
Robots.txt — как настроить и загрузить на сайт
Михаил Шумовский
07 октября, 2022
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
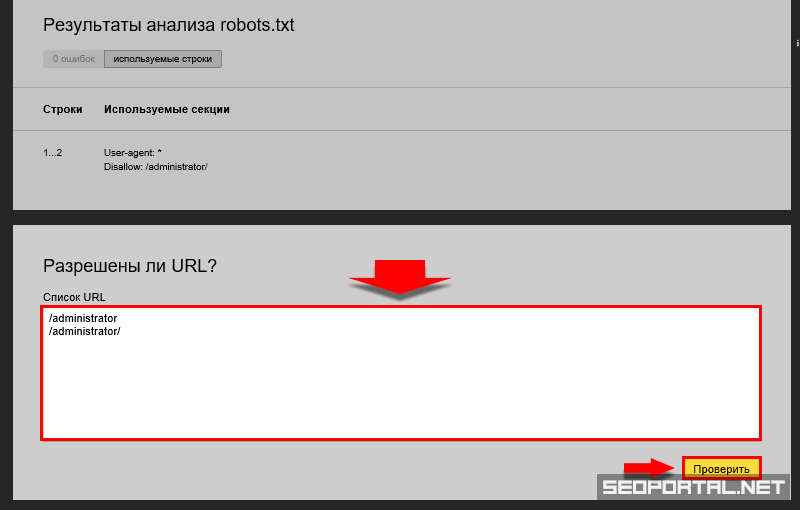
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т.
 д.
д.
 д.
д.Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot-Image. Индексирует изображения.
 Индексирует изображения.
Индексирует изображения.Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow
и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.

Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *. js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txt Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
Robots.
 txt — как настроить и загрузить на сайт
txt — как настроить и загрузить на сайтМихаил Шумовский
07 октября, 2022
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта.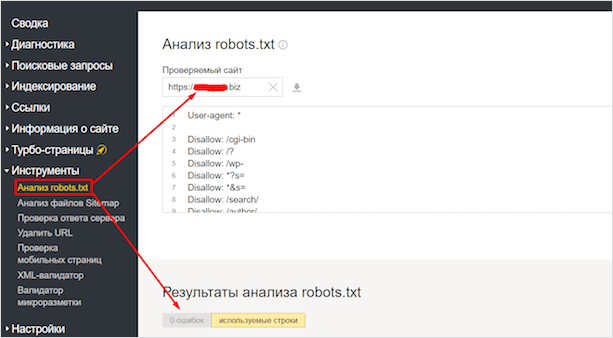 С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т. д.
 д.
д.Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image. Индексирует изображения.
 Индексирует изображения.
Индексирует изображения.Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.

Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *. js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой.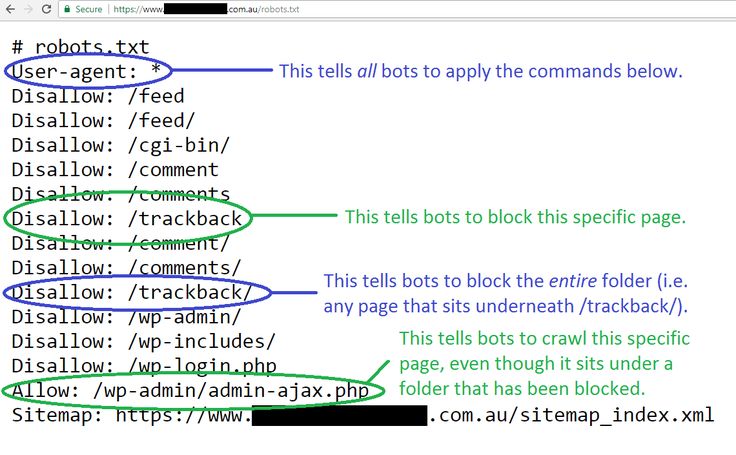 Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public.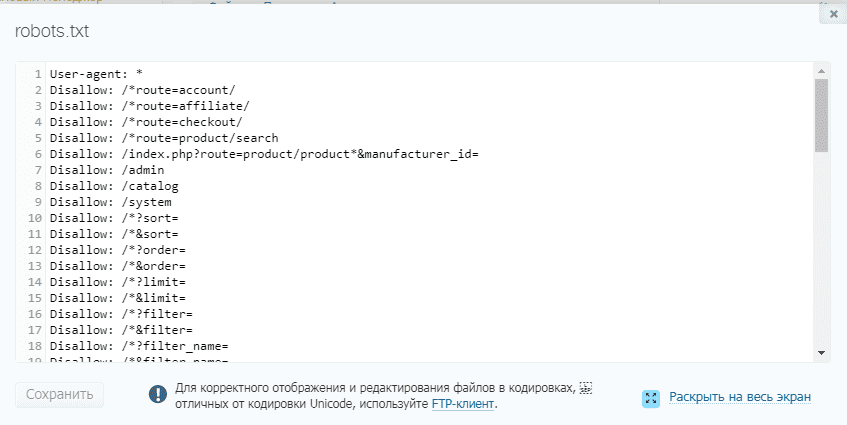 html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
Что такое Robots.
Поддержка > Продвижение вашего сайта > Поисковая оптимизация
Как использовать Robots.txt
Перейти к разделу
- Что такое robots.txt?
- Как работает файл robots.txt?
- Как настроить файл robots.txt на моем веб-сайте?
- Где находится файл robots.txt?
- Как настроить файл robots.txt (примеры)
- Как загрузить собственный файл robots.txt
Что такое robots.txt?
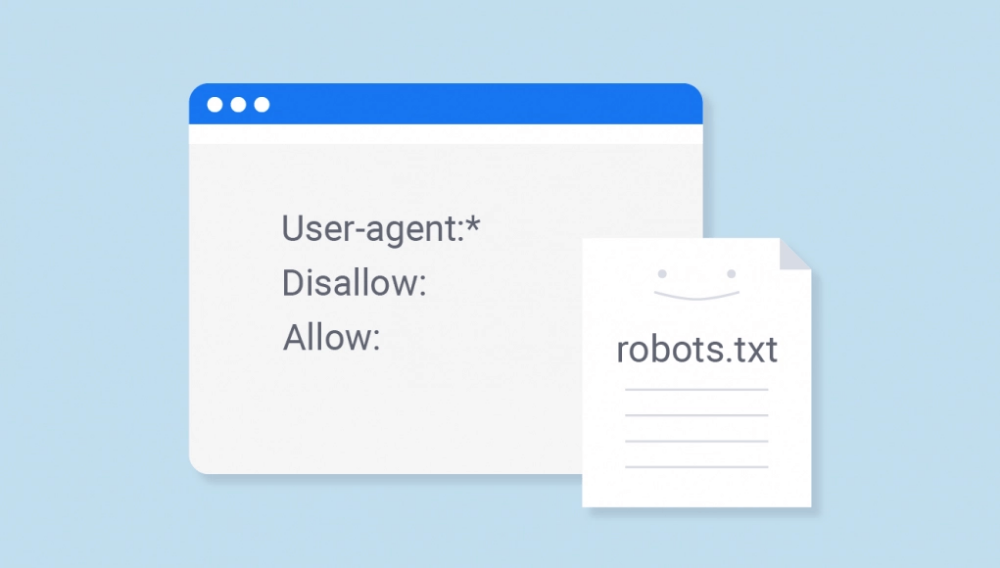
Файл Robots.txt — это текстовый файл, связанный с вашим веб-сайтом, который используется поисковыми системами для определения того, какие страницы вашего веб-сайта вы хотите, чтобы они посещали, а какие нет.
Как работает файл robots.txt?
Структура файла robots.txt очень проста. По сути, это заметка, которая сообщает поисковым системам, как вы хотите, чтобы они индексировали ваши страницы. Самый простой файл robots.txt выглядит так, как показано в примере ниже, что позволяет любой поисковой системе индексировать все, что она может найти:
Самый простой файл robots.txt выглядит так, как показано в примере ниже, что позволяет любой поисковой системе индексировать все, что она может найти:
User-agent: *
Disallow:
Это направление разбито на две части, первой является User-agent. Это (по большей части) поисковые системы, которые сканируют ваш сайт. Вы можете структурировать файл robots.txt, чтобы применять правила к определенным поисковым системам. Например, вы можете использовать следующее правило для ссылки на роботов Bing:
User-agent: bingbot
Disallow:
В большинстве случаев после User-agent стоит *, который означает, что правила применяются ко всем роботам.
Вторая часть — это функция Disallow:, которая указывает страницу или каталог, которые поисковые системы не должны индексировать. Таким образом, приведенный выше пример сообщает Bing, что они могут получить доступ ко всему, поскольку команда не указана.
Как настроить файл robots.txt на моем веб-сайте?
Мы автоматически настроим ваш файл robots.txt следующим образом:
пользовательский агент: *
Карта сайта: http://yourdomain.co.uk/sitemap.xml
запретить: /include/
запретить: /shop/basket_new.php
запретить: /shop/checkout_process.php
запретить: /account/
запретить: /cdn-cgi/
запретить: /веб-сайт users.html
Где находится файл robots.txt Файл?
Чтобы получить доступ к файлу robots.txt, как это сделают поисковые системы, введите свое полное доменное имя в адресную строку браузера и добавьте «/robots.txt» в конце адреса вашего веб-сайта.
Например: https://www.yourdomain.co.uk/robots.txt
Как настроить файл robots.
 txt
txtВы можете полностью настроить файл robots.txt, следуя приведенным ниже инструкциям:
На компьютере откройте Блокнот (или TextEdit на Mac)
Используйте эту программу для записи нового файла robots в виде обычного текста без стилей и форматирования
Сохраните файл под именем: robots.txt
Примеры
Ниже приведены несколько сценариев, которые могут потребоваться для вашего веб-сайта, и способы настройки файла robots.txt для разрешения этого:
1. Разрешить всем поисковым системам доступ к изображениям
Чтобы указать все поисковые системы вам нужно будет добавить символ * в качестве пользовательского агента, так как он представляет все поисковые системы:
Пользовательский агент: *
Разрешить: /siteimages/
2. Запретить всем поисковым системам доступ к изображения
Запретить всем поисковым системам доступ к изображения
Агент пользователя: *
Запретить: /siteimages/
3. Разрешить только некоторые поисковые системы
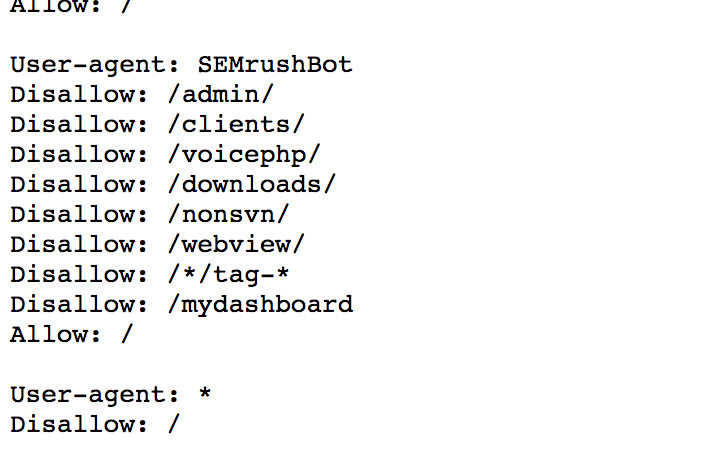
Если вы хотите разрешить только определенные поисковые системы, которые вам нужно будет указать, как показано ниже:
User-agent: *
Disallow: /sitefiles/
Disallow: /siteimages/
User-agent: google бот
Запретить:
User-agent: bingbot
Disallow:
В приведенном выше примере всем поисковым системам запрещено сканировать ваши файлы и изображения, кроме Bing (bingbot) и Google (googlebot).
4. Разрешить только некоторые поисковые системы доступ к изображениям
, если вы хотите, чтобы только определенные поисковые системы ползали ваши изображения, вам необходимо указать их, как ниже:
пользователь-агент: *
. User-agent: googlebot-image Disallow: 5. Разрешить Google сканировать ваши изображения, но не отображать их в Google Images Если вы хотите, чтобы Google сканировал ваши изображения но для того, чтобы они не отображались в Google Images, вам нужно указать это, указав робота Google Image в файле robots.txt, как показано ниже: User-agent: * Disallow: /sitefiles/ User-agent: googlebot-image Disallow: /siteimages/ Указав конкретно этого робота Google Image, вы не позволяете своим изображениям появляться в поиске Google Image, однако разрешаете Google продолжать сканирование это означает, что они все еще могут появляться в веб-поиске Google. 6. Запретите некоторые поисковые системы, чтобы они ничего не сканировали Если вы хотите, чтобы конкретная поисковая система вообще не сканировала ваш сайт, вам нужно будет добавить символ /, так как он представляет весь ваш контент: Агент пользователя: * Запретить: /sitefiles/ Запретить: /siteimages/ Агент пользователя: bingbot 90 042 Запретить: / В приведенном выше примере ваши роботы не позволяют Bing получить доступ к вашему веб-сайту, но все другие сайты, такие как Google, могут! 7. Если вы хотите разрешить всем поисковым системам доступ ко всему, вам необходимо добавить в файл robots.txt следующее: User-agent: * Disallow: 8. Запретить поисковым системам доступ к некоторым страницам сайта доступ к определенным страницам вы будете необходимо добавить имя файла страницы в ваш файл, как показано ниже: User-agent: * Disallow: /guestbook/ Disallow: /onlineshop/ С защитой паролем страницы, эти страницы могут быть сканируется вашими роботами, но посетитель сайта не может получить к нему доступ без имени пользователя и пароля. Из-за этого, а также из-за того, что страница, вероятно, будет иметь очень мало преимуществ для SEO, если вы вообще не хотите, чтобы эта страница индексировалась, вы можете добавить это в свой файл robots. 9. Запретить поисковым системам доступ к личным документам Агент пользователя: * Запретить: /sitefiles/27/3/6/273678/contact_form.pdf любые страницы или личные документы, проиндексированные на вашем веб-сайте с помощью robots.txt, чтобы люди могли найти их через ваш файл robots.txt, если они искали его. Если вы хотите ограничить доступ к этим ресурсам на своем веб-сайте, мы рекомендуем защитить вашу страницу паролем. Чтобы загрузить свой файл robots.txt и заменить созданный, выполните следующие действия: Войдите в свою учетную запись Создать учетную запись Щелкните Content в верхнем меню Нажмите «Файлы» в меню слева Нажмите зеленую кнопку «Добавить файл» в правом верхнем углу Нажмите кнопку «Загрузить» и выберите файл. Нажмите зеленую кнопку Загрузить файл Опубликуйте свой веб-сайт, чтобы изменения вступили в силу Теперь файл robots.txt будет изменен. Если у вас есть дополнительные вопросы, свяжитесь с нами, и мы будем рады помочь. Свяжитесь с нами Документация AIOSEO Документация, справочные материалы и учебные пособия для AIOSEO Уведомление: Для этого элемента нет устаревшей документации, поэтому вы видите текущую документацию. Посмотрите наше видео о том, как использовать инструмент Robots.txt здесь. Вы хотите создать файл robots.txt для своего сайта? Эта статья поможет. Модуль robots.txt в All in One SEO позволяет вам управлять файлом robots.txt, который создает WordPress. Это позволяет лучше контролировать инструкции, которые вы даете поисковым роботам в отношении вашего сайта. В этой статье Во-первых, важно понимать, что WordPress создает динамический файл robots.txt для каждого сайта WordPress. Этот файл robots.txt по умолчанию содержит стандартные правила для любого сайта, работающего на WordPress. Во-вторых, поскольку WordPress генерирует динамический файл robots.txt, на вашем сервере нет статического файла. Содержимое robots.txt хранится в вашей базе данных WordPress и отображается в веб-браузере. Наконец, All-in-One SEO не создает файл robots.txt, он просто предоставляет очень простой способ добавления пользовательских правил в файл robots.txt по умолчанию, который генерирует WordPress. Чтобы начать работу, нажмите Инструменты в меню All-in-One SEO . Вы должны увидеть Редактор Robots.txt и первым параметром будет Enable Custom Robots.txt . Щелкните переключатель, чтобы включить пользовательский редактор robots.txt. ВАЖНО : По умолчанию файл robots.txt, сгенерированный WordPress, идеально подходит для 99% всех сайтов. Функция Custom Robots.txt предназначена для тех пользователей, которым нужны настраиваемые правила для блокировки доступа к настраиваемым каталогам на их сервере. Вы должны увидеть раздел Robots.txt Preview в нижней части экрана, в котором показаны правила по умолчанию, добавленные WordPress. Правила по умолчанию, которые отображаются в разделе предварительного просмотра Robots.txt (показан на снимке экрана выше), просят роботов не сканировать ваши основные файлы WordPress. Поисковым системам нет необходимости напрямую обращаться к этим файлам, потому что они не содержат релевантного контента сайта. Если по какой-то причине вы хотите удалить правила по умолчанию, добавленные WordPress, вам нужно будет использовать фильтр-хук robots_txt в WordPress. Построитель правил используется для добавления ваших собственных правил для определенных путей на вашем сайте. Например, если вы хотите добавить правило для блокировки всех роботов из временного каталога, вы можете добавить его с помощью конструктора правил. Чтобы добавить правило, введите пользовательский агент в поле User Agent . Использование * применит правило ко всем пользовательским агентам. Затем выберите либо Разрешить , либо Запретить , чтобы разрешить или заблокировать пользовательский агент. Затем введите путь к каталогу или имя файла в поле Путь к каталогу . Наконец, нажмите кнопку Сохранить изменения . Если вы хотите добавить больше правил, нажмите кнопку Добавить правило , повторите шаги, описанные выше, и нажмите кнопку Сохранить изменения . Ваши правила появятся в разделе Robots.txt Preview и в файле robots.txt, который можно просмотреть, нажав кнопку Открыть кнопку Robots.txt . Чтобы изменить любое добавленное вами правило, просто измените данные в конструкторе правил и нажмите кнопку Сохранить изменения . Чтобы удалить добавленное правило, щелкните значок корзины справа от правила. Существует также редактор Robots.txt для многосайтовых сетей. Подробности можно найти в нашей документации по редактору Robots.txt для многосайтовых сетей здесь. Вот видео о том, как использовать инструмент Robots.txt в All in One SEO: Уведомление: В настоящее время вы просматриваете устаревшую документацию. Модуль robots.txt в All in One SEO позволяет настроить файл robots.txt для вашего сайта, который заменит файл robots.txt по умолчанию, созданный WordPress. Создав файл robots. Правила по умолчанию, которые отображаются в окне «Создать файл Robots.txt» (показано на снимке экрана выше), просят роботов не сканировать ваши основные файлы WordPress. Поисковым системам нет необходимости обращаться к этим файлам напрямую, потому что они не содержат никакого релевантного контента сайта. Если по какой-то причине вы хотите удалить правила по умолчанию, добавленные WordPress, вам нужно будет использовать фильтр-хук robots_txt в WordPress. Конструктор правил используется для добавления ваших собственных правил для определенных путей на вашем сайте. Например, если вы хотите добавить правило для блокировки всех роботов из временного каталога, вы можете использовать конструктор правил, чтобы добавить это правило, как показано ниже. Запретить: /siteimages/
Запретить: /siteimages/ 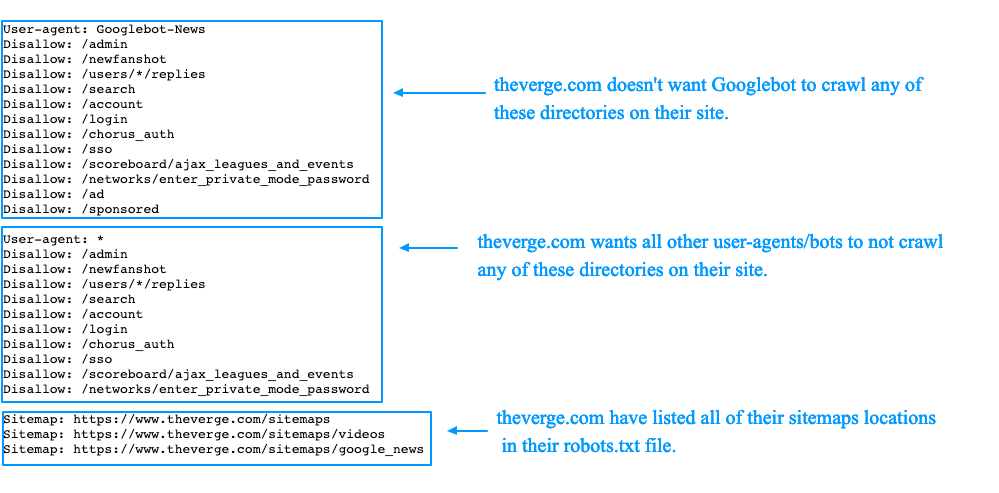 Разрешить всем поисковым системам доступ ко всем страницам сайта
Разрешить всем поисковым системам доступ ко всем страницам сайта  txt, но это не обязательно, так как к ней не может получить доступ все посетители.
txt, но это не обязательно, так как к ней не может получить доступ все посетители. Как загрузить собственный файл robots.txt

Еще вопросы?
Использование инструмента Robots.txt в All-in-One SEO
О файле robots.txt в WordPress
 Это совершенно нормально и намного лучше, чем использование физического файла на вашем сервере.
Это совершенно нормально и намного лучше, чем использование физического файла на вашем сервере. Использование редактора Robots.txt в All-in-One SEO
Вам не нужно включать Custom Robots.txt, если у вас нет особой причины для добавления пользовательского правила robots.
Правила Robots.txt по умолчанию в WordPress
Добавление правил с помощью построителя правил

Редактирование правил с помощью конструктора правил

Удаление правила в конструкторе правил
Редактор Robots.txt для мультисайтов WordPress
 txt с All in One SEO Pack, вы сможете лучше контролировать инструкции, которые вы даете поисковым роботам в отношении вашего сайта. Как и WordPress, All in One SEO генерирует динамический файл, поэтому на вашем сервере нет статического файла. Содержимое файла robots.txt хранится в вашей базе данных WordPress.
txt с All in One SEO Pack, вы сможете лучше контролировать инструкции, которые вы даете поисковым роботам в отношении вашего сайта. Как и WordPress, All in One SEO генерирует динамический файл, поэтому на вашем сервере нет статического файла. Содержимое файла robots.txt хранится в вашей базе данных WordPress. Правила по умолчанию
Добавление правил
