
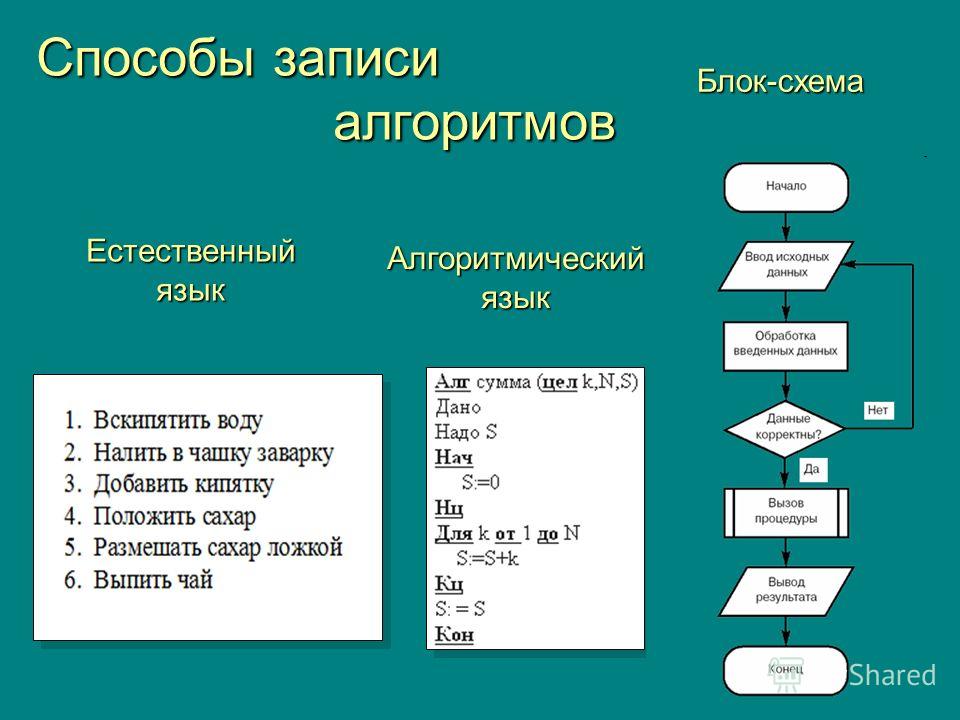
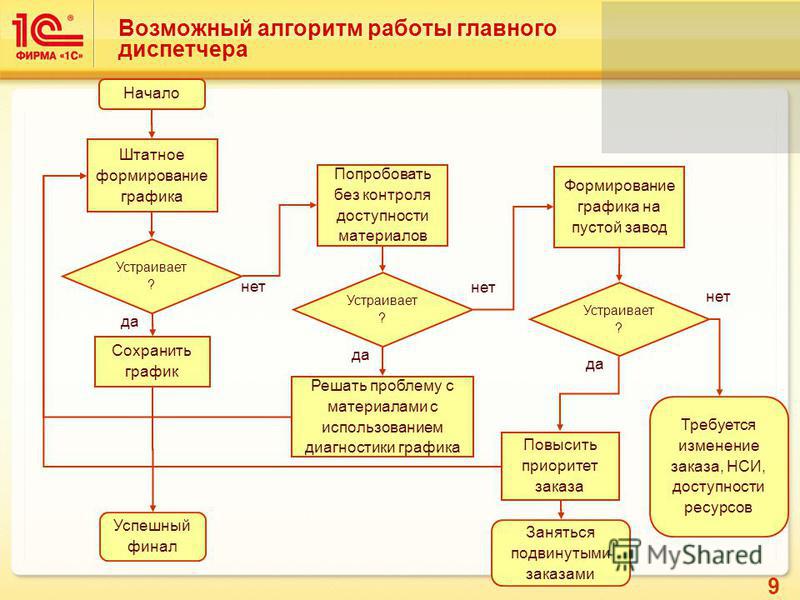
Настройка оценки релевантности — Azure Cognitive Search
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 3 мин
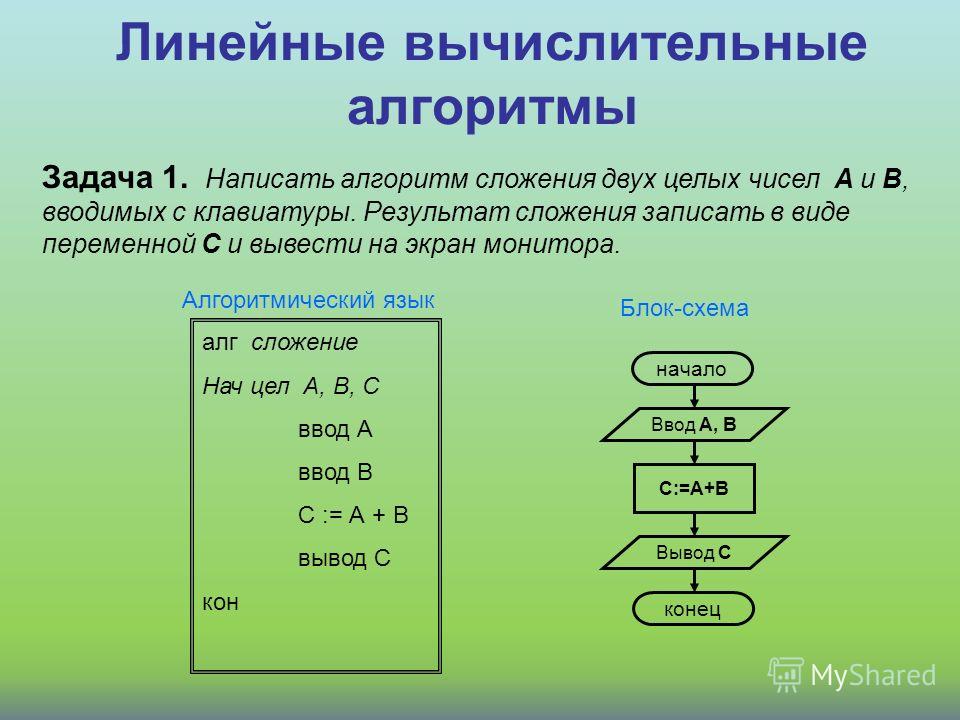
Из этой статьи вы узнаете, как настроить алгоритм оценки подобия, используемый Когнитивный поиск Azure. Модель оценки BM25 имеет значения по умолчанию для взвешивания частоты терминов и длины документа. Эти свойства можно настроить, если значения по умолчанию не подходят для вашего содержимого.
Модель оценки BM25 имеет значения по умолчанию для взвешивания частоты терминов и длины документа. Эти свойства можно настроить, если значения по умолчанию не подходят для вашего содержимого.
Изменения конфигурации ограничены отдельными индексами, что означает, что вы можете настроить оценку релевантности на основе характеристик каждого индекса.
Алгоритм оценки по умолчанию
В зависимости от возраста службы поиска Когнитивный поиск Azure поддерживает два алгоритма оценки подобия для присвоения релевантности результатам в запросе полнотекстового поиска:
- Алгоритм Okapi BM25 , используемый во всех службах поиска, созданных после 15 июля 2020 г.
- Классический алгоритм сходства, используемый всеми службами поиска, созданными до 15 июля 2020 г.
Рейтинг BM25 используется по умолчанию, так как он, как правило, создает ранжирование поиска, которое лучше соответствует ожиданиям пользователей. Он включает параметры для настройки результатов на основе таких факторов, как размер документа.
Для более старых служб классическим подобием остается алгоритм по умолчанию. Старые службы могут обновляться до BM25 по индексу. При переключении с классической модели на BM25 можно увидеть некоторые различия в порядке упорядочения результатов поиска.
Задание параметров BM25
Сходство BM25 добавляет два параметра для управления вычислением оценки релевантности.
Сформулируйте запрос на создание или обновление индекса , как показано в следующем примере.
PUT [service-name].search.windows.net/indexes/[index-name]?api-version=2020-06-30&allowIndexDowntime=true { "similarity": { "@odata.type": "#Microsoft.Azure.Search.BM25Similarity", "b" : 0.75, "k1" : 1.2 } }Задайте для «b» и «k1» пользовательские значения.
 Дополнительные сведения см. в описании свойств в следующем разделе.
Дополнительные сведения см. в описании свойств в следующем разделе.Если индекс является динамическим, добавьте параметр URI allowIndexDowntime=true в запрос.
Так как Когнитивный поиск не позволяет обновлять динамический индекс, необходимо перевести индекс в автономный режим, чтобы можно было добавить параметры. Индексирование и запросы завершаются ошибкой, пока индекс находится в автономном режиме. Длительность сбоя — это время, необходимое для обновления индекса, обычно не более нескольких секунд. После завершения обновления индекс возвращается автоматически.
Отправьте запрос.
 Дополнительные сведения см. в описании свойств в следующем разделе.
Дополнительные сведения см. в описании свойств в следующем разделе.Описания свойств BM25
| Свойство | Тип | Описание |
|---|---|---|
| k1 | number | Управляет функцией взвешивания частоты употребления каждого термина для конечной оценки релевантности пары «документ-запрос». Диапазон значений: 0,0–3,0. Значение по умолчанию: 1,2. Значение 0,0 представляет собой «двоичную модель», в которой вклад одного соответствующего термина одинаков для всех соответствующих документов, независимо от того, сколько раз этот термин отображается в тексте, в то время как большее значение k1 позволяет увеличить оценку по мере обнаружения в документе большего числа экземпляров того же термина. Использование более высокого значения k1 может быть важно в тех случаях, когда мы ожидаем, что несколько терминов будут частью поискового запроса. В таких случаях мы скорее отдадим предпочтение документам, которые содержат много различных терминов из поискового запроса,чем тем, в которых один нужный термин встречается несколько раз. Например, при запросе индекса для документов, содержащих термины “Космическая программа “Аполлон”, будет лучше, если оценка статьи о греческой мифологии, где слово “Аполлон” встречается несколько десятков раз, но нет упоминаний о “космической программе”, будет меньше, чем у статьи, в которой хотя бы пару раз явно упоминается и “Аполлон”, и “космическая программа”. Использование более высокого значения k1 может быть важно в тех случаях, когда мы ожидаем, что несколько терминов будут частью поискового запроса. В таких случаях мы скорее отдадим предпочтение документам, которые содержат много различных терминов из поискового запроса,чем тем, в которых один нужный термин встречается несколько раз. Например, при запросе индекса для документов, содержащих термины “Космическая программа “Аполлон”, будет лучше, если оценка статьи о греческой мифологии, где слово “Аполлон” встречается несколько десятков раз, но нет упоминаний о “космической программе”, будет меньше, чем у статьи, в которой хотя бы пару раз явно упоминается и “Аполлон”, и “космическая программа”. |
| b | number | Определяет зависимость оценки релевантности от длины документа. Диапазон значений: 0–1. Значение по умолчанию: 0,75. Значение 0,0 означает, что длина документа не повлияет на оценку, а значение 1,0 означает, что влияние частоты терминов на оценку релевантности будет нормализовано по длине документа. Нормализация частоты терминов по длине документа полезна в тех случаях, когда мы хотим наказать более длинные документы. В некоторых случаях более длинные документы (например, объемный роман) содержат много ненужных терминов в сравнении с более короткими документами. Нормализация частоты терминов по длине документа полезна в тех случаях, когда мы хотим наказать более длинные документы. В некоторых случаях более длинные документы (например, объемный роман) содержат много ненужных терминов в сравнении с более короткими документами. |
Включение оценки BM25 в старых службах
Если вы используете службу поиска, созданную с марта 2014 г. по 15 июля 2020 г., вы можете включить BM25, задав свойство «сходство» для новых индексов. Свойство предоставляется только для новых индексов, поэтому, если требуется использовать BM25 для существующего индекса, необходимо удалить и перестроить индекс со свойством «сходство», для которого задано значение «Microsoft.Azure.Search.BM25Similarity».
После существования индекса со свойством «сходство» можно переключаться между BM25Similarity или ClassicSimilarity.
Следующие ссылки описывают свойство сходства в пакетах Azure SDK.
| Клиентская библиотека | Свойство сходства |
|---|---|
. NET NET | SearchIndex.Similarity |
| Java | SearchIndex.setSimilarity |
| JavaScript | SearchIndex.Similarity |
| Python | свойство сходства для SearchIndex |
Пример REST
Можно также использовать REST API. В следующем примере создается новый индекс со свойством «сходство», равным BM25:
PUT [service-name].search.windows.net/indexes/[index name]?api-version=2020-06-30
{
"name": "indexName",
"fields": [
{
"name": "id",
"type": "Edm.String",
"key": true
},
{
"name": "name",
"type": "Edm.String",
"searchable": true,
"analyzer": "en.lucene"
},
...
],
"similarity": {
"@odata.type": "#Microsoft.Azure.Search.BM25Similarity"
}
}
См. также раздел
- Сходство и оценка в Когнитивном поиске Azure
- Справочник по REST API
- Добавление профилей повышения в индекс
- Создание API индекса
- Библиотеки службы «Поиск Azure» для . NET
 NET
NETАлгоритм BM25
Впервые данный алгоритм встретил на Википедии и не обратил на него особого внимания. Позже изучая научные труды сотрудников Яндекса, я обратил внимание на то, что они ссылаются на него, например, в статье Сегаловича об алгоритмах определения нечетких дубликатов, поэтому решил разобраться, в чем смысл его использования. Постараюсь на простых примерах это объяснить. Итак, для чего этот алгоритм?
Первое. Вводится зависимость релевантности от вхождения или не вхождения слов в запросах с более чем одного слова.
- купить смартфон Samsung
- купить смартфон Samsung Galaxy
Пусть сравниваются два документы (опять же иллюстративно) и первый документ не содержит слова Galaxy. Согласно расчетов оценка релевантности эта сума релевантностей каждого из слов.
Релевантность каждого из слова равна его IDF * на второй множитель в выражении выше. Релевантность всего поискового запроса равна сумме релевантностей всех слов. Таким образом, отсутствие слова или другими словами (его частота) равна 0 дает релевантность 0. Поэтому если по двум первым словам score будет одинаково то более релевантным будет тот документ, который содержит слово Galaxy.
Второе. Преимущество при поиске в запросах с более чем 2-ух слов, одно из которых менее употребительно (более узкоспециализированное) будет отдаваться документам которые содержат это узкоспециализированное слово. Например, есть запрос купить Samsung Galaxy Note 2 (чисто иллюзорный пример). Пусть Note 2 – это более редкое слово (меньше раз встречается в коллекции чем Samsung и Galaxy). Пусть есть 2-а документа каждый из которых релевантен запросу и каждый из них содержит кроме Samsung и Galaxy также Note 2. При этом в первом документе note 2 употребляется только один раз, тогда как во втором – 3 раза (подразумевается, что документ содержит больше информации о Note 2). Но сначала рассмотрим, результат вычисление релевантности алгоритмом, если частоты всех указанных слов в документах одинаковы. Вот что получается по BM25 в Excel.
Но сначала рассмотрим, результат вычисление релевантности алгоритмом, если частоты всех указанных слов в документах одинаковы. Вот что получается по BM25 в Excel.
Обратите также внимание, что из-за того, что количество документов содержащее слово Note 2 меньше равно в 50 раз от содержащих слово galaxy (500) мы получаем IDF равный 3,279634 что значительно больше IDF для слова galaxy.
Пока что у нас были одинаковые значения частот для слова note 2 (для других слов также). Теперь давайте в Excel увеличим частотность слова note 2 для док2, вместо 0,02 сделаем 0,05 (5 вхождений слова).
Обратите внимание, что значение IDF не изменяется но значение формула (второй множитель на изображении в самом вверху) теперь стало равно 0,061856 и именно это значение участвует в вычислении score, которое теперь для док2 равно уже 0,290559
Теперь самое главное. Увеличим частоту вхождения слова galaxy до 5 в док 1
Как мы видим суммарная частота каждого из слов в док1 и док2 одинакова. Но значение score (релевантность) выше у док2, потому что слово note2 является более редко встречающимся соответственно его результирующее влияние больше чем слово galaxy.
Но значение score (релевантность) выше у док2, потому что слово note2 является более редко встречающимся соответственно его результирующее влияние больше чем слово galaxy.
На практике наличие слов в многосложных запросах очень важно. Конечно же релевантность современных поисковых систем определяется не только исходя из частот как это было показано на примере формулы BM25, но все же некоторые корреляции провести можно. В основном это касается того, что если в документе нет слова из поискового запроса то такому документу значительно сложнее подняться в ТОП по запросу по сравнению с теми, у которых это слово содержится. Давайте рассмотрим пример на поисковой системе Яндекс.
Вводим запрос Samsung galaxy. У меня выдача касалась Samsung galaxy в целом (2 сайта, как обычно Википедия) остальное модели, картинки и т.д.
Вводим запрос samsung galaxy note 2. Выдача полностью меняется, теперь представлены страницы, которые содержат информацию не просто о Samsung galaxy, а о Samsung galaxy note 2.
Вводим запрос samsung galaxy note 2 ценаОпять выдача меняется теперь в выдаче страницы, которые уже содержат слово цена, а не просто Samsung galaxy.
Вводим запрос samsung galaxy note 2 цена Харьков. Выдача кардинально меняется, все страницы в ТОП10 содержат слово Харьков.
Можно ли сказать, что слово Харьков является более узкоспециализированным, как это приводилось в алгоритме BM25 выше? IDF cлова Харьков знает только поисковая система, но в контексте поискового запроса Samsung galaxy note 2 оно без сомнения сужает область поиска. Может быть пример с Яндексом немного неудачен, в силу того, что в приведенном случае большую роль будет играть учет региональности запроса, но я думаю со мной согласится любой сеошник, что слово из поискового запроса обязательно должно быть в тексте, я же всего лишь постарался показать работу алгоритма BM25 и раскрыть 2-а важных его аспекта.
Автор: kshiian
Источник
BM25 Артикул
функция ранга bm25
реализует
Окапи БМ25
функция ранжирования, используемая для оценки релевантности текстового документа заданному поисковому запросу. Это чисто текстовая функция ранжирования, которая работает на
индексированное строковое поле.
Эта функция дешева в вычислении, примерно в 3-4 раза быстрее, чем
родной ранг,
при этом обеспечивая хороший рейтинг качества.
Это хороший кандидат для использования в функции ранжирования первой фазы при ранжировании текстовых документов.
Это чисто текстовая функция ранжирования, которая работает на
индексированное строковое поле.
Эта функция дешева в вычислении, примерно в 3-4 раза быстрее, чем
родной ранг,
при этом обеспечивая хороший рейтинг качества.
Это хороший кандидат для использования в функции ранжирования первой фазы при ранжировании текстовых документов.
Функция ранжирования
Функция bm25 вычисляет оценку того, насколько хорош запрос с терминами. q1,…,qn соответствует индексированному строковому полю t в документе D . Оценка рассчитывается следующим образом:
∑inIDF(qi)⋅f(qi,D)⋅(k1+1)f(qi,D)+k1⋅(1-b+b⋅field_lenavg_field_len)
Где компоненты в функции:
ЦАХАЛ(ци): обратная частота документа ( IDF ) термина запроса i в поле т . Это рассчитывается как:
log(1+N-n(qi)+0,5n(qi)+0,5)
N — общее количество документов на узле контента. п (ци)
количество документов, содержащих термин запроса i для поля t ,
который рассчитывается для индекса, существующего для этого поля.
В расчете используется максимальное значение среди индексов,
который обычно исходит из самого большого дискового индекса.Поскольку IDF рассчитывается для каждого узла содержимого и индекса, могут возникать небольшие отклонения. Использовать те же IDF для всех узлов контента, установите его как значение по каждому термину запроса с помощью аннотаций.
- f(qi,D): количество вхождений (частота терминов) термина запроса i в поле т документа Д . Для полей с несколькими значениями мы используем сумму вхождений по всем элементам.
- field_len: Длина поля (количество слов) поля t в документе D .
Для полей с несколькими значениями мы используем сумму длин полей по всем элементам.
- avg_field_len: средняя длина поля от до среди документов на узле контента.
- k1: параметр, используемый для ограничения того, насколько одно условие запроса может повлиять на оценку для документа D . При более высоком значении оценка за один термин может продолжать расти относительно больше. когда существует больше вхождений для этого термина. Значение по умолчанию — 1,2. Можно настроить с помощью ранг-свойства.
- b: Параметр, используемый для управления влиянием длины поля поля t по сравнению со средней длиной поля. Значение по умолчанию — 0,75. Можно настроить с помощью ранг-свойства.
 п (ци)
количество документов, содержащих термин запроса i для поля t ,
который рассчитывается для индекса, существующего для этого поля.
В расчете используется максимальное значение среди индексов,
который обычно исходит из самого большого дискового индекса.
п (ци)
количество документов, содержащих термин запроса i для поля t ,
который рассчитывается для индекса, существующего для этого поля.
В расчете используется максимальное значение среди индексов,
который обычно исходит из самого большого дискового индекса.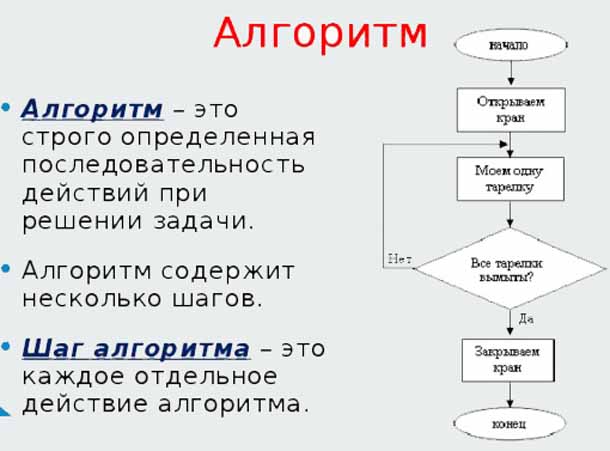
Пример
В следующем примере у нас есть индексированное строковое поле , содержимое ,
и ранговый профиль с использованием функции ранга bm25 .
Обратите внимание, что поле должно быть включено для использования с функцией bm25.
установив enable-bm25 флаг в
индекс
раздел определения поля.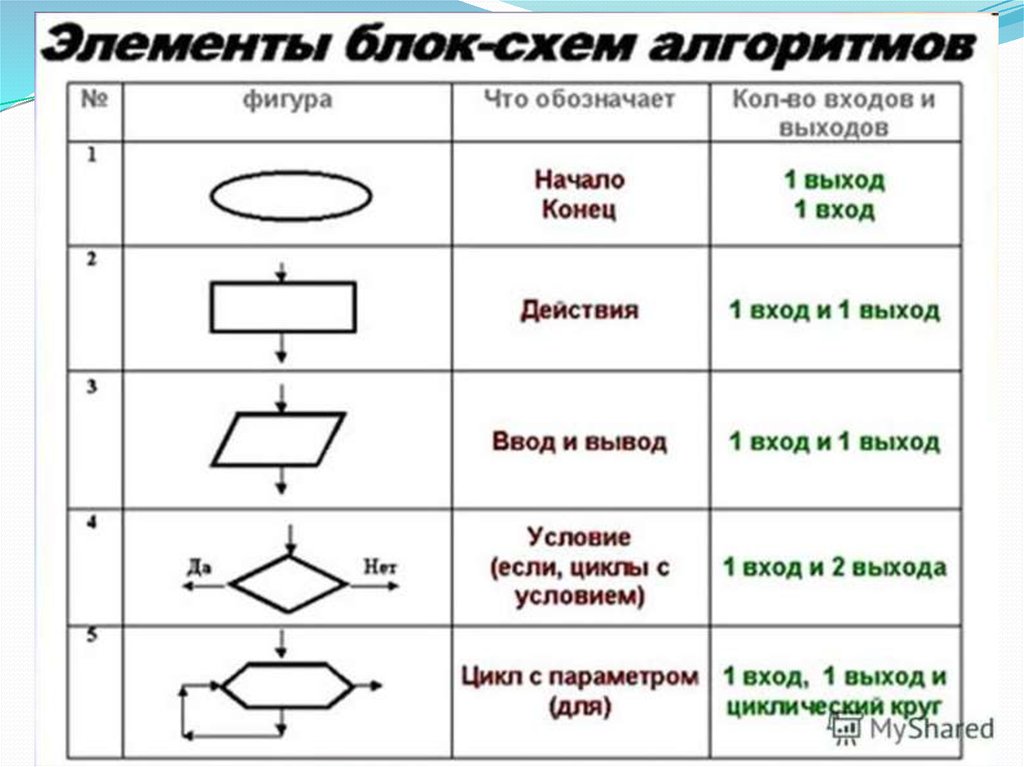
пример схемы {
пример документа {
тип содержимого поля строка {
индексация: индекс | краткое содержание
индекс: включить-bm25
}
}
ранг-профиль по умолчанию {
первая фаза {
выражение {
бм25(содержание)
}
}
}
}
Если флаг enable-bm25 установлен после того, как документы уже поданы, необходимо выполнить некоторые дополнительные шаги для подготовки списков размещения в памяти и дисковых индексах для этого поля. Для каждого узла контента выполните следующие действия:
- Выполнить сброс индекса памяти с помощью
Веспа-протон-cmd:
vespa-proton-cmd --local triggerFlush
- Выполнить слияние индексов дисков,
подготовка списков проводок для использования с bm25 :
vespa-proton-cmd --local triggerFlush
bm25_intro
- 1 Краткое введение в Okapi BM25
- 1.1 Получение интуиции для Okapi BM25
- 1. 2 Реализация
- BM5 Search 9arch 1.3 2 Elastic0044
- 2 Ссылка
 2 Реализация
2 РеализацияВ [1]:
# код загрузки формата для блокнота
импорт ОС
# path : сохранить текущий путь, чтобы вернуться к нему позже
путь = os.getcwd()
os.chdir(os.path.join('..', 'notebook_format'))
из форматов импортировать load_style
load_style (plot_style = Ложь)
Исходящий[1]:
Входящий [2]:
os.chdir(путь) импортировать математику импортировать json запросы на импорт # 1. магия в печатной версии # 2. магия, чтобы ноутбук перезагрузил внешние модули python %load_ext водяной знак %load_ext автоперезагрузка %автоперезагрузка 2 %watermark -a 'Ethen' -d -t -v -p запросы
Этен 2018-11-17 17:24:06 CPython 3.6.4 IPython 6.4.0 запросы 2.20.1
Проблема, которую пытается решить BM25 (Best Match 25) , аналогична проблеме TFIDF (частота терминов, обратная частота документа), которая представляет наш текст в векторном пространстве (ее можно применить к полю вне текста).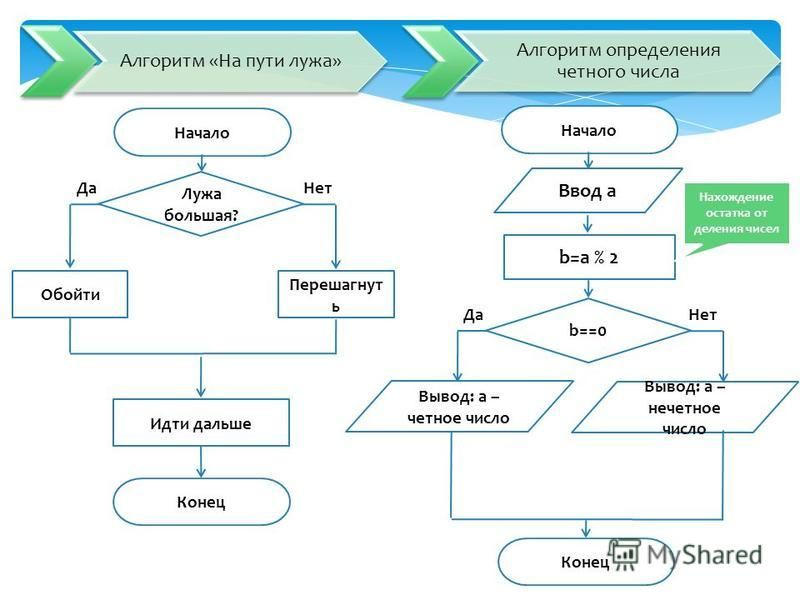 , но текст — это то место, где он присутствует больше всего), поэтому мы можем искать/находить похожие документы для данного документа или запроса.
, но текст — это то место, где он присутствует больше всего), поэтому мы можем искать/находить похожие документы для данного документа или запроса.
Суть TFIDF заключается в том, что он полагается на два основных фактора, чтобы определить, похож ли документ на наш запрос.
- Частота терминов, также известная как tf: как часто этот термин встречается в документе? 3 раза? 10 раз?
- Обратная частота документа, также известная как idf: измеряет количество документов, в которых появился термин. Затем обратная частота документа (1/df) измеряет, насколько особенным является термин. Является ли этот термин очень редким (встречается только в одном документе) словом? Или относительно распространенный (встречается почти во всех документах)?
Используя эти два фактора, TFIDF измеряет относительную концентрацию термина в данном фрагменте документа. Если термин часто встречается в этой статье, но относительно редко встречается в других местах, то оценка TFIDF будет высокой, а документы с более высокой оценкой TFIDF будут считаться очень релевантными для поискового запроса.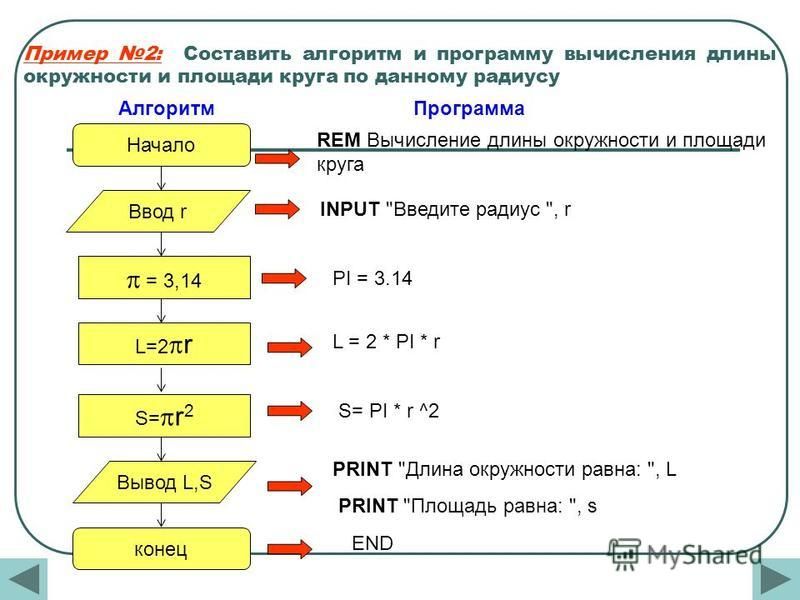
BM25 улучшает TFIDF, рассматривая релевантность как проблему вероятности. Оценка релевантности, согласно вероятностному поиску информации, должна отражать вероятность того, что пользователь сочтет результат релевантным. Вместо того, чтобы рассказывать, как была получена формула, здесь мы рассмотрим формулу и попробуем переварить ее, чтобы понять, почему она имеет какой-то смысл.
Gaining Intuition for Okapi BM25¶
BM25 (Лучшее совпадение 25) Функция оценивает каждый документ в корпусе в соответствии с релевантностью документа для конкретного текстового запроса. Для запроса $Q$ с терминами $q_1, \ldots, q_n$ оценка BM25 для документа $D$ составляет: 9n IDF(q_i, D) \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i) + k_1 \cdot (1-b + b \cdot |D|/d_{avg}) )} \end{align}
где:
- $f(q_i, D)$ — количество раз, когда термин $q_i$ встречается в документе $D$.
- $|D|$ — количество слов в документе $D$.
- $d_{avg}$ — среднее количество слов в документе.
- $b$ и $k_1$ — это гиперпараметры для BM25.
Давайте разобьем формулу на более мелкие компоненты, чтобы понять, почему она имеет смысл.
- Прежде всего, это $f(q_i, D)$ и $k_1$. $f(q_i, D)$ должно соответствовать нашей интуиции, поскольку это означает, что чем больше раз термин запроса появляется в документе, тем выше будет оценка документа. Интересной частью является параметр $k_1$, определяющий характеристику насыщения частоты члена. Чем выше значение, тем медленнее насыщение. И когда мы говорим о насыщении, мы имеем в виду тот факт, что если термины встречаются больше раз, это добавляет дополнительные баллы. Мы можем наблюдать эту уменьшающуюся отдачу по частоте терминов на графике ниже.
- Тогда часть $|D|/d_{avg}$ в знаменателе означает, что документ, который длиннее среднего документа, приведет к большему знаменателю, что приведет к снижению оценки. Интуиция подсказывает, что чем больше в документе терминов, не соответствующих нашему входному запросу, тем ниже должна быть оценка документа. Другими словами, если в 300-страничном документе термин запроса упоминается один раз, вероятность того, что он будет иметь такое же отношение к запросу, меньше, чем в коротком твите, в котором запрос упоминается один раз.
 Другими словами, если в 300-страничном документе термин запроса упоминается один раз, вероятность того, что он будет иметь такое же отношение к запросу, меньше, чем в коротком твите, в котором запрос упоминается один раз.
Другими словами, если в 300-страничном документе термин запроса упоминается один раз, вероятность того, что он будет иметь такое же отношение к запросу, меньше, чем в коротком твите, в котором запрос упоминается один раз.Из графика выше видно, что более короткие документы достигают асимптоты намного быстрее. Будем надеяться, что это соответствует нашей интуиции, поскольку чем больше совпадений у нас есть с более короткими документами, тем больше мы уверены в релевантности, в то время как для длинной книги нам может потребоваться больше времени, чтобы добраться до точки, в которой мы чувствуем уверенность в том, что книга действительно имеет отношение к заданному запросу.
- Параметр $b$ (граница 0.0 ~ 1.0) в знаменателе умножается на коэффициент длины документа, который мы только что обсуждали. Чем больше $b$, тем сильнее влияние длины документа по сравнению со средней длиной. Мы можем себе представить, что если мы установим $b$ в 0, эффект отношения длин будет полностью сведен на нет.
Что касается частотной части обратного документа, ${IDF}(q_i, D)$. Для корпуса с $N$ документами обратная частота документов для термина $q_i$ вычисляется следующим образом:
\начать{выравнивать} \mbox{IDF}(q_i, D) = \log \frac{N — N(q_i) + 0,5}{N(q_i) + 0,5} \end{выравнивание}
, где
- $N(q_i)$ — количество документов в корпусе, содержащих термин $q_i$.
Часть обратной частоты документа очень похожа на часть TFIDF, роль которой состоит в том, чтобы гарантировать, что более редкие слова будут иметь более высокий балл и вносить больший вклад в окончательный балл.
Обратите внимание, что приведенная выше формула IDF имеет недостаток при использовании ее для терминов, встречающихся более чем в половине корпуса, поскольку значение будет отрицательным, что приведет к отрицательному общему баллу. например если у нас есть 10 документов в корпусе, и термин «the» появился в 6 из них, его IDF будет $log(10 — 6 + 0,5/6 + 0,5) = log(4,5/6,5)$. Хотя мы можем утверждать, что наша реализация уже должна была удалить эти часто встречающиеся слова, поскольку эти слова в основном используются для формирования полного предложения и не несут особого смысла, различные программы/пакеты по-прежнему вносят различные коррективы, чтобы предотвратить появление отрицательной оценки. например
Хотя мы можем утверждать, что наша реализация уже должна была удалить эти часто встречающиеся слова, поскольку эти слова в основном используются для формирования полного предложения и не несут особого смысла, различные программы/пакеты по-прежнему вносят различные коррективы, чтобы предотвратить появление отрицательной оценки. например
- Добавьте 1 к уравнению.
\начать{выравнивать} \mbox{IDF}(q_i) = \log \big( 1 + \frac{N — N(q_i) + 0,5}{N(q_i) + 0,5} \big) \end{align}
- Для термина, который привел к отрицательному значению IDF, замените его небольшим положительным значением, обычно обозначаемым как $\epsilon$
Как и все гиперпараметры в целом, параметры по умолчанию обычно являются хорошей отправной точкой, и нам, вероятно, следует сосредоточиться на настройке других вещей, прежде чем прыгать в кроличью нору настройки гиперпараметров. В контексте поиска это может быть связано с тем, что в нашем рейтинге более старые документы оцениваются ниже в таких приложениях, как рейтинг новостей. Но если мы приступим к настройке, не забывайте всегда измерять производительность различных настроек, и следующие вопросы являются общими отправными точками, на которые мы можем ссылаться.
Но если мы приступим к настройке, не забывайте всегда измерять производительность различных настроек, и следующие вопросы являются общими отправными точками, на которые мы можем ссылаться.
- Для $k_1$ мы должны задать вопрос: «Когда, по нашему мнению, терм, вероятно, будет насыщен?» Для очень длинных документов, таких как книги, очень вероятно, что множество различных терминов будет появляться в произведении несколько раз, даже если термин не является основным предметом документа. Возможно, в этой ситуации мы не хотим, чтобы термины насыщались так быстро, поэтому предлагается, чтобы $k_1$ обычно стремился к большим числам, когда текст намного длиннее и разнообразнее. С другой стороны, было предложено установить $k_1$ в нижней части. Очень маловероятно, что в наборе коротких твитов будет несколько раз упоминаться термин, не имеющий тесной связи с этим термином.
- Для $b$ мы должны задаться вопросом: «Когда, по нашему мнению, документ может быть очень длинным, а когда это должно препятствовать его релевантности термину?» Документы, которые являются очень конкретными, такими как технические спецификации или патенты, являются длинными, чтобы быть более конкретными по предмету. Их длина вряд ли повлияет на релевантность, и меньший $b$ может быть более подходящим. С другой стороны, документы, затрагивающие несколько разных тем в широком смысле — новостные статьи (политическая статья может касаться экономики, международных отношений и некоторых корпораций), обзоры пользователей и т. д. — часто выигрывают от выбора больше $b$, чтобы нерелевантные темы для поиска пользователя, включая спам и тому подобное, наказывались.
 Их длина вряд ли повлияет на релевантность, и меньший $b$ может быть более подходящим. С другой стороны, документы, затрагивающие несколько разных тем в широком смысле — новостные статьи (политическая статья может касаться экономики, международных отношений и некоторых корпораций), обзоры пользователей и т. д. — часто выигрывают от выбора больше $b$, чтобы нерелевантные темы для поиска пользователя, включая спам и тому подобное, наказывались.
Их длина вряд ли повлияет на релевантность, и меньший $b$ может быть более подходящим. С другой стороны, документы, затрагивающие несколько разных тем в широком смысле — новостные статьи (политическая статья может касаться экономики, международных отношений и некоторых корпораций), обзоры пользователей и т. д. — часто выигрывают от выбора больше $b$, чтобы нерелевантные темы для поиска пользователя, включая спам и тому подобное, наказывались.Реализация¶
В [3]:
# мы создадим несколько поддельных текстов для экспериментов.
корпус = [
«Человеко-машинный интерфейс для лабораторных компьютерных приложений abc»,
«Опрос мнения пользователей о времени отклика компьютерной системы»,
«Система управления пользовательским интерфейсом EPS»,
«Системные и человеческие системные испытания EPS»,
«Отношение воспринимаемого пользователем времени отклика к измерению ошибки»,
«Генерация случайных бинарных неупорядоченных деревьев»,
'График пересечения путей в деревьях',
«График миноров IV. Ширина деревьев и квазиупорядочение скважин»,
'График несовершеннолетних Опрос'
]
# удаляем стоп-слова и токенизируем их (вероятно, мы хотим сделать еще кое-что
# предварительная обработка нашего текста в реальных условиях, но мы продолжим
# здесь все просто)
стоп-слова = set(['для', 'а', 'из', 'то', 'и', 'к', 'в'])
тексты = [
[дословно в document.lower().split(), если слово не в стоп-словах]
для документа в корпусе
]
# создать словарь подсчета слов, чтобы мы могли удалять слова, которые встречаются только один раз
word_count_dict = {}
для текста в текстах:
для токена в тексте:
word_count = word_count_dict.get (токен, 0) + 1
word_count_dict[токен] = word_count
texts = [[токен для токена в тексте, если word_count_dict[токен] > 1] для текста в текстах]
тексты
 Ширина деревьев и квазиупорядочение скважин»,
'График несовершеннолетних Опрос'
]
# удаляем стоп-слова и токенизируем их (вероятно, мы хотим сделать еще кое-что
# предварительная обработка нашего текста в реальных условиях, но мы продолжим
# здесь все просто)
стоп-слова = set(['для', 'а', 'из', 'то', 'и', 'к', 'в'])
тексты = [
[дословно в document.lower().split(), если слово не в стоп-словах]
для документа в корпусе
]
# создать словарь подсчета слов, чтобы мы могли удалять слова, которые встречаются только один раз
word_count_dict = {}
для текста в текстах:
для токена в тексте:
word_count = word_count_dict.get (токен, 0) + 1
word_count_dict[токен] = word_count
texts = [[токен для токена в тексте, если word_count_dict[токен] > 1] для текста в текстах]
тексты
Ширина деревьев и квазиупорядочение скважин»,
'График несовершеннолетних Опрос'
]
# удаляем стоп-слова и токенизируем их (вероятно, мы хотим сделать еще кое-что
# предварительная обработка нашего текста в реальных условиях, но мы продолжим
# здесь все просто)
стоп-слова = set(['для', 'а', 'из', 'то', 'и', 'к', 'в'])
тексты = [
[дословно в document.lower().split(), если слово не в стоп-словах]
для документа в корпусе
]
# создать словарь подсчета слов, чтобы мы могли удалять слова, которые встречаются только один раз
word_count_dict = {}
для текста в текстах:
для токена в тексте:
word_count = word_count_dict.get (токен, 0) + 1
word_count_dict[токен] = word_count
texts = [[токен для токена в тексте, если word_count_dict[токен] > 1] для текста в текстах]
тексты
Исходящий[3]:
[['человек', 'интерфейс', 'компьютер'], ['опрос', 'пользователь', 'компьютер', 'система', 'ответ', 'время'], ['eps', 'пользователь', 'интерфейс', 'система'], ['система', 'человек', 'система', 'eps'], ['пользователь', 'ответ', 'время'], ['деревья'], ['график', 'деревья'], ['граф', 'младшие', 'деревья'], ['график', 'второстепенные', 'опрос']]
В [4]:
класс BM25:
"""
Лучший матч 25.
Параметры
----------
k1 : с плавающей запятой, по умолчанию 1,5
b : с плавающей запятой, по умолчанию 0,75
Атрибуты
----------
tf_ : список[dict[str, int]]
Срок Периодичность на документ. Итак, [{'привет': 1}] означает
первый документ содержит термин «привет» 1 раз.
df_ : словарь[str, int]
Документ Периодичность за семестр. т. е. количество документов в
корпус, содержащий термин.
idf_ : dict[str, float]
Частота обратного документа за термин.
doc_len_ : список[целое число]
Количество терминов в документе. Итак, [3] означает первый
документ содержит 3 термина.
corpus_ : список[список[строка]]
Входной корпус.
corpus_size_ : целое число
Количество документов в корпусе.
avg_doc_len_ : с плавающей запятой
Среднее количество терминов для документов в корпусе.
"""
def __init__(самостоятельно, k1=1,5, b=0,75):
я.б = б
сам.k1 = k1
def fit (я, корпус):
"""
Сопоставьте различные статистические данные, необходимые для расчета рейтинга BM25.
оценка с использованием данного корпуса.
Параметры
----------
корпус: список[список[строка]]
Каждый элемент в списке представляет документ, и каждый документ
представляет собой список терминов.
Возвращает
-------
себя
"""
тф = []
ДФ = {}
ИДФ = {}
doc_len = []
размер_корпуса = 0
для документа в корпусе:
размер_корпуса += 1
doc_len.append (длина (документ))
# вычислить tf (частоту терминов) для каждого документа
частоты = {}
на срок в документе:
term_count = частоты. Получить (термин, 0) + 1
частоты[термин] = число_терминов
tf.append(частоты)
# вычислить df (частоту документов) на терм
для термина, _ в Frequency.items():
df_count = df.get (термин, 0) + 1
df[термин] = df_count
для срока, частота в df. items():
idf[term] = math.log(1 + (размер_корпуса - частота + 0,5) / (частота + 0,5))
self.tf_ = tf
self.df_ = дф
self.idf_ = idf
self.doc_len_ = doc_len
self.corpus_ = корпус
self.corpus_size_ = размер_корпуса
self.avg_doc_len_ = сумма (doc_len) / размер_корпуса
вернуть себя
поиск по определению (я, запрос):
scores = [self._score(query, index) для индекса в диапазоне(self.corpus_size_)]
обратные баллы
def _score (я, запрос, индекс):
оценка = 0,0
doc_len = self.doc_len_[индекс]
частоты = self.tf_[index]
для термина в запросе:
если термин не в частотах:
продолжать
частота = частоты [срок]
числитель = self.idf_[термин] * частота * (self.k1 + 1)
знаменатель = частота + self.k1 * (1 - self.b + self.b * doc_len / self.avg_doc_len_)
оценка += (числитель/знаменатель)
обратный счет
 Параметры
----------
k1 : с плавающей запятой, по умолчанию 1,5
b : с плавающей запятой, по умолчанию 0,75
Атрибуты
----------
tf_ : список[dict[str, int]]
Срок Периодичность на документ. Итак, [{'привет': 1}] означает
первый документ содержит термин «привет» 1 раз.
df_ : словарь[str, int]
Документ Периодичность за семестр. т. е. количество документов в
корпус, содержащий термин.
idf_ : dict[str, float]
Частота обратного документа за термин.
doc_len_ : список[целое число]
Количество терминов в документе. Итак, [3] означает первый
документ содержит 3 термина.
corpus_ : список[список[строка]]
Входной корпус.
corpus_size_ : целое число
Количество документов в корпусе.
avg_doc_len_ : с плавающей запятой
Среднее количество терминов для документов в корпусе.
"""
def __init__(самостоятельно, k1=1,5, b=0,75):
я.б = б
сам.k1 = k1
def fit (я, корпус):
"""
Сопоставьте различные статистические данные, необходимые для расчета рейтинга BM25.
Параметры
----------
k1 : с плавающей запятой, по умолчанию 1,5
b : с плавающей запятой, по умолчанию 0,75
Атрибуты
----------
tf_ : список[dict[str, int]]
Срок Периодичность на документ. Итак, [{'привет': 1}] означает
первый документ содержит термин «привет» 1 раз.
df_ : словарь[str, int]
Документ Периодичность за семестр. т. е. количество документов в
корпус, содержащий термин.
idf_ : dict[str, float]
Частота обратного документа за термин.
doc_len_ : список[целое число]
Количество терминов в документе. Итак, [3] означает первый
документ содержит 3 термина.
corpus_ : список[список[строка]]
Входной корпус.
corpus_size_ : целое число
Количество документов в корпусе.
avg_doc_len_ : с плавающей запятой
Среднее количество терминов для документов в корпусе.
"""
def __init__(самостоятельно, k1=1,5, b=0,75):
я.б = б
сам.k1 = k1
def fit (я, корпус):
"""
Сопоставьте различные статистические данные, необходимые для расчета рейтинга BM25.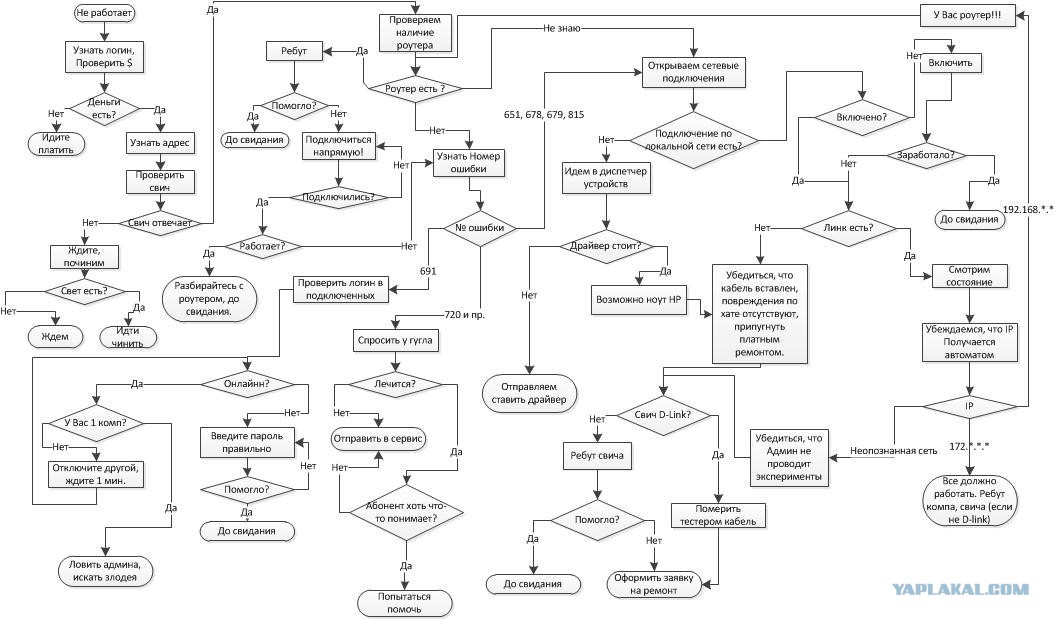 оценка с использованием данного корпуса.
Параметры
----------
корпус: список[список[строка]]
Каждый элемент в списке представляет документ, и каждый документ
представляет собой список терминов.
Возвращает
-------
себя
"""
тф = []
ДФ = {}
ИДФ = {}
doc_len = []
размер_корпуса = 0
для документа в корпусе:
размер_корпуса += 1
doc_len.append (длина (документ))
# вычислить tf (частоту терминов) для каждого документа
частоты = {}
на срок в документе:
term_count = частоты. Получить (термин, 0) + 1
частоты[термин] = число_терминов
tf.append(частоты)
# вычислить df (частоту документов) на терм
для термина, _ в Frequency.items():
df_count = df.get (термин, 0) + 1
df[термин] = df_count
для срока, частота в df.
оценка с использованием данного корпуса.
Параметры
----------
корпус: список[список[строка]]
Каждый элемент в списке представляет документ, и каждый документ
представляет собой список терминов.
Возвращает
-------
себя
"""
тф = []
ДФ = {}
ИДФ = {}
doc_len = []
размер_корпуса = 0
для документа в корпусе:
размер_корпуса += 1
doc_len.append (длина (документ))
# вычислить tf (частоту терминов) для каждого документа
частоты = {}
на срок в документе:
term_count = частоты. Получить (термин, 0) + 1
частоты[термин] = число_терминов
tf.append(частоты)
# вычислить df (частоту документов) на терм
для термина, _ в Frequency.items():
df_count = df.get (термин, 0) + 1
df[термин] = df_count
для срока, частота в df. items():
idf[term] = math.log(1 + (размер_корпуса - частота + 0,5) / (частота + 0,5))
self.tf_ = tf
self.df_ = дф
self.idf_ = idf
self.doc_len_ = doc_len
self.corpus_ = корпус
self.corpus_size_ = размер_корпуса
self.avg_doc_len_ = сумма (doc_len) / размер_корпуса
вернуть себя
поиск по определению (я, запрос):
scores = [self._score(query, index) для индекса в диапазоне(self.corpus_size_)]
обратные баллы
def _score (я, запрос, индекс):
оценка = 0,0
doc_len = self.doc_len_[индекс]
частоты = self.tf_[index]
для термина в запросе:
если термин не в частотах:
продолжать
частота = частоты [срок]
числитель = self.idf_[термин] * частота * (self.k1 + 1)
знаменатель = частота + self.k1 * (1 - self.b + self.b * doc_len / self.avg_doc_len_)
оценка += (числитель/знаменатель)
обратный счет
items():
idf[term] = math.log(1 + (размер_корпуса - частота + 0,5) / (частота + 0,5))
self.tf_ = tf
self.df_ = дф
self.idf_ = idf
self.doc_len_ = doc_len
self.corpus_ = корпус
self.corpus_size_ = размер_корпуса
self.avg_doc_len_ = сумма (doc_len) / размер_корпуса
вернуть себя
поиск по определению (я, запрос):
scores = [self._score(query, index) для индекса в диапазоне(self.corpus_size_)]
обратные баллы
def _score (я, запрос, индекс):
оценка = 0,0
doc_len = self.doc_len_[индекс]
частоты = self.tf_[index]
для термина в запросе:
если термин не в частотах:
продолжать
частота = частоты [срок]
числитель = self.idf_[термин] * частота * (self.k1 + 1)
знаменатель = частота + self.k1 * (1 - self.b + self.b * doc_len / self.avg_doc_len_)
оценка += (числитель/знаменатель)
обратный счет
In [5]:
# запросите наш корпус, чтобы увидеть, какой документ более актуален.
0.0 Человеко-машинный интерфейс для лабораторных компьютерных приложений abc 1.025 Опрос мнения пользователей о времени отклика компьютерной системы 0.0 Система управления пользовательским интерфейсом EPS 0,0 Системные и инженерные испытания систем человека для EPS 0,0 Отношение воспринимаемого пользователем времени отклика к измерению ошибки 1.462. Генерация случайных бинарных неупорядоченных деревьев. 2.485. Граф пересечений путей в деревьях 2.161. Миноры графов IV. Ширины деревьев и хорошо квазиупорядочение. 2.507 Несовершеннолетние графы Опрос
В приведенном выше фрагменте кода мы распечатали оценку релевантности BM25 каждого корпуса вместе с исходным текстом, обратите внимание, что это еще не отсортировано в порядке убывания оценки релевантности, что обычно мы хотим сделать в реальных условиях. . То есть найти более релевантный документ, отсортировать их в порядке убывания и представить пользователю. Кроме того, здесь мы вычисляем баллы для каждого документа, это становится дорогостоящим в вычислительном отношении, когда мы начинаем иметь большой размер корпуса. Таким образом, поисковая система использует перевернул индекс , чтобы ускорить процесс. Инвертированный индекс состоит из списка всех уникальных слов, встречающихся в каком-либо документе, а для каждого слова — списка документов, в которых оно встречается, это позволяет нам быстро находить документы, содержащие термин в нашем запросе, и только затем мы вычисляем показатель релевантности для этого меньшего набора отзывов. Эта ссылка содержит хорошее описание этой концепции на высоком уровне.
ElasticSearch BM25¶
Мы можем увидеть BM25 в действии для ранжирования документов с помощью ElasticSearch, эта записная книжка не является учебным пособием по ElasticSearch, так что, надеюсь, читатель немного знаком с этим инструментом, если нет, каждый фрагмент кода содержит ссылки на некоторые полезные ссылки.
Мы будем следовать стандартному процессу создания индекса для хранения наших документов, добавим несколько образцов документов в индекс и предоставим запрос к индексу, чтобы вернуть соответствующие документы, отсортированные в порядке убывания на основе оценки релевантности, которая будет основана на БМ25.
В [8]:
# инструкция по установке
# https://www.elastic.co/guide/en/elasticsearch/reference/current/_installation.html
# создание индекса
# https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-create-index.html
настройки = {
'настройки': {
'индекс': {
'количество_осколков': 1,
'количество_реплик': 1,
# явно настроить наш алгоритм подобия по умолчанию для использования bm25,
# это позволяет использовать его для всех полей
'сходство': {
'по умолчанию': {
«тип»: «BM25»
}
}
}
},
# мы будем индексировать наши документы в поле заголовка с помощью анализатора английского языка,
# который убирает за нас стоп-слова, стандартный анализатор по умолчанию не имеет
# этот шаг предварительной обработки
# https://www. elastic.co/guide/en/elasticsearch/reference/current/analysis.html
'отображения': {
# этот ключ является "типом", который будет объяснен в следующем фрагменте кода
'_doc': {
'характеристики': {
'заголовок': {
'тип': 'текст',
'анализатор': 'английский'
}
}
}
}
}
заголовки = {'Тип контента': 'приложение/json'}
ответ = запросы.пут('http://localhost:9200/experiment', data=json.dumps(настройки), заголовки=заголовки)
ответ
Out[8]:
In [9]:
# индексирующий документ # https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html # https://www.elastic.co/guide/en/elasticsearch/guide/master/index-doc.html # документ однозначно идентифицируется индексом, типом и идентификатором # стоит отметить, что есть примечание об удалении возможностей # иметь несколько типов под одним индексом, и в дальнейшем тип будет # просто установить в '_doc' # https://www.
Out[9]:
In [10]:
поиск по определению (запрос, заголовки):
url = 'http://localhost:9200/experiment/_doc/_search'
ответ = запросы.получить (url, данные = json.dumps (запрос), заголовки = заголовки)
# ответ содержит другую информацию, например, время, затраченное на
# возвращаем ответ, здесь нас интересует только совпавший
# результаты, которые хранятся в разделе "посещения"
search_hits = json.loads(response.text)['попадания']['попадания']
print('Число\tОценка релевантности\tTitle')
для idx нажмите enumerate(search_hits):
print('%s\t%s\t%s' % (idx + 1, hit['_score'], hit['_source']['title']))
В [11]:
# запрос соответствия # https://www.