Как ускорить сбор семантического ядра для B2B
Гульназ Фатыхова
SEO-специалист агентства digital-маркетинга «Реаспект»
В этой статье я хочу пошагово показать, как применение метода фильтрации с помощью «похожести» сайтов из топ-10 помогло мне ускорить процесс чистки и сбора семантического ядра и сэкономить время без потери качества.
Суть метода состоит в том, чтобы взять в продвижение только те запросы, по которым топ-10 «похож», то есть состоит из сайтов того же типа, как продвигаемый проект. Метод разработан Андреем Буйловым (руководитель студии интернет-маркетинга «Муравейник»).
Я расскажу о своем опыте применения метода на примере ниши «Ножи» для интернет-магазина оборудования для ресторанов и общепита.
Составление семантического ядра
Составление семантического ядра (списка ключевых слов) для интернет-магазина является трудоемким процессом и времязатратным, поскольку требуется собрать и обработать большое число запросов.
Весь процесс сбора семантики можно поделить на четыре больших этапа:
- Сбор маркеров.
- Парсинг запросов.
- Чистка запросов.
- Кластеризация запросов.
Для проектов из сферы B2B особенность сбора семантики заключается в том, чтобы до этапа кластеризации исключить поисковые фразы для B2C, тем самым значительно сократить время. Для этого и подходит метод, который использует оценку похожести для приоритизации – выбора тех групп запросов, с которых стоит начать оптимизацию сайта, а какие отложить.
Сбор маркеров
При сборе маркерных запросов я использовала три группы маркеров:
1. Первая группа маркеров с коммерческими словами – «купить нож», «цена нож», «нож интернет-магазин» и т.п.
2. Вторая группа маркеров с B2B фразами:
(барные|+для баров|+для кафе|+для кондитерских|+для кофейни|+для кофеен|+для магазина|+для общепита|+для сферы общественного питания|+для отелей|+для гостиниц|+для пекарен|+для пиццерии|+для ресторанов|+для столовой|+для кафетерия|+для супермаркетов|+для таверны|+для трактира|+для фастфуда|+для фаст фуда|+для стритфуда|+для стрит фуда|+для бургерных|+для харчевни|+для пищевых производств|+для точек быстрого питания|инвентарь|оснащение|готовые решения|оптовик|оптовый|оптом для бизнеса|оптом и в розницу|оптово розничный|официальный дилер|официальный представитель|официальный дистрибьютор|официальный поставщик|профессиональные|b2b)
3. Третья группа маркеров по типу – «обвалочный нож», «филейный нож» и т.п.
Третья группа маркеров по типу – «обвалочный нож», «филейный нож» и т.п.
Парсинг запросов
Этот этап подробно описывать не буду, перечислю только основные инструменты и сервисы, которые я использую для сбора маркеров и ключевых фраз:
- Яндекс Wordstat,
- Wordstat Assistant,
- поисковые подсказки Яндекса и Google,
- рекомендованные запросы в Яндекс Вебмастере,
- поисковые запросы в Яндекс Метрике и Google Analytics,
- Screaming Frog SEO Spider,
- Keys.so,
- Rush Analytics,
- Key Collector.
Необходимо отметить, по умолчанию Wordstat отдает всего 41 страницу результатов. Чтобы обойти ограничение, я использую метод сбора частотности для запросов заданной длины (до 7 слов).
Для этого добавляю запросы в сервис Rush Analytics следующим образом (кавычки обязательны):
«ножи ножи»
«ножи ножи ножи»
«ножи ножи ножи ножи»
и так далее до 7 слов.
Чистка семантического ядра
После парсинга подсказок и ключевых фраз нужно удалить все нерелевантные запросы, но делать это вручную очень долго.
Загружаю фразы в Key Collector 4. Через функции «Минус слова», «Анализ групп», «Неявные дубли» убираю нецелевую мусорную семантику. Снимаю частотность и убираю нулевые запросы. Вы это можете сделать через удобный для вас сервис.
Собираю данные о поисковой выдаче Яндекс и Google:
Выгружаю результаты поисковой выдачи Яндекс и Google в отдельные таблицы.
Теперь переходим к применению методики:
1. Создать копию шаблона в Google Таблицах, перейдя по ссылке.
2. Скопировать все столбцы выгруженной таблицы и вставить во вкладку «KeyCollector» Google Таблицы.
В шаблоне для наглядности имеются данные. Если ваших запросов меньше, то удалить ненужные строки. Если ваших запросов больше, то протянуть формулы в столбцах с «G» до «J» до конца ваших данных.
Кстати, если запросов много и есть трудности переноса данных в Google Таблицу в силу большого количества строк, то я делала так:
- загружала Excel-таблицу на Google Диск, открывала через Google Таблицы;
- сохраняла как Google-таблицу;
- и уже в преобразованную таблицу переносила формулы и остальные листы из шаблона.


С первого раза может показаться, что сложно. Но когда речь идет о десятках тысяч запросов, применение шаблонов стоит того, чтобы разобраться в вопросе.
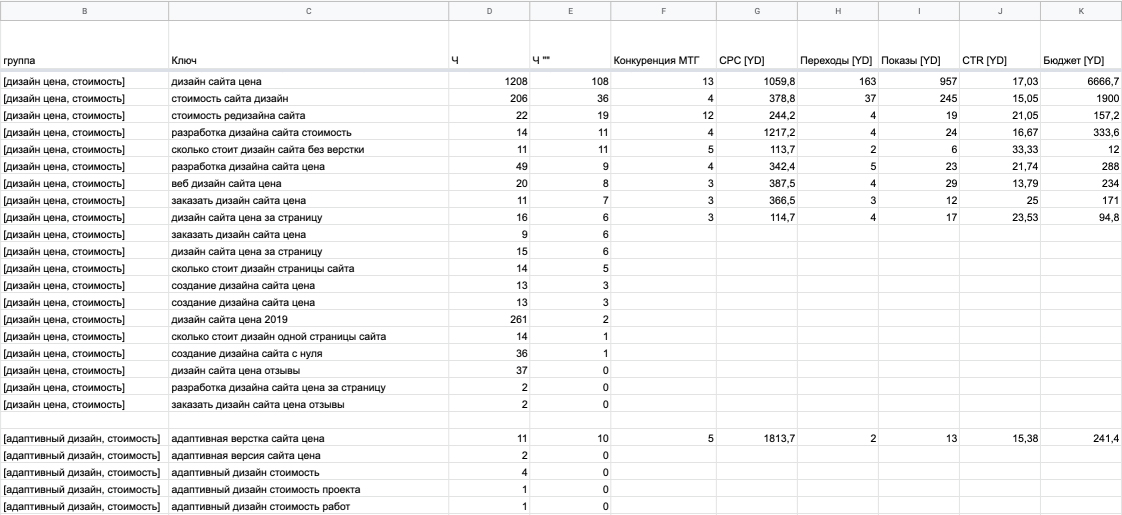
3. Переходим во вкладку «Разметка похожих». Это сводная таблица. Чтобы не запутаться, рекомендую сначала всем доменам в столбце «С» убрать галочки, а в столбце «D» проставить, протянув мышкой.
Если у вас есть готовый список конкурентов, то можете, загрузив в новую вкладку, через функцию «=ВПР()» найти их и отметить галочкой в столбце «C», в столбце «D» убрать галочку.
Далее пройтись по доменам из столбца «A». Найти конкурентов. Не забыть отметить галочкой в столбце «C», в столбце «D» убрать галочку для сайтов, похожих на продвигаемый проект.
4. Переходим во вкладку «Итог». Я добавляю в ячейку «C1» функцию =SORT(A:B;B:B;ЛОЖЬ), чтобы отсортировать ключевые фразы по убыванию похожести. Далее копирую и забираю в работу запросы похожестью не менее 10.
То же самое проделываю для таблицы с данными поисковой выдачи Google.
Объединяю итоги по похожести из Яндекс и Google, удалив дубликаты.
Итоговые запросы из полученного списка загружаем для кластеризации.
Кластеризация запросов
Распределяем похожие запросы по группам.
Я группирую в кластеры через Key Collector 4. Выставляю тип кластеризации «по поисковой выдаче (v.3)», режим группировки «пересечение», сила группировки 3 или 4 в зависимости от количества ключей и частотности.
После кластеризации совмещаем группы с посадочными страницами. Готовим технические задания для написания тегов и метатегов, задания на перелинковку и при необходимости для написания, корректировки текстов.
Разумеется, инструментов для сборки и чистки семантического ядра гораздо больше. И у каждого SEO-специалиста найдутся лайфхаки по работе с семантикой.
В этой статье я рассказала о своем опыте работы с запросами для B2B. Вы можете поделиться используемыми в своей работе методиками в комментариях.
Как составить семантическое ядро сайта правильно — составление СЯ
Составление семантического ядра относится к одному из важнейших этапов работы с рекламной компанией. Сюда входит поиск ключевых фраз, которые и будут указаны в объявлениях. Если сделать всё правильно, это поможет не только привлечь внимание целевой аудитории, но и значительно сэкономить бюджет. Конечно, можно написать любые словосочетания. Только без изучения семантики переходы по ним будут гораздо дороже. Чтобы понять, как составить семантическое ядро, читайте подробную инструкцию от Rookee.
Сюда входит поиск ключевых фраз, которые и будут указаны в объявлениях. Если сделать всё правильно, это поможет не только привлечь внимание целевой аудитории, но и значительно сэкономить бюджет. Конечно, можно написать любые словосочетания. Только без изучения семантики переходы по ним будут гораздо дороже. Чтобы понять, как составить семантическое ядро, читайте подробную инструкцию от Rookee.
Этапы составления семантического ядра
Этап 1. Поиск основных ключевых слов
В первую очередь вы должны подумать, какие слова подойдут для вашего бизнеса. Например, речь идёт о продаже запчастей к иномаркам. Значит, для продвижения стоит использовать такие слова: запчасти, иномарки, купить, заказать и так далее. Фраз может быть очень много. Все зависит от объёмов вашей компании, характеристик бизнеса и выбранной ниши. А чтобы работать было удобнее, составьте таблицу в Excel.
2.1.jpg
2. 1.jpg
1.jpg
Даже при очень хорошем воображении не получится записать все фразы, которые люди ищут через поисковые системы. Поэтому можно использовать сервис Яндекс.Вордстат. Вот какие запросы набирают люди, которые хотят купить запчасти для иномарок:
Список слов Wordstat
Ключевые слова Вордстат
Теперь в список можно добавить и другие слова. Причём все их придётся связать между собой. Сделать это не так уж сложно, подойдут даже стандартные средства Excel. Всё будет выглядеть примерно так:
группировка ключевых слов Excel
ключевые фразы в таблице
С этими фразами мы поработаем на следующем этапе.
Этап 2. Разработка семантического ядра
И здесь нам опять поможет сервис Wordstat. Он покажет, сколько запросов пользователи набирают в месяц. Эта информация тоже важна при составлении СЯ. Чтобы работать быстрее и удобнее, установите специальное расширение Wordstat Assistant.
Wordstat Asistant
Расширение для Яндекс.Вордстат
В Excel остаётся одна колонка для фраз, а во вторую следует записать стоп-слова.
Стоп-слова в Excel
Таблица в две колонки для семантики
Этап 3. Удаляем лишнее
Некоторые ключевики не подходят для продвижения. Например, «купить бу запчасти» и «купить запчасти в минске». Поэтому от них нужно сразу избавиться. Если этого не сделать, они могут так и остаться в основных фразах.
Удаление лишних фраз в Excel
Лишние фразы в таблице Excel
Чтобы не тратить время на каждую строку, воспользуйтесь фильтром.
Фильтр ключевых слов Excel
Фильтр в таблице Excel
В Яндекс можно увидеть много полезной информации, но ведь некоторые используют Google.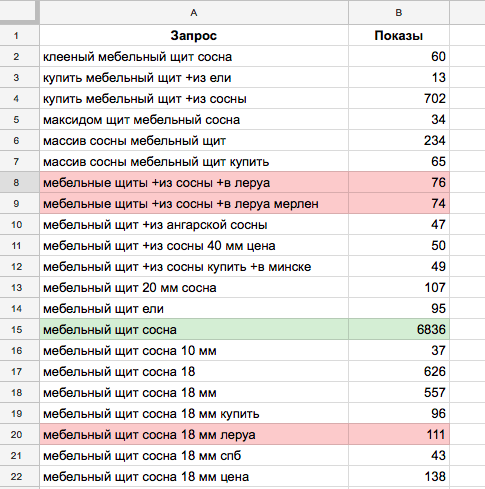
Google ADS ключевые фразы
Планировщик ключевых фраз Google
Помимо пополнения семантического ядра, сервис предлагает и другие полезные инструменты:
- определение конкуренции в вашей отрасли и статистика по объявлениям;
- минимальные и максимальные цены в разных рекламных позициях.
Некоторые запросы отличаются всего одним словом. Например, «купить запчасти на иномарки Москва» и «купить запчасти на иномарки СПБ». Выбирайте среди них такой запрос, который лучше всего подходит под ваши условия. А достичь лучшего результата поможет работа со всеми возможными инструментами.
Этап 4. Финальная стадия
Теперь пришло время составлять объявления. Ведь у вас для этого есть всё необходимое. Список ключевиков и стоп-слова помогают увидеть реальную статистику, что позволяет увеличить CTR, а цену наоборот уменьшить.
Рекламные объявления в Яндексе
Примеры рекламных объявлений
Операторы в Яндекс и Google
Операторы помогают изучать запросы более точно. Например, вы увидите, сколько раз искали конкретное слово, а не его морфологические формы. Для этого используют кавычки («») и восклицательный знак (!). Вы удалите фразы, которые по каким-то причинам не подходят для ваших целей. Причём работать с операторами можно одновременно, например:
Операторы в Яндекс
Популярные операторы Вордстат
Все виды операторов находятся у Яндекса в разделе помощи, а у Google в ответах на вопросы.
Ключевые слова в КМС и РСЯ
Сервисы Яндекса и Google хороши тем, что ключевики не придётся заново проверять. Нужно только правильно их сгруппировать и связать. Но если вы боитесь случайно привлечь на свой сайт низкосортный трафик, можно воспользоваться одним из инструментов Google ADS. Для этого перейдите в раздел «Ключевые слова», а затем найдите «Ключевые слова КМС или видео». Чтобы увидеть релевантные ключи, достаточно будет ввести адрес сайта. При этом подойдут они как для КМС, так и для РСЯ.
Для этого перейдите в раздел «Ключевые слова», а затем найдите «Ключевые слова КМС или видео». Чтобы увидеть релевантные ключи, достаточно будет ввести адрес сайта. При этом подойдут они как для КМС, так и для РСЯ.
Заключение
Собирать семантическое ядро не так просто, как кажется на первый взгляд. Но с нашей подробной инструкцией вы легко справитесь с этой задачей. Добавляйте важные слова, удаляйте лишние. Только следите внимательно за каждым этапом, и вы 100 % увидите положительный результат
Справка: Формат таблицы — Semantic -Mediawiki.org
v3.1.0+
| Статус: | |
| Прогресс: | 100% |
| Версия: | ,1,05%|
| Версия: | ,1,05%|
| Версия: | ,1,05%|
| . Версия: | ,1,01,05%|
| . |
From semantic-mediawiki. org
org
Перейти к:навигация, поиск
| Формат таблицы | |
|---|---|
| Выводит результаты в таблицу (по умолчанию для запросов с распечаткой операторов). | |
| Дополнительная информация | |
| Предоставлено: | Семантическая МедиаВики |
| Добавлено: | 0,4 |
| Удалено: | все еще поддерживается |
| Требования: | нет |
| Название формата: | таблица |
| Включено? Указывает, включен ли формат результата по умолчанию при установке соответствующего расширения. | да |
| Авторов: | Маркус Крётч |
| Категории: | разное |
| Содержание | |
Содержимое
| |
 1 Общие
1 ОбщиеФормат результата таблица используется для форматирования результатов запроса в виде таблиц. Это способ Semantic MediaWiki по умолчанию форматировать результаты запроса для всех запросов, которые имеют один или несколько дополнительных операторов вывода. Он почти идентичен формату результатов «Broadtable». Выводит результаты в виде широкой таблицы.
Параметры[править]
Общие[править]
| Параметр | Тип | По умолчанию | Описание |
|---|---|---|---|
| источник | текст | пустой | Альтернативный источник запроса |
| предел | целое число | 50 | Максимальное количество возвращаемых результатов |
| смещение | целое число | 0 | Смещение первого результата |
| ссылка | текст | все | Показать значения в виде ссылок |
| сортировать | список текстов | пустой | Свойство для сортировки запроса по |
| заказ | список текстов | пустой | Порядок сортировки запроса |
| заголовки | текст | шоу | Показать заголовки/имена свойств |
| основная этикетка | текст | нет | Ярлык для имени главной страницы |
| введение | текст | пустой | Текст для отображения перед результатами запроса, если таковые имеются |
| конец | текст | пустой | Текст для отображения после результатов запроса, если таковые имеются |
| Метка поиска | текст | . .. дальнейшие результаты .. дальнейшие результаты | Текст для продолжения поиска |
| по умолчанию | текст | пустой | Текст для отображения при отсутствии результатов запроса |
Совет: Параметр « headers=hide » особенно полезен для скрытия заголовков таблиц. В большинстве других случаев достаточно использовать пустые метки распечатки, чтобы скрыть заголовки операторов распечатки.
Зависит от формата[править]
| Параметр | Тип | По умолчанию | Описание |
|---|---|---|---|
| класс | текст | сортируемая викитаблица smwtable | Дополнительный класс CSS для таблицы |
| транспонировать | да/нет | нет | Отображение заголовков таблицы по вертикали и результатов по горизонтали |
| сент. | текст | пустой | Разделитель между результатами |
Сортировка[править]
Таблицы имеют специальную функцию для сортировки их содержимого по любому из столбцов в таблице. Общие комментарии по сортировке и сравнение с сортировкой результатов запроса в вики см. в разделе Выбор страниц. Браузеры без включенного JavaScript вообще не увидят кнопок для сортировки.
Общие комментарии по сортировке и сравнение с сортировкой результатов запроса в вики см. в разделе Выбор страниц. Браузеры без включенного JavaScript вообще не увидят кнопок для сортировки.
Примеры[править]
Следующие примеры демонстрируют вывод простых запросов с использованием различных классов для создания соответствующего общего вида таблицы.
сортируемая вики-таблица smwtable [править] Это класс по умолчанию для запросов с операторами распечатки, и его не нужно указывать явно. То же самое для указания используемого формата, т. е. формат=таблица , который используется по умолчанию для запросов с операторами распечатки.
- Синтаксис
{{#спросить:
[[Категория:Город]]
[[Расположен в::Германия]]
|?Население
|?Площадь#км²=Размер
|mainlabel=Город
| сортировать = Население
|порядок=по убыванию
|заголовки=простой
}}
- Result
| City | Population | Size | |
|---|---|---|---|
| Berlin | 3,520,061 | ||
| Meredan/Sandbox | 1,353,186 | 310.43 km²119 .86 кв. | 405.02 km²156.38 sqmi |
| Frankfurt | 679,664 | 248.31 km²95.87 sqmi | |
| Stuttgart | 606,588 | 207.35 km²80.06 sqmi | |
| Würzburg | 126 635 | 87,63 км²33,83 SQMI |
 85″> 891.85 km²344.34 sqmi
85″> 891.85 km²344.34 sqmi SMWTable-CLEAN [EDIT]Доступны с SEMANTICLIK-CLEAN [EDIT]
Доступны с SEMANTIAL-CLEAN.и совместим с MW 1.31.0 – 1.33.x..6 Используемый формат ( format=table ) не нужно указывать явно, так как он используется по умолчанию для запросов с операторами распечатки.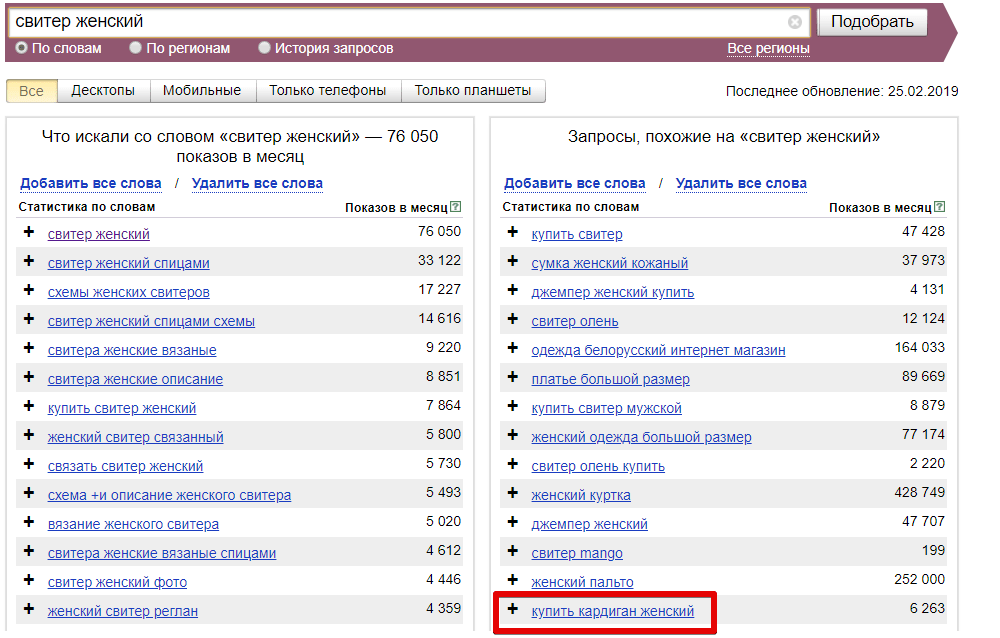 Его можно комбинировать с классом
Его можно комбинировать с классом sortable , предоставляемым ядром MediaWiki, в качестве утилиты, позволяющей пользователям управлять сортировкой содержимого столбцов ( class=smwtable-clean sortable ).
- Синтаксис
{{#спросить:
[[Категория:Город]]
[[Расположен в::Германия]]
|?Население
|?Площадь#км²=Размер
|mainlabel=Город
| сортировать = Население
|порядок=по убыванию
|заголовки=простой
|класс=smwtable-чистый
}}
- Result
| City | Population | Size | |||
|---|---|---|---|---|---|
| Berlin | 3,520,061 | 891.85 km²344.34 sqmi | |||
| Meredan/Sandbox | 1,353,186 | 310.43 km²119 .86 кв. | 405.02 km²156.38 sqmi | ||
| Frankfurt | 679,664 | ||||
| Stuttgart | 606,588 | 207.35 km²80.06 sqmi | |||
| Würzburg | 126,635 | 87,63 км²33,83 кв. .x..1 Используемый формат ( format=table ) не нужно указывать явно, так как это значение по умолчанию для запросов с операторами распечатки. Ниже приведены другие связанные классы.
{{#спросить:
[[Категория:Город]]
[[Расположен в::Германия]]
|?Население
|?Площадь#км²=Размер
|mainlabel=Город
| сортировать = Население
|порядок=по убыванию
|заголовки=простой
|класс=данные
}}
Подробнее …[править]
Внешний вид[править]Применение форматирования CSS[править] Начиная с Semantic MediaWiki 1.
Таким образом, определенное форматирование, такое как цвета и размеры шрифта, может быть установлено для одной таблицы или для определенного столбца, или может быть установлено для чередующихся строк. Рекомендуемый способ установить любой пользовательский CSS в вики — изменить страницу «MediaWiki:Common.css».
В приведенном ниже примере показано чередование строк. /* четные и нечетные в таблицах */
.smwtable .строка-даже {
цвет фона: #fff;
}
.smwtable .row-нечетный {
цвет фона: #cde6ea;
}
Semantic MediaWiki 1.9.0Выпущено 3 января 2014 г. и совместимо с MW 1.19.0 – 1.22.x. вводит атрибуцию, связанную с типом, позволяющую применять определенные правила форматирования на основе использования типа данных (типы значений данных, такие как » Атрибут class представляет собой составную строку, которая включает » /* Форматирование типа DataValue */ . Предопределенные классы с таблицами данных . представил набор предопределенных классов, поддерживающих вывод данных1 в формате таблицы, что позволяет выполнять поиск в таблице и отображать больше результатов, не увеличивая отображение таблицы на вики-странице.23Возможные варианты параметра «класс»:
Эти классы используют подключаемый модуль таблицы DataTables для jQuery5. Использование этих классов дает базовый вывод, предлагаемый форматом результатов «Datatables». Принтер результатов с прогрессивной таблицей, который интегрирует библиотеку JavaScript DataTables, предоставляемую расширением «Semantic Result Formats». Предоставляет дополнительные форматы для семантических запросов, которые также используют таблицу «DataTables». Особенности этого класса:
Пользовательские скины[править]Если вы используете пользовательские скины, могут быть доступны другие атрибуты класса. напр. если вы используете скин, который реализует boostrap, вы можете использовать атрибуты класса, такие как
Существуют специализированные форматы результатов с большим количеством функций для экспорта данных, чем те, которые выбираются путем применения одного из классов «datatable». См. формат результатов «CSV». Выводит результаты в формате значений, разделенных запятыми, в стиле Windows., формат результатов «JSON».
|
 31″> 248.31 km²95.87 sqmi
31″> 248.31 km²95.87 sqmi  5.1. х — 1.18.х. используются собственные сортируемые таблицы MediaWiki. Таким образом, этот формат теперь предоставляет несколько способов применения пользовательского форматирования к таблицам:
5.1. х — 1.18.х. используются собственные сортируемые таблицы MediaWiki. Таким образом, этот формат теперь предоставляет несколько способов применения пользовательского форматирования к таблицам:
 smwtable .smwtype_num {
выравнивание текста: вправо;
}
smwtable .smwtype_num {
выравнивание текста: вправо;
}
 плагин для jQuery. Последний, однако, более мощный в своем использовании. 2
плагин для jQuery. Последний, однако, более мощный в своем использовании. 2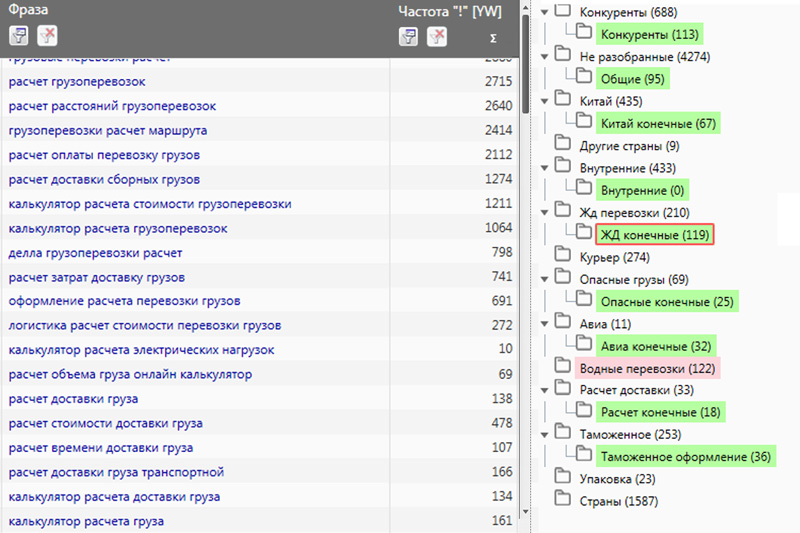 Выводит результаты в виде сериализации на основе JSON., формат результатов «Feed». Результаты экспортируются в виде каналов RSS и Atom. и формат результата «RDF». Экспортирует результаты в сериализации на основе RDF.. 9
Выводит результаты в виде сериализации на основе JSON., формат результатов «Feed». Результаты экспортируются в виде каналов RSS и Atom. и формат результата «RDF». Экспортирует результаты в сериализации на основе RDF.. 9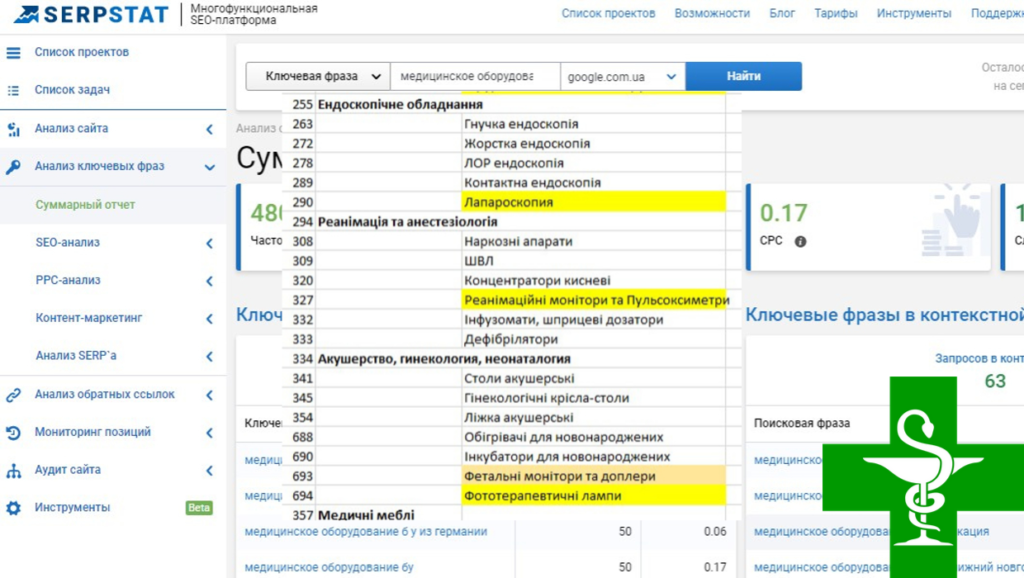 Примеры включают использование подсвойств if, явное использование свойств, таких как транзитивность и т. д.; графовые структуры в этой работе выглядят просто как контейнеры данных.
Примеры включают использование подсвойств if, явное использование свойств, таких как транзитивность и т. д.; графовые структуры в этой работе выглядят просто как контейнеры данных. Хотя я этого не опровергаю, это не обязательно означает, что это плохо. В принципе, можно использовать эти сети и классифицировать всю часть входных данных (используя, например, архитектуру трансформатора). Можно даже представить себе использование генерирующей модели графа после кодировщика. Я не говорю, что это как-то легко, но ваше утверждение, кажется, игнорирует этот подход без надлежащей аргументации. Некоторые ссылки на соответствующие документы: https://www.aclweb.org/anthology/2020.acl-main.398.pdf https://www.aclweb.org/anthology/2020.findings-emnlp.27.pdf https://arxiv.org/pdf/2103.12011.pdf https://arxiv.org/pdf/2105.07624.pdf и https://arxiv.org/pdf/2005.08314.pdf
Хотя я этого не опровергаю, это не обязательно означает, что это плохо. В принципе, можно использовать эти сети и классифицировать всю часть входных данных (используя, например, архитектуру трансформатора). Можно даже представить себе использование генерирующей модели графа после кодировщика. Я не говорю, что это как-то легко, но ваше утверждение, кажется, игнорирует этот подход без надлежащей аргументации. Некоторые ссылки на соответствующие документы: https://www.aclweb.org/anthology/2020.acl-main.398.pdf https://www.aclweb.org/anthology/2020.findings-emnlp.27.pdf https://arxiv.org/pdf/2103.12011.pdf https://arxiv.org/pdf/2105.07624.pdf и https://arxiv.org/pdf/2005.08314.pdf Однако вы выбираете такие вещи, как статистика длины строки и т. д., что добавляет предположения об используемых строках. пример, который вы приводите о Германии и Германии, иллюстрирует это. Языковая модель, скорее всего, не будет иметь никаких проблем с этим.
Однако вы выбираете такие вещи, как статистика длины строки и т. д., что добавляет предположения об используемых строках. пример, который вы приводите о Германии и Германии, иллюстрирует это. Языковая модель, скорее всего, не будет иметь никаких проблем с этим.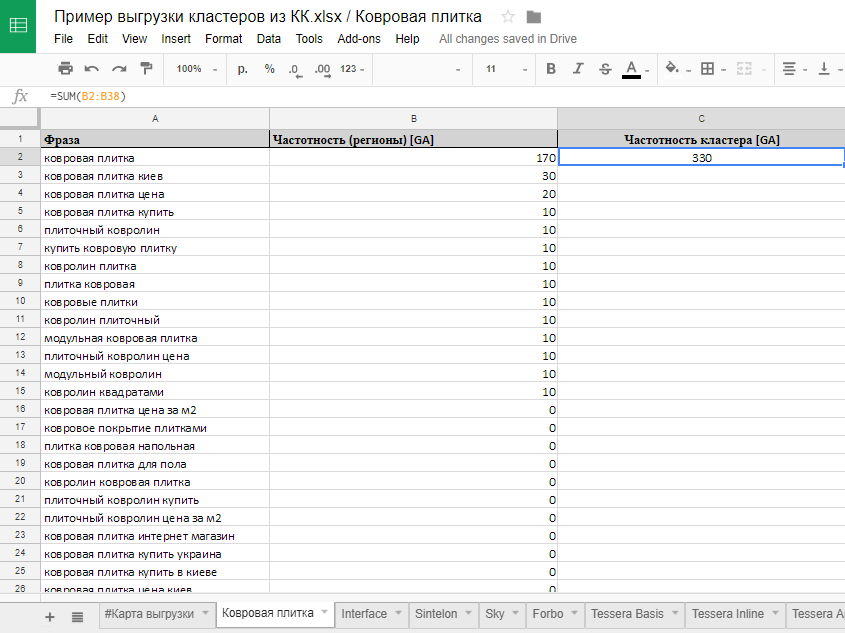 Разве метод year не должен обнаруживать такие случаи и обрабатывать их?
Разве метод year не должен обнаруживать такие случаи и обрабатывать их?