Алгоритм Палех — искусственный интеллект в поиске
Уже несколько лет Яндекс при ранжировании сайтов использует Матрикснет — метод машинного обучения, опирающийся на большое количество факторов: текстовые, коммерческие, поведенческие и т.д. Количество факторов каждый год растет и на данный момент составляет более 1500.
В начале ноября 2016 года Яндекс представил новый поисковый алгоритм Палех, помогающий основному алгоритму Матрикснет работать с редкими низкочастотными запросами.
По статистике Яндекса около 40% из всех вводимых пользователями запросов являются низкочастотными, даже уникальными. График распределения частотностей запросов чаще всего представляют в виде птицы, где клюв олицетворяет более общие высокочастотные запросы, процент которых относительно всех запросов низок. Далее туловище представляет собой среднечастотные запросы из Клюва со словами-уточнениями, и наконец, Хвост – очень низкочастотные редкие запросы.
В связи с тем, что низкочастотных запросов очень много, то получить наиболее релевантный ответ с помощью Матрикснета становится очень сложно. Подсказок от пользователей в виде поведенческих факторов нет, т.к. запросы сами по себе могут быть уникальны, поэтому для построения наиболее отвечающей пользовательскому вопросу выдачи Яндекс решил научиться понимать смысловое соответствие между запросом и документом.
Подсказок от пользователей в виде поведенческих факторов нет, т.к. запросы сами по себе могут быть уникальны, поэтому для построения наиболее отвечающей пользовательскому вопросу выдачи Яндекс решил научиться понимать смысловое соответствие между запросом и документом.
Решением поставленной задачи для Яндекса стал еще один метод машинного обучения: ИНС – искусственные нейронные сети.
Как работает новый алгоритм Палех?
Технология ИНС уже испытана в распознавании картинок или музыки. В случае поисковых систем речь пойдет о понимании смысла текстов.
Суть данного метода в том, чтобы система обучалась на положительных и отрицательных примерах поисковой системы, накопленных ранее, по наиболее популярным запросам, сопоставляла пользовательские запросы и заголовки документов и находила наиболее релевантный ответ.
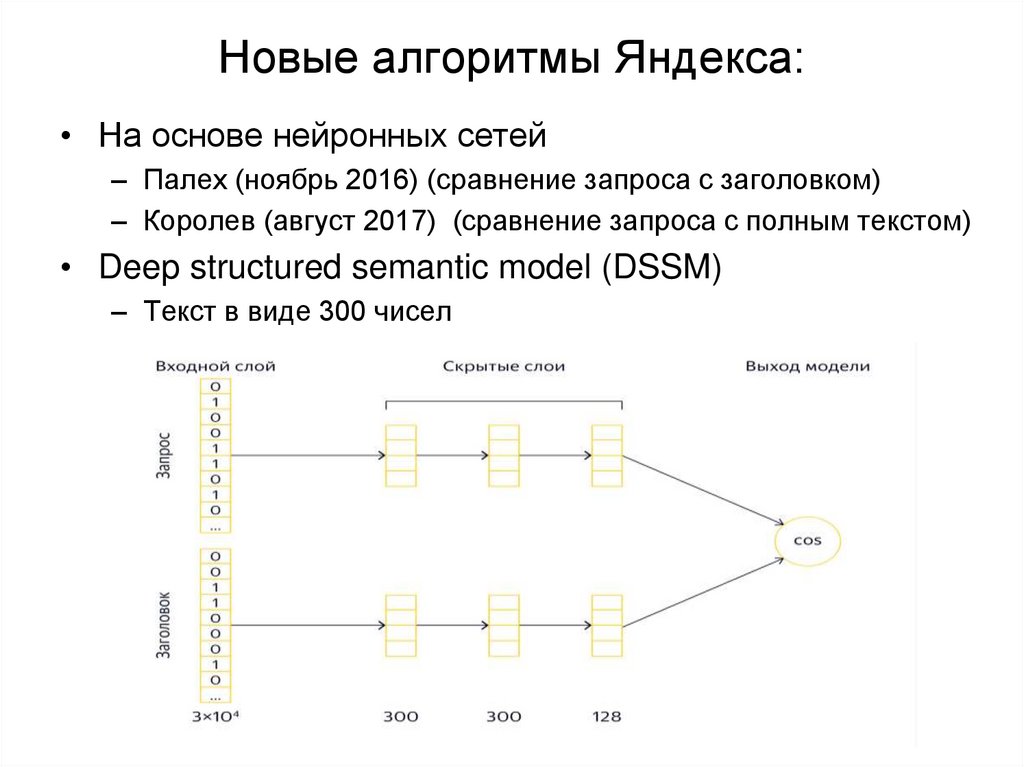
Для сопоставления системой запросов и заголовков их переводят в специальное 300-мерное пространство, где каждому запросу и заголовку соответствует группа из 300 чисел. Таким образом, выделяется семантический вектор.
Таким образом, выделяется семантический вектор.
Когда пользователь вводит длинный запрос в поисковую строку, Палех переводит его в 300-мерное пространство на соответствующих параллелях и показывает документ, наиболее подходящий к этому запросу в построенной системе координат.
На данный момент обрабатывается не весь текст ресурса, а только заголовки, но Яндекс говорит, что в планах работа со всем текстом. Это позволит еще лучше понимать, удовлетворяет ли требованиям пользователя сайт, и формировать максимально релевантные результаты поиска.
Примеры работы алгоритма Палех
Работу нового алгоритма Яндекса Палех можно оценить только на низкочастотных запросах, так как на ВЧ запросах приоритетнее другие факторы ранжирования.
При запросе «фильм в котором человек родил и зачал себя сам» мы получим в ответ информацию о фильме «Патруль времени» 2014 года, а не сайты с ответами на вопросы на форумах.
Что делать коммерческим сайтам с Палехом?
Новый алгоритм Яндекса практически никак не влияет на ранжирование интернет-магазинов и сайтов услуг, так как Палех направлен в первую очередь на ресурсы с большим текстовым контентом. Для продвижения сайтов продажи услуг и товаров гораздо важнее цены, юзабилити, дизайн, коммерческие и поведенческие факторы.
Для продвижения сайтов продажи услуг и товаров гораздо важнее цены, юзабилити, дизайн, коммерческие и поведенческие факторы.
Но следует учитывать, что новый алгоритм влияет на коммерческие контент-проекты, такие как, например, строительные порталы, где публикуется большое количество статей строительной тематики. В общем, этот алгоритм внедрен, чтобы улучшить качество поиска для низкочастотных запросов с «большим хвостом». Преимущества получают качественные информационные сайты.
Вместо заключения
Особенности нового алгоритма года Палех:
- Большое количество вхождений слов, связанных с запросом по смыслу повышает значение нового фактора;
- По информации Яндекса: Палех пока работает только с title страниц, а не с самим содержимым;
- Качество алгоритма измеряется поведенческими метриками пользовательской удовлетворенности.
- Влияние на ранжирование коммерческих сайтов в настоящее время алгоритм Палех не имеет, но это очередной повод задуматься о способах продвижения — что пора забыть времена, когда на позицию сайта можно было повлиять только ссылками или количеством ключей в тексте.


Современные реалии требуют создания удобных сайтов для людей, написание качественного контента, который будет полезен пользователям.
Поисковый алгоритм Яндекса «Палех»
«Палех» – новый поисковый алгоритм Яндекса
Эволюция поисковых интернет-машин за последние 16 лет проделала огромный путь. Начиная когда-то развитие с простого обнаружения слов, сегодня крупные поисковики пришли к алгоритму так называемого «умного поиска» при помощи нейронных сетей.
Не отстаёт от актуальных мировых трендов и российский Яндекс – в начале ноября 2016 года в корпоративном блоге интернет-компании появилась статья с анонсом запуска нового поискового алгоритма «Палех».
Что такое нейронные сети – краткий ликбез, понятный и гуманитарию
Само понятие нейронных сетей появилось ещё на заре тотальной компьютеризации и зарождения интернета, однако, актуализировалось только в последние годы. Название программистами было выбрано по аналогии с научным термином биологических нейронов, которые, как известно, организуют работу нервной системы человека (и в том числе головного мозга). Ключевая задача каждого нейрона заключается в организации электрохимического импульса, – с его помощью один нейрон осуществляет взаимосвязь со всеми другими нейронами.
Ключевая задача каждого нейрона заключается в организации электрохимического импульса, – с его помощью один нейрон осуществляет взаимосвязь со всеми другими нейронами.
И этот же принцип общего одновременного взаимодействия одной части поступающих запросов с другими частями большой сети лежит в основе работы компьютерных нейросетей.
Биология нейронных сетей в виде единого живого организма
К прорывной технологической особенности машинных нейронных сетей можно отнести их «умение» работать с образами. Привычная классика подхода к обработке информация заключается в последовательной (алгоритмической) обработке символов, тогда как нейронные сети способны уже параллельно друг другу распознавать образы.
В сфере поисковых систем под символами и образами понимаются те «слова», которые люди вбивают в строку браузеров. Символы отличаются от образов своей размерностью, – условный размер вторых может на несколько порядков превышать размер символов.
«Палех» – низкочастотный словесный хвост поискового трафика Яндекса
Наглядности схематичной работе современных компьютерных нейросетей могут добавить простые факты результативности работы: сегодня машины способны работать с изображениями, звуками, текстом и другими образчиками образного мышления (присущего, казалось бы, только человеку). Машину можно обучить различать на картинках любые объекты действительности: людей, машины, животных, еду и т. д.
Работа поискового алгоритма «Палех» настроена на различении смысла забиваемых в поисковик пользователями слов. Притом даже не простых, популярных в народе, а – сложных, многосоставных, неконкретных, имеющих очень далёкое отношение к тому, что человек пытается найти (то есть, по сути образных).
Почему, собственно, новый алгоритм называется «Палехом»? Разработчики Яндекса все пользовательские запросы разделили на три части, представив их в виде туловища мифологической Жар-птицы, частой героини, отображаемой на изделиях в стиле русского палехского ремесла.
Палехская Жар-птица – мифологическое существо, как символ поискового потока Яндекса
Примеры фантастических, ассоциативно-образных многочастотных запросов
Примеры многочастотных образных запросов в Рунете бывают поистине причудливыми, если не сказать даже фантастическими. Ищущие фильм «Бойцовский клуб» люди, например, могут вбить в поисковик следующее: «офисный клерк и его воображаемый друг фильм». Интересующиеся днём Благодарения, но забывшие название торжества люди обращаются за помощью с запросом «праздник с курицами в Америке».
Понятно, что такие длинные и сложные по семантике запросы машинная система Яндекса встречает гораздо реже, чем короткие, одночастотные из «клюва» условной Жар-птицы. Соответственно, и чётко работающего алгоритма для понимания того, что всё же нужно человеку в каждом конкретном случае нет. Задача нередко осложняется тем, что человеческое слово многозначно: в поисковой выдаче вообще может выпадать с десяток ссылок на источники не имеющие отношения к искомой информации.
В решении этой сложной проблемы понимания образного, ассоциативного мышления человека и участвует нейронные системы нового поискового алгоритма «Палех».
Суть работы «Палеха» – немного простейшей математики
Для представления того, как функционирует нейросети русскоязычного поисковика при обработке многочастотных запросов, нужно понимать, что они накапливают внутри себя необходимую статистику правильности/неправильности соответствия выдачи страниц тому, что ищут люди. Эта статистика основывается на поведенческом факторе пользователей: если в выдаче нет сайтов с нужной информации, – человек ни по одной странице просто не кликнет. Или, кликнув и поняв, что на том или ином сайте необходимая информация отсутствует, он её тут же, в течение двух-трёх секунд закроет.
Эта статистика основывается на поведенческом факторе пользователей: если в выдаче нет сайтов с нужной информации, – человек ни по одной странице просто не кликнет. Или, кликнув и поняв, что на том или ином сайте необходимая информация отсутствует, он её тут же, в течение двух-трёх секунд закроет.
Понятно, что количество удачных (или неудачных) соответствий запросов с веб-страницами миллиарды. Нейронная сеть «Палех» позволяет для внутреннего математического удобства переводить это количество соответствий в группы, состоящие из трёхсот чисел каждая. Способ обработки запросов с близкими им вероятными ответами в трёхсотмерной системе координат называется семантическим вектором.
Математика семантического вектора помогает человеку искать нужную информацию
Поисковая технология семантического вектора имеет в интернете огромный потенциал развития. Она позволяет, к примеру, работать, анализировать не только заголовки, но и сами тексты различных документов. Более того, в качестве семантического вектора можно представить всю совокупность сведений о пользователе в интернете – взятые со страничек соцсетей интересы, статистику предыдущих поисковых запросов и переходов по ссылкам, и это очень полезная информация не только для поисковиков, но и для маркетологов, веб-мастеров и других, связанных с интернет-бизнесом, людей.
Более того, в качестве семантического вектора можно представить всю совокупность сведений о пользователе в интернете – взятые со страничек соцсетей интересы, статистику предыдущих поисковых запросов и переходов по ссылкам, и это очень полезная информация не только для поисковиков, но и для маркетологов, веб-мастеров и других, связанных с интернет-бизнесом, людей.
Не исключено, что в перспективе алгоритмы нейронных поисковых систем по способу образного мышления, понимания запросов вплотную приблизятся к людям. И как знать, каким будет этот самый интернет в эпоху, когда поисковики будут понимать любого человека буквально с полуслова…
Яндекс — История — История Яндекса
Алиса Яндекс запустил первого диалогового ИИ-помощника, не ограниченного набором заранее заданных сценариев. Названный Alice, он объединяет несколько сервисов, чтобы помочь пользователям эффективно выполнять самые разные задачи – среди прочего находить информацию в Интернете, планировать маршрут, воспроизводить музыку или получать прогноз погоды. | CatBoostКомпания открыла исходный код CatBoost, новой библиотеки машинного обучения, основанной на повышении градиента. CatBoost является преемником алгоритма машинного обучения MatrixNet и имеет множество преимуществ по сравнению со своим предшественником: его прогнозы более точны, он более устойчив к переобучению и, что наиболее важно, поддерживает нечисловые признаки — например, породы собак или типы облаков. — то есть он может учиться на различных формах данных, которые не были предварительно обработаны и преобразованы в цифровую форму. |
Королев Яндекс разработал и внедрил новый алгоритм поиска Королев. Как и его предшественник Палех, он основан на нейронных сетях и ищет по смыслу, а не по ключевым словам. | Беспилотный автомобильКомпания начала тестировать беспилотную автомобильную технологию. Два прототипа автономных автомобилей, оснащенные датчиками, а также программным обеспечением, обрабатывающим информацию об окружающей обстановке и рассчитывающим траекторию движения автомобиля, успешно двигались по заданным маршрутам, распознавая и объезжая препятствия на пути. |
Сделка года Яндекс.Такси и Uber договорились об объединении бизнеса в России, Азербайджане, Армении, Беларуси, Грузии и Казахстане. В рамках сделки Uber должен был инвестировать 225 миллионов долларов, а Яндекс инвестировал 100 миллионов долларов наличными в новую компанию при закрытии, оценивая ее в 3,725 миллиарда долларов после оплаты. | УслугиЯндекс.Переводчик добавил нейронную модель машинного перевода к статистическим моделям, которые он использовал ранее для реализации гибридной системы машинного перевода. Турбо-страницы стали доступны в Яндекс.Поиске, Яндекс.Дзен и Яндекс.Новостях, что ускорило загрузку сайта на мобильных устройствах. Яндекс.Погода добавила карты погоды, охватывающие весь мир. Компания также представила ряд новых услуг и продуктов для бизнеса, в том числе многофункциональное голосовое решение для подключенных автомобилей Яндекс.Авто и платформу для совместной работы на рабочем месте Яндекс.Коннект. |
 Используя глубокие нейронные сети, обученные на массивных наборах данных, Алиса обеспечивает пользовательский опыт, очень похожий на взаимодействие с другим человеком. У него превосходные знания русского языка, ярко выраженная личность с чувством юмора и способность понимать незаконченные фразы и вопросы.
Используя глубокие нейронные сети, обученные на массивных наборах данных, Алиса обеспечивает пользовательский опыт, очень похожий на взаимодействие с другим человеком. У него превосходные знания русского языка, ярко выраженная личность с чувством юмора и способность понимать незаконченные фразы и вопросы. Но если Палех просматривал только заголовки, то Королев просматривает веб-страницы целиком. Также учитывается значение других запросов, которые привели пользователей на веб-страницу. Обновление улучшает работу Яндекса с нечастыми и сложными запросами и обеспечивает пользователям превосходные результаты поиска.
Но если Палех просматривал только заголовки, то Королев просматривает веб-страницы целиком. Также учитывается значение других запросов, которые привели пользователей на веб-страницу. Обновление улучшает работу Яндекса с нечастыми и сложными запросами и обеспечивает пользователям превосходные результаты поиска.
Утечка Яндекса раскрывает 1922 фактора ранжирования в поиске для SEO
Яндекс является четвертой по величине поисковой системой в мире, и ее основная доля рынка приходится на Россию. 27 января 2023 года она стала жертвой утечки данных, которая входит в число крупнейших, с которыми сталкивалась технологическая компания за последнее время. Хуже всего то, что это вторая утечка Яндекса почти за десятилетие.
Хуже всего то, что это вторая утечка Яндекса почти за десятилетие.
Бывший сотрудник Яндекса пытался продать код поисковой системы Яндекса на черном рынке за 30 000 долларов в 2015 году. Начальный Появившаяся утечка Яндекса выявила 1922 фактора ранжирования, 64% из которых были указаны как устаревшие или неиспользуемые. Хотя утечка была названа «ядром», было обнаружено больше файлов в сочетании с 17 800 компонентами ранжирования. Когда дело доходит до SEO для Яндекса, большая часть применима.
«Утечка» Яндекса раскрывает 1922 фактора ранжирования в поискеЯндекс, как и Google, всегда был прозрачным в отношении обновлений и изменений алгоритмов, хотя в последние годы он внедрил машинное обучение. Некоторые из заметных обновлений за последние два-три года включают
- Обновление Y2K (конец 2022 г.)
- Обновление YI (представление YATI)
- Vega (что удваивает размер индекса)
- принятие индексного потока
- Ожидаемое обновление фильтра PF и новый выпуск
На личном уровне эта утечка Яндекса воспроизводит второе Рождество.
Хотя Яндекс прежде всего известен своим присутствием в России, необходимо отметить, что поисковая система присутствует в Грузии, Турции и Казахстане. Существует общее ощущение, что утечка данных была политически мотивированной и включала в себя ряд фрагментов кода из монолитного репозитория Яндекс Аркадия. Утекло около 44 ГБ данных, содержащих информацию, связанную с Яндексом, включая приложения, почту, поиск и диски, а также облако.
Какие просмотры у Яндекса?
Яндекс публично заявил, что по состоянию на 31 января 2023 года
- Содержимое базы утекшего кода соответствует устаревшей версии репозитория, поскольку она отличается от текущей версии, используемой сервисами.
- Важно учитывать, что в опубликованных фрагментах кода заведомо присутствуют алгоритмы, которые использовались только вместе с Яндексом, что исправляет корректность работы сервисов.

Сколько кода можно активно использовать — это совсем другой вопрос.
Яндекс сообщил, что в ходе проверки и расследования он обнаружил ряд ошибок, нарушающих его собственные принципы. Таким образом, вполне вероятно, что части просочившегося кода, которые используются в настоящее время, могут измениться в будущем.
Классификация факторов
Яндекс классифицирует факторы ранжирования по трем основным компонентам. В общедоступной документации Яндекс SEO это было указано впервые. Это помогает лучше понять утечку фактора ранжирования.
- Статические факторы — это факторы, непосредственно связанные с веб-сайтом. Примерами являются входящие внутренние ссылки, входящие ссылки, заголовки и т. д.
- динамических фактора — факторы, связанные с сайтом и поисковым запросом. Примерами являются релевантность ключевых слов и включение ключевых слов.
- Использовать факторы, связанные с поиском: факторы, связанные с запросом пользователя (точное местоположение пользователя, модификаторы намерений и язык запроса).

Информация об утечке Яндекса на данный момент
Из данных, полученных на данный момент, некоторые выводы и подтверждения, которые мы смогли сделать, таковы. В утечке содержится много данных, и мы, вероятно, через новые связи и вещи в ближайшие недели. Среди них
- Яндекс до сих пор использует мета-ключевые слова, которые упоминаются в документации.
- Нет ничего нового в том, что Яндекс может сканировать JavaScript, который все еще находится за пределами общедоступных документированных процессов.
- У Яндекса есть специальные коэффициенты для юридических, медицинских и финансовых тем.
- При ранжировании учитывается время суток.
- Ошибки сервера и чрезмерные 4-кратные коэффициенты могут повлиять на ранжирование.
Matrix Net
Matrix Net упоминается в нескольких факторах ранжирования; о нем было объявлено в 2009 году, но в 2017 году его заменил CatBoast, который был развернут во всей продуктовой сфере Яндекса. Это еще раз подтверждает комментарии Яндекса, и одним из факторов стал устаревший репозиторий кода.
Это еще раз подтверждает комментарии Яндекса, и одним из факторов стал устаревший репозиторий кода.
Он был представлен как новый базовый алгоритм, который учитывал множество факторов ранжирования и присваивал веса на основе пользовательского запроса, фактического поискового запроса и предполагаемого намерения. Его можно сравнить с ранней версией Google Rank Brain, которая действительно представляет собой пару систем. Matrix Net была построена, что неудивительно, учитывая, что ей 14 лет.
В 2016 году Яндекс представил алгоритм Палеха, который использовал глубокие нейронные сети для лучшего сопоставления документов и запросов, даже если они не содержали нужных уровней общих ключевых слов, но удовлетворяли намерения пользователя. Палех мог обрабатывать 150 страниц за раз.
Факторы URL и уровня страницы
Из утечки Яндекса , учитывается построение URL.
- Наличие цифр в URL
- Если в URL-адресе слишком много обучающих косых черт, они будут удалены.
- Количество заглавных букв в URL является фактором.

Возраст документа с датой последнего обновления также важен, так как это имеет смысл. Кроме того, ряд точек данных относится к его свежести, особенно для запросов, связанных с новостями. Раньше Яндекс использовал временные метки для целей ранжирования, но для целей изменения порядка их следует классифицировать как «неиспользуемые».
Важность обратных ссылок
Известно, что у Яндекса есть такие же алгоритмы для борьбы с манипулированием ссылками, как и у Google, и он существует после фильтра Непота в 2005 году. предположение о построении ссылок, связанных с Яндексом, может относиться к следующему:
- Ссылки должны строиться с разным количеством и собственной частотой.
- Ссылки должны быть построены с брендированным анкорным текстом и коммерческими ключевыми словами.
- Если вы покупаете ссылки, не покупайте ссылки на веб-сайтах со смешанной тематикой.
Ниже приведено утверждение, которое является подтверждением лучших практик.
- Возраст обратной ссылки является важным фактором.
- Релевантность ссылки на тему
- Релевантность ссылки зависит от качества каждой ссылки.
- Релевантность ссылки, учитывающая качество каждой ссылки и тему каждой ссылки
- Процент входящих ссылок с качественными ключевыми словами
Но есть некоторые факторы, связанные со ссылками, которые необходимо учитывать при планировании, мониторинге и интерпретации обратных ссылок.
- Соотношение хороших и плохих обратных ссылок на сайт
- Частота ссылок на сайт
- • Количество входящих SEO-мусорных ссылок между хостами
Соединение для передачи данных также показало, что в калькуляторе спам-ссылок будет около 80 активных компонентов. принимая во внимание, что существует ряд устаревших факторов. Далее возникает вопрос о том, как Яндекс Seo работает, так как показывает, насколько плоха ссылка. С другой стороны, негативная SEO-атака, скорее всего, будет кратковременной. Модели машинного обучения используются Яндексом для проверки PBN и рекламных ссылок. Предположение относительно скорости связи и временных рамок, в течение которых она получена, такое же.
С другой стороны, негативная SEO-атака, скорее всего, будет кратковременной. Модели машинного обучения используются Яндексом для проверки PBN и рекламных ссылок. Предположение относительно скорости связи и временных рамок, в течение которых она получена, такое же.
Платные ссылки генерируются в течение более длительного периода времени, и эти шаблоны были введены для борьбы.
Реклама на странице
Когда дело доходит до рекламы на странице, необходимо учитывать ряд факторов, и некоторые из них считаются устаревшими. Из самого описания неизвестно, каков был мыслительный процесс, но нужно учитывать, насколько Google воспримет это, если реклама закроет основное содержание страницы.
Механизмы Яндекса учли обновление Proxima в соотношении полезного и рекламного контента на странице.
Можно ли применить знания Яндекса к Google?
Google и Яндекс — это разные поисковые системы с рядом отличий. И это несмотря на то, что в обеих компаниях работали тысячи инженеров.