Парсер: что это такое простыми словами
Скопировано
Содержание
Парсер — это программа для сбора и систематизации информации, размещенной на различных сайтах. Источником данных может служить текстовое наполнение, HTML-код сайта, заголовки, пункты меню, базы данных и другие элементы. Процесс сбора информации называется парсинг (parsing).
Парсеры используются в интернет-маркетинге для сбора информации с сайтов-конкурентов, а также для анализа собственных веб-ресурсов. Они позволяют обрабатывать большие массивы данных в автоматическом режиме. Это ускоряет и упрощает проведение маркетинговых исследований.
Схема работы парсераКак работает парсер
Термин «парсинг» произошел от английского глагола to parse, означающего в переводе с английского «по частям». Процесс представляет собой синтаксический анализ любого набора связанных друг с другом данных. В общем виде парсинг выполняется в несколько этапов:
- Сканирование исходного массива информации (HTML-кода, текста, базы данных и т.

- Вычленение семантически значимых единиц по заданным параметрам — например заголовков, ссылок, абзацев, выделенных жирным шрифтом фрагментов, пунктов меню.
- Конвертация полученных данных в формат, удобный для изучения, а также их систематизация в виде таблиц или отчетов для дальнейшего использования.

Объектом парсинга может быть любая грамматически структурированная система: информация, закодированная естественным языком, языком программирования, математическими выражениями и т.д. Например, если исходный массив данных представляет собой HTML-страницу, парсер может вычленить из кода информацию и перевести ее в текст, понятный для человека. Или конвертировать в JSON — формат для приложений и скриптов.
Доступ парсера к сайту возможен:
- через протоколы HTTP, HTTPS или веб-браузер;
- с использованием бота, имеющего права администратора.
Получение данных парсером — семантический анализ исходного массива информации. Программа разбивает его на отдельные части (лексемы): слова, словосочетания и т. д. Парсер проводит их грамматический анализ, преобразуя линейную структуру текста в древовидную (синтаксическое дерево). Такая форма упрощает «понимание» информационного массива компьютерной программой и бывает двух типов:
д. Парсер проводит их грамматический анализ, преобразуя линейную структуру текста в древовидную (синтаксическое дерево). Такая форма упрощает «понимание» информационного массива компьютерной программой и бывает двух типов:
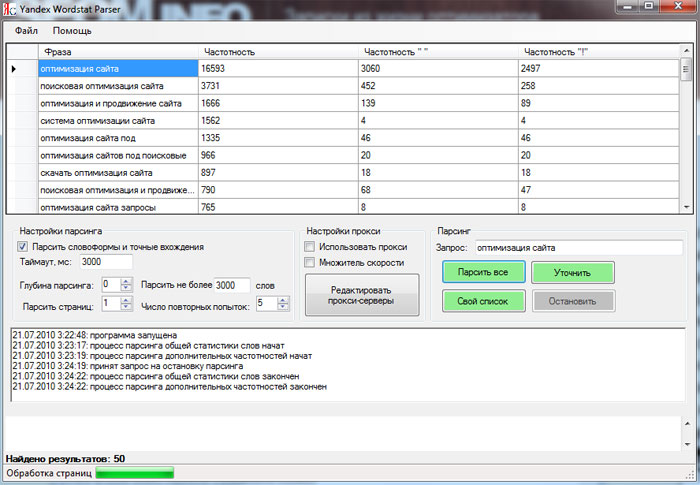
- дерево зависимостей — такая структура состоит из компонентов, находящихся в иерархических отношениях друг к другу;
- дерево составляющих — в структуре этого типа компоненты находятся в тесной зависимости друг с другом, но без иерархических отношений.
Также результат работы парсера может представлять собой сочетание моделей. Программа действует по одному из двух алгоритмов:
- Нисходящий парсинг. Анализ осуществляется от общего к частному, а синтаксическое дерево разрастается вниз.
- Восходящий парсинг. Анализ и построение синтаксического дерева осуществляются снизу вверх.
Выбор конкретного метода парсинга зависит от конечной цели. В любом случае, парсер должен уметь вычленять из общего массива только необходимые данные, а также преобразовывать их в удобный для решения задачи формат.
Преимущества и недостатки парсеров
Применение программ-парсеров позволяет:
- автоматизировать процесс анализа и снижать нагрузку на сотрудников, перенаправлять их время и силы на решение других задач;
- ускорять анализ большого объема информации — например, нескольких сотен страниц интернет-магазина или обширную базу данных;
- выявлять ошибки на сайте или в любом другом информационном продукте, если в программе заданы настройки на их поиск.
К недостаткам парсеров можно отнести не всегда релевантный анализ данных. Однако в большинстве случаев это зависит от возможностей программы, качества ее настройки пользователем. В большинстве случаев информация, выдаваемая парсером, требует незначительной обработки для дальнейшего использования.
Применение парсеров
Парсинг применяется в любых областях, где требуется проанализировать и систематизировать большой объем данных:
- В программировании. Компьютер может воспринимать и «понимать» только машинный код — набор нулей и единиц. Чтобы заставить машину выполнить какую-либо операцию, человек использует языки программирования, которые непонятны компьютеру. Поэтому специальное приложение сначала проводит парсинг написанной пользователем программы и переводит полученные данные в бинарный машинный код.
- В создании сайтов. Как и языки программирования, языки разметки (например HTML) непонятны компьютеру. Чтобы он смог отобразить HTML-разметку в виде визуально структурированного и понятного интерфейса сайта, парсер браузера анализирует исходный код страницы, вычленяет нужные данные, переводит их в понятный машине формат. Также парсинг позволяет выявить ошибки и недочеты в созданном сайте.
- Веб-краулинг. Это частный случай парсинга. Робот-парсер поисковика в ответ на запрос пользователя просматривает релевантные ему сайты, после чего выбирает наиболее подходящую по содержанию страницу. Особенность краулеров в том, что они не извлекают данные со страниц, как другие парсеры, а ищут в них совпадения с запросом пользователя.
- Агрегация новостей. Для упорядоченной подачи новостей сайты-агрегаторы или новостные агентства используют парсеры. Они собирают обновления со всех доступных источников, анализируют их и подают сотрудникам для конечной редактуры и публикации.
- Интернет-маркетинг. В SEO и SMM с помощью парсеров собираются и анализируются данные пользователей, товарные позиции в интернет-магазинах, метатеги (заголовки, title и description), ключевые слова и другая информация. Эти данные используются для оптимизации сайта, продвижения коммерческих групп в социальных сетях, настройки таргетированной и контекстной рекламы. Проверка размещенного на веб-ресурсе текста на плагиат также является разновидностью парсинга.
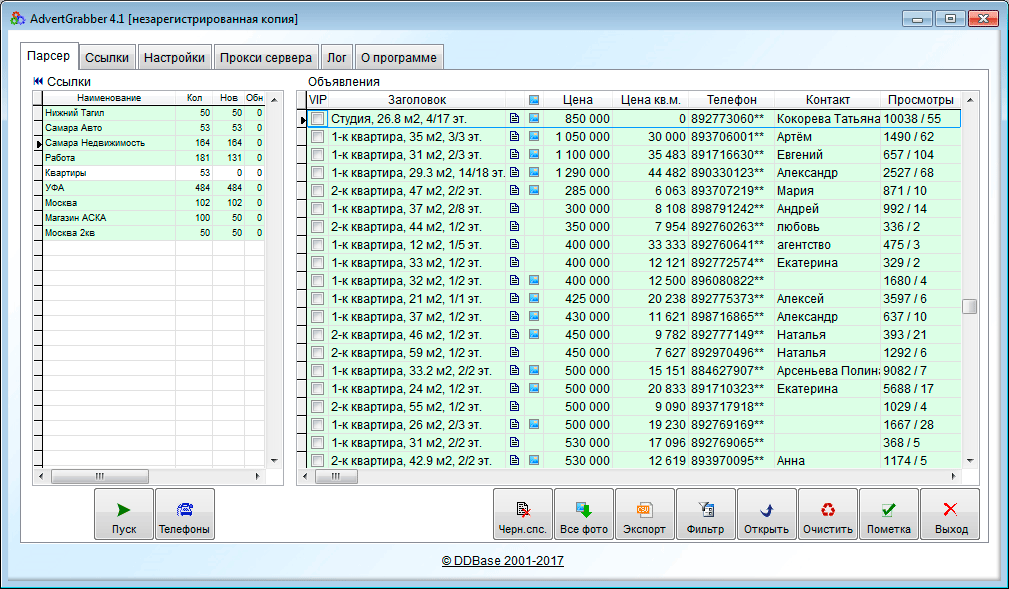
- Мониторинг цен. Парсерами можно извлечь расценки товаров на сайтах-конкурентах, чтобы проанализировать текущую ситуацию на рынке и выработать ценовую политику. Также с их помощью можно привести прайс-листы на собственном сайте в соответствие с ценами у поставщиков.
 Чтобы заставить машину выполнить какую-либо операцию, человек использует языки программирования, которые непонятны компьютеру. Поэтому специальное приложение сначала проводит парсинг написанной пользователем программы и переводит полученные данные в бинарный машинный код.
Чтобы заставить машину выполнить какую-либо операцию, человек использует языки программирования, которые непонятны компьютеру. Поэтому специальное приложение сначала проводит парсинг написанной пользователем программы и переводит полученные данные в бинарный машинный код.
Программы-парсеры
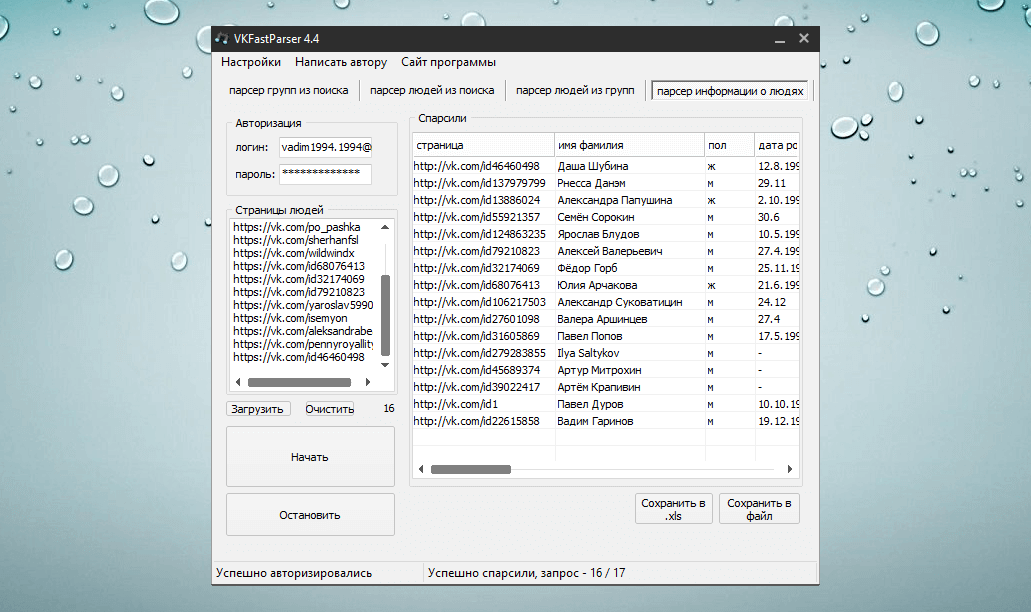
В веб-разработке и продвижении используется большое количество бесплатных и платных программ для парсинга сайтов. К числу самых популярных относятся:
- Screaming Frog SEO Spider. Это британская программа для комплексного анализа сайтов со множеством полезных опций. Она осуществляет поиск битых ссылок, входящих и исходящих ссылок, выявляет дубли метатегов и заголовков, ключевые слова, отдельные URL и т.д. Среди полезных дополнительных опций — генерация sitemap, сканирование сайтов, требующих оптимизации, проверка файла robots.txt. Программа имеет бесплатную версию, но функционал ограничен базовыми возможностями.
- ComparseR. Это приложение также позволяет парсить сайты, но у нее отсутствует функция поиска внутренних и внешних ссылок. В остальном оно не уступает Screaming Frog по возможностям, хотя имеются ограничения по производительности при анализе крупных сайтов — например, интернет-магазинов или больших информационных порталов. Дополнительным преимуществом является более удобный интерфейс, упрощающий освоение программы и ее использование.
 Дополнительным преимуществом является более удобный интерфейс, упрощающий освоение программы и ее использование.
Дополнительным преимуществом является более удобный интерфейс, упрощающий освоение программы и ее использование.- Netpeak Spider. Одно из самых популярных приложений для парсинга, ориентированное на работу с крупными сайтами (с миллионом и более страниц). Среди преимуществ — наличие всего набора инструментов для анализа и продвижения веб-ресурсов разного типа, настраиваемые фильтры параметров, дополнительные опции наподобие генерации HTML-карты сайта, поиска ссылок nofollow, выгрузки отчетов и т.д. Единственный недостаток — полный функционал доступен по подписке, которую нужно регулярно продлевать.
- Xenu Link Sleuth. Бесплатный парсер, предназначенный для поиска битых ссылок и других ошибок на сайте. Xenu нельзя использовать для комплексного и подробного анализа веб-ресурсов. Также есть проблемы с производительностью, но с учетом доступности недостатки приемлемы.
Можно ли использовать парсеры
Распространено мнение, что парсинг сайтов как минимум неэтичен, а в некоторых случаях и незаконен. Действительно, парсеры собирают информацию с чужих веб-ресурсов, баз данных и других источников. Однако в большинстве случаев сведения находятся в открытом доступе, то есть использование программ не нарушает закон. Противозаконным может стать применение данных, например:
Действительно, парсеры собирают информацию с чужих веб-ресурсов, баз данных и других источников. Однако в большинстве случаев сведения находятся в открытом доступе, то есть использование программ не нарушает закон. Противозаконным может стать применение данных, например:
- для спам-рассылки и звонков. Это нарушает закон о защите персональных данных;
- копирование и использование информации с сайта-конкурента на собственном ресурсе. Это может нарушать авторские права.
В целом, парсинг не нарушает нормы законодательства и этики. Автоматизированный сбор информации позволяет сделать сайт и реализуемый с его помощью продукт более удобным для клиентов.
Скопировано
Что такое парсинг, зачем он нужен и законно ли парсить данные
Парсинг — это автоматический процесс сбора и систематизации данных в интернете. Для него используют специальные программы — парсеры, которые отбирают с сайтов информацию по заданным критериям.
Личный кабинет сервиса для парсинга постов и профилей в Instagram* в программе Apify
Зачем нужен парсинг
Анализ конкурентов. Парсер поможет собрать информацию о том, какие товары и по каким ценам продают другие компании.
Парсер поможет собрать информацию о том, какие товары и по каким ценам продают другие компании.
SEO-продвижение. При помощи парсинга вы можете собрать семантическое ядро, найти ошибки на своем сайте, проанализировать поисковую выдачу.
Запуск рекламы. Парсинг позволяет собрать базу целевой аудитории или найти потенциальные рекламные площадки.
Наполнение сайтов. Парсинг помогает наполнить сайты, на которые требуется большой объем информации. Например, распространена схема, когда парсят иностранные сайты и переводят информацию о товарах на нужный язык.
Анализ контента. Вы можете проанализировать посты, комментарии, сообщения, хештэги и другой контент, чтобы лучше понять поведение и потребности аудитории.
Сквозная аналитика. Парсер интегрируется с нужной площадкой, автоматически сводит данные о бюджетах и результатах сделок, подсчитывает окупаемость рекламных кампаний.
Как работает парсинг
Процесс парсинга можно схематично разделить на три шага.
- Вы указываете в программе условия, по которым нужно найти данные.
- Парсер сканирует код указанных сайтов — их называют целевыми — и ищет нужные данные.
- Собранные данные выводятся в отчете или собираются в таблицу.
Например, вы выходите на рынок товаров для животных и хотите узнать, какие цены устанавливают конкуренты на аналогичные продукты. Вы указываете в парсере товары, на которые нужно найти цены, выбираете нужный регион, перечисляете сайты конкурентов и запускаете программу.
Парсер анализирует указанные сайты, находит нужные товары и собирает расценки в единую базу. После окончания анализа программа формирует отчет — и вы можете наглядно увидеть ценовую политику в вашей отрасли.
Отчет о ценовой политике конкурентов на рынке электротранспорта в сервисе uXprice. Источник
Законность парсинга
Несмотря на большое количество плюсов, парсинг часто считают «серым» инструментом продвижения из-за последствий, к которым он может привести. Поэтому нужно учитывать некоторые нюансы.
Поэтому нужно учитывать некоторые нюансы.
Сам по себе сбор данных из открытых источников законом не запрещен — программы просто автоматизируют то, что маркетолог может сделать вручную. Право искать общедоступную информацию и использовать ее по своему усмотрению гарантируют статья 29 Конституции и статья 7 Закона об информации. При этом и искать, и использовать информацию нужно с соблюдением законодательства — и тут в силу вступают другие правовые нормы:
- Если при помощи парсеров вы полностью копируете информацию с сайтов конкурентов на собственный ресурс, это может привести к нарушению интеллектуального права.
- Чрезмерно агрессивный парсер может создать большую нагрузку на целевой сайт, которая будет выглядеть как DDOS-атака. Если вы парсите такой программой интернет-магазин, то он может стать недоступным на несколько часов, и владельцы сайта потерпят убытки. Даже если сайт не «приляжет», могут возрасти затраты на обслуживание серверов.
- В 272 статье Уголовного кодекса предусмотрена ответственность за «неправомерный доступ к охраняемой законом информации». Эта формулировка включает в себя персональные данные или коммерческую тайну. Например, нельзя парсить чужие списки клиентов, защищенную от несанкционированного доступа информацию, адреса электронной почты для последующей рассылки.
- Согласно поправкам 2021 года к Закону о персональных данных, для сбора и использования даже находящихся в открытом доступе персональных данных нужно получить согласие пользователя. Строго говоря, один из популярных способов использовать парсеры — собирать данные пользователей для запуска таргетированной рекламы — тоже незаконен. Но установить факт парсинга данных при запуске рекламы сейчас технически невозможно, поэтому многие компании продолжают использовать этот инструмент.

Вывод: парсить можно, главное, чтобы этот процесс не приводил к случаям, когда может возникнуть дополнительная ответственность. В частности нельзя продавать полученные данные, использовать персональные данные для рекламы и рассылок, копировать информацию на собственные ресурсы, создавать чрезмерную нагрузку на целевой сайт.
В частности нельзя продавать полученные данные, использовать персональные данные для рекламы и рассылок, копировать информацию на собственные ресурсы, создавать чрезмерную нагрузку на целевой сайт.
Плюсы парсинга
- Он ускоряет процесс сбора данных. Все эти действия обычно можно совершить вручную, но программа автоматизирует процесс и позволяет получить результат значительно быстрее.
- В программе можно тонко настроить параметры для сбора данных.
Парсер TargetHunter позволяет найти слушателей конкретного музыканта
- Парсинг защищает от ошибок, вызванных человеческим фактором.
- Парсер позволяет сэкономить бюджет как на сборе данных (вместо большого количества сотрудников процесс выполняет одна программа), так и на оптимизации рекламных кампаний. Например, парсеры социальных сетей позволяют более тонко настроить таргетированную рекламу, а значит, сэкономить на продвижении.
Парсинг можно проводить регулярно и автоматически: например, еженедельно отслеживать изменение цен конкурентов.
Виды парсинга
Парсинг товаров. Программа собирает информацию из каталога интернет-магазинов. На основе этих данных можно анализировать ассортимент конкурентов, заполнять страницы собственного сайта.
Парсинг цен. Позволяет проанализировать цены конкурентов и отслеживать изменения в ценовой политике.
Парсинг для SEO. Программа анализирует семантическое ядро целевых сайтов. Данные можно использовать как для наполнения собственного сайта ключевыми словами, так и для контекстной рекламы. Также этот вид парсинга используют, чтобы найти ошибки в мета-тегах, дублирующие элементы, битые ссылки и другие недочеты на собственном сайте.
Парсинг контактов. При этом виде парсинга программа собирает адреса электронной почты, номера телефонов и другую контактную информацию, которая находится в открытом доступе.
Парсинг аудитории. Помогает найти потенциальных клиентов, как правило, среди пользователей социальных сетей. Этот вид парсинга обычно используют для настройки таргетированной рекламы.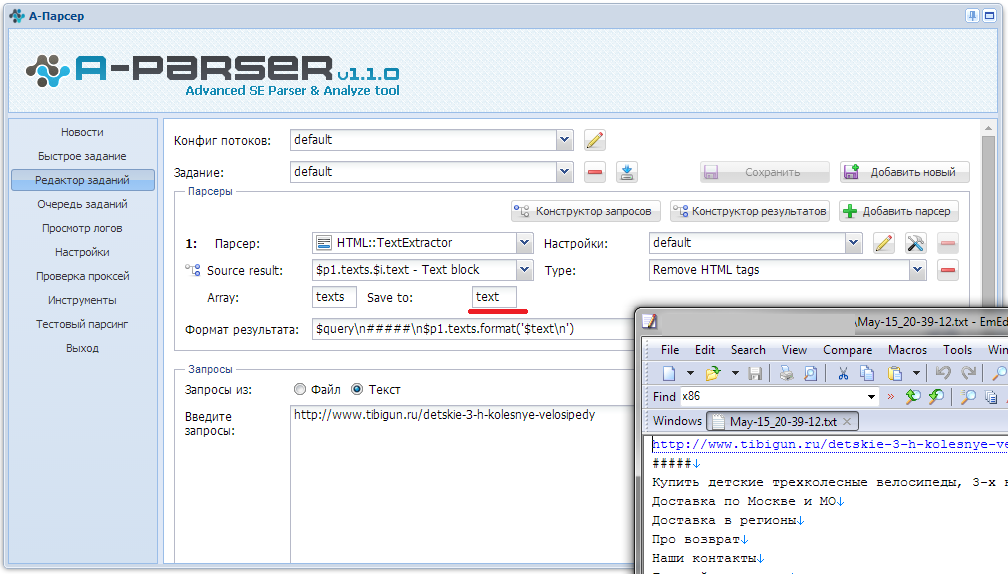
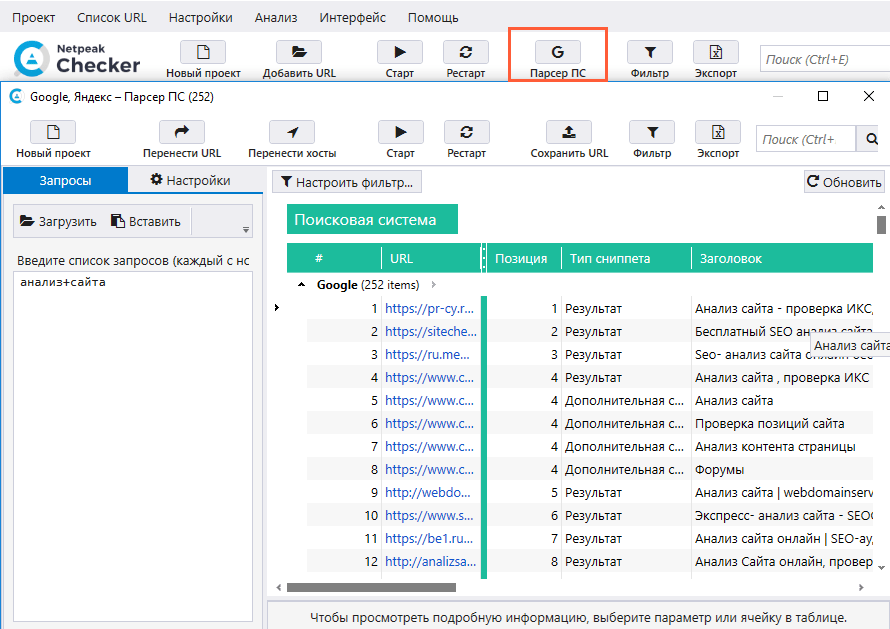
Парсинг выдачи. Выявляет лидеров поисковой выдачи по заданным ключевым словам и предоставляет дополнительную информацию — тип сниппета, заголовок, описание, анкоры, связанные ключевые слова. Можно использовать для анализа конкурентов или поиска подходящих рекламных площадок — это позволит размещать рекламу на ресурсах, которые лучше всего индексируются по нужным ключевым словам.
Результатом парсинга выдачи может быть Excel-таблица со всеми интересующими данными: запросом, ссылкой, заголовком, сниппетом. Источник
Программы для парсинга
Программу для парсинга можно разработать самостоятельно, а можно воспользоваться уже готовыми решениями. Вот несколько вариантов:
- Облачные парсеры сайтов: Диггернаут, Import.io, Apify, Mozenda (есть и десктопная версия).
- Десктопные парсеры сайтов: ParserOK, Neatpeak Spider, ComparseR, Parsehub (бесплатный)
- Парсеры социальных сетей: Церебро Таргет, TargetHunter, Pepper. Ninja.
- Парсеры email-адресов: Scrapp.io, Scrapebox Email Scraper.
 Ninja.
Ninja.Как правило, большинство парсеров предоставляют бесплатную версию, но она ограничена либо по времени, либо по возможностям.
Главные мысли
Что такое парсер? Определение, типы и примеры
Архитектура приложенияК
- Бен Луткевич, Технические характеристики Писатель
В компьютерных технологиях синтаксический анализатор — это программа, которая обычно является частью компилятора. Он получает входные данные в виде последовательных инструкций исходной программы, интерактивных онлайн-команд, тегов разметки или какого-либо другого определенного интерфейса.
Парсеры разбивают входные данные, которые они получают, на такие части, как существительные (объекты), глаголы (методы) и их атрибуты или параметры.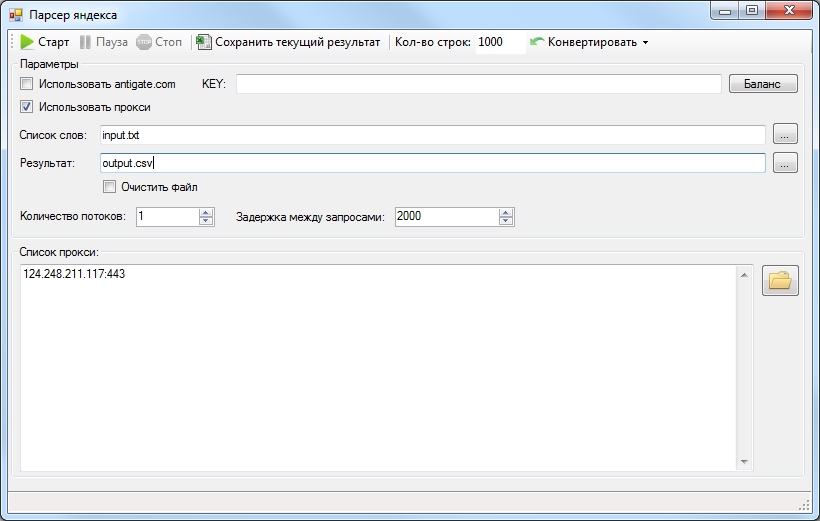 Затем они управляются другими программами, такими как другие компоненты компилятора. Синтаксический анализатор также может проверить, были ли предоставлены все необходимые входные данные.
Затем они управляются другими программами, такими как другие компоненты компилятора. Синтаксический анализатор также может проверить, были ли предоставлены все необходимые входные данные.
Синтаксический анализатор — это программа, входящая в состав компилятора, а синтаксический анализ — часть процесса компиляции. Парсинг происходит на этапе анализа компиляции.
При синтаксическом анализе код берется из препроцессора, разбивается на более мелкие части и анализируется, чтобы другое программное обеспечение могло его понять. Синтаксический анализатор делает это, создавая структуру данных из входных данных.
Точнее, человек пишет код на понятном человеку языке, таком как C++ или Java, и сохраняет его в виде набора текстовых файлов. Синтаксический анализатор принимает эти текстовые файлы в качестве входных данных и разбивает их, чтобы их можно было перевести на целевую платформу.
Анализатор состоит из трех компонентов, каждый из которых обрабатывает разные этапы процесса анализа. Три этапа:
Три этапа:
Этап 1: Лексический анализ
Лексический анализатор — или сканер — берет код из препроцессора и разбивает его на более мелкие части. Он группирует входной код в последовательности символов, называемые лексемами, каждая из которых соответствует токену. Токены — это единицы грамматики языка программирования, понятные компилятору.
Лексические анализаторы также удаляют пробельные символы, комментарии и ошибки из ввода.
Этап 2: синтаксический анализ
Синтаксический анализатор принимает (x+y)*3 в качестве входных данных и возвращает это дерево синтаксического анализа, которое позволяет синтаксическому анализатору понять уравнение. На этом этапе синтаксического анализа проверяется синтаксическая структура ввода с использованием структуры данных, называемой деревом синтаксического анализа или деревом вывода. Анализатор синтаксиса использует маркеры для построения дерева синтаксического анализа, которое объединяет предопределенную грамматику языка программирования с маркерами входной строки. Синтаксический анализатор сообщает о синтаксической ошибке, если синтаксис неверен.
Анализатор синтаксиса использует маркеры для построения дерева синтаксического анализа, которое объединяет предопределенную грамматику языка программирования с маркерами входной строки. Синтаксический анализатор сообщает о синтаксической ошибке, если синтаксис неверен.
Этап 3: Семантический анализ
Семантический анализ сверяет дерево синтаксического анализа с таблицей символов и определяет, является ли оно семантически непротиворечивым. Этот процесс также известен как контекстно-зависимый анализ. Он включает проверку типов данных, проверку меток и проверку управления потоком.
Если предоставлен код:
с плавающей запятой а = 30,2; число с плавающей запятой b = a*20
, то анализатор будет рассматривать 20 как 20.0 перед выполнением операции.
Некоторые источники называют синтаксическим анализом только стадию синтаксического анализа, поскольку она генерирует дерево синтаксического анализа. Они не учитывают лексический и семантический анализ.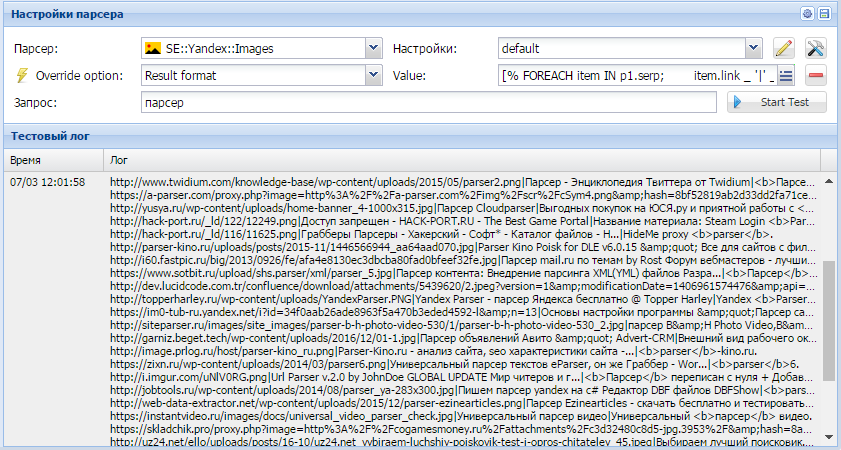
При создании языка программного обеспечения его создатели должны указать набор правил. Эти правила обеспечивают грамматику, необходимую для построения правильных операторов языка.
Ниже приведен набор грамматических правил для простого вымышленного языка, который содержит всего несколько слов:
<предложение> ::= <субъект> <глагол> <объект>
<тема> ::= <статья> <существительное>
<статья> ::= the | a
<существительное> ::= собака | кошка | человек
<глагол> ::= домашние животные | fed
<объект> ::= <статья> <существительное>
В этом языке предложение должно содержать подлежащее, глагол и существительное в указанном порядке, а отдельные слова должны соответствовать частям речи. Подлежащее – это артикль, за которым следует существительное. Существительное может быть одним из следующих трех слов: собака , кошка или лицо . А глаголом может быть только домашних животных или накормленных .
Существительное может быть одним из следующих трех слов: собака , кошка или лицо . А глаголом может быть только домашних животных или накормленных .
Синтаксический анализ проверяет оператор, предоставленный пользователем в качестве входных данных, на соответствие этим правилам, чтобы доказать, что оператор действителен. Разные алгоритмы парсинга проверяют в разном порядке. Существует два основных типа парсеров:
- Нисходящие парсеры. Они начинаются с правила вверху, например <предложение> ::= <субъект> <глагол> <объект>. Имея входную строку «Человек накормил кошку», синтаксический анализатор просматривает первое правило и просматривает все правила, проверяя их правильность. В этом случае первое слово — это
, оно следует правилу подлежащего, и синтаксический анализатор продолжит чтение предложения в поисках . - Парсеры «снизу вверх». Они начинаются с правила внизу. В этом случае синтаксический анализатор сначала будет искать
 В этом случае синтаксический анализатор сначала будет искать
В этом случае синтаксический анализатор сначала будет искать Проще говоря, нисходящие синтаксические анализаторы начинают свою работу с начального символа грамматики в верхней части дерева синтаксического анализа. Затем они продвигаются вниз от правила к предложению. Синтаксические анализаторы снизу вверх работают от предложения к правилу.
Помимо этих типов важно знать два типа деривации. Вывод — это порядок, в котором грамматика согласовывает входную строку. Их:
- Парсеры LL . Они анализируют входные данные слева направо, используя крайнее левое производное, чтобы сопоставить правила грамматики с входными данными. Этот процесс выводит строку, которая проверяет ввод, расширяя крайний левый элемент дерева синтаксического анализа.
- LR-парсеры . Эти входные данные анализируются слева направо, используя самое правое производное. Этот процесс извлекает строку, расширяя крайний правый элемент дерева синтаксического анализа.
 Этот процесс извлекает строку, расширяя крайний правый элемент дерева синтаксического анализа.
Этот процесс извлекает строку, расширяя крайний правый элемент дерева синтаксического анализа.Кроме того, существуют другие типы парсеров, в том числе следующие:
- Парсеры рекурсивного спуска. Парсеры рекурсивного спуска возвращаются после каждой точки решения, чтобы перепроверить точность. Парсеры рекурсивного спуска используют синтаксический анализ сверху вниз.
- Парсеры Эрли. Они анализируют все контекстно-свободные грамматики, в отличие от парсеров LL и LR. Большинство реальных языков программирования не используют контекстно-свободные грамматики.
- Парсеры Shift-reduce. Сдвигают и сокращают входную строку. На каждом этапе строки они сокращают слово до правила грамматики. Этот подход уменьшает строку до тех пор, пока она не будет полностью проверена.
Парсеры используются, когда необходимо абстрактно представить входные данные из исходного кода в виде структуры данных, чтобы их можно было проверить на правильность синтаксиса.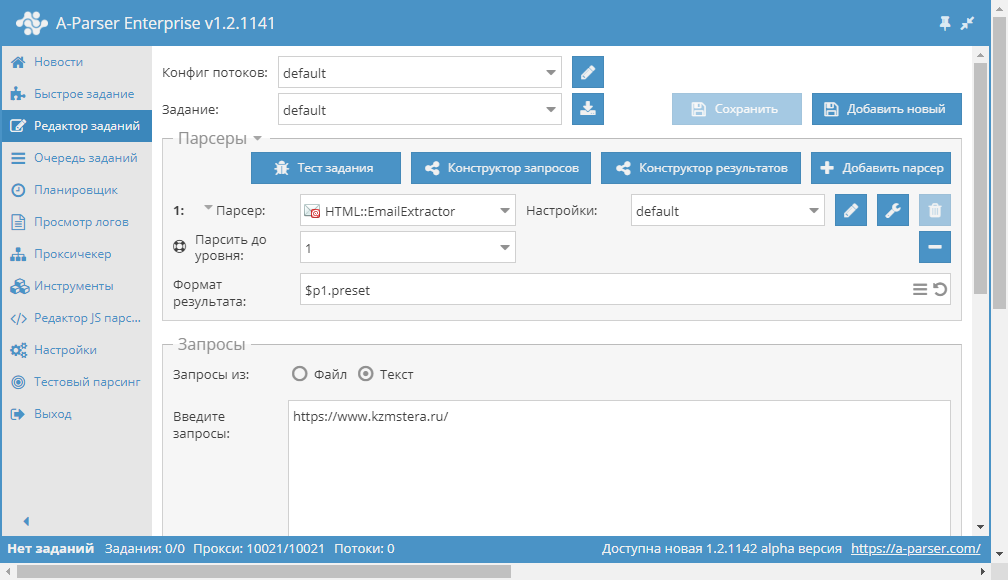 Языки кодирования и другие технологии используют синтаксический анализ некоторого типа для этой цели.
Языки кодирования и другие технологии используют синтаксический анализ некоторого типа для этой цели.
К технологиям, использующим синтаксический анализ для проверки входных данных кода, относятся следующие:
Языки программирования. Парсеры используются во всех языках программирования высокого уровня, включая следующие:
- С++
- Расширяемый язык разметки или XML
- Язык гипертекстовой разметки или HTML
- Препроцессор гипертекста или PHP
- Ява
- JavaScript
- Обозначение объекта JavaScript или JSON
- Перл
- Питон
Языки базы данных. Языки баз данных, такие как язык структурированных запросов, также используют синтаксические анализаторы.
Протоколы . Такие протоколы, как протокол передачи гипертекста и удаленные вызовы функций через Интернет, используют синтаксические анализаторы.
Генератор парсеров . Генераторы синтаксического анализа принимают грамматику в качестве входных данных и генерируют исходный код, который выполняет синтаксический анализ в обратном порядке. Они создают синтаксические анализаторы из регулярных выражений, которые представляют собой специальные строки, используемые для управления и сопоставления шаблонов в тексте.
Синтаксический анализ — это фундаментальная концепция разработки программного обеспечения и теории вычислений. Однако большинство ИТ-специалистов могут обойтись без глубокого понимания синтаксического анализа, используя платформы с низким кодом, которые позволяют пользователям создавать программы без написания тысяч строк кода.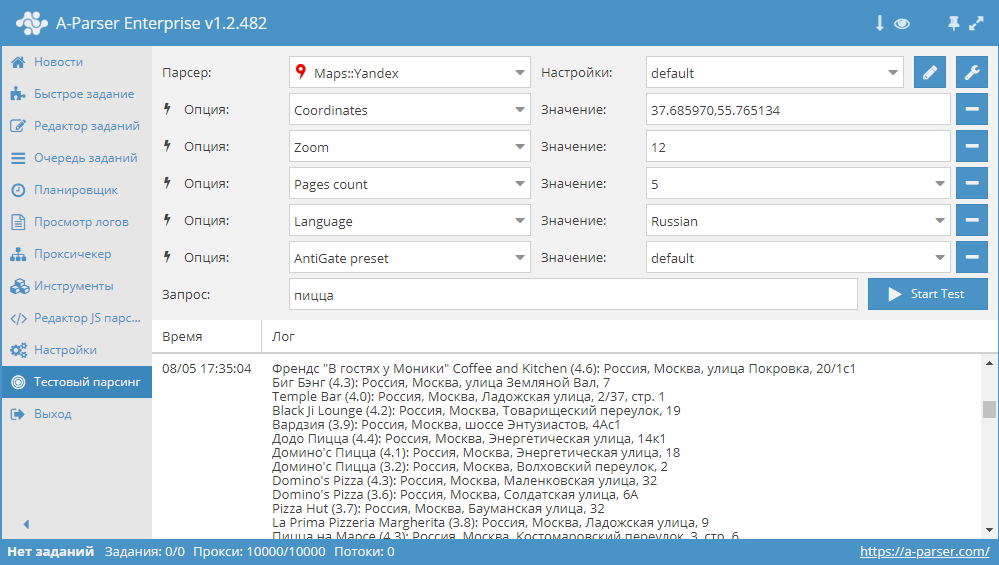 Узнайте о плюсах и минусах использования платформ с низким кодом на предприятии.
Узнайте о плюсах и минусах использования платформ с низким кодом на предприятии.
Последнее обновление: июль 2022 г.
Продолжить чтение О парсере- Памятка Terraform: известные команды, HCL и многое другое
- Как стать хорошим Java-программистом без диплома
- Интерпретируемые и компилируемые языки: в чем разница?
- Исправление 10 самых распространенных ошибок времени компиляции в Java
- 7 советов по выбору правильной библиотеки Java
командлет
Автор: Стивен Бигелоу
обработка естественного языка (NLP)
Автор: Бен Луткевич
компилятор
Автор: Роберт Шелдон
компьютерная лингвистика (CL)
Автор: Александр Гиллис
Качество ПО
- Как создать набор регрессионных тестов
Изменения кода являются неизбежным аспектом разработки программного обеспечения.
Команды должны провести надлежащее тестирование, чтобы убедиться, что эти изменения не … - Как сбалансировать доступ к данным и безопасность в финтех-тестировании
Использование реальных данных полезно при тестировании программного обеспечения, но команды должны быть осторожны, чтобы не поставить под угрозу безопасность и конфиденциальность. Шесть ядер …
- Тестовые фреймворки и примеры для модульного тестирования кода Python
Модульное тестирование является важным аспектом разработки программного обеспечения. Команды могут использовать Python для модульного тестирования, чтобы оптимизировать преимущества Python…
 Команды должны провести надлежащее тестирование, чтобы убедиться, что эти изменения не …
Команды должны провести надлежащее тестирование, чтобы убедиться, что эти изменения не …Облачные вычисления
- Преимущества и ограничения Google Cloud Recommender
Расходы на облако могут выйти из-под контроля, но такие службы, как Google Cloud Recommender, предоставляют информацию для оптимизации ваших рабочих нагрузок.
Но… - Zadara выбирает нового генерального директора, поскольку основатель переходит на роль технического директора
Йорам Новик, второй генеральный директор облачного стартапа Zadara, привносит в эту должность многолетний опыт руководства ИТ и рассказывает о …
- Как работает маршрутизация на основе задержки в Amazon Route 53
Если вы рассматриваете Amazon Route 53 как способ уменьшить задержку, вот как работает этот сервис.
 Но…
Но…TheServerSide.com
- Как избежать выгорания удаленного инженера-программиста
Выгорание разработчика программного обеспечения реально. Вот несколько стратегий, которые программисты могут использовать, чтобы этого избежать.
- JavaScript против TypeScript: в чем разница?
TypeScript и JavaScript — это две дополняющие друг друга технологии, которые стимулируют разработку как внешнего, так и внутреннего интерфейса.
Вот… - Как применить принцип единой ответственности в Java
Как работает модель единой ответственности в программе Java? Здесь мы покажем вам, что означает этот принцип SOLID, и как …
 Вот…
Вот…языков программирования: парсинг
Языки программирования: ПарсингАбстрактный синтаксис
Абстрактный синтаксис — это представление программы, которая:
- абстрагирует ненужные детали конкретного синтаксиса;
- хранит ровно столько информации, чтобы мы могли назначить значение (семантика) терминов; и
- соответствует структуре BNF языка.
Разбор означает интерпретацию входного потока как термов
на подручном языке. Напомним, что мы рассматриваем язык
синтаксиса как состоящего из трех слоев: лексических элементов, контекстно-свободного синтаксиса,
и контекстно-зависимый синтаксис.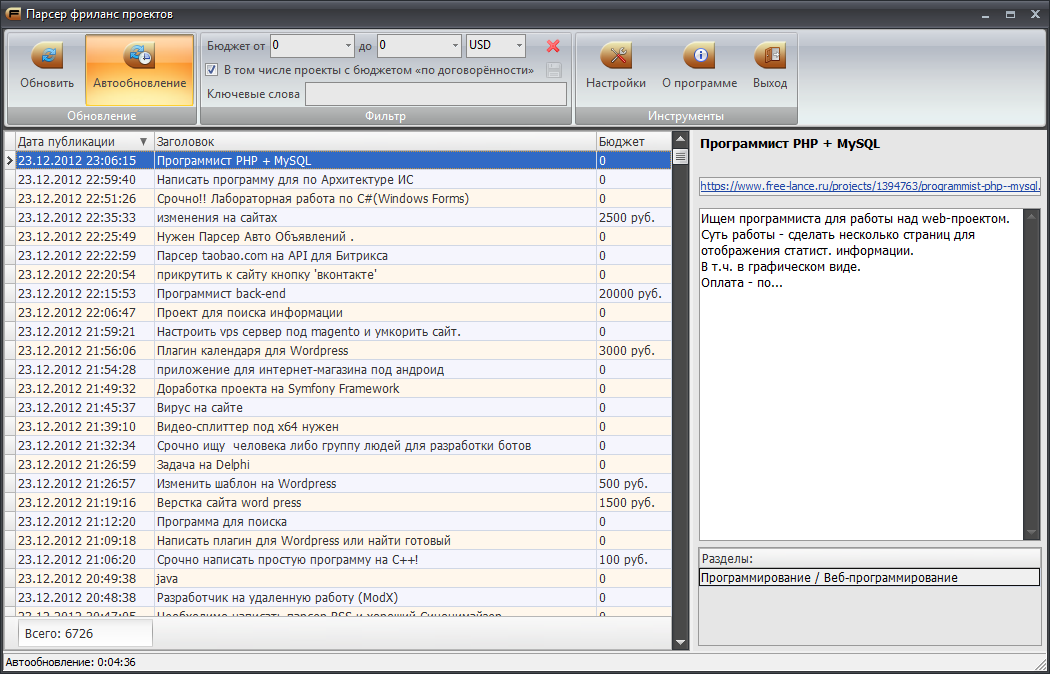 Следовательно, мы будем анализировать язык
рассматривая эти три слоя по отдельности.
Следовательно, мы будем анализировать язык
рассматривая эти три слоя по отдельности.
Лексический анализатор или токенизатор принимает входной поток символов и разбивает его на токены. Для этого курса мы будем использовать Scheme tokenizer, чтобы сделать это за нас.
Синтаксический анализатор берет поток токенов, созданный лексическим анализатором, и строит представление абстрактного синтаксиса программы, называемое абстрактное синтаксическое дерево или дерево разбора . Как видите, термин синтаксический анализ часто (ab) используется для обозначения простой интерпретации поток токенов в контекстно-свободный синтаксис.
Вернемся к примеру запроса. Запрос:
запрос ::= Слово
| НЕ запрашивать
| (запрос И запрос)
Чтобы разобрать запросы, мы должны исправить представление для токенов.
и представление для запросов, т.е. для реферата
синтаксис запросов. Для токенов,
мы будем использовать следующие представления:
Слово - символ
НЕ НЕ
И И
(-"("
) - ")"
Предположим, что у нас есть функция tokenize : ввод -> список токенов
который преобразует входной поток в список таких токенов. Мы возьмем на себя функции сделай-Слово, сделай-Не и сделай-И
построить соответствующие представления запросов.
Мы возьмем на себя функции сделай-Слово, сделай-Не и сделай-И
построить соответствующие представления запросов.Теперь мы можем написать функцию parse для разбора запросов. Эта функция примет список токенов в качестве входных данных и вернет пара абстрактного запроса и оставшаяся часть ввода.
(определить синтаксический анализ
(лямбда (вход)
(cond ((равно? 'НЕ (автомобильный ввод))
(let* ((r (анализ (ввод cdr)))
(q (автомобиль г))
(остальное (cdr r)))
(минусы(сделать-не д) остальное)))
((символ? (ввод автомобиля))
(минусы (сделать-Word (ввод автомобиля)) (ввод cdr)))
((равно? "(" (автомобильный ввод))
(let* ((r1 (анализ (ввод cdr)))
(q1 (автомобиль r1))
(остаток1 (cdr r1))
(остаток2 (cdr остаток1)); пропустить "И"
(r2 (разбор остальных2))
(q2 (автомобиль r2))
(остальное3 (cdr r2))
(остальное4 (cdr оставшееся3))) ; пропускать ")"
(минусы(сделать-И д1 д2)остальные4)))
(иначе (ошибка "Неверный ввод")))))
Это довольно просто, потому что грамматика для запросов — LL0. Но мы можем сделать это еще проще, воспользовавшись
встроенный синтаксический анализатор Scheme имеет для языка с именем s-выражений .
S-выражения определяются следующим образом:
Но мы можем сделать это еще проще, воспользовавшись
встроенный синтаксический анализатор Scheme имеет для языка с именем s-выражений .
S-выражения определяются следующим образом:
секс-выражение ::= #t | #f | номер | символ | символ | () | нить
| (половое выражение . половое выражение) | #(sexp*) | (секс*)
S-выражение вида (sexp .sexp) это пара; s-выражение вида #(sexp*) вектор; и (sexp*) — это список. Списки
представлено с помощью пар и нуля. S-выражения построены
на читается и (цитата sexp) ,
сокращенно 'sexp .Если мы теперь немного изменим синтаксис запросов, чтобы запросы являются подмножеством s-выражений, мы можем использовать s-выражение parser, чтобы сделать часть синтаксического анализа для нас. Давайте переопределим запросы следующим образом:
д ::= слово | (НЕ д) | (И q q)Обратите внимание на круглые скобки, которые теперь требуются вокруг запроса NOT.
 Наша новая функция разбора принимает список токенов и возвращает
просто проанализированный запрос:
Наша новая функция разбора принимает список токенов и возвращает
просто проанализированный запрос:
(определить синтаксический анализ
(лямбда (sexp)
(cond ((символ? sexp) (make-Word sexp))
((пара? секс)
(состояние ((равно? 'НЕ (автомобильное выражение))
(сделать-не (разобрать (кадр sexp))))
((равно? 'И (автомобильное секс-выражение))
(make-And (parse (caddr sexp)) (parse (caddr sexp))))
(иначе (ошибка "Неверный ввод"))))
(иначе (ошибка "Неверный ввод")))))
Давайте теперь создадим синтаксический анализатор для подмножества Scheme. мы рассмотрим следующее подмножество:
е ::= #t | #f | () | номер | ...
| Икс
| (лямбда (х*) е)
| (если е е е)
| (cond (e e)* [(else e)])
| (э э*)
Мы будем представлять токены точно так же, как Scheme представляет их в
s-выражения. Мы используем определить-запись средство для создания представлений абстрактного синтаксиса:(определить запись Const (значение)) (определить запись Var (имя)) (определить-записать Лам (формальное тело)) (определить-записать, если (проверить, а затем еще)) (определение-запись Cond (предложения еще)) (определить запись Ap (забавные аргументы))Каждое выражение
(define-record Foo (field1 . .. fieldN)) строит следующие процедуры:  .. fieldN))
.. fieldN)) make-Foo , Фу? и Foo->field1 через Foo->fieldN .
Они называются конструктором, предикатом и селекторами (или средствами доступа).
для данных типа Foo .
Следующие тождества будут иметь место:(Foo? (make-Foo v1 ... vN)) = #t (Foo->fieldM (make-Foo v1 ... vN)) = vMдля значений
v1 ... vN .
Теперь давайте разберем Схему. (определить синтаксический анализ (лямбда (sexp) (cond ((член sexp '(#t #f ())) (сделать-константное секс-выражение)) ((или (число? секс-выражение) (строка? секс-выражение) (символ? секс-выражение)) (сделать-константное секс-выражение)) ((символ? секс-выражение) (сделать-Var секс)) ((пара? секс) (cond ((равно? 'лямбда (автомобильное выражение)) (сделать-лам (кадр sexp) (разобрать (каддр sexp)))) ((равно? 'если (автомобильное выражение)) (make-If (кадр sexp) (каддр sexp) (каддр sexp))) ((равно? 'cond (автомобиль секс)) .