
Robots.txt Tester: используйте бесплатный онлайн-инструмент для SEO
Файл robots.txt – это текстовый файл, размещаемый на веб-сайтах для информирования роботов поисковых систем (таких как Google), какие страницы в этом домене можно сканировать. . Если на вашем веб-сайте есть файл robots.txt, вы можете выполнить проверку с помощью нашего бесплатного генератора Robots.txt инструмента. Вы можете интегрировать ссылку на XML карту сайта в файл robots.txt.
Прежде чем боты поисковых систем просканируют ваш сайт, они сначала найдут файл robots.txt сайта. Таким образом, они увидят инструкции, какие страницы сайта можно индексировать, а какие не следует индексировать консолью поисковой системы.
С помощью этого простого файла вы можете настроить параметры сканирования и индексирования для роботов поисковых систем. И чтобы проверить, настроен ли на вашем сайте файл robots.txt, вы можете использовать наши бесплатные и простые инструменты для тестирования Robots. txt. В этой статье объясняется, как проверить файл с помощью этого инструмента и почему важно использовать Robots.txt Tester на своем сайте.
txt. В этой статье объясняется, как проверить файл с помощью этого инструмента и почему важно использовать Robots.txt Tester на своем сайте.
Использование средства проверки robots.txt: пошаговое руководство
Тестирование файла robots.txt поможет вам протестировать файл robots.txt в вашем домене или любом другом домене, который вы хотите проанализировать.
Средство проверки robots.txt быстро обнаружит ошибки в настройках файла robots.txt. Наш инструмент проверки очень прост в использовании и может помочь даже неопытному профессионалу или веб-мастеру проверить файл Robots.txt на своем сайте. Вы получите результаты через несколько минут.
Шаг 1. Вставьте URL-адрес
Чтобы начать сканирование, все, что вам нужно сделать, это ввести интересующий URL-адрес в пустую строку и нажать кнопку с синей стрелкой. Затем инструмент начнет сканирование и выдаст результаты. Вам не нужно регистрироваться на нашем сайте, чтобы использовать его.
В качестве примера мы решили проанализировать наш сайт https://sitechecker.pro. На приведенных ниже снимках экрана вы можете увидеть процесс сканирования в нашем инструменте веб-сайта.
Шаг 2. Интерпретация результатов тестера Robots.txt
Затем, когда сканирование завершится, вы увидите, разрешает ли файл Robots.txt сканирование и индексирование конкретной доступной страницы. Таким образом, вы можете проверить, будет ли ваша веб-страница получать трафик из поисковой системы. Здесь вы также можете получить несколько полезных советов по мониторингу.
Случаи, когда требуется проверка robots.txt
Проблемы с файлом robots.txt или его отсутствие могут негативно повлиять на ваш рейтинг в поисковых системах. Вы можете потерять рейтинговые очки в SERP. Анализ этого файла и его значения перед сканированием веб-сайта позволяет избежать проблем с сканированием. Кроме того, вы можете предотвратить добавление контента вашего веб-сайта на страницы исключения из индекса, которые вы не хотите сканировать. Используйте этот файл, чтобы ограничить доступ к определенным страницам вашего сайта. Если есть пустой файл, вы можете получить сообщение Robots.txt не найден в SEO-краулер.
Используйте этот файл, чтобы ограничить доступ к определенным страницам вашего сайта. Если есть пустой файл, вы можете получить сообщение Robots.txt не найден в SEO-краулер.
Вы можете создать файл с помощью простого текстового редактора. Во-первых, укажите пользовательский агент для выполнения инструкции и поместите директиву блокировки, например, disallow, noindex. После этого перечислите URL-адреса, для которых вы ограничиваете сканирование. Перед запуском файла убедитесь, что он правильный. Даже опечатка может привести к тому, что бот Googlebot проигнорирует ваши инструкции по проверке.
Какие инструменты проверки robots.txt могут помочьКогда вы создаете файл robots.txt, вам необходимо проверить, не содержат ли они ошибок. Есть несколько инструментов, которые помогут вам справиться с этой задачей.
Консоль поиска GoogleТеперь только в старой версии Google Search Console есть инструмент для тестирования файла robots. Войдите в учетную запись с текущим сайтом, подтвержденным на его платформе, и используйте этот путь, чтобы найти валидатор.
Войдите в учетную запись с текущим сайтом, подтвержденным на его платформе, и используйте этот путь, чтобы найти валидатор.
Старая версия Google Search Console > Сканировать > Тестер robots.txt
Этот тест robot.txt позволяет:
Войдите в аккаунт Яндекс Вебмастер с текущим сайтом и подтвержден на своей платформе и используйте этот путь, чтобы найти инструмент.
Яндекс для веб-мастеров > Инструменты > Анализ robots.txt
Этот тестер предлагает почти такие же возможности для проверки, как и описанный выше. Разница заключается в:
 txt;
txt;Это решение для массовой проверки, если вам нужно просканировать веб-сайт. Наш краулер помогает проверить весь сайт и определить, какие URL-адреса запрещены в robots.txt, а какие закрыты от индексации с помощью метатега noindex.
Внимание: для обнаружения запрещенных страниц необходимо просканировать веб-сайт с настройкой игнорировать robots.txt.
Обнаружение и анализ не только файла robots.txt, но и других проблем SEO на вашем сайте!
Проведите полный аудит, чтобы выяснить и исправить проблемы с вашим сайтом, чтобы улучшить результаты поисковой выдачи.
Часто задаваемые вопросы
Зачем мне проверять файл robots.txt?
Robots.txt показывает поисковым системам, какие URL-адреса на вашем сайте они могут сканировать и индексировать, в основном, чтобы не перегружать ваш сайт запросами. Проверка этого действительного файла рекомендуется, чтобы убедиться, что он работает правильно.
Проверка этого действительного файла рекомендуется, чтобы убедиться, что он работает правильно.
Является ли нарушение файла Robots.txt незаконным?
Сегодня нет закона, требующего строго следовать инструкциям в файле. Это не обязывающий договор между поисковыми системами и веб-сайтами.
Что делает файл robots.txt?
Robots.txt показывает агентам поисковых систем, какие страницы вашего сайта можно сканировать и индексировать, а какие страницы были исключены из просмотра. Разрешение поисковым системам сканировать и индексировать некоторые страницы вашего сайта — это возможность контролировать конфиденциальность некоторых страниц. Это необходимо для поисковой оптимизации вашего сайта.
Является ли Robot.txt безопасным?
Файл robots.txt не ставит под угрозу безопасность вашего сайта, поэтому его правильное использование может быть отличным способом защитить конфиденциальные страницы вашего сайта. Тем не менее, не ожидайте, что все сканеры поисковых систем будут следовать инструкциям в этом файле. Злоумышленники смогут отключать инструкции и сканировать запрещенные страницы.
Тем не менее, не ожидайте, что все сканеры поисковых систем будут следовать инструкциям в этом файле. Злоумышленники смогут отключать инструкции и сканировать запрещенные страницы.
Robots.txt — что это и как его правильно настроить
Что такое robots.txt? Это файл, который располагается в корневой папке почти любого сайта. Он включает определённые команды, которые указывают поисковым роботам, какую информацию они могут просканировать на вашем сайте, а какую нет. Если такого файла на ресурсе не будет, боты отсканируют всё подряд, и в выдаче могут оказаться личные данные ваших клиентов или другая скрытая информация.
Разбираемся, как правильно подойти к настройке файла. А если он у вас уже есть, посмотрим, как проверить корректно ли он работает.
Зачем всем сайтам нужен robots.txt?
Прежде чем сайт окажется в поисковой выдаче, ему нужно пройти индексацию. Это процесс, во время которого боты обходят ресурс, сканируют его, а потом добавляют информацию о нём в свой каталог, откуда она уже попадает в выдачу. После этого люди смогут найти этот сайт в поисковике. Позиции, на которых конкретные страницы будут находиться в выдаче, зависят от множества факторов, но на саму возможность оказаться в ней влияет именно индексация.
После этого люди смогут найти этот сайт в поисковике. Позиции, на которых конкретные страницы будут находиться в выдаче, зависят от множества факторов, но на саму возможность оказаться в ней влияет именно индексация.
Так вот файл robots.txt как раз и отвечает за управление индексацией сайта в поисковике. В нём прописаны указания для роботов: какие данные они могут сканировать и потом предлагать пользователям, а какие нет. С помощью robots.txt сайт в принципе можно закрыть от индексации, если вы не хотите, чтобы ссылки на него были в поиске. Например, это может понадобиться, если прямо сейчас на ресурсе происходят какие-то технические работы. В файл вы можете вносить правки в любое время, когда у вас появится потребность открыть или закрыть что-то.
Наличие robots.txt очень важно, ведь на каждом ресурсе есть информация, которая не должна оказаться в общем доступе. Например, платёжные данные или личная информация клиентов. Подробнее о том, что ещё важно скрыть от роботов, поговорим дальше.
А вот для чего ещё нужен robots.txt:
- Снизить нагрузку на сервер. Ведь вы запрещаете сканировать второстепенную для пользователей информацию, которой может быть довольно много. Следовательно, нагрузка заметно снижается.
- Указать ботам путь к карте сайта. Это служебная страница, где перечислены все страницы и разделы ресурса. Она также помогает роботам быстрее и качественнее проводить сканирование. Если добавить карту в robots.txt, поисковые боты быстрее её обнаружат.
Важно знать, что иногда роботы могут проигнорировать директивы запрета, которые есть в файле. Например, Google в своём руководстве пишет о том, что если на скрытую страницу есть ссылки с других страниц или ресурсов, то роботы всё равно могут её проиндексировать. В этой статье мы рассказывали про другие способы закрыть сайт от индексации, которые могут помочь в таких случаях.
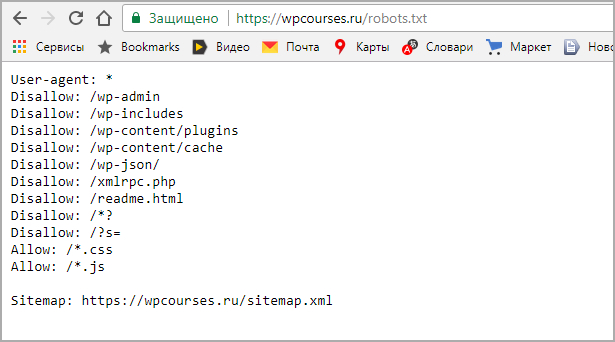
Создаём и настраиваем команды в robots.
 txt
txtRobots.txt — это текстовый файл. А значит для его создания подойдёт любой текстовый редактор. Например, обычный Блокнот или Word. Из названия файла понятно, что он должен быть сохранён в формате txt, и назвать его нужно “robots”.
После того как файл будет готов, его нужно разместить в корневой папке сайта. Её можно найти на хостинге. В результате у вас должна появиться ссылка на файл такого формата: вашсайт.рф/robots.txt.
А теперь давайте посмотрим, что должно находиться внутри этого файла. Начнём с основных директив, которые используются в документе.
User-agent
Это обращение к поисковым ботам. Такая директива всегда должна находиться в начале файла, потому что иначе непонятно, кому предназначены дальнейшие инструкции. Если после директивы стоит звёздочка, это означает обращение ко всем роботам. Если название конкретного бота, то обращаются только к нему. Самые популярные боты — Yandex и Googlebot.
Вот как может выглядеть такая директива:
User-agent: Yandex
Disallow
Запрещающая директива, которая используется, чтобы показать, какие страницы, файлы, папки или целые разделы должны быть скрыты от индексации. При этом действует принцип “всё, что не запрещено — разрешено”. Поэтому к использованию директивы стоит подойти ответственно и точно прописать в ней всё, что должно быть скрыто.
Как именно закрывать элементы сайта от индексации? Так как домен у всех страниц одинаковый, после названия директивы и двоеточия нам нужно указать только оставшуюся часть адреса. При этом каждый URL не нужно прописывать отдельно. Например, если нам нужно закрыть от индексации разные результаты поиска в форматах:
/search/?q=купить+коньки
/search/?q=чайник+серебряный
/search/?q=елочная+игрушка,
мы возьмём только общую их часть “search”.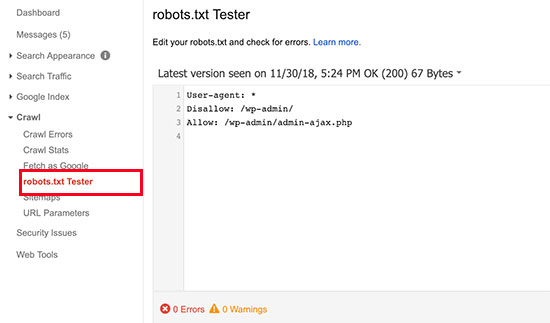 Тогда директива будет выглядеть так:
Тогда директива будет выглядеть так:
Disallow: /search/
Но предварительно стоит проверить, нет ли в этом разделе какой-то важной информации, которая обязательно должна оказаться в поиске.
Allow
Это разрешающая директива. Но мы помним про правило “всё, что не запрещено — разрешено”. Тогда для чего же нужна команда allow? Она помогает добавить исключения из правил. Например, вы хотите запретить индексацию всем, кроме Google. Тогда с помощью disallow мы закрываем индексацию для всех, а потом добавляем allow, где обращаемся только к роботам Google.
Пример:
User-agent: *
Disallow: /
User-agent: Googlebot
Allow: /
Sitemap
Эта команда показывает ботам путь, по которому находится карта сайта. Нужна она в первую очередь для того, чтобы ботам было проще ориентироваться на ресурсе.![]() Без этого какие-то страницы могут не попасть в индекс, а сама индексация займёт больше времени. Логично, что всё, что вы закроете в robots.txt нет смысла добавлять и в карту сайта.
Без этого какие-то страницы могут не попасть в индекс, а сама индексация займёт больше времени. Логично, что всё, что вы закроете в robots.txt нет смысла добавлять и в карту сайта.
Ссылку на карту нужно указывать, чтобы поисковым ботам было проще её найти. Ведь первое, на что они обращают внимание при сканировании сайта, как раз файл robots.txt.
Вот как выглядит строка с директивой:
Sitemap: https://site.ru/sitemap.xml
Clean param
Эта директива используется довольно редко, но при этом она довольно полезная. Её задача — сэкономить ваш краулинговый бюджет, не дав роботу несколько раз сканировать одни и те же страницы.
В URL помимо основного адреса страницы могут отображаться разные параметры. Например, уникальный код пользователя, данные рекламной кампании, с которой он пришёл и т.д. Так вот если вы укажете все эти мелочи в clean param, робот поймёт, что они никак не влияют на основное содержание страницы и будет более эффективно подходить к сканированию ресурса.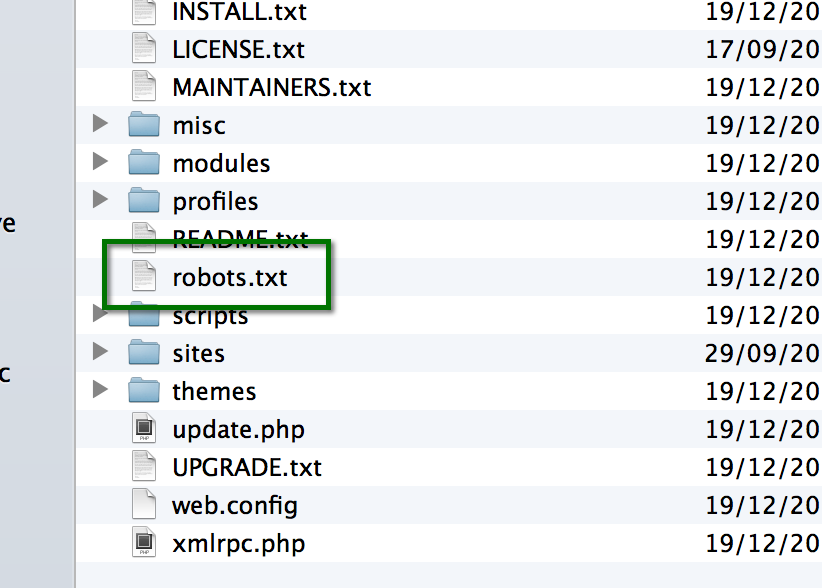
Crawl-delay
Сразу скажем, что Google эту директиву игнорирует. Но она тоже достаточно полезная. Используется она для того, чтобы немного разгрузить сервер. С её помощью вы можете установить продолжительность интервала между завершением сканирования одной страницы и началом сканирования другой. Ведь если бот будет сразу анализировать всё подряд, это может привести к неполадкам в работе системы. Измеряется эта пауза в секундах. Обратите внимание, что сразу большой интервал (например, 2 секунды) задавать не стоит. Лучше начать с минимальных (например, 0,1 секунда), а потом постепенно повышать показатели. При этом для роботов, которые посещают вас редко и не так важны для продвижения, задержку можно установить больше, чем для Яндекса.
Host
Это директива, которая отвечает за то, чтобы сообщить роботам адрес главного зеркала сайта. Но сейчас эта команда уже устарела, и её перестали использовать. Вместо этого на всех неосновных версиях теперь нужно прописывать 301 редирект.
Также в документе можно использовать несколько дополнительных символов:
- Решётка #. С её помощью можно оставлять комментарии к директивам. Робот такие пометки не прочитает, но зато их поймут люди, которые в будущем будут работать с файлом. Например, через какое-то время вы можете не вспомнить, почему закрывали от ботов ту или иную страницу. Или вы найдёте нового SEO-специалиста, которого нужно будет погрузить в контекст. С такими пометками это будет сделать гораздо проще.
- Звёздочка *. Означает, что после неё может идти любая последовательность знаков. В каждой строке её можно не проставлять, потому что по умолчанию и так подразумевается, что команда распространяется на все URL, входящие в папку или раздел. Символ можно использовать для более тонких настроек. Например, если у вас на ресурсе есть функция поиска в разных разделах, директива для того, чтобы закрыть все результаты, может выглядеть так: Disallow: /*/search/
-
Доллар $.
 Используется, чтобы обозначить конец строки. То есть все символы, которые будут находиться после $, не будут попадать под правило. Например, если мы напишем директиву:
Используется, чтобы обозначить конец строки. То есть все символы, которые будут находиться после $, не будут попадать под правило. Например, если мы напишем директиву:
Disallow: /image/,
то она запретит индексирование всех страниц в этом разделе. А если закрыть её с помощью доллара:
Disallow: /image$,то под запрет не попадут адреса вроде /image1 или /images.
 Используется, чтобы обозначить конец строки. То есть все символы, которые будут находиться после $, не будут попадать под правило. Например, если мы напишем директиву:
Используется, чтобы обозначить конец строки. То есть все символы, которые будут находиться после $, не будут попадать под правило. Например, если мы напишем директиву:
Какую информацию важно скрыть?
- Страницы, которые ещё не готовы. Если у вас есть страницы, которые сейчас находятся в процессе разработки, лучше скройте их до тех пор, пока они не будут полностью готовы. То же самое и с целым сайтом. Если он ещё не готов, он не должен оказаться в выдаче. Ведь если половина функций не будет корректно работать, это может испортить репутацию компании, а ещё плохо повлияет на поведенческие факторы. Ведь люди могут просто открывать страницу и быстро закрывать её, когда увидят, что ничего не работает.
- Страницы для печати. Это отдельная версия страницы, которая упрощает её контент для печати. Понятно, что информация там одна и та же, поэтому дублировать её в выдаче не стоит.
- Технические страницы. Например, сюда можно отнести страницу авторизации. Такие данные нужны только для сотрудников компании, а не для всех пользователей.
- Персональные клиентские данные. Это могут быть не только имя и номер телефона, но и платёжные данные. Думаем, не стоит объяснять, почему всё это не должно оказаться в открытом доступе.
- Страницы сортировки. Они содержат практически одинаковый контент, а поисковые системы не любят, когда в выдаче находится повторяющаяся информация. Из-за этого репутация сайта может падать.

А что делать со страницами пагинации? Так называют большие массивы данных, которые разделяют на отдельные страницы, чтобы пользователю не пришлось слишком долго проматывать контент вниз.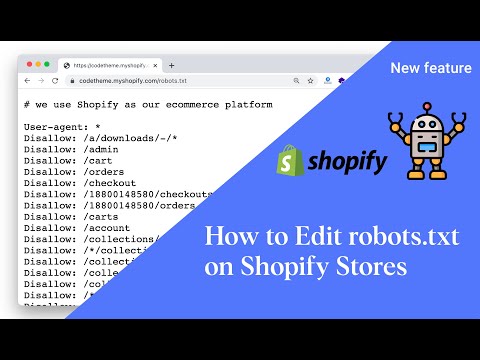 Чаще всего такой формат встречается в каталогах интернет-магазинов. Мы не рекомендуем закрывать страницы пагинации в robots.txt. Лучше решить проблему с помощью тега canonical. Им можно обозначить основную страницу. Тогда поисковая система не будет рассматривать такой контент, как дублирующий.
Чаще всего такой формат встречается в каталогах интернет-магазинов. Мы не рекомендуем закрывать страницы пагинации в robots.txt. Лучше решить проблему с помощью тега canonical. Им можно обозначить основную страницу. Тогда поисковая система не будет рассматривать такой контент, как дублирующий.
Почему всё, что мы обсудили выше, стоит закрыть от индексации?
- Какая-то информация просто не должна стать доступна большому количеству людей. Например, пароли и личные данные.
- Какой-то контент не несёт никакой пользы для людей. В этом случае пострадают поведенческие факторы, ведь даже если люди зайдут на ресурс, они будут очень быстро с него уходить.
-
Впустую тратится краулинговый бюджет. Это определённое количество страниц, которое роботы могут отсканировать за один раз, и периодичность, с которой они это делают. Краулинговый бюджет различается для каждого отдельного сайта. Если он будет потрачен на бесполезные страницы, то до реально полезного контента дело может так и не дойти.
- Система не любит дублирующий контент. Из-за этого может страдать авторитетность ресурса.
Частые ошибки, которые допускают при создании robots.txt
- Объединение нескольких элементов в одну директиву. Если вам нужно скрыть из поиска несколько разделов, каждый из них должен быть прописан с новой строки.
- Разный регистр символов. Следите за тем, чтобы в ваших директивах был прописан правильный регистр. Если некоторые боты могут проигнорировать такую опечатку, другие из-за этого не смогут распознать важную команду.
- Точка или точка с запятой в конце строки. Закрытие строки не нужно никак дополнительно помечать. Наоборот, это может помешать читать их.
-
Неправильное название файла. Он может называться только robots.txt и никак иначе. Обратите внимание на нижний регистр и отсутствие лишних символов. В противном случае боты просто не смогут его распознать.
- Наличие символов на кириллице. В robots.txt можно использовать только латинские символы, иначе боты вас не поймут. Это касается всех директив, кроме комментариев, сопровождаемых знаком #. Если домен вашего сайта на русском языке, его URL придётся дополнительно преобразовывать с помощью кодировки Punycode. Для этого существуют онлайн-конвертеры.
- Слишком большой размер файла. Его вес не должен быть больше 32 Кб. Иначе боты опять же не смогут его прочитать. Поэтому следите за размером и удаляйте всё, что стало неактуальным.
- Команды вроде “Disallow: Yandex”. Правило всегда одно: сначала обращаемся к роботу с помощью user-agent, а уже потом просим его выполнить то, что нам нужно.
- Перечисление каждого отдельного файла в папке. Если вы закрываете какую-то папку, то к индексации будут запрещены и все файлы, находящиеся внутри неё. Поэтому их не нужно прописывать отдельно.
-
Отсутствие проверки корректности работы. Даже если вы несколько раз перечитали все команды в своём robots.txt, не помешает проверить его автоматическими сервисами. Ведь иногда глаз замыливается, и ошибки перестаёшь замечать. О том, какими способами можно проверить файл, мы расскажем в конце статьи.
 Даже если вы несколько раз перечитали все команды в своём robots.txt, не помешает проверить его автоматическими сервисами. Ведь иногда глаз замыливается, и ошибки перестаёшь замечать. О том, какими способами можно проверить файл, мы расскажем в конце статьи.
Даже если вы несколько раз перечитали все команды в своём robots.txt, не помешает проверить его автоматическими сервисами. Ведь иногда глаз замыливается, и ошибки перестаёшь замечать. О том, какими способами можно проверить файл, мы расскажем в конце статьи.Другие способы создания robots.txt
Способ, который мы разобрали выше, можно назвать ручным. Ведь в нём мы сами создаём документ и прописываем в нём все нужные нам запреты и разрешения. Но есть и другие более автоматизированные способы.
Инструменты CMS
Если ваш сайт сделан на CMS, создать robots.txt можно с помощью встроенных инструментов в админ-панели или добавленных плагинов. Например, для сайтов на WordPress есть плагин Virtual Robots.txt. А в модуле поисковой оптимизации Битрикс, начиная с 14 версии, есть встроенный инструмент для работы с файлом. Находится он по пути Маркетинг — Поисковая оптимизация — Настройка robots.txt.
Tilda обещает полностью автоматически сгенерировать за вас файл.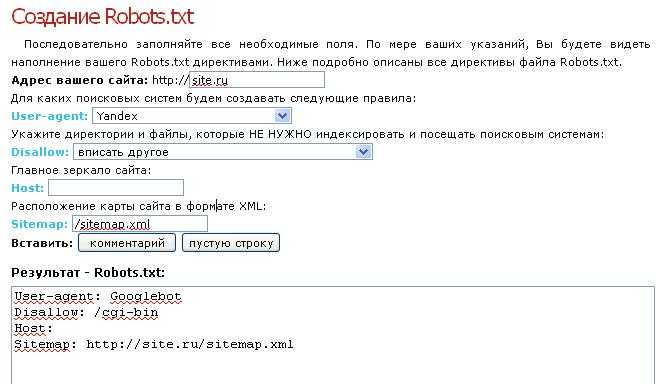 Найти его можно по обычному адресу: вашсайт.рф/robots.txt. Вносить корректировки в сам файл нельзя, но в настройках каждой страницы можно отдельно запретить её индексирование поисковыми системами.
Найти его можно по обычному адресу: вашсайт.рф/robots.txt. Вносить корректировки в сам файл нельзя, но в настройках каждой страницы можно отдельно запретить её индексирование поисковыми системами.
Онлайн-генераторы
Также существуют простые онлайн-сервисы, которые помогут быстро сформировать для вас готовый файл. Конечно, они не смогут учесть тонкие материи в виде отдельных исключений для каких-то роботов или файлов из скрытых разделов, но для простых команд такие сервисы вполне подойдут.
Обычно в них достаточно указать домен сайта, отметить ботов, для которых вы хотите запретить индексацию, и прописать адреса нужных разделов, страниц или файлов. Также иногда туда можно добавить ссылку на карту сайта и указать значение директивы crawl-delay. Вот несколько примеров таких онлайн-генераторов: CY-PR, SAS, Daruse. В целом все они практически одинаковые, поэтому такой сервис можно просто найти в поисковике.
Как убедиться, что всё работает правильно?
Проверить, правильный ли файл robots.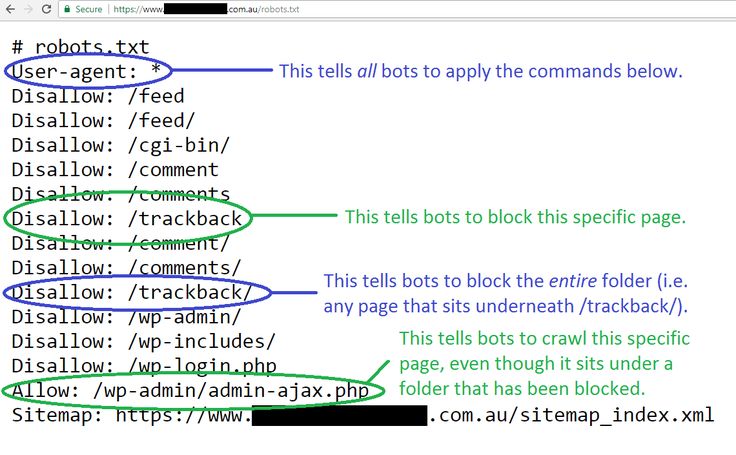 txt вы создали, можно в сервисах от поисковых систем.
txt вы создали, можно в сервисах от поисковых систем.
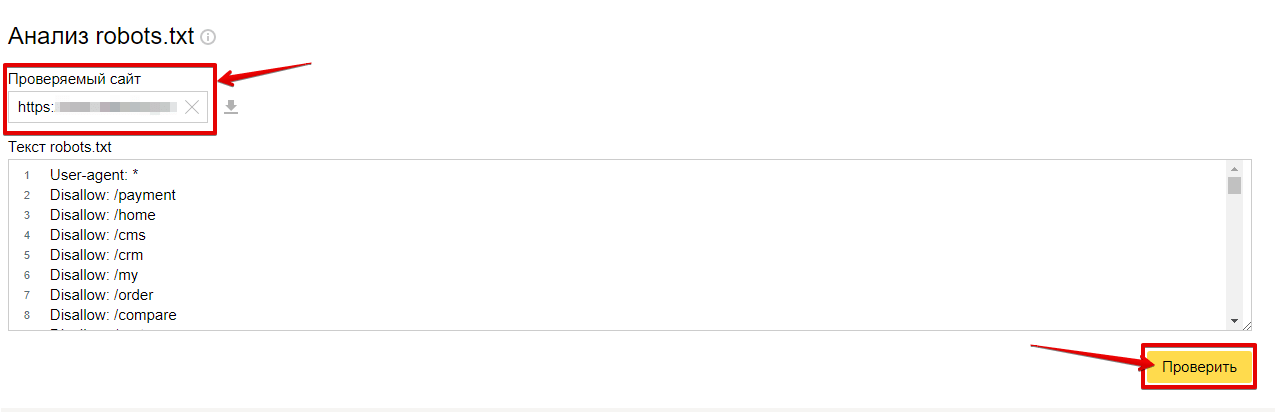
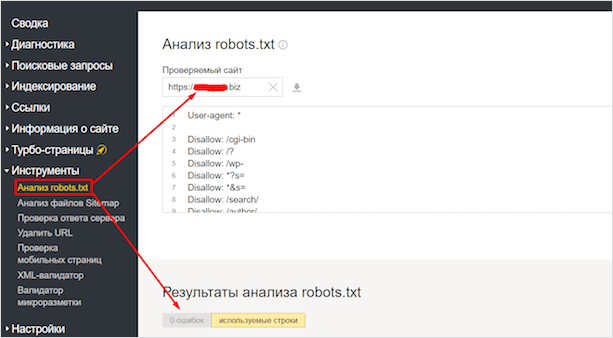
Яндекс.Вебмастер
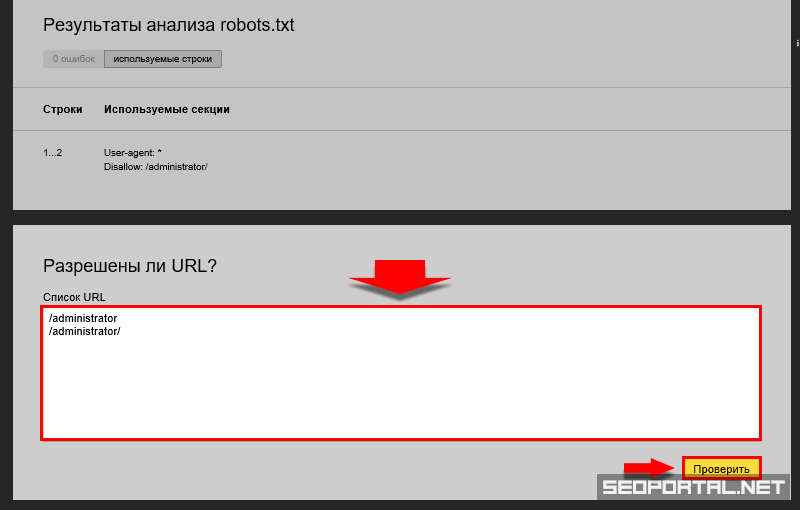
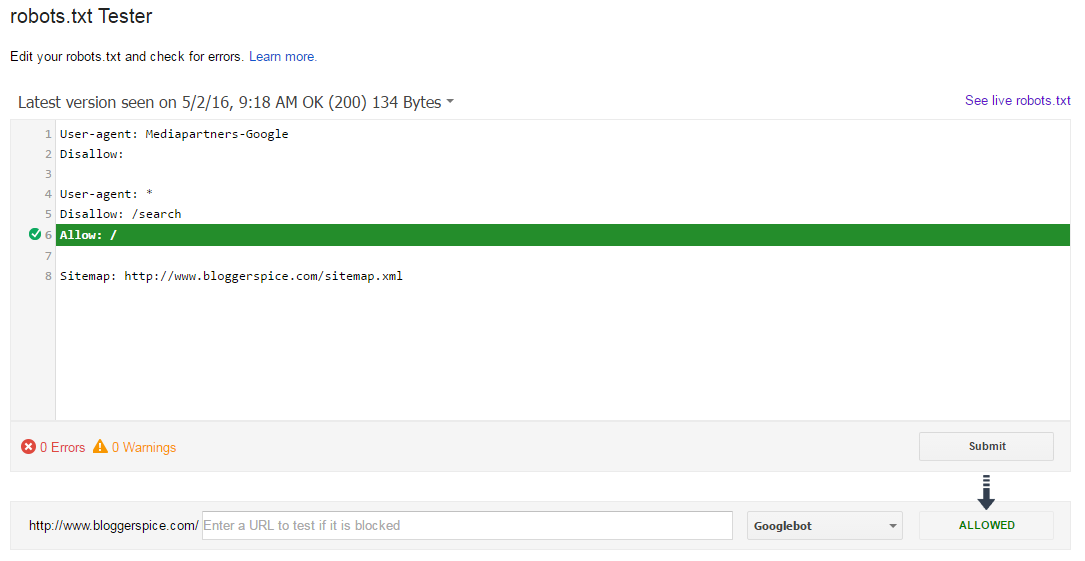
В левой колонке найдите раздел “Инструменты”. В нём кликните по “Анализ robots.txt”. Вам нужно указать, на какой сайт вы собираетесь добавить файл, а потом вставить текст его содержимого в поле ниже. После проверки сервис может сказать о том, что всё хорошо, либо выдать ошибки и предупреждения. Ошибки — более серьёзная вещь. Из-за них может быть необработана какая-то строка, а может не читаться даже весь документ. Предупреждения указывают на то, что вы немного отклонились от правил или сделали опечатку. И ошибки, и предупреждения желательно исправить.
В Вебмастере, в отличие от сервиса Google, можно проверить правильность любого файла, а необязательно того, который находится на ресурсе, куда у вас есть доступ администратора. Но если вы подтвердили права на владение сайтом, то можете настроить уведомления о любых ошибках и предупреждениях, которые могут в будущем возникать в файле, если вы его отредактируете. Это поможет лучше контролировать ситуацию.
Это поможет лучше контролировать ситуацию.
Также в этом же инструменте можно проверить, разрешено ли индексирование конкретных URL. Их можно загрузить в соответствующее поле списком.
Google Search Console
В левом столбце нужно нажать на раздел “Подробнее”, а потом в справке зайти в “Инструмент проверки файла robots.txt”. Доступ сюда у вас будет только если сайт добавлен в Search Console, и у вас подтверждены права на него.
В поле копируем текст из нашего документа, а ниже указываем адрес сайта и нажимаем “Проверить”. Если в директивах есть ошибки, система покажет их в результатах.
Ещё несколько полезных советов
Если правила сканирования у вас различаются для разных поисковиков, объедините их в группы. Блоки можно отделить пустыми строками. Так каждому боту понадобится меньше времени на то, чтобы найти информацию, предназначенную именно ему.
- Обязательно откройте для индексации стили css и js. Без этого боты не смогут увидеть страницы так, как их видит живой человек. Поэтому они могут сделать вывод, что ресурс не адаптирован под мобильные. Также если какая-то часть контента подгружается с помощью js, то боты просто её не увидят. Это может плохо повлиять на ранжирование сайта, потому что в таком случае контент может выглядеть бесполезным и некачественным. Поэтому рекомендуем добавить в ваш robots такие директивы: Allow: /*.js Allow: /*.css
- Не добавляйте на свой сайт первый попавшийся в интернете robots.txt, который вроде бы вам подходит. Это серьёзный инструмент, который может полностью лишить вас поискового трафика, поэтому если вы не уверены в том, что разбираетесь в работе директив, лучше посоветоваться с профессионалами.
Генератор
Robots.txt | SEO-инструменты Appy Pie
| По умолчанию — все роботы: | РазрешеноОтклонено | |
| Задержка сканирования: | По умолчанию — без задержки5 секунд10 секунд20 секунд60 секунд120 секунд | |
| Карта сайта: (оставьте поле пустым, если его нет) | ||
| Поисковые роботы: | Гугл | То же, что и DefaultAllowedRefused |
| Изображение Google | То же, что и DefaultAllowedRefused | |
| Google Мобильный | То же, что и DefaultAllowedRefused | |
| Поиск MSN | То же, что и DefaultAllowedRefused | |
| Яху | То же, что и DefaultAllowedRefused | |
| Яху ММ | То же, что и DefaultAllowedRefused | |
| Блоги Yahoo | То же, что и DefaultAllowedRefused | |
| Аск/Теома | То же, что и DefaultAllowedRefused | |
| Гигавзрыв | То же, что и DefaultAllowedRefused | |
| Проверка ДМОЗ | То же, что и DefaultAllowedRefused | |
| Натч | То же, что и DefaultAllowedRefused | |
| Алекса/Путь назад | То же, что и DefaultAllowedRefused | |
| Байду | То же, что и DefaultAllowedRefused | |
| Навер | То же, что и DefaultAllowedRefused | |
| MSN PicSearch | То же, что и DefaultAllowedRefused | |
| Запрещенные каталоги: | Путь указан относительно корня и должен содержать завершающую косую черту «/» | |
Теперь создайте файл robots. txt в корневом каталоге. Скопируйте текст выше и вставьте в текстовый файл.
txt в корневом каталоге. Скопируйте текст выше и вставьте в текстовый файл.
О генераторе Robots.txt
Что такое генератор Robots.txt?
Генератор Robots.txt позволяет создавать файл Robots.txt, не требуя знания стандарта исключения роботов. Это простая текстовая форма, которая позволяет вам выбрать, какие каталоги и файлы вы хотите скрыть от роботов поисковых систем, а какие каталоги и файлы вы хотите, чтобы они проиндексировали.
Это может значительно сэкономить время для веб-мастеров, у которых большой сайт и которые не хотят часами писать файл Robots.txt с нуля. Вместо этого вы можете использовать один из этих бесплатных инструментов для создания файла Robots.txt за считанные минуты.
Помните, что ваш файл robots.txt сообщает поисковым системам, какие страницы вашего веб-сайта сканировать, а какие нет. Чем больше страниц вы запрещаете поисковым системам сканировать, тем менее эффективным будет показ вашего веб-сайта.
Как использовать онлайн генератор Robots.
 txt?
txt?- Введите URL-адрес страницы, которую вы хотите просканировать.
- Выберите файл Robots.txt.
- Нажмите кнопку «Создать».
- Загрузите или скопируйте и вставьте сгенерированный текст в файл с расширением «.txt» и загрузите его на свой сервер.
Бесплатный онлайн-генератор Robots.txt — быстрое создание файла robots.txt
| Разрешить или запретить всех роботов: DefaultAllowRefuse | |
| Задержка сканирования (в секундах): | |
| Карта сайта: | |
| Выберите роботов для разрешения или отказа: | |
| Google Image: Дефолталловрефузе | Google для мобильных устройств: Дефолталловрефузе |
| MSN-поиск: Дефолталловрефузе | Яху: Дефолталловрефузе |
| Яху ММ: Дефолталловрефузе | Блоги Yahoo: Дефолталловрефузе |
| Спросите/Тема: DefaultAllowRefuse | Гигавзрыв: Дефолталловрефузе |
| Проверка ДМОЗ: Дефолталловрефузе | Алекса/Обратный путь: Дефолталловрефузе |
| Байду: Дефолталловрефузе | Навер: Дефолталловрефузе |
| MSN PicSearch: Дефолталловрефузе | |
| Запрещенные каталоги: | |
Файл robots.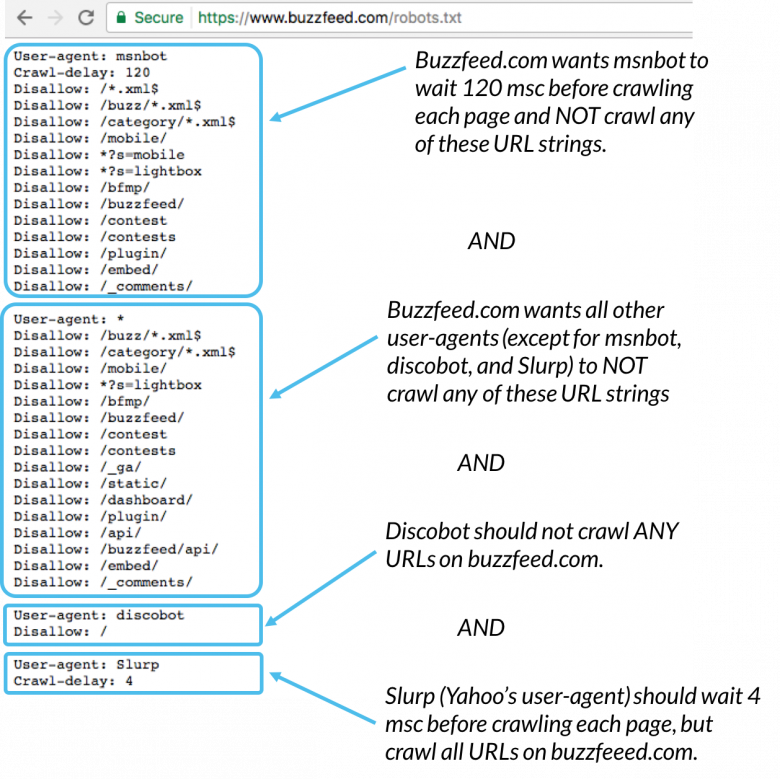 txt: txt: | |
Что такое файл robots.txt
Файл robots.txt — это текстовый файл, который используется для связи с поисковыми роботами и другими автоматическими агентами, например поисковыми роботами, которые посещают веб-сайт. Файл размещается в корневом каталоге веб-сайта и содержит инструкции для этих агентов, какие страницы или разделы веб-сайта следует сканировать или индексировать.
Формат файла robots.txt прост и понятен. Он состоит из ряда строк «User-agent», за которыми следует одна или несколько строк «Disallow». Строка «User-agent» указывает, к какой поисковой системе или боту применяются инструкции, а строка «Disallow» указывает, какие страницы или каталоги веб-сайта не следует сканировать.
Например, файл robots.txt может содержать следующую строку: User-agent: * Disallow: /private-page/
Это сообщает всем поисковым роботам, что им не следует сканировать или индексировать страницу, расположенную по адресу «http: //www.![]() example.com/private-page/».
example.com/private-page/».
Важно отметить, что, хотя файл robots.txt можно использовать для предотвращения сканирования определенных страниц поисковыми системами, на самом деле он не препятствует доступу пользователей к этим страницам.
Почему файл robots.txt важен
Файл robots.txt сообщает поисковым системам, какие страницы или разделы веб-сайта не следует сканировать или индексировать. Robots.txt важен по нескольким причинам:
- Поисковая оптимизация (SEO): Файл robots.txt не позволяет поисковым системам индексировать двигатели фокусируются на самых важных страницах веб-сайта.
- Защита конфиденциальной информации: Файл robots.txt не позволяет поисковым системам сканировать определенные страницы или разделы веб-сайта, что помогает владельцам веб-сайтов защитить конфиденциальную информацию от индексации и публикации.
- Экономия ресурсов сервера: Владельцы веб-сайтов могут запретить поисковым системам сканирование ненужных страниц или разделов веб-сайта с помощью файла robots. txt, что помогает экономить ресурсы сервера и избегать потенциальной перегрузки сервера.
- Защита конфиденциальности: Владельцы веб-сайтов могут защитить конфиденциальность своих пользователей, заблокировав поисковым системам сканирование страниц, не предназначенных для общего пользования.
- Соответствие требованиям законодательства: файл Robots.txt можно использовать, чтобы запретить поисковым системам сканировать определенные страницы или разделы веб-сайта, чтобы убедиться, что веб-сайт соответствует правовым требованиям, таким как Общий регламент по защите данных (GDPR) или Закон о защите конфиденциальности детей в Интернете (COPPA).
 txt, что помогает экономить ресурсы сервера и избегать потенциальной перегрузки сервера.
txt, что помогает экономить ресурсы сервера и избегать потенциальной перегрузки сервера. Важно помнить, что хотя файл robots.txt может быть полезным инструментом для улучшения SEO веб-сайта и защиты конфиденциальной информации, он не дает 100% гарантии того, что страница не будет проиндексирована или кэширована поисковыми системами, и не является безопасный способ блокировки страниц.
robotx.txt директивы
В основном файл robots.txt состоит из 4-х директив: «User-agent» и «Disallow».
Директива «User-agent»: Используется для указания, к какой поисковой системе или боту относятся инструкции в файле. Например, «User-agent: Googlebot» применит правила из файла к пауку поисковой системы Google. Подстановочный знак «*» можно использовать для применения правил ко всем поисковым роботам.
Директива «Запретить»: Используется для указания того, какие страницы или каталоги веб-сайта не следует сканировать. Например, «Запретить: /private-page/» не позволит поисковым роботам сканировать страницу, расположенную по адресу «http://www.example.com/private-page/».
Директива «Разрешить»: разрешает индексацию определенных страниц или каталогов. «Разрешить: /public-page/», это позволит поисковым роботам сканировать страницу, расположенную по адресу «http://www.
example.com/public-page/».Директива «Карта сайта»: Используется для указания местоположения карты сайта на веб-сайте. Например, «Карта сайта: https://www.example.com/sitemap.xml».
 example.com/public-page/».
example.com/public-page/».Как создать robotx.txt
- Создайте новый текстовый файл с помощью текстового редактора.
- Добавьте в файл следующую строку кода:
User-agent: * (это сообщает всем поисковым системам, что следующие правила применяются ко всем ботам поисковых систем) - Чтобы заблокировать определенную страницу или раздел вашего веб-сайта, добавьте следующую строку кода, заменив «page-path» фактическим путем к странице, которую вы хотите заблокировать:
Запретить: /путь-страницы/ - Чтобы запретить индексацию всех страниц вашего сайта, добавьте следующую строку кода:
Disallow: / - Сохраните файл как robots.txt и загрузите его в корневой каталог вашего веб-сайта.
- После загрузки вы можете проверить, работает ли он, посетив «http://www. example.com/robots.txt» в браузере.
 example.com/robots.txt» в браузере.
example.com/robots.txt» в браузере.Примечание: Будьте очень осторожны при редактировании файла robots.txt, так как ошибка может привести к тому, что поисковые системы перестанут сканировать весь ваш сайт.
Что такое robots.txt Generator
A robots.txt Generator — это инструмент, который помогает владельцам веб-сайтов создавать файл robots.txt для своего веб-сайта. Инструмент предоставляет удобный интерфейс, который позволяет пользователям легко указывать, какие страницы или разделы их веб-сайта должны быть заблокированы для поисковых систем.
Процесс использования генератора robotstxt обычно довольно прост и понятен. Вам будет предложено выбрать, какие страницы или разделы вашего сайта вы хотите заблокировать, после чего генератор создаст соответствующий код для файла robots.txt. Генератор текстовых файлов Somerobots также имеет функцию добавления карты сайта веб-сайта в файл robots.txt.
После создания файла robots. txt вам необходимо загрузить его в корневой каталог вашего веб-сайта. Обычно это можно сделать с помощью FTP-клиента или через панель управления вашего сайта.
txt вам необходимо загрузить его в корневой каталог вашего веб-сайта. Обычно это можно сделать с помощью FTP-клиента или через панель управления вашего сайта.
Важно помнить, что, хотя генератор robots.txt может быть полезным инструментом, по-прежнему важно понимать основы работы robots.txt и проверять правильность работы файла после его загрузки на веб-сайт.
Зачем использовать онлайн-генератор robots.txt
- Удобство: Создание файла robots.txt с нуля может занять много времени и утомительно, особенно для владельцев веб-сайтов, которые не знакомы с синтаксисом и форматом файла. Генератор текста робота упрощает создание файла, предоставляя простой и удобный интерфейс, который помогает пользователям в процессе.
- Предотвращение ошибок: Создание файла robots.txt вручную может привести к ошибкам, особенно если владелец веб-сайта не знаком с синтаксисом и форматом. Бесплатный генератор robots.txt может помочь предотвратить ошибки, предоставляя предварительно отформатированный файл, который легко понять и настроить.
- Экономия времени: Генератор файлов роботов может сэкономить владельцам веб-сайтов значительное количество времени за счет автоматизации процесса создания файла robots.txt.
- Знание программирования не требуется: Одним из основных преимуществ использования генератора robots.txt является то, что он позволяет владельцам веб-сайтов создавать файл robots.txt без каких-либо навыков программирования.

Как использовать бесплатный генератор robots.txt
- Выберите разрешить/запретить всех роботов на сайте.
- Введите задержку сканирования в секундах.
- Добавить карту сайта веб-сайта.
- Выберите разрешение или запрет для роботов различных поисковых систем.
- Вход в каталоги с ограниченным доступом.
- Нажмите кнопку «Создать robots.txt», чтобы сгенерировать текстовый файл robots для Google, и генератор автоматически загрузит файл robots.txt с соответствующим кодом.
