запросы, связанные со здоровьем (например, здоровье , женское здоровье и PubMed ) были самыми высокими в период после 11 сентября 2001 г. и со временем заметно снизились. Например, количество запросов, касающихся здоровья, сократилось с 96 на миллион запросов (27 октября 2001 г.) до 48 на миллион запросов (20 июля 2002 г.), в то время как ни женское здоровье и PubMed появились в топ-300 списков после января 2002 года.
Напротив, запросы, связанные с диабетом, занимали неизменное место в течение всего периода времени. В целом самыми популярными категориями (после исключения порнографии) были товары, связанные с компьютерами, поисковые системы, музыка/тексты песен, онлайн-продажи, словари/книги и поп-звезды/фильмы. С точки зрения популярности среди пользователей запросы о здоровье оказались ниже запросов о погоде, домашних животных, гороскопах и татуировках. Более того, в течение исследуемого периода сумма всех запросов, перечисленных в таблице 1, составляла менее 1% от всех 300 лучших запросов.
Комментарии
Наши результаты показывают, что информация как об общем состоянии здоровья, так и о конкретных расстройствах имеет очень низкий приоритет для людей, использующих поисковые системы Интернета. Обоснованность нашего подхода подтверждается ожидаемым периодическим увеличением конкретных ключевых терминов, связанных с праздниками, развлечениями и спортивными мероприятиями, а также внезапными всплесками активности в ответ на новости. Эти результаты бросают вызов утверждениям о высоком потребительском спросе на информацию о здоровье в Интернете. Сильные стороны нашего исследования включают его продолжительность и большую выборку, хотя мы признаем, что не смогли оценить характеристики и демографические данные участников, а также возможное использование других поисковых систем. Тот факт, что только одно заболевание, диабет, занимает постоянное место, является неожиданным. Диабет является распространенным хроническим заболеванием, в отношении которого текущая медицинская стратегия преимущественно направлена на самоконтроль и расширение возможностей пациента. 7 Однако существуют и другие столь же распространенные хронические заболевания, такие как гипертония и артрит. Наши результаты показывают, что термины, связанные со здоровьем, редко используются в качестве поисковых терминов для интернет-запросов.
использованная литература
1.
Вульф РМ, Шарп ЛК, Липский РС. Атрибуты содержания и дизайна антипрививочных веб-сайтов. ДЖАМА . 2002; 287:3245-3248. PubMedGoogle ScholarCrossref
2.
Диас Дж. А., Гриффит РА, Нг Джей Джей, Райнерт СЭ, Фридманн ПД, Моултон АВ. Использование пациентами Интернета для получения медицинской информации. J Gen Intern Med . 2002; 17:180-185. PubMedGoogle ScholarCrossref
3.
Слейтер Доктор медицины, Циммерман DE. Характеристики веб-сайтов, связанных со здоровьем, идентифицированных общими интернет-порталами. ДЖАМА . 2002; 288:316-317. PubMedGoogle ScholarCrossref
4.
Недоступно Отчет о ключевых словах Wordtracker 500 .