Как ускорить сбор семантического ядра для B2B
Гульназ Фатыхова
SEO-специалист агентства digital-маркетинга «Реаспект»
В этой статье я хочу пошагово показать, как применение метода фильтрации с помощью «похожести» сайтов из топ-10 помогло мне ускорить процесс чистки и сбора семантического ядра и сэкономить время без потери качества.Суть метода состоит в том, чтобы взять в продвижение только те запросы, по которым топ-10 «похож», то есть состоит из сайтов того же типа, как продвигаемый проект. Метод разработан Андреем Буйловым (руководитель студии интернет-маркетинга «Муравейник»).
Я расскажу о своем опыте применения метода на примере ниши «Ножи» для интернет-магазина оборудования для ресторанов и общепита.
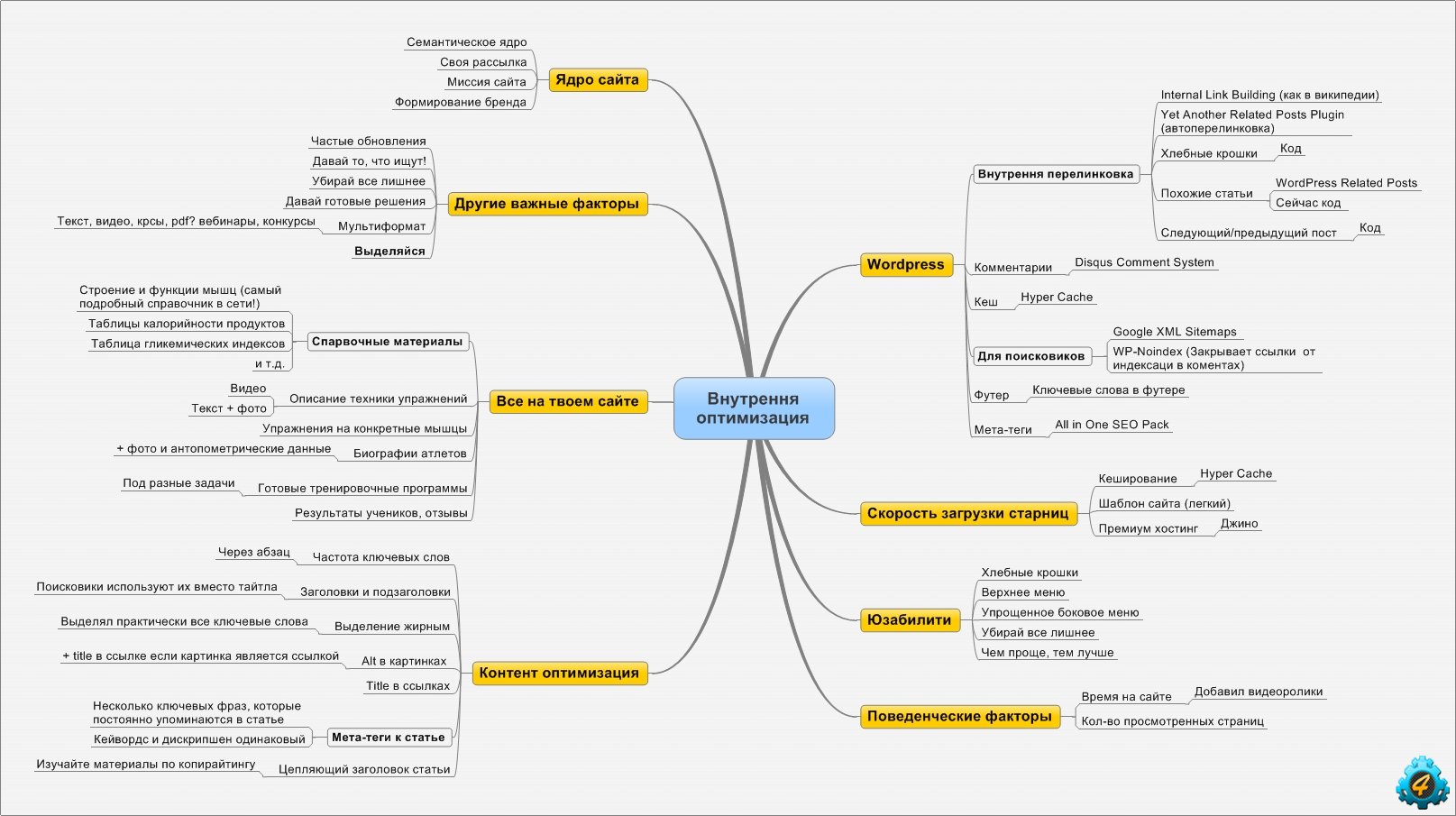
Составление семантического ядра
Составление семантического ядра (списка ключевых слов) для интернет-магазина является трудоемким процессом и времязатратным, поскольку требуется собрать и обработать большое число запросов.
Весь процесс сбора семантики можно поделить на четыре больших этапа:
- Сбор маркеров.
- Парсинг запросов.
- Чистка запросов.
- Кластеризация запросов.
Для проектов из сферы B2B особенность сбора семантики заключается в том, чтобы до этапа кластеризации исключить поисковые фразы для B2C, тем самым значительно сократить время. Для этого и подходит метод, который использует оценку похожести для приоритизации – выбора тех групп запросов, с которых стоит начать оптимизацию сайта, а какие отложить.
Сбор маркеров
При сборе маркерных запросов я использовала три группы маркеров:
1. Первая группа маркеров с коммерческими словами – «купить нож», «цена нож», «нож интернет-магазин» и т.п.
2. Вторая группа маркеров с B2B фразами:
(барные|+для баров|+для кафе|+для кондитерских|+для кофейни|+для кофеен|+для магазина|+для общепита|+для сферы общественного питания|+для отелей|+для гостиниц|+для пекарен|+для пиццерии|+для ресторанов|+для столовой|+для кафетерия|+для супермаркетов|+для таверны|+для трактира|+для фастфуда|+для фаст фуда|+для стритфуда|+для стрит фуда|+для бургерных|+для харчевни|+для пищевых производств|+для точек быстрого питания|инвентарь|оснащение|готовые решения|оптовик|оптовый|оптом для бизнеса|оптом и в розницу|оптово розничный|официальный дилер|официальный представитель|официальный дистрибьютор|официальный поставщик|профессиональные|b2b)
3. Третья группа маркеров по типу – «обвалочный нож», «филейный нож» и т.п.
Третья группа маркеров по типу – «обвалочный нож», «филейный нож» и т.п.
Парсинг запросов
Этот этап подробно описывать не буду, перечислю только основные инструменты и сервисы, которые я использую для сбора маркеров и ключевых фраз:
- Яндекс Wordstat,
- Wordstat Assistant,
- поисковые подсказки Яндекса и Google,
- рекомендованные запросы в Яндекс Вебмастере,
- поисковые запросы в Яндекс Метрике и Google Analytics,
- Screaming Frog SEO Spider,
- Keys.so,
- Rush Analytics,
- Key Collector.
Необходимо отметить, по умолчанию Wordstat отдает всего 41 страницу результатов. Чтобы обойти ограничение, я использую метод сбора частотности для запросов заданной длины (до 7 слов).
Для этого добавляю запросы в сервис Rush Analytics следующим образом (кавычки обязательны):
«ножи ножи»
«ножи ножи ножи»
«ножи ножи ножи ножи»
и так далее до 7 слов.
Чистка семантического ядра
После парсинга подсказок и ключевых фраз нужно удалить все нерелевантные запросы, но делать это вручную очень долго.
Загружаю фразы в Key Collector 4. Через функции «Минус слова», «Анализ групп», «Неявные дубли» убираю нецелевую мусорную семантику. Снимаю частотность и убираю нулевые запросы. Вы это можете сделать через удобный для вас сервис.
Собираю данные о поисковой выдаче Яндекс и Google:
Выгружаю результаты поисковой выдачи Яндекс и Google в отдельные таблицы.
Теперь переходим к применению методики:
1. Создать копию шаблона в Google Таблицах, перейдя по ссылке.
2. Скопировать все столбцы выгруженной таблицы и вставить во вкладку «KeyCollector» Google Таблицы.
В шаблоне для наглядности имеются данные. Если ваших запросов меньше, то удалить ненужные строки. Если ваших запросов больше, то протянуть формулы в столбцах с «G» до «J» до конца ваших данных.
Кстати, если запросов много и есть трудности переноса данных в Google Таблицу в силу большого количества строк, то я делала так:
- загружала Excel-таблицу на Google Диск, открывала через Google Таблицы;
- сохраняла как Google-таблицу;
- и уже в преобразованную таблицу переносила формулы и остальные листы из шаблона.


С первого раза может показаться, что сложно. Но когда речь идет о десятках тысяч запросов, применение шаблонов стоит того, чтобы разобраться в вопросе.
3. Переходим во вкладку «Разметка похожих». Это сводная таблица. Чтобы не запутаться, рекомендую сначала всем доменам в столбце «С» убрать галочки, а в столбце «D» проставить, протянув мышкой.
Если у вас есть готовый список конкурентов, то можете, загрузив в новую вкладку, через функцию «=ВПР()» найти их и отметить галочкой в столбце «C», в столбце «D» убрать галочку.
Далее пройтись по доменам из столбца «A». Найти конкурентов. Не забыть отметить галочкой в столбце «C», в столбце «D» убрать галочку для сайтов, похожих на продвигаемый проект.
4. Переходим во вкладку «Итог». Я добавляю в ячейку «C1» функцию =SORT(A:B;B:B;ЛОЖЬ), чтобы отсортировать ключевые фразы по убыванию похожести. Далее копирую и забираю в работу запросы похожестью не менее 10.
То же самое проделываю для таблицы с данными поисковой выдачи Google.
Объединяю итоги по похожести из Яндекс и Google, удалив дубликаты.
Итоговые запросы из полученного списка загружаем для кластеризации.
Кластеризация запросов
Распределяем похожие запросы по группам.
Я группирую в кластеры через Key Collector 4. Выставляю тип кластеризации «по поисковой выдаче (v.3)», режим группировки «пересечение», сила группировки 3 или 4 в зависимости от количества ключей и частотности.
После кластеризации совмещаем группы с посадочными страницами. Готовим технические задания для написания тегов и метатегов, задания на перелинковку и при необходимости для написания, корректировки текстов.
Разумеется, инструментов для сборки и чистки семантического ядра гораздо больше. И у каждого SEO-специалиста найдутся лайфхаки по работе с семантикой.
В этой статье я рассказала о своем опыте работы с запросами для B2B. Вы можете поделиться используемыми в своей работе методиками в комментариях.
Как собрать семантическое ядро в Вордстат Яндекса
Без применения специализированных программ
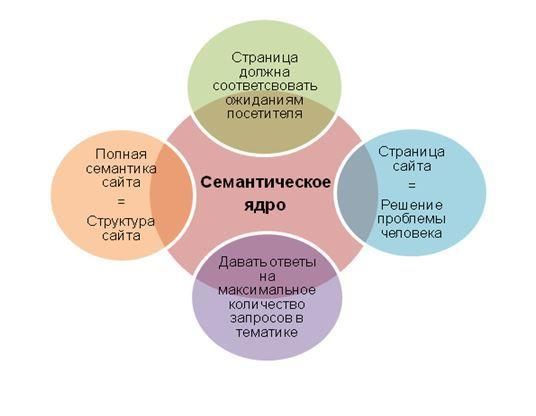
Рассмотрим этапы формирования семантического ядра на основе сервиса Яндекс Вордстат (как им пользоваться). Будем использовать ручной метод сбора, который трудозатратен, при постоянной работе с семантикой целесообразно пользоваться профессиональными программами. Для понимания процессов разберем вариант сбора и обработки фраз без специлизированного софта и сервисов.
Будем использовать ручной метод сбора, который трудозатратен, при постоянной работе с семантикой целесообразно пользоваться профессиональными программами. Для понимания процессов разберем вариант сбора и обработки фраз без специлизированного софта и сервисов.
Возьмем направление «рольставни» для компании, которая занимается установкой защитных конструкций и их обслуживанием по Москве и области. В первую очередь актуальны запросы, которые формулируют люди, заинтересованные в покупке таких изделий или у которых возникли проблемы с эксплуатацией. Вводим маску в строку подбора, выбираем регион, например, Москва и область:
В колонке слева Wordstat показывает запросы пользователей, которые набирали со словом «рольставни». В правой колонке дополнительные запросы. Ориентируйтесь на левую колонку, скопируйте фразы и частоту в таблицу. Переходите по пагинации снизу на следующие странице и скопируйте предлагаемые варианты фраз.
Вордстат даёт 2000 запросов по одному направлению. На одной странице показывается 50 фраз, получается 20 страниц нужно пролистать. Для примера я собрал первые 350 фраз, получилась таблица:
На одной странице показывается 50 фраз, получается 20 страниц нужно пролистать. Для примера я собрал первые 350 фраз, получилась таблица:
Скачать файл Эксель-исходник
Группировка (кластеризация) запросов в семантическом ядре
После сбора запросов, группируем (кластеризируем). Для этого используют 3 вида кластеризации:
- по смыслу;
- по SERP;
- смешанный.
Разбивка «По смыслу» предполагает, что из запросов выделяется основной посыл, что хочет получить человек. В собранном перечне запросы делятся так:
- рольставни +в туалет
- рольставни +на окна
- сантехнические рольставни
- рольставни +в туалет купить
- рольставни +в санузел
- рольставни наружные
- рольставни +в туалет москва
- сантехнические рольставни +в туалет
- рольставни +на окна наружные
- рольставни +в туалет купить москва
- прозрачные рольставни
- рольставни сантехнические купить
- рольставни +в туалет цена
- рольставни +на окна цена
- рольставни +в санузел москва
- прозрачные рольставни +для веранды
Туалет: 1, 3, 4, 5, 7, 8, 10, 12, 13, 15. Так как санузел, туалет и сантехнический предполагает один вид помещения для установки.
Так как санузел, туалет и сантехнический предполагает один вид помещения для установки.
Окна: 2, 6, 9, 14. Установка на окна предполагает, что рольставни буду наружными (запрос №6).
Прозрачные: 11, 16.
Кластеризация по «SERP» предполагает использование специализированной программы или сервиса (например, keyassort.ru). Получается, что это автоматизированный процесс. SERP – это результат поисковой выдачи, проще говоря ТОП-10. Алгоритм действий здесь такой:
- Выбранные фразы добавляются в программу.
- По каждому запросу программа проверяет ТОП-10 или ТОП-20 в Яндекс (Гугл) и сохраняет результат в таблице.
- Далее программа анализирует сохраненные данные и соотносит страницы в выдаче и фразы. И запросы, по которым встречаются одни и те же страницы сайтов в выдаче, объединяет в одну группу.
Такой способ кластеризации подходит для многотысячной семантики и экономит время. По опыту студии, в результате разбивки качество получаемых ядер низкое и требует корректировок.
Смешанный метод – «SERP» и здравый смысл. Применение двух способов одновременно. Случается, что разбив ядро по смыслу, остаются фразы, назначение которых спорно и их сложно объединить в группы. В этом случае снимается СЕРП и на основе анализа разбиваются фразы.
Популярный вопрос «сколько фраз должно быть в одном кластере?». Ограничений нет, от одного запроса до нескольких сотен. Студия DIUS ведет проекты, где одна страница ранжируется по 200-300 запросам. Бывает наоборот, что первоначально добавили в кластер 100 запросов, но при оптимизации зашли только 50. Тогда детально и подробно изучаем оставшиеся фразы, делим по дополнительным признакам и создаем под них новые разделы или оптимизируем другие страницы.
Но такой подход требует опыта, т.к. поисковики негативно относятся, когда под похожие запросы создаются две страницы. В этом случае понижаются позиции по обеим страницам. В этом случае, внимательно изучайте конкурентов в выдаче, возможно на одну страницу следует добавить вхождений.
Для группировки ядра по направлению «Рольставни» воспользуемся методом «По смыслу», т.к. фраз всего 350 и группировка не займет много времени.
Делим фразы по: типу продукции, назначению, параметрам (цвет, материал) и т.д. И также нужно будет отбросить ненужные фразы, назовем эту группу «мусор». В неё попадают нецелевые фразы, которые содержат слова:
- леруа мерлен;
- своими руками;
- фото и видео;
- города не из Московской области;
- бу, схемы, инструкции.
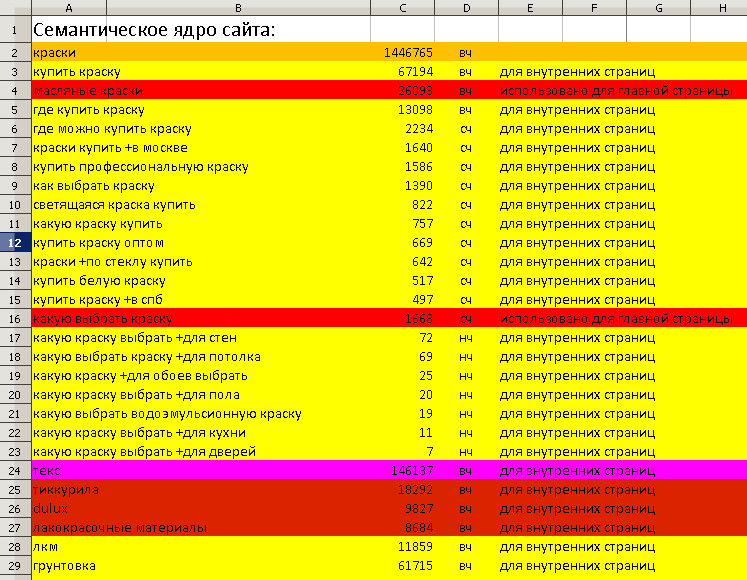
Просмотрев и задав кластер для каждого запроса, получаются следующие группы:
Из 350 подобранных фраз получилось 85 мусорных, остальные распределились на 36 групп по типам и назначению изделия. В первой колонке группа, во второй сколько содержит слов из 350 подобранных:
| Группа | Количество фраз |
| основная | 63 |
| туалет | 61 |
| область | 35 |
| на окна | 28 |
| гараж | 7 |
| прозрачные | 6 |
| монтаж | 5 |
| электропривод | 5 |
| ремонт | 4 |
| шкаф | 4 |
| фотопечать | 4 |
| ванная | 3 |
| дача | 3 |
| комната | 3 |
| дверь | 3 |
| терраса | 2 |
| алютех | 2 |
| балкон | 2 |
| дорхан | 2 |
| перфорированные | 2 |
| торговые | 2 |
| встроенные | 2 |
| веранда | 2 |
| беседка | 2 |
| двери | 1 |
| проем | 1 |
| внутренние | 1 |
| управление | 1 |
| поликарбонат | 1 |
| защитные | 1 |
| мебельные | 1 |
| антивандальные | 1 |
| паркинг | 1 |
| противопожарные | 1 |
| стеклянные | 1 |
| квартира | 1 |
| утепленные | 1 |
| мусор | 85 |
Полученные кластеры в свою очередь группируем по смыслу и получаем структуру сайта для оптимизации:
- Рольставни:
- Вид: прозрачные, поликарбонат, перфорированные, противопожарные, и т. д.
- Назначение: окна, двери, квартира, проем, торговые, мебельные, туалет, гараж, паркинг и т.д.
- Профиль: алютех, дорхан.
- Опции: с электроприводом, с фотопечатью.
- Вид: прозрачные, поликарбонат, перфорированные, противопожарные, и т.
- Сервис
- Ремонт
- Монтаж
 д.
д.Из 2000 фраз, которые выдает Вордстат по заданному слову, получится составить структуру сайт гораздо шире, чем приведенная в примере. Естественно ориентируйтесь на ключевики, которые характеризуют продукцию или услуги компании. Если какой-то тип продукции или услуг компания не производит отправляйте их в раздел «мусор».
Как подсказывает вордстат на скрине выше, некоторые называют рольставни другим словом – «роллеты». Поэтому для расширения ядра получения дополнительных фраз по ним также собираются фразы:
И:
Эти фразы добавляются в созданные группы или по ним создаются новые. Поисковики понимают, что «рольставни» и «роллеты» — это одно и тоже, поэтому совмещайте их в одних целевых кластерах.
Расширение ядра при помощи поисковых подсказок Yandex.ru
Дополнительным способом расширения семантики используют такой метод как «поисковые подсказки». Когда пользователь Яндекса вводит запрос в строку, поисковик предлагает варианты, исходя из статистики популярных запросов, дополняющие слова:
Видно, что на запрос «рольставни» поисковик предлагает запросы, которые уже были отобраны из сервиса Вордстат. Ориентируйтесь на фразы из 3-4 слов:
Тогда получится дополнить ядро. Вручную собирать подсказки трудозатратно, для этого целесообразно использовать профессиональные программы по сбору семантики или сервисы. РашАналитикс помогает собирать подсказки. На сервисе предусмотрена бесплатная регистрация, и сразу даётся 200 баллов.
Для сбора добавьте фразы из 3-4 слов из семантического ядра. Задайте популярные мусорные слова, чтобы сервис автоматически из убрал из результатов: своими руками, бу, леруа мерлен. В результате получаем такие дополнительные слова из подсказок:
Полученные фразы чистим от мусорных и проверяем частоту через Вордстат:
Сколько запросов собирать в ядро
По сути ограничений нет, чем больше фраз подобрано в семантическое ядро, тем лучше будет проработан сайт с точки зрения структуры и содержания. Отталкиваясь от групп запросов оптимизатор формирует не только разделы, но и планирует контент. Посмотрим на 28 запросов в группе «Рольставни на окна»:
Отталкиваясь от групп запросов оптимизатор формирует не только разделы, но и планирует контент. Посмотрим на 28 запросов в группе «Рольставни на окна»:
Ясно, что посетителей интересует:
- Цена такой конструкции.
- Варианты исполнения: с электроприводом или механические.
- Материалы изготовления: тканевые, металлические.
- Как устанавливают изделие.
- Для каких окон: квартиры, дачи, частный дом.
- Дополнительные функциональные свойства: защитные, антивандальные и т.д.
Каждый запрос в группе – это единица смысла, которую нужно отразить на созданной странице. Во-первых, это позволит употребить ключевые слова, что сделает сайт релевантным этому кластеру. Во-вторых, на странице будет опубликована полезная для посетителя информация.
Очистка семантики от мусора
При сборе многотысячного семантического ядра в список попадёт много нецелевых фраз:
- Тип продукции или схожий вид услуг, которыми компания не занимается. В случае с рольставнями, это материалы, из которых компания не производит изделия, либо дополнительные услуги – обслуживание, доставка, установка.
- В запросах часто появляются названия фирм конкурентов, когда пользователь пишет товар или услугу, и указывает название компании.
- У людей, проживающих в Москве и имеющих коттедж в другом регионе, например, Твери, отразится это в запросах, когда они будут заказывать рольставни, ворота и т.д. Указывая город в сервисе, вы задаете географию пользователей, интересы которых могут лежать за пределами этого региона.
- Также убирайте из ядра ошибочные написания и опечатки. Если раньше под такие запросы создавались страницы, то сейчас поисковые алгоритмы обнаружив опечатку исправляют её и выдача формируется по корректной словоформе. И если появятся новые ошибки в названиях, это значит, что в ближайшее время алгоритм это учтет.
 В случае с рольставнями, это материалы, из которых компания не производит изделия, либо дополнительные услуги – обслуживание, доставка, установка.
В случае с рольставнями, это материалы, из которых компания не производит изделия, либо дополнительные услуги – обслуживание, доставка, установка.От нецелевых запросов следует избавляться по следующим причинам:
- Если пользователь зайдет на сайт и обнаружит, что компания из другого региона – он закроет страницу. Это сказывается на поведенческих характеристиках сайта, в результате поисковик понизит в выдаче и по другим запросам, которые будут целевыми.
- Также это расценивается алгоритмами как поисковый спам, когда компания привлекает посетителей по запросам, задачи по которым она не решает.
- По некоторым запросам, типа «рейтинг компаний по рольставням», поисковики показывают сайты справочники, бизнес-каталоги, агрегаторы. По таким фразам не добраться до ТОП-10, если только не делать каталог организаций. Убрав их из ядра оптимизатор экономит время и ресурсы.
 Это сказывается на поведенческих характеристиках сайта, в результате поисковик понизит в выдаче и по другим запросам, которые будут целевыми.
Это сказывается на поведенческих характеристиках сайта, в результате поисковик понизит в выдаче и по другим запросам, которые будут целевыми.Как разбить семантическое ядро по типу запросов
Также стоит учесть разделение запросов по интенту пользователя:
- информационные;
- коммерческие.
Подробнее об этом в материале блога.
Для коммерческих запросов создаются разделы услуг, на которых предлагаются к продаже услуги и товары. Они называются коммерческими, т.к. предполагают, что у пользователя, при запросе прямое намерение купить или заказать продукцию, представленную на сайте.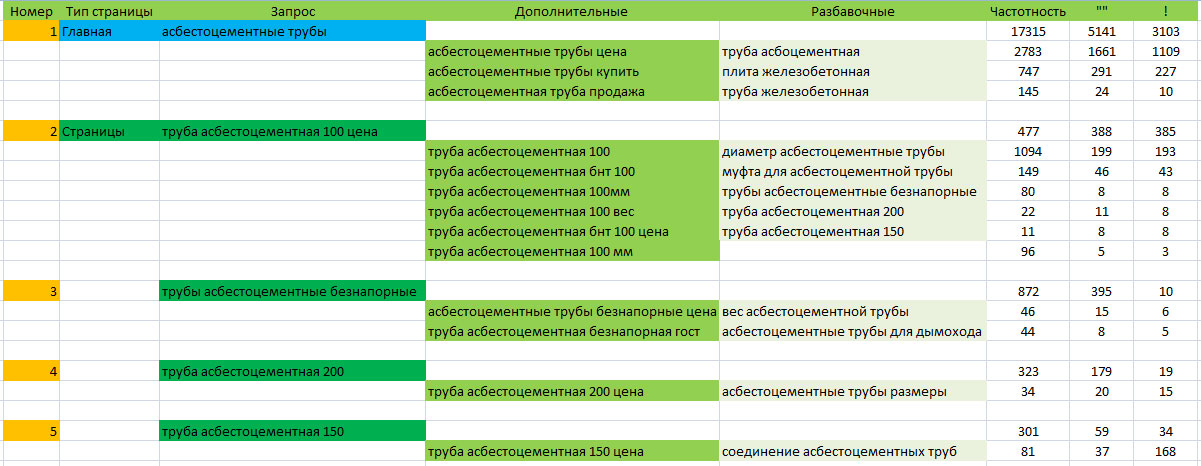 В таких запросах непосредственное название продукции или бренда, а также слова: купить, цена, заказать и т.п.
В таких запросах непосредственное название продукции или бренда, а также слова: купить, цена, заказать и т.п.
Информационные запросы подразумевают, что пользователь хочет получить сведения о пользовании продукцией, инструкций и т.п. В таких запросах часто фигурируют вопросы: как, какой, зачем, что лучше, почему и т.д. Для таких групп создается раздел статей на сайте, который отвечают на популярные вопросы людей перед покупкой, например, по рольставняим: как выбрать, какой профиль лучше и т.д. Формируется дополнительное ядро запросов для написания полезных материалов. Его собирают из Вордстат, добавив к фразе конструкцию «+как»:
Также с «+где», «+когда» и т.д.
При этом информационные запросы геонезависимые, поэтому регион ставьте Россия. Грамотное использование инфозапросов даёт целевые переходы из поисковиков, которые также конвертятся в обращения и покупки. Для этого используйте «Лестницу Бена Ханта» — подробней в статье.
Предлагаем создание
семантического ядра для сайта
Узнать стоимость
Что делать с семантическим ядром после составления
Итак, семантика собрана, разбита на группы. Приступаем к завершающему и целевому действию – разработка структуры сайта и планирование содержания страниц.
Приступаем к завершающему и целевому действию – разработка структуры сайта и планирование содержания страниц.
Сначала еще раз посмотрите каждую группу, проверьте на соответствие ассортименту компании. На сколько формулировки соответствуют предлагаемым видам продукции или услуг.
Структура сайта на основе семантики
На основе семантического ядра разрабатываем структуру сайта:
- Главная страница под высокочастотные и прямые фразы. В случае с «Рольставни» — это: рольставни, рольставни купить / цена / заказать и т.д.
- Планируем разделы, в которые включаются виды продукции (услуг) и вспомогательные страницы (гарантии, отзывы, доставка, контактная информация, о компании) цель которых убедить посетителя в надежности представленной компании.
- Подразделы – группы запросов распределенные по видам, типам и т.д. В представленном примере «Рольставни» в разделе Профиль, будут 2 подраздела: Алютех и Дорхан, из которых производят изделия.
Содержание страниц
Как говорилось выше, семантика для маркетолога – это источник креатива и полезного контента.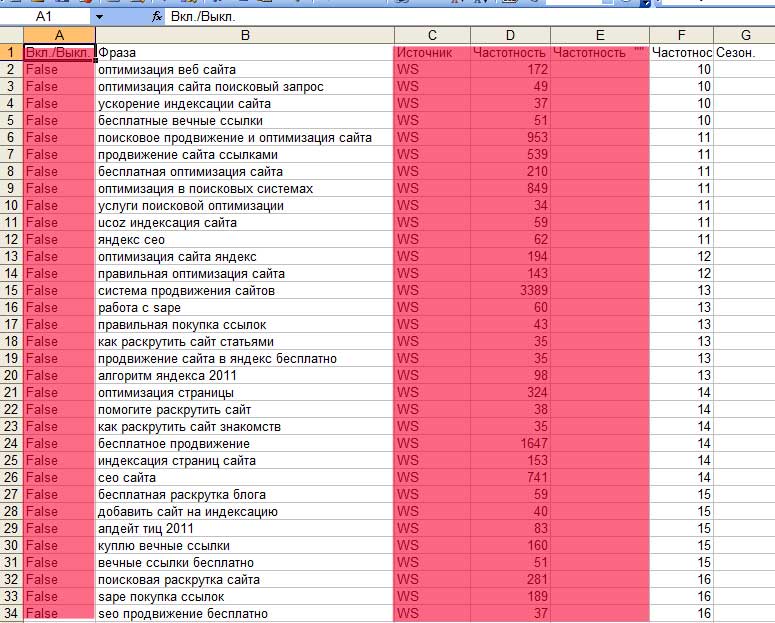 В запросах пользователя он видит какие проблемы хочет решить клиент и формирует содержание, которое вовлекает посетителя, цепляет и вызывает доверие, а также мотивирует оставить заявку, позвонить или заказать товар.
В запросах пользователя он видит какие проблемы хочет решить клиент и формирует содержание, которое вовлекает посетителя, цепляет и вызывает доверие, а также мотивирует оставить заявку, позвонить или заказать товар.
Превратитесь на время в маркетолога, изучите каждую фразу под микроскопом. Что подразумевает человек в запросе. Какие у него опасения и как их развеять. В какой формате человек хочет получить решение проблемы и как показать, что компания выполнит желаемое. Какие факторы принятия решения влияют на него и как их усилить на странице? Таким образом составится уникальный контент, полезный для посетителя с коммерческим эффектом.
Вывод
Ручное составление семантического ядра при помощи Яндекс Вордстат трудозатратное мероприятие. Оно подходит для разовой работы и для небольших сайтов. При профессиональном продвижении сайтов целесообразно приобрести программу Кей Коллектор, которая упрощает работы и сокращает время по формирование семантики в разы. При этом она позволяет детально работать с группой и каждым словом.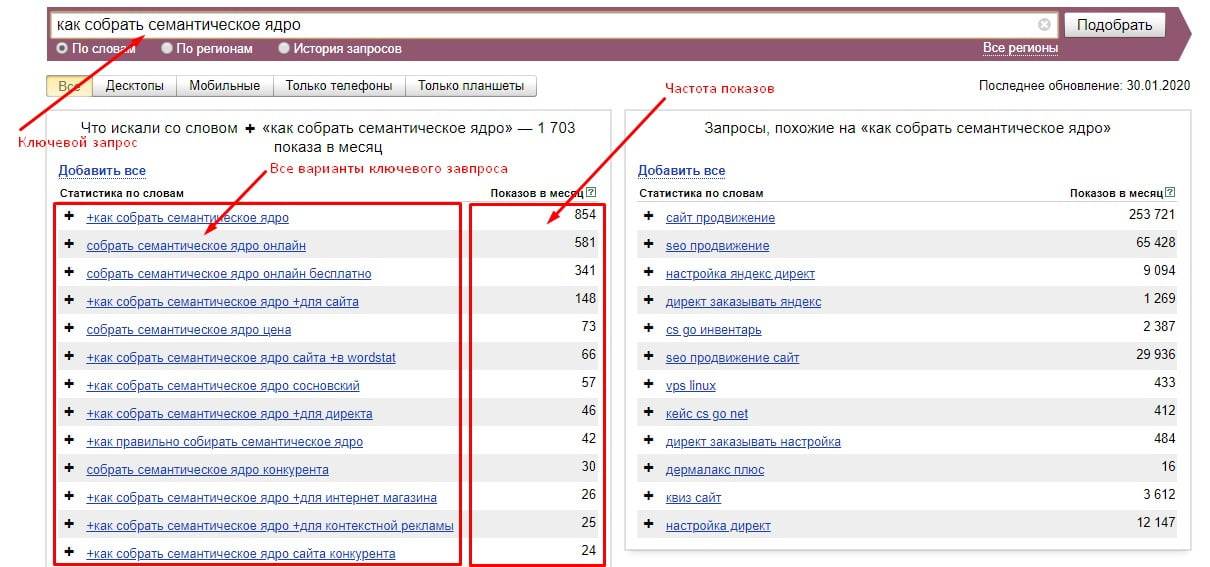 Пример сбора ядра в Key Collector можете посмотреть здесь.
Пример сбора ядра в Key Collector можете посмотреть здесь.
Обсудим сотрудничество?
Какие задачи нужно решить:
Разработка сайта / интернет-магазина
Продвижение (SEO, Директ и т.п.)
Контент-маркетинг
Поддержка сайта (информационная, техническая)
Аудит сайта / интернет-магазина
Консультация
Семантический анализ и таблицы символов
Семантический анализ
На этом этапе мы говорили о лексировании и разборе. Лексический анализ преобразовал входной поток символов в токены, а синтаксический анализ (парсинг) преобразовал поток токенов в абстрактное синтаксическое дерево. Следующий этап компилятора — семантический. анализ, который проверяет, что AST представляет собой действительную, правильно сформированную программу.
Каждый из этих первых трех этапов может обнаружить какую-либо ошибку в программе. Лексический анализ
выявляет лексические ошибки (неверно сформированные токены), синтаксический анализ выявляет синтаксические ошибки и
семантический анализ обнаруживает семантические ошибки, такие как ошибки статического типа, неопределенные переменные,
и неинициализированные переменные.
В дополнение к проверке того, что AST является действительной программой, семантический анализ может также вычислить дополнительную информацию, которая полезна для остальных процесс компиляции: например, типы выражений, структура памяти структур данных или представлений классов и модулей, отличных от AST. Таким образом, результатом успешного семантического анализа является украшенный AST, в котором AST был дополнен этой дополнительной информацией.
Проверка типа
Для многих языков статическая проверка типов является основной задачей семантического анализа. Это
обычно реализуется как рекурсивный обход AST. Чтобы увидеть, как это
работает, рассмотрим проблему проверки типов с использованием оператора +. С тех пор
разделяет многие функции с другими бинарными операторами в объектно-ориентированной среде, такой как Java. естественно определить класс
который фиксирует общие черты всех бинарных операторов, таких как левый и
правые операнды:
естественно определить класс
который фиксирует общие черты всех бинарных операторов, таких как левый и
правые операнды:
класс BinaryExpr расширяет Expr {
Выражение влево, вправо;
...
}
Предположим, что наша проверка типов предназначена для записи типа каждого выражения.
узел в АСТ. Это украшение может быть выражено добавлением переменной экземпляра к
общий суперкласс Expr :
код
Переменная типа является украшением, которое необходимо заполнить семантическим анализом.
с реальным типом. Метод typeCheck() используется для реализации проверки типов,
с каждым классом узлов, обеспечивающим логику для проверки типов описываемых им выражений;
это естественно для typeCheck() как рекурсивный метод. Обратите внимание, что без аргументов
даны для typeCheck() ; вскоре мы увидим, что необходим хотя бы один аргумент.
Теперь попробуем написать код для добавления проверки типов на Java. Вот
упрощенная версия этого кода с некоторыми недостающими частями. Предполагая, что у нас есть
существующее представление типов
Вот
упрощенная версия этого кода с некоторыми недостающими частями. Предполагая, что у нас есть
существующее представление типов int и String ,
мы могли бы написать код, подобный следующему, используя вызовы рекурсивных методов для проверки типов.
поддеревья слева
справа :код
Контексты ввода
То, что чего-то все еще не хватает, можно увидеть, если мы рассмотрим, как проверить тип идентификатора.
выражение (например, локальная переменная). Тело метода typeCheck() :
невозможно реализовать, потому что у нас нет возможности узнать, какой идентификатор типа имя следует ассоциировать с.
код
В общем, при семантическом анализе какой-либо части программы нам нужен
описание окружающих контекст , в котором находится этот фрагмент программы.
Для обработки идентификаторов проверки типов контекст должен включать среду .
который сопоставляет имена идентификаторов с типами. В настройках компиляторов эта среда известна
как таблица символов . Простой контекст ввода может выглядеть следующим образом:
В настройках компиляторов эта среда известна
как таблица символов . Простой контекст ввода может выглядеть следующим образом:
код
Затем мы модифицируем подпись typeCheck , чтобы принять Context как
Аргумент. Реализация Id.typeCheck становится проще:
код
Однако изменение подписи typeCheck означает, что контекст должен проходить через все рекурсивные вызовы. Например,
соответственно обновляется метод Plus.typeCheck :
код
Формализация контекстов ввода
Мы представляем среды более формально как отображение \(Г\) из идентификаторов \(х\) в типы \(t\). Окружение \(Γ\) записывается как \(Γ = x_1:t_1, x_2:t_2, \dots x_n:t_n\), что означает, что каждый идентификатор \(x_i\) отображается в соответствующий тип \(t_i\).
Используя эту нотацию, давайте рассмотрим следующий пример, предполагая, что первоначальный ввод
контекст не имеет переменных в области видимости: \(Γ=∅\).
{ // Г=∅
инт я, н; // Г=i:целое, n:целое
для (я = 0; я
Как мы видим, контекст ввода меняется по мере того, как мы сталкиваемся с объявлениями переменных и
выход на просторы. Например, мы можем реализовать проверку типов для объявлений переменных.
следующим образом, добавив объявленную переменную в контекст:
код
Эта реализация разработана в предположении, что операторы в данном блоке
проверяются последовательно, что позволяет накапливать новые объявления путем простого изменения
текущая среда.
код
Однако, как показывает приведенный выше пример, блоки создают еще одну проблему: переменные должны
вне сферы действия. Один из способов реализации этого показан в блоке . Контекст
поддерживает стек сред, так что c.push() сохраняет текущую среду
и c.pop() восстанавливает последнюю сохраненную среду, которая не была восстановлена.
Реализация контекстов ввода
Языки программирования, как правило, имеют множество механизмов для введения новых областей видимости. Например,
в Java у нас есть блоки, методы, классы (включая вложенные классы) и пакеты.
Контекст ввода должен иметь возможность отслеживать, какие идентификаторы связаны во всех этих
масштабы.
Стек хеш-таблиц. Традиционная реализация представляет собой таблицу символов, реализованную в виде стека хэш-таблиц.
Таблица символов обязательно обновляется во время проверки типов. При входе в новую сферу, новый,
пустая хеш-таблица помещается в стек, что занимает \(O(1)\) времени. При выходе из области видимости
верхняя хеш-таблица извлекается из стека, что занимает \(O(1)\) времени. Добавление нового идентификатора
в контексте просто требуется добавить сопоставление в верхнюю хэш-таблицу за время \(O(1)\). Однако,
поиск идентификатора требует, как правило, обхода стека, проверки каждой хеш-таблицы.
Для идентификатора на глубине \(d\) это занимает \(O(d)\) времени. Конечно, значение \(d\) мало в
большинство программ.
Неизменяемое дерево поиска. Второй способ реализации контекста типизации — использование постоянной (неразрушающей) структуры данных,
Например, бинарное дерево поиска. Двоичное дерево поиска может быть обновлено за время \(O(\lg n)\) для получения
новое бинарное дерево поиска, не затрагивая исходное. Это возможно, потому что структура данных
неизменяемо, и новое бинарное дерево поиска имеет общие узлы, кроме \(O(\lg n)\), с
оригинальное дерево. При входе в область никаких изменений не требуется; по мере добавления привязок к
среда, создаются новые контексты. При выходе из области действия расширенный контекст просто отбрасывается.
Одним из преимуществ этой реализации является то, что контекст, используемый для проверки данного выражения, может быть сохранен.
как украшение, так как оно неизменно.
Хэш-таблица с повторяющимися записями и журналом. Если изменяемая реализация приемлема, асимпотически оптимальные данные
структура представляет собой единую связанную хеш-таблицу, в которой мы допускаем дублирование ключей для
появляются в том же ведре. Кроме того, контекст отслеживает журнал
обновленные ключи, которые могут быть реализованы в виде связанного списка. Идентификатор
искал, используя хэш-таблицу напрямую, и брал самое раннее совпадение
отображение в своем ведре, занимая время \(O(1)\). Могут быть и другие отображения, но
те, которые принадлежат внешним областям, будут позже в списке ведер. Ан
идентификатор добавляется в структуру данных путем вставки его в начало
список ведер, а также запись его в начале журнала, принимая общее время
\(О(1)\). При входе в новый прицел в начале поля ставится специальный маркер.
log, операция с постоянным временем. При выходе из области видимости все идентификаторы
выскочил из журнала до включения первого маркера. Каждый такой идентификатор
удаляются из хеш-таблицы обычным способом. Общее время, чтобы сделать это
операция пропорциональна количеству переменных в самой внутренней области видимости,
но это число также пропорционально числу положить() операций, поэтому общее время входа, добавления переменных и выхода из области составляет
по-прежнему пропорционально количеству добавленных переменных. Следовательно, амортизируемая
сложность выхода также \(O(1)\). Эта реализация, вероятно,
самый быстрый, но его не так просто построить с использованием готовых структур данных.
 Например,
в Java у нас есть блоки, методы, классы (включая вложенные классы) и пакеты.
Контекст ввода должен иметь возможность отслеживать, какие идентификаторы связаны во всех этих
масштабы.
Например,
в Java у нас есть блоки, методы, классы (включая вложенные классы) и пакеты.
Контекст ввода должен иметь возможность отслеживать, какие идентификаторы связаны во всех этих
масштабы. Двоичное дерево поиска может быть обновлено за время \(O(\lg n)\) для получения
новое бинарное дерево поиска, не затрагивая исходное. Это возможно, потому что структура данных
неизменяемо, и новое бинарное дерево поиска имеет общие узлы, кроме \(O(\lg n)\), с
оригинальное дерево. При входе в область никаких изменений не требуется; по мере добавления привязок к
среда, создаются новые контексты. При выходе из области действия расширенный контекст просто отбрасывается.
Одним из преимуществ этой реализации является то, что контекст, используемый для проверки данного выражения, может быть сохранен.
как украшение, так как оно неизменно.
Двоичное дерево поиска может быть обновлено за время \(O(\lg n)\) для получения
новое бинарное дерево поиска, не затрагивая исходное. Это возможно, потому что структура данных
неизменяемо, и новое бинарное дерево поиска имеет общие узлы, кроме \(O(\lg n)\), с
оригинальное дерево. При входе в область никаких изменений не требуется; по мере добавления привязок к
среда, создаются новые контексты. При выходе из области действия расширенный контекст просто отбрасывается.
Одним из преимуществ этой реализации является то, что контекст, используемый для проверки данного выражения, может быть сохранен.
как украшение, так как оно неизменно. Идентификатор
искал, используя хэш-таблицу напрямую, и брал самое раннее совпадение
отображение в своем ведре, занимая время \(O(1)\). Могут быть и другие отображения, но
те, которые принадлежат внешним областям, будут позже в списке ведер. Ан
идентификатор добавляется в структуру данных путем вставки его в начало
список ведер, а также запись его в начале журнала, принимая общее время
\(О(1)\). При входе в новый прицел в начале поля ставится специальный маркер.
log, операция с постоянным временем. При выходе из области видимости все идентификаторы
выскочил из журнала до включения первого маркера. Каждый такой идентификатор
удаляются из хеш-таблицы обычным способом. Общее время, чтобы сделать это
операция пропорциональна количеству переменных в самой внутренней области видимости,
но это число также пропорционально числу
Идентификатор
искал, используя хэш-таблицу напрямую, и брал самое раннее совпадение
отображение в своем ведре, занимая время \(O(1)\). Могут быть и другие отображения, но
те, которые принадлежат внешним областям, будут позже в списке ведер. Ан
идентификатор добавляется в структуру данных путем вставки его в начало
список ведер, а также запись его в начале журнала, принимая общее время
\(О(1)\). При входе в новый прицел в начале поля ставится специальный маркер.
log, операция с постоянным временем. При выходе из области видимости все идентификаторы
выскочил из журнала до включения первого маркера. Каждый такой идентификатор
удаляются из хеш-таблицы обычным способом. Общее время, чтобы сделать это
операция пропорциональна количеству переменных в самой внутренней области видимости,
но это число также пропорционально числу 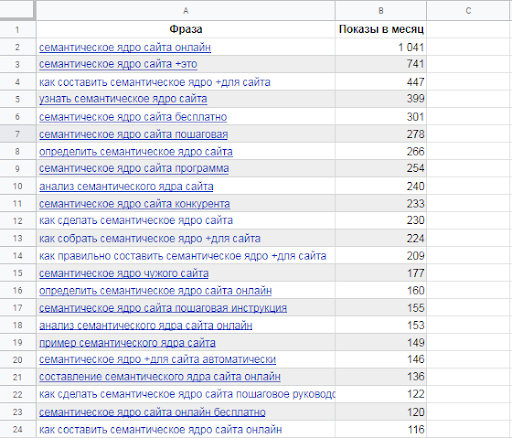 Следовательно, амортизируемая
сложность выхода также \(O(1)\). Эта реализация, вероятно,
самый быстрый, но его не так просто построить с использованием готовых структур данных.
Следовательно, амортизируемая
сложность выхода также \(O(1)\). Эта реализация, вероятно,
самый быстрый, но его не так просто построить с использованием готовых структур данных.Как извлечь табличные данные из PDF с помощью Semantic Table Extract? - Семантическая эволюция
Выдержка из семантической таблицы
Автор Semantic Evolution
В этом видео Semantic Evolution обсуждает, как Semantic Table Extract анализирует неструктурированные документы путем поиска и извлечения табличных данных.
Semantic Table Extract основан на глубоком обучении, сочетающем современное компьютерное зрение и обработку естественного языка, для точной локализации таблиц и распознавания их внутренней структуры.
Почему сложно извлекать табличные данные из файлов PDF?
Таблицы рядом с диаграммами или графиками
Таблицы с заголовком или абзацем между ними
Таблицы с большим количеством текста
Столы, расположенные рядом
Таблицы с разным расположением страниц
Таблицы с разными цветами
Таблицы большие и маленькие
Таблицы с большими линиями или без строк
Преимущества Semantic Table Extract
может обрабатывать широкий спектр сложных таблиц.
может определять внутреннюю структуру таблицы.
поддерживает пустые и сложные связующие ячейки.
обрабатывает сложные слияния и разделения ячеек.
поддерживает основные и второстепенные заголовки.
поддерживает итоговые и промежуточные итоги.

О Semantic Evolution
Мы — быстрорастущая технологическая компания с офисами в Лондоне и Манхэттене, работающая с крупными клиентами по всему миру.
Наш продукт использует методы искусственного интеллекта для сбора данных из неструктурированных документов, таких как PDF-файлы, электронные таблицы и электронные письма. Наша технология синтаксического анализа обеспечивает эффективность повторяющихся задач, которые обычно требуют трудоемкого ручного извлечения данных.
Наш уникальный научный подход, лидерство в отрасли и полная прозрачность привносят интеллект в данные наших клиентов.
Извлечение данныхИзвлечение данныхИзвлечение табличных данныхКомпьютерное зрениеОбработка естественного языкаГлубокое обучениеИзвлечение табличных данныхИзвлечение семантической таблицы
Семантическая эволюция Компания Semantic Evolution занимает лидирующие позиции в области искусственного интеллекта и фокусируется на интеллектуальном извлечении данных.